



Introduction
A growing body of research has documented the impact of persistent viral and chronic bacterial infections on a host of health outcomes, including cardiovascular disease [Reference Simanek, Dowd and Aiello1, Reference Simanek2] and cognitive impairment [Reference Tarter3] as well as markers of cellular aging such as telomere length [Reference Dowd4]. Persistent infections may operate through several biological mechanisms such as tissue damage, localised inflammation and/or cellular processes [Reference Pawelec, Goldeck and Derhovanessian5]. Of particular interest are the chronic effects of the reactivation of latent infections over the life course which cause the release of pro-inflammatory cytokines, such as interleukin-6 and acute-phase, C-reactive protein (CRP) both of which have been implicated in many of the hallmark diseases of aging. These infections likely result in biological dysfunction across multiple body systems, beginning early in the life course before clinical deficits are manifest by traditional biomarker assessment [Reference Aiello6]. Thus, using a clinical laboratory value-based deficits index that detects those at the higher (or lower) end of the normal range may highlight individuals on a trajectory for the development of multiple, chronic conditions.
Given the increasing numbers of chronic diseases with an infectious etiology, understanding the biological consequences of persistent infection is of critical importance. Pathogen burden, or infection burden, is a construct developed to assess the cumulative effects of multiple, persistent pathogens on morbidity and mortality [Reference Zhu7]. Pathogen burden has been measured in several different ways [Reference Simanek, Dowd and Aiello1, Reference Simanek8–Reference Katan13]. Some studies have focused on single pathogen associations examining the impact of each individual infection on a distal health outcome. Other studies have examined pathogen burden as a summary index of all pathogens for which an individual is seropositive. In 2015, Simanek et al. conducted a study that demonstrated the need to go beyond the ‘black box’ of pathogen burden, by incorporating both the number of pathogens and the specific combinations of different pathogens that may influence health [Reference Simanek8].
Few studies have explicitly examined the impact of the pathogen on a cumulative deficits index (CDI) among individuals in young and mid-adulthood. Using data from two waves of the National Health and Nutrition Examination Survey (NHANES), we compared three alternative methods for measuring pathogen burden using a laboratory-based CDI as an outcome [Reference Howlett and Rockwood14]. The CDI offers a way to quantify multi-system biological dysfunction before clinical disease is apparent [Reference King, Fillenbaum and Cohen15]. We hypothesised that latent class methods that incorporate both the number and combination of pathogens would show the most robust relationship between pathogen burden and the CDI.
Methods
Study sample
We used two waves of the continuous NHANES collected by the National Center for Health Statistics. NHANES is a cross-sectional, nationally representative survey of the health and nutritional status of the US non-institutionalised, civilian population aged 2 months and older. Our study population was drawn from the 2003–2004 and 2009–2010 waves. Details of the sampling strategy for the continuous NHANES can be found at: https://wwwn.cdc.gov/nchs/nhanes/analyticguidelines.aspx.
For each of the NHANES 2003–2004 and 2009–2010 waves, individuals provided information on a range of demographic characteristics based on the in-home interview. A subset of individuals also participated in the physical examinations and laboratory studies performed at the mobile examination center. We selected two waves so as to replicate the findings across samples and with slightly different combinations of pathogens. The 2003–2004 and 2009–2010 waves were preferable due to the quantity and types of pathogens tested in these waves. We did not use a combined study sample because we were also interested in testing the association of individual pathogens (not all of which were the same in each wave) with the CDI.
Our study sample included 20–49 years old who participated in the survey, physical examination and laboratory studies (Supplementary Fig. 1). The study sample included pregnant women, confirmed either by self-report or laboratory testing. There were 14 623 participants in the 2003–2004 wave and 10 846 in the 2009–2010 wave. Of those, 4980 participants were excluded because they did not participate in the interview, physical examination and laboratory studies in the 2003–2004 wave; 560 in the 2009–2010 wave. An additional 6934 individuals were excluded for whom there was not complete pathogen sample information available in the 2003–2004 wave; 8043 in the 2009–2010 wave. The final sample included only those with complete covariate information (2003–2004 Wave Final N = 2168; 2009–2010 Wave Final N = 2546).
This study was approved by the Campus Institutional Review Board of Duke University.
Laboratory analyses
Laboratory information used to construct the CDI was based on the biomarkers assessed from blood serum collected as part of the standard biochemistry profile of the NHANES laboratory examination. Additional information on specimen collection can be found in the NHANES Laboratory/Medical Technologists Procedures Manual. The specific biomarkers included in the CDI are shown in Table 1. The pathogen measurement information is included in the Supplementary files.
Table 1. Biomarkers included in the laboratory-based cumulative deficits index based on the National Health and Nutrition Examination Survey
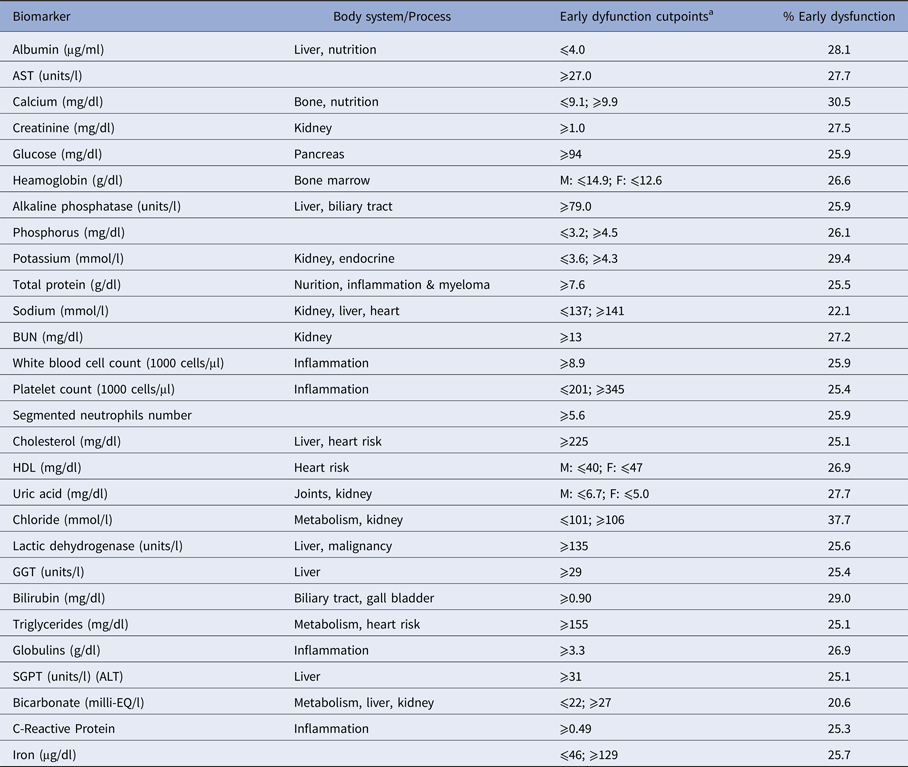
M, male; F, female.
a Early dysfunction based on below or above the quartile cutpoint.
Results based on 2003–2004 wave; process was replicated in subsequent waves.
Measures
The pathogen burden summary score was created by summing the number of pathogens for which an individual was seropositive. The construction of the CDI followed a methodology utilised by King et al. [Reference King, Fillenbaum and Cohen15] and others examining laboratory indices of frailty [Reference Howlett and Rockwood14, Reference Rockwood and Mitnitski16]. Twenty-eight biomarkers were incorporated in the CDI such as albumin levels, white blood cell count, calcium levels and cholesterol. Table 1 describes each of the 28 biomarkers utilised in the CDI along with their corresponding body system/process and the cut-points utilised. King et al. used cut-points based on clinical significance in older adults. Given the young age of our study sample, many are not likely showing abnormal values for the biomarkers assessed. Thus, we utilised an approach aimed at ascertaining those at the higher/lower end of the normal range depending on the specific biomarker. This determination was made for each biomarker depending on the direction indicating dysfunction. Each biomarker was split into quartiles and those in the highest (or lowest) quartile of the distribution received a score of 1. For some biomarkers, both high and low values can indicate dysfunction. For those markers, the distribution was split into eighths and both the top eighth and bottom eighth received a score of 1. This approach has been used in other biomarker studies [Reference Cohen, Harris and Pieper17]. The final CDI was constructed by summing the number of biomarkers for which an individual received a score of 1 divided by the total number of biomarkers available for that individual. We then examined the distribution of the CDI in the population as a whole and then by age, gender, race/ethnicity, education, smoking behavior and body mass index (BMI).
Covariates
We included covariates in our regression analyses that are well established in the literature as relating to pathogen burden and/or the CDI. These covariates included basic demographic information as well as health characteristics.
Basic demographic variables included age, sex, race/ethnicity and education. Age was analysed as a continuous variable in years. Sex was binary coded as male or female. Race/ethnicity was categorised according to the NHANES guidelines as non-Hispanic White, non-Hispanic Black, Mexican American, other Hispanic and other race. Education was treated categorically according to NHANES classifications as less than a high school education, high school graduate, some college education and college graduate and above.
Health status characteristics included BMI and smoking status. BMI was examined categorically with those with a BMI less than 18.5 classified as underweight; 18.5–25 classified as normal; 25–30 classified as overweight and greater than 30 classified as obese. Smoking status was classified as having ever smoked vs. never smoked.
Statistical analyses
Single pathogen associations
Linear regression models were constructed to investigate the association between each individual pathogen and the CDI. We estimated the mean difference and 95% confidence interval (CI) for those with- and without infection.
Pathogen burden summary score
We investigated the association between the pathogen burden summary score in two different ways. First, we examined the association between the continuous pathogen burden summary score and the CDI using linear regression models. The incremental increase in the CDI and 95% CI were calculated for each one-unit increase in the pathogen summary score. We then split the pathogen burden summary score into categories: 0–1 pathogens, 2 pathogens, 3 pathogens, and 4+ pathogens. Using linear regression models, we then examined the mean difference in the CDI using 0–1 pathogens as the referent.
Latent class analyses
To further characterise pathogen burden, we performed latent class analyses on each wave of data. This method assigns individuals with similar profiles to mutually exclusive classes using both manifest (measured) and latent (unmeasured) characteristics. We followed a three-step inclusive classify-analyse approach developed by Bray et al. [Reference Bray, Lanza and Tan18]. This approach separates the classification of individuals into latent classes from the regression of the outcome on the latent classes.
In the first phase, we determined the appropriate number of latent classes for each wave by comparing a series of model fit indices: the likelihood-ratio value (G2), Akaike information criteria (AIC), Bayesian information criterion (BIC), sample size-adjusted BIC, log-likelihood and entropy. Lower values for the AIC, BIC, adjusted AIC are preferred as they indicate better model fit. Higher values of entropy indicate the greater distinction between the classes. When deciding on the optimal number of classes, we prioritised both model fit and interpretability of the classes. Model estimation was repeated 1000 times with random starts to confirm model identification. Latent class models were estimated using PROC LCA SAS Version 9.4.
Once the appropriate number of latent classes was determined, we assigned individuals to a specific latent class based on their posterior probability of most likely class membership. Following the inclusive classify-analyse approach, the outcome variable, the CDI, was used as a covariate in the final model to reduce bias in estimation in the outcome model [Reference Bray, Lanza and Tan18].
Regression analyses
Using the three methods of classifying pathogen burden (single pathogen association, pathogen burden summary score and latent class analysis), we constructed a series of linear regression models to examine the association with each measure of pathogen burden and the CDI. For each method of pathogen burden, model 1 shows the association without any control variables (i.e. unadjusted model); model 2 shows the association with base controls (i.e. age, sex, BMI and smoking status); model 3 shows the association with base controls and race/ethnicity status; model 4 shows the association with base controls and education; and model 5 is the full model with base controls, race/ethnicity and education. These models were replicated using wave 1 and wave 2 study samples.
All regression analyses used appropriate sampling weights and adjustments to account for the complex survey design features. A two-side alpha of 0.05 was used to determine significance in all statistical analyses.
Statistical analyses were performed in SAS v.9.4 (Cary, NC).
Results
Sample characteristics
Wave 1 (2003–2004) consisted of 2168 individuals (Table 2). The mean age was 34.9 years and the sample was 69% non-Hispanic White. One-quarter of participants had a college education or above. Over half (52%) of the sample reported no smoking history. Moreover, a majority of the sample was classified as overweight or obese (64%). Wave 2 (2009–2010) consisted of 2546 individuals. The mean age was 34.7 years and the sample was 62% non-Hispanic White. In wave 2, 28% of participants had a college education or above. Again, over half the sample (58%) reported no smoking history and a majority were overweight or obese (66%).
Table 2. Population-weighted demographic and pathogen characteristics of the study population in the National Health and Nutrition Examination Survey, 2003–2004 and 2009–2010

NM, not measured.
In wave 1, we examined the proportion of the population that was seropositive to seven pathogens. Of the wave 1 sample, 60% were seropositive to HSV-1; 19% to HSV-2; 25% to HPV; 13% to toxoplasmosis; 52% to CMV; 0.44% to HIV; and 2% to syphilis. In wave 2, we examined the proportion of the study population seropositive to five pathogens. Of the wave 2 sample, 57% were seropositive to HSV-1; 15% to HSV-2; 34% to HPV; 12% to toxoplasmosis; and 0.37% to HIV. Pathogen correlations are given in Supplementary Table 1.
Cumulative deficits index
In wave 1, the CDI ranged from 0.04 to 0.78 with a mean of 0.30 (standard error of the mean = 0.003) (Table 3, Supplementary Fig. 2a). Increasing age was associated with an increase of 0.002 in the CDI (P < 0.001). There were also significant differences in the CDI by sex, race/ethnicity, education, smoking status and BMI.
Table 3. The descriptive statistics of the cumulative deficits index and the distribution of the cumulative deficits index by key demographic characteristics in the National Health and Nutrition Examination Survey, 2003–2004 and 2009–2010.
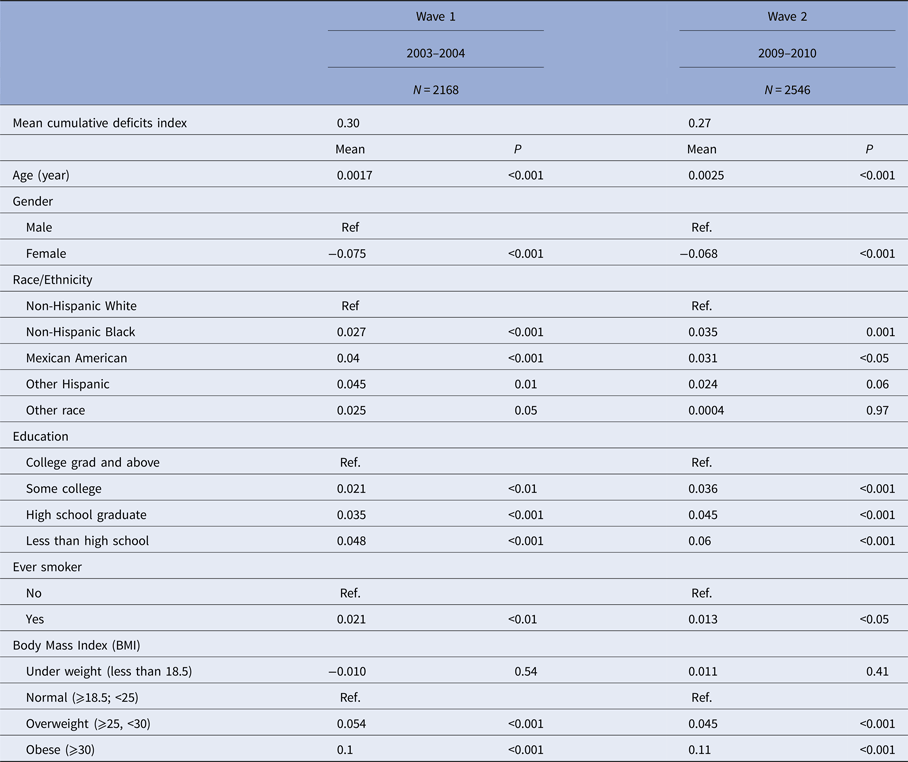
Results based on linear regression models; P values reflect a two-sided test.
In wave 2, the CDI ranged from 0 to 0.74 with a mean of 0.27 (standard error of the mean = 0.004) (Table 3, Supplementary Fig. 2b). Similar trends were observed in the wave 2 study population for race/ethnicity, education, smoking status and BMI.
Latent class assignment of pathogen burden
Model fit statistics were assessed for latent class models with one to six latent classes. Based on both model fit indices and interpretability, a three-class solution seemed best for both waves 1 and 2 as it optimised BIC, adjusted BIC and entropy, with near optimal levels of AIC (Supplementary Tables 2a and b).
Figures 1a and b show the conditional probabilities of pathogen positivity for each latent class. For each wave, one class of individuals had lower probabilities of being positive on all pathogens, the ‘low burden’ class. Similarly, for each wave one class of individuals had higher probabilities of being positive on several of the pathogens tested, the ‘high burden’ class. Finally, each wave had a significant portion of individuals who were positive for common pathogens such as CMV and HSV-1, the ‘common pathogens’ class. For statistical modeling, the low burden class was used as the referent.
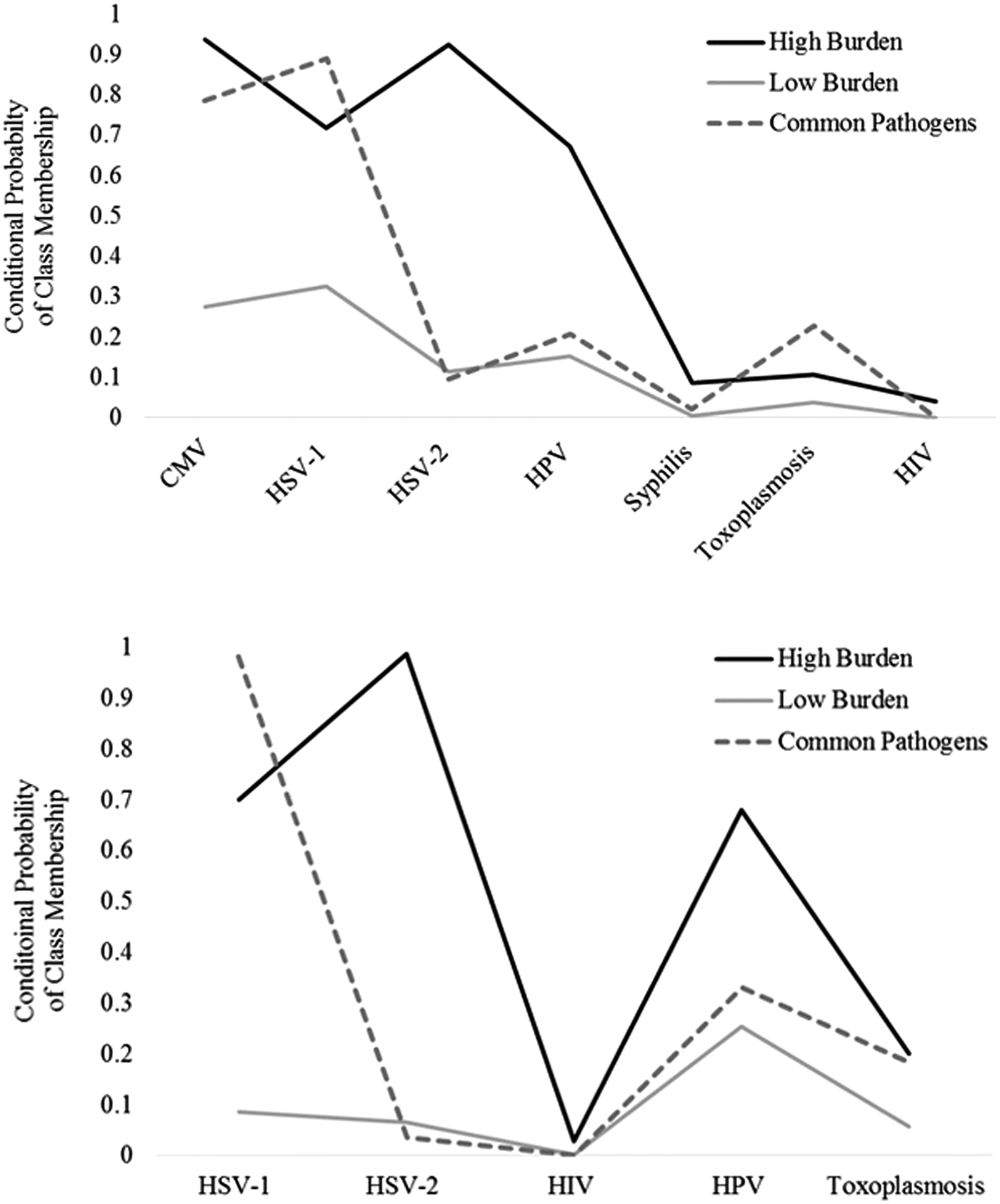
Fig. 1. (a) The conditional probability of each infection given a three class solution for the National Health and Examination Survey, 2003–2004 wave (N = 2168). (b) The conditional probability of each infection given a three class solution for the National Health and Examination Survey, 2009–2010 wave (N = 2546).
For wave 1, 50% of participants were assigned to the low burden class; 37% to the common pathogens class; and 13% to the high burden class. For the wave 2 sample, 37% of the participants were assigned to the low burden class; 46% to the common pathogens class; and 17% to the high burden class.
Regression results
Single pathogen associations
In wave 1 unadjusted single pathogen models, we observed a significant relationship between CMV, HSV-1, HPV, Toxoplasmosis, HIV and the CDI (Table 4). With the exception of HPV, infection with a pathogen resulted in a greater mean CDI compared with no infection. However, in the full model (model 5) only HIV remained significantly associated with the CDI. Individuals with HIV had a mean CDI 0.11 higher than those without HIV (P < 0.05).
Table 4. Results of the regression analysis examining the association between measures of pathogen burden and the cumulative deficits index in the National Health and Nutrition Examination Survey, 2003–2004 and 2009–2010

Coeff, coefficient; P, P-value.
Results are based on linear regression models using complex survey weights.
Significant results at α = 0.05 are bolded.
In wave 2, a similar pattern was observed with the exception of HPV. In the full model (model 5), both HPV and HIV were significantly associated with the CDI. Individuals with HPV had a mean CDI 0.01 higher than those without HPV (P < 0.05). Those with HIV had a mean CDI 0.12 higher than those without HIV (P < 0.01).
Pathogen summary score
A significant relationship was observed between the pathogen summary score and the CDI in models 1–4 in wave 1. However, in the full model (model 5) this relationship was null (P = 0.11). Similarly, when the pathogen summary score was split into categories, there were no significant relationships observed in the full model.
While a significant relationship between the pathogen summary score and the CDI appeared in models 1–4 in wave 2, in the full model this relationship was null (P = 0.06). However, when the pathogen summary score was split into categories, a significant relationship across models was observed between individuals having four or more pathogens compared with those having 0–1 pathogens. Those having four or more pathogens had a mean CDI 0.06 higher than those having only 0–1 pathogens (P < 0.001).
Latent class analyses
A significant relationship between latent classes of pathogen burden and the CDI was observed across all models in wave 1. In the full model (model 5), those in the high burden class had a mean CDI 0.03 higher than those in the low burden class (P < 0.001). Those in the common pathogens class had a mean CDI 0.04 higher than those in the low burden class (P < 0.001).
Similarly, in wave 2 there was a significant relationship between those in the high burden class and those in the low burden class with the CDI across models. In model 5, those in the high burden class had a mean CDI 0.02 greater than those in the low burden class (P < 0.05).
Sensitivity analyses
The finding in the single pathogen analysis in wave 1 that infection with HPV and syphilis both resulted in a lower mean CDI did not follow our hypothesised direction. We performed sensitivity analyses in which we removed HPV and syphilis from the pathogen summary score. We found modest changes in the association between the pathogen summary score and the CDI; however, the precision of the estimates did increase (Supplementary Table 3).
We also performed additional analyses excluding HIV from the pathogen burden summary score. While there was a modest attenuation in the effect size across models, the inferences regarding the associations were unchanged. In the full model (model 5), there remained a null relationship between the pathogen burden summary score and the CDI (results not shown).
We ran sensitivity analyses controlling for self-reported chronic conditions. Nearly a quarter (21%) of the study sample had one or more self-reported chronic health conditions. When we controlled for this in the analyses, we found no substantive changes in the effect estimates or the inferences. These results lend further support to the CDI as a preclinical marker of biological dysfunction. We also tested whether excluding pregnant women would change the association between the infections and the CDI. Excluding pregnant did not result in a substantial change in either the effect estimates or the inferences.
Discussion
We used a cumulative deficits approach to examine the impact of total pathogen burden on biological functioning in a nationally representative sample of individuals aged 20–49 years. We found significant heterogeneity in the distribution of the CDI by age, sex, race/ethnicity and education suggesting that it may indeed be detecting underlying disparities in biological dysfunction, even in a middle-aged sample (aged 20–49 years). While other studies have demonstrated the impact of persistent infections on morbidity and mortality later in the life course, our findings demonstrate the impact of these infections on biological function before clinical disease typically manifests. We also compared several methods of assessing pathogen burden and their associations with the CDI. Our results suggest that the CDI may be a useful way to assess the impact of pathogen burden. Latent class analyses, in particular, may be advantageous for characterising pathogen burden as they can account for both the number and combinations of pathogen burden, as well as detect and adjust for unobserved heterogeneity in the population.
Detecting biological wear and tear before clinical dysfunction is critical to understanding patterns of morbidity and mortality throughout the life course and particularly how they relate to the aging process. Many of the hallmark diseases of aging begin with physiological changes earlier in the life course [Reference Barker19]. A growing body of work is examining biomarkers of aging [Reference Belsky20] in younger cohorts as a way to pinpoint when in the life course these changes happen as well as to design interventions that may slow the aging process in younger individuals. The CDI we employed can be conceptualised as a manifestation of the health status of multiple body systems. Since our population spanned young adulthood to middle age, our aim in the use of the CDI was to detect individuals at pre-dysfunction levels, on a trajectory towards the development of multiple clinical deficits. The significant variation we observed by age, gender, race/ethnicity, education, smoking status and BMI suggest that CDI may be useful in detecting pre-dysfunction in a younger cohort. Additionally, the social disparities by race/ethnicity and education suggest that the CDI may be another method for examining the origins of health disparities. Current work is under way to further investigate these social disparities.
An increasing number of age-related processes and chronic diseases have been shown to have an infectious aetiology [Reference Bjerke21, Reference O'Connor, Taylor and Hughes22]. Persistent infections are often subclinical and may not cause severe illness at the time of infection [Reference Smith and Robinson23–Reference Malaty, El-Kasabany and Graham25] but the chronic reactivation of these infections across the life course can lead to a host of chronic diseases. Much of the seminal research in this area focused on understanding the link between persistent infections and cardiovascular disease, specifically atherosclerosis [Reference Zhu7, Reference Epstein26–Reference Epstein29]. Studies of CMV specifically have found links with not only cardiovascular mortality [Reference Roberts30] but incident depression [Reference Simanek31] and frailty in older adults [Reference Wang32]. Current work has extended this body of research to include understanding the underlying distribution of these infections along lines of social disadvantage [Reference Simanek, Dowd and Aiello1, Reference Dowd, Zajacova and Aiello12, Reference Aiello33, Reference Zajacova, Dowd and Aiello34].
Recently research in this area has begun to examine the effects of pathogen burden on markers of biological aging. Dowd et al. reported that infection with several herpesvirus coinfections resulted in substantial declines in leukocyte telomere length over a 3-year period [Reference Dowd4]. The magnitude of the association reported was suggestive of substantial accelerated biological aging resultant from pathogen burden. Previous studies using a cumulative deficits approach to examine frailty have reported consistent relationships with mortality [Reference Rockwood35, Reference Mitnitski36] and have proposed that such indices may proxy biological age [Reference Mitnitski36]. While we could not quantify the direct impact of pathogen burden on other biomarkers of aging in this study, our results are consistent with the hypothesis that persistent infections are likely increasing the pace of decline, even in younger cohorts.
We also sought to compare several different methods of pathogen burden measurement using the CDI as an outcome. Capturing the impact of persistent, latent infections on the body system is complex; measurement techniques need to account for both the number of pathogens present as well as the interactions between pathogens.
Our results suggest latent class analyses may be advantageous for characterising pathogen burden. The particular utility of latent class methods is that they account for unobserved heterogeneity in the study population. In contrast to approaches driven by the distribution and covariance of different variables, latent class methods assume that individuals belong to different subpopulations [Reference Lubke and Muthén37], with differing combinations of manifest and latent traits. In this way, latent class methods can be considered person-centered.
A similar method was employed by Meier et al. to classify levels of cumulative immune response by examining pathogen IgG antibody levels [Reference Meier10]. In their study, three latent classes emerged: a low cumulative immune response class, a moderate immune response class and a high immune response class with elevated antibody levels for each of the four pathogens examined [Reference Meier10].
Our findings suggest that in the case of characterising pathogen burden the latent class method is advantageous for detecting and adjusting for unobserved heterogeneity in clusters of individuals with similar pathogen profiles. In this study, the latent construct may be best described as a means of sorting individuals based both on their likelihood of exposure to pathogens as well as on their susceptibility to infection once exposed to a pathogen. The high burden group may then be conceptualised as those most vulnerable to infection in the study population: more likely to be exposed to pathogens and more susceptible to infection once exposed.
The attenuation of the associations in the single pathogen associations and pathogen summary score when race/ethnicity and education were included in the model suggests the influence of a strong social component affecting the distribution of these pathogens. The results of the latent class analyses, however, were largely unchanged in models controlling for race/ethnicity and education. The underlying unmeasured social structuring of the distribution of pathogen burden may be a part of what the latent class analysis is detecting. Future studies would benefit from a more explicit examination of socioeconomic status and other social/behavioral indicators and how they affect exposure and infection with pathogens.
Our study has several limitations. First, this is a cross-sectional analysis thus precluding any causal inferences regarding pathogen burden and the CDI. Future studies should investigate whether pathogen burden is predictive of changes in the CDI over time. Nonetheless, most of the infections of interest are transmitted in early childhood or adolescence while the CDI includes predominantly measures that emerge in later life, strengthening the likelihood that infection temporally precedes the CDI.
As discussed above, the results of this study suggest an underlying social structuring of the distribution of pathogens. We were limited by data availability on social variables in NHANES. Replication of this study with datasets that offer a more robust measurement of the social environment could shed further light on the social processes at work.
Our measurement of pathogen burden was limited by the pathogens tested in NHANES. There are likely other infections that may be important predictors of physiological dysfunction that we were not able to examine because they were not tested in NHANES. Moreover, the NHANES reports only seropositivity and not circulating antibody levels of infection. There is research to suggest that antibody levels may indicate the severity of infection [Reference Aiello38, Reference Aiello, Haan and Blythe39] and thus is a stronger measure of infection rather than simply seropositivity. Future studies should investigate whether antibody levels of infections are associated with early markers of dysfunction.
Finally, while the CDI is useful in detecting global dysfunction, it is not specific to a single physiological process. Follow-up studies should further interrogate specific pathophysiological pathways linking chronic infection to biological dysfunction.
In conclusion, our results suggest that pathogen burden may influence early clinical indicators of poor health as measured by the CDI. Our results are salient because we were able to detect associations between pathogen burden and CDI in a relatively young population, where the onset of the disease is rarer but represents a period in which interventions targeting pathogen burden may help offset early changes in CDI and ultimately disease risk. These findings suggest that reducing overall pathogen burden and particularly the specific pathogens that drive the CDI, may provide a target for preventing the early development of age-related physiological changes.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S095026881800153X.
Acknowledgements
G.A. Noppert received support from the National Institute on Aging and the National Institute of Child Health and Human Development at the National Institutes of Health (grant numbers 5 T32-AG000029-41 and 1 T32 HD091058-01). This work was also partially supported by the Claude D. Pepper Older Americans Independence Center grant P30-AG028716. A.E. Aiello received support from the National Institute of Health Grants: P2C HD050924, R01 DK087864, R01 AG040115, T32 HD091058.
Disclaimers
None.







