



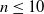
1. Introduction
This paper is focused on the classical online learning problem of prediction with expert advice. Given the advice of
 $n$
experts who each make predictions in real time about an unknown time-varying quantity (e.g., the price of a stock or option at some time in the future), a player must decide which expert’s advice to follow. The problem is often formulated in an online setting, whereby at each step of the game, the player has knowledge of the historical performance of each expert and may use this information to decide which expert to follow at that step. The overall goal is to perform as well as the best-performing expert, or as close to this as possible. We are particularly interested in the adversarial setting, where the performance of the experts is controlled by an adversary, whose goal is to minimize the gains of the player.
$n$
experts who each make predictions in real time about an unknown time-varying quantity (e.g., the price of a stock or option at some time in the future), a player must decide which expert’s advice to follow. The problem is often formulated in an online setting, whereby at each step of the game, the player has knowledge of the historical performance of each expert and may use this information to decide which expert to follow at that step. The overall goal is to perform as well as the best-performing expert, or as close to this as possible. We are particularly interested in the adversarial setting, where the performance of the experts is controlled by an adversary, whose goal is to minimize the gains of the player.
A simple and common way to formulate the game is to assume each expert’s prediction is either correct or incorrect at each time step. Given
 $n$
experts, this can be described by a binary vector
$n$
experts, this can be described by a binary vector
 ${\mathbf {v}}\in {\mathcal B}^n$
,
${\mathbf {v}}\in {\mathcal B}^n$
,
 ${\mathcal B}\,:\!=\,\{0,1\}$
, where
${\mathcal B}\,:\!=\,\{0,1\}$
, where
 $v_i=1$
if expert
$v_i=1$
if expert
 $i$
is correct, and
$i$
is correct, and
 $v_i=0$
otherwise. The player gains
$v_i=0$
otherwise. The player gains
 $1$
if the expert they chose made a correct prediction, and gains nothing otherwise; thus the player gains
$1$
if the expert they chose made a correct prediction, and gains nothing otherwise; thus the player gains
 $v_i$
if they follow expert
$v_i$
if they follow expert
 $i$
. The performance of the player is often measured with the notion of regret with respect to each expert, which is the difference between a given expert’s gains and the player’s gains. We let
$i$
. The performance of the player is often measured with the notion of regret with respect to each expert, which is the difference between a given expert’s gains and the player’s gains. We let
 $x=(x_1,\ldots, x_n)\in {\mathbb {R}}^n$
denote the regret vector with respect to all
$x=(x_1,\ldots, x_n)\in {\mathbb {R}}^n$
denote the regret vector with respect to all
 $n$
experts, so
$n$
experts, so
 $x_i$
is the regret to the
$x_i$
is the regret to the
 $i^{\textrm {th}}$
expert, or rather, the number of times the
$i^{\textrm {th}}$
expert, or rather, the number of times the
 $i^{\textrm {th}}$
expert was correct minus the number of times the player was correct. After
$i^{\textrm {th}}$
expert was correct minus the number of times the player was correct. After
 $T$
steps, the gain of the player and any given expert is at most
$T$
steps, the gain of the player and any given expert is at most
 $T$
, and the worst-case regret with respect to any given expert is at most
$T$
, and the worst-case regret with respect to any given expert is at most
 $T$
. The goal of the player is to minimize their regret with respect to the best-performing expert; thus, the player would like to minimize
$T$
. The goal of the player is to minimize their regret with respect to the best-performing expert; thus, the player would like to minimize
 $\max \{x_1,\ldots, x_n\}$
at the end of the game. The goal of mathematical and numerical analysis is to compute or approximate the optimal player strategies (i.e., determine which expert the player should follow). There are two standard approaches for how long the game is played; the finite horizon setting, where the game is played for a fixed number of steps
$\max \{x_1,\ldots, x_n\}$
at the end of the game. The goal of mathematical and numerical analysis is to compute or approximate the optimal player strategies (i.e., determine which expert the player should follow). There are two standard approaches for how long the game is played; the finite horizon setting, where the game is played for a fixed number of steps
 $T$
, and the geometric horizon setting, where the game ends with probability
$T$
, and the geometric horizon setting, where the game ends with probability
 $\delta \gt 0$
at each step. In the geometric horizon setting, the number of steps of the game is a random variable following the geometric distribution with parameter
$\delta \gt 0$
at each step. In the geometric horizon setting, the number of steps of the game is a random variable following the geometric distribution with parameter
 $\delta$
. In this work, we focus on the geometric horizon problem, but we expect our techniques to work in the finite horizon setting as well.
$\delta$
. In this work, we focus on the geometric horizon problem, but we expect our techniques to work in the finite horizon setting as well.
In order to proceed further, we need to make a modelling assumption on the experts. In this paper, we follow the convention of a worst-case analysis where we assume the experts are controlled by an adversary whose goal is to maximize the player’s regret at the end of the game. The adversarial setting yields a two-player zero sum game and introduces another mathematical problem of determining the optimal strategies for the adversary. We also focus on the more general setting of mixed strategies where the player and adversary both employ randomized strategies. At each step, the player chooses a probability distribution
 $\alpha$
over the experts
$\alpha$
over the experts
 $\{1,\ldots, n\}$
, and the expert followed by the player is drawn independently (from other steps and the adversary’s choices) from the distribution
$\{1,\ldots, n\}$
, and the expert followed by the player is drawn independently (from other steps and the adversary’s choices) from the distribution
 $\alpha$
. Likewise, the adversary chooses a probability distribution
$\alpha$
. Likewise, the adversary chooses a probability distribution
 $\beta$
over the binary sequences
$\beta$
over the binary sequences
 ${\mathbf {v}}\in {\mathcal B}^n$
, and the experts are advanced by drawing a sample
${\mathbf {v}}\in {\mathcal B}^n$
, and the experts are advanced by drawing a sample
 ${\mathbf {v}}\in {\mathcal B}^n$
from the distribution
${\mathbf {v}}\in {\mathcal B}^n$
from the distribution
 $\beta$
. The problem of determining optimal strategies then boils down to deciding how the player and market should set their probability distributions
$\beta$
. The problem of determining optimal strategies then boils down to deciding how the player and market should set their probability distributions
 $\alpha$
and
$\alpha$
and
 $\beta$
at each time step, given the current regret vector
$\beta$
at each time step, given the current regret vector
 $x\in {\mathbb {R}}^n$
. The goal of the player is to minimize their expected regret, while the adversary’s goal is to maximize the expected regret.
$x\in {\mathbb {R}}^n$
. The goal of the player is to minimize their expected regret, while the adversary’s goal is to maximize the expected regret.
It is a difficult problem to determine the optimal strategies for the player and the adversary for a general number of experts
 $n$
and a large number of steps
$n$
and a large number of steps
 $T$
in the game. Initial results were established in Cover’s original paper [Reference Cover18] for
$T$
in the game. Initial results were established in Cover’s original paper [Reference Cover18] for
 $n=2$
experts, and more recently in [Reference Gravin, Peres and Sivan27] for
$n=2$
experts, and more recently in [Reference Gravin, Peres and Sivan27] for
 $n=3$
experts. A breakthrough occurred in a series of papers by Drenska and Kohn [Reference Drenska20, Reference Drenska and Kohn22, Reference Drenska and Kohn23], who took the perspective that the prediction from expert advice problem is a discrete analogue of two-player differential games [Reference Friedman26]. They formulated a value function for the game and showed that as the number of steps
$n=3$
experts. A breakthrough occurred in a series of papers by Drenska and Kohn [Reference Drenska20, Reference Drenska and Kohn22, Reference Drenska and Kohn23], who took the perspective that the prediction from expert advice problem is a discrete analogue of two-player differential games [Reference Friedman26]. They formulated a value function for the game and showed that as the number of steps
 $T$
of the game tends to infinity, the rescaled value function converges to the viscosity solution
$T$
of the game tends to infinity, the rescaled value function converges to the viscosity solution
 $u\in C({\mathbb {R}}^n)$
of the degenerate elliptic partial differential equation (PDE)
$u\in C({\mathbb {R}}^n)$
of the degenerate elliptic partial differential equation (PDE)
 \begin{equation} u(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^n} {\mathbf {v}}^T\nabla ^2u(x)\,{\mathbf {v}} = \max \{x_1,\ldots, x_n\} \ \ \text {for} \ \ x\in {\mathbb {R}}^n. \end{equation}
\begin{equation} u(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^n} {\mathbf {v}}^T\nabla ^2u(x)\,{\mathbf {v}} = \max \{x_1,\ldots, x_n\} \ \ \text {for} \ \ x\in {\mathbb {R}}^n. \end{equation}
The state variable
 $x\in {\mathbb {R}}^n$
of the PDE (1.1) is the regret vector at the start of the game, and the solution of the PDE
$x\in {\mathbb {R}}^n$
of the PDE (1.1) is the regret vector at the start of the game, and the solution of the PDE
 $u(x)$
is the worst-case regret over all the experts at the end of the game, provided each player plays optimally (and in the limit as
$u(x)$
is the worst-case regret over all the experts at the end of the game, provided each player plays optimally (and in the limit as
 $T\to \infty$
). Thus, the long-time behaviour of the adversarial prediction with expert advice problem, and the corresponding asymptotically optimal strategies for the player and adversary, can be determined by solving a PDE! It turns out that the optimal player strategy is to choose the probability distribution
$T\to \infty$
). Thus, the long-time behaviour of the adversarial prediction with expert advice problem, and the corresponding asymptotically optimal strategies for the player and adversary, can be determined by solving a PDE! It turns out that the optimal player strategy is to choose the probability distribution
 $\alpha (x) = \nabla u(x)$
, while the optimal adversarial strategy involves the binary vectors
$\alpha (x) = \nabla u(x)$
, while the optimal adversarial strategy involves the binary vectors
 $\mathbf {v}$
saturating the maximum over
$\mathbf {v}$
saturating the maximum over
 ${\mathbf {v}}\in {\mathcal B}^n$
in (1.1) (we give more detail in Section 1.1).
${\mathbf {v}}\in {\mathcal B}^n$
in (1.1) (we give more detail in Section 1.1).
In this paper, we develop numerical methods for approximating the viscosity solution of (1.1), so that we may shed light on the optimal strategies for the player and adversary. There are two challenging aspects of solving (1.1). First, the PDE is posed on all of
 ${\mathbb {R}}^n$
and does not have any kind of natural restriction to a compact computational domain with boundary conditions. To address this, we prove a localization result for (1.1) showing that the domain may be restricted to a box
${\mathbb {R}}^n$
and does not have any kind of natural restriction to a compact computational domain with boundary conditions. To address this, we prove a localization result for (1.1) showing that the domain may be restricted to a box
 $\Omega _T=[\!-T,T]^n$
and that errors in the Dirichlet boundary condition
$\Omega _T=[\!-T,T]^n$
and that errors in the Dirichlet boundary condition
 $u\vert _{\partial \Omega _T}$
do not propagate far into the interior of
$u\vert _{\partial \Omega _T}$
do not propagate far into the interior of
 $\Omega$
, allowing us to obtain an accurate solution sufficiently interior to
$\Omega$
, allowing us to obtain an accurate solution sufficiently interior to
 $\Omega _T$
(precise results are given later). The second challenge is that the theory is fairly complete for the
$\Omega _T$
(precise results are given later). The second challenge is that the theory is fairly complete for the
 $n=2,3,4$
expert problems, so the interesting cases to study are in the fairly high dimensional setting of
$n=2,3,4$
expert problems, so the interesting cases to study are in the fairly high dimensional setting of
 $n\geq 5$
experts, where it is generally difficult to solve PDEs on regular grids or meshes, due to the curse of dimensionality. To overcome this issue, we exploit symmetries in the equation (1.1)–in particular, permutation invariance of the coordinates
$n\geq 5$
experts, where it is generally difficult to solve PDEs on regular grids or meshes, due to the curse of dimensionality. To overcome this issue, we exploit symmetries in the equation (1.1)–in particular, permutation invariance of the coordinates
 $x_1,\ldots, x_n$
– in order to restrict the computational domain to the sector in
$x_1,\ldots, x_n$
– in order to restrict the computational domain to the sector in
 ${\mathbb {R}}^{n-1}$
where
${\mathbb {R}}^{n-1}$
where
 $T\geq x_1 \geq x_2 \geq \cdots x_{n-1}\geq x_n = 0$
. We develop a numerical method that allows us to restrict all computations to this sector, which has vanishingly small measure compared to the whole box
$T\geq x_1 \geq x_2 \geq \cdots x_{n-1}\geq x_n = 0$
. We develop a numerical method that allows us to restrict all computations to this sector, which has vanishingly small measure compared to the whole box
 $\Omega _T$
. This allows us to numerically solve the PDE (1.1) on reasonably fine grids up to dimension
$\Omega _T$
. This allows us to numerically solve the PDE (1.1) on reasonably fine grids up to dimension
 $n=10$
. Based on our numerical results, we make a number of conjectures about optimality of various strategies. We summarize these results in Section 1.2 after giving a more thorough description of the background material.
$n=10$
. Based on our numerical results, we make a number of conjectures about optimality of various strategies. We summarize these results in Section 1.2 after giving a more thorough description of the background material.
1.1 Background
Online prediction with expert advice is an example of a sequential decision-making problem and has applications in algorithm boosting [Reference Freund and Schapire25], stock price prediction and portfolio optimization [Reference Freund and Schapire25], self-driving car software [Reference Amin, Kale, Tesauro and Turaga2], and many other problems. The prediction with expert advice problem originated in the works of Cover [Reference Cover18] and Hannan [Reference Hannan29], who provided optimal strategies for the two expert problems. In the intervening years, much attention has been focused on heuristic algorithms that give good performance, but may not be optimal. A commonly used algorithm is the multiplicative weights algorithm, in which the player maintains a set of positive weights
 $w_1,\ldots, w_n$
for each expert that are used to form a weighted average of the expert advice, and the weights are updated in real time based on the performance of each expert. For the finite horizon problem, it has been shown [Reference Cesa-Bianchi and Lugosi16] that the multiplicative weights algorithm is optimal in an asymptotic sense, as the number of experts
$w_1,\ldots, w_n$
for each expert that are used to form a weighted average of the expert advice, and the weights are updated in real time based on the performance of each expert. For the finite horizon problem, it has been shown [Reference Cesa-Bianchi and Lugosi16] that the multiplicative weights algorithm is optimal in an asymptotic sense, as the number of experts
 $n$
and number of steps of the game
$n$
and number of steps of the game
 $T$
both tend to infinity, but fails to be optimal when the numbers of experts are fixed and finite, as is the case in practice. Optimal algorithms for the geometric horizon and finite horizon problems for
$T$
both tend to infinity, but fails to be optimal when the numbers of experts are fixed and finite, as is the case in practice. Optimal algorithms for the geometric horizon and finite horizon problems for
 $n \leq 3$
experts were developed and studied in Gravin et al. [Reference Gravin, Peres and Sivan27] and Abbasi et al. [Reference Abbasi-Yadkori, Bartlett and Gabillon1]. Additionally, lower bounds for regrets in a broader class than multiplicative weights have been shown [Reference Gravin, Peres and Sivan28]. Further work on algorithms for both the finite and geometric horizon problems is contained in [Reference Abbasi-Yadkori, Bartlett and Gabillon1, Reference Cesa-Bianchi, Freund, Haussler, Helmbold, Schapire and Warmuth15, Reference Cesa-Bianchi and Lugosi16, Reference Haussler, Kivinen and Warmuth30, Reference Littlestone and Warmuth36, Reference Rokhlin42].
$n \leq 3$
experts were developed and studied in Gravin et al. [Reference Gravin, Peres and Sivan27] and Abbasi et al. [Reference Abbasi-Yadkori, Bartlett and Gabillon1]. Additionally, lower bounds for regrets in a broader class than multiplicative weights have been shown [Reference Gravin, Peres and Sivan28]. Further work on algorithms for both the finite and geometric horizon problems is contained in [Reference Abbasi-Yadkori, Bartlett and Gabillon1, Reference Cesa-Bianchi, Freund, Haussler, Helmbold, Schapire and Warmuth15, Reference Cesa-Bianchi and Lugosi16, Reference Haussler, Kivinen and Warmuth30, Reference Littlestone and Warmuth36, Reference Rokhlin42].
Recently, attention has shifted back to the problem of optimal strategies for a finite number of experts [Reference Bayraktar, Ekren and Zhang5–Reference Bayraktar, Poor and Zhang8, Reference Calder and Drenska12, Reference Drenska20–Reference Drenska and Kohn23, Reference Gravin, Peres and Sivan27]. The focus of this paper is on the problem with mixed strategies (i.e., random strategies) against an adversarial environment that was briefly described in the previous section. We now describe this setting in more detail. We have
 $n$
experts making predictions, a player who chooses at each step which expert to follow, and an adversarial environment that decides which experts gain or lose at each step of the game. The strategies are mixed, so both the player and the adversary choose probability distributions over their possible plays, and their actual plays are random variables drawn from those distributions. At the
$n$
experts making predictions, a player who chooses at each step which expert to follow, and an adversarial environment that decides which experts gain or lose at each step of the game. The strategies are mixed, so both the player and the adversary choose probability distributions over their possible plays, and their actual plays are random variables drawn from those distributions. At the
 $k^{\textrm {th}}$
step of the game, the player chooses a probability distribution
$k^{\textrm {th}}$
step of the game, the player chooses a probability distribution
 $\alpha _k$
over the experts
$\alpha _k$
over the experts
 ${\mathcal A}_n\,:\!=\,\{1,2,\ldots, n\}$
and the adversary chooses a probability distribution
${\mathcal A}_n\,:\!=\,\{1,2,\ldots, n\}$
and the adversary chooses a probability distribution
 $\beta _k$
over the binary sequences
$\beta _k$
over the binary sequences
 ${\mathcal B}^n = \{0,1\}^n$
. Random variables from these distributions
${\mathcal B}^n = \{0,1\}^n$
. Random variables from these distributions
 $i_k\sim \alpha _k$
and
$i_k\sim \alpha _k$
and
 ${\mathbf {v}}_k\sim \beta _k$
are drawn, and the player chooses to follow expert
${\mathbf {v}}_k\sim \beta _k$
are drawn, and the player chooses to follow expert
 $i_k$
and the market advances the experts corresponding to the positions of the ones in the binary vector
$i_k$
and the market advances the experts corresponding to the positions of the ones in the binary vector
 ${\mathbf {v}}_k$
.
${\mathbf {v}}_k$
.
The performance of the player is measured by their regret to each expert, which is the difference between the expert’s gains and those of the player. We let
 $x=(x_1,\ldots, x_n)\in {\mathbb {R}}^n$
denote the regret vector, so
$x=(x_1,\ldots, x_n)\in {\mathbb {R}}^n$
denote the regret vector, so
 $x_i$
is the current regret with respect to expert
$x_i$
is the current regret with respect to expert
 $i$
. Let us write the coordinates of
$i$
. Let us write the coordinates of
 ${\mathbf {v}}_k$
as
${\mathbf {v}}_k$
as
 ${\mathbf {v}}_k=(v_{k,1},v_{k,2},\ldots, v_{k,n})$
. Then on the
${\mathbf {v}}_k=(v_{k,1},v_{k,2},\ldots, v_{k,n})$
. Then on the
 $k^{\textrm {th}}$
step the player accumulates regret of
$k^{\textrm {th}}$
step the player accumulates regret of
 $v_{k,j}-v_{k,i_k}$
with respect to expert
$v_{k,j}-v_{k,i_k}$
with respect to expert
 $j$
. If the regret vector started at
$j$
. If the regret vector started at
 $x\in {\mathbb {R}}^n$
on the first step of the game, then the regret after
$x\in {\mathbb {R}}^n$
on the first step of the game, then the regret after
 $T$
steps is
$T$
steps is
 \begin{equation*}R_T\,:\!=\, x + \sum _{k=1}^T ({\mathbf {v}}_k - v_{k,i_k}\unicode {x1D7D9}).\end{equation*}
\begin{equation*}R_T\,:\!=\, x + \sum _{k=1}^T ({\mathbf {v}}_k - v_{k,i_k}\unicode {x1D7D9}).\end{equation*}
At the end of the game, the regret
 $R_T$
is evaluated with a payoff function
$R_T$
is evaluated with a payoff function
 $g:{\mathbb {R}}^n\to {\mathbb {R}}$
. The player’s goal is to minimize
$g:{\mathbb {R}}^n\to {\mathbb {R}}$
. The player’s goal is to minimize
 $g(R_T)$
while the adversary’s goal is to maximize
$g(R_T)$
while the adversary’s goal is to maximize
 $g(R_T)$
. The most commonly used payoff is the maximum regret
$g(R_T)$
. The most commonly used payoff is the maximum regret
 $g(x) = \max \{x_1,x_2,\ldots, x_n\}$
, which simply reports the regret of the player with respect to the best-performing expert. The game can be played in the finite horizon setting where
$g(x) = \max \{x_1,x_2,\ldots, x_n\}$
, which simply reports the regret of the player with respect to the best-performing expert. The game can be played in the finite horizon setting where
 $T$
is fixed, or the geometric horizon setting where the game ends with probability
$T$
is fixed, or the geometric horizon setting where the game ends with probability
 $\delta \gt 0$
at each step, so
$\delta \gt 0$
at each step, so
 $T$
is a random variable.
$T$
is a random variable.
We focus on the geometric horizon problem. In this case, the value function
 $U_\delta :{\mathbb {R}}^n \to {\mathbb {R}}$
is defined by
$U_\delta :{\mathbb {R}}^n \to {\mathbb {R}}$
is defined by
 \begin{equation} U_\delta (x) = \inf _{\alpha }\sup _{\beta }{\mathbb E}\left [ g\left (x + \sum _{k=1}^T ({\mathbf {v}}_k - v_{k,i_k}\unicode {x1D7D9}) \right )\right ], \end{equation}
\begin{equation} U_\delta (x) = \inf _{\alpha }\sup _{\beta }{\mathbb E}\left [ g\left (x + \sum _{k=1}^T ({\mathbf {v}}_k - v_{k,i_k}\unicode {x1D7D9}) \right )\right ], \end{equation}
where
 $\alpha =(\alpha _1,\alpha _2,\ldots )$
,
$\alpha =(\alpha _1,\alpha _2,\ldots )$
,
 $\beta =(\beta _1,\beta _2,\ldots )$
, and
$\beta =(\beta _1,\beta _2,\ldots )$
, and
 $T$
is the time at which the game stops, which is a geometric random variable with parameter
$T$
is the time at which the game stops, which is a geometric random variable with parameter
 $\delta$
. The value function
$\delta$
. The value function
 $U_\delta (x)$
is the expected value of the payoff at the end of the game given that the regret vector starts at
$U_\delta (x)$
is the expected value of the payoff at the end of the game given that the regret vector starts at
 $x\in {\mathbb {R}}^n$
on the first step and both players play optimally. The
$x\in {\mathbb {R}}^n$
on the first step and both players play optimally. The
 $\inf$
and the
$\inf$
and the
 $\sup$
are over strategies for the players, which enforce that
$\sup$
are over strategies for the players, which enforce that
 $\alpha _k$
and
$\alpha _k$
and
 $\beta _k$
depend only on the current value of the regret and the past choices of both players. The value function is unchanged by swapping the
$\beta _k$
depend only on the current value of the regret and the past choices of both players. The value function is unchanged by swapping the
 $\inf$
and
$\inf$
and
 $\sup$
in (1.2).
$\sup$
in (1.2).
It was shown in [Reference Drenska20, Reference Drenska and Kohn22] that the rescaled value functions
 \begin{equation*}u_\delta (x) \,:\!=\, \sqrt {\delta }\,U_\delta \left ( \frac {x}{\delta }\right )\end{equation*}
\begin{equation*}u_\delta (x) \,:\!=\, \sqrt {\delta }\,U_\delta \left ( \frac {x}{\delta }\right )\end{equation*}
converge locally uniformly, as
 $\delta \to 0$
, to the viscosity solution of the degenerate elliptic PDE
$\delta \to 0$
, to the viscosity solution of the degenerate elliptic PDE
 \begin{equation} u -\frac {1}{2}\max _{{\mathbf {v}}\in B_{n}}{\mathbf {v}}^T \nabla ^2 u \,{\mathbf {v}} = g \ \ \text { on } {\mathbb {R}}^n, \end{equation}
\begin{equation} u -\frac {1}{2}\max _{{\mathbf {v}}\in B_{n}}{\mathbf {v}}^T \nabla ^2 u \,{\mathbf {v}} = g \ \ \text { on } {\mathbb {R}}^n, \end{equation}
which is the same as (1.1) except with a general payoff
 $g$
. The PDE (1.3) contains all of the information about the prediction problem in the asymptotic regime where the number of steps
$g$
. The PDE (1.3) contains all of the information about the prediction problem in the asymptotic regime where the number of steps
 $T$
tends to
$T$
tends to
 $\infty$
, which is equivalent to sending the geometric stopping probability
$\infty$
, which is equivalent to sending the geometric stopping probability
 $\delta \to 0$
. It was shown in [Reference Drenska and Kohn22] that the asymptotically optimal player strategy is to use the probability distributionFootnote
1
$\delta \to 0$
. It was shown in [Reference Drenska and Kohn22] that the asymptotically optimal player strategy is to use the probability distributionFootnote
1
 \begin{equation} \alpha _k = \nabla u(x), \end{equation}
\begin{equation} \alpha _k = \nabla u(x), \end{equation}
where
 $x\in {\mathbb {R}}^n$
is the current regret on the
$x\in {\mathbb {R}}^n$
is the current regret on the
 $k^{\textrm {th}}$
step of the game, and the optimal adversary strategy is to choose
$k^{\textrm {th}}$
step of the game, and the optimal adversary strategy is to choose
 \begin{equation} {\mathbf {v}}_k \in \textrm {argmax}_{{\mathbf {v}} \in {\mathcal B}^n} \{{\mathbf {v}}^T \nabla ^2 u(x){\mathbf {v}}\}, \end{equation}
\begin{equation} {\mathbf {v}}_k \in \textrm {argmax}_{{\mathbf {v}} \in {\mathcal B}^n} \{{\mathbf {v}}^T \nabla ^2 u(x){\mathbf {v}}\}, \end{equation}
and then advance the experts in
 ${\mathbf {v}}_k$
with probability
${\mathbf {v}}_k$
with probability
 $\frac {1}{2}$
and those in
$\frac {1}{2}$
and those in
 $\unicode {x1D7D9}-{\mathbf {v}}_k$
with probability
$\unicode {x1D7D9}-{\mathbf {v}}_k$
with probability
 $\frac {1}{2}$
. Notice that the adversarial strategy
$\frac {1}{2}$
. Notice that the adversarial strategy
 $\mathbf {v}$
is equivalent to
$\mathbf {v}$
is equivalent to
 $\unicode {x1D7D9}-{\mathbf {v}}$
.
$\unicode {x1D7D9}-{\mathbf {v}}$
.
Determining the adversary’s optimal strategies in the max-regret setting, where we take
 $g(x)=\max \{x_1,\ldots, x_n\}$
, is an open problem for a general number of experts
$g(x)=\max \{x_1,\ldots, x_n\}$
, is an open problem for a general number of experts
 $n$
. It was conjectured in [Reference Gravin, Peres and Sivan27] that the COMB strategy of ordering the experts by regret and using the alternating zeros and ones vector
$n$
. It was conjectured in [Reference Gravin, Peres and Sivan27] that the COMB strategy of ordering the experts by regret and using the alternating zeros and ones vector
 ${\mathbf {v}}=(0,1,0,1,\ldots )$
, which resembles the teeth of a comb, is asymptotically optimal as
${\mathbf {v}}=(0,1,0,1,\ldots )$
, which resembles the teeth of a comb, is asymptotically optimal as
 $T\to \infty$
for all
$T\to \infty$
for all
 $n$
, though this was proven in [Reference Gravin, Peres and Sivan27] only for
$n$
, though this was proven in [Reference Gravin, Peres and Sivan27] only for
 $n=2$
and
$n=2$
and
 $n=3$
experts. The idea behind the COMB strategy is to group the experts into as equally matched groups as possible and advance one group or the other with equal probability, which makes it difficult for the player to gain any advantage. However, since the experts are ordered by regret
$n=3$
experts. The idea behind the COMB strategy is to group the experts into as equally matched groups as possible and advance one group or the other with equal probability, which makes it difficult for the player to gain any advantage. However, since the experts are ordered by regret
 $x_1\geq x_2 \geq \cdots \geq x_n$
, they are essentially ordered by performance, and so the even-numbered experts are slightly worse on average compared to the odd-numbered experts. Hence, there is reason to believe that COMB can be improved upon for larger numbers of experts by modifying the COMB vector slightly.
$x_1\geq x_2 \geq \cdots \geq x_n$
, they are essentially ordered by performance, and so the even-numbered experts are slightly worse on average compared to the odd-numbered experts. Hence, there is reason to believe that COMB can be improved upon for larger numbers of experts by modifying the COMB vector slightly.
The PDE perspective developed in [Reference Drenska20] can help shed light on the optimal adversarial strategy, since it turns out we can derive explicit solutions for the PDE (1.1) for
 $n\leq 4$
experts. Below, we present the solutions in the sector
$n\leq 4$
experts. Below, we present the solutions in the sector
 \begin{equation*}{\mathbb {S}}_n = \{x\in {\mathbb {R}}^n \, : \, x_1 \geq x_2 \geq \cdots \geq x_n\}.\end{equation*}
\begin{equation*}{\mathbb {S}}_n = \{x\in {\mathbb {R}}^n \, : \, x_1 \geq x_2 \geq \cdots \geq x_n\}.\end{equation*}
Since the PDE is unchanged under permutations of the coordinates, this completely determines the solution. It was shown in [Reference Drenska20] that for
 $n = 2$
experts the solution of (1.1) is given in the sector
$n = 2$
experts the solution of (1.1) is given in the sector
 ${\mathbb {S}}_2$
by
${\mathbb {S}}_2$
by
 \begin{equation} u(x) = x_1 + \dfrac {1}{2\sqrt {2}}e^{\sqrt {2}(x_2-x_1)}, \end{equation}
\begin{equation} u(x) = x_1 + \dfrac {1}{2\sqrt {2}}e^{\sqrt {2}(x_2-x_1)}, \end{equation}
and for
 $n = 3$
, the solution is given in
$n = 3$
, the solution is given in
 ${\mathbb {S}}_3$
by
${\mathbb {S}}_3$
by
 \begin{equation} u(x) = x_1 + \dfrac {1}{2\sqrt {2}}e^{\sqrt {2}(x_2-x_1)} + \dfrac {1}{6\sqrt {2}}e^{\sqrt {2}(2x_3-x_2-x_1).} \end{equation}
\begin{equation} u(x) = x_1 + \dfrac {1}{2\sqrt {2}}e^{\sqrt {2}(x_2-x_1)} + \dfrac {1}{6\sqrt {2}}e^{\sqrt {2}(2x_3-x_2-x_1).} \end{equation}
Since we have explicit solutions, we can check the optimal adversarial strategies via (1.5) within the sector
 ${\mathbb {S}}_n$
. For
${\mathbb {S}}_n$
. For
 $n=2$
both
$n=2$
both
 ${\mathbf {v}}=(1,0)$
and
${\mathbf {v}}=(1,0)$
and
 $\mathbf {w}=(0,1)$
are globally optimal for all
$\mathbf {w}=(0,1)$
are globally optimal for all
 $x\in {\mathbb {S}}_n$
, which are both the same COMB strategy since
$x\in {\mathbb {S}}_n$
, which are both the same COMB strategy since
 ${\mathbf {v}} = \unicode {x1D7D9} - \mathbf {w}$
. For
${\mathbf {v}} = \unicode {x1D7D9} - \mathbf {w}$
. For
 $n=3$
, both
$n=3$
, both
 $(1,0,0)$
and
$(1,0,0)$
and
 $(0,1,0)$
are globally optimal (as well as a their equivalent strategies
$(0,1,0)$
are globally optimal (as well as a their equivalent strategies
 $(0,1,1)$
and
$(0,1,1)$
and
 $(1,0,1)$
, which we will omit from now on). The second strategy
$(1,0,1)$
, which we will omit from now on). The second strategy
 $(0,1,0)$
is the COMB strategy, while the first
$(0,1,0)$
is the COMB strategy, while the first
 $(1,0,0)$
is not.
$(1,0,0)$
is not.
For
 $n = 4$
experts, it was shown in [Reference Bayraktar, Ekren and Zhang7] that the solution of (1.1) is given by
$n = 4$
experts, it was shown in [Reference Bayraktar, Ekren and Zhang7] that the solution of (1.1) is given by
 \begin{equation} \begin{aligned} u(x) ={} & x_1 - \dfrac {\sqrt {2}}{4}\text {sinh}(\sqrt {2}(x_1-x_2)) \\ &+ \dfrac {\sqrt {2}}{2}\text {arctan}\left (e^{\frac {x_4+x_3-x_2-x_1}{\sqrt {2}}}\right )\cdot \\&\text {cosh}\left (\frac {x_4-x_3+x_2-x_1}{\sqrt {2}}\right )\text {cosh}\left (\frac {-x_4+x_3+x_2-x_1}{\sqrt {2}}\right )\text {cosh}\left (\frac {-x_4-x_3+x_2+x_1}{\sqrt {2}}\right )\\ &+ \dfrac {\sqrt {2}}{2}\text {arctanh}\left (e^{\frac {x_4+x_3-x_2-x_1}{\sqrt {2}}}\right )\cdot \\&\text {sinh}\left (\dfrac {x_4-x_3+x_2-x_1}{\sqrt {2}}\right )\text {sinh}\left (\dfrac {-x_4+x_3+x_2-x_1}{\sqrt {2}}\right )\text {sinh}\left (\dfrac {-x_4-x_3+x_2+x_1}{\sqrt {2}}\right ), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} u(x) ={} & x_1 - \dfrac {\sqrt {2}}{4}\text {sinh}(\sqrt {2}(x_1-x_2)) \\ &+ \dfrac {\sqrt {2}}{2}\text {arctan}\left (e^{\frac {x_4+x_3-x_2-x_1}{\sqrt {2}}}\right )\cdot \\&\text {cosh}\left (\frac {x_4-x_3+x_2-x_1}{\sqrt {2}}\right )\text {cosh}\left (\frac {-x_4+x_3+x_2-x_1}{\sqrt {2}}\right )\text {cosh}\left (\frac {-x_4-x_3+x_2+x_1}{\sqrt {2}}\right )\\ &+ \dfrac {\sqrt {2}}{2}\text {arctanh}\left (e^{\frac {x_4+x_3-x_2-x_1}{\sqrt {2}}}\right )\cdot \\&\text {sinh}\left (\dfrac {x_4-x_3+x_2-x_1}{\sqrt {2}}\right )\text {sinh}\left (\dfrac {-x_4+x_3+x_2-x_1}{\sqrt {2}}\right )\text {sinh}\left (\dfrac {-x_4-x_3+x_2+x_1}{\sqrt {2}}\right ), \end{aligned} \end{equation}
from which it is possible to prove [Reference Bayraktar, Ekren and Zhang7] that the COMB strategy
 $(1,0,1,0)$
is optimal, as well as the non-COMB strategy
$(1,0,1,0)$
is optimal, as well as the non-COMB strategy
 $(0,1,1,0)$
. For
$(0,1,1,0)$
. For
 $n\geq 5$
experts, an explicit solution is unknown, and the question of the optimality of the COMB strategy is open.
$n\geq 5$
experts, an explicit solution is unknown, and the question of the optimality of the COMB strategy is open.
It is worthwhile mentioning that it is remarkable that explicit solutions have been obtained for the degenerate elliptic PDE (1.1) for
 $n\leq 4$
dimension. Usually, explicit solutions for nonlinear PDE are not available. Furthermore, the solutions given in (1.6), (1.7) and (1.8) are all twice continuously differentiable with Lipschitz second partial derivatives, i.e., they are classical
$n\leq 4$
dimension. Usually, explicit solutions for nonlinear PDE are not available. Furthermore, the solutions given in (1.6), (1.7) and (1.8) are all twice continuously differentiable with Lipschitz second partial derivatives, i.e., they are classical
 $C^{2,1}({\mathbb {R}}^n)$
solutions. This is also remarkable, since one would only expect this for uniformly elliptic equations (since the right-hand side is Lipschitz continuous) and not for degenerate elliptic equations. As far as we are aware, there is no general regularity theory that can explain this.
$C^{2,1}({\mathbb {R}}^n)$
solutions. This is also remarkable, since one would only expect this for uniformly elliptic equations (since the right-hand side is Lipschitz continuous) and not for degenerate elliptic equations. As far as we are aware, there is no general regularity theory that can explain this.
In fact, the existence of classical solutions of (1.1) is closely tied to the existence of a globally optimal strategy. As a simple example, for
 $n=2$
experts the strategy
$n=2$
experts the strategy
 ${\mathbf {v}}=(1,0)$
is optimal in
${\mathbf {v}}=(1,0)$
is optimal in
 ${\mathbb {S}}_2$
, and so the PDE (1.1) reduces to the one-dimensional linear equation
${\mathbb {S}}_2$
, and so the PDE (1.1) reduces to the one-dimensional linear equation
 \begin{equation*}u - \frac {1}{2}u_{x_1x_1} = x_1 \ \ \text {in} \ {\mathbb {S}}_2.\end{equation*}
\begin{equation*}u - \frac {1}{2}u_{x_1x_1} = x_1 \ \ \text {in} \ {\mathbb {S}}_2.\end{equation*}
We can integrate this, keeping only the exponentially decaying solution, to obtain
 \begin{equation*}u(x) = x_1 + f(x_2) e^{-\sqrt {2x}_1} \ \ \text {on} \ {\mathbb {S}}_2.\end{equation*}
\begin{equation*}u(x) = x_1 + f(x_2) e^{-\sqrt {2x}_1} \ \ \text {on} \ {\mathbb {S}}_2.\end{equation*}
Using the symmetry
 $u(x_1,x_2)=u(x_2,x_1)$
we obtain
$u(x_1,x_2)=u(x_2,x_1)$
we obtain
 $u_{x_1}=u_{x_2}$
on
$u_{x_1}=u_{x_2}$
on
 $\partial {\mathbb {S}}_2 = \{x\in {\mathbb {R}}^2 \, : \, x_1=x_2\}$
. This yields
$\partial {\mathbb {S}}_2 = \{x\in {\mathbb {R}}^2 \, : \, x_1=x_2\}$
. This yields
 \begin{equation*}1 - \sqrt {2} f(x) e^{-\sqrt {2x}} = u_{x_1}(x,x) = u_{x_2}(x,x) = f'(x) e^{-\sqrt {2x}},\end{equation*}
\begin{equation*}1 - \sqrt {2} f(x) e^{-\sqrt {2x}} = u_{x_1}(x,x) = u_{x_2}(x,x) = f'(x) e^{-\sqrt {2x}},\end{equation*}
and so
 \begin{equation*}f(x) = Ce^{-\sqrt {2x}} + \frac {1}{2\sqrt {2}}e^{\sqrt {2x}}.\end{equation*}
\begin{equation*}f(x) = Ce^{-\sqrt {2x}} + \frac {1}{2\sqrt {2}}e^{\sqrt {2x}}.\end{equation*}
Since
 $u_{x_1}(0)=u_{x_2}(0)=\frac {1}{2}$
we have
$u_{x_1}(0)=u_{x_2}(0)=\frac {1}{2}$
we have
 $f(0) = \frac {1}{2\sqrt {2}}$
and so
$f(0) = \frac {1}{2\sqrt {2}}$
and so
 $C=0$
. Substituting this above yields the two expert solutions
$C=0$
. Substituting this above yields the two expert solutions
 $u$
given by (1.6). Roughly the same procedure can be carried out for
$u$
given by (1.6). Roughly the same procedure can be carried out for
 $n=3$
and
$n=3$
and
 $n=4$
experts, though the
$n=4$
experts, though the
 $n=4$
case is particularly tedious (see [Reference Bayraktar, Ekren and Zhang7]).
$n=4$
case is particularly tedious (see [Reference Bayraktar, Ekren and Zhang7]).
The question of whether the COMB strategy is asymptotically optimal for
 $n\geq 5$
experts is an open problem. Some recent work [Reference Chase17] gives experimental numerical evidence that COMB is not optimal for
$n\geq 5$
experts is an open problem. Some recent work [Reference Chase17] gives experimental numerical evidence that COMB is not optimal for
 $n=5$
experts. The numerical experiments in [Reference Chase17] simulated the two-player game and compared the COMB strategy against the strategy
$n=5$
experts. The numerical experiments in [Reference Chase17] simulated the two-player game and compared the COMB strategy against the strategy
 $(1,0,1,0,0)$
, the latter appearing to be strictly better. It was shown in [Reference Kobzar, Kohn and Wang31, Reference Kobzar, Kohn and Wang32] that COMB is at least as powerful as the setting of randomly choosing which half of the experts to advance (the so-called Bernoulli strategy). This motivates our work of numerically solving the PDE (1.1) in order to shed light on the optimality of COMB and other strategies for
$(1,0,1,0,0)$
, the latter appearing to be strictly better. It was shown in [Reference Kobzar, Kohn and Wang31, Reference Kobzar, Kohn and Wang32] that COMB is at least as powerful as the setting of randomly choosing which half of the experts to advance (the so-called Bernoulli strategy). This motivates our work of numerically solving the PDE (1.1) in order to shed light on the optimality of COMB and other strategies for
 $n\geq 5$
experts.
$n\geq 5$
experts.
We mention that an analogous parabolic PDE exists for the finite-horizon setting of this problem [Reference Drenska20], motivating a similar treatment in terms of numerics for the parabolic equation as well. Some progress in the parabolic case can be found in [Reference Bayraktar, Ekren and Zhang5]. Further, related settings such as prediction against a limited adversary [Reference Bayraktar, Ekren and Zhang6] (rather than the optimal adversary being studied in this work) and malicious experts [Reference Bayraktar, Poor and Zhang8] have been studied as well. A related PDE where
 $\mathbf {v}$
is chosen just from the standard basis vectors
$\mathbf {v}$
is chosen just from the standard basis vectors
 $\{{\mathbf {e}}_1, \ldots, {\mathbf {e}}_n\}$
has been studied and has a closed-form solution for a general number
$\{{\mathbf {e}}_1, \ldots, {\mathbf {e}}_n\}$
has been studied and has a closed-form solution for a general number
 $n$
of experts [Reference Kobzar, Kohn and Wang31, Reference Kobzar, Kohn and Wang32]. Additionally, some PDE approaches to online learning problems and neural network-based problems can be found in [Reference Wang43]. We also mention that repeated two-player games also appear in the PDE literature in multiple other settings [Reference Antunovic, Peres, Sheffield and Somersille3, Reference Armstrong and Smart4, Reference Calder9, Reference Calder11, Reference Calder and Drenska13, Reference Calder and Smart14, Reference Flores, Calder and Lerman24, Reference Kohn and Serfaty33–Reference Lewicka and Manfredi35, Reference Naor and Sheffield37, Reference Peres, Schramm, Sheffield and Wilson39, Reference Peres and Sheffield40].
$n$
of experts [Reference Kobzar, Kohn and Wang31, Reference Kobzar, Kohn and Wang32]. Additionally, some PDE approaches to online learning problems and neural network-based problems can be found in [Reference Wang43]. We also mention that repeated two-player games also appear in the PDE literature in multiple other settings [Reference Antunovic, Peres, Sheffield and Somersille3, Reference Armstrong and Smart4, Reference Calder9, Reference Calder11, Reference Calder and Drenska13, Reference Calder and Smart14, Reference Flores, Calder and Lerman24, Reference Kohn and Serfaty33–Reference Lewicka and Manfredi35, Reference Naor and Sheffield37, Reference Peres, Schramm, Sheffield and Wilson39, Reference Peres and Sheffield40].
1.2 Main results and conjectures
In Section 4, we present the results of numerical experiments solving the prediction with expert advice PDE (1.1) for
 $n\leq 10$
experts. We summarize the main results we obtain from the numerical experiments here.
$n\leq 10$
experts. We summarize the main results we obtain from the numerical experiments here.
-
1. We have strong numerical evidence that the COMB strategy is not globally optimal for
 $5 \leq n \leq 10$
. This validates the numerical evidence from [Reference Chase17] for
$n=5$
experts.
$5 \leq n \leq 10$
. This validates the numerical evidence from [Reference Chase17] for
$n=5$
experts. -
2. For
$n=5$
experts, we have strong numerical evidence that the non-COMB adversarial strategy
$(0,1,0,1,1)$
, equivalent to
$(1,0,1,0,0)$
, is the only globally optimal strategy. This is the same strategy that was numerically shown to be better than COMB in [Reference Chase17]. -
3. For
$6 \leq n \leq 10$
experts, we have strong numerical evidence that there are no globally optimal adversary strategies.






From these numerical results, we state a number of conjectures that we leave for future work.
Conjecture 1.1.
The COMB strategy is globally asymptotically optimal (i.e., on the sector
 ${\mathbb {S}}_n$
) only for
${\mathbb {S}}_n$
) only for
 $n\leq 4$
experts.
$n\leq 4$
experts.
Conjecture 1.2.
The non-COMB strategy
 $(1,0,1,0,0)$
is the only globally asymptotically optimal strategy for
$(1,0,1,0,0)$
is the only globally asymptotically optimal strategy for
 $n=5$
experts.
$n=5$
experts.
Conjecture 1.3.
There is no globally asymptotically optimal adversary strategy that is constant on the sector
 $\mathbb {S}_n$
for
$\mathbb {S}_n$
for
 $n\geq 6$
experts.
$n\geq 6$
experts.
Recalling our discussion in Section 1.1 about the connection between explicit solutions of the PDE (1.1) and the existence of optimal strategies, if Conjecture 1.2 is true, then we expect there to exist a classical explicit solution of the
 $n=5$
expert PDE, similar to the solutions given in (1.6), (1.7), and (1.8) for the
$n=5$
expert PDE, similar to the solutions given in (1.6), (1.7), and (1.8) for the
 $n=2,3,4$
expert problems.
$n=2,3,4$
expert problems.
1.2.1 Open problem
Determine an analytic expression for the solution of the PDE (1.1) for
 $n=5$
.
$n=5$
.
An explicit solution for
 $n=5$
experts would allow one to check the validity of Conjecture 1.2, as was done for
$n=5$
experts would allow one to check the validity of Conjecture 1.2, as was done for
 $n=4$
experts in [Reference Bayraktar, Ekren and Zhang7]. If Conjecture 1.3 is true, then this strongly suggests that it will be impossible to find an explicit solution of the PDE for
$n=4$
experts in [Reference Bayraktar, Ekren and Zhang7]. If Conjecture 1.3 is true, then this strongly suggests that it will be impossible to find an explicit solution of the PDE for
 $n\geq 6$
experts and that the solution may fail to be a classical solution in
$n\geq 6$
experts and that the solution may fail to be a classical solution in
 $C^{2,1}({\mathbb {R}}^n)$
when
$C^{2,1}({\mathbb {R}}^n)$
when
 $n\geq 6$
. If there is no globally optimal strategy, then there will be regions of
$n\geq 6$
. If there is no globally optimal strategy, then there will be regions of
 ${\mathbb {S}}_n$
corresponding to different optimal strategies
${\mathbb {S}}_n$
corresponding to different optimal strategies
 ${\mathbf {v}}\in {\mathcal B}^n$
, and the solution may fail to be twice continuously differentiable across these interfaces.
${\mathbf {v}}\in {\mathcal B}^n$
, and the solution may fail to be twice continuously differentiable across these interfaces.
Remark 1.4.
It is important to point out that there are certainly some limitations to our numerical results. In particular, we cannot solve the PDE
(1.1)
numerically on the full space
 ${\mathbb {R}}^n$
and must restrict our attention to a compact subset. Our numerical results are obtained over the box
${\mathbb {R}}^n$
and must restrict our attention to a compact subset. Our numerical results are obtained over the box
 $[/!-1,1]^n$
. We cannot rule out, for example, that Conjecture 1.2 fails somewhere outside of the box
$[/!-1,1]^n$
. We cannot rule out, for example, that Conjecture 1.2 fails somewhere outside of the box
 $[/!-1,1]^n$
. However, we do find that for
$[/!-1,1]^n$
. However, we do find that for
 $n=2,3,4$
experts, the optimality observed on the box matches perfectly with the global theory. The negative results of Conjectures 1.1 and 1.3 do not suffer the same limitations, since non-optimality need only be observed at a single point. Finally, our numerical convergence rates rely on classical regularity of the viscosity solution, which is only known for
$n=2,3,4$
experts, the optimality observed on the box matches perfectly with the global theory. The negative results of Conjectures 1.1 and 1.3 do not suffer the same limitations, since non-optimality need only be observed at a single point. Finally, our numerical convergence rates rely on classical regularity of the viscosity solution, which is only known for
 $n\leq 4$
experts.
$n\leq 4$
experts.
Remark 1.5.
We also remark that it may be possible to use our techniques for reducing the computational grid to the sector
 ${\mathbb {S}}_n$
in combination with the dynamic programming approaches of [17, 27]. We leave this interesting direction to future work.
${\mathbb {S}}_n$
in combination with the dynamic programming approaches of [17, 27]. We leave this interesting direction to future work.
1.3 Outline
The rest of the paper is organized as follows. In Sections 2 and 3, we present and analyse our numerical scheme for solving the prediction PDE (1.1). The first part in Section 2 is written for a more general class of degenerate elliptic PDEs, while the second part Section 3 contains results that require the specific form of our prediction with expert advice equation. Finally in Section 4, we present the results of our numerical experiments that provide the evidence for the conjectures given in Section 1.2.
2 Analysis of a general numerical scheme
We study here a finite difference scheme for the PDE (1.3) consisting of replacing the pure second derivatives
 ${\mathbf {v}}^T \nabla ^2 u {\mathbf {v}}$
with finite difference approximations. We work on the grid
${\mathbf {v}}^T \nabla ^2 u {\mathbf {v}}$
with finite difference approximations. We work on the grid
 $\mathbb {Z}_h^n$
, where
$\mathbb {Z}_h^n$
, where
 $\mathbb {Z}_h=h\mathbb {Z}$
and
$\mathbb {Z}_h=h\mathbb {Z}$
and
 $h\gt 0$
is the grid spacing. For a function
$h\gt 0$
is the grid spacing. For a function
 $u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
, we define the discrete gradient as the mapping
$u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
, we define the discrete gradient as the mapping
 $\nabla _h:{\mathbb {Z}^n_h} \times {\mathbb {Z}^n}\to {\mathbb {R}}$
defined by
$\nabla _h:{\mathbb {Z}^n_h} \times {\mathbb {Z}^n}\to {\mathbb {R}}$
defined by
 \begin{equation} \nabla _h u(x,{\mathbf {v}}) \,:\!=\, \frac {u(x + h{\mathbf {v}}) - u(x)}{h}. \end{equation}
\begin{equation} \nabla _h u(x,{\mathbf {v}}) \,:\!=\, \frac {u(x + h{\mathbf {v}}) - u(x)}{h}. \end{equation}
The discrete Hessian is defined as the mapping
 $\nabla ^2_h u:{\mathbb {Z}^n_h}\times {\mathbb {Z}^n} \to {\mathbb {R}}$
given by
$\nabla ^2_h u:{\mathbb {Z}^n_h}\times {\mathbb {Z}^n} \to {\mathbb {R}}$
given by
 \begin{equation} \nabla ^2_h u(x,{\mathbf {v}}) \,:\!=\, \frac {u(x + h{\mathbf {v}}) - 2u(x) + u(x- h{\mathbf {v}})}{h^2}. \end{equation}
\begin{equation} \nabla ^2_h u(x,{\mathbf {v}}) \,:\!=\, \frac {u(x + h{\mathbf {v}}) - 2u(x) + u(x- h{\mathbf {v}})}{h^2}. \end{equation}
We note that
 \begin{equation} \nabla ^2_h u(x,{\mathbf {v}}) = \frac {\nabla _h u(x,{\mathbf {v}}) + \nabla _h u(x,-{\mathbf {v}})}{h}. \end{equation}
\begin{equation} \nabla ^2_h u(x,{\mathbf {v}}) = \frac {\nabla _h u(x,{\mathbf {v}}) + \nabla _h u(x,-{\mathbf {v}})}{h}. \end{equation}
Also, the definition of the discrete Hessian leads immediately to the discrete Taylor-type expansions
 \begin{equation} \frac {1}{2}(u(x+h{\mathbf {v}}) + u(x-h{\mathbf {v}})) = u(x) + \frac {h^2}{2}\nabla ^2_h u(x,{\mathbf {v}}), \end{equation}
\begin{equation} \frac {1}{2}(u(x+h{\mathbf {v}}) + u(x-h{\mathbf {v}})) = u(x) + \frac {h^2}{2}\nabla ^2_h u(x,{\mathbf {v}}), \end{equation}
and
 \begin{equation} u(x+h{\mathbf {v}}) = u(x) - h\nabla _h(u,-{\mathbf {v}}) + h^2 \nabla ^2_h u(x,{\mathbf {v}}). \end{equation}
\begin{equation} u(x+h{\mathbf {v}}) = u(x) - h\nabla _h(u,-{\mathbf {v}}) + h^2 \nabla ^2_h u(x,{\mathbf {v}}). \end{equation}
Define
 ${\mathcal H}_n = \{X:\mathbb {Z}_n \to {\mathbb {R}}\}$
. We will use the notation
${\mathcal H}_n = \{X:\mathbb {Z}_n \to {\mathbb {R}}\}$
. We will use the notation
 $\nabla _h u(x)\in {\mathcal H}_n$
and
$\nabla _h u(x)\in {\mathcal H}_n$
and
 $\nabla ^2_h u(x)\in {\mathcal H}_n$
for the mappings
$\nabla ^2_h u(x)\in {\mathcal H}_n$
for the mappings
 ${\mathbf {v}}\mapsto \nabla _h u(x,{\mathbf {v}})$
and
${\mathbf {v}}\mapsto \nabla _h u(x,{\mathbf {v}})$
and
 ${\mathbf {v}} \mapsto \nabla ^2 u_h(x,{\mathbf {v}})$
, respectively. For
${\mathbf {v}} \mapsto \nabla ^2 u_h(x,{\mathbf {v}})$
, respectively. For
 $u\in C^{k,1}({\mathbb {R}}^n)$
with
$u\in C^{k,1}({\mathbb {R}}^n)$
with
 $k=2$
or
$k=2$
or
 $k=3$
and any
$k=3$
and any
 ${\mathbf {v}} \in {\mathbb {Z}^n}$
we have via Taylor expansion that
${\mathbf {v}} \in {\mathbb {Z}^n}$
we have via Taylor expansion that
 \begin{equation*} \nabla ^2_h u(x,{\mathbf {v}}) = {\mathbf {v}}^T \nabla ^2 u(x) {\mathbf {v}} + {\mathcal O}(|{\mathbf {v}}|^{k+1}h^{k-1}).\end{equation*}
\begin{equation*} \nabla ^2_h u(x,{\mathbf {v}}) = {\mathbf {v}}^T \nabla ^2 u(x) {\mathbf {v}} + {\mathcal O}(|{\mathbf {v}}|^{k+1}h^{k-1}).\end{equation*}
Our discrete approximation of (1.3) is given by
 \begin{equation*}u(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^n}\nabla ^2_h u(x,{\mathbf {v}}) = g(x) \ \ \text {for } x\in {\mathbb {Z}^n_h}.\end{equation*}
\begin{equation*}u(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^n}\nabla ^2_h u(x,{\mathbf {v}}) = g(x) \ \ \text {for } x\in {\mathbb {Z}^n_h}.\end{equation*}
Since our methods are not specific to this equation, we will study a more general class of equations of the form
 \begin{equation} u - F(\nabla ^2_h u) = g \ \ \text {on } {\mathbb {Z}^n_h}, \end{equation}
\begin{equation} u - F(\nabla ^2_h u) = g \ \ \text {on } {\mathbb {Z}^n_h}, \end{equation}
where
 $F\,:\,{\mathcal H}_n\to {\mathbb {R}}$
. The PDE (1.3) is obtained by setting
$F\,:\,{\mathcal H}_n\to {\mathbb {R}}$
. The PDE (1.3) is obtained by setting
 \begin{equation} F(X) = \frac {1}{2}\max _{{\mathbf {v}}\in {\mathcal B}^n}X({\mathbf {v}}). \end{equation}
\begin{equation} F(X) = \frac {1}{2}\max _{{\mathbf {v}}\in {\mathcal B}^n}X({\mathbf {v}}). \end{equation}
We need to place a monotonicity assumption on
 $F$
.
$F$
.
Definition 2.1.
We say that
 $F:{\mathcal H}_n\to {\mathbb {R}}$
is monotone if for all
$F:{\mathcal H}_n\to {\mathbb {R}}$
is monotone if for all
 $X,Y\in {\mathcal H}_n$
with
$X,Y\in {\mathcal H}_n$
with
 $X\leq Y$
we have
$X\leq Y$
we have
 $F(X) \leq F(Y)$
.
$F(X) \leq F(Y)$
.
We note that
 $X,Y:{\mathcal H}_n\to {\mathbb {R}}$
are real-valued functions, so
$X,Y:{\mathcal H}_n\to {\mathbb {R}}$
are real-valued functions, so
 $X\leq Y$
means that
$X\leq Y$
means that
 $X({\mathbf {v}})\leq Y({\mathbf {v}})$
for all
$X({\mathbf {v}})\leq Y({\mathbf {v}})$
for all
 ${\mathbf {v}}\in \mathbb {Z}_n$
. The class of monotone equations of the form (2.6) is closely related to the wide stencil finite difference schemes introduced and studied by Oberman [Reference Oberman38]. The main difference in this section is that we are focused on the unbounded domain
${\mathbf {v}}\in \mathbb {Z}_n$
. The class of monotone equations of the form (2.6) is closely related to the wide stencil finite difference schemes introduced and studied by Oberman [Reference Oberman38]. The main difference in this section is that we are focused on the unbounded domain
 $\mathbb {Z}^n_h$
, and we are interested in properties of the solution
$\mathbb {Z}^n_h$
, and we are interested in properties of the solution
 $u$
, such as Lipschitzness, convexity, permutation invariance, etc., that hold under certain structure conditions and the source term
$u$
, such as Lipschitzness, convexity, permutation invariance, etc., that hold under certain structure conditions and the source term
 $g$
.
$g$
.
For
 $X\in {\mathcal H}_n$
we define
$X\in {\mathcal H}_n$
we define
 \begin{equation} \|X\|_{N,\infty }= \max _{\substack {{\mathbf {v}}\in {\mathbb {Z}^n} \\ |{\mathbf {v}}|_\infty \leq N}}|X({\mathbf {v}})|, \end{equation}
\begin{equation} \|X\|_{N,\infty }= \max _{\substack {{\mathbf {v}}\in {\mathbb {Z}^n} \\ |{\mathbf {v}}|_\infty \leq N}}|X({\mathbf {v}})|, \end{equation}
where
 $|{\mathbf {v}}|_\infty = \max _{1\leq i \leq n}|v_i|$
. We need to place a condition on the width of the stencil
$|{\mathbf {v}}|_\infty = \max _{1\leq i \leq n}|v_i|$
. We need to place a condition on the width of the stencil
 $F$
.
$F$
.
Definition 2.2.
We say
 $F:{\mathcal H}_n\to {\mathbb {R}}$
has width
$F:{\mathcal H}_n\to {\mathbb {R}}$
has width
 $N$
if there exists
$N$
if there exists
 $C\gt 0$
such that for all
$C\gt 0$
such that for all
 $X,Y\in {\mathcal H}_n$
we have
$X,Y\in {\mathcal H}_n$
we have
 \begin{equation*}|F(X) - F(Y)| \leq C\|X - Y\|_{N,\infty }.\end{equation*}
\begin{equation*}|F(X) - F(Y)| \leq C\|X - Y\|_{N,\infty }.\end{equation*}
The smallest such constant
 $C\gt 0$
is called the Lipschitz constant of
$C\gt 0$
is called the Lipschitz constant of
 $F$
and denoted
$F$
and denoted
 $\textrm {Lip}_N(F)$
.
$\textrm {Lip}_N(F)$
.
The choice of
 $F$
given in (2.7) is monotone and has width
$F$
given in (2.7) is monotone and has width
 $N=1$
, with
$N=1$
, with
 $\textrm {Lip}_1(F)=\frac {1}{2}$
.
$\textrm {Lip}_1(F)=\frac {1}{2}$
.
2.1 Existence and uniqueness
We first establish a comparison principle.
Theorem 2.3.
Assume
 $F$
is monotone and has width
$F$
is monotone and has width
 $N$
. Let
$N$
. Let
 $u,v:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
satisfy
$u,v:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
satisfy
 \begin{equation} u- F(\nabla ^2_h u) \leq v - F(\nabla ^2_h v) \ \ \text {on } {\mathbb {Z}^n_h}, \end{equation}
\begin{equation} u- F(\nabla ^2_h u) \leq v - F(\nabla ^2_h v) \ \ \text {on } {\mathbb {Z}^n_h}, \end{equation}
and
 \begin{equation} \lim _{|x|\to \infty } \frac {u(x) - v(x)}{|x|^2 }=0. \end{equation}
\begin{equation} \lim _{|x|\to \infty } \frac {u(x) - v(x)}{|x|^2 }=0. \end{equation}
Then
 $u\leq v$
on
$u\leq v$
on
 $\mathbb {Z}^n_h$
.
$\mathbb {Z}^n_h$
.
Proof.
For
 ${\varepsilon }\gt 0$
we define
${\varepsilon }\gt 0$
we define
 \begin{equation*}u_{\varepsilon }(x) = u(x) - \frac {{\varepsilon }}{2}|x|^2 - {\varepsilon } N^2 - {\varepsilon }.\end{equation*}
\begin{equation*}u_{\varepsilon }(x) = u(x) - \frac {{\varepsilon }}{2}|x|^2 - {\varepsilon } N^2 - {\varepsilon }.\end{equation*}
We claim that
 $u_{\varepsilon } \leq v$
for all
$u_{\varepsilon } \leq v$
for all
 ${\varepsilon }\gt 0$
, from which the result follows. Fix
${\varepsilon }\gt 0$
, from which the result follows. Fix
 ${\varepsilon }\gt 0$
and assume by way of contradiction that
${\varepsilon }\gt 0$
and assume by way of contradiction that
 $\sup _{{\mathbb {Z}^n_h}}(u_{\varepsilon } - v) \gt 0$
. By (2.10), there exists
$\sup _{{\mathbb {Z}^n_h}}(u_{\varepsilon } - v) \gt 0$
. By (2.10), there exists
 $R\gt 0$
, depending on
$R\gt 0$
, depending on
 ${\varepsilon }\gt 0$
, such that
${\varepsilon }\gt 0$
, such that
 $u_{\varepsilon }(x) \lt v(x)$
for
$u_{\varepsilon }(x) \lt v(x)$
for
 $|x| \gt R$
. Thus,
$|x| \gt R$
. Thus,
 $u_{\varepsilon } - v$
attains its maximum over
$u_{\varepsilon } - v$
attains its maximum over
 $\mathbb {Z}^n_h$
at some
$\mathbb {Z}^n_h$
at some
 $x_0\in {\mathbb {Z}^n_h}$
, and
$x_0\in {\mathbb {Z}^n_h}$
, and
 $u_{\varepsilon }(x_0) \gt v(x_0)$
. Since
$u_{\varepsilon }(x_0) \gt v(x_0)$
. Since
 $u_{\varepsilon }(x) - v(x) \leq u_{\varepsilon }(x_0) - v(x_0)$
for all
$u_{\varepsilon }(x) - v(x) \leq u_{\varepsilon }(x_0) - v(x_0)$
for all
 $x\in {\mathbb {Z}^n_h}$
we have
$x\in {\mathbb {Z}^n_h}$
we have
 \begin{equation*}u_{\varepsilon }(x) - u_{\varepsilon }(x_0) \leq v(x) - v(x_0).\end{equation*}
\begin{equation*}u_{\varepsilon }(x) - u_{\varepsilon }(x_0) \leq v(x) - v(x_0).\end{equation*}
It follows that
 \begin{align*} \nabla ^2_h u_{\varepsilon }(x_0,{\mathbf {v}}) &= \frac {1}{h^2}(u_{\varepsilon }(x_0+h{\mathbf {v}}) - u(x_0) + u_{\varepsilon }(x_0-h{\mathbf {v}}) - u(x_0)) \\ &\leq \frac {1}{h^2}(v(x_0+h{\mathbf {v}}) - v(x_0) + v(x_0-h{\mathbf {v}}) - v(x_0)) = \nabla ^2_h v(x_0,{\mathbf {v}}) \end{align*}
\begin{align*} \nabla ^2_h u_{\varepsilon }(x_0,{\mathbf {v}}) &= \frac {1}{h^2}(u_{\varepsilon }(x_0+h{\mathbf {v}}) - u(x_0) + u_{\varepsilon }(x_0-h{\mathbf {v}}) - u(x_0)) \\ &\leq \frac {1}{h^2}(v(x_0+h{\mathbf {v}}) - v(x_0) + v(x_0-h{\mathbf {v}}) - v(x_0)) = \nabla ^2_h v(x_0,{\mathbf {v}}) \end{align*}
for all directions
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
. Since
${\mathbf {v}}\in {\mathbb {Z}^n}$
. Since
 $F$
is monotone we have
$F$
is monotone we have
 \begin{equation} F(\nabla ^2_h u_{\varepsilon }(x_0)) \leq F(\nabla ^2_h v(x_0)). \end{equation}
\begin{equation} F(\nabla ^2_h u_{\varepsilon }(x_0)) \leq F(\nabla ^2_h v(x_0)). \end{equation}
We now compute
 \begin{equation*} \nabla ^2_h u_{\varepsilon } (x,{\mathbf {v}}) = \nabla ^2_h u (x,{\mathbf {v}}) - {\varepsilon } |{\mathbf {v}}|^2,\end{equation*}
\begin{equation*} \nabla ^2_h u_{\varepsilon } (x,{\mathbf {v}}) = \nabla ^2_h u (x,{\mathbf {v}}) - {\varepsilon } |{\mathbf {v}}|^2,\end{equation*}
from which it follows that
 \begin{align*} u_{\varepsilon }(x_0) - F(\nabla ^2_h u_{\varepsilon }(x_0)) &= u(x_0) - \frac {{\varepsilon }}{2}|x_0|^2 -{\varepsilon } N^2 - {\varepsilon } - F(\nabla ^2_h u(x_0) - {\varepsilon }|{\mathbf {v}}|^2)\\ &\leq u(x_0) - F(\nabla ^2_h u(x_0)) - \frac {{\varepsilon }}{2}|x_0|^2- {\varepsilon }\\ &\lt v(x_0) - F(\nabla ^2_h v(x_0))\\ &\leq v(x_0) -F(\nabla ^2_h u_{\varepsilon }(x_0)), \end{align*}
\begin{align*} u_{\varepsilon }(x_0) - F(\nabla ^2_h u_{\varepsilon }(x_0)) &= u(x_0) - \frac {{\varepsilon }}{2}|x_0|^2 -{\varepsilon } N^2 - {\varepsilon } - F(\nabla ^2_h u(x_0) - {\varepsilon }|{\mathbf {v}}|^2)\\ &\leq u(x_0) - F(\nabla ^2_h u(x_0)) - \frac {{\varepsilon }}{2}|x_0|^2- {\varepsilon }\\ &\lt v(x_0) - F(\nabla ^2_h v(x_0))\\ &\leq v(x_0) -F(\nabla ^2_h u_{\varepsilon }(x_0)), \end{align*}
where the last line follows from (2.11). Therefore
 $u_{\varepsilon } (x_0) \leq v(x_0)$
, which is a contradiction.
$u_{\varepsilon } (x_0) \leq v(x_0)$
, which is a contradiction.
Existence of a solution follows from the comparison principle and the Perron method.
Theorem 2.4.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and
$N$
, and
 $F(0)=0$
. Suppose there exists
$F(0)=0$
. Suppose there exists
 $C_g\gt 0$
so that
$C_g\gt 0$
so that
 \begin{equation} |g(x)| \leq C_g (1 + |x|) \ \ \text {for all } x\in {\mathbb {Z}^n_h}. \end{equation}
\begin{equation} |g(x)| \leq C_g (1 + |x|) \ \ \text {for all } x\in {\mathbb {Z}^n_h}. \end{equation}
Then there exists a unique solution
 $u:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
of
(2.6)
satisfying
$u:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
of
(2.6)
satisfying
 $\lim _{|x|\to \infty } \frac {u(x)}{|x|^2 }=0$
. Furthermore, we have
$\lim _{|x|\to \infty } \frac {u(x)}{|x|^2 }=0$
. Furthermore, we have
 \begin{equation} |u(x)| \leq C C_g(\textrm {Lip}_N(F)N^3 + 1 + |x|) \ \ \text {for all } x\in {\mathbb {Z}^n_h}, \end{equation}
\begin{equation} |u(x)| \leq C C_g(\textrm {Lip}_N(F)N^3 + 1 + |x|) \ \ \text {for all } x\in {\mathbb {Z}^n_h}, \end{equation}
where
 $C$
depends only on
$C$
depends only on
 $n$
.
$n$
.
Proof. We define
 \begin{equation*}\psi (x) = \sqrt {1 + |x|^2},\end{equation*}
\begin{equation*}\psi (x) = \sqrt {1 + |x|^2},\end{equation*}
and note that
 $\psi$
is a smooth function with linear growth satisfying
$\psi$
is a smooth function with linear growth satisfying
 \begin{equation} \frac {1}{ \sqrt {2}}(1+|x|) \leq \psi (x) \leq 1+|x| \ \ \text {for all } x\in {\mathbb {R}}^n. \end{equation}
\begin{equation} \frac {1}{ \sqrt {2}}(1+|x|) \leq \psi (x) \leq 1+|x| \ \ \text {for all } x\in {\mathbb {R}}^n. \end{equation}
For any
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
and
${\mathbf {v}}\in {\mathbb {Z}^n}$
and
 $x\in {\mathbb {Z}^n_h}$
, we have
$x\in {\mathbb {Z}^n_h}$
, we have
 \begin{align*} |\nabla ^2_h \psi (x,{\mathbf {v}})| &\leq |\nabla ^2_h \psi (x,{\mathbf {v}}) - {\mathbf {v}}^T \nabla ^2 \psi (x){\mathbf {v}} | + C|{\mathbf {v}}|^2\\ &\leq |\nabla ^2_h \psi (x,{\mathbf {v}}) - {\mathbf {v}}^T \nabla ^2 \psi (x){\mathbf {v}} | + C|{\mathbf {v}}|^2\\ &\leq C\left (|{\mathbf {v}}|^3h+ |{\mathbf {v}}|^2\right ) \leq C |{\mathbf {v}}|^3, \end{align*}
\begin{align*} |\nabla ^2_h \psi (x,{\mathbf {v}})| &\leq |\nabla ^2_h \psi (x,{\mathbf {v}}) - {\mathbf {v}}^T \nabla ^2 \psi (x){\mathbf {v}} | + C|{\mathbf {v}}|^2\\ &\leq |\nabla ^2_h \psi (x,{\mathbf {v}}) - {\mathbf {v}}^T \nabla ^2 \psi (x){\mathbf {v}} | + C|{\mathbf {v}}|^2\\ &\leq C\left (|{\mathbf {v}}|^3h+ |{\mathbf {v}}|^2\right ) \leq C |{\mathbf {v}}|^3, \end{align*}
where we used a Taylor series expansion of
 $\nabla ^2_h \psi (x,{\mathbf {v}})$
in the last line, along with
$\nabla ^2_h \psi (x,{\mathbf {v}})$
in the last line, along with
 $h\leq 1$
and
$h\leq 1$
and
 $|{\mathbf {v}}|\geq 1$
. Since
$|{\mathbf {v}}|\geq 1$
. Since
 $F(0)=0$
we have
$F(0)=0$
we have
 \begin{equation} |F(\nabla ^2_h\psi )| = |F(\nabla ^2_h\psi ) - F(0)|\leq \textrm {Lip}_N(F) \|\nabla ^2_h \psi \|_{N,\infty }\leq C\textrm {Lip}_N(F)N^3=:\xi . \end{equation}
\begin{equation} |F(\nabla ^2_h\psi )| = |F(\nabla ^2_h\psi ) - F(0)|\leq \textrm {Lip}_N(F) \|\nabla ^2_h \psi \|_{N,\infty }\leq C\textrm {Lip}_N(F)N^3=:\xi . \end{equation}
We now define
 \begin{equation*}w = C_g(\xi + \sqrt {2} \psi ).\end{equation*}
\begin{equation*}w = C_g(\xi + \sqrt {2} \psi ).\end{equation*}
Then by (2.14) and (2.15), we have
 \begin{equation*} w - F(\nabla ^2_h w) = C_g\xi + \sqrt {2}C_g \psi - F(C_g \nabla ^2_h \psi ) \geq \sqrt {2}C_g \psi \geq C_g(1+|x|) \geq g.\end{equation*}
\begin{equation*} w - F(\nabla ^2_h w) = C_g\xi + \sqrt {2}C_g \psi - F(C_g \nabla ^2_h \psi ) \geq \sqrt {2}C_g \psi \geq C_g(1+|x|) \geq g.\end{equation*}
A similar argument shows that
 $v=-w$
satisfies
$v=-w$
satisfies
 $v - F(\nabla ^2_h v) \leq g$
.
$v - F(\nabla ^2_h v) \leq g$
.
Define
 \begin{equation} {\mathcal F} = \left \{v:{\mathbb {Z}^n_h} \to {\mathbb {R}} \, : \, v - F(\nabla ^2_h v) \leq g \ \text {and} \ v \leq w\right \} \end{equation}
\begin{equation} {\mathcal F} = \left \{v:{\mathbb {Z}^n_h} \to {\mathbb {R}} \, : \, v - F(\nabla ^2_h v) \leq g \ \text {and} \ v \leq w\right \} \end{equation}
and
 \begin{equation} u(x) = \sup \{v(x)\, : \, v \in {\mathcal F}\}. \end{equation}
\begin{equation} u(x) = \sup \{v(x)\, : \, v \in {\mathcal F}\}. \end{equation}
Since
 $v=-w$
belongs to
$v=-w$
belongs to
 $\mathcal F$
, the set
$\mathcal F$
, the set
 $\mathcal F$
is nonempty and we have
$\mathcal F$
is nonempty and we have
 $-w \leq u \leq w$
. Hence,
$-w \leq u \leq w$
. Hence,
 $u$
satisfies (2.13).
$u$
satisfies (2.13).
We now claim that
 \begin{equation*}u - F(\nabla ^2_h u) \leq g \ \ \text {on } \mathbb {Z}_h.\end{equation*}
\begin{equation*}u - F(\nabla ^2_h u) \leq g \ \ \text {on } \mathbb {Z}_h.\end{equation*}
To see this, fix
 $x_0 \in {\mathbb {Z}^n_h}$
and let
$x_0 \in {\mathbb {Z}^n_h}$
and let
 $v_k\in {\mathcal F}$
such that
$v_k\in {\mathcal F}$
such that
 $\lim _{k\to \infty }v_k(x_0)=u(x_0)$
. By passing to a subsequence, if necessary, we can assume that
$\lim _{k\to \infty }v_k(x_0)=u(x_0)$
. By passing to a subsequence, if necessary, we can assume that
 $\lim _{k\to \infty }v_k(x)$
exists for all
$\lim _{k\to \infty }v_k(x)$
exists for all
 $x\in {\mathbb {Z}^n_h}$
. Let us denote
$x\in {\mathbb {Z}^n_h}$
. Let us denote
 $v(x)\,:\!=\,\lim _{k\to \infty }v_k(x)$
, noting that
$v(x)\,:\!=\,\lim _{k\to \infty }v_k(x)$
, noting that
 $v(x_0)=u(x_0)$
. By continuity we have
$v(x_0)=u(x_0)$
. By continuity we have
 $v - F(\nabla ^2_h v) \leq g$
and
$v - F(\nabla ^2_h v) \leq g$
and
 $v \leq w$
, thus
$v \leq w$
, thus
 $v\in {\mathcal F}$
and
$v\in {\mathcal F}$
and
 $v\leq u$
. Since
$v\leq u$
. Since
 $v(x_0)=u(x_0)$
, we have that
$v(x_0)=u(x_0)$
, we have that
 $v-u$
attains its maximum at
$v-u$
attains its maximum at
 $x_0$
. As in the proof of Theorem2.3 we have
$x_0$
. As in the proof of Theorem2.3 we have
 $\nabla ^2_hv(x_0,{\mathbf {v}}) \leq \nabla ^2_h u(x_0,{\mathbf {v}})$
for all
$\nabla ^2_hv(x_0,{\mathbf {v}}) \leq \nabla ^2_h u(x_0,{\mathbf {v}})$
for all
 $\mathbf {v}$
, and so by the monotonicity of
$\mathbf {v}$
, and so by the monotonicity of
 $F$
we have
$F$
we have
 $F(\nabla ^2_h v(x_0)) \leq F(\nabla ^2_h u(x_0))$
, which when combined with
$F(\nabla ^2_h v(x_0)) \leq F(\nabla ^2_h u(x_0))$
, which when combined with
 $u(x_0)=v(x_0)$
and
$u(x_0)=v(x_0)$
and
 $v - F(\nabla ^2_h v)\leq g$
, establishes the claim.
$v - F(\nabla ^2_h v)\leq g$
, establishes the claim.
To complete the proof, we show that
 \begin{equation*}u - F(\nabla ^2_h u) \geq g \ \ \text {on } {\mathbb {Z}^n_h}.\end{equation*}
\begin{equation*}u - F(\nabla ^2_h u) \geq g \ \ \text {on } {\mathbb {Z}^n_h}.\end{equation*}
Assume to the contrary that there is some
 $x_0\in {\mathbb {Z}^n_h}$
such that
$x_0\in {\mathbb {Z}^n_h}$
such that
 \begin{equation*}u(x_0) - F(\nabla ^2_h u(x_0)) \lt g(x_0).\end{equation*}
\begin{equation*}u(x_0) - F(\nabla ^2_h u(x_0)) \lt g(x_0).\end{equation*}
Define
 \begin{equation*}v(x) = \begin{cases} u(x_0) + {\varepsilon },& \text {if } x=x_0\\ u(x),& \text {otherwise.} \end{cases}\end{equation*}
\begin{equation*}v(x) = \begin{cases} u(x_0) + {\varepsilon },& \text {if } x=x_0\\ u(x),& \text {otherwise.} \end{cases}\end{equation*}
By continuity, we can choose
 ${\varepsilon }\gt 0$
small enough so that
${\varepsilon }\gt 0$
small enough so that
 \begin{equation*}v(x_0) - F(\nabla ^2_h v(x_0)) \leq g(x_0).\end{equation*}
\begin{equation*}v(x_0) - F(\nabla ^2_h v(x_0)) \leq g(x_0).\end{equation*}
For
 $x\neq x_0$
, we already have
$x\neq x_0$
, we already have
 \begin{equation*}v(x) - F(\nabla ^2_h v(x)) \leq g(x),\end{equation*}
\begin{equation*}v(x) - F(\nabla ^2_h v(x)) \leq g(x),\end{equation*}
and the definition of
 $v$
and the monotonicity of
$v$
and the monotonicity of
 $F$
imply that
$F$
imply that
 $\nabla ^2 v(x,{\mathbf {v}}) \geq \nabla ^2_h u(x,{\mathbf {v}})$
for all
$\nabla ^2 v(x,{\mathbf {v}}) \geq \nabla ^2_h u(x,{\mathbf {v}})$
for all
 $x\neq x_0$
and
$x\neq x_0$
and
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
. This completes the proof.
${\mathbf {v}}\in {\mathbb {Z}^n}$
. This completes the proof.
2.2 Properties of solutions
We recall that a function
 $u:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
is Lipschitz continuous if there exists
$u:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
is Lipschitz continuous if there exists
 $C\gt 0$
such that
$C\gt 0$
such that
 \begin{equation*}|u(x) - u(y)| \leq C\|x-y\|\end{equation*}
\begin{equation*}|u(x) - u(y)| \leq C\|x-y\|\end{equation*}
holds for all
 $x,y \in {\mathbb {Z}^n_h}$
. The Lipschitz constant of
$x,y \in {\mathbb {Z}^n_h}$
. The Lipschitz constant of
 $u$
, denoted
$u$
, denoted
 $\textrm {Lip}(u)$
, is the smallest such constant, given by
$\textrm {Lip}(u)$
, is the smallest such constant, given by
 \begin{equation*}\textrm {Lip}(u) = \sup _{\substack {x,y\in {\mathbb {Z}^n_h} \\ x\neq y}} \frac {|u(x)-u(y)|}{\|x-y\|}.\end{equation*}
\begin{equation*}\textrm {Lip}(u) = \sup _{\substack {x,y\in {\mathbb {Z}^n_h} \\ x\neq y}} \frac {|u(x)-u(y)|}{\|x-y\|}.\end{equation*}
Lemma 2.5 (Basic properties). Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Assume
$F(0)=0$
. Assume
 $g$
satisfies
(2.12)
and let
$g$
satisfies
(2.12)
and let
 $u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
be the unique solution of
(2.6)
. The following hold.
$u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
be the unique solution of
(2.6)
. The following hold.
-
(i) If
$g$
is Lipschitz then so is
$u$
, and
$\textrm {Lip}(u) \leq \textrm {Lip}(g)$
. -
(ii) If
$F\geq 0$
then
$u\geq g$
on
$\mathbb {Z}^n_h$
. -
(iii) There exists a constant
$C\gt 0$
such that
(2.18)
\begin{equation} \|u - g\|_\infty \leq C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ). \end{equation}








Proof.
(i) Let
 $z\in {\mathbb {Z}^n_h}$
and define
$z\in {\mathbb {Z}^n_h}$
and define
 $w(x) = u(x+z) - \textrm {Lip}(g) \|z\|$
. Then we have
$w(x) = u(x+z) - \textrm {Lip}(g) \|z\|$
. Then we have
 \begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(x+z) - \textrm {Lip} (g) \|z\| - F(\nabla ^2_h u(x+z)) = g(x+z) - \textrm {Lip}(g) \leq g(x).\end{equation*}
\begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(x+z) - \textrm {Lip} (g) \|z\| - F(\nabla ^2_h u(x+z)) = g(x+z) - \textrm {Lip}(g) \leq g(x).\end{equation*}
By the comparison principle, Theorem2.3, we have
 $w \leq u$
, and so
$w \leq u$
, and so
 \begin{equation*}u(x+z) - u(x) \leq \textrm {Lip}(g)\|z\|.\end{equation*}
\begin{equation*}u(x+z) - u(x) \leq \textrm {Lip}(g)\|z\|.\end{equation*}
Since this holds for all
 $x,z\in {\mathbb {Z}^n_h}$
, the proof of (i) is complete.
$x,z\in {\mathbb {Z}^n_h}$
, the proof of (i) is complete.
(ii) If
 $F\geq 0$
then
$F\geq 0$
then
 $u(x) = g(x) + F(\nabla ^2_h u(x)) \geq g(x)$
.
$u(x) = g(x) + F(\nabla ^2_h u(x)) \geq g(x)$
.
(iii) Let
 ${\overline {g}}:{\mathbb {R}}^n\to {\mathbb {R}}$
be the piecewise constant extension of
${\overline {g}}:{\mathbb {R}}^n\to {\mathbb {R}}$
be the piecewise constant extension of
 $g$
to a function on
$g$
to a function on
 ${\mathbb {R}}^n$
, defined so that
${\mathbb {R}}^n$
, defined so that
 ${\overline {g}}(y)=g(x)$
for all
${\overline {g}}(y)=g(x)$
for all
 $y\in x+[0,h)^n$
and any
$y\in x+[0,h)^n$
and any
 $x\in Zh$
. While the extension is discontinuous, it satisfies
$x\in Zh$
. While the extension is discontinuous, it satisfies
 \begin{equation*}|\nabla _h {\overline {g}}(y,{\mathbf {v}})| = \left | \frac {g(x+h{\mathbf {v}}) - g(x)}{h}\right | \leq \textrm {Lip}(g)|{\mathbf {v}}|\end{equation*}
\begin{equation*}|\nabla _h {\overline {g}}(y,{\mathbf {v}})| = \left | \frac {g(x+h{\mathbf {v}}) - g(x)}{h}\right | \leq \textrm {Lip}(g)|{\mathbf {v}}|\end{equation*}
provided
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
, where
${\mathbf {v}}\in {\mathbb {Z}^n}$
, where
 $x\in {\mathbb {Z}^n_h}$
satisfies
$x\in {\mathbb {Z}^n_h}$
satisfies
 $y\in x+[0,h)^n$
. Let
$y\in x+[0,h)^n$
. Let
 $\varepsilon \gt 0$
and define the standard mollification
$\varepsilon \gt 0$
and define the standard mollification
 $g_\varepsilon \,:\!=\,\eta _\varepsilon * {\overline {g}}$
, where
$g_\varepsilon \,:\!=\,\eta _\varepsilon * {\overline {g}}$
, where
 $\eta _{\varepsilon }(x) = \frac {1}{{\varepsilon }^d}\eta \left ( \frac {x}{{\varepsilon }}\right )$
, and
$\eta _{\varepsilon }(x) = \frac {1}{{\varepsilon }^d}\eta \left ( \frac {x}{{\varepsilon }}\right )$
, and
 $\eta _{\varepsilon }$
is compactly supported in
$\eta _{\varepsilon }$
is compactly supported in
 $B(0,{\varepsilon })$
. Note that
$B(0,{\varepsilon })$
. Note that
 \begin{equation*}\nabla _h g_{\varepsilon }(x,{\mathbf {v}}) = \int _{{\mathbb {R}}^n} \eta _\varepsilon (y) \nabla _h {\overline {g}}(x-y,{\mathbf {v}}) \, dy = \int _{{\mathbb {R}}^n }\eta _\varepsilon (x-z) \nabla _h {\overline {g}}(z,{\mathbf {v}}) \, dz,\end{equation*}
\begin{equation*}\nabla _h g_{\varepsilon }(x,{\mathbf {v}}) = \int _{{\mathbb {R}}^n} \eta _\varepsilon (y) \nabla _h {\overline {g}}(x-y,{\mathbf {v}}) \, dy = \int _{{\mathbb {R}}^n }\eta _\varepsilon (x-z) \nabla _h {\overline {g}}(z,{\mathbf {v}}) \, dz,\end{equation*}
where we used the change of variables
 $z=x-y$
above. We also have
$z=x-y$
above. We also have
 \begin{equation*}\nabla _h g_{\varepsilon }(x,-{\mathbf {v}}) = \int _{{\mathbb {R}}^n} \eta _\varepsilon (y) \nabla _h {\overline {g}}(x-y,-{\mathbf {v}}) \, dy = -\int _{{\mathbb {R}}^n }\eta _\varepsilon (x-z - h{\mathbf {v}}) \nabla _h {\overline {g}}(z,{\mathbf {v}}) \, dz,\end{equation*}
\begin{equation*}\nabla _h g_{\varepsilon }(x,-{\mathbf {v}}) = \int _{{\mathbb {R}}^n} \eta _\varepsilon (y) \nabla _h {\overline {g}}(x-y,-{\mathbf {v}}) \, dy = -\int _{{\mathbb {R}}^n }\eta _\varepsilon (x-z - h{\mathbf {v}}) \nabla _h {\overline {g}}(z,{\mathbf {v}}) \, dz,\end{equation*}
where we now use the change of variables
 $z=x-y - h{\mathbf {v}}$
. Therefore
$z=x-y - h{\mathbf {v}}$
. Therefore
 \begin{align*} \nabla ^2_h g_{\varepsilon }(x,{\mathbf {v}}) &= \frac {1}{h}(\nabla _h {\overline {g}}_{\varepsilon }(x,{\mathbf {v}}) + \nabla _h {\overline {g}}_{\varepsilon }(x,-v)) \\ &= -\int _{{\mathbb {R}}^n}\nabla _h \eta _{\varepsilon }(x-z,-{\mathbf {v}}) \nabla _h {\overline {g}}(z,{\mathbf {v}})\, dz. \end{align*}
\begin{align*} \nabla ^2_h g_{\varepsilon }(x,{\mathbf {v}}) &= \frac {1}{h}(\nabla _h {\overline {g}}_{\varepsilon }(x,{\mathbf {v}}) + \nabla _h {\overline {g}}_{\varepsilon }(x,-v)) \\ &= -\int _{{\mathbb {R}}^n}\nabla _h \eta _{\varepsilon }(x-z,-{\mathbf {v}}) \nabla _h {\overline {g}}(z,{\mathbf {v}})\, dz. \end{align*}
Therefore,
 \begin{equation*} |\nabla ^2_h g_{\varepsilon }(x,{\mathbf {v}})| \leq \int _{B(x,{\varepsilon })\cup B(x-h{\mathbf {v}},{\varepsilon })}|\nabla _h \eta _{\varepsilon }(x-z,-{\mathbf {v}})| |\nabla _h {\overline {g}}(z,{\mathbf {v}})|\, dz \leq \frac {C}{{\varepsilon }}\textrm {Lip}(g)|{\mathbf {v}}|^2.\end{equation*}
\begin{equation*} |\nabla ^2_h g_{\varepsilon }(x,{\mathbf {v}})| \leq \int _{B(x,{\varepsilon })\cup B(x-h{\mathbf {v}},{\varepsilon })}|\nabla _h \eta _{\varepsilon }(x-z,-{\mathbf {v}})| |\nabla _h {\overline {g}}(z,{\mathbf {v}})|\, dz \leq \frac {C}{{\varepsilon }}\textrm {Lip}(g)|{\mathbf {v}}|^2.\end{equation*}
Since
 $F$
has width
$F$
has width
 $N$
, it follows that
$N$
, it follows that
 \begin{equation} |F(\nabla ^2_h g_{\varepsilon }(x))| = |F(\nabla ^2_h g_{\varepsilon }(x)) - F(0)| \leq \textrm {Lip}_N (F)\|\nabla ^2_h g_{\varepsilon }\|_{N,{\varepsilon }} \leq \frac {C}{{\varepsilon }}\textrm {Lip}_N(F)\textrm {Lip}(g)N^2. \end{equation}
\begin{equation} |F(\nabla ^2_h g_{\varepsilon }(x))| = |F(\nabla ^2_h g_{\varepsilon }(x)) - F(0)| \leq \textrm {Lip}_N (F)\|\nabla ^2_h g_{\varepsilon }\|_{N,{\varepsilon }} \leq \frac {C}{{\varepsilon }}\textrm {Lip}_N(F)\textrm {Lip}(g)N^2. \end{equation}
We also have that
 $|{\overline {g}}(y) - g(x)| \leq |y-x| + \sqrt {d}h$
, and so
$|{\overline {g}}(y) - g(x)| \leq |y-x| + \sqrt {d}h$
, and so
 \begin{align*} |g_{\varepsilon }(x) - g(x)| &= \left |\int _{B(x,{\varepsilon })} \eta _{\varepsilon }(x-y)( {\overline {g}}(y) - g(x))\, dy \right |\\ &\leq \int _{B(x,{\varepsilon })} \eta _{\varepsilon }(x-y)|{\overline {g}}(y) - g(x)|\, dy\\ &\leq \textrm {Lip}(g)({\varepsilon } + \sqrt {d}h). \end{align*}
\begin{align*} |g_{\varepsilon }(x) - g(x)| &= \left |\int _{B(x,{\varepsilon })} \eta _{\varepsilon }(x-y)( {\overline {g}}(y) - g(x))\, dy \right |\\ &\leq \int _{B(x,{\varepsilon })} \eta _{\varepsilon }(x-y)|{\overline {g}}(y) - g(x)|\, dy\\ &\leq \textrm {Lip}(g)({\varepsilon } + \sqrt {d}h). \end{align*}
Combining this with (2.19) we have
 \begin{equation*}|g_\varepsilon (x) + F(\nabla ^2 g_\varepsilon (x)) - g(x)| \leq \textrm {Lip}(g)({\varepsilon } + \sqrt {d}h) + \frac {C}{{\varepsilon }}\textrm {Lip}_N(F)\textrm {Lip}(g)N^2.\end{equation*}
\begin{equation*}|g_\varepsilon (x) + F(\nabla ^2 g_\varepsilon (x)) - g(x)| \leq \textrm {Lip}(g)({\varepsilon } + \sqrt {d}h) + \frac {C}{{\varepsilon }}\textrm {Lip}_N(F)\textrm {Lip}(g)N^2.\end{equation*}
Choosing
 ${\varepsilon }=N \sqrt {\textrm {Lip}_N(F)}$
yields
${\varepsilon }=N \sqrt {\textrm {Lip}_N(F)}$
yields
 \begin{equation*}|g_\varepsilon (x) + F(\nabla ^2 g_\varepsilon (x)) - g(x)| \leq C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ).\end{equation*}
\begin{equation*}|g_\varepsilon (x) + F(\nabla ^2 g_\varepsilon (x)) - g(x)| \leq C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ).\end{equation*}
By the comparison principle, Theorem2.3, we have
 \begin{equation*}g_{\varepsilon } - C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ) \leq u \leq g_{\varepsilon } + C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ),\end{equation*}
\begin{equation*}g_{\varepsilon } - C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ) \leq u \leq g_{\varepsilon } + C\textrm {Lip}(g)\left ( N\sqrt {\textrm {Lip}_N(F)} + h\right ),\end{equation*}
which completes the proof.
To study further properties of
 $u$
, we need some additional definitions.
$u$
, we need some additional definitions.
Definition 2.6.
We say that
 $F:{\mathcal H}_n\to {\mathbb {R}}$
is convex if for all
$F:{\mathcal H}_n\to {\mathbb {R}}$
is convex if for all
 $X,Y\in {\mathcal H}_n$
and
$X,Y\in {\mathcal H}_n$
and
 $\lambda \in [0,1]$
we have
$\lambda \in [0,1]$
we have
 \begin{equation*}F(\lambda X + (1-\lambda )Y) \leq \lambda F(X) + (1-\lambda )F(Y).\end{equation*}
\begin{equation*}F(\lambda X + (1-\lambda )Y) \leq \lambda F(X) + (1-\lambda )F(Y).\end{equation*}
Definition 2.7.
We say that
 $u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
is convex if
$u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
is convex if
 $\nabla ^2_h u(x) \geq 0$
for all
$\nabla ^2_h u(x) \geq 0$
for all
 $x\in {\mathbb {Z}^n_h}.$
$x\in {\mathbb {Z}^n_h}.$
We note that by (2.4), the convexity of
 $u$
is equivalent to the inequality
$u$
is equivalent to the inequality
 \begin{equation*}u(x) \leq \frac {1}{2}(u(x+h{\mathbf {v}}) + u(x-h{\mathbf {v}}))\end{equation*}
\begin{equation*}u(x) \leq \frac {1}{2}(u(x+h{\mathbf {v}}) + u(x-h{\mathbf {v}}))\end{equation*}
holding for all
 $x\in {\mathbb {Z}^n_h}$
and
$x\in {\mathbb {Z}^n_h}$
and
 ${\mathbf {v}} \in {\mathbb {Z}^n}$
. We also note that the choice of
${\mathbf {v}} \in {\mathbb {Z}^n}$
. We also note that the choice of
 $F$
given in (2.7) is convex.
$F$
given in (2.7) is convex.
We also consider a permutation invariance property.
Definition 2.8.
We say
 $u:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
is permutation invariant if
$u:{\mathbb {Z}^n_h} \to {\mathbb {R}}$
is permutation invariant if
 $u \circ \sigma = u$
for all permutations
$u \circ \sigma = u$
for all permutations
 $\sigma$
on
$\sigma$
on
 $\{1,\ldots, n\}$
.
$\{1,\ldots, n\}$
.
Definition 2.9.
We say
 $F:{\mathcal H}_n \to {\mathbb {R}}$
is permutation invariant if
$F:{\mathcal H}_n \to {\mathbb {R}}$
is permutation invariant if
 $F(X\circ \sigma )=F(X)$
for all
$F(X\circ \sigma )=F(X)$
for all
 $X\in {\mathcal H}_n$
and all permutations
$X\in {\mathcal H}_n$
and all permutations
 $\sigma$
on
$\sigma$
on
 $\{1,\ldots, n\}$
.
$\{1,\ldots, n\}$
.
We note that
 $F$
given in (2.7) is permutation invariant.
$F$
given in (2.7) is permutation invariant.
Finally, we also study translation properties.
Definition 2.10.
For
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
, we say
${\mathbf {v}}\in {\mathbb {Z}^n}$
, we say
 $u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
satisfies the
$u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
satisfies the
 $\mathbf {v}$
-translation property if there exists a constant
$\mathbf {v}$
-translation property if there exists a constant
 $c_{\mathbf {v}}$
such that
$c_{\mathbf {v}}$
such that
 \begin{equation} u(x+s{\mathbf {v}}) = u(x) + c_{\mathbf {v}} s \end{equation}
\begin{equation} u(x+s{\mathbf {v}}) = u(x) + c_{\mathbf {v}} s \end{equation}
for all
 $x\in {\mathbb {Z}^n_h}$
and
$x\in {\mathbb {Z}^n_h}$
and
 $s\in {\mathbb {R}}$
such that
$s\in {\mathbb {R}}$
such that
 $s{\mathbf {v}} \in {\mathbb {Z}^n_h}$
.
$s{\mathbf {v}} \in {\mathbb {Z}^n_h}$
.
The next lemma shows that these properties for
 $u$
are inherited from
$u$
are inherited from
 $F$
and
$F$
and
 $g$
.
$g$
.
Lemma 2.11.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Assume
$F(0)=0$
. Assume
 $g$
satisfies
(2.12)
and let
$g$
satisfies
(2.12)
and let
 $u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
denote the unique solution of
(2.6)
. The following hold:
$u:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
denote the unique solution of
(2.6)
. The following hold:
-
(i) If
$F$
and
$g$
are convex, then
$u$
is convex.
-
(ii) If
$F$
and
$g$
are permutation invariant, then
$u$
is permutation invariant.
-
(iii) If
$g$
satisfies the
$\mathbf {v}$
-translation property with constant
$c_{\mathbf {v}}$
, then
$u$
does as well.










Proof.
(i) Let
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
and define
${\mathbf {v}}\in {\mathbb {Z}^n}$
and define
 \begin{equation*}w(x) = \frac {1}{2}(u(x+h{\mathbf {v}}) + u(x-h{\mathbf {v}})).\end{equation*}
\begin{equation*}w(x) = \frac {1}{2}(u(x+h{\mathbf {v}}) + u(x-h{\mathbf {v}})).\end{equation*}
Then for
 $x\in {\mathbb {Z}^n_h}$
we compute, using the convexity of
$x\in {\mathbb {Z}^n_h}$
we compute, using the convexity of
 $F$
, that
$F$
, that
 \begin{align*} w(x) - F(\nabla ^2_h w(x)) &= \frac {1}{2}u(x+h{\mathbf {v}}) + \frac {1}{2}u(x-h{\mathbf {v}}) - F\left ( \frac {1}{2}\nabla ^2_h u(x+h{\mathbf {v}}) + \frac {1}{2}\nabla ^2_h u(x-h{\mathbf {v}})\right )\\ &\geq \frac {1}{2}u(x+h{\mathbf {v}}) + \frac {1}{2}u(x-h{\mathbf {v}}) - \frac {1}{2}F(\nabla ^2_h u(x+h{\mathbf {v}})) - \frac {1}{2}F(\nabla ^2_h u(x-h{\mathbf {v}})) \\ &= \frac {1}{2}g(x+h{\mathbf {v}}) + \frac {1}{2}g(x-h{\mathbf {v}})\\ &= \frac {h^2}{2}\nabla ^2_h g(x,{\mathbf {v}}) + g(x)\\ &\geq g(x), \end{align*}
\begin{align*} w(x) - F(\nabla ^2_h w(x)) &= \frac {1}{2}u(x+h{\mathbf {v}}) + \frac {1}{2}u(x-h{\mathbf {v}}) - F\left ( \frac {1}{2}\nabla ^2_h u(x+h{\mathbf {v}}) + \frac {1}{2}\nabla ^2_h u(x-h{\mathbf {v}})\right )\\ &\geq \frac {1}{2}u(x+h{\mathbf {v}}) + \frac {1}{2}u(x-h{\mathbf {v}}) - \frac {1}{2}F(\nabla ^2_h u(x+h{\mathbf {v}})) - \frac {1}{2}F(\nabla ^2_h u(x-h{\mathbf {v}})) \\ &= \frac {1}{2}g(x+h{\mathbf {v}}) + \frac {1}{2}g(x-h{\mathbf {v}})\\ &= \frac {h^2}{2}\nabla ^2_h g(x,{\mathbf {v}}) + g(x)\\ &\geq g(x), \end{align*}
where the last line follows from the convexity of
 $g$
. By Theorem2.3 we have
$g$
. By Theorem2.3 we have
 $w \geq u$
, and so
$w \geq u$
, and so
 \begin{equation*}\nabla ^2_h u(x,{\mathbf {v}}) = \frac {2}{h^2}(w(x) - u(x)) \geq 0\end{equation*}
\begin{equation*}\nabla ^2_h u(x,{\mathbf {v}}) = \frac {2}{h^2}(w(x) - u(x)) \geq 0\end{equation*}
for all
 $x\in {\mathbb {Z}^n_h}$
. Since
$x\in {\mathbb {Z}^n_h}$
. Since
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
is arbitrary, we have
${\mathbf {v}}\in {\mathbb {Z}^n}$
is arbitrary, we have
 $\nabla ^2_h u(x)\geq 0$
for all
$\nabla ^2_h u(x)\geq 0$
for all
 $x\in {\mathbb {Z}^n}$
, hence
$x\in {\mathbb {Z}^n}$
, hence
 $u$
is convex.
$u$
is convex.
(ii) Let
 $\sigma$
be a permutation and set
$\sigma$
be a permutation and set
 $w = u\circ \sigma$
. Then we have
$w = u\circ \sigma$
. Then we have
 \begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(\sigma (x)) - F(\nabla ^2_h (u\circ \sigma )(x)).\end{equation*}
\begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(\sigma (x)) - F(\nabla ^2_h (u\circ \sigma )(x)).\end{equation*}
We note that for any
 ${\mathbf {v}}\in {\mathbb {Z}^n}$
we have
${\mathbf {v}}\in {\mathbb {Z}^n}$
we have
 $\nabla ^2_h (u\circ \sigma )(x,{\mathbf {v}}) = \nabla ^2_h u(\sigma (x),\sigma ({\mathbf {v}}))$
. Therefore
$\nabla ^2_h (u\circ \sigma )(x,{\mathbf {v}}) = \nabla ^2_h u(\sigma (x),\sigma ({\mathbf {v}}))$
. Therefore
 $\nabla ^2_h (u\circ \sigma )(x) = \nabla ^2_h u(\sigma (x)) \circ \sigma$
. Since
$\nabla ^2_h (u\circ \sigma )(x) = \nabla ^2_h u(\sigma (x)) \circ \sigma$
. Since
 $F$
is permutation invariant we have
$F$
is permutation invariant we have
 \begin{equation*}F(\nabla ^2_h (u\circ \sigma )(x)) = F(\nabla ^2_h u(\sigma (x))\circ \sigma ) = F(\nabla ^2_h u(\sigma (x))).\end{equation*}
\begin{equation*}F(\nabla ^2_h (u\circ \sigma )(x)) = F(\nabla ^2_h u(\sigma (x))\circ \sigma ) = F(\nabla ^2_h u(\sigma (x))).\end{equation*}
Therefore,
 \begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(\sigma (x)) - F(\nabla ^2_h u(\sigma (x))) = 0.\end{equation*}
\begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(\sigma (x)) - F(\nabla ^2_h u(\sigma (x))) = 0.\end{equation*}
By uniqueness of the solution
 $u$
of (2.6), we have
$u$
of (2.6), we have
 $w=u$
, which completes the proof.
$w=u$
, which completes the proof.
(iii) Let
 $s\in {\mathbb {R}}$
such that
$s\in {\mathbb {R}}$
such that
 $s{\mathbf {v}} \in {\mathbb {Z}^n_h}$
, and define
$s{\mathbf {v}} \in {\mathbb {Z}^n_h}$
, and define
 $w(x) = u(x + s{\mathbf {v}}) - c_{\mathbf {v}} s$
. Then,
$w(x) = u(x + s{\mathbf {v}}) - c_{\mathbf {v}} s$
. Then,
 \begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(x+s{\mathbf {v}}) - c_{\mathbf {v}} s - F(\nabla ^2_h u(x+s{\mathbf {v}})) = g(x+s{\mathbf {v}}) - c_{\mathbf {v}} s = g(x).\end{equation*}
\begin{equation*}w(x) - F(\nabla ^2_h w(x)) = u(x+s{\mathbf {v}}) - c_{\mathbf {v}} s - F(\nabla ^2_h u(x+s{\mathbf {v}})) = g(x+s{\mathbf {v}}) - c_{\mathbf {v}} s = g(x).\end{equation*}
Since the solution of (2.6) is unique, we have
 $w=u$
, which completes the proof.
$w=u$
, which completes the proof.
2.3 Convergence rates
In this section, we prove convergence of the numerical scheme (2.6) towards the viscosity solution of the second-order degenerate elliptic equation
 \begin{equation} u - F(\nabla ^2 u) = g \ \ \text { on } {\mathbb {R}}^n. \end{equation}
\begin{equation} u - F(\nabla ^2 u) = g \ \ \text { on } {\mathbb {R}}^n. \end{equation}
As before, we assume
 $F:{\mathcal H}_n\to {\mathbb {R}}$
, and we interpret
$F:{\mathcal H}_n\to {\mathbb {R}}$
, and we interpret
 $F(X)$
for an
$F(X)$
for an
 $n\times n$
symmetric matrix
$n\times n$
symmetric matrix
 $X$
as
$X$
as
 \begin{equation*}F(X) \,:\!=\, F({\mathbf {v}} \mapsto {\mathbf {v}}^T X{\mathbf {v}}).\end{equation*}
\begin{equation*}F(X) \,:\!=\, F({\mathbf {v}} \mapsto {\mathbf {v}}^T X{\mathbf {v}}).\end{equation*}
We recall the definitions of viscosity solutions in Appendix A. Throughout this section, we will use the notation
 $\text {USC}({\mathcal O})$
(resp.
$\text {USC}({\mathcal O})$
(resp.
 $\text {LSC}({\mathcal O})$
) for the set of functions that are upper (resp. lower) semicontinuous at all points in
$\text {LSC}({\mathcal O})$
) for the set of functions that are upper (resp. lower) semicontinuous at all points in
 ${\mathcal O} \subset {\mathbb {R}}^n$
. For more details on the theory of viscosity solutions, we refer the reader to the user’s guide [Reference Crandall, Ishii and Lions19] and [Reference Calder10].
${\mathcal O} \subset {\mathbb {R}}^n$
. For more details on the theory of viscosity solutions, we refer the reader to the user’s guide [Reference Crandall, Ishii and Lions19] and [Reference Calder10].
Existence and uniqueness of a linear growth viscosity solution to (2.21) is standard material for viscosity solutions, and proofs can be found in [Reference Calder10, Reference Crandall, Ishii and Lions19]. For use later on, we recall the comparison principle for (2.21) in Lemma 2.12 below. The proof of this result is standard in viscosity solution theory; a self-contained proof can be found in [Reference Calder10, Lemma 12.17].
Lemma 2.12.
Assume
 $F$
is uniformly continuous, monotone, has width
$F$
is uniformly continuous, monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Let
$F(0)=0$
. Let
 $u\in \text {USC}({\mathbb {R}}^n)$
be a viscosity subsolution of
(2.21)
and let
$u\in \text {USC}({\mathbb {R}}^n)$
be a viscosity subsolution of
(2.21)
and let
 $v \in \text {LSC}({\mathbb {R}}^n)$
be a viscosity supersolution of
(2.21)
. If
$v \in \text {LSC}({\mathbb {R}}^n)$
be a viscosity supersolution of
(2.21)
. If
 \begin{equation} \lim _{|x|\to \infty }\frac {u(x)-v(x)}{|x|^2}=0 \end{equation}
\begin{equation} \lim _{|x|\to \infty }\frac {u(x)-v(x)}{|x|^2}=0 \end{equation}
then
 $u\leq v$
on
$u\leq v$
on
 ${\mathbb {R}}^n$
.
${\mathbb {R}}^n$
.
Using this comparison principle and the Perron method, we can prove existence of a linear growth solution (Theorem2.13 below). The application of the Perron method is standard and a self-contained proof can be found in [Reference Calder10, Theorem 12.18].Footnote 2
Theorem 2.13.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Assume
$F(0)=0$
. Assume
 $g$
is Lipschitz continuous and there exists
$g$
is Lipschitz continuous and there exists
 $C_g\gt 0$
such that
$C_g\gt 0$
such that
 \begin{equation} |g(x)| \leq C_g (1 + |x|). \end{equation}
\begin{equation} |g(x)| \leq C_g (1 + |x|). \end{equation}
Then there exists a unique viscosity solution
 $u\in C({\mathbb {R}}^n)$
of
(2.21)
satisfying
$u\in C({\mathbb {R}}^n)$
of
(2.21)
satisfying
 \begin{equation*}\lim _{|x|\to \infty }\frac {u(x)}{|x|^2} = 0.\end{equation*}
\begin{equation*}\lim _{|x|\to \infty }\frac {u(x)}{|x|^2} = 0.\end{equation*}
Furthermore, there exists
 $C\gt 0$
such that
$C\gt 0$
such that
 \begin{equation} |u(x)| \leq C(1 + |x|). \end{equation}
\begin{equation} |u(x)| \leq C(1 + |x|). \end{equation}
Convergence of the discrete scheme (2.6) to the PDE (2.21) is a standard result in viscosity solution theory. We state the theorem in the following result and briefly sketch the proof.
Theorem 2.14.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Assume
$F(0)=0$
. Assume
 $g:{\mathbb {R}}^n\to {\mathbb {R}}$
is Lipschitz continuous and satisfies
(2.23)
. Let
$g:{\mathbb {R}}^n\to {\mathbb {R}}$
is Lipschitz continuous and satisfies
(2.23)
. Let
 $u_h$
be the solution of
(2.6)
and let
$u_h$
be the solution of
(2.6)
and let
 $u$
be the viscosity solution of
(2.21)
. Then
$u$
be the viscosity solution of
(2.21)
. Then
 $u_h$
converges to
$u_h$
converges to
 $u$
locally uniformly as
$u$
locally uniformly as
 $h\to 0$
, that is for all
$h\to 0$
, that is for all
 $R\gt 0$
we have
$R\gt 0$
we have
 \begin{equation} \lim _{h\to 0} \max _{\substack {x\in {\mathbb {Z}^n_h} \\ |x| \leq R}} |u_h(x) - u(x)| = 0. \end{equation}
\begin{equation} \lim _{h\to 0} \max _{\substack {x\in {\mathbb {Z}^n_h} \\ |x| \leq R}} |u_h(x) - u(x)| = 0. \end{equation}
Proof.
By Lemma 2.5 (i), we have
 $\textrm {Lip}(u_h)\leq \textrm {Lip}(g)$
. By the Arzelá-Ascoli Theorem there exists a Lipschitz continuous function
$\textrm {Lip}(u_h)\leq \textrm {Lip}(g)$
. By the Arzelá-Ascoli Theorem there exists a Lipschitz continuous function
 $u:{\mathbb {R}}^n\to {\mathbb {R}}$
such that, upon passing to a subsequence
$u:{\mathbb {R}}^n\to {\mathbb {R}}$
such that, upon passing to a subsequence
 $u_{h_k}$
, we have
$u_{h_k}$
, we have
 \begin{equation*}\lim _{k\to \infty } \max _{\substack {x\in \mathbb {Z}^n_{h_k} \\ |x| \leq R}} |u_{h_k}(x) - u(x)| = 0\end{equation*}
\begin{equation*}\lim _{k\to \infty } \max _{\substack {x\in \mathbb {Z}^n_{h_k} \\ |x| \leq R}} |u_{h_k}(x) - u(x)| = 0\end{equation*}
for all
 $R\gt 0$
. The proof will be completed by showing that
$R\gt 0$
. The proof will be completed by showing that
 $u$
is a viscosity solution of (2.21). By uniqueness of viscosity solutions of (2.21), the whole sequence
$u$
is a viscosity solution of (2.21). By uniqueness of viscosity solutions of (2.21), the whole sequence
 $u_h$
converges locally uniformly to
$u_h$
converges locally uniformly to
 $u$
.
$u$
.
We verify the subsolution property for
 $u$
; the supersolution property is similar. Let
$u$
; the supersolution property is similar. Let
 $x_0 \in {\mathbb {R}}^n$
and
$x_0 \in {\mathbb {R}}^n$
and
 ${\varphi }\in C^\infty ({\mathbb {R}}^n)$
such that
${\varphi }\in C^\infty ({\mathbb {R}}^n)$
such that
 $u-{\varphi }$
has a local maximum at
$u-{\varphi }$
has a local maximum at
 $x_0$
. Without loss of generality, we can assume
$x_0$
. Without loss of generality, we can assume
 $x_0$
is a strict global maximum of
$x_0$
is a strict global maximum of
 $u-{\varphi }$
. It follows that there exists
$u-{\varphi }$
. It follows that there exists
 $x_k \to x_0$
such that
$x_k \to x_0$
such that
 $u_{h_k} - {\varphi }$
attains its maximum over
$u_{h_k} - {\varphi }$
attains its maximum over
 $\mathbb {Z}_{h_k}^n$
at
$\mathbb {Z}_{h_k}^n$
at
 $x_k$
. Therefore
$x_k$
. Therefore
 $\nabla ^2_h u_{h_k}(x_k,{\mathbf {v}}) \leq \nabla ^2_h {\varphi }(x_k)$
, and since
$\nabla ^2_h u_{h_k}(x_k,{\mathbf {v}}) \leq \nabla ^2_h {\varphi }(x_k)$
, and since
 $F$
is monotone we have
$F$
is monotone we have
 \begin{equation*}u(x_k) - F(\nabla ^2_{h_k} {\varphi }(x_k)) \leq {\varphi }(x_k) - F(\nabla ^2_h u_{h_k}(x_k)) =u(x_k) -u_{h_k}(x_k) - g(x_k).\end{equation*}
\begin{equation*}u(x_k) - F(\nabla ^2_{h_k} {\varphi }(x_k)) \leq {\varphi }(x_k) - F(\nabla ^2_h u_{h_k}(x_k)) =u(x_k) -u_{h_k}(x_k) - g(x_k).\end{equation*}
Sending
 $k\to \infty$
we obtain
$k\to \infty$
we obtain
 \begin{equation*}u(x_0) - F(\nabla ^2 {\varphi }(x_0)) \leq g(x_0),\end{equation*}
\begin{equation*}u(x_0) - F(\nabla ^2 {\varphi }(x_0)) \leq g(x_0),\end{equation*}
which completes the proof.
If we have additional regularity for the solution
 $u$
of (2.21), we can prove convergence rates. We recall the
$u$
of (2.21), we can prove convergence rates. We recall the
 $C^{k,1}$
seminorm of
$C^{k,1}$
seminorm of
 $u:{\mathbb {R}}^n\to {\mathbb {R}}$
is defined by
$u:{\mathbb {R}}^n\to {\mathbb {R}}$
is defined by
 \begin{equation*}[u]_{C^{k,1}({\mathbb {R}}^n)} = \sum _{1\leq |\alpha | \leq k} \textrm {Lip}(D^\alpha u).\end{equation*}
\begin{equation*}[u]_{C^{k,1}({\mathbb {R}}^n)} = \sum _{1\leq |\alpha | \leq k} \textrm {Lip}(D^\alpha u).\end{equation*}
Theorem 2.15.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Assume
$F(0)=0$
. Assume
 $g:{\mathbb {R}}^n\to {\mathbb {R}}$
is Lipschitz continuous and satisfies
(2.23)
. Let
$g:{\mathbb {R}}^n\to {\mathbb {R}}$
is Lipschitz continuous and satisfies
(2.23)
. Let
 $u_h$
be the solution of
(2.6)
and let
$u_h$
be the solution of
(2.6)
and let
 $u$
be the viscosity solution of
(2.6)
. If
$u$
be the viscosity solution of
(2.6)
. If
 $[u]_{C^{k,1}({\mathbb {R}}^n)} \lt \infty$
for
$[u]_{C^{k,1}({\mathbb {R}}^n)} \lt \infty$
for
 $k=2$
or
$k=2$
or
 $k=3$
, then we have
$k=3$
, then we have
 \begin{equation} \|u - u_h\|_\infty \leq C\textrm {Lip}_N(F)[u]_{C^{k,1}({\mathbb {R}}^n)}N^{k+1}h^{k-1} \end{equation}
\begin{equation} \|u - u_h\|_\infty \leq C\textrm {Lip}_N(F)[u]_{C^{k,1}({\mathbb {R}}^n)}N^{k+1}h^{k-1} \end{equation}
Proof. By Taylor expansion, we have
 \begin{equation*} |\nabla ^2_h u(x,{\mathbf {v}}) - {\mathbf {v}}^T \nabla ^2 u(x) {\mathbf {v}}| \leq C[u]_{C^{k,1}({\mathbb {R}}^n)}|{\mathbf {v}}|^{k+1}h^{k-1}.\end{equation*}
\begin{equation*} |\nabla ^2_h u(x,{\mathbf {v}}) - {\mathbf {v}}^T \nabla ^2 u(x) {\mathbf {v}}| \leq C[u]_{C^{k,1}({\mathbb {R}}^n)}|{\mathbf {v}}|^{k+1}h^{k-1}.\end{equation*}
Therefore,
 \begin{equation*}|F(\nabla ^2_h u(x)) - F(\nabla ^2 u(x))| \leq C\textrm {Lip}_N(F)[u]_{C^{k,1}({\mathbb {R}}^n)}N^{k+1}h^{k-1}=:{\varepsilon }.\end{equation*}
\begin{equation*}|F(\nabla ^2_h u(x)) - F(\nabla ^2 u(x))| \leq C\textrm {Lip}_N(F)[u]_{C^{k,1}({\mathbb {R}}^n)}N^{k+1}h^{k-1}=:{\varepsilon }.\end{equation*}
It follows that
 \begin{equation*}u(x) - F(\nabla ^2_hu(x)) \leq u(x) - F(\nabla ^2 u(x)) + {\varepsilon } = g(x) + {\varepsilon } \ \ \text {for } x\in {\mathbb {Z}^n_h}.\end{equation*}
\begin{equation*}u(x) - F(\nabla ^2_hu(x)) \leq u(x) - F(\nabla ^2 u(x)) + {\varepsilon } = g(x) + {\varepsilon } \ \ \text {for } x\in {\mathbb {Z}^n_h}.\end{equation*}
By Theorem2.3, we have
 $u \leq u_h + {\varepsilon }$
on
$u \leq u_h + {\varepsilon }$
on
 $\mathbb {Z}^n_h$
. The opposite inequality is obtained similarly.
$\mathbb {Z}^n_h$
. The opposite inequality is obtained similarly.
From the convergence results in Theorems2.14 and 2.15, we immediately obtain that all the properties of the discrete solutions proved in Section 2.2 extend to the viscosity solution
 $u$
.
$u$
.
Proposition 2.16.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Assume
$F(0)=0$
. Assume
 $g:{\mathbb {R}}^n\to {\mathbb {R}}$
is Lipschitz continuous and satisfies
(2.23)
. Let
$g:{\mathbb {R}}^n\to {\mathbb {R}}$
is Lipschitz continuous and satisfies
(2.23)
. Let
 $u$
be the viscosity solution of
(2.6)
. Then the following hold.
$u$
be the viscosity solution of
(2.6)
. Then the following hold.
-
(i)
$u$
is Lipschitz continuous and
$\textrm {Lip}(u) \leq \textrm {Lip}(g)$
. -
(ii) If
$F\geq 0$
then
$u\geq g$
on
${\mathbb {R}}^n$
. -
(iii) There exists a constant
$C\gt 0$
such that
(2.27)
\begin{equation} \|u - g\|_\infty \leq CN\textrm {Lip}(g)\sqrt {\textrm {Lip}_N(F)}. \end{equation}
-
(iv) If
$F$
and
$g$
are convex, then
$u$
is convex.
-
(v) If
$F$
and
$g$
are permutation invariant, then
$u$
is permutation invariant.
-
(vi) If
$g$
satisfies the
$\mathbf {v}$
-translation property with constant
$c_{\mathbf {v}}$
, then
$u$
does as well.













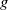



We note that in (iv), the notion of convexity for
 $F$
is the same as in Definition 2.6, while for
$F$
is the same as in Definition 2.6, while for
 $u$
it is the usual one for functions on
$u$
it is the usual one for functions on
 ${\mathbb {R}}^n$
, that is
${\mathbb {R}}^n$
, that is
 \begin{equation*}u(\lambda x + (1-\lambda ) y) \leq \lambda u(x) + (1-\lambda ) u(y).\end{equation*}
\begin{equation*}u(\lambda x + (1-\lambda ) y) \leq \lambda u(x) + (1-\lambda ) u(y).\end{equation*}
In (v), the definition of permutation invariance for
 $u:{\mathbb {R}}^n\to {\mathbb {R}}$
is identical to Definition 2.8; namely
$u:{\mathbb {R}}^n\to {\mathbb {R}}$
is identical to Definition 2.8; namely
 $u=u\circ \sigma$
. The translation property is defined similarly, but is slightly different so we give the definition below for functions on
$u=u\circ \sigma$
. The translation property is defined similarly, but is slightly different so we give the definition below for functions on
 ${\mathbb {R}}^n$
.
${\mathbb {R}}^n$
.
Definition 2.17.
For
 ${\mathbf {v}}\in {\mathbb {R}}^n$
, we say
${\mathbf {v}}\in {\mathbb {R}}^n$
, we say
 $u:{\mathbb {R}}^n\to {\mathbb {R}}$
satisfies the
$u:{\mathbb {R}}^n\to {\mathbb {R}}$
satisfies the
 $\mathbf {v}$
-translation property if there exists a constant
$\mathbf {v}$
-translation property if there exists a constant
 $c_{\mathbf {v}}$
such that
(2.20)
holds for all
$c_{\mathbf {v}}$
such that
(2.20)
holds for all
 $x\in {\mathbb {R}}^n$
and
$x\in {\mathbb {R}}^n$
and
 $s\in {\mathbb {R}}$
.
$s\in {\mathbb {R}}$
.
The proof of Proposition 2.16 follows from Lemmas 2.5 and 2.11, and the convergence result in Theorem2.14.
2.4 Restricting the domain
In order to compute the solution of the discrete scheme (2.6) on an unbounded domain
 $\mathbb {Z}^n_h$
, it is necessary to restrict the domain to a compact set. In this section, we study restrictions of (1.3) to computational domains of the form
$\mathbb {Z}^n_h$
, it is necessary to restrict the domain to a compact set. In this section, we study restrictions of (1.3) to computational domains of the form
 $\Omega _{T,h} \,:\!=\, [\!-T,T]^n\cap {\mathbb {Z}^n_h}$
. In this section, we always assume
$\Omega _{T,h} \,:\!=\, [\!-T,T]^n\cap {\mathbb {Z}^n_h}$
. In this section, we always assume
 $T=mh$
for some integer
$T=mh$
for some integer
 $m\geq 1$
. We define the width
$m\geq 1$
. We define the width
 $N$
boundary as
$N$
boundary as
 \begin{equation} \partial _N \Omega _{T,h} = \{x\in {\mathbb {Z}^n_h}\setminus \Omega _{T,h}\, : \, \text {there exists }y\in \Omega _{T,h} \text { with } |x-y|_\infty \leq N\}. \end{equation}
\begin{equation} \partial _N \Omega _{T,h} = \{x\in {\mathbb {Z}^n_h}\setminus \Omega _{T,h}\, : \, \text {there exists }y\in \Omega _{T,h} \text { with } |x-y|_\infty \leq N\}. \end{equation}
We set a Dirichlet boundary condition on
 $\partial _N \Omega _{T,h}$
and show that this condition affects the solution only near the boundary, and the solution remains accurate in the interior of
$\partial _N \Omega _{T,h}$
and show that this condition affects the solution only near the boundary, and the solution remains accurate in the interior of
 $\Omega _{T,h}$
.
$\Omega _{T,h}$
.
In this section, we study the equation
 \begin{equation} u - F(\nabla ^2_h u) = g \ \ \text { on } \ \Omega _{T,h}, \end{equation}
\begin{equation} u - F(\nabla ^2_h u) = g \ \ \text { on } \ \Omega _{T,h}, \end{equation}
which is the restriction of (2.6) to the computational domains
 $\Omega _{T,h}$
. We first recall the comparison principle for (2.29).
$\Omega _{T,h}$
. We first recall the comparison principle for (2.29).
Lemma 2.18.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Let
$F(0)=0$
. Let
 $u,v:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
satisfy
$u,v:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
satisfy
 \begin{equation} u - F(\nabla ^2_h u) \leq v - F(\nabla ^2_h v) \ \ \text { on } \ \Omega _{T,h} \end{equation}
\begin{equation} u - F(\nabla ^2_h u) \leq v - F(\nabla ^2_h v) \ \ \text { on } \ \Omega _{T,h} \end{equation}
and
 $u\leq v$
on
$u\leq v$
on
 $\partial _N \Omega _{T,h}$
. Then
$\partial _N \Omega _{T,h}$
. Then
 $u\leq v$
on
$u\leq v$
on
 $\Omega _{T,h}$
.
$\Omega _{T,h}$
.
Proof.
Let
 $x_0\in \Omega _{T,h}\cup \partial _N \Omega _{T,h}$
be a point where
$x_0\in \Omega _{T,h}\cup \partial _N \Omega _{T,h}$
be a point where
 $u-v$
attains its maximum value over
$u-v$
attains its maximum value over
 $\Omega _{T,h}\cup \partial _N \Omega _{T,h}$
. If
$\Omega _{T,h}\cup \partial _N \Omega _{T,h}$
. If
 $x_0 \in \partial _N \Omega _{T,h}$
then
$x_0 \in \partial _N \Omega _{T,h}$
then
 $u\leq v$
, so we may assume
$u\leq v$
, so we may assume
 $x_0 \in \Omega _{T,h}$
. In this case we have
$x_0 \in \Omega _{T,h}$
. In this case we have
 $\nabla ^2_h u(x_0,{\mathbf {v}}) \leq \nabla ^2_h v(x_0,{\mathbf {v}})$
, and since
$\nabla ^2_h u(x_0,{\mathbf {v}}) \leq \nabla ^2_h v(x_0,{\mathbf {v}})$
, and since
 $F$
is monotone, we obtain
$F$
is monotone, we obtain
 \begin{equation*} u(x_0) - v(x_0) \leq F(\nabla ^2_h u(x_0)) - F(\nabla ^2_h v(x_0)) \leq 0.\end{equation*}
\begin{equation*} u(x_0) - v(x_0) \leq F(\nabla ^2_h u(x_0)) - F(\nabla ^2_h v(x_0)) \leq 0.\end{equation*}
This completes the proof.
We now establish localization of solutions of (2.29).
Theorem 2.19.
Assume
 $F$
is monotone, has width
$F$
is monotone, has width
 $N$
, and satisfies
$N$
, and satisfies
 $F(0)=0$
. Let
$F(0)=0$
. Let
 $u,v:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
satisfy
(2.30)
. Then for any
$u,v:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
satisfy
(2.30)
. Then for any
 $\alpha \in (0,1)$
we have
$\alpha \in (0,1)$
we have
 \begin{equation} \max _{\Omega _{\alpha T,h}}(u-v) \leq \frac {C \textrm {Lip}_N(F)N^2}{(1-\alpha )^2T^2}\left (\log \left ( \frac {T^2}{\textrm {Lip}_N(F) N^2}\right )^2+1 \right )\max _{\partial _N \Omega _{T,h}}(u-v). \end{equation}
\begin{equation} \max _{\Omega _{\alpha T,h}}(u-v) \leq \frac {C \textrm {Lip}_N(F)N^2}{(1-\alpha )^2T^2}\left (\log \left ( \frac {T^2}{\textrm {Lip}_N(F) N^2}\right )^2+1 \right )\max _{\partial _N \Omega _{T,h}}(u-v). \end{equation}
Remark 2.20.
The estimate
(2.31)
in Theorem
2.19
shows that the Dirichlet boundary conditions on
 $\partial _N \Omega _{T,h}$
have a limited domain of influence on the solution in
$\partial _N \Omega _{T,h}$
have a limited domain of influence on the solution in
 $\Omega _{T,h}$
when
$\Omega _{T,h}$
when
 $T\gt 0$
is large. Indeed, if we fix, say,
$T\gt 0$
is large. Indeed, if we fix, say,
 $\alpha =\tfrac 12$
, and if
$\alpha =\tfrac 12$
, and if
 $u,v:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
are solutions of
(2.29)
, then
$u,v:{\mathbb {Z}^n_h}\to {\mathbb {R}}$
are solutions of
(2.29)
, then
 $u$
and
$u$
and
 $v$
satisfy
(2.30)
with equality, and so it follows from two applications of Theorem
2.19
, applied to
$v$
satisfy
(2.30)
with equality, and so it follows from two applications of Theorem
2.19
, applied to
 $u-v$
and
$u-v$
and
 $v-u$
, that
$v-u$
, that
 \begin{equation} \max _{\Omega _{T/2,h}}|u-v|\leq \frac {C\log (T)^2}{T^2}\max _{\partial _N \Omega _{T,h}}|u-v|, \end{equation}
\begin{equation} \max _{\Omega _{T/2,h}}|u-v|\leq \frac {C\log (T)^2}{T^2}\max _{\partial _N \Omega _{T,h}}|u-v|, \end{equation}
holds, where
 $C$
depends on
$C$
depends on
 $\textrm {Lip}_N(F)$
and
$\textrm {Lip}_N(F)$
and
 $N$
, and
$N$
, and
 $T\geq 3$
. This shows that errors in the Dirichlet condition on
$T\geq 3$
. This shows that errors in the Dirichlet condition on
 $\partial _N\Omega _{T,h}$
can be tolerated numerically, provided
$\partial _N\Omega _{T,h}$
can be tolerated numerically, provided
 $T\gt 0$
is large enough. For example, by Lemma 2.5 (iii), we can set
$T\gt 0$
is large enough. For example, by Lemma 2.5 (iii), we can set
 $u=g$
on
$u=g$
on
 $\partial _N \Omega _{T,h}$
and obtain an
$\partial _N \Omega _{T,h}$
and obtain an
 ${\mathcal O}(\log (T)^2/T^2)$
approximation of the solution of
(2.21)
on the interior domain
${\mathcal O}(\log (T)^2/T^2)$
approximation of the solution of
(2.21)
on the interior domain
 $\Omega _{T/2,h}$
. We show how to obtain even more accurate solutions with better choices of boundary conditions in Section
3.1
.
$\Omega _{T/2,h}$
. We show how to obtain even more accurate solutions with better choices of boundary conditions in Section
3.1
.
Proof.
Let
 $\mu = \max _{\partial _N \Omega _{T,h}}(u-v)$
and define
$\mu = \max _{\partial _N \Omega _{T,h}}(u-v)$
and define
 \begin{equation} w(x) = v(x) + \gamma + \mu \sum _{i=1}^n \left (e^{\lambda \left ( \frac {x_i}{T}-1 \right )} + e^{-\lambda \left ( \frac {x_i}{T}+1 \right )}\right ) \end{equation}
\begin{equation} w(x) = v(x) + \gamma + \mu \sum _{i=1}^n \left (e^{\lambda \left ( \frac {x_i}{T}-1 \right )} + e^{-\lambda \left ( \frac {x_i}{T}+1 \right )}\right ) \end{equation}
for parameters
 $\lambda, \gamma \gt 0$
to be determined. For
$\lambda, \gamma \gt 0$
to be determined. For
 $x\in \partial _N \Omega _{T,h}$
, there exists
$x\in \partial _N \Omega _{T,h}$
, there exists
 $i$
such that
$i$
such that
 $x_i\geq T$
or
$x_i\geq T$
or
 $x_i\leq -T$
, and so
$x_i\leq -T$
, and so
 $w(x) \geq v(x) + \mu \geq u(x)$
. Note that we have
$w(x) \geq v(x) + \mu \geq u(x)$
. Note that we have
 \begin{equation*}|F(\nabla ^2_h w) - F(\nabla ^2_h v)| \leq \textrm {Lip}_N(F) \|\nabla ^2_h w - \nabla ^2_h v\|_{N,\infty } \leq C\textrm {Lip}_N(F)\frac {\mu \lambda ^2N^2}{T^{2}}.\end{equation*}
\begin{equation*}|F(\nabla ^2_h w) - F(\nabla ^2_h v)| \leq \textrm {Lip}_N(F) \|\nabla ^2_h w - \nabla ^2_h v\|_{N,\infty } \leq C\textrm {Lip}_N(F)\frac {\mu \lambda ^2N^2}{T^{2}}.\end{equation*}
Choosing
 $\gamma = C\textrm {Lip}_N(F)\mu \lambda ^2N^2T^{-2}$
we find that
$\gamma = C\textrm {Lip}_N(F)\mu \lambda ^2N^2T^{-2}$
we find that
 \begin{equation*}w(x) - F(\nabla ^2_h w(x)) \geq v(x) + \gamma - F(\nabla ^2_h v(x)) - C\textrm {Lip}_N(F)\mu \lambda ^2N^2T^{-2} \geq 0.\end{equation*}
\begin{equation*}w(x) - F(\nabla ^2_h w(x)) \geq v(x) + \gamma - F(\nabla ^2_h v(x)) - C\textrm {Lip}_N(F)\mu \lambda ^2N^2T^{-2} \geq 0.\end{equation*}
By Lemma 2.18 we have
 $w \geq u$
on
$w \geq u$
on
 $\Omega _{T,h}$
, and so
$\Omega _{T,h}$
, and so
 \begin{equation*}u(x) - v(x) \leq \gamma + \mu \sum _{i=1}^n \left (e^{\lambda \left ( \frac {x_i}{T}-1 \right )} + e^{-\lambda \left ( \frac {x_i}{T}+1 \right )}\right )\end{equation*}
\begin{equation*}u(x) - v(x) \leq \gamma + \mu \sum _{i=1}^n \left (e^{\lambda \left ( \frac {x_i}{T}-1 \right )} + e^{-\lambda \left ( \frac {x_i}{T}+1 \right )}\right )\end{equation*}
for all
 $x\in \Omega _{T,h}$
. For
$x\in \Omega _{T,h}$
. For
 $x\in \Omega _{\alpha T,h}$
with
$x\in \Omega _{\alpha T,h}$
with
 $\alpha \in (0,1)$
we have
$\alpha \in (0,1)$
we have
 \begin{equation*}u(x) - v(x) \leq \gamma + 2n\mu e^{-\lambda (1-\alpha )}. \end{equation*}
\begin{equation*}u(x) - v(x) \leq \gamma + 2n\mu e^{-\lambda (1-\alpha )}. \end{equation*}
Choosing
 $\lambda$
so that
$\lambda$
so that
 $(1-\alpha )\lambda = \log \left ( \frac {T^2}{\textrm {Lip}_N(F) N^2}\right )$
completes the proof.
$(1-\alpha )\lambda = \log \left ( \frac {T^2}{\textrm {Lip}_N(F) N^2}\right )$
completes the proof.
3. Numerical analysis of the prediction PDE
This section is concerned with numerical analysis specific to the prediction from expert advice numerical scheme
 \begin{equation} u(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^n}\nabla ^2_h u(x,{\mathbf {v}}) = g(x) \ \ \text {for } x\in {\mathbb {Z}^n_h}. \end{equation}
\begin{equation} u(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^n}\nabla ^2_h u(x,{\mathbf {v}}) = g(x) \ \ \text {for } x\in {\mathbb {Z}^n_h}. \end{equation}
In particular, we show in Section 3.1 how to use the translation property (2.20) to reduce the dimension by one, and in Section 3.2, we show how to reduce the computational domain to a sector where the coordinates are ordered.
3.1 Reducing the dimension
We show here how to reduce the problem from
 $n$
dimensional to
$n$
dimensional to
 $n-1$
dimensional. This requires the translation property (2.20) and is based on the following lemma.
$n-1$
dimensional. This requires the translation property (2.20) and is based on the following lemma.
Lemma 3.1.
Suppose
 $u$
satisfies the translation property
(2.20)
with
$u$
satisfies the translation property
(2.20)
with
 ${\mathbf {v}} = \unicode {x1D7D9}$
and
${\mathbf {v}} = \unicode {x1D7D9}$
and
 $c_{\mathbf {v}} = 1$
. Then for all
$c_{\mathbf {v}} = 1$
. Then for all
 ${\mathbf {v}} \in {\mathcal B}^n$
we have
${\mathbf {v}} \in {\mathcal B}^n$
we have
 \begin{equation} \nabla ^2_h u(x,{\mathbf {v}}) = \nabla ^2_h u(x,\unicode {x1D7D9}-{\mathbf {v}}). \end{equation}
\begin{equation} \nabla ^2_h u(x,{\mathbf {v}}) = \nabla ^2_h u(x,\unicode {x1D7D9}-{\mathbf {v}}). \end{equation}
Proof. By assumption we have
 \begin{equation} u(x + s\unicode {x1D7D9}) = u(x) + s \end{equation}
\begin{equation} u(x + s\unicode {x1D7D9}) = u(x) + s \end{equation}
for all
 $s\in \mathbb {Z}_h$
and
$s\in \mathbb {Z}_h$
and
 $x\in {\mathbb {Z}^n_h}$
. We now compute, using (3.3), that
$x\in {\mathbb {Z}^n_h}$
. We now compute, using (3.3), that
 \begin{align*} h^2\nabla ^2_h u(x,{\mathbf {v}}) &= u(x+h{\mathbf {v}}) - 2u(x) + u(x-h{\mathbf {v}}) \\ &=u(x + h{\mathbf {v}} - h\unicode {x1D7D9}) + h - 2u(x) + u(x -h{\mathbf {v}}+h\unicode {x1D7D9}) - h\\ &=u(x - h(\unicode {x1D7D9}-{\mathbf {v}})) - 2u(x) + u(x + h(\unicode {x1D7D9} - {\mathbf {v}}))\\ &=h^2 \nabla ^2_h u(x,\unicode {x1D7D9}-{\mathbf {v}}), \end{align*}
\begin{align*} h^2\nabla ^2_h u(x,{\mathbf {v}}) &= u(x+h{\mathbf {v}}) - 2u(x) + u(x-h{\mathbf {v}}) \\ &=u(x + h{\mathbf {v}} - h\unicode {x1D7D9}) + h - 2u(x) + u(x -h{\mathbf {v}}+h\unicode {x1D7D9}) - h\\ &=u(x - h(\unicode {x1D7D9}-{\mathbf {v}})) - 2u(x) + u(x + h(\unicode {x1D7D9} - {\mathbf {v}}))\\ &=h^2 \nabla ^2_h u(x,\unicode {x1D7D9}-{\mathbf {v}}), \end{align*}
which completes the proof.
For
 $x\in {\mathbb {R}}^{n-1}$
and
$x\in {\mathbb {R}}^{n-1}$
and
 $a\in {\mathbb {R}}$
we define
$a\in {\mathbb {R}}$
we define
 $(x,a)\in {\mathbb {R}}^n$
by
$(x,a)\in {\mathbb {R}}^n$
by
 \begin{equation*}(x,a) = (x_1,x_2,\ldots, x_{n-1},a).\end{equation*}
\begin{equation*}(x,a) = (x_1,x_2,\ldots, x_{n-1},a).\end{equation*}
The next lemma shows how we can use the translation property (2.20) to reduce (3.1) to a similar equation in one less variable.
Lemma 3.2.
Let
 $u$
be the solution of
(3.1)
and suppose
$u$
be the solution of
(3.1)
and suppose
 $u$
satisfies the translation property
(2.20)
with
$u$
satisfies the translation property
(2.20)
with
 ${\mathbf {v}} = \unicode {x1D7D9}$
and
${\mathbf {v}} = \unicode {x1D7D9}$
and
 $c_{\mathbf {v}} = 1$
. Define
$c_{\mathbf {v}} = 1$
. Define
 $w,f:\mathbb {Z}^{n-1}_h \to {\mathbb {R}}$
by
$w,f:\mathbb {Z}^{n-1}_h \to {\mathbb {R}}$
by
 $w(x)\,:\!=\,u(x,0)$
and
$w(x)\,:\!=\,u(x,0)$
and
 $f(x)=g(x,0)$
. The following hold.
$f(x)=g(x,0)$
. The following hold.
-
(i) The function
$w$
satisfies
(3.4)
\begin{equation} w(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) = f(x) \ \ \text {for all } \ x\in \mathbb {Z}^{n-1}_h. \end{equation}
-
(ii) If
$g$
is permutation invariant, then so is
$w$
, and furthermore
$w$
satisfies
(3.5)
\begin{equation} w(x) =w\left (x - x_i(\unicode {x1D7D9}+{\mathbf {e}}_i)\right ) + x_i \ \ \text {for all } x\in \mathbb {Z}^{n-1}_h \text { and } i=1,\ldots, n-1. \end{equation}






Proof.
By Lemma 3.1, for any
 $x\in \mathbb {Z}^{n-1}_h$
we have
$x\in \mathbb {Z}^{n-1}_h$
we have
 \begin{equation*}\max _{{\mathbf {v}} \in {\mathcal B}^n}\nabla ^2_h u((x,0),{\mathbf {v}}) = \max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h u((x,0),({\mathbf {v}},0)) = \max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}).\end{equation*}
\begin{equation*}\max _{{\mathbf {v}} \in {\mathcal B}^n}\nabla ^2_h u((x,0),{\mathbf {v}}) = \max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h u((x,0),({\mathbf {v}},0)) = \max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}).\end{equation*}
Since
 $u$
satisfies (3.1) we have
$u$
satisfies (3.1) we have
 \begin{equation*}w(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) = g(x,0)=f(x),\end{equation*}
\begin{equation*}w(x) - \frac {1}{2}\max _{{\mathbf {v}} \in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) = g(x,0)=f(x),\end{equation*}
which completes the proof.
(ii) Since
 $g$
is permutation invariant, so is
$g$
is permutation invariant, so is
 $u$
(by Lemma 2.11) and hence
$u$
(by Lemma 2.11) and hence
 $w$
. Let
$w$
. Let
 $\sigma _{ij}$
denote the permutation swapping coordinates
$\sigma _{ij}$
denote the permutation swapping coordinates
 $i$
and
$i$
and
 $j$
. Let
$j$
. Let
 $x\in {\mathbb {R}}^{n-1}$
and let
$x\in {\mathbb {R}}^{n-1}$
and let
 $y=(x,0)$
. For any
$y=(x,0)$
. For any
 $1 \leq i\leq n-1$
we use the translation property and permutation invariance to obtain
$1 \leq i\leq n-1$
we use the translation property and permutation invariance to obtain
 \begin{align*} w(x)=u( \left (x,0\right )) &= u\left ( (x,0) - x_i\unicode {x1D7D9}\right ) + x_i\\ &= u\left ( \left (x - x_i\unicode {x1D7D9},-x_i\right )\right ) + x_i\\ &=u\left (\sigma _{i,n}\left (x - x_i\unicode {x1D7D9},-x_i\right )\right ) + x_i\\ &=u\left (x - x_i\unicode {x1D7D9} - x_i{\mathbf {e}}_i,0\right ) + x_i\\ &=w\left (x - x_i\unicode {x1D7D9} - x_i{\mathbf {e}}_i\right ) + x_i, \end{align*}
\begin{align*} w(x)=u( \left (x,0\right )) &= u\left ( (x,0) - x_i\unicode {x1D7D9}\right ) + x_i\\ &= u\left ( \left (x - x_i\unicode {x1D7D9},-x_i\right )\right ) + x_i\\ &=u\left (\sigma _{i,n}\left (x - x_i\unicode {x1D7D9},-x_i\right )\right ) + x_i\\ &=u\left (x - x_i\unicode {x1D7D9} - x_i{\mathbf {e}}_i,0\right ) + x_i\\ &=w\left (x - x_i\unicode {x1D7D9} - x_i{\mathbf {e}}_i\right ) + x_i, \end{align*}
which completes the proof.
By Lemma 3.2 and Remark 2.20, we may instead solve the equation
 \begin{equation} \left \{ \begin{aligned} w(x) - \frac {1}{2}\max _{{\mathbf {v}}\in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) &= g(x,0),&& \text {if } x \in \Omega _{T,h}\\ w(x) &= g(x,0), && \text {if } x \in \partial _1 \Omega _{T,h} \end{aligned} \right . \end{equation}
\begin{equation} \left \{ \begin{aligned} w(x) - \frac {1}{2}\max _{{\mathbf {v}}\in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) &= g(x,0),&& \text {if } x \in \Omega _{T,h}\\ w(x) &= g(x,0), && \text {if } x \in \partial _1 \Omega _{T,h} \end{aligned} \right . \end{equation}
in dimension
 $n-1$
, where we take
$n-1$
, where we take
 $T=mh$
to be a multiple of the grid resolution. Provided we restrict our attention to the localized interior set
$T=mh$
to be a multiple of the grid resolution. Provided we restrict our attention to the localized interior set
 $\Omega _{\alpha T,h}$
for some
$\Omega _{\alpha T,h}$
for some
 $\alpha \in (0,1)$
, then as per Remark 2.20 we incur an
$\alpha \in (0,1)$
, then as per Remark 2.20 we incur an
 $O(1/T^2)$
error term, up to logarithmic factors.
$O(1/T^2)$
error term, up to logarithmic factors.
3.2 Reducing the domain to a sector
It turns out that in addition to reducing the dimension of the equation from
 $n$
to
$n$
to
 $n-1$
, we can also drastically reduce the size of the computational grid by restricting our attention to the sector
$n-1$
, we can also drastically reduce the size of the computational grid by restricting our attention to the sector
 \begin{equation} {\mathbb {D}}_n = \{x\in {\mathbb {Z}^n_h}\, : \, x_1 \geq x_2 \geq \cdots \geq x_n\}, \end{equation}
\begin{equation} {\mathbb {D}}_n = \{x\in {\mathbb {Z}^n_h}\, : \, x_1 \geq x_2 \geq \cdots \geq x_n\}, \end{equation}
and the positive sector
 \begin{equation} {\mathbb {D}}^+_n = \{x\in {\mathbb {D}}_n\, : \, x_n \geq 0\}. \end{equation}
\begin{equation} {\mathbb {D}}^+_n = \{x\in {\mathbb {D}}_n\, : \, x_n \geq 0\}. \end{equation}
Whenever
 $g$
is permutation invariant, e.g., the max-regret
$g$
is permutation invariant, e.g., the max-regret
 $g(x)=\max \{x_1,\ldots, x_n\}$
, the solution
$g(x)=\max \{x_1,\ldots, x_n\}$
, the solution
 $u$
of (3.1) and the reduced solution
$u$
of (3.1) and the reduced solution
 $w(x)=u(x,0)$
are also permutation invariant. As we show in this section, this, combined with the translation property, or (3.5), allows us to reduce the domain of the discrete PDE (3.1) to
$w(x)=u(x,0)$
are also permutation invariant. As we show in this section, this, combined with the translation property, or (3.5), allows us to reduce the domain of the discrete PDE (3.1) to
 ${\mathbb {D}}_n^+$
, which is drastically smaller than the full computational grid
${\mathbb {D}}_n^+$
, which is drastically smaller than the full computational grid
 $\Omega _{T,h}$
.
$\Omega _{T,h}$
.
In order to do this in a computational setting, for
 $x\in {\mathbb {D}}_{n-1}^+$
and
$x\in {\mathbb {D}}_{n-1}^+$
and
 $v\in {\mathcal B}^{n-1}$
, we need to be able to evaluate
$v\in {\mathcal B}^{n-1}$
, we need to be able to evaluate
 $w(x+{\mathbf {v}})$
and
$w(x+{\mathbf {v}})$
and
 $w(x-{\mathbf {v}})$
in terms of only the values of
$w(x-{\mathbf {v}})$
in terms of only the values of
 $w$
within the positive sector
$w$
within the positive sector
 ${\mathbb {D}}_{n-1}^+$
. This will allow us to evaluate the discrete second derivative
${\mathbb {D}}_{n-1}^+$
. This will allow us to evaluate the discrete second derivative
 $\nabla ^2_h w(x,{\mathbf {v}})$
without reference to the values of
$\nabla ^2_h w(x,{\mathbf {v}})$
without reference to the values of
 $u$
outside of
$u$
outside of
 ${\mathbb {D}}^{n-1}_+$
. To do this, we need to define two operations. First, let
${\mathbb {D}}^{n-1}_+$
. To do this, we need to define two operations. First, let
 $\pi _n:{\mathbb {R}}^n\to {\mathbb {R}}^n$
be the sorting function that sorts the coordinates of an
$\pi _n:{\mathbb {R}}^n\to {\mathbb {R}}^n$
be the sorting function that sorts the coordinates of an
 $n$
-dimensional vectors. Thus,
$n$
-dimensional vectors. Thus,
 $\pi _n({\mathbb {Z}^n_h}) = {\mathbb {D}}_n$
. We also define the function
$\pi _n({\mathbb {Z}^n_h}) = {\mathbb {D}}_n$
. We also define the function
 $\xi :{\mathbb {D}}^n\to {\mathbb {R}}^n$
by
$\xi :{\mathbb {D}}^n\to {\mathbb {R}}^n$
by
 \begin{equation} \xi _n(x) = \begin{cases} x,& \text {if } x\in {\mathbb {D}}_n^+,\\ x +h(\unicode {x1D7D9} + {\mathbf {e}}_i),& \text {where } x_1,\ldots, x_{i-1} \geq 0 \gt x_i\geq \cdots \geq x_n. \end{cases} \end{equation}
\begin{equation} \xi _n(x) = \begin{cases} x,& \text {if } x\in {\mathbb {D}}_n^+,\\ x +h(\unicode {x1D7D9} + {\mathbf {e}}_i),& \text {where } x_1,\ldots, x_{i-1} \geq 0 \gt x_i\geq \cdots \geq x_n. \end{cases} \end{equation}
To indicate the cases above, we write
 \begin{equation*}\unicode {x1D7D9}_{\xi _n}(x) = \begin{cases} 0,& \text {if } \xi _n(x) = x\\ 1,& \text {otherwise.} \end{cases}\end{equation*}
\begin{equation*}\unicode {x1D7D9}_{\xi _n}(x) = \begin{cases} 0,& \text {if } \xi _n(x) = x\\ 1,& \text {otherwise.} \end{cases}\end{equation*}
The following lemma shows how to evaluate
 $w(x\pm {\mathbf {v}})$
within the positive sector
$w(x\pm {\mathbf {v}})$
within the positive sector
 ${\mathbb {D}}_{n-1}^+$
.
${\mathbb {D}}_{n-1}^+$
.
Lemma 3.3.
Suppose
 $w:\mathbb {Z}_h^{n-1} \to {\mathbb {R}}$
is permutation invariant and satisfies
(3.5)
. Let
$w:\mathbb {Z}_h^{n-1} \to {\mathbb {R}}$
is permutation invariant and satisfies
(3.5)
. Let
 $T\gt 0$
,
$T\gt 0$
,
 $x\in {\mathbb {D}}_{n-1}^+ \cap [0,T-h]^{n-1}$
and
$x\in {\mathbb {D}}_{n-1}^+ \cap [0,T-h]^{n-1}$
and
 ${\mathbf {v}}\in {\mathcal B}^{n-1}$
. Then the following hold.
${\mathbf {v}}\in {\mathcal B}^{n-1}$
. Then the following hold.
-
(i) For
$y\,:\!=\,\pi _{n-1}(x+h{\mathbf {v}})$
we have
$y \in {\mathbb {D}}_{n-1}^+\cap [0,T]^{n-1}$
and
$w(x + h{\mathbf {v}}) = w(y)$
. -
(ii) For
$y\,:\!=\,\pi _{n-1}(x-h{\mathbf {v}})$
we have
$\xi _{n-1}(y) \in {\mathbb {D}}_{n-1}^+\cap [0,T]^{n-1}$
and
\begin{equation*}w(x - h{\mathbf {v}}) = w(\xi _{n-1}(y)) - h\unicode {x1D7D9}_{\xi _{n-1}}(y).\end{equation*}






Proof.
Part (i) follows directly from the permutation invariance of
 $w$
and that
$w$
and that
 $\mathbf {v}$
is a binary vector.
$\mathbf {v}$
is a binary vector.
For part (ii), let
 $y = \pi _{n-1}(x - h{\mathbf {v}}) \in {\mathbb {D}}_{n-1}$
. If
$y = \pi _{n-1}(x - h{\mathbf {v}}) \in {\mathbb {D}}_{n-1}$
. If
 $y\in {\mathbb {D}}_{n-1}^+$
, then
$y\in {\mathbb {D}}_{n-1}^+$
, then
 $\xi _{n-1}(y)=y$
,
$\xi _{n-1}(y)=y$
,
 $\unicode {x1D7D9}_{\xi _{n-1}}(y)=0$
, and the result follows from the permutation invariance of
$\unicode {x1D7D9}_{\xi _{n-1}}(y)=0$
, and the result follows from the permutation invariance of
 $w$
, as in part (i). If
$w$
, as in part (i). If
 $y\not \in {\mathbb {D}}_{n-1}^+$
, then
$y\not \in {\mathbb {D}}_{n-1}^+$
, then
 $\xi _{n-1}(y)\neq y$
and
$\xi _{n-1}(y)\neq y$
and
 $\unicode {x1D7D9}_{\xi _{n-1}}(y)=1$
. Since
$\unicode {x1D7D9}_{\xi _{n-1}}(y)=1$
. Since
 $x\in {\mathbb {D}}_{n-1}^+$
we must have
$x\in {\mathbb {D}}_{n-1}^+$
we must have
 \begin{equation*}y_1\geq \cdots \geq y_{i-1}\geq 0 \gt -h=y_i = \cdots = y_{n-1},\end{equation*}
\begin{equation*}y_1\geq \cdots \geq y_{i-1}\geq 0 \gt -h=y_i = \cdots = y_{n-1},\end{equation*}
for some
 $1 \leq i \leq n-1$
. Therefore
$1 \leq i \leq n-1$
. Therefore
 \begin{equation*}\xi _{n-1}(y) = y + h(\unicode {x1D7D9} + {\mathbf {e}}_i) = y - y_i(\unicode {x1D7D9} + {\mathbf {e}}_i),\end{equation*}
\begin{equation*}\xi _{n-1}(y) = y + h(\unicode {x1D7D9} + {\mathbf {e}}_i) = y - y_i(\unicode {x1D7D9} + {\mathbf {e}}_i),\end{equation*}
and so by (3.5) and the permutation invariance of
 $w$
we have
$w$
we have
 \begin{equation*}w(x - h{\mathbf {v}}) = w(y) = w(\xi _{n-1}(y)) + y_i = w(\xi _{n-1}(\pi _{n-1}(x-h{\mathbf {v}}))) - h,\end{equation*}
\begin{equation*}w(x - h{\mathbf {v}}) = w(y) = w(\xi _{n-1}(y)) + y_i = w(\xi _{n-1}(\pi _{n-1}(x-h{\mathbf {v}}))) - h,\end{equation*}
which completes the proof.
Lemma 3.3 allows us to restrict the reduced
 $n-1$
dimensional equation for
$n-1$
dimensional equation for
 $w$
to the sector
$w$
to the sector
 ${\mathbb {D}}^+_{n-1}$
, yielding the equation
${\mathbb {D}}^+_{n-1}$
, yielding the equation
 \begin{equation} \left \{ \begin{aligned} w(x) - \frac {1}{2}\max _{{\mathbf {v}}\in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) &= g(x,0),&& \text {if } x\in {\mathbb {D}}^+_{n-1}\cap \{x_1 \leq T - h\}\\ w(x) &= g(x,0), && \text {if } x \in {\mathbb {D}}^+_{n-1}\cap \{x_1=T\}, \end{aligned} \right . \end{equation}
\begin{equation} \left \{ \begin{aligned} w(x) - \frac {1}{2}\max _{{\mathbf {v}}\in {\mathcal B}^{n-1}}\nabla ^2_h w(x,{\mathbf {v}}) &= g(x,0),&& \text {if } x\in {\mathbb {D}}^+_{n-1}\cap \{x_1 \leq T - h\}\\ w(x) &= g(x,0), && \text {if } x \in {\mathbb {D}}^+_{n-1}\cap \{x_1=T\}, \end{aligned} \right . \end{equation}
where
 $T=mh$
is a multiple of the grid resolution. By Lemma 3.3 we can compute the derivative
$T=mh$
is a multiple of the grid resolution. By Lemma 3.3 we can compute the derivative
 $\nabla ^2_h w(x,{\mathbf {v}})$
for
$\nabla ^2_h w(x,{\mathbf {v}})$
for
 $x\in {\mathbb {D}}^+_{n-1}\cap \{x_1 \leq T - h\}$
via
$x\in {\mathbb {D}}^+_{n-1}\cap \{x_1 \leq T - h\}$
via
 \begin{equation} \nabla ^2_h w(x,{\mathbf {v}}) = \frac {w(y_+) + w(\xi _{n-1}(y_-)) - h\unicode {x1D7D9}_{\xi _{n-1}}(y_-) - 2w(x)}{h^2}, \end{equation}
\begin{equation} \nabla ^2_h w(x,{\mathbf {v}}) = \frac {w(y_+) + w(\xi _{n-1}(y_-)) - h\unicode {x1D7D9}_{\xi _{n-1}}(y_-) - 2w(x)}{h^2}, \end{equation}
where
 $y_+ = \pi _{n-1}(x + h{\mathbf {v}})$
and
$y_+ = \pi _{n-1}(x + h{\mathbf {v}})$
and
 $y_- = \pi _{n-1}(x - h{\mathbf {v}})$
. By Lemma 3.3 the expression on the right-hand side of (3.11) involves evaluating
$y_- = \pi _{n-1}(x - h{\mathbf {v}})$
. By Lemma 3.3 the expression on the right-hand side of (3.11) involves evaluating
 $w$
only at points in the sector
$w$
only at points in the sector
 ${\mathbb {D}}^+_{n-1}\cap \{x_1\leq T\}$
. This is essentially equivalent to setting boundary conditions on the sector
${\mathbb {D}}^+_{n-1}\cap \{x_1\leq T\}$
. This is essentially equivalent to setting boundary conditions on the sector
 ${\mathbb {D}}^+_{n-1}$
, though the explicit identification of those boundary conditions is a complicated task that we do not undertake here.
${\mathbb {D}}^+_{n-1}$
, though the explicit identification of those boundary conditions is a complicated task that we do not undertake here.
Now, the number of grid points in the full computational grid
 $[\!-T,T]^n\cap \mathbb {Z}_h^n$
grows exponentially in the dimension
$[\!-T,T]^n\cap \mathbb {Z}_h^n$
grows exponentially in the dimension
 $n$
as
$n$
as
 ${\mathcal O}((2Th^{-1})^n)$
, which is known as the curse of dimensionality. However, the number of grid points in the sector
${\mathcal O}((2Th^{-1})^n)$
, which is known as the curse of dimensionality. However, the number of grid points in the sector
 ${\mathbb {D}}^+_{n-1}\cap \{x_1\leq T\}$
grows much slower in
${\mathbb {D}}^+_{n-1}\cap \{x_1\leq T\}$
grows much slower in
 $n$
, as the following lemma shows.
$n$
, as the following lemma shows.
Lemma 3.4.
Let
 $G_{n,T}$
denote the number of grid points in the sector
$G_{n,T}$
denote the number of grid points in the sector
 ${\mathbb {D}}^+_{n}\cap \{x_1\leq T\}$
, where
${\mathbb {D}}^+_{n}\cap \{x_1\leq T\}$
, where
 $T=mh$
with
$T=mh$
with
 $m$
a positive integer. Then
$m$
a positive integer. Then
 $G_{n,T}\leq \frac {1}{n!}(Th^{-1} + n)^n$
.
$G_{n,T}\leq \frac {1}{n!}(Th^{-1} + n)^n$
.
Proof.
Let
 $T = mh$
and define
$T = mh$
and define
 \begin{equation} a_{m,n} = \sum _{i_1=0}^{m}\sum _{i_2=0}^{i_1}\cdots \sum _{i_{n-1}=0}^{i_{n-2}}\sum _{i_n=0}^{i_{n-1}}1. \end{equation}
\begin{equation} a_{m,n} = \sum _{i_1=0}^{m}\sum _{i_2=0}^{i_1}\cdots \sum _{i_{n-1}=0}^{i_{n-2}}\sum _{i_n=0}^{i_{n-1}}1. \end{equation}
Note that
 $G_{n,T}=a_{m,n}$
. Hence, the proof boils down to showing that
$G_{n,T}=a_{m,n}$
. Hence, the proof boils down to showing that
 $a_{m,n}\leq \frac {1}{n!}(m+n)^{n}$
. We will prove this with induction on
$a_{m,n}\leq \frac {1}{n!}(m+n)^{n}$
. We will prove this with induction on
 $n$
, using the recursive identity
$n$
, using the recursive identity
 \begin{equation*}a_{m,n}=\sum _{i=0}^m a_{i,n-1},\end{equation*}
\begin{equation*}a_{m,n}=\sum _{i=0}^m a_{i,n-1},\end{equation*}
which follows directly from (3.12). For the base step of
 $n=1$
, we have
$n=1$
, we have
 $a_{m,1} = m+1$
by direct computation. For the inductive step, assume that for some
$a_{m,1} = m+1$
by direct computation. For the inductive step, assume that for some
 $n\geq 1$
and all
$n\geq 1$
and all
 $m$
we have
$m$
we have
 $a_{m,n}\leq \frac {1}{n!}(m+n)^{n}$
. Then we compute
$a_{m,n}\leq \frac {1}{n!}(m+n)^{n}$
. Then we compute
 \begin{equation*}a_{m,n+1} = \sum _{i=0}^m a_{i,n} \leq \sum _{i=0}^m \frac {1}{n!}(i+n)^n \leq \int _0^{m+1}\frac {1}{n!}(x + n)^n \, dx = \frac {1}{(n+1)!}(m+n+1)^{n+1}, \end{equation*}
\begin{equation*}a_{m,n+1} = \sum _{i=0}^m a_{i,n} \leq \sum _{i=0}^m \frac {1}{n!}(i+n)^n \leq \int _0^{m+1}\frac {1}{n!}(x + n)^n \, dx = \frac {1}{(n+1)!}(m+n+1)^{n+1}, \end{equation*}
which completes the inductive step and hence the proof.
If we choose
 $h$
small enough so that
$h$
small enough so that
 $n \leq Th^{-1}$
, then the bound in Lemma 3.4 implies
$n \leq Th^{-1}$
, then the bound in Lemma 3.4 implies
 \begin{equation*}G_{n,T} \leq \frac {(2 T h^{-1})^n}{n!}.\end{equation*}
\begin{equation*}G_{n,T} \leq \frac {(2 T h^{-1})^n}{n!}.\end{equation*}
This is a factor of
 $n!$
smaller than the number of grid points on the full computational domain
$n!$
smaller than the number of grid points on the full computational domain
 $[\!-T,T]^n\cap \mathbb {Z}_h^n$
, which reflects the exponentially small size of the sector
$[\!-T,T]^n\cap \mathbb {Z}_h^n$
, which reflects the exponentially small size of the sector
 ${\mathbb {D}}^+_{n}$
. In order to understand better how
${\mathbb {D}}^+_{n}$
. In order to understand better how
 $G_{n,T}$
scales with
$G_{n,T}$
scales with
 $n$
in Lemma 3.4, we use a version of Stirling’s formula
$n$
in Lemma 3.4, we use a version of Stirling’s formula
 $n! \geq \sqrt {2\pi n} (n/e)^n$
[Reference Robbins41] to obtain
$n! \geq \sqrt {2\pi n} (n/e)^n$
[Reference Robbins41] to obtain
 \begin{equation*}G_{n,T}\leq \frac {1}{n!}(Th^{-1} + n)^n \leq \frac {e^n}{\sqrt {2\pi n}}(1 + Th^{-1}n^{-1})^n \leq \frac {e^{n + Th^{-1}}}{\sqrt {2\pi n}}.\end{equation*}
\begin{equation*}G_{n,T}\leq \frac {1}{n!}(Th^{-1} + n)^n \leq \frac {e^n}{\sqrt {2\pi n}}(1 + Th^{-1}n^{-1})^n \leq \frac {e^{n + Th^{-1}}}{\sqrt {2\pi n}}.\end{equation*}
While this complexity is still exponential in
 $n$
and
$n$
and
 $h^{-1}$
, these two quantities do not directly interact. For example, with the full grid
$h^{-1}$
, these two quantities do not directly interact. For example, with the full grid
 $[\!-T,T]^n\cap \mathbb {Z}_h^n$
, increasing from
$[\!-T,T]^n\cap \mathbb {Z}_h^n$
, increasing from
 $n$
to
$n$
to
 $n+1$
dimensions requires a factor of
$n+1$
dimensions requires a factor of
 ${\mathcal O}(h^{-1})$
more grid points, while for the sector
${\mathcal O}(h^{-1})$
more grid points, while for the sector
 ${\mathbb {D}}^+_{n}\cap \{x_1\leq T\}$
we require at most
${\mathbb {D}}^+_{n}\cap \{x_1\leq T\}$
we require at most
 $e$
times as many grid points, which is independent of the grid resolution
$e$
times as many grid points, which is independent of the grid resolution
 $h$
. However, it is important to point out that the curse of dimensionality is not overcome. It is rather more accurate to say that we have postponed the curse to larger values of
$h$
. However, it is important to point out that the curse of dimensionality is not overcome. It is rather more accurate to say that we have postponed the curse to larger values of
 $n$
. For example, in Section 4, we conduct experiments with up to
$n$
. For example, in Section 4, we conduct experiments with up to
 $n=7$
experts, using the reduced computational grid in dimension
$n=7$
experts, using the reduced computational grid in dimension
 $n-1=6$
, with a grid resolution of
$n-1=6$
, with a grid resolution of
 $h=0.1$
. Using the full computational grid we are only able to compute solutions of the
$h=0.1$
. Using the full computational grid we are only able to compute solutions of the
 $n=4$
expert problem, on the reduced
$n=4$
expert problem, on the reduced
 $n-1=3$
dimensional grid.
$n-1=3$
dimensional grid.
Remark 3.5.
It is important to point out that the computational costs are more expensive than the memory required to store the grid, since we must compute the maximum over
 ${\mathbf {v}}\in {\mathcal B}^n$
in the operator, which is a maximum over
${\mathbf {v}}\in {\mathcal B}^n$
in the operator, which is a maximum over
 $2^n$
directions. Thus, the computational cost admits an additional
$2^n$
directions. Thus, the computational cost admits an additional
 $2^n$
factor over the memory costs.
$2^n$
factor over the memory costs.
4 Numerical results
In this section, we present numerical results for
 $n=2$
up to
$n=2$
up to
 $n=10$
experts. In all cases, we solve the reduced equation (3.4) for
$n=10$
experts. In all cases, we solve the reduced equation (3.4) for
 $w(x)=u(x,0)$
, which is a problem in
$w(x)=u(x,0)$
, which is a problem in
 $n-1$
dimensions. In Section 4.1 we present experiments on the full computational grid, while in Section 4.2 we present results on the smaller and more efficient sector grid. In each case, to solve the equation
$n-1$
dimensions. In Section 4.1 we present experiments on the full computational grid, while in Section 4.2 we present results on the smaller and more efficient sector grid. In each case, to solve the equation
 $w - F(\nabla ^2_h w) = g$
, we iterate the fixed point scheme
$w - F(\nabla ^2_h w) = g$
, we iterate the fixed point scheme
 \begin{equation} w_{k+1} = (1-dt)w_k + dt(F(\nabla ^2_h w_k) + g) \end{equation}
\begin{equation} w_{k+1} = (1-dt)w_k + dt(F(\nabla ^2_h w_k) + g) \end{equation}
until
 \begin{equation*}|w - F(\nabla ^2_h w) - g| \leq \frac {h^2}{100}.\end{equation*}
\begin{equation*}|w - F(\nabla ^2_h w) - g| \leq \frac {h^2}{100}.\end{equation*}
In this section, we use
 $F$
defined in (2.7). In all cases, we use
$F$
defined in (2.7). In all cases, we use
 $T=5$
and restrict the solutions to the unit box
$T=5$
and restrict the solutions to the unit box
 $[0,1]^{n-1}$
. The code for all experiments is available on GitHub: https://github.com/jwcalder/PredictionPDE.
$[0,1]^{n-1}$
. The code for all experiments is available on GitHub: https://github.com/jwcalder/PredictionPDE.
4.1 Full computational grid

Figure 1.
Plots of the numerical solution
 $w$
versus the true solutions for
$w$
versus the true solutions for
 $n=2$
and
$n=2$
and
 $n=3$
experts.
$n=3$
experts.
We first present results on the full computational grid, so we solve the equation (3.6). Due to the curse of dimensionality, we can only solve the equation for
 $n=2,3,4$
experts. The finest grid we used was
$n=2,3,4$
experts. The finest grid we used was
 $h=0.01$
for
$h=0.01$
for
 $n\leq 3$
and
$n\leq 3$
and
 $h=0.025$
for
$h=0.025$
for
 $n=4$
. In Figure 1 we show plots of the numerical solutions versus the true solutions for
$n=4$
. In Figure 1 we show plots of the numerical solutions versus the true solutions for
 $n=2,3$
experts. Since we solve the reduced
$n=2,3$
experts. Since we solve the reduced
 $d=n-1$
dimensional equation, these are PDEs in
$d=n-1$
dimensional equation, these are PDEs in
 $d=1$
and
$d=1$
and
 $d=2$
dimensions. The
$d=2$
dimensions. The
 $n=2$
expert solution is accurate on the full domain
$n=2$
expert solution is accurate on the full domain
 $[\!-5,5]$
since the boundary condition
$[\!-5,5]$
since the boundary condition
 $u(\pm 5) = \max \{5,0\}$
is exponentially accurate; see (1.6). For
$u(\pm 5) = \max \{5,0\}$
is exponentially accurate; see (1.6). For
 $n=3$
experts, the solution loses accuracy away from the restricted domain
$n=3$
experts, the solution loses accuracy away from the restricted domain
 $[\!-1,1]^2$
.
$[\!-1,1]^2$
.

Figure 2.
Convergence rates and optimal strategies for
 $n=2,3,4$
experts, computed from the numerical solutions. The dashed red line indicates the COMB strategy, which is numerically observed to be optimal for
$n=2,3,4$
experts, computed from the numerical solutions. The dashed red line indicates the COMB strategy, which is numerically observed to be optimal for
 $n=2,3,4$
experts, as the theory predicts.
$n=2,3,4$
experts, as the theory predicts.
In Figure 2 (a) we show a convergence analysis for varying grid resolution
 $h$
for
$h$
for
 $n=2,3,4$
experts, where the exact solutions of the PDEs are known. In all cases, we observe second-order
$n=2,3,4$
experts, where the exact solutions of the PDEs are known. In all cases, we observe second-order
 ${\mathcal O}(h^2)$
convergence rates. Figure 2 also shows the optimality of each adversarial strategy. We define the optimality of strategy
${\mathcal O}(h^2)$
convergence rates. Figure 2 also shows the optimality of each adversarial strategy. We define the optimality of strategy
 ${\mathbf {v}}\in {\mathcal B}^{n-1}$
at a grid point
${\mathbf {v}}\in {\mathcal B}^{n-1}$
at a grid point
 $x$
by the ratio
$x$
by the ratio
 \begin{equation*}\textrm {opt}(x,{\mathbf {v}}) = \frac {\nabla ^2_h w(x,{\mathbf {v}})}{\max _{\mathbf {p}\in {\mathcal B}^{n-1}}\nabla ^2_h w(x,\mathbf {p})} = \frac {\nabla ^2_h w(x,{\mathbf {v}})}{2(u(x) - g(x,0))}.\end{equation*}
\begin{equation*}\textrm {opt}(x,{\mathbf {v}}) = \frac {\nabla ^2_h w(x,{\mathbf {v}})}{\max _{\mathbf {p}\in {\mathcal B}^{n-1}}\nabla ^2_h w(x,\mathbf {p})} = \frac {\nabla ^2_h w(x,{\mathbf {v}})}{2(u(x) - g(x,0))}.\end{equation*}
An optimality value of
 $\textrm {opt}(x,{\mathbf {v}})=1$
indicates that strategy
$\textrm {opt}(x,{\mathbf {v}})=1$
indicates that strategy
 $\mathbf {v}$
is optimal at grid point
$\mathbf {v}$
is optimal at grid point
 $x$
. In order to measure the optimality of all the competing strategies, we plot the minimum, maximum, and average optimality values over the intersection of the computational grid with the positive sector
$x$
. In order to measure the optimality of all the competing strategies, we plot the minimum, maximum, and average optimality values over the intersection of the computational grid with the positive sector
 ${\mathbb {D}}^{+}_{n-1}$
. Since the solution is permutation invariant, the scores are the same in all other sectors. If the minimum score is
${\mathbb {D}}^{+}_{n-1}$
. Since the solution is permutation invariant, the scores are the same in all other sectors. If the minimum score is
 $1$
, up to the numerical precision
$1$
, up to the numerical precision
 $O(h^2)$
, then that strategy is globally optimal over the unit box
$O(h^2)$
, then that strategy is globally optimal over the unit box
 $[\!-1,1]^{n-1}$
. In Figure 2 we denote the strategies, which are binary vectors, by the decimal number that strategy corresponds to, and we indicate the COMB strategy with a dashed red line. Since
$[\!-1,1]^{n-1}$
. In Figure 2 we denote the strategies, which are binary vectors, by the decimal number that strategy corresponds to, and we indicate the COMB strategy with a dashed red line. Since
 $\mathbf {v}$
and
$\mathbf {v}$
and
 $\unicode {x1D7D9}-{\mathbf {v}}$
are equivalent strategies, we only show the optimality scores for the first half of the strategies; the plot for the second half is a mirror image of the plots shown.
$\unicode {x1D7D9}-{\mathbf {v}}$
are equivalent strategies, we only show the optimality scores for the first half of the strategies; the plot for the second half is a mirror image of the plots shown.
In Figure 2 (b), we see that strategies
 $1=(0,1)$
and
$1=(0,1)$
and
 $2=(1,0)$
are optimal, both of which correspond to the COMB strategy. In Figure 2 (c), we see that for
$2=(1,0)$
are optimal, both of which correspond to the COMB strategy. In Figure 2 (c), we see that for
 $n=3$
experts, the COMB strategy
$n=3$
experts, the COMB strategy
 $2=(0,1,0)$
is optimal, as well as the non-COMB strategy
$2=(0,1,0)$
is optimal, as well as the non-COMB strategy
 $3=(0,1,1)$
. In this case, we recall that the complement strategies
$3=(0,1,1)$
. In this case, we recall that the complement strategies
 $(1,0,1)$
and
$(1,0,1)$
and
 $(1,0,0)$
are equivalent, and hence also optimal, but are not depicted. For
$(1,0,0)$
are equivalent, and hence also optimal, but are not depicted. For
 $n=4$
experts in Figure 2 (d), we see that the COMB strategy
$n=4$
experts in Figure 2 (d), we see that the COMB strategy
 $5=(0,1,0,1)$
is optimal, as well as the non-COMB strategy
$5=(0,1,0,1)$
is optimal, as well as the non-COMB strategy
 $6=(0,1,1,0)$
. All of these results have already been established theoretically in previous work; see Section 1.1. We presented these results to verify that the numerical solvers are working properly and give results that agree with previous work.
$6=(0,1,1,0)$
. All of these results have already been established theoretically in previous work; see Section 1.1. We presented these results to verify that the numerical solvers are working properly and give results that agree with previous work.
We are unable to solve the PDE (3.6) for
 $w$
on a full computational grid for the
$w$
on a full computational grid for the
 $n=5$
expert problem, so for this we must resort to the sparse grid method that restricts attention to the positive sector.
$n=5$
expert problem, so for this we must resort to the sparse grid method that restricts attention to the positive sector.
4.2 Sparse grids
We now turn to computations on the positive sector
 ${\mathbb {D}}^+_{n-1}\cap [0,T]^{n-1}$
, which is far smaller than the full grid and allows us to run experiments for
${\mathbb {D}}^+_{n-1}\cap [0,T]^{n-1}$
, which is far smaller than the full grid and allows us to run experiments for
 $n=5,6,7,8,9,10$
experts. In this case, we are solving equation (3.10) using the methods described in Section 3.2. To facilitate computations, we flatten the sector
$n=5,6,7,8,9,10$
experts. In this case, we are solving equation (3.10) using the methods described in Section 3.2. To facilitate computations, we flatten the sector
 ${\mathbb {D}}^+_{n-1}\cap [0,T]^{n-1}$
to a one-dimensional array, and store the solution
${\mathbb {D}}^+_{n-1}\cap [0,T]^{n-1}$
to a one-dimensional array, and store the solution
 $w$
as a one-dimensional array with linear indexing. We pre-computed and stored the stencils for second derivatives in all directions
$w$
as a one-dimensional array with linear indexing. We pre-computed and stored the stencils for second derivatives in all directions
 ${\mathbf {v}}\in {\mathcal B}^{n-1}$
using the methods outlined in Section 3.2 prior to the running the iteration (4.1) to solve the equation. All code is written in Python using the Numpy package and fully vectorized operations.
${\mathbf {v}}\in {\mathcal B}^{n-1}$
using the methods outlined in Section 3.2 prior to the running the iteration (4.1) to solve the equation. All code is written in Python using the Numpy package and fully vectorized operations.

Figure 3.
Numerical computation of strategy optimality for the
 $n=5,6$
expert problems.
$n=5,6$
expert problems.
We used grid resolutions of
 $h=0.025$
for
$h=0.025$
for
 $n=5$
,
$n=5$
,
 $h=0.05$
for
$h=0.05$
for
 $n=6$
and
$n=6$
and
 $h=0.1$
for
$h=0.1$
for
 $n=7$
,
$n=7$
,
 $h=0.2$
for
$h=0.2$
for
 $n=8$
,
$n=8$
,
 $h=0.25$
for
$h=0.25$
for
 $n=9$
, and
$n=9$
, and
 $h=0.35$
for
$h=0.35$
for
 $n=10$
experts. Table 1 shows the number of grid points used in each dimension, compared to the number of grid points that would be required on the full grid. The simulations required between 25 GB and 75 GB of memory and each took less than one day to run on a single processor. Figures 3, 4, and 5 show the numerically computed optimality of the adversary’s strategies for
$n=10$
experts. Table 1 shows the number of grid points used in each dimension, compared to the number of grid points that would be required on the full grid. The simulations required between 25 GB and 75 GB of memory and each took less than one day to run on a single processor. Figures 3, 4, and 5 show the numerically computed optimality of the adversary’s strategies for
 $n=5,6,7,8,9,10$
experts. In all cases, we have strong numerical evidence to indicate that the COMB strategy is not globally optimal. This corroborates numerical evidence from [Reference Chase17] for
$n=5,6,7,8,9,10$
experts. In all cases, we have strong numerical evidence to indicate that the COMB strategy is not globally optimal. This corroborates numerical evidence from [Reference Chase17] for
 $n=5$
.
$n=5$
.
Table 1.
Number of grid points in the sector computational domain
 ${\mathbb {D}}^+_d\cap [0,5]^d$
compared to the full grid
${\mathbb {D}}^+_d\cap [0,5]^d$
compared to the full grid
 $\mathbb {Z}_h^d\cap [\!-5,5]^d$
. We use fewer grid points as the dimension increases since evaluating the PDE involves computing derivatives in
$\mathbb {Z}_h^d\cap [\!-5,5]^d$
. We use fewer grid points as the dimension increases since evaluating the PDE involves computing derivatives in
 $2^d$
directions, so the computational time and memory storage increase exponentially with
$2^d$
directions, so the computational time and memory storage increase exponentially with
 $d$
$d$


Figure 4.
Numerical computation of strategy optimality for the
 $n=7,8$
expert problems.
$n=7,8$
expert problems.

Figure 5.
Numerical computation of strategy optimality for the
 $n=9,10$
expert problems.
$n=9,10$
expert problems.
We have strong numerical evidence in Figure 3 that the strategy
 $11=(0,1,0,1,1)$
is optimal for the
$11=(0,1,0,1,1)$
is optimal for the
 $n=5$
expert problem over the box
$n=5$
expert problem over the box
 $[\!-1,1]^5$
. Furthermore, the numerical evidence points to this being the only optimal strategy, over the unit box, for
$[\!-1,1]^5$
. Furthermore, the numerical evidence points to this being the only optimal strategy, over the unit box, for
 $n=5$
experts. The minimum optimality score for strategy
$n=5$
experts. The minimum optimality score for strategy
 $11$
is
$11$
is
 $0.9999999999991459$
, which is far more accurate than the second-order
$0.9999999999991459$
, which is far more accurate than the second-order
 $O(h^2)$
accuracy for
$O(h^2)$
accuracy for
 $h=0.05$
would suggest. The second best competing strategy is
$h=0.05$
would suggest. The second best competing strategy is
 $13=(0,1,1,0,1)$
with a minimum optimality score of
$13=(0,1,1,0,1)$
with a minimum optimality score of
 $0.966$
, which is well outside the range of numerical precision, suggesting that strategy
$0.966$
, which is well outside the range of numerical precision, suggesting that strategy
 $13$
is not globally optimal.
$13$
is not globally optimal.
The remaining plots in Figures 3, 4, and 5 provide very strong numerical evidence that there are no globally optimal adversarial strategies for
 $n=6,7,8,9,10$
experts. The highest minimum optimality scores are well outside of numerical precision. The one exception is the
$n=6,7,8,9,10$
experts. The highest minimum optimality scores are well outside of numerical precision. The one exception is the
 $n=10$
expert problem, where there are strategies with minimum optimality scores above
$n=10$
expert problem, where there are strategies with minimum optimality scores above
 $0.98$
, while the grid resolution of
$0.98$
, while the grid resolution of
 $h=0.35$
yields
$h=0.35$
yields
 $h^2 = 0.1225$
. However, we expect this is an artefact from using a very coarse grid. We observed a similar phenomenon with
$h^2 = 0.1225$
. However, we expect this is an artefact from using a very coarse grid. We observed a similar phenomenon with
 $n=9$
experts, where some strategies appeared more optimal on a coarse grid.
$n=9$
experts, where some strategies appeared more optimal on a coarse grid.
5 Conclusion and future work
This paper developed and analysed a numerical scheme to solve a degenerate elliptic PDE arising from prediction with expert advice in relatively high dimensions (
 $n \leq 10$
) by exploiting symmetries in the equation and solution. Based on numerical results, we are able to make a number of conjectures for the optimality of various adversarial strategies in Section 1.2. Our results have some limitations; mainly we are not able to solve the PDE on all of
$n \leq 10$
) by exploiting symmetries in the equation and solution. Based on numerical results, we are able to make a number of conjectures for the optimality of various adversarial strategies in Section 1.2. Our results have some limitations; mainly we are not able to solve the PDE on all of
 ${\mathbb {R}}^n$
, and so our results are restricted to the box
${\mathbb {R}}^n$
, and so our results are restricted to the box
 $[\!-1,1]^n$
.
$[\!-1,1]^n$
.
We expect these numerical methods could be extended to a few more experts, perhaps the
 $n=11$
and
$n=11$
and
 $n=12$
expert problems, using parallel processing or computational clusters with vastly more memory. The finite horizon problem should be amenable to similar techniques. There are also other prediction with expert advice PDEs, in particular the history-dependent experts setting [Reference Calder and Drenska12, Reference Drenska and Calder21], that would benefit from numerical explorations. In terms of theory, we posed a number of conjectures and open problems that stem from this work in Section 1.2 that would be interesting to explore in future work.
$n=12$
expert problems, using parallel processing or computational clusters with vastly more memory. The finite horizon problem should be amenable to similar techniques. There are also other prediction with expert advice PDEs, in particular the history-dependent experts setting [Reference Calder and Drenska12, Reference Drenska and Calder21], that would benefit from numerical explorations. In terms of theory, we posed a number of conjectures and open problems that stem from this work in Section 1.2 that would be interesting to explore in future work.
Funding
Calder and Mosaphir were partially supported by NSF-DMS grant 1944925, and Calder was partially supported by the Alfred P. Sloan Foundation, a McKnight Presidential Fellowship, and the Albert and Dorothy Marden Professorship. Drenska was partially supported by NSF-DMS grant 2407839.
Data availability statement
Competing interests
The authors declare that they have no competing interests.
A Definition of a viscosity solution
For convenience, we recall the definitions of viscosity solutions for a general second-order nonlinear partial differential equation
 \begin{equation} H(\nabla ^2u,\nabla u,u,x) = 0 \ \ \text { in } {\mathcal O}, \end{equation}
\begin{equation} H(\nabla ^2u,\nabla u,u,x) = 0 \ \ \text { in } {\mathcal O}, \end{equation}
where
 $H$
is continuous and
$H$
is continuous and
 ${\mathcal O} \subset {\mathbb {R}}^n$
. Let
${\mathcal O} \subset {\mathbb {R}}^n$
. Let
 $\text {USC}({\mathcal O})$
(resp.
$\text {USC}({\mathcal O})$
(resp.
 $\text {LSC}({\mathcal O})$
) denote the collection of functions that are upper (resp. lower) semicontinuous at all points in
$\text {LSC}({\mathcal O})$
) denote the collection of functions that are upper (resp. lower) semicontinuous at all points in
 $\mathcal O$
. We make the following definitions.
$\mathcal O$
. We make the following definitions.
We first recall the test function definition of viscosity solution.
Definition A.1 (Viscosity solution).We say that
 $u \in \text {USC}({\mathcal O})$
is a viscosity subsolution of
(A.1)
if for every
$u \in \text {USC}({\mathcal O})$
is a viscosity subsolution of
(A.1)
if for every
 $x \in {\mathcal O}$
and every
$x \in {\mathcal O}$
and every
 ${\varphi } \in C^\infty ({\mathbb {R}}^n)$
such that
${\varphi } \in C^\infty ({\mathbb {R}}^n)$
such that
 $u - {\varphi }$
has a local maximum at
$u - {\varphi }$
has a local maximum at
 $x$
with respect to
$x$
with respect to
 $\mathcal O$
$\mathcal O$
 \begin{equation*}H(\nabla ^2{\varphi }(x),\nabla {\varphi }(x),u(x),x) \leq 0.\end{equation*}
\begin{equation*}H(\nabla ^2{\varphi }(x),\nabla {\varphi }(x),u(x),x) \leq 0.\end{equation*}
We will often say that
 $u \in \text {USC}({\mathcal O})$
is a viscosity solution of
$u \in \text {USC}({\mathcal O})$
is a viscosity solution of
 $H \leq 0$
in
$H \leq 0$
in
 $\mathcal O$
when
$\mathcal O$
when
 $u$
is a viscosity subsolution of
(A.1)
.
$u$
is a viscosity subsolution of
(A.1)
.
Similarly, we say that
 $u \in \text {LSC}({\mathcal O})$
is a viscosity supersolution of
(A.1)
if for every
$u \in \text {LSC}({\mathcal O})$
is a viscosity supersolution of
(A.1)
if for every
 $x \in {\mathcal O}$
and every
$x \in {\mathcal O}$
and every
 ${\varphi } \in C^\infty ({\mathbb {R}}^n)$
such that
${\varphi } \in C^\infty ({\mathbb {R}}^n)$
such that
 $u - {\varphi }$
has a local minimum at
$u - {\varphi }$
has a local minimum at
 $x$
with respect to
$x$
with respect to
 $\mathcal O$
$\mathcal O$
 \begin{equation*}H(\nabla ^2{\varphi }(x),\nabla {\varphi }(x),u(x),x) \geq 0.\end{equation*}
\begin{equation*}H(\nabla ^2{\varphi }(x),\nabla {\varphi }(x),u(x),x) \geq 0.\end{equation*}
We also say that
 $u \in \text {LSC}({\mathcal O})$
is a viscosity solution of
$u \in \text {LSC}({\mathcal O})$
is a viscosity solution of
 $H \geq 0$
in
$H \geq 0$
in
 $\mathcal O$
when
$\mathcal O$
when
 $u$
is a viscosity supersolution of
(A.1)
.
$u$
is a viscosity supersolution of
(A.1)
.
Finally, we say
 $u$
is viscosity solution of
(A.1)
if
$u$
is viscosity solution of
(A.1)
if
 $u$
is both a viscosity subsolution and a viscosity supersolution.
$u$
is both a viscosity subsolution and a viscosity supersolution.
For more details on the rich theory of viscosity solutions, we refer the reader to the user’s guide [Reference Crandall, Ishii and Lions19] and [Reference Calder10].























 Open access
Open access