


1. Desiderata
Subwords/word pieces have become quite popular recently, especially for deep nets. They are used in the front end of BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) and ERNIE (Sun et al. Reference Sun, Wang, Li, Feng, Tian, Wu and Wang2019), two very successful deep nets for language applications. BERT provides the following motivation for word pieces:
“Using wordpieces gives a good balance between the flexibility of single characters and the efficiency of full words for decoding, and also sidesteps the need for special treatment of unknown words.” (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018)
Subwords are based on byte pair encoding (BPE) (Sennrich, Haddow, and Birch Reference Sennrich, Haddow and Birch2016), which borrows ideas from information theory to learn a dictionary of word pieces from a training corpus. Word pieces are being used for a variety of applications: speech (Schuster and Nakajima Reference Schuster and Nakajima2012), translation (Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao, Macherey, Klingner, Shah, Johnson, Liu, Kaiser, Gouws, Kato, Kudo, Kazawa, Stevens, Kurian, Patil, Wang, Young, Smith, Riesa, Rudnick, Vinyals, Corrado, Hughes and Dean2016), as well as tasks in the GLUE benchmark (Wang et al. Reference Wang, Singh, Michael, Hill, Levy and Bowman2018),Footnote c such as: sentiment, paraphrase, and coreference. Many of these papers are massively cited (more than one thousand citations in Google Scholar).
Some examples of the BERT/ERNIE tokenizer are shown in Tables 1, 2, and 3. These tokenizers are intended to be used on text that is like what they were trained on (often wikipedia and newswire), but many of the examples in this paper are selected from something very different to challenge tokenization with lots of out of vocabulary (OOV) words. We collected a small sample of 10k medical abstracts (1.9M words) from PubMed abstracts. More than 30M abstracts are available for download.Footnote d Medical abstracts are rich in technical terminology (OOVs).
Table 1. Some examples of the BERT/ERNIE tokenizer
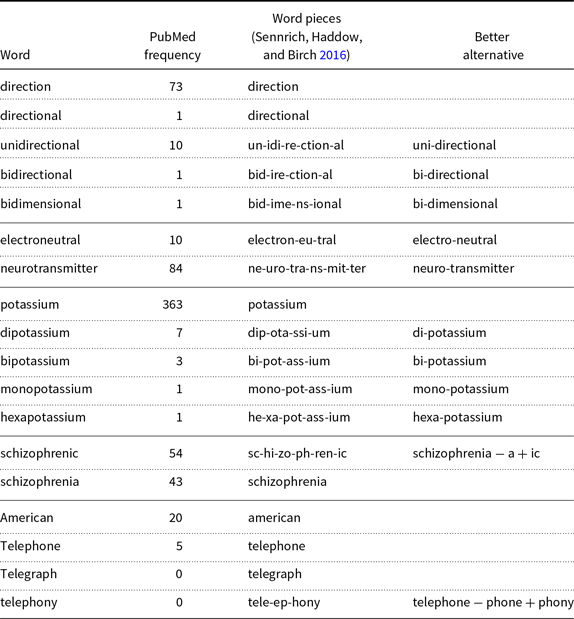
Many of the analyses in Tables 1, 2, and 3 are surprising. Consider “electron-eu-tral” and “electro-neutral.” BPE is more about training (how to learn a dictionary of word pieces) than inference (how to parse an OOV into a sequence of word pieces). In this case, the parse is ambiguous. How do we choose between “electron-eu-tral” and “electro-neutral”? We suggest minimizing the number of word pieces.
Table 2. The analysis of + and + reflects frequency. The more frequent form is more likely to be in the dictionary. Regular inflection is relatively safe, but every split is risky, as illustrated by the surprising analysis for “mediates”

Table 3. The analysis of hypo-x should be similar to hyper-x. Hypertension and hypotension, for example, mean high blood pressure and low blood pressure, respectively. Unfortunately, BERT/ERNIE tokenizer splits many of these into too many pieces, making it difficult to see the similarity
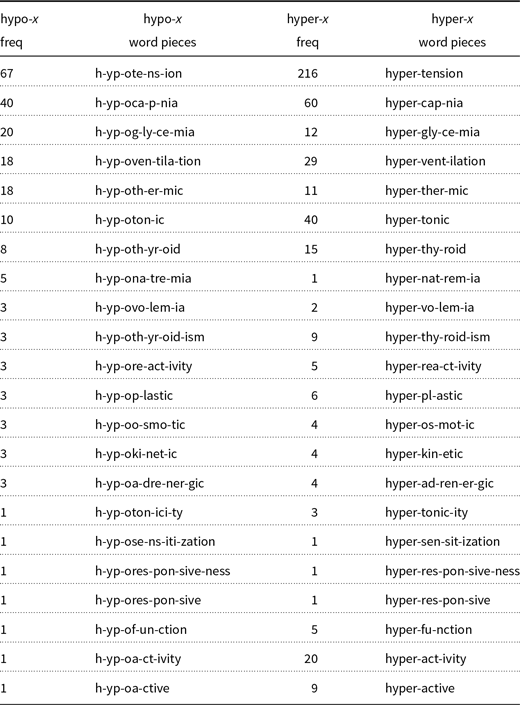
The examples in Tables 1, 2, and 3 raise a number of engineering and linguistic issues. BPE considers letter statistics, but not risk (variance), sound, meaning, etymology, etc. Many of these other factors are considered important for morphological analysis by various communities for various purposes.
1. Engineering considerations
(a) Flexibility and coverage: See quote from Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2018) above.
(b) Maximize coverage and minimize splits (and especially risky splits): Since every split is risky, it is better to use as few word pieces as necessary, especially for frequent words. It should be possible to represent most (frequent) words with one or two word pieces, and almost no words should require more than three word pieces.
(c) Avoid risky splits: Infixes (word pieces in the middle) are more risky than prefixes and suffixes (word pieces at the ends). Short word pieces are more risky than long word pieces.Footnote e Splits near the middle of words are more risky than splits near the ends. Overlapping splits such as “telephone − phone + phony” are safer than simple concatenation (especially for carefully chosen pairs of affixes like “phone” and “phony”).
(d) Stability: Similar words should share similar analyses. Small changes should not change the results much.
2. Linguistic considerations
(a) Capturing relevant generalizations: Morphological analyses should make it easy to identify related words: “bidirectional” and “bidimensional” share a common prefix, with similar sound and meaning (and history); “bidirectional” and “unidirectional” share all but the prefix.
(b) Sound: Word pieces should support grapheme to phoneme conversion.
(i) “bidrectional” and “bidimensional” start with the prefix “bi-” with a long vowel (not “bid-” with a short vowel).
(ii) “unidirectional” starts with the prefix “uni-” (not “un-”); again, the two prefixes have different vowels.
(iii) “ction” is unlikely to be a morpheme because English syllables do not start with “ct.”
(iv) Avoid splitting digraphs like “ph” across different word pieces (as in “tele-ep-hony”).
(c) Meaning: “bi” is from the Latin word for two, unlike “bid,” which means something else (“offer”), and has a different etymology (Germanic).Footnote f Similarly, “uni” is from the Latin word for one, unlike the Germanic “un,” which means something else (“not” (for adjectives) or “to do in the reverse direction” (for verbs)).Footnote g
2. Maximize coverage and minimize splits
As suggested above, it should be possible to represent frequent words with one or perhaps two word pieces. Almost no word should require more than three word pieces. Table 1 shows a number of examples such as “neurotransmitter” where the BERT/ERNIE tokenizer violates this limit of three word pieces. When this happens, we believe there is almost always a better alternative analysis.
Tables 4 and 5 report coverage by type and by token. Rare words are split more than frequent words, but too many words are split more than necessary. That is, compare the top line in Table 4 for more frequent words to other lines in Table 4 for less frequent words. The top line has relatively more mass in the first few columns, indicating that more frequent words are split into fewer pieces. That said, there are way too many splits. Hardly any words should require more than three pieces, but 30% (by type) and 5% (by token) have more than three word pieces.
Table 4. Rare words are split more than frequent words, but too many words are split more than necessary
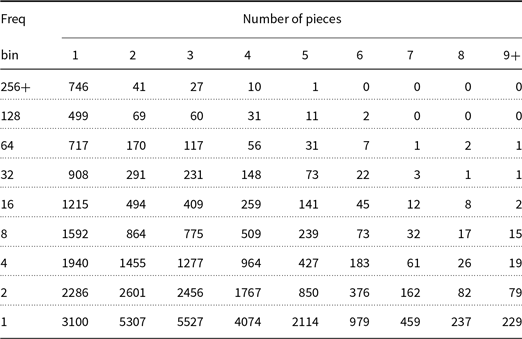
Table 5. Since every split is risky, it is better to use as few word pieces as necessary, especially for frequent words. Most words are in the dictionary (83% by token), but 5% are split into three or more pieces, and 2% are split into five or more pieces

3. Risky business
Every split is risky, but some splits are more risky than others. Table 2 shows a number of examples of regular inflection. This is one of the safer splits, but even in this case, “media-tes” is surprising.
In (Coker, Church, and Liberman Reference Coker, Church and Liberman1991), we evaluated 11 splitting processes for use in the Bell Labs speech synthesizer. We found that splits near the middle of a word are more risky than splits toward the end. (Among other things, splits in the middle are more likely to split digraphs such as “ph” as in “tele-ep-hony.”)
1. Compounding: air-field, anchor-woman, arm-rest, Adul-hussein.
2. Stress neutral: abandon-s, abandon-ing, abandon-ment, Abbott-s, Abel-son.
3. Rhyming analogy: Plotsky (from Trotsky), Alifano (from Califano).
See Table 6 for the results of an evaluation. We asked a native speaker to listen to about a hundred examples of each case and label each example as:
1. Good: that is how I would have said it,
2. OK: I probably would not say it that way, but I could imagine someone else doing so, and
3. Poor: I know that is wrong.
In addition to accuracy by the 11 splitting processes, we also reported coverage. The splitting processes were designed (as much as possible) to make more use of the more accurate processes and less use of the less accurate processes.
4. Etymology
How can rhyming be risky? Consider the digraph “ch,” which usually sounds like the beginning (or end) of my name, “Church,” but not in words that come from Italian such as “Pinocchio.” So too, if one did not have the Spanish name “Jose” in the dictionary, then one might try to infer that by rhyming with “hose” (and end up with the wrong number of syllables).
Table 6. All splits are risky, but splits in the middle (compounding) are particularly risky

In addition to interactions with sound, etymology can also interact with meaning. Consider the the word “digraph.” The prefixes “di-” and “bi-” both mean two, but the former is from Greek and the latter is from Latin. Latin also has a prefix “di-,” but this prefix means something else (“away from”).
This history of English is a long and complicated story that often starts with the Norman Invasion (1066). For a few hundred years after that, the upper classes spoke French and the masses did not. As a result, English now has two words for many things. The Romance (Latin/French) form is often a bit fancier (higher register) than Saxon equivalent. This is particularly clear for food terms, where the upper classes eat beef, pork, and venison (and the serfs raise/hunt cow, pig, and deer).Footnote h The Norman Invasion introduced many new words for the powers that be in churchFootnote i and state.Footnote j Many more examples can be found here.Footnote k
Many of the PubMed terms entered the language starting with the scientific enlightenment (at least 500 years after the Norman Invasion),Footnote l when it was fashionable to coin new terms based on a “revival” of Greek and Latin. The word potassium entered the language relatively recently (1807).Footnote m
These new words tend to separate Greek and Latin, but not always. My first employer, AT&T underwent a number of reorganizations over the 20 years that I was there. One of them introduced an interesting new word, “trivest,”Footnote n when AT&T split itself into three parts, soon after “divestment.” This is a misanalysis of “divestment” where “di-” is from Latin (meaning “away from”)Footnote o and not the Greek “two.” BERT’s analyses of these words are surprising: dive-st, tri-ves-t, dive-st-ment, and tri-ves-tment.
AT&T used to be called American Telephone and Telegraph, but they changed their name to AT&T because the telegraph technology (and even the word) does not have much of a future. Interestingly, though, all three words (American, Telephone and Telegraph) are in the BERT lexicon. One might have expected the BERT lexicon to include frequent words with a future, and exclude infrequent words, especially those without a future.
5. Conclusions
Subwords are extremely popular. Many of the papers mentioned here are massively cited. BPE provides a simple information theoretic method for sidestepping OOVs. The method is currently being used for a wide range of applications in speech, translation, GLUE, etc.
That said, it is easy to find surprising analyses such as “electron-eu-tral.” If we introduce an additional constraint, minimize the number of word pieces, then we produce the more natural analysis: “electro-neutral.”
While the information theoretic BPE criterion sounds attractive to engineers, our field should make room for additional perspectives. Linguists are taught that sound and meaning are better sources of evidence than spelling. This is not an unreasonable position. We should be concerned by the fact that BPE often produces analyses with the wrong meaning and the wrong sound (wrong vowel, splitting digraphs). Such analyses have obvious implications for grapheme to phoneme conversion. For other applications, modern deep nets are so powerful that they can often overcome such issues in preprocessing, but even so, if we can avoid such issues with simple suggestions such as minimizing the number of word pieces, we should do so.







 Open access
Open access