



1. Introduction
The current work uses a mathematical model of the property listing task (PLT, Canessa & Chaigneau, Reference Canessa and Chaigneau2020; Canessa et al., Reference Canessa, Chaigneau and Moreno2021) to predict processing time in semantic and lexical decision tasks (SDT and LDT). In the PLT, people freely list properties that are typically true of a given concept (Chaigneau et al., Reference Chaigneau, Canessa, Barra and Lagos2018; Hough & Ferraris, Reference Hough and Ferraris2010; Perri et al., Reference Perri, Zannino, Caltagirone and Carlesimo2012; Walker & Hennig, Reference Walker and Hennig2004; Wu & Barsalou, Reference Wu and Barsalou2009). Following an approach championed by Simon (Reference Simon and Miller1964), the model is formulated as a set of differential equations that characterize the PLT’s listing dynamics (Canessa & Chaigneau, Reference Canessa and Chaigneau2020). Note that, though, we are interested in the underlying cognitive mechanisms, our focus is on the variables’ functional relations. As discussed in the next section, several putative mechanisms could account for the empirical temporal trends in PLT listing, but our goal is not to resolve between those different mechanisms. Thus, our theoretical claim is that the model summarizes various processing mechanisms that could, in principle, account for the same trends in the data.
To provide evidence of the model’s generality, we now extend its applicability beyond the original PLT task for which it was developed. The coefficients computed when applying the PLT model for each concept used in the present study were estimated from a PLT task in an independent study (Canessa et al., Reference Canessa, Chaigneau and Moreno2023). By using a multiple regression approach, we now compare those coefficients’ ability to predict reaction time (RT) in an SDT and LDT to other generally used psycholinguistic variables that have been shown to be predictors in those tasks (concreteness, imageability, frequency familiarity) (Barber et al., Reference Barber, Otten, Kousta and Vigliocco2013; Khanna & Cortese, Reference Khanna and Cortese2021; Muraki et al., Reference Muraki, Sidhu and Pexman2020; Yap et al., Reference Yap, Sibley, Balota, Ratcliff and Rueckl2015).
Because the concrete/abstract distinction continues to generate controversy, we were particularly interested in differences in processing time attributable to different levels in this continuum (Canessa et al., Reference Canessa, Chaigneau and Moreno2021). In particular, consider that abstract concepts’ referents are not spatially and physically bounded, so they pose the question of whether and how the cognitive system processes them differently from concrete concepts. This is particularly challenging for embodied approaches to cognition (see Dove, Reference Dove2022; for discussions regarding varieties of abstract concepts, see also Barsalou, Reference Barsalou2003; Borghi et al., Reference Borghi, Barca, Binkofski and Tummolini2018; Borghi et al., Reference Borghi, Shaki and Fischer2022; Langland-Hassan & Davis, Reference Langland-Hassan and Davis2023).
2. The mathematical model of the PLT
2.1. The PLT
The PLT and resulting semantic property norms (SPNs) are widely used in cognitive research to investigate conceptual content and the organization of semantic memory (SM; Canessa & Chaigneau, Reference Canessa and Chaigneau2020; Chaigneau et al., Reference Chaigneau, Canessa, Barra and Lagos2018). Researchers apply the PLT to elicit semantic properties that are typically associated with a given concept. These properties serve as carefully controlled stimuli for experiments and can predict performance in linguistic and nonlinguistic tasks.
Following the PLT, SPNs are created from the elicited properties, providing a means of characterizing a semantic space. SPNs are matrices containing different concepts and their corresponding property frequency distributions (Canessa et al., Reference Canessa, Chaigneau, Moreno and Lagos2020; Devereux et al., Reference Devereux, Tyler, Geertzen and Randall2014; Kremer & Baroni, Reference Kremer and Baroni2011; Lenci et al., Reference Lenci, Baroni, Cazzolli and Marotta2013; McRae et al., Reference McRae, Cree, Seidenberg and McNorgan2005; Montefinese et al., Reference Montefinese, Ambrosini, Fairfield and Mammarella2013; Vivas et al., Reference Vivas, Vivas, Comesaña, Coni and Vorano2017).
The PLT and associated SPNs have found applications in both basic cognitive research and applied or field studies (Hough & Ferraris, Reference Hough and Ferraris2010; Perri et al., Reference Perri, Zannino, Caltagirone and Carlesimo2012; Walker & Hennig, Reference Walker and Hennig2004; Wu & Barsalou, Reference Wu and Barsalou2009). These norms serve as tools for testing theories, generating carefully controlled experimental stimuli and evaluating the extraction of conceptual knowledge from corpora in computational linguistics (Baroni & Lenci, Reference Baroni and Lenci2008; Cree & McRae, Reference Cree and McRae2003; Devereux et al., Reference Devereux, Pilkington, Poibeau and Korhonen2009; Fagarasan et al., Reference Fagarasan, Vecchi and Clark2015; Taylor et al., Reference Taylor, Devereux and Tyler2011; Vigliocco et al., Reference Vigliocco, Vinson, Lewis and Garrett2004; Wu & Barsalou, Reference Wu and Barsalou2009).
2.2. PLT mathematical model
The PLT mathematical model describes the property listing process as it unfolds using the listing order of properties (Canessa & Chaigneau, Reference Canessa and Chaigneau2020). It has been validated with data collected in three different SPNs, spanning three countries (Italy, Argentina and Chile), two different languages (Italian and two Spanish dialects), and with 958 participants producing properties for 497 abstract and concrete concepts and verbs (Canessa & Chaigneau, Reference Canessa and Chaigneau2020). The following description of the model summarizes those parts of the PLT model which were used in this paper (Canessa & Chaigneau, Reference Canessa and Chaigneau2020; Canessa et al., Reference Canessa, Chaigneau and Moreno2023). The PLT model describes the dynamics of the listing process using six equations that relate four variables. Here, we use only two of those six equations and the variables defined in Table 1. We must note that the model’s equations are somewhat redundant, in the sense that some equations are derived from the previous ones, allowing to relate all our variables in a single model of interrelated variables. The two equations we chose to keep for the analyses we report are foundational of the model, in the sense that other equations that we could have included are derived from them. Additionally, those two equations are the ones that receive stronger support from data (in terms of R 2 > 0.96) in the original study where the corresponding coefficients were computed (Canessa et al., Reference Canessa, Chaigneau and Moreno2023).
Table 1. Variables employed to describe the PLT listing process dynamics used in the present analyses

First, the model hypothesizes that as the PLT unfolds, participants’ property listing rates decrease. This decreasing rate may be due to different factors, such as decreasing property availability, proactive interference (PI) and control processes such as monitoring for intrusions and repetitions (probably not an exhaustive list). We are not committed to any of the following factors, as our model attempts only to describe the time course of listing.
In listing tasks, the frequency of each property is a powerful factor in recalling from SM. In general, given a certain stimulus context, properties that are more frequent in that context are more available for processing (Balota & Spieler, Reference Balota and Spieler1999; Maki, Reference Maki2007). Differences in availability could lead to changes in listing rates because highly available properties, which tend to be produced at the beginning of the list, may result in higher production rates than less available properties, which tend to be produced at the end of the list.
Furthermore, listing properties requires managing access to long-term memory (LTM) under PI conditions. In listing tasks, clusters of properties occur due to facilitation among items in memory that are in the same semantic field (Abwender et al., Reference Abwender, Swan, Bowerman and Connolly2001; Hills et al., Reference Hills, Todd and Jones2015; Rosen & Engle, Reference Rosen and Engle1997; Troyer, Reference Troyer2000). However, as a semantic field is sampled, properties in short-term memory proactively interfere with other properties in the same field (Conway & Engle, Reference Conway and Engle1994; Kane & Engle, Reference Kane and Engle2000; Wickens et al., Reference Wickens, Born and Allen1963; Reference Wickens, Dalezman and Eggemeier1976; Reference Wickens, Moody and Dow1981). PI is the interference caused by content already recalled, in the retrieval of content not yet accessed from LTM. Consequently, in listing tasks, memory performance decreases on successive trials (Keppel & Underwood, Reference Keppel and Underwood1962). This phenomenon is called PI buildup (Fox et al., Reference Fox, Dennis and Osth2020; Kliegl & Bäuml, Reference Kliegl and Bäuml2021). It is known that this process is influenced by the semantic field from which content is retrieved, because changes in semantic field increase performance (release from PI; Wickens et al., Reference Wickens, Dalezman and Eggemeier1976). The PI mechanism also suggests that the rate of listing in the PLT will decrease with listing time.
Finally, when listing properties, subjects need to monitor for intrusions and repetitions (Rosen & Engle, Reference Rosen and Engle1997). As participants continue listing, intrusions and repetitions become increasingly likely, such that attentional resources are taxed and listing properties becomes harder. This factor also implies that the rate of listing will decrease with time.
All these issues imply that the property listing rate (i.e., how the average list size s varies with time) should be inversely proportional to time, which can be expressed by the differential equation ds/dt = 1 / t. Solving that equation gives eq. (1):
 $$ s={a}_0+{a}_1\mathit{\ln}\left|t\right| $$
$$ s={a}_0+{a}_1\mathit{\ln}\left|t\right| $$
For empirical evidence for this functional form, see Canessa and Chaigneau (Reference Canessa and Chaigneau2020) and Canessa et al. (Reference Canessa, Chaigneau and Moreno2023)). The constants a0 and a1 come from solving the differential equation and can be calculated from data through Ordinary Least Squares (OLS) regression.
Another important relation in the model is between s (average cumulative number of properties) and k (number of different or unique properties produced through the listing process). As discussed above, properties that are more available for listing should be produced earlier in subjects’ lists and be of higher frequency. In contrast, less available properties should be produced later and be more idiosyncratic. Thus, given that k represents the total number of unique properties during the listing process, the rate of increase in k should be directly proportional to s. In previous research, k has been shown to increase with s at different rates depending on concept type (Canessa & Chaigneau, Reference Canessa and Chaigneau2020; Canessa et al., Reference Canessa, Chaigneau and Moreno2023). Concepts characterized by highly available and shared properties, show a slow increase in k in the initial listing phase, and a faster rate toward the end of lists, where the less shared, more idiosyncratic properties emerge (i.e., a nonlinear increase). On the other hand, concepts characterized by low availability properties show an approximately constant rate of low-frequency properties, such that the rate of increase in k relative to s is approximately constant (i.e., a linear increase).
Thus, to summarize both alternatives, we can say that the rate of increase of k with respect to s is constant and/or directly proportional to s. This can be expressed by the differential equation dk/ds = e0 + e1 s. The solution to that equation is the following expression:
 $$ k={e}_0+{e}_1s+{e}_2\;{s}^2 $$
$$ k={e}_0+{e}_1s+{e}_2\;{s}^2 $$
The constants e0, e1 and e2 come from solving the differential equation and can be calculated from data through regression methods such as OLS. Consequently, eq. (2) allows analyzing whether the linear and/or quadratic terms are more prevalent for each concept, according to the abovementioned arguments.
Note that eq. (2) is related to “semantic richness.” In general, richer concepts are easier to process because they have a denser semantic neighborhood (i.e., a set of closely knit and interrelated concepts), more semantically related terms (i.e., the sheer number of associates) or are characterized by more features (Mirman & Magnuson, Reference Mirman and Magnuson2008; Yap et al., Reference Yap, Tan, Pexman and Hargreaves2011). To illustrate, concrete concepts are generally thought to be relatively rich, with more features, more associates and a set of interrelated concepts (e.g., all things that people know about dogs). In contrast, many abstract concepts are thought to be relatively poor, with only a few associates, and depending strongly on the specific contexts in which they occur (e.g., the concept beauty depends on the specific things about which beauty is being predicated).
In the model, coefficient e1 indicates that the increase of k relative to s is approximately linear, due to more idiosyncratic and low-frequency properties being uniformly distributed during subjects’ listing. Given that a richer concept should evoke relatively few unique or idiosyncratic properties (i.e., those not strongly associated to the cue word), this will cause k to grow at a smaller rate relative to s, and the e1 slope representing the relation of k to s will be shallower. Relatedly, if unique and low-frequency properties tend to occur at the end of subjects’ lists, then the e2 coefficient will be significantly different from zero, showing that unique properties increase k at a higher rate at the end of listing. Here, a relatively larger slope indicates more semantic richness (i.e., people only diverge in their lists when many accessible properties have been listed). The combined effect of both coefficients allows eq. (2) to simultaneously represent the density of the unique properties during listing and their distribution throughout listing, allowing the characterization of rich concepts as low density of unique and low frequency properties and/or that accumulate unique and low frequency properties toward the end of listing.
2.3. Computing the coefficients
To predict RTs in the SDT and LDT, we use the coefficients computed in Canessa et al. (Reference Canessa, Chaigneau and Moreno2023)). To that effect, that previous work conducted a SPN study involving 120 concepts (60 concrete and 60 abstract concepts). A total of 221 participants (all Chilean Spanish native speakers) performed the PLT and the study measured RTs from the moment the cue word was presented to the moment in which each semantic property was produced. Note that this is an independent sample from the one that was used for SDT and LDT studies reported here. Therefore, the previous data were time series produced by each subject for each concept, reflecting their listing processes (for details, see Canessa et al., Reference Canessa, Chaigneau and Moreno2023).
To estimate the coefficients, the same basic procedure used in Canessa and Chaigneau (Reference Canessa and Chaigneau2020) was followed, which involves computing the regression equations (OLS) for each concept, using the corresponding functional forms in eqs. (1) and (2) and time series data (Canessa et al., Reference Canessa, Chaigneau and Moreno2023). The individual coefficients for each concept used in the LDT and SDT tasks reported here can be found at the Open Science Foundation (OSF, https://osf.io/zsn4c/).
3. SDT and LDT tasks
In the SDT, people must decide whether a given word shown on a screen is concrete or abstract. It is widely assumed that in this task, semantic variables account for an important amount of RT’s variance in the SDT (Pexman et al., Reference Pexman, Heard, Lloyd and Yap2017). In the LDT, subjects must decide if a string of letters is a word or a pseudoword (i.e., a letter string that can be pronounced but has no meaning). Though semantic variables play a role in the LDT (Pexman, Reference Pexman and Adelman2012; Pexman et al., Reference Pexman, Lupker and Hino2002), less variance is explained by those semantic variables (Pexman, Reference Pexman and Adelman2012), presumably because sub-lexical variables play significant roles in aiding word recognition in the LDT (Plaut, Reference Plaut1997).
In our study, semantic variables were the three coefficients previously computed (a1, e1 and e2), and the concreteness and imageability ratings for each concept. Sub-lexical variables were text frequency and ratings of familiarity. All these variables usually appear as predictors in the SDT and LDT tasks (Barber et al., Reference Barber, Otten, Kousta and Vigliocco2013). Because our materials are in Spanish, the variables of concreteness/abstractness, imageability, familiarity and frequency of use were obtained from the EsPal database (Duchon et al., Reference Duchon, Perea, Sebastián-Gallés, Martí and Carreiras2013).
To obtain a measure of concreteness/abstractness, researchers often rely on subjective ratings collected in normative studies (Holcomb et al., Reference Holcomb, Kounios, Anderson and West1999; Villani et al., Reference Villani, Lugli, Liuzza and Borghi2019). Instructions typically used for participants to generate concreteness ratings are based on Spreen and Schulz (Reference Spreen and Schulz1966), and define concrete concepts as nouns that refer to persons, places and things that can be perceived through the senses. On the other hand, abstract concepts, which cannot be directly experienced through the senses, should receive low concreteness ratings.
A second type of rating typically collected in databases is imageability, which measures the ease with which a word can evoke mental images or sensory representations. Words with high imageability are often concrete and have strong sensory associations, while abstract words may have lower imageability (Cortese & Fugett, Reference Cortese and Fugett2004). As expected, given the instructions described above, concreteness and imageability tend to be highly correlated (Kousta et al., Reference Kousta, Vigliocco, Vinson, Andrews and Del Campo2011). The reader will find that our data show this same correlational pattern.
Familiarity is a subjective rating that assesses the degree of exposure to a particular word that individuals have. It reflects how common and recognizable a word is within a given population. Familiar words have been found to be easier to process than less familiar words, though this seems not to be a linear relation (Bridger et al., Reference Bridger, Bader and Mecklinger2014).
Word frequency refers to the frequency with which a word occurs in a given language or corpus. It is often measured by counting the number of times a word appears in written or spoken texts. High-frequency words are typically easier to process and access from memory (Neville et al., Reference Neville, Raaijmakers and van Maanen2019). Because frequency distributions are highly skewed and non-normal, a typical procedure is to take the logarithm of frequency for statistical analyses. Frequency (or the log of frequency) has been shown to predict access time (Segalowitz & Lane, Reference Segalowitz and Lane2000).
4. Predictions for the current work
In summary, we claim that the PLT mathematical model describes access to SM, and that eqs. (1) and (2) reflect different but related aspects of that access. A higher a1 coefficient directly reflects easier access in the PLT and presumably a general easier access to a concept’s semantic information. Coefficients e1 and e2 reflect semantic richness, which implies differences in ease of processing. Relatively smaller e1 coefficient and/or a relatively larger e2 coefficient reflect a richer concept. Importantly, if the model describes ease of semantic access, then it should generalize beyond the PLT task for which it was originally developed.
Following our review of the SDT and LDT tasks in the previous section, we predicted that the semantic variables would account for more variance in SDT than in the LDT. If the coefficients reflect ease of access to semantic content, then they should behave similarly to the other semantic variables (i.e., concreteness and imageability ratings). In contrast, the sub-lexical variables (i.e., frequency and familiarity ratings) should dominate in the LDT, though not exclusively of semantic variables.
Finally, we also aimed at testing whether the coefficients in the PLT model made an independent contribution to the prediction of RTs in our tasks, relative to the contribution made by their psycholinguistic counterparts. In particular, we were interested in the model’s coefficients’ relationship to concreteness and imageability ratings, because they have become the de facto operational definition of concreteness (Löhr, Reference Löhr2022).
5. Preliminary correlation analysis
As a preliminary analysis, we computed Pearson correlations between our variables. To linearize word frequency, we used Log frequency in all our analyses (Log10 of the word token frequency in the EsPal database). Table 2 shows those correlations. Figure 1 shows scatterplots so the reader can get a sense of the data structure. As shown in Table 2 and Figure 1, sub-lexical variables correlate with each other and semantic variables also correlate with each other. Importantly, the PLT model coefficients cluster with the semantic variables and not with the sub-lexical ones, consistent with our hypothesis that the model’s coefficients reflect semantic access. Note also the positive correlations shown by the a1 coefficient (higher coefficients indicate higher concreteness ratings), but the negative correlations for the e1 coefficient (i.e., a larger e1 coefficient indicates lower concreteness ratings), consistent with our analysis of Eq. (2).
Table 2. Correlation matrix between sub-lexical and semantic variables with PLT model coefficients
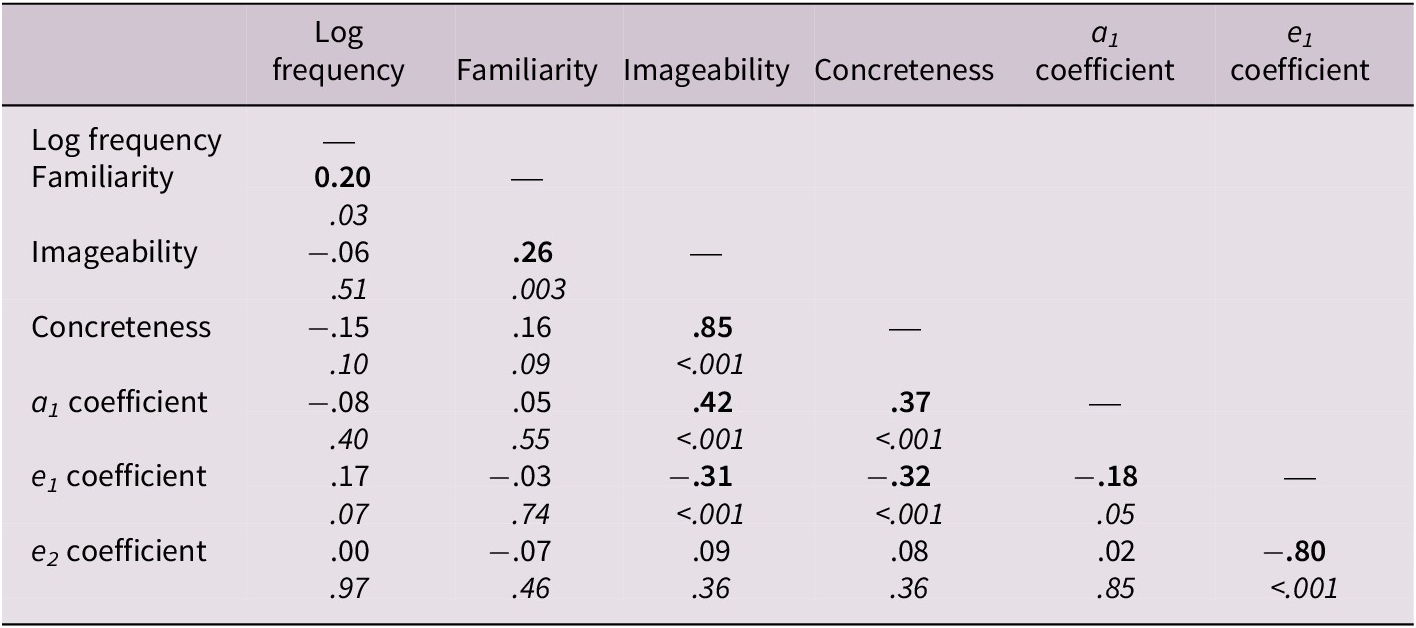
Note: Pearson’s coefficients and p-values (in italics). Significant coefficients in bold.

Figure 1. Scatterplots between sub-lexical and semantic variables with property listing task (PLT) model’s coefficients. Note. Best regression line in red and standard errors filled-in-gray shape.
6. Methods
6.1. LDT study
In this study, participants had to decide whether a letter string presented on a computer screen was a word or a pseudoword. We used concrete and abstract words to check for evidence of semantic processing but expected to find that sub-lexical variables explained most of the variance. Previous evidence showing small but significant semantic effects (Pexman, Reference Pexman and Adelman2012; Pexman et al., Reference Pexman, Lupker and Hino2002), suggested that the coefficients might also be predictive in this task. Consequently, we predicted that a model with semantic and sub-lexical variables would be a good model, and therefore adding the coefficients should improve the regression model in terms of predicted variance (i.e., coefficients contribute independently).
6.1.1. Participants
Then, 101 undergraduate Spanish speaker students of Universidad Adolfo Ibáñez voluntarily agreed to participate in the study (Mage = 21.58, SDage = 2.52; 23 females) and received a small no-monetary academic incentive. All participants gave their informed consent to participate, and the study was approved by the Ethics Committee of Universidad Adolfo Ibáñez.
6.1.2. Materials and procedure
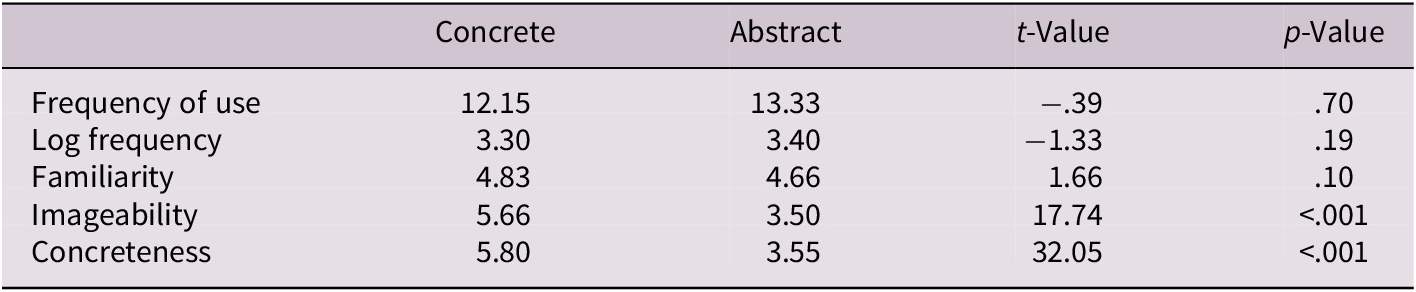
Materials consisted of 120 concepts (60 concrete and 60 abstract) used in a previous study to validate the PLT mathematical model with RT (Canessa et al., Reference Canessa, Chaigneau and Moreno2023). Those concepts were selected so that they were not significantly different in frequency of use, familiarity and number of syllables. Also, the concrete and abstract concepts were selected so that they had a substantial difference in their concreteness ratings between those two types of concepts, so as to allow a good analysis of the difference between abstract and concrete concepts as it is shown in Table 3.
Table 3. Mean values of lexical and sub-lexical variables for concrete and abstract concepts
We wanted that our results be as generalizable as possible, and not restricted to a single or to a few types of abstract concepts. Thus, we selected a wide range of abstract concepts including, abstract actions (e.g., errand); behavior descriptions (e.g., clumsiness); personality traits (e.g., shyness); emotions (e.g., pity); physical (e.g., inertia) or aesthetic (e.g., ugliness).
Additionally, 120 pseudowords were derived from their corresponding word. Those pseudowords were produced from the 120 concepts controlling by relevant lexical variables (number of letters, number of syllables and sub-syllabic structure), with the multilingual pseudoword generator Wuggy (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010), and using methods described in Perea et al. (Reference Perea, Marcet, Vergara-Martínez and Gomez2016) and in Keuleers and Brysbaert (Reference Keuleers and Brysbaert2010). While the pseudowords were derived from both concrete and abstract words, it is important to note that all of them are considered to belong to a single category (i.e., pseudowords).
The LDT was programmed using PsychoPy (Peirce et al., Reference Peirce, Gray, Simpson, MacAskill, Höchenberger, Sogo, Kastman and Lindeløv2019). All words and pseudowords were sequentially presented on a computer screen in random order, controlling that trials in the same condition (i.e., concrete words, abstract words and pseudowords) were not presented more than three times in a row. Each stimulus was preceded by a fixation cross on the screen for 250 ms. After that, each stimulus was displayed for 500 ms. The total duration of the trial was 2000 ms. Participants were instructed to respond as fast as possible by pressing two different keys on a computer keyboard. To control the effect of lateralized motor responses, we implemented a counterbalancing strategy for the response keys following the completion of the first half of trials (i.e., the key to indicate that a presented word/pseudoword was a real word and the key to denote that the presented word/pseudoword was a pseudoword were switched). At the beginning of each experimental block, a training session was conducted using the same procedure (including the switching of the response keys) employing different stimuli from those used in the actual experiment. Each participant took approximately 20 minutes to complete the task.
6.1.3. Results
To assess the performance on the LDT task, we measured accuracy (i.e., hit rate) and response time (RT) for each participant. As has been frequently reported, responses to words are faster (shorter RTs) and more accurate (higher hit rates) than responses to pseudowords (e.g., Wühr & Heuer, Reference Wühr and Heuer2022). Thus, finding this same pattern would function as a sanity check for our data. Note, however, that our main regression analyses were performed with RT as criterion, due to our interest on access and processing speed.
As is a common practice in related studies (e.g., Yap et al., Reference Yap, Sibley, Balota, Ratcliff and Rueckl2015), we excluded incorrect trials and trials with RTs faster than 200 ms and 2.5 standard deviations above the participant mean (12.28% of data was removed for RT analyses). To compare accuracy and RTs across the different concept types, we performed a 2 × 2 repeated measures ANOVA, semantic content (concrete vs. abstract) and the cue type (words vs. pseudowords) as factors. Recall that the pseudowords were derived from a corresponding word, which is why we label them concrete or abstract, even though they are not proper words. In total, we had 60 words and pseudowords for concrete and abstract concepts. Table 4 shows the descriptive statistics.
Table 4. Descriptive statistics on LDT performance

Note: Mean and SD (in parenthesis) for accuracy and RT in the LDT.
To test for evidence of semantic processing, we performed 2 × 2 repeated measures ANOVAs using accuracy and RTs as dependent variables. For the accuracy-dependent variable, we found a significant main effect of cue type (words vs. pseudowords), F(1, 100) = 33.1, MSe = .01, p < .001,
 $ {\eta}_p^2 $
= .25, no significant main effect of semantic content (concrete vs. abstract), F(1, 100) = .40, MSe = .002, p = .53,
$ {\eta}_p^2 $
= .25, no significant main effect of semantic content (concrete vs. abstract), F(1, 100) = .40, MSe = .002, p = .53,
 $ {\eta}_p^2 $
= .004, and a significant interaction between cue type and semantic content, F(1, 100) = 4.60, MSe = .001, p = .034,
$ {\eta}_p^2 $
= .004, and a significant interaction between cue type and semantic content, F(1, 100) = 4.60, MSe = .001, p = .034,
 $ {\eta}_p^2 $
= .04. As expected from previous literature (Pexman, Reference Pexman and Adelman2012), we found no statistical differences when comparing semantic content (i.e., concrete vs. abstract words) for both types of cues (words vs. pseudowords) (see Figure 2 panel A). The overall significant difference in the ANOVA is driven by the words against pseudowords comparison.
$ {\eta}_p^2 $
= .04. As expected from previous literature (Pexman, Reference Pexman and Adelman2012), we found no statistical differences when comparing semantic content (i.e., concrete vs. abstract words) for both types of cues (words vs. pseudowords) (see Figure 2 panel A). The overall significant difference in the ANOVA is driven by the words against pseudowords comparison.
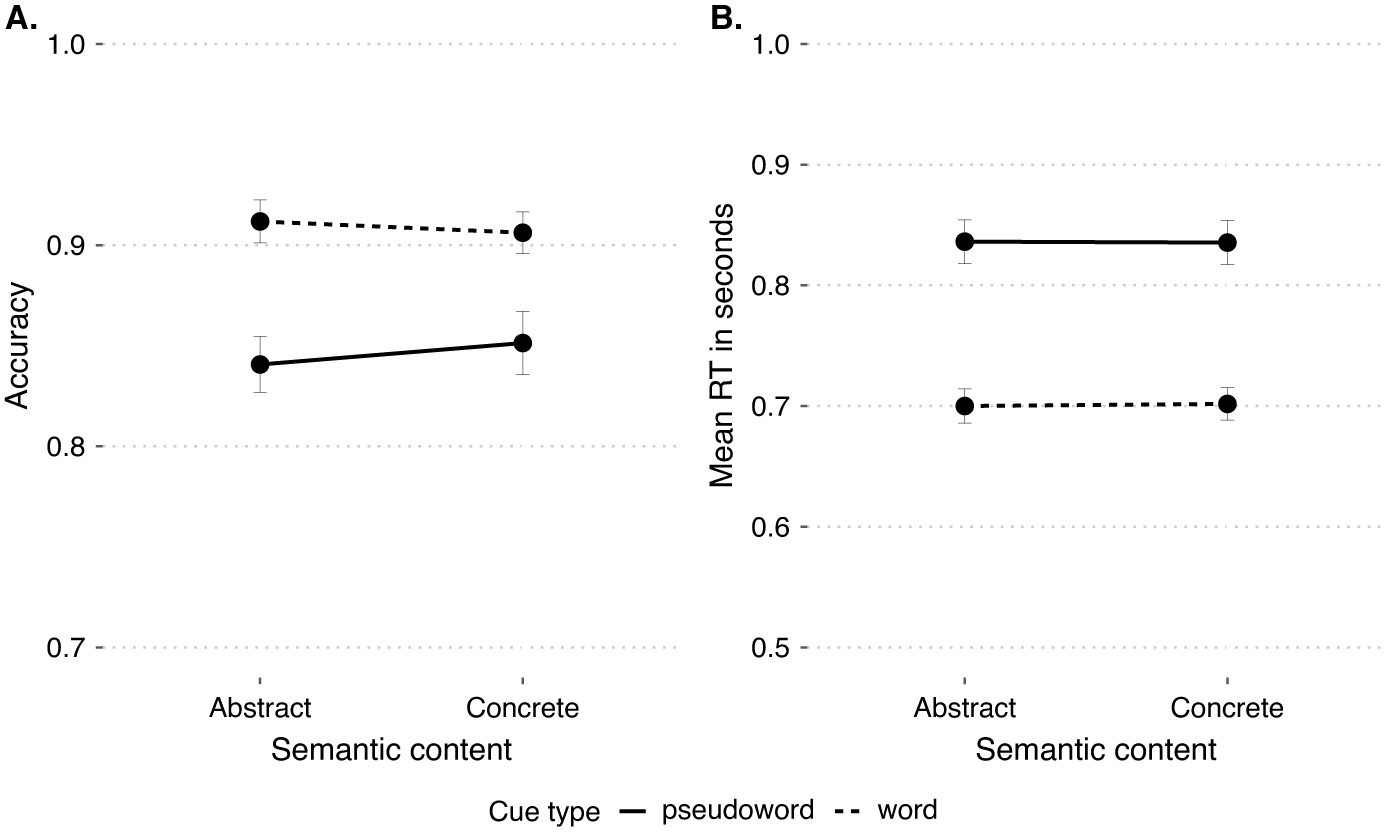
Figure 2. Mean accuracy and RTs in the lexical decision task (LDT). Note. Mean responses in accuracy (panel A) and RTs (panel B) for the 2 × 2 repeated design in the LDT. Intervals show standard error of the mean.
When using RTs as dependent variable, we observed a significant main effect of cue type, F(1, 100) = 296.3, MSe = .006, p < .001,
 $ {\eta}_p^2 $
= .75. More specifically, we found that participants’ RTs were slower when dealing with pseudowords (derived either from concrete or abstract words) compared to real words. We did not find a main effect of semantic content, F(1, 100) = .04, MSe < .001, p = .85,
$ {\eta}_p^2 $
= .75. More specifically, we found that participants’ RTs were slower when dealing with pseudowords (derived either from concrete or abstract words) compared to real words. We did not find a main effect of semantic content, F(1, 100) = .04, MSe < .001, p = .85,
 $ {\eta}_p^2 $
= .001, nor an interaction, F(1, 100) = .21, MSe < .001, p = .65,
$ {\eta}_p^2 $
= .001, nor an interaction, F(1, 100) = .21, MSe < .001, p = .65,
 $ {\eta}_p^2= $
.002. This pattern of results suggests that semantic content is not relevant for the LDT. However, the forthcoming regression analyses offer a more nuanced view.
$ {\eta}_p^2= $
.002. This pattern of results suggests that semantic content is not relevant for the LDT. However, the forthcoming regression analyses offer a more nuanced view.
6.1.4. Regression analyses
To assess the influence of the PLT mathematical model’s coefficients (i.e., a1, e1 and e2), other semantic variables (concreteness and imageability) and sub-lexical variables (log frequency, familiarity) we performed multiple regressions following a model comparison approach with nested models. In all our analyses, we compared regression models’ fit to the data by testing differences in explained variances, and by using the Akaike information criterion (AIC; Akaike, Reference Akaike, Petrov and Csaki1973; Hurvich & Tsai, Reference Hurvich and Tsai1991). The AIC penalizes models with more parameters.
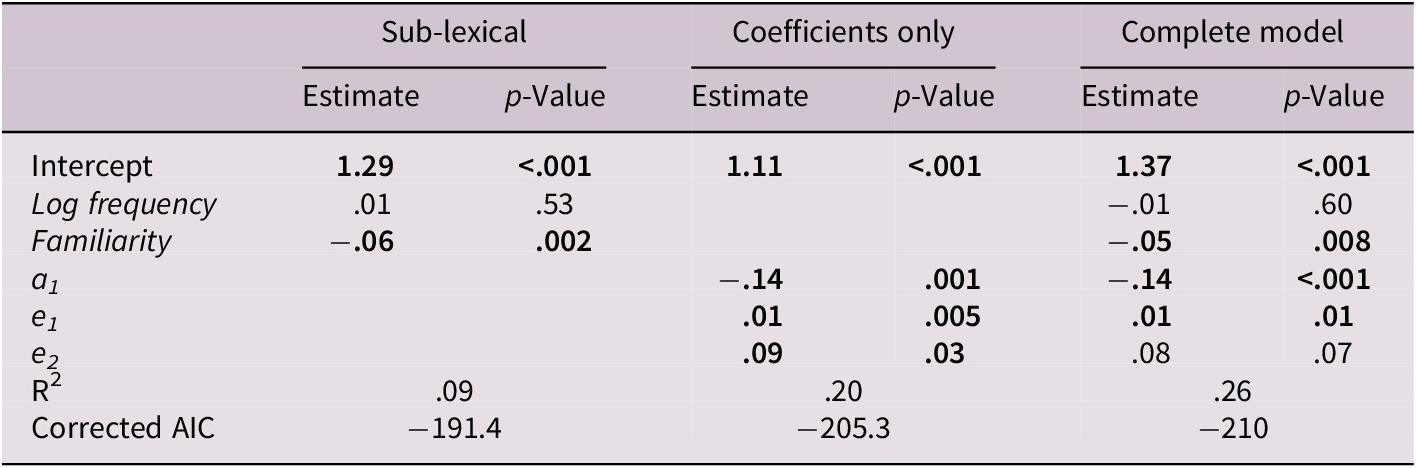
For the full data set (i.e., including concrete and abstract words), we fitted three models to the data: sub-lexical only, model coefficients only and a full model (combining sub-lexical with model coefficients). Table 5 shows the regression estimates and their corresponding p values for each predictor for the full dataset in the LDT. When performing analyses for the full dataset, it was not possible to use concreteness or imageability ratings as predictors. Recall that words were selected avoiding intermediate concreteness ratings and that in our data, the correlation between both ratings was high (r = .85). Thus, concreteness and imageability were (by design, and for the full dataset) highly correlated with RTs. Noteworthy, including the coefficients in the complete model accounts for greater RT variance (36%) in the LDT than in the other models. To test whether the models’ R 2 values were significantly different, we used an F test for nested models (Hastie & Pregibon, Reference Hastie, Pregibon, Chambers and Hastie1992). Our main question regarding R 2s was whether there was a statistically significant difference between models that can be accounted for by the addition of the mathematical model’s coefficients in the full regression model. Results showed that the full model was significantly better than the sub-lexical model (F(3, 114) = 3.79, p = .012) and then the coefficients only model (F(2, 114) = 24.26, p < .001). Furthermore, the full model showed a better AIC coefficient. Examining the full model shows that log frequency, familiarity and coefficients a1 and e2 are significant.
Table 5. Regression models on RTs for the full dataset in the LDT

Note: Significant results at the. 05 level are shown in bold.
Abbreviation: AIC, Akaike information criterion.
In contrast to the analysis for the entire data set, regressions within each level of the concrete/abstract factor allowed us to use concreteness and imageability ratings along with sub-lexical variables (i.e., the Sub-lexical+semantic model in Tables 6 and 7). Although the complete model achieves a better fit to the data, with log frequency, familiarity and coefficient a1 being significant, both for concrete (Table 6) and abstract concepts (Table 7), the difference does not achieve significance. For concrete concepts, the F test for nested models showed that the complete model was not significantly better for predicting RTs than the sub-lexical+semantic model (F(3, 52) = 2.72, p = .053). Similarly, for the abstract concepts data, the F test for nested models showed that the complete model was not significantly better for predicting RTs than the sub-lexical+semantic model (F(3, 52) = 2.77, p = .051). However, for both datasets, the AIC shows that the full model that includes the equations’ coefficients is the best model, and coefficient a1 is significant in both models even in the presence of log frequency, familiarity, concreteness and imageability (see Tables 6 and 7).
Table 6. Regression models on RTs for concrete concepts in the LDT

Note: Significant results at the. 05 level are shown in bold.
Abbreviation: AIC, Akaike information criterion.
Table 7. Regression models on RTs for abstract concepts in the LDT

Note: Significant results at the. 05 level are shown in bold.
Abbreviation: AIC, Akaike information criterion.
6.2. SDT study
In this study, participants had to decide whether a word presented on a computer screen was abstract or concrete. We predicted that, additional to the effect of sub-lexical variables, we would observe important effects of semantic variables, including the PLT mathematical model’s coefficients. Importantly, we predicted that the coefficients should align with the semantic variables and account for an independent part of the variance, showing that they measure semantic processing, and that a full regression model including the coefficients would be the best regression model in accounting for RT variance.
6.2.1. Participants
Here, 130 undergraduate Spanish speaker students of Universidad Adolfo Ibáñez voluntarily agreed to participate in the study (Mage = 21.48, SDage = 1.52; 31 females). Participants received a small academic incentive. All participants gave informed consent to participate. The study was approved by the Ethics Committee of Universidad Adolfo Ibáñez.
6.2.2. Materials and procedure
Materials consisted of the 120 concepts (60 concrete and 60 abstract) used in the previous LDT study. The SDT was programmed using PsychoPy (Peirce et al., Reference Peirce, Gray, Simpson, MacAskill, Höchenberger, Sogo, Kastman and Lindeløv2019). Concepts were presented in random order on a computer screen (but making sure that no more than three concepts of each type were consecutively displayed), and each concept was displayed during 500 ms. Each response and its corresponding RT was recorded. Preceding each displayed word, a fixation cross appeared on screen for 250 ms. Participants were instructed to indicate whether the presented concept was concrete or abstract, by pressing two different keys on a keyboard. At the middle of the experiment, response keys were inverted (i.e., the key to indicate that a presented concept was concrete and the key to denote that the presented concept was abstract were switched). Before starting the actual experiment, a training session was conducted using the same procedure (including the switching of the response keys) but employing different words from those used in the actual experiment. The experiment for each participant lasted for about 20 minutes.
6.2.3. Results
To assess the performance on the SDT task, we measured accuracy (i.e., hit rate) and response times (RTs) for each participant. It is well documented that concrete concepts have a processing advantage over abstract concepts (i.e., higher accuracy and shorter RTs; Paivio, Reference Paivio1991). Thus, finding this same pattern would function as a sanity check for our data. Note, however, that our main regression analyses were done with RTs as criterion, due to our interest on access and processing speed.
As in the LDT study, we excluded incorrect trials and trials with RTs faster than 200 ms and longer than 2.5 standard deviations from the participant mean (21.4% of data was removed for RT analyses). This percentage may seem high but consider that the SDT is generally a more difficult task than the LDT, and people may genuinely differ in their judgments about whether a given concept is concrete or abstract, all of which means an increase in errors and RT relative to the LDT.
For the SDT, we followed a similar analysis approach to the LDT study. We carried out a one factor repeated measures ANOVA, using semantic content (i.e., concrete vs. abstract) as the repeated factor. Using accuracy as the dependent variable, we found a main effect of semantic content, F(1, 129) = 75.7, MSe = .025, p < .001,
 $ {\eta}_p^2 $
= .37. As Figure 3(A) and Table 8 show, participants made more errors for abstract concepts than for concrete concepts. By examining the RTs in the SDT, we found again a significant main effect of semantic content, F(1, 129) = 102.2, MSe = .007, p < .001,
$ {\eta}_p^2 $
= .37. As Figure 3(A) and Table 8 show, participants made more errors for abstract concepts than for concrete concepts. By examining the RTs in the SDT, we found again a significant main effect of semantic content, F(1, 129) = 102.2, MSe = .007, p < .001,
 $ {\eta}_p^2= $
.44. This shows that participants made faster responses for concrete concepts than for abstract concepts (see Figure 3(B)).
$ {\eta}_p^2= $
.44. This shows that participants made faster responses for concrete concepts than for abstract concepts (see Figure 3(B)).

Figure 3. Mean accuracy and RTs in the semantic decision task (SDT). Note. Mean responses in accuracy (panel A) and RTs (panel B) for the one factor repeated design in the SDT. Intervals show the standard error of the mean.
Table 8. Descriptive statistics on SDT performance

Note: Mean and SD (in parenthesis) for accuracy and RT in the SDT.
6.2.4. Regression analysis
For the full data set (i.e., concrete and abstract words), we fitted three models: sub-lexical only, model coefficients only, and a full model (combining sub-lexical with model coefficients). Table 9 shows the regression estimates and their corresponding p values for each predictor for the full dataset in the SDT. As explained above, when performing analyses for the full dataset, it was not possible to use concreteness or imageability ratings as predictors. Noteworthy, including the coefficients in the full model accounts for more RT variance (26%) in the SDT than the other nested models. To test whether the models’ R 2 values were significantly different, we used the F test for nested models. Results showed that the full model was significantly better than the sub-lexical model (F(3, 114) = 8.9, p < .001) and the coefficients only model (F(2, 114) = 4.52, p = .013). Furthermore, the full model showed a better AIC coefficient. Examining the full model shows that log frequency, familiarity and coefficients a1 and e2 are significant.
Table 9. Regression models on RTs for the complete dataset in the SDT
Note: Significant results at the. 05 level are shown in bold.
Abbreviation: AIC, Akaike information criterion.
As done for the LDT, regressions within each level of the concrete/abstract factor allowed us to use concreteness and imageability ratings along sub-lexical variables (i.e., the Sub-lexical+semantic model in Tables 10 and 11). For concrete concepts, the full model achieved a better fit to the data, with log frequency, familiarity and a1 coefficient being significant (F(3, 52) = 4.48, p = .007). Furthermore, the full model also outperformed the Sub-lexical+semantic model according to the AIC. However, for abstract concepts, the difference in R 2 did not achieve significance (F(3, 52) = .28, p = .84), and the AIC favored the partial model including only Sub-lexical+semantic variables.
Table 10. Regression models on RTs for concrete concepts in the SDT
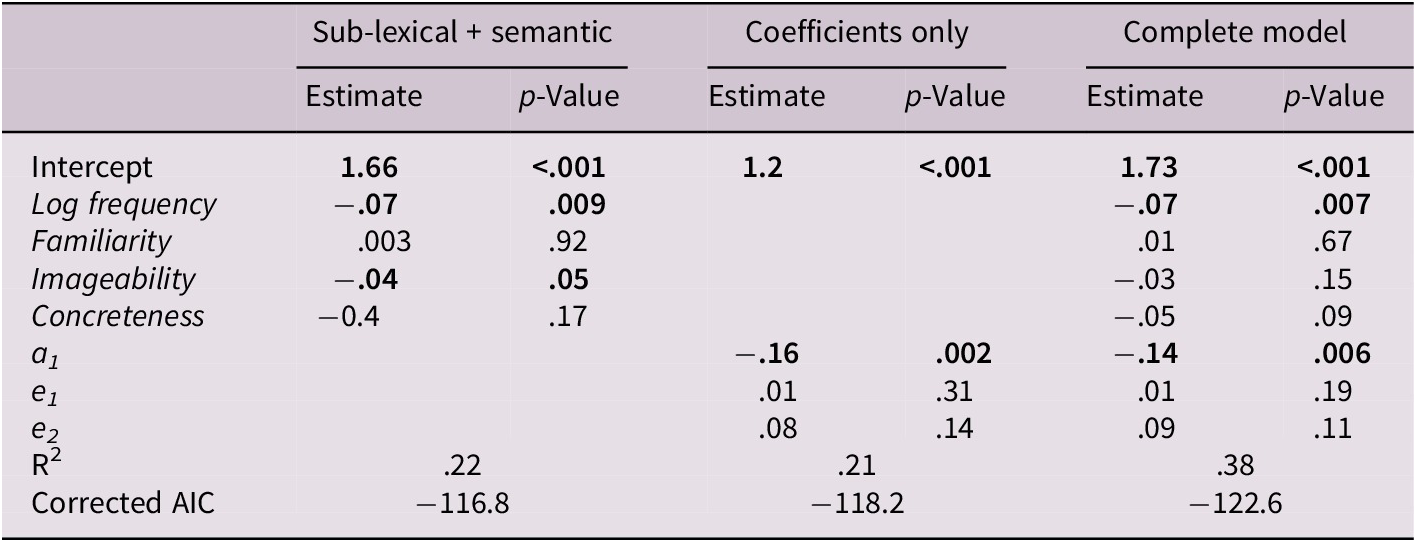
Note: Significant results at the. 05 level are shown in bold.
Abbreviation: AIC, Akaike information criterion.
Table 11. Regression models on RTs for abstract concepts in the SDT

Note: Significant results at the. 05 level are shown in bold.
Abbreviation: AIC, Akaike information criterion.
7. Discussion
The mathematical model described in the current paper aims at understanding how SM is accessed during language processing tasks. The model includes coefficients that represent different aspects of semantic accessibility. These coefficients are derived from regression analyses and are used to predict RTs in LDTs and SDTs. The model provides quantitative measures for the fact that concepts with denser semantic neighborhoods and more features are easier to process (e.g., Pexman et al., Reference Pexman, Lupker and Hino2002; Reference Pexman, Holyk and Monfils2003). The coefficients in the model provide insights into the relationship between different variables and the speed of access to semantic information.
In the current work, we tested the model’s ability to predict RTs in the LDT and SDT tasks, extending its applicability. In the LDT, participants are presented with a string of letters and are asked to determine whether the string forms a real word or a pseudoword. The SDT requires participants to decide whether a given word shown on a screen is concrete or abstract. Concrete words refer to objects or things that can be perceived through the senses, while abstract words represent ideas, concepts or emotions. The task examines how semantic variables, such as concreteness, influence participants’ RTs and accuracy in categorizing words.
Our results are consistent with the main trends that characterize the performance in LDT and SDT tasks according to prior literature. On the LDT, the main variables that predict RTs are sub-lexical variables. In previous research, participants tend to have slower RTs and lower accuracies when dealing with pseudowords compared to real words, a pattern we replicate in our results. On the SDT, though both sub-lexical and semantic variables play a role, semantic variables have a more significant impact on performance. Also, concrete concepts tend to be associated with higher accuracy and shorter RTs compared with abstract concepts, which is the pattern we replicate in our results (Schwanenflugel et al., Reference Schwanenflugel, Harnishfeger and Stowe1988; Plaut & Shallice, Reference Plaut and Shallice1993; though see Kousta et al., Reference Kousta, Vigliocco, Vinson, Andrews and Del Campo2011; Barber et al., Reference Barber, Otten, Kousta and Vigliocco2013).
In this context, the current work aimed at comparing the PLT mathematical model against more traditional psycholinguistic variables. If the model in fact offers a measure of semantic access for a concept, then it should predict RTs in the SDT. As a more stringent test, we also tested it in the LDT, given that there is evidence that semantic variables do allow predicting performance in the LDT (Pexman et al., Reference Pexman, Heard, Lloyd and Yap2017).
Consistent with our overarching hypothesis, the coefficients clustered with the semantic and not with the sub-lexical variables (see Table 2). Noteworthy, we found positive correlations for the a1 coefficient (higher coefficients indicate higher concreteness ratings), and negative correlations for the e1 coefficient (i.e., a larger e1 coefficient indicates lower concreteness ratings), a pattern that is consistent with our theoretical analysis of Eq. (2).
In the LDT, semantic variables (i.e., concreteness and imageability) were not found to be predictive of RTs. When the same nested regression models were tested within concrete and within abstract concepts, though the full model including the mathematical model coefficients outperformed the simpler models according to the AIC, the F test comparisons did not achieve significance. Adding the PLT mathematical model’s coefficients did not significantly improve the prediction of the RTs. However, when coefficients were included in the full model, the a1 coefficient achieved significance in both concrete and abstract concepts, even in the presence of the sub-lexical variables. This suggests that the semantic accessibility of a concept, as measured by the coefficients, influences performance in the LDT. Interestingly, concreteness and imageability were not predictive of RTs.
In the SDT, when the full data set and concrete concepts were considered, the coefficients from the PLT mathematical model increased the prediction of the RTs. For the full data set, including a1 and e1 significantly improved the regression model. When only concrete concepts were considered and a1 was included in the full model, the effect of imageability was lost, which is consistent with their shared variance (see Table 2), and adding the PLT model’s coefficients significantly improved explained variance. This suggests that coefficients, in particular a1, reflect semantic information that affects processing speed. We will discuss the contradictory results we obtained for abstract concepts in the SDT in the next subsection.
In conclusion, the current work offers evidence that the PLT model’s coefficients (a1, e1 and e2) reflect different aspects of semantic accessibility. The a1 coefficient represents the ease of access to a concept’s semantic information. A higher a1 coefficient indicates easier access to semantic content. This suggests that the concept is more readily available in memory and that its semantic information can be accessed more easily. The e1 and e2 coefficients reflect semantic richness. A relatively smaller e1 coefficient and/or a relatively larger e2 coefficient indicate a richer concept. These measures provide insights into how easily semantic information can be accessed and processed. Furthermore, though the PLT mathematical model’s coefficients correlate with concreteness and imageability ratings, they make an independent contribution to the prediction of RTs in LDT and SDT tasks, suggesting that they tap onto a different dimension of the concrete/abstract dimension from that which is captured by the psycholinguistic ratings.
7.1. Consequences for the concrete/abstract distinction
There is extensive literature discussing the disparities between abstract and concrete concepts. Consistently with our results, concrete concepts are generally considered easier to learn and process compared with abstract concepts (the concreteness effect, e.g., Jones, Reference Jones1985; Paivio, Reference Paivio1991; Vigliocco et al., Reference Vigliocco, Ponari and Norbury2018; Walker & Hulme, Reference Walker and Hulme1999). Some researchers propose that the distinction between the two can be qualitatively characterized by the type of features associated with each type of concept (Barsalou et al., Reference Barsalou, Santos, Simmons, Wilson, Vega, Glenberg and Graesser2008; Paivio, Reference Paivio1986; Wiemer-Hastings & Xu, Reference Wiemer-Hastings and Xu2005). Concrete concepts are best described by perceptible physical properties, whereas abstract concepts are linked to other types of features. The specific characterization of these other features varies among authors (Barsalou et al., Reference Barsalou, Santos, Simmons, Wilson, Vega, Glenberg and Graesser2008; Borghi & Cimatti, Reference Borghi, Cimatti, Taatgen and van Rijn2009; Borghi et al., Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017; Breedin et al., Reference Breedin, Saffran and Coslett1994; Paivio, Reference Paivio1986; Wiemer-Hastings & Xu, Reference Wiemer-Hastings and Xu2005). The qualitative view has wide appeal, as evidenced from the de facto definition of concreteness implicit in instructions given to subjects that provide concreteness ratings (Löhr, Reference Löhr2022).
While qualitative distinctions are likely to be critical to our understanding of the concrete/abstract distinction, our current work takes a processing perspective that emphasizes quantitative differences between abstract and concrete concepts. From a quantitative point of view, concrete concepts are characterized by a larger number of conceptual features and exhibit stronger contextual associations (Plaut & Shallice, Reference Plaut and Shallice1991; Reference Plaut and Shallice1993; Schwanenflugel et al., Reference Schwanenflugel, Harnishfeger and Stowe1988; Schwanenflugel & Shoben, Reference Schwanenflugel and Shoben1983). Consistently with these differences, research suggests that SM is more densely structured for concrete concepts, facilitating easier access (Jones, Reference Jones1985; Plaut & Shallice, Reference Plaut and Shallice1993; Recchia & Jones, Reference Recchia and Jones2012; Reilly & Desai, Reference Reilly and Desai2017; Yap & Pexman, Reference Yap and Pexman2016). This richer semantic structure of concrete concepts relative to abstract ones aligns with abstract concepts having multiple senses compared to concrete concepts (Hoffman et al., Reference Hoffman, Lambon Ralph and Rogers2013).
Because the PLT model’s coefficients correlate with concreteness and imageability ratings and are able to predict processing speed in ways consistent with the concreteness effect, we believe that the PLT mathematical model offers measures of the concrete/abstract dimension. As such, we believe that this model can be considered a summary of previous literature that adopts a quantitative perspective on the topic. However, we acknowledge that when only abstract concepts were considered, the PLT mathematical model’s coefficients did not follow the expected pattern in the SDT. Only log frequency, familiarity and imageability contributed to the prediction of RTs. Because all our independent variables were the same across all our analyses for the LDT and SDT, the only possible culprit of this null result is the distribution of RTs in the SDT for abstract concepts. Visual inspection of this distribution showed that not only were RTs higher on average than in the other conditions (see Tables 4 and 8), but that a large proportion of data points were well above the 1 s mark (see Supplementary Material, Figure 1, at https://osf.io/zsn4c/). Thus, it is possible that subjects experienced more difficulty when having to classify abstract concepts, perhaps engaging more reflective and relatively slower processes when responding.
Interestingly, a similar pattern was previously reported. In a study using the PLT mathematical model to classify concrete and abstract concepts (Canessa et al., Reference Canessa, Chaigneau and Moreno2021), better classifications were achieved for concrete than for abstract concepts. The explanation provided for those results was that concrete concepts in that study were more homogeneously concrete and that abstract concepts were more graded in that same factor. This is consistent with the observation that concreteness ratings for abstract concepts are often bimodal, with some subjects judging them relatively low in concreteness and others judging them relatively higher in concreteness (Gary Lupyan, personal communication, 08-29-2023), which again suggests that judging abstract concepts is harder because they require subjects to reflect in order to decide on a specific sense that is relevant to their current task. In the future, it will be interesting to control for number of different senses. There is evidence that words with multiple meanings (e.g., bark, which has different and unrelated senses) are slower to process in lexical decision tasks, but words with multiple but related senses are relatively faster (e.g., twist which has different but related senses) (Rodd et al., Reference Rodd, Gaskell and Marslen-Wilson2002, Reference Rodd, Gaskell and Marslen-Wilson2004). This has been explained as an effect of competition (different meanings compete and make access difficult). In our model, abstract concepts are precisely those with multiple senses, not those with multiple meanings. Thus, we would predict that, for example, Equation 1’s coefficient would vary with the number of senses (but not with the number of meanings).
Also, as previously discussed, it may be that abstract concepts are a heterogeneous bunch (e.g., actions, emotions and values, cognitive processes, social institutions moral terms; see Dove, Reference Dove2022), and cannot be easily placed on a single univariate concreteness dimension. An anonymous reviewer was concerned about whether emotional processing (such as valence and arousal) could explain differences in response times between concrete and abstract concepts. We performed a brief correlational analysis of our empirical distributions of RTs in the SDT with valence and arousal values obtained for the 14031 Spanish word database from Stadthagen-Gonzalez et al. (Reference Stadthagen-Gonzalez, Imbault, Pérez Sánchez and Brysbaert2017). Our results (shown in Supplementary Material, Figure 2) show that these variables do not account for differences in RT in SDT, suggesting that emotional variables do not account for our findings. However, we believe that designing studies using different types of abstract concepts (such as emotional abstractions) is something we would like to explore in the future.
With relative independence of the actual cognitive or neural mechanisms that account for the concreteness effect, our contribution to this literature is that we offer a model that is able to measure the ease of semantic access and processing that depends on very general assumptions about semantic access, that generalizes across at least two different tasks, is correlated with traditional measures of concreteness, but that taps on a source of variance in the LDT and SDT tasks that is independent from variance accounted for by traditional psycholinguistic variables.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/langcog.2024.17.
Acknowledgment
This work received financial support from ANID Fondecyt (Fondo Nacional de Desarrollo Científico y Tecnológico) grant 1200139.
Competing interest
The author(s) declare none.

















 Open access
Open access