


Most of the words a child encounters when reading are morphologically complex (Lázaro, Camacho, & Burani, Reference Lázaro, Camacho and Burani2013; Nagy & Anderson, Reference Nagy and Anderson1984). This is particularly true for new words (Angelelli, Marinelli, & Burani, Reference Angelelli, Marinelli and Burani2014; Carlisle, Reference Carlisle2000). Morphologically complex words are words composed of two or more morphemes. Morphemes are the minimal units of grammatical analysis and the smallest meaning-bearing units (Bosque & Demonte, Reference Bosque and Demonte1999).
A series of studies has aimed at examining the reading of morphologically complex words during literacy acquisition. However, most of the studies have been performed in opaque orthographies, such as English (Carlisle & Stone, Reference Carlisle and Stone2005; Colé, Bouton, Leuwers, Casalis, & Sprenger-Charolles, Reference Colé, Bouton, Leuwers, Casalis and Sprenger-Charolles2011; Elbro & Arnbak, Reference Elbro and Arnbak1996; Laxon, Rickard, & Coltheart, Reference Laxon, Rickard and Coltheart1992; Verhoeven & Perfetti, Reference Verhoeven and Perfetti2011). For example, Carlisle and Stone (Reference Carlisle and Stone2005) and Laxon et al. (Reference Laxon, Rickard and Coltheart1992) found that children in 2nd, 3rd, 5th, and 6th grades were more accurate when reading affixed words than when reading pseudoaffixed words (i.e., words that share a segment that is a homophone to an affix but is not a real affix in those words; e.g., hilly is an affixed word containing the suffix –ly, but silly is not). Moreover, children in the lower grades were also faster at reading derived words than at reading pseudoaffixed words (Carlisle & Stone, Reference Carlisle and Stone2005). Further evidence of the role of morphology in word reading in English is the fact that base frequency (i.e., the frequency of the base for a derivation) contributes to the accuracy of low surface frequency word reading in children in the upper grades (Carlisle & Stone, Reference Carlisle and Stone2005). Studies in this language also show that the influence of morphology for word reading in children is determined by family size (i.e., the number of items derived from one stem; Carlisle & Katz, Reference Carlisle and Katz2006) and phonological and orthographical transparency of the stem+affix combination (Carlisle, Reference Carlisle2000). Likewise, in French, pseudowords with a morphological structure were found to be read faster and more accurately than pseudowords with no morphological structure by children in the early years of elementary education (Colé et al., Reference Colé, Bouton, Leuwers, Casalis and Sprenger-Charolles2011).
While the results in English and other opaque orthographies are quite profuse, the number of studies focusing on the role of morphology in learning to read in transparent orthographies, such as Spanish or Italian, is still very limited (Burani, Marcolini, De Luca, & Zoccolotti, Reference Burani, Marcolini, De Luca and Zoccolotti2008; Defior Citoler, Jiménez-Fernández, Calet, & Serrano, Reference Defior Citoler, Jiménez-Fernández, Calet and Serrano2015). This is an important issue that requires further exploration as there is a fundamental difference on the predicted influence of morphology according to the type of script. In an opaque orthography, such as that of English, the spelling of many words does not obey grapheme–phoneme conversion rules but is derived from its constituent morphemes. This means that the orthography of many words is morphologically based (Nagy, Carlisle, & Goodwin, Reference Nagy, Carlisle and Goodwin2014). Consequently, knowing the morphemes inside a word would allow a beginner reader of an opaque orthography to accurately pronounce an unfamiliar word. In contrast, when reading in transparent orthographies, the pronunciations of almost all words can be obtained through grapheme-to-phoneme sublexical conversion rules. Therefore, accurate word pronunciation is not predicted to be dependent on morphology in transparent scripts (Casalis, Quémart, & Duncan, Reference Casalis, Quémart and Duncan2015; Seymour, Aro, & Erskine, Reference Seymour, Aro and Erskine2003).
However, other than deriving the accurate pronunciation from print (i.e., accuracy), children have to achieve fluency in order to master reading and reading comprehension (Oakhill & Cain, Reference Oakhill and Cain2012). Reading through grapheme-to-phoneme conversion rules can guarantee word-reading accuracy in transparent orthographies. Notwithstanding, this procedure is very slow and costly because it involves the segmentation of a word into its graphemes, the transcoding of them into phonemes, and the reassembly of phonemes in order to correctly pronounce a word (Wimmer, Reference Wimmer2006). Therefore, direct access to units larger than graphemes, such as whole words and morphemes, allows for faster and more fluent reading, not only in opaque but also in transparent orthographies (Burani, Reference Burani2010; Ehri, Reference Ehri2005).
Whole-word variables such as surface word frequency (henceforth, word frequency) have been shown to affect reading fluency in transparent orthographies from the beginning of reading acquisition. Children and adults read frequent words faster than less frequent ones (Ardila & Cuetos, Reference Ardila and Cuetos2016; Burani, Marcolini, & Stella, Reference Burani, Marcolini and Stella2002; Davies, Cuetos, & Glez-Seijas, Reference Davies, Cuetos and Glez-Seijas2007; Jaichenco & Wilson, Reference Jaichenco and Wilson2013). Nonetheless, although reading through the whole-word procedure is probably the most efficient mechanism to achieve fluency, children who are learning to read do not have enough experience with the whole forms of many of the words they encounter. Therefore, other processing units, such as morphemes, could prove beneficial for reading fluency in transparent orthographies, at least until children earn enough expertise with whole words (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini, Traficante, Zoccolotti, & Burani, Reference Marcolini, Traficante, Zoccolotti and Burani2011; Schreuder & Baayen, Reference Schreuder, Baayen and Feldman1995). Similar to words, morphemes are associated to meaning, but they are smaller processing units. At the same time, morphemes are larger processing units than single graphemes, and thus, accessing morphemes would allow children to avoid the costly grapheme-to-phoneme conversion rules.
In Spanish, the number of studies that explored morphological processing during reading acquisition is limited (see, e.g., Jaichenco & Wilson, Reference Jaichenco and Wilson2013; Lázaro et al., Reference Lázaro, Camacho and Burani2013; Suárez-Coalla & Cuetos, Reference Suárez-Coalla and Cuetos2013). Only two of these studies analyzed this issue using naming tasks. Suárez-Coalla and Cuetos (Reference Suárez-Coalla and Cuetos2013) presented one group of children with dyslexia aged 7 to 10 years old and a group of age-matched controls with simple and complex words and pseudowords. They found that morphology played a role on the reading speed of the group of children with dyslexia, who read all morphologically complex stimuli faster than morphologically simple ones, although the effect was larger for pseudowords, and seemed to use morphology as a compensatory strategy for their phonological deficits. In contrast, they did not find an effect of morphology on reading speed in the control group. Neither children with dyslexia nor age-matched controls presented effects of morphology on reading accuracy of words or pseudowords. This study shows that morphology helps fluency and that this effect is modulated by reading ability. However, Suárez-Coalla and Cuetos (Reference Suárez-Coalla and Cuetos2013) did not focus on the effect of morphology in normally developing children or on the possible modulatory effect of frequency for morpheme-based reading; moreover, the age range of the children in both the group of children with dyslexia and the control group was quite large. This may have caused differences between age groups, which could have been expected according to the literature (Carlisle & Stone, Reference Carlisle and Stone2005), not to be appreciated. In a previous study, we manipulated the morphological complexity of derivational morphemes in a naming task using pseudowords (Jaichenco & Wilson, Reference Jaichenco and Wilson2013). Children in 2nd, 3rd, and 4th grades of primary education (ages 7 to 10 years old) read aloud morphologically complex pseudowords made of two real morphemes (i.e., anillero, “ringer”) and pseudowords with no morphological structure (i.e., anullaro). We found that morphologically complex pseudowords were read more accurately than pseudowords with no morphological structure. In addition, this effect was comparable among grades. These results are taken as evidence that morphemes are accessed during naming, regardless of the school grade, when learning to read in Spanish. However, this study did not explore the role of morphology when reading actual words and it only analyzed reading accuracy but not fluency (i.e., latencies). Furthermore, neither this study nor Suárez-Coalla and Cuetos (Reference Suárez-Coalla and Cuetos2013) explored the way in which other variables, such as word frequency, might modulate the role of morphology in reading in Spanish.
Studies of the role of morphology in word naming in Italian are more numerous than in Spanish. Italian is a language with a transparent script similar to that of Spanish (Seymour et al., Reference Seymour, Aro and Erskine2003), and this similarity can shed some additional light on the role of morphology in Spanish. Studies in Italian have shown that morphology benefits word-reading fluency, but not word-reading accuracy, of children from an early age of their literacy acquisition, as well as children with reading difficulties (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). These studies also show that this benefit disappears once whole representations of more words become available, either because words are frequent or because readers are more experienced (i.e., they advance in grade or have no reading disabilities). For example, Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) performed a word-naming experiment in which they measured the naming latencies for morphologically complex and simple words of the same word frequency in 6th-grade children with dyslexia, chronologically matched skilled readers, reading-matched younger normally developing children of 2nd and 3rd grades, and normal adults. They found that only children with dyslexia and younger children benefited from morphology in reading low to medium frequency morphologically complex words. Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) performed a word-naming experiment in which morphologically complex and simple words of high and low word frequency were presented to poor readers of 6th grade, chronologically matched skilled readers, and normal adults. They found that less skilled readers benefited from the presence of morphemes for the reading of all morphologically complex words, while morphemes benefited young skilled readers only for the reading of morphologically complex words of low word frequency. Even though the studies by Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) and Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) focus on reading in children with reading disabilities, they allow to derive conclusions regarding the role of morphology in normally developing children for the reading of actual words. Of note, morphology benefits word-reading fluency but not word-reading accuracy in Italian, and the effect of morphology disappears as children become more skilled readers. However, these results cannot be directly assumed to apply to the Spanish orthography. Differences between Spanish and Italian have been found at a structural level (see, e.g., Filiaci, Reference Filiaci, Borgonovo, Espanol-Echevarria and Prevost2010), in vocabulary development (see, e.g., Bornstein et al., Reference Bornstein, Cote, Maital, Painter, Park, Pascual and Vyt2004), but also in the variables that might affect reading in each language, such as the role of word frequency and age of acquisition in word reading (Cuetos & Barbón, Reference Cuetos and Barbón2006; Davies et al., Reference Davies, Cuetos and Glez-Seijas2007; Davies, Wilson, Cuetos, & Burani, Reference Davies, Wilson, Cuetos and Burani2014). Moreover, there is evidence of differences in the outcomes of children learning to read in different transparent orthographies (Defior, Martos, & Cary, Reference Defior, Martos and Cary2002). The relevance of cross-linguistic studies of literacy acquisition has been pointed out in several studies (see, e.g., Seymour et al., Reference Seymour, Aro and Erskine2003; Ziegler, Perry, Ma-Wyatt, Ladner, & Schulte-Körne, Reference Ziegler, Perry, Ma-Wyatt, Ladner and Schulte-Körne2003).
The aim of the two experiments of the present study is to explore the factors that affect reading of morphologically complex words during normal literacy acquisition in Spanish. To this end, its goal is to study the effect of grade, morphology, and word frequency when reading morphologically complex words. In addition, it aims at studying whether the effect of morphology in reading is modulated by grade and word frequency, as suggested by studies performed in other transparent orthographies (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). To the best of our knowledge, this is the first study in Spanish to explore this subject when reading actual words. Furthermore, its original contribution resides in the fact that it focuses specifically on typically developing readers, unlike previous studies such as Suárez-Coalla and Cuetos (Reference Suárez-Coalla and Cuetos2013) for Spanish and Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) and Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) for Italian. We argue that this would provide more straightforward results on the way in which morphology affects normal reading development. On top of this, the studies presented here broaden the age range considered in previous word-naming experiments (Jaichenco & Wilson, Reference Jaichenco and Wilson2013; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011; Suárez-Coalla & Cuetos, Reference Suárez-Coalla and Cuetos2013), and one of its main strengths is that they explore this issue both cross-sectionally and longitudinally.
In Experiment 1, we compared word naming of morphologically complex and simple words of high and low frequency in Spanish-speaking children from three different grades of primary school (2nd, 4th, and 6th grades). In Experiment 2, a sample of the children who were in 2nd and 4th grades in Experiment 1 were retested with the same task 2 years later (i.e., in 4th and 6th grades). Based on previous literature, we predicted that children learning to read in Spanish would benefit from grade and word frequency in both word-reading fluency and word-reading accuracy (Ardila & Cuetos, Reference Ardila and Cuetos2016; Burani et al., Reference Burani, Marcolini and Stella2002; Davies et al., Reference Davies, Cuetos and Glez-Seijas2007; Jaichenco & Wilson, Reference Jaichenco and Wilson2013). We also expected children to benefit from the presence of morphemes in morphologically complex words (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). However, this prediction would apply mainly to fluency but not necessarily to accuracy, as Spanish is a language with a transparent orthography. Furthermore, we predicted that the role of morphology in learning to read would be modulated by grade. As children advance in their schooling, the influence of morphemes would become less important because children would favor whole-word reading (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). We also predicted that morphology would be modulated by frequency and that the effect of morphology would be present only for low-frequency words (Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011).
EXPERIMENT 1
In Experiment 1, we tested word naming of morphologically complex and simple Spanish words of high and low frequency in 2nd-, 4th- and 6th-grade children. We expected to replicate the results obtained in other transparent orthographies using a broader age range of normally developing children (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). We expected to find an effect of grade and word frequency on both word-reading fluency and word-reading accuracy (Ardila & Cuetos, Reference Ardila and Cuetos2016; Burani et al., Reference Burani, Marcolini and Stella2002; Davies et al., Reference Davies, Cuetos and Glez-Seijas2007; Jaichenco & Wilson, Reference Jaichenco and Wilson2013). We also expected to find an effect of morphology on fluency, but not on accuracy, given the transparency of the Spanish orthography (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008). Finally, we predicted an interaction between grade and morphology, and word frequency and morphology, as previous studies had shown that morphemes are particularly beneficial for children who have not mastered whole-word reading and for the reading of words of low word frequency (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011).
Method
Participants
Three groups of normally developing Spanish-speaking children from 2nd, 4th and 6th grades of primary schools of Buenos Aires, Argentina, participated in this study. Thirty children were from 2nd grade (43% girls, mean age = 7.11 years old), 32 from 4th grade (60% girls, mean age = 9.10 years old), and 35 from 6th grade (51% girls, mean age = 12.2 years old; see Table 1). All children were within the normal range for reading according to their age as assessed by standardized Spanish reading tests. Second and 4th graders’ reading ability was assessed using the word-reading and pseudoword-reading subtests of the LEE test (Defior Citoler et al., Reference Defior Citoler, Fonseca, Gottheil, Aldrey, Pujals, Rosa and Serrano Chica2007), which is standardized for the variety of Spanish spoken in Buenos Aires. LEE norms are available only from 1st to 4th grades. In each subtest, children had to read 42 items (words or pseudowords, depending on the task) and obtained 2 points for an accurate and fluent reading, and 1 point for an accurate but not fluent reading (e.g., syllabifications or hesitations). Because there are no standardized reading tests for 6th graders of the Spanish spoken in Buenos Aires, these participants were tested with the word-reading and pseudoword-reading subtests from the Prolec-SE Test (Ramos & Cuetos, Reference Ramos and Cuetos2009), standardized in Spain. In these subtests, children had to read 40 words or pseudowords and obtained 1 point for accurate reading. In both the LEE and the Prolec-SE subtests, time is also measured in order to evaluate fluency. All children had a normal schooling trajectory, without having repeated any grade, had no history of learning disabilities, and had normal or corrected-to-normal vision. Participants came from private schools of Buenos Aires.
Table 1. Characteristics of the participants of Experiment 1 by grade

Note: Mean age and range in years; word reading score max = 84 for LEE test and max = 40 for Prolec-SE test; pseudoword reading score max = 84 for LEE test and max = 40 for Prolec-SE test. Scores and reading times (in seconds) on LEE test, for 2nd and 4th graders and on Prolec-SE test, for 6th graders; SD in parentheses. Cutoff values for this test (min and max scores obtained by the participants in the present study): a60 (60–78); b71 (71–83); c37 (38–40); d117 s (36–94 s); e73 s (36–73 s); f54 s (32–54 s); g53 (53–75); h61 (63–80); i34 (35–40); j137 s (50–102 s); k93 s (44–88 s); l79 s (44–71 s).
Materials
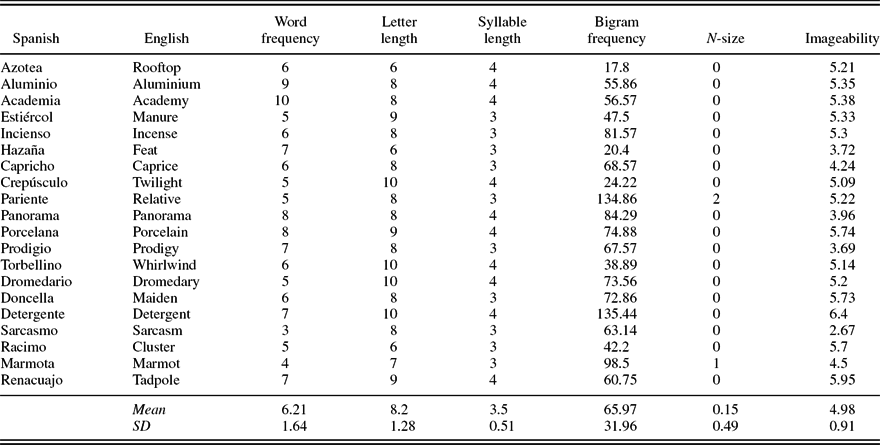
Morphology (simple and suffixed words) and word frequency (high and low) were factorially manipulated to create four experimental groups of 20 words each (high-frequency suffixed words, low-frequency suffixed words, high-frequency simple words, and low-frequency simple words). All groups of stimuli were nouns and were matched by initial phoneme characteristics, word length (in letters and syllables), affix and root length, bigram frequency, N-size, and imageability (all ps > .05). In spite of the fact that the experimental groups of stimuli were matched for bigram frequency, the means in two particular groups (i.e., suffixed and simple low-frequency words) seemed particularly different (85.47 vs. 65.97, respectively), though not statistically significant. For this reason, and because bigram frequency might be a relevant variable for word-naming experiments (Arduino & Burani, Reference Arduino and Burani2004), we ran additional analyses with bigram frequency as a covariable.
Word frequencies for children were obtained Martínez Martín and García Pérez (Reference Martínez Martín and García Pérez2004) database, show the cumulated frequency of appearance of a word from 1st through 6th grades and are reported in occurrencies per million. The frequency values on Martínez Martín and García Pérez (Reference Martínez Martín and García Pérez2004) are based on a 2,600,000-word corpus. For the present study we have recalculated these frequency values on occurrencies per million to make them more easily comparable to those used in previous studies. The lowest frequency value for high-frequency words was 40 occurrences per million, and the highest frequency value for low-frequency words was 13 occurrences per million. All other values were extracted from BuscaPalabras (Davis & Perea, Reference Davis and Perea2005). All items were phonologically transparent (Lázaro, García, & Burani, Reference Lázaro, García and Burani2015). Table 2 shows the descriptive statistics for the four groups of stimuli. Family size, suffix frequency, root frequency, and suffix productivity could not be controlled, because, to the best of our knowledge, these variables are not available in Spanish.
Table 2. Means (and standard deviations) of the items used in the word-naming task, as a function of morphology (suffixed and simple) and frequency (high and low).
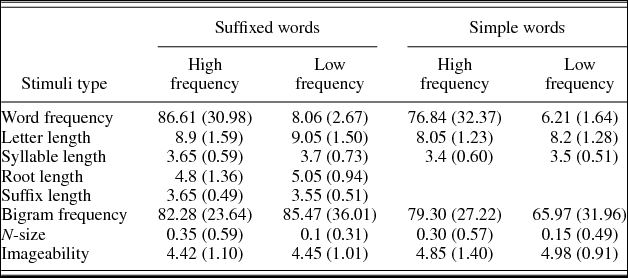
Because imageability values were not available for 9 words, following the same procedure used to collect the Spanish ratings on imageability, 20 adult participants were asked to grade how easily a mental image came to mind for each of the words on a 7-point scale (Sebastián Gallés, Reference Sebastián Gallés2000). The list included the 9 new words and 30 words taken from BuscaPalabras for which imageability ratings were already available. The correlation between the new and old values for the words already listed in BuscaPalabras was positive, strong, and significant, r (30) = .86, p < .001. This shows that the results obtained for the new imageability values are comparable to the old ones.
Fillers (n = 140) were added in order to avoid suffix repetition. The fillers respected the same characteristics of the experimental items. Half of the fillers were complex, half were simple; half of them were of high frequency and half of low frequency. They were all nouns and were matched to the experimental items on word, root, and affix length. The addition of these fillers allowed us to have the same amount of repetitions of all suffixes and to have an equal number of suffixed and nonsuffixed words. Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) and Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) also controlled for the number of repetitions of the endings of the morphologically simple words. In the present study, we followed Traficante, Marcolini, Luci, Zoccolotti, and Burani (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011) to develop a definition for the comparison of suffix and nonsuffix final endings. The mean length of the suffixes used in this study was 3.45. Hence, we compared the consonant (C)–vowel (V) structure of the three-letter endings of nonsuffixed words to the suffix in suffixed words. We found five ending structures (CVC, VCV, VVC, CVV, and CCV). All ending structures had a comparable number of repetitions in suffixed and nonsuffixed simple words, as measured by chi-square tests (all ps >.05), except for two endings: VVC (that had 10 more occurrences in suffixed words) and CCV (that had 19 more occurrences in suffixed words). These differences represent a small proportion of the stimuli in the study (5%, in the case of VVC endings, and 9%, in the case of CCV endings).
Procedure
Stimuli were presented in black uppercase letters in 22-pt Arial font on a white background. In this way, we would guarantee no confounders concerning font knowledge would be involved in the analysis per grade, as many schools in Buenos Aires teach beginner readers uppercase first. Stimuli were presented using DMDX (Forster & Forster, Reference Forster and Forster2003).
A fixation point (500 ms) preceded each trial. Stimuli remained on the screen for 3000 ms, followed by a blank screen (500 ms). The 220 items (80 experimental stimuli and 140 fillers) were presented interleaved in 10 blocks of 22 stimuli each. The presentation of the stimuli was randomized both within and between blocks. Each block contained 2 stimuli from each of the experimental conditions and 14 fillers. Presentation of the stimuli was preceded by a 10-item practice with words of similar characteristics to those of the experiment. Participants had a pause between blocks and could decide when to continue the experiment. They were instructed to read the words on the screen as fast and accurately as possible. Children were tested in a quiet room in their schools at the end of the school year (i.e., October–November). Reading latencies (RTs) to correctly pronounced items and accuracy were corrected using CheckVocal, a software that allows to check for accuracy and timing of results obtained using DMDX (Protopapas, Reference Protopapas2007). CheckVocal allows to check the triggering of the voice key and to manually replace the timing mark in case it is mistriggered. In addition, it allows to manually indicate whether the response is accurate or not.
Data analysis
Log transformed RTs to accurately pronounced items were analyzed using a linear mixed-effects model, which allows to control for the random effects of participants and items (Baayen, Davidson, & Bates, Reference Baayen, Davidson and Bates2008). Accuracy was analyzed using logistic mixed-effect models (Angelelli et al., Reference Angelelli, Marinelli and Burani2014; Guo & Zhao, Reference Guo and Zhao2000; Quené & Van den Bergh, Reference Quené and Van den Bergh2008). In both analyses, grade, morphology, and frequency were introduced as fixed factors. Participants and items were introduced as random effects. We chose the simpler and thus more parsimonious structure justified by the data, with subject and item random intercepts (Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013; Bates, Kliegl, Vasishth, & Baayen, Reference Bates, Kliegl, Vasishth and Baayen2015). The interaction between the main factors was also tested. The variables were not centered. The coding of the fixed effects for the analysis was as follows: for grade, 2 = 2nd grade, 4 = 4th grade, and 6 = 6th grade; for morphology, 1 = suffixed words and 2 = simple words; and for frequency, 1 = high frequency and 2 = low frequency. The analyses were carried out in SPSS 22.
Results of Experiment 1
No subjects scored 2.5 SD above or below the mean of RTs or accuracy of all participants in their grade. Descriptive statistics (means and standard deviations) for RTs and accuracy are shown in Table 3.
Table 3. Mean latencies in milliseconds (RT) and accuracy (and standard deviations) as a function of grade (2nd, 4th, and 6th), morphology (suffixed and simple), and frequency (high and low) in the word-naming task in Experiment 1
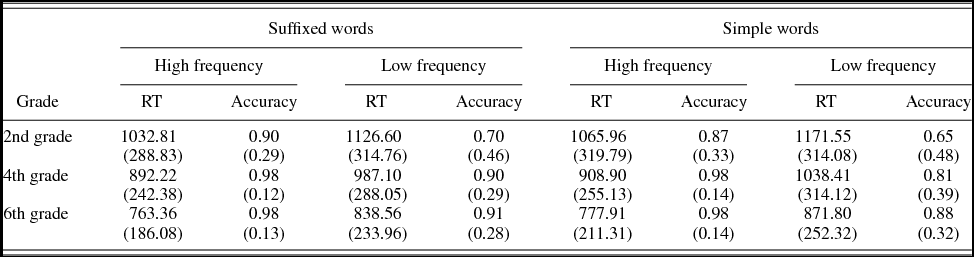
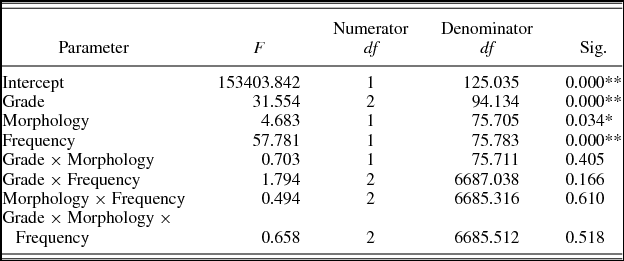
Table 4 shows the mixed-model analysis estimates and tests of fixed effects for log transformed RTs. These show that grade (p < .01), morphology (p < .05), and frequency (p < .01) significantly affected RTs. Children read words faster as grade increased. Morphologically complex words and frequent words were read faster than simple and less frequent words. The interactions Grade × Morphology, Grade × Frequency, Morphology × Frequency, and Grade × Morphology × Frequency were not significant (all ps > .05). Linear mixed-effects analyses with bigram frequency as a covariate showed the same pattern of results. The effects of grade (p < .01), morphology (p < .05), and frequency (p < .01) were not altered by the addition of this covariate. None of the interactions reached significance (all ps >.05). Bigram frequency did not reach significance either, F (1, 74.139) = 0.248, p = .62.
Table 4. Mixed-model analysis estimates and tests of fixed effects in log transformed RTs in Experiment 1.
* p < .05. **p < .01.
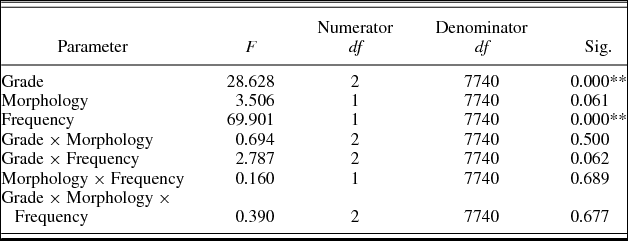
Table 5 shows the logistic mixed model analysis estimates and tests of fixed effects for accuracy. The effects of grade (p < .01) and frequency (p < .01) were significant. Children read more accurately as grade increased. Frequent words were read more accurately than less frequent ones. Morphology was marginally significant (p = .06). The interactions Grade × Morphology, Grade × Frequency, Morphology × Frequency, and Grade × Morphology × Frequency did not reach significance either (all ps > .05). The inclusion of bigram frequency as a covariate in this analysis did not alter the pattern of results: grade (p < .01) and frequency (p < .01) were significant. All other effects did not reach significance (all ps > .05). Bigram frequency did not reach significance, F (1, 7.739) = 0.090, p = .77.
Table 5. Logistic mixed-model analysis estimates and tests of fixed effects in accuracy in Experiment 1
* p < .05. **p < .01.
Discussion of Experiment 1
The results of Experiment 1 showed that grade and frequency affected both reading fluency and accuracy. As predicted, morphology only affected latencies. Morphologically complex words were read faster than morphologically simple ones. However, we did not find evidence for one of our predictions. Grade and frequency did not modulate the effect of morphology in fluency.
EXPERIMENT 2
In Experiment 1, and contrary to our prediction, we failed to find any evidence of the modulation of grade and frequency on the effect of morphology in Experiment 1 (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). In order to study the evolution of the effects of morphology and frequency as grade progressed, we conducted Experiment 2.
In Experiment 2, a subgroup of the same 2nd- and 4th-grade children were tested 2 years later with the same stimuli. At the second time of testing, children were, thus, in 4th and 6th grades, respectively. We expected to find effects of grade and frequency on fluency and accuracy and an effect of morphology on fluency, as those found in Experiment 1. In addition, we also expected to find an effect of time (i.e., the improvement of both accuracy and fluency between the two testings). Furthermore, we expected to find an interaction of morphology and grade, time, and frequency on fluency, as should be expected according to previous studies in transparent orthographies (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011). However, if the results found in Experiment 1 were due to the normal developmental trajectory of reading acquisition in Spanish, then the same effects of Experiment 1 should be found. In other words, if the lack of an interaction of morphology, grade, and frequency was not spurious in Experiment 1, we expected to replicate the general effect of morphology without interactions for fluency.
Method
Participants
Two groups of children from 2nd and 4th grades from Experiment 1 were tested again (T2) 2 years after the first testing (T1), when they were in 4th and 6th grades, respectively. No group of 6th-grade students could be retested because primary education in Buenos Aires ends at Grade 7. Thus, the children in 6th grade in Experiment 1 were already in different secondary schools at T2. Sixteen children from 4th grade (31% girls, mean age = 10 years old) and 14 children from 6th grade (64% girls, mean age = 11.11 years old) participated in this second experiment (see Table 6). Experiment 2 took place at the end of the school year (i.e., October–November).
Table 6. Characteristics of the participants of Experiment 2 by grade

Note: Mean age and range in years. At T2, children were in 4th and 6th grades, respectively.
Materials
The materials were the same as those described in Experiment 1.
Procedure
The procedure and registration methods were the same as those described in Experiment 1.
Data analysis
Log transformed RTs of accurately pronounced items were analyzed using a linear mixed-effects model (Baayen et al., Reference Baayen, Davidson and Bates2008). Accuracy was analyzed using logistic mixed-effect models (Angelelli et al., Reference Angelelli, Marinelli and Burani2014; Guo & Zhao, Reference Guo and Zhao2000; Quené & Van den Bergh, Reference Quené and Van den Bergh2008). Time, grade, morphology, and frequency were introduced as fixed factors. Participants and items were introduced as random effects. As in Experiment 1, we chose the simpler and thus more parsimonious structure justified by the data, with subject and item random intercepts (Barr et al., Reference Barr, Levy, Scheepers and Tily2013; Bates et al., Reference Bates, Kliegl, Vasishth and Baayen2015). The interaction between the main factors was also tested. The variables were not centered.
For the analysis, the fixed factors grade, morphology, and frequency were coded in the same way as in Experiment 1. For time, 1 = T1 and 2 = T2. The analyses were carried out in SPSS 22.
Results of Experiment 2
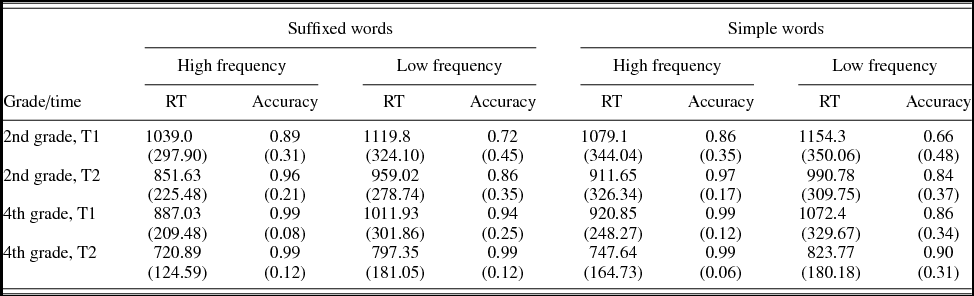
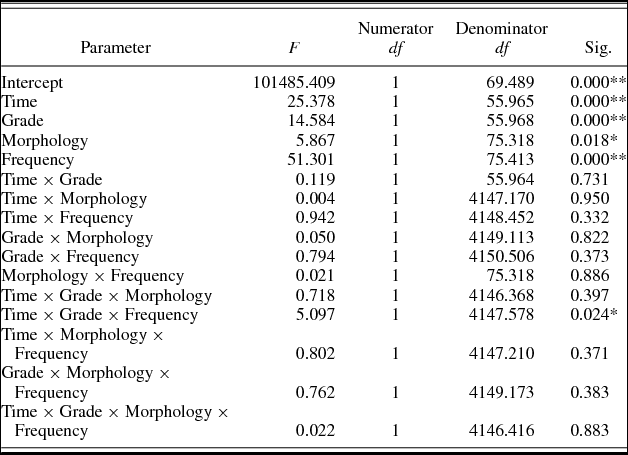
Descriptive statistics (means and standard deviations) for RTs and accuracy are shown in Table 7. Table 8 shows the mixed-model analysis estimates and tests of fixed effects for log transformed RTs. These show that time (p < .01), grade (p < .01), morphology (p < .05), and frequency (p < .01) significantly affected RTs. Children from both grades read faster at T2 as compared to T1. In addition, children in the higher grades read words faster. Morphologically complex words and frequent words are read faster than less frequent and simple words.
Table 7. Mean latencies in milliseconds (RT) and accuracy (and standard deviations) as a function of grade (2nd and 4th), morphology (suffixed and simple), and frequency (high and low) in the word-naming task in Experiment 2
Note: At T2, children were in 4th and 6th grades, respectively.
Table 8. Mixed-model analysis estimates and tests of fixed effects in log transformed RTs in Experiment 2
* p < .05. **p < .01.
The interaction Time × Grade × Frequency was also significant. The analysis of this interaction showed that the interaction Grade × Frequency was significant at both times, and that frequency was significant for both grades at both times, but, at T1, its effect was larger for 4th grade (high-frequency words were read 13.49% faster than low-frequency words) as compared to 2nd grade (high-frequency words were read 8.68% faster than low-frequency words) and at T2, its effect was larger for 2nd grade (i.e., children who were at 4th grade in T2; high-frequency words were read 10.60% faster than low-frequency words) as compared to 4th grade (i.e., children who were at 6th grade in T2; high-frequency words were read 9.62 % faster than low-frequency words). All the other interactions were not significant (all ps > .05). The addition of bigram frequency as a covariate in the model did not alter the results: time (p < .01), grade (p < .01), morphology (p < .05), and frequency (p < .01) were still significant, as well as the interaction Time × Grade × Frequency (p < .05). None of the other interactions reached significance (all ps > .05). Bigram frequency did not reach significance, F (1, 73.837) = 0.100, p = .75.
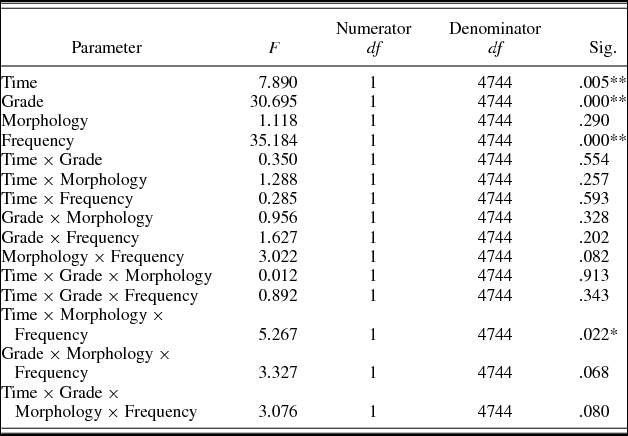
Table 9 shows the logistic mixed-model analysis estimates and tests of fixed effects for accuracy. The effects of time (p < .01), grade (p < .01), and frequency (p < .01) were significant. Children from both grades read more accurately at T2 as compared to T1. In addition, children in the higher grades read words more accurately. Frequent words were read more accurately than less frequent ones. Morphology was not significant (p > .05). The interaction Time × Morphology × Frequency was significant. Simple effects analyses as a function of time (T1 and T2) showed that the interaction Morphology × Frequency was not significant at T1 (p = .73) and closer to significance at T2 (p = .09). All other interactions did not reach significance (ps > .05). When we added bigram frequency to the model, the pattern of results remained unchanged. Time (p < .01), grade (p < .01), and frequency (p < .01) and the interaction Time × Morphology × Frequency (p < .05) were significant. The other interactions were not significant (ps > .05). Bigram frequency did not reach significance, F (1, 4.773) = 2.065, p = .15.
Table 9. Logistic mixed-model analysis estimates and tests of fixed effects for accuracy in Experiment 2
* p < .05. **p < .01.
Discussion of Experiment 2
In general, the results of this longitudinal study replicate those found in Experiment 1. The results were obtained with a smaller group than that of Experiment 1. However, the experiment allowed us to arrive at a number of relevant results. In the analysis of RTs in Experiment 2 we found that time, grade, frequency, and morphology affected reading fluency. We also found that time interacted with frequency and grade. Frequent words are generally read faster, although the effect of frequency is larger for children in 4th grade. As in Experiment 1, we failed to find evidence that time, grade, or frequency modulated the effect of morphology.
As for accuracy, we found that time, grade, and frequency affected accuracy. This is also a replication of the results found in Experiment 1. As expected, we did not find an effect of morphology. As in Experiment 1, we did not find any interactions in the analysis of accuracy, except for the interaction of time, morphology, and frequency. However, the interaction of morphology and frequency was not significant at T1 and only closer to significance at T2.
GENERAL DISCUSSION
The role of morphology when learning to read Spanish is a subject that has received little attention. Most studies that have explored this issue have focused on how morphology affects reading in children with reading disabilities or using morphologically structured pseudowords. The present study explored the variables that might affect morphologically complex word reading (i.e., grade, morphology, and frequency) when learning to read words in Spanish from a cross-sectional and a longitudinal perspective. We have explored the effect of morphology in both fluency and accuracy when naming morphologically complex words. We also studied whether the effect of morphology is beneficial and modulated by grade and word frequency. In order to explore this issue, we performed two word-naming experiments. In Experiment 1, we compared 2nd, 4th, and 6th graders’ reading of morphologically complex and simple words of high and low word frequency in Spanish. In Experiment 2, the children in 2nd and 4th grades in the first experiment were tested again after 2 years, when they were in 4th and 6th grades, respectively. In Experiment 2 we wanted to explore whether the effects of morphology on fluency (and the lack of a morphology effect on accuracy) observed in a cross-sectional study could also be replicated from a longitudinal perspective.
The results of Experiment 1 showed an effect of grade, morphology, and frequency in fluency. In contrast, our results showed an effect of grade and frequency in accuracy. We performed Experiment 2 in order to explore the evolution of the effects of frequency and morphology in schooling. The results of Experiment 2 largely replicated those of Experiment 1. Time, grade, and frequency affected both fluency and accuracy, and morphology only affected fluency. In addition, time, grade, and frequency modulated each other in fluency and time, morphology, and frequency modulated each other in accuracy. For fluency, frequency effects were larger for children in 4th grade at T1. For accuracy, the interaction of morphology and frequency was not significant at T1 but close to significance at T2. Contrary to our predictions, we failed to find that time, grade, or frequency modulated the effect of morphology in the two experiments we present here. In the following, we elaborate a possible explanation for this pattern of results.
Morphology had a general effect on fluency. This shows that readers benefit from the presence of morphemes in morphologically complex words and that, in Spanish, morphology contributes to reading fluency. These results are compatible with those found earlier for Italian children. Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) showed that morphology affected word-naming fluency. Italian children of 2nd and 3rd grades and children with dyslexia were faster when naming morphologically complex words as compared to simple words. Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) showed similar results for 6th-grade normally developing Italian readers and poor readers. The present study makes the extra contribution of showing that this effect is also present in a broader age range of normally developing readers studied both from a cross-sectional and a longitudinal perspective.
Regarding the variables that modulate the role of morphology in fluency, Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) found that word frequency and reading ability affected the probability of morpheme-based reading. They found that in normally developing children of 6th grade, morphology did not facilitate fluency for frequent words. They also found that, in adults, morphology did not benefit reading fluency when naming both frequent and infrequent words. Conversely, morphology benefited 6th-grade poor readers’ naming fluency of all complex words. Following Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011), we expected that the effect of morphology would be modulated by the frequency of the words. In other words, that the influence of morphology for reading fluency would be found in low-frequency words only, at least in children in the higher grades of our studies. However, our results showed that the effect of morphology on fluency was present for both low- and high-frequency words for all grades. We did not find that frequency, grade, or time modulated the effect of morphology. In addition, in Italian, Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) found evidence of the influence of grade on the role of morphology in reading. Their analysis showed that morphology benefited the naming of medium-frequency words only for children in the lower grades and children with dyslexia. Our results are not in line with those of Italian. We still found an effect of morphology in 6th graders’ reading of high-frequency morphologically complex words in both experiments. It is noteworthy that Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) found this critical interaction only when using z-transformed RTs.
Two main arguments can be used to explain the differences between our results and those of Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) and Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008). On the one hand, as previously mentioned, our study was performed on normally developing children only, while both their studies included children with reading disabilities in the analyses. On the other hand, in both of their studies, the data were analyzed using analyses of variance by participants and by items. We used mixed-effects analyses, a cutting-edge technique that, among other advantages, allows to control for the random effects of participants and items in one single analysis. Furthermore, for Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) specifically, other reasons might explain the differences between our results. In the first place, our high-frequency morphologically complex words were less frequent than the high-frequency words in Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011; mean frequency: 87 and 117 counts per million for our studies and Marcolini et al.’s, respectively). Therefore, some of the words in the high-frequency group in our experiments may not have been frequent enough to be processed as whole words, forcing children to rely on known morphemes. Finally, there were two methodological differences between the design of our study and that of Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011). First, in their study, they controlled for certain morpheme characteristics, such as root family size, suffix frequency, root frequency, or suffix productivity. These variables, together with word frequency, might affect the decomposability of a lexical item (see, e.g., Burani & Thornton, Reference Burani, Thornton, Baayen and Schreuder2003; Hay, Reference Hay2001; Schreuder & Baayen, Reference Schreuder, Baayen and Feldman1995). This difference between our study and that of Marcolini et al. might explain some of the differences between our study and theirs. For example, suffixed high-frequency words might have been processed on a decompositional basis in our experiment because their roots were of high frequency (Hay, Reference Hay2001). Unfortunately, to the best of our knowledge, these variables are not available in Spanish. Therefore, accurate control of these morphological variables was not possible in our study. Second, the repetition of the endings of morphologically simple stimuli was similar to the repetition of suffix endings in the Italian studies by Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008), Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011), and also in Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011). In the studies by Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) and Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) there is no clear definition of what “nonsuffix ending” means, or how the similarity was measured and controlled for. For instance, the ending of a morphologically simple Spanish word as molino (mill) could be the final vowel (-o), the final syllable (-no), and so on. That is why, and to compare the endings between suffixed and nonsuffixed words, we developed an approach similar to that used by Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011). The distribution of three-letter endings between suffixed and nonsuffixed words was comparable, except for 14% of the stimuli. It could be argued that the repetition of a final sequence in suffixed words might have induced a larger morphological decomposition in both high- and low-frequency words. Nevertheless, in our opinion, the small differences in the matching of suffixed and nonsuffixed words in our study could not have resulted in a bias toward larger morphological decomposition for both high- and low-frequency words. In sum, morphology effects were present in both our experiments, and therefore, morphology proved to be a relevant variable for Spanish-speaking children's word-reading fluency.
Our results showed that morphology did not affect reading accuracy. In line with what was found in other languages with transparent orthographies (Burani et al., Reference Burani, Marcolini, De Luca and Zoccolotti2008; Marcolini et al., Reference Marcolini, Traficante, Zoccolotti and Burani2011), we did not expect morphemes to affect the accuracy of reading Spanish words. Spanish has transparent orthography-to-phonology mappings. Thus, the pronunciation of most words can be achieved through grapheme-to-phoneme conversion rules. Although this mechanism is very slow and costly, it allows children to achieve accuracy at an early age. Notwithstanding, morphological information can be beneficial for the accurate reading of morphological pseudowords, as shown for Spanish in Jaichenco and Wilson (Reference Jaichenco and Wilson2013) and for Italian in Burani et al. (Reference Burani, Marcolini and Stella2002) and Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011). Likewise, Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008) found that morphology was significant for accuracy when naming morphologically complex pseudowords but not words.
How can we explain this effect of morphology on accuracy when reading morphologically complex pseudowords but not for morphologically complex words in transparent orthographies? One could suggest that, if accurate pronunciation of all legal letter strings can be achieved through grapheme-to-phoneme conversion rules in transparent languages, then morphology should not affect either word or pseudoword-reading accuracy. A possible explanation may come from a sublexical variable, bigram frequency. Bigram frequency can be considered an approximation to the frequency of grapheme–phoneme conversion rules in transparent orthographies and has been shown to affect word naming in transparent orthographies such as Italian (Arduino & Burani, Reference Arduino and Burani2004). Thus, the extent to which morphemes benefit reading accuracy in transparent orthographies might be related to the bigram frequency of the stimuli. For instance, when the bigram frequency of a stimulus is low (and so is the frequency of grapheme–phoneme conversion rules), recourse to larger units as morphemes might be beneficial for reading accuracy. This would be even more so in the case of morphemic pseudowords, which are composed of real morphemes in a nonexisting combination, as those used by Jaichenco and Wilson (Reference Jaichenco and Wilson2013), Burani et al. (Reference Burani, Marcolini and Stella2002), Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008), and Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011). In order to explore this possible explanation, we compared the morphologically complex words of our study (n = 40) with the morphological pseudowords used in our previous study (Jaichenco & Wilson, Reference Jaichenco and Wilson2013; n = 15). If the bigram frequency of the morphological pseudowords is lower than that of morphological words, this could explain why an effect of morphology was found for pseudoword but not word reading. After controlling for the effect of stimulus length (in letters) and N-size, the token bigram frequency of the morphological pseudowords that we have used in Jaichenco and Wilson (Reference Jaichenco and Wilson2013; M = 364.24; SD = 157.34) was significantly lower than the token bigram frequency of the morphological words of this study (M = 591.94; SD = 189.26), F (1, 51) = 15.84, p <.001. These results provide preliminary post hoc evidence of the explanation of the effect of morphology for pseudowords (but not word) reading. However, the results found in Italian by Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011) might seem to come into conflict with our proposal. They found that the higher the bigram frequency of the root or the suffix, the lower the accuracy when reading aloud pseudowords formed by real morphemes. They also found that higher root and suffix frequency increased accuracy. There are at least two major differences that make comparison of our explanation and that put forward by Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011) difficult. Unlike Spanish, stress assignment is not usually orthographically marked in Italian and is unpredictable for words longer than two syllables (Colombo, Reference Colombo1992; Colombo & Zevin, Reference Colombo and Zevin2009; Sulpizio & Colombo, Reference Sulpizio and Colombo2017; Wilson, Ellis, & Burani, Reference Wilson, Ellis and Burani2012). Moreover, the addition of a suffix might also imply the reassignment of the stress of the word (Traficante et al., Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011). In Spanish, stress assignment is not always altered by the addition of a suffix to the root (as can be seen, e.g., in suffixed words ending in –ncia or –nza), and stress assignment is completely transparent and follows orthographic rules. Hence, the role of morphology for achieving accurate pronunciation seems to be less relevant in Spanish than in Italian. The other difference is methodological. The results of Traficante et al. (Reference Traficante, Marcolini, Luci, Zoccolotti and Burani2011) are based on the bigram frequency of each component of the pseudoword and not on the complete concatenation of root and suffix (i.e., the whole stimulus), as we propose here. To the best of our knowledge, no study in a transparent orthography has compared morphologically complex words and morphological pseudowords in terms of their bigram frequency. This should be further explored in future studies in order to provide evidence for or against our explanation.
The effects of grade and time were not the main focus of this study. However, both variables affected fluency and accuracy in both experiments. These results are not surprising. The fact that grade affects both measures in both experiments supports the idea that schooling and, therefore, advancing in grade, in general, makes readers faster and more accurate. As children gain expertise in the mechanisms underlying reading, they become more accurate and efficient, irrespective of the strategies used for reading (see Dehaene, Reference Dehaene2009, for a comprehensive account).
In spite of the fact that Spanish has a transparent script, frequency affected both fluency and accuracy in both experiments. This shows that whole-word reading is already present, though not very efficiently at the beginning, from the first years of literacy acquisition in Spanish. This is in agreement with the results obtained in other transparent orthographies like Italian (Burani et al., Reference Burani, Marcolini and Stella2002). Burani et al. (Reference Burani, Marcolini and Stella2002) found frequency effects in fluency and accuracy in both word naming and lexical decision in children from 3rd, 4th, and 5th grades. This frequency effect showed that lexical information is accessed for reading from an early age. In a previous study in Spanish, we also showed that frequency affected reading accuracy (Jaichenco & Wilson, Reference Jaichenco and Wilson2013). Here, we replicate these results found for Italian and Spanish with a larger range of age and exploring both fluency and accuracy. In addition, in Experiment 2, the effect of frequency was modulated by grade and time for fluency. In Experiment 2, 4th graders showed the largest effects of frequency in fluency. This shows that in 4th grade, faster whole-word lexical reading is already available for reading many frequent words. On the contrary, it seems likely that infrequent words are still accessed mainly through slower mechanisms that involve other units, such as morphemes and graphemes. Sixth graders showed smaller effects of frequency for fluency in this experiment, compared to 4th graders. This suggests that many low-frequency words are also accessed through whole-word lexical reading at this age. This makes the difference between high- and low-frequency words smaller. This decrease in the benefit obtained from word frequency for word naming for children in the higher grades was also found in other studies that explored the effect of frequency on reading accuracy. Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) found that 6th-grade skilled readers benefited less from word frequency for accuracy than poor readers of the same age. Likewise, in a previous study with 2nd, 3rd, and 4th graders, we found that the size of the frequency effect on accuracy decreased as children advanced in schooling (Jaichenco & Wilson, Reference Jaichenco and Wilson2013).
Finally, different theoretical models have sought to account for the influence of morphology on word recognition. Among these, the so-called hybrid models posit that both whole words and morphemic units are activated and contribute to the processing of morphologically complex words (Chialant & Caramazza, Reference Chialant, Caramazza and Feldman1995; Schreuder & Baayen, Reference Schreuder, Baayen and Feldman1995). Schreuder and Baayen (Reference Schreuder, Baayen and Feldman1995) proposed that when processing a morphologically complex word, the representation of the whole word as well as the representations of its morphemes activate the semantic and syntactic information associated with it. Our results provide support to hybrid models of morphological processing. The fact that both morphology and frequency effects are present in fluency from the earliest stages of reading development suggests that the lexicon of a young reader is organized by morphology. It also suggests that both morphological constituents and whole words provide activation at the same time for the recognition of morphologically complex stimuli. However, Schreuder and Baayen (Reference Schreuder, Baayen and Feldman1995) also predict that after a complex word has been frequently processed, the representation for the full word will have a more important role than its component morphemes. Therefore, Schreuder and Baayen's (Reference Schreuder, Baayen and Feldman1995) model predicts results such as that of Marcolini et al. (Reference Marcolini, Traficante, Zoccolotti and Burani2011) and Burani et al. (Reference Burani, Marcolini, De Luca and Zoccolotti2008). We argue that such results could have been found in our studies if more experienced readers had taken part in our experiments and with higher frequency words than the ones we used. Future studies need to address this hypothesis in Spanish.
In sum, our results show that during literacy acquisition in Spanish, grade, frequency, and morphology have a beneficial role when reading words. However, while grade and frequency affect both fluency and accuracy, morphology benefits reading fluency, but not accuracy. These results put together evidence of Spanish and Italian, a similar language with a transparent script, although focusing on normally developing readers and taking both a cross-sectional and a longitudinal perspective. Our study provides evidence in support of hybrid models of processing, such as that of Schreuder and Baayen (Reference Schreuder, Baayen and Feldman1995), which put forward that both morphemes and full words contribute to the activation of lexical items. Among the limitations of this study we can state that, although we included students of a broad age range, we did not include adult participants. Including adult participants might allow to fully understand the developmental trajectory of the relationship between morphology and reading. In addition, the inclusion of higher frequency words might have been desirable in order to better compare our results with previous literature. Furthermore, the unavailability of instruments for controlling certain variables such as family size, suffix frequency, root frequency, and suffix productivity for the Spanish language and the lack of a universal definition of the concept of nonsuffix ending for this language forced some methodological differences between this and previous studies, which may account for some discrepancy with their results.
APPENDIX A Stimuli of the word naming experiment and their psycholinguistic characteristics
High-frequency suffixed words

APPENDIX A. (cont.) Low-frequency suffixed words

APPENDIX A. (cont.) High-frequency simple words

APPENDIX A. (cont.) Low-frequency simple words
ACKNOWLEDGMENTS
This research was supported by UBACyT Grant 20020120100210 (to V.J.); Insight Development Grant 430-2015-00699 by the Social Sciences and Humanities Research Council (CRSH) of Canada (to M.A.W.); and by PhD scholarships from Universidad de Buenos Aires and CONICET (to M.J.D.). The authors would like to thank Bruno Bianchi for his help and the children and their parents for their participation in this study.













