


Introduction
Phonological representations play a fundamental role in word reading development (Perfetti, Reference Perfetti2007; Perfetti & Hart, Reference Perfetti, Hart and Gorfien2001; Perfetti & Stafura, Reference Perfetti and Stafura2014), and in the development of other critical academic skills, such as phonological processing, word retrieval, word learning, word decoding, and reading comprehension (e.g., Gathercole & Baddeley, Reference Gathercole and Baddeley1990; Gray, Reference Gray2005; Nouwens, Groen, Kleemans, & Verhoeven, Reference Nouwens, Groen, Kleemans and Verhoeven2018; Perfetti, Wlotko, & Hart, Reference Perfetti, Wlotko and Hart2005; Verhoeven, Leeuwe, Irausquin, & Segers, Reference Verhoeven, van Leeuwel, Irausquin and Segers2016). This warrants an in-depth understanding of the linguistic factors that impact the establishment and development of phonological representations. Also warranted is an investigation of the role of sociolinguistic factors that pertain to language exposure and use on phonological representations, especially in bilectal and bilingual contexts (Gibson, Summers, Pena, Dedore, Gillam, & Bohman, Reference Gibson, Summers, Pena, Dedore, Gillam and Bohman2015; Saiegh-Haddad & Ghawi-Dakwar, Reference Saiegh-Haddad and Ghawi-Dakwar2017; Themistocleous, Reference Themistocleous2017). The current study investigates phonological representations in Arabic diglossia. In this context, children simultaneously develop two linguistic systems: Spoken Arabic (SpA) for everyday informal speech and Standard Arabic (StA) for formal speech and reading/writing. Importantly, the StA phonological form of the word may vary in extent of distance from (alternatively proximity or overlap with) its form in SpA, and this distance can range from almost identical to entirely different forms. The study tests the impact of the phonological distance between the SpA and StA forms on quality of phonological representations in children at different developmental stages from kindergarten to sixth grade. By studying the impact of the phonological distance between StA and SpA on the establishment and development of phonological representations in StA, this investigation will shed light on the factors that impact phonological representations in diglossic Arabic, in particular, and in analogous bilectal and bilingual contexts.
Phonological representations
Lexical Quality (Perfetti, Reference Perfetti2007; Perfetti & Hart, Reference Perfetti, Hart and Gorfien2001) refers to the quality of stored phonological, orthographic, and semantic representations of lexical items, as well as the retrieval efficiency of these representations. High-quality lexical representations are thought to develop over time and to allow for efficient retrieval of words. Phonological representations, which capture the range of phonological information about words that language users store in long-term memory (Elbro & Jensen, Reference Elbro and Jensen2005), are a fundamental component of the lexical representations of words and are essential to language and literacy development (e.g., Elbro, Borstrøm, & Petersen, Reference Elbro, Borstrøm and Petersen1998; Nouwens et al., Reference Nouwens, Groen, Kleemans and Verhoeven2018; Verhoeven et al., Reference Verhoeven, van Leeuwel, Irausquin and Segers2016).
Research on phonological representations concerned the underlying nature of this construct and the linguistic underpinnings that underlie its establishment and development. In this respect, it has been demonstrated that phonological representations are multilayered and allow speakers to represent and process phonological information at different levels (e.g., the syllable, the onset-rime, the phoneme). At the same time, phonological representations are dynamic and developmental and they undergo enormous change during the first few years of a child's speech and language development (Fowler, Reference Fowler and Shankweiler1991). The Lexical Restructuring Model (Metsala & Walley, Reference Metsala and Walley1998) captures the factors that influence the development of phonological representations. According to this model, because the vocabulary store of young children is small, there is no need to represent words in a detailed manner, and therefore early word representations may be holistic. As vocabulary grows, however, these holistic representations are gradually restructured, so that smaller units of sound such as syllables, onset-rimes, and, ultimately, phonemes are encoded (Metsala, Reference Metsala1997; Metsala & Walley, Reference Metsala and Walley1998; Walley, Reference Walley1993).
Phonological representations are also word-specific, and as a result sensitive to the phonological properties of the word, such as the size of the phonological family (or phonological neighborhood density); As such, the increasing number of similarly sounding words in the child's mental lexicon creates developmental pressure to develop representations that encode smaller units of sound for words in dense phonological neighborhoods (De Cara & Goswami, Reference De Cara and Goswami2003). Research shows that functional properties of words, such as familiarity status, indexed by word frequency and age of acquisition, also impact phonological representational quality (Metsala, Reference Metsala1997; Storkel, Armbrüster, & Hogan, Reference Storkel, Armbrüster and Hogan2006). Finally, phonological representations are affected by letter knowledge and by exposure to literacy. As such, understanding that a particular letter corresponds to a particular phoneme might precipitate the restructuring of the lexicon (Carroll & Snowling, Reference Carroll and Snowling2001; Dollaghan & Campbell, Reference Dollaghan and Campbell1998; Gray & Brinkley, Reference Gray and Brinkley2011; Walley, Reference Walley1993), especially when the orthography is transparent (de Gelder & Vroomen, Reference de Gelder and Vroomen1991; Goswami, Schneider, & Scheurich, Reference Goswami, Schneider and Scheurich1999).
Phonological representations capture abstract knowledge of phonological probabilities and phonological properties of words, and this may be tested using pseudo-word stimuli too. In fact, a commonly used task of phonological memory, and one that is argued to be strongly affected by phonological representations, is a task that requires the repetition of nonwords (Gathercole, Reference Gathercole1995). Nonword repetition was found to be affected by language-specific lexical factors, or wordlikeness, operationalized as the extent to which a nonword is similar to a real word in lexical parameters: phonotactic probability, syllabic length, morphological structure, and stress patterns (Gathercole, Reference Gathercole1995; Gathercole & Baddeley, Reference Gathercole and Baddeley1990). These findings endorse the role of phonological representations in verbal memory tasks and are in keeping with Baddeley's (Reference Baddeley2003) multi-componential model of working memory which posits a positive influence of phonological representational quality in long-term memory on phonological processing in working memory.
Because phonological representations are extracted from the lexicon, they show a significant correlation with vocabulary size, both in L1 (e.g., Conti-Ramsden, Reference Conti-Ramsden2003 ; Hoff, Core, & Bridges, Reference Hoff, Core and Bridges2008 ; Rispens & Baker, Reference Rispens and Baker2012) and in L2 (Dufva & Voeten, Reference Dufva and Voeten1999; Masoura & Gathercole, Reference Masoura and Gathercole1999; Schwartz, Yeh, & Shaw, Reference Schwartz, Yeh and Shaw2008). Relatedly, children who struggle with vocabulary acquisition, such as children with developmental language disorders (DLD), show a strong nonword repetition deficit (Gathercole, Reference Gathercole1995) and are more strongly affected by wordlikeness than typically developing children, even when degree of language exposure is similar (Armon-Lotem, Reference Armon-Lotem2017). This suggests a deficit in phonological representations in these children. Children with developmental reading disorder also show a phonological representations deficit (Hansen & Bowey, Reference Hansen and Bowey1994; Katz, Reference Katz1986; Snowling, Stackhouse, & Rack Reference Snowling, Stackhouse and Rack1986; Stackhouse & Wells, Reference Stackhouse and Wells1997). It has been argued by several researchers that lack of distinctness and/or segmental specificity in the representations supporting spoken word recognition and production might underlie the phonological processing and reading difficulties observed in individuals with reading disability (Adlard & Hazan, Reference Adlard and Hazan1998; Elbro, Reference Elbro1998; Goswami, Reference Goswami2000; Snowling, Reference Snowling2000). Evidence in support of this argument is offered by Elbro et al. (Reference Elbro, Borstrøm and Petersen1998), who show that a measure of the distinctness of phonological representations taken in kindergarten is a particularly sensitive predictor of poor phoneme awareness two years later in children of dyslexic parents. In the same way, Swan and Goswami (Reference Swan and Goswami1997a) demonstrate a picture naming deficit in developmental dyslexia, implying difficulty in the underlying phonological representations of words. Moreover, they show that when phonological representational quality is taken into account some of the phonological awareness deficits observed in dyslexic children disappear (Swan & Goswami, Reference Swan and Goswami1997b).
Despite significant progress in our understanding of the nature of phonological representations and their relationship with language and reading development, research in this domain remains lacking in two ways. First, it focuses mainly on impaired populations. Second, it addresses structural linguistic factors to the exclusion of sociolinguistic factors. In effect, two issues remain unaddressed. The first is the nature and development of phonological representations among typically developing children. The second is the role of sociolinguistic factors that pertain to language exposure and use on phonological representations. Arabic diglossia, in which children simultaneously acquire and use two linguistic systems that vary in their phonological structure – SpA for everyday speech and StA for formal speech and writing – provides a natural setting for testing these questions. The current study explores phonological representations in Arabic diglossia; it tests the impact of the phonological distance between the two language varieties, and of related differences in extent of exposure and use, on phonological representational quality for StA words. This question has important theoretical implications. Furthermore, because young Arabic-speaking children first learn to read in StA, and before they have fully acquired the phonological system of this language variety, the impact of the phonological distance between SpA and StA on phonological representations may turn out to be fundamental for understanding some of the underpinnings of language and reading development and difficulties in Arabic (Saiegh-Haddad, Reference Saiegh-Haddad2017a; Saiegh-Haddad & Everatt, Reference Saiegh-Haddad, Everatt, Kucirkova, Snow, Grover and McBride-Chang2017).
Diglossia and phonological processing in Arabic
All Arabic native-speaking children are born into a dual linguistic context called ‘diglossia’ (Ferguson, Reference Ferguson1959). In diglossic Arabic, children grow up speaking a local dialect of SpA that they hear at home and in the neighborhood. Yet, at school, around the age of six, they are formally and extensively exposed to (Modern) Standard Arabic as the language of reading and writing, while Spoken Arabic remains the language of informal speech, even inside the classroom (Amara, Reference Amara, Izrae'el and Drory1995). Outside the school context, there is a stable co-existence of the two major varieties, each functioning for distinct spheres of social communication: SpA is used by all native speakers – young and old, educated and uneducated – for informal and intimate verbal interaction in the home, at work, and in the community. StA is at least expected to be used for formal oral interactions, such as delivering a speech or a lecture, and is the only variety considered appropriate for writing (however, see Al-Khatib & Sabbah, Reference Al-Khatib and Sabbah2008, Haggan, Reference Haggan2007, and Mostari, Reference Mostari2009, on use of SpA in electronic writing in Arabic). Notwithstanding the fact that extensive exposure to StA begins with the inception of formal schooling and reading instruction in the first grade, Arabic-speaking children are simultaneously exposed to StA: they pray in StA, watch TV programs and dubbed series in StA, read stories (or are read to) in StA, and do all their written school work in StA. Thus, linguistic proficiency in Arabic requires proficiency in both SpA and StA.
StA is a largely uniform code (Holes, Reference Holes2004). In contrast, spoken Arabic vernaculars are mainly regional varieties and they vary from one country to another and from one city, town, or village to another. Despite the vast linguistic differences between the different vernaculars of SpA (which might lead to linguistic unintelligibility, as between Western and Eastern dialects of Arabic), they are all structurally related to StA (Maamouri, Reference Maamouri1998). At the same time, a contrastive linguistic comparison of StA with any specific dialect of SpA always reveals differences in all domains of language, including the phonological, morphological, morphosyntactic, and lexical–semantic domains (Saiegh-Haddad & Henkin-Roitfarb, Reference Saiegh-Haddad, Henkin-Roitfarb, Saiegh-Haddad and Joshi2014).
Given the linguistic distance between SpA and StA, any given linguistic unit in Arabic may have any one of three linguistic affiliations: only-StA, only-SpA, or StA-and-SpA. This trichotomy may be applied to all domains of language. In the domain of phonology, for instance, Arabic phonemes may belong (for speakers of a given vernacular) to one of the following categories: (a) only-SpA phonemes, which are used in a specific SpA vernacular but are not within the phonemic inventory of StA (e.g., the voiceless affricate /č/ used in some rural dialects of Palestinian Arabic used in Israel); (b) only-StA phonemes, which are only standard and not within a given spoken vernacular (e.g., interdental fricatives: voiced /ð/ and voiceless /Ɵ/ in most urban dialects of Palestinian Arabic spoken in the north of Israel); and (c) StA-and-SpA phonemes, which are phonemes used in both SpA and StA. In the domain of phonology, this last category comprises by far the largest set of Arabic phonemes.
Applying the same three-way classification delineated above to the lexical domain, a recent study analyzed a corpus of 4,408 word types derived from a total of 17,499 word tokens collected from five-year-old speakers of Palestinian Arabic in Central Israel (Saiegh-Haddad & Spolsky, Reference Saiegh-Haddad, Spolsky, Saiegh-Haddad and Joshi2014). This analysis revealed the following distribution of lexical items: (a) identical words, words that have an identical phonological form in SpA and StA (e.g., /na:m/ ‘sleep’, /janu:b/ ‘south’, or /daftar/ ‘notebook’), made up 21.2% of the word types in the children's lexicon – note that StA case and mood inflections were not regarded in this analysis; (b) cognate words, words that are phonologically related yet show only partially overlapping phonological forms when used in each of the two varieties (e.g., SpA /dahab /versus StA /ðahab/ ‘gold’; SpA /sama/ versus StA /sama:Ɂ/ ‘sky’), made up another 40.6%; and (c) unique SpA words, words that have a unique form in SpA that is completely different from the one used in StA (e.g., SpA /juzda:n/ versus StA /ħaqi:bah/ ‘bag’; SpA /ħaṭ/ versus StA /waḍaʕ/ ‘he put’), made up 38.2% of the total number of word types in the children's lexicon. This study also showed that the majority of cognate words (~42%) depicted one phonological distance parameter between their form in SpA and StA, such as consonant substitution, glottal stop deletion, vowel change, and vowel insertion. This was followed by cognates depicting two phonological distance parameters (~24%) and three phonological distance parameters (~11%), with all other word types depicting more than three phonological distance parameters each making up less than 5% of the total number of cognates.
The results reported above have serious implications for StA language and literacy acquisition in Arabic. This is because they show that only about 20% of the word types in the SpA lexicon of a five-year-old child, who will soon embark on the reading acquisition journey, have identical phonological forms in StA, the language of literacy, whereas almost 80% of the total number of word types in their lexicon have different forms (either completely different – unique word – or partially different – cognate words). Given established evidence for the important role of oral language skills, and of lexical quality in language and reading development, such a massive orality–literacy gap is expected to have a strong impact on children's ability to develop language and literacy skills in StA (Perfetti & Stafura, Reference Perfetti and Stafura2014; Verhoeven et al., Reference Verhoeven, van Leeuwel, Irausquin and Segers2016).
The study of the impact of the linguistic distance between SpA and StA on language and literacy development in diglossic Arabic is scarce. With a focus on reading, and on phonological skills in particular, Saiegh-Haddad and colleagues (Saiegh-Haddad, Reference Saiegh-Haddad2003, Reference Saiegh-Haddad2004, Reference Saiegh-Haddad2005, Reference Saiegh-Haddad2007a; Saiegh-Haddad, Levin, Hende, & Ziv, Reference Saiegh Haddad, Levin, Hende and Ziv2011; Saiegh-Haddad & Schiff, Reference Saiegh-Haddad and Schiff2016; Schiff & Saiegh-Haddad, Reference Schiff and Saiegh-Haddad2017, Reference Schiff and Saiegh-Haddad2018) tested the impact of the phonological distance between SpA and StA on the acquisition of literacy-related skills in StA, including phonological awareness, pseudo-word decoding, and word reading accuracy and fluency. These studies showed that the acquisition of reading, and of related phonological processing skills, is impacted by the phonological distance between SpA and StA, both in impaired and in typically developing readers. Research has also endorsed the debilitative impact of phonological distance on letter naming (Asaad & Eviatar, Reference Asaad and Eviatar2013) and on phonological memory in typically developing and in children with developmental language disorder (Saiegh-Haddad & Ghawi-Dakwar, Reference Saiegh-Haddad and Ghawi-Dakwar2017). Altogether, the results from these studies suggest difficulty among Arabic-speaking children in developing high-quality phonological representations for StA words.
To sum up, research shows that phonological representations are gradient, and that their construction and acquisition are affected by structural linguistic factors (e.g., neighborhood density) as well as by functional factors (e.g., frequency). Moreover, phonological representations affect the acquisition of language and literacy skills. These findings are fundamental when conceived within the framework of comparative linguality, which situates multilectalism and its impact on language and literacy development on a gradient scale (Grohmann & Kambanaros, Reference Grohmann and Kambanaros2016; Rowe & Grohmann, Reference Rowe and Grohmann2013). The current study tests the role of phonological distance between the two forms of a word: a dialectal spoken form and a standardized mainly written form, on the development of phonological representations in a bilectal context. The study addresses this question in diglossic Arabic. It tests the impact of the phonological distance between SpA and StA on phonological representations for StA words by asking children in senior kindergarten (one year before first grade), and first-, second-, and sixth-grade children to make pronunciation accuracy judgments on StA words that vary in phonological distance from their forms in SpA. By manipulating the phonological distance/overlap between the form of the word in StA and in SpA, the study allows an exploration of whether the construction of phonological representations for StA words in Arabic is affected by the phonological distance between StA and SpA. Moreover, by testing children at different grade levels, and particularly at the point of transition from kindergarten to the first grade and into the second grade, it is possible to test the developmental trajectory of phonological representations and the extent to which they benefit from extensive exposure to StA and from learning to read in StA. In this context, sixth-graders are included as a comparison group.
It was hypothesized that the larger the distance between the SpA and the StA forms the more difficult it would be for children to make a correct pronunciation accuracy judgment; hence, identical words were expected to yield the highest accuracy rates, followed by cognate words and then by unique words. It was also hypothesized that cognate words would yield variations in representational accuracy that would be commensurate with the degree of phonological distance. Finally, it was predicted that the older the participant the more accurate phonological representations would become, with sixth-grade children faring the highest among all four groups and probably showing ceiling levels of performance.
Method
Participants
The sample for the study consisted of 120 children enrolled in a Christian private school in northern Israel. All children were native speakers of an urban dialect of Palestinian Arabic spoken in the north of Israel and were from a middle socioeconomic background. No child had reported hearing, language, psychological, behavioral, or neurological problems. Four age-groups were targeted: Senior Kindergarten (N = 30; Mean age = 5.9 years; 15 females); First grade (N = 30; Mean age = 7.2 years; 17 females); Second grade (N = 30; Mean age = 7.7 years; 14 females); and Sixth grade (N = 30; Mean age = 11.4 years, 15 females).
Materials
Item words for the study were selected from a Spoken Arabic corpus collected from five-year-old native speakers of Palestinian Arabic in northern and central Israel as well as from elementary school textbooks (Saiegh-Haddad, Reference Saiegh-Haddad, Verhoeven and Perfetti2007b; Saiegh-Haddad & Spolsky, Reference Saiegh-Haddad, Spolsky, Saiegh-Haddad and Joshi2014). The following criteria were followed in the selection of words. All items were concrete nouns that could be easily represented in a picture, and they were between 1 and 3 syllables long. All words were within the receptive vocabulary of all children. In order to verify this, a picture-naming vocabulary pre-test was conducted. In this pre-test, each of the candidate StA words was embedded within a simple sentence in StA and was orally presented to the children along with four pictures (correct picture plus 3 distractors). Participants were instructed to point to the picture that best represented the target sentence. For instance, the word /țabah/ ‘ball’ was inserted within the sentence ‘the girl is playing with a ball’ and was presented together with four pictures, a girl playing with a ball and three other distractors: a girl dancing, a girl playing with blocks, and a girl playing with toys. Recognizing the correct sentence required that children recognize the target word ‘ball’ which distinguished the target picture from the three distractors. Only those words that were recognized by all children were included in the experiment.
A total of 108 words were selected that belonged to one of the three following word categories: (1) identical words (N items = 18, e.g., SpA-StA /bațți:x/ ‘watermelon’; (2) unique StA words (N items = 18, e.g., StA /miծallah/ ‘umbrella’; and (3) cognate words (N items = 72). Cognate words were classified into four subclasses that varied in degree of phonological distance/overlap between their SpA and StA forms (N items = 18 per category): (a) 1-phoneme distant cognates; within this category, words were further divided into two types: 1-vowel distant cognates (e.g., StA /fuțu:r/; SpA /fțu:r/ ‘breakfast’; vowel deletion) and 1-consonant distant cognates (e.g., StA /qalam/; SpA /Ɂalam/ ‘pen’; consonant substitution); (b) 2-phoneme distant cognates: a vowel and a consonant (e.g., StA /miqlama/, SpA /miɁlami/ ‘pencil bag’; (d) more than 2-phoneme distant cognates (e.g., StA /ța:Ɂira/; SpA /țayya:ra/ ‘airplane’). Modelled after similar methodological procedures (Brenders, Hell, & Dijkstra, Reference Brenders, Hell and Dijkstra2011; Cristoffaninia, Kirsnera, & Milecha, Reference Cristoffaninia, Kirsnera and Milecha1986), half of the stimuli were used in their intact form (N items = 54) while the second half were subjected to a phoneme substitution procedure yielding a pseudo-word (N items = 54). Four criteria were considered in selecting the location of the phonological substitution procedure and the phonological profile of the two phonemes to be exchanged: (a) the target phoneme to be replaced was not a phonological distance parameter in the word, and therefore replacing it by another phoneme did not alter the phonological distance of the StA word from its SpA form. For instance, if the StA word varied from its SpA form in one consonant (e.g., StA /mu ծi:ʕ/; SpA /mu zi:ʕ/ ‘newscaster’), consonant substitution could not apply to the variable consonant /ծ/ but to another consonant within the word; (b) the target phoneme to be replaced was a consonant, not a vowel; (c) the target phoneme to be replaced was a medial consonant; not the initial nor the final; and (d) the phoneme which would replace the target original phoneme was also a consonant and was different from the original phoneme in only one feature of articulation: voicing, place of articulation, or manner of articulation. It is important to point out that the nouns selected for the study were not deverbal nouns (not derived by a root), so affiliation of the consonant with the root morpheme of the word was not relevant for the phoneme substitution procedure. It is also important to add that, whereas words in the first two categories of cognates (1- and 2-phoneme distant cognates) involved paradigmatic phonological differences between SpA and StA (e.g., vowel insertion, vowel change, consonant substitution, word-final glottal stop deletion, word-initial glottal stop deletion, etc.), words in the third category (more than 2-phoneme distant cognates) involved mainly words that depicted word-specific phonological differences. Because all words targeted in the study were within the receptive vocabulary of children, and because the phoneme substitution procedure did not alter the phonological distance of the StA word from its SpA form, these words too were deemed appropriate for inclusion in this study. All pseudo-words that resulted from the phoneme substitution procedure were pronounceable strings of sound that abided by the phonotactics of StA. See ‘Appendix’ for examples of items.
Procedure
The experiment used a computerized, picture-supported pronunciation accuracy judgment task (Anthony, Williams, Aghara, Dunkelberger, Novak, & Mukherjee, Reference Anthony, Williams, Aghara, Dunkelberger, Novak and Mukherjee2010). The task was designed using the Opensesame software (Mathôt, Schreij, & Theeuwes, Reference Mathôt, Schreij and Theeuwes2012). Each of the target StA words was presented on a computer screen together with a picture illustrating the object noun it represented, and a sound file of its correct pronunciation if it was a real word and its twisted form if it was a pseudo-word. Participants were asked to decide if the pronunciation of the target StA word was correct or not. If correct, s/he was asked to press a green bar. If incorrect, s/he was asked to press a red bar. A picture of a broadcaster holding a microphone always appeared on the left-hand top corner of the screen to remind participants that the experiment involved StA words. The participant was told that this broadcaster (pointing to the picture on the left-hand top corner of the computer screen) did not speak StA properly, and therefore her/his task was to judge if the pronunciation of the word represented in the picture was accurate or not.
Data was collected by the second author, a graduate student of speech and language pathology and a native speaker of the dialect targeted in this study. Authorization for data collection was obtained from the office of the chief scientist of the Ministry of Education. Written parental consent was obtained from all children participating in the study. The child received one score if s/he pressed the correct bar – green for correct and red for incorrect – and a zero score if s/he pressed the wrong bar. Alpha Cronbach reliability across all tested words was α = .80.
Results
The study tested the effect of the phonological distance between SpA and StA on phonological representations by targeting three types of StA words – identical, cognate, and unique – in four grade levels: kindergarten, first, second, and sixth grade. Furthermore, we tested phonological representations for different types of cognate words that varied in degree of phonological distance between their forms in StA and SpA. Table 1 presents summary statistics of pronunciation accuracy judgments by phonological distance and grade.
Table 1. Summary Statistics of Pronunciation Accuracy Judgments by Phonological Distance and Grade (N = 120)
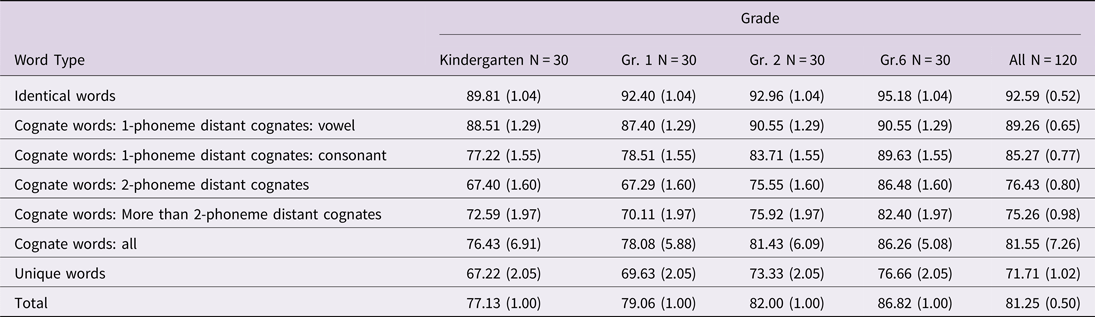
In order to assess the word's phonological distance effect and the individual child's effect on each pronunciation accuracy judgment, we used a mixed-effects model within a cross-classification approach with subjects and items as crossed random effects (Baayen, Davidson, & Bates, Reference Baayen, Davidson and Bates2008). This multilevel analysis assumes that children differ from each other over all pronunciation accuracy judgments they perform, and that words differ from each other across the children who performed the judgment tasks across all words. The smallest unit of measurement in this analysis is a single pronunciation accuracy judgment. The pool of data for the study consisted of 12,960 measurements (120 children × 108 words) To determine the grade-level effect and the word-type effect as independent variables, Multilevel Binary Logistic Regression analysis was used. Our first modeling attempt was to assess intra-class correlation (ICC) indices. Two ICC measurements were calculated, one for the children's level (subjects), and the other for the word's level variance (words).
Table 2 provides the ICC modeling results. The second panel of Table 2 shows an inter-class correlation of .05 for the children's level variance (ICC subjects) and .33 for the word level variance (ICC words). This means significant variation across words and children in the propensity to make a correct judgment. Model 1 is the unconditional model, that is the intercept not explained by word type and grade. Model 2 is the fixed-effects part which shows the overall grade and word effects compared to a reference category. Model 2 was performed twice, once with identical words as a reference category and once with unique words as a reference category. In both model runs, the reference-grade category is kindergarten. In addition, the variance component section in Table 2 (second panel) shows to what extent children differ from each other and to what extent words differ from each other. Model 2 shows significant variation across children and words (0.14, p < .001; 1.34, p < .001, respectively).
Table 2. Cross-Classified Multilevel Binary Logistic Regression: Testing Pronunciation Accuracy Judgment by Grade and Word Level

Notes. Standard errors are in parentheses for fixed effects and Standard deviation for random parameters; ~ p < .10, * p < .05, ** p < .01, *** p < .001.
As Table 2 shows, two main effects were examined to understand differences in successful performance: grade (L2: Grade level) and word type (L2: Word level). Effects (the unstandardized b coefficients) are the log odds, or the log ratio of the probability of successful judgment by a specific category versus that probability of the reference category. The results for Model 2 represented in Table 2 regarding grade effect show that while first-graders showed no difference in pronunciation accuracy judgments in comparison to kindergarten children (b = 1.14, p > .05), second-graders and sixth-graders did (b = 0.39, p < .01; b = 0.87, p < .001, respectively). The results of the word-type effect show that identical words were correctly judged more easily than unique words, 1-consonant distant cognates (category 3), 2-phoneme distant cognates (category 4), and more than 2-phoneme distant cognates (category 5) (b = –1.82, p < .001; b = –1.19, p < .01; b = –1.51, p < .01; b = –1.67, p < .001, respectively). However, identical words were not more significantly easily judged than 1-vowel distant cognates (category 2). At the same time, unique words were judged significantly more easily than identical words (b = 1.82, p < .001), and 1-vowel distant cognates (category 2) (b = 1.45, p < .001). Yet, they were not significantly different in pronunciation accuracy judgment from any of the other three types of cognates (category 3, 4, 5), not even those which were distant by just one consonantal phoneme.
Next, we asked whether differences in phonological representations for the different types of words were different in the different grades. To achieve this, we expanded the analysis to test all word categories one against the other, for each grade separately. Results are shown in Table 3.
Table 3. Cross-Classified Multilevel Binary Logistic Regression Testing Pronunciation Accuracy Judgment by Word Level for Each Grade Separately
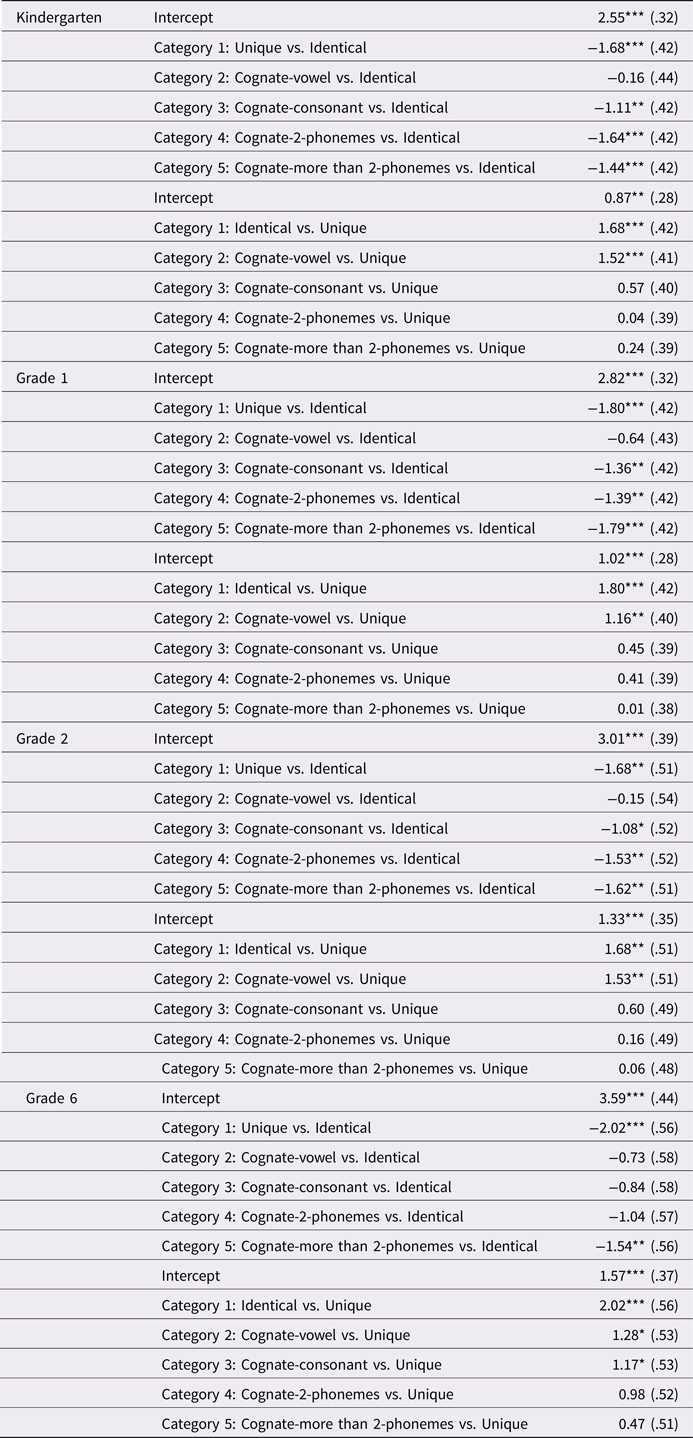
Notes. Standard errors are in parentheses for fixed effects and Standard deviation for random parameters; p-value signs: * p < .05, ** p < .01, *** p < .001.
As can be seen from Table 3, within the group of kindergarteners, identical words were easier to judge than unique words (b = –1.68, p < .001), and they were easier than all other types of cognates, except 1-vowel distant cognates (category 2) (b = –1.11, p < .01, b = −1.64, p < .001, b = –1.44, p < .001). At the same time, 1-vowel distant cognates were easier than unique words (b = 1.52, p < .001), but no other significant differences were found between unique words and the other word categories. The same pattern was replicated among first- and second-graders, but it changed among sixth-graders. Within the sixth-grade group, cognates distant by one phoneme (vowel or consonant) and by two phonemes yielded similar accuracy scores to identical words (category 2, 3, 4). However, unique words and more than 2-phoneme distant cognates were significantly more difficult than identical words (b = –2.02, p < .001; b = –1.54, p < .01, respectively). At the same time, only 1-phoneme distant cognates (1 vowel or 1 consonant) were significantly easier than unique words (b = 1.17, p < .05). The rest of the cognates were not significantly different from unique words even in this group of sixth-graders.
Discussion
The current study had a two-fold objective. First, to investigate whether phonological distance between word forms in SpA and StA, which is a predominant phenomenon in Arabic diglossia (Ferguson, Reference Ferguson1959) and a prominent feature of child Arabic (Saiegh-Haddad & Spolsky, Reference Saiegh-Haddad, Spolsky, Saiegh-Haddad and Joshi2014), impacts the ability of young children to establish and develop accurate phonological representations for StA words, the language of literacy. Second, to probe whether schooling, and the concomitant exposure to Standard Arabic and to literacy, results in a significant refinement of phonological representations among children. The study targeted three classes of StA words. The first is identical words, which are the closest or the least distant from their form in SpA because they keep an almost identical form in SpA and StA (e.g., /na:m/ ‘sleep’ or /daftar/ ‘notebook’). The second category is cognate words, which are used in both SpA and StA but which have a different surface phonological form in each of them. Words in this class are very heterogeneous and vary in degree of distance from SpA. Four categories of cognate words were targeted: 1-phoneme distant cognates; these were further classified into 1-vowel distant cognates and 1-consonant distant cognates, and 2-phoneme distant cognates (a consonant and a vowel). In both cases, the distance between the StA and the SpA forms of cognates was paradigmatic and computable via rule-based phonological transformations, such as vowel insertion, vowel change, glottal stop deletion, consonant substitution, etc. The third class of cognates was more than 2-phoneme distant cognates, and included words depicting word-specific alterations (e.g., StA /riƷl/; SpA /ɁiƷir ‘leg’). The last category was unique words, whose StA phonological form was unrelated and completely different from its form in SpA (StA /miծallah/; SpA /ʃamsiyyih/ ‘umbrella’).
The first question addressed in this study was whether words that vary in degree of phonological distance/overlap also vary in quality of phonological representation, despite being equal in familiarity; note that all words used in the study were within the receptive vocabulary of children. Using children's ability to judge if the pronunciation of a picture-supported StA word was accurate or not, the results showed that phonological distance had a significant and a very strong impact on phonological representational quality. Moreover, this effect was not limited to young kindergarten children, but extended to older first- and second-graders, and was significant even among the sixth-grade comparison group. This finding is compelling because it shows that, even though children were familiar with the word, they still found it difficult to judge if pronunciation was accurate when the phonological form of the word was distant or only partially overlapping with its form in their SpA dialect. Furthermore, it was found that, in general, the more distant the word was, the more difficult the task turned out to be, with identical words producing the highest accuracy scores, unique words producing the lowest scores, and cognate words mostly faring in between. Similarly, the more similar and overlapping the StA word was with the children's SpA dialectal form, the easier it was for them to correctly judge if it was accurately pronounced or not. These findings imply that phonological distance between the StA of the word and its form in the spoken dialect of children interferes with children's ability to encode an accurate phonological representation, even when the word is within the receptive vocabulary of the child. This finding supports the separability of lemma activation processes (including activation of the semantic features of the word) from phonological encoding (Levelt, Reference Levelt1989), and it suggests that phonological distance may be a specific constraint on the phonological encoding process. Alternatively, phonological overlap between the StA form of the word and its form in the spoken dialect appears to bootstrap children's phonological encoding, resulting in higher pronunciation accuracy judgment performance.
These results have important theoretical implications for phonological representations in general, and for the factors that impact lexical specificity and children's ability to establish and develop high-quality phonological representations. One important factor that the current results demonstrate is phonological distance/overlap between the form of the word in the spoken language, or dialect, and its form in the language of formal discourse and literacy. This factor is fundamental when conceived within the framework of comparative linguality, and its effect on language development and metalinguistic skills in bilingual and bilectal children (Grohmann & Kambanaros, Reference Grohmann and Kambanaros2016; Rowe & Grohmann, Reference Rowe and Grohmann2013). This is because it implies that linguistic distance is not a monolithic construct but is a gradable one, and that its impact on processing is commensurate with degree of distance. Moreover, these results show that the impact of linguistic distance on processing is quantifiable and may, hence, be reliably measured (Kambanaros, Michaelides, & Grohmann, Reference Kambanaros, Michaelides and Grohmann2017).
The impact of the phonological distance between SpA and StA on phonological representational quality that this study has demonstrated supports earlier evidence endorsing the impact of phonological distance on Arabic-speaking children's phonological awareness (Saiegh-Haddad, Reference Saiegh-Haddad2003, Reference Saiegh-Haddad2004, Reference Saiegh-Haddad2007a; Saiegh-Haddad et al., Reference Saiegh Haddad, Levin, Hende and Ziv2011), letter-naming (Assad & Eviatar, Reference Asaad and Eviatar2013), pseudo-word decoding (Saiegh-Haddad, Reference Saiegh-Haddad2003, Reference Saiegh-Haddad2005), and word reading (Saiegh-Haddad & Schiff, Reference Saiegh-Haddad and Schiff2016; Schiff & Saiegh-Haddad, Reference Schiff and Saiegh-Haddad2018). It also aligns with evidence for the effect of phonological distance on word decoding observed among disabled readers (Schiff & Saiegh-Haddad, Reference Schiff and Saiegh-Haddad2017) and on typically developing and language impaired children's phonological processing in working memory (Saiegh-Haddad & Ghawi-Dakwar, Reference Saiegh-Haddad and Ghawi-Dakwar2017). Given that phonological processing and reading development are predicated on phonological representations (Elbro, Reference Elbro1998; Goswami, Reference Goswami2000; Katz, Reference Katz1986; Swan & Goswami, Reference Swan and Goswami1997a, Reference Swan and Goswami1997b), the current results suggest that the phonological processing and reading difficulties encountered by Arabic native-speaking children may be, at least partly, attributed to difficulty in constructing accurate phonological representations for StA lexical items in long-term memory. This idea is captured by MAWRID, a Model of Arabic Word Reading in Development (Saiegh-Haddad, Reference Saiegh-Haddad2017a), which argues that diglossia and the linguistic distance between SpA and StA governs the acquisition of basic reading skills across development (Saiegh-Haddad, Reference Saiegh-Haddad, Verhoeven and Perfetti2017b).
The observed impact of phonological distance/overlap on phonological representations has important educational implications for language and reading instruction too, as well as for assessment and material development for Arabic-speaking learners. If the phonological distance between the StA form of the word, which children encounter in reading, and its form in SpA, the form children use in everyday speech, impacts phonological representations, and in turn probably also phonological processing and decoding, and if the more distant the word is the more difficult it is for her to establish an accurate representation for it, then reading instruction as well as assessment should take this factor into account (Saiegh-Haddad & Everatt, Reference Saiegh-Haddad, Everatt, Kucirkova, Snow, Grover and McBride-Chang2017). This principle of gradability and control over the ‘what’ (which words to use) and ‘when’ (when to introduce different words) questions in reading curriculum development constitutes a core principle of the Exposure-through-Reading Program (Saiegh-Haddad & Spolsky, Reference Saiegh-Haddad, Spolsky, Saiegh-Haddad and Joshi2014), which is proposed as a way of bridging the gap between the language of the child and the language of the book in teaching reading in diglossic Arabic (Saiegh-Haddad & Everatt, Reference Saiegh-Haddad, Everatt, Kucirkova, Snow, Grover and McBride-Chang2017).
For instance, instruction in phonemic awareness and decoding should probably start with StA words that keep an identical phonological form in the SpA dialect spoken by the children, and then progress gradually to non-overlapping words. This is because phonological awareness and phonological recoding involve operations on a phonological representation, and the extent to which this representation is high in quality would impact phonological analysis (Saiegh-Haddad, Reference Saiegh-Haddad2017c). Furthermore, instruction should devote particular attention to cognate words. Cognate words are less accurately represented than identical words because they are only semi-familiar, and their processing might involve an activation and competition of two phonological forms – a standard and a spoken form – hence the lower pronunciation accuracy judgments. Yet cognate words are easier than unique words, probably because they are only semi-novel and the overlap between the two forms of the word might bootstrap children's ability to encode an accurate phonological representation. Future research should further explore the role of distance/proximity in children's phonological representation and processing to shed light on whether partially overlapping cognate words would always yield a less accurate representation than completely novel unique words. It might be reasonable to argue that a unique StA word that does not encode a StA phoneme might be easier to process than a StA cognate word that has a competing SpA form in the lexicon of children. Note that the unique words used in the current study were a combination of unique words encoding StA phonemes and those not encoding StA phonemes. Earlier research has shown that unique words that do not encode StA phonemes are easier to process in memory (using a nonword repetition task) than unique words that do not encode StA phonemes (Saiegh-Haddad & Ghawi-Dakwar, Reference Saiegh-Haddad and Ghawi-Dakwar2017). This factor may turn out to be important in clarifying some of the underlying differences in phonological representation between cognates and different types of unique words, and is a question is for future research to pursue.
Another question that the current study tested pertained to the developmental trajectory of phonological representations for the different types of words, and specifically at the transitional point from preliteracy in kindergarten to literacy in the first grade. The results of the study showed that the impact of phonological distance on phonological representations is not transient, and neither is it a characteristic of the lexicons of young preliterate children. Rather, it is persistent and long-standing and it extends to literate children in elementary school, as well as to older children in middle school. At the same time, the results support a developmental progression in phonological representations with second- and sixth-graders performing generally higher than kindergarteners and first-graders, yet no developmental difference was noted between the kindergarten and the first-grade sample. These findings endorse a beneficial effect of oral exposure to StA and of literacy in StA at school on quality of phonological representations. At the same time, the finding that first-grade children were not different from kindergarten children is puzzling, especially when evaluated in light of earlier findings in other languages which indicate an upsurge in phonological representational accuracy with the inception of literacy in the first grade (de Gelder & Vroomen, Reference de Gelder and Vroomen1991; Goswami et al., Reference Goswami, Schneider and Scheurich1999; Swan & Goswami, Reference Swan and Goswami1997a). This unexpected finding might reflect cross-linguistic differences in the challenges that confront children in constructing phonological representations in different languages. As such, it might imply that the challenge which diglossia poses to the construction of high-quality phonological representations might supersede the impact of other challenges undermining this undertaking in other languages, such as the encoding of consonantal clusters, for instance. Two features of Arabic are in order: the simple syllabic structure of Arabic and the transparent orthography of voweled Arabic, the orthography children learn to read in (Saiegh-Haddad & Henkin-Roitfarb, Reference Saiegh-Haddad, Henkin-Roitfarb, Saiegh-Haddad and Joshi2014). It may be argued that, given the simple syllabic structure of StA, with the absence of complex consonantal clusters, the contribution of exposure to the shallow orthography of voweled Arabic to phonological representations in the first grade is significantly reduced, giving way to extended oral exposure to StA as the main factor. To address this conjecture, future research should address the question of the relative effect of oral exposure to StA vis-à-vis exposure to reading in shallow voweled Arabic orthography on quality of phonological representations.
Besides a general effect of phonological distance on phonological representations reflected as greatest facility with pronunciation accuracy judgment for identical words, followed by cognates and then unique words, the results of the study showed an interesting pattern of results: 1-vowel distant cognates were indistinguishable from identical words, whereas the rest of the cognates, namely categories 1–3 (1-consonant distant, 2-phoneme distant, and more than 2-phoneme distant cognates) were all indistinguishable from unique words (Table 2). This pattern of results was unaltered in the three younger groups: kindergarten, first grade, and second grade (Table 3). This finding is outstanding and it shows that cognate words, which are usually regarded as easy to recognize by children because they are half similar and their forms in StA and StA are overlapping, are in fact not as accurately represented and may therefore not be as easily accessible or retrievable by children as they are often assumed to be. This has important implications for the acquisition of decoding skills in young children (Verhoeven et al., Reference Verhoeven, van Leeuwel, Irausquin and Segers2016) and of reading comprehension later on (Nouwens et al., Reference Nouwens, Groen, Kleemans and Verhoeven2018). Note that cognate words that vary in just one or two paradigmatic rule-based phonological change parameters, such as a consonant substitution (StA /ծahab/; SpA /dahab/ ‘gold’) or word-final glottal stop deletion plus preceding vowel reduction (e.g., StA /sama:ʔ/; SpA /sama/ ‘sky’), were more difficult to judge than identical words and, unexpectedly, not significantly easier than unique words. This finding should be taken very seriously in Arabic language and reading instruction and assessment, especially in light of widespread folk wisdom usually endorsed by educational policy-makers, according to whom, if a StA word also exists in SpA (i.e., is a cognate) or “has its origin in StA” as some put it, it should not cause any difficulty for children. This finding should be equally heeded in Arabic psycholinguistic research, especially when the research design relies heavily on word-based manipulations.
The finding that 1-vowel distant cognates aligned with identical words and were significantly different from 1-consonant distant cognates might also imply a different status of vowels versus consonants in the Arabic lexicon. The results showed that when StA cognate words varied from their SpA form in just one vowel, they were indistinguishable from identical words. This was not the case for a StA cognate that varied from its SpA form in one consonant. This suggests greater salience of Arabic consonants over vowels, and may be attributed to the fact that Arabic is a consonantal root-based language in which the meaning of the word is carried mainly on its consonantal structure (Saiegh-Haddad & Henkin-Roitfarb, Reference Saiegh-Haddad, Henkin-Roitfarb, Saiegh-Haddad and Joshi2014). In contrast, vowels are mostly part of the word pattern template, which encodes the word's grammatical properties, and these tend to vary in different dialects, and even within StA for variants of the same template. Evidence in support of this hypothesis comes from research showing that awareness of the consonantal root morpheme in Arabic develops early, and before awareness of the word-pattern morpheme (Taha & Saiegh-Haddad, Reference Taha and Saiegh-Haddad2017). Moreover, research shows that morphological processing using the consonantal root is observed in spelling and reading in young children (Saiegh-Haddad & Taha, Reference Saiegh-Haddad and Taha2017), and is more common among young children than morphological processing using the word-pattern (Saiegh-Haddad, Reference Saiegh-Haddad2013). To directly test the hypothesis that consonants may be psycholinguistically more salient than vowels, future research should directly compare phonological awareness for Arabic vowels versus consonants (Saiegh-Haddad, Reference Saiegh-Haddad, Verhoeven and Perfetti2017b).
Thus, cognates were found to behave in different ways depending on the type of distance, with 1-vowel distant cognates being indistinguishable from identical words and with the rest of the cognates indistinguishable from unique words. This pattern was replicated in the three younger groups of children and was only different in the sixth grade (Table 3). In the latter group, all cognate words except category 4 (more than 2-phoneme distant cognates) aligned with identical words. However, category 4 of cognates aligned with unique words. This observation is compelling, especially in light of the fact that all other cognates (category 1–3) depict a phonological distance between StA and SpA that is regular, paradigmatic, and rule-based, i.e., that the SpA form may be computed from the StA form by applying a set of phonological processes, whereas category 4 (more than 2-phneme distant) depict word-specific phonological alterations. This finding implies that children might find it easier to develop accurate phonological representation for StA words whose distance from SpA is paradigmatic and whose StA forms are regularly related to their form in SpA, yet they only appear to show this advantage in the sixth grade. In contrast, younger children find all cognate words, even those that regularly alternate with their SpA form in just one consonant, indistinguishable from unique words. This advantage observed in sixth-graders as against all the other three younger groups might reflect the combined effect of extended exposure to StA (6 years as against 1–3 years in kindergarten and second grade, respectively), as well as extended experience with literacy in the transparent orthography of Arabic. Extended exposure to StA enhances children's ability to extract statistical patterns from the language, including patterns that govern the relationship between StA forms and their paradigmatically related SpA parallel forms, and this could in turn lead to greater grasp and awareness of these transformations as reflected in higher pronunciation accuracy judgments. Research supports a fast increase in linguistic awareness – phonological and morphological – during the first six years of literacy instruction among Arabic native-speaking children (Saiegh-Haddad & Taha, Reference Saiegh-Haddad and Taha2017). One outcome of enhanced phonological and morphological awareness may be increased awareness of the phonological and morphophonological differences and similarities between lexical items as they are used in SpA and StA, and this might bootstrap phonological encoding in memory, as reflected in performance on our task. A second factor could be extended literacy experience with the orthography of Arabic in general and with unvoweled Arabic in particular. Children are taught how to read using the voweled Arabic orthography, and they only start reading in unvoweled Arabic approximately around the fourth grade. Developing reading fluency in unvoweled Arabic appears to be particularly dependent on morphological processing skills, in addition to phonological skills (Saiegh-Haddad & Taha, Reference Saiegh-Haddad and Taha2017; Schiff & Saiegh-Haddad, Reference Schiff and Saiegh-Haddad2018). This is because the unvoweled word is morphologically transparent and because morphological awareness (especially pattern awareness) enables the reader to recover the missing vocalic information that is mapped by the diacritics (Saiegh-Haddad, Reference Saiegh-Haddad2017a). It may be argued that enhanced morphological processing in reading unvoweled Arabic contributes to enhanced awareness of the linguistic relatedness of SpA and StA lexical items. This may be especially so as phonological distance/overlap may be obscured in speech yet preserved in the spellings of words. It is noteworthy in this respect that Arabic spelling is loyal to morphological structure (root and word pattern) and, given strong velarization assimilation processes operating on the phonological form of the word, yet not represented in its spelling (Saiegh-Haddad, Reference Saiegh-Haddad2013), morphological processing might be particularly conducive to awareness of the linguistic distance/overlap between SpA and StA forms of words. This question is for future research to explore. Future research should also test children's knowledge of SpA-StA transformations and their ability to apply these transformations to unfamiliar or pseudo-word stimuli, as well as the relationship between this ability, phonological representations, and statistical learning. This avenue may turn out to be critical for understanding individual variations in children's ability to develop a range of language and literacy skills in Arabic diglossia (Saiegh-Haddad, Reference Saiegh-Haddad, Verhoeven and Perfetti2017b). Future research should also test the role of awareness of cognates and of cognate training in bootstrapping vocabulary acquisition. Also, whether cognate training would have the same impact on phonological representations in bilingual contexts (e.g., Kambanaros et al., Reference Kambanaros, Michaelides and Grohmann2017).
Conclusion and limitations
The results of the current study demonstrate the psychological reality of phonological distance in Arabic diglossia, reflected as differences in the phonological representational quality for different StA words in the lexicons of Arabic native-speaking children. The results show that the accuracy with which the phonological form of StA words is represented may be predicted by the relative distance or overlap of the StA word from its form in SpA, with the least distant words, the identical words which preserve an identical phonological form in SpA and StA, showing the most accurate representations. In contrast, cognate words, including those that are distant by a single consonant or more, show lower level of representational accuracy, which may be as low as the representation of unique words which have two completely different forms in SpA and StA. Interestingly, we also found that enhancement of phonological representations in Arabic is very slow and not evident in the early school grades, and certainly not by the transition from orality to literacy in the first grade. These results have significant and far-reaching implications for language and literacy acquisition and education in diglossic Arabic.
Two critical limitations on the generalizability of the results of this study are warranted: sample size and socio-cultural context. The findings we report in this study are based on a sample of 120 children. Future research should aim for a larger sample. Moreover, the results are based on Arabic native-speaking children living in Israel. These children are monolingual native speakers of Arabic and they attend Arabic-medium instruction schools, in which Hebrew is taught as a second language starting in the third grade only. Nonetheless, the presence of Hebrew in the linguistic landscape of Israel and in the linguistic repertoire of young children in Israel is not to be overlooked. Future research is needed that replicates the current study among speakers of Arabic living in other regions in the Arabic-speaking world.
Appendix
Examples of stimulus items by word category (Identical, Cognate, Unique) and condition (real, pseudo). Bold symbols indicate location and identity of consonant substitution.
Identical words
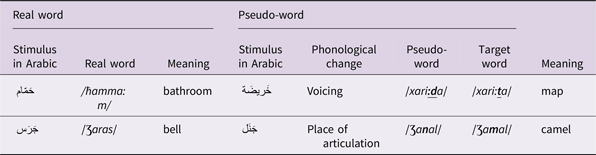
Cognate words
One-vowel distant cognates

One-consonant distant cognates

Two-phoneme-distant cognates: one vowel and one consonant

More than two-phoneme distant cognates

Unique words




