



Impact Statement
Hybrid twins are a special type of digital twins able to learn and correct themselves once significant and persistent biases between data and predictions is found. Here, we develop a method that constructs, under real-time constraints, data-driven corrections to unsatisfactory models within the twin. Of particular importance is the issue of stability of the resulting, corrected model, which is here guaranteed.
1. Introduction
The hybrid twin (HT) paradigm is a powerful tool to make better predictions, increase control performance or improve decision-making (Chinesta et al., Reference Chinesta, Cueto, Abisset, Duval and Khaldi2020; Martín et al., Reference Martín, Méndez, Sainges, Petiot, Barasinski, Piana, Ratier and Chinesta2020). The main idea, see Figure 1, is to develop on-the-fly data-driven models to correct the gap between data (i.e., measurements) and model predictions. In other words, there are two main ingredients of a HT:
• The first one is to enrich physics description with data.
• The second one is to accelerate physics-based models using model order reduction (MOR) techniques, as in Chinesta et al. (Reference Chinesta, Ladevèze and Cueto2011, Reference Chinesta, Huerta, Rozza and Willcox2015), or Sancarlos et al. (Reference Sancarlos, Cueto, Chinesta and Duval2021).

Figure 1. Diagram illustrating the hybrid twin (HT) concept. The HT is able to correct the discrepancy between the coarse model (CM) and the pseudo-experimental data (PED, denoted by a superscript  $ m $). Its prediction
$ m $). Its prediction  $ z $ is here denoted by a superscript
$ z $ is here denoted by a superscript  $ \mathrm{HT} $ whereas the enrichment model is denoted by
$ \mathrm{HT} $ whereas the enrichment model is denoted by  $ \Delta z $. The superscript
$ \Delta z $. The superscript  $ \mathrm{CM} $ refers to the “coarse model,” and
$ \mathrm{CM} $ refers to the “coarse model,” and  $ \Delta \unicode{x1D544} $ is the model correction. Both concepts are introduced in Section 2.
$ \Delta \unicode{x1D544} $ is the model correction. Both concepts are introduced in Section 2.
In any case, when addressing dynamical systems in the HT framework, it is important to guarantee the stability of the system when adding corrections to the physical model. It is worth noting that this is an important issue, because sometimes the best model, computed with state-of-the-art algorithms, completely fails to obtain a stable time-integrator. For example, when considering a linear dynamical model by the dynamic mode decomposition (DMD) approach (Schmid, Reference Schmid2010; Kutz et al., Reference Kutz, Brunton, Brunton and Proctor2016), the feasible region constrained by the stability condition is nonconvex (Huang et al., Reference Huang, Cao, Sun, Zhao, Liu and Yu2016), and no general methodology exists to solve it.
For this reason, this work proposes a new, fast, and efficient methodology, covering several subvariants and guaranteeing a low computational cost as well as the achievement of a stable dynamical system. This technique will therefore be used to add a stable correction term into the HT concept.
The methodology is tested for an industrial case detailed in Section 4.1, where an excellent agreement was observed when employing the HT approach.
The work is organized as follows: in Section 2, the system modeling with the HT concept is presented and compared to the direct (so to speak, from scratch) data-driven approach. An alternative approach that benefits from transfer learning, for instance, can be found in Guastoni et al. (Reference Guastoni, Güemes, Ianiro, Discetti, Schlatter, Azizpour and Vinuesa2020). Then, in Section 3, the proposed technique to obtain stable systems is described as well as the subvariants to deal with high-dimensional systems. Finally, in Sections 4 and 5, the results and general conclusions of the present work are discussed, respectively.
2. System Modeling
In what follows, we consider the system as described by a vector  $ \mathbf{z}\,\in\,{\mathrm{\mathbb{R}}}^{\mathtt{D}} $ (with
$ \mathbf{z}\,\in\,{\mathrm{\mathbb{R}}}^{\mathtt{D}} $ (with  $ \mathtt{D} $ the number of variables involved in the system evolution). The state (snapshot of the system) at time
$ \mathtt{D} $ the number of variables involved in the system evolution). The state (snapshot of the system) at time  $ {t}_n=n\Delta t $ is stored at vectors
$ {t}_n=n\Delta t $ is stored at vectors  $ {\mathbf{Z}}_n $, with
$ {\mathbf{Z}}_n $, with  $ n\,\ge\,0 $, with
$ n\,\ge\,0 $, with  $ {\mathbf{Z}}_0 $ assumed known. In addition,
$ {\mathbf{Z}}_0 $ assumed known. In addition,  $ \mathrm{d} $ control parameters are considered, giving rise to a parametric space
$ \mathrm{d} $ control parameters are considered, giving rise to a parametric space  $ \boldsymbol{\mu}\,\in\,{\mathrm{\mathbb{R}}}^{\mathtt{d}} $.
$ \boldsymbol{\mu}\,\in\,{\mathrm{\mathbb{R}}}^{\mathtt{d}} $.
We assume the existence of a model  $ {\unicode{x1D544}}^c\left(\mathbf{z},\boldsymbol{\mu} \right) $ which we refer to as coarse, since we assume that some form of enrichment is necessary. Often, this model is physics-based, it arises from the corresponding PDEs governing the problem and can contain nonlinearities. Other times, it is based on Model Based System Engineering modeling. This approximate representation of the reality is sought to be computable under real-time constraints. These constraints depend on the context and can range from some seconds to the order of milliseconds. If the complexity of the model does not allow to obtain such a response under constraints, MOR techniques constitute an appealing alternative. These that can be linear or not, allow us to timely integrate the state of the system.
$ {\unicode{x1D544}}^c\left(\mathbf{z},\boldsymbol{\mu} \right) $ which we refer to as coarse, since we assume that some form of enrichment is necessary. Often, this model is physics-based, it arises from the corresponding PDEs governing the problem and can contain nonlinearities. Other times, it is based on Model Based System Engineering modeling. This approximate representation of the reality is sought to be computable under real-time constraints. These constraints depend on the context and can range from some seconds to the order of milliseconds. If the complexity of the model does not allow to obtain such a response under constraints, MOR techniques constitute an appealing alternative. These that can be linear or not, allow us to timely integrate the state of the system.
Because of the simplifying hypotheses involved in the construction of the model  $ {\unicode{x1D544}}^c $, it is expected that model predictions
$ {\unicode{x1D544}}^c $, it is expected that model predictions  $ {\mathbf{Z}}_n^c $ differ from measurements to some extent, that is,
$ {\mathbf{Z}}_n^c $ differ from measurements to some extent, that is,  $ \parallel {\mathbf{Z}}_n-{\mathbf{Z}}_n^c\parallel >\unicode{x03B5} $, for most time steps
$ \parallel {\mathbf{Z}}_n-{\mathbf{Z}}_n^c\parallel >\unicode{x03B5} $, for most time steps  $ n $, thus needing for a correction.
$ n $, thus needing for a correction.
2.1. Extracting the model of the system from scratch
Several routes exist to construct a model for a given dynamical system. The first one consists in performing a completely data-driven approach from experimental measurements  $ \left({\mathbf{Z}}_n,{\boldsymbol{\mu}}_n\right) $,
$ \left({\mathbf{Z}}_n,{\boldsymbol{\mu}}_n\right) $,  $ n=0,\hskip0.5em 1,\dots $. A valuable option is to consider the so-called DMD to extract a matrix model of a discrete linear system (Schmid, Reference Schmid2010). As suggested by several works, many different systems can be well approximated using this approach (Schmid, Reference Schmid2011; Schmid et al., Reference Schmid, Li, Juniper and Pust2011). If problems arise due to complex system behaviors, the procedure of extending the state vector to a higher dimensional space can often solve the problem (Kutz et al., Reference Kutz, Brunton, Brunton and Proctor2016; Eivazi et al., Reference Eivazi, Guastoni, Schlatter, Azizpour and Vinuesa2021).
$ n=0,\hskip0.5em 1,\dots $. A valuable option is to consider the so-called DMD to extract a matrix model of a discrete linear system (Schmid, Reference Schmid2010). As suggested by several works, many different systems can be well approximated using this approach (Schmid, Reference Schmid2011; Schmid et al., Reference Schmid, Li, Juniper and Pust2011). If problems arise due to complex system behaviors, the procedure of extending the state vector to a higher dimensional space can often solve the problem (Kutz et al., Reference Kutz, Brunton, Brunton and Proctor2016; Eivazi et al., Reference Eivazi, Guastoni, Schlatter, Azizpour and Vinuesa2021).
A second alternative could be a variant of the technique presented in Sancarlos et al. (Reference Sancarlos, Cameron, Abel, Cueto, Duval and Chinesta2020), that consists in grouping all the states close to  $ {\mathbf{Z}}_n $ and the control parameters close to
$ {\mathbf{Z}}_n $ and the control parameters close to  $ {\boldsymbol{\mu}}_n $ into a set
$ {\boldsymbol{\mu}}_n $ into a set  $ {\mathcal{S}}_n $. For the sake of clarity, in what follows
$ {\mathcal{S}}_n $. For the sake of clarity, in what follows  $ \mathcal{S} $ will refer to one of these generic sets. A linear model for the set
$ \mathcal{S} $ will refer to one of these generic sets. A linear model for the set  $ \mathcal{S} $, denoted
$ \mathcal{S} $, denoted  $ {\mathbf{M}}_{\mathcal{S}} $, which in this case is simply a matrix, is extracted from:
$ {\mathbf{M}}_{\mathcal{S}} $, which in this case is simply a matrix, is extracted from:
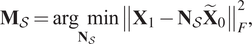 $$ {\mathbf{M}}_{\mathcal{S}}=\underset{{\mathbf{N}}_{\mathcal{S}}}{\arg \hskip0.5em \min }{\left\Vert {\mathbf{X}}_1-{\mathbf{N}}_{\mathcal{S}}{\tilde{\mathbf{X}}}_0\right\Vert}_F^2, $$
$$ {\mathbf{M}}_{\mathcal{S}}=\underset{{\mathbf{N}}_{\mathcal{S}}}{\arg \hskip0.5em \min }{\left\Vert {\mathbf{X}}_1-{\mathbf{N}}_{\mathcal{S}}{\tilde{\mathbf{X}}}_0\right\Vert}_F^2, $$with
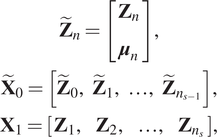 $$ {\displaystyle \begin{array}{c}{\tilde{\mathbf{Z}}}_n=\left[\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\end{array}\right],\\ {}{\tilde{\mathbf{X}}}_0=\left[{\tilde{\mathbf{Z}}}_0,\hskip0.5em {\tilde{\mathbf{Z}}}_1,\hskip0.5em \dots, \hskip0.5em {\tilde{\mathbf{Z}}}_{n_{s-1}}\right],\\ {}{\mathbf{X}}_1=\left[\begin{array}{cccc}{\mathbf{Z}}_1,& {\mathbf{Z}}_2,& \dots, & {\mathbf{Z}}_{n_s}\end{array}\right],\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\tilde{\mathbf{Z}}}_n=\left[\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\end{array}\right],\\ {}{\tilde{\mathbf{X}}}_0=\left[{\tilde{\mathbf{Z}}}_0,\hskip0.5em {\tilde{\mathbf{Z}}}_1,\hskip0.5em \dots, \hskip0.5em {\tilde{\mathbf{Z}}}_{n_{s-1}}\right],\\ {}{\mathbf{X}}_1=\left[\begin{array}{cccc}{\mathbf{Z}}_1,& {\mathbf{Z}}_2,& \dots, & {\mathbf{Z}}_{n_s}\end{array}\right],\end{array}} $$if stability problems do not arise. Note that in this case the model is composed of local matrices defining different linear maps in each set. A reduced version of this approach was extensively discussed in Reille et al. (Reference Reille, Hascoet, Ghnatios, Ammar, Cueto, Duval, Chinesta and Keunings2019).
Quite often, an issue can appear because of the difficulties to learn stable models when constructing these dynamical systems. For this reason, in Section 3, we propose a new methodology when using these techniques to guarantee that the obtained systems remain stable.
2.2. Enriching a physics-based model within the HT framework
Constructing a model  $ \unicode{x1D544} $ of the physical system from scratch is not the most valuable route as discussed in our former works (Chinesta et al., Reference Chinesta, Cueto, Abisset, Duval and Khaldi2020). Purely data-driven, black-box models are not popular in industry, due to the lack of interpretability and guaranteed error estimators. Thus, a more valuable option consists of constructing corrections to physics-based models—if these provide unsatisfactory results—from an additive correction of this coarse prediction.
$ \unicode{x1D544} $ of the physical system from scratch is not the most valuable route as discussed in our former works (Chinesta et al., Reference Chinesta, Cueto, Abisset, Duval and Khaldi2020). Purely data-driven, black-box models are not popular in industry, due to the lack of interpretability and guaranteed error estimators. Thus, a more valuable option consists of constructing corrections to physics-based models—if these provide unsatisfactory results—from an additive correction of this coarse prediction.
In fact, since the coarse model (CM) is expected to perform reasonably well for predicting the state of the system, bias will in general remain reasonably small. If this is true, the correction model will be much less nonlinear, and it will accept a more accurate description from the same amount of data.
Thus, we define the correction contribution  $ {\mathbf{C}}_n $ (or, equivalently, the model enrichment) as:
$ {\mathbf{C}}_n $ (or, equivalently, the model enrichment) as:
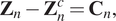 $$ {\mathbf{Z}}_n-{\mathbf{Z}}_n^c={\mathbf{C}}_n, $$
$$ {\mathbf{Z}}_n-{\mathbf{Z}}_n^c={\mathbf{C}}_n, $$where  $ {\mathbf{Z}}_n^c $ refers the model prediction.
$ {\mathbf{Z}}_n^c $ refers the model prediction.
Taking as a proof of concept a dynamic linear system with control inputs, the correction term is searched as:
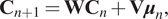 $$ {\mathbf{C}}_{n+1}={\mathbf{WC}}_n+\mathbf{V}{\boldsymbol{\mu}}_n, $$
$$ {\mathbf{C}}_{n+1}={\mathbf{WC}}_n+\mathbf{V}{\boldsymbol{\mu}}_n, $$where  $ \mathbf{W} $ and
$ \mathbf{W} $ and  $ \mathbf{V} $ are the matrices defining the time evolution of the correction term. Thus, the total response of the system is finally predicted by using:
$ \mathbf{V} $ are the matrices defining the time evolution of the correction term. Thus, the total response of the system is finally predicted by using:
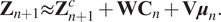 $$ {\mathbf{Z}}_{n+1}\approx {\mathbf{Z}}_{n+1}^c+{\mathbf{WC}}_n+\mathbf{V}{\boldsymbol{\mu}}_n. $$
$$ {\mathbf{Z}}_{n+1}\approx {\mathbf{Z}}_{n+1}^c+{\mathbf{WC}}_n+\mathbf{V}{\boldsymbol{\mu}}_n. $$ By taking into consideration that  $ {\mathbf{Z}}^c $ is stable and integrated independently of the correction term, the stability condition of the system should apply just on the correction term.
$ {\mathbf{Z}}^c $ is stable and integrated independently of the correction term, the stability condition of the system should apply just on the correction term.
We propose an approach to guarantee the construction of stable systems with low computational cost in the next section. In addition, this technique can be used either to build models from scratch or the correction term of the HT approach.
3. Efficiently Learning Stable Linear Dynamical Systems and DMDc Models
Frequently, difficulties to learn stable models arise when learning linear dynamical systems, specially when dealing with high-dimensional data. This is an important issue to deal with because of the growing importance of the data-driven approximations. For instance, it is usual to search the best linear approach of a set of high-dimensional data to make, for example, fast predictions of the system or to develop control strategies. In fact, there is a growing success of techniques such as the DMD to discover dynamical systems from high-dimensional data (Schmid, Reference Schmid2010; Kutz et al., Reference Kutz, Brunton, Brunton and Proctor2016). This success steams from its capability of providing an accurate decomposition of a complex system into spatiotemporal coherent structures while constructing the model dynamics evolving on a low-rank subspace.
However, when operating in the above scenarios, sometimes the best model computed with state-of-the-art algorithms fails to obtain a stable time-integration. In fact, for a given a set of data, the problem to guarantee a stable system is defined by Equation (7) below but, unfortunately, the feasible region constrained by the spectral radius is nonconvex and no general methodology exists to solve it (Huang et al., Reference Huang, Cao, Sun, Zhao, Liu and Yu2016). Moreover, if a fast procedure is needed to obtain a correction model in a real-time application, this problem is further exacerbated.
For these reasons, this paper proposes a methodology to compute a stable model for a given dataset at low computational cost. The strategy is discussed for a discrete linear system, for a DMD model and for a DMD with control (DMDc) model. In addition, other strategies are discussed.
Let us assume the following dynamical systems defined in Equations (5) and (6), the first one without considering inputs,
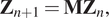 $$ {\mathbf{Z}}_{n+1}={\mathbf{MZ}}_n, $$
$$ {\mathbf{Z}}_{n+1}={\mathbf{MZ}}_n, $$and the second one considering inputs,
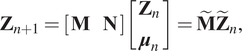 $$ {\mathbf{Z}}_{n+1}=\left[\begin{array}{cc}\mathbf{M}& \mathbf{N}\end{array}\right]\left[\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\end{array}\right]={\tilde{\mathbf{M}}\tilde{\mathbf{Z}}}_n, $$
$$ {\mathbf{Z}}_{n+1}=\left[\begin{array}{cc}\mathbf{M}& \mathbf{N}\end{array}\right]\left[\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\end{array}\right]={\tilde{\mathbf{M}}\tilde{\mathbf{Z}}}_n, $$where  $ \mathbf{M} $ and
$ \mathbf{M} $ and  $ \mathbf{N} $ are the matrices defining the time evolution of the system. To guarantee stability in the above systems, the following condition must be satisfied:
$ \mathbf{N} $ are the matrices defining the time evolution of the system. To guarantee stability in the above systems, the following condition must be satisfied:
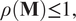 $$ \rho \left(\mathbf{M}\right)\le 1, $$
$$ \rho \left(\mathbf{M}\right)\le 1, $$where  $ \rho \left(\cdot \right) $ denotes the spectral radius.
$ \rho \left(\cdot \right) $ denotes the spectral radius.
Therefore, in relation to Equation (6), the solution minimizes:
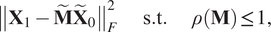 $$ {\displaystyle \begin{array}{lllll}{\left\Vert {\mathbf{X}}_1-{\tilde{\mathbf{M}}\tilde{\mathbf{X}}}_0\right\Vert}_F^2& & \mathrm{s}.\mathrm{t}.& & \rho \left(\mathbf{M}\right)\,\le\,1,\end{array}} $$
$$ {\displaystyle \begin{array}{lllll}{\left\Vert {\mathbf{X}}_1-{\tilde{\mathbf{M}}\tilde{\mathbf{X}}}_0\right\Vert}_F^2& & \mathrm{s}.\mathrm{t}.& & \rho \left(\mathbf{M}\right)\,\le\,1,\end{array}} $$with
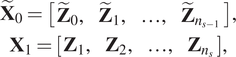 $$ {\displaystyle \begin{array}{c}{\tilde{\mathbf{X}}}_0=\left[\begin{array}{cccc}{\tilde{\mathbf{Z}}}_0,& {\tilde{\mathbf{Z}}}_1,& \dots, & {\tilde{\mathbf{Z}}}_{n_{s-1}}\end{array}\right],\\ {}{\mathbf{X}}_1=\left[\begin{array}{cccc}{\mathbf{Z}}_1,& {\mathbf{Z}}_2,& \dots, & {\mathbf{Z}}_{n_s}\end{array}\right],\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\tilde{\mathbf{X}}}_0=\left[\begin{array}{cccc}{\tilde{\mathbf{Z}}}_0,& {\tilde{\mathbf{Z}}}_1,& \dots, & {\tilde{\mathbf{Z}}}_{n_{s-1}}\end{array}\right],\\ {}{\mathbf{X}}_1=\left[\begin{array}{cccc}{\mathbf{Z}}_1,& {\mathbf{Z}}_2,& \dots, & {\mathbf{Z}}_{n_s}\end{array}\right],\end{array}} $$where  $ {n}_s $ is the number of different snapshots for the training and the matrices
$ {n}_s $ is the number of different snapshots for the training and the matrices  $ {\tilde{\mathbf{X}}}_0 $ and
$ {\tilde{\mathbf{X}}}_0 $ and  $ {\mathbf{X}}_1 $ contain the data to construct the model. In them, each column corresponds to a snapshot of the system at a given time instant.
$ {\mathbf{X}}_1 $ contain the data to construct the model. In them, each column corresponds to a snapshot of the system at a given time instant.
Unfortunately, as already said, the feasible region constrained by  $ \rho \left(\mathbf{M}\right)\,\le\,1 $ is nonconvex and no general methodology exists to solve it (Huang et al., Reference Huang, Cao, Sun, Zhao, Liu and Yu2016). This can lead to the problems already discussed where an unstable model is obtained or, in other cases, simply an extremely bad model is extracted due to a failure of the optimization methodology employed.
$ \rho \left(\mathbf{M}\right)\,\le\,1 $ is nonconvex and no general methodology exists to solve it (Huang et al., Reference Huang, Cao, Sun, Zhao, Liu and Yu2016). This can lead to the problems already discussed where an unstable model is obtained or, in other cases, simply an extremely bad model is extracted due to a failure of the optimization methodology employed.
The proposed approach, which can always guarantee the creation of a stable model, is based on an observation of the following inequality, which is satisfied by any matrix norm:
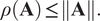 $$ \rho \left(\mathbf{A}\right)\,\le\,\left\Vert \mathbf{A}\right\Vert . $$
$$ \rho \left(\mathbf{A}\right)\,\le\,\left\Vert \mathbf{A}\right\Vert . $$ To prove it, let  $ \omega $ be an eigenvalue of
$ \omega $ be an eigenvalue of  $ \mathbf{A} $, and let
$ \mathbf{A} $, and let  $ \mathbf{x}\ne 0 $ be a corresponding eigenvector. From
$ \mathbf{x}\ne 0 $ be a corresponding eigenvector. From  $ \mathbf{Ax}=\omega \mathbf{x} $, we have:
$ \mathbf{Ax}=\omega \mathbf{x} $, we have:
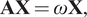 $$ \mathbf{AX}=\omega \mathbf{X}, $$
$$ \mathbf{AX}=\omega \mathbf{X}, $$where  $ \mathbf{X}=\left[\mathbf{x},\cdots, \mathbf{x}\right] $.
$ \mathbf{X}=\left[\mathbf{x},\cdots, \mathbf{x}\right] $.
It follows that:
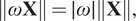 $$ \left\Vert \omega \mathbf{X}\right\Vert =\mid \omega \mid \left\Vert \mathbf{X}\right\Vert, $$
$$ \left\Vert \omega \mathbf{X}\right\Vert =\mid \omega \mid \left\Vert \mathbf{X}\right\Vert, $$and taking into account that,
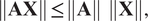 $$ \left\Vert \mathbf{A}\mathbf{X}\right\Vert\,\le\,\left\Vert \mathbf{A}\right\Vert \hskip0.5em \left\Vert \mathbf{X}\right\Vert, $$
$$ \left\Vert \mathbf{A}\mathbf{X}\right\Vert\,\le\,\left\Vert \mathbf{A}\right\Vert \hskip0.5em \left\Vert \mathbf{X}\right\Vert, $$it follows that,
 $$ \mid \omega \mid \hskip0.5em \left\Vert \mathbf{X}\right\Vert\,\le\,\left\Vert \mathbf{A}\right\Vert \hskip0.5em \left\Vert \mathbf{X}\right\Vert . $$
$$ \mid \omega \mid \hskip0.5em \left\Vert \mathbf{X}\right\Vert\,\le\,\left\Vert \mathbf{A}\right\Vert \hskip0.5em \left\Vert \mathbf{X}\right\Vert . $$ Simplifying the above expression by  $ \left\Vert \mathbf{X}\right\Vert $ (
$ \left\Vert \mathbf{X}\right\Vert $ ( $ >0 $) gives:
$ >0 $) gives:
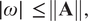 $$ \mid \omega \mid \hskip0.5em \,\le\,\left\Vert \mathbf{A}\right\Vert, $$
$$ \mid \omega \mid \hskip0.5em \,\le\,\left\Vert \mathbf{A}\right\Vert, $$that taking the maximum over all eigenvalues  $ \omega $ gives the desired proof.
$ \omega $ gives the desired proof.
Taking for the reasoning the following induced norm,
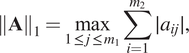 $$ {\left\Vert \mathbf{A}\right\Vert}_1=\underset{1\,\le\,j\,\le\,{m}_1}{\max}\sum \limits_{i=1}^{m_2}\mid {a}_{ij}\mid, $$
$$ {\left\Vert \mathbf{A}\right\Vert}_1=\underset{1\,\le\,j\,\le\,{m}_1}{\max}\sum \limits_{i=1}^{m_2}\mid {a}_{ij}\mid, $$where  $ {m}_1 $ is the number of columns, and
$ {m}_1 $ is the number of columns, and  $ {m}_2 $ is the number of rows—which is simply the maximum absolute column sum of the matrix. It can be observed that by decreasing the absolute value of the matrix coefficients, a smaller matrix norm is obtained, and if it is decreased sufficiently, a smaller
$ {m}_2 $ is the number of rows—which is simply the maximum absolute column sum of the matrix. It can be observed that by decreasing the absolute value of the matrix coefficients, a smaller matrix norm is obtained, and if it is decreased sufficiently, a smaller  $ \rho \left(\mathbf{A}\right) $ is got, because of Equation (9).
$ \rho \left(\mathbf{A}\right) $ is got, because of Equation (9).
Therefore, the idea to obtain a stable system is to shrink the matrix coefficients of  $ \mathbf{M} $. In fact, we propose to do so by using the ridge regression (Hastie et al., Reference Hastie, Tibshirani and Friedman2009), also known as a special case of the Tikhonov regularization. Many advantages can be obtained from this choice. For instance, a closed mathematical expression is obtained. This implies that there is no need to use complex optimization procedures (that can fail to converge). In addition, there is a low added computational cost when changing the ordinary least squares problem to the ridge one.
$ \mathbf{M} $. In fact, we propose to do so by using the ridge regression (Hastie et al., Reference Hastie, Tibshirani and Friedman2009), also known as a special case of the Tikhonov regularization. Many advantages can be obtained from this choice. For instance, a closed mathematical expression is obtained. This implies that there is no need to use complex optimization procedures (that can fail to converge). In addition, there is a low added computational cost when changing the ordinary least squares problem to the ridge one.
This way, we proved a new feature and use for the ridge regression. Ridge regression was employed in certain way for regression of dynamical systems, see, for example, Erichson et al. (Reference Erichson, Mathelin, Kutz and Brunton2019), but just to use the classical function of ridge: to deal with ill-posed problems. Now, we have extended the employment of the technique to a broader problem area: the construction of stable dynamical systems.
To reformulate the resolution of the systems (5) and (6), and then extend the procedure for the DMDc (a more general version of the DMD considering control inputs), two options are envisaged. The first one is solving the following problem:
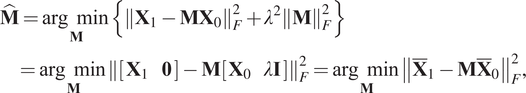 $$ {\displaystyle \begin{array}{l}\hat{\mathbf{M}}=\underset{\mathbf{M}}{\arg \hskip0.5em \min}\left\{{\left\Vert {\mathbf{X}}_1-{\mathbf{M}\mathbf{X}}_0\right\Vert}_F^2+{\lambda}^2{\left\Vert \mathbf{M}\right\Vert}_F^2\right\}\\ {}\hskip8pt =\underset{\mathbf{M}}{\arg \hskip0.5em \min }{\left\Vert \left[\begin{array}{cc}{\mathbf{X}}_1& \mathbf{0}\end{array}\right]-\mathbf{M}\left[\begin{array}{cc}{\mathbf{X}}_0& \lambda \mathbf{I}\end{array}\right]\right\Vert}_F^2=\underset{\mathbf{M}}{\arg \hskip0.5em \min }{\left\Vert {\overline{\mathbf{X}}}_1-\mathbf{M}{\overline{\mathbf{X}}}_0\right\Vert}_F^2,\end{array}} $$
$$ {\displaystyle \begin{array}{l}\hat{\mathbf{M}}=\underset{\mathbf{M}}{\arg \hskip0.5em \min}\left\{{\left\Vert {\mathbf{X}}_1-{\mathbf{M}\mathbf{X}}_0\right\Vert}_F^2+{\lambda}^2{\left\Vert \mathbf{M}\right\Vert}_F^2\right\}\\ {}\hskip8pt =\underset{\mathbf{M}}{\arg \hskip0.5em \min }{\left\Vert \left[\begin{array}{cc}{\mathbf{X}}_1& \mathbf{0}\end{array}\right]-\mathbf{M}\left[\begin{array}{cc}{\mathbf{X}}_0& \lambda \mathbf{I}\end{array}\right]\right\Vert}_F^2=\underset{\mathbf{M}}{\arg \hskip0.5em \min }{\left\Vert {\overline{\mathbf{X}}}_1-\mathbf{M}{\overline{\mathbf{X}}}_0\right\Vert}_F^2,\end{array}} $$where:
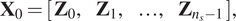 $$ {\mathbf{X}}_0=\left[\begin{array}{cccc}{\mathbf{Z}}_0,& {\mathbf{Z}}_1,& \dots, & {\mathbf{Z}}_{n_s-1}\end{array}\right], $$
$$ {\mathbf{X}}_0=\left[\begin{array}{cccc}{\mathbf{Z}}_0,& {\mathbf{Z}}_1,& \dots, & {\mathbf{Z}}_{n_s-1}\end{array}\right], $$ $ {\overline{\mathbf{X}}}_1 $ and
$ {\overline{\mathbf{X}}}_1 $ and  $ {\overline{\mathbf{X}}}_0 $ are the augmented matrices,
$ {\overline{\mathbf{X}}}_0 $ are the augmented matrices,  $ \mathbf{I} $ is an identity matrix of size
$ \mathbf{I} $ is an identity matrix of size  $ \mathtt{D}\times \mathtt{D} $, and
$ \mathtt{D}\times \mathtt{D} $, and  $ \mathbf{0} $ is a zero matrix of size
$ \mathbf{0} $ is a zero matrix of size  $ \mathtt{D}\times \mathtt{D} $.
$ \mathtt{D}\times \mathtt{D} $.
The solution of the above problem can be computed using the Moore–Penrose pseudoinverse, therefore:
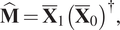 $$ \hat{\mathbf{M}}={\overline{\mathbf{X}}}_1{\left({\overline{\mathbf{X}}}_0\right)}^{\dagger }, $$
$$ \hat{\mathbf{M}}={\overline{\mathbf{X}}}_1{\left({\overline{\mathbf{X}}}_0\right)}^{\dagger }, $$where  $ \dagger $ is the Moore–Penrose pseudoinverse.
$ \dagger $ is the Moore–Penrose pseudoinverse.
A second procedure to solve Equation (10) is to employ a ridge regression for each variable to be predicted. Concerning the system (6),
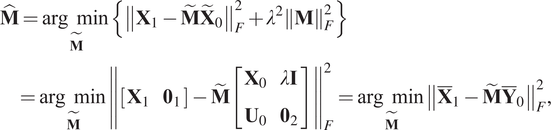 $$ {\displaystyle \begin{array}{l}\hat{\mathbf{M}}=\underset{\tilde{\mathbf{M}}}{\arg \hskip0.5em \min}\left\{{\left\Vert {\mathbf{X}}_1-{\tilde{\mathbf{M}}\tilde{\mathbf{X}}}_0\right\Vert}_F^2+{\lambda}^2{\left\Vert \mathbf{M}\right\Vert}_F^2\right\}\\ {}\hskip8pt =\underset{\tilde{\mathbf{M}}}{\arg \hskip0.5em \min }{\left\Vert \left[\begin{array}{cc}{\mathbf{X}}_1& {\mathbf{0}}_1\end{array}\right]-\tilde{\mathbf{M}}\left[\begin{array}{cc}{\mathbf{X}}_0& \lambda \mathbf{I}\\ {}{\mathbf{U}}_0& {\mathbf{0}}_2\end{array}\right]\right\Vert}_F^2=\underset{\tilde{\mathbf{M}}}{\arg \hskip0.5em \min }{\left\Vert {\overline{\mathbf{X}}}_1-{\tilde{\mathbf{M}}\overline{\mathbf{Y}}}_0\right\Vert}_F^2,\end{array}} $$
$$ {\displaystyle \begin{array}{l}\hat{\mathbf{M}}=\underset{\tilde{\mathbf{M}}}{\arg \hskip0.5em \min}\left\{{\left\Vert {\mathbf{X}}_1-{\tilde{\mathbf{M}}\tilde{\mathbf{X}}}_0\right\Vert}_F^2+{\lambda}^2{\left\Vert \mathbf{M}\right\Vert}_F^2\right\}\\ {}\hskip8pt =\underset{\tilde{\mathbf{M}}}{\arg \hskip0.5em \min }{\left\Vert \left[\begin{array}{cc}{\mathbf{X}}_1& {\mathbf{0}}_1\end{array}\right]-\tilde{\mathbf{M}}\left[\begin{array}{cc}{\mathbf{X}}_0& \lambda \mathbf{I}\\ {}{\mathbf{U}}_0& {\mathbf{0}}_2\end{array}\right]\right\Vert}_F^2=\underset{\tilde{\mathbf{M}}}{\arg \hskip0.5em \min }{\left\Vert {\overline{\mathbf{X}}}_1-{\tilde{\mathbf{M}}\overline{\mathbf{Y}}}_0\right\Vert}_F^2,\end{array}} $$where:
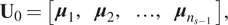 $$ {\mathbf{U}}_0=\left[\begin{array}{cccc}{\boldsymbol{\mu}}_1,& {\boldsymbol{\mu}}_2,& \dots, & {\boldsymbol{\mu}}_{n_{s-1}}\end{array}\right], $$
$$ {\mathbf{U}}_0=\left[\begin{array}{cccc}{\boldsymbol{\mu}}_1,& {\boldsymbol{\mu}}_2,& \dots, & {\boldsymbol{\mu}}_{n_{s-1}}\end{array}\right], $$ $ {\overline{\mathbf{X}}}_1 $ and
$ {\overline{\mathbf{X}}}_1 $ and  $ {\overline{\mathbf{Y}}}_0 $ are the augmented matrices,
$ {\overline{\mathbf{Y}}}_0 $ are the augmented matrices,  $ \mathbf{I} $ is an identity matrix of size
$ \mathbf{I} $ is an identity matrix of size  $ \mathtt{D}\times \mathtt{D} $,
$ \mathtt{D}\times \mathtt{D} $,  $ {\mathbf{0}}_1 $ is a zero matrix of size
$ {\mathbf{0}}_1 $ is a zero matrix of size  $ \mathtt{D}\times \mathtt{D} $, and
$ \mathtt{D}\times \mathtt{D} $, and  $ {\mathbf{0}}_2 $ is a zero matrix of size
$ {\mathbf{0}}_2 $ is a zero matrix of size  $ \mathtt{d}\times \mathtt{D} $.
$ \mathtt{d}\times \mathtt{D} $.
In addition, the same procedures used to solve system (10) can be used to solve (11), either the Moore–Penrose pseudoinverse or the individual ridge regressions.
The above model can be extended in the context of high-dimensional systems when using the DMDc taking the formulation expressed in Equation (11). To do that, we take the singular value decomposition (SVD) of matrix  $ {\overline{\mathbf{Y}}}_0=\tilde{\boldsymbol{\Xi}}\tilde{\boldsymbol{\Sigma}}{\tilde{\mathbf{V}}}^{\ast } $ (where the star symbol * indicates the conjugate transpose). Therefore:
$ {\overline{\mathbf{Y}}}_0=\tilde{\boldsymbol{\Xi}}\tilde{\boldsymbol{\Sigma}}{\tilde{\mathbf{V}}}^{\ast } $ (where the star symbol * indicates the conjugate transpose). Therefore:
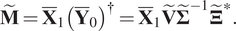 $$ \tilde{\mathbf{M}}={\overline{\mathbf{X}}}_1{\left({\overline{\mathbf{Y}}}_0\right)}^{\dagger }={\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}^{\ast }. $$
$$ \tilde{\mathbf{M}}={\overline{\mathbf{X}}}_1{\left({\overline{\mathbf{Y}}}_0\right)}^{\dagger }={\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}^{\ast }. $$ Approximations of the operators  $ \mathbf{M} $ and
$ \mathbf{M} $ and  $ \mathbf{N} $ can be found as follows:
$ \mathbf{N} $ can be found as follows:
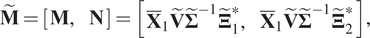 $$ \tilde{\mathbf{M}}=\left[\begin{array}{cc}\mathbf{M},& \mathbf{N}\end{array}\right]=\left[\begin{array}{cc}{\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_1^{\ast },& {\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_2^{\ast}\end{array}\right], $$
$$ \tilde{\mathbf{M}}=\left[\begin{array}{cc}\mathbf{M},& \mathbf{N}\end{array}\right]=\left[\begin{array}{cc}{\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_1^{\ast },& {\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_2^{\ast}\end{array}\right], $$where  $ \tilde{r} $ is the truncation value of the SVD applied to decompose matrix
$ \tilde{r} $ is the truncation value of the SVD applied to decompose matrix  $ {\overline{\mathbf{Y}}}_0=\tilde{\boldsymbol{\Xi}}\tilde{\boldsymbol{\Sigma}}{\tilde{\mathbf{V}}}^{\ast } $,
$ {\overline{\mathbf{Y}}}_0=\tilde{\boldsymbol{\Xi}}\tilde{\boldsymbol{\Sigma}}{\tilde{\mathbf{V}}}^{\ast } $,  $ {\tilde{\boldsymbol{\Xi}}}^{\ast }=\left[\begin{array}{cc}{\tilde{\boldsymbol{\Xi}}}_1^{\ast },& {\tilde{\boldsymbol{\Xi}}}_2^{\ast}\end{array}\right] $, and the sizes of
$ {\tilde{\boldsymbol{\Xi}}}^{\ast }=\left[\begin{array}{cc}{\tilde{\boldsymbol{\Xi}}}_1^{\ast },& {\tilde{\boldsymbol{\Xi}}}_2^{\ast}\end{array}\right] $, and the sizes of  $ {\tilde{\boldsymbol{\Xi}}}_1^{\ast } $ and
$ {\tilde{\boldsymbol{\Xi}}}_1^{\ast } $ and  $ {\tilde{\boldsymbol{\Xi}}}_2^{\ast } $ are
$ {\tilde{\boldsymbol{\Xi}}}_2^{\ast } $ are  $ \tilde{r}\times \mathtt{D} $ and
$ \tilde{r}\times \mathtt{D} $ and  $ \tilde{r}\times \mathtt{d} $, respectively.
$ \tilde{r}\times \mathtt{d} $, respectively.
For high-dimensional systems ( $ \mathtt{D}\gg 1 $) a reduced-order approximation can be solved for instead, leading to a more tractable computational model. Thus, we look for a transformation to a lower-dimensional subspace on which the dynamics evolve.
$ \mathtt{D}\gg 1 $) a reduced-order approximation can be solved for instead, leading to a more tractable computational model. Thus, we look for a transformation to a lower-dimensional subspace on which the dynamics evolve.
The output space  $ {\overline{\mathbf{X}}}_1 $ is chosen to find the reduced-order subspace. Consequently, the SVD of
$ {\overline{\mathbf{X}}}_1 $ is chosen to find the reduced-order subspace. Consequently, the SVD of  $ {\overline{\mathbf{X}}}_1 $ is defined as:
$ {\overline{\mathbf{X}}}_1 $ is defined as:
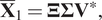 $$ {\overline{\mathbf{X}}}_1=\boldsymbol{\Xi} \boldsymbol{\Sigma} {\mathbf{V}}^{\ast }, $$
$$ {\overline{\mathbf{X}}}_1=\boldsymbol{\Xi} \boldsymbol{\Sigma} {\mathbf{V}}^{\ast }, $$where the truncation value for this SVD will be denoted as  $ r $. Please note that usually both SVDs will have different truncation values.
$ r $. Please note that usually both SVDs will have different truncation values.
Then, by employing the change of coordinates  $ \mathbf{Z}=\boldsymbol{\Xi} \hskip0.1em \hat{\mathbf{Z}} $ (or equivalently
$ \mathbf{Z}=\boldsymbol{\Xi} \hskip0.1em \hat{\mathbf{Z}} $ (or equivalently  $ \hat{\mathbf{Z}}={\boldsymbol{\Xi}}^{\ast}\hskip0.1em \mathbf{Z} $), the following reduced-order approximations can be obtained,
$ \hat{\mathbf{Z}}={\boldsymbol{\Xi}}^{\ast}\hskip0.1em \mathbf{Z} $), the following reduced-order approximations can be obtained,
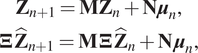 $$ {\displaystyle \begin{array}{c}{\mathbf{Z}}_{n+1}={\mathbf{MZ}}_n+\mathbf{N}{\boldsymbol{\mu}}_n,\\ {}\boldsymbol{\Xi} \hskip0.1em {\hat{\mathbf{Z}}}_{n+1}=\mathbf{M}\hskip0.1em \boldsymbol{\Xi} \hskip0.1em {\hat{\mathbf{Z}}}_n+\mathbf{N}\hskip0.1em {\boldsymbol{\mu}}_n,\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\mathbf{Z}}_{n+1}={\mathbf{MZ}}_n+\mathbf{N}{\boldsymbol{\mu}}_n,\\ {}\boldsymbol{\Xi} \hskip0.1em {\hat{\mathbf{Z}}}_{n+1}=\mathbf{M}\hskip0.1em \boldsymbol{\Xi} \hskip0.1em {\hat{\mathbf{Z}}}_n+\mathbf{N}\hskip0.1em {\boldsymbol{\mu}}_n,\end{array}} $$so that
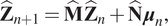 $$ {\hat{\mathbf{Z}}}_{n+1}=\hat{\mathbf{M}}\hskip0.1em {\hat{\mathbf{Z}}}_n+\hat{\mathbf{N}}\hskip0.1em {\boldsymbol{\mu}}_n, $$
$$ {\hat{\mathbf{Z}}}_{n+1}=\hat{\mathbf{M}}\hskip0.1em {\hat{\mathbf{Z}}}_n+\hat{\mathbf{N}}\hskip0.1em {\boldsymbol{\mu}}_n, $$where:
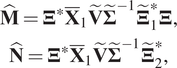 $$ {\displaystyle \begin{array}{c}\hat{\mathbf{M}}={\boldsymbol{\Xi}}^{\ast }{\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_1^{\ast}\boldsymbol{\Xi}, \\ {}\hat{\mathbf{N}}={\boldsymbol{\Xi}}^{\ast }{\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_2^{\ast },\end{array}} $$
$$ {\displaystyle \begin{array}{c}\hat{\mathbf{M}}={\boldsymbol{\Xi}}^{\ast }{\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_1^{\ast}\boldsymbol{\Xi}, \\ {}\hat{\mathbf{N}}={\boldsymbol{\Xi}}^{\ast }{\overline{\mathbf{X}}}_1\tilde{\mathbf{V}}{\tilde{\boldsymbol{\Sigma}}}^{-1}{\tilde{\boldsymbol{\Xi}}}_2^{\ast },\end{array}} $$and the sizes of  $ \hat{\mathbf{M}} $ and
$ \hat{\mathbf{M}} $ and  $ \hat{\mathbf{N}} $ are
$ \hat{\mathbf{N}} $ are  $ r\times r $ and
$ r\times r $ and  $ r\times \mathtt{d} $, respectively.
$ r\times \mathtt{d} $, respectively.
To select the penalty factor, when the standard procedure leads to a matrix that violates the stability condition, several options can be envisaged. Here, we propose to use the bisection method (which guarantees convergence toward the solution) or the regula falsi method (to speed up the process). Of course, faster algorithms can be used such as the Illinois algorithm, but our experience suggests that the former ones are enough in practice.
For example, if the bisection method is selected, the zero of the following function is sought:
 $$ f\left(\lambda \right)={\rho}_{\mathrm{desired}}-\rho \left(\mathbf{M}\left(\lambda \right)\right), $$
$$ f\left(\lambda \right)={\rho}_{\mathrm{desired}}-\rho \left(\mathbf{M}\left(\lambda \right)\right), $$where  $ {\rho}_{\mathrm{desired}} $ is a chosen value very close to one, representing the target when the initial constructed model violates the stability condition.
$ {\rho}_{\mathrm{desired}} $ is a chosen value very close to one, representing the target when the initial constructed model violates the stability condition.
Taking into consideration that the bracketing interval at step  $ k $ of the algorithm is
$ k $ of the algorithm is  $ \left[{\lambda}_k^a,{\lambda}_k^b\right] $, then the Equation (14) is employed to compute the new solution estimate for the penalty
$ \left[{\lambda}_k^a,{\lambda}_k^b\right] $, then the Equation (14) is employed to compute the new solution estimate for the penalty  $ {\lambda}_k^c $ at step
$ {\lambda}_k^c $ at step  $ k $:
$ k $:
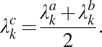 $$ {\lambda}_k^c=\frac{\lambda_k^a+{\lambda}_k^b}{2}. $$
$$ {\lambda}_k^c=\frac{\lambda_k^a+{\lambda}_k^b}{2}. $$ If  $ f\left({\lambda}_k^c\right) $ is satisfactory, the iteration stops. If this is not the case, the sign of
$ f\left({\lambda}_k^c\right) $ is satisfactory, the iteration stops. If this is not the case, the sign of  $ f\left({\lambda}_k^c\right) $ is examinated and the bracking interval is updated for the following iteration so that there is a zero crossing within the new interval.
$ f\left({\lambda}_k^c\right) $ is examinated and the bracking interval is updated for the following iteration so that there is a zero crossing within the new interval.
4. Application to a Dynamical System
4.1. System to model and types of data
The modeled system corresponds to an air distribution system of an aircraft and is characterized by eight variables defining the state of the system: six temperatures  $ {T}_n^i $,
$ {T}_n^i $,  $ i=1,2,\dots, 6 $, and two pressures
$ i=1,2,\dots, 6 $, and two pressures  $ {p}_n^j $,
$ {p}_n^j $,  $ j=1,2 $. The model should also take into account three control variables
$ j=1,2 $. The model should also take into account three control variables  $ {\mu}_n^k $,
$ {\mu}_n^k $,  $ k=\mathrm{1,2,3} $, for each time instant
$ k=\mathrm{1,2,3} $, for each time instant  $ n $.
$ n $.
With the knowledge and experience of Dassault Aviation, two models are constructed with the help of the software Dymola (Dassault Systemes, 2021):
• CM: This model deliberately fails to provide accurate predictions due to over-simplification. It is important to note that in industry, this type of model is often physics-based (although this is not mandatory) but still requires an important computing time.
• A high-fidelity model that will therefore be considered as the ground truth (GT), which is consequently still more time consuming. This model is going to emulate in this work the real state of the system.
Due to confidentiality issues, Dassault Aviation simulated different flights with both models and provided three different types of pseudo-experimental data (PED) which are employed in the present work:
• The CM data. These data correspond to the predictions of the CM for the given set of simulated flights.
• The GT data. These data correspond to the predictions of the GT model. It will be considered in the present work for evaluation purposes.
• PED. A white noise is added artificially to the GT data. Consequently, these data will emulate experimental measurements including experimental errors.
Additionally, in Figures 2 and 3, a comparison is shown between the three types of data (CM, GT, and PED) for a given flight simulation.

Figure 2. Comparison of the state evolution  $ \mathbf{Z}(t)=\left[{p}_1,{p}_2,{T}_1,{T}_2,{T}_3,{T}_4,{T}_5,{T}_6\right] $ for a given flight between the CM and the ground truth (GT).
$ \mathbf{Z}(t)=\left[{p}_1,{p}_2,{T}_1,{T}_2,{T}_3,{T}_4,{T}_5,{T}_6\right] $ for a given flight between the CM and the ground truth (GT).
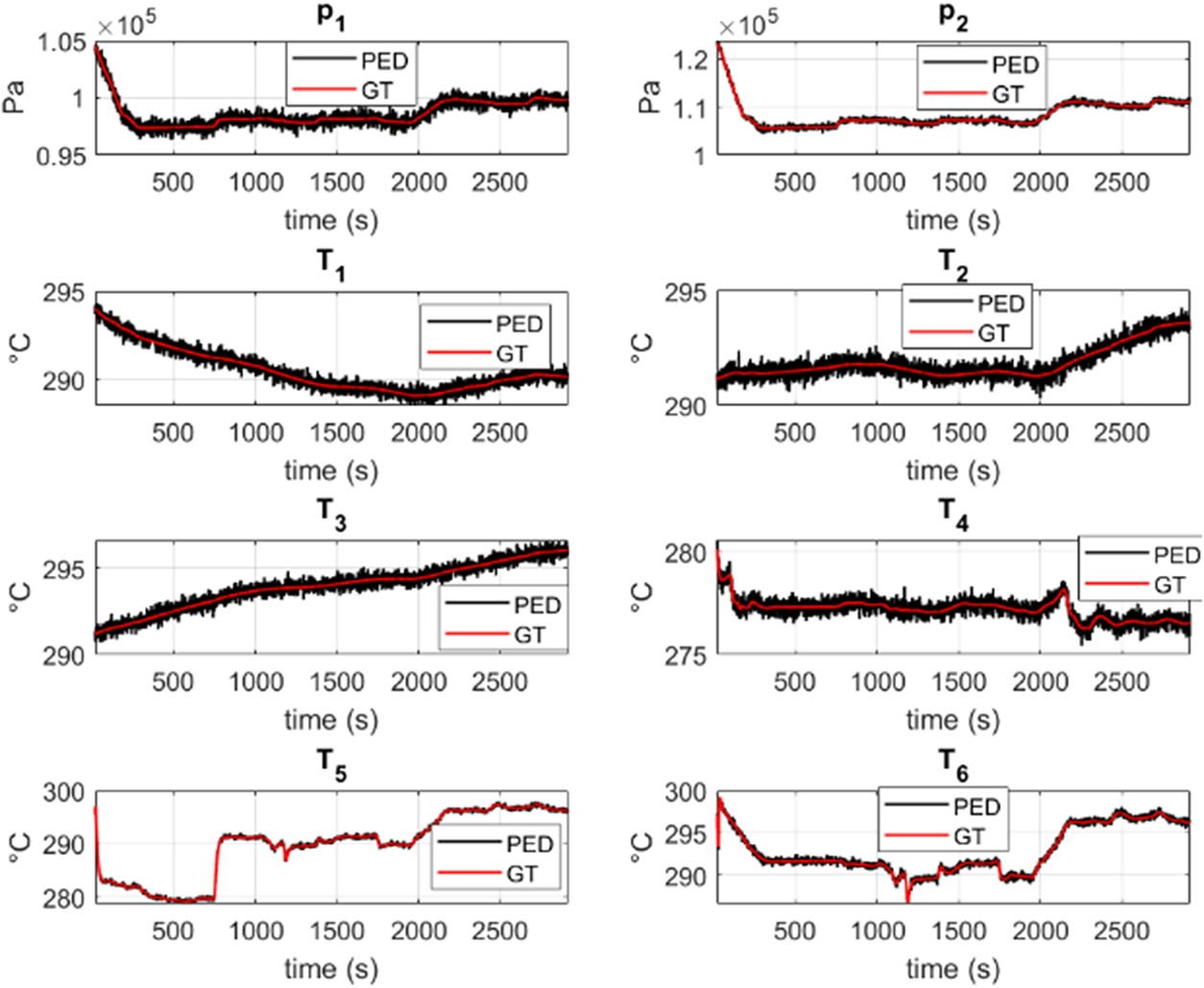
Figure 3. Comparison of the system evolution,  $ \mathbf{Z}(t)=\left[{p}_1,{p}_2,{T}_1,{T}_2,{T}_3,{T}_4,{T}_5,{T}_6\right] $, for a given flight between the ground truth (GT) and the pseudo-experimental (noisy) data, PED.
$ \mathbf{Z}(t)=\left[{p}_1,{p}_2,{T}_1,{T}_2,{T}_3,{T}_4,{T}_5,{T}_6\right] $, for a given flight between the ground truth (GT) and the pseudo-experimental (noisy) data, PED.
At this point, three different approaches were tested:
• Extracting a model from scratch from GT data (Section 4.2).
• Obtaining a model from scratch using the noisy PED (Section 4.3).
• Extracting a correction term to enrich the CM, thus constructing the HT (Section 4.4).
Advantages and weaknesses of each approach will be discussed. The mathematical details of the CM and GT models are omitted for confidentiality reasons. However, this is not important for presenting, discussing and employing the proposed methodology and, moreover, a successful outcome will be a sign that the proposed approach can address current industrial needs.
4.2. Extracting a model from scratch using the GT data
4.2.1. Procedure and results
It is interesting to analyse whether the proposed approach presented in Section 3 is able to learn a model from scratch employing the GT data. Therefore, this section is focused on this goal. In next sections, we will analyse if it is able to obtain similar results when learning in the presence of noise (PED data) and finally, we will see the advantages of using the HT rational instead of the complete data-driven approach.
We sketch the technique in the diagram of Figure 4. As it can be noticed, the system is characterized by eight variables defining the state of the system (six temperatures  $ {T}_n^i $,
$ {T}_n^i $,  $ i=1,2,\dots, 6 $, and two pressures
$ i=1,2,\dots, 6 $, and two pressures  $ {p}_n^j $,
$ {p}_n^j $,  $ j=1,2 $) and three control variables
$ j=1,2 $) and three control variables  $ {\mu}_n^k $,
$ {\mu}_n^k $,  $ k=\mathrm{1,2,3} $ for each time instant
$ k=\mathrm{1,2,3} $ for each time instant  $ n $.
$ n $.
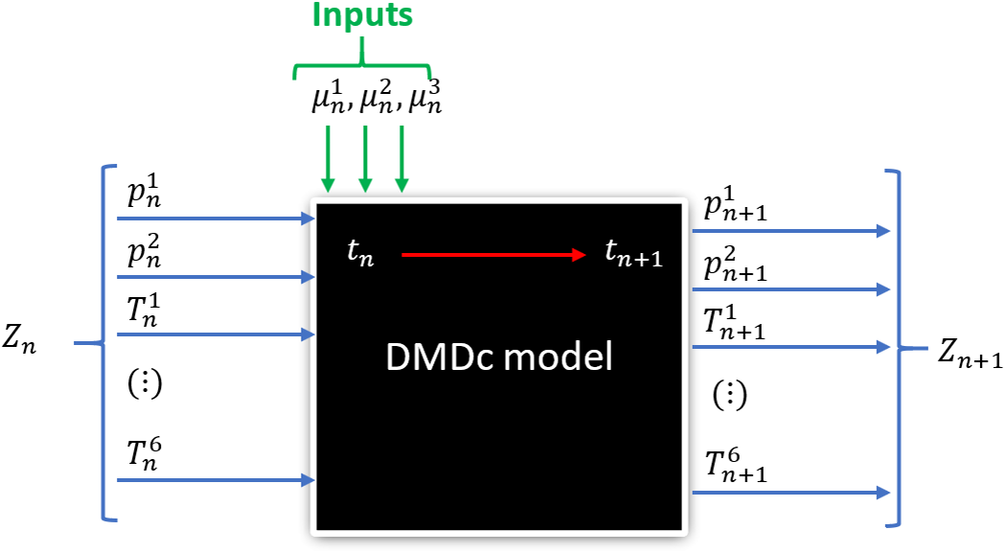
Figure 4. Diagram illustrating the inputs and the state vector of the proposed DMDc model to reproduce the pruned data of the system.
In the present case, we consider the simplest modeling approach in which the model consists in a simple linear application that maps the present state and control parameters  $ {\mathbf{Z}}_n $ and
$ {\mathbf{Z}}_n $ and  $ {\boldsymbol{\mu}}_n $, respectively, onto the next system state
$ {\boldsymbol{\mu}}_n $, respectively, onto the next system state  $ {\mathbf{Z}}_{n+1} $.
$ {\mathbf{Z}}_{n+1} $.
The available data consist in  $ \mathtt{F}=82 $ flights, each one leading to eight time series
$ \mathtt{F}=82 $ flights, each one leading to eight time series  $ {\mathbf{Z}}_n^{\mathrm{f}} $, with
$ {\mathbf{Z}}_n^{\mathrm{f}} $, with  $ \mathtt{f}=1,\dots, \mathtt{F} $, and
$ \mathtt{f}=1,\dots, \mathtt{F} $, and  $ n=1,\dots, {\mathtt{n}}^{\mathtt{f}} $ (the number of collected data depends on the flight, these having different duration). It is important to note that, for any flight
$ n=1,\dots, {\mathtt{n}}^{\mathtt{f}} $ (the number of collected data depends on the flight, these having different duration). It is important to note that, for any flight  $ {t}_{n+1}-{t}_n=\Delta t $, with constant
$ {t}_{n+1}-{t}_n=\Delta t $, with constant  $ \Delta t $, for any component state and any flight.
$ \Delta t $, for any component state and any flight.
We define the extended state as shown in Section 3:
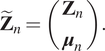 $$ {\tilde{\mathbf{Z}}}_n=\left(\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\end{array}\right). $$
$$ {\tilde{\mathbf{Z}}}_n=\left(\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\end{array}\right). $$ To learn the model, we select arbitrarily two flights from the  $ \mathtt{F} $ available,
$ \mathtt{F} $ available,  $ \mathtt{f}=\mathtt{r} $ and
$ \mathtt{f}=\mathtt{r} $ and  $ \mathtt{f}=\mathtt{s} $, and define the training matrices:
$ \mathtt{f}=\mathtt{s} $, and define the training matrices:
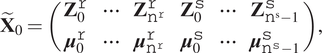 $$ {\tilde{\mathbf{X}}}_0=\left(\begin{array}{cccccc}{\mathbf{Z}}_0^{\mathtt{r}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathtt{r}}}^{\mathtt{r}}& {\mathbf{Z}}_0^{\mathtt{s}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathrm{s}}-1}^{\mathtt{s}}\\ {}{\boldsymbol{\mu}}_0^{\mathtt{r}}& \cdots & {\boldsymbol{\mu}}_{{\mathtt{n}}^{\mathtt{r}}}^{\mathtt{r}}& {\boldsymbol{\mu}}_0^{\mathtt{s}}& \cdots & {\boldsymbol{\mu}}_{{\mathtt{n}}^{\mathtt{s}}-1}^{\mathtt{s}}\end{array}\right), $$
$$ {\tilde{\mathbf{X}}}_0=\left(\begin{array}{cccccc}{\mathbf{Z}}_0^{\mathtt{r}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathtt{r}}}^{\mathtt{r}}& {\mathbf{Z}}_0^{\mathtt{s}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathrm{s}}-1}^{\mathtt{s}}\\ {}{\boldsymbol{\mu}}_0^{\mathtt{r}}& \cdots & {\boldsymbol{\mu}}_{{\mathtt{n}}^{\mathtt{r}}}^{\mathtt{r}}& {\boldsymbol{\mu}}_0^{\mathtt{s}}& \cdots & {\boldsymbol{\mu}}_{{\mathtt{n}}^{\mathtt{s}}-1}^{\mathtt{s}}\end{array}\right), $$and
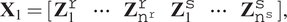 $$ {\mathbf{X}}_1=\left[\begin{array}{llllll}{\mathbf{Z}}_1^{\mathtt{r}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathtt{r}}}^{\mathtt{r}}& {\mathbf{Z}}_1^{\mathtt{s}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathtt{s}}}^{\mathtt{s}}\end{array}\right], $$
$$ {\mathbf{X}}_1=\left[\begin{array}{llllll}{\mathbf{Z}}_1^{\mathtt{r}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathtt{r}}}^{\mathtt{r}}& {\mathbf{Z}}_1^{\mathtt{s}}& \cdots & {\mathbf{Z}}_{{\mathtt{n}}^{\mathtt{s}}}^{\mathtt{s}}\end{array}\right], $$that allows extracting the model by solving the problem indicated in Equation (11) or its reduced counterpart (12).
Then, as soon as the model is extracted, we proceed to predict the state evolution for each one of the  $ \mathtt{F} $ flights, from their initial states, by simply writing at each time
$ \mathtt{F} $ flights, from their initial states, by simply writing at each time  $ {t}_n $,
$ {t}_n $,  $ n=1,\dots, {\mathtt{n}}^{\mathtt{f}} $,
$ n=1,\dots, {\mathtt{n}}^{\mathtt{f}} $,
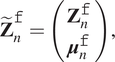 $$ {\tilde{\mathbf{Z}}}_n^{\mathtt{f}}=\left(\begin{array}{c}{\mathbf{Z}}_n^{\mathtt{f}}\\ {}{\boldsymbol{\mu}}_n^{\mathtt{f}}\end{array}\right), $$
$$ {\tilde{\mathbf{Z}}}_n^{\mathtt{f}}=\left(\begin{array}{c}{\mathbf{Z}}_n^{\mathtt{f}}\\ {}{\boldsymbol{\mu}}_n^{\mathtt{f}}\end{array}\right), $$and applying the updating of Equations (6) or (12). Training data are composed of two flights while the other eighty are used to test the performance of the present approach.
Figure 5 compares the predicted states at each time instant by integrating the just unveiled model from the initial condition. It employs a GT data series corresponding to one particular, previously unseen flight. It can be observed that the proposed approach achieves an excellent agreement for variables  $ {p}_1 $,
$ {p}_1 $,  $ {p}_2 $,
$ {p}_2 $,  $ {T}_1 $,
$ {T}_1 $,  $ {T}_2 $,
$ {T}_2 $,  $ {T}_3 $, and
$ {T}_3 $, and  $ {T}_4 $.
$ {T}_4 $.
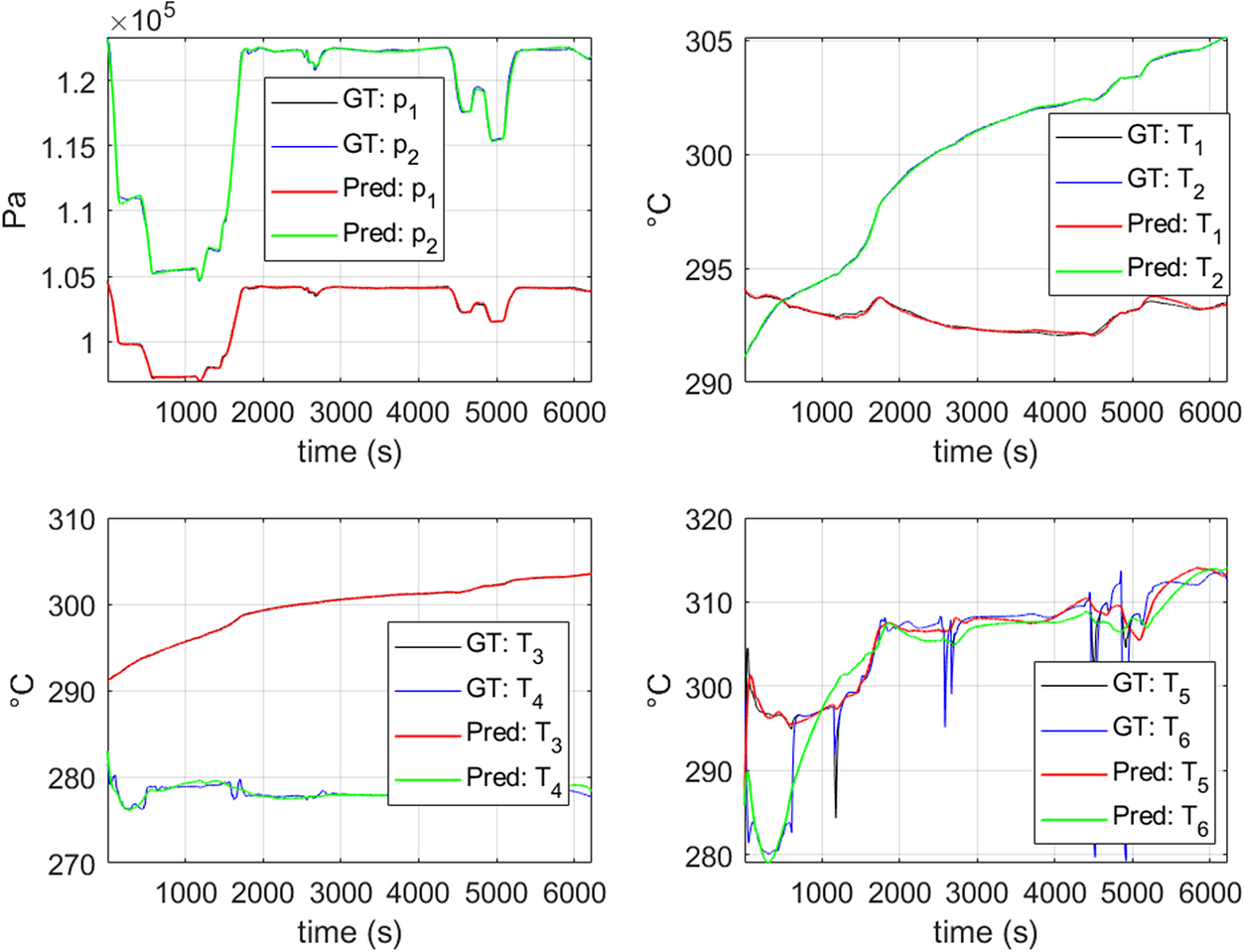
Figure 5. Prediction of the GT data using the proposed technique for a flight which is not used in the training set. “GT” refers to GT data series described in Section 4.1 and “Pred” refers to the stabilized DMDc model obtained with the proposed approach discussed in Section 3.
On the other hand, although the error in variables  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $ is larger it achieves to follow the general trend, despite the fast time evolutions that these variables exhibit. The same tendency is observed in all the flights as in Figure 6) proves. To better capture the fast evolutions of these two variables, the procedure described in Section 2.1 for addressing nonlinear behaviors (Sancarlos et al., Reference Sancarlos, Cameron, Abel, Cueto, Duval and Chinesta2020) could be employed. However, in this work it is preferred to improve the accuracy in the prediction of these special variables by employing a Hybrid approach, for the reasons exposed in Section 4.4.
$ {T}_6 $ is larger it achieves to follow the general trend, despite the fast time evolutions that these variables exhibit. The same tendency is observed in all the flights as in Figure 6) proves. To better capture the fast evolutions of these two variables, the procedure described in Section 2.1 for addressing nonlinear behaviors (Sancarlos et al., Reference Sancarlos, Cameron, Abel, Cueto, Duval and Chinesta2020) could be employed. However, in this work it is preferred to improve the accuracy in the prediction of these special variables by employing a Hybrid approach, for the reasons exposed in Section 4.4.
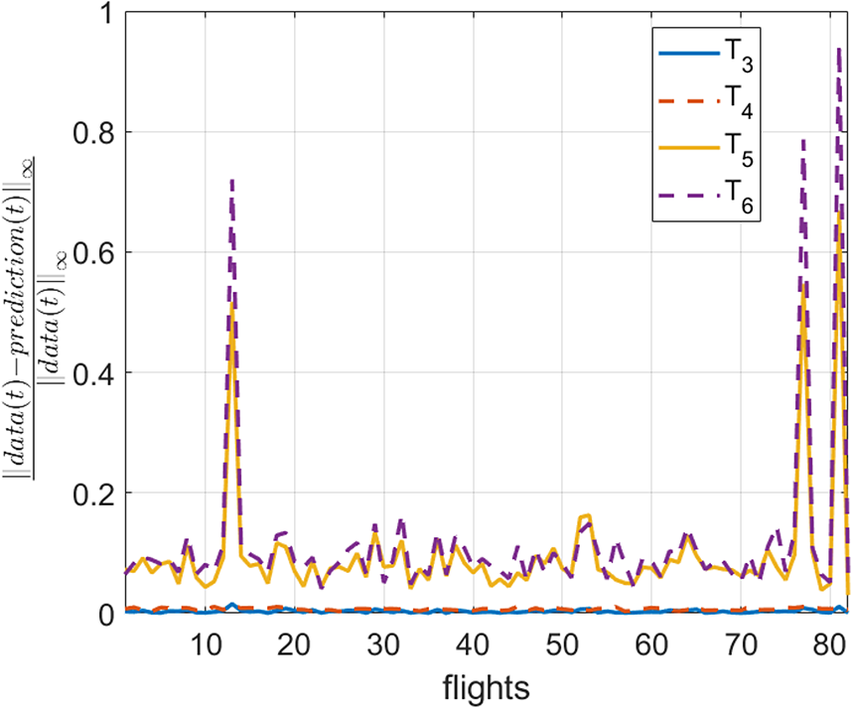
Figure 6. Error in the prediction of  $ {T}_3 $,
$ {T}_3 $,  $ {T}_4 $,
$ {T}_4 $,  $ {T}_5 $, and
$ {T}_5 $, and  $ {T}_6 $ for different flights which are not in the training set. The prediction error in variables
$ {T}_6 $ for different flights which are not in the training set. The prediction error in variables  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $ is higher than the other ones due to their fast time evolution.
$ {T}_6 $ is higher than the other ones due to their fast time evolution.
In Figure 7, it is observed that a similar accuracy is obtained for more than 85 % of the flights in the testing set (concerning variables  $ {p}_1 $,
$ {p}_1 $,  $ {p}_2 $,
$ {p}_2 $,  $ {T}_1 $, and
$ {T}_1 $, and  $ {T}_2 $). A similar conclusion follows from Figure 8 for variables
$ {T}_2 $). A similar conclusion follows from Figure 8 for variables  $ {T}_3 $ and
$ {T}_3 $ and  $ {T}_4 $. Therefore, it is concluded that the model has a good ability for generalization taking into consideration that just two flights are considered in the training.
$ {T}_4 $. Therefore, it is concluded that the model has a good ability for generalization taking into consideration that just two flights are considered in the training.
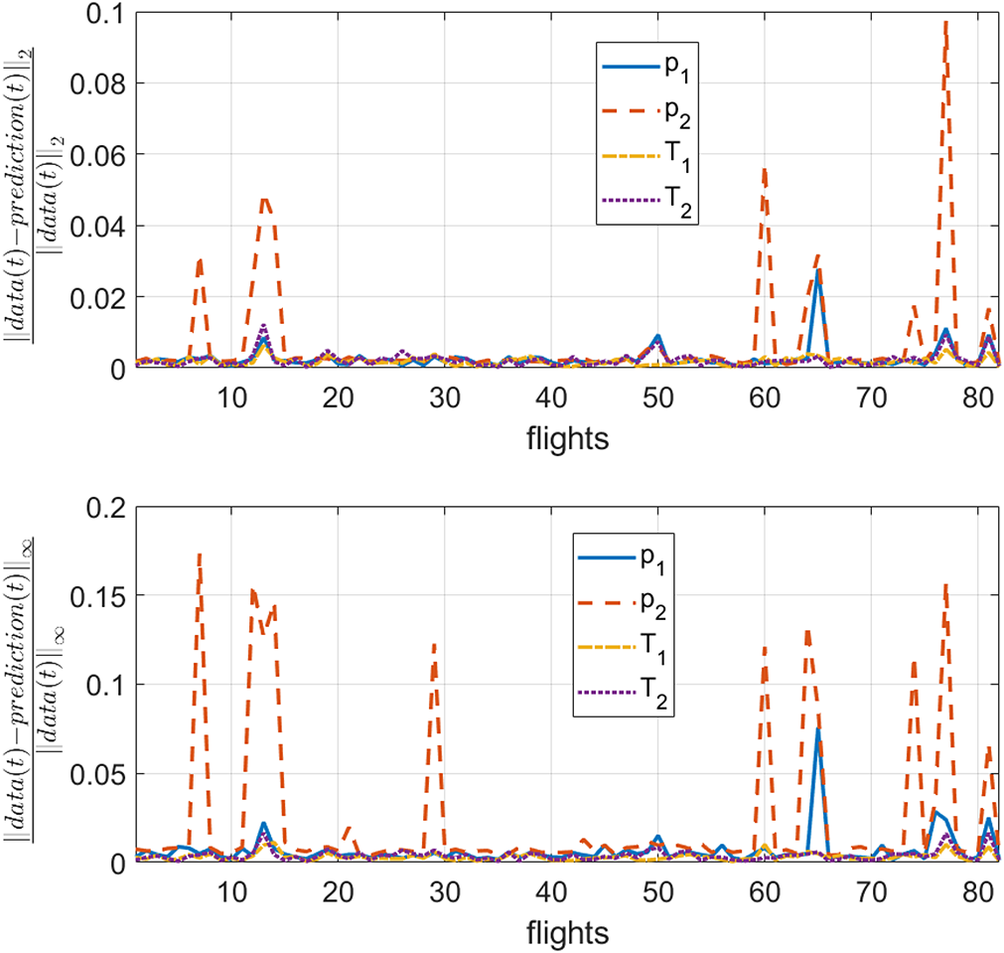
Figure 7. Error in the prediction of  $ {p}_1 $,
$ {p}_1 $,  $ {p}_2 $,
$ {p}_2 $,  $ {T}_1 $, and
$ {T}_1 $, and  $ {T}_2 $ of the proposed technique for lights which are not in the training set.
$ {T}_2 $ of the proposed technique for lights which are not in the training set.
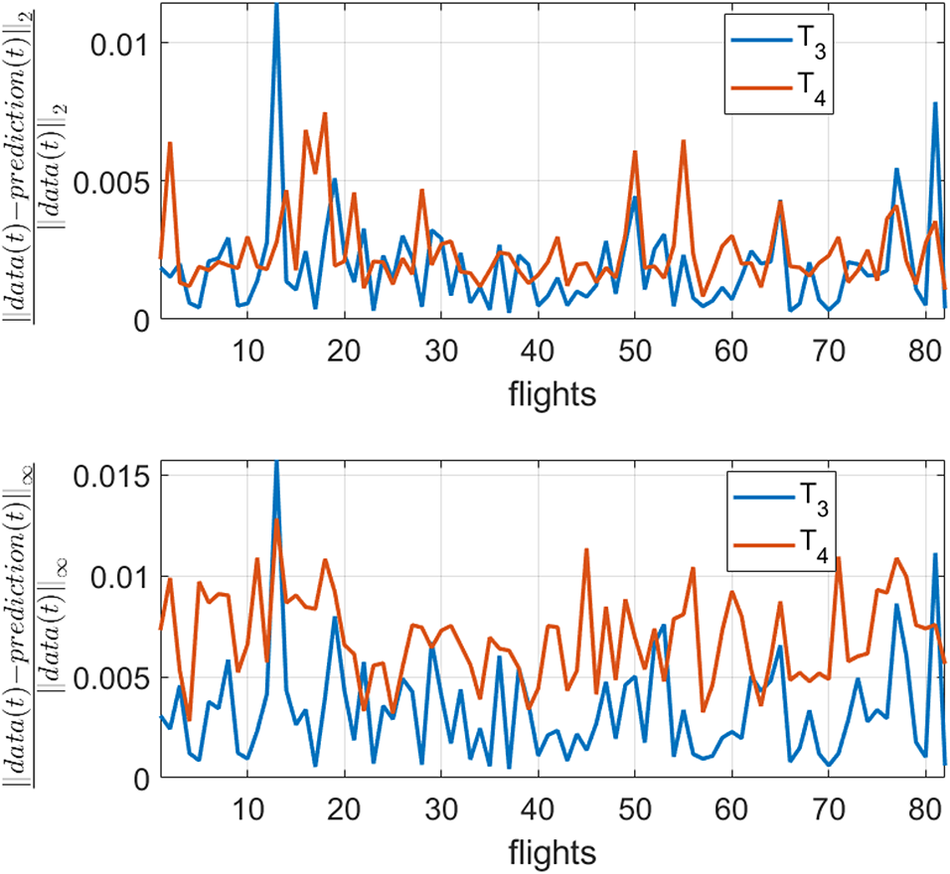
Figure 8. Error in the prediction of  $ {T}_3 $ and
$ {T}_3 $ and  $ {T}_4 $ of the proposed technique for flights which are not in the training set.
$ {T}_4 $ of the proposed technique for flights which are not in the training set.
However, the error in variables  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $ can reach high values in a considerable part of the testing set. To address that, the HT rationale will be proposed and discussed.
$ {T}_6 $ can reach high values in a considerable part of the testing set. To address that, the HT rationale will be proposed and discussed.
Before that, we will see what happens if stability is not enforced when extracting the GT model from scratch in Section 4.2.2 as well as the improvements of the proposed procedure.
4.2.2. Checking explicitly the improvements of the proposed approach to learn stable systems: Example when proceeding from the GT data
In the above section, the results when modeling the GT data were shown when using the stabilization procedure for the DMDc proposed in this work. However, it is interesting to analyze what happens when using other algorithms or by simply using standard procedures to observe the benefits of the proposed stabilization.
To this end, the GT data for a particular flight is considered. The time evolution of the system can be observed in Figure 9.
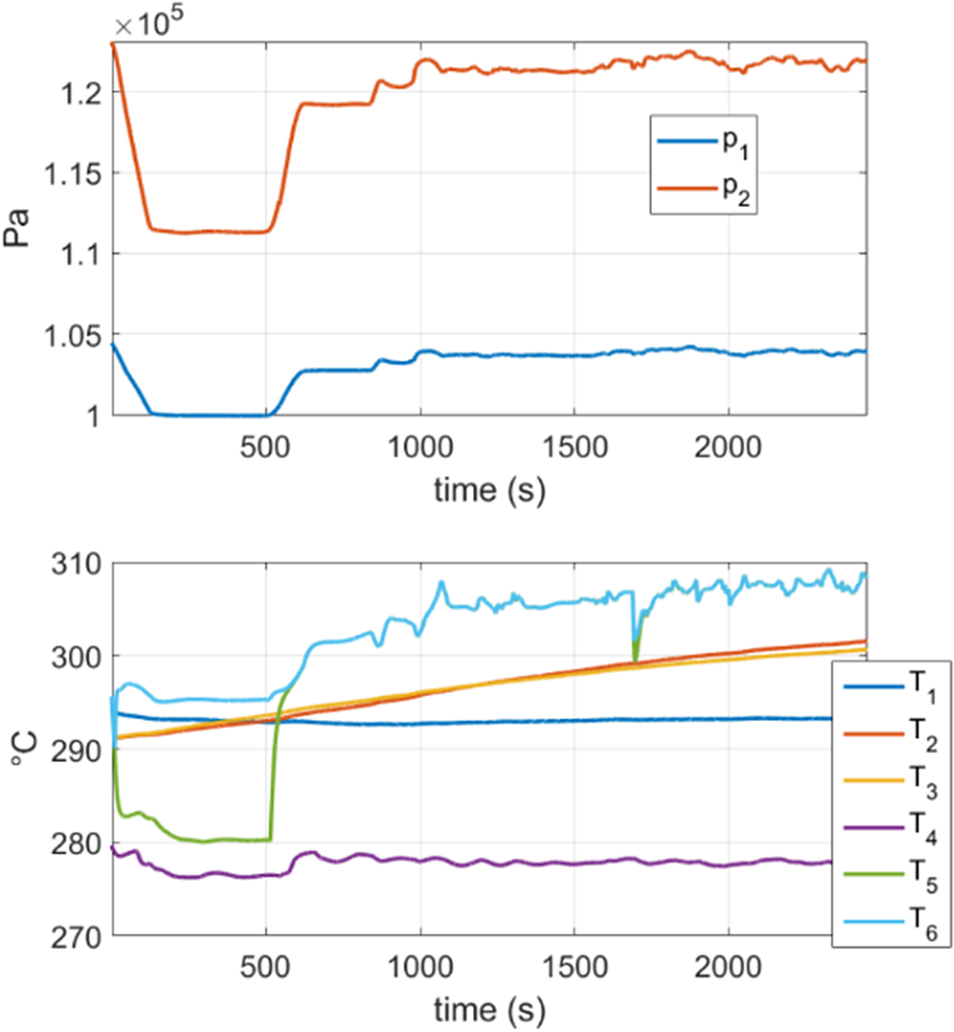
Figure 9. GT data for the example in Section 4.2.2.
The first objective is to see if we can approximate the dynamics of Figure 9 by constructing a standard DMDc model without stabilizing it. Moreover, we are interested in observing if stability issues arise.
Therefore, a model is constructed following the DMDc procedure with the state vector and inputs exposed in Section 4.2.1.
As shown in Figure 10 below, the DMDc model reports stability issues giving useless predictions.
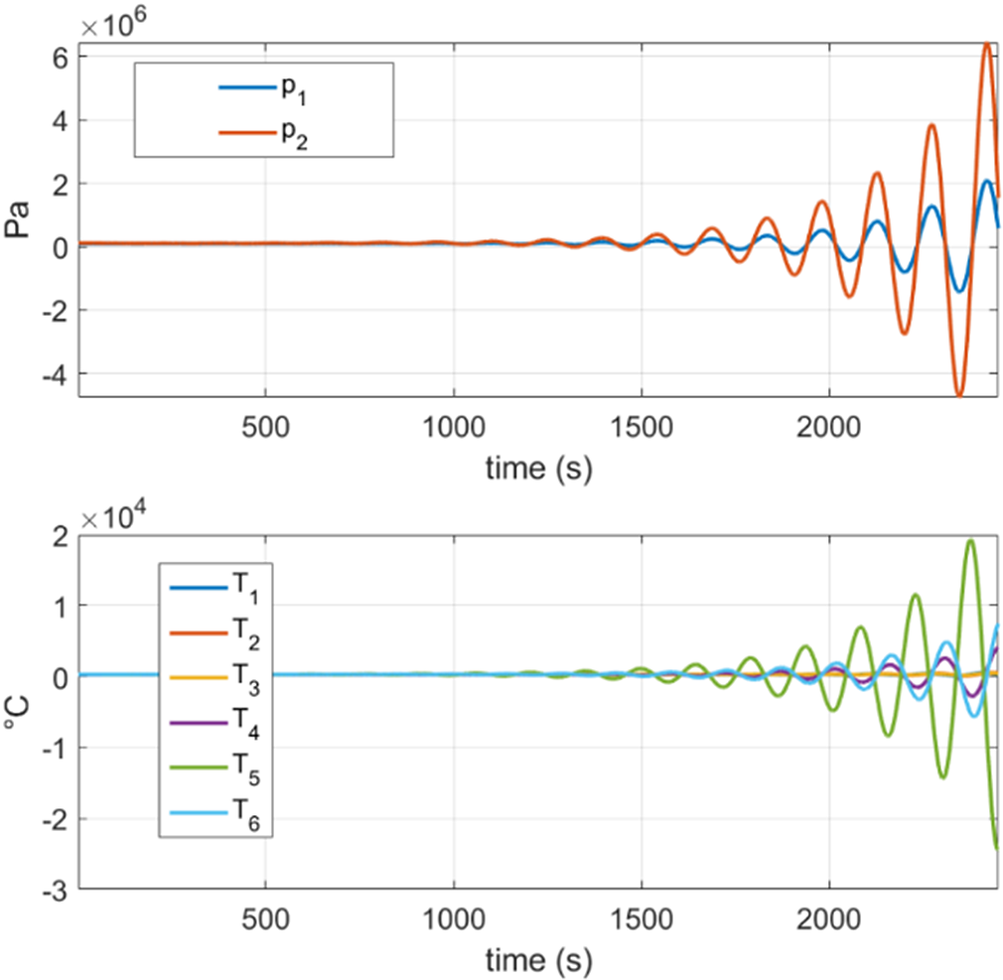
Figure 10. Prediction  $ \mathbf{Z}(t)=\left[{p}_1,{p}_2,{T}_1,{T}_2,{T}_3,{T}_4,{T}_5,{T}_6\right] $ of the GT obtained through DMDc. This prediction tries to reproduce the flight of Figure 9 but fails to provide with stable results.
$ \mathbf{Z}(t)=\left[{p}_1,{p}_2,{T}_1,{T}_2,{T}_3,{T}_4,{T}_5,{T}_6\right] $ of the GT obtained through DMDc. This prediction tries to reproduce the flight of Figure 9 but fails to provide with stable results.
Nevertheless, by applying the proposed stabilization approach to the DMDc algorithm (as discussed in Section 3), a stable model is easily obtained quick and fast. The flight predicted by the proposed approach is shown in Figure 11. It is worth noting the great improvement observed by comparing the standard nonstabilized DMDc model (Figure 10) with the stabilized one (Figure 11) able to capture complex dynamics while completely overcoming the stability issues.


Now, in the next section, we will examine the possibility of unveiling an accurate model from noisy data. In this way, two important aspects will be analyzed: the interest of employing a HT approach and the ability of the proposed technique to filter noise.
4.3. Extracting a model from scratch using noisy data (PED)
In this section, we attempt to unveil a model from scratch using noisy data. This will allow us to study the robustness of the approach in the filtering process.
After applying the technique in different flights and studying the reconstruction error by considering different extended states  $ \tilde{\mathbf{Z}} $, the proposed model is composed of:
$ \tilde{\mathbf{Z}} $, the proposed model is composed of:
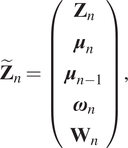 $$ {\tilde{\mathbf{Z}}}_n=\left(\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\\ {}{\boldsymbol{\mu}}_{n-1}\\ {}{\boldsymbol{\omega}}_n\\ {}{\mathbf{W}}_n\end{array}\right), $$
$$ {\tilde{\mathbf{Z}}}_n=\left(\begin{array}{c}{\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\\ {}{\boldsymbol{\mu}}_{n-1}\\ {}{\boldsymbol{\omega}}_n\\ {}{\mathbf{W}}_n\end{array}\right), $$where:
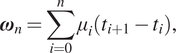 $$ {\boldsymbol{\omega}}_n=\sum \limits_{i=0}^n{\mu}_i\left({t}_{i+1}-{t}_i\right), $$
$$ {\boldsymbol{\omega}}_n=\sum \limits_{i=0}^n{\mu}_i\left({t}_{i+1}-{t}_i\right), $$and
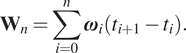 $$ {\mathbf{W}}_n=\sum \limits_{i=0}^n{\boldsymbol{\omega}}_i\left({t}_{i+1}-{t}_i\right). $$
$$ {\mathbf{W}}_n=\sum \limits_{i=0}^n{\boldsymbol{\omega}}_i\left({t}_{i+1}-{t}_i\right). $$ The same methodology of the previous section is applied, by using the new extended states  $ \tilde{\mathbf{Z}} $. This way, we can address the more complex behavior of the noisy data. In this case, nine flights of different duration are used for the training set.
$ \tilde{\mathbf{Z}} $. This way, we can address the more complex behavior of the noisy data. In this case, nine flights of different duration are used for the training set.
In Figure 12, a comparison is shown between the dynamics predicted by the DMDc model obtained from scratch using the PED and the PED itself (see Section 4.1), for a flight contained in the training set. Here, it is observed that the model can capture the dynamics of the system with an excellent accuracy, by just employing the initial state of the system and the corresponding control inputs while filtering the noise contained in the training data.
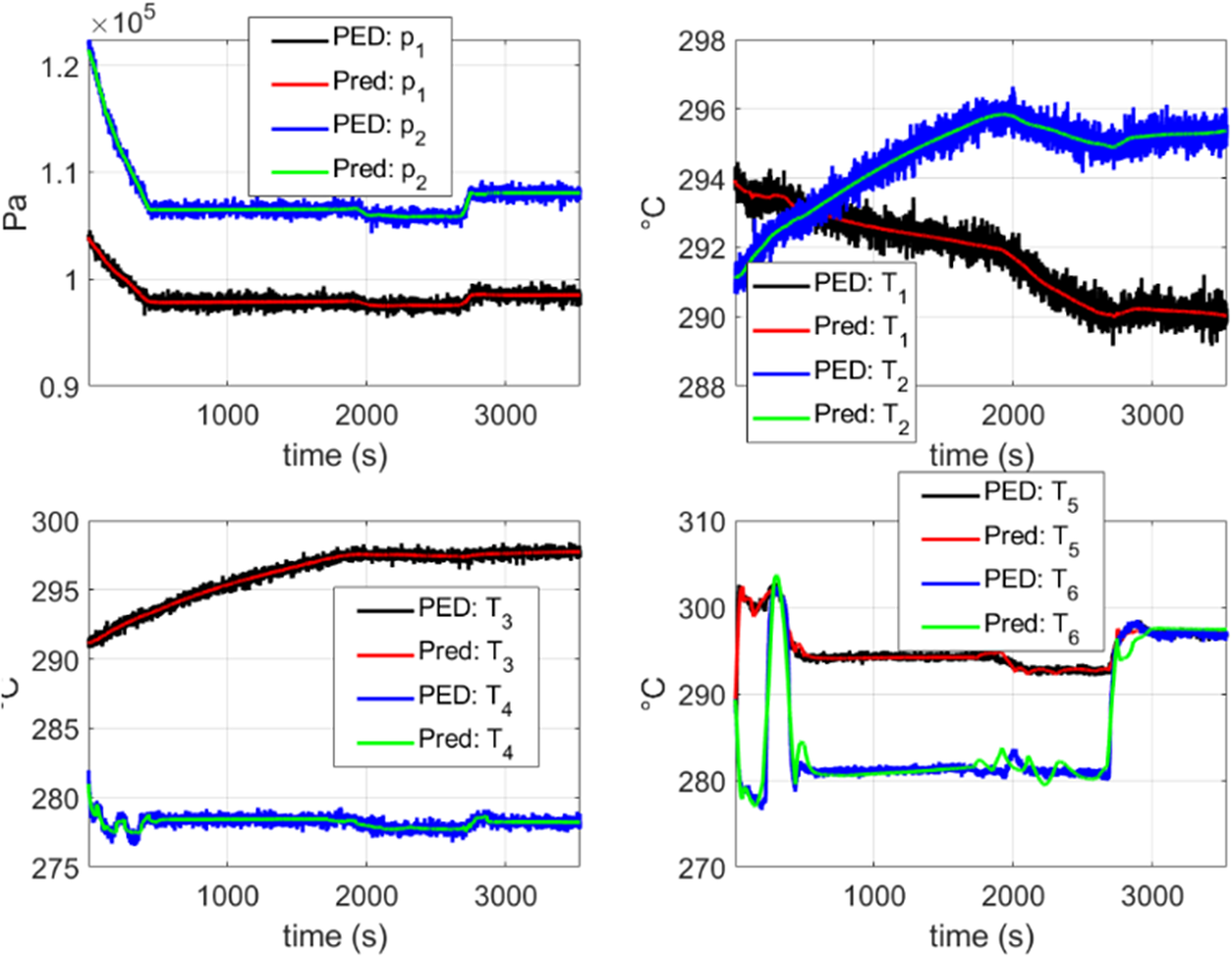
Figure 12. Comparison between the model obtained from scratch using PED data and the PED data itself. In this figure, the reconstruction of a flight contained in the training set is shown. “PED” refers to the pseudo-experimental data with noise described in Section 4.1 and “Pred” refers to the stabilized DMDc model obtained with the proposed approach discussed in Section 3. It can be observed that an excellent agreement is obtained for every variable while filtering the noise.
In Figure 13, a comparison is shown between the dynamics predicted by the DMDc model obtained from scratch using the PED and the PED itself (see Section 4.1), for a flight contained in the testing set (never considered in the model construction). In these plots, it is shown that a good agreement is obtained for all the variables with the exception of  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $. Similar results are reported in the other flights of the testing set.
$ {T}_6 $. Similar results are reported in the other flights of the testing set.
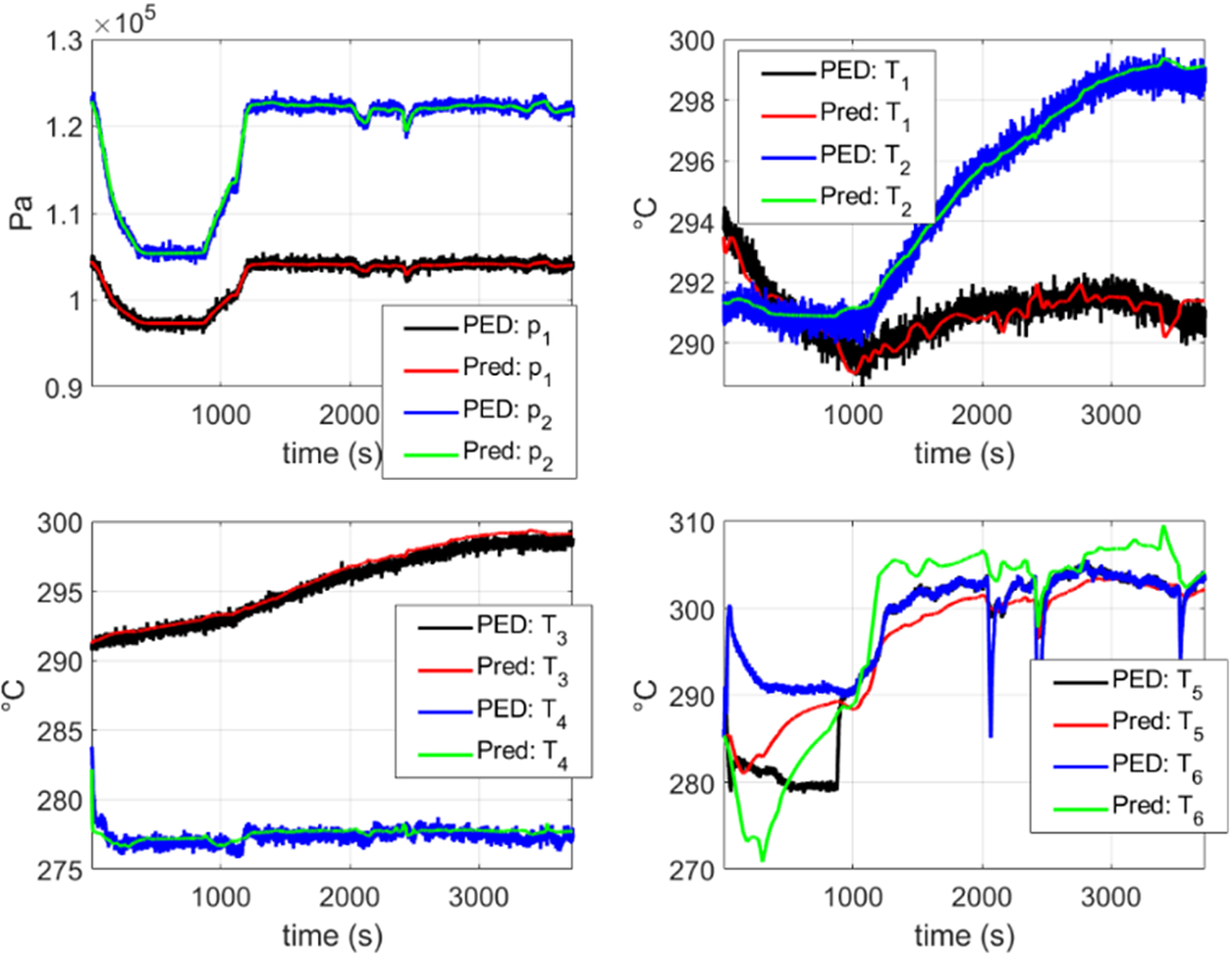
Figure 13. Comparison between the model obtained from scratch using PED data and the PED data itself. In this figure, the reconstruction of a flight which is not contained in the training set is shown. “PED” refers to the pseudo-experimental data with noise described in Section 4.1 and “Pred” refers to the stabilized DMDc model obtained with the proposed approach discussed in Section 3. It can be observed that a good agreement is obtained for all the variables with the exception of  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $.
$ {T}_6 $.
Variables  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $ are more challenging to predict because of their fast time evolution. Nevertheless, we are going to deal with them in the next section. Therefore, the HT concept, which follows, is expected leading to more accurate results.
$ {T}_6 $ are more challenging to predict because of their fast time evolution. Nevertheless, we are going to deal with them in the next section. Therefore, the HT concept, which follows, is expected leading to more accurate results.
4.4. Extracting the correction model: HT paradigm
As discussed in Section 2.2, constructing a model of the real system from scratch is not the most valuable route when addressing complex systems. For the system analyzed in the present work, outputs  $ {p}_1 $,
$ {p}_1 $,  $ {p}_2 $,
$ {p}_2 $,  $ {T}_1 $,
$ {T}_1 $,  $ {T}_2 $,
$ {T}_2 $,  $ {T}_3 $, and
$ {T}_3 $, and  $ {T}_4 $ are predicted to a great accuracy for the approaches shown in Sections 4.2 and 4.3. On the other hand, outputs
$ {T}_4 $ are predicted to a great accuracy for the approaches shown in Sections 4.2 and 4.3. On the other hand, outputs  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $ present difficulties. In these cases, an interesting option consists in expressing the state of the system from an additive correction of the CM. Therefore, in this case, the proposed model is going to capture just the ignorance that the CM contains.
$ {T}_6 $ present difficulties. In these cases, an interesting option consists in expressing the state of the system from an additive correction of the CM. Therefore, in this case, the proposed model is going to capture just the ignorance that the CM contains.
One of the advantages of this concept is that the main response is provided by the physics-based model, thus guaranteeing that the model is going to exhibit a behavior coherent with the physical phenomenon under scrutiny as well as being explained by practitioners. In addition, the part of the response which has difficulties in being modeled—for instance, the appearance of degradation of the system—can be approximated by the data-driven model.
The HT concept is illustrated in Figure 1. Note that only the first measurement is mandatory to run what we coined as the  $ \Delta \unicode{x1D544} $. Therefore, knowing the initial state of the system, the real response can be reproduced adding the correction model to the CM without further measurements.
$ \Delta \unicode{x1D544} $. Therefore, knowing the initial state of the system, the real response can be reproduced adding the correction model to the CM without further measurements.
Again, the extended state  $ \Delta \tilde{\mathbf{Z}} $ for the discrepancy model is:
$ \Delta \tilde{\mathbf{Z}} $ for the discrepancy model is:
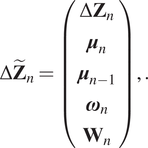 $$ \Delta {\tilde{\mathbf{Z}}}_n=\left(\begin{array}{c}\Delta {\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\\ {}{\boldsymbol{\mu}}_{n-1}\\ {}{\boldsymbol{\omega}}_n\\ {}{\mathbf{W}}_n\end{array}\right),. $$
$$ \Delta {\tilde{\mathbf{Z}}}_n=\left(\begin{array}{c}\Delta {\mathbf{Z}}_n\\ {}{\boldsymbol{\mu}}_n\\ {}{\boldsymbol{\mu}}_{n-1}\\ {}{\boldsymbol{\omega}}_n\\ {}{\mathbf{W}}_n\end{array}\right),. $$Nine flights are considered in the training set. As expected for a real-life application, the measured data (i.e., the PED) is employed to obtain the discrepancy to be modeled within the HT concept.
Figures 14–16 are obtained by just integrating from the initial state of the system and by employing and enriching the CM prediction without any further measurement. This proves the excellent agreement that can be achieved within the HT rationale.
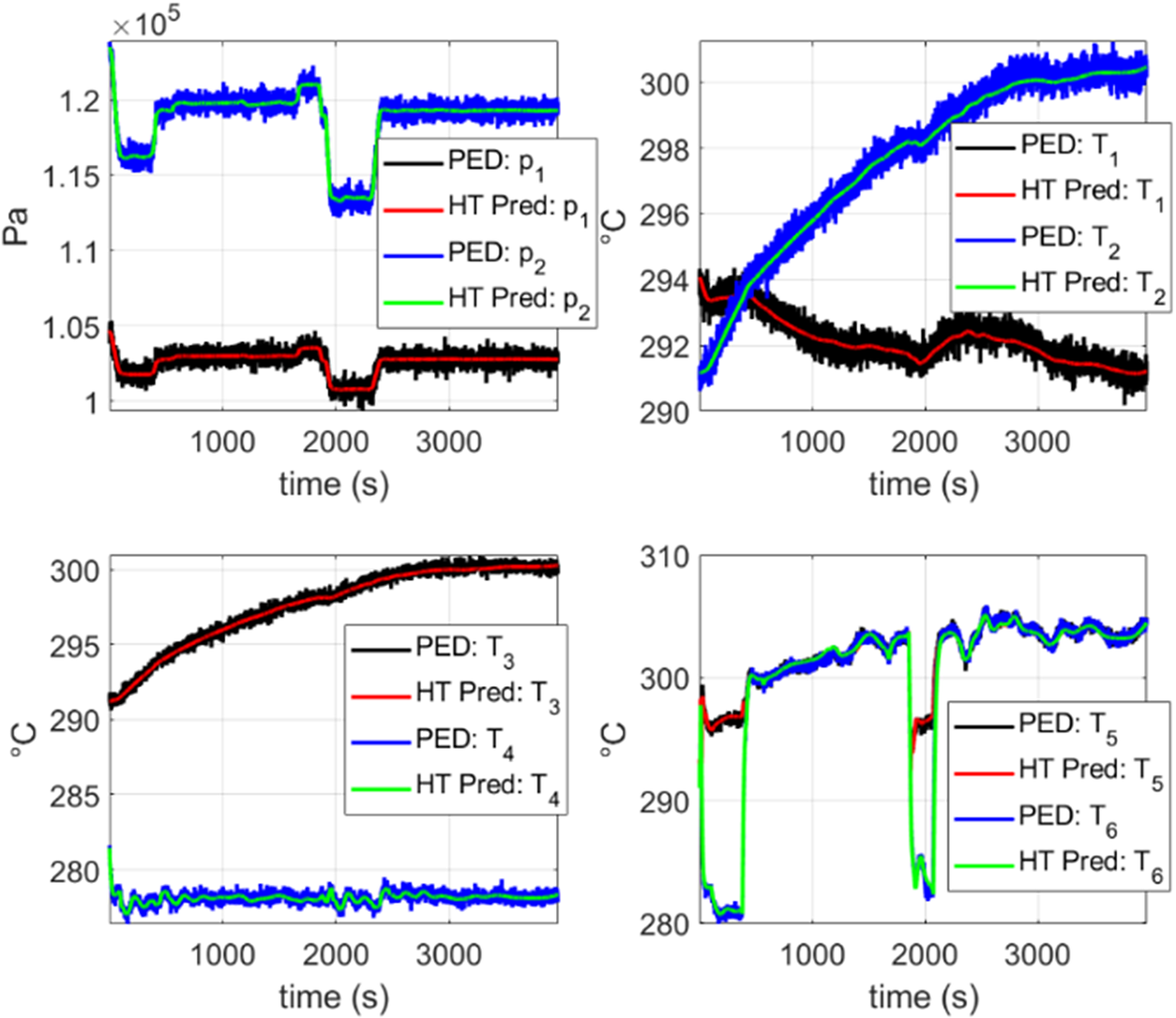
Figure 14. Prediction of the hybrid twin (HT) approach considering a flight in the testing set. “PED” refers to the pseudo-experimental data with noise described in Section 4.1 and “HT Pred” refers to the HT approach whose correction term corresponds to a stabilized DMDc model obtained with the methodology discussed in Section 3. The correction term was constructed using the PED. It can be observed that an excellent agreement is obtained for all the variables.

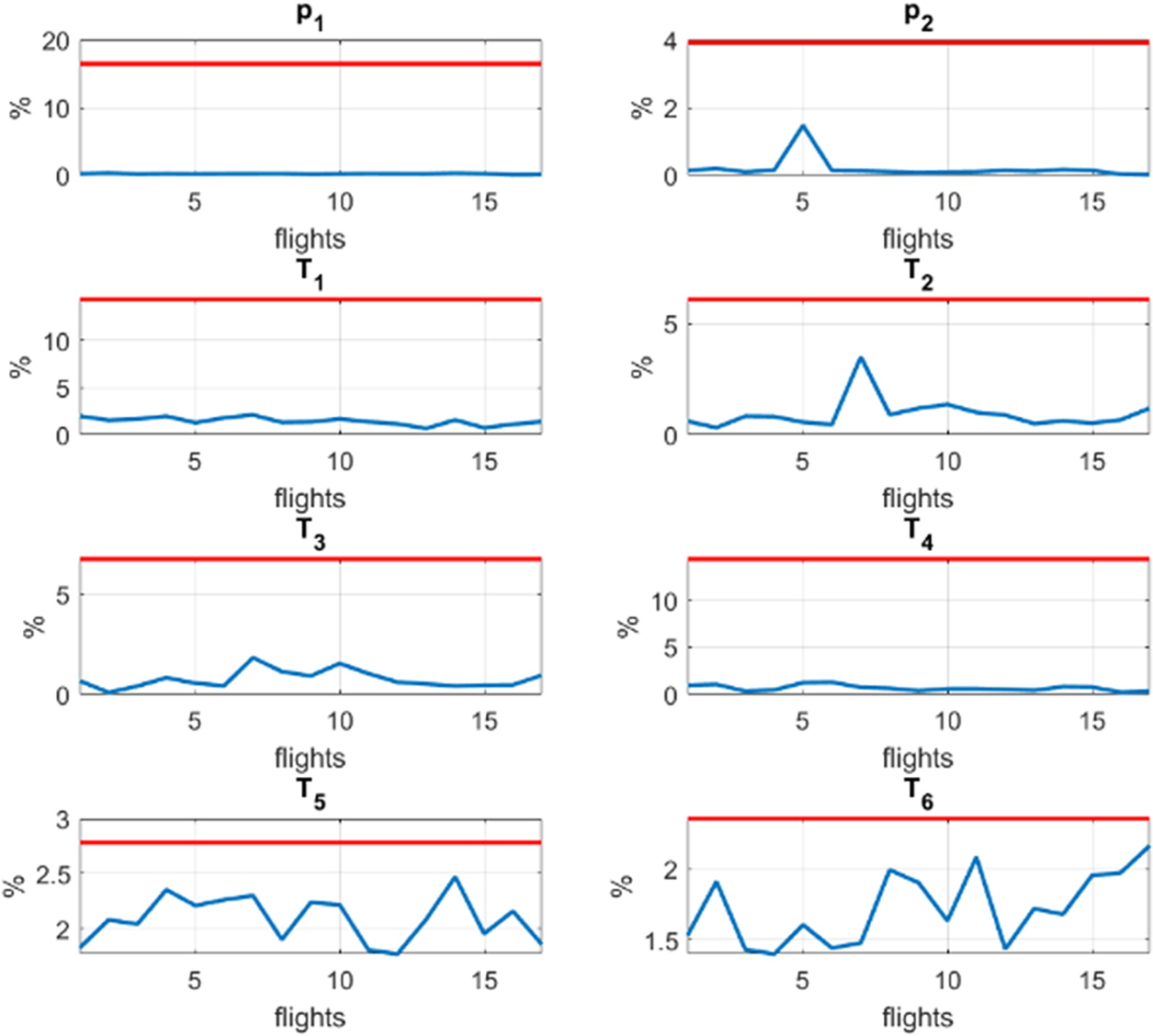
Figure 16. Error of the hybrid twin (HT) approach (blue line) considering different flights which are not used for the training. The red line refers to the maximum error in the pseudo measurements. The error assigned to a flight is the mean value of the error defined in Equation (21).
In Figure 14, a comparison is shown between the HT prediction and the PED for a previously unseen flight. In these plots, an excellent agreement is noticed for all the variables. Moreover, predictions filter the noisy measurements.
An error criterion is defined to compare the prediction of the HT approach with the accuracy of the measuring instruments:
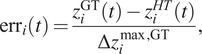 $$ {\mathrm{err}}_i(t)=\frac{z_i^{\mathrm{GT}}(t)-{z}_i^{HT}(t)}{\Delta {z}_i^{\max, \mathrm{GT}}}, $$
$$ {\mathrm{err}}_i(t)=\frac{z_i^{\mathrm{GT}}(t)-{z}_i^{HT}(t)}{\Delta {z}_i^{\max, \mathrm{GT}}}, $$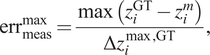 $$ {\mathrm{err}}_{\mathrm{meas}}^{\mathrm{max}}=\frac{\max \left({z}_i^{\mathrm{GT}}-{z}_i^m\right)}{\Delta {z}_i^{\max, \mathrm{GT}}}, $$
$$ {\mathrm{err}}_{\mathrm{meas}}^{\mathrm{max}}=\frac{\max \left({z}_i^{\mathrm{GT}}-{z}_i^m\right)}{\Delta {z}_i^{\max, \mathrm{GT}}}, $$where:
•
 $ i $ refers to the $ i $th variable $ {z}_i $ of the state vector.
$ i $ refers to the $ i $th variable $ {z}_i $ of the state vector.•
$ {z}_i^{HT} $ is the predicted value of the HT for $ {z}_i $.•
$ {z}_i^m $ is the measured value of $ {z}_i $. These data include the corresponding noise. In other words, these data are the PED.•
$ {z}_i^{\mathrm{GT}} $ is the true value of $ {z}_i $ which is theoretically unknown and cannot be accessed by an observer in a real application. We use this value for evaluation purposes.•
$ \Delta {z}_i^{\max, \mathrm{GT}} $ is the difference between the maximum and the minimum value of $ {z}_i^{\mathrm{GT}} $ considering all the flights.











Using Equations (21) and (22), it is possible to compare the accuracy of the HT with the one obtained by measuring the data (i.e., the PED). Moreover, the relative errors are computed taking as a base the maximum variation of each variable when regarding all the available flights. Figure 17 shows the maximum variation of a signal as well as the deviation caused by the noise to illustrate the concept.
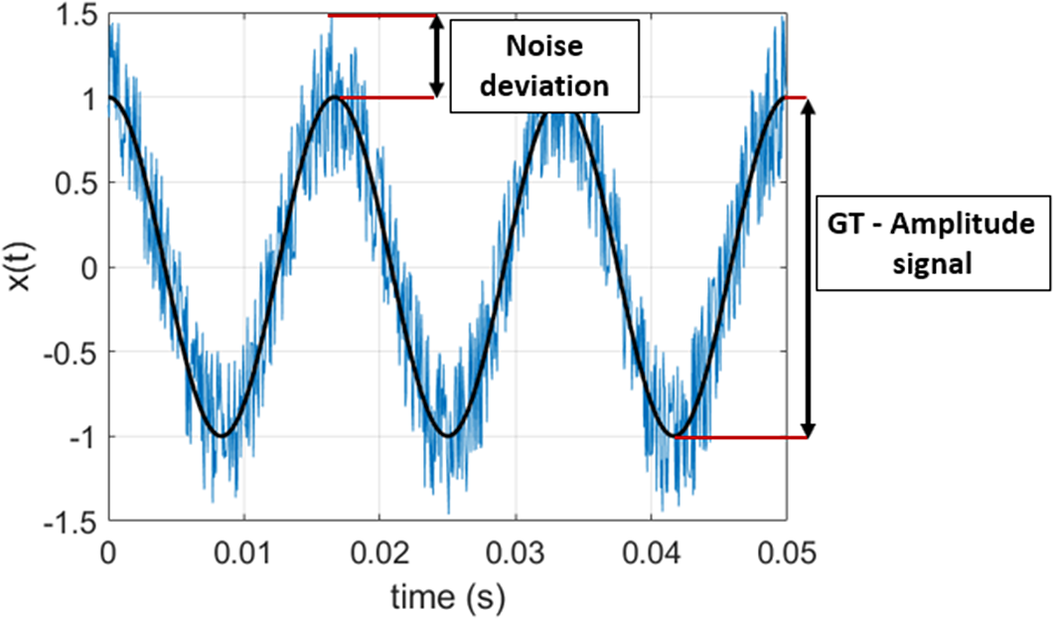
Figure 17. Sine wave with noise. In the plot, the maximum variation of the signal is indicated as well as the deviation caused by the noise to illustrate the concept used to define the error criterion.
Observing Figures 15 and 16, we can confirm that the HT concept allow us to improve, not only the accuracy of the CM but the accuracy of the measuring instruments regardless of whether or not flights come from training by filtering the noise. In this way, two goals are achieved at the same time: enriching the CM by learning the difference with the measured data while filtering the noise.
Therefore, the HT concept is a valuable route to enrich physics-based models with data-driven corrections. It is important to note that for HT to be applied, the CM must not be extremely bad, since in this case a direct data-driven or reduced-order modeling approach would be preferred (because there is no point in correcting such a model).
5. Conclusions
This work presents a fast and efficient methodology, covering several variants to learn dynamical models while guaranteeing a low computational cost as well as the achievement of stable dynamical time integrations. This technique was used with success to predict a practical scenario under the HT rationale, being able to impose stability in the correction term. In addition, the proposed technique filters noise improving the knowledge of the system state.
We also compared the proposed technique in two scenarios: when it is employed to obtain models from scratch versus when it is employed for an enrichment in the HT rationale.
We concluded that for more complex systems the HT paradigm seems advantageous for two reasons. The first one is that more complex behaviors can be captured (as variables  $ {T}_5 $ and
$ {T}_5 $ and  $ {T}_6 $). The second one is that, in the HT, the main response is relied on the physics-based model thus guaranteeing that the model is going to exhibit a behavior coherent with the physical phenomenon at hand. Consequently, just the part of the response which has difficulties in being modeled is carried out by the data-driven model, for instance, degradation or aging.
$ {T}_6 $). The second one is that, in the HT, the main response is relied on the physics-based model thus guaranteeing that the model is going to exhibit a behavior coherent with the physical phenomenon at hand. Consequently, just the part of the response which has difficulties in being modeled is carried out by the data-driven model, for instance, degradation or aging.
Funding Statement
This research work was done in the context of a project as part of the PEA MMT (Plan d’Etudes Amont Man Machine Teaming) financed by the DGA (French Government Defense procurement and technology agency) and managed by French aircraft and jets manufacturer Dassault Aviation. The authors are grateful for the support of ESI Group through the ESI Chair at ENSAM Arts et Metiers Institute of Technology, and through the project 2019-0060 “Simulated Reality” at the University of Zaragoza. The support of the Spanish Ministry of Economy and Competitiveness through grant number CICYT-DPI2017-85139-C2-1-R and by the Regional Government of Aragon and the European Social Fund, are also gratefully acknowledged.
Competing Interests
The authors declare no competing interests exist.
Data Availability Statement
Data not available due to commercial restrictions. Due to the nature of this research, participants of this study did not agree for their data to be shared publicly, so supporting data is not available.
Author Contributions
Conceptualization, A.S., F.C.; Methodology, A.S., F.C., E.C.; Data curation, A.S., M.C., J.-M.L.P., J.G.; Data visualization, A.S., E.C.; Writing—original draft, A.S., E.C., F.C. All authors approved the final submitted draft.










































 Open access
Open access
Comments
No Comments have been published for this article.