


1. Introduction
Hyperfinite and expander graph sequences are perhaps the two most fundamental concepts studied in the theory of sparse graph limits. Hyperfinite graph sequences were explicitly introduced in [Reference Elek2] (and implicitly they are present in earlier works, e.g. in [Reference Lipton and Tarjan5]). Expander graph sequences (frequently informally referred to as ‘expander graphs’) have been studied since at least the 70s in many different branches of mathematics and computer science (see [Reference Hoory, Linial and Wigderson4] for a survey with some historical information). Both notions (or their close relatives) are broadly used in combinatorics, group theory, ergodic theory, and operator algebras.
In this article, we study the analogues of hyperfinite and expander graph sequences in the context of oriented graphs, particularly directed acyclic graphs. We call these analogues ‘hypershallow’ and ‘extender’ graph sequences, respectively. Our main result (see Theorem 5 below) is a stochastic construction of graph sequences which are not hypershallow (we do not know any deterministic construction of such graph sequences). The question whether non-hypershallow graph sequences exist was partially motivated by the techniques presented in [Reference Afshani, Freksen, Kamma and Larsen1] and in [Reference Lipton and Tarjan5] for obtaining conditional lower bounds in circuit complexity. We will discuss this in Section 4.
Let us now precisely define hypershallow graph sequences and state our main result.
Basic conventions. The set of natural numbers is  $\mathbb N :=\{0,1,2,\ldots\}$. We use the shorthand
$\mathbb N :=\{0,1,2,\ldots\}$. We use the shorthand  $(X_n)$ for denoting a sequence
$(X_n)$ for denoting a sequence  $(X_n)_{n=0}^\infty$.
$(X_n)_{n=0}^\infty$.
A graph is a pair  $G=(V,E)$ where V is a non-empty finite set, and
$G=(V,E)$ where V is a non-empty finite set, and  $E\subset V\times V$ is a subset which is disjoint from the diagonal. We say that G is undirected if E is a symmetric subset of
$E\subset V\times V$ is a subset which is disjoint from the diagonal. We say that G is undirected if E is a symmetric subset of  $V\times V$. A path of length D in a graph
$V\times V$. A path of length D in a graph  $G=(V,E)$ is a tuple
$G=(V,E)$ is a tuple  $(x_0,\ldots, x_D)\in V^{D+1}$, such that for
$(x_0,\ldots, x_D)\in V^{D+1}$, such that for  $i<D$ we have either
$i<D$ we have either  $(x_i,x_{i+1})\in E$ or
$(x_i,x_{i+1})\in E$ or  $(x_{i+1}, x_i)\in E$.
$(x_{i+1}, x_i)\in E$.
A path  $(x_0,\ldots, x_D)$ is simple if
$(x_0,\ldots, x_D)$ is simple if  $x_i\neq x_j$ for
$x_i\neq x_j$ for  $i \neq j$. It is a directed path if for all
$i \neq j$. It is a directed path if for all  $i<D$ we have
$i<D$ we have  $(x_i,x_{i+1}) \in E(G)$. A cycle is a path
$(x_i,x_{i+1}) \in E(G)$. A cycle is a path  $(x_0,\ldots, x_D)$ such that
$(x_0,\ldots, x_D)$ such that  $x_0=x_{D}$. We say that G is a dag (which stands for directed acyclic graph) if it does not have directed cycles.
$x_0=x_{D}$. We say that G is a dag (which stands for directed acyclic graph) if it does not have directed cycles.
We are now ready to define hypershallow graph sequences.
1. Let G be a graph and let
 $S\subsetneq V(G)$ be a proper subset. We define $(S;G)\in \mathbb N$ as the maximal D such that there exists a directed simple path $(x_0,\ldots,x_D)$ in G disjoint from S.
$S\subsetneq V(G)$ be a proper subset. We define $(S;G)\in \mathbb N$ as the maximal D such that there exists a directed simple path $(x_0,\ldots,x_D)$ in G disjoint from S.-
2. Let
$(G_n)$ be a sequence of dags with uniformly bounded in-degrees. We say that $(G_n)$ is hypershallow if $\forall {\varepsilon}>0,\ \exists D\in\mathbb N,\ \exists (S_n)$ with $S_n\subsetneq V(G_n)$ and $|S_n|<{\varepsilon}|V(G_n)|$, such that $\forall n\in \mathbb N$ we have $(S_n;G_n)\le D$.










Remark 2. Let us take a moment to explicitly state the analogy between the definitions of hypershallow and hyperfinite graph sequences.
1. We first recall the definition of hyperfinite graph sequences. If G is an undirected graph and
$S\subsetneq V(G)$, then we note that codepth $(S;G)$ is the maximum of lengths of simple paths disjoint from S. We define a sequence $(G_n)$ of undirected graphs with uniformly bounded degrees to be hyperfinite if $\forall {\varepsilon}>0,\ \exists D\in \mathbb N,\ \exists (S_n)$ with $S_n\subsetneq V(G_n)$ and $|S_n|<{\varepsilon}|V(G_n)|$, such that $\forall n\in \mathbb N$ we have $(S_n;G_n)\le D$. This is easily seen to be equivalent to the definition of hyperfiniteness in [Reference Elek2]. From this point of view, and with our convention that undirected graphs form a subclass of all graphs, within the class of bounded degree undirected graphs the hypershallow sequences are exactly the same as hyperfinite sequences.-
2. Let us explain the choice of the word ‘hypershallow’, again by analogy with the word ‘hyperfinite’. One of the simplest classes of undirected graph sequences consists of those sequences
$(G_n)$ which have uniformly finite connected components, that is, $\exists D$ such that $\forall n$ we have that the connected components of $G_n$ are of size at most D. We recall that the expression ‘hyperfinite graph sequence’ is meant to suggest that we are dealing with ‘the next simplest thing’: informally, a sequence $(G_n)$ is hyperfinite if it is possible to obtain from $(G_n)$ a sequence with uniformly finite connected components by removing an arbitrarily small proportion of vertices from $(G_n)$. The motivation to use the word ‘hypershallow’ is similar. For a dag G, let depth (G) denote the maximum of lengths of directed paths in G. One of the simplest classes of dag sequences with uniformly bounded in-degrees consists of the ‘uniformly shallow’ sequences, that is, $\exists D$ such that $\forall n$ we have $(G_n)\le D$. The name ‘hypershallow graph sequence’ is meant to suggest that we are dealing with ‘the next simplest thing’: after removing a small proportion of vertices, we get a sequence which is uniformly shallow.Footnote a


















The following definition allows us, informally speaking, to capture ‘how badly’ a sequence of graphs fails at being hypershallow.
1. Let G be a dag, let
${\varepsilon}, \rho>0$. We say that G is an $({\varepsilon},\rho)$-extender if for every $S\subsetneq V(G)$ with $|S|\le{\varepsilon} |V(G)|$ we have $(S;G) \ge \rho$.-
2. Let
$(G_n)$ be a sequence of dags with uniformly bounded in-degrees, and let $(\rho_n)$ be a sequence of positive real numbers with $\lim_{n\to\infty} \rho_n = \infty$. We say that $(G_n)$ is a $(\rho_n)$-extender sequence if $\lim_{n\to\infty} |V(G_n)| = \infty$ and $\exists {\varepsilon}>0$, $\exists C>0$, $\forall n\in \mathbb N:$ $G_n$ is an $({\varepsilon}, C\rho_{|V(G_n)|})$-extender.
















Remark 4. It is easy to check that a sequence  $(G_n)$ of dags with uniformly bounded in-degrees is not hypershallow if and only if it contains a subsequence which is a
$(G_n)$ of dags with uniformly bounded in-degrees is not hypershallow if and only if it contains a subsequence which is a  $(\rho_n)$-extender for some
$(\rho_n)$-extender for some  $(\rho_n)$ with
$(\rho_n)$ with  $\lim_{i\to\infty} \rho_n = \infty$.
$\lim_{i\to\infty} \rho_n = \infty$.
We are now ready to state our main theorem.
Theorem 5. There exists a sequence of directed acyclic graphs with uniformly bounded degrees which is an  $(n^{\delta})$-extender sequence, with
$(n^{\delta})$-extender sequence, with  ${\delta}\approx 0.019$.
${\delta}\approx 0.019$.
Our proof of this theorem is probabilistic. The most important part of the proof consists of studying the random graphs  $\mathbf G^d_n$ which will be introduced in Section 3. We do not know of a non-probabilistic way of constructing a non-hypershallow sequence of dags with uniformly bounded degrees.
$\mathbf G^d_n$ which will be introduced in Section 3. We do not know of a non-probabilistic way of constructing a non-hypershallow sequence of dags with uniformly bounded degrees.
On the other hand, we can ask how fast the sequence  $(\rho_n)$ can grow, provided that there exists a
$(\rho_n)$ can grow, provided that there exists a  $(\rho_n)$-extender sequence. In this direction, we have the following result.
$(\rho_n)$-extender sequence. In this direction, we have the following result.
Theorem 6. Let  $({\delta}_n)$ be a sequence of numbers in [0,1] such that
$({\delta}_n)$ be a sequence of numbers in [0,1] such that  $\lim_{n\to\infty} {\delta}_n = 1$. If
$\lim_{n\to\infty} {\delta}_n = 1$. If  $(G_n)$ is a sequence of directed acyclic graphs with uniformly bounded in-degrees, then
$(G_n)$ is a sequence of directed acyclic graphs with uniformly bounded in-degrees, then  $(G_n)$ is not an
$(G_n)$ is not an  $(n^{{\delta}_n})$-extender sequence.
$(n^{{\delta}_n})$-extender sequence.
Remark 7. Theorem 6 implies, for example, that there are no  $(\frac{n}{\log(n)})$-extender sequences. However, we do not know whether there exists an
$(\frac{n}{\log(n)})$-extender sequences. However, we do not know whether there exists an  $(n^{\delta})$-extender sequence for every
$(n^{\delta})$-extender sequence for every  ${\delta} < 1$.
${\delta} < 1$.
In Section 2, we list some standard definitions and conventions, and we discuss a variant of Pinsker’s inequality which involves the Shannon entropy (Proposition 12). Pinsker’s inequality is the most important external result in our analysis of the random graphs  $\mathbf G_n^d$.
$\mathbf G_n^d$.
The main part of this article is Section 3 where we introduce the random graphs  $\mathbf G_n^d$ and use them to prove Theorem 5.
$\mathbf G_n^d$ and use them to prove Theorem 5.
We conclude this article with Section 4, where we present the proof of Theorem 6, and we discuss our initial motivations for studying hypershallow and extender graph sequences which are related to the theory of boolean circuits.
2. Preliminaries
We use the following conventions. If  $n\in \mathbb N$, then
$n\in \mathbb N$, then  $n=\{0,1,\ldots,n-1\}$. If X is a set, then
$n=\{0,1,\ldots,n-1\}$. If X is a set, then  ${\rm Pow}(X)$ denotes the power set of X, that is, the set of all subsets of X.
${\rm Pow}(X)$ denotes the power set of X, that is, the set of all subsets of X.
2.1 Graphs
Definition 8. Let  $G=(V,E)$ be a graph, and let
$G=(V,E)$ be a graph, and let  $v,w\in V$.
$v,w\in V$.
1. In
$(v;G):= \{x\in V\colon (x,v)\in G\}$, ${\rm indeg}(v;G):= |{\rm In}(v;G)|$,-
2. Out
$(v;G) := \{x\in V\colon (v,x)\in G\}$, ${\rm outdeg}(v;G):= |{\rm Out}(v;G)|$, -
3. deg
$(v;G) := {\rm indeg}(v;G) + {\rm outdeg}(v;G)$, -
4. In
$(G) :=\{v\in V\colon {\rm indeg}(v;G)=0\}$, ${\rm Out}(G):=\{v\in V\colon {\rm outdeg}(v;G) = 0\}$, -
5. maxindeg
$(G) := \max_{v\in V}{\rm indeg}(v;G)$, ${\rm maxoutdeg}(G):= \max_{v\in V}{\rm outdeg}(v;G)$,









 ${\rm maxdeg}(G) := \max_{v\in V}\deg(v;G)$,
${\rm maxdeg}(G) := \max_{v\in V}\deg(v;G)$,
Definition 9. Let  $(G_n)$ be a sequence of graphs. We say that
$(G_n)$ be a sequence of graphs. We say that  $(G_n)$ has, respectively, bounded degree, bounded in-degree, or bounded out-degree, if, respectively,
$(G_n)$ has, respectively, bounded degree, bounded in-degree, or bounded out-degree, if, respectively,
 $\max_{n\in \mathbb N}\ {\rm{maxdeg}}(G_n)< \infty$,
$\max_{n\in \mathbb N}\ {\rm{maxdeg}}(G_n)< \infty$,  $\max_{n\in \mathbb N}\ {\rm{maxindeg}}(G_n)< \infty$, or
$\max_{n\in \mathbb N}\ {\rm{maxindeg}}(G_n)< \infty$, or  $\max_{n\in \mathbb N}\ {\rm{maxoutdeg}}(G_n)< \infty$.
$\max_{n\in \mathbb N}\ {\rm{maxoutdeg}}(G_n)< \infty$.
2.2 Probability
1. If
$\mu$ is a probability measure on $\mathbb N$, then we also use the symbol $\mu$ for the function $\mathbb N\to \mathbb R$ which sends $k\in\mathbb N$ to $\mu(\{k\}$) (so in particular we can write $\mu(k)$ instead of $\mu(\{k\}))$, and we let
where by convention
\begin{align*} H(\mu) := -\sum_{i\in\mathbb N} \mu(i)\log(\mu(i)),\end{align*}
$0\log(0)=0$.
-
2. A random variable on a standard probability space
$(X,\mu)$ with values in a standard Borel space Y is a Borel function $f\colon X \to Y$. The law of f is the push-forward measure $f^\ast(\mu)$ on Y, that is, for $U\subset Y$ we let $f^\ast(\mu)(U):= \mu(f^{-1}(U))$. -
3. If f is an
$\mathbb N$-valued random variable and ${\alpha}$ is its law, then we define $H(f):=H({\alpha})$. -
4. If f and g are random variables with values in a standard Borel space Z, then we define a new random variable
$f\sqcup g$ with values in Z by, informally speaking, choosing between f and g with probability $\frac{1}{2}$. Formally, suppose that f and g are defined on $(X,\mu)$ and $(Y,\nu)$, respectively. The probability space on which $f\sqcup g$ is defined is $(X\sqcup Y,{\omega})$, where ${\omega}$ is the unique measure on $X\sqcup Y$ such that ${\omega}(U) = \frac{\mu(U)}{2}$ when $U\subset X$ and ${\omega}(U) = \frac{\nu(U)}{2}$ when $U\subset Y$. We let $f\sqcup g(x):= f(x)$ for $x\in X\subset X\sqcup Y$ and $f\sqcup g(y) := g(y)$ for $y\in Y\subset X\sqcup Y$. -
5. For
${\alpha}\colon \mathbb N \to \mathbb R$, we let $\|{\alpha}\|_1 := \sum_{i\in \mathbb N} |{\alpha}(i)|$.




































a. If f and g are random variables with values in the same space Y, with laws
${\alpha}$ and ${\beta}$, respectively, then the law of $f\sqcup g$ is $\frac{{\alpha}+{\beta}}{2}$.-
b. If f is a random variable with values in
$\{0,1,\ldots, k-1\}$ then $H(f)\le \log(k)$.






Proof.
The main point of the following proposition is contained in its second item. Informally, it allows us to say the following: if f and g are  $\mathbb N$-valued random variables with laws
$\mathbb N$-valued random variables with laws  ${\alpha}$ and
${\alpha}$ and  ${\beta}$, respectively, and
${\beta}$, respectively, and  $(x,y)\in \mathbb N^2$ is chosen according to the law
$(x,y)\in \mathbb N^2$ is chosen according to the law  ${\alpha}\times {\beta}$, then either it is roughly as probable that
${\alpha}\times {\beta}$, then either it is roughly as probable that  $x>y$ as it is that
$x>y$ as it is that  $y>x$, or the entropy of
$y>x$, or the entropy of  $f\sqcup g$ is substantially larger than the average of the entropies of f and g.
$f\sqcup g$ is substantially larger than the average of the entropies of f and g.
Proposition 12. Let f and g be  $\mathbb N$-valued random variables with laws
$\mathbb N$-valued random variables with laws  ${\alpha}$ and
${\alpha}$ and  ${\beta}$, respectively.
${\beta}$, respectively.
1. We have
$2H(f\sqcup g) - H(f) - H(g) \ge 0$.-
2. We have
(1)
\begin{equation} {\alpha}\times {\beta}\left(\{(x,y)\in \mathbb N^2\colon x> y\}\right) \le \frac{1}{2} + 2\sqrt{2H(f\sqcup g)- H(f)-H(g)}.\end{equation}


Proof. By the previous lemma, we have that the law of  $f\sqcup g$ is
$f\sqcup g$ is  ${\gamma}:= \frac{{\alpha}+{\beta}}{2}$. As such the first item follows from Jensen’s inequality.
${\gamma}:= \frac{{\alpha}+{\beta}}{2}$. As such the first item follows from Jensen’s inequality.
The second item is a simple corollary of Pinsker’s inequality (see e.g. [6, Theorem 2.16] for the statement and proof of Pinsker’s inequality). To derive it, we start by stating the following two special cases of Pinsker’s inequality:
 \begin{align*} \|{\alpha}-{\gamma}\|_1^2 \le 2D({\alpha} \|{\gamma})\end{align*}
\begin{align*} \|{\alpha}-{\gamma}\|_1^2 \le 2D({\alpha} \|{\gamma})\end{align*}
and
 \begin{align*} \|{\beta}-{\gamma}\|_1^2 \le 2D({\beta} \|{\gamma}),\end{align*}
\begin{align*} \|{\beta}-{\gamma}\|_1^2 \le 2D({\beta} \|{\gamma}),\end{align*}
where
 \begin{align*} D( {\alpha} \| {\gamma}) := \sum_{i\in \mathbb N} {\alpha}(i)\log\left(\frac{{\alpha}(i)}{{\gamma}(i)}\right),\end{align*}
\begin{align*} D( {\alpha} \| {\gamma}) := \sum_{i\in \mathbb N} {\alpha}(i)\log\left(\frac{{\alpha}(i)}{{\gamma}(i)}\right),\end{align*}
and similarly for  $D({\beta}\|{\gamma})$. By convention, we set
$D({\beta}\|{\gamma})$. By convention, we set  $0\log(0) = 0\log(\frac{0}{0}) =0$ in the definitions of
$0\log(0) = 0\log(\frac{0}{0}) =0$ in the definitions of  $D({\alpha}\|{\gamma})$ and
$D({\alpha}\|{\gamma})$ and  $D({\beta}\|{\gamma})$.
$D({\beta}\|{\gamma})$.
Noting that  $\|{\alpha} -{\gamma}\|_1 = \|{\beta} - {\gamma}\|_1$, summing the two inequalities above gives
$\|{\alpha} -{\gamma}\|_1 = \|{\beta} - {\gamma}\|_1$, summing the two inequalities above gives
 \begin{align*} 2\|{\beta} -{\gamma}\|^2_1 = 2\|{\alpha}-{\gamma}\|^2_1 \le 2D({\alpha} \|{\gamma}) + 2D({\beta} \|{\gamma}).\end{align*}
\begin{align*} 2\|{\beta} -{\gamma}\|^2_1 = 2\|{\alpha}-{\gamma}\|^2_1 \le 2D({\alpha} \|{\gamma}) + 2D({\beta} \|{\gamma}).\end{align*}
A direct computation shows that  $D({\alpha} \|{\gamma}) + D({\beta} \|{\gamma}) = 2H({\gamma}) -H({\alpha}) - H({\beta})$, so together with the triangle inequality we deduce that
$D({\alpha} \|{\gamma}) + D({\beta} \|{\gamma}) = 2H({\gamma}) -H({\alpha}) - H({\beta})$, so together with the triangle inequality we deduce that
 \begin{equation}\|{\alpha} -{\beta}\|_1 \le 2\sqrt{2H({\gamma}) - H({\alpha})-H({\beta})}.\end{equation}
\begin{equation}\|{\alpha} -{\beta}\|_1 \le 2\sqrt{2H({\gamma}) - H({\alpha})-H({\beta})}.\end{equation}
On the other hand, the left-hand side of (1) is equal to
 \begin{align*}\sum_{i,j\in \mathbb N\colon i<j} {\alpha}(i){\beta}(j) &\le \sum_{i,j\in \mathbb N\colon i<j} {\alpha}(i)({\alpha}(j)+ \|{\alpha}-{\beta}\|_1)\\& \le {\alpha}\times {\alpha} \left(\{(x,y)\in \mathbb N^2\colon x>y\}\right)+ \|{\alpha}-{\beta}\|_1\\\le \frac{1}{2} + \|{\alpha}-{\beta}\|_1\end{align*}
\begin{align*}\sum_{i,j\in \mathbb N\colon i<j} {\alpha}(i){\beta}(j) &\le \sum_{i,j\in \mathbb N\colon i<j} {\alpha}(i)({\alpha}(j)+ \|{\alpha}-{\beta}\|_1)\\& \le {\alpha}\times {\alpha} \left(\{(x,y)\in \mathbb N^2\colon x>y\}\right)+ \|{\alpha}-{\beta}\|_1\\\le \frac{1}{2} + \|{\alpha}-{\beta}\|_1\end{align*}
which together with (2) finishes the proof.
![]()
3. Existence of non-hypershallow sequences
In this section, we will describe a probabilistic construction of non-hypershallow sequences of dags. They will be in fact  $n^{\delta}$-expander sequences for
$n^{\delta}$-expander sequences for  ${\delta}\approx 0.019$.
${\delta}\approx 0.019$.
We will construct a sequence of random graphs  $\mathbf G_n^d$ which asymptotically almost surely forms, after small modifications, an
$\mathbf G_n^d$ which asymptotically almost surely forms, after small modifications, an  $n^{\delta}$-extender sequence. The graphs
$n^{\delta}$-extender sequence. The graphs  $\mathbf G_n^d$ will be essentially defined as follows. The vertices are
$\mathbf G_n^d$ will be essentially defined as follows. The vertices are  $\{1, 2, ..., n\}$ and for every
$\{1, 2, ..., n\}$ and for every  $i < j$, we add an edge (i, j) independently with probability proportional to
$i < j$, we add an edge (i, j) independently with probability proportional to  $\frac{1}{j-i}$. In order to simplify the proof, we will slightly change the probabilities when we define
$\frac{1}{j-i}$. In order to simplify the proof, we will slightly change the probabilities when we define  $\mathbf G_n^d$ in Subsection 3.2.
$\mathbf G_n^d$ in Subsection 3.2.
We start with the definition and discussion of depth functions in Subsection 3.1, as they provide a convenient way of characterising the property of being an  $({\varepsilon}, \rho)$-extender, which will be crucial in the analysis of the random graphs
$({\varepsilon}, \rho)$-extender, which will be crucial in the analysis of the random graphs  $\mathbf G_n^d$ in Subsection 3.3.
$\mathbf G_n^d$ in Subsection 3.3.
3.1 Depth functions
Given a graph G and  $S\subset V(G)$, we can associate to it a function which ‘measures the maximal distance to
$S\subset V(G)$, we can associate to it a function which ‘measures the maximal distance to  $S\cup {\rm Out}(G)$’. More precisely, we define
$S\cup {\rm Out}(G)$’. More precisely, we define  ${\delta}_S\colon V(G) \to \mathbb N$ by setting
${\delta}_S\colon V(G) \to \mathbb N$ by setting  ${\delta}_S(x)=0$ when
${\delta}_S(x)=0$ when  $x\in S\cup{\rm Out}(G)$, and for
$x\in S\cup{\rm Out}(G)$, and for  $x\notin S\cup{\rm Out}(G)$ we let
$x\notin S\cup{\rm Out}(G)$ we let  ${\delta}_S(x)$ to be the maximal
${\delta}_S(x)$ to be the maximal  $l\in \mathbb N$ for which there exists a directed simple path
$l\in \mathbb N$ for which there exists a directed simple path  $x_0,\ldots, x_l$ with
$x_0,\ldots, x_l$ with  $x_0=x$,
$x_0=x$,  $x_l\in S\cup {\rm Out}(G)$, and
$x_l\in S\cup {\rm Out}(G)$, and  $x_i\notin S$ when
$x_i\notin S$ when  $0\le i<l$. Let us start by abstracting some properties of
$0\le i<l$. Let us start by abstracting some properties of  ${\delta}_S$ into the notion of a depth function as follows.
${\delta}_S$ into the notion of a depth function as follows.
Definition 13. Let G be a graph.
1. A depth function for G is a function
$f\colon V(G) \to \mathbb N$ such that the following conditions hold For every $(a,b)\in E(G)$, we have either $f(a)>f(b)$ or $f(a)=0$ For every $a\in V(G)$ such that $f(a)\neq 0$, there exists $b\in V(G)$ such that $(a,b)\in E(G)$ and $f(b)=f(a)-1$.-
2. Let
${\varepsilon}>0$ and let $\rho\in \mathbb N$. An $({\varepsilon},\rho)$-depth function for G is a depth function f for G such that for all $v\in V(G)$ we have $f(v) \le \rho$ and $|f^{-1}(0)\setminus {\rm Out}(G)| \le {\varepsilon} |V(G)|$.















Example 14. It is straightforward to verify that if  $S\subset V(G)$ then
$S\subset V(G)$ then  ${\delta}_S$ is a
${\delta}_S$ is a
 \begin{align*} \left(\frac{|S\setminus {\rm Out}(G)|}{|V(G)|},\,\, {\rm{codepth}}(S;G)+1\right)\end{align*}
\begin{align*} \left(\frac{|S\setminus {\rm Out}(G)|}{|V(G)|},\,\, {\rm{codepth}}(S;G)+1\right)\end{align*}
-depth function.
Lemma 15. If f is a  $({\varepsilon},\rho)$-depth function, then
$({\varepsilon},\rho)$-depth function, then  ${\rm{codepth}}(f^{-1}(0)\setminus {\rm Out}(G);G) \le\rho$.
${\rm{codepth}}(f^{-1}(0)\setminus {\rm Out}(G);G) \le\rho$.
Proof. Let  $(x_0,x_1,\ldots, x_k)$ be a simple path disjoint from
$(x_0,x_1,\ldots, x_k)$ be a simple path disjoint from  $f^{-1}(0)\setminus {\rm Out}(G)$. We have
$f^{-1}(0)\setminus {\rm Out}(G)$. We have  $f(x_0) \le \rho$ and
$f(x_0) \le \rho$ and  $f(x_{i+1})< f(x_i)$ for all
$f(x_{i+1})< f(x_i)$ for all  $i<k$, by 1(a) in Definition 13. The only vertex, in any simple path, which can be in
$i<k$, by 1(a) in Definition 13. The only vertex, in any simple path, which can be in  ${\rm Out}(G)$ is the last vertex, so we deduce that
${\rm Out}(G)$ is the last vertex, so we deduce that  $x_{k-1} \notin f^{-1}(0)$, i.e.
$x_{k-1} \notin f^{-1}(0)$, i.e.  $f(x_{k-1}) >0$. This shows that
$f(x_{k-1}) >0$. This shows that  $k-1<\rho$, and thus
$k-1<\rho$, and thus  $k\le \rho$. This shows that any simple path disjoint from
$k\le \rho$. This shows that any simple path disjoint from  $f^{-1}(0)\setminus {\rm Out}(G)$ has length at most
$f^{-1}(0)\setminus {\rm Out}(G)$ has length at most  $\rho$, which proves the lemma.
$\rho$, which proves the lemma.
![]()
This lemma allows us to characterise extender graphs as follows.
Corollary 16. Let  ${\varepsilon},\rho>0$ and let G be a directed acyclic graph.
${\varepsilon},\rho>0$ and let G be a directed acyclic graph.
a. If G is an
$({\varepsilon},\rho)$-extender, then there are no $({\varepsilon},\rho)$-depth functions for G.-
b. If there are no
$({\varepsilon},\rho+1)$-depth functions for G, then G is an $({\varepsilon},\rho)$-extender.




Proof.
a. Let
${\varepsilon}'>0$ and suppose that f is a $({\varepsilon}',\rho)$-depth function for G. By the previous lemma, we have ${\rm{codepth}}(f^{-1}(0)\setminus {\rm Out}(G);G) \le \rho$. Therefore, since we assume that G is an $({\varepsilon},\rho)$-extender, we have $|f^{-1}(0)\setminus {\rm Out}(G)| > {\varepsilon} |V(G)|$. By the definition of being a $({\varepsilon}',\rho)$-depth function, we have $|f^{-1}(0)\setminus {\rm Out}(G)| \le {\varepsilon}' |V(G)|$, which shows ${\varepsilon}'>{\varepsilon}$.-
b. Let
$S\subset V(G)$ be a set with $|S|\le {\varepsilon} |V(G)|$. Then by Example 14, we have that ${\delta}_S$ is a $({\varepsilon}, {\rm{codepth}}(S; G)+1)$-depth function. Since we assume that there are no $({\varepsilon},\rho+1)$-depth functions, we deduce ${\rm{codepth}}(S;G)+1> \rho+1$, and hence ${\rm{codepth}}(S;G) >\rho$. This shows that G is an $({\varepsilon},\rho)$-extender and finishes the proof.
















It will be useful to restate the above corollary for the case of graph sequences.
Corollary 17. Let  $(G_n)$ be a bounded in-degree sequence of directed acyclic graphs and let
$(G_n)$ be a bounded in-degree sequence of directed acyclic graphs and let  $(\rho_n)$ be a sequence of positive real numbers with
$(\rho_n)$ be a sequence of positive real numbers with  $\lim_{n\to \infty} \rho_n = \infty$. The following conditions are equivalent.
$\lim_{n\to \infty} \rho_n = \infty$. The following conditions are equivalent.
a. The sequence
$(G_n)$ is a $(\rho_n)$-extender sequence-
b. There exists
$C>0$, ${\varepsilon}>0$ such that for all $n\in\mathbb N$ we have that $G_n$ does not admit a $({\varepsilon},C\cdot \rho_{|V(G_n)|})$-depth function.







One of the steps in the proof of Theorem 5, Proposition 22, requires bounding the number of depth functions on a graph. We finish this subsection with a lemma which is used to count depth functions in the proof of Proposition 22. First, we need the following definition.
Definition 18. For  $D\subset E(G)$, we define
$D\subset E(G)$, we define  ${\delta}'_D\colon V(G) \to \mathbb N\cup \{\infty\}$ by setting
${\delta}'_D\colon V(G) \to \mathbb N\cup \{\infty\}$ by setting  ${\delta}'_D(v)$ to be equal to the maximal length of a directed simple path in the graph (V(G),D) which connects v to a vertex in
${\delta}'_D(v)$ to be equal to the maximal length of a directed simple path in the graph (V(G),D) which connects v to a vertex in  ${\rm Out}((V(G),D))$.
${\rm Out}((V(G),D))$.
In other words,  ${\delta}'_D$ is the ‘standard’ depth function for the graph (V(G),D). While it is not true that for every
${\delta}'_D$ is the ‘standard’ depth function for the graph (V(G),D). While it is not true that for every  $D\subset E(G)$, we have that
$D\subset E(G)$, we have that  ${\delta}'_D$ is a depth function for the graph G, the following lemma shows in particular that for every depth function f we can find D such that
${\delta}'_D$ is a depth function for the graph G, the following lemma shows in particular that for every depth function f we can find D such that  $f={\delta}'_D$.
$f={\delta}'_D$.
Lemma 19. Let G be a graph and f be a depth function for G. Then there exists  $D\subset E(G)$ such that
$D\subset E(G)$ such that  $|D|\le |V(G)|$ and
$|D|\le |V(G)|$ and  ${\delta}'_D = f$.
${\delta}'_D = f$.
Proof. By Condition 1b) of Definition 13, there exists a function  $n\colon V(G)\setminus f^{-1}(0) \to V(G)$ such that for every
$n\colon V(G)\setminus f^{-1}(0) \to V(G)$ such that for every  $v\in V(G)\setminus f^{-1}(0)$ we have
$v\in V(G)\setminus f^{-1}(0)$ we have  $f(n(v)) = f(v)-1$. We let
$f(n(v)) = f(v)-1$. We let  $D:=\{(v,n(v))\colon v\in V(G)\setminus f^{-1}(0)\}$. It is straightforward to check that D has the desired properties.
$D:=\{(v,n(v))\colon v\in V(G)\setminus f^{-1}(0)\}$. It is straightforward to check that D has the desired properties.
![]()
3.2
Definition and basic properties of the random graphs $\mathbf G_n^d$

In this article, a random graph is a pair  $(V, \mathbf E)$ where V is a non-empty finite set and
$(V, \mathbf E)$ where V is a non-empty finite set and  $\mathbf E$ is a random variable with values in
$\mathbf E$ is a random variable with values in  ${\rm Pow}(V\times V)$ such that
${\rm Pow}(V\times V)$ such that  $\mathbf E$ is disjoint from the diagonal in
$\mathbf E$ is disjoint from the diagonal in  $V\times V$ almost surely.
$V\times V$ almost surely.
For  $n\in \mathbb N$ let
$n\in \mathbb N$ let  $\mathbb Z_n:= \mathbb Z/n\mathbb Z$. For
$\mathbb Z_n:= \mathbb Z/n\mathbb Z$. For  $a,b\in \mathbb Z_n$, we write
$a,b\in \mathbb Z_n$, we write  $a>b$ if
$a>b$ if  $a = \overline a + n\mathbb Z$,
$a = \overline a + n\mathbb Z$,  $b = \overline b + n\mathbb Z$, where
$b = \overline b + n\mathbb Z$, where  $\overline a, \overline b\in \{0,1,\ldots, n-1\}$ and
$\overline a, \overline b\in \{0,1,\ldots, n-1\}$ and  $\overline a >\overline b$. We also let
$\overline a >\overline b$. We also let  $R(n):=\lfloor\log(n)\rfloor$.
$R(n):=\lfloor\log(n)\rfloor$.
We start by defining a random variable  $J_n$ with values in
$J_n$ with values in  $\mathbb Z_n\times \mathbb Z_n$, as follows. We first choose
$\mathbb Z_n\times \mathbb Z_n$, as follows. We first choose  $v\in \mathbb Z_n$ uniformly at random, then we choose
$v\in \mathbb Z_n$ uniformly at random, then we choose  $r\in R(n)$ uniformly at random, and we choose (x,y) uniformly at random in
$r\in R(n)$ uniformly at random, and we choose (x,y) uniformly at random in
 \begin{align*}\{v,v+1,\ldots, v+2^r-1\} \times \{v+2^r, v+2^r+1,\ldots, v+2^{r+1}-1\}\subset \mathbb Z_n\times \mathbb Z_n.\end{align*}
\begin{align*}\{v,v+1,\ldots, v+2^r-1\} \times \{v+2^r, v+2^r+1,\ldots, v+2^{r+1}-1\}\subset \mathbb Z_n\times \mathbb Z_n.\end{align*}
The law of  $J_n$ will be denoted with
$J_n$ will be denoted with  $\iota_n$.
$\iota_n$.
Now for  $d, n\in \mathbb N$, we define a random graph
$d, n\in \mathbb N$, we define a random graph  $\mathbf G_n^d$ as follows: we let
$\mathbf G_n^d$ as follows: we let  $V(\mathbf G_n^d) := \mathbb Z_n$, and the random variable
$V(\mathbf G_n^d) := \mathbb Z_n$, and the random variable  $\mathbf E_n^d$ with values in
$\mathbf E_n^d$ with values in  ${\rm Pow}(\mathbb Z_n\times \mathbb Z_n)$ is defined by choosing dn elements of
${\rm Pow}(\mathbb Z_n\times \mathbb Z_n)$ is defined by choosing dn elements of  $\mathbb Z_n\times \mathbb Z_n$ independently at random according to the law
$\mathbb Z_n\times \mathbb Z_n$ independently at random according to the law  $\iota_n$. This finishes the definition of
$\iota_n$. This finishes the definition of  $\mathbf G_n^d$.
$\mathbf G_n^d$.
Let us note that  $\mathbf G_n^d$ is typically neither a dag nor of bounded degree, but the following lemma implies that with high probability
$\mathbf G_n^d$ is typically neither a dag nor of bounded degree, but the following lemma implies that with high probability  $\mathbf G_n^d$ becomes a bounded degree dag after removing a small amount of vertices.
$\mathbf G_n^d$ becomes a bounded degree dag after removing a small amount of vertices.
Lemma 20. Let  ${\varepsilon}>0$,
${\varepsilon}>0$,  $d,n,{\Delta}\in \mathbb N$, and let
$d,n,{\Delta}\in \mathbb N$, and let  $\mathbf E:= \mathbf E_n^d$. We have
$\mathbf E:= \mathbf E_n^d$. We have
 \begin{equation}{\mathbb P}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E)) \ge 2{\Delta} \}| \ge {\varepsilon} \cdot n ) \le \frac{2d^{\Delta}}{{\Delta}!\cdot {\varepsilon}}\end{equation}
\begin{equation}{\mathbb P}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E)) \ge 2{\Delta} \}| \ge {\varepsilon} \cdot n ) \le \frac{2d^{\Delta}}{{\Delta}!\cdot {\varepsilon}}\end{equation}
and
 \begin{equation} {\mathbb P}_{\mathbf E}( |\{(x,y)\in \mathbf E \colon x>y \}| \ge {\varepsilon}\cdot d n) \le \frac{2d}{{\varepsilon}\cdot R(n)}\end{equation}
\begin{equation} {\mathbb P}_{\mathbf E}( |\{(x,y)\in \mathbf E \colon x>y \}| \ge {\varepsilon}\cdot d n) \le \frac{2d}{{\varepsilon}\cdot R(n)}\end{equation}
Proof. Note that we have the following  $(\mathbb Z_n\times \mathbb Z_n)$-valued random variable
$(\mathbb Z_n\times \mathbb Z_n)$-valued random variable  $J'_n$ whose law is the same as the law of
$J'_n$ whose law is the same as the law of  $J_n$, that is, it is equal to
$J_n$, that is, it is equal to  $\iota_n$. We choose
$\iota_n$. We choose  $(v,r)\in \mathbb Z_n \times R(n)$ uniformly at random, then we choose
$(v,r)\in \mathbb Z_n \times R(n)$ uniformly at random, then we choose  $(a,b)\in 2^r\times 2^r$ uniformly at random and we choose the edge
$(a,b)\in 2^r\times 2^r$ uniformly at random and we choose the edge  $(v,v+2^r+b-a)$.
$(v,v+2^r+b-a)$.
Therefore, if we fix  $v\in \mathbb Z_n$, then
$v\in \mathbb Z_n$, then
 \begin{align*} {\mathbb P}_{\mathbf E}({\rm outdeg}(v; (\mathbb Z_n, \mathbf E))\ge {\Delta}) \le {nd \choose {\Delta}} \frac{1}{n^{\Delta}} \le \frac{d^{\Delta}}{{\Delta}!},\end{align*}
\begin{align*} {\mathbb P}_{\mathbf E}({\rm outdeg}(v; (\mathbb Z_n, \mathbf E))\ge {\Delta}) \le {nd \choose {\Delta}} \frac{1}{n^{\Delta}} \le \frac{d^{\Delta}}{{\Delta}!},\end{align*}
where the last inequality is obtained by writing
 \begin{align*}{nd \choose {\Delta}} \frac{1}{n^{\Delta}} = \frac{nd\cdot\ldots\cdot (nd-{\Delta}+1)}{{\Delta}!} \frac{1}{n^{\Delta}} \le\frac{(nd)^{\Delta}}{{\Delta}!} \frac{1}{n^{\Delta}} = \frac{d^{\Delta}}{{\Delta}!}.\end{align*}
\begin{align*}{nd \choose {\Delta}} \frac{1}{n^{\Delta}} = \frac{nd\cdot\ldots\cdot (nd-{\Delta}+1)}{{\Delta}!} \frac{1}{n^{\Delta}} \le\frac{(nd)^{\Delta}}{{\Delta}!} \frac{1}{n^{\Delta}} = \frac{d^{\Delta}}{{\Delta}!}.\end{align*}
Similarly, for a fixed  $v\in \mathbb Z_n$, we have
$v\in \mathbb Z_n$, we have
 \begin{align*} {\mathbb P}_{\mathbf E}({\rm indeg}(v; (\mathbb Z_n, \mathbf E))\ge {\Delta}) \le \frac{d^{\Delta}}{{\Delta}!},\end{align*}
\begin{align*} {\mathbb P}_{\mathbf E}({\rm indeg}(v; (\mathbb Z_n, \mathbf E))\ge {\Delta}) \le \frac{d^{\Delta}}{{\Delta}!},\end{align*}
and hence
 \begin{align*} {\mathbb P}_{\mathbf E}(\deg(v; (\mathbb Z_n, \mathbf E))\ge 2{\Delta}) \le \frac{2d^{\Delta}}{{\Delta}!}.\end{align*}
\begin{align*} {\mathbb P}_{\mathbf E}(\deg(v; (\mathbb Z_n, \mathbf E))\ge 2{\Delta}) \le \frac{2d^{\Delta}}{{\Delta}!}.\end{align*}
Now by linearity of expectation, we have
 \begin{align*}{{\mathbb E}}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E))\ge 2{\Delta} \}|) = \sum_{v\in \mathbb Z_n} {\mathbb P}_{\mathbf E}(\deg(v; (\mathbb Z_n, \mathbf E))\ge 2{\Delta}),\end{align*}
\begin{align*}{{\mathbb E}}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E))\ge 2{\Delta} \}|) = \sum_{v\in \mathbb Z_n} {\mathbb P}_{\mathbf E}(\deg(v; (\mathbb Z_n, \mathbf E))\ge 2{\Delta}),\end{align*}
and the right-hand side is bounded from above by  $\frac{2nd^{\Delta}}{{\Delta}!}$. Thus, by Markov’s inequality we have
$\frac{2nd^{\Delta}}{{\Delta}!}$. Thus, by Markov’s inequality we have
 \begin{align*}{\mathbb P}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E))\ge 2{\Delta} \}| \ge {\varepsilon} \cdot n ) <\frac{2nd^{\Delta}}{{\Delta}! {\varepsilon} n} = \frac{2d^{\Delta}}{{\Delta}!{\varepsilon}},\end{align*}
\begin{align*}{\mathbb P}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E))\ge 2{\Delta} \}| \ge {\varepsilon} \cdot n ) <\frac{2nd^{\Delta}}{{\Delta}! {\varepsilon} n} = \frac{2d^{\Delta}}{{\Delta}!{\varepsilon}},\end{align*}
which finishes the proof of (3).
In order to prove (4), we start by bounding  $\iota_n(\{(x,y)\in {\mathbb Z}_n\times {\mathbb Z}_n\colon x>y\})$ from above. By the definition of
$\iota_n(\{(x,y)\in {\mathbb Z}_n\times {\mathbb Z}_n\colon x>y\})$ from above. By the definition of  $J_n'$, the only way in which
$J_n'$, the only way in which  $J_n'$ might take a value (x,y) with
$J_n'$ might take a value (x,y) with  $x>y$ is when we start by choosing
$x>y$ is when we start by choosing  $(v,r)\in \mathbb Z_n \times R(n)$ such that
$(v,r)\in \mathbb Z_n \times R(n)$ such that  $v>n-2^{r+1}$. As such we have
$v>n-2^{r+1}$. As such we have
 \begin{align*} \iota_n(\{(x,y)\in {\mathbb Z}_n\times {\mathbb Z}_n\colon x>y\}) \le \frac{1}{R(n)}\sum_{r
< R(n)} \frac{1}{n}|\{a\in \mathbb Z_n\colon a>n-2^{r+1}\}|,\end{align*}
\begin{align*} \iota_n(\{(x,y)\in {\mathbb Z}_n\times {\mathbb Z}_n\colon x>y\}) \le \frac{1}{R(n)}\sum_{r
< R(n)} \frac{1}{n}|\{a\in \mathbb Z_n\colon a>n-2^{r+1}\}|,\end{align*}
which is bounded from above by
 \begin{align*}\frac{1}{nR(n)} \sum_{r<R(n)} 2^{r+1}
< \frac{1}{nR(n)} 2^{R(n)+1} \le \frac{2n}{nR(n)} = \frac{2}{R(n)}\end{align*}
\begin{align*}\frac{1}{nR(n)} \sum_{r<R(n)} 2^{r+1}
< \frac{1}{nR(n)} 2^{R(n)+1} \le \frac{2n}{nR(n)} = \frac{2}{R(n)}\end{align*}
Therefore, we have
 \begin{align*}{{\mathbb E}}_{\mathbf E}( |\{(a,b)\in \mathbf E \colon a>b \}|)
< \frac{2nd}{R(n)}\end{align*}
\begin{align*}{{\mathbb E}}_{\mathbf E}( |\{(a,b)\in \mathbf E \colon a>b \}|)
< \frac{2nd}{R(n)}\end{align*}
and Markov’s inequality again gives us the desired bound.
![]()
3.3
Construction of an $n^{\delta}$-extender sequence from $\mathbf G_n^d$


The key lemma which we need is the following.
Lemma 21. Let  $d,n\in \mathbb N$, let
$d,n\in \mathbb N$, let  ${\varepsilon}>0$, let
${\varepsilon}>0$, let  $k:=\lfloor n^{{\varepsilon}^3}\rfloor$, and let
$k:=\lfloor n^{{\varepsilon}^3}\rfloor$, and let  $l\colon {\mathbb Z}_n \to k$. We have
$l\colon {\mathbb Z}_n \to k$. We have
 \begin{equation}\iota_n(\{(a,b)\in \mathbb Z_n\times \mathbb Z_n\colon l(a)>l(b)\})
< \frac{1}{2} + 4{\varepsilon}\end{equation}
\begin{equation}\iota_n(\{(a,b)\in \mathbb Z_n\times \mathbb Z_n\colon l(a)>l(b)\})
< \frac{1}{2} + 4{\varepsilon}\end{equation}
Let us discuss the intuition behind the proof of Lemma 21. First, let us discuss the meaning of the left-hand side of (5). We first choose  $(v,r)\in \mathbb Z_n\times R(n)$ uniformly at random, then we look at the distribution of l(v),
$(v,r)\in \mathbb Z_n\times R(n)$ uniformly at random, then we look at the distribution of l(v),  $l(v+1)$, …,
$l(v+1)$, …,  $l(v+2^r-1)$ on the one side and the distribution of
$l(v+2^r-1)$ on the one side and the distribution of  $l(v+2^r)$,
$l(v+2^r)$,  $l(v+2^r+1)$, …,
$l(v+2^r+1)$, …,  $l(v+2^{r+1}-1)$ on the other side. We sample an element of
$l(v+2^{r+1}-1)$ on the other side. We sample an element of  $\{0,\ldots, k-1\}$ from the first distribution and an element of
$\{0,\ldots, k-1\}$ from the first distribution and an element of  $\{0,\ldots, k-1\}$ from the second distribution. Then the left-hand side of (5) is the probability that the first element is larger than the second element.
$\{0,\ldots, k-1\}$ from the second distribution. Then the left-hand side of (5) is the probability that the first element is larger than the second element.
If the distribution of l(v),  $l(v+1)$, …,
$l(v+1)$, …,  $l(v+2^r-1)$ is very close to the distribution of
$l(v+2^r-1)$ is very close to the distribution of  $l(v+2^r)$,
$l(v+2^r)$,  $l(v+2^r+1)$, …,
$l(v+2^r+1)$, …,  $l(v+2^{r+1}-1)$, then for a random edge between the two vertex sets, l increases or decreases with approximately the same probability. But if the two distributions are not very close, then the entropy of the distribution of the union l(v),
$l(v+2^{r+1}-1)$, then for a random edge between the two vertex sets, l increases or decreases with approximately the same probability. But if the two distributions are not very close, then the entropy of the distribution of the union l(v),  $l(v+1)$, …,
$l(v+1)$, …,  $l(v+2^{r+1}-1)$ is larger than the average of the two entropies (this statement is formalised by Proposition 12).
$l(v+2^{r+1}-1)$ is larger than the average of the two entropies (this statement is formalised by Proposition 12).
As the entropy of the distribution of  $l(v),\ldots, l(v+2^{R(n)})$ is bounded from above by
$l(v),\ldots, l(v+2^{R(n)})$ is bounded from above by  $\log(k)$ (by Lemma 11(b)), it should be clear that when we choose k sufficiently small, then for a fixed
$\log(k)$ (by Lemma 11(b)), it should be clear that when we choose k sufficiently small, then for a fixed  $v\in \mathbb Z_n$ there will be only a small amount of r’s for which the distribution of l(v),
$v\in \mathbb Z_n$ there will be only a small amount of r’s for which the distribution of l(v),  $l(v+1)$, …,
$l(v+1)$, …,  $l(v+2^r-1)$ and
$l(v+2^r-1)$ and  $l(v+2^r)$,
$l(v+2^r)$,  $l(v+2^r+1)$, …,
$l(v+2^r+1)$, …,  $l(2^{r+1}-1)$ is very different.
$l(2^{r+1}-1)$ is very different.
Proof of Lemma 21. For  $v\in \mathbb Z_n$,
$v\in \mathbb Z_n$,  $r<R(n)$, let
$r<R(n)$, let  $X_{v,r}$ denote the restriction of l to
$X_{v,r}$ denote the restriction of l to  $[v,v+2^r-1]\subset {\mathbb Z}_n$, and let
$[v,v+2^r-1]\subset {\mathbb Z}_n$, and let  $Y_{v,r}$ denote the restriction of l to
$Y_{v,r}$ denote the restriction of l to  $[v+2^r,v+2^{r+1}-1]$. We consider
$[v+2^r,v+2^{r+1}-1]$. We consider  $X_{v,r}$ and
$X_{v,r}$ and  $Y_{v,r}$ as k-valued random variables.
$Y_{v,r}$ as k-valued random variables.
Note that  $X_{v,r+1} = X_{v,r} \sqcup Y_{v,r}$. As such, by the first item of Proposition 12, for all v,r we have
$X_{v,r+1} = X_{v,r} \sqcup Y_{v,r}$. As such, by the first item of Proposition 12, for all v,r we have
 \begin{align*}2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) \ge 0.\end{align*}
\begin{align*}2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) \ge 0.\end{align*}
On the other hand, we have  ${{\mathbb E}}_{v,r} (H(X_{v,r})) = {{\mathbb E}}_{v,r} ( H(Y_{v,r}))$, where (v,r) is chosen uniformly at random from
${{\mathbb E}}_{v,r} (H(X_{v,r})) = {{\mathbb E}}_{v,r} ( H(Y_{v,r}))$, where (v,r) is chosen uniformly at random from  $\mathbb Z_n\times R(n)$. Hence,
$\mathbb Z_n\times R(n)$. Hence,
 \begin{align*}{{\mathbb E}}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r})) = 2{{\mathbb E}}_{v,r}(H(X_{v,r+1})) - 2{{\mathbb E}}_{v,r}(H(X_{v,r})),\end{align*}
\begin{align*}{{\mathbb E}}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r})) = 2{{\mathbb E}}_{v,r}(H(X_{v,r+1})) - 2{{\mathbb E}}_{v,r}(H(X_{v,r})),\end{align*}
and so
 \begin{align*}{{\mathbb E}}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}))&= \frac{2}{R(n)} {{\mathbb E}}_v(\sum_{r<R(n)} H(X_{v,r+1}) - H(X_{v,r}))\\&= \frac{2}{R(n)} {{\mathbb E}}_v ( H(X_{v,R(n)})-H(X_{v,0}))\\&\le \frac{2\log(k)}{R(n)}.\end{align*}
\begin{align*}{{\mathbb E}}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}))&= \frac{2}{R(n)} {{\mathbb E}}_v(\sum_{r<R(n)} H(X_{v,r+1}) - H(X_{v,r}))\\&= \frac{2}{R(n)} {{\mathbb E}}_v ( H(X_{v,R(n)})-H(X_{v,0}))\\&\le \frac{2\log(k)}{R(n)}.\end{align*}
Now Markov’s inequality shows that
 \begin{align*}{\mathbb P}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) \ge {\varepsilon}^2) \le \frac{2\log(k)}{{\varepsilon}^2 \cdot R(n)} \le 2{\varepsilon}.\end{align*}
\begin{align*}{\mathbb P}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) \ge {\varepsilon}^2) \le \frac{2\log(k)}{{\varepsilon}^2 \cdot R(n)} \le 2{\varepsilon}.\end{align*}
By the second item of Proposition 12, if for some  $r,v,{\varepsilon}$ we have
$r,v,{\varepsilon}$ we have  $H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) < {\varepsilon}^2$, then
$H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) < {\varepsilon}^2$, then  ${\mathbb P}_{x,y}(X_{v,r}(x) > Y_{v,r}(y)) \le \frac{1}{2} +2{\varepsilon}$. Thus by the definition of
${\mathbb P}_{x,y}(X_{v,r}(x) > Y_{v,r}(y)) \le \frac{1}{2} +2{\varepsilon}$. Thus by the definition of  $\iota_n$, we have
$\iota_n$, we have
 \begin{align*}\iota_n(\{(a,b)&\in \mathbb Z_n\times \mathbb Z_n\colon l(a)>l(b)\}) <\\&
< \frac{1}{2} + 2{\varepsilon} + {\mathbb P}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) \ge {\varepsilon}^2)\\&\le \frac{1}{2}+4{\varepsilon},\end{align*}
\begin{align*}\iota_n(\{(a,b)&\in \mathbb Z_n\times \mathbb Z_n\colon l(a)>l(b)\}) <\\&
< \frac{1}{2} + 2{\varepsilon} + {\mathbb P}_{v,r} (2 \cdot H(X_{v,r+1}) - H(X_{v,r}) -H(Y_{v,r}) \ge {\varepsilon}^2)\\&\le \frac{1}{2}+4{\varepsilon},\end{align*}
which finishes the proof.
Proposition 22. Let  $d,n\in \mathbb N$,
$d,n\in \mathbb N$,  $d\ge 3$, let
$d\ge 3$, let  $\mathbf E:= \mathbf E_n^d$, let
$\mathbf E:= \mathbf E_n^d$, let  ${\varepsilon}\in(0,1)$, and let
${\varepsilon}\in(0,1)$, and let  $k:=\lfloor n^{{\varepsilon}^3}\rfloor$,
$k:=\lfloor n^{{\varepsilon}^3}\rfloor$,
 \begin{equation} {\mathbb P}_\mathbf E(\text{$(\mathbb Z_n,\mathbf E)$ admits a $({\varepsilon},k)$-depth function})
< 2^{H(\frac{1}{d})dn} (\frac{1}{2} + 4{\varepsilon})^{(d-1)n},\end{equation}
\begin{equation} {\mathbb P}_\mathbf E(\text{$(\mathbb Z_n,\mathbf E)$ admits a $({\varepsilon},k)$-depth function})
< 2^{H(\frac{1}{d})dn} (\frac{1}{2} + 4{\varepsilon})^{(d-1)n},\end{equation}
where for  $x\in (0,1)$ we set
$x\in (0,1)$ we set  $H(x) = -x\log(x) - (1-x)\log(1-x)$.
$H(x) = -x\log(x) - (1-x)\log(1-x)$.
Proof. Clearly it is enough to show that
 \begin{equation} {{\mathbb E}}_\mathbf E(\text{number of $({\varepsilon},k)$-depth functions for $(\mathbb Z_n,\mathbf E)$})
< 2^{H\left(\frac{1}{d}\right)dn} \left(\frac{1}{2} + 4{\varepsilon}\right)^{(d-1)n}.\end{equation}
\begin{equation} {{\mathbb E}}_\mathbf E(\text{number of $({\varepsilon},k)$-depth functions for $(\mathbb Z_n,\mathbf E)$})
< 2^{H\left(\frac{1}{d}\right)dn} \left(\frac{1}{2} + 4{\varepsilon}\right)^{(d-1)n}.\end{equation}
By Lemma 19, the left-hand side of (7) is bounded above by
 \begin{align} {{\mathbb E}}_\mathbf E\Big(\big| &\big\{D\subset \mathbf E\colon\end{align}
\begin{align} {{\mathbb E}}_\mathbf E\Big(\big| &\big\{D\subset \mathbf E\colon\end{align}
 \begin{align}&\text{ $|D|\le n$ and ${\delta}'_D$ is an $({\varepsilon},k)$-depth function for $(\mathbb Z_n,\mathbf E)$}\big\}\big|\Big).\nonumber\end{align}
\begin{align}&\text{ $|D|\le n$ and ${\delta}'_D$ is an $({\varepsilon},k)$-depth function for $(\mathbb Z_n,\mathbf E)$}\big\}\big|\Big).\nonumber\end{align}
Given  $I\subset dn$, let
$I\subset dn$, let  ${\rm Set}_I\colon (\mathbb Z_n\times \mathbb Z_n)^{dn} \to {\rm Pow}(\mathbb Z_n\times \mathbb Z_n)$ be defined by
${\rm Set}_I\colon (\mathbb Z_n\times \mathbb Z_n)^{dn} \to {\rm Pow}(\mathbb Z_n\times \mathbb Z_n)$ be defined by
 \begin{align*} {\rm Set}_I(x_0,\ldots, x_{dn-1}) := \{x_i\colon i\in I\},\end{align*}
\begin{align*} {\rm Set}_I(x_0,\ldots, x_{dn-1}) := \{x_i\colon i\in I\},\end{align*}
and let  ${\rm Set}:= {\rm Set}_{dn}$. Furthermore, if G is a graph and
${\rm Set}:= {\rm Set}_{dn}$. Furthermore, if G is a graph and  $D\subset E(G)$ is such that
$D\subset E(G)$ is such that  ${\delta}'_D$ is a
${\delta}'_D$ is a  $({\varepsilon},k)$-depth function, then let us say that D is an
$({\varepsilon},k)$-depth function, then let us say that D is an  $({\varepsilon},k)$-depth set for G.
$({\varepsilon},k)$-depth set for G.
Recall that the law of  $\mathbf E$ is the push-forward of
$\mathbf E$ is the push-forward of  $\iota^{dn}_n$ through the map Set. As such, we deduce that (8) is bounded above by:
$\iota^{dn}_n$ through the map Set. As such, we deduce that (8) is bounded above by:
 \begin{align} \sum_{I\subset dn\colon |I|\le n} \iota_n^{dn}\Big(&\big\{(e_i)_{i\in dn} \in (\mathbb Z_n\times \mathbb Z_n)^{dn}\colon\end{align}
\begin{align} \sum_{I\subset dn\colon |I|\le n} \iota_n^{dn}\Big(&\big\{(e_i)_{i\in dn} \in (\mathbb Z_n\times \mathbb Z_n)^{dn}\colon\end{align}
 \begin{align}&\text{${\rm Set}_I((e_i)_{i\in dn})$ is a $({\varepsilon},k)$-depth set for $(\mathbb Z_n, {\rm Set}((e_i)_{i\in dn})$}\big\}\Big)\nonumber \end{align}
\begin{align}&\text{${\rm Set}_I((e_i)_{i\in dn})$ is a $({\varepsilon},k)$-depth set for $(\mathbb Z_n, {\rm Set}((e_i)_{i\in dn})$}\big\}\Big)\nonumber \end{align}
Let us first estimate the number of summands in (9). Recall that for  $0<{\alpha}\le\frac{1}{2}$ and
$0<{\alpha}\le\frac{1}{2}$ and  $m\in \mathbb N$ we have
$m\in \mathbb N$ we have  $\sum_{i\le {\alpha} m} {m \choose i} \le 2^{H({\alpha}) m}$ (see e.g. [3, Theorem 3.1]). Since
$\sum_{i\le {\alpha} m} {m \choose i} \le 2^{H({\alpha}) m}$ (see e.g. [3, Theorem 3.1]). Since  ${\varepsilon}<1$ and
${\varepsilon}<1$ and  $d\ge 3$, we see that the number of summands in (9) is therefore at most
$d\ge 3$, we see that the number of summands in (9) is therefore at most  $2^{H(\frac{1}{d})dn}$.
$2^{H(\frac{1}{d})dn}$.
To estimate each summand, let us fix  $I\subset dn$, and let us fix
$I\subset dn$, and let us fix  $(e_i)_{i\in I}\in (\mathbb Z_n\times \mathbb Z_n)^I$. Let
$(e_i)_{i\in I}\in (\mathbb Z_n\times \mathbb Z_n)^I$. Let  $D:= \{e_i\colon i \in I\}$ and let l be the depth function
$D:= \{e_i\colon i \in I\}$ and let l be the depth function  ${\delta}'_D$ on the graph
${\delta}'_D$ on the graph  $(\mathbb Z_n,D)$. The probability that l will still be a depth function after we add
$(\mathbb Z_n,D)$. The probability that l will still be a depth function after we add  $nd-|I|$ remaining edges is, by Lemma 21, at most
$nd-|I|$ remaining edges is, by Lemma 21, at most
 \begin{align*}\left(\frac{1}{2} + 4{\varepsilon}\right)^{dn-|I|} \le \left(\frac{1}{2} + 4{\varepsilon}\right)^{(d-1)n}.\end{align*}
\begin{align*}\left(\frac{1}{2} + 4{\varepsilon}\right)^{dn-|I|} \le \left(\frac{1}{2} + 4{\varepsilon}\right)^{(d-1)n}.\end{align*}
As such, we have that (9) is bounded above by
 \begin{align*}2^{H(\frac{1}{d})dn} \left(\frac{1}{2} + 4{\varepsilon}\right)^{(d-1)n},\end{align*}
\begin{align*}2^{H(\frac{1}{d})dn} \left(\frac{1}{2} + 4{\varepsilon}\right)^{(d-1)n},\end{align*}
and hence (7) and (6) hold true. This finishes the proof.
![]()
We are now ready to prove Theorem 5. Clearly, it follows from the following theorem.
Theorem 23. Let  ${\varepsilon}\in(0,\frac{1}{8})$. Then there exists a bounded degree sequence
${\varepsilon}\in(0,\frac{1}{8})$. Then there exists a bounded degree sequence  $(H_n)$ of directed acyclic graphs which is an
$(H_n)$ of directed acyclic graphs which is an  $\left(n^{{\varepsilon}^3}\right)$-extender sequence.
$\left(n^{{\varepsilon}^3}\right)$-extender sequence.
Proof. Let  ${\delta}>0$ be such that
${\delta}>0$ be such that  $p:= \frac{1}{2} + 4({\varepsilon} +2{\delta}) <1$. Let d be such that
$p:= \frac{1}{2} + 4({\varepsilon} +2{\delta}) <1$. Let d be such that
 \begin{equation}2^{H\left(\frac{1}{d}\right)} \cdot \left(\frac{1}{2} + 4({\varepsilon}+2{\delta})\right)^{\frac{d-1}{d}}
< 1.\end{equation}
\begin{equation}2^{H\left(\frac{1}{d}\right)} \cdot \left(\frac{1}{2} + 4({\varepsilon}+2{\delta})\right)^{\frac{d-1}{d}}
< 1.\end{equation}
It is possible to choose such d since  $H(x)\to 0$ as
$H(x)\to 0$ as  $x\to 0$. Let
$x\to 0$. Let  ${\Delta}\in \mathbb N$ be such that
${\Delta}\in \mathbb N$ be such that  $\frac{2d^{\Delta}}{{\Delta}!\cdot {\delta}}<{\delta}$, and let
$\frac{2d^{\Delta}}{{\Delta}!\cdot {\delta}}<{\delta}$, and let  $n_0$ be such that for
$n_0$ be such that for  $n>n_0$ we have
$n>n_0$ we have  $\frac{2d^2}{{\delta} R(n)} <{\delta}$ and
$\frac{2d^2}{{\delta} R(n)} <{\delta}$ and
 \begin{align*} 2^{H\left(\frac{1}{d}\right)dn} \left(\frac{1}{2} + 4({\varepsilon}+2{\delta})\right)^{(d-1)n}<1-2{\delta},\end{align*}
\begin{align*} 2^{H\left(\frac{1}{d}\right)dn} \left(\frac{1}{2} + 4({\varepsilon}+2{\delta})\right)^{(d-1)n}<1-2{\delta},\end{align*}
which is possible by (10).
Therefore, by Proposition 22, we have for  $n>n_0$ that
$n>n_0$ that
 \begin{align*} {\mathbb P}_\mathbf E(\text{$(\mathbb Z_n,\mathbf E)$ admits a $({\varepsilon}+2{\delta},n^{({\varepsilon}+2{\delta})^3})$-depth function})
< 1-2{\delta}.\end{align*}
\begin{align*} {\mathbb P}_\mathbf E(\text{$(\mathbb Z_n,\mathbf E)$ admits a $({\varepsilon}+2{\delta},n^{({\varepsilon}+2{\delta})^3})$-depth function})
< 1-2{\delta}.\end{align*}
Furthermore, by Lemma 20, we have
 \begin{align*} {\mathbb P}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E))\ge 2{\Delta} \}| \ge {\delta} \cdot n ) \le \frac{2d^{\Delta}}{{\Delta}!\cdot {\delta}}<{\delta}\end{align*}
\begin{align*} {\mathbb P}_{\mathbf E} (|\{v\in \mathbb Z_n \colon \deg(v; (\mathbb Z_n,\mathbf E))\ge 2{\Delta} \}| \ge {\delta} \cdot n ) \le \frac{2d^{\Delta}}{{\Delta}!\cdot {\delta}}<{\delta}\end{align*}
and
 \begin{align*} {\mathbb P}_{\mathbf E}( |\{(a,b)\in \mathbf E \colon a>b \}| \ge\frac{{\delta}}d\cdot dn={\delta} n) \le \frac{2d}{\frac{{\delta}}{d} R(n)}<{\delta}.\end{align*}
\begin{align*} {\mathbb P}_{\mathbf E}( |\{(a,b)\in \mathbf E \colon a>b \}| \ge\frac{{\delta}}d\cdot dn={\delta} n) \le \frac{2d}{\frac{{\delta}}{d} R(n)}<{\delta}.\end{align*}
As such, by the union bound, we get for each  $n>n_0$ a graph
$n>n_0$ a graph  $G_n$ with
$G_n$ with  $V(G_n)=\mathbb Z_n$ such that
$V(G_n)=\mathbb Z_n$ such that  $G_n$ does not admit a
$G_n$ does not admit a  $({\varepsilon}+2{\delta},n^{({\varepsilon}+2{\delta})^3})$-depth function, and furthermore
$({\varepsilon}+2{\delta},n^{({\varepsilon}+2{\delta})^3})$-depth function, and furthermore
 \begin{align*} |\{v\in \mathbb Z_n \colon \deg(v; G_n)\ge 2{\Delta} \}| \le {\delta} \cdot n\end{align*}
\begin{align*} |\{v\in \mathbb Z_n \colon \deg(v; G_n)\ge 2{\Delta} \}| \le {\delta} \cdot n\end{align*}
and
 \begin{align*} |\{(a,b)\in E(G_n) \colon a>b \}| \le{\delta}\cdot n.\end{align*}
\begin{align*} |\{(a,b)\in E(G_n) \colon a>b \}| \le{\delta}\cdot n.\end{align*}
Let  $B\subset \mathbb Z_n$ be the union of
$B\subset \mathbb Z_n$ be the union of
 \begin{align*} \{v\in \mathbb Z_n\colon \deg(v;G_n)\ge 2{\Delta}\}\end{align*}
\begin{align*} \{v\in \mathbb Z_n\colon \deg(v;G_n)\ge 2{\Delta}\}\end{align*}
and
 \begin{align*} \{a\in \mathbb Z_n\colon \exists b\in \mathbb Z_n \text{ such that } (a,b)\in E(G_n) \text{ and } a>b\}.\end{align*}
\begin{align*} \{a\in \mathbb Z_n\colon \exists b\in \mathbb Z_n \text{ such that } (a,b)\in E(G_n) \text{ and } a>b\}.\end{align*}
We let  $H_n$ be the subgraph of
$H_n$ be the subgraph of  $G_n$ induced by the set of vertices
$G_n$ induced by the set of vertices  $\mathbb Z_n\setminus B$. Clearly,
$\mathbb Z_n\setminus B$. Clearly,  $H_n$ is a sequence of bounded degree dags, and since
$H_n$ is a sequence of bounded degree dags, and since  $|B|\le 2{\delta} n$, we see that
$|B|\le 2{\delta} n$, we see that  $H_n$ does not admit a
$H_n$ does not admit a  $({\varepsilon},n^{({\varepsilon}+2{\delta})^3})$-depth function, and hence it also does not admit a
$({\varepsilon},n^{({\varepsilon}+2{\delta})^3})$-depth function, and hence it also does not admit a  $({\varepsilon},n^{{\varepsilon}^3})$-depth function. By Corollary 17, this finishes the proof.
$({\varepsilon},n^{{\varepsilon}^3})$-depth function. By Corollary 17, this finishes the proof.
![]()
4. Final remarks
Let us proceed with the proof of Theorem 6. Clearly, Theorem 6 follows from the following proposition.
Proposition 24. Let  $(G_n)$ be a sequence of bounded in-degree directed acyclic graphs and let
$(G_n)$ be a sequence of bounded in-degree directed acyclic graphs and let  $({\delta}_n)$ be a sequence of real numbers in the interval (0,1] such that
$({\delta}_n)$ be a sequence of real numbers in the interval (0,1] such that  $\lim_{n\to \infty} {\delta}_n =1$. For every
$\lim_{n\to \infty} {\delta}_n =1$. For every  ${\varepsilon}>0$, there exists a sequence
${\varepsilon}>0$, there exists a sequence  $(S_n)$ with
$(S_n)$ with  $S_n\subsetneq V(G_n)$ such that
$S_n\subsetneq V(G_n)$ such that  $|S_n| <{\varepsilon}|V(G_n)|$ and
$|S_n| <{\varepsilon}|V(G_n)|$ and
 \begin{equation} \lim_{n\to \infty} \frac{{\rm{codepth}}(S_n;G_n)}{|V(G_n)|^{{\delta}_n}} = 0\end{equation}
\begin{equation} \lim_{n\to \infty} \frac{{\rm{codepth}}(S_n;G_n)}{|V(G_n)|^{{\delta}_n}} = 0\end{equation}
Proof. Let  $m_n := |V(G_n)|$, let
$m_n := |V(G_n)|$, let  $d\in \mathbb N$ be such that
$d\in \mathbb N$ be such that  ${\rm maxindeg}(G_n) \le d$ for all
${\rm maxindeg}(G_n) \le d$ for all  $n\in \mathbb N$, and let us fix
$n\in \mathbb N$, and let us fix  ${\varepsilon}>0$. Since the graphs
${\varepsilon}>0$. Since the graphs  $G_n$ are dags, we may assume that
$G_n$ are dags, we may assume that  $V(G_n)=\{0,\ldots, m_n-1\}$ and that
$V(G_n)=\{0,\ldots, m_n-1\}$ and that  $(x,y)\in E(G_n)$ implies
$(x,y)\in E(G_n)$ implies  $x<y$.
$x<y$.
Let us informally describe our strategy for constructing the sets  $S_n$: first, we will include in
$S_n$: first, we will include in  $S_n$ all vertices adjacent to an edge of length between
$S_n$ all vertices adjacent to an edge of length between  $m_n^{c_n}$ and
$m_n^{c_n}$ and  $m_n^{c_n+{\varepsilon}}$ for a suitable
$m_n^{c_n+{\varepsilon}}$ for a suitable  $c_n$. This way any directed path disjoint from
$c_n$. This way any directed path disjoint from  $S_n$ will have edges of length either less than
$S_n$ will have edges of length either less than  $m_n^{c_n}$ (‘short edges’) or larger than
$m_n^{c_n}$ (‘short edges’) or larger than  $m_n^{c_n+{\varepsilon}}$ (‘long edges’).
$m_n^{c_n+{\varepsilon}}$ (‘long edges’).
The number of the long edges in a directed path is at most  $m_n^{1-c_n-{\varepsilon}}$. To bound the number of short edges, we will also include in
$m_n^{1-c_n-{\varepsilon}}$. To bound the number of short edges, we will also include in  $S_n$ all vertices which are congruent to at most
$S_n$ all vertices which are congruent to at most  $m_n^{c_n}$ modulo
$m_n^{c_n}$ modulo  $\frac{m_n^{c_n}}{{\varepsilon}}$. This way any path disjoint from
$\frac{m_n^{c_n}}{{\varepsilon}}$. This way any path disjoint from  $S_n$ and consisting only of short edges must be contained in an interval of length
$S_n$ and consisting only of short edges must be contained in an interval of length  $\frac{m_n^{c_n}}{{\varepsilon}}$, and so in particular its length is at most
$\frac{m_n^{c_n}}{{\varepsilon}}$, and so in particular its length is at most  $\frac{m_n^{c_n}}{{\varepsilon}}$.
$\frac{m_n^{c_n}}{{\varepsilon}}$.
These bounds on the total number of long edges, and the maximal number of consecutive short edges allow us to obtain the desired bound on  ${\rm{codepth}}(S_n;G_n)$. Let us now make it precise.
${\rm{codepth}}(S_n;G_n)$. Let us now make it precise.
Since  $|E(G_n)|\le dm_n$, by the pigeon hole principle we may find
$|E(G_n)|\le dm_n$, by the pigeon hole principle we may find  $c_n\in [0,1)$ such that the set:
$c_n\in [0,1)$ such that the set:
 \begin{align*} X_n:= \{(x,y)\in E(G_n)\colon y-x \in [m_n^{c_n}, m_n^{c_n+{\varepsilon}})\}\end{align*}
\begin{align*} X_n:= \{(x,y)\in E(G_n)\colon y-x \in [m_n^{c_n}, m_n^{c_n+{\varepsilon}})\}\end{align*}
has cardinality at most  ${\varepsilon} \cdot d m_n$. Let
${\varepsilon} \cdot d m_n$. Let  $A:=\lfloor \frac{m_n^{c_n}}{{\varepsilon}}\rfloor $, let
$A:=\lfloor \frac{m_n^{c_n}}{{\varepsilon}}\rfloor $, let  $B:=\lfloor m_n^{c_n} \rfloor$, and let
$B:=\lfloor m_n^{c_n} \rfloor$, and let
 \begin{align*} Y_n: =\{ x\in V(G_n)\colon x \equiv k \operatorname{mod} A \text{ for some \textit{k} with $0\le k
< B$}\}.\end{align*}
\begin{align*} Y_n: =\{ x\in V(G_n)\colon x \equiv k \operatorname{mod} A \text{ for some \textit{k} with $0\le k
< B$}\}.\end{align*}
Finally, we let
 \begin{align*} S_n := \{x\in V(G_n)\colon \exists y\in V(G_n) \text{ such that } (x,y)\in X_n\} \cup Y_n.\end{align*}
\begin{align*} S_n := \{x\in V(G_n)\colon \exists y\in V(G_n) \text{ such that } (x,y)\in X_n\} \cup Y_n.\end{align*}
Clearly, we have  $|S_n| \le |X_n| +|Y_n| \le {\varepsilon} dm_n + {\varepsilon} m_n= {\varepsilon}(d+1)m_n$. Thus, since
$|S_n| \le |X_n| +|Y_n| \le {\varepsilon} dm_n + {\varepsilon} m_n= {\varepsilon}(d+1)m_n$. Thus, since  ${\varepsilon}$ was arbitrary, in order to finish the proof it is enough to argue that (11) holds.
${\varepsilon}$ was arbitrary, in order to finish the proof it is enough to argue that (11) holds.
In order to estimate  ${\rm{codepth}}(S_n;G_n)$ let us fix
${\rm{codepth}}(S_n;G_n)$ let us fix  $n\in \mathbb N$ and let
$n\in \mathbb N$ and let
 \begin{equation} (x_0,\ldots,x_{l})\end{equation}
\begin{equation} (x_0,\ldots,x_{l})\end{equation}
be a directed path in  $G_n$ disjoint from
$G_n$ disjoint from  $S_n$. By the definition of
$S_n$. By the definition of  $X_n$, and since
$X_n$, and since  $S_n$ contains all starting vertices of edges in
$S_n$ contains all starting vertices of edges in  $X_n$, we see that for all
$X_n$, we see that for all  $i< l$ we have either
$i< l$ we have either  $x_i-x_{i+1}< m_n^{c_n}$ or
$x_i-x_{i+1}< m_n^{c_n}$ or  $x_i-x_{i+1} \ge m_n^{c_n+{\varepsilon}}$.
$x_i-x_{i+1} \ge m_n^{c_n+{\varepsilon}}$.
Let  $(x_{j},x_{j+1},\ldots, x_{j+M})$ be a maximal subpath of (12) such that for all
$(x_{j},x_{j+1},\ldots, x_{j+M})$ be a maximal subpath of (12) such that for all  $k<M$ we have
$k<M$ we have  $x_{j+k+1} -x_j < m_n^{c_n}$. Since
$x_{j+k+1} -x_j < m_n^{c_n}$. Since  $Y_n\subset S_n$, we see that
$Y_n\subset S_n$, we see that  $M\le\frac{m_n^{c_n}}{{\varepsilon}}$. On the other hand, the maximal number of edges in the path (12) with length at least
$M\le\frac{m_n^{c_n}}{{\varepsilon}}$. On the other hand, the maximal number of edges in the path (12) with length at least  $m_n^{c_n+{\varepsilon}}$ is at most
$m_n^{c_n+{\varepsilon}}$ is at most  $\frac{m_n}{m_n^{c_n+{\varepsilon}}}$.
$\frac{m_n}{m_n^{c_n+{\varepsilon}}}$.
In other words, there are at most  $n^{c_n+{\varepsilon}}$ segments in (12), where each segment consists of at most M ‘short’ edges and a single ‘long’ edge. It follows that the length of the path (12) is bounded by:
$n^{c_n+{\varepsilon}}$ segments in (12), where each segment consists of at most M ‘short’ edges and a single ‘long’ edge. It follows that the length of the path (12) is bounded by:
 \begin{align*} (M+1) \cdot \frac{m_n}{m_n^{c_n+{\varepsilon}}} \le \left(\frac{m_n^{c_n}}{{\varepsilon}} +1\right)\frac{m_n}{m_n^{c_n+{\varepsilon}}}\le \left(\frac{2m_n^{c_n}}{{\varepsilon}}\right)\frac{m_n}{m_n^{c_n+{\varepsilon}}}=\frac{2}{{\varepsilon}}m_n^{1-{\varepsilon}},\end{align*}
\begin{align*} (M+1) \cdot \frac{m_n}{m_n^{c_n+{\varepsilon}}} \le \left(\frac{m_n^{c_n}}{{\varepsilon}} +1\right)\frac{m_n}{m_n^{c_n+{\varepsilon}}}\le \left(\frac{2m_n^{c_n}}{{\varepsilon}}\right)\frac{m_n}{m_n^{c_n+{\varepsilon}}}=\frac{2}{{\varepsilon}}m_n^{1-{\varepsilon}},\end{align*}
and hence
 \begin{align*}{\rm{codepth}}(S_n,G_n) \le \frac{2}{{\varepsilon}}m_n^{1-{\varepsilon}}.\end{align*}
\begin{align*}{\rm{codepth}}(S_n,G_n) \le \frac{2}{{\varepsilon}}m_n^{1-{\varepsilon}}.\end{align*}
In particular, since  $m_n = |V(G_n)|$, this establishes (11) and finishes the proof.
$m_n = |V(G_n)|$, this establishes (11) and finishes the proof.
![]()
Circuit complexity. We finish this article by explaining some conjectural applications of hypershallow graph sequences to the theory of boolean circuits. As this is not of crucial importance for this article, we allow ourselves to be a little bit less precise for the sake of brevity.
If X is a set, then  $2^X$ is the set of all functions from X to
$2^X$ is the set of all functions from X to  $2=\{0,1\}$. This leads to the following notational clash: for
$2=\{0,1\}$. This leads to the following notational clash: for  $n\in \mathbb N$, the symbol
$n\in \mathbb N$, the symbol  $2^n$ can either denote a number (and hence a set of numbers) or the set of all functions from
$2^n$ can either denote a number (and hence a set of numbers) or the set of all functions from  $\{0,1,\ldots, n-1\}$ to
$\{0,1,\ldots, n-1\}$ to  $\{0,1\}$. We believe that resolving this ambiguity will not cause any difficulty for the reader.
$\{0,1\}$. We believe that resolving this ambiguity will not cause any difficulty for the reader.
A convenient informal way of thinking about it is that if  $k\in 2^n$ then k is both a number smaller than
$k\in 2^n$ then k is both a number smaller than  $2^n$ and a function from
$2^n$ and a function from  $n=\{0,\ldots, n-1\}$ to
$n=\{0,\ldots, n-1\}$ to  $2=\{0,1\}$, and the translation between the two interpretations is that the binary expansion of a number k smaller than
$2=\{0,1\}$, and the translation between the two interpretations is that the binary expansion of a number k smaller than  $2^n$ can be thought of as a function from
$2^n$ can be thought of as a function from  $\{0,\ldots, n-1\}$ to
$\{0,\ldots, n-1\}$ to  $\{0,1\}$.
$\{0,1\}$.
A circuit is a pair  $\mathcal{C} = (G,{\tt gate})$, where G is a dag and
$\mathcal{C} = (G,{\tt gate})$, where G is a dag and  ${\tt gate}$ is a function which assigns to each vertex
${\tt gate}$ is a function which assigns to each vertex  $v\in V(G)\setminus {\rm In}(G)$ a function
$v\in V(G)\setminus {\rm In}(G)$ a function  ${\tt gate}(v)\colon 2^{{\rm In}(v;G)}\to 2$. We will inherit the notation for
${\tt gate}(v)\colon 2^{{\rm In}(v;G)}\to 2$. We will inherit the notation for  $\mathcal{C}$ from the notation for G, thus, for example, we may write
$\mathcal{C}$ from the notation for G, thus, for example, we may write  ${\rm In}(\mathcal{C})$ for
${\rm In}(\mathcal{C})$ for  ${\rm In}(G)$.
${\rm In}(G)$.
For any  $f\in 2^{{\rm In}(\mathcal{C})}$, there exists exactly one function
$f\in 2^{{\rm In}(\mathcal{C})}$, there exists exactly one function  $F\in 2^{V(\mathcal{C})}$ with the property that for every
$F\in 2^{V(\mathcal{C})}$ with the property that for every  $v\in V(\mathcal{C})\setminus {\rm In}(\mathcal{C})$ we have
$v\in V(\mathcal{C})\setminus {\rm In}(\mathcal{C})$ we have  ${\tt gate}(v)(F|_{{\rm In}(v;\mathcal{C})}) =F(v)$. In particular, we think of the restriction of F to
${\tt gate}(v)(F|_{{\rm In}(v;\mathcal{C})}) =F(v)$. In particular, we think of the restriction of F to  ${\rm Out}(G)$ as the output of the circuit
${\rm Out}(G)$ as the output of the circuit  $\mathcal{C}$ when f is ‘fed’ as the input.
$\mathcal{C}$ when f is ‘fed’ as the input.
Typically, both  ${\rm In}(\mathcal{C})$ and
${\rm In}(\mathcal{C})$ and  ${\rm Out}(\mathcal{C})$ have some labels, for example, both
${\rm Out}(\mathcal{C})$ have some labels, for example, both  ${\rm In}(\mathcal{C})$ and
${\rm In}(\mathcal{C})$ and  ${\rm Out}(\mathcal{C})$ are labelled with elements of
${\rm Out}(\mathcal{C})$ are labelled with elements of 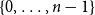 $\{0,\ldots, n-1\}$, in which case we may consider
$\{0,\ldots, n-1\}$, in which case we may consider  $\mathcal{C}$ to implement a function
$\mathcal{C}$ to implement a function  $2^n\to 2^n$.
$2^n\to 2^n$.
By a simple counting argument, ‘almost every’ sequence of functions  $(f_n\colon 2^n\to 2^n)$ cannot be implemented by a sequence of bounded in-degree circuits
$(f_n\colon 2^n\to 2^n)$ cannot be implemented by a sequence of bounded in-degree circuits  $(\mathcal{C}_n)$ such that
$(\mathcal{C}_n)$ such that  $|V(G_n)| = O(n)$. However, it is notoriously difficult to give ‘explicit’ examples of sequences which cannot be computed by linear-sized circuits.
$|V(G_n)| = O(n)$. However, it is notoriously difficult to give ‘explicit’ examples of sequences which cannot be computed by linear-sized circuits.
Following [Reference Afshani, Freksen, Kamma and Larsen1], let us state one precise question.
Definition 25. For  $i\in \mathbb N$ we let
$i\in \mathbb N$ we let  $l(i) = \lceil\log(i)\rceil$, and we define
$l(i) = \lceil\log(i)\rceil$, and we define  ${\texttt{shift}}_n\colon 2^{n\sqcup l(n)} \to 2^n$ as follows: if
${\texttt{shift}}_n\colon 2^{n\sqcup l(n)} \to 2^n$ as follows: if  $f\in 2^n$ and
$f\in 2^n$ and  $k\in 2^{l(n)}$, then for
$k\in 2^{l(n)}$, then for  $j<n$ we let
$j<n$ we let
 \begin{align*} {\texttt{shift}}_n(f\sqcup k) (j) := f(j-k),\end{align*}
\begin{align*} {\texttt{shift}}_n(f\sqcup k) (j) := f(j-k),\end{align*}
where  $j-k$ should be understood as an operation modulo n. In other words,
$j-k$ should be understood as an operation modulo n. In other words,  ${\texttt{shift}}_n(f\sqcup k)$ is equal to ‘f shifted by k’.
${\texttt{shift}}_n(f\sqcup k)$ is equal to ‘f shifted by k’.
Question 26. Suppose that  $(\mathcal{C}_n)$ is a bounded in-degree sequence of circuits which computes
$(\mathcal{C}_n)$ is a bounded in-degree sequence of circuits which computes  ${\texttt{shift}}_n$. Is it the case that
${\texttt{shift}}_n$. Is it the case that  $n = o(|V( G_n)|)$ ?
$n = o(|V( G_n)|)$ ?
This innocent-looking question seems difficult to resolve (though there are some conditional results in [Reference Afshani, Freksen, Kamma and Larsen1]). The authors of this article came up with the notion of hypershallow graph sequences motivated by the following strategy to attack this question: (1) ‘Clearly’ if  $(\mathcal{C}_n)$ is a hypershallow sequence which computes
$(\mathcal{C}_n)$ is a hypershallow sequence which computes  ${\texttt{shift}}_n$, then
${\texttt{shift}}_n$, then  $n = o(|V(\mathcal{C}_n)|)$ and (2) perhaps all graph sequences are hypershallow.
$n = o(|V(\mathcal{C}_n)|)$ and (2) perhaps all graph sequences are hypershallow.
The main result of this paper is that not all graph sequences are hypershallow (Theorem 5). More annoyingly, the authors have not even been able to establish the first point of the above strategy. As such, the following question is also open.
Question 27. Suppose that  $(\mathcal{C}_n)$ is a bounded in-degree sequence of circuits which computes
$(\mathcal{C}_n)$ is a bounded in-degree sequence of circuits which computes  ${\texttt{shift}}_n$ and which is hypershallow. Is it the case that
${\texttt{shift}}_n$ and which is hypershallow. Is it the case that  $n = o (|V(\mathcal{C}_n|)$?
$n = o (|V(\mathcal{C}_n|)$?
Let us finish this article by stating another question to which positive answer would imply a positive answer to Question 27. We need to start with some definitions.
An advice circuit is a circuit  $\mathcal{C}$ together with a partition of
$\mathcal{C}$ together with a partition of  ${\rm In}(\mathcal{C})$ into two disjoint subsets
${\rm In}(\mathcal{C})$ into two disjoint subsets  ${\rm In}_{std}(\mathcal{C})$ and
${\rm In}_{std}(\mathcal{C})$ and  ${\rm In}_{adv}(\mathcal{C})$. We think of such a circuit as receiving its input on the vertices in
${\rm In}_{adv}(\mathcal{C})$. We think of such a circuit as receiving its input on the vertices in  ${\rm In}_{std}(\mathcal{C})$, together with some extra advice tailored specifically for a given input on the vertices in
${\rm In}_{std}(\mathcal{C})$, together with some extra advice tailored specifically for a given input on the vertices in  ${\rm In}_{adv}(\mathcal{C})$. This is made precise in the following definition.
${\rm In}_{adv}(\mathcal{C})$. This is made precise in the following definition.
Definition 28. Let  $\mathcal{C}$ be an advice circuit. We say that
$\mathcal{C}$ be an advice circuit. We say that  $\mathcal{C}$ computes
$\mathcal{C}$ computes  $f\colon 2^{{\rm In}_{std}(\mathcal{C})} \to 2^{{\rm Out}(\mathcal{C})}$ if for every
$f\colon 2^{{\rm In}_{std}(\mathcal{C})} \to 2^{{\rm Out}(\mathcal{C})}$ if for every  $s\in 2^{{\rm In}_{std}(\mathcal{C})}$ there exists
$s\in 2^{{\rm In}_{std}(\mathcal{C})}$ there exists  $t\in 2^{{\rm In}_{adv}(\mathcal{C})}$ such that the output of
$t\in 2^{{\rm In}_{adv}(\mathcal{C})}$ such that the output of  $\mathcal{C}$ on
$\mathcal{C}$ on  $s\sqcup t$ is equal to f(s).
$s\sqcup t$ is equal to f(s).
An  ${\varepsilon}$-advice circuit is an advice circuit
${\varepsilon}$-advice circuit is an advice circuit  $\mathcal{C}$ with
$\mathcal{C}$ with  $|{\rm In}_{adv}(\mathcal{C})|\le {\varepsilon} |{\rm In}(\mathcal{C})|$. With this we are ready to state the following question.
$|{\rm In}_{adv}(\mathcal{C})|\le {\varepsilon} |{\rm In}(\mathcal{C})|$. With this we are ready to state the following question.
Question 29. Is it true that there exists  ${\varepsilon}>0$ such that the sequence
${\varepsilon}>0$ such that the sequence  $({\tt shift}_n)$ cannot be computed by a sequence
$({\tt shift}_n)$ cannot be computed by a sequence  $(\mathcal{C}_n)$ of bounded in-degree
$(\mathcal{C}_n)$ of bounded in-degree  ${\varepsilon}$-advice circuits which have depth 1?
${\varepsilon}$-advice circuits which have depth 1?
It is not difficult to see that the positive answer to this question implies the positive answer to Question 27.
Acknowledgements
We thank one of the anonymous referees for correcting several typos and errors, and for very useful suggestions for improving the readability of this article. We also thank the organisers of the workshop Measurability, Ergodic Theory and Combinatorics which took place at Warwick University in July 2019. A very substantial progress on this project happened during that workshop, and we are grateful for inviting both of us and for providing an excellent environment for mathematical collaboration. Finally, we thank the authors of the blog Gödel’s Lost Letter and P=NP for blogging about the paper [Reference Afshani, Freksen, Kamma and Larsen1] and thereby bringing it to our attention (as well as for many other very interesting posts over the years). This was the starting point for this project.

 Open access
Open access