



1. Introduction
Agriculture is a critical sector in the global economy. Farmers and the agro-food industry have been adapting to meet the demands of the worldwide population, which is increasing fast [Reference Kitzes, Wackernagel, Loh, Peller, Goldfinger, Cheng and Tea1]. Several studies support that the population should keep increasing fast and reach about nine billion people by the year 2050 [2, Reference Perry3]. Besides the increasing food demands to fulfil the global population [2], the area dedicated to agriculture can only increase marginally, requiring more optimised and precise strategies to improve production and cultivation ratios. These factors, associated with the labour shortage for agricultural tasks [Reference Leshcheva and Ivolga4, Reference Rica, Delan, Tan and Monte5], ally technology to farming and the agro-food industry.
Several scientific studies in the literature have been proving that robots can support farmers in agricultural tasks [6–Reference Schmitz and Moss8] and overcome the labour shortage. Mobile and intelligent robots can successfully perform tasks such as monitoring and harvesting. However, these robots require dedicated sensors to perceive fruits and other objects and estimate their localisation to the tools.
Recent literature reviews proved that most works for perceiving fruits use RGB-D sensors [Reference Colucci, Tagliavini, Botta, Baglieri and Quaglia9–Reference Shen and Gans13]. For instance, Sa et al. [Reference Sa, Lehnert, English, McCool, Dayoub, Upcroft and Perez14] performed a complete digitalisation of the scene to gather a digital twin of it and easily perceive the fruits and their three-dimension (3D) position. A support vector machine (SVM), based on colour and geometry features, performed a classification of the fruits. In another work, Jun et al. [Reference Jun, Kim, Seol, Kim and Son15] used a YOLO v3 to detect the fruits in the scene, and, through an RGB-D camera, digitalised the fruit. Using this information, the authors built the Tool Centre Point algorithm to compute the centre of the fruit and the target point to harvest it. The point about these strategies is that they are being performed under controlled conditions at the laboratory or in controlled greenhouses. Therefore, most of these essays were performed under controlled lightening, ensuring the sensors’ correct functioning [Reference Kumar and Mohan10]. RGB-D sensors tend to malfunction under open-field environments due to reflections or intense illumination [Reference Kumar and Mohan10, Reference Gené-Mola, Llorens, Rosell-Polo, Gregorio, Arnó, Solanelles, Martínez-Casasnovas and Escolà16, Reference Ringdahl, Kurtser and Edan17]. So, using auxiliary algorithms and alternative technology is important to overcome the lightning effects.
The previous conceptualisation permits the establishment of a common problem in open-field contexts, which we aim to approach in this study: “How can we use and control monocular sensors to perceive the objects’ positioning in the 3D task space?”.
Concerning estimating the depth using monocular cameras, most of the more recent works focused in convolution neural networks (CNNs) to infer this relative depth to the sensor [Reference Birkl, Wofk and Müller18–Reference ul Haq, Haq, Ruan, Liang and Gao23]. Mousavian et al. [Reference Mousavian, Anguelov, Flynn and Kosecka21] used a CNN to estimate the 3D pose of an object and deployed a MultiBin loss function to optimise the model. Ma et al. [Reference Ma, Liu, Xia, Zhang, Zeng and Ouyang19, Reference Ma, Wang, Li, Zhang, Ouyang and Fan20] deployed custom-made CNNs named MonoPointNet and PatchNet to generate 3D images from monocular images and detect objects. Recently, Ranft et al. [Reference Ranftl, Lasinger, Hafner, Schindler and Koltun22] and Birkl et al. [Reference Birkl, Wofk and Müller18] released a family of CNNs based on MiDaS networks that aimed to estimate the relative depth to the cameras. The networks were trained and essayed on the set of the different datasets of RGB-D data in the literature. Also, Haq et al. [Reference ul Haq, Haq, Ruan, Liang and Gao23] designed a new regional proposal network (RPN) with geometric constraints to detect 3D objects using monocular cameras. This architecture performed similarly to [Reference Ma, Liu, Xia, Zhang, Zeng and Ouyang19, Reference Ma, Wang, Li, Zhang, Ouyang and Fan20]. Van and Do [Reference Van and Do24] used a chessboard background and a regression-based CNN to estimate the 3D pose of irregular objects using cuboids. The dependency on a chessboard background to predict the objects poses constraints on the model’s applicability for unstructured environments.
In the literature, we can also find purposeful deep learning solutions to extract the pose of the objects directly. Table I reports some examples of algorithms in the state of the art. SilhoNet [Reference Billings and Johnson-Roberson25], Nerf-Pose [Reference Li, Vutukur, Yu, Shugurov, Busam, Yang and Ilic26], MORE [Reference Parisotto, Mukherjee and Kasaei29], GhostPose [Reference Chang, Kim, Kang, Han, Hong, Jang and Kang30], and GDR-Net [Reference Wang, Manhardt, Tombari and Ji27] are some of these solutions. SilhoNet reports an overall translation error of about 2.45 cm using a complex state-of-the-art dataset containing multiple objects. Similarly, Nerf-Pose, MORE, GhostPose, and GDR-Net report an overall estimation error lower than 2 cm. Collet and Srinivasa [Reference Collet and Srinivasa28] developed the introspective multiview algorithm that could estimate the pose of objects with estimation errors between 0.46 cm and 1.45 cm. These solutions illustrate remarkable results in the literature for objects’ pose estimation. However, all of them are model dependent in successfully estimating the pose of an object. An exception to this factor is the Imitrob [Reference Sedlar, Stepanova, Skoviera, Behrens, Tuna, Sejnova, Sivic and Babuska31] that analyses the objects’ configuration and structure and learns to estimate the pose of the objects from multiple perspectives.
Table I. Comparision with literature review.

Despite being largely explored in the literature, deep learning-based solutions are data exhaustive, requiring much and varied data with their features well identified and represented. Acquiring data to train deep learning models is expensive and difficult. For natural environments that requires going to the natural scenes and mapping the objects for the robot’s context.
Other works used auxiliary sensors to create 3D scenes or depth estimation, such as light detection and rangings (LiDARs) [Reference Iyer, Ram, Murthy and Krishna32]. However, high resolution and quality LiDARs are expensive and increase the effort over robotic manipulators to manoeuvre and pick objects and also constrained by their operation in open-field robotics.
There are still some researchers that opted for using monocular cameras and controlling the path to the objects using visual servoing strategies [Reference Küçük, Parker and Baumgartner33, Reference Qu, Zhang, Fu and Guo34]. Shen et al. [Reference Shen and Gans13] applied visual servoing using RGB-D cameras. A distinctive work is presented by Xu et al. [Reference Xu, Li, Hao, Zhang, Ciuti, Dario and Huang35], which used the brightness of the environment and the movement of the camera to estimate the depth and reconstruct the structure of the colon during endoscopies.
Probabilistic algorithms are also capable of estimating the objects’ poses accurately. Algorithms such as Bayesian histogram filters were explored in the literature to identify and localise objects in the scenes using different kinds of sensors. Bayesian histogram filters are commonly used in robotics for localisation and navigation purposes [Reference Boyko and Hladun36–Reference Thrun, Burgard and Fox38], but their potentialities enable it for other aims such as identifying and localising other objects. Sarmento et al. [Reference Sarmento, Santos, Aguiar, Sobreira, Regueiro and Valente39] applied region histogram filters to identify people, animals and other obstacles in the ultrawideband scene to avoid collisions and to follow people. Also, Engin and Isler [Reference Engin and Isler40] used this algorithm to localise random objects. Márton et al. [Reference Márton, Türker, Rink, Brucker, Kriegel, Bodenmüller and Riedel41] used a histogram filter to complement the information provided by a state-of-the-art position estimator and accurately estimate the object’s orientation.
The advantage associated with histogram filters is that they are only constrained by the detection capabilities of the algorithms behind the sensors. Therefore, using a well-defined model to perceive the fruits through monocular images, we can translate their 2D relation to the 3D and accurately estimate the objects’ positions. Besides, the histogram filters propose a working philosophy similar to triangulation, which has their accuracy and functionality well proved in geospatial and cartography disciplines.
1.1. System and requirements
Greenhouses are a target-designed scene to optimise the production of fruits in environment-controlled conditions. They also have the advantage that the crops can be modelled to better fit the farm and objectives constraints. So, besides the complexity of agricultural scenes, the modelisation of the environment can be simplified in greenhouses, if robust perception algorithms are used. Besides, the greenhouse context actually has the purpose and the need to adapt to human and robotic systems [Reference Bac, van Henten, Hemming and Edan42, Reference van Herck, Kurtser, Wittemans and Edan43], becoming more effective and ergonomic for different operations.
Actual robotised greenhouses are usually operated by robots on trails [Reference Arad, Balendonck, Barth, Ben-Shahar, Edan, Hellström, Hemming, Kurtser, Ringdahl, Tielen and van Tuijl44]. However, these environments require the development of robot-specific environments and do not fit in the commonly operated greenhouses. Therefore, robots operating in the most common greenhouses should be composed of wheeled mobile robots. AgRob v16 from INESC TEC (Figure 1) is a wheeled robot based on the Clearpath Husky platformFootnote 1 and all-terrain wheels designed for operating under open-field and controlled agricultural environments. This robot is currently being essayed in Douro steep slope vineyards and tomato greenhouses. It has a perception and controlling head that gathers data and information from the environment for navigation and mapping. Additionally, the Robotis Manipulator-H was assembled at the backside to perform tasks in the cultivars, such as monitoring, pruning, or harvesting.

Figure 1. Robot AgRob v16 from INESC TEC to operate under open-field and controlled agricultural environments.
Perception for manipulation is usually performed through eye-in-hand techniques. The Robotis Manipulator-H can handle either monocular or RGB-D cameras. RGB-D cameras can perceive the 3D pose of objects, but they are bigger and more difficult to handle. Besides, RGB-D cameras have difficulty perceiving and estimating the objects’ depth in open-field environments due to natural lightning interferences [Reference Kumar and Mohan10, Reference Gené-Mola, Llorens, Rosell-Polo, Gregorio, Arnó, Solanelles, Martínez-Casasnovas and Escolà16, Reference Ringdahl, Kurtser and Edan17]. Therefore, using monocular cameras, the manipulator can perceive the position of the objects from multiple perspectives and estimate the objects’ pose. Approaches based on machine learning or statistics are commonly explored in the literature [Reference Ma, Liu, Xia, Zhang, Zeng and Ouyang19–Reference Mousavian, Anguelov, Flynn and Kosecka21, Reference ul Haq, Haq, Ruan, Liang and Gao23], albeit statistical approaches are more analytical solutions and with more predictable results.
Therefore, as reviewed, Bayesian histogram filters are suitable for identifying the 3D position of objects and do not require the model’s knowledge. Besides, the histogram filters are more predictable and explainable than deep learning-based solutions, which makes it also easier to readjust to new scenarios. So, for this work, we applied the histogram filter to identify the 3D position of tomatoes in a testbed using a monocular camera assembled in a robotic arm, in a solution called MonoVisual3DFilter. At the current stage, the arm used fixed multi-viewpoint to observe the tomatoes from multiple perspectives.
The current work benefits, in our knowledge, for the first essay in using Bayesian histogram filters for estimating the 3D position of objects in the range of a robotic manipulator using monocular cameras. The implemented algorithm was evaluated for fruit detection under simulation and testbed conditions in the laboratory. Therefore, the current work contributes by
-
• Introducing and essaying the MonoVisual3DFilter;
-
• First, apply histogram filters to detect the centre position of objects;
-
• Apply the algorithm to real-world problems, such as fruit detection in the plants’ canopy; and
-
• Study the effect and advantages of different kernel types.
The following sections are structured: material and methods, results, discussion and conclusion. In section 2, we detail the conditions of the experiments and formalise the algorithm application. Section 3 introduces the different results for the different experiments, which are analysed and discussed, in section 4, and concluded in section 5.
2. Materials and methods
2.1. Real data and simulation
The development and the experiments with the algorithm MonoVisual3DFilter were done under two environments: simulation and a testbed in the laboratory (near real-world conditions).
A simplistic simulation environment was designed using the Ignition Gazebo Simulator.Footnote 2 The scene comprises six spheres to assess the algorithm’s validity and test during implementation (Figure 2). The spheres have sizes of 5 cm and 10 cm. A bounding box camera was added to the scene to perceive the objects and support the position estimation algorithm. During the execution of the MonoVisual3DFilter (a histogram filter), the bounding box camera is moved to fixed viewpoints to enable and validate the estimator. The bounding box camera detects the objects through object detection algorithms using bounding boxes, detecting only their visible regions.
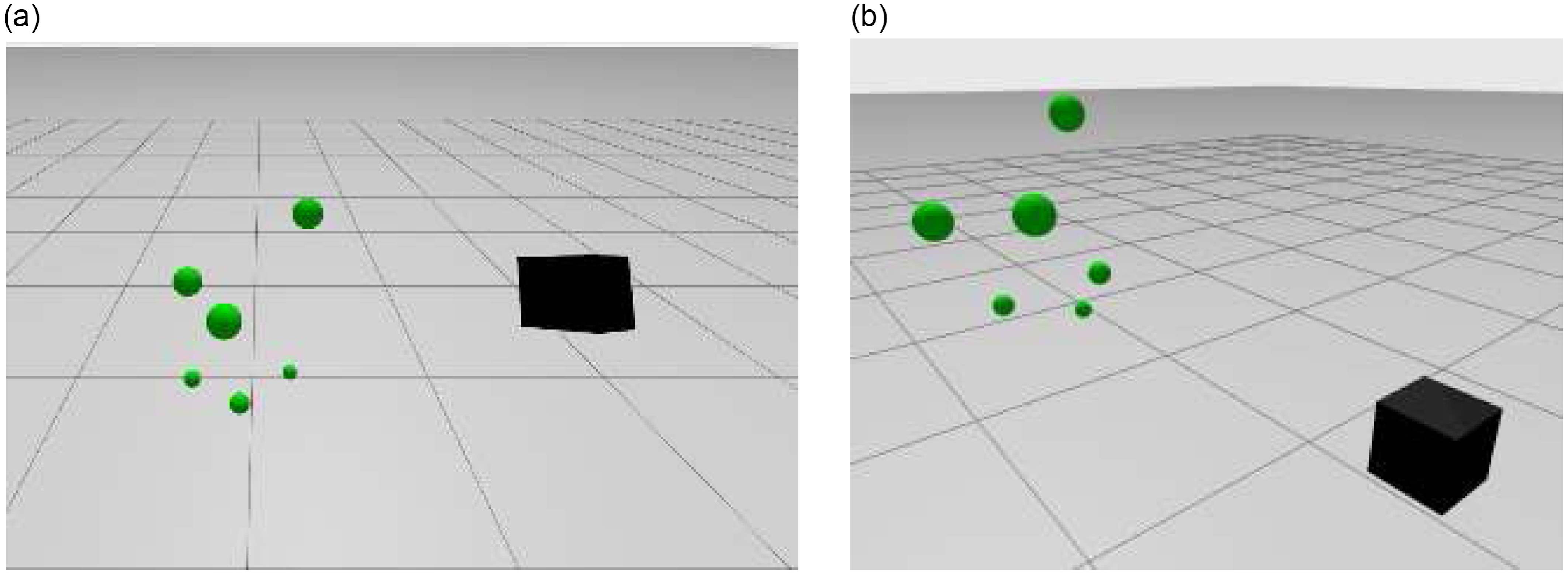
Figure 2. Simulated environment to validate the histogram filter effectiveness. Green spheres are the objects being detected, representing the tomatoes, and the black box is the bounding box camera looking at the spheres.

Figure 3. Simulated testbed in the laboratory to essay the histogram filter algorithm.
To essay the algorithm in the laboratory, near real-world greenhouse conditions, we designed a testbed with realistic leaves and plastic realistic tomatoes (Figure 3a and 3b). For perceiving the tomatoes, we assembled an OAK-1 cameraFootnote 3 (Figure 3d), as a bounding box camera, to the 6 degrees of freedom (DoF) Robotis Manipulator-H (Figure 3c). The OAK-1 camera computes an object detection model algorithm trained to perceive tomatoes. We used the You Only Look Once (YOLO) v8 Tiny trained on the tomato dataset [Reference Magalhães, Castro, Moreira, dos Santos, Cunha, Dias and Moreira45, Reference Magalhães46] and some samples of the plastic tomato from multiple perspectives. However, any object detection or instance segmentation algorithm can be used to perceive the objects of interest in the scene, since they can effectively lead with the different environment perturbances, such as lighting variations or are robust to occlusion. The manipulator also moved to fixed viewpoints that ensured the tomatoes’ visibility. The manipulator was assembled on the mobile platform AgRob v16 from INESC TEC (Figure 1), but 3D position of tomatoes was computed to the manipulator’s base frame.
The OAK-1 is a fully integrated system for bounding box cameras. This camera was designed by the Luxonis Holding Corporation and has a single 12 MP RGB camera module. To allow the on-system object detection, the camera module is connected to the OAK-SoM.Footnote 4 The full camera connects to other devices through USB-C communication. The OAK-SoM is a system on module (SoM) designed to integrate into top-level and low-power systems and has the capability to process artificial neural networks (ANNs). This camera module was integrated into the AgRob v16 robot (Figure 1).
This robot is based on the Clearpath HuskyFootnote 5 mobile platform and was designed to operate in harsh agricultural environments, such as the Douro’s steep slope vineyards. At the front of the mobile platform, there is a controlling head, which is the unit with the computer and all the required devices to control the robot and establish communications. At the backside, the robot has the 6 DoF anthropomorphic manipulator Robotis Manipulator-H.Footnote 6
2.2. Histogram filter
Histogram filters have been widely used in literature for self-localisation and navigation in mobile robots [Reference Boyko and Hladun36, Reference Moscowsky37]. However, for the current study, we intend to apply histogram filters to localise the 3D position of tomatoes concerning the manipulator’s base frame, in a solution called MonoVisual3DFilter.
The histogram filter is a computationally intensive algorithm that can estimate the relative position of objects. The filter computes probabilities for multiple points in a discretised space. After, it intersects the chances of various views to estimate the localisation and the occupied area of the regions of interest (Figure 4).

Figure 4. Intersection between multiple viewpoints in 2D plane.
Histogram filters can be set as an application of a discrete Bayes filter to the continuous state space. For this study, we applied the histogram filter as stated by Thrun [Reference Thrun, Burgard and Fox38].
The histogram filter decomposes the continuous state space in a finite number of regions. Eq. 1 describes a discretised state space.
 $X_t$
is the random variable describing the state of the objects being detected at the time
$X_t$
is the random variable describing the state of the objects being detected at the time
 $t$
.
$t$
.
 $\text{dom}(X_t)$
denotes the state space, which is all the possible values that
$\text{dom}(X_t)$
denotes the state space, which is all the possible values that
 $X_t$
might assume. The most straightforward discretisation of a continuous state space is through a multidimensional grid, where
$X_t$
might assume. The most straightforward discretisation of a continuous state space is through a multidimensional grid, where
 $x_{k,t}$
denotes each grid cell.
$x_{k,t}$
denotes each grid cell.
 \begin{equation} \text{dom}(X_t) = x_{1,t} \cup x_{2,t} \cup \cdots \cup x_{K,t} \end{equation}
\begin{equation} \text{dom}(X_t) = x_{1,t} \cup x_{2,t} \cup \cdots \cup x_{K,t} \end{equation}
Only part of the state space must be discredited to limit computation efforts, mainly due to the manipulator’s reachability. Therefore, as soon as the manipulator’s camera detects an object of interest, in the first viewpoint, the space behind the camera is decomposed through a grid scheme. We considered the probable space around the object as twice the manipulator’s reaching limits. Twice the manipulator’s reachability offers enough margin to identify and validate some fruits in the limits of the manipulator’s reachability. The 3D decomposition is centred in the camera in
 $y\mathcal{O}z$
, i.e. in
$y\mathcal{O}z$
, i.e. in
 $(0, 0)$
in the camera’s frame and further distanced by the manipulator’s reachability radius in
$(0, 0)$
in the camera’s frame and further distanced by the manipulator’s reachability radius in
 $\mathcal{O}x$
. Once decomposed, the discrete state space remains static and only
$\mathcal{O}x$
. Once decomposed, the discrete state space remains static and only
 $\text{dom}(X_t)$
is updated.
$\text{dom}(X_t)$
is updated.
The histogram filter demands moving the camera to multiple strategic viewpoints and updating the probabilities grid. So, at the space decomposition, an associated probabilities matrix is created with a probability to each cell initialised to one, i.e.
 $\text{dom}(X_0) = [1 \ldots 1]$
. This means that at the beginning, the object of interest is probable to be anywhere in the decomposed space.
$\text{dom}(X_0) = [1 \ldots 1]$
. This means that at the beginning, the object of interest is probable to be anywhere in the decomposed space.
For estimating the position of the objects,
 $\text{dom}(X_t)$
is updated in each viewpoint. Each cell,
$\text{dom}(X_t)$
is updated in each viewpoint. Each cell,
 $x_{i,t}$
, from the decomposed state space is transformed from the manipulator’s base frame to the image’s frame. The probability of an object in a given cell,
$x_{i,t}$
, from the decomposed state space is transformed from the manipulator’s base frame to the image’s frame. The probability of an object in a given cell,
 $x_{i,t}$
, knowing the viewpoint, is given by (2). Finally, the updated probability of an object being in the cell
$x_{i,t}$
, knowing the viewpoint, is given by (2). Finally, the updated probability of an object being in the cell
 $x_{i,t}$
is given by (3).
$x_{i,t}$
is given by (3).
 \begin{equation} p(x_{i,t} | \text{viewpoint}_k) = \dfrac{1}{N} \sum _j^N p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k) \end{equation}
\begin{equation} p(x_{i,t} | \text{viewpoint}_k) = \dfrac{1}{N} \sum _j^N p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k) \end{equation}
 \begin{equation} p(x_{i,t}) = p(x_{i,t} | \text{viewpoint}_k) \cdot p(x_{i,t-1}) \end{equation}
\begin{equation} p(x_{i,t}) = p(x_{i,t} | \text{viewpoint}_k) \cdot p(x_{i,t-1}) \end{equation}
In eq. 2, to get
 $p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k)$
, a kernel function was designed. Two kernel functions were essayed to localise the objects in the state space: the square and Gaussian functions. The square kernel, applied to each bounding box, states that if the transformed point is inside a bounding box of the image’s frame, the probability is one; otherwise is zero (4). Using the square kernel function, we will have a binary mask stating that if a point is inside the bounding box, then we can have an object. Otherwise, we don’t.
$p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k)$
, a kernel function was designed. Two kernel functions were essayed to localise the objects in the state space: the square and Gaussian functions. The square kernel, applied to each bounding box, states that if the transformed point is inside a bounding box of the image’s frame, the probability is one; otherwise is zero (4). Using the square kernel function, we will have a binary mask stating that if a point is inside the bounding box, then we can have an object. Otherwise, we don’t.
 \begin{equation} p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k) = \begin{cases} 1 & \text{if inside bounding box} \\[5pt] 0 & \text{otherwise} \end{cases} \end{equation}
\begin{equation} p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k) = \begin{cases} 1 & \text{if inside bounding box} \\[5pt] 0 & \text{otherwise} \end{cases} \end{equation}
As an alternative to the aggressive behaviour of the square function, we also essayed the bidimensional Gaussian function (5). This function delivers a smooth effect for the borders of the bounding box and some cells
 $x_{i,t}$
outside the bounding boxes. Therefore, a Gaussian function should better tolerate irregular objects and noise. In Eq. 5,
$x_{i,t}$
outside the bounding boxes. Therefore, a Gaussian function should better tolerate irregular objects and noise. In Eq. 5,
 $(x_0, y_0)$
is the centre of bounding box
$(x_0, y_0)$
is the centre of bounding box
 $j$
in the sensor’s frame, and
$j$
in the sensor’s frame, and
 $(x,y)$
is the position of each cell
$(x,y)$
is the position of each cell
 $x_{i,t}$
in the sensor’s frame. The coordinates in the image’s frame are projected by a projection model stated in section 2.3. The standard deviation values
$x_{i,t}$
in the sensor’s frame. The coordinates in the image’s frame are projected by a projection model stated in section 2.3. The standard deviation values
 $(\sigma _x, \sigma _y)$
correspond to half of the size of the bounding box
$(\sigma _x, \sigma _y)$
correspond to half of the size of the bounding box
 $j$
. All the values were obtained experimentally and had reasonable results. If we use the Gaussian kernel (5) to estimate the objects’ position, Eq. 2 will correspond to a mixture of Gaussians, attending that the detection camera detects multiple objects. The mixture of Gaussians results in a function that smooths with increasing Gaussians in the mixture. To avoid this effect, a normalised version of the mixture of Gaussians is used to highlight the different detected objects (6). Besides, the updated state space
$j$
. All the values were obtained experimentally and had reasonable results. If we use the Gaussian kernel (5) to estimate the objects’ position, Eq. 2 will correspond to a mixture of Gaussians, attending that the detection camera detects multiple objects. The mixture of Gaussians results in a function that smooths with increasing Gaussians in the mixture. To avoid this effect, a normalised version of the mixture of Gaussians is used to highlight the different detected objects (6). Besides, the updated state space
 $\text{dim}(X_t)$
is also normalised at the end of each iteration of the histogram filter.
$\text{dim}(X_t)$
is also normalised at the end of each iteration of the histogram filter.
 \begin{equation} p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k) = \exp{\left (-\dfrac{(x-x_0)^2}{2\sigma _x^2}-\dfrac{(y-y_0)^2}{2\sigma _y^2}\right )} \end{equation}
\begin{equation} p(x_{i,t} | \text{bbox}_j, \text{viewpoint}_k) = \exp{\left (-\dfrac{(x-x_0)^2}{2\sigma _x^2}-\dfrac{(y-y_0)^2}{2\sigma _y^2}\right )} \end{equation}
 \begin{equation} p(x_{i,t} | \text{viewpoint}_k) = \dfrac{p(x_{i,t} | \text{viewpoint}_k)}{\max (p(x_{i,t} | \text{viewpoint}_k))} \end{equation}
\begin{equation} p(x_{i,t} | \text{viewpoint}_k) = \dfrac{p(x_{i,t} | \text{viewpoint}_k)}{\max (p(x_{i,t} | \text{viewpoint}_k))} \end{equation}
The algorithm 1 summarises the procedures for updating the cell’s weights during the histogram filtering.
Algorithm 1. Histogram filter – updating weights

2.3. Camera projection model
While applying the histogram filter, we decomposed the state space in a finite state space grid. To effectively estimate the 3D position of the object, we moved the detection camera around the object and the decomposed state space to visualise the scene from multiple perspectives (Figure 5).

Figure 5. Intersection of the camera around in the decomposed space.
Detecting objects using the detection camera requires an effective projection model to estimate the object’s position in the 3D space, transforming between the 3D space coordinates and the image’s frame. For simplification, we applied the Pinhole model to transform the 3D space coordinates to the image’s frame.
Acknowledging the points of the 3D space in the camera’s frame, before we project them in the image’s frame, we have to convert them to the sensor’s frame. Both are placed in the same origin, but they have different orientations. The sensor uses the frame as illustrated in Figure 6. The illustrated rotation can be stated by Euler angles like Euler(YZX)
 $=$
(
$=$
(
 $0^{\circ }$
,
$0^{\circ }$
,
 $90^{\circ }$
,
$90^{\circ }$
,
 $-90^{\circ }$
) which reflects in the quaternion
$-90^{\circ }$
) which reflects in the quaternion
 $q=(\!-0.5, 0.5, -0.5, 0.5)$
.
$q=(\!-0.5, 0.5, -0.5, 0.5)$
.

Figure 6. Conversion between the camera’s and sensor’s frames (blue – sensor’s frame; black – camera’s frame).
The transformation between the sensor’s frame and the image’s coordinates can be made by the intrinsics parameters matrix as stated in Eq. 7. This matrix depends on the image’s width (
 $w$
) and height (
$w$
) and height (
 $h$
), as well as on the camera’s focal length (
$h$
), as well as on the camera’s focal length (
 $f$
). The focal length depends on the camera’s horizontal field of view (HFOV) and the image’s width and can be calculated by Eq. 8.
$f$
). The focal length depends on the camera’s horizontal field of view (HFOV) and the image’s width and can be calculated by Eq. 8.
 \begin{equation} (u,v,1) = \begin{bmatrix} f & 0 & \frac{w}{2} \\[5pt] 0 & f & \frac{h}{2} \\[5pt] 0 & 0 & 1 \\[5pt] \end{bmatrix} \cdot \begin{bmatrix} \frac{x}{z} \\[5pt] \frac{y}{z} \\[5pt] 1 \end{bmatrix} \end{equation}
\begin{equation} (u,v,1) = \begin{bmatrix} f & 0 & \frac{w}{2} \\[5pt] 0 & f & \frac{h}{2} \\[5pt] 0 & 0 & 1 \\[5pt] \end{bmatrix} \cdot \begin{bmatrix} \frac{x}{z} \\[5pt] \frac{y}{z} \\[5pt] 1 \end{bmatrix} \end{equation}
 \begin{equation} f = \dfrac{0.5 \times w}{\tan \left (0.5 \times HFOV \times \dfrac{\pi }{180}\right )} \end{equation}
\begin{equation} f = \dfrac{0.5 \times w}{\tan \left (0.5 \times HFOV \times \dfrac{\pi }{180}\right )} \end{equation}
However, this model type is only valid behind ideal scenes, such as in the simulation. For the OAK-1 camera, an additional calibration step was required to estimate the intrinsic parameters. For calibration, we used the Kalibr software [Reference Maye, Furgale and Siegwart47].
2.4. Objects positioning
At the end of the execution of the histogram filter for multiple viewpoints, the state space
 $\text{dom}(X_t)$
should have different clusters of points. As we know the number of objects in the scene through the number of detected objects by the detection camera, we can use the k-means algorithm to aggregate the points and compute the centre of each cluster.
$\text{dom}(X_t)$
should have different clusters of points. As we know the number of objects in the scene through the number of detected objects by the detection camera, we can use the k-means algorithm to aggregate the points and compute the centre of each cluster.
The k-means algorithm tries to cluster the different points of the discrete state space by minimising the geometric distance between points to the cluster’s centre (9). In Eq. 9, we minimise the Euclidean distance between points to
 $\mu _j$
, the centre point of each cluster in
$\mu _j$
, the centre point of each cluster in
 $C$
.
$C$
.
 \begin{equation} \sum _{i=0}^{n} \min _{\mu _j \in C}(||x_{i,t} - \mu _j||^2) \end{equation}
\begin{equation} \sum _{i=0}^{n} \min _{\mu _j \in C}(||x_{i,t} - \mu _j||^2) \end{equation}
After clustering by the k-means, the state space should have as many point clouds as the number of objects detected by the detection camera. The computation of the centre of the clouds to get the position of the detected objects can be done in two ways:
-
1. computation of the geometric centre of the cloud; or
-
2. computation of the weighted centre of the cloud.
The geometric centre of each point cloud is the Euclidean centre
 $\mu _j$
minimised during the k-means algorithm for Eq. 9. Besides the geometric centre, the k-means also return the points,
$\mu _j$
minimised during the k-means algorithm for Eq. 9. Besides the geometric centre, the k-means also return the points,
 $x_{i,t}$
, that belong to each cloud,
$x_{i,t}$
, that belong to each cloud,
 $S_j$
. Considering the state of each element of the state space
$S_j$
. Considering the state of each element of the state space
 $\text{dom}(X_t)$
at the end of the histogram filter, each element
$\text{dom}(X_t)$
at the end of the histogram filter, each element
 $x_{i,t}$
should have a weight attributed,
$x_{i,t}$
should have a weight attributed,
 $w_i$
. So the weighted centre is the weighted average (10) of the coordinates of
$w_i$
. So the weighted centre is the weighted average (10) of the coordinates of
 $x_{i,t}$
that belong to the set
$x_{i,t}$
that belong to the set
 $S_j$
.
$S_j$
.
 \begin{equation} \mu _j = \begin{bmatrix} \dfrac{\sum _i^N w_i \cdot x_{{i,t}_1}}{N} & \dfrac{\sum _i^N w_i \cdot x_{{i,t}_2}}{N} & \dfrac{\sum _i^N w_i \cdot x_{{i,t}_3}}{N} \end{bmatrix}^T \qquad \forall x_{i,t} \in S_j \end{equation}
\begin{equation} \mu _j = \begin{bmatrix} \dfrac{\sum _i^N w_i \cdot x_{{i,t}_1}}{N} & \dfrac{\sum _i^N w_i \cdot x_{{i,t}_2}}{N} & \dfrac{\sum _i^N w_i \cdot x_{{i,t}_3}}{N} \end{bmatrix}^T \qquad \forall x_{i,t} \in S_j \end{equation}
2.5. Experiments
Three essays were performed in different environments to validate the effectiveness of the MonoVisual3DFilter.
Using the Gazebo simulator, we created a scene with multiple spheres to estimate their position in the scene (Figure 2). Once we used a bounding box camera without noise, this approach allowed validating the real performance of the filter without external artefacts or noise. Additionally, we performed an additional essay, introducing some Gaussian noise that randomly changes the position and size of the bounding box of the detected objects, as well as whether the object is successfully detected. Because we do not assemble any manipulator at the simulator, the bounding box camera has more freedom to state its pose. So, during the simulations, we set the camera’s pose to ensure the spheres’ visibility. Figure 7 illustrates the visible image of the camera at each pose. In the first pose, the camera looks straight towards the spheres (Figure 7a). After the camera moves down and left, looking upwards (Figure 7b), and finally, the camera moves up and right to the first pose, looking downwards (Figure 7c). This composition of the camera was kept for both experiments in the simulator.

Figure 7. View of the spheres by the bounding box camera at each fixed viewpoint. The green square boxes around the spheres are the bounding boxes of the detected spheres by the bounding box camera.
In the third essay, a realistic testbed was deployed to experiment with the algorithm in near-real-world conditions at the laboratory (Figure 3). The testbed is composed of realistic artificial leaves and realistic plastic tomatoes. The tomatoes were hung in the testbed between the leaves. For baselining the tomatoes’ position in the testbed, we relied on the manipulator’s kinematics. For each tomato in the testbed, we moved the manipulator end-effector until the fruit and retrieved the end-effector’s position. This will be the tomato position to the manipulator’s base frame. Similarly to the essays in simulation, the bounding box camera at the simulator moved to three fixed poses that always assured the visibility of the tomatoes. A similar scheme to the one used before was set concerning the several limitations of the manipulator’s manoeuvrability that made it difficult to set some poses to the camera. Unlike the simulation essays, several experiments were performed in the testbed. In the different experiments, we considered between one to three tomatoes being localised simultaneously, summing up to ten tomatoes and sixty measures. Figure 8 illustrates the tomatoes’ visibility by the OAK camera at each selected pose, for the different experiments. The rows represent the different considered experiments and each image has the tomatoes being localised simultaneously.

Figure 8. View of the tomatoes in the testbed at each pose of the OAK-1 camera. The blue squares around the tomatoes are the detected tomatoes by the bounding box camera OAK-1 using a custom-trained YOLO v8 tiny detector. Inside each bounding box are the detected class (tomato) and the detection confidence. Each row is an experiment, in a total of six experiments, and each figure contains the number of tomatoes being detected.
To better assess the performance of the histogram filter to estimate the position of objects, we extracted some error metrics, namely, the mean absolute error (11), the mean square error (12), the root mean square error or standard deviation (13), and the mean absolute percentage error (14). In these equations,
 $\mu _j$
is the real centre of the object for the cluster
$\mu _j$
is the real centre of the object for the cluster
 $S_j$
, and
$S_j$
, and
 $\hat{\mu }_j$
is the estimated one using the previous methods, given the cluster
$\hat{\mu }_j$
is the estimated one using the previous methods, given the cluster
 $j$
until the maximum of clusters
$j$
until the maximum of clusters
 $M$
.
$M$
.
 \begin{equation} \text{MAE }(\mu _j,\hat{\mu }_j) = \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M |\mu _{ij} - \hat{\mu }_{ij}| \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
\begin{equation} \text{MAE }(\mu _j,\hat{\mu }_j) = \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M |\mu _{ij} - \hat{\mu }_{ij}| \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
 \begin{equation} \text{MSE }(\mu _j,\hat{\mu }_j) = \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M (\mu _{ij} - \hat{\mu }_{ij})^2 \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
\begin{equation} \text{MSE }(\mu _j,\hat{\mu }_j) = \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M (\mu _{ij} - \hat{\mu }_{ij})^2 \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
 \begin{equation} \text{RMSE }(\mu _j,\hat{\mu }_j) = \sqrt{ \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M (\mu _{ij} - \hat{\mu }_{ij})^2} \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
\begin{equation} \text{RMSE }(\mu _j,\hat{\mu }_j) = \sqrt{ \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M (\mu _{ij} - \hat{\mu }_{ij})^2} \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
 \begin{equation} \text{MAPE }(\mu _j, \hat{\mu }_j) = \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M \left |\dfrac{\mu _{ij}-\hat{\mu }_{ij}}{\mu _{ij}}\right | \times 100 \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
\begin{equation} \text{MAPE }(\mu _j, \hat{\mu }_j) = \dfrac{1}{N\cdot M} \sum _i^N \sum _j^M \left |\dfrac{\mu _{ij}-\hat{\mu }_{ij}}{\mu _{ij}}\right | \times 100 \qquad \forall j \in \mathbb{N}\;:\;\{1 .. M\} \end{equation}
Figure 9. Iteration of the histogram filter during simulation for detecting the six spheres, considering a square kernel. (a) Decomposition of the state space at the beginning of the algorithm; (b) detection at the end of the first viewpoint; (c) detection at the end of the second viewpoint; (d) detection at the end of the third viewpoint.
3. Results
As referred to in the previous section, we made three essays to validate the MonoVisual3DFilter’s performance. Two essays happened in simulation, while the third was in a simulated testbed at the laboratory. To measure the performance, we recurred to different error metrics: (11), (12), (13) and (14). The manipulator and the bounding box camera were moved to fixed poses where all the fruits were always visible. All permutations between poses were considered for the essays, resulting in six estimations of each tomato for each experiment. The computed error results from the error of each estimated pose to ground truth pose of each corresponding tomato.
In the first essay, we used the simulation to estimate the 3D position of the green spheres (Figure 2) without any noise. During the execution of the histogram filter, the bounding box camera moved to different poses to intersect and be these positions. At each pose, the state space is operated to remove or smooth the existence of objects in each state according to the used kernel. Two kinds of kernels were considered, the square kernel (Figure 9) and the Gaussian kernel (Figure 10). Visually, both kernels performed similarly; however, the Gaussian kernel has two hyperparameters that deliver more freedom to set the kernel’s size and estimate the objects’ position, allowing the Gaussian filter to be more aggressive or smooth. We considered a two-dimensional Gaussian filter with
 $\mathcal{N}(0, \text{size}/2)$
for the current experiment, where size is the width or the height of the detected object. The plot of Figure 11 illustrates the error using a square or Gaussian kernel and the geometric centres from the k-means algorithm or the weighted centre resulting from applying the computed weights of the histogram filter. For this essay, using a Gaussian kernel with a weighted centre estimation was advantageous.
$\mathcal{N}(0, \text{size}/2)$
for the current experiment, where size is the width or the height of the detected object. The plot of Figure 11 illustrates the error using a square or Gaussian kernel and the geometric centres from the k-means algorithm or the weighted centre resulting from applying the computed weights of the histogram filter. For this essay, using a Gaussian kernel with a weighted centre estimation was advantageous.

Figure 10. Iteration of the histogram filter during simulation for detecting the six spheres, considering a Gaussian kernel,
 $\mathcal{N}(0, 0.2)$
. (a) Decomposition of the state space at the beginning of the algorithm; (b) detection at the end of the first viewpoint; (c) detection at the end of the second viewpoint; (d) detection at the end of the third viewpoint.
$\mathcal{N}(0, 0.2)$
. (a) Decomposition of the state space at the beginning of the algorithm; (b) detection at the end of the first viewpoint; (c) detection at the end of the second viewpoint; (d) detection at the end of the third viewpoint.

Figure 11. Error in estimating the position of the spheres in simulation without noise.
Adding some noise to the simulation by moving the bounding box’s centre and size and deleting it randomly, we get the results of Figure 12. For moving the bounding box’s centre and dimensions, we considered a Gaussian profile with
 $\mathcal{N}(0, 0.05)$
. The bounding box will likely fail of 2%. Once again, the Gaussian kernel with a weighted estimation of the spheres’ centre performed better. Besides, in this experiment, the Gaussian kernel was more robust and accurate than the square kernel. The behaviour of the histogram filter in each pose is similar to the previous essay, but now, the algorithm has reported more noise. We set the Gaussian kernel such as
$\mathcal{N}(0, 0.05)$
. The bounding box will likely fail of 2%. Once again, the Gaussian kernel with a weighted estimation of the spheres’ centre performed better. Besides, in this experiment, the Gaussian kernel was more robust and accurate than the square kernel. The behaviour of the histogram filter in each pose is similar to the previous essay, but now, the algorithm has reported more noise. We set the Gaussian kernel such as
 $\mathcal{N}(0, size/3)$
to overcome this effect and have a more stable filter. This is the smallest value that assures that any fruit is lost and the point cloud is not too sparse, intersecting with the cloud of other fruits.
$\mathcal{N}(0, size/3)$
to overcome this effect and have a more stable filter. This is the smallest value that assures that any fruit is lost and the point cloud is not too sparse, intersecting with the cloud of other fruits.

Figure 12. Error in estimating the position of the spheres in simulation with noise.

Figure 13. Error in estimating the position of the tomatoes at the testbed.
Given the overall success of the essays with a mean absolute error smaller than 1 cm, we essayed the algorithm in a testbed at the laboratory. Figure 13 illustrates the box plot error of the MonoVisual3DFilter in the testbed, using the Robotis Manipulator-H and the OAK-1 camera. A descriptive statement of the error is made in Table II. In this analysis, we also considered the average Euclidean error distance and the MAPE to better assess the feasibility of the MonoVisual3DFilter. In all the camera poses, all the tomatoes were always visible (Figure 8). For this essay, we considered six experiments that aimed to estimate the position between one to three tomatoes simultaneously, as stated in Figure 8, and summing up to sixty estimated measures for the position of the tomatoes. Against the expected, Gaussian kernels performed worse than square kernels, and the results of weighted and geometric centres are identical, despite the weighted method tending to have a lower error for the same standard deviation.
4. Discussion
The overall use of MonoVisual3DFilter for estimating the 3D position of tomato fruits looks effective.
Under a simulated environment, the system always got a maximum error smaller than 10 mm. Increasing the resolution of the discretised state space could leverage better system accuracy, but increase the processing time and memory usage. As made in the second experiment, adding noise to the system makes the importance of using smooth kernels visible. The square kernel’s aggressive binary behaviour rejects some state space positions and can never be recovered. On the other hand, the Gaussian filter has a smooth behaviour, and the positions are iteratively removed according to their distance from the filter’s centre. So, smooth kernels can recover some state space points since they are never completely rejected. Besides, the Gaussian filter also was more failure-prone than the square kernel because the last one failed many times to detect the fruits, forcing us to repeat some experiments. Because the positions near the centre of the tomato have a bigger score, using weighted centre estimation procedures allows for a better fit of the estimated centre to the real centre of the tomato, reducing the effect and deviations of sparse clouds.
Table II. Error computations to the testbed experiments for the different kernels and centre estimation methods.
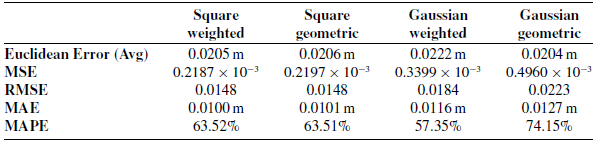
When moving the implemented algorithm to a real robot and camera in a testbed, we reported that, against expectations, the Gaussian kernels were not very effective and square kernels reached a higher accuracy. In this case, it is always irrelevant to consider geometric or weighted estimations of the centre. In the testbed, the system reported a mean absolute error around 20 mm, but the error can evolute to near 60 mm that can compromise the use of the algorithm for more demanding tasks. However, it is still important to better identify the source of the error, whether it comes from the MonoVisual3DFilter or the ground-truth’s baseline, which was badly fitted to the tomato centre. Although the experiment was made with the viewpoints distanced by around 0.5 m of the fruits, the error should improve if a closer assessment of the tomato position is made. However, the reported error could not be critical whether using soft-grippers to aid harvesting tasks or using complementary algorithms. For tasks such as monitoring, this error could even be less relevant.
Additional experiments also allowed us to assess the importance of the selected viewpoints. Co-linear viewpoints do not allow for effective estimation of the position of the objects. However, normal viewpoints aim to better intersect the filter views and effectively estimate the position of the objects. This topic should be a concern under real world and testbed experiments because we frequently use manipulators with several positioning and orienting constraints.
Experiments as reported in Figs. 8j, 8k, 8l, and some others, could assess the feasibility of the MonoVisual3DFilter to partially occluded fruits. First, due to the limitations of detection algorithms to detect completely occluded objects, the MonoVisual3DFilter do not work for these cases. Concerning partial occlusion, we verified that the MonoVisual3DFilter could lead with the occlusion and effectively estimate the position of the tomato (Figure 14). Going further, we can even state that the MonoVisual3DFilter is occlusion independent and estimates the position of occluded objects so good as good is the object detector.


Figure 15. RGB and depth images from the MiDaS v3.1 DPT SWIN2 Large 384 for estimating the tomatoes’ distance to the camera’s sensor.
Observing the literature (section 1), we can conclude that it tends to use deep learning solutions to infer the depth from monocular RGB cameras. A solution already available in the literature and that aims to effectively estimate the depth from images is the MiDaS network [Reference Birkl, Wofk and Müller18, Reference Ranftl, Lasinger, Hafner, Schindler and Koltun22]. For comparison with the MonoVisual3DFilter, we used the MiDaS v3.1 DPT SWIN2 Large 384, and applied it to the images of the experiment composed by the Figs. 8g, 8h, and 8i. Figure 15 reports the output of the MiDaS CNN for the proposed images. Once the network reports a relative pose, a calibration is required to estimate the real depth to the camera. According to [Reference Ranftl, Lasinger, Hafner, Schindler and Koltun22], the absolute depth can be computed through a linear regression curve. So, a rough calibration was performed and reported the curve of Figure 16a. As can be visually concluded from Figure 15, the depth image reports a flat image, and it is difficult to understand the depth of the fruit. So, the network cannot effectively estimate the position of the fruit and reports errors up to 10 cm (Figure 16b). However, depth essays and calibration procedures should be made to purposefully conclude the noneffectiveness of MiDaS to estimate the depth of the image, i.e., MiDaS requires a complete RGB-D system to correctly calibrate the RGB sensor and network. Despite this error, deep learning-based solutions are much more computing demanding and less straightforward, difficulting to improve the results and track the origin of the errors. Besides, they also require much training and reliable data. On the other hand, MonoVisual3DFilter is data-independent, and its behaviour is more predictable.
Such as identified during the literature review in the introduction section are algorithms such as the SilhoNet, Nerf-Pose, or the GDR-Net. All of these algorithms have detection errors of about 2 cm. Near the MonoVisual3DFilter is the Imitrob model that can estimate the pose of the objects without their model, but reaches an estimation error of 6.5 cm on average. These solutions are competitive with the MonoVisual3DFilter, mainly if we consider complex datasets such as the one where they were essayed. Besides these algorithms can estimate the 6D pose of the target objects. Although these advantages are against the MonoVisual3DFilter, almost all of the solutions are model-dependent and computing-demanding. The MonoVisual3DFilter that we are here proposing is model-independent and only requires a mechanism capable of accurately detecting the target objects in a 2D scene. Besides, from these approaches, we can also conclude that our solution can be improved if we provide it with instance segmentation masks instead of rectangular bounding boxes that contain areas that do not belong to the objects.

Figure 16. Calibration curve to estimate the absolute depth in metres to the camera sensor for MiDaS CNN.
The MonoVisual3DFilter can estimate objects’ position in the 3D, mainly the circular ones. However, this algorithm is, currently, computationally demanding and requires many resources and time to compute a solution. In our case, the system took about one minute in each pose to compute the decomposed state-space using an Intel Core i7 with 8 GB of random-access memory (RAM). However, this is a highly parallelisable algorithm once all the positions are independent and can be computed simultaneously. So parallel implementation of the MonoVisual3DFilter at the computer processing unit (CPU), graphical processing unit (GPU), or mainly at the field programmable gate array (FPGA) can proportionally boost the speed of inference. Additionally, better optimisation of the implemented code can be done, mainly by using more efficient programming languages such as C or C++ instead of Python, which is less efficient and is interpreted during execution.

Figure 17. Maximum speedup analysis for parallelisation according to Amdahl’s law for the Gaussian and square kernels.
To better understand the advantages of parallelising the MonoVisual3DFilter, we studied the algorithm speedup through Amdahl’s law [Reference Amdahl48] (15). In this equation, (15),
 $\sigma (n)$
is the inherently sequential computations,
$\sigma (n)$
is the inherently sequential computations,
 $\varphi (n)$
is the potentially parallel computations, and
$\varphi (n)$
is the potentially parallel computations, and
 $p$
is the number of processors (processes computing in parallel). It is important to mind that Amdahl’s law ignores the communications between processes, so this law only computes the maximum speedup,
$p$
is the number of processors (processes computing in parallel). It is important to mind that Amdahl’s law ignores the communications between processes, so this law only computes the maximum speedup,
 $\Psi (n,p)$
. Figure 17 illustrates the maximum reachable speedup by parallelising the histogram filter. The Gaussian filter reaches a higher speedup of about 17.5, but the square is a simpler kernel that operates faster, so the speedup is limited by the inherently sequential operations that cannot be optimised. During simulation, in a computer with an Intel Core i7 and 8 GB of RAM, the histogram filter took about 115 s/pose using the Gaussian Filter and 99s/pose using the square kernel, without parallelisation. The number of available cores also limits the speedup of the histogram filter. Once it is a very parallelisable algorithm, it benefits from using many cores, so the CPU is not so interesting such as GPU or FPGA because it is usually limited to 16 cores.
$\Psi (n,p)$
. Figure 17 illustrates the maximum reachable speedup by parallelising the histogram filter. The Gaussian filter reaches a higher speedup of about 17.5, but the square is a simpler kernel that operates faster, so the speedup is limited by the inherently sequential operations that cannot be optimised. During simulation, in a computer with an Intel Core i7 and 8 GB of RAM, the histogram filter took about 115 s/pose using the Gaussian Filter and 99s/pose using the square kernel, without parallelisation. The number of available cores also limits the speedup of the histogram filter. Once it is a very parallelisable algorithm, it benefits from using many cores, so the CPU is not so interesting such as GPU or FPGA because it is usually limited to 16 cores.
 \begin{equation} \Psi (n,p) \leqslant \frac{\sigma (n)+\varphi (n)}{\sigma (n)+\dfrac{\varphi (n)}{p}} \end{equation}
\begin{equation} \Psi (n,p) \leqslant \frac{\sigma (n)+\varphi (n)}{\sigma (n)+\dfrac{\varphi (n)}{p}} \end{equation}
5. Conclusion
During this experiment, we designed a histogram filter-based algorithm, the MonoVisual3DFilter, to infer the 3D position of tomatoes in the tomato plant canopy using monocular cameras. The algorithm performed reasonably with an overall error of about 20 mm in laboratory-controlled conditions.
Despite the MonoVisual3DFilter being valid for estimating the tomatoes’ position, some additional improvements are required. The next steps should focus on optimising the selection of the observation poses, making these poses adjustable and variable according to the fruit being analysed, and maximising observability through intelligent algorithms. The proposed algorithm can probably be improved if we feed it with instance segmentation masks instead of bounding boxes. Besides, improvements in execution time are still needed by optimising the developed code and implementing parallelisation strategies.
Other opportunities can also be explored while using the proposed algorithm. An example of that is using radar technology that allows one to perceive occluded objects behind the scene. Other similarly perceiving sensors can also be considered, acquiring the system with more robust sensors to perturbances in the scene.
Therefore, using histogram filters to estimate the position of objects, namely, the MonoVisual3DFilter, is viable and suitable for operating in the field under controlled scenarios. Further essays should be conducted on real scenarios and the implementation of active perception strategies.
Author contributions
Conceptualisation, S.C.M. and F.N.d.S.; funding acquisition, S.A.M and F.N.d.S.; investigation, S.C.M.; methodology, S.C.M.; software, S.C.M; formal analysis, S.C.M.; resources, F.N.d.S and A.P.M.; project administration, S.A.M, F.N.d.S., J.D. and A.P.M; supervision, F.N.d.S., J.D. and A.P.M.; validation, F.N.d.S., J.D. and A.P.M.; writing – original draft, S.C.M.; writing – review and editing, S.C.M., F.N.d.S., J.D. and A.P.M.
Financial support
This work is co-financed by Component 5 – Capitalization and Business Innovation, integrated in the Resilience Dimension of the Recovery and Resilience Plan within the scope of the Recovery and Resilience Mechanism (MRR) of the European Union (EU), framed in the Next Generation EU, for the period 2021–2026, within project PhenoBot-LA8.3, with reference PRR-C05-i03-I-000134-LA8.3.
Sandro Costa Magalhães is granted by the Portuguese Foundation for Science and Technology (FCT – Fundação para a Ciência e Tecnologia), through the European Social Fund (ESF) integrated into the Program NORTE2020, under scholarship agreement SFRH/BD/147117/2019 (DOI:10.54499/SFRH/BD/147117/2019).
Competing interests
The authors declare no conflicts of interest exist.
Ethical approval
Not applicable.






















 Open access
Open access