



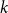

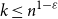
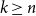
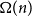
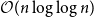
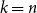
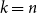

1. Introduction
Mastermind is a famous code-breaking board game for two players. One player, codemaker, creates a hidden codeword consisting of a sequence of four colours. The goal of the second player, the codebreaker, is to determine this codeword in as few guesses as possible. After each guess, codemaker provides a certain number of black and white pegs indicating how close the guess is to the real codeword. The game is over when codebreaker has made a guess identical to the hidden string.
The board game version was first released in 1971, though the idea of the game is older, and variations of this game have been played earlier under other names, such as the pen-and-paper-based games of Bulls and Cows, and Jotto. The game has been played on TV as a game show in multiple countries under the name of Lingo. Recently, a similar web-based game has gained much attention under the name of Wordle.
Guessing games such as Mastermind have gained much attention in the scientific community. This is in part due to their popularity as recreational games, but importantly also as natural problems in the intersection of information theory and algorithms. In particular, it is not too hard to see that two-colour Mastermind is equivalent to coin-weighing with a spring scale. This problem was first introduced in 1960 by Shapiro and Fine [Reference Shapiro and Fine14]. In subsequent years, a number of different approaches have been devised which solve this problem up to a constant factor of the information-theoretic lower bound.
The general
 $k$
colour
$k$
colour
 $n$
slot Mastermind first appeared in the scientific literature in 1983 in a paper by Chvátal [Reference Chvátal3]. By extending ideas of Erdős and Rényi [Reference Erdős and Rényi5] from coin-weighing he showed that the information-theoretic lower bound is sharp up to a constant factor for
$n$
slot Mastermind first appeared in the scientific literature in 1983 in a paper by Chvátal [Reference Chvátal3]. By extending ideas of Erdős and Rényi [Reference Erdős and Rényi5] from coin-weighing he showed that the information-theoretic lower bound is sharp up to a constant factor for
 $k\leq n^{1-\varepsilon }$
for any fixed
$k\leq n^{1-\varepsilon }$
for any fixed
 $\varepsilon \gt 0$
.
$\varepsilon \gt 0$
.
Surprisingly, for a larger number of colours, the number of guesses needed to reconstruct the codeword has remained unknown. In particular, for
 $k=n$
, the best known upper bound remained for a long time
$k=n$
, the best known upper bound remained for a long time
 $\mathcal{O}(n \log n)$
as shown by Chvátal, with only constant factor improvements given in [Reference Chen, Cunha, Homer, Cai and Wong2], [Reference Goodrich8], and [Reference Jäger and Peczarski9]. Only quite recently, this bound was improved to
$\mathcal{O}(n \log n)$
as shown by Chvátal, with only constant factor improvements given in [Reference Chen, Cunha, Homer, Cai and Wong2], [Reference Goodrich8], and [Reference Jäger and Peczarski9]. Only quite recently, this bound was improved to
 $\mathcal{O}(n \log \log n)$
in an article by Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4] published in Journal of the ACM in 2016. At the same time, no significant improvement on the information-theoretic lower bound of
$\mathcal{O}(n \log \log n)$
in an article by Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4] published in Journal of the ACM in 2016. At the same time, no significant improvement on the information-theoretic lower bound of
 $n$
queries has been obtained.
$n$
queries has been obtained.
The challenge of finding short solutions to Mastermind in the setting of
 $k=n$
colours and positions can be thought of as a bootstrapping paradox. On the one hand, a query could in principle return anything between
$k=n$
colours and positions can be thought of as a bootstrapping paradox. On the one hand, a query could in principle return anything between
 $0$
and
$0$
and
 $n$
black pegs, awarding codebreaker potentially with as many as
$n$
black pegs, awarding codebreaker potentially with as many as
 $\log (n+1)$
bits of information about the codeword. As it takes
$\log (n+1)$
bits of information about the codeword. As it takes
 $\log (n^n)=n\log n$
bits of information to encode an arbitrary codeword, it follows that any strategy needs
$\log (n^n)=n\log n$
bits of information to encode an arbitrary codeword, it follows that any strategy needs
 $\Omega (n\log n/\log (n+1))=\Omega (n)$
queries. On the other hand, given no prior information about the codeword, codebreaker can only expect to get a constant number of correct guesses, meaning that the query only awards codebreaker with
$\Omega (n\log n/\log (n+1))=\Omega (n)$
queries. On the other hand, given no prior information about the codeword, codebreaker can only expect to get a constant number of correct guesses, meaning that the query only awards codebreaker with
 $\mathcal{O}(1)$
bits of information.Footnote
1
Morally, one expects queries with higher information content to gradually become available as codebreaker gains information about the codeword, but making sense of this formally has turned out to be difficult problem. In particular, should one expect the entropy lower bound of
$\mathcal{O}(1)$
bits of information.Footnote
1
Morally, one expects queries with higher information content to gradually become available as codebreaker gains information about the codeword, but making sense of this formally has turned out to be difficult problem. In particular, should one expect the entropy lower bound of
 $\Omega (n)$
to be the truth, or could it be that this bound is unattainable as it takes too long to reach the point where queries give the full
$\Omega (n)$
to be the truth, or could it be that this bound is unattainable as it takes too long to reach the point where queries give the full
 $\Theta (\log n)$
bits of information?
$\Theta (\log n)$
bits of information?
In this paper, we resolve this problem after almost 40 years by showing how the
 $n$
colour
$n$
colour
 $n$
slot Mastermind can be solved with
$n$
slot Mastermind can be solved with
 $\mathcal{O}(n)$
guesses with high probability, matching the information-theoretic lower bound up to a constant factor. By combining this with a result by Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4], we determine asymptotically the optimal number of guesses for all
$\mathcal{O}(n)$
guesses with high probability, matching the information-theoretic lower bound up to a constant factor. By combining this with a result by Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4], we determine asymptotically the optimal number of guesses for all
 $k$
and
$k$
and
 $n$
.
$n$
.
1.1 Game of Mastermind
We define a game of Mastermind with
 $k \geq 1$
colours and
$k \geq 1$
colours and
 $n \geq 1$
positions as a two-player game played as follows. One player, the codemaker, initially chooses a hidden codeword
$n \geq 1$
positions as a two-player game played as follows. One player, the codemaker, initially chooses a hidden codeword
 $c = (c_1, \ldots,c_n)$
in
$c = (c_1, \ldots,c_n)$
in
 $[k]^n$
. The other player, the codebreaker, is then tasked with determining the hidden codeword by submitting a sequence of queries of the form
$[k]^n$
. The other player, the codebreaker, is then tasked with determining the hidden codeword by submitting a sequence of queries of the form
 $q = (q_1, \ldots,q_n) \in [k]^n$
. For each query, the codemaker must directly respond with information on how well the query matches the codeword. The codebreaker may use this information to adapt subsequent queries. The precise information given depends on which variation of Mastermind is played, as will be specified below. The game is over as soon as codebreaker makes a query such that
$q = (q_1, \ldots,q_n) \in [k]^n$
. For each query, the codemaker must directly respond with information on how well the query matches the codeword. The codebreaker may use this information to adapt subsequent queries. The precise information given depends on which variation of Mastermind is played, as will be specified below. The game is over as soon as codebreaker makes a query such that
 $q=c$
. The goal of the codebreaker is to make the game ends after as few queries as possible.
$q=c$
. The goal of the codebreaker is to make the game ends after as few queries as possible.
For each pair of a codeword
 $c$
and a query
$c$
and a query
 $q$
, we associate two integers called the number of black pegs and white pegs, respectively. The number of black pegs,
$q$
, we associate two integers called the number of black pegs and white pegs, respectively. The number of black pegs,
 \begin{equation*}b(q)=b_c(q) \;:\!=\; |\{i\in [n] \;:\; q_i=c_i\}|,\end{equation*}
\begin{equation*}b(q)=b_c(q) \;:\!=\; |\{i\in [n] \;:\; q_i=c_i\}|,\end{equation*}
is the number of positions in which the codeword matches the query string. The number of white pegs is often referred to as the number of correctly guessed colours that do not have the correct position. More precisely, the number of white pegs,
 \begin{equation*}w(q)=w_c(q)\;:\!=\; \max _{\sigma \in S_n} |\{i\in [n] \;:\; q_{\sigma (i)}=c_i\}| - b_c(q),\end{equation*}
\begin{equation*}w(q)=w_c(q)\;:\!=\; \max _{\sigma \in S_n} |\{i\in [n] \;:\; q_{\sigma (i)}=c_i\}| - b_c(q),\end{equation*}
is the number of additional correct positions one can maximally obtain by permuting the entries of
 $q$
.
$q$
.
In this paper, we will consider two versions of Mastermind. First, in black-peg Mastermind the codemaker gives only the number of black pegs as an answer to every query. Second, in black-white-peg Mastermind the codemaker gives both the number of black and the number of white pegs as answers to every query.
1.2 Our results
Our contribution lies in resolving the black-peg Mastermind game for
 $k = n$
where we have as many possible colours as positions.
$k = n$
where we have as many possible colours as positions.
Theorem 1.1.
There exists a randomised algorithm that solves black-peg Mastermind with
 $n$
colours and
$n$
colours and
 $n$
positions with high probability using
$n$
positions with high probability using
 $\mathcal{O}(n)$
queries. Moreover, the runtime of the algorithm is polynomial in
$\mathcal{O}(n)$
queries. Moreover, the runtime of the algorithm is polynomial in
 $n$
.
$n$
.
The above result is best possible up to a constant factor. This can be seen by observing that there are at most
 $n+1$
possible answers to any query. Hence, codebreaker gains at most
$n+1$
possible answers to any query. Hence, codebreaker gains at most
 $\log _2(n+1)$
bits of information from a query. As
$\log _2(n+1)$
bits of information from a query. As
 $\log _2(n^n)=n\log _2 n$
bits are required to uniquely determine the codeword, any strategy needs at least
$\log _2(n^n)=n\log _2 n$
bits are required to uniquely determine the codeword, any strategy needs at least
 $\Omega (n)$
queries. Moreover, if we additionally assume that the codeword can only be a permutation of the colours, that is each colour must appear exactly once, then we can solve it deterministically with
$\Omega (n)$
queries. Moreover, if we additionally assume that the codeword can only be a permutation of the colours, that is each colour must appear exactly once, then we can solve it deterministically with
 $\mathcal{O}(n)$
queries.
$\mathcal{O}(n)$
queries.
Combining our results with earlier results by Doerr, Doerr, Spöhel, and Thomas we are able to resolve the randomised query complexity of Mastermind in the full parameter range, thus finally resolving this problem after almost 40 years. We define the randomised query complexity as the minimum (over all strategies) maximum (over all codewords) expected number of queries needed to win the game.
Theorem 1.2.
For
 $k$
colours and
$k$
colours and
 $n$
positions, the randomised query complexity of Mastermind is
$n$
positions, the randomised query complexity of Mastermind is
 \begin{equation*}\Theta (n \log k/ \log n + k/n),\end{equation*}
\begin{equation*}\Theta (n \log k/ \log n + k/n),\end{equation*}
if codebreaker receives both black-peg and white-peg information for each query, and
 \begin{equation*}\Theta (n \log k/ \log n + k),\end{equation*}
\begin{equation*}\Theta (n \log k/ \log n + k),\end{equation*}
if codebreaker only receives black-peg information.
We believe the same result holds true for the deterministic query complexity, but we will not attempt to prove it here.
1.3 Related work
The study of two-colour Mastermind dates back to an American Mathematical Monthly post in 1960 by Shapiro and Fine [Reference Shapiro and Fine14]: “Counterfeit coins weigh 9 grams and genuine coins all weigh 10 grams. One is given
 $n$
coins of unknown composition, and an accurate scale (not a balance). How many weighings are needed to isolate the counterfeit coins?”
$n$
coins of unknown composition, and an accurate scale (not a balance). How many weighings are needed to isolate the counterfeit coins?”
It can be observed, already for
 $n=4$
, that fewer than
$n=4$
, that fewer than
 $n$
weighings are required. The authors consequently conjecture that
$n$
weighings are required. The authors consequently conjecture that
 $o(n)$
weighings suffice for large
$o(n)$
weighings suffice for large
 $n$
. Indeed, the entropy lower bound states that at least
$n$
. Indeed, the entropy lower bound states that at least
 $n/\log _2(n+1)$
weighings are necessary. In the subsequent years, many techniques were independently discovered that attain this bound within a constant factor [Reference Cantor and Mills1, Reference Erdős and Rényi5, Reference Lindström12, Reference Lindström13], see also [Reference Erdős and Rényi5] for further early works. Erdős and Rényi [Reference Erdős and Rényi5] showed that a sequence of
$n/\log _2(n+1)$
weighings are necessary. In the subsequent years, many techniques were independently discovered that attain this bound within a constant factor [Reference Cantor and Mills1, Reference Erdős and Rényi5, Reference Lindström12, Reference Lindström13], see also [Reference Erdős and Rényi5] for further early works. Erdős and Rényi [Reference Erdős and Rényi5] showed that a sequence of
 $(2+o(1))n/\log _2 n$
random weighings would uniquely identify the counterfeit coins with high probability, and by the probabilistic method, there is a deterministic sequence of
$(2+o(1))n/\log _2 n$
random weighings would uniquely identify the counterfeit coins with high probability, and by the probabilistic method, there is a deterministic sequence of
 $\mathcal{O}(n/\log n)$
weighings that identify any set of counterfeit coins.
$\mathcal{O}(n/\log n)$
weighings that identify any set of counterfeit coins.
Cantor and Mills [Reference Cantor and Mills1] proposed a recursive solution to this problem. Here it is natural to consider signed coin weighings, where, for each coin on the scale, we may choose whether it contributes with its weight or minus its weight. We call a
 $\{-1, 0, 1\}$
valued matrix
$\{-1, 0, 1\}$
valued matrix
 $A$
an identification matrix if any binary vector
$A$
an identification matrix if any binary vector
 $x$
of compatible length to
$x$
of compatible length to
 $A$
can be uniquely determined by the values of
$A$
can be uniquely determined by the values of
 $Ax$
. So for example
$Ax$
. So for example
 $\begin{pmatrix} 1\;\;\;\; & 0\\ 0\;\;\;\; & 1\end{pmatrix}$
is an identification matrix for binary vectors of length
$\begin{pmatrix} 1\;\;\;\; & 0\\ 0\;\;\;\; & 1\end{pmatrix}$
is an identification matrix for binary vectors of length
 $2$
. It is not too hard to show that if
$2$
. It is not too hard to show that if
 $A$
is an identification matrix, then so is
$A$
is an identification matrix, then so is
 \begin{equation} \begin{pmatrix} A\;\;\;\; & A\;\;\;\; & I\\[5pt] A\;\;\;\; & -A\;\;\;\; & 0\end{pmatrix}. \end{equation}
\begin{equation} \begin{pmatrix} A\;\;\;\; & A\;\;\;\; & I\\[5pt] A\;\;\;\; & -A\;\;\;\; & 0\end{pmatrix}. \end{equation}
By putting
 $A_0=(1)$
and recursing this formula, we obtain an identification matrix
$A_0=(1)$
and recursing this formula, we obtain an identification matrix
 $A_k$
with
$A_k$
with
 $2^k$
rows and
$2^k$
rows and
 $(k+2)2^{k-1}$
columns. Thus, we can identify which out of
$(k+2)2^{k-1}$
columns. Thus, we can identify which out of
 $n=(k+2)2^{k-1}$
coins are counterfeit by using
$n=(k+2)2^{k-1}$
coins are counterfeit by using
 $2^k \sim 2 n/\log _2 n$
signed weighings, or, by weighing the
$2^k \sim 2 n/\log _2 n$
signed weighings, or, by weighing the
 $+1$
s and
$+1$
s and
 $-1$
s separately, using
$-1$
s separately, using
 $\sim 4 n/\log _2 n$
(unsigned) weighings. Using a more careful analysis, the authors show that
$\sim 4 n/\log _2 n$
(unsigned) weighings. Using a more careful analysis, the authors show that
 $\sim 2 n/\log _2 n$
weighings suffice.
$\sim 2 n/\log _2 n$
weighings suffice.
It was shown in [Reference Erdős and Rényi5] that
 $2n/ \log _2 n$
is best possible, up to lower-order terms, for non-adaptive strategies. It is a central open problem to determine the optimal constant for general strategies, but it is currently not known whether adaptiveness can be used to get a leading term improvement.
$2n/ \log _2 n$
is best possible, up to lower-order terms, for non-adaptive strategies. It is a central open problem to determine the optimal constant for general strategies, but it is currently not known whether adaptiveness can be used to get a leading term improvement.
Knuth [Reference Knuth10] studied optimal strategies for the commercially available version of Mastermind, consisting of four positions and six colours. He showed that the optimal deterministic strategy needs 5 guesses in the worst case. In the randomised setting, it was shown by Koyama [Reference Koyama11] that optimal strategy needs in expectation
 $5625/1296 = 4.34\dots$
guesses for the worst-case distribution of codewords.
$5625/1296 = 4.34\dots$
guesses for the worst-case distribution of codewords.
The generalisation of Mastermind to
 $k$
colours and
$k$
colours and
 $n$
positions first appeared in the scientific literature in 1983 in a paper by Chvátal [Reference Chvátal3], who attributed the idea to Pierre Duchet. Here the entropy lower bound states that
$n$
positions first appeared in the scientific literature in 1983 in a paper by Chvátal [Reference Chvátal3], who attributed the idea to Pierre Duchet. Here the entropy lower bound states that
 $\Omega (n \log k/ \log n)$
guesses are necessary. For
$\Omega (n \log k/ \log n)$
guesses are necessary. For
 $k\leq n^{1-\varepsilon }$
, Chvátal showed that a simple random guessing strategy uniquely determines the codeword within a constant factor of the entropy bound.
$k\leq n^{1-\varepsilon }$
, Chvátal showed that a simple random guessing strategy uniquely determines the codeword within a constant factor of the entropy bound.
For larger
 $k$
, less has been known. For
$k$
, less has been known. For
 $k$
between
$k$
between
 $n$
and
$n$
and
 $n^2$
, Chvátal showed that
$n^2$
, Chvátal showed that
 $2n\log _2 k + 4n$
guesses suffice. For any
$2n\log _2 k + 4n$
guesses suffice. For any
 $k\geq n$
, this was improved to
$k\geq n$
, this was improved to
 $2n \log _2 n +2n+\lceil k/n\rceil + 2$
by Chen, Cunha, and Homer [Reference Chen, Cunha, Homer, Cai and Wong2], further to
$2n \log _2 n +2n+\lceil k/n\rceil + 2$
by Chen, Cunha, and Homer [Reference Chen, Cunha, Homer, Cai and Wong2], further to
 $n\lceil \log _2 k\rceil + \lceil (2-1/k)n\rceil + k$
by Goodrich [Reference Goodrich8], and again to
$n\lceil \log _2 k\rceil + \lceil (2-1/k)n\rceil + k$
by Goodrich [Reference Goodrich8], and again to
 $n\lceil \log _2 n\rceil$
$n\lceil \log _2 n\rceil$
 $-n+k+1$
by Jäger and Peczarski [Reference Jäger and Peczarski9]. As a comparison, we note that if
$-n+k+1$
by Jäger and Peczarski [Reference Jäger and Peczarski9]. As a comparison, we note that if
 $k=k(n)$
is polynomial in
$k=k(n)$
is polynomial in
 $n$
, then the entropy lower bound is simply
$n$
, then the entropy lower bound is simply
 $\Omega (n)$
. This gap is a very natural one as Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4] showed in a relatively recent paper that if one uses a non-adaptive strategy, there is in fact a lower bound of
$\Omega (n)$
. This gap is a very natural one as Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4] showed in a relatively recent paper that if one uses a non-adaptive strategy, there is in fact a lower bound of
 $\Omega (n \log n)$
when
$\Omega (n \log n)$
when
 $k = n$
. In the same paper, they also use an adaptive strategy to significantly narrow this gap, showing that
$k = n$
. In the same paper, they also use an adaptive strategy to significantly narrow this gap, showing that
 $\mathcal{O}(n \log \log n)$
guesses suffice for
$\mathcal{O}(n \log \log n)$
guesses suffice for
 $k=n$
. Moreover, they present a randomised reduction from black-white-peg Mastermind to black-peg Mastermind which shows that
$k=n$
. Moreover, they present a randomised reduction from black-white-peg Mastermind to black-peg Mastermind which shows that
 \begin{equation*} \operatorname {bwmm}(n, k) = \Theta ( k/n + \operatorname {bmm}(n, n)),\end{equation*}
\begin{equation*} \operatorname {bwmm}(n, k) = \Theta ( k/n + \operatorname {bmm}(n, n)),\end{equation*}
for any
 $k\geq n$
where
$k\geq n$
where
 $\operatorname{bwmm}(n, k)$
denotes the randomised query complexity for black-white-peg Mastermind with
$\operatorname{bwmm}(n, k)$
denotes the randomised query complexity for black-white-peg Mastermind with
 $k$
colours and
$k$
colours and
 $n$
positions, and where
$n$
positions, and where
 $\operatorname{bmm}(n, n)$
denotes the randomised query complexity for black-peg Mastermind with
$\operatorname{bmm}(n, n)$
denotes the randomised query complexity for black-peg Mastermind with
 $n$
colours and positions. As a consequence, they concluded that
$n$
colours and positions. As a consequence, they concluded that
 $\operatorname{bwmm}(n, k)=\mathcal{O}(n \log \log n + k/n)$
for all
$\operatorname{bwmm}(n, k)=\mathcal{O}(n \log \log n + k/n)$
for all
 $k$
and
$k$
and
 $n$
.
$n$
.
Stuckman and Zhang [Reference Stuckman and Zhang15] showed that it is NP-hard to determine whether a sequence of guesses with black and white peg answers is consistent with any codeword. The analogous result was shown by Goodrich [Reference Goodrich8] assuming only black-peg answers are given. It was shown by Viglietta [Reference Viglietta16] that both of these results hold even for
 $k=2$
.
$k=2$
.
Variations of Mastermind have furthermore been proposed to model problems in security, such as revealing someone’s identity by making queries to a genomic database [Reference Goodrich7], and API-based attacks to determine bank PINs [Reference Focardi, Luccio, Boldi and Gargano6].
2. Proof outline
The proof of Theorem 1.1 can be broken up in two main steps. In the first step, contained in Section 3, we reduce the traditional form of Mastermind to what we call signed permutation Mastermind. This can be described as the variation of Mastermind on
 $n$
positions and colours where
$n$
positions and colours where
-
1. codemaker is restricted to choosing the codeword
 $c$
to be a permutation of
$[n]$
, and
$c$
to be a permutation of
$[n]$
, and -
2. codebreaker can make signed queries
$q\in \{-n, \dots n\},$
where, after each query, codemaker must respond with the value
\begin{equation*}\hat {b}(q) = \hat {b}_c(q) \;:\!=\; |\{i \in [n] | c_i = q_i \}| - |\{i \in [n] | c_i = - q_i \}| .\end{equation*}




In other words, codebreaker can decide, for each position in a query, whether a correct guess should count as a
 $+1$
or as a
$+1$
or as a
 $-1$
. Note also that codebreaker can choose to leave an entry in a query “blank” by giving it the value
$-1$
. Note also that codebreaker can choose to leave an entry in a query “blank” by giving it the value
 $0$
, in which case it will never contribute to the returned value.
$0$
, in which case it will never contribute to the returned value.
This is all done in preparation for the second step, contained in Section 4, where we take a more constructive approach and recursively as well as deterministically provide a set of adaptive queries that give the answer to the signed permutation Mastermind problem.
Our approach to determining the codeword in this version of Mastermind can be described as resolving
 $\mathcal{O}(n \log n)$
subtasks of the form “Given that a colour
$\mathcal{O}(n \log n)$
subtasks of the form “Given that a colour
 $x$
is present in an interval
$x$
is present in an interval
 $I$
, determine whether
$I$
, determine whether
 $x$
is present in the left or right half of
$x$
is present in the left or right half of
 $I$
”. In other words, we attempt a binary search for each colour. We can make such a task part of a query by putting
$I$
”. In other words, we attempt a binary search for each colour. We can make such a task part of a query by putting
 $q_i=x$
for all indices
$q_i=x$
for all indices
 $i$
in the left half of
$i$
in the left half of
 $I$
, and putting
$I$
, and putting
 $q_i=0$
in all indices
$q_i=0$
in all indices
 $i$
in the right half of
$i$
in the right half of
 $I$
. Then this will contribute a with
$I$
. Then this will contribute a with
 $+1$
to the answer of the query if colour
$+1$
to the answer of the query if colour
 $x$
is in the left half of
$x$
is in the left half of
 $I$
, and
$I$
, and
 $0$
and if
$0$
and if
 $x$
is in the right half of
$x$
is in the right half of
 $I$
. Clearly, a single task can be resolved after a single query, however the challenge is to find a way to resolve these tasks by performing only
$I$
. Clearly, a single task can be resolved after a single query, however the challenge is to find a way to resolve these tasks by performing only
 $\mathcal{O}(n)$
queries.
$\mathcal{O}(n)$
queries.
Similar to the algorithm by Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4], we will base our solution on coin-weighing schemes. Here, we think of the
 $\mathcal{O}(n \log n)$
tasks described above as our coins, where a coin has the value
$\mathcal{O}(n \log n)$
tasks described above as our coins, where a coin has the value
 $1$
if the colour in the corresponding task is present in the left half of its interval, and
$1$
if the colour in the corresponding task is present in the left half of its interval, and
 $0$
otherwise. Weighing a collection of coins together corresponds to making one query where each of the corresponding tasks is encoded as described above. Note that if there were no further restrictions on how tasks could be queried together, then any of the classical solutions to coin-weighing would let us resolve the
$0$
otherwise. Weighing a collection of coins together corresponds to making one query where each of the corresponding tasks is encoded as described above. Note that if there were no further restrictions on how tasks could be queried together, then any of the classical solutions to coin-weighing would let us resolve the
 $\mathcal{O}(n \log n)$
tasks in
$\mathcal{O}(n \log n)$
tasks in
 $\mathcal{O}( n \log n/ \log ( n \log n)) = \mathcal{O}(n)$
queries, which is the conclusion we want, but under far too weak assumptions. The classical coin-weighing problem assumes that any collection of coins can be weighed together. This is far from true in the problem at hand. First, we cannot encode two tasks into the same query if their corresponding intervals overlap. Second, tasks depend on each other in the sense that certain tasks are only available for querying after another task is resolved. For instance, we cannot query in which quarter of the codeword the colour red is present until we have first determined in which half of the codeword it is in. This is of particular concern for tasks corresponding to big intervals as, on the one hand, they, intuitively, have little potential to be resolved in parallel, and on the other hand, these are the only tasks that are available initially.
$\mathcal{O}( n \log n/ \log ( n \log n)) = \mathcal{O}(n)$
queries, which is the conclusion we want, but under far too weak assumptions. The classical coin-weighing problem assumes that any collection of coins can be weighed together. This is far from true in the problem at hand. First, we cannot encode two tasks into the same query if their corresponding intervals overlap. Second, tasks depend on each other in the sense that certain tasks are only available for querying after another task is resolved. For instance, we cannot query in which quarter of the codeword the colour red is present until we have first determined in which half of the codeword it is in. This is of particular concern for tasks corresponding to big intervals as, on the one hand, they, intuitively, have little potential to be resolved in parallel, and on the other hand, these are the only tasks that are available initially.
One natural approach to circumvent this is to resolve the tasks ordered by the interval size from large to small, layer by layer. That is, we first determine which half each colour is present in by querying colours one at a time. We then determine which quarter each colour is present in two at a time, and so on. That is, in the
 $i$
th layer we query
$i$
th layer we query
 $2^i$
colours at a time. Using optimal coin-weighing schemes, this can be done in
$2^i$
colours at a time. Using optimal coin-weighing schemes, this can be done in
 $\mathcal{O}( (n/2^i) \cdot 2^i/\log (2^i) )=\mathcal{O}(n/i)$
queries. Alas, this is too slow as summing this over all layers
$\mathcal{O}( (n/2^i) \cdot 2^i/\log (2^i) )=\mathcal{O}(n/i)$
queries. Alas, this is too slow as summing this over all layers
 $i=0, \dots, \log _2 n$
gives a total of
$i=0, \dots, \log _2 n$
gives a total of
 $\mathcal{O}(n\log \log n)$
queries. In order to speed this up to
$\mathcal{O}(n\log \log n)$
queries. In order to speed this up to
 $\mathcal{O}(n)$
queries, we need to find a novel take on coin-weighing schemes where intervals of all different sizes are queried together in one big phase, which respects the dependencies between tasks.
$\mathcal{O}(n)$
queries, we need to find a novel take on coin-weighing schemes where intervals of all different sizes are queried together in one big phase, which respects the dependencies between tasks.
In fact, our solution to this problem is surprisingly elegant. We start by performing a procedure we call preprocess. The aim of which is to use
 $\mathcal{O}(n)$
queries (so far without any information-theoretic speedup) in order to determine the positions of colours sufficiently well so that, after this point, it is possible to query
$\mathcal{O}(n)$
queries (so far without any information-theoretic speedup) in order to determine the positions of colours sufficiently well so that, after this point, it is possible to query
 $n^{\Omega (1)}$
colours together. We then perform a procedure we call solve that employs the parallelism unlocked by preprocess to determine the codeword in an additional
$n^{\Omega (1)}$
colours together. We then perform a procedure we call solve that employs the parallelism unlocked by preprocess to determine the codeword in an additional
 $\mathcal{O}(n)$
queries. This procedure is recursively constructed in a manner similar to divide and conquer algorithms, and using a technique similar to the coin-weighing scheme by Cantor-Mills [Reference Cantor and Mills1] to achieve the information-theoretic speedup.
$\mathcal{O}(n)$
queries. This procedure is recursively constructed in a manner similar to divide and conquer algorithms, and using a technique similar to the coin-weighing scheme by Cantor-Mills [Reference Cantor and Mills1] to achieve the information-theoretic speedup.
Section 5 is then dedicated to the general case where the number of colours k and number of positions n may differ Mastermind. We prove Theorem 1.2. This can be seen as a direct consequence of Theorem 1.1 and applying previous results by Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4].
3. Signed permutation Mastermind
In the following section, we show how to reduce the traditional form of Mastermind to signed permutation Mastermind, as defined in Section 2.
3.1 Finding a zero query
We first show how one can simulate “blank” guesses in Mastermind. To achieve this, it suffices to find a query
 $z$
such that
$z$
such that
 $b(z)=0$
, which can be done as follows.
$b(z)=0$
, which can be done as follows.
Lemma 3.1.
For any
 $k\geq 2$
, it is possible to find a string
$k\geq 2$
, it is possible to find a string
 $q$
with
$q$
with
 $b_c(q)=0$
using at most
$b_c(q)=0$
using at most
 $n+1$
queries.
$n+1$
queries.
Proof. Query the string of all
 $1$
s,
$1$
s,
 $t^{(0)}$
, as well as the strings
$t^{(0)}$
, as well as the strings
 $t^{(i)}$
for all
$t^{(i)}$
for all
 $i \in \{1, \ldots, n\}$
where
$i \in \{1, \ldots, n\}$
where
 $t^{(i)}$
is the string of all ones except at the
$t^{(i)}$
is the string of all ones except at the
 $i$
th position it has a
$i$
th position it has a
 $2$
. Now if
$2$
. Now if
 $b_c(t^{(i)}) = b_c(t^{(0)}) -1$
, then
$b_c(t^{(i)}) = b_c(t^{(0)}) -1$
, then
 $c_i\neq 2$
, otherwise
$c_i\neq 2$
, otherwise
 $c_i\neq 1$
and we have at every position a colour that is incorrect, so we have a string
$c_i\neq 1$
and we have at every position a colour that is incorrect, so we have a string
 $z$
which satisfies
$z$
which satisfies
 $b_c(z)=0$
.
$b_c(z)=0$
.
Note that if
 $k=n$
and we are content with a randomised search then we can find an all-zero string by choosing queries
$k=n$
and we are content with a randomised search then we can find an all-zero string by choosing queries
 $z\in [n]^n$
uniformly at random until a query is obtained with
$z\in [n]^n$
uniformly at random until a query is obtained with
 $b_c(z)=0$
. As the success probability of one iteration
$b_c(z)=0$
. As the success probability of one iteration
 $(1-1/n)^n\geq 1/4$
, this takes on average
$(1-1/n)^n\geq 1/4$
, this takes on average
 $4$
guesses.
$4$
guesses.
3.2 Finding pairwise elementwise distinct one queries
We say that a set of queries
 $f^{(1)}, f^{(2)}, \dots$
are pairwise elementwise distinct if
$f^{(1)}, f^{(2)}, \dots$
are pairwise elementwise distinct if
 $f^{(s)}_i\neq f^{(t)}_i$
for all
$f^{(s)}_i\neq f^{(t)}_i$
for all
 $i \in [n]$
and all
$i \in [n]$
and all
 $s\neq t$
.
$s\neq t$
.
The second part of the reduction is to show how codebreaker can transform the problem to the setting where the codeword is a permutation of
 $[n]$
. It turns out codebreaker can achieve this by first finding
$[n]$
. It turns out codebreaker can achieve this by first finding
 $n$
pairwise elementwise distinct queries
$n$
pairwise elementwise distinct queries
 $f^{(1)}, \dots f^{(n)}$
such that
$f^{(1)}, \dots f^{(n)}$
such that
 $b_c(f^{(i)})=1$
for all
$b_c(f^{(i)})=1$
for all
 $i$
. This can be done with high probability using
$i$
. This can be done with high probability using
 $\mathcal{O}(n)$
random queries in the following fashion.
$\mathcal{O}(n)$
random queries in the following fashion.
This argument is due to Angelika Steger (from personal communication).
Algorithm 1: Permutation

Lemma 3.2.
Algorithm
1
will, with high probability, need at most
 $\mathcal{O}(n)$
many queries to identify pairwise elementwise distinct query strings
$\mathcal{O}(n)$
many queries to identify pairwise elementwise distinct query strings
 $f^{(1)}, \dots, f^{(n)}$
of length
$f^{(1)}, \dots, f^{(n)}$
of length
 $n$
such that
$n$
such that
 $b_c(f^{(i)})=1$
for all
$b_c(f^{(i)})=1$
for all
 $i\in [n]$
.
$i\in [n]$
.
Proof. The finding of these strings is done by random queries. Let
 $S^{(1)} = [n]^n$
start out to be the entire space of possible queries. Sample uniform random queries
$S^{(1)} = [n]^n$
start out to be the entire space of possible queries. Sample uniform random queries
 $X$
from
$X$
from
 $S^{(1)}$
until one of them gives
$S^{(1)}$
until one of them gives
 $b(X) = 1$
. Set this query to be
$b(X) = 1$
. Set this query to be
 $f^{(1)}$
. Now set aside all colours at the corresponding positions and keep querying. That is,
$f^{(1)}$
. Now set aside all colours at the corresponding positions and keep querying. That is,
 $S^{(2)} = [n]\backslash \{f^{(1)}_1\} \times \ldots \times [n]\backslash \{f^{(1)}_n\}$
and sample again random queries
$S^{(2)} = [n]\backslash \{f^{(1)}_1\} \times \ldots \times [n]\backslash \{f^{(1)}_n\}$
and sample again random queries
 $X$
from
$X$
from
 $S^{(2)}$
until one of them gives
$S^{(2)}$
until one of them gives
 $b(X)= 1$
. In this way set aside
$b(X)= 1$
. In this way set aside
 $f^{(i)}$
which was received by querying randomly from
$f^{(i)}$
which was received by querying randomly from
 $S^{(i)} = [n]\backslash \{f^{(1)}_1,\ldots,f^{(i-1)}_1\} \times \ldots \times [n]\backslash \{f^{(1)}_n,\ldots,f^{(i-1)}_n\}$
.
$S^{(i)} = [n]\backslash \{f^{(1)}_1,\ldots,f^{(i-1)}_1\} \times \ldots \times [n]\backslash \{f^{(1)}_n,\ldots,f^{(i-1)}_n\}$
.
We analyse how many queries this takes. The set
 $S^{(i)}$
has
$S^{(i)}$
has
 $n-i+1$
many possible colours at every position and also
$n-i+1$
many possible colours at every position and also
 $n-i+1$
many positions at which there is still a correct colour available. So for each position where there still is an available correct colour, there is a chance of
$n-i+1$
many positions at which there is still a correct colour available. So for each position where there still is an available correct colour, there is a chance of
 $1/(n-i+1)$
that this is guessed correctly in
$1/(n-i+1)$
that this is guessed correctly in
 $X$
, independently of every other position. So the probability that
$X$
, independently of every other position. So the probability that
 $b(X) = 1$
for a random query is
$b(X) = 1$
for a random query is
 \begin{equation} \mathbb{P}[b(X) = 1] = (n-i+1) \cdot \frac{1}{n-i+1} \left (1 - \frac{1}{n-i+1}\right )^{n-i} \ge e ^{-1}. \end{equation}
\begin{equation} \mathbb{P}[b(X) = 1] = (n-i+1) \cdot \frac{1}{n-i+1} \left (1 - \frac{1}{n-i+1}\right )^{n-i} \ge e ^{-1}. \end{equation}
Let
 $Y_t$
be the number of queries it takes to find the
$Y_t$
be the number of queries it takes to find the
 $t$
th string to set aside. Then
$t$
th string to set aside. Then
 $Y_t$
is geometrically distributed and the total time is the sum of all
$Y_t$
is geometrically distributed and the total time is the sum of all
 $Y_t$
,
$Y_t$
,
 $t\in [n]$
, which is an independent sum of geometrically distributed random variables with success probabilities as in (2), so expected at most
$t\in [n]$
, which is an independent sum of geometrically distributed random variables with success probabilities as in (2), so expected at most
 $e^{-1}$
. Applying the Chebychev inequality gives us that, w.h.p. we can find
$e^{-1}$
. Applying the Chebychev inequality gives us that, w.h.p. we can find
 $f^{(1)}$
to
$f^{(1)}$
to
 $f^{(n)}$
with
$f^{(n)}$
with
 $\mathcal{O}(n)$
many queries.
$\mathcal{O}(n)$
many queries.
3.3 Reduction to signed permutation Mastermind
The previous subsections set the stage for the following lemma, which shows the dependency between the signed permutation Mastermind and the black-peg Mastermind Problem. With only
 $\mathcal{O}(n)$
additional queries that result from Lemma 3.2 it is possible to solve black-peg Mastermind assuming we can solve signed permutation Mastermind with the same number of queries up to a constant factor. We denote by
$\mathcal{O}(n)$
additional queries that result from Lemma 3.2 it is possible to solve black-peg Mastermind assuming we can solve signed permutation Mastermind with the same number of queries up to a constant factor. We denote by
 $\textrm{spmm}(n)$
the minimum number of guesses needed by any deterministic strategy to solve signed permutation Mastermind.
$\textrm{spmm}(n)$
the minimum number of guesses needed by any deterministic strategy to solve signed permutation Mastermind.
Lemma 3.3.
Black-peg Mastermind with
 $n$
colours and slots can be solved in
$n$
colours and slots can be solved in
 $\mathcal{O}(n + \textrm{spmm}(n))$
guesses with high probability.
$\mathcal{O}(n + \textrm{spmm}(n))$
guesses with high probability.
Proof. First apply the algorithms from Lemmas 3.1 and 3.2 to obtain the corresponding queries
 $z$
and
$z$
and
 $f^{(1)}, \dots, f^{(n)}$
. Given this, run any optimal solution to signed permutation Mastermind. Whenever this solution wants to perform a query
$f^{(1)}, \dots, f^{(n)}$
. Given this, run any optimal solution to signed permutation Mastermind. Whenever this solution wants to perform a query
 $q\in \{-n, \dots, n \}^n$
, we construct queries
$q\in \{-n, \dots, n \}^n$
, we construct queries
 $q^+, q^- \in [n]^n$
according to
$q^+, q^- \in [n]^n$
according to
 \begin{equation*}q^+_i = \begin {cases} f^{(q_i)}_i &\text { if }q_i\gt 0\\ z_i &\text {otherwise,}\end {cases}\end{equation*}
\begin{equation*}q^+_i = \begin {cases} f^{(q_i)}_i &\text { if }q_i\gt 0\\ z_i &\text {otherwise,}\end {cases}\end{equation*}
and
 \begin{equation*}q^-_i = \begin {cases} f^{(-q_i)}_i &\text { if }q_i\lt 0\\ z_i &\text {otherwise.}\end {cases}\end{equation*}
\begin{equation*}q^-_i = \begin {cases} f^{(-q_i)}_i &\text { if }q_i\lt 0\\ z_i &\text {otherwise.}\end {cases}\end{equation*}
We consequently query
 $b_c(q^+)$
and
$b_c(q^+)$
and
 $b_c(q^-)$
and return the value
$b_c(q^-)$
and return the value
 $b_c(q^+)-b_c(q^-)$
as the answer to query
$b_c(q^+)-b_c(q^-)$
as the answer to query
 $q$
.
$q$
.
We want to show that the answers given by this procedure are equal to
 $\hat{b}_{c'}(q)$
for some permutation
$\hat{b}_{c'}(q)$
for some permutation
 $c'$
of
$c'$
of
 $[n]$
not depending on
$[n]$
not depending on
 $q$
. Let
$q$
. Let
 $\varphi \;:\; [n]^n \rightarrow [n]^n$
be the map given by
$\varphi \;:\; [n]^n \rightarrow [n]^n$
be the map given by
 $\varphi (x)_i = f^{(x_i)}_i$
. As
$\varphi (x)_i = f^{(x_i)}_i$
. As
 $f^{(1)}_i, \dots, f^{(n)}_i$
are all distinct values between
$f^{(1)}_i, \dots, f^{(n)}_i$
are all distinct values between
 $1$
and
$1$
and
 $n$
, by construction, it follows that
$n$
, by construction, it follows that
 $\varphi$
acts as a bijection on each position of the input. In fact, we claim that
$\varphi$
acts as a bijection on each position of the input. In fact, we claim that
 \begin{equation} \hat{b}_{\varphi ^{-1}(c)}(q)=b_c(q^+)-b_c(q^-) \qquad \forall q\in \{-n, \dots, n\}^n. \end{equation}
\begin{equation} \hat{b}_{\varphi ^{-1}(c)}(q)=b_c(q^+)-b_c(q^-) \qquad \forall q\in \{-n, \dots, n\}^n. \end{equation}
In other words, any signed query
 $q$
made in this setting will be answered as if the codeword is
$q$
made in this setting will be answered as if the codeword is
 $c'\;:\!=\;\varphi ^{-1}(c).$
Observe that (3) implies that
$c'\;:\!=\;\varphi ^{-1}(c).$
Observe that (3) implies that
 $c'$
is a permutation as
$c'$
is a permutation as
 $\hat{b}_{c'}(i\dots i)$
is, by the definition of
$\hat{b}_{c'}(i\dots i)$
is, by the definition of
 $\hat{b}_{c'}(\cdot )$
, equal to the number of occurrences of colour
$\hat{b}_{c'}(\cdot )$
, equal to the number of occurrences of colour
 $i$
in
$i$
in
 $c'$
, and by definitions of
$c'$
, and by definitions of
 $b_c(\cdot ), q^+$
and
$b_c(\cdot ), q^+$
and
 $q-$
equal to
$q-$
equal to
 $b_c(f^{(i)})-b_c(z)=1-0=1$
, so each colour appears exactly once in
$b_c(f^{(i)})-b_c(z)=1-0=1$
, so each colour appears exactly once in
 $c'$
.
$c'$
.
To see that (3) holds, let
 $q\in \{-n, \dots, n\}^n$
let
$q\in \{-n, \dots, n\}^n$
let
 $q^+, q^-$
be as above, and consider the contributions to
$q^+, q^-$
be as above, and consider the contributions to
 $\hat{b}_{c'}(q)$
and
$\hat{b}_{c'}(q)$
and
 $b_c(q^+)-b_c(q^-)$
respectively from the
$b_c(q^+)-b_c(q^-)$
respectively from the
 $i$
th position. If
$i$
th position. If
 $q_i=0$
, then
$q_i=0$
, then
 $q^+_i=q^-_i = z_i$
where, by choice of
$q^+_i=q^-_i = z_i$
where, by choice of
 $z$
,
$z$
,
 $c_i\neq z_i$
, so the contribution to both expressions is
$c_i\neq z_i$
, so the contribution to both expressions is
 $0$
. If
$0$
. If
 $q_i\gt 0$
, then the contribution from the
$q_i\gt 0$
, then the contribution from the
 $i$
th position to
$i$
th position to
 $\hat{b}_{c'}(q)$
is
$\hat{b}_{c'}(q)$
is
 $1$
if
$1$
if
 $c'_i = \varphi ^{-1}(c)_i = q_i$
, and
$c'_i = \varphi ^{-1}(c)_i = q_i$
, and
 $0$
otherwise. Similarly, the contribution to
$0$
otherwise. Similarly, the contribution to
 $b_c(q^+)-b_c(q^-)$
is
$b_c(q^+)-b_c(q^-)$
is
 $1$
if
$1$
if
 $c_i = q^+_i = f^{(q_i)}_i = \varphi (q)_i$
, and
$c_i = q^+_i = f^{(q_i)}_i = \varphi (q)_i$
, and
 $0$
otherwise. One immediately checks because
$0$
otherwise. One immediately checks because
 $\varphi$
is a bijection at any position that the two conditions are equivalent. This works analogously if
$\varphi$
is a bijection at any position that the two conditions are equivalent. This works analogously if
 $q_i\lt 0$
.
$q_i\lt 0$
.
As the answers given to the signed permutation Mastermind solution are consistent with
 $\hat{b}_{c'}(q)$
, the solution will terminate by outputting the string
$\hat{b}_{c'}(q)$
, the solution will terminate by outputting the string
 $c'$
. We can consequently compute the codeword
$c'$
. We can consequently compute the codeword
 $c$
to the original game according to
$c$
to the original game according to
 $c=\varphi (c')$
.
$c=\varphi (c')$
.
With high probability, this process uses only
 $\mathcal{O}(n)$
queries to obtain
$\mathcal{O}(n)$
queries to obtain
 $z, f^{(1)}, \dots, f^{(n)}$
. Additionally, it uses two times the number of queries used by the signed permutation Mastermind strategy in order to solve the corresponding signed permutation Mastermind instance, which then obtains the codeword for the original game.
$z, f^{(1)}, \dots, f^{(n)}$
. Additionally, it uses two times the number of queries used by the signed permutation Mastermind strategy in order to solve the corresponding signed permutation Mastermind instance, which then obtains the codeword for the original game.
4. Proof of Theorem 1.1
With the reduction from the previous section at hand, we may assume that each colour appears in the hidden codeword exactly once. It remains to show that we can determine the position of every colour by using
 $\mathcal{O}(n)$
signed queries. Before presenting our algorithm, we will first present a token sliding game that will be used to housekeep, at any point while playing signed permutation Mastermind, the information we currently have for each colour.
$\mathcal{O}(n)$
signed queries. Before presenting our algorithm, we will first present a token sliding game that will be used to housekeep, at any point while playing signed permutation Mastermind, the information we currently have for each colour.
Definition 4.1.
Given an instance of signed permutation Mastermind, we define the corresponding information tree
 $T$
as a rooted complete balanced binary tree of depth
$T$
as a rooted complete balanced binary tree of depth
 $\lceil \log _2 n \rceil$
. We denote by
$\lceil \log _2 n \rceil$
. We denote by
 $n_T$
the number of leaves of the tree. In other words,
$n_T$
the number of leaves of the tree. In other words,
 $n_T$
is the smallest power of two bigger than or equal to
$n_T$
is the smallest power of two bigger than or equal to
 $n$
. For each vertex in
$n$
. For each vertex in
 $T$
, we associate a (sub-)interval of
$T$
, we associate a (sub-)interval of
 $[n_T]$
as follows. We order the vertices at depth
$[n_T]$
as follows. We order the vertices at depth
 $d$
in the canonical way from left to right and associate the
$d$
in the canonical way from left to right and associate the
 $j$
th such vertex with the interval
$j$
th such vertex with the interval
 $[(n_T/2^d )(j-1)+1, (n_T/2^d )\,j]$
.
$[(n_T/2^d )(j-1)+1, (n_T/2^d )\,j]$
.
Note that if
 $n$
is not a power of two, some vertices will be associated with intervals that go outside
$n$
is not a power of two, some vertices will be associated with intervals that go outside
 $[n]$
. An example of an information tree for
$[n]$
. An example of an information tree for
 $n=8$
is illustrated in Figure 1.
$n=8$
is illustrated in Figure 1.

Figure 1. Information Tree for
 $n= 8$
. Every node corresponds to an interval, here marked in red.
$n= 8$
. Every node corresponds to an interval, here marked in red.
We introduce handy notation for the complete binary tree
 $T$
. The root of
$T$
. The root of
 $T$
is denoted by
$T$
is denoted by
 $r$
. For any vertex, we denote by
$r$
. For any vertex, we denote by
 $v_L$
and
$v_L$
and
 $v_R$
its left and right child respectively if they exist and if we descend multiple vertices we write
$v_R$
its left and right child respectively if they exist and if we descend multiple vertices we write
 $v_{LR}$
for
$v_{LR}$
for
 $(v_L)_R$
. Further
$(v_L)_R$
. Further
 $T_L$
denotes the induced subtree rooted at
$T_L$
denotes the induced subtree rooted at
 $r_L$
, similarly
$r_L$
, similarly
 $T_\star$
is the the induced subtree rooted at
$T_\star$
is the the induced subtree rooted at
 $r_\star$
for
$r_\star$
for
 $\star$
being any combination of
$\star$
being any combination of
 $R$
and
$R$
and
 $L$
such that
$L$
such that
 $r_\star$
exists.
$r_\star$
exists.
For any instance of signed permutation Mastermind, we perform the following token game on the information tree as follows. We initially place
 $n$
coloured tokens at the root
$n$
coloured tokens at the root
 $r$
, one for each possible colour in our Mastermind instance. At any point, we may take a token at position
$r$
, one for each possible colour in our Mastermind instance. At any point, we may take a token at position
 $v$
and slide it to either
$v$
and slide it to either
 $v_L$
or
$v_L$
or
 $v_R$
, if we can prove that the position of its colour in the hidden codeword lies in the corresponding sub-interval. See Figure 2 for an example.
$v_R$
, if we can prove that the position of its colour in the hidden codeword lies in the corresponding sub-interval. See Figure 2 for an example.
Observation 4.2.
When all tokens are positioned on leaves of
 $T$
, we know the complete codeword.
$T$
, we know the complete codeword.
The simplest way to move a token is by performing a query that equals that colour on, say, the left half of its current position, and zero everywhere else. We call this step querying a token.
Definition 4.3.
For a colour
 $f$
with its token at non-leaf node
$f$
with its token at non-leaf node
 $v$
, we say we query the colour
$v$
, we say we query the colour
 $f$
if we make a query of the colour
$f$
if we make a query of the colour
 $f$
only in the left half of the interval corresponding to
$f$
only in the left half of the interval corresponding to
 $v$
(zero everywhere else).
$v$
(zero everywhere else).
We note that any query of this form can only give
 $0$
or
$0$
or
 $1$
as output. We will refer to any such queries as zero-one queries.
$1$
as output. We will refer to any such queries as zero-one queries.

Figure 2. Example configuration for
 $n= 8$
. Tokens of colours
$n= 8$
. Tokens of colours
 $1$
through
$1$
through
 $8$
are at different positions in the information tree and there are four remaining possibilities for the codeword.
$8$
are at different positions in the information tree and there are four remaining possibilities for the codeword.
4.1 Solving signed permutation Mastermind
We are now ready to present our main strategy to solve signed permutation Mastermind by constructing a sequence of entropy dense queries that allows us to slide all tokens on
 $T$
from the root to their respective leaves. This will be done in two steps, which we call Preprocess(T) and Solve(T).
$T$
from the root to their respective leaves. This will be done in two steps, which we call Preprocess(T) and Solve(T).
As intervals corresponding to vertices close to the root of
 $T$
are so large, there is initially not much room to include many colours in the same query. Thus the idea of the preprocessing step is to perform
$T$
are so large, there is initially not much room to include many colours in the same query. Thus the idea of the preprocessing step is to perform
 $\mathcal{O}(n)$
zero-one queries, in order to move some of the tokens down the left side of the tree.
$\mathcal{O}(n)$
zero-one queries, in order to move some of the tokens down the left side of the tree.
Algorithm 2: Preprocess(T)

Preprocess(T), see Algorithm 2, takes the tree, queries (Definition 4.3) all colours whose tokens are at the root
 $r$
and slides the tokens accordingly. Then repeats for the left child of the root
$r$
and slides the tokens accordingly. Then repeats for the left child of the root
 $r_L$
. Then we recursively apply the algorithm to the subtrees of the left two grandchildren of the root
$r_L$
. Then we recursively apply the algorithm to the subtrees of the left two grandchildren of the root
 $T_{LL}$
and
$T_{LL}$
and
 $T_{LR}$
. If the tree has a depth of
$T_{LR}$
. If the tree has a depth of
 $2$
or less, we skip all the steps on vertices that do not exist.
$2$
or less, we skip all the steps on vertices that do not exist.
Proposition 4.4.
The Algorithm
2
Preprocess(T)
requires at most
 $3n_T$
zero-one queries and runs in polynomial time.
$3n_T$
zero-one queries and runs in polynomial time.
Proof. Clearly, if the depth of the tree is
 $\le 2$
this holds, as we make only a single zero-one query. Then the rest follows by induction, if we analyse the number of queries needed we see, at the root
$\le 2$
this holds, as we make only a single zero-one query. Then the rest follows by induction, if we analyse the number of queries needed we see, at the root
 $r$
we need to query at most
$r$
we need to query at most
 $n_T$
tokens, and at the left child
$n_T$
tokens, and at the left child
 $r_L$
we query at most
$r_L$
we query at most
 $n_T/2$
. In the left grandchildren, we recurse. So if
$n_T/2$
. In the left grandchildren, we recurse. So if
 $a(n_T)$
is the total number of queries we need for Preprocess(T) for a tree with
$a(n_T)$
is the total number of queries we need for Preprocess(T) for a tree with
 $n_T$
leafs, then it holds that
$n_T$
leafs, then it holds that
 \begin{equation*}a(n_T) \le n_T + n_T/2 + a(n_{T_{LL}})+ a(n_{T_{LR}}) = n_T + n_T/2 + a(n_{T}/4)+ a(n_{T}/4)\end{equation*}
\begin{equation*}a(n_T) \le n_T + n_T/2 + a(n_{T_{LL}})+ a(n_{T_{LR}}) = n_T + n_T/2 + a(n_{T}/4)+ a(n_{T}/4)\end{equation*}
From which follows that
 $a(n_T) \le 3n_T$
. Since we only query tokens all queries we do are zero-one queries and this can be done in polynomial time concluding the proof.
$a(n_T) \le 3n_T$
. Since we only query tokens all queries we do are zero-one queries and this can be done in polynomial time concluding the proof.
The result of running Preprocess(T) is illustrated in Figure 3. All tokens have either been moved to leaves, or to a vertex of the form
 $r_R, r_{*R}, r_{**R}, \dots$
where each ‘
$r_R, r_{*R}, r_{**R}, \dots$
where each ‘
 $*$
’ denotes either
$*$
’ denotes either
 $LL$
or
$LL$
or
 $LR$
. This we call a preprocessed tree. Another way of viewing this is that a tree
$LR$
. This we call a preprocessed tree. Another way of viewing this is that a tree
 $T$
is preprocessed if there are no tokens at
$T$
is preprocessed if there are no tokens at
 $r$
or
$r$
or
 $r_L$
, and the subtrees
$r_L$
, and the subtrees
 $T_{LL}$
and
$T_{LL}$
and
 $T_{LR}$
are preprocessed.
$T_{LR}$
are preprocessed.

Figure 3. Tree preprocessed for n = 32, all black vertices have been emptied, tokens are at red vertices.
Once
 $T$
is preprocessed we can run the second algorithm Solve(T), see Algorithm 3. This is constructed recursively as follows. First note that when
$T$
is preprocessed we can run the second algorithm Solve(T), see Algorithm 3. This is constructed recursively as follows. First note that when
 $n_T=1$
or
$n_T=1$
or
 $2$
, then the preprocessing has already put all tokens at leaves, so the problem is already solved. Now suppose we already know how to run Solve(T‘) for all preprocessed trees
$2$
, then the preprocessing has already put all tokens at leaves, so the problem is already solved. Now suppose we already know how to run Solve(T‘) for all preprocessed trees
 $T'$
with
$T'$
with
 $n_{T'}\lt n$
, and let
$n_{T'}\lt n$
, and let
 $T$
be a preprocessed tree with
$T$
be a preprocessed tree with
 $n_T=n$
. Observe that preprocessing
$n_T=n$
. Observe that preprocessing
 $T$
means that
$T$
means that
 $T_{LL}$
and
$T_{LL}$
and
 $T_{LR}$
are both preprocessed. Hence, we already know procedures Solve(TLL
) and Solve(TLR
) that move all tokens in the respective subtrees to leaves by making a sequence of queries whose support are restricted to the first and second quarter of the available positions respectively. Similarly, as the preprocessing has determined all colours that belong in the right half of the codeword, we know how to move all tokens in
$T_{LR}$
are both preprocessed. Hence, we already know procedures Solve(TLL
) and Solve(TLR
) that move all tokens in the respective subtrees to leaves by making a sequence of queries whose support are restricted to the first and second quarter of the available positions respectively. Similarly, as the preprocessing has determined all colours that belong in the right half of the codeword, we know how to move all tokens in
 $T_R$
to leaves by first performing Preprocess(TR
) and then Solve(TR
), both of which make queries whose support are restricted to the second half of the available positions.
$T_R$
to leaves by first performing Preprocess(TR
) and then Solve(TR
), both of which make queries whose support are restricted to the second half of the available positions.
Algorithm 3: Solve(T)

In order to achieve the information-theoretic speedup of queries, the idea is to perform the queries of Solve(TLL
), Solve(TLR
) and Preprocess(TR
) in parallel. This can be thought of as follows. Codebreaker runs the respective algorithms until each of them attempts to make a query. Instead of actually asking codemaker about these queries, codebreaker simply notes the query and pauses the respective algorithm. This continues until all three have proposed queries. Suppose the queries given are
 $q^{(1)}, q^{(2)}$
and
$q^{(1)}, q^{(2)}$
and
 $s$
respectively. Codebreaker combines these into two queries, determined by Lemma 4.5 explained later, that are asked to codemaker, and given the answers, codebreaker computes
$s$
respectively. Codebreaker combines these into two queries, determined by Lemma 4.5 explained later, that are asked to codemaker, and given the answers, codebreaker computes
 $\hat{b}(q^{(1)})$
,
$\hat{b}(q^{(1)})$
,
 $\hat{b}(q^{(2)})$
, and
$\hat{b}(q^{(2)})$
, and
 $\hat{b}(s)$
that are then presented to the respective algorithms as if they were given from codemaker as answers to the respective queries, after which the algorithms are allowed to continue. This is repeated until all three algorithms have terminated. (In case one of the algorithms terminates while another still makes queries, we can simply treat the terminated algorithm as if it is making the all zeros query until the other ones finish.) Finally, this leaves
$\hat{b}(s)$
that are then presented to the respective algorithms as if they were given from codemaker as answers to the respective queries, after which the algorithms are allowed to continue. This is repeated until all three algorithms have terminated. (In case one of the algorithms terminates while another still makes queries, we can simply treat the terminated algorithm as if it is making the all zeros query until the other ones finish.) Finally, this leaves
 $T_{LL}$
and
$T_{LL}$
and
 $T_{LR}$
solved and
$T_{LR}$
solved and
 $T_R$
preprocessed. Hence we can solve
$T_R$
preprocessed. Hence we can solve
 $T$
by running Solve(TR
) (without any parallelism).
$T$
by running Solve(TR
) (without any parallelism).
In order to combine queries as mentioned above, we employ an idea similar to the Cantor-Mills construction (1) for coin-weighing.
Lemma 4.5.
Define the support of a query
 $q$
as the set of indices
$q$
as the set of indices
 $i\in [n]$
such that
$i\in [n]$
such that
 $q_i\neq 0$
. For any three queries
$q_i\neq 0$
. For any three queries
 $q^{(1)}, q^{(2)}$
, and
$q^{(1)}, q^{(2)}$
, and
 $s$
with disjoint supports and such that
$s$
with disjoint supports and such that
 $s$
is a zero-one query, we can determine
$s$
is a zero-one query, we can determine
 $\hat{b}(q^{(1)}), \hat{b}(q^{(2)}),$
and
$\hat{b}(q^{(1)}), \hat{b}(q^{(2)}),$
and
 $\hat{b}(s)$
by making only two queries.
$\hat{b}(s)$
by making only two queries.
Proof. We query
 $w^{(1)} = q^{(1)} + q^{(2)} + s$
and
$w^{(1)} = q^{(1)} + q^{(2)} + s$
and
 $w^{(2)} = q^{(1)} - q^{(2)}$
, where
$w^{(2)} = q^{(1)} - q^{(2)}$
, where
 $+$
and
$+$
and
 $-$
denote element-wise addition subtraction respectively. Then we can retrieve the answers from just the information of
$-$
denote element-wise addition subtraction respectively. Then we can retrieve the answers from just the information of
 $\hat{b}(w^{(1)})$
and
$\hat{b}(w^{(1)})$
and
 $\hat{b}(w^{(2)})$
. If we combine the queries,
$\hat{b}(w^{(2)})$
. If we combine the queries,
 $\hat{b}(w^{(2)}) + \hat{b}(w^{(2)})= 2 \hat{b}(q^{(1)}) + \hat{b}(s)$
. So we can retrieve
$\hat{b}(w^{(2)}) + \hat{b}(w^{(2)})= 2 \hat{b}(q^{(1)}) + \hat{b}(s)$
. So we can retrieve
 $\hat{b}(s) = \hat{b}(w^{(2)}) + \hat{b}(w^{(2)}) \mod 2$
. And then also the queries,
$\hat{b}(s) = \hat{b}(w^{(2)}) + \hat{b}(w^{(2)}) \mod 2$
. And then also the queries,
 $\hat{b}(q^{(2)}) = ( \hat{b}(w^{(1)}) + \hat{b}(w^{(2)}) - \hat{b}(s))/ 2$
and
$\hat{b}(q^{(2)}) = ( \hat{b}(w^{(1)}) + \hat{b}(w^{(2)}) - \hat{b}(s))/ 2$
and
 $\hat{b}(q^{(2)}) = ( \hat{b}(w^{(1)}) - \hat{b}(w^{(2)}) - \hat{b}(s))/ 2$
are recoverable.
$\hat{b}(q^{(2)}) = ( \hat{b}(w^{(1)}) - \hat{b}(w^{(2)}) - \hat{b}(s))/ 2$
are recoverable.
Proposition 4.6.
Calling Algorithm
3
,
Solve()
, for a preprocessed tree will move all the tokens to leaves. Moreover, the algorithm will use at most
 $6n_T$
queries and runs in polynomial time.
$6n_T$
queries and runs in polynomial time.
Proof. The first statement follows by induction. If
 $n_T\leq 2$
a preprocessed tree already has all its tokens at leaves, nothing needs to be done. The induction step follows by the correctness of Lemma 4.5.
$n_T\leq 2$
a preprocessed tree already has all its tokens at leaves, nothing needs to be done. The induction step follows by the correctness of Lemma 4.5.
For the runtime analysis, we also use induction. If the depth
 $n_T\leq 2$
then clearly the statement holds. If
$n_T\leq 2$
then clearly the statement holds. If
 $n_T\gt 2$
the procedure first runs Solve(TLL
), Solve(TLR
) and Preprocess(TR
) in parallel. In each iteration of the main loop, we resolve one query from each of the subprocesses by making two actual queries. This continues until all three processes have terminated, meaning that the number of iterations is the maximum of the number of queries made by the respective subprocesses. After which, we run Solve(TR
). In total, we get the following recursion where
$n_T\gt 2$
the procedure first runs Solve(TLL
), Solve(TLR
) and Preprocess(TR
) in parallel. In each iteration of the main loop, we resolve one query from each of the subprocesses by making two actual queries. This continues until all three processes have terminated, meaning that the number of iterations is the maximum of the number of queries made by the respective subprocesses. After which, we run Solve(TR
). In total, we get the following recursion where
 $c(n_T)$
is the total number of queries we must make during Solve(T) and
$c(n_T)$
is the total number of queries we must make during Solve(T) and
 $a(n_T)$
the total number of queries that Preprocess(T) must make in a tree with
$a(n_T)$
the total number of queries that Preprocess(T) must make in a tree with
 $n_T$
leaves.
$n_T$
leaves.
 \begin{align*} c(n_T) &\le 2 \cdot \max (c(n_{T_{LL}}), c(n_{T_{LR}}), a(n_{T_{R}} )) + c(n_{T_R})\\ &= 2 \cdot \max (c(n_{T}/4), a(n_{T}/2 )) + c(n_{T}/2) \end{align*}
\begin{align*} c(n_T) &\le 2 \cdot \max (c(n_{T_{LL}}), c(n_{T_{LR}}), a(n_{T_{R}} )) + c(n_{T_R})\\ &= 2 \cdot \max (c(n_{T}/4), a(n_{T}/2 )) + c(n_{T}/2) \end{align*}
By Proposition 4.4 we know that
 $a(n_{T}/2) \le 3n_T/2$
so by induction we get that
$a(n_{T}/2) \le 3n_T/2$
so by induction we get that
 $c(n_T) \le 6n_T$
. All the operations as well as the computing and decoding of the combined queries in Lemma 4.5 are clearly in polynomial time so this concludes the proof.
$c(n_T) \le 6n_T$
. All the operations as well as the computing and decoding of the combined queries in Lemma 4.5 are clearly in polynomial time so this concludes the proof.
Now we have all the tools at hand to prove our main result.
Proof of Theorem
1.1. We have Lemma 3.3 which reduces the problem of solving black-peg Mastermind to solving signed permutation Mastermind. For the new instance of signed permutation Mastermind that results from this, we consider the information tree. We move the tokens of this tree to the leaves by first running the algorithm Preprocess(T) and then applying the algorithm Solve(T) on the preprocessed tree. By Propositions 4.4 and 4.6, this takes at most
 $9n_T$
signed queries and is done in polynomial time. By Observation 4.2 we have found the hidden codeword of the signed permutation Mastermind, and therefore also the hidden codeword of the black-peg Mastermind game. The transformation can be done in polynomial time and by Lemma 3.3 we need at most
$9n_T$
signed queries and is done in polynomial time. By Observation 4.2 we have found the hidden codeword of the signed permutation Mastermind, and therefore also the hidden codeword of the black-peg Mastermind game. The transformation can be done in polynomial time and by Lemma 3.3 we need at most
 $\mathcal{O}(n + 9n_T) = \mathcal{O}(n)$
queries to solve black-peg Mastermind.
$\mathcal{O}(n + 9n_T) = \mathcal{O}(n)$
queries to solve black-peg Mastermind.
5. Playing Mastermind with arbitrarily many colours
We briefly make some remarks on other ranges of
 $k$
and
$k$
and
 $n$
for Mastermind. By combining Theorem 1.1 with results of Chvátal [Reference Chvátal3] and Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4], we determine up to a constant factor the smallest expected number of queries needed to solve black-peg and black-white-peg Mastermind for any
$n$
for Mastermind. By combining Theorem 1.1 with results of Chvátal [Reference Chvátal3] and Doerr, Doerr, Spöhel, and Thomas [Reference Doerr, Doerr, Spöhel and Thomas4], we determine up to a constant factor the smallest expected number of queries needed to solve black-peg and black-white-peg Mastermind for any
 $n$
and
$n$
and
 $k$
.
$k$
.
For any
 $n$
and
$n$
and
 $k$
, let
$k$
, let
 $\textrm{bmm}(n, k)$
denote the minimum (over all strategies) worst-case (over all codewords) expected number of guesses to solve Mastermind if only black peg information can be used. Similarly, denote
$\textrm{bmm}(n, k)$
denote the minimum (over all strategies) worst-case (over all codewords) expected number of guesses to solve Mastermind if only black peg information can be used. Similarly, denote
 $\textrm{bwmm}(n, k)$
the smallest expected number of queries needed if both black and white peg information can be used. The following relation between black-peg and black-white-peg Mastermind was shown by Doerr, Doerr, Spöhel, and Thomas.
$\textrm{bwmm}(n, k)$
the smallest expected number of queries needed if both black and white peg information can be used. The following relation between black-peg and black-white-peg Mastermind was shown by Doerr, Doerr, Spöhel, and Thomas.
Theorem 5.1 (Theorem 4, [Reference Doerr, Doerr, Spöhel and Thomas4]). For all
 $k\geq n \geq 1$
,
$k\geq n \geq 1$
,
 \begin{equation*}\textrm {bwmm}(n, k) = \Theta \left ( \textrm {bmm}(n, n) + k/n\right ).\end{equation*}
\begin{equation*}\textrm {bwmm}(n, k) = \Theta \left ( \textrm {bmm}(n, n) + k/n\right ).\end{equation*}
Proof of Theorem
1.2. For small
 $k$
, say
$k$
, say
 $k\leq \sqrt{n}$
, the result follows by the results of Chvátal [Reference Chvátal3]. Moreover, for
$k\leq \sqrt{n}$
, the result follows by the results of Chvátal [Reference Chvátal3]. Moreover, for
 $k\geq n$
the white peg statement follows directly by combining Theorems 1.1 and 5.1. Thus it remains to consider the case of
$k\geq n$
the white peg statement follows directly by combining Theorems 1.1 and 5.1. Thus it remains to consider the case of
 $\sqrt{n}\leq k \leq n$
, and the case of
$\sqrt{n}\leq k \leq n$
, and the case of
 $k\geq n$
for black-peg Mastermind.
$k\geq n$
for black-peg Mastermind.
For
 $\sqrt{n}\leq k \leq n$
, the leading terms in both bounds in Theorem 1.2 are of order
$\sqrt{n}\leq k \leq n$
, the leading terms in both bounds in Theorem 1.2 are of order
 $n$
, which matches the entropy lower bound. On the other hand, using Lemma 3.1 we can find a query such that
$n$
, which matches the entropy lower bound. On the other hand, using Lemma 3.1 we can find a query such that
 $b(z)=0$
in
$b(z)=0$
in
 $\mathcal{O}(n)$
queries. Having found this, we simply follow the same strategy as for
$\mathcal{O}(n)$
queries. Having found this, we simply follow the same strategy as for
 $n$
colour black-peg Mastermind by replacing any colour
$n$
colour black-peg Mastermind by replacing any colour
 $\gt k$
in a query by the corresponding entry of
$\gt k$
in a query by the corresponding entry of
 $z$
. Thus finishing in
$z$
. Thus finishing in
 $\mathcal{O}(n)$
queries.
$\mathcal{O}(n)$
queries.
Finally, for black-peg Mastermind with
 $k \ge n$
, the leading term in Theorem 1.2 is of order
$k \ge n$
, the leading term in Theorem 1.2 is of order
 $k$
. This can be attained by using
$k$
. This can be attained by using
 $k$
guesses to determine which colours appear in the codeword and then reduce to the case of
$k$
guesses to determine which colours appear in the codeword and then reduce to the case of
 $n$
colours. On the other hand,
$n$
colours. On the other hand,
 $\Omega (k)$
is clearly necessary as this is the expected number of queries needed to guess the correct colour in a single position, provided the codeword is chosen uniformly at random.
$\Omega (k)$
is clearly necessary as this is the expected number of queries needed to guess the correct colour in a single position, provided the codeword is chosen uniformly at random.











 Open access
Open access