


The community grammar and individual grammars
This paper uses data from rhoticity variation in Bristol English to investigate the nature of constraints on sociolinguistic variables and the relationship between the grammars of individuals and the community grammar. The identification of the community grammar as the object of study and the relationship between community grammar and individual grammars allow a number of interpretations. Firstly, we might define the speech community as a community of individuals who share the same variable grammar (i.e., a system of constraints) and evaluative norms. Under this understanding, studying the grammar of the speech community is equivalent in definition to studying the grammars of individuals within it; this is probably the most common understanding (Tamminga, MacKenzie, & Embick, Reference Tamminga, MacKenzie and Embick2016:307; cf., Labov, Reference Labov1966). Secondly, we might define the speech community independently (by shared location, overlapping social networks, other shared cultural practices, etc.) but assume that all individuals within it share the same grammar. In this case, studying the grammar of the speech community is assumed to be a good proxy for studying the grammar of individuals. This is implicit, for example, in work which attempts to determine a formal representation for variation in historical data reflecting multiple speakers (e.g., Abramowicz, Reference Abramowicz2008; Nevins & Parrott, Reference Nevins and Parrott2010; Santorini, Reference Santorini1992, Reference Santorini1994). Thirdly, we could avoid the question by asserting that the grammars of individuals are entirely outside the scope of study, as Labov did when he wrote that “the individual does not exist as a unit of linguistic analysis” (Reference Labov, Celata and Calamai2014:18). Under this conception, individual grammars could be largely uniform and identical to the community grammar (as is Labov's position: “The end result [of native acquisition] is a high degree of uniformity in both the categorical and variable aspects of language production, where individual variation is reduced below the level of linguistic significance” [Labov, Reference Labov, Celata and Calamai2014:17]), or could vary substantially and arbitrarily relative to it.
The assumption that groups of individuals in a given location whose social networks overlap share near identical grammars has been tested. Guy (Reference Guy and Labov1980) investigated t/d deletion in Philadelphia and New York speakers, concluding that individual deviations from the overall constraint hierarchy merely reflected statistical noise, with two exceptions to prove the rule: the effect of a following pause, which differed systematically between New York and Philadelphia speakers, demonstrating that these represented different speech communities, and a morphological condition that differed between middle-class adults and others. Meyerhoff and Walker (Reference Meyerhoff and Walker2007:353–359), investigating variable zero copula in Caribbean English, found no differences between the community grammar and the grammars of speakers who had spent a significant time away from the community as adults.
However, Horvath and Horvath (Reference Horvath and Horvath2003), in a study of l-vocalization in New Zealand and Australian English datasets, found individual deviations in sizes, relative orders, and even directions of effects, although they pointed out that “the percentage of individuals was quite small and statistical fluctuation cannot be ruled out” (Horvath & Horvath, Reference Horvath and Horvath2003:167). Forrest, investigating (ing) in the English of Raleigh, North Carolina, with the caveat that “a reorganization of the hierarchy of internal constraints never truly occurs” (Reference Forrest2015:400), went so far as to say that “it would be overstating the case to say that an aggregate representation of constraint weight values accurately represents all members of the community; rather, they seem to represent a central tendency of speakers, given enough speakers in a corpus” (Reference Forrest2015:401).
Beyond the empirical findings, there is a particular conceptual problem with features undergoing change due to contact. The transmission-diffusion distinction (Labov, Reference Labov2007) suggests that, due to the degraded language-learning ability of adults, when features are transferred among adult speakers (diffusion) rather than from adults to children (transmission), the grammatical detail of those features is disrupted and their complexity reduced. This is proposed to give rise to a distinction between features that have spread into communities from the outside and, therefore, show the disrupted signature of diffusion and undisrupted features with a long history of community-internal transfer. The argument is that the agents of transfer between communities must be mobile adults, and so the mechanism must be diffusion. Intercommunity contact will often involve many independent agents traveling in both directions and will be spread over a longer time; such agents will undergo different degrees of contact-induced adult change (diffusion) at different times. Thus, we must assume that both undisrupted grammars and many grammars with differently disrupted systems of constraints enter such speech communities.
Additionally, longitudinal studies of various ongoing changes have found that a subset of speakers participate in changes during their adulthoods (lifespan change) (e.g., Buchstaller, Reference Buchstaller2006; Raumolin-Brunberg, Reference Raumolin-Brunberg, Nevala, Nurmi and Palander-Collin2009; Sankoff & Blondeau, Reference Sankoff and Blondeau2007). Some studies (such as Blondeau, Reference Blondeau2006; Bowie, Reference Bowie2005; Sankoff & Wagner, Reference Sankoff and Wagner2006; Wagner & Sankoff, Reference Wagner and Sankoff2011) even find retrograde lifespan change—perhaps a sign of advanced changes of which speakers are highly conscious (Sankoff, Reference Sankoff, Bayley, Cameron and Lucas2013:10). The point here is that adults do participate in change, including changing their underlying vernacular grammar (Sankoff & Blondeau, Reference Sankoff, Blondeau, van de Helde, van Hout, Demolin and Zonnevelde2010:15–17; Sankoff & Blondeau, Reference Sankoff, Blondeau, Spreafico and Vietti2013; contra Meyerhoff & Walker, Reference Meyerhoff and Walker2007). This must be understood, in at least some cases, as diffusion, and so we should expect those adults who have undertaken large enough lifespan change to exhibit disrupted grammars for their newly acquired features.
The question then is: if we have a change spreading into a speech community from outside (diffusion) in which some adults are participating (lifespan change), is the end result still somehow a variable grammar that is consistent across individuals? Do learners manage to settle on a common core of constraints that they then reproduce faithfully (koinéization?), or is input variation from the diffusers so great that our transmitters, too, end up with disagreeing grammars?
Mechanisms behind statistical effects
There is good reason to think that not all statistical effects on variable linguistic phenomena reflect constraints in the grammar. Guy (Reference Guy, Hinskens, van Hout and Wetzels1997) distinguished between articulatory universals, which reflect physiological properties of the articulators, functional universals, and the truly linguistic, variety-specific constraints that can evolve from these two types. Horvath and Horvath (Reference Horvath and Horvath2003), investigating l-vocalization, aimed to discover which effects are constant across varieties (‘scale-independent,’ in their vocabulary) and which are variety-specific (‘scale-dependent’) on the assumption that effects that are constant may reflect universal phonetic processes, whereas those that are specific must be “open to social intervention” (Horvath & Horvath, Reference Horvath and Horvath2003:148). Nagy and Irwin (Reference Nagy and Irwin2010) compared constraints from past studies of rhoticity to identify which can and cannot vary between varieties, suggesting that only those which can vary should be used as metrics for relatedness. Tamminga, MacKenzie, and Embick(Reference Tamminga, MacKenzie and Embick2016) distinguished three types of effects:
1. ‘s-conditioning’ = sociostylistic factors
2. ‘i-conditioning’ = internal linguistic factors
3. ‘p-conditioning’ = physical and cognitive factors
These types differ in their relationship to the grammar: i-conditioning is clearly part of the grammar; s-conditioning might fall inside or outside the grammar, depending on your theoretical orientation and whether we are talking about the community grammar or the individual grammar; p-conditioning is clearly outside the grammar. A necessary caveat here is that, over time, p-conditioning can give rise to s- and i-conditioning (see also, Janda & Joseph, Reference Janda, Joseph, Blake and Burridge2003). They also differ in their universality: p-conditioning is universal (even if factors such as short-term memory capacity vary between speakers, they do not vary between populations), whereas i-conditioning and s-conditioning are variety- and/or community-specific. There are potential exceptions to this. It is perfectly conceivable that a variable i- or s-conditioning factor might counteract an invariant p-conditioning factor, giving the appearance of an inconsistent p-conditioning factor. Likewise, it is perfectly conceivable that, within a given set of varieties, an s- or i-conditioning factor might happen to be universal, especially if the varieties in question are related. Nevertheless, we can expect these broad tendencies to hold. Note also that they seem to hold at the level of individuals: in Horvath and Horvath's study (Reference Horvath and Horvath2003:160–161), it appeared that an effect that was more consistent across communities was also more consistent across individuals within a community.
The problem
If there is considerable interindividual disagreement in variable grammars (constraint hierarchy variation), then effects that have conflicting directions for different speakers will tend to cancel each other out in pooled data. With pooled data, we will most consistently be able to identify effects that reflect universal physical and cognitive factors (i.e., p-conditioning), since these will usually be invariable across individuals: but these effects are precisely those that are not part of the grammar. Effects that are part of the grammar (i-conditioning) will only emerge from analyses of pooled data if they are shared by most speakers or are very strong for the subset of speakers to whom they apply. What is more, the exact composition of the sample from the speech community may have a decisive effect on what effects we find.
This problem is most acute for studies that compare constraint hierarchies identified from different populations of speakers to make arguments about community identities and histories. Examples are studies that compare constraint hierarchies for variable phenomena in African American Vernacular English (AAVE) to the grammars of English-lexifier creoles to interrogate the possibility that AAVE is the descendent of such a creole (e.g., Cukor-Avila, Reference Cukor-Avila1999; Poplack & Sankoff, Reference Poplack and Sankoff1987; Poplack & Tagliamonte, Reference Poplack and Tagliamonte1989; Poplack & Tagliamonte, Reference Poplack and Tagliamonte1991; Tagliamonte, Reference Tagliamonte, Chambers and Schilling2013). Other examples include studies that use shared constraint hierarchies in different ethnic groups (e.g., Becker, Reference Becker2014; Hoffman & Walker, Reference Hoffman and Walker2010) or generations (e.g., Blondeau, Reference Blondeau2006) to demonstrate membership of a larger speech community, or, indeed, studies that use differences in constraint hierarchies to argue for a history of diffusion (Buchstaller & D'Arcy, Reference Buchstaller and D'Arcy2009; Labov, Reference Labov2007). These approaches assume that findings of effects in pooled data are findings of constraints in grammars; they are weakened if their methodology is most effective at discovering those effects which are not parts of grammars. They also rely on the assumption that individuals share the grammar of their group. Should we assume, for example, that speakers of AAVE with certain constraints speak a variety descended from a creole and others with different constraints do not?
BACKGROUND ON RHOTICITY
Rhoticity in Bristol English
Loss of rhoticity in Bristol English offers us an excellent case study to explore these issues. The realization of nonprevocalic /r/ is undergoing change in many English varieties: rhoticity is declining in many previously rhotic British English varieties, but being gained in traditionally nonrhotic varieties in North America. The loss of rhoticity in West Country Englishes like Bristol English is a change in which adults participate and one triggered by an external norm: Standard Southern British English (SSBE) has categorical nonrhoticity in nonprevocalic contexts. Variable rhoticity in other English varieties has been extremely widely studied. Thus, effects found to be universal across previous studies of rhoticity are potential candidates for p-conditioning, whereas variable effects are more likely to reflect i- or s-conditioning. If the above discussion is on the mark, we will find that older Bristol speakers (who were agents of diffusion and/or participated in community-internal lifespan change) vary in the effects of such i- and s-conditioning factors. For younger speakers, we might find that a consistent consensus system has emerged, or we might find yet more constraint hierarchy variation, the result of acquiring the variable from a mixed input. Since the external standard has categorical nonrhoticity, there should be no external standard constraint hierarchy that could play a role.
This study is based on the use of rhoticity by 30 speakers of Bristol English in unstructured sociolinguistic interviews. The sample population was made up of 15 speakers born between 1920 and 1947, four speakers born between 1983 and 1989, and 11 speakers born between 2000 and 2003. A minimum of 20 tokens were collected per speaker for each preceding vowel context, except where fewer occurred in the interview; there were insufficient tokens following certain vowels (exemplified by the lexical sets cure, fire, and hour) and so these were excluded. Tokens were judged by ear as rhotic or nonrhotic and the spectrogram for each token examined; where tokens were perceptually indeterminate, they were classified as rhotic if the spectrogram showed a discernible drop in f3 across the vowel segment. These judgements were made by a single coder, Blaxter. Four speakers with (near-)categorical nonrhoticity (b1, b2, 9, 11) were excluded from the analysis (although they are included in Table 1 and Figure 1). The remaining dataset consists of 5817 tokens.
Table 1. Observations and rhoticity rates per speaker, listed by year of birth
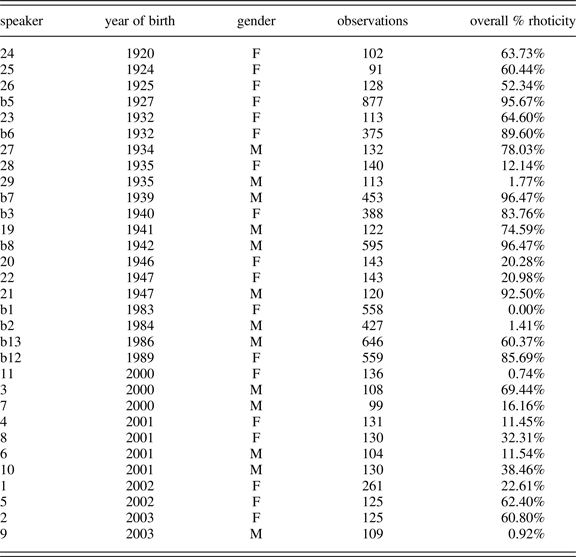
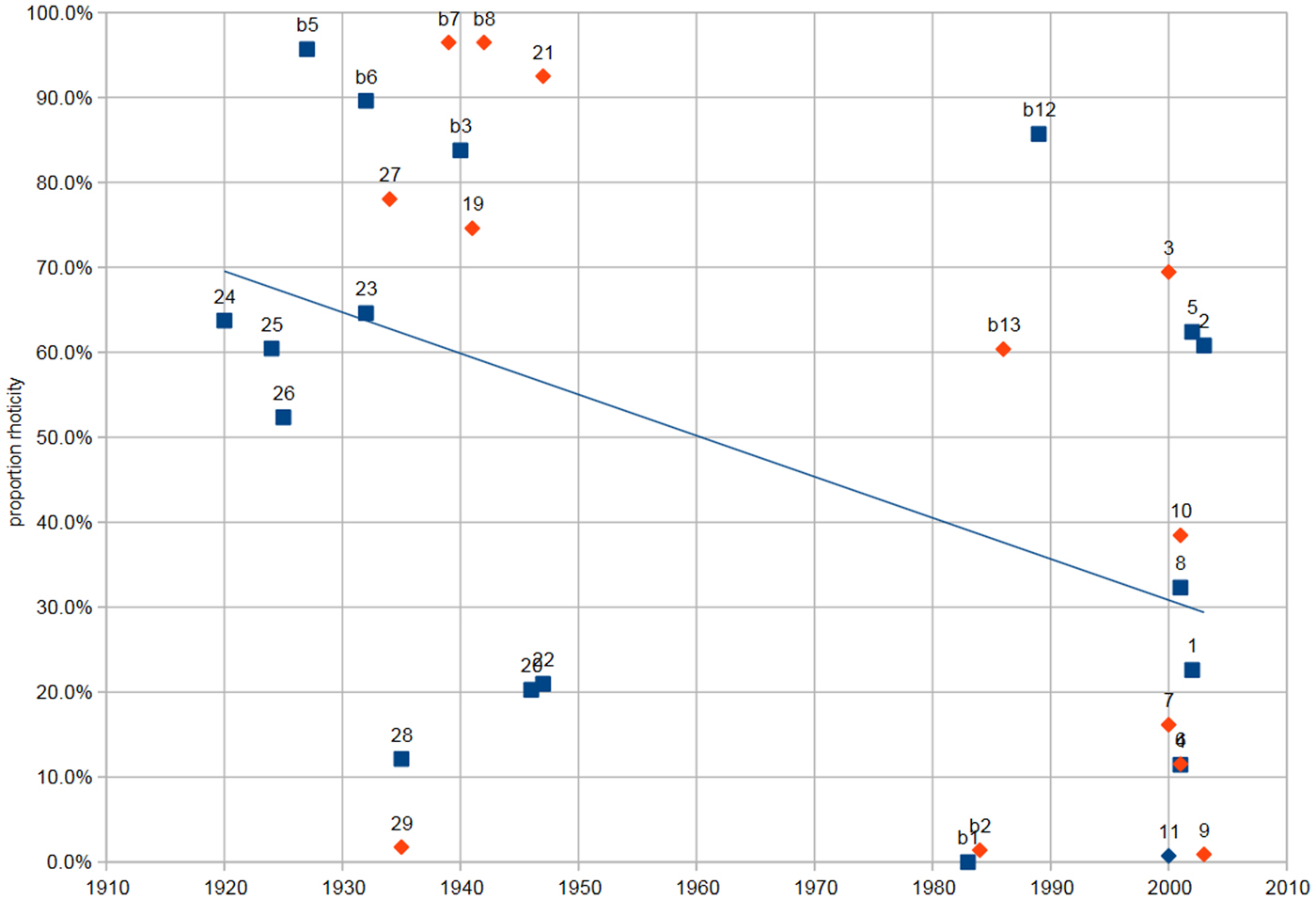
Figure 1. Rates of rhoticity by speaker for the sample population.
Ongoing change, with traditional rhoticity declining under the influence of the nonrhotic standard, is visible in these data as change in apparent time (Blaxter et al., Reference Blaxter and Coatesforthcoming).Footnote 1 Table 1 and Figure 1 show the number of observations and proportion of rhoticity per speaker against speaker age (the line is the linear trend line; points for female speakers are squares and male speakers diamonds).Footnote 2 As is also clear from this figure, there is a high degree of within-group variability. There are speakers with less than 30% rhoticity born before 1950 and speakers with greater than 70% rhoticity born after 2000. The Survey of English Dialects (SED) suggests that the traditional variety when these oldest speakers were children was fully rhotic. Instructively, Piercy (Reference Piercy2012:79) found that 97% of tokens produced by five SED speakers in Dorset were rhotic, a figure similar to the most conservative speakers in this study (b5, b7, and b8 all have over 95% rhoticity). Taken together, these observations suggest that much of the change away from rhoticity has taken place over the course of these speakers' lifetimes. We might guess, then, that the older speakers with the highest rates of rhoticity reflect community usage at the time of their childhoods, whereas the adults who exhibit low rates of rhoticity (such as speakers 26, 28, 20, and 22) have undergone substantial lifespan change.
Independent variables
To identify the relevant independent variables, 34 studies of rhoticity were surveyed. These include seven studies of other West Country varieties (Dudman, Reference Dudman2000; Hollitzer, Reference Hollitzer2013; Jones, Reference Jones1998; Piercy, Reference Piercy2006, Reference Piercy2007, Reference Piercy2012; Sullivan, Reference Sullivan1992), seven of varieties elsewhere in the UK (Barras, Reference Barras2010; French, Reference French, Auer and di Luzio1988; Schützler, Reference Schützler, Cummins, Elder, Godard, Macleod, Schmidt and Walkden2010; Simpson, Reference Simpson1996; Vivian, Reference Vivian2000; Watt, Llamas, & Johnson, Reference Watt, Llamas and Johnson2014; Williams, Reference Williams1991), 16 studies of North American varieties (Baxter, Reference Baxter2008; Becker, Reference Becker2014; Cychosz & Johnson, Reference Cychosz and Johnson2017; Elliott, Reference Elliott2000; Ellis, Groff, & Mead, Reference Ellis, Groff and Mead2006; Feagin, Reference Feagin1990; Hinton & Pollock, Reference Hinton and Pollock2000; Irwin & Nagy, Reference Irwin and Nagy2007; Labov, Reference Labov1972; Miller, Reference Miller and Vera1998; Myhill, Reference Myhill1988; Nagy & Irwin, Reference Nagy and Irwin2010; Parslow, Reference Parslow1967; Parslow, Reference Parslow, Williamson and Burke1971; Pollock & Bernie, Reference Pollock and Bernie1997; Villard, Reference Villard2009), and four studies of English varieties elsewhere (Hartmann & Zerbian, Reference Hartmann and Zerbian2010; Sharbawi & Deterding, Reference Sharbawi and Deterding2010; Sudbury & Hay, Reference Sudbury and Hay2002; Trudgill & Gordon, Reference Trudgill and Gordon2006). Table summaries showing the independent variables and their effects in each study are given in the online appendix. Here, we will concentrate on generalizations across studies. Since even coefficients from similarly designed regression models are not strictly comparable, the findings have been simplified to whether a variable was found to favor, disfavor, or be neutral for rhoticity.
One of the most striking findings of this review is the high degree of intervariety agreement. Especially if we do not consider findings of no effect as strong evidence, most factors either consistently disfavor rhoticity:
• higher word frequency (disfavoring in 3/3 studies),
• another /r/ in the word (disfavoring in 3/4 studies, no effect in 1),
• function words (disfavoring in 2/3 studies, no effect in 1)
or consistently favor it:
• stress (favoring in 10/10 studies),
• a following tautosyllabic consonant (favoring in 7/10 studies, no effect in 2, mixed in 1).
Thus, the only factors for which we find substantial intervariety disagreement are:
• word-final position (disfavoring in 8/12 studies, favoring in 3 and no effect in 1),
• prepausal position (favoring in 6/7 studies, disfavoring in 1),
• and morpheme-final (word-internal) position (disfavoring in 3/5 studies, no effect in 1, mixed in 1).
There is some slight evidence that direction of change (or perhaps dialect family) determines the effect of word-final position: all three studies that found word-final position favored rhoticity were studies of North American varieties with increasing rhoticity.
The effects of preceding vowel are more heterogenous. Where studies have simply compared back and front vowels, they have usually found that back vowels favor rhoticity compared with front vowels (Barras, Reference Barras2010; Baxter, Reference Baxter2008; Labov, Reference Labov1972; Sudbury & Hay, Reference Sudbury and Hay2002), although there are contradictory findings (Pollock & Bernie, Reference Pollock and Bernie1997). Where studies have distinguished vowel phonemes (generally denoted by lexical sets), we find considerable variation. Table 2 shows the proportion of studies in which the vowel in the row was found to favor rhoticity compared with the vowel in the column, excluding those in which the vowel was not included or the two were found to have equal effect. Studies that grouped vowels have been coded as finding an identical effect for all of them. On the one hand, certain vowels stand out as having consistent effects: preceding nurse is almost always one of the most favorable contexts (an exception is Nagy and Irwin's [Reference Nagy and Irwin2010] findings for younger speakers); preceding letter, north, and force are usually among the most disfavoring contexts (exceptions include Asprey [Reference Asprey2007] and Trudgill & Gordon [Reference Trudgill and Gordon2006]). On the other, there is no pair of vowels with totally consistent relative effects across previous studies.
Table 2. Proportion of previous studies finding that the vowel in the row favored rhoticity compared with the vowel in the column
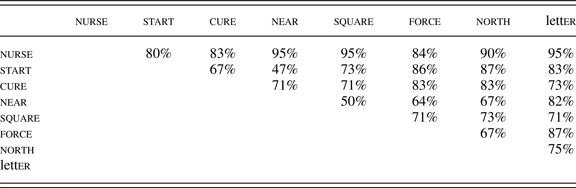
These findings offer some evidence for the classification of these factors in terms of the typology proposed by Tamminga, MacKenzie, and Embick (Reference Tamminga, MacKenzie and Embick2016). Since, barring interactions with other factors, p-conditioning should be universal, whereas i-conditioning need not be, factors that were found to have a consistent effect across previous studies are more likely to reflect p-conditioning, and factors found to have inconsistent effects across previous studies are more likely to reflect i-conditioning. This classification can be further informed by other properties of the factors in question. Factors that are crosslinguistically observed never to have categorical effects (such as lexical frequency) must be p-conditioning; in any case, we should be able to posit a plausible mechanism of effect in the relevant domain. Suggested classifications are summarized in Table 3.
Table 3. Classification of internal effects on rhoticity according to the typology proposed by Tamminga, MacKenzie, and Embick (Reference Tamminga, MacKenzie and Embick2016)
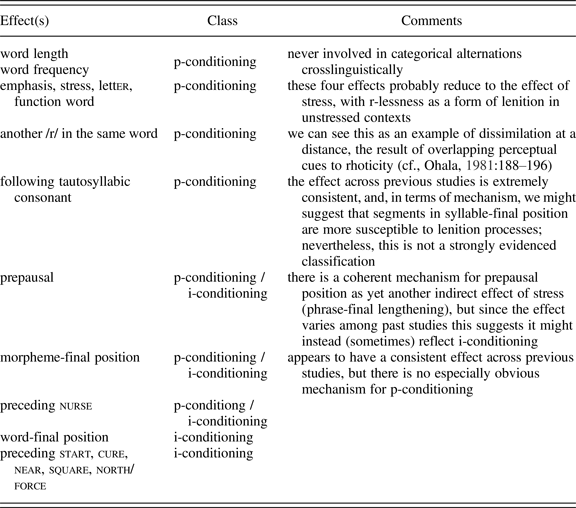
This typology guides variable selection for this study. We want to include all potential i-conditioning effects (which are of most interest for our research questions), as well as some of the strongest and best-studied p-conditioning effects. The independent variables included are:
• preceding vowel,
• morphological position (morpheme-internal versus word-internal morpheme-final versus word-final),
• prepausal position,
• function word versus content word,
• frequency (on the basis of the spoken BNC [Leech, Rayson, & Wilson, Reference Leech, Rayson and Wilson2001]),
• and time during the interview measured in seconds (which gives a very crude measure of shifting style).
Finally, note that past studies also identified external effects on rhoticity, which are summarized in online Appendix 1, Table 5A; we can assume that all of these reflect static s-conditioning.
METHODOLOGICAL ISSUES WITH STUDYING INDIVIDUALS
Investigating variation between individuals in conditioning systems is methodologically tricky. We can fit a separate regression model to the data from each speaker and compare them (e.g., Guy, Reference Guy and Labov1980). However, from a purely practical standpoint, we normally do not have enough data per speaker. Moreover, although we can identify differences in the strengths, directions, and relative orders of coefficients by comparing our models, we do not have a measure of whether those differences were significant. In order to reach his conclusion that individuals agree with the community grammar, Guy had to write off a number of disagreeing individuals as the results of statistical noise in small samples, and he noted that at least one reported effect was from a model that did not converge (Guy, Reference Guy and Labov1980:22).
Simply comparing raw rates in different contexts (as was done in several past studies: Horvath & Horvath, Reference Horvath and Horvath2003; Meyerhoff & Walker, Reference Meyerhoff and Walker2007; Poplack & Sankoff, Reference Poplack and Sankoff1987; Tagliamonte, Reference Tagliamonte, Chambers and Schilling2013:137–142) creates some of the same problems as using regression analyses (i.e., we do not know whether differences in constraints between different individuals are significant), without the benefits (i.e., we also do not know whether apparent effects are secondary). Tagliamonte (Reference Tagliamonte, Chambers and Schilling2013:148–149) also used conditional inference trees to compare speakers, but again this offers us no way of deciding whether differences are significant or just the result of small sample sizes.
Returning to regression analysis, we can fit a single model to the whole dataset but add a means to identify individual deviations from the community constraint hierarchy. This can be done by adding fixed interaction terms between speaker and each of our internal predictors or by examining random slopes for speaker/predictor combinations in a mixed-effects model (see Forrest, Reference Forrest2015). This gives us a test of whether at least one speaker differs from the baseline model for a given predictor (whether the model fit is significantly improved by adding the interaction or by adding random slopes), but it does not give us a significance test per speaker/predictor combination or any other way to undertake feature selection on a per speaker/predictor combination basis. It still potentially suffers from the problems of small data.
Another alternative is elastic net regression (Zou & Hastie, Reference Zou and Hastie2005), a method that combines ridge regression with lasso regression. These are methods of fitting regression models that ‘penalize’ large coefficients in order to avoid overfitting. Like ridge regression, elastic net regression is robust when predictors are highly, or even perfectly, correlated (as is likely when dealing with a large number of predictors) and shrinks highly inflated coefficients (which sometimes arise when dealing with small datasets). Like lasso regression, it can deal with large numbers of predictors (even where p > n) and incorporates a form of automatic feature selection, tending to reduce small coefficients to zero and thus effectively removing them from the model. Thus, an elastic net regression model, including interaction terms between speaker and all internal predictors, offers us a solution to the problems laid out above:
• the method achieves a parsimonious model by reducing as many coefficients as possible to zero;
• although we have no measure of significance per se for elastic net regression, since it automatically performs variable selection on a per-coefficient basis we can confidently interpret the results for each coefficient that remains in the model;
• the model offers interpretable results with small per-speaker datasets and can converge under perfect separation;
• it is able to deal with highly correlated predictors, which are often a problem with linguistic data.
A fuller explanation of this and related methods is given in the online appendix. Here, the implementation of penalized logistic regression from the R package ‘penalized’ (Goeman, Reference Goeman2009; Goeman, Meijer, Chaturvedi, & Lueder, Reference Goeman, Meijer, Chaturvedi and Lueder2017) was used to fit a single model for the whole dataset. The model included all of the linguistic variables listed at the end of the ‘Independent variables' section above plus interaction terms between speaker and each of these predictors. The coefficients for noninteraction terms will be described as the ‘baseline model’: these represent the average constraint ranking for the whole community. The sums of noninteraction and interaction coefficients then give us our models for each speaker (these are given rather than giving the interaction coefficients directly so as to be able to give a constraint ranking for each speaker).Footnote 3
RESULTS
Figure 2 gives the model coefficientsFootnote 4 for different preceding vowels and Figure 3 for all other predictors (raw cell values on which all coefficients are based are reported in online Appendix 1). These figures show roughly the expected picture: preceding vowels favor rhoticity in a hierarchy nurse > near > start > square > letter > north/force. Among other predictors, the largest effects are the favoring effect of prepausal position and the disfavoring effect of being a function word. The magnitudes of other effects are relatively small. All effects, except word frequency, are in the same directions as identified in the majority of previous studies.
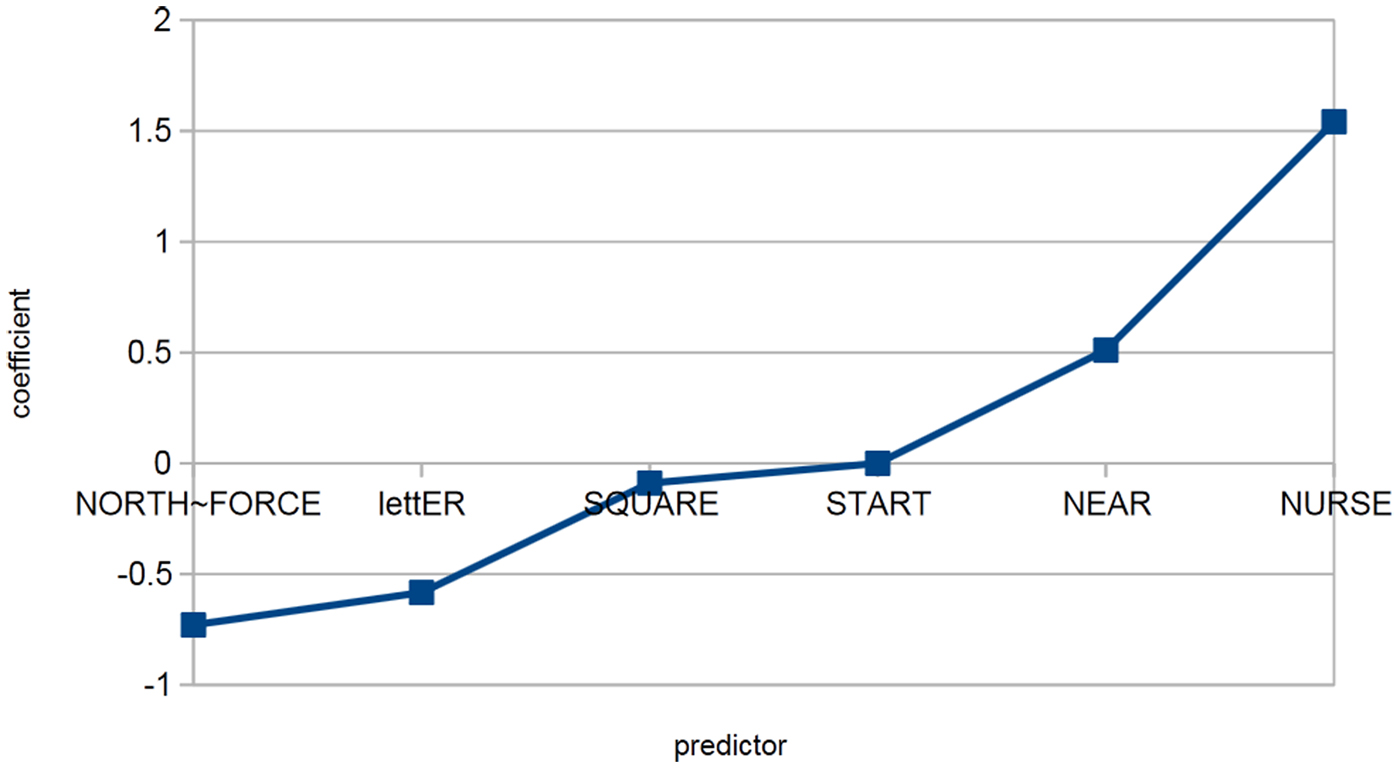
Figure 2. Coefficients for preceding vowels (baseline model).

Figure 3. Coefficients for other predictors (baseline model).
The interesting results, however, are in individual speaker deviations from this baseline model. Of the 338 possible interactions in the model, 212 had nonzero coefficients. Figure 4 shows the sums of the coefficients of the interaction terms between speaker and preceding vowels and the coefficients of preceding vowels in the baseline model, and Figure 5 shows the same for other predictors; the orders of predictors are the same as in Figure 2 and Figure 3.

Figure 4. Coefficients for interactions between speaker and preceding vowel (ordered by speaker number).
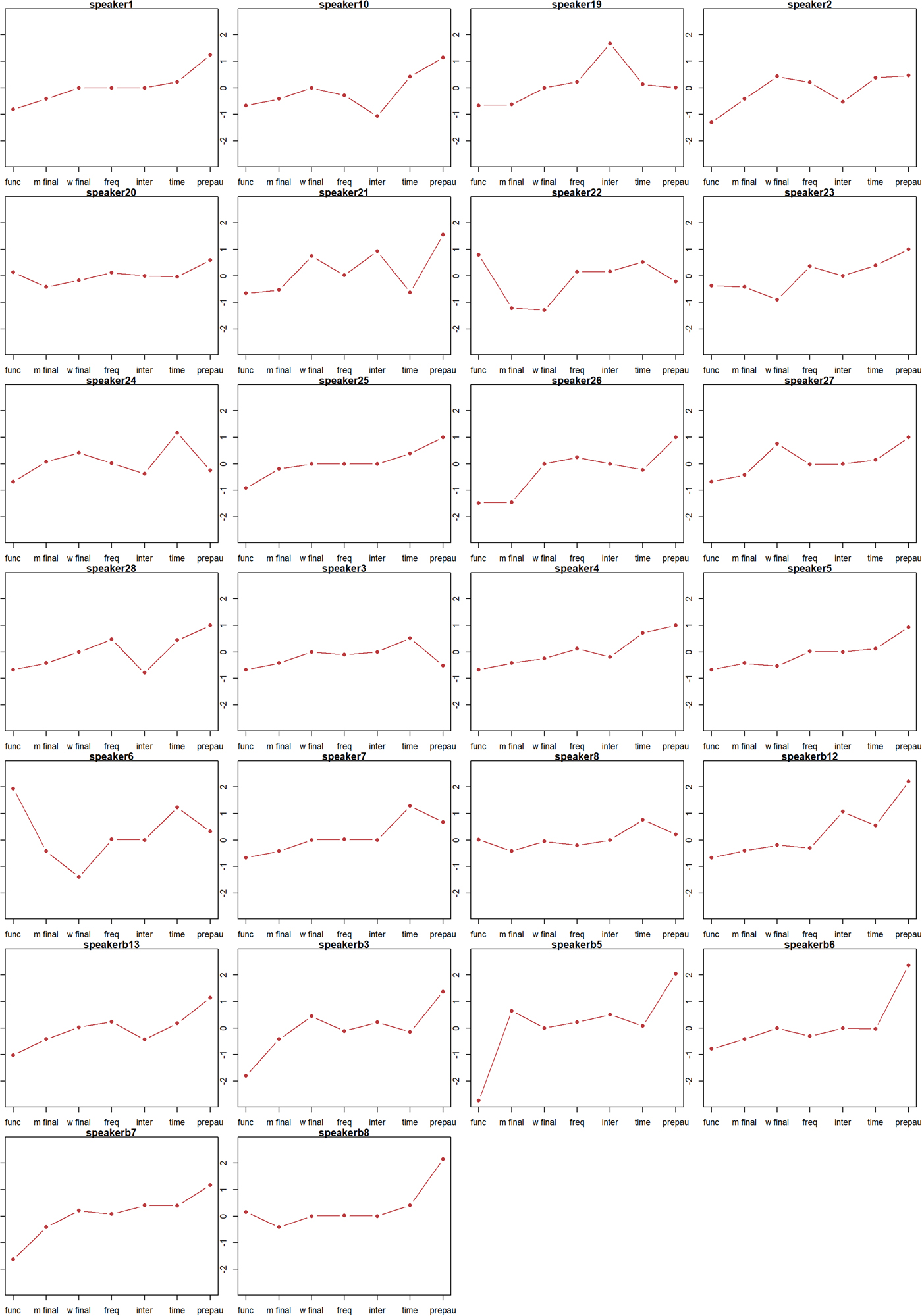
Figure 5. Coefficients for interactions between speaker and word class, morphological position, frequency, time, and prepausal position (ordered by speaker number).
At one end of the spectrum, we find speakers whose systems are basically in complete agreement with the community system (cf., the preceding vowel coefficients for speaker b8 [ Figure 6Footnote 5] or the coefficients for other predictors for speaker 1 [Figure 7]). Most speakers, however, have at least some significant deviations from the common system. At the other extreme, we find highly divergent systems, such as the preceding vowel system of speaker b12 in which north/force and square slightly favor rhoticity (Figure 8), or the system of other predictors for speaker 24, where prepausal position slightly disfavors rhoticity, and most influence comes from morphological position and time (Figure 9).

Figure 6. Coefficients for preceding vowels (speaker b8).
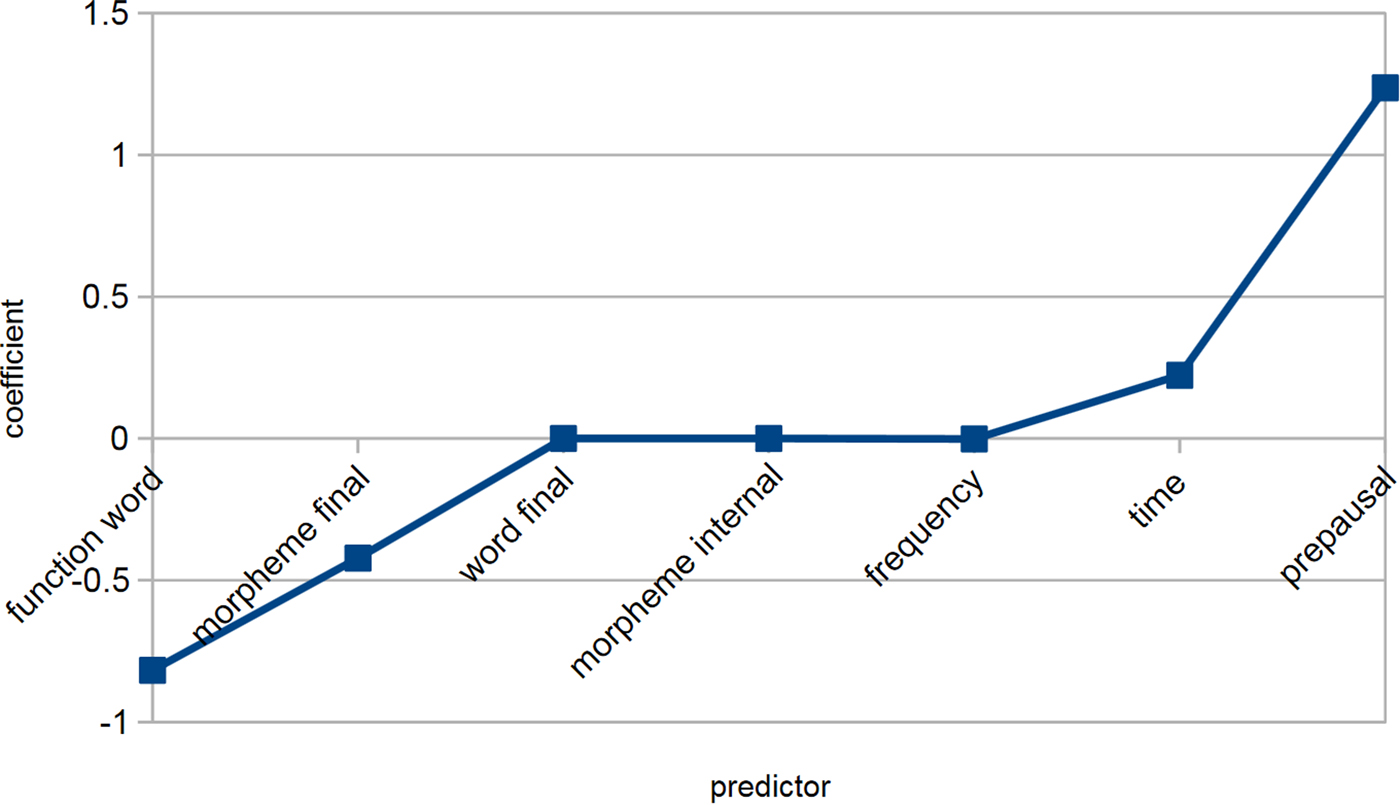
Figure 7. Coefficients for other predictors (speaker 1).
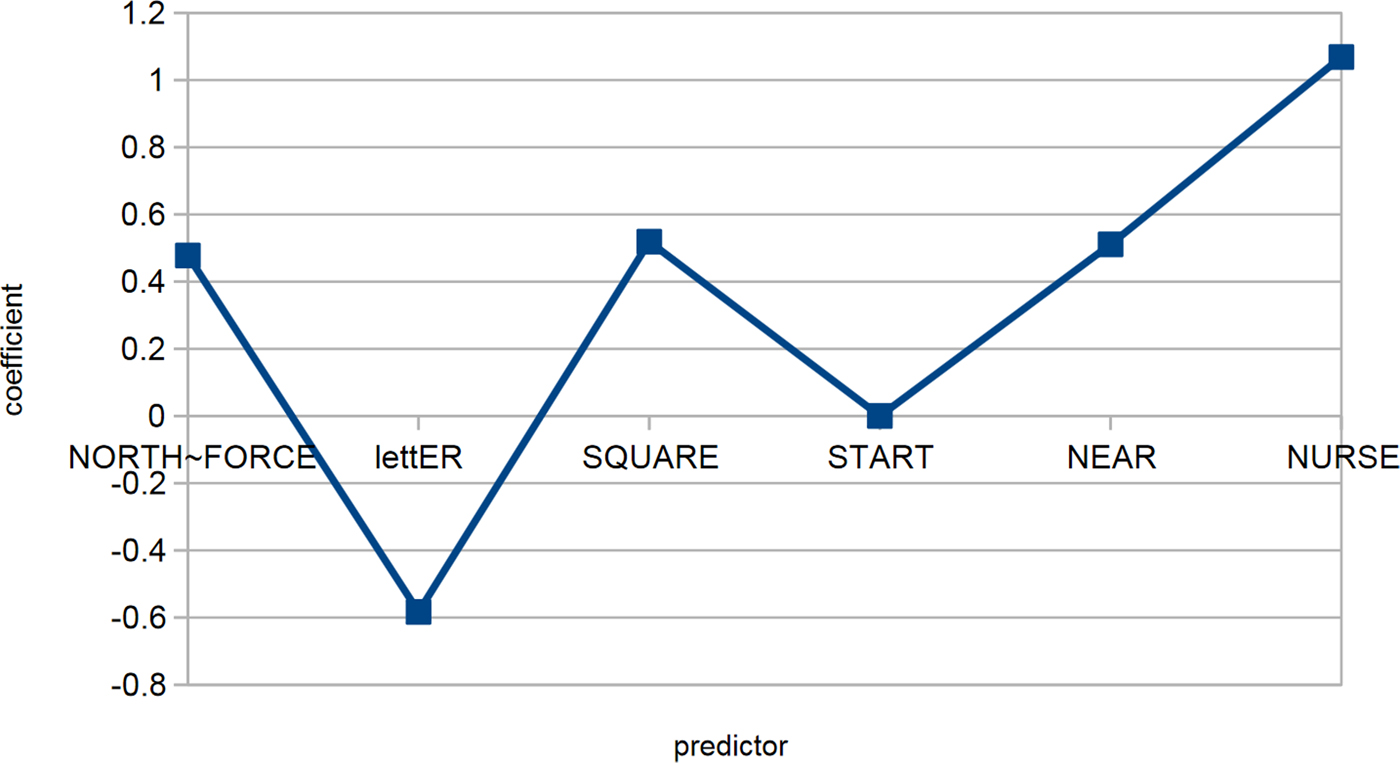
Figure 8. Coefficients for preceding vowels (speaker b12).
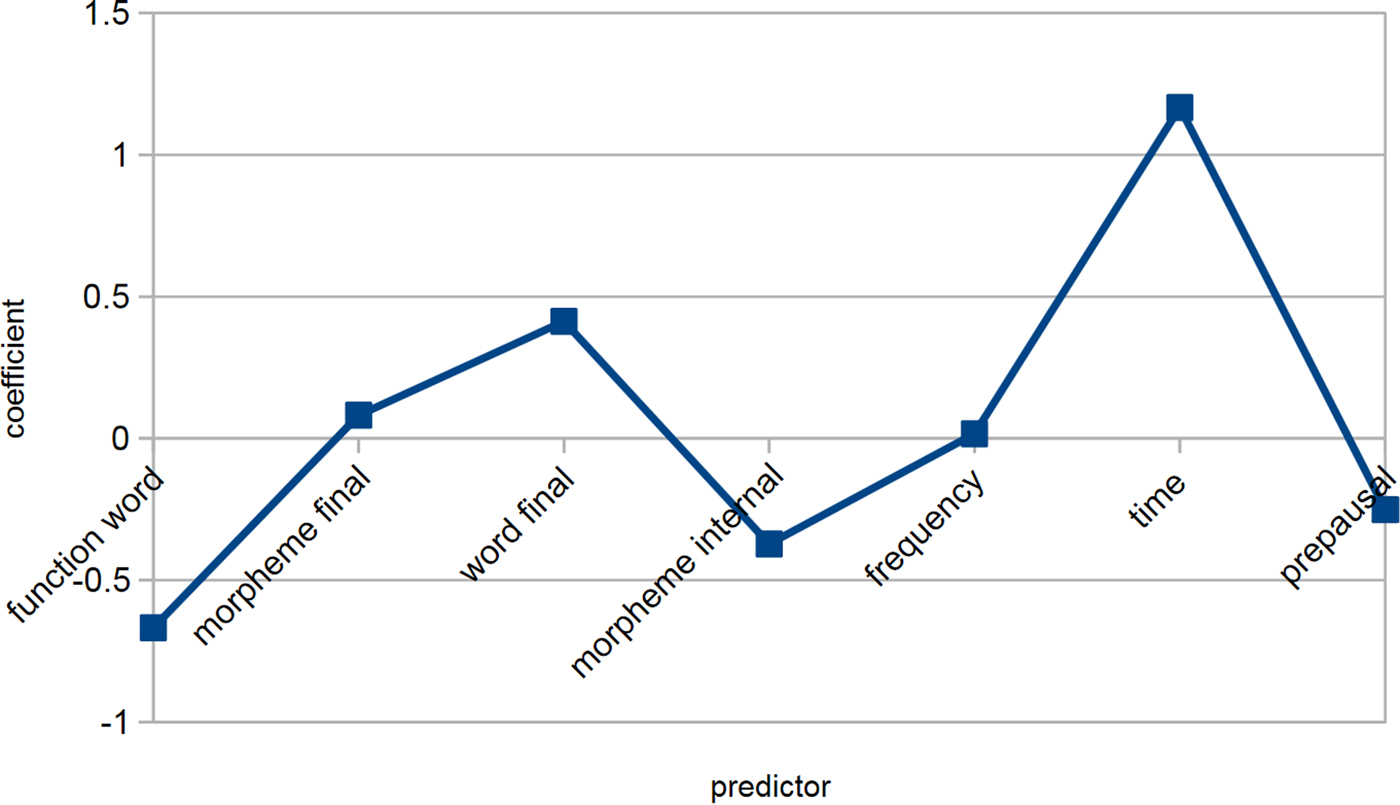
Figure 9. Coefficients for other predictors (speaker 24).
One way of measuring speakers' levels of agreement with the community norms is to look at rank correlations between the coefficients of the baseline model and coefficients from individual speaker models (i.e., sums of baseline coefficients and interaction coefficients): a perfect rank correlation would imply that, even if a speaker's system differs from the community norm in details, the overall constraint hierarchy is the same; a correlation coefficient of zero would imply that a speaker's system bore no relation to the community norm. Figure 10 visualizes these rank correlation coefficients for vowels and for other predictors. There are no obvious patterns by age or gender: highly agreeing and highly disagreeing speakers are found in the young and old, male and female groups. Note too that there is no significant correlation between these two measures: having a vowel system that deviates from the community norm is not a good predictor of having other effects that deviate from the community norm, and vice versa.
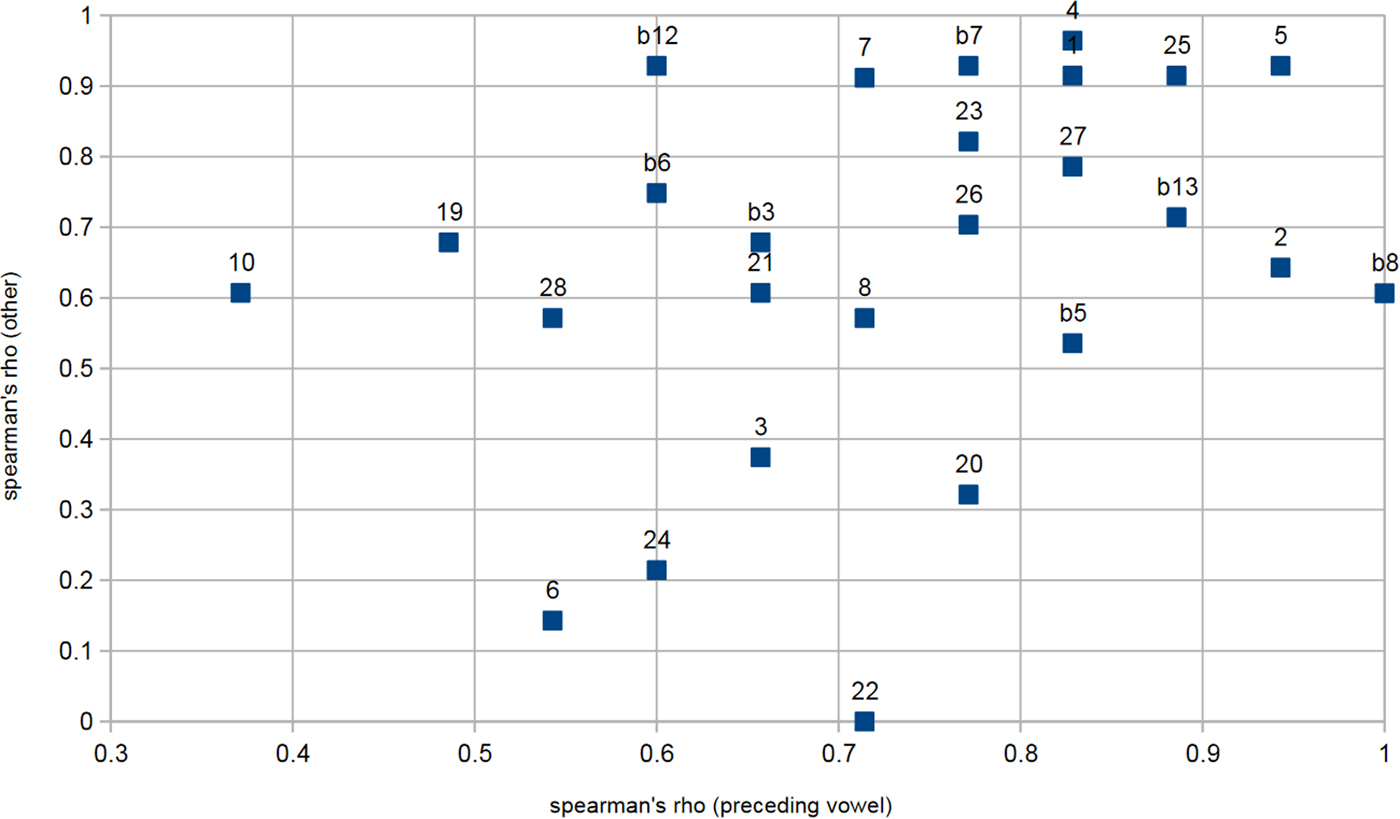
Figure 10. Rank correlation coefficients between speaker coefficients and global coefficients.
Turning from speakers to variables, we find some highly consistent predictors. The strongest example is preceding vowel nurse, which is the most favoring vowel for all but six speakers (and for five of those it is the second most favoring). However, we also find some highly variable predictors such as word final position, which varies from being one of the most favoring contexts for rhoticity (speakers 2, 3, 24, 27, and b8) to the most disfavoring (speakers 6, 22, and 23).
Figure 11 visualizes the ranges of coefficients across speakers. In summary, we can say that the following relatively consistently favor rhoticity:
• preceding nurse (weak reversed effect for speaker 6),
• prepausal position (reversed effect for speakers 3, 22, and 24),
• time in the interview (reversed effect for speakers 21, 26, b3, and b6);
the following relatively consistently disfavor rhoticity:
• function words (with a clearly reversed effect for speakers 6 and 22, and very weakly reversed effects for speakers 8, 20, and b8),
• preceding north/force (reversed effect for speakers 23 and b12),
• preceding letter (reversed effect for speakers 3, 19, 21, and 26),
• morpheme-final position (reversed effect for speakers b5 and 24);
and the following have inconsistent effects:
• preceding near (favors for 19 speakers but disfavors for speakers 1, 6, 8, 10, 19, 20, and 22),
• word frequency (disfavors for nine speakers, favors for 18 speakers, of which six only very weakly),
• morpheme-internal position (disfavors for six speakers, neutral for 13 speakers, favors for seven speakers),
• preceding start (disfavors for eight speakers, neutral for 10 speakers, favors for eight speakers),
• word-final position (disfavors for eight speakers, neutral for 11 speakers, favors for seven speakers),
• and preceding square (disfavors for 21 speakers, of whom 11 only very weakly, favors for speakers 24, 25, b7, b12, and b13).
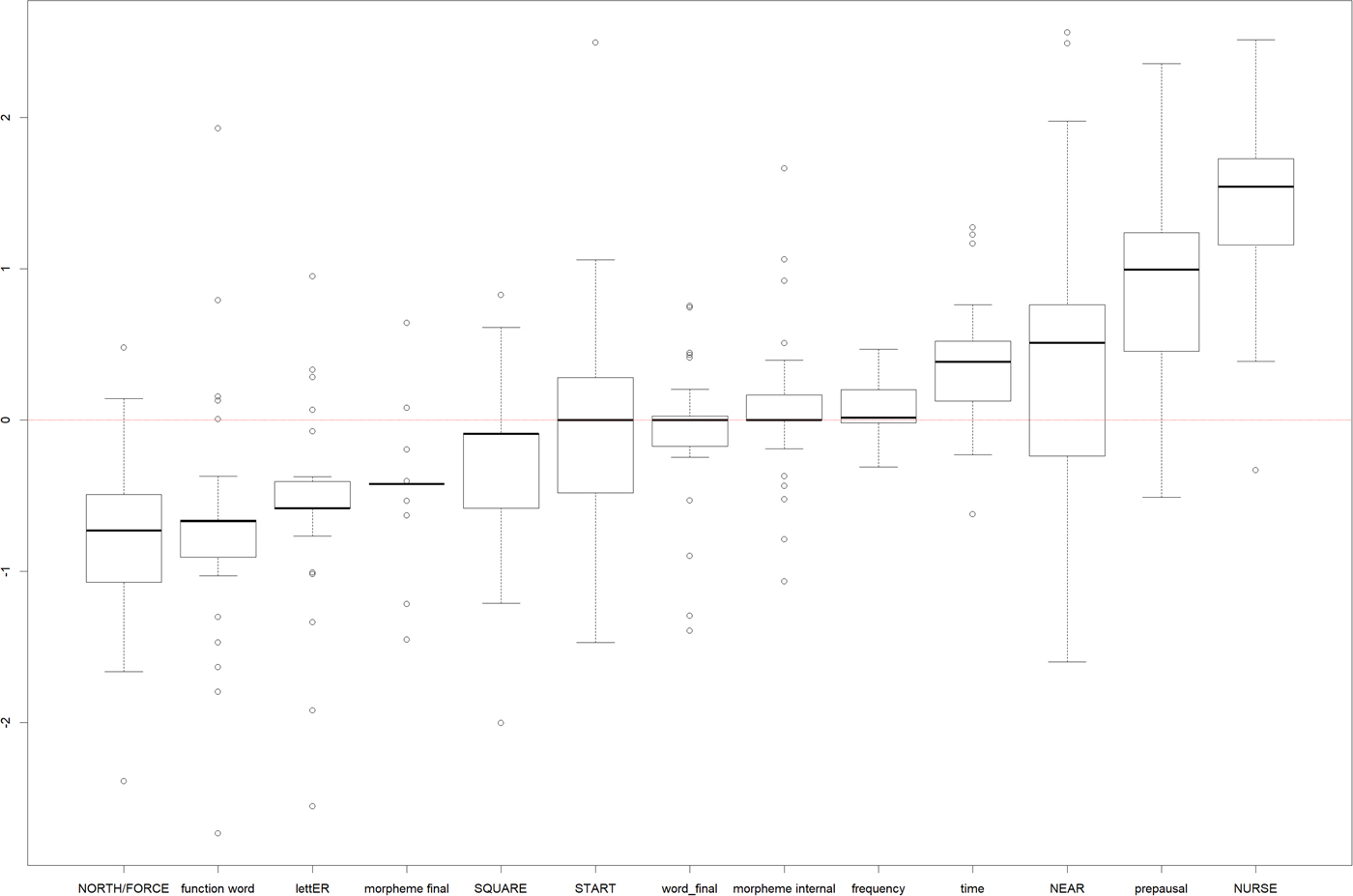
Figure 11. Ranges of coefficients across speakers.
DISCUSSION
In the discussion above, we sketched the following scenario:
• following Tamminga, MacKenzie, and Embick (Reference Tamminga, MacKenzie and Embick2016), influences on the occurrence of rhoticity fall into three categories, i-conditioning, p-conditioning, and s-conditioning;
• p-conditioning reflects universal physical and psychological factors: excepting interactions with other factors, it should be found to be consistent across studies of different speech communities and (for direction if not necessarily for degree) across individuals within speech communities;
• s- and i-conditioning are community-specific: they should be found to vary across studies of different communities;
• in speech communities undergoing external change (diffusion), s- and i-conditioning should be disrupted and so vary across individuals.
On the basis of these observations, and given that Bristol English is a variety undergoing just such external change, we predicted that:
1. variation across individuals in this study should be substantial, with true reorganizations of systems of constraints;
2. there might be greater consistency for younger speakers, who have koinéized the mixed community input to settle on a common system of constraints;
3. certain factors should recur across all past studies and all individuals within this study; these should otherwise fit the profile of p-conditioning factors;
4. whereas factors which differ across past studies and between individuals in this study should have plausible s- and i-conditioning mechanisms.
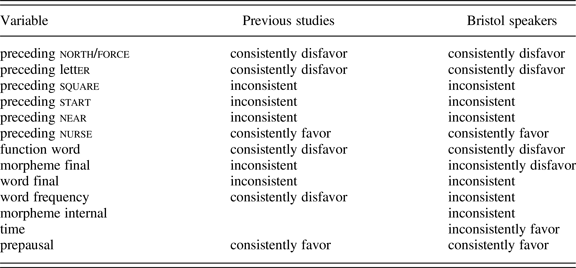
Considering the first of these predictions in light of the summary of findings in Table 4, we find that this is clearly borne out by the data. There are three highly consistent findings across all speakers: preceding nurse is almost always one of the strongest favoring contexts for rhoticity (the only real exception is speaker b6); preceding north/force always has a disfavoring effect; word frequency is always one of the weakest effects. In every other respect, we find variation across speakers. Comparing the magnitude of coefficients, we find speakers (6, b5, b7) for whom function word status has the largest effect, speakers (21, b6, b8, b12) for whom prepausal position has the largest effect, and many speakers for whom the largest effect is from preceding vowel. There are speakers (7 and 24) for whom the predictor with the third largest magnitude is the time in the interview, suggesting that these speakers showed a particularly high degree of style shifting.Footnote 6 Among preceding vowels, there is substantial variation: preceding start ranges from most favoring to least favoring context; preceding near ranges from the most favoring to second most disfavoring; preceding square and letter from the second most favoring to most disfavoring. All in all, we find such substantial differences between systems exhibited by different speakers that we cannot describe these as merely minor variations in strengths or reorderings of otherwise similar effects: it is only reasonable to describe these as true reorganizations of systems of constraints.
Table 4. comparison of effects across previous studies and across Bristol English speakers
Our second prediction fares much more poorly. There are younger speakers (such as speaker 5) whose systems agree relatively well with the global model, but there are also younger speakers with highly divergent systems (such as speaker 6, whose function word constraint is reversed); the same is true of older speakers. Overall, there is no evidence that interindividual variation is lessening with successive generations of speakers.
Turning to the third prediction, we do find some convincing examples. Function words consistently disfavor rhoticity across past studies and across all but two speakers in this study. An obvious mechanism for this effect is that function words are chronically understressed and so more subject to lenition and fast-speech processes: this is a mechanical consequence of the nature of function words and so qualifies as p-conditioning. There is no reason to think this constraint is part of competence for these speakers (although hypothetically it could easily give rise to a truly linguistic constraint, such as by developing into a lexical split where function words lose underlying rhoticity but content words do not).
Likewise, the preceding vowel letter seems a good candidate for p-conditioning. This disfavors rhoticity across a large majority of previous studies, and it disfavors rhoticity for a large majority of speakers in this study. Again, the mechanism here would be to do with stress: letter is the only fully unstressed rhotic vowel.
The influence of prepausal position on rhoticity may also reflect p-conditioning: it favors rhoticity for all but three speakers in this study and favors rhoticity in all but one previous study. Here, the mechanism is presumably derived from phrase-final lengthening, with rhoticity more likely to be preserved in lengthened syllables and words. Since this phrase-final lengthening is a common phenomenon across languages, there is no reason to imagine this effect would be part of learned competence. The varying size of this effect across speakers in this study might reflect individual differences in speech-rate or propensity for phrase-final lengthening.
Turning to our fourth prediction, we find several effects which fit well into our account. The inclusion of time in the model can give us a (very crude) measure of style shifting—dynamic s-conditioning in the terms of Tamminga, MacKenzie, and Embick (Reference Tamminga, MacKenzie and Embick2016)—and, as expected for s-conditioning, we see variation across individuals. Some speakers (such as 7 or 24) substantially increase their rate of rhoticity over the course of the interview, while others (such as speaker 20 or b5) show close to no change, and a few (21, 26, and b3) decrease their rate of rhoticity over the course of the interview.
In terms of i-conditioning, the preceding vowels square, start, and near clearly behave as predicted for i-conditioning factors. The effects of these contexts vary both between past studies and between individuals in this study, implying that they are learnt effects which can be disrupted by diffusion. Likewise, the effects of morphological context (a following word boundary versus a following word-internal morpheme boundary versus neither) are inconsistent across previous studies and inconsistent across Bristol English speakers, suggesting that these are arbitrary, learnt effects that are part of the grammar and can be disrupted by diffusion.
Three effects are a problem for our account and deserve closer comment. The favoring effect of preceding vowel nurse on rhoticity is very consistent across speakers in this study and one of the most consistent across past studies, suggesting that it might reflect p-conditioning, yet there is no immediately obvious universal mechanical or psychological mechanism to account for it. Similarly, the disfavoring effect of preceding north/force on rhoticity is quite consistent across previous studies and very consistent across speakers in this study. It is, of course, possible that these reflect i-conditioning factors that simply happen to be consistent across all varieties of English studied. If this were the case, we might hypothesize that they would be less liable to disruption by diffusion, since they would be a constant across all varieties a potential diffuser was exposed to, explaining their interspeaker consistency in this study.
A different possibility is that these are explained by structural phonological factors. Considering the loss of rhoticity, we could classify words by whether the change is a merger—that is, the phonological transfer of the word from one class into another existing class—or involves the creation of a new vowel phoneme. By this classification, north/force words are at one end of the spectrum (the thought vowel and for some speakers the cloth vowel are large, well-established lexical sets into which north/force words are transferred), whereas nurse words are at the other (there is no other source of /ɜː/). Other lexical sets fall between these extremes, with the loss of rhoticity involving transfer into marginal existing sets (idea for near, yeah for square) or sets that only exist in certain varieties (bath for start only in varieties with the trap/bath split, a phenomenon discussed more extensively in Blaxter and Coates [Reference Blaxter and Coatesforthcoming]). The one other preceding vowel for which loss of rhoticity involves merger into a large, well-established lexical set is letter, which merges with comma, and this vowel, like north/force, consistently disfavors rhoticity across speakers and past studies. This implies that there may be a universal psychological mechanism at work here: that it is easier to transfer a word into an existing phonemic class than it is to create a new phoneme.
Finally, word frequency fails to fit our predicted picture: more frequent words consistently disfavored rhoticity in (admittedly only three) past studies, but had a small and inconsistent positive influence on rhoticity for Bristol English speakers. Here, we have two possibilities. First, it is possible that this reflects i-conditioning and that the sample of previous studies is simply too small to have identified the fact that the direction of this effect can differ between varieties. However, the problem would then be that it seems very unlikely a priori that word frequency is a variable that can be involved in i-conditioning, since it is not a variable that can be involved in categorical grammatical rules (no language, for example, has one allomorph which is used on stems above a certain threshold frequency in connected discourse and a different allomorph for other stems). We must turn, then, to the second possibility, which is that there is some methodological problem in the approach to frequency in this study or in past studies: either the source of frequency data used here (the spoken component of the British National Corpus) is not a good measure of frequency for these speakers, the effect is too small to capture accurately in the datasets used, or an interaction with other predictors interferes with the effect. There is, in fact, good evidence for this last conclusion: the three studies which found that higher word frequency disfavored rhoticity did not investigate the effect of function versus content word status, and the one past study that investigated both found no effect of frequency. As the most frequent words are typically function words, it is likely that past findings that frequency favors rhoticity are due to the status of function words, explaining the disagreement with the findings of this study.
CONCLUSIONS
This study has proposed that, in light of Labov's (Reference Labov2007) transmission-diffusion distinction and the work of Tamminga, MacKenzie, and Embick (Reference Tamminga, MacKenzie and Embick2016) on the nature of constraints on variation, more attention must be paid to individual differences in the conditioning of variables within speech communities. What is more, this study has proposed that the standard variationist methodology of pooling data from multiple speakers in order to investigate variable conditioning may be flawed in some cases: if there is substantial individual variation in conditioning systems, which may be typical of cases of ongoing diffusion, the pooling method may miss this variation; in such cases it may also be less effective at identifying precisely those effects in which variationists are usually most interested, effects which are part of the grammar (i-conditioning). In order to investigate these claims, data on rhoticity variation from speakers of Bristol English were compared to 34 previous studies of rhoticity in varieties of English around the world.
In keeping with predictions, it was observed that certain factors have highly consistent effects across different varieties studied and across speakers in Bristol English. This is taken as suggestive that these effects reflect universal physical (in the case of function word, prepausal position and preceding letter) or structural-psychological (in the case of nurse/north/force) factors. This suggests that these effects may not be learned and encoded in the grammar. Other factors had variable effects both across past studies and across speakers in this study, offering evidence that they are part of the grammar and so subject to disruption through imperfect learning when undergoing external change.
Contrary to predictions, there was no indication that younger speakers had more consistent variable grammars than older speakers. This implies that no process of koinéization, in which new generations of speakers systematize and simplify unstructured variation in the input generated by contact and diffusion, has taken place. This is perhaps unsurprising in light of the fact that the external pressure to change (knowledge of prestigious SSBE/RP) has remained a constant for the entire trajectory of the change. There was no defined period of contact and diffusion after which disrupted grammars could be transmitted and koinéized: rather, contact, adult change, and, accordingly, new disruption have presumably continued to take place throughout.
These findings problematize both the notion of the community grammar and the method of pooling data from multiple speakers when studying certain communities. From a conceptual standpoint, it is not clear that a notion of speech community as defined by shared grammar is tenable for data like those presented here (although by the definition of shared evaluative norms, it might still be). If the idea that individuals in the speech community share underlying production norms is understood as an assumption rather than as definitional, these data suggest that it should instead be seen as a hypothesis that must be confirmed for any given dataset. Either way, the rich individual variation in these data suggest that we should be wary of investigating variable conditioning in data pooled from multiple speakers without first investigating how much those speakers' grammars differ from one another. Not only does this give us a better chance of identifying real grammatical constraints that can vary between speakers, it also provides us with evidence for the nature and interpretation of the effects we find.
SUPPLEMENTARY MAT ERIAL
To view supplementary material for the article, please visit https://doi.org/10.1017/S0954394519000048.

















 Open access
Open access