


1. Introduction
The distribution of various random variables associated with trees is widely studied in the literature. Typically, the tree parameters that behave additively exhibit normal distribution, which was observed by Drmota [Reference Drmota7, Chapter 3], Janson [Reference Janson16], and Wagner [Reference Wagner27]. For example, the number of leaves or, more generally, the number of vertices of a given degree satisfies a central limit theorem (CLT) for many random models: labelled trees, unlabelled trees, plane trees, forests; see Drmota and Gitteberger [Reference Drmota and Gittenberger8] and references therein for more details.
The classical limit theorems of probability theory are impractical for random trees due to the dependency of adjacencies. Instead, one employs more elaborate tools such as the analysis of generating functions [Reference Bender and Richmond2], the conditional limit theorems [Reference Holst12], and Hwang’s quasi-power theorem [Reference Hwang13]. These methods are particularly efficient for parameters that admit a recurrence relation, which is often the case for trees.
The martingale CLT [Reference Brown4] is a powerful tool that has been extensively used to study random structures. Nevertheless, it is surprisingly overlooked in the context of the distribution of tree parameters and the vast majority of known results rely on the methods mentioned in the paragraph above. We are aware of only a few applications of the martingale CLT: Smythe [Reference Smythe25] and Mahmoud [Reference Mahmoud18] analysed growth of leaves in the random trees related to urn models; Móri [Reference Móri22] examined the max degree for Barabási–Albert random trees; Fen and Hu [Reference Feng and Hu9] considered the Zagreb index for random recursive trees; Sulzbach [Reference Sulzbach26] studied the path length in a random model encapsulating binary search trees, recursive trees and plane-oriented recursive trees.
We prove a CLT for an arbitrary tree parameter using the martingale approach. Unlike other methods, the parameter is not required to be of a specific form or to satisfy a recurrence relation. Our only assumption is that the parameter is stable with respect to small perturbations in the sense that precisely specified below. We also bound the rate of convergence to the normal distribution. In this paper, we restrict our attention to unrooted labelled trees even though martingales appear naturally in many other random settings. This is sufficient to demonstrate the power of the new approach and cover several important applications that go beyond the toolkit of existing methods.
Let
 $\mathcal{T}_n$
be the set of trees whose vertices are labelled by
$\mathcal{T}_n$
be the set of trees whose vertices are labelled by
 $[n]\,:\!=\,\{1,\ldots, n\}$
and
$[n]\,:\!=\,\{1,\ldots, n\}$
and
 ${\textbf{T}}$
be a uniform random element of
${\textbf{T}}$
be a uniform random element of
 $\mathcal{T}_n$
. By Cayley’s formula, we have
$\mathcal{T}_n$
. By Cayley’s formula, we have
 $|\mathcal{T}_n| = n^{n-2}$
. For a tree
$|\mathcal{T}_n| = n^{n-2}$
. For a tree
 $T \in \mathcal{T}_n$
and two vertices
$T \in \mathcal{T}_n$
and two vertices
 $i,j\in[n]$
, let
$i,j\in[n]$
, let
 $d_T(i,j)$
denote the distance between i and j that is the number of edges in the unique path from i to j in T. For
$d_T(i,j)$
denote the distance between i and j that is the number of edges in the unique path from i to j in T. For
 $A,B \subseteq [n]$
, let
$A,B \subseteq [n]$
, let
 \begin{equation*}d_T(A,B) \,:\!=\, \min_{u \in A,v \in B} d_T(u,v).\end{equation*}
\begin{equation*}d_T(A,B) \,:\!=\, \min_{u \in A,v \in B} d_T(u,v).\end{equation*}
Throughout the paper, we identify graphs and their edge sets. Consider an operation defined
 $\textrm{S}_{i}^{jk}$
as follows. If
$\textrm{S}_{i}^{jk}$
as follows. If
 $ij \in T$
and
$ij \in T$
and
 $ik \notin T$
, let
$ik \notin T$
, let
 $\textrm{S}_{i}^{jk} T$
be the graph obtained from T by deleting the edge ij and inserting the edge ik; see Figure 1 below.
$\textrm{S}_{i}^{jk} T$
be the graph obtained from T by deleting the edge ij and inserting the edge ik; see Figure 1 below.

Figure 1.
 $\textrm{S}_{i}^{jk}$
removes ij from a tree and adds ik (dashed).
$\textrm{S}_{i}^{jk}$
removes ij from a tree and adds ik (dashed).
Observe that
 $\textrm{S}_{i}^{jk}T$
is a tree if and only if the path from j to k in T does not contain the vertex i. We refer the operation
$\textrm{S}_{i}^{jk}T$
is a tree if and only if the path from j to k in T does not contain the vertex i. We refer the operation
 $\textrm{S}_{i}^{jk}$
as a tree perturbation.
$\textrm{S}_{i}^{jk}$
as a tree perturbation.
Let
 ${\mathbb{R}}^+$
denote the set of non-negative real numbers. For
${\mathbb{R}}^+$
denote the set of non-negative real numbers. For
 $\alpha \in {\mathbb{R}}^+$
, we say a tree parameter
$\alpha \in {\mathbb{R}}^+$
, we say a tree parameter
 $F\,:\, \mathcal T_n \rightarrow {\mathbb{R}}$
is
$F\,:\, \mathcal T_n \rightarrow {\mathbb{R}}$
is
 $\alpha$
-Lipschitz if
$\alpha$
-Lipschitz if
 \begin{equation*} |F(T) - F\left(\textrm{S}_{i}^{jk} T\right) | \leqslant \alpha.\end{equation*}
\begin{equation*} |F(T) - F\left(\textrm{S}_{i}^{jk} T\right) | \leqslant \alpha.\end{equation*}
for all
 $T \in \mathcal{T}_n$
and triples (i, j, k) that
$T \in \mathcal{T}_n$
and triples (i, j, k) that
 $\textrm{S}_{i}^{jk} T$
is a tree. We also require that the effects on the parameter F of sufficiently distant perturbations
$\textrm{S}_{i}^{jk} T$
is a tree. We also require that the effects on the parameter F of sufficiently distant perturbations
 $\textrm{S}_{i}^{jk}$
and
$\textrm{S}_{i}^{jk}$
and
 $\textrm{S}_{a}^{bc}$
superpose; that is
$\textrm{S}_{a}^{bc}$
superpose; that is
 \begin{equation*} F\left(\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T\right) - F(T) = \left(F\left(\textrm{S}_{i}^{jk}T\right) - F(T)\right) + \left(F\left(\textrm{S}_{a}^{bc}T\right) - F(T)\right). \end{equation*}
\begin{equation*} F\left(\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T\right) - F(T) = \left(F\left(\textrm{S}_{i}^{jk}T\right) - F(T)\right) + \left(F\left(\textrm{S}_{a}^{bc}T\right) - F(T)\right). \end{equation*}
For
 $\rho \in {\mathbb{R}}^+$
, we say F is
$\rho \in {\mathbb{R}}^+$
, we say F is
 $\rho$
-superposable if the above equation holds for all
$\rho$
-superposable if the above equation holds for all
 $T \in \mathcal{T}_n$
and triples (i, j, k), (a, b, c) such that
$T \in \mathcal{T}_n$
and triples (i, j, k), (a, b, c) such that
 $\textrm{S}_{i}^{jk}T$
,
$\textrm{S}_{i}^{jk}T$
,
 $\textrm{S}_{a}^{bc}T$
,
$\textrm{S}_{a}^{bc}T$
,
 $\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T$
are trees and
$\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T$
are trees and
 $d_T(\{j,k\}, \{b,c\})\geqslant \rho$
. Note that the sets
$d_T(\{j,k\}, \{b,c\})\geqslant \rho$
. Note that the sets
 $\{j,k\}$
and
$\{j,k\}$
and
 $\{b,c\}$
are at the same distance in all four trees T,
$\{b,c\}$
are at the same distance in all four trees T,
 $\textrm{S}_{i}^{jk}T$
,
$\textrm{S}_{i}^{jk}T$
,
 $\textrm{S}_{a}^{bc}T$
, and
$\textrm{S}_{a}^{bc}T$
, and
 $\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T$
. Thus,
$\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T$
. Thus,
 $d_T(\{j,k\}, \{b,c\})$
is an appropriate measure for the distance between the two tree perturbations
$d_T(\{j,k\}, \{b,c\})$
is an appropriate measure for the distance between the two tree perturbations
 $\textrm{S}_{i}^{jk}$
and
$\textrm{S}_{i}^{jk}$
and
 $\textrm{S}_{a}^{bc}$
.
$\textrm{S}_{a}^{bc}$
.
For a random variable X let
 \begin{equation*} \delta_{\textrm{K}} \left[X\right] \,:\!=\, \sup_{t \in {\mathbb{R}}} \left| \mathbb{P}\left(X - {\mathbb{E}}[X] \leqslant t (\textrm{Var} [X])^{1/2} \right) - \Phi(t)\right|,\end{equation*}
\begin{equation*} \delta_{\textrm{K}} \left[X\right] \,:\!=\, \sup_{t \in {\mathbb{R}}} \left| \mathbb{P}\left(X - {\mathbb{E}}[X] \leqslant t (\textrm{Var} [X])^{1/2} \right) - \Phi(t)\right|,\end{equation*}
where
 $\Phi(t) = (2\pi)^{-1/2} \int_{-\infty}^t e^{-x^2/2} dx$
. In other words,
$\Phi(t) = (2\pi)^{-1/2} \int_{-\infty}^t e^{-x^2/2} dx$
. In other words,
 $\delta_{\textrm{K}} [X]$
is the Kolmogorov distance between the scaled random variable X and the standard normal distribution. We say
$\delta_{\textrm{K}} [X]$
is the Kolmogorov distance between the scaled random variable X and the standard normal distribution. We say
 $X=X_n$
is asymptotically normal if
$X=X_n$
is asymptotically normal if
 $\delta_{\textrm{K}} [X] \rightarrow 0$
as
$\delta_{\textrm{K}} [X] \rightarrow 0$
as
 $n \rightarrow \infty$
.
$n \rightarrow \infty$
.
In the following theorem, F,
 $\alpha$
, and
$\alpha$
, and
 $\rho$
stand for sequences parametrised by a positive integer n that is
$\rho$
stand for sequences parametrised by a positive integer n that is
 $(F,\alpha, \rho) = (F_n, \alpha_n, \rho_n)$
. We omit the subscripts for notation simplicity. All asymptotics in the paper refer to
$(F,\alpha, \rho) = (F_n, \alpha_n, \rho_n)$
. We omit the subscripts for notation simplicity. All asymptotics in the paper refer to
 $n\rightarrow \infty$
and the notations
$n\rightarrow \infty$
and the notations
 $o(\cdot)$
,
$o(\cdot)$
,
 $O(\cdot)$
,
$O(\cdot)$
,
 $\Theta(\cdot)$
have the standard meaning.
$\Theta(\cdot)$
have the standard meaning.
Theorem 1.1. Let a tree parameter
 $F\,:\, \mathcal T_n \rightarrow {\mathbb{R}}$
be
$F\,:\, \mathcal T_n \rightarrow {\mathbb{R}}$
be
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable for some
$\rho$
-superposable for some
 $\alpha> 0$
and
$\alpha> 0$
and
 $\rho\geqslant 1$
. Assume also that, for a fixed constant
$\rho\geqslant 1$
. Assume also that, for a fixed constant
 $\varepsilon>0$
,
$\varepsilon>0$
,
 \begin{equation*} \frac{n \alpha^3}{(\rm{Var}\left[{F({\textbf{T}})}\right])^{3/2}} + \frac{n^{1/4}\alpha \rho}{(\rm{Var}\left[{F({\textbf{T}})}\right])^{1/2}} = O(n^{-\varepsilon}). \end{equation*}
\begin{equation*} \frac{n \alpha^3}{(\rm{Var}\left[{F({\textbf{T}})}\right])^{3/2}} + \frac{n^{1/4}\alpha \rho}{(\rm{Var}\left[{F({\textbf{T}})}\right])^{1/2}} = O(n^{-\varepsilon}). \end{equation*}
Then,
 $F({\textbf{T}})$
is asymptotically normal. Moreover,
$F({\textbf{T}})$
is asymptotically normal. Moreover,
 $\delta_{\rm{K}}[F({\textbf{T}})] = O(n^{-\varepsilon'})$
for any
$\delta_{\rm{K}}[F({\textbf{T}})] = O(n^{-\varepsilon'})$
for any
 $\varepsilon' \in (0,\varepsilon)$
.
$\varepsilon' \in (0,\varepsilon)$
.
To clarify the assumptions Theorem 1.1, we consider a simple application to the aforementioned parameter L(T), the number of leaves in a tree T. The distribution of
 $L({\textbf{T}})$
was derived for the first time by Kolchin [Reference Kolchin17], using generating functions and the connection to the Galton–Watson branching process. Theorem 1.1 immediately leads to the following result:
$L({\textbf{T}})$
was derived for the first time by Kolchin [Reference Kolchin17], using generating functions and the connection to the Galton–Watson branching process. Theorem 1.1 immediately leads to the following result:
Corollary 1.2.
 $L({\textbf{T}})$
is asymptotically normal and
$L({\textbf{T}})$
is asymptotically normal and
 $\delta_{\rm{K}}[L({\textbf{T}})] = O(n^{-1/4+\epsilon})$
for any
$\delta_{\rm{K}}[L({\textbf{T}})] = O(n^{-1/4+\epsilon})$
for any
 $\epsilon>0$
.
$\epsilon>0$
.
Proof. For any tree
 $T\in \mathcal{T}_n$
and a triple (i, j, k) that
$T\in \mathcal{T}_n$
and a triple (i, j, k) that
 $\textrm{S}_{i}^{jk}T$
is a tree, the numbers of leaves of T and
$\textrm{S}_{i}^{jk}T$
is a tree, the numbers of leaves of T and
 $\textrm{S}_{i}^{jk}T$
differ by at most one. Thus, L is
$\textrm{S}_{i}^{jk}T$
differ by at most one. Thus, L is
 $\alpha$
-Lipchitz on
$\alpha$
-Lipchitz on
 $\mathcal{T}_n$
with
$\mathcal{T}_n$
with
 $\alpha=1$
.
$\alpha=1$
.
Next, observe that if T,
 $\textrm{S}_{i}^{jk} T$
,
$\textrm{S}_{i}^{jk} T$
,
 $\textrm{S}_{a}^{bc} T$
, and
$\textrm{S}_{a}^{bc} T$
, and
 $\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T$
are trees and
$\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T$
are trees and
 $\{j,k\}\cap \{b,c\} = \emptyset$
, then
$\{j,k\}\cap \{b,c\} = \emptyset$
, then
 \begin{equation*} L(T) - L\left(\textrm{S}_{i}^{jk} T\right) - L\left(\textrm{S}_{a}^{bc} T \right) + L\left(\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T \right) =0.\end{equation*}
\begin{equation*} L(T) - L\left(\textrm{S}_{i}^{jk} T\right) - L\left(\textrm{S}_{a}^{bc} T \right) + L\left(\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T \right) =0.\end{equation*}
Indeed, the trees T,
 $\textrm{S}_{i}^{jk} T$
,
$\textrm{S}_{i}^{jk} T$
,
 $\textrm{S}_{a}^{bc} T$
,
$\textrm{S}_{a}^{bc} T$
,
 $\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T$
have the same sets of leaves except possibly vertices
$\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T$
have the same sets of leaves except possibly vertices
 $\{j,k,b,c\}$
. However, any vertex from
$\{j,k,b,c\}$
. However, any vertex from
 $\{j,k,b,c\}$
contributes to the same number of negative and positive terms in the left-hand side of the above. This implies that L is
$\{j,k,b,c\}$
contributes to the same number of negative and positive terms in the left-hand side of the above. This implies that L is
 $\rho$
-superposable with
$\rho$
-superposable with
 $\rho=1$
.
$\rho=1$
.
It is well known that
 $\textrm{Var} [L({\textbf{T}})] =(1+o(1))n/e$
; see, for example, [Reference Moon21, Theorem 7.7]. Then, all the assumptions of Theorem 1.1 are satisfied with
$\textrm{Var} [L({\textbf{T}})] =(1+o(1))n/e$
; see, for example, [Reference Moon21, Theorem 7.7]. Then, all the assumptions of Theorem 1.1 are satisfied with
 $ \alpha = \rho = 1$
and
$ \alpha = \rho = 1$
and
 $\varepsilon = 1/4$
. This completes the proof.
$\varepsilon = 1/4$
. This completes the proof.
Remark 1.3. The rates of convergence
 $\delta_K[F({\textbf{T}})]= O(n^{-1/4+\epsilon})$
are typical in applications of Theorem 1.1 because, for many examples,
$\delta_K[F({\textbf{T}})]= O(n^{-1/4+\epsilon})$
are typical in applications of Theorem 1.1 because, for many examples,
 $\textrm{Var} [F({\textbf{T}})]$
is linear and
$\textrm{Var} [F({\textbf{T}})]$
is linear and
 $\alpha$
,
$\alpha$
,
 $\rho$
are bounded by some power of
$\rho$
are bounded by some power of
 ${\textrm{log}}\, n$
. Wagner [Reference Wagner29] pointed out that Hwang’s quasi-power theorem [Reference Hwang13] leads to a better estimate
${\textrm{log}}\, n$
. Wagner [Reference Wagner29] pointed out that Hwang’s quasi-power theorem [Reference Hwang13] leads to a better estimate
 $\delta_K[L({\textbf{T}})]= O(n^{-1/2+\epsilon})$
for the number of leaves. This matches the rates of convergence in the classical Berry–Esseen result (for a sum of i.i.d. variables) and, thus, is likely optimal. It remains an open question whether the bound
$\delta_K[L({\textbf{T}})]= O(n^{-1/2+\epsilon})$
for the number of leaves. This matches the rates of convergence in the classical Berry–Esseen result (for a sum of i.i.d. variables) and, thus, is likely optimal. It remains an open question whether the bound
 $\delta_K[F({\textbf{T}})]= O(n^{-1/2+\epsilon})$
always hold for an arbitrary
$\delta_K[F({\textbf{T}})]= O(n^{-1/2+\epsilon})$
always hold for an arbitrary
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable tree parameter F (assuming the variance is linear and
$\rho$
-superposable tree parameter F (assuming the variance is linear and
 $\alpha$
and
$\alpha$
and
 $\rho$
are not too large).
$\rho$
are not too large).
The asymptotic normality of the number of vertices in
 ${\textbf{T}}$
with a given degree is proved identically to Corollary 1.2. However, for many other applications, a tree parameter F might behave badly on a small set of trees. Then, Theorem 1.1 does not work directly since
${\textbf{T}}$
with a given degree is proved identically to Corollary 1.2. However, for many other applications, a tree parameter F might behave badly on a small set of trees. Then, Theorem 1.1 does not work directly since
 $\alpha$
and
$\alpha$
and
 $\rho$
are too large. For example, a single perturbation
$\rho$
are too large. For example, a single perturbation
 $\textrm{S}_{i}^{jk}$
can destroy a lot of paths on three vertices in a tree with large degrees. To overcome this difficulty, one can apply Theorem 1.1 to a parameter
$\textrm{S}_{i}^{jk}$
can destroy a lot of paths on three vertices in a tree with large degrees. To overcome this difficulty, one can apply Theorem 1.1 to a parameter
 $\tilde{F}$
, which is related to F, but ignores the vertices with degrees larger
$\tilde{F}$
, which is related to F, but ignores the vertices with degrees larger
 ${\textrm{log}}\, n$
. This trick does not change the limiting distribution because the trees with large degrees are rare: Moon [Reference Moon21, formula (7.3)] showed that, for any
${\textrm{log}}\, n$
. This trick does not change the limiting distribution because the trees with large degrees are rare: Moon [Reference Moon21, formula (7.3)] showed that, for any
 $d \in [n]$
,
$d \in [n]$
,
 \begin{equation} \mathbb{P}({\textbf{T}} \text{ has a vertex with degree $>d$} ) \leqslant n/d! \end{equation}
\begin{equation} \mathbb{P}({\textbf{T}} \text{ has a vertex with degree $>d$} ) \leqslant n/d! \end{equation}
Similarly, one can restrict attention to the trees for which the neighbourhoods of vertices do not grow very fast. Let
 \begin{equation} \beta(T) = \max_{i,d \in [n]} \frac{|\{j \in[n] \mathrel{:} d_T(i,j) = d\}|} {d}. \end{equation}
\begin{equation} \beta(T) = \max_{i,d \in [n]} \frac{|\{j \in[n] \mathrel{:} d_T(i,j) = d\}|} {d}. \end{equation}
In this paper, we prove the following result, which might be of independent interest.
Theorem 1.4.
 $ \displaystyle \mathbb{P} \left( \beta({\textbf{T}}) \geqslant {\rm{log}}^4 n \right) \leqslant e^{-\omega({\rm{log}}\, n)}. $
$ \displaystyle \mathbb{P} \left( \beta({\textbf{T}}) \geqslant {\rm{log}}^4 n \right) \leqslant e^{-\omega({\rm{log}}\, n)}. $
Remark 1.5. The distribution of the height profiles in branching processes is a well-studied topic. In particular, the number of vertices in
 ${\textbf{T}}$
at distance at most d from a given vertex was already considered by Kolchin [Reference Kolchin17]. However, we could not find a suitable large deviation bound for
${\textbf{T}}$
at distance at most d from a given vertex was already considered by Kolchin [Reference Kolchin17]. However, we could not find a suitable large deviation bound for
 $\beta({\textbf{T}})$
in the literature. In fact, the constant 4 in the exponent of the logarithm in the bound above is not optimal, but sufficient for our purposes.
$\beta({\textbf{T}})$
in the literature. In fact, the constant 4 in the exponent of the logarithm in the bound above is not optimal, but sufficient for our purposes.
The structure of the paper is as follows. In Section 2, we analyse the number of occurrences of an arbitrary tree pattern. For various interpretations of the notion “occurrence,” the asymptotic normality in this problem was established by Chysak, Drmota, Klausner, Kok [Reference Chysak, Drmota, Klausner and Kok5] and Janson [Reference Janson16]. Applying Theorem 1.1, we not only confirm these results but also allow much more general types of occurrences. In particular, we prove the asymptotical normality for the number of induced subgraphs isomorphic to a given tree of fixed size and for the number of paths of length up to
 $n^{1/8 -\varepsilon}$
. Both of these applications go beyond the setup of [Reference Chysak, Drmota, Klausner and Kok5, Reference Janson16]. In Section 3, we derive the distribution of the number of automorphisms of
$n^{1/8 -\varepsilon}$
. Both of these applications go beyond the setup of [Reference Chysak, Drmota, Klausner and Kok5, Reference Janson16]. In Section 3, we derive the distribution of the number of automorphisms of
 ${\textbf{T}}$
and confirm the conjecture by Yu [Reference Yu30]. To our knowledge, this application of Theorem 1.1 is also not covered by any of the previous results.
${\textbf{T}}$
and confirm the conjecture by Yu [Reference Yu30]. To our knowledge, this application of Theorem 1.1 is also not covered by any of the previous results.
We prove Theorem 1.1 in Section 5, using a martingale construction based on the Aldous–Broder algorithm [Reference Aldous1] for generating random labelled spanning trees of a given graph. Section 4 contains the necessary background on the theory of martingales. We also use martingales to prove Theorem 1.4 in Section 6. This proof is independent of Section 5 and, in fact, Theorem 1.4 is one of the ingredients that we need for our main result, Theorem 1.1. We also use Theorem 1.4 in the application to long induced paths to bound the number of the paths affected by one perturbation; see Theorem 2.9.
Tedious technical calculations of the variance for the pattern and automorphism counts are given in Appendices A and B.
2. Pattern counts
In this section, we apply Theorem 1.1 to analyse the distribution of the number of occurrences of a tree pattern H as an induced subtree in uniform random labelled tree
 ${\textbf{T}}$
. To our knowledge, the strongest results for this problem were obtained by Chysak et al. [Reference Chysak, Drmota, Klausner and Kok5] and Janson [Reference Janson16].
${\textbf{T}}$
. To our knowledge, the strongest results for this problem were obtained by Chysak et al. [Reference Chysak, Drmota, Klausner and Kok5] and Janson [Reference Janson16].
Chysak et al. [Reference Chysak, Drmota, Klausner and Kok5] consider occurrences of a pattern H as an induced subgraph of a tree T with the additional restriction that the internal vertices in the pattern match the degrees the corresponding vertices in T. That is, the other edges of T can only be adjacent to leaves of H. For example, the tree T on Figure 2 contains only three paths on three vertices in this sense, namely
 $T[\{1,5,8\}]$
,
$T[\{1,5,8\}]$
,
 $T[\{1,3,6\}]$
, and
$T[\{1,3,6\}]$
, and
 $T[\{3,6,13\}]$
. In particular, the induced path on vertices 1, 2, 7 is not counted since the internal vertex 2 is adjacent to 4. The result by Chysak, Drmota, Klausner, Kok is given below.
$T[\{3,6,13\}]$
. In particular, the induced path on vertices 1, 2, 7 is not counted since the internal vertex 2 is adjacent to 4. The result by Chysak, Drmota, Klausner, Kok is given below.

Figure 2. A labelled tree T and a pattern H.
Theorem 2.1 ([Reference Chysak, Drmota, Klausner and Kok5, Theorem 1]). Let H to be a given finite tree. Then the limiting distribution of the number of occurrences of H (in the sense described above) in
 ${\textbf{T}}$
is asymptotically normal with mean and variance asymptotically equivalent to
${\textbf{T}}$
is asymptotically normal with mean and variance asymptotically equivalent to
 $\mu n$
and
$\mu n$
and
 $\sigma^2 n$
, where
$\sigma^2 n$
, where
 $\mu>0$
and
$\mu>0$
and
 $\sigma^2\geqslant 0$
depend on the pattern H and can be computed explicitly and algorithmically and can be represented as polynomials (with rational coefficients) in
$\sigma^2\geqslant 0$
depend on the pattern H and can be computed explicitly and algorithmically and can be represented as polynomials (with rational coefficients) in
 $1/e$
.
$1/e$
.
Janson [Reference Janson16] considers the subtree counts
 $\eta_H(T)$
defined differently. Set vertex 1 to be a root of
$\eta_H(T)$
defined differently. Set vertex 1 to be a root of
 $T\in \mathcal{T}_n$
. For any other vertex v, let
$T\in \mathcal{T}_n$
. For any other vertex v, let
 $T_v$
be the subtree consisting of v an all its descendants. Such subtrees are called fringe subtrees. The parameter
$T_v$
be the subtree consisting of v an all its descendants. Such subtrees are called fringe subtrees. The parameter
 $\eta_H(T)$
equals the number of fringe subtrees isomorphic to H (with a root). For example, the tree T on Figure 2 contains only one path with three vertices (rooted at end vertex), namely
$\eta_H(T)$
equals the number of fringe subtrees isomorphic to H (with a root). For example, the tree T on Figure 2 contains only one path with three vertices (rooted at end vertex), namely
 $T[\{3,6,13\}]$
. In particular, the induced paths
$T[\{3,6,13\}]$
. In particular, the induced paths
 $T[\{1,5,8\}]$
and
$T[\{1,5,8\}]$
and
 $T[\{1,3,6\}]$
are not counted since they are not fringe subtrees. Janson [Reference Janson16] proved the following result about joint asymptotic normality for several such subtree counts.
$T[\{1,3,6\}]$
are not counted since they are not fringe subtrees. Janson [Reference Janson16] proved the following result about joint asymptotic normality for several such subtree counts.
Theorem 2.2 ([Reference Janson16, Corollary 1.8]) Let
 ${\textbf{T}}^{\rm{GW}}_n$
be a conditioned Galton–Watson tree of order n with offspring distribution
${\textbf{T}}^{\rm{GW}}_n$
be a conditioned Galton–Watson tree of order n with offspring distribution
 $\xi$
, where
$\xi$
, where
 ${\mathbb{E}}[\xi] = 1$
and
${\mathbb{E}}[\xi] = 1$
and
 $0 < \sigma^2 \,:\!=\, \rm{Var} [\xi] <\infty$
. Then, the subtree counts
$0 < \sigma^2 \,:\!=\, \rm{Var} [\xi] <\infty$
. Then, the subtree counts
 $\eta_H({\textbf{T}}^{\rm{GW}}_n)$
(for all H from a given set of patterns) are asymptotically jointly normal.
$\eta_H({\textbf{T}}^{\rm{GW}}_n)$
(for all H from a given set of patterns) are asymptotically jointly normal.
Janson [Reference Janson16, Corollary 1.8] also gives expressions for the covariances of the limiting distribution in terms of the distribution of the corresponding unconditioned Galton–Watson tree. To relate this model to uniform random labelled tree
 ${\textbf{T}}$
, one need to take the conditioned Galton–Watson tree of order n with the Poisson offspring distribution.
${\textbf{T}}$
, one need to take the conditioned Galton–Watson tree of order n with the Poisson offspring distribution.
We consider a more general type of tree counts which encapsulates both counts from above. In fact, it was suggested by Chysak et al. [Reference Chysak, Drmota, Klausner and Kok5]: “…we could also consider pattern-matching problems for patterns in which some degrees of certain possibly external “filled” nodes must match exactly while the degrees of the other, possibly internal “empty” nodes might be different. But then the situation is more involved.” Then, in [Reference Chysak, Drmota, Klausner and Kok5, Section 5.3] they explain that having an internal “empty” node leads to serious complications in their approach.
We define our tree parameter formally. Let H be a tree with
 $\ell$
vertices
$\ell$
vertices
 $v_1,\ldots,v_{\ell}$
. Let
$v_1,\ldots,v_{\ell}$
. Let
 $\boldsymbol{\theta} = (\theta_1,\ldots,\theta_\ell) \in \{0,1\}^{\ell}$
. We say the pattern
$\boldsymbol{\theta} = (\theta_1,\ldots,\theta_\ell) \in \{0,1\}^{\ell}$
. We say the pattern
 $(H,\boldsymbol{\theta})$
occurs in a tree
$(H,\boldsymbol{\theta})$
occurs in a tree
 $T \in \mathcal{T}_n$
if there exists a pair of sets (U, W) such that
$T \in \mathcal{T}_n$
if there exists a pair of sets (U, W) such that
 $W\subset U \subset [n]$
and
$W\subset U \subset [n]$
and
-
• the induced subgraph T[U] is isomorphic to H,
-
• the set W corresponds to all vertices
 $v_i$
with
$\theta_i=1$
(“empty” nodes),
$v_i$
with
$\theta_i=1$
(“empty” nodes), -
• there is no edge in T between
$U-W$
and
$[n] - U$
.




Denote by
 $N_{H,\boldsymbol{\theta}}(T)$
the number of occurrences of the pattern
$N_{H,\boldsymbol{\theta}}(T)$
the number of occurrences of the pattern
 $(H,\boldsymbol{\theta})$
in T that is the number of different pairs (U, W) satisfying the above. It equals the number of ways to choose suitable identities for
$(H,\boldsymbol{\theta})$
in T that is the number of different pairs (U, W) satisfying the above. It equals the number of ways to choose suitable identities for
 $v_1,\ldots, v_\ell$
in [n] divided by
$v_1,\ldots, v_\ell$
in [n] divided by
 $|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|$
, the number of automorphisms of H that preserve
$|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|$
, the number of automorphisms of H that preserve
 $\boldsymbol{\theta}$
. In particular, if
$\boldsymbol{\theta}$
. In particular, if
 $\theta_i = 1$
for all
$\theta_i = 1$
for all
 $i\in [\ell]$
then
$i\in [\ell]$
then
 $N_{H,\boldsymbol{\theta}}(T)$
is the number of induced subgraphs in T isomorphic H. If
$N_{H,\boldsymbol{\theta}}(T)$
is the number of induced subgraphs in T isomorphic H. If
 $\theta_i = 1$
whenever i is a leaf of H, then
$\theta_i = 1$
whenever i is a leaf of H, then
 $N_{H,\boldsymbol{\theta}}(T)$
is the tree count considered in Theorem 2.1. If
$N_{H,\boldsymbol{\theta}}(T)$
is the tree count considered in Theorem 2.1. If
 $\theta_i=1$
for exactly one vertex
$\theta_i=1$
for exactly one vertex
 $i\in [\ell]$
which is a leaf in H, then
$i\in [\ell]$
which is a leaf in H, then
 $N_{H,\boldsymbol{\theta}}(T)$
counts fringe subtrees.
$N_{H,\boldsymbol{\theta}}(T)$
counts fringe subtrees.
In Section 2.2, we prove that
 $ N_{H,\boldsymbol{\theta}}({\textbf{T}})$
is asymptotically normal for any fixed H and
$ N_{H,\boldsymbol{\theta}}({\textbf{T}})$
is asymptotically normal for any fixed H and
 $\boldsymbol{\theta}\in \{0,1\}^{\ell}$
with at least one non-zero component (where
$\boldsymbol{\theta}\in \{0,1\}^{\ell}$
with at least one non-zero component (where
 $\ell$
is the number of vertices in H). Note that if
$\ell$
is the number of vertices in H). Note that if
 $\theta_i=0$
for all
$\theta_i=0$
for all
 $i \in [\ell]$
and
$i \in [\ell]$
and
 $n>\ell$
, then
$n>\ell$
, then
 $N_{H,\boldsymbol{\theta}}({\textbf{T}}) = 0$
since at least one vertex corresponding to H must be adjacent to other vertices in T. Our approach also works for growing patterns. We demonstrate it for the case when H is a path.
$N_{H,\boldsymbol{\theta}}({\textbf{T}}) = 0$
since at least one vertex corresponding to H must be adjacent to other vertices in T. Our approach also works for growing patterns. We demonstrate it for the case when H is a path.
2.1. Moments calculation
To apply Theorem 1.1, we need a lower bound for
 $\textrm{Var}(N_{H,\boldsymbol{\theta}}({\textbf{T}}))$
. One can compute the moments of
$\textrm{Var}(N_{H,\boldsymbol{\theta}}({\textbf{T}}))$
. One can compute the moments of
 $N_{H,\boldsymbol{\theta}}({\textbf{T}})$
using the following formula for the number of trees containing a given spanning forest. Lemma 2.3 is a straightforward generalisation of [Reference Moon21, Theorem 6.1] with almost identical proof, which we include here for the sake of completeness.
$N_{H,\boldsymbol{\theta}}({\textbf{T}})$
using the following formula for the number of trees containing a given spanning forest. Lemma 2.3 is a straightforward generalisation of [Reference Moon21, Theorem 6.1] with almost identical proof, which we include here for the sake of completeness.
Lemma 2.3. Let
 $S = H_1 \sqcup\ldots\sqcup H_k$
be a forest on [n] and
$S = H_1 \sqcup\ldots\sqcup H_k$
be a forest on [n] and
 $B_i$
be non-empty subsets (not necessarily proper) of
$B_i$
be non-empty subsets (not necessarily proper) of
 $V(H_i)$
for all
$V(H_i)$
for all
 $i \in [k]$
. Then, the number of trees T on [n] containing all edges of H such that
$i \in [k]$
. Then, the number of trees T on [n] containing all edges of H such that
 $\rm{deg}_T(v) = \rm{deg}_S(v)$
for every v outside
$\rm{deg}_T(v) = \rm{deg}_S(v)$
for every v outside
 $B_1 \cup \ldots \cup B_{k}$
equals
$B_1 \cup \ldots \cup B_{k}$
equals
 $b_1\cdots b_k (b_1+\cdots + b_k)^{k-2}$
, where
$b_1\cdots b_k (b_1+\cdots + b_k)^{k-2}$
, where
 $b_i$
is the number of vertices in
$b_i$
is the number of vertices in
 $B_i$
.
$B_i$
.
Proof. Any desired tree T corresponds to a tree
 $T_H$
on k vertices labelled by
$T_H$
on k vertices labelled by
 $H_1,\ldots, H_k$
for which the vertices
$H_1,\ldots, H_k$
for which the vertices
 $H_i$
and
$H_i$
and
 $H_j$
are adjacent if and only if there is an edge between
$H_j$
are adjacent if and only if there is an edge between
 $H_i$
and
$H_i$
and
 $H_j$
in T. If
$H_j$
in T. If
 $d_1,\ldots, d_k$
are degrees of
$d_1,\ldots, d_k$
are degrees of
 $T_H$
, then the number of trees T corresponding to
$T_H$
, then the number of trees T corresponding to
 $T_H$
equals
$T_H$
equals
 $b_1^{d_1} \ldots b_{k}^{d_{k}}$
since we can only use vertices from
$b_1^{d_1} \ldots b_{k}^{d_{k}}$
since we can only use vertices from
 $B_1 \cup \ldots \cup B_{k}$
for edges of T. From [Reference Moon21, Theorem 3.1], we know that the number of trees on k vertices with degrees
$B_1 \cup \ldots \cup B_{k}$
for edges of T. From [Reference Moon21, Theorem 3.1], we know that the number of trees on k vertices with degrees
 $d_1,\ldots, d_k$
is
$d_1,\ldots, d_k$
is
 $\binom{k-2}{d_1-1, \ldots ,d_k-1}.$
Thus, the total number of such trees T is
$\binom{k-2}{d_1-1, \ldots ,d_k-1}.$
Thus, the total number of such trees T is
 \begin{equation*} \sum_{(d_1,\ldots, d_k)} b_1^{d_1} \ldots b_{k}^{d_{k}} \binom{k-2}{d_1-1, \ldots ,d_k-1} = b_1\ldots b_k (b_1+\cdots +b_k)^{k-2},\end{equation*}
\begin{equation*} \sum_{(d_1,\ldots, d_k)} b_1^{d_1} \ldots b_{k}^{d_{k}} \binom{k-2}{d_1-1, \ldots ,d_k-1} = b_1\ldots b_k (b_1+\cdots +b_k)^{k-2},\end{equation*}
where the sum is over all positive integers sequences that
 $d_1+\cdots+ d_k = 2k-2$
.
$d_1+\cdots+ d_k = 2k-2$
.
For an
 $\ell$
-tuple
$\ell$
-tuple
 ${\textbf{u}}= (u_1,\ldots,u_\ell) \in [n]^{\ell}$
with distinct coordinates, let
${\textbf{u}}= (u_1,\ldots,u_\ell) \in [n]^{\ell}$
with distinct coordinates, let
 $\mathbb{1}_{{\textbf{u}}}({\textbf{T}})$
be the indicator of the event that a pattern
$\mathbb{1}_{{\textbf{u}}}({\textbf{T}})$
be the indicator of the event that a pattern
 $(H,\boldsymbol{\theta})$
occurs in
$(H,\boldsymbol{\theta})$
occurs in
 ${\textbf{T}}$
with
${\textbf{T}}$
with
 $u_1, \ldots, u_\ell$
corresponding to the vertices of H. Let
$u_1, \ldots, u_\ell$
corresponding to the vertices of H. Let
 $s\,:\! =\, \sum_{i=1}^{\ell} \theta_i$
. Applying Lemma 2.3 to a forest consisting of one nontrivial component isomorphic to H and dividing by
$s\,:\! =\, \sum_{i=1}^{\ell} \theta_i$
. Applying Lemma 2.3 to a forest consisting of one nontrivial component isomorphic to H and dividing by
 $|\mathcal{T}_n| = n^{n-2}$
, we find that
$|\mathcal{T}_n| = n^{n-2}$
, we find that
 \begin{equation} {\mathbb{E}} \left[ \mathbb{1}_{{\textbf{u}}}({\textbf{T}})\right] = \frac{s \left(n - \ell + s \right)^{n-\ell -1}} {n^{n-2}} = \frac{s e^{-\ell + s+ O(\ell^2/n) }}{ n^{\ell-1}}.\end{equation}
\begin{equation} {\mathbb{E}} \left[ \mathbb{1}_{{\textbf{u}}}({\textbf{T}})\right] = \frac{s \left(n - \ell + s \right)^{n-\ell -1}} {n^{n-2}} = \frac{s e^{-\ell + s+ O(\ell^2/n) }}{ n^{\ell-1}}.\end{equation}
Summing over all choices for
 ${\textbf{u}}$
and dividing by
${\textbf{u}}$
and dividing by
 $|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|$
to adjust overcounting, we get
$|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|$
to adjust overcounting, we get
 \begin{align*} {\mathbb{E}} \left[N_{H,\boldsymbol{\theta}}({\textbf{T}}) \right]&= \frac{1}{|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|} \sum_{{\textbf{u}}} {\mathbb{E}} \left[ \mathbb{1}_{{\textbf{u}}}({\textbf{T}})\right] =n \, \frac{s e^{-\ell +s + O(\ell^2/n) } }{\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)} .\end{align*}
\begin{align*} {\mathbb{E}} \left[N_{H,\boldsymbol{\theta}}({\textbf{T}}) \right]&= \frac{1}{|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|} \sum_{{\textbf{u}}} {\mathbb{E}} \left[ \mathbb{1}_{{\textbf{u}}}({\textbf{T}})\right] =n \, \frac{s e^{-\ell +s + O(\ell^2/n) } }{\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)} .\end{align*}
In particular, this formula agrees with Theorem 2.1 that
 $\mu$
is a polynomial with rational coefficients in
$\mu$
is a polynomial with rational coefficients in
 $1/e$
. Similarly, for the variance, we have
$1/e$
. Similarly, for the variance, we have
 \begin{equation} \textrm{Var} \left[N_{H,\boldsymbol{\theta}}({\textbf{T}})\right] = \frac{1}{|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|^2} \sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ),\end{equation}
\begin{equation} \textrm{Var} \left[N_{H,\boldsymbol{\theta}}({\textbf{T}})\right] = \frac{1}{|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|^2} \sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ),\end{equation}
where the sum over all
 $\ell$
-tuples
$\ell$
-tuples
 ${\textbf{u}},{\textbf{u}}' \in [n]^{\ell}$
with distinct coordinates. Then, we can also use Lemma 2.3 (with one or two nontrivial components) to compute
${\textbf{u}},{\textbf{u}}' \in [n]^{\ell}$
with distinct coordinates. Then, we can also use Lemma 2.3 (with one or two nontrivial components) to compute
 $ \textrm{Cov} ( \mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}))$
. However, this computation is much more involved: one needs to consider all possible ways the pattern
$ \textrm{Cov} ( \mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}))$
. However, this computation is much more involved: one needs to consider all possible ways the pattern
 $(H,\boldsymbol{\theta})$
intersects with itself. Nevertheless, for a fixed pattern, it is not difficult to see that
$(H,\boldsymbol{\theta})$
intersects with itself. Nevertheless, for a fixed pattern, it is not difficult to see that
 ${\mathbb{E}} \left[\mathbb{1}_{{\textbf{u}}}({\textbf{T}})\right]$
and
${\mathbb{E}} \left[\mathbb{1}_{{\textbf{u}}}({\textbf{T}})\right]$
and
 ${\mathbb{E}} \left[\mathbb{1}_{{\textbf{u}}}({\textbf{T}}) \mathbb{1}_{{\textbf{u}}'}({\textbf{T}})\right]$
are polynomials with integer coefficients in
${\mathbb{E}} \left[\mathbb{1}_{{\textbf{u}}}({\textbf{T}}) \mathbb{1}_{{\textbf{u}}'}({\textbf{T}})\right]$
are polynomials with integer coefficients in
 $1/e$
divided by some power of n. This observation is already sufficient to establish the bound
$1/e$
divided by some power of n. This observation is already sufficient to establish the bound
 $\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right]= \Omega(n)$
for the case when
$\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right]= \Omega(n)$
for the case when
 $\sum_{i=1}^{\ell} \theta_i <\ell$
.
$\sum_{i=1}^{\ell} \theta_i <\ell$
.
Lemma 2.4. Let
 $(H,\boldsymbol{\theta})$
be a fixed pattern,
$(H,\boldsymbol{\theta})$
be a fixed pattern,
 $\ell$
be the number of vertices in tree H, and
$\ell$
be the number of vertices in tree H, and
 $s\,:\!=\,\sum_{i=1}^{\ell} \theta_i$
. Then, there exist a polynomial
$s\,:\!=\,\sum_{i=1}^{\ell} \theta_i$
. Then, there exist a polynomial
 $p_{H,\boldsymbol{\theta}}$
of degree at most
$p_{H,\boldsymbol{\theta}}$
of degree at most
 $2\ell-2s$
with integer coefficients that
$2\ell-2s$
with integer coefficients that
 \begin{equation*} \rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] = n \, \frac{p_{H,\boldsymbol{\theta}} (1/e)}{|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|^2} + O(1). \end{equation*}
\begin{equation*} \rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] = n \, \frac{p_{H,\boldsymbol{\theta}} (1/e)}{|\rm{A}\small{UT}\left({H,\boldsymbol{\theta}}\right)|^2} + O(1). \end{equation*}
Moreover, if
 $s <\ell$
then
$s <\ell$
then
 $p_{H,\boldsymbol{\theta}} (1/e) > 0$
.
$p_{H,\boldsymbol{\theta}} (1/e) > 0$
.
Proof. Consider any
 $\ell$
-tuples
$\ell$
-tuples
 ${\textbf{u}},{\textbf{u}}' \in [n]^{\ell}$
with distinct coordinates. If the coordinates of
${\textbf{u}},{\textbf{u}}' \in [n]^{\ell}$
with distinct coordinates. If the coordinates of
 ${\textbf{u}}$
and
${\textbf{u}}$
and
 ${\textbf{u}}'$
form disjoint sets, then applying Lemma 2.3 to a forest consisting of two nontrivial component isomorphic to H, we find that
${\textbf{u}}'$
form disjoint sets, then applying Lemma 2.3 to a forest consisting of two nontrivial component isomorphic to H, we find that
 \begin{equation*} {\mathbb{E}} \left[\mathbb{1}_{{\textbf{u}}}({\textbf{T}}) \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) \right] = \frac{s^2 \left(n - 2\ell + 2s \right)^{n-2\ell}} {n^{n-2}}.\end{equation*}
\begin{equation*} {\mathbb{E}} \left[\mathbb{1}_{{\textbf{u}}}({\textbf{T}}) \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) \right] = \frac{s^2 \left(n - 2\ell + 2s \right)^{n-2\ell}} {n^{n-2}}.\end{equation*}
Using (3), we get that
 \begin{align*} \textrm{Cov} ( \mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) &= \frac{s^2}{n^{2\ell-2}} \left( e^{-2 \ell \,+\, 2s \,-\, \frac{(2\ell\,-\,2s)^2}{2n} \,+\,O(n^{-2}) } - e^{2 \left(- \ell + s \,-\, \frac{(\ell-s)^2}{2n} \right) \,+\,O(n^{-2})} \right)\\[4pt] &= - \frac{s^2 (\ell\,-\,s)^2 e^{-2 \ell \,+\, 2s} }{n^{2\ell-1}} + O(n^{-2\ell}). \end{align*}
\begin{align*} \textrm{Cov} ( \mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) &= \frac{s^2}{n^{2\ell-2}} \left( e^{-2 \ell \,+\, 2s \,-\, \frac{(2\ell\,-\,2s)^2}{2n} \,+\,O(n^{-2}) } - e^{2 \left(- \ell + s \,-\, \frac{(\ell-s)^2}{2n} \right) \,+\,O(n^{-2})} \right)\\[4pt] &= - \frac{s^2 (\ell\,-\,s)^2 e^{-2 \ell \,+\, 2s} }{n^{2\ell-1}} + O(n^{-2\ell}). \end{align*}
Then, the contribution of such
 ${\textbf{u}},{\textbf{u}}'$
to the sum
${\textbf{u}},{\textbf{u}}'$
to the sum
 $\sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) )$
in (4) equals
$\sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) )$
in (4) equals
 \begin{equation*}-n s^2 (\ell-s)^2 e^{-2 \ell \,+\, 2s} + O(1).\end{equation*}
\begin{equation*}-n s^2 (\ell-s)^2 e^{-2 \ell \,+\, 2s} + O(1).\end{equation*}
Next, we proceed to the case when the sets formed by the coordinates of
 ${\textbf{u}}$
and
${\textbf{u}}$
and
 ${\textbf{u}}'$
intersect. Let a be the size of the union of these two sets and
${\textbf{u}}'$
intersect. Let a be the size of the union of these two sets and
 \begin{equation*} b\,:\!=\,|\{u_i \mathrel{:} \theta_i=1\}\cap \{u^{\prime}_i \mathrel{:} \theta_i=1\}|. \end{equation*}
\begin{equation*} b\,:\!=\,|\{u_i \mathrel{:} \theta_i=1\}\cap \{u^{\prime}_i \mathrel{:} \theta_i=1\}|. \end{equation*}
Note that
 $\ell - s \leqslant a-b \leqslant 2\ell -2 s$
. Then, using Lemma 2.3 (and also (3)), we find that
$\ell - s \leqslant a-b \leqslant 2\ell -2 s$
. Then, using Lemma 2.3 (and also (3)), we find that
 \begin{align*} \textrm{Cov}(\mathbb{1}_{{\textbf{u}}}({\textbf{T}}),\mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) &= \frac{b(n - a +b)^{n\,-\,a\,-\,1}}{n^{n\,-\,2}} - \left(\frac{s (n-\ell +s)^{n\,-\,\ell\,-\,1}}{n^{n\,-\,2}}\right)^2 \\[7pt] & = \frac{1 + O(n^{-1})}{n^{a\,-\,1}} \cdot \begin{cases} be^{-a\,+\,b} , &\text{if } a\leqslant 2\ell-2, \\[5pt] b e^{-a\,+\,b} - s^2 e^{-2\ell \,+\, 2s}, &\text{if } a=2\ell -1. \end{cases} \end{align*}
\begin{align*} \textrm{Cov}(\mathbb{1}_{{\textbf{u}}}({\textbf{T}}),\mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) &= \frac{b(n - a +b)^{n\,-\,a\,-\,1}}{n^{n\,-\,2}} - \left(\frac{s (n-\ell +s)^{n\,-\,\ell\,-\,1}}{n^{n\,-\,2}}\right)^2 \\[7pt] & = \frac{1 + O(n^{-1})}{n^{a\,-\,1}} \cdot \begin{cases} be^{-a\,+\,b} , &\text{if } a\leqslant 2\ell-2, \\[5pt] b e^{-a\,+\,b} - s^2 e^{-2\ell \,+\, 2s}, &\text{if } a=2\ell -1. \end{cases} \end{align*}
We say a pair
 $({\textbf{u}},{\textbf{u}}')$
is equivalent to
$({\textbf{u}},{\textbf{u}}')$
is equivalent to
 $({\textbf{w}},{\textbf{w}}')$
if there is a permutation
$({\textbf{w}},{\textbf{w}}')$
if there is a permutation
 $\sigma$
of the set [n] that
$\sigma$
of the set [n] that
 $w_i = \sigma(u_i)$
and
$w_i = \sigma(u_i)$
and
 $w^{\prime}_i = \sigma(u^{\prime}_i)$
for all
$w^{\prime}_i = \sigma(u^{\prime}_i)$
for all
 $i \in [\ell]$
. Note that the number of pairs equivalent to
$i \in [\ell]$
. Note that the number of pairs equivalent to
 $({\textbf{u}},{\textbf{u}}')$
is exactly
$({\textbf{u}},{\textbf{u}}')$
is exactly
 $(n)_{a}$
. Then, the contribution of the equivalence class to the sum
$(n)_{a}$
. Then, the contribution of the equivalence class to the sum
 $\sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) )$
in (4) is
$\sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) )$
in (4) is
 $n be^{-a+b} +O(1)$
or
$n be^{-a+b} +O(1)$
or
 $nbe^{-a+b} - s^2 e^{-2\ell +2s}+ O(1)$
. Summing over all equivalence classes, we complete the proof of the first part.
$nbe^{-a+b} - s^2 e^{-2\ell +2s}+ O(1)$
. Summing over all equivalence classes, we complete the proof of the first part.
For the second part, observe in the above that
 $a-b = \ell -s$
if and only if the sets of coordinates of
$a-b = \ell -s$
if and only if the sets of coordinates of
 ${\textbf{u}}$
and
${\textbf{u}}$
and
 ${\textbf{u}}'$
coincide and
${\textbf{u}}'$
coincide and
 $\{u_i \mathrel{:} \theta_i=1\}=\{u^{\prime}_i \mathrel{:} \theta_i=1\}$
. In particular, we have
$\{u_i \mathrel{:} \theta_i=1\}=\{u^{\prime}_i \mathrel{:} \theta_i=1\}$
. In particular, we have
 $a<2\ell -1$
so
$a<2\ell -1$
so
 $ \textrm{Cov}(\mathbb{1}_{{\textbf{u}}}({\textbf{T}}),\mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) >0$
. Then, the coefficient corresponding to
$ \textrm{Cov}(\mathbb{1}_{{\textbf{u}}}({\textbf{T}}),\mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) >0$
. Then, the coefficient corresponding to
 $x^{-\ell + s}$
in
$x^{-\ell + s}$
in
 $p_{H,\theta}(x)$
is strictly positive so the polynomial
$p_{H,\theta}(x)$
is strictly positive so the polynomial
 $p_{H,\theta}(x)$
is not trivial. Since the number
$p_{H,\theta}(x)$
is not trivial. Since the number
 $1/e$
is transcendental, we conclude that
$1/e$
is transcendental, we conclude that
 $p_{H,\theta}(1/e)$
is not zero. Also,
$p_{H,\theta}(1/e)$
is not zero. Also,
 $p_{H,\theta}(1/e)$
cannot be negative since
$p_{H,\theta}(1/e)$
cannot be negative since
 $\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] \geqslant 0$
so it can only be positive. This completes the proof.
$\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] \geqslant 0$
so it can only be positive. This completes the proof.
For a tree
 $T\in \mathcal{T}_n$
, let
$T\in \mathcal{T}_n$
, let
 $N_{H}(T) \,:\!=\, N_{H, \boldsymbol{\theta}}(T)$
if
$N_{H}(T) \,:\!=\, N_{H, \boldsymbol{\theta}}(T)$
if
 $\theta_i=1$
for all
$\theta_i=1$
for all
 $i \in [\ell]$
that is
$i \in [\ell]$
that is
 $N_{H}(T)$
is the number of induced subgraphs of T isomorphic to H. Unfortunately, the lemma above cannot guarantee that
$N_{H}(T)$
is the number of induced subgraphs of T isomorphic to H. Unfortunately, the lemma above cannot guarantee that
 $\rm{Var}\left[{N_{H}({\textbf{T}})}\right] = \Omega(n)$
. In this case, the polynomial
$\rm{Var}\left[{N_{H}({\textbf{T}})}\right] = \Omega(n)$
. In this case, the polynomial
 $p_{H,\theta}$
is a non-negative constant, but an additional argument is required to show that it is not zero.
$p_{H,\theta}$
is a non-negative constant, but an additional argument is required to show that it is not zero.
Lemma 2.5. For any fixed tree H with degrees
 $h_1,\ldots,h_\ell$
, we have
$h_1,\ldots,h_\ell$
, we have
 \begin{equation*} \rm{Var}\left[{N_{H}({\textbf{T}})}\right] \geqslant \frac{n}{|\rm{A}\small{UT}\left({H}\right)|^2}\sum_{j \geqslant 2} c_j^2 \, j! + O(1), \end{equation*}
\begin{equation*} \rm{Var}\left[{N_{H}({\textbf{T}})}\right] \geqslant \frac{n}{|\rm{A}\small{UT}\left({H}\right)|^2}\sum_{j \geqslant 2} c_j^2 \, j! + O(1), \end{equation*}
where
 $c_j = \sum_{i=1}^\ell \left( \binom{h_i}{j} + (\ell-1) \binom{h_i-1}{j} \right)$
. In particular,
$c_j = \sum_{i=1}^\ell \left( \binom{h_i}{j} + (\ell-1) \binom{h_i-1}{j} \right)$
. In particular,
 $c_2>0$
if
$c_2>0$
if
 $\ell \geqslant 3$
.
$\ell \geqslant 3$
.
The proof of Lemma 2.5 is given in Appendix A of the ArXiv version [Reference Isaev, Southwell and Zhukovskii15] of the current paper. The key idea of this proof is to estimate the variance of the conditional expection value of
 $N_{H}({\textbf{T}})$
given the degree sequence of
$N_{H}({\textbf{T}})$
given the degree sequence of
 ${\textbf{T}}$
.
${\textbf{T}}$
.
Remark 2.6. There is a different way to show
 $\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] =\Omega(n)$
for any fixed H and
$\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] =\Omega(n)$
for any fixed H and
 $\boldsymbol{\theta}$
(including the case
$\boldsymbol{\theta}$
(including the case
 $\theta_i=1$
for all
$\theta_i=1$
for all
 $i \in [\ell]$
). First, one establishes that
$i \in [\ell]$
). First, one establishes that
 $\mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n) = o(1)$
for any sequence
$\mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n) = o(1)$
for any sequence
 $x_n$
. Reducing/incrementing the number of fringe copies of H in a clever way shows that
$x_n$
. Reducing/incrementing the number of fringe copies of H in a clever way shows that
 $\mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n)$
is not much larger than
$\mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n)$
is not much larger than
 $\mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n -k) + \mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n +k)$
for all k from a sufficiently large set. This implies that
$\mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n -k) + \mathbb{P}(N_{H,\boldsymbol{\theta}}({\textbf{T}}) = x_n +k)$
for all k from a sufficiently large set. This implies that
 $\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] \rightarrow \infty$
. Therefore,
$\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] \rightarrow \infty$
. Therefore,
 $p_{H,\theta}>0$
so
$p_{H,\theta}>0$
so
 $\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] = \Omega(n)$
. In fact, the proof of Lemma 2.5 given in [Reference Isaev, Southwell and Zhukovskii15, Appendix A] is more technically involved than this idea, but it extends better to growing substructures.
$\rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] = \Omega(n)$
. In fact, the proof of Lemma 2.5 given in [Reference Isaev, Southwell and Zhukovskii15, Appendix A] is more technically involved than this idea, but it extends better to growing substructures.
Using formula (4), we also obtain a precise estimate of
 $\rm{Var}\left[{N_{H}({\textbf{T}})}\right]$
for the case when H is a path. With slight abuse of notations, let
$\rm{Var}\left[{N_{H}({\textbf{T}})}\right]$
for the case when H is a path. With slight abuse of notations, let
 $P_\ell(T)\,:\!=\, N_{P_\ell}(T)$
that is the number of paths on
$P_\ell(T)\,:\!=\, N_{P_\ell}(T)$
that is the number of paths on
 $\ell$
vertices in a tree
$\ell$
vertices in a tree
 $T\in \mathcal{T}_n$
.
$T\in \mathcal{T}_n$
.
Lemma 2.7. Let
 $\ell>2$
and
$\ell>2$
and
 $\ell = O(n^{1/2})$
, then
$\ell = O(n^{1/2})$
, then
 \begin{equation*} \rm{Var}\left[{P_{\ell}({\textbf{T}})}\right] =\left (1+O\left(\dfrac{\ell^2}{n}\right)\right) n\ \frac{\ell(\ell-1)^2 (\ell-2)}{24}. \end{equation*}
\begin{equation*} \rm{Var}\left[{P_{\ell}({\textbf{T}})}\right] =\left (1+O\left(\dfrac{\ell^2}{n}\right)\right) n\ \frac{\ell(\ell-1)^2 (\ell-2)}{24}. \end{equation*}
Proof. For the induced path counts formula (4) simplifies as follows:
 \begin{equation*} \rm{Var}\left[{ P_{\ell}({\textbf{T}})}\right] = \dfrac{1}{4} \sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ).\end{equation*}
\begin{equation*} \rm{Var}\left[{ P_{\ell}({\textbf{T}})}\right] = \dfrac{1}{4} \sum_{{\textbf{u}},{\textbf{u}}'} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ).\end{equation*}
For
 $i \in [\ell]$
, let
$i \in [\ell]$
, let
 $\Sigma_i$
be the set of pairs
$\Sigma_i$
be the set of pairs
 $({\textbf{u}},{\textbf{u}}')$
that the sets formed by its coordinates have exactly i elements in common. From (3), we have that
$({\textbf{u}},{\textbf{u}}')$
that the sets formed by its coordinates have exactly i elements in common. From (3), we have that
 $\mathbb{E}\left[{ \mathbb{1}_{{\textbf{u}}}({\textbf{T}})}\right] = \ell n^{1-\ell}$
. Using Lemma 2.3, we get
$\mathbb{E}\left[{ \mathbb{1}_{{\textbf{u}}}({\textbf{T}})}\right] = \ell n^{1-\ell}$
. Using Lemma 2.3, we get
 $\mathbb{E}\left[{\mathbb{1}_{{\textbf{u}}}({\textbf{T}})\mathbb{1}_{{\textbf{u}}'}({\textbf{T}})} \right]= \ell^2 n^{2-2\ell}$
for
$\mathbb{E}\left[{\mathbb{1}_{{\textbf{u}}}({\textbf{T}})\mathbb{1}_{{\textbf{u}}'}({\textbf{T}})} \right]= \ell^2 n^{2-2\ell}$
for
 $({\textbf{u}},{\textbf{u}}') \in \Sigma_0$
, so
$({\textbf{u}},{\textbf{u}}') \in \Sigma_0$
, so
 \begin{equation*} \sum_{({\textbf{u}},{\textbf{u}}')\in \Sigma_0} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) = 0.\end{equation*}
\begin{equation*} \sum_{({\textbf{u}},{\textbf{u}}')\in \Sigma_0} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}})) = 0.\end{equation*}
Applying Lemma 2.3, it is a routine to check that
 \begin{align*} \sum_{({\textbf{u}},{\textbf{u}}') \in \Sigma_1} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ) &= |\Sigma_1| \left( (2\ell -1) n^{2\,-\,2\ell} - \ell^2 n^{2\,-\,2\ell}\right) \\&= - \frac{(n)_{2\ell\,-\,1}}{n^{2\ell\,-\,2}} \ell^2 (\ell-1)^2 = - \left (1+O\left(\dfrac{\ell^2}{n}\right)\right) n \ell^2 (\ell-1)^2. \end{align*}
\begin{align*} \sum_{({\textbf{u}},{\textbf{u}}') \in \Sigma_1} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ) &= |\Sigma_1| \left( (2\ell -1) n^{2\,-\,2\ell} - \ell^2 n^{2\,-\,2\ell}\right) \\&= - \frac{(n)_{2\ell\,-\,1}}{n^{2\ell\,-\,2}} \ell^2 (\ell-1)^2 = - \left (1+O\left(\dfrac{\ell^2}{n}\right)\right) n \ell^2 (\ell-1)^2. \end{align*}
Similarly, for
 $2 \leqslant i\leqslant \ell$
, we get
$2 \leqslant i\leqslant \ell$
, we get
 \begin{align*} \sum_{({\textbf{u}},{\textbf{u}}') \in \Sigma_i} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ) &= |\Sigma_i| \left( (2\ell -i) n^{1\,-\,2 \ell \,+\,i} - \ell^2 n^{2\,-\,2\ell}\right) \\ &= \left (1+O\left(\dfrac{\ell}{n}\right) \right)\frac{2 (n)_{2\ell\,-\,i}}{n^{2\ell\,-\,i\,-\,1}} (\ell- i+1)^2 (2\ell-i) \\[4pt] &=\left (1+O\left(\dfrac{\ell^2}{n}\right)\right) 2n (\ell- i+1)^2 (2\ell-i). \end{align*}
\begin{align*} \sum_{({\textbf{u}},{\textbf{u}}') \in \Sigma_i} \textrm{Cov} (\mathbb{1}_{{\textbf{u}}}({\textbf{T}}), \mathbb{1}_{{\textbf{u}}'}({\textbf{T}}) ) &= |\Sigma_i| \left( (2\ell -i) n^{1\,-\,2 \ell \,+\,i} - \ell^2 n^{2\,-\,2\ell}\right) \\ &= \left (1+O\left(\dfrac{\ell}{n}\right) \right)\frac{2 (n)_{2\ell\,-\,i}}{n^{2\ell\,-\,i\,-\,1}} (\ell- i+1)^2 (2\ell-i) \\[4pt] &=\left (1+O\left(\dfrac{\ell^2}{n}\right)\right) 2n (\ell- i+1)^2 (2\ell-i). \end{align*}
Summing the above bounds for
 $\Sigma_0,\ldots, \Sigma_{\ell}$
and using
$\Sigma_0,\ldots, \Sigma_{\ell}$
and using
 \begin{equation*} -\ell^2 (\ell-1)^2 + 2 \sum_{i=2}^{\ell} (\ell- i+1)^2 (2\ell-i) = \frac{\ell(\ell-1)^2 (\ell-2)}{6}, \end{equation*}
\begin{equation*} -\ell^2 (\ell-1)^2 + 2 \sum_{i=2}^{\ell} (\ell- i+1)^2 (2\ell-i) = \frac{\ell(\ell-1)^2 (\ell-2)}{6}, \end{equation*}
we get the stated formula for
 $\textrm{Var} P_{\ell}({\textbf{T}}) $
.
$\textrm{Var} P_{\ell}({\textbf{T}}) $
.
2.2. Asymptotic normality of pattern counts
Here we apply Theorem 1.1 to derive the limiting distribution of the pattern counts
 $N_{H,\boldsymbol{\theta}}({\textbf{T}})$
. In fact, all applications of Theorem 1.1 typically have short proofs leaving the lower bound for the variance to be the most technically involved part.
$N_{H,\boldsymbol{\theta}}({\textbf{T}})$
. In fact, all applications of Theorem 1.1 typically have short proofs leaving the lower bound for the variance to be the most technically involved part.
Theorem 2.8. Let H be a tree on
 $\ell$
vertices and
$\ell$
vertices and
 $\boldsymbol{\theta}\in\{0,1\}^{\ell}$
be a non-zero vector. Then
$\boldsymbol{\theta}\in\{0,1\}^{\ell}$
be a non-zero vector. Then
 $N_{H,\boldsymbol{\theta}}({\textbf{T}})$
is asymptotically normal and
$N_{H,\boldsymbol{\theta}}({\textbf{T}})$
is asymptotically normal and
 $\delta_{\rm{K}}\left[N_{H,\boldsymbol{\theta}}({\textbf{T}})\right]=O(n^{-1/4 + \varepsilon})$
for any
$\delta_{\rm{K}}\left[N_{H,\boldsymbol{\theta}}({\textbf{T}})\right]=O(n^{-1/4 + \varepsilon})$
for any
 $\varepsilon>0$
.
$\varepsilon>0$
.
Proof. For a tree
 $T\in\mathcal{T}_n$
, let F(T) be the number of occurrences of
$T\in\mathcal{T}_n$
, let F(T) be the number of occurrences of
 $(H,\boldsymbol{\theta})$
in the induced subforest of T for the set of vertices with degrees at most
$(H,\boldsymbol{\theta})$
in the induced subforest of T for the set of vertices with degrees at most
 ${\textrm{log}}\, n$
in T.
${\textrm{log}}\, n$
in T.
Removing one edge from T can only destroy at most
 $ {\textrm{log}}^{\ell} n$
patterns
$ {\textrm{log}}^{\ell} n$
patterns
 $(H,\boldsymbol{\theta})$
counted in F(T). Thus, F is
$(H,\boldsymbol{\theta})$
counted in F(T). Thus, F is
 $\alpha$
-Lipschitz with
$\alpha$
-Lipschitz with
 $\alpha = 2\, {\textrm{log}}^{\ell} n$
. If two perturbations
$\alpha = 2\, {\textrm{log}}^{\ell} n$
. If two perturbations
 $\textrm{S}_{i}^{jk}$
and
$\textrm{S}_{i}^{jk}$
and
 $\textrm{S}_{a}^{bc}$
are at distance at least
$\textrm{S}_{a}^{bc}$
are at distance at least
 $3\ell$
in T, then every pattern
$3\ell$
in T, then every pattern
 $(H,\boldsymbol{\theta})$
counted in
$(H,\boldsymbol{\theta})$
counted in
 $F(\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T) - F(T)$
(with positive or negative sign) is present in exactly one of the terms
$F(\textrm{S}_{i}^{jk} \textrm{S}_{a}^{bc} T) - F(T)$
(with positive or negative sign) is present in exactly one of the terms
 $F(\textrm{S}_{i}^{jk}T) - F(T)$
and
$F(\textrm{S}_{i}^{jk}T) - F(T)$
and
 $F(\textrm{S}_{a}^{bc} T) - F(T)$
(with the same sign). Thus, F is
$F(\textrm{S}_{a}^{bc} T) - F(T)$
(with the same sign). Thus, F is
 $\rho$
-superposable with
$\rho$
-superposable with
 $\rho= 3 \ell$
.
$\rho= 3 \ell$
.
From (1), we know that
 \begin{equation*} \mathbb{P} (F({\textbf{T}})\neq N_{H,\boldsymbol{\theta}}({\textbf{T}})) = e^{-\omega({\textrm{log}}\, n)}. \end{equation*}
\begin{equation*} \mathbb{P} (F({\textbf{T}})\neq N_{H,\boldsymbol{\theta}}({\textbf{T}})) = e^{-\omega({\textrm{log}}\, n)}. \end{equation*}
Since the values of these random variables are not bigger than
 $n^{\ell}$
, we get
$n^{\ell}$
, we get
 \begin{align*} \mathbb{E}\left[{F({\textbf{T}})}\right] &= \mathbb{E}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] + e^{-\omega({\textrm{log}}\, n)},\\[4pt] \rm{Var}\left[{F({\textbf{T}})}\right] &= \rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] + e^{-\omega({\textrm{log}}\, n)}. \end{align*}
\begin{align*} \mathbb{E}\left[{F({\textbf{T}})}\right] &= \mathbb{E}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] + e^{-\omega({\textrm{log}}\, n)},\\[4pt] \rm{Var}\left[{F({\textbf{T}})}\right] &= \rm{Var}\left[{N_{H,\boldsymbol{\theta}}({\textbf{T}})}\right] + e^{-\omega({\textrm{log}}\, n)}. \end{align*}
Combining Lemmas 2.4 and 2.5, we get that
 $\rm{Var}\left[{F({\textbf{T}})}\right] = \Omega(n)$
. Applying Theorem 1.1, we complete the proof.
$\rm{Var}\left[{F({\textbf{T}})}\right] = \Omega(n)$
. Applying Theorem 1.1, we complete the proof.
In the next result, we allow the pattern to grow, but restricted to the case when H is a path and all
 $\theta_i$
equal 1 (all vertices are “empty”).
$\theta_i$
equal 1 (all vertices are “empty”).
Theorem 2.9. Let
 $\ell = O(n^{1/8-\delta})$
for some fixed
$\ell = O(n^{1/8-\delta})$
for some fixed
 $\delta \in (0,1/8)$
. Then
$\delta \in (0,1/8)$
. Then
 $P_\ell({\textbf{T}})$
is asymptotically normal and
$P_\ell({\textbf{T}})$
is asymptotically normal and
 $\delta_{\rm{K}}\left[P_{\ell}({\textbf{T}})\right]=O(n^{-\varepsilon'})$
for any
$\delta_{\rm{K}}\left[P_{\ell}({\textbf{T}})\right]=O(n^{-\varepsilon'})$
for any
 $\varepsilon' \in (0, 2\delta)$
.
$\varepsilon' \in (0, 2\delta)$
.
Proof. For a tree
 $T\in \mathcal{T}_n$
, let
$T\in \mathcal{T}_n$
, let
 \begin{equation*}V_{\textrm{good}}(T) \,:\!=\, \left\{ i \in [n] \mathrel{:} \text{for all $d\in [n]$, we have } |\{j \in[n] \mathrel{:} d_T(i,j) = d\}| \leqslant d\ {\textrm{log}}^4\, n\right\}.\end{equation*}
\begin{equation*}V_{\textrm{good}}(T) \,:\!=\, \left\{ i \in [n] \mathrel{:} \text{for all $d\in [n]$, we have } |\{j \in[n] \mathrel{:} d_T(i,j) = d\}| \leqslant d\ {\textrm{log}}^4\, n\right\}.\end{equation*}
Define F(T) to be the number of induced paths on
 $\ell$
vertices in the forest
$\ell$
vertices in the forest
 $T[V_{\rm{good}}(T)]$
.
$T[V_{\rm{good}}(T)]$
.
The number of
 $\ell$
-paths counted in F(T) containing any fixed edge is at most
$\ell$
-paths counted in F(T) containing any fixed edge is at most
 \begin{equation*} {\textrm{log}}^8 n \sum_{i = 1}^{\ell\,-\,2} i (\ell-i-1) \leqslant \dfrac12\ell^3\ {\textrm{log}}^8 n.\end{equation*}
\begin{equation*} {\textrm{log}}^8 n \sum_{i = 1}^{\ell\,-\,2} i (\ell-i-1) \leqslant \dfrac12\ell^3\ {\textrm{log}}^8 n.\end{equation*}
Arguing similarly to the proof of Theorem 2.8, we conclude that F is
 $\alpha$
-Lipschitz with
$\alpha$
-Lipschitz with
 $\alpha= \ell^3\ {\textrm{log}}^8 n$
and
$\alpha= \ell^3\ {\textrm{log}}^8 n$
and
 $\rho$
-superposable with
$\rho$
-superposable with
 $\rho=3\ell$
. From Theorem 1.4, we also get
$\rho=3\ell$
. From Theorem 1.4, we also get
 \begin{equation*} \mathbb{P} (F({\textbf{T}})\neq P_{\ell}({\textbf{T}})) = e^{-\omega({\textrm{log}}\, n)}. \end{equation*}
\begin{equation*} \mathbb{P} (F({\textbf{T}})\neq P_{\ell}({\textbf{T}})) = e^{-\omega({\textrm{log}}\, n)}. \end{equation*}
Next, for a tree
 $T\in \mathcal{T}_n$
, observe that
$T\in \mathcal{T}_n$
, observe that
 $F(T)\leqslant P_{\ell}(T) \leqslant n^2$
since any path in T is uniquely determined by the choice of its end vertices. The rest of the argument is identical to the proof of Theorem 2.8.
$F(T)\leqslant P_{\ell}(T) \leqslant n^2$
since any path in T is uniquely determined by the choice of its end vertices. The rest of the argument is identical to the proof of Theorem 2.8.
3. Number of automorphisms
An automorphism of a graph G is a bijection
 $\sigma\,:\, V(G) \to V(G)$
such that the edge set of G is preserved under
$\sigma\,:\, V(G) \to V(G)$
such that the edge set of G is preserved under
 $\sigma$
. Bona and Flajolet [Reference Bóna and Flajolet3] studied this parameter for random unlabelled rooted non-plane trees and random phylogenetic trees (rooted non-plane binary trees with labelled leaves). They showed that in both cases the distribution is asymptotically lognormal; that is, the logarithm of the number of automorphisms in a random tree is asymptotically normal. McKeon [Reference McKeon20] proved asymptotic formulas for the number automorphisms in related random models of unlabelled locally restricted trees.
$\sigma$
. Bona and Flajolet [Reference Bóna and Flajolet3] studied this parameter for random unlabelled rooted non-plane trees and random phylogenetic trees (rooted non-plane binary trees with labelled leaves). They showed that in both cases the distribution is asymptotically lognormal; that is, the logarithm of the number of automorphisms in a random tree is asymptotically normal. McKeon [Reference McKeon20] proved asymptotic formulas for the number automorphisms in related random models of unlabelled locally restricted trees.
In her PhD thesis, Yu [Reference Yu30] determined the asymptotics of
 $\mathbb{E}\left[{{\textrm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|}\right]$
for uniform random labelled tree
$\mathbb{E}\left[{{\textrm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|}\right]$
for uniform random labelled tree
 ${\textbf{T}}$
. She also made the following conjecture:
${\textbf{T}}$
. She also made the following conjecture:
Conjecture 3.1. [Reference Yu30] The distribution of
 $\left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|$
is asymptotically lognormal.
$\left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|$
is asymptotically lognormal.
In this section, we prove this conjecture. Unfortunately, we cannot immediately apply Theorem 1.1 to derive the distribution of the number of automorphisms since the logarithm of this parameter is not
 $\rho$
-superposable for a sufficiently small
$\rho$
-superposable for a sufficiently small
 $\rho$
. This happens because some trees have automorphisms affected by both perturbations
$\rho$
. This happens because some trees have automorphisms affected by both perturbations
 $\textrm{S}_{i}^{jk}$
and
$\textrm{S}_{i}^{jk}$
and
 $\textrm{S}_{a}^{bc}$
even if
$\textrm{S}_{a}^{bc}$
even if
 $d_T(\{j,k\}, \{b,c\})$
is large. Instead, we start by looking at
$d_T(\{j,k\}, \{b,c\})$
is large. Instead, we start by looking at
 $\rm{A}\small{UT}_r\left({T}\right)$
, the subgroup of
$\rm{A}\small{UT}_r\left({T}\right)$
, the subgroup of
 $\rm{A}\small{UT}\left({T}\right)$
consisting of automorphisms
$\rm{A}\small{UT}\left({T}\right)$
consisting of automorphisms
 $\sigma \in \rm{A}\small{UT}\left({T}\right)$
such that
$\sigma \in \rm{A}\small{UT}\left({T}\right)$
such that
 $\sigma(r) = r$
, where r is some fixed vertex from [n]. In other words,
$\sigma(r) = r$
, where r is some fixed vertex from [n]. In other words,
 $\rm{A}\small{UT}_r\left({T}\right)$
is the number of rooted automorphisms of a tree T with root r, or equivalently the stabilizer of r.
$\rm{A}\small{UT}_r\left({T}\right)$
is the number of rooted automorphisms of a tree T with root r, or equivalently the stabilizer of r.
The parameter
 $ \rm{A}\small{UT}_r\left({{\textbf{T}}}\right)$
is easier to work with while also remaining asymptotically very similar to
$ \rm{A}\small{UT}_r\left({{\textbf{T}}}\right)$
is easier to work with while also remaining asymptotically very similar to
 $\rm{A}\small{UT}\left({{\textbf{T}}}\right)$
. The ease of analysis comes from the product representation of
$\rm{A}\small{UT}\left({{\textbf{T}}}\right)$
. The ease of analysis comes from the product representation of
 $\left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
given by Yu [Reference Yu30, Corollary 2.1.3].
$\left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
given by Yu [Reference Yu30, Corollary 2.1.3].
 \begin{align} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| &= \prod_{i \in [n]} \prod_{B}N_i(B,T,r)!\end{align}
\begin{align} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| &= \prod_{i \in [n]} \prod_{B}N_i(B,T,r)!\end{align}
The product over B represents a product over isomorphism classes of rooted unlabelled trees. Define a branch of T at v to be a subtree rooted at an immediate descendent (with respect to r) of v. That is the branch is a fringe subtree of T at this descendent. The term
 $N_i(B,T,r)$
denotes the number of branches isomorphic to B at vertex i. Factorisation (5) also follows from the result of Stacey and Holton that says every rooted automorphism is a product of branch transpositions [Reference Stacey and Holton24, Lemma 2.4].
$N_i(B,T,r)$
denotes the number of branches isomorphic to B at vertex i. Factorisation (5) also follows from the result of Stacey and Holton that says every rooted automorphism is a product of branch transpositions [Reference Stacey and Holton24, Lemma 2.4].
We give an example of (5) in Figure 3 for a tree on 9 vertices. There are only three types of branches in this tree with respect to the root
 $r=1$
, namely
$r=1$
, namely
 $B_1$
,
$B_1$
,
 $B_2$
, and
$B_2$
, and
 $B_3$
. Vertex 1 has two branches isomorphic to
$B_3$
. Vertex 1 has two branches isomorphic to
 $B_2$
, and thus
$B_2$
, and thus
 $N_1(B_2,T,r)! = 2! = 2$
. It also has one branch isomorphic to
$N_1(B_2,T,r)! = 2! = 2$
. It also has one branch isomorphic to
 $B_1$
, and thus
$B_1$
, and thus
 $N_1(B_1,T,r)! = 1$
. Vertex 2 has three branches isomorphic to
$N_1(B_1,T,r)! = 1$
. Vertex 2 has three branches isomorphic to
 $B_3$
, and thus
$B_3$
, and thus
 $N_2(B_3, T, r)! = 3! = 6$
. Vertices 3 and 4 each have one branch isomorphic to
$N_2(B_3, T, r)! = 3! = 6$
. Vertices 3 and 4 each have one branch isomorphic to
 $B_3$
, and thus
$B_3$
, and thus
 $N_3(B_3,T, r)! = N_4(B_3, T,r)! = 1$
. Applying (5) shows that
$N_3(B_3,T, r)! = N_4(B_3, T,r)! = 1$
. Applying (5) shows that
 $|\rm{A}\small{UT}_r(T)| = 3! \cdot 2! = 12$
.
$|\rm{A}\small{UT}_r(T)| = 3! \cdot 2! = 12$
.

Figure 3. A labelled tree on the left and its (rooted, unlabelled) branches on the right.
To define our tree parameter F(T), we look at a subgroup of
 $\rm{A}\small{UT}_r\left({T}\right)$
based on small automorphisms. We define a small branch to be a branch with at most
$\rm{A}\small{UT}_r\left({T}\right)$
based on small automorphisms. We define a small branch to be a branch with at most
 $4\,{\textrm{log}}\, n$
vertices, any branch that is not small is large. A small automorphism is an automorphism where any vertex that is the root of a large branch is fixed. For a given tree T, let
$4\,{\textrm{log}}\, n$
vertices, any branch that is not small is large. A small automorphism is an automorphism where any vertex that is the root of a large branch is fixed. For a given tree T, let
 $\rm{A}\small{UT}_{\rm{small}} \subseteq \rm{A}\small{UT}_r\left({T}\right)$
be the set of small automorphisms.
$\rm{A}\small{UT}_{\rm{small}} \subseteq \rm{A}\small{UT}_r\left({T}\right)$
be the set of small automorphisms.
Lemma 3.2.
 $\rm{A}\small{UT}_{\rm{small}}$
is a subgroup of
$\rm{A}\small{UT}_{\rm{small}}$
is a subgroup of
 $\rm{A}\small{UT}_r\left({T}\right)$
.
$\rm{A}\small{UT}_r\left({T}\right)$
.
Proof. Observe that any automorphism in
 $\rm{A}\small{UT}_{\rm{small}}$
must also have an inverse in
$\rm{A}\small{UT}_{\rm{small}}$
must also have an inverse in
 $\rm{A}\small{UT}_{\rm{small}}$
, since they move the same vertices. Furthermore, to prove closure under composition, suppose that
$\rm{A}\small{UT}_{\rm{small}}$
, since they move the same vertices. Furthermore, to prove closure under composition, suppose that
 $a,b \in \rm{A}\small{UT}_{\rm{small}}$
but
$a,b \in \rm{A}\small{UT}_{\rm{small}}$
but
 $ab \notin \rm{A}\small{UT}_{\rm{small}}$
. Let B be a large branch that is mapped by ab onto
$ab \notin \rm{A}\small{UT}_{\rm{small}}$
. Let B be a large branch that is mapped by ab onto
 $B^\prime$
. Then all of the vertices in B are moved by either a or b. Since
$B^\prime$
. Then all of the vertices in B are moved by either a or b. Since
 $a \in \rm{A}\small{UT}_{\rm{small}}$
, there are some vertices in B not moved by a; denote this set by X. Since B is connected, there exists an edge between X and
$a \in \rm{A}\small{UT}_{\rm{small}}$
, there are some vertices in B not moved by a; denote this set by X. Since B is connected, there exists an edge between X and
 $V(B)\backslash X$
in the edge set of B. Thus, there exists an edge between aX and aV(B) in T; however, this creates a cycle and thus a contradiction. Thus, ab must also only move small branches, and thus
$V(B)\backslash X$
in the edge set of B. Thus, there exists an edge between aX and aV(B) in T; however, this creates a cycle and thus a contradiction. Thus, ab must also only move small branches, and thus
 $ab \in \rm{A}\small{UT}_{\rm{small}}$
. Thus,
$ab \in \rm{A}\small{UT}_{\rm{small}}$
. Thus,
 $\rm{A}\small{UT}_{\rm{small}}$
is a subgroup.
$\rm{A}\small{UT}_{\rm{small}}$
is a subgroup.
The parameter F(T) is obtained by writing
 $|\rm{A}\small{UT}_{\rm{small}}|$
in the same product representation as
$|\rm{A}\small{UT}_{\rm{small}}|$
in the same product representation as
 $\left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
and taking the logarithm:
$\left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
and taking the logarithm:
 \begin{align}F(T) &\,:\!=\, {\textrm{log}} |\rm{A}\small{UT}_{\rm{small}}| = \sum_{i\in [n]}\sum_{B \in \mathcal{B}_{\rm{small}}}\, {\textrm{log}} (N_i(B, T,r)!).\end{align}
\begin{align}F(T) &\,:\!=\, {\textrm{log}} |\rm{A}\small{UT}_{\rm{small}}| = \sum_{i\in [n]}\sum_{B \in \mathcal{B}_{\rm{small}}}\, {\textrm{log}} (N_i(B, T,r)!).\end{align}
Here
 $\mathcal{B}_{\rm{small}}$
is the set of small branches.
$\mathcal{B}_{\rm{small}}$
is the set of small branches.
Remark 3.3. In fact, the parameter F defined above belongs to a larger class of additive functionals considered by Janson [Reference Janson16] and Wagner [Reference Wagner27]. They established a general CLT for this type of parameters. [Reference Janson16, Theorem 1.3] and [Reference Wagner27, Theorem 2] do not cover the number of automorphisms in
 ${\textbf{T}}$
because
${\textbf{T}}$
because
 $ {\mathbb{E}} \left[ \left(\sum_{B} {\textrm{log}} (N_i(B, {\textbf{T}}, r)!)\right)^{2} \right] $
is not vanishing. In fact, it is bounded below by the second moment of the number of leaves attached to a given vertex which tends to a positive constant; see also the estimates given in [Reference Isaev, Southwell and Zhukovskii15, Appendix B].
$ {\mathbb{E}} \left[ \left(\sum_{B} {\textrm{log}} (N_i(B, {\textbf{T}}, r)!)\right)^{2} \right] $
is not vanishing. In fact, it is bounded below by the second moment of the number of leaves attached to a given vertex which tends to a positive constant; see also the estimates given in [Reference Isaev, Southwell and Zhukovskii15, Appendix B].
Next, we show that F(T) satisfies assumptions of Theorem 1.1 while also being very close to
 ${\textrm{log}} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
.
${\textrm{log}} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
.
Lemma 3.4. Let
 $\alpha = 3{\rm{log}}\, n$
and
$\alpha = 3{\rm{log}}\, n$
and
 $\rho = 10\ {\rm{log}}\, n$
. Then
$\rho = 10\ {\rm{log}}\, n$
. Then
 $F({\textbf{T}})$
as defined in (6) is
$F({\textbf{T}})$
as defined in (6) is
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable.
$\rho$
-superposable.
Proof. To prove the Lipschitz property, we show that for any two trees T and
 $T^\prime$
differing by a perturbation
$T^\prime$
differing by a perturbation
 $\textrm{S}_i^{jk}$
, the order of
$\textrm{S}_i^{jk}$
, the order of
 $\rm{A}\small{UT}_{\rm{small}}$
for each tree can differ by at most a factor of
$\rm{A}\small{UT}_{\rm{small}}$
for each tree can differ by at most a factor of
 $n^3$
. Any automorphism of T fixing
$n^3$
. Any automorphism of T fixing
 $\left\{i,j,k \right\}$
is an automorphism of
$\left\{i,j,k \right\}$
is an automorphism of
 $T^\prime$
, since all other edges remained static so their orbits are unaffected. Let
$T^\prime$
, since all other edges remained static so their orbits are unaffected. Let
 $G_{ijk}$
be the subgroup of
$G_{ijk}$
be the subgroup of
 $\rm{A}\small{UT}_{\rm{small}}$
that fixes
$\rm{A}\small{UT}_{\rm{small}}$
that fixes
 $\left\{ i,j,k \right\}$
. Then the cosets of this subgroup are defined by where they send each of these vertices. Since there are at most n such options for each element in the set, we get at most
$\left\{ i,j,k \right\}$
. Then the cosets of this subgroup are defined by where they send each of these vertices. Since there are at most n such options for each element in the set, we get at most
 $n^3$
cosets. By Lagrange’s theorem, we get that
$n^3$
cosets. By Lagrange’s theorem, we get that
 \begin{align*} \rm{A}\small{UT}_{\rm{small}}(T) \geqslant \frac{|\rm{A}\small{UT}_{\rm{small}}(T^\prime)|}{n^3} \end{align*}
\begin{align*} \rm{A}\small{UT}_{\rm{small}}(T) \geqslant \frac{|\rm{A}\small{UT}_{\rm{small}}(T^\prime)|}{n^3} \end{align*}
and vice versa by swapping the roles of T and
 $T^\prime$
. Taking the logarithm of both sides gives the desired bound.
$T^\prime$
. Taking the logarithm of both sides gives the desired bound.
Next, we show that F is
 $\rho$
-superposable. Suppose
$\rho$
-superposable. Suppose
 $d = d_T \left( \left\{ j,k \right\}, \left\{ b,c\right\} \right) > 10\,{\textrm{log}}\, n$
. Then suppose an automorphism
$d = d_T \left( \left\{ j,k \right\}, \left\{ b,c\right\} \right) > 10\,{\textrm{log}}\, n$
. Then suppose an automorphism
 $\sigma \in \rm{A}\small{UT}_{\rm small}(T)$
is created or destroyed by
$\sigma \in \rm{A}\small{UT}_{\rm small}(T)$
is created or destroyed by
 $\textrm{S}^{jk}_i$
. Then
$\textrm{S}^{jk}_i$
. Then
 $\sigma$
must not fix
$\sigma$
must not fix
 $\left\{ i, j, k \right\}$
. Any path between one of
$\left\{ i, j, k \right\}$
. Any path between one of
 $\left\{j,k\right\}$
and one of
$\left\{j,k\right\}$
and one of
 $\left\{b,c\right\}$
must be longer than
$\left\{b,c\right\}$
must be longer than
 $10\,{\textrm{log}}\, n$
. Therefore, any parent vertex in the tree is strictly more than
$10\,{\textrm{log}}\, n$
. Therefore, any parent vertex in the tree is strictly more than
 $5\,{\textrm{log}}\, n$
distance from at least one vertex in each pair. So
$5\,{\textrm{log}}\, n$
distance from at least one vertex in each pair. So
 $\sigma$
must fix
$\sigma$
must fix
 $\left\{a,b,c\right\}$
and all lower branches, since each branch moved by the automorphism is at most
$\left\{a,b,c\right\}$
and all lower branches, since each branch moved by the automorphism is at most
 $4\,{\textrm{log}}\, n$
. So
$4\,{\textrm{log}}\, n$
. So
 $\textrm{S}_a^{bc}$
cannot affect the presence or absence of
$\textrm{S}_a^{bc}$
cannot affect the presence or absence of
 $\sigma$
in
$\sigma$
in
 $\rm{A}\small{UT}\left({T}\right)$
. Similarly, any automorphism created or destroyed by
$\rm{A}\small{UT}\left({T}\right)$
. Similarly, any automorphism created or destroyed by
 $\textrm{S}_a^{bc}$
cannot be affected by
$\textrm{S}_a^{bc}$
cannot be affected by
 $\textrm{S}_{i}^{jk}$
. Thus,
$\textrm{S}_{i}^{jk}$
. Thus,
 \begin{equation*} F\left(\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T\right) - F(T) = \left(F\left(\textrm{S}_{i}^{jk}T\right) - F(T)\right) + \left(F\left(\textrm{S}_{a}^{bc}T\right) - F(T)\right). \end{equation*}
\begin{equation*} F\left(\textrm{S}_{i}^{jk}\textrm{S}_{a}^{bc}T\right) - F(T) = \left(F\left(\textrm{S}_{i}^{jk}T\right) - F(T)\right) + \left(F\left(\textrm{S}_{a}^{bc}T\right) - F(T)\right). \end{equation*}
This completes the proof.
In the next lemma, we derive bounds needed to compare
 $\rm{A}\small{UT}({\textbf{T}})$
and
$\rm{A}\small{UT}({\textbf{T}})$
and
 $F({\textbf{T}})$
.
$F({\textbf{T}})$
.
Lemma 3.5. The following statements hold.
-
a.
$\Big| {\rm{log}} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| - {\rm{log}} \left|\rm{A}\small{UT}\left({T}\right)\right|\Big| \leqslant {\rm{log}}\, n$
for all
$T\in \mathcal{T}_n$
, -
b.
$\mathbb{P}\left({F({\textbf{T}}) \neq {\rm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|}\right) = O\left( \frac{1}{n^3} \right)$
, -
c.
$\mathbb{E}\left[{{\rm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|}\right] - \mathbb{E}\left[{F({\textbf{T}})}\right] = O({\rm{log}}\, n)$
, -
d.
$\rm{Var}\left[{ {\rm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|}\right] - \rm{Var}\left[{F({\textbf{T}})}\right] = O\left(\sqrt{n\ {\rm{log}}\, n}\right)$
.





Proof. Each automorphism in
 $\rm{A}\small{UT}_r\left({T}\right)$
is an automorphism in
$\rm{A}\small{UT}_r\left({T}\right)$
is an automorphism in
 $\rm{A}\small{UT}\left({T}\right)$
. The group
$\rm{A}\small{UT}\left({T}\right)$
. The group
 $\rm{A}\small{UT}\left({T}\right)$
operates on [n] such that
$\rm{A}\small{UT}\left({T}\right)$
operates on [n] such that
 $\rm{A}\small{UT}_r\left({T}\right)$
is the stabilizer of r. Hence,
$\rm{A}\small{UT}_r\left({T}\right)$
is the stabilizer of r. Hence,
 \begin{equation*} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| \leqslant \left|\rm{A}\small{UT}\left({T}\right)\right| = |\textrm{Orbit}(r)| \times \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| \leqslant n \left|\rm{A}\small{UT}_r\left({{T}}\right)\right|. \end{equation*}
\begin{equation*} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| \leqslant \left|\rm{A}\small{UT}\left({T}\right)\right| = |\textrm{Orbit}(r)| \times \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| \leqslant n \left|\rm{A}\small{UT}_r\left({{T}}\right)\right|. \end{equation*}
Thus, we get (a). Parts (b) follows almost immediately from results by Yu [Reference Yu30, Corollary 2.2.2]. To show part (c), we use parts (a) and (b) and observe
 $F(T) \leqslant \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| \leqslant {\textrm{log}}\, n! \leqslant n\, {\textrm{log}}\, n$
to get that
$F(T) \leqslant \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| \leqslant {\textrm{log}}\, n! \leqslant n\, {\textrm{log}}\, n$
to get that
 \begin{align*} \mathbb{E}\left[{{\textrm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right| - F({\textbf{T}})}\right] &< \max_{T} \lvert{ {\textrm{log}} \left|\rm{A}\small{UT}\left({T}\right)\right| - {\textrm{log}} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| }\rvert \\ & \quad + \mathbb{P}\left({F({\textbf{T}}) \neq {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|}\right) n\,{\textrm{log}}\, n\\ & \leqslant {\textrm{log}}\, n + O\left( \frac{{\textrm{log}}\, n}{n^2} \right) = O\left( {\textrm{log}}\, n \right). \end{align*}
\begin{align*} \mathbb{E}\left[{{\textrm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right| - F({\textbf{T}})}\right] &< \max_{T} \lvert{ {\textrm{log}} \left|\rm{A}\small{UT}\left({T}\right)\right| - {\textrm{log}} \left|\rm{A}\small{UT}_r\left({{T}}\right)\right| }\rvert \\ & \quad + \mathbb{P}\left({F({\textbf{T}}) \neq {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|}\right) n\,{\textrm{log}}\, n\\ & \leqslant {\textrm{log}}\, n + O\left( \frac{{\textrm{log}}\, n}{n^2} \right) = O\left( {\textrm{log}}\, n \right). \end{align*}
Finally, we proceed to part (d). Let
 $W = F({\textbf{T}}) - {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|$
and
$W = F({\textbf{T}}) - {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|$
and
 $Z = {\textrm{log}} \left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right| - {\textrm{log}}\left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|$
. From Lemma 3.5(a,b,c), we get that
$Z = {\textrm{log}} \left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right| - {\textrm{log}}\left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|$
. From Lemma 3.5(a,b,c), we get that
 \begin{align*} |\rm{Var}\left[{W}\right] + \textrm{Cov}(Z,W)| &\leqslant \mathbb{P}\left({F({\textbf{T}}) \neq {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|}\right) 2 n^2\,{\textrm{log}}^2 n = O\left(\frac{{\textrm{log}}^2 n} {n}\right) \\ \rm{Var}\left[{Z}\right] &\leqslant {\mathbb{E}} Z^2 \leqslant {\textrm{log}}^2 n, \\ | {\textrm{Cov}\left({F({\textbf{T}}),W+Z}\right)}| &\leqslant \left( \rm{Var}\left[{F({\textbf{T}})}\right] \rm{Var}\left[{W+Z}\right]\right)^{1/2} = O\left(\sqrt{n\, {\textrm{log}}\, n}\right). \end{align*}
\begin{align*} |\rm{Var}\left[{W}\right] + \textrm{Cov}(Z,W)| &\leqslant \mathbb{P}\left({F({\textbf{T}}) \neq {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|}\right) 2 n^2\,{\textrm{log}}^2 n = O\left(\frac{{\textrm{log}}^2 n} {n}\right) \\ \rm{Var}\left[{Z}\right] &\leqslant {\mathbb{E}} Z^2 \leqslant {\textrm{log}}^2 n, \\ | {\textrm{Cov}\left({F({\textbf{T}}),W+Z}\right)}| &\leqslant \left( \rm{Var}\left[{F({\textbf{T}})}\right] \rm{Var}\left[{W+Z}\right]\right)^{1/2} = O\left(\sqrt{n\, {\textrm{log}}\, n}\right). \end{align*}
Then, we have
 \begin{align*} \rm{Var}\left[{{\textrm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|}\right] = \rm{Var}\left[{F({\textbf{T}}) - [W + Z]}\right]= \rm{Var}\left[{F({\textbf{T}})}\right] + O\left(\sqrt{n\, {\textrm{log}}\, n}\right). \end{align*}
\begin{align*} \rm{Var}\left[{{\textrm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right|}\right] = \rm{Var}\left[{F({\textbf{T}}) - [W + Z]}\right]= \rm{Var}\left[{F({\textbf{T}})}\right] + O\left(\sqrt{n\, {\textrm{log}}\, n}\right). \end{align*}
The final ingredient needed to apply Theorem 1.1 is a bound on the variance of
 $F({\textbf{T}})$
, given in the lemma below.
$F({\textbf{T}})$
, given in the lemma below.
Lemma 3.6. For sufficiently large n, we have
 $\rm{Var}\left[{F({\textbf{T}})}\right] \geqslant 0.002\,n$
.
$\rm{Var}\left[{F({\textbf{T}})}\right] \geqslant 0.002\,n$
.
The proof of Lemma 3.6 is lengthy and quite technical. We include it in Appendix B of the ArXiv version [Reference Isaev, Southwell and Zhukovskii15] of the current paper.
Now, we are ready to prove the following result.
Theorem 3.7. Conjecture 3.1 is true. Furthermore,
 $\delta_K\left[ {\rm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right| \right] = O\left(n^{-\frac{1}{4} \,+\, \epsilon}\right)$
and
$\delta_K\left[ {\rm{log}} \left|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\right| \right] = O\left(n^{-\frac{1}{4} \,+\, \epsilon}\right)$
and
 $\delta_K\left[ {\rm{log}} \left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right| \right]= O\left(n^{-\frac{1}{4} \,+\, \epsilon}\right)$
for any
$\delta_K\left[ {\rm{log}} \left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right| \right]= O\left(n^{-\frac{1}{4} \,+\, \epsilon}\right)$
for any
 $\epsilon > 0$
.
$\epsilon > 0$
.
Proof of Theorem 3.7. Combining Lemmas 3.4, 3.5, and 3.6, we get that the parameter F defined in (6) satisfies all the assumptions of Theorem 1.1 and
 $\delta_k[F({\textbf{T}})] = O(n^{-1/4 + \epsilon})$
for any
$\delta_k[F({\textbf{T}})] = O(n^{-1/4 + \epsilon})$
for any
 $\epsilon >0$
. Using Lemma 3.5 and recalling that
$\epsilon >0$
. Using Lemma 3.5 and recalling that
 $F(T) \leqslant {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right| \leqslant {\textrm{log}}\rm{A}\small{UT}\left({{\textbf{T}}}\right) $
, we get that
$F(T) \leqslant {\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right| \leqslant {\textrm{log}}\rm{A}\small{UT}\left({{\textbf{T}}}\right) $
, we get that
 ${\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|$
and
${\textrm{log}}\left|\rm{A}\small{UT}_r\left({{{\textbf{T}}}}\right)\right|$
and
 ${\textrm{log}}|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\!|$
have the same limiting distribution as F(T) (with the same bound for the Kolmogorov distance).
${\textrm{log}}|\rm{A}\small{UT}\left({{\textbf{T}}}\right)\!|$
have the same limiting distribution as F(T) (with the same bound for the Kolmogorov distance).
Remark 3.8. Recently, Stufler and Wagner [Reference Wagner and Stufler28] have also announced progress in showing that the distributions of
 $\left|\rm{A}\small{UT}\left({T}\right)\right|$
and
$\left|\rm{A}\small{UT}\left({T}\right)\right|$
and
 $\left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
are asymptotically lognormal; however, it has not yet appear in any published or arXiv paper. Their method is based on the analysis of the generating function and is different from our approach. Stufler and Wagner gave much more accurate values for the mean and variance in their talk [Reference Wagner and Stufler28], specifically
$\left|\rm{A}\small{UT}_r\left({{T}}\right)\right|$
are asymptotically lognormal; however, it has not yet appear in any published or arXiv paper. Their method is based on the analysis of the generating function and is different from our approach. Stufler and Wagner gave much more accurate values for the mean and variance in their talk [Reference Wagner and Stufler28], specifically
 $\mathbb{E}\left[{{\textrm{log}}\left|\rm{A}\small{UT}\left({T}\right)\right|}\right] \approx 0.052290n$
and
$\mathbb{E}\left[{{\textrm{log}}\left|\rm{A}\small{UT}\left({T}\right)\right|}\right] \approx 0.052290n$
and
 $\rm{Var}\left[{{\textrm{log}}\left|\rm{A}\small{UT}\left({T}\right)\right|}\right] = 0.039498n$
.
$\rm{Var}\left[{{\textrm{log}}\left|\rm{A}\small{UT}\left({T}\right)\right|}\right] = 0.039498n$
.
4. Tools from the theory of martingales
Let
 $\mathcal{P}=(\varOmega,\mathcal{F}, \mathbb{P})$
be a probability space. A sequence
$\mathcal{P}=(\varOmega,\mathcal{F}, \mathbb{P})$
be a probability space. A sequence
 $\mathcal{F}_0,\ldots,\mathcal{F}_n$
of sub-
$\mathcal{F}_0,\ldots,\mathcal{F}_n$
of sub-
 $\sigma$
-fields of
$\sigma$
-fields of
 $\mathcal{F}$
is a filtration if
$\mathcal{F}$
is a filtration if
 $\mathcal{F}_0\subseteq\cdots\subseteq\mathcal{F}_n$
. A sequence
$\mathcal{F}_0\subseteq\cdots\subseteq\mathcal{F}_n$
. A sequence
 $Y_0,\ldots,Y_n$
of random variables on
$Y_0,\ldots,Y_n$
of random variables on
 $\mathcal{P}$
is a martingale with respect to
$\mathcal{P}$
is a martingale with respect to
 $\mathcal{F}_0,\ldots,\mathcal{F}_n$
if
$\mathcal{F}_0,\ldots,\mathcal{F}_n$
if
-
i.
$Y_i$
is
$\mathcal{F}_i$
-measurable and
$\left| Y_i \right|$
has finite expectation, for
$0\le i\le n$
; -
ii.
$\mathbb{E}\left[{ Y_i \mid \mathcal{F}_i}\right] = Y_{i-1}$
for
$1\le i\le n$
.






In the following we will always assume that
 $\mathcal{F}_0 = \{\emptyset, \varOmega \}$
and so
$\mathcal{F}_0 = \{\emptyset, \varOmega \}$
and so
 $Y_0 = {\mathbb{E}} [ Y_n]$
.
$Y_0 = {\mathbb{E}} [ Y_n]$
.
In this section, we state some general results on concentration and limiting distribution for martingales. In fact, we only need these results for discrete uniform probability spaces, where the concept of martingale reduces to average values over increasing set systems. In this case,
 $\varOmega$
is a finite set and each
$\varOmega$
is a finite set and each
 $\sigma$
-field
$\sigma$
-field
 $\mathcal{F}_{i}$
is generated by unions of blocks of a partion of
$\mathcal{F}_{i}$
is generated by unions of blocks of a partion of
 $\varOmega$
. Following McDiarmid [Reference McDiarmid19], for
$\varOmega$
. Following McDiarmid [Reference McDiarmid19], for
 $i=0,\ldots, n$
we define the conditional range of a random variable X on
$i=0,\ldots, n$
we define the conditional range of a random variable X on
 $\mathcal{P}$
as
$\mathcal{P}$
as
 \begin{equation} \textrm{ran} [X \mid \mathcal{F}_{i}] \,:\!=\, \sup [X\mid \mathcal{F}_{i}] + \sup[- X\mid \mathcal{F}_{i}].\end{equation}
\begin{equation} \textrm{ran} [X \mid \mathcal{F}_{i}] \,:\!=\, \sup [X\mid \mathcal{F}_{i}] + \sup[- X\mid \mathcal{F}_{i}].\end{equation}
Here,
 $\sup[X\mid \mathcal{F}_{i}] $
is the
$\sup[X\mid \mathcal{F}_{i}] $
is the
 $\mathcal{F}_{i}$
-measurable random variable which takes the value at
$\mathcal{F}_{i}$
-measurable random variable which takes the value at
 $\omega \in \varOmega$
equal to the maximum value of X over the block of
$\omega \in \varOmega$
equal to the maximum value of X over the block of
 $\mathcal{F}_{i}$
containing
$\mathcal{F}_{i}$
containing
 $\omega$
(and similarly for
$\omega$
(and similarly for
 $-X$
). More generally, “supremum” can be replaced by “essential supremum”. For more information about conditional range and diameter, see, for example, [Reference Isaev and McKay14, Section 2.1] and references therein. We will use that the conditional range is a seminorm and, in particular, it is subadditive.
$-X$
). More generally, “supremum” can be replaced by “essential supremum”. For more information about conditional range and diameter, see, for example, [Reference Isaev and McKay14, Section 2.1] and references therein. We will use that the conditional range is a seminorm and, in particular, it is subadditive.
Our first tool is the following result of McDiarmid [Reference McDiarmid19]. Further in this section, the notation
 $\textrm{ran}_i [\cdot]$
stands for
$\textrm{ran}_i [\cdot]$
stands for
 $\textrm{ran} [\cdot \mid \mathcal{F}_{i}]$
.
$\textrm{ran} [\cdot \mid \mathcal{F}_{i}]$
.
Theorem 4.1 ([Reference McDiarmid19, Theorem 3.14]) Let
 $Y_0,Y_1,\ldots, Y_n$
be a real-valued martingale with respect to the filtration
$Y_0,Y_1,\ldots, Y_n$
be a real-valued martingale with respect to the filtration
 $\{\emptyset,\varOmega\}=\mathcal{F}_0,\mathcal{F}_1\ldots,\mathcal{F}_n$
. Denote
$\{\emptyset,\varOmega\}=\mathcal{F}_0,\mathcal{F}_1\ldots,\mathcal{F}_n$
. Denote
 \begin{equation*} R^2 \,:\!=\, \sum_{i=1}^n \left( \rm{ran}_{i-1} [Y_i] \right)^2.\end{equation*}
\begin{equation*} R^2 \,:\!=\, \sum_{i=1}^n \left( \rm{ran}_{i-1} [Y_i] \right)^2.\end{equation*}
Then, for any
 $r,t > 0$
$r,t > 0$
 \begin{equation*} \mathbb{P}\left(|Y_n - Y_0| \geqslant t \right)\leqslant 2\exp\!( -2t^2/r^2) + 2 \mathbb{P} \left( R^2 > r^2 \right).\end{equation*}
\begin{equation*} \mathbb{P}\left(|Y_n - Y_0| \geqslant t \right)\leqslant 2\exp\!( -2t^2/r^2) + 2 \mathbb{P} \left( R^2 > r^2 \right).\end{equation*}
The normalized quadratic variation of a martingale sequence
 ${\textbf{Y}}= (Y_0, \ldots, Y_n)$
is defined by
${\textbf{Y}}= (Y_0, \ldots, Y_n)$
is defined by
 \begin{equation*} Q[{\textbf{Y}}] \,:\!=\, \frac{1}{\rm{Var}\left[{Y_n}\right]} \sum_{i=1}^n (Y_i - Y_{i-1})^2.\end{equation*}
\begin{equation*} Q[{\textbf{Y}}] \,:\!=\, \frac{1}{\rm{Var}\left[{Y_n}\right]} \sum_{i=1}^n (Y_i - Y_{i-1})^2.\end{equation*}
Observe that
 \begin{equation} \mathbb{E}\left[{ (Y_i - Y_{i\,-\,1})^2}\right] = \mathbb{E}\left[{\textrm{Var}[Y_i \mid F_{i\,-\,1}]}\right]= \mathbb{E}\left[{{\mathbb{E}} \left[ Y_i^2 - Y_{i\,-\,1}^2 \mid F_{i\,-\,1}\right] }\right]= \mathbb{E}\left[{Y_i^2 - Y_{i\,-\,1}^2}\right].\end{equation}
\begin{equation} \mathbb{E}\left[{ (Y_i - Y_{i\,-\,1})^2}\right] = \mathbb{E}\left[{\textrm{Var}[Y_i \mid F_{i\,-\,1}]}\right]= \mathbb{E}\left[{{\mathbb{E}} \left[ Y_i^2 - Y_{i\,-\,1}^2 \mid F_{i\,-\,1}\right] }\right]= \mathbb{E}\left[{Y_i^2 - Y_{i\,-\,1}^2}\right].\end{equation}
Thus,
 \begin{equation*}{\mathbb{E}} Q[{\textbf{Y}}] = \frac{1}{\rm{Var}\left[{Y_n}\right]} \sum_{i=1}^n \left(\mathbb{E}\left[{Y_i^2}\right] - \mathbb{E}\left[{Y_{i\,-\,1}^2}\right]\right)= 1.\end{equation*}
\begin{equation*}{\mathbb{E}} Q[{\textbf{Y}}] = \frac{1}{\rm{Var}\left[{Y_n}\right]} \sum_{i=1}^n \left(\mathbb{E}\left[{Y_i^2}\right] - \mathbb{E}\left[{Y_{i\,-\,1}^2}\right]\right)= 1.\end{equation*}
A classical result by Brown [Reference Brown4] states that if the increments
 $Y_{i}-Y_{i-1}$
have finite variances,
$Y_{i}-Y_{i-1}$
have finite variances,
 $ Q[{\textbf{Y}}] \xrightarrow{prob.} 1$
as
$ Q[{\textbf{Y}}] \xrightarrow{prob.} 1$
as
 $n \rightarrow \infty$
and a certain Lindeberg-type condition is satisfied then the limiting distribution of
$n \rightarrow \infty$
and a certain Lindeberg-type condition is satisfied then the limiting distribution of
 $Y_n$
is normal, i.e.
$Y_n$
is normal, i.e.
 $\delta_{\textrm{K}}[Y_n] \rightarrow 0$
. For a more restricted class of martingales with bounded differences, these conditions can be slightly simplified and will be sufficient for our purposes. Our second tool is the following result of Mourrat [Reference Mourrat23] which gives an explicit bound on the rate of convergence in the CLT under a strengthened condition that the normalized quadratic variation
$\delta_{\textrm{K}}[Y_n] \rightarrow 0$
. For a more restricted class of martingales with bounded differences, these conditions can be slightly simplified and will be sufficient for our purposes. Our second tool is the following result of Mourrat [Reference Mourrat23] which gives an explicit bound on the rate of convergence in the CLT under a strengthened condition that the normalized quadratic variation
 $Q[{\textbf{Y}}]$
converges to 1 in
$Q[{\textbf{Y}}]$
converges to 1 in
 $L^p$
.
$L^p$
.
Theorem 4.2 ([Reference Mourrat23, Theorem 1.5.]) Let
 $p \in [1,+\infty)$
and
$p \in [1,+\infty)$
and
 $\gamma \in (0,+\infty)$
. There exists a constant
$\gamma \in (0,+\infty)$
. There exists a constant
 $C_{p,\gamma}>0$
such that, for any real martingale sequence
$C_{p,\gamma}>0$
such that, for any real martingale sequence
 ${\textbf{Y}}= (Y_0, \ldots, Y_n)$
satisfying
${\textbf{Y}}= (Y_0, \ldots, Y_n)$
satisfying
 $|Y_i - Y_{i-1}| \leqslant \gamma$
for all
$|Y_i - Y_{i-1}| \leqslant \gamma$
for all
 $i=1,\ldots, n$
,
$i=1,\ldots, n$
,
 \begin{equation*} \delta_{\rm{K}} [Y_n] \leqslant C_{p,\gamma} \left( \frac{n\ {\rm{log}}\, n}{(\rm{Var}\left[{Y_n}\right])^{3/2}} + \left( \mathbb{E}\left[{|Q[{\textbf{Y}}] -1|^p}\right] + \left(\rm{Var}\left[{ Y_n}\right]\right)^{-p}\right)^{1/(2p\,+\,1)} \right). \end{equation*}
\begin{equation*} \delta_{\rm{K}} [Y_n] \leqslant C_{p,\gamma} \left( \frac{n\ {\rm{log}}\, n}{(\rm{Var}\left[{Y_n}\right])^{3/2}} + \left( \mathbb{E}\left[{|Q[{\textbf{Y}}] -1|^p}\right] + \left(\rm{Var}\left[{ Y_n}\right]\right)^{-p}\right)^{1/(2p\,+\,1)} \right). \end{equation*}
One way to bound the term
 $\mathbb{E}\left[{ |Q[{\textbf{Y}}] -1|^p}\right]$
in the above is by applying Theorem 4.1 to the martingale for
$\mathbb{E}\left[{ |Q[{\textbf{Y}}] -1|^p}\right]$
in the above is by applying Theorem 4.1 to the martingale for
 $Q[{\textbf{Y}}]$
with respect to the same filtration, as which gives the following lemma.
$Q[{\textbf{Y}}]$
with respect to the same filtration, as which gives the following lemma.
Lemma 4.3. Let
 $Y_0,\ldots, Y_n$
be a real-valued martingale with respect to the filtration
$Y_0,\ldots, Y_n$
be a real-valued martingale with respect to the filtration
 $\{\emptyset,\varOmega\}=\mathcal{F}_0,\ldots,\mathcal{F}_n$
. For
$\{\emptyset,\varOmega\}=\mathcal{F}_0,\ldots,\mathcal{F}_n$
. For
 $\hat{q}>0$
, let
$\hat{q}>0$
, let
 $\mathcal{A}_{\hat{q}}$
denote the event
$\mathcal{A}_{\hat{q}}$
denote the event
 \begin{equation*} \sum_{i=1}^n \left(\rm{ran}_{i-1} \left[\rm{Var}\left[{ Y_n \mid \mathcal{F}_{i}}\right]\right] + (\rm{ran}_{i-1} [Y_i] )^2 \right)^2 > \left( \hat{q}\,\rm{Var}\left[{Y_n}\right]\right)^2. \end{equation*}
\begin{equation*} \sum_{i=1}^n \left(\rm{ran}_{i-1} \left[\rm{Var}\left[{ Y_n \mid \mathcal{F}_{i}}\right]\right] + (\rm{ran}_{i-1} [Y_i] )^2 \right)^2 > \left( \hat{q}\,\rm{Var}\left[{Y_n}\right]\right)^2. \end{equation*}
Then, for any
 $p \in [1,+\infty)$
, we have
$p \in [1,+\infty)$
, we have
 \begin{equation*} \mathbb{E}\left[{|Q[{\textbf{Y}}] -1|^p} \right]\leqslant c_p \,\hat{q}^{p} + 2 \mathbb{P} \left(\mathcal{A}_{\hat{q}}\right) \sup\! |Q[{\textbf{Y}}] -1|^p,\end{equation*}
\begin{equation*} \mathbb{E}\left[{|Q[{\textbf{Y}}] -1|^p} \right]\leqslant c_p \,\hat{q}^{p} + 2 \mathbb{P} \left(\mathcal{A}_{\hat{q}}\right) \sup\! |Q[{\textbf{Y}}] -1|^p,\end{equation*}
where
 $ c_p = 2p \int_{0}^{+\infty} e^{-2x^2} x^{p-1} dx$
.
$ c_p = 2p \int_{0}^{+\infty} e^{-2x^2} x^{p-1} dx$
.
Proof. By definition, we have that
 $|Y_i - Y_{i\,-\,1}| \leqslant \textrm{ran}_{i\,-\,1} [Y_i]$
for all
$|Y_i - Y_{i\,-\,1}| \leqslant \textrm{ran}_{i\,-\,1} [Y_i]$
for all
 $i \in [n]$
. Therefore,
$i \in [n]$
. Therefore,
 \begin{equation*} \textrm{ran}_{i\,-\,1} \left[(Y_i - Y_{i\,-\,1})^2\right] \leqslant (\textrm{ran}_{i\,-\,1} [Y_i])^2. \end{equation*}
\begin{equation*} \textrm{ran}_{i\,-\,1} \left[(Y_i - Y_{i\,-\,1})^2\right] \leqslant (\textrm{ran}_{i\,-\,1} [Y_i])^2. \end{equation*}
Observe also
 $\textrm{ran}_{i-1} \left[ (Y_j - Y_{j-1})^2\right] = 0$
for any
$\textrm{ran}_{i-1} \left[ (Y_j - Y_{j-1})^2\right] = 0$
for any
 $j<i$
. Then, using (8) and the subadditivity of the conditional range, we get that
$j<i$
. Then, using (8) and the subadditivity of the conditional range, we get that
 \begin{align*} \textrm{ran}_{i\,-\,1} \left[ \mathbb{E}\left[{Q[{\textbf{Y}}] \mid \mathcal{F}_i }\right] \right] & = \frac{1}{\rm{Var}\left[{Y_n}\right]} \textrm{ran}_{i\,-\,1} \left[ \sum_{j\,=\,i}^{n} \mathbb{E}\left[{(Y_{j}- Y_{j\,-\,1})^2 \mid \mathcal{F}_i }\right] \right]\\[5pt] &= \frac{\textrm{ran}_{i\,-\,1} \left[ \rm{Var}\left[{Y_n \mid \mathcal{F}_i}\right] + (Y_i - Y_{i\,-\,1})^2 \right] }{\rm{Var}\left[{Y_n}\right] } \\[5pt] & \leqslant \frac{ \textrm{ran}_{i\,-\,1} \left[\rm{Var}\left[{Y_n \mid \mathcal{F}_i}\right] \right ]+ \left(\textrm{ran}_{i\,-\,1}[Y_i]\right)^2 }{\rm{Var}\left[{Y_n}\right] } . \end{align*}
\begin{align*} \textrm{ran}_{i\,-\,1} \left[ \mathbb{E}\left[{Q[{\textbf{Y}}] \mid \mathcal{F}_i }\right] \right] & = \frac{1}{\rm{Var}\left[{Y_n}\right]} \textrm{ran}_{i\,-\,1} \left[ \sum_{j\,=\,i}^{n} \mathbb{E}\left[{(Y_{j}- Y_{j\,-\,1})^2 \mid \mathcal{F}_i }\right] \right]\\[5pt] &= \frac{\textrm{ran}_{i\,-\,1} \left[ \rm{Var}\left[{Y_n \mid \mathcal{F}_i}\right] + (Y_i - Y_{i\,-\,1})^2 \right] }{\rm{Var}\left[{Y_n}\right] } \\[5pt] & \leqslant \frac{ \textrm{ran}_{i\,-\,1} \left[\rm{Var}\left[{Y_n \mid \mathcal{F}_i}\right] \right ]+ \left(\textrm{ran}_{i\,-\,1}[Y_i]\right)^2 }{\rm{Var}\left[{Y_n}\right] } . \end{align*}
Applying Theorem 4.1 to the martingale
 $\{\mathbb{E}\left[{Q[{\textbf{Y}}] \mid \mathcal{F}_i }\right]\}_{i=0,\ldots, n}$
, we find that
$\{\mathbb{E}\left[{Q[{\textbf{Y}}] \mid \mathcal{F}_i }\right]\}_{i=0,\ldots, n}$
, we find that
 \begin{equation*} \mathbb{P} \left(|Q[{\textbf{Y}}] -1| \geqslant t\right) \leqslant 2 \exp (-2t^2 /\hat{q}^2) + 2 \mathbb{P} \left(\mathcal{A}_{\hat{q}}\right). \end{equation*}
\begin{equation*} \mathbb{P} \left(|Q[{\textbf{Y}}] -1| \geqslant t\right) \leqslant 2 \exp (-2t^2 /\hat{q}^2) + 2 \mathbb{P} \left(\mathcal{A}_{\hat{q}}\right). \end{equation*}
Substituting this bound into
 \begin{equation*} \mathbb{E}\left[{|Q({\textbf{Y}}) -1|^p}\right] = \int_{0}^{ t_{\max}} \mathbb{P} \left(|Q({\textbf{Y}}) -1| \geqslant t\right) p t^{p-1}dt \end{equation*}
\begin{equation*} \mathbb{E}\left[{|Q({\textbf{Y}}) -1|^p}\right] = \int_{0}^{ t_{\max}} \mathbb{P} \left(|Q({\textbf{Y}}) -1| \geqslant t\right) p t^{p-1}dt \end{equation*}
and changing the variable
 $t = \hat{q} x$
, we complete the proof. Here,
$t = \hat{q} x$
, we complete the proof. Here,
 $t_{\max}= \sup |Q({\textbf{Y}}) -1|$
.
$t_{\max}= \sup |Q({\textbf{Y}}) -1|$
.
Using the formulas for
 $\mathbb{E}\left[{ (Y_j-Y_{j-1})^2 \mid \mathcal{F}_{i}}\right] $
similar to (8), we find that
$\mathbb{E}\left[{ (Y_j-Y_{j-1})^2 \mid \mathcal{F}_{i}}\right] $
similar to (8), we find that
 \begin{equation} \rm{Var}\left[{ Y_n \mid \mathcal{F}_{i}}\right] = \sum_{j=i+1}^n \mathbb{E}\left[{ (Y_j-Y_{j-1})^2 \mid \mathcal{F}_{i}}\right].\end{equation}
\begin{equation} \rm{Var}\left[{ Y_n \mid \mathcal{F}_{i}}\right] = \sum_{j=i+1}^n \mathbb{E}\left[{ (Y_j-Y_{j-1})^2 \mid \mathcal{F}_{i}}\right].\end{equation}
Then, by the subadditivity of the conditional range, we get the next bound, which will be useful in applying Lemma 4.3.
 \begin{equation} \textrm{ran}_{i-1} \left[\rm{Var}\left[{ Y_n \mid \mathcal{F}_{i})}\right]\right] \leqslant \sum_{j=i+1}^n \textrm{ran}_{i-1} \mathbb{E}\left[{(Y_j - Y_{j-1})^2 \mid \mathcal{F}_i}\right].\end{equation}
\begin{equation} \textrm{ran}_{i-1} \left[\rm{Var}\left[{ Y_n \mid \mathcal{F}_{i})}\right]\right] \leqslant \sum_{j=i+1}^n \textrm{ran}_{i-1} \mathbb{E}\left[{(Y_j - Y_{j-1})^2 \mid \mathcal{F}_i}\right].\end{equation}
The Doob martingale construction is another important tool in our argument. Suppose
 ${\textbf{X}} = (X_1,\ldots,X_n)$
is a random vector on
${\textbf{X}} = (X_1,\ldots,X_n)$
is a random vector on
 $\mathcal{P}$
taking values in S and
$\mathcal{P}$
taking values in S and
 $f\,:\,S\rightarrow {\mathbb{R}}$
is such that
$f\,:\,S\rightarrow {\mathbb{R}}$
is such that
 $f({\textbf{X}})$
has bounded expectation. Consider the filtration
$f({\textbf{X}})$
has bounded expectation. Consider the filtration
 $\mathcal{F}_0,\ldots \mathcal{F}_n$
defined by
$\mathcal{F}_0,\ldots \mathcal{F}_n$
defined by
 $\mathcal{F}_i = \sigma(X_1,\ldots,X_i)$
which is the
$\mathcal{F}_i = \sigma(X_1,\ldots,X_i)$
which is the
 $\sigma$
-field generated by random variables
$\sigma$
-field generated by random variables
 $X_1,\ldots X_i$
. Then, the Doob martingale
$X_1,\ldots X_i$
. Then, the Doob martingale
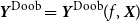 ${\textbf{Y}}^{\rm Doob} = {\textbf{Y}}^{\rm Doob} (f,{\textbf{X}})$
is defined by, for all
${\textbf{Y}}^{\rm Doob} = {\textbf{Y}}^{\rm Doob} (f,{\textbf{X}})$
is defined by, for all
 $i=0,\ldots,n$
,
$i=0,\ldots,n$
,
 \begin{equation*} Y_i^{\rm Doob} \,:\!=\, \mathbb{E}\left[{f(X_1,\ldots,X_n) \mid \mathcal{F}_i}\right].\end{equation*}
\begin{equation*} Y_i^{\rm Doob} \,:\!=\, \mathbb{E}\left[{f(X_1,\ldots,X_n) \mid \mathcal{F}_i}\right].\end{equation*}
In case of finite S, the random variables
 $Y_i^{\rm Doob} $
,
$Y_i^{\rm Doob} $
,
 $\rm{Var}\left[{Y_n^{\rm Doob} \mid \mathcal{F}_j}\right] $
and
$\rm{Var}\left[{Y_n^{\rm Doob} \mid \mathcal{F}_j}\right] $
and
 $\textrm{ran}_{i} [Y_n^{\rm Doob}] $
can be seen as functions
$\textrm{ran}_{i} [Y_n^{\rm Doob}] $
can be seen as functions
 $f_i, v_i, r_i \,:\, S \rightarrow {\mathbb{R}}$
of the random vector
$f_i, v_i, r_i \,:\, S \rightarrow {\mathbb{R}}$
of the random vector
 ${\textbf{X}}$
defined as follows: for
${\textbf{X}}$
defined as follows: for
 ${\textbf{x}} \in S$
,
${\textbf{x}} \in S$
,
 \begin{equation}\begin{aligned} f_i({\textbf{x}}) &\,:\!=\, \mathbb{E}\left[{f({\textbf{X}}) \mid X_1 = x_1, \ldots, X_i=x_i}\right] =\mathbb{E}\left[{f(x_1,\ldots,x_i, X_{i+1} \ldots, X_n)}\right] ,\\[4pt] v_i({\textbf{x}}) &\,:\!=\, \rm{Var}\left[{f({\textbf{X}}) \mid X_1 = x_1, \ldots, X_i=x_i}\right] = \rm{Var}\left[{f(x_1,\ldots,x_i, X_{i+1} \ldots, X_n)}\right] ,\\[4pt] r_{i}({\textbf{x}}) &\,:\!=\, \textrm{ran}\left[f({\textbf{X}}) \mid X_1 = x_1, \ldots, X_i=x_i\right] \\[4pt] &\phantom{:}=\max_{{\textbf{y}}} f(x_1,\ldots,x_i, y_{i+1} \ldots, y_n) -\min_{{\textbf{y}}} f(x_1,\ldots,x_i, y_{i+1} \ldots, y_n),\end{aligned}\end{equation}
\begin{equation}\begin{aligned} f_i({\textbf{x}}) &\,:\!=\, \mathbb{E}\left[{f({\textbf{X}}) \mid X_1 = x_1, \ldots, X_i=x_i}\right] =\mathbb{E}\left[{f(x_1,\ldots,x_i, X_{i+1} \ldots, X_n)}\right] ,\\[4pt] v_i({\textbf{x}}) &\,:\!=\, \rm{Var}\left[{f({\textbf{X}}) \mid X_1 = x_1, \ldots, X_i=x_i}\right] = \rm{Var}\left[{f(x_1,\ldots,x_i, X_{i+1} \ldots, X_n)}\right] ,\\[4pt] r_{i}({\textbf{x}}) &\,:\!=\, \textrm{ran}\left[f({\textbf{X}}) \mid X_1 = x_1, \ldots, X_i=x_i\right] \\[4pt] &\phantom{:}=\max_{{\textbf{y}}} f(x_1,\ldots,x_i, y_{i+1} \ldots, y_n) -\min_{{\textbf{y}}} f(x_1,\ldots,x_i, y_{i+1} \ldots, y_n),\end{aligned}\end{equation}
where
 $x_1,\ldots,x_i$
are fixed and
$x_1,\ldots,x_i$
are fixed and
 $X_{i+1},\ldots, X_n$
are random and both
$X_{i+1},\ldots, X_n$
are random and both
 $\max$
and
$\max$
and
 $\min$
are over
$\min$
are over
 ${\textbf{y}} \in S$
such that
${\textbf{y}} \in S$
such that
 $y_j=x_j$
for
$y_j=x_j$
for
 $j=1,\ldots,i$
. If, in addition, random variables
$j=1,\ldots,i$
. If, in addition, random variables
 $X_1, \ldots, X_n$
are independent then
$X_1, \ldots, X_n$
are independent then
 \begin{equation} |Y_i^{\rm Doob} - Y_{i-1}^{\rm Doob} | \leqslant \textrm{ran}_{i-1} \left[Y_i^{\rm Doob}\right] \leqslant \max_{{\textbf{x}},{\textbf{x}}'} |f({\textbf{x}}) - f({\textbf{x}}')|, \end{equation}
\begin{equation} |Y_i^{\rm Doob} - Y_{i-1}^{\rm Doob} | \leqslant \textrm{ran}_{i-1} \left[Y_i^{\rm Doob}\right] \leqslant \max_{{\textbf{x}},{\textbf{x}}'} |f({\textbf{x}}) - f({\textbf{x}}')|, \end{equation}
where the maximum is over
 ${\textbf{x}}, {\textbf{x}}' \in S$
that differ only in the ith coordinate.
${\textbf{x}}, {\textbf{x}}' \in S$
that differ only in the ith coordinate.
In particular, the Doob martingale process is applicable for functions of random permutations since we can represent them as vectors. Let
 $S_n$
be the set of permutations of [n]. We write
$S_n$
be the set of permutations of [n]. We write
 $\omega =(\omega_1,\ldots,\omega_n) \in S_n$
if
$\omega =(\omega_1,\ldots,\omega_n) \in S_n$
if
 $\omega$
maps j to
$\omega$
maps j to
 $\omega_j$
. The product of two permutuations
$\omega_j$
. The product of two permutuations
 $\omega,\sigma \in S_n$
is defined by
$\omega,\sigma \in S_n$
is defined by
 \begin{equation*} \omega \circ \sigma \,:\!=\, (\omega_{\sigma_1}, \ldots, \omega_{\sigma_n})\end{equation*}
\begin{equation*} \omega \circ \sigma \,:\!=\, (\omega_{\sigma_1}, \ldots, \omega_{\sigma_n})\end{equation*}
which corresponds to the composition of
 $\omega$
and
$\omega$
and
 $\sigma$
if we treat them as functions on [n]. For a function
$\sigma$
if we treat them as functions on [n]. For a function
 $f\,:\, S_n \rightarrow {\mathbb{R}}$
and
$f\,:\, S_n \rightarrow {\mathbb{R}}$
and
 $1\leqslant i\neq j \leqslant n-1$
, define
$1\leqslant i\neq j \leqslant n-1$
, define
 \begin{align*} \alpha_i [f] &\,:\!=\, \sum_{a=i+1}^n \frac{\max_{\omega \in S_n} |f(\omega) - f(\omega \circ (ia))|}{n-i}, \\ \varDelta_{ij} [f] &\,:\!=\, \sum_{a=i+1}^n \sum_{b=j+1}^n \frac{ \max_{\omega \in S_n} |f(\omega) - f(\omega \circ (ia)) - f(\omega \circ (jb)) + f(\omega \circ (jb)\circ(ia))|}{(n-i)(n-j)}. \end{align*}
\begin{align*} \alpha_i [f] &\,:\!=\, \sum_{a=i+1}^n \frac{\max_{\omega \in S_n} |f(\omega) - f(\omega \circ (ia))|}{n-i}, \\ \varDelta_{ij} [f] &\,:\!=\, \sum_{a=i+1}^n \sum_{b=j+1}^n \frac{ \max_{\omega \in S_n} |f(\omega) - f(\omega \circ (ia)) - f(\omega \circ (jb)) + f(\omega \circ (jb)\circ(ia))|}{(n-i)(n-j)}. \end{align*}
Let
 ${\textbf{X}} = (X_1,\ldots,X_n)$
be a uniform random element of
${\textbf{X}} = (X_1,\ldots,X_n)$
be a uniform random element of
 $S_n$
and
$S_n$
and
 ${\textbf{Y}}^{\rm Doob}(f, {\textbf{X}})$
be the Doob martingale sequence for
${\textbf{Y}}^{\rm Doob}(f, {\textbf{X}})$
be the Doob martingale sequence for
 $f({\textbf{X}})$
. Note that
$f({\textbf{X}})$
. Note that
 $Y^{\rm Doob}_n = Y^{\rm Doob}_{n-1} = f({\textbf{X}})$
since the first
$Y^{\rm Doob}_n = Y^{\rm Doob}_{n-1} = f({\textbf{X}})$
since the first
 $n-1$
coordinates
$n-1$
coordinates
 $X_i$
determine the permutation
$X_i$
determine the permutation
 ${\textbf{X}}$
uniquely.
${\textbf{X}}$
uniquely.
Lemma 4.4. If
 $Y^{\rm Doob} = Y^{\rm Doob}(f,{\textbf{X}})$
where
$Y^{\rm Doob} = Y^{\rm Doob}(f,{\textbf{X}})$
where
 $f\,:\, S_n \rightarrow {\mathbb{R}}$
and
$f\,:\, S_n \rightarrow {\mathbb{R}}$
and
 ${\textbf{X}}$
is a uniform random element of
${\textbf{X}}$
is a uniform random element of
 $S_n$
, then
$S_n$
, then
-
a.
$\displaystyle |Y^{\rm Doob}_i - Y^{\rm Doob}_{i-1}|\leqslant \rm{ran}_{i-1} \left[ Y^{\rm Doob}_i \right] \leqslant \alpha_i[f],$
for all
$1\leqslant i \leqslant n-1$
. -
b.
$ \displaystyle \rm{ran}_{i-1} \left[ \mathbb{E}\left[{(Y^{\rm Doob}_j-Y^{\rm Doob}_{j-1})^2 \mid \mathcal{F}_i}\right] \right]\leqslant 2 \alpha_j[f] \varDelta_{ij}[f]$
, for all
$1\leqslant i< j \leqslant n-1$
.




Proof. To show the first inequality in part (a), we observe that
 \begin{equation*} -\textrm{sup}(\!-Y^{\rm Doob}_i \mid \mathcal{F}_{i-1}) \leqslant Y^{\rm Doob}_{i-1} \leqslant \textrm{sup} (Y^{\rm Doob}_i \mid \mathcal{F}_{i-1}),\end{equation*}
\begin{equation*} -\textrm{sup}(\!-Y^{\rm Doob}_i \mid \mathcal{F}_{i-1}) \leqslant Y^{\rm Doob}_{i-1} \leqslant \textrm{sup} (Y^{\rm Doob}_i \mid \mathcal{F}_{i-1}),\end{equation*}
by definition. The other bounds is a special case of [Reference Greenhill, Isaev and McKay11, Lemma 2.1.] for real-valued random variables, where the conditional range is the same as the conditional diameter.
5. Martingales for tree parameters
To prove Theorem 1.1, we use the martingale based on the Aldous–Broder algorithm, which generates a random spanning tree of a given graph G. Here is a quick summary: (1) consider the random walk starting from any vertex; (2) every time we traverse an edge which takes us to a vertex we have not yet explored, add this edge to the tree; (3) stop when we visited all vertices. The resulting random graph has uniform distribution over the set of spanning trees of G, for more details see [Reference Aldous1]. If G is the complete graph
 $K_n$
,
$K_n$
,
 $n\geqslant 2$
, this construction can be rephrased as the following two-stage procedure [Reference Aldous1, Algorithm 2]:
$n\geqslant 2$
, this construction can be rephrased as the following two-stage procedure [Reference Aldous1, Algorithm 2]:
-
I. For
$1\leqslant i \leqslant n-1$
connect vertex
$i+1$
to vertex
$V_{i} = \min\{i, U_{i}\}$
, where
${\textbf{U}} = (U_1,\ldots, U_{n-1})$
is uniformly distributed on
$[n]^{n-1}$
. -
II. Relabel vertices
$1,\ldots,n$
as
$X_1,\ldots,X_n$
, where
${\textbf{X}} = (X_1,\ldots,X_n)$
is a uniform random permutation from
$S_n$
.









Let
 $T({\textbf{u}})$
is the tree produced at stage I given that
$T({\textbf{u}})$
is the tree produced at stage I given that
 ${\textbf{U}}= {\textbf{u}}$
. For a permutation
${\textbf{U}}= {\textbf{u}}$
. For a permutation
 $\omega\in S_n$
and a tree
$\omega\in S_n$
and a tree
 $T\in \mathcal{T}_n$
, let
$T\in \mathcal{T}_n$
, let
 \begin{equation*} \text{$T^{\omega}\,:\!=\,$ the tree obtained from T by relabelling according to $\omega$.} \end{equation*}
\begin{equation*} \text{$T^{\omega}\,:\!=\,$ the tree obtained from T by relabelling according to $\omega$.} \end{equation*}
From [Reference Aldous1] we know that
 $T({\textbf{U}})^{{\textbf{X}}}$
has uniform distribution on the set
$T({\textbf{U}})^{{\textbf{X}}}$
has uniform distribution on the set
 $\mathcal{T}_n$
. Now, a tree parameter
$\mathcal{T}_n$
. Now, a tree parameter
 $F\,:\, \mathcal{T}_n \rightarrow {\mathbb{R}} $
can be seen as a function with domain
$F\,:\, \mathcal{T}_n \rightarrow {\mathbb{R}} $
can be seen as a function with domain
 $[n]^{n-1} \times S_n$
. Consider the functions
$[n]^{n-1} \times S_n$
. Consider the functions
 $\hat{F}\,:\, \mathcal{T}_n \rightarrow {\mathbb{R}} $
and
$\hat{F}\,:\, \mathcal{T}_n \rightarrow {\mathbb{R}} $
and
 $F_T\,:\, S_n \rightarrow {\mathbb{R}}$
defined by
$F_T\,:\, S_n \rightarrow {\mathbb{R}}$
defined by
 \begin{equation} \hat{F}(T) \,:\!=\, \mathbb{E}\left[{F(T^{{\textbf{X}}})}\right], \qquad F_T(\omega) \,:\!=\, F(T^{\omega}). \end{equation}
\begin{equation} \hat{F}(T) \,:\!=\, \mathbb{E}\left[{F(T^{{\textbf{X}}})}\right], \qquad F_T(\omega) \,:\!=\, F(T^{\omega}). \end{equation}
Let
 ${\textbf{Y}} = (Y_0, \ldots, Y_{n-1})$
and
${\textbf{Y}} = (Y_0, \ldots, Y_{n-1})$
and
 ${\textbf{Z}}(T) = (Z_0(T), \ldots, Z_{n-1}(T))$
be the Doob martingale sequences for
${\textbf{Z}}(T) = (Z_0(T), \ldots, Z_{n-1}(T))$
be the Doob martingale sequences for
 $ \hat{F}(T({\textbf{U}}))$
and
$ \hat{F}(T({\textbf{U}}))$
and
 $F_T({\textbf{X}})$
, respectively: for
$F_T({\textbf{X}})$
, respectively: for
 $i = 0,\ldots ,n-1$
,
$i = 0,\ldots ,n-1$
,
 \begin{equation} Y_i \,:\!=\, {\mathbb{E}} \big[ \hat{F}(T({\textbf{U}})) \mid \mathcal{F}_i \big]\qquad \text{and} \qquad Z_i(T) \,:\!=\, {\mathbb{E}} \big[ F_T({\textbf{X}}) \mid \mathcal{G}_i \big], \end{equation}
\begin{equation} Y_i \,:\!=\, {\mathbb{E}} \big[ \hat{F}(T({\textbf{U}})) \mid \mathcal{F}_i \big]\qquad \text{and} \qquad Z_i(T) \,:\!=\, {\mathbb{E}} \big[ F_T({\textbf{X}}) \mid \mathcal{G}_i \big], \end{equation}
where the filtrations are
 $\mathcal{F}_i = \sigma(U_1,\ldots,U_i)$
and
$\mathcal{F}_i = \sigma(U_1,\ldots,U_i)$
and
 $\mathcal{G}_i = \sigma(X_1,\ldots, X_{i})$
. We construct the martingale for
$\mathcal{G}_i = \sigma(X_1,\ldots, X_{i})$
. We construct the martingale for
 $F({\textbf{T}})$
by combining the above two sequences together. Further in this section, we will use the following notations for conditional statistics of a random variable W with respect to
$F({\textbf{T}})$
by combining the above two sequences together. Further in this section, we will use the following notations for conditional statistics of a random variable W with respect to
 $\mathcal{F}_i$
and
$\mathcal{F}_i$
and
 $\mathcal{G}_i$
:
$\mathcal{G}_i$
:
 \begin{equation*}\begin{split} {\mathbb{E}}_{\mathcal{F}_i} [W] &\,:\!=\, \mathbb{E}\left[{W \mid \mathcal{F}_i}\right],\\[5pt] \textrm{Var}_{\mathcal{F}_i} [W] &\,:\!=\, \rm{Var}\left[{W \mid \mathcal{F}_i}\right], \\[5pt] \textrm{sup}_{\mathcal{F}_i} [W] &\,:\!=\, \textrm{sup} [W \mid \mathcal{F}_i],\\[5pt] \textrm{ran}_{\mathcal{F}_i} [W] &\,:\!=\, \textrm{ran} [W \mid \mathcal{F}_i], \end{split} \qquad \begin{split} {\mathbb{E}}_{\mathcal{G}_i} [W] &\,:\!=\, {\mathbb{E}} [W \mid \mathcal{G}_i],\\[5pt] \textrm{Var}_{\mathcal{G}_i} [W] &\,:\!=\, \textrm{Var} [W \mid \mathcal{G}_i],\\[5pt] \textrm{sup}_{\mathcal{G}_i} [W] &\,:\!=\, \textrm{sup} [W \mid \mathcal{G}_i],\\[5pt] \textrm{ran}_{\mathcal{G}_i} [W] &\,:\!=\, \textrm{ran} [W \mid \mathcal{G}_i].\end{split} \end{equation*}
\begin{equation*}\begin{split} {\mathbb{E}}_{\mathcal{F}_i} [W] &\,:\!=\, \mathbb{E}\left[{W \mid \mathcal{F}_i}\right],\\[5pt] \textrm{Var}_{\mathcal{F}_i} [W] &\,:\!=\, \rm{Var}\left[{W \mid \mathcal{F}_i}\right], \\[5pt] \textrm{sup}_{\mathcal{F}_i} [W] &\,:\!=\, \textrm{sup} [W \mid \mathcal{F}_i],\\[5pt] \textrm{ran}_{\mathcal{F}_i} [W] &\,:\!=\, \textrm{ran} [W \mid \mathcal{F}_i], \end{split} \qquad \begin{split} {\mathbb{E}}_{\mathcal{G}_i} [W] &\,:\!=\, {\mathbb{E}} [W \mid \mathcal{G}_i],\\[5pt] \textrm{Var}_{\mathcal{G}_i} [W] &\,:\!=\, \textrm{Var} [W \mid \mathcal{G}_i],\\[5pt] \textrm{sup}_{\mathcal{G}_i} [W] &\,:\!=\, \textrm{sup} [W \mid \mathcal{G}_i],\\[5pt] \textrm{ran}_{\mathcal{G}_i} [W] &\,:\!=\, \textrm{ran} [W \mid \mathcal{G}_i].\end{split} \end{equation*}
5.1. Properties of
$F_T$
and
$\hat{F}$


First, we study properties of functions
 $F_T$
and
$F_T$
and
 $\hat{F}$
from (13) given that the parameter F is
$\hat{F}$
from (13) given that the parameter F is
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable.
$\rho$
-superposable.
Lemma 5.1. Let a tree parameter
 $F\,:\, \mathcal{T}_n\rightarrow {\mathbb{R}}$
be
$F\,:\, \mathcal{T}_n\rightarrow {\mathbb{R}}$
be
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable for some
$\rho$
-superposable for some
 $\alpha\geqslant 0$
and
$\alpha\geqslant 0$
and
 $\rho\geqslant 1$
, then
$\rho\geqslant 1$
, then
-
a.
$\hat{F}$
is
$\alpha$
-Lipschitz and
$\rho$
-superposable.



Furthermore, the following holds for all trees
 $T \in \mathcal{T}_n$
and permutations
$T \in \mathcal{T}_n$
and permutations
 $\omega \in S_n$
.
$\omega \in S_n$
.
-
b. If (ia) is a transposition from
$S_n$
, then where
\begin{equation*} |F_T(\omega) - F_T(\omega \circ (ia))| \leqslant \alpha (\rm{deg}_T (i)+\rm{deg}_T (a)), \end{equation*}
$\rm{deg}_T (i)$
,
$\rm{deg}_T (a)$
are degrees of i, a in the tree T.
-
c. Let
$T' = \rm{S}_{q}^{rs} T$
be a tree for some triple (q, r, s). If (ia) is a transposition from
$S_n$
that
$d_T(\{i,a\}, \{r,s\}) \geqslant \rho+1$
, then
\begin{equation*} F_T(\omega) - F_T(\omega \circ (ia) ) - F_{T'}(\omega) + F_{T'} (\omega \circ (ia)) = 0. \end{equation*}
-
d. If (ia), (jb) are transpositions from
$S_n$
such that
$d_T(\{i,a\}, \{j,b\}) \geqslant \rho+2$
, then
\begin{equation*} F_T(\omega) - F_T(\omega \circ (ia) ) - F_T(\omega \circ (jb) ) + F_T(\omega \circ (jb) \circ (ia)) = 0. \end{equation*}











Proof. For any permutation
 $\omega = (\omega_1,\ldots,\omega_n)\in S_n$
define the function
$\omega = (\omega_1,\ldots,\omega_n)\in S_n$
define the function
 $F_\omega\,:\, \mathcal{T}_n \rightarrow {\mathbb{R}}$
by
$F_\omega\,:\, \mathcal{T}_n \rightarrow {\mathbb{R}}$
by
 $F_\omega(T)\,:\!=\, F(T^\omega)$
. If
$F_\omega(T)\,:\!=\, F(T^\omega)$
. If
 $\textrm{S}_{i}^{jk}T$
is a tree then
$\textrm{S}_{i}^{jk}T$
is a tree then
 $(\textrm{S}_{i}^{jk}T)^{\omega} = \textrm{S}_{\omega_i}^{\omega_j \omega_k} T^\omega$
. Relabelling also does not change the distances, that is,
$(\textrm{S}_{i}^{jk}T)^{\omega} = \textrm{S}_{\omega_i}^{\omega_j \omega_k} T^\omega$
. Relabelling also does not change the distances, that is,
 $d_T(a,b) = d_{T^{\omega}} (\omega_a,\omega_b)$
for all
$d_T(a,b) = d_{T^{\omega}} (\omega_a,\omega_b)$
for all
 $a,b\in [n]$
. Thus,
$a,b\in [n]$
. Thus,
 $F_\omega$
is
$F_\omega$
is
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable. Averaging over all
$\rho$
-superposable. Averaging over all
 $\omega$
proves part (a).
$\omega$
proves part (a).
For part (b), we show that the tree
 $T^{(ia)}$
can be obtained from T by performing at most
$T^{(ia)}$
can be obtained from T by performing at most
 $\textrm{deg}_T(i)+\textrm{deg}_T(a)$
tree perturbations
$\textrm{deg}_T(i)+\textrm{deg}_T(a)$
tree perturbations
 $\textrm{S}_{x}^{yz}$
. We denote the set of these perturbations by
$\textrm{S}_{x}^{yz}$
. We denote the set of these perturbations by
 $\mathcal{P}^{ia}_T$
. Let u and v be the vertices on the path from i to a in T adjacent to i and a, respectively. Consider
$\mathcal{P}^{ia}_T$
. Let u and v be the vertices on the path from i to a in T adjacent to i and a, respectively. Consider
 $\textrm{deg}_T(i)-1$
perturbations
$\textrm{deg}_T(i)-1$
perturbations
 $\textrm{S}_{x}^{ia}$
for all vertices
$\textrm{S}_{x}^{ia}$
for all vertices
 $x \neq u$
adjacent to i and
$x \neq u$
adjacent to i and
 $\textrm{deg}_T(a)-1$
perturbations
$\textrm{deg}_T(a)-1$
perturbations
 $\textrm{S}_{x}^{ai}$
for all for all vertices
$\textrm{S}_{x}^{ai}$
for all for all vertices
 $x \neq v$
adjacent to a. If
$x \neq v$
adjacent to a. If
 $d_T(a,i) \leqslant 2$
then performing these
$d_T(a,i) \leqslant 2$
then performing these
 $\textrm{deg}_T(i) + \textrm{deg}_T(a)-2$
perturbations in any order turns T into
$\textrm{deg}_T(i) + \textrm{deg}_T(a)-2$
perturbations in any order turns T into
 $T^{(ia)}$
. Otherwise, all vertices i, a, u, v are distinct and we need two more perturbations
$T^{(ia)}$
. Otherwise, all vertices i, a, u, v are distinct and we need two more perturbations
 $\textrm{S}_{i}^{uv}$
and
$\textrm{S}_{i}^{uv}$
and
 $\textrm{S}_{a}^{vu}$
to obtain
$\textrm{S}_{a}^{vu}$
to obtain
 $T^{(ia)}$
. This defines the set
$T^{(ia)}$
. This defines the set
 $\mathcal{P}^{ia}_T$
. Now, since F is
$\mathcal{P}^{ia}_T$
. Now, since F is
 $\alpha$
-Lipschitz, the value of the function changes by at most
$\alpha$
-Lipschitz, the value of the function changes by at most
 $\alpha$
after each perturbation so
$\alpha$
after each perturbation so
 \begin{equation*} |F(T) - F\left(T^{(ia)}\right)| \leqslant \alpha (\textrm{deg}_T(i)+\textrm{deg}_T(a)). \end{equation*}
\begin{equation*} |F(T) - F\left(T^{(ia)}\right)| \leqslant \alpha (\textrm{deg}_T(i)+\textrm{deg}_T(a)). \end{equation*}
The above holds for any
 $T\in \mathcal{T}_n$
. Substituting
$T\in \mathcal{T}_n$
. Substituting
 $T^{\omega}$
and observing
$T^{\omega}$
and observing
 $\textrm{deg}_{T^{\omega}}(\omega_i) =\textrm{deg}_T(i)$
, we prove part (b).
$\textrm{deg}_{T^{\omega}}(\omega_i) =\textrm{deg}_T(i)$
, we prove part (b).
Before proving parts (c) and (d), we outline some important properties of the set
 $\mathcal{P}^{ia}_T $
of the tree perturbations that turn T into
$\mathcal{P}^{ia}_T $
of the tree perturbations that turn T into
 $T^{(ia)}$
.
$T^{(ia)}$
.
-
i. The perturbations of
$\mathcal{P}^{ia}_T$
can be performed in any order, that is, all intermediate graphs are trees. -
ii.
$d_T(\{x,y,z\}, \{i,a\}) =0$
for any
$\textrm{S}_{x}^{yz} \in \mathcal{P}^{ia}_T$
, that is,
$\{x,y,z\} \cap \{i,a\} \neq \emptyset$
. -
iii. the distance from any
$w\in[n]$
to
$\{i,a\}$
is unchanged by perturbations
$\textrm{S}_{x}^{ia}$
or
$\textrm{S}_{x}^{ai}$
. -
iv. the distance from any
$w\in[n]$
to
$\{i,a\}$
can increase after performing one of the perturbations
$\textrm{S}_{i}^{uv}$
or
$\textrm{S}_{a}^{vu}$
but then it decreases back to the initial value after performing the second (so it never gets smaller than the initial distance
$d_T(w,\{i,a\})$
).













For (c), observe first that
 $d_T(\{i,a\},\{r,s\}) \geqslant 2$
implies that i and a are adjacent to the same sets of vertices in T and T ′. Consider first the case when both u and v belong to the path from i to a in the tree T ′. For example, this is always the case when the path from i to a is not affected by removing the edge qr. Then, by definition,
$d_T(\{i,a\},\{r,s\}) \geqslant 2$
implies that i and a are adjacent to the same sets of vertices in T and T ′. Consider first the case when both u and v belong to the path from i to a in the tree T ′. For example, this is always the case when the path from i to a is not affected by removing the edge qr. Then, by definition,
 $\mathcal{P}^{ia}_T = \mathcal{P}^{ia}_{T'}$
that is we can use the same sets of perturbations to change labels i and a in both trees. We order them arbitrary to form a sequence
$\mathcal{P}^{ia}_T = \mathcal{P}^{ia}_{T'}$
that is we can use the same sets of perturbations to change labels i and a in both trees. We order them arbitrary to form a sequence
 $(\textrm{S}_1, \ldots, \textrm{S}_k)$
. Note also that for any perturbation
$(\textrm{S}_1, \ldots, \textrm{S}_k)$
. Note also that for any perturbation
 $\textrm{S}_x^{yz} \in \mathcal{P}^{ia}_T $
we have
$\textrm{S}_x^{yz} \in \mathcal{P}^{ia}_T $
we have
 $d_T(\{y,z\},\{r,s\}) \geqslant \rho$
due to the property (ii) and
$d_T(\{y,z\},\{r,s\}) \geqslant \rho$
due to the property (ii) and
 $d_T(\{i,a\},\{r,s\}) \geqslant \rho+1$
. Since F is
$d_T(\{i,a\},\{r,s\}) \geqslant \rho+1$
. Since F is
 $\rho$
-superposable and using properties (iii) and (iv), we get that
$\rho$
-superposable and using properties (iii) and (iv), we get that
 \begin{equation*} F( \textrm{S}_t \cdots \textrm{S}_1 T ) - F( \textrm{S}_t \cdots \textrm{S}_1 T' ) - F( \textrm{S}_{t+1} \cdots \textrm{S}_1 T ) + F( \textrm{S}_{t+1} \cdots \textrm{S}_1T' ) =0. \end{equation*}
\begin{equation*} F( \textrm{S}_t \cdots \textrm{S}_1 T ) - F( \textrm{S}_t \cdots \textrm{S}_1 T' ) - F( \textrm{S}_{t+1} \cdots \textrm{S}_1 T ) + F( \textrm{S}_{t+1} \cdots \textrm{S}_1T' ) =0. \end{equation*}
Summing up these equalities for all
 $t =0, \ldots k-1$
, we get that
$t =0, \ldots k-1$
, we get that
 \begin{equation} F(T) - F(T') - F\left(T^{(ia)}\right) + F\left(T'^{(ia)}\right)=0.\end{equation}
\begin{equation} F(T) - F(T') - F\left(T^{(ia)}\right) + F\left(T'^{(ia)}\right)=0.\end{equation}
We still need to consider the case when removing qr changes the path from i to a such that u or v do not lie on the path anymore. In this case, one have to be slightly more careful with the order of perturbations
 $(\textrm{S}_1, \ldots, \textrm{S}_k)$
to avoid the appearance of cycles in
$(\textrm{S}_1, \ldots, \textrm{S}_k)$
to avoid the appearance of cycles in
 $\textrm{S}_t \cdots \textrm{S}_1 T'$
. Without loss of generality, we may assume that
$\textrm{S}_t \cdots \textrm{S}_1 T'$
. Without loss of generality, we may assume that
 $d_T(i,q)<d_T(i,r)$
(otherwise, swap the roles of i and a). Let v ′ be the vertex adjacent to a that lies on the path from i to a in T ′. In notations of part (b), we define
$d_T(i,q)<d_T(i,r)$
(otherwise, swap the roles of i and a). Let v ′ be the vertex adjacent to a that lies on the path from i to a in T ′. In notations of part (b), we define
 $\textrm{S}_1 = \textrm{S}_i^{uv}$
and
$\textrm{S}_1 = \textrm{S}_i^{uv}$
and
 $\textrm{S}_2 = \textrm{S}_{v'}^{ai}$
, then put the remaining perturbations in any order. A sequence
$\textrm{S}_2 = \textrm{S}_{v'}^{ai}$
, then put the remaining perturbations in any order. A sequence
 $(\textrm{S}_1, \ldots, \textrm{S}_k)$
defined in this way ensures that all intermediate steps from T ′ to
$(\textrm{S}_1, \ldots, \textrm{S}_k)$
defined in this way ensures that all intermediate steps from T ′ to
 $T'^{(ia)}$
are trees. Repeating the same argument as above, we prove (15). To complete the proof of part (c), we just need to substitute T by
$T'^{(ia)}$
are trees. Repeating the same argument as above, we prove (15). To complete the proof of part (c), we just need to substitute T by
 $T^{\omega}$
similarly to part (b).
$T^{\omega}$
similarly to part (b).
Finally, we prove (d) by repeatedly using part (c) for a sequence of perturbations
 $\textrm{S}_{q}^{rs} \in \mathcal{P}_T^{jb}$
that turn T into
$\textrm{S}_{q}^{rs} \in \mathcal{P}_T^{jb}$
that turn T into
 $T^{(jb)}$
. We can apply part (c) for all intermediate trees T ′ because the assumption
$T^{(jb)}$
. We can apply part (c) for all intermediate trees T ′ because the assumption
 $d_T(\{i,a\}, \{j,b\}) \geqslant \rho +2$
together with properties (ii), (iii), (iv) implies that
$d_T(\{i,a\}, \{j,b\}) \geqslant \rho +2$
together with properties (ii), (iii), (iv) implies that
 $d_{T'}(\{i,a\}, \{r,s\}) \geqslant$
$d_{T'}(\{i,a\}, \{r,s\}) \geqslant$
 $\rho +1$
.
$\rho +1$
.
5.2. Martingale properties
Here, we establish the properties of martingales
 ${\textbf{Y}}$
and
${\textbf{Y}}$
and
 ${\textbf{Z}}(T)$
from (14) needed to apply the results of Section 4. For a tree
${\textbf{Z}}(T)$
from (14) needed to apply the results of Section 4. For a tree
 $T\in \mathcal{T}_n$
and
$T\in \mathcal{T}_n$
and
 $A,B\subset [n]$
, define
$A,B\subset [n]$
, define
 \begin{equation*} \mathbb{1}_T^\rho(A,B) \,:\!=\, \begin{cases} 1, & \text{if } d_T(A,B)< \rho,\\[4pt] 0, & \text{otherwise.} \end{cases} \end{equation*}
\begin{equation*} \mathbb{1}_T^\rho(A,B) \,:\!=\, \begin{cases} 1, & \text{if } d_T(A,B)< \rho,\\[4pt] 0, & \text{otherwise.} \end{cases} \end{equation*}
We will repeatedly use the fact that for any
 $T\in \mathcal{T}_n$
and
$T\in \mathcal{T}_n$
and
 $i \in [n]$
, we have
$i \in [n]$
, we have
 \begin{equation} \sum_{j=1}^{n} \mathbb{1}_T^\rho(\{i\},\{j\}) \leqslant \rho^2 \beta(T), \end{equation}
\begin{equation} \sum_{j=1}^{n} \mathbb{1}_T^\rho(\{i\},\{j\}) \leqslant \rho^2 \beta(T), \end{equation}
where
 $\beta(T)$
is the parameter defined in (2). In the following, for simplicity of notations, we write
$\beta(T)$
is the parameter defined in (2). In the following, for simplicity of notations, we write
 $ \mathbb{1}_T^\rho(i,B)$
, or
$ \mathbb{1}_T^\rho(i,B)$
, or
 $ \mathbb{1}_T^\rho(A,j)$
, or
$ \mathbb{1}_T^\rho(A,j)$
, or
 $ \mathbb{1}_T^\rho(i,j)$
when A, or B, or both are one-element sets. Let
$ \mathbb{1}_T^\rho(i,j)$
when A, or B, or both are one-element sets. Let
 $\mathcal{T}_n^d\subset \mathcal{T}_n$
be the set of trees with degrees at most d. We denote by
$\mathcal{T}_n^d\subset \mathcal{T}_n$
be the set of trees with degrees at most d. We denote by
 $a\wedge b$
the minimum of two real numbers a, b.
$a\wedge b$
the minimum of two real numbers a, b.
Lemma 5.2. Let
 $F\,:\, \mathcal{T}_n\rightarrow {\mathbb{R}}$
be
$F\,:\, \mathcal{T}_n\rightarrow {\mathbb{R}}$
be
 $\alpha$
-Lipschitz and
$\alpha$
-Lipschitz and
 $\rho$
-superposable for some
$\rho$
-superposable for some
 $\alpha\geqslant 0$
and
$\alpha\geqslant 0$
and
 $\rho\geqslant 1$
. Then, the following holds for all
$\rho\geqslant 1$
. Then, the following holds for all
 $i\in[n-1]$
,
$i\in[n-1]$
,
 $d \in {\mathbb{R}}^+$
and
$d \in {\mathbb{R}}^+$
and
 $T \in \mathcal{T}_n^d$
.
$T \in \mathcal{T}_n^d$
.
-
a.
$|Y_i-Y_{i-1}| \leqslant \rm{ran}_{\mathcal{F}_{i-1}} [Y_i] \leqslant \alpha$
. -
b.
$ \displaystyle \rm{ran}_{\mathcal{F}_{i-1}} \left[\rm{Var}_{\mathcal{F}_i} [Y_{n-1}] \right] \leqslant 32\alpha^2 \rho^2 \rm{sup}_{\mathcal{F}_{i-1}} \left[ {\mathbb{E}}_{\mathcal{F}_{i}} [\beta(T({\textbf{U}}))] \right]. $
-
c.
$\displaystyle |Z_i(T)-Z_{i-1}(T)|\leqslant \rm{ran}_{\mathcal{G}_{i-1}} [Z_i(T)] \leqslant \max_{\omega,(ia)\in S_n} |F(T^{\omega}) - F(T^{ \omega \circ (ia) })| \leqslant 2\alpha d. $
-
d.
$\displaystyle \rm{ran}_{\mathcal{G}_{i-1}} \left[\rm{Var}_{\mathcal{G}_i} [Z_{n-1}(T)]\right] \leqslant 64\alpha^2 d^2 (\rho+2)^2 \beta(T) {\rm{log}}\, n. $
-
e. Let
$V({\textbf{u}}) \,:\!=\, \rm{Var}\left[{Z_{n-1}(T({\textbf{u}}))}\right] = \rm{Var}\left[{F_{T({\textbf{u}})} ({\textbf{X}})}\right] $
. Then,
$0\leqslant V({\textbf{U}}) \leqslant 4 \alpha^2 n^2$
and
\begin{align*} \rm{ran}_{\mathcal{F}_{i-1}} \Big[ {\mathbb{E}}_{\mathcal{F}_i} &\left[V({\textbf{U}}) \mathbb{1}_{T({\textbf{U}}) \in \mathcal{T}_n^d}\right] \Big] \\[5pt] &\leqslant \alpha^2 \rm{sup}_{\mathcal{F}_{i-1}} \left[ {\mathbb{E}}_{\mathcal{F}_{i}} \left[4n^2 \mathbb{1}_{T({\textbf{U}}) \notin \mathcal{T}_n^d} + 8d^2 (\rho+1)^2 \beta(T({\textbf{U}})) \right]\right]. \end{align*}







Proof. Using bound (12), we find that
 \begin{equation*} |Y_i - Y_{i-1}|\leqslant \textrm{ran}_{\mathcal{F}_{i-1}} [Y_i] \leqslant \max |\hat{F}(T({\textbf{u}})) - \hat{F}(T({\textbf{u}}'))|, \end{equation*}
\begin{equation*} |Y_i - Y_{i-1}|\leqslant \textrm{ran}_{\mathcal{F}_{i-1}} [Y_i] \leqslant \max |\hat{F}(T({\textbf{u}})) - \hat{F}(T({\textbf{u}}'))|, \end{equation*}
where
 ${\textbf{u}},{\textbf{u}}' \in [n]^{n-1}$
differ in ith coordinate. Observe that
${\textbf{u}},{\textbf{u}}' \in [n]^{n-1}$
differ in ith coordinate. Observe that
 \begin{equation} T({\textbf{u}}') = \textrm{S}_{i+1}^{i \wedge u_i \, i\wedge u^{\prime}_i} T({\textbf{u}}). \end{equation}
\begin{equation} T({\textbf{u}}') = \textrm{S}_{i+1}^{i \wedge u_i \, i\wedge u^{\prime}_i} T({\textbf{u}}). \end{equation}
From Lemma 5.1(a), we know that
 $\hat{F}(T)$
is
$\hat{F}(T)$
is
 $\alpha$
-Lipschitz. Part (a) follows.
$\alpha$
-Lipschitz. Part (a) follows.
As explained in
 $(11)$
, we have
$(11)$
, we have
 $Y_i = f_i({\textbf{U}})$
, where
$Y_i = f_i({\textbf{U}})$
, where
 \begin{equation*} f_i({\textbf{u}}) = \mathbb{E}\left[{\hat{F}(T({\textbf{U}})) \mid u_{\leqslant i}}\right] \end{equation*}
\begin{equation*} f_i({\textbf{u}}) = \mathbb{E}\left[{\hat{F}(T({\textbf{U}})) \mid u_{\leqslant i}}\right] \end{equation*}
and
 ${\mathbb{E}} (\cdot \mid u_{\leqslant i})$
stands for
${\mathbb{E}} (\cdot \mid u_{\leqslant i})$
stands for
 ${\mathbb{E}} (\cdot \mid U_1=u_1,\ldots,U_i=u_i)$
. Let
${\mathbb{E}} (\cdot \mid U_1=u_1,\ldots,U_i=u_i)$
. Let
 $0\leqslant i<j \leqslant n-1$
. Using formula (17), we find that
$0\leqslant i<j \leqslant n-1$
. Using formula (17), we find that
 \begin{equation*} f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}) = \dfrac{1}{n}\sum_{u = 1}^n \mathbb{E}\left[{ \hat{F}(T({\textbf{U}})) - \hat{F}\left(\textrm{S}_{j+1}^{j\wedge u_j\, j \wedge u}T({\textbf{U}}) \right) \mid u_{\leqslant j}}\right]. \end{equation*}
\begin{equation*} f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}) = \dfrac{1}{n}\sum_{u = 1}^n \mathbb{E}\left[{ \hat{F}(T({\textbf{U}})) - \hat{F}\left(\textrm{S}_{j+1}^{j\wedge u_j\, j \wedge u}T({\textbf{U}}) \right) \mid u_{\leqslant j}}\right]. \end{equation*}
Consider
 ${\textbf{u}}'\in [n]^{n-1}$
that differs from
${\textbf{u}}'\in [n]^{n-1}$
that differs from
 ${\textbf{u}}$
only in ith coordinate. Then, we have
${\textbf{u}}$
only in ith coordinate. Then, we have
 \begin{align*} f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}) &- f_{j}({\textbf{u}}') + f_{j-1}({\textbf{u}}') = \dfrac{1}{n}\sum_{u = 1}^n {\mathbb{E}} \bigg[ \hat{F}(T({\textbf{U}})) - \hat{F}\left(\textrm{S}_{j+1}^{j\wedge u_j \, j \wedge u}T({\textbf{U}}) \right) \\&\qquad \qquad - \hat{F}\left(\textrm{S}_{i+1}^{i \wedge u_i \, i\wedge u^{\prime}_i}T({\textbf{U}})\right) + \hat{F}\left( \textrm{S}_{j+1}^{j\wedge u_j \, j \wedge u} \textrm{S}_{i+1}^{i \wedge u_i \, i\wedge u^{\prime}_i} T({\textbf{U}})\right) \mid u_{\leqslant j} \bigg] \end{align*}
\begin{align*} f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}) &- f_{j}({\textbf{u}}') + f_{j-1}({\textbf{u}}') = \dfrac{1}{n}\sum_{u = 1}^n {\mathbb{E}} \bigg[ \hat{F}(T({\textbf{U}})) - \hat{F}\left(\textrm{S}_{j+1}^{j\wedge u_j \, j \wedge u}T({\textbf{U}}) \right) \\&\qquad \qquad - \hat{F}\left(\textrm{S}_{i+1}^{i \wedge u_i \, i\wedge u^{\prime}_i}T({\textbf{U}})\right) + \hat{F}\left( \textrm{S}_{j+1}^{j\wedge u_j \, j \wedge u} \textrm{S}_{i+1}^{i \wedge u_i \, i\wedge u^{\prime}_i} T({\textbf{U}})\right) \mid u_{\leqslant j} \bigg] \end{align*}
From part (a), we have
 $0\leqslant |f_j - f_{j-1}| \leqslant \alpha$
. Observe also that if
$0\leqslant |f_j - f_{j-1}| \leqslant \alpha$
. Observe also that if
 $U_1=u_1, \ldots,U_{j-1}=u_{j-1} $
and
$U_1=u_1, \ldots,U_{j-1}=u_{j-1} $
and
 $v \in [i]$
then
$v \in [i]$
then
 \begin{equation*} d_{T({\textbf{U}})}(v, \{i \wedge u_i, i \wedge u^{\prime}_i\}) =d_{T({\textbf{u}})}(v, \{i \wedge u_i, i \wedge u^{\prime}_i\}). \end{equation*}
\begin{equation*} d_{T({\textbf{U}})}(v, \{i \wedge u_i, i \wedge u^{\prime}_i\}) =d_{T({\textbf{u}})}(v, \{i \wedge u_i, i \wedge u^{\prime}_i\}). \end{equation*}
That is, the distance between v and
 $\{i \wedge u_i,i \wedge u^{\prime}_i\}$
is completely determined by
$\{i \wedge u_i,i \wedge u^{\prime}_i\}$
is completely determined by
 $u_1, \ldots, u_{j-1}$
and v. From Lemma 5.1(a), we know that
$u_1, \ldots, u_{j-1}$
and v. From Lemma 5.1(a), we know that
 $\hat{F}(T)$
is
$\hat{F}(T)$
is
 $\rho$
-superposable. Thus, we find that
$\rho$
-superposable. Thus, we find that
 \begin{align*} |(f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}))^2 &- (f_{j}({\textbf{u}}') - f_{j-1}({\textbf{u}}'))^2| \leqslant 2 \alpha |f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}) -f_{j}({\textbf{u}}') + f_{j-1}({\textbf{u}}')| \\ & \leqslant \dfrac{4\alpha^2}{n}\sum_{u = 1}^n \mathbb{1}_{T({\textbf{u}})}^\rho (\{j\wedge u_j, j \wedge u\}, \{i\wedge u_i,i\wedge u^{\prime}_i\})) \end{align*}
\begin{align*} |(f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}))^2 &- (f_{j}({\textbf{u}}') - f_{j-1}({\textbf{u}}'))^2| \leqslant 2 \alpha |f_j({\textbf{u}}) - f_{j-1}({\textbf{u}}) -f_{j}({\textbf{u}}') + f_{j-1}({\textbf{u}}')| \\ & \leqslant \dfrac{4\alpha^2}{n}\sum_{u = 1}^n \mathbb{1}_{T({\textbf{u}})}^\rho (\{j\wedge u_j, j \wedge u\}, \{i\wedge u_i,i\wedge u^{\prime}_i\})) \end{align*}
Using (16), we can bound
 \begin{align*} \dfrac{1}{n}\sum_{u = 1}^n {\mathbb{E}} &\left[ \mathbb{1}_{T({\textbf{u}})}^\rho (\{j\wedge u_j, j \wedge u\}, \{i\wedge u_i,i\wedge u^{\prime}_i\}) \mid u_{\leqslant j-1} \right] \\ &= \dfrac{1}{n^2}\sum_{u = 1}^n \sum_{u_j =1}^n \mathbb{1}_{T({\textbf{u}})}^\rho (\{j\wedge u_j, j \wedge u\}, \{i\wedge u_i,i\wedge u^{\prime}_i\}) \\ &\leqslant 2\cdot \mathbb{1}_{T({\textbf{u}})}^\rho (j, \{i\wedge u_i,i\wedge u^{\prime}_i\}) + \dfrac{2}{n} \sum_{k=1}^{j-1} \mathbb{1}_{T({\textbf{u}})}^\rho (k, \{i\wedge u_i,i\wedge u^{\prime}_i\}) \\ &\leqslant 2\cdot \mathbb{1}_{T({\textbf{u}})}^\rho (j, i\wedge u_i) + 2\cdot \mathbb{1}_{T({\textbf{u}})}^\rho (j, i\wedge u^{\prime}_i) + \dfrac{4 }{n} \rho^2 \beta(T({\textbf{u}})). \end{align*}
\begin{align*} \dfrac{1}{n}\sum_{u = 1}^n {\mathbb{E}} &\left[ \mathbb{1}_{T({\textbf{u}})}^\rho (\{j\wedge u_j, j \wedge u\}, \{i\wedge u_i,i\wedge u^{\prime}_i\}) \mid u_{\leqslant j-1} \right] \\ &= \dfrac{1}{n^2}\sum_{u = 1}^n \sum_{u_j =1}^n \mathbb{1}_{T({\textbf{u}})}^\rho (\{j\wedge u_j, j \wedge u\}, \{i\wedge u_i,i\wedge u^{\prime}_i\}) \\ &\leqslant 2\cdot \mathbb{1}_{T({\textbf{u}})}^\rho (j, \{i\wedge u_i,i\wedge u^{\prime}_i\}) + \dfrac{2}{n} \sum_{k=1}^{j-1} \mathbb{1}_{T({\textbf{u}})}^\rho (k, \{i\wedge u_i,i\wedge u^{\prime}_i\}) \\ &\leqslant 2\cdot \mathbb{1}_{T({\textbf{u}})}^\rho (j, i\wedge u_i) + 2\cdot \mathbb{1}_{T({\textbf{u}})}^\rho (j, i\wedge u^{\prime}_i) + \dfrac{4 }{n} \rho^2 \beta(T({\textbf{u}})). \end{align*}
Similarly to (11), let
 $\textrm{ran}_{\mathcal{F}_{i-1}} \left[\textrm{Var}_{\mathcal{F}_i} [Y_{n-1}]\right] = r(U_1,\ldots,U_{i-1})$
. Using (9), (12) and taking the conditional expectation given
$\textrm{ran}_{\mathcal{F}_{i-1}} \left[\textrm{Var}_{\mathcal{F}_i} [Y_{n-1}]\right] = r(U_1,\ldots,U_{i-1})$
. Using (9), (12) and taking the conditional expectation given
 $U_1= u_1,\ldots,U_{i-1}=u_{i-1}$
for the bounds above, we obtain that
$U_1= u_1,\ldots,U_{i-1}=u_{i-1}$
for the bounds above, we obtain that
 \begin{align*} r(u_1,\ldots,u_{i-1}) &= \max _{u_i, u^{\prime}_i \in [n]} \bigg|\sum_{j=i+1}^n {\mathbb{E}}\left[ (f_j({\textbf{U}}) - f_{j-1}({\textbf{U}}))^2 \mid u_{\leqslant i-1}, U_i = u_i\right] \\ &\qquad \qquad -\sum_{j=i+1}^n {\mathbb{E}}\left[ (f_j({\textbf{U}}) - f_{j-1}({\textbf{U}}))^2 \mid u_{\leqslant i-1}, U_i = u^{\prime}_i\right] \bigg| \\ & \leqslant \dfrac{16\alpha^2}{n} \max_{u \in [n]} \sum_{j=i+1}^n {\mathbb{E}} \left[ \mathbb{1}_{T({\textbf{u}})}^\rho (j, i\wedge u) + \rho^2 \beta(T({\textbf{U}})) \mid u_{\leqslant i-1}, U_i = u \right] \\ &\leqslant 32\alpha^2 \rho^2 \max_{u_i \in [n]} {\mathbb{E}} (\beta(T({\textbf{U}})) \mid u_{\leqslant i}). \end{align*}
\begin{align*} r(u_1,\ldots,u_{i-1}) &= \max _{u_i, u^{\prime}_i \in [n]} \bigg|\sum_{j=i+1}^n {\mathbb{E}}\left[ (f_j({\textbf{U}}) - f_{j-1}({\textbf{U}}))^2 \mid u_{\leqslant i-1}, U_i = u_i\right] \\ &\qquad \qquad -\sum_{j=i+1}^n {\mathbb{E}}\left[ (f_j({\textbf{U}}) - f_{j-1}({\textbf{U}}))^2 \mid u_{\leqslant i-1}, U_i = u^{\prime}_i\right] \bigg| \\ & \leqslant \dfrac{16\alpha^2}{n} \max_{u \in [n]} \sum_{j=i+1}^n {\mathbb{E}} \left[ \mathbb{1}_{T({\textbf{u}})}^\rho (j, i\wedge u) + \rho^2 \beta(T({\textbf{U}})) \mid u_{\leqslant i-1}, U_i = u \right] \\ &\leqslant 32\alpha^2 \rho^2 \max_{u_i \in [n]} {\mathbb{E}} (\beta(T({\textbf{U}})) \mid u_{\leqslant i}). \end{align*}
This completes the proof part (b).
Part (c) immediately follows from Lemma 4.4(a) and Lemma 5.1(b). Indeed,
 \begin{equation} \alpha_i[F_T] \leqslant \max_{\omega, (ia)\in S_n} |F_T(\omega) - F_T(\omega\circ (ia))| \leqslant 2\alpha d. \end{equation}
\begin{equation} \alpha_i[F_T] \leqslant \max_{\omega, (ia)\in S_n} |F_T(\omega) - F_T(\omega\circ (ia))| \leqslant 2\alpha d. \end{equation}
For (d), recall from (10) that
 \begin{equation} \textrm{ran}_{\mathcal{G}_{i-1}} \left[ \textrm{Var}_{\mathcal{G}_i} [Z_{n-1}(T)]\right] \leqslant \sum_{j=i+1}^{n-1} \textrm{ran}_{\mathcal{G}_{i-1}} \left[ {\mathbb{E}}_{\mathcal{G}_i} \left[(Z_{j}(T) - Z_{j-1}(T))^2\right] \right]. \end{equation}
\begin{equation} \textrm{ran}_{\mathcal{G}_{i-1}} \left[ \textrm{Var}_{\mathcal{G}_i} [Z_{n-1}(T)]\right] \leqslant \sum_{j=i+1}^{n-1} \textrm{ran}_{\mathcal{G}_{i-1}} \left[ {\mathbb{E}}_{\mathcal{G}_i} \left[(Z_{j}(T) - Z_{j-1}(T))^2\right] \right]. \end{equation}
We will apply Lemma 4.4(b) to estimate the right-hand side of (19). From Lemma 5.1(d) and the bound (18), we get that
 \begin{equation*} |F_T(\omega) - F_T(\omega\circ(ia)) - F_T(\omega\circ(jb)) + F_T(\omega \circ(jb)\circ(ia)) | \leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+2}(\{i,a\}, \{j,b\}). \end{equation*}
\begin{equation*} |F_T(\omega) - F_T(\omega\circ(ia)) - F_T(\omega\circ(jb)) + F_T(\omega \circ(jb)\circ(ia)) | \leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+2}(\{i,a\}, \{j,b\}). \end{equation*}
Bounding
 \begin{equation*}\mathbb{1}_{T}^{\rho+2}(\{i,a\}, \{j,b\}) \leqslant \mathbb{1}_{T}^{\rho+2}(i,j) + \mathbb{1}_{T}^{\rho+2}(i,b) + \mathbb{1}_{T}^{\rho+2}(a,j) + \mathbb{1}_{T}^{\rho+2}(a,b) \end{equation*}
\begin{equation*}\mathbb{1}_{T}^{\rho+2}(\{i,a\}, \{j,b\}) \leqslant \mathbb{1}_{T}^{\rho+2}(i,j) + \mathbb{1}_{T}^{\rho+2}(i,b) + \mathbb{1}_{T}^{\rho+2}(a,j) + \mathbb{1}_{T}^{\rho+2}(a,b) \end{equation*}
and using (16), we find that, for
 $1\leqslant i <j \leqslant n-1$
,
$1\leqslant i <j \leqslant n-1$
,
 \begin{align*} \varDelta_{ij} [F_T] \leqslant 4 \alpha d \sum_{a=i+1}^n \sum_{b=j+1}^n \frac{ \mathbb{1}_{T}^{\rho+2}(\{i,a\}, \{j,b\})}{(n-i)(n-j)} \leqslant 4 \alpha d \left( \mathbb{1}^{\rho+2}_T(i,j) + \frac{3 (\rho+2)^2 \beta(T)}{n-j} \right). \end{align*}
\begin{align*} \varDelta_{ij} [F_T] \leqslant 4 \alpha d \sum_{a=i+1}^n \sum_{b=j+1}^n \frac{ \mathbb{1}_{T}^{\rho+2}(\{i,a\}, \{j,b\})}{(n-i)(n-j)} \leqslant 4 \alpha d \left( \mathbb{1}^{\rho+2}_T(i,j) + \frac{3 (\rho+2)^2 \beta(T)}{n-j} \right). \end{align*}
Combining (16), (18), Lemma 4.4(b) and the inequality
 \begin{equation*} 1+3 \sum_{k=1}^{n-1} k^{-1} \leqslant 4+ 3\, {\textrm{log}}\, n \leqslant 4\,{\textrm{log}}\, n, \end{equation*}
\begin{equation*} 1+3 \sum_{k=1}^{n-1} k^{-1} \leqslant 4+ 3\, {\textrm{log}}\, n \leqslant 4\,{\textrm{log}}\, n, \end{equation*}
we obtain that
 \begin{align*} \textrm{ran}_{\mathcal{G}_{i-1}} \left[ \textrm{Var}_{\mathcal{G}_i} [Z_{n-1}(T)] \right] &\leqslant \sum_{j=i+1}^{n-1} 16 \alpha^2 d^2 \left( \mathbb{1}^{\rho+2}_T(i,j) + \frac{3(\rho+2)^2 \beta(T)}{n-j} \right) \\&\leqslant 64 \alpha^2 d^2 (\rho+2)^2 \beta(T) {\textrm{log}}\, n. \end{align*}
\begin{align*} \textrm{ran}_{\mathcal{G}_{i-1}} \left[ \textrm{Var}_{\mathcal{G}_i} [Z_{n-1}(T)] \right] &\leqslant \sum_{j=i+1}^{n-1} 16 \alpha^2 d^2 \left( \mathbb{1}^{\rho+2}_T(i,j) + \frac{3(\rho+2)^2 \beta(T)}{n-j} \right) \\&\leqslant 64 \alpha^2 d^2 (\rho+2)^2 \beta(T) {\textrm{log}}\, n. \end{align*}
Finally, we proceed to part (e). Since F is
 $\alpha$
-Lipschitz, we have
$\alpha$
-Lipschitz, we have
 $|F(T) - F(T')| \leqslant 2 \alpha n$
for any two trees
$|F(T) - F(T')| \leqslant 2 \alpha n$
for any two trees
 $T,T'\in \mathcal{T}_n$
. Indeed, applying at most n perturbations of type
$T,T'\in \mathcal{T}_n$
. Indeed, applying at most n perturbations of type
 $\textrm{S}_{x}^{y 1}$
, where x is a leaf, we can turn any tree into a star centered at vertex 1. Thus, we can bound
$\textrm{S}_{x}^{y 1}$
, where x is a leaf, we can turn any tree into a star centered at vertex 1. Thus, we can bound
 \begin{equation*} 0 \leqslant V({\textbf{u}})\leqslant 4 \alpha^2 n^2. \end{equation*}
\begin{equation*} 0 \leqslant V({\textbf{u}})\leqslant 4 \alpha^2 n^2. \end{equation*}
Then, for any
 $\mathcal{A} \subset [n]^{n-1}$
and
$\mathcal{A} \subset [n]^{n-1}$
and
 $u_1, \ldots, u_{i-1} \in [n]$
,
$u_1, \ldots, u_{i-1} \in [n]$
,
 \begin{align*} &\textrm{ran} \Big[ {\mathbb{E}}_{\mathcal{F}_i} \left[V({\textbf{U}})\mathbb{1}_{{\textbf{U}} \in \mathcal{A}}\right] \mid u_{\leqslant i-1} \Big] \\ &= \max_{u \in[n]} {\mathbb{E}} \left[V({\textbf{U}})\mathbb{1}_{{\textbf{U}} \in \mathcal{A}} \mid u_{\leqslant i-1}, U_i =u\right] - \min_{u \in [n]} {\mathbb{E}} \left[V({\textbf{U}})\mathbb{1}_{{\textbf{U}} \in \mathcal{A}} \mid u_{\leqslant i-1}, U_i =u\right] \\ &\leqslant 4 \alpha^2 n^2 \max_{u_i \in[n]} \mathbb{P}({\textbf{U}} \notin \mathcal{A} \mid u_{\leqslant i}) + \max_{u_i,u \in [n]} {\mathbb{E}} \left[ (V({\textbf{U}}) - V({\textbf{U}}')) \mathbb{1}_{{\textbf{U}},{\textbf{U}}' \in \mathcal{A}} \mid {\textbf{u}}_{\leqslant i}, U^{\prime}_i =u \right] \end{align*}
\begin{align*} &\textrm{ran} \Big[ {\mathbb{E}}_{\mathcal{F}_i} \left[V({\textbf{U}})\mathbb{1}_{{\textbf{U}} \in \mathcal{A}}\right] \mid u_{\leqslant i-1} \Big] \\ &= \max_{u \in[n]} {\mathbb{E}} \left[V({\textbf{U}})\mathbb{1}_{{\textbf{U}} \in \mathcal{A}} \mid u_{\leqslant i-1}, U_i =u\right] - \min_{u \in [n]} {\mathbb{E}} \left[V({\textbf{U}})\mathbb{1}_{{\textbf{U}} \in \mathcal{A}} \mid u_{\leqslant i-1}, U_i =u\right] \\ &\leqslant 4 \alpha^2 n^2 \max_{u_i \in[n]} \mathbb{P}({\textbf{U}} \notin \mathcal{A} \mid u_{\leqslant i}) + \max_{u_i,u \in [n]} {\mathbb{E}} \left[ (V({\textbf{U}}) - V({\textbf{U}}')) \mathbb{1}_{{\textbf{U}},{\textbf{U}}' \in \mathcal{A}} \mid {\textbf{u}}_{\leqslant i}, U^{\prime}_i =u \right] \end{align*}
where
 ${\textbf{U}}'$
differs from
${\textbf{U}}'$
differs from
 ${\textbf{U}}$
in ith coordinate only. For the following we put
${\textbf{U}}$
in ith coordinate only. For the following we put
 $\mathcal{A} = \{{\textbf{u}} \in [n]^{n-1} \mathrel{:} T({\textbf{u}}) \in \mathcal{T}_n^d\}$
. It remains to bound
$\mathcal{A} = \{{\textbf{u}} \in [n]^{n-1} \mathrel{:} T({\textbf{u}}) \in \mathcal{T}_n^d\}$
. It remains to bound
 $V({\textbf{U}})- V({\textbf{U}}')$
when
$V({\textbf{U}})- V({\textbf{U}}')$
when
 $T({\textbf{U}}),T({\textbf{U}}') \in \mathcal{T}_n^d$
.
$T({\textbf{U}}),T({\textbf{U}}') \in \mathcal{T}_n^d$
.
Consider any
 ${\textbf{u}},{\textbf{u}}' \in [n]^{n-1}$
that differ in ith coordinate only and
${\textbf{u}},{\textbf{u}}' \in [n]^{n-1}$
that differ in ith coordinate only and
 $T({\textbf{u}}), T({\textbf{u}}') \in \mathcal{T}_n^d$
. If
$T({\textbf{u}}), T({\textbf{u}}') \in \mathcal{T}_n^d$
. If
 $T({\textbf{u}}) = T({\textbf{u}}')$
, then
$T({\textbf{u}}) = T({\textbf{u}}')$
, then
 $V({\textbf{u}}) = V({\textbf{u}}')$
. Otherwise, recalling (17), we can find some relabelling
$V({\textbf{u}}) = V({\textbf{u}}')$
. Otherwise, recalling (17), we can find some relabelling
 $\sigma \in S_n$
that the trees
$\sigma \in S_n$
that the trees
 $T = T({\textbf{u}})^{\sigma}$
,
$T = T({\textbf{u}})^{\sigma}$
,
 $T'=T({\textbf{u}}')^{\sigma}$
satisfy
$T'=T({\textbf{u}}')^{\sigma}$
satisfy
 $T' = \textrm{S}_{3}^{12} T$
and
$T' = \textrm{S}_{3}^{12} T$
and
 \begin{equation*} 0 = d_T(1, \{1,2\}) \leqslant \cdots \leqslant d_T(n, \{1,2\}). \end{equation*}
\begin{equation*} 0 = d_T(1, \{1,2\}) \leqslant \cdots \leqslant d_T(n, \{1,2\}). \end{equation*}
Note that
 $\textrm{Var} [F_T({\textbf{X}})] = V({\textbf{u}})$
and
$\textrm{Var} [F_T({\textbf{X}})] = V({\textbf{u}})$
and
 $\textrm{Var} [F_{T'}({\textbf{X}})] = V({\textbf{u}}')$
. Using Lemma 5.1(c) and (18), we find that, for any
$\textrm{Var} [F_{T'}({\textbf{X}})] = V({\textbf{u}}')$
. Using Lemma 5.1(c) and (18), we find that, for any
 $1\leqslant i <a\leqslant n$
,
$1\leqslant i <a\leqslant n$
,
 \begin{align*} |F_T(\omega) - F_T(\omega\circ(ia)) - F_{T'}(\omega) + F_{T'}(\omega \circ(ia)) | &\leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+1}(\{i,a\}, \{1,2\}) \\ &\leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+1}(i, \{1,2\}). \end{align*}
\begin{align*} |F_T(\omega) - F_T(\omega\circ(ia)) - F_{T'}(\omega) + F_{T'}(\omega \circ(ia)) | &\leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+1}(\{i,a\}, \{1,2\}) \\ &\leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+1}(i, \{1,2\}). \end{align*}
Applying Lemma 4.4(a) to the function
 $F_T - F_{T'}$
, we obtain
$F_T - F_{T'}$
, we obtain
 \begin{align*} |Z_i(T) - Z_{i-1}(T) - Z_i(T') + Z_{i-1}(T')| \leqslant \alpha_i(F_T - F_{T'}) \leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+1}(i, \{1,2\}). \end{align*}
\begin{align*} |Z_i(T) - Z_{i-1}(T) - Z_i(T') + Z_{i-1}(T')| \leqslant \alpha_i(F_T - F_{T'}) \leqslant 4 \alpha d \, \mathbb{1}_{T}^{\rho+1}(i, \{1,2\}). \end{align*}
We have already proved in part (b) that
 $|Z_i(T) - Z_{i-1}(T)| \leqslant 2 \alpha d$
. Using (8) and (16), we bound
$|Z_i(T) - Z_{i-1}(T)| \leqslant 2 \alpha d$
. Using (8) and (16), we bound
 \begin{align*} V({\textbf{u}}) - V({\textbf{u}}') &= \rm{Var}\left[{Z_{n-1}(T)}\right]- \rm{Var}\left[{Z_{n-1}(T')}\right] \\ &= \sum_{i=1}^{n-1} {\mathbb{E}} \left[ ( Z_i(T) - Z_{i-1}(T))^2 - (Z_i(T') - Z_{i-1}(T'))^2\right] \\[5pt] &\leqslant \sum_{i=1}^{n-1} 4\alpha^2 d^2 \mathbb{1}_{T}^{\rho+1}(i, \{1,2\}) \leqslant 8 \alpha^2d^2 (\rho+1)^2 \beta(T). \end{align*}
\begin{align*} V({\textbf{u}}) - V({\textbf{u}}') &= \rm{Var}\left[{Z_{n-1}(T)}\right]- \rm{Var}\left[{Z_{n-1}(T')}\right] \\ &= \sum_{i=1}^{n-1} {\mathbb{E}} \left[ ( Z_i(T) - Z_{i-1}(T))^2 - (Z_i(T') - Z_{i-1}(T'))^2\right] \\[5pt] &\leqslant \sum_{i=1}^{n-1} 4\alpha^2 d^2 \mathbb{1}_{T}^{\rho+1}(i, \{1,2\}) \leqslant 8 \alpha^2d^2 (\rho+1)^2 \beta(T). \end{align*}
Part (e) follows.
5.3. Proof of Theorem 1.1
Before proving of Theorem 1.1, we need one more lemma. Let
 \begin{align*} \mathcal{U}_{\rm small} &\,:\!=\, \{{\textbf{u}}\in [n]^{n-1} \mathrel{:} T({\textbf{u}}) \in \mathcal{T}_{n}^{{\textrm{log}}\, n} \text{ and } \beta(T({\textbf{u}})) \leqslant {\textrm{log}}^4\, n\},\\[5pt] \mathcal{U}_{\rm big} &\,:\!=\, \{{\textbf{u}}\in [n]^{n-1} \mathrel{:} T({\textbf{u}}) \in \mathcal{T}_{n}^{ 2\, {\textrm{log}}\, n} \text{ and } \beta(T({\textbf{u}})) \leqslant 2\, {\textrm{log}}^4\, n\}.\end{align*}
\begin{align*} \mathcal{U}_{\rm small} &\,:\!=\, \{{\textbf{u}}\in [n]^{n-1} \mathrel{:} T({\textbf{u}}) \in \mathcal{T}_{n}^{{\textrm{log}}\, n} \text{ and } \beta(T({\textbf{u}})) \leqslant {\textrm{log}}^4\, n\},\\[5pt] \mathcal{U}_{\rm big} &\,:\!=\, \{{\textbf{u}}\in [n]^{n-1} \mathrel{:} T({\textbf{u}}) \in \mathcal{T}_{n}^{ 2\, {\textrm{log}}\, n} \text{ and } \beta(T({\textbf{u}})) \leqslant 2\, {\textrm{log}}^4\, n\}.\end{align*}
Lemma 5.3. The following asymptotics bounds hold for any
 ${\textbf{u}} \in \mathcal{U}_{\rm small}$
,
${\textbf{u}} \in \mathcal{U}_{\rm small}$
,
 $u \in [n]$
:
$u \in [n]$
:
 \begin{equation*} \mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm small}) = e^{-\omega({\rm{log}}\, n)}, \qquad \mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm big} \mid u_{\leqslant i-1}, U_i =u) = e^{-\omega({\rm{log}}\, n)}.\end{equation*}
\begin{equation*} \mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm small}) = e^{-\omega({\rm{log}}\, n)}, \qquad \mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm big} \mid u_{\leqslant i-1}, U_i =u) = e^{-\omega({\rm{log}}\, n)}.\end{equation*}
Proof. The first bound follows immediately from (1) and Theorem 1.4. For the second, observe that, for any
 $u^{\prime}_1,\ldots, u^{\prime}_{i-1} \in [n]$
,
$u^{\prime}_1,\ldots, u^{\prime}_{i-1} \in [n]$
,
 \begin{equation*} \mathbb{P} \left({\textbf{U}} \in \mathcal{U}_{\rm small} \mid U_1 = u^{\prime}_1, \ldots, U_{i-1} = u^{\prime}_{i-1} \right) \leqslant \mathbb{P} \left({\textbf{U}} \in \mathcal{U}_{\rm big} \mid u_{\leqslant i-1} \right).\end{equation*}
\begin{equation*} \mathbb{P} \left({\textbf{U}} \in \mathcal{U}_{\rm small} \mid U_1 = u^{\prime}_1, \ldots, U_{i-1} = u^{\prime}_{i-1} \right) \leqslant \mathbb{P} \left({\textbf{U}} \in \mathcal{U}_{\rm big} \mid u_{\leqslant i-1} \right).\end{equation*}
Indeed, let
 ${\textbf{U}}$
,
${\textbf{U}}$
,
 ${\textbf{U}}'$
are such that
${\textbf{U}}'$
are such that
 $U_j = u_j$
and
$U_j = u_j$
and
 $U^{\prime}_j = u^{\prime}_j$
for
$U^{\prime}_j = u^{\prime}_j$
for
 $j \in [i-1]$
and
$j \in [i-1]$
and
 $U_j = U^{\prime}_j$
for
$U_j = U^{\prime}_j$
for
 $j \geqslant i$
. Then,
$j \geqslant i$
. Then,
 $T({\textbf{U}}) \subset T(U') \cup T({\textbf{u}})$
because the edges corresponding from
$T({\textbf{U}}) \subset T(U') \cup T({\textbf{u}})$
because the edges corresponding from
 $i-1$
steps of the Aldous–Broder algorithm for
$i-1$
steps of the Aldous–Broder algorithm for
 $T({\textbf{U}})$
lie in
$T({\textbf{U}})$
lie in
 $T({\textbf{u}})$
, while the remaining edges are covered by T(U ′)). We know that
$T({\textbf{u}})$
, while the remaining edges are covered by T(U ′)). We know that
 ${\textbf{u}} \in \mathcal{U}_{\rm small}$
. Therefore, if
${\textbf{u}} \in \mathcal{U}_{\rm small}$
. Therefore, if
 ${\textbf{U}}' \in \mathcal{U}_{\rm small}$
, then
${\textbf{U}}' \in \mathcal{U}_{\rm small}$
, then
 ${\textbf{U}} \in \mathcal{U}_{\rm big}$
.
${\textbf{U}} \in \mathcal{U}_{\rm big}$
.
Next, averaging over all
 $u^{\prime}_1,\ldots, u^{\prime}_{i-1} \in [n]$
, we conclude that
$u^{\prime}_1,\ldots, u^{\prime}_{i-1} \in [n]$
, we conclude that
 \begin{equation*} \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm big} \mid u_{\leqslant i-1} \right) \leqslant \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm small}\right).\end{equation*}
\begin{equation*} \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm big} \mid u_{\leqslant i-1} \right) \leqslant \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm small}\right).\end{equation*}
Note that, for any
 $u \in [n]$
,
$u \in [n]$
,
 \begin{align*} \mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm big} \mid u_{\leqslant i-1}, U_i = u) = \frac{\mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm big}, U_i = u\mid u_{\leqslant i-1})} {\mathbb{P} (U_i = u \mid u_{\leqslant i-1})} \leqslant n \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm small} \right). \end{align*}
\begin{align*} \mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm big} \mid u_{\leqslant i-1}, U_i = u) = \frac{\mathbb{P}({\textbf{U}} \notin \mathcal{U}_{\rm big}, U_i = u\mid u_{\leqslant i-1})} {\mathbb{P} (U_i = u \mid u_{\leqslant i-1})} \leqslant n \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm small} \right). \end{align*}
Recalling
 $ \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm small}\right) = e^{-\omega({\textrm{log}}\, n)}$
, we complete the proof.
$ \mathbb{P} \left({\textbf{U}} \notin \mathcal{U}_{\rm small}\right) = e^{-\omega({\textrm{log}}\, n)}$
, we complete the proof.
Now we are ready to prove Theorem 1.1, our main result. Let
 ${\textbf{Y}}$
and
${\textbf{Y}}$
and
 ${\textbf{Z}}(T)$
be the martingales from (14). Consider the sequence
${\textbf{Z}}(T)$
be the martingales from (14). Consider the sequence
 ${\textbf{W}} = (W_0, \ldots, W_{2n-2})$
defined by
${\textbf{W}} = (W_0, \ldots, W_{2n-2})$
defined by
 \begin{equation*}W_i \,:\!=\,\begin{cases} Y_i, &\text{if } i =0,\ldots, n-1, \\[5pt] Z_{i-n+1}(T({\textbf{U}})), & \text{if $i \geqslant n$ and $T({\textbf{U}}) \in \mathcal{T}_n^{{\textrm{log}}\, n}$,} \\[5pt] Y_{n-1}, & \text{if $i \geqslant n$ and $T({\textbf{U}}) \notin \mathcal{T}_n^{{\textrm{log}}\, n}$.}\end{cases}\end{equation*}
\begin{equation*}W_i \,:\!=\,\begin{cases} Y_i, &\text{if } i =0,\ldots, n-1, \\[5pt] Z_{i-n+1}(T({\textbf{U}})), & \text{if $i \geqslant n$ and $T({\textbf{U}}) \in \mathcal{T}_n^{{\textrm{log}}\, n}$,} \\[5pt] Y_{n-1}, & \text{if $i \geqslant n$ and $T({\textbf{U}}) \notin \mathcal{T}_n^{{\textrm{log}}\, n}$.}\end{cases}\end{equation*}
Note that
 ${\textbf{W}}$
is a martingale with the respect to the filtration
${\textbf{W}}$
is a martingale with the respect to the filtration
 $\mathcal{F}^{\prime}_0, \ldots, \mathcal{F}^{\prime}_{2n-2}$
, where
$\mathcal{F}^{\prime}_0, \ldots, \mathcal{F}^{\prime}_{2n-2}$
, where
 $\mathcal{F}^{\prime}_i = \mathcal{F}_i,$
for
$\mathcal{F}^{\prime}_i = \mathcal{F}_i,$
for
 $i\leqslant n-1$
and
$i\leqslant n-1$
and
 $ \mathcal{F}^{\prime}_i = \mathcal{F}_{n-1} \times \mathcal{G}_{i-n+1},$
for
$ \mathcal{F}^{\prime}_i = \mathcal{F}_{n-1} \times \mathcal{G}_{i-n+1},$
for
 $i \geqslant n$
. Using (1), (8), and Lemma 5.2(e), we get that
$i \geqslant n$
. Using (1), (8), and Lemma 5.2(e), we get that
 \begin{align*} \rm{Var}\left[{W_{2n-2}}\right] &= \rm{Var}\left[{Y_{n-1}}\right] + {\mathbb{E}} \left[ V({\textbf{U}}) \mathbb{1}_{T({\textbf{U}}) \in \mathcal{T}_n^{{\textrm{log}}\, n}} \right] \\[5pt]&= \rm{Var}\left[{Y_{n-1}}\right] + \mathbb{E}\left[{ V({\textbf{U}})}\right] - 4\alpha^2 n^2 e^{-\omega({\textrm{log}}\, n)} = \rm{Var}\left[{F({\textbf{T}})}\right] - \alpha^2 e^{-\omega({\textrm{log}}\, n)}.\end{align*}
\begin{align*} \rm{Var}\left[{W_{2n-2}}\right] &= \rm{Var}\left[{Y_{n-1}}\right] + {\mathbb{E}} \left[ V({\textbf{U}}) \mathbb{1}_{T({\textbf{U}}) \in \mathcal{T}_n^{{\textrm{log}}\, n}} \right] \\[5pt]&= \rm{Var}\left[{Y_{n-1}}\right] + \mathbb{E}\left[{ V({\textbf{U}})}\right] - 4\alpha^2 n^2 e^{-\omega({\textrm{log}}\, n)} = \rm{Var}\left[{F({\textbf{T}})}\right] - \alpha^2 e^{-\omega({\textrm{log}}\, n)}.\end{align*}
Then, by assumptions of Theorem 1.1, we get
 $\rm{Var}\left[{W_{2n-2}}\right] = \left(1+ e^{-\omega({\textrm{log}}\, n)}\right)\rm{Var}\left[{F({\textbf{T}})}\right] $
and
$\rm{Var}\left[{W_{2n-2}}\right] = \left(1+ e^{-\omega({\textrm{log}}\, n)}\right)\rm{Var}\left[{F({\textbf{T}})}\right] $
and
 \begin{equation} \alpha^2 = O\left(n^{-2/3 - 2\varepsilon/3}\right) \rm{Var}\left[{W_{2n-2}}\right] , \qquad \alpha^2 \rho^2 = O\left(n^{-1/2 - 2\varepsilon}\right) \rm{Var}\left[{W_{2n-2}}\right] .\end{equation}
\begin{equation} \alpha^2 = O\left(n^{-2/3 - 2\varepsilon/3}\right) \rm{Var}\left[{W_{2n-2}}\right] , \qquad \alpha^2 \rho^2 = O\left(n^{-1/2 - 2\varepsilon}\right) \rm{Var}\left[{W_{2n-2}}\right] .\end{equation}
Using Lemma 5.2(a,c), we obtain that, for all
 $i\in [2n-2]$
,
$i\in [2n-2]$
,
 \begin{equation} W_i - W_{i-1} = O(\alpha {\textrm{log}}\, n). \end{equation}
\begin{equation} W_i - W_{i-1} = O(\alpha {\textrm{log}}\, n). \end{equation}
Let
 ${\textbf{u}} \in [n]^{n-1} \in U_{\rm small}$
. Combining Lemmas 5.2(b,d,e) and 5.3 and observing
${\textbf{u}} \in [n]^{n-1} \in U_{\rm small}$
. Combining Lemmas 5.2(b,d,e) and 5.3 and observing
 $\beta(T)\leqslant n^2$
for all
$\beta(T)\leqslant n^2$
for all
 $T \in \mathcal{T}_n$
, we get that, for all
$T \in \mathcal{T}_n$
, we get that, for all
 $i\in [n-1]$
$i\in [n-1]$
 \begin{align*} \textrm{ran}\left[ \textrm{Var}_{\mathcal{F}_i} [Y_{n-1}] \mid u_{\leqslant i-1} \right] &= O\left(\alpha^2 \rho^2 {\textrm{log}}^4\, n\right) \\[5pt] \textrm{ran}_{\mathcal{G}_{i-1}}[ Z_i(T({\textbf{u}}))] &= O\left(\alpha^2 \rho^2 {\textrm{log}}^7 n\right) \\[5pt] \textrm{ran}\left[ {\mathbb{E}}_{\mathcal{F}_i} [V({\textbf{U}})] \mid u_{\leqslant i-1} \right] &= O\left(\alpha^2 \rho^2 {\textrm{log}}^6 n\right) \end{align*}
\begin{align*} \textrm{ran}\left[ \textrm{Var}_{\mathcal{F}_i} [Y_{n-1}] \mid u_{\leqslant i-1} \right] &= O\left(\alpha^2 \rho^2 {\textrm{log}}^4\, n\right) \\[5pt] \textrm{ran}_{\mathcal{G}_{i-1}}[ Z_i(T({\textbf{u}}))] &= O\left(\alpha^2 \rho^2 {\textrm{log}}^7 n\right) \\[5pt] \textrm{ran}\left[ {\mathbb{E}}_{\mathcal{F}_i} [V({\textbf{U}})] \mid u_{\leqslant i-1} \right] &= O\left(\alpha^2 \rho^2 {\textrm{log}}^6 n\right) \end{align*}
Note that, in the case of the event
 ${\textbf{U}} \in \mathcal{U}_{\rm small}$
, we have
${\textbf{U}} \in \mathcal{U}_{\rm small}$
, we have
 $W_i = Z_i(T({\textbf{U}}))$
and
$W_i = Z_i(T({\textbf{U}}))$
and
 \begin{equation*} \textrm{Var} [W_{2n-2} \mid \mathcal{F}_{i}] = \textrm{Var}_{\mathcal{F}_i} [Y_{n-1}] + {\mathbb{E}}_{\mathcal{F}_i} [V({\textbf{U}})]. \end{equation*}
\begin{equation*} \textrm{Var} [W_{2n-2} \mid \mathcal{F}_{i}] = \textrm{Var}_{\mathcal{F}_i} [Y_{n-1}] + {\mathbb{E}}_{\mathcal{F}_i} [V({\textbf{U}})]. \end{equation*}
Then, we obtain that if
 ${\textbf{U}} \in \mathcal{U}_{\rm small}$
then, for all
${\textbf{U}} \in \mathcal{U}_{\rm small}$
then, for all
 $i \in [2n-2]$
,
$i \in [2n-2]$
,
 \begin{equation*} \textrm{ran}\left[ \textrm{Var} [W_{2n-2} \mid \mathcal{F}^{\prime}_{i}] \mid \mathcal{F}^{\prime}_{i-1}\right] = O(\alpha^2 \rho^2 {\textrm{log}}^7 n). \end{equation*}
\begin{equation*} \textrm{ran}\left[ \textrm{Var} [W_{2n-2} \mid \mathcal{F}^{\prime}_{i}] \mid \mathcal{F}^{\prime}_{i-1}\right] = O(\alpha^2 \rho^2 {\textrm{log}}^7 n). \end{equation*}
Using (20), we conclude that, with probability
 $1-e^{-\omega({\textrm{log}}\, n)}$
,
$1-e^{-\omega({\textrm{log}}\, n)}$
,
 \begin{align*} \sum_{i=1}^{2n-2} &\left( \textrm{ran}\big[ \textrm{Var} [W_{2n-2} \mid \mathcal{F}^{\prime}_{i}] \mid \mathcal{F}^{\prime}_{i-1}\big] + \big(\textrm{ran}\left[ W_i \mid \mathcal{F}^{\prime}_{i-1}\right]\big)^2 \right)^2 \\&\qquad = O(\alpha^4 \rho^4 n {\textrm{log}}^{14} n) = O(n^{-4\varepsilon}{\textrm{log}}^{14} n) \left( \textrm{Var} [W_{2n-2}]\right)^2. \end{align*}
\begin{align*} \sum_{i=1}^{2n-2} &\left( \textrm{ran}\big[ \textrm{Var} [W_{2n-2} \mid \mathcal{F}^{\prime}_{i}] \mid \mathcal{F}^{\prime}_{i-1}\big] + \big(\textrm{ran}\left[ W_i \mid \mathcal{F}^{\prime}_{i-1}\right]\big)^2 \right)^2 \\&\qquad = O(\alpha^4 \rho^4 n {\textrm{log}}^{14} n) = O(n^{-4\varepsilon}{\textrm{log}}^{14} n) \left( \textrm{Var} [W_{2n-2}]\right)^2. \end{align*}
Let
 $\tilde{\varepsilon} \in (0,\varepsilon)$
. Setting
$\tilde{\varepsilon} \in (0,\varepsilon)$
. Setting
 $\hat{q}= n^{-2\tilde{\varepsilon}}$
and applying Lemma 4.3, we get that, for any
$\hat{q}= n^{-2\tilde{\varepsilon}}$
and applying Lemma 4.3, we get that, for any
 $p \in[1,+\infty)$
,
$p \in[1,+\infty)$
,
 \begin{align*} \mathbb{E}\left[{|Q[{\textbf{W}}]-1|^p}\right] =O\left( n^{-2\tilde{p\varepsilon}} + \sup| Q[{\textbf{W}}]-1|^p e^{-\omega({\textrm{log}}\, n)} \right).\end{align*}
\begin{align*} \mathbb{E}\left[{|Q[{\textbf{W}}]-1|^p}\right] =O\left( n^{-2\tilde{p\varepsilon}} + \sup| Q[{\textbf{W}}]-1|^p e^{-\omega({\textrm{log}}\, n)} \right).\end{align*}
Using (21) and (20), we can bound
 \begin{equation*} Q[{\textbf{W}}] = \frac{1}{\textrm{Var} [W_{2n-2}]}\sum_{i=1}^{2n-2} (W_i - W_{i-1})^2 = O\left(n^{1/3}\right). \end{equation*}
\begin{equation*} Q[{\textbf{W}}] = \frac{1}{\textrm{Var} [W_{2n-2}]}\sum_{i=1}^{2n-2} (W_i - W_{i-1})^2 = O\left(n^{1/3}\right). \end{equation*}
Applying Theorem 4.2 to the scaled martingale sequence
 ${\textbf{W}} / (\alpha\, {\textrm{log}}\, n)$
, we get that
${\textbf{W}} / (\alpha\, {\textrm{log}}\, n)$
, we get that
 \begin{align*} \delta_{K}[W_{2n-2}] &= O\left( \left( \frac{\alpha^2 {\textrm{log}}^2 n }{ \textrm{Var} [W_{2n-2}]}\right)^{3/2} n {\textrm{log}}\, n + \left(n^{-2\tilde{p\varepsilon}} + e^{-\omega({\textrm{log}}\, n)} n^{p/3} \right)^{1/(2p+1)} \right) \\ &= O\left(n^{-\varepsilon} {\textrm{log}}^4\, n + n^{-2p \tilde{\varepsilon}/(2p+1) }\right) = O(n^{-2p \tilde{\varepsilon}/(2p+1) }). \end{align*}
\begin{align*} \delta_{K}[W_{2n-2}] &= O\left( \left( \frac{\alpha^2 {\textrm{log}}^2 n }{ \textrm{Var} [W_{2n-2}]}\right)^{3/2} n {\textrm{log}}\, n + \left(n^{-2\tilde{p\varepsilon}} + e^{-\omega({\textrm{log}}\, n)} n^{p/3} \right)^{1/(2p+1)} \right) \\ &= O\left(n^{-\varepsilon} {\textrm{log}}^4\, n + n^{-2p \tilde{\varepsilon}/(2p+1) }\right) = O(n^{-2p \tilde{\varepsilon}/(2p+1) }). \end{align*}
We can make
 $2p \tilde{\varepsilon}/(2p+1) \geqslant \varepsilon'$
for any
$2p \tilde{\varepsilon}/(2p+1) \geqslant \varepsilon'$
for any
 $\varepsilon'\in (0,\varepsilon)$
by taking
$\varepsilon'\in (0,\varepsilon)$
by taking
 $\tilde{\varepsilon}$
to be sufficiently close to
$\tilde{\varepsilon}$
to be sufficiently close to
 $\varepsilon$
and p to be sufficiently large. Recalling that
$\varepsilon$
and p to be sufficiently large. Recalling that
 $W_{2n-2} = F(T({\textbf{U}})^{{\textbf{X}}})$
with probability
$W_{2n-2} = F(T({\textbf{U}})^{{\textbf{X}}})$
with probability
 $1 - e^{\omega({\textrm{log}}\, n)}$
(that is for the event
$1 - e^{\omega({\textrm{log}}\, n)}$
(that is for the event
 $T({\textbf{U}}) \in \mathcal{T}_n^{{\textrm{log}}\, n}$
) and
$T({\textbf{U}}) \in \mathcal{T}_n^{{\textrm{log}}\, n}$
) and
 $\textrm{Var} [W_{2n-2}] = \left(1+ e^{-\omega({\textrm{log}}\, n)}\right) \rm{Var}\left[{F({\textbf{T}})}\right]$
, the required bound for
$\textrm{Var} [W_{2n-2}] = \left(1+ e^{-\omega({\textrm{log}}\, n)}\right) \rm{Var}\left[{F({\textbf{T}})}\right]$
, the required bound for
 $\delta_{K}[F({\textbf{T}})]$
follows.
$\delta_{K}[F({\textbf{T}})]$
follows.
Remark 5.4. The proof of Theorem 1.1 can be significantly simplified under additional assumption that the tree parameter F is symmetric. Namely, we would not need the martingale sequence
 ${\textbf{Z}}(T)$
, the bounds of Section 5.1, and we would only use parts (a), (b) from Lemma 5.2. In fact, a symmetric version of Theorem 1.1 would be sufficient to cover all applications given in Sections 2 and 3. Our decision to consider arbitrary tree parameters serves two purposes. First, the result is significantly stronger. Second, the analysis of martingales based on functions with dependent random variables is essential for extensions to more sophisticated tree models.
${\textbf{Z}}(T)$
, the bounds of Section 5.1, and we would only use parts (a), (b) from Lemma 5.2. In fact, a symmetric version of Theorem 1.1 would be sufficient to cover all applications given in Sections 2 and 3. Our decision to consider arbitrary tree parameters serves two purposes. First, the result is significantly stronger. Second, the analysis of martingales based on functions with dependent random variables is essential for extensions to more sophisticated tree models.
Remark 5.5. Combining Lemma 5.2(a,c) and Theorem 4.1 one can easily derive fast decreasing bounds for the tail of the distribution of
 $F({\textbf{T}})$
, provided a tree parameter F is
$F({\textbf{T}})$
, provided a tree parameter F is
 $\alpha$
-Lipschitz. Cooper, McGrae and Zito [Reference Cooper, McGrae and Zito6, Section 4] used a different martingale construction for trees to establish the concentration of
$\alpha$
-Lipschitz. Cooper, McGrae and Zito [Reference Cooper, McGrae and Zito6, Section 4] used a different martingale construction for trees to establish the concentration of
 $F({\textbf{T}})$
around its expectation; however, they needed more restrictive assumptions about the tree parameter F.
$F({\textbf{T}})$
around its expectation; however, they needed more restrictive assumptions about the tree parameter F.
6. The balls in random trees are not too large
In this section, we prove Theorem 1.4 using martingales. For a tree
 $T\in \mathcal{T}_n$
, let
$T\in \mathcal{T}_n$
, let
 $\Gamma^k_{T}(v)$
be the set of all vertices at distance exactly k from v. Theorem 1.4 follows immediately from Lemmas 6.2 and 6.4 (stated below) by summing over all
$\Gamma^k_{T}(v)$
be the set of all vertices at distance exactly k from v. Theorem 1.4 follows immediately from Lemmas 6.2 and 6.4 (stated below) by summing over all
 $|\Gamma_{{\textbf{T}}}^k(v)|$
for
$|\Gamma_{{\textbf{T}}}^k(v)|$
for
 $k=1,\ldots, d$
and using the union bound over all vertices
$k=1,\ldots, d$
and using the union bound over all vertices
 $v \in [n]$
.
$v \in [n]$
.
Let
 $a>b$
be positive integers. Let A be an arbitrary set of a vertices from [n], and B be its subset on b vertices. Consider event
$a>b$
be positive integers. Let A be an arbitrary set of a vertices from [n], and B be its subset on b vertices. Consider event
 $\mathcal{E}_{A,B}$
that A induces a tree and vertices of
$\mathcal{E}_{A,B}$
that A induces a tree and vertices of
 $A{\setminus}B$
have neighbours only in A. For
$A{\setminus}B$
have neighbours only in A. For
 $T\in\mathcal{T}_n$
, let
$T\in\mathcal{T}_n$
, let
 $\xi_{A,B}(T)$
be the number of neighbours of B in T outside A. Below, we denote the random variable
$\xi_{A,B}(T)$
be the number of neighbours of B in T outside A. Below, we denote the random variable
 $\xi_{A,B}({\textbf{T}})$
simply
$\xi_{A,B}({\textbf{T}})$
simply
 $\xi_{A,B}$
.
$\xi_{A,B}$
.
Lemma 6.1. The conditional distribution of
 $\xi_{A,B}-1$
subject to
$\xi_{A,B}-1$
subject to
 $\mathcal{E}_{A,B}$
is binomial with parameters
$\mathcal{E}_{A,B}$
is binomial with parameters
 $(n-a-1,\frac{b}{n-a+b})$
.
$(n-a-1,\frac{b}{n-a+b})$
.
Proof. Let
 $T_0$
be a tree on A. Consider event
$T_0$
be a tree on A. Consider event
 $\mathcal{E}_{A,B,T_0}$
that A induces exactly the given subtree
$\mathcal{E}_{A,B,T_0}$
that A induces exactly the given subtree
 $T_0$
and vertices of
$T_0$
and vertices of
 $A{\setminus}B$
have neighbours only in A. By Lemma 2.3,
$A{\setminus}B$
have neighbours only in A. By Lemma 2.3,
 \begin{equation*} \left|\mathcal{E}_{A,B,T_0}\right|=b(n-a+b)^{n-a-1}.\end{equation*}
\begin{equation*} \left|\mathcal{E}_{A,B,T_0}\right|=b(n-a+b)^{n-a-1}.\end{equation*}
Let
 $k\in\mathbb{N}$
. By Lemma 2.3,
$k\in\mathbb{N}$
. By Lemma 2.3,
 \begin{equation*} \left|\{\xi_{A,B}=k\}\cap\mathcal{E}_{A,B,T_0}\right|=b^k \left(\begin{array}{c}n-a-1\\k-1\end{array}\right) (n-a)^{n-a-k}.\end{equation*}
\begin{equation*} \left|\{\xi_{A,B}=k\}\cap\mathcal{E}_{A,B,T_0}\right|=b^k \left(\begin{array}{c}n-a-1\\k-1\end{array}\right) (n-a)^{n-a-k}.\end{equation*}
Therefore,
 \begin{align*} \mathbb{P}(\xi_{A,B}=k \mid \mathcal{E}_{A,B})&=\frac{\sum_{T}\mathbb{P}(\xi_{A,B}=k \mid \mathcal{E}_{A,B,T})\mathbb{P}(\mathcal{E}_{A,B,T})}{\sum_{T}\mathbb{P}(\mathcal{E}_{A,B,T})} \\[5pt] &=\mathbb{P}(\xi_{A,B}=k \mid \mathcal{E}_{A,B,T_0}) \\[5pt] &= \left(\frac{b}{n-a+b}\right)^{k-1}\left(1-\frac{b}{n-a+b}\right)^{n-a-k}\left(\begin{array}{c}n-a-1\\k-1\end{array}\right),\end{align*}
\begin{align*} \mathbb{P}(\xi_{A,B}=k \mid \mathcal{E}_{A,B})&=\frac{\sum_{T}\mathbb{P}(\xi_{A,B}=k \mid \mathcal{E}_{A,B,T})\mathbb{P}(\mathcal{E}_{A,B,T})}{\sum_{T}\mathbb{P}(\mathcal{E}_{A,B,T})} \\[5pt] &=\mathbb{P}(\xi_{A,B}=k \mid \mathcal{E}_{A,B,T_0}) \\[5pt] &= \left(\frac{b}{n-a+b}\right)^{k-1}\left(1-\frac{b}{n-a+b}\right)^{n-a-k}\left(\begin{array}{c}n-a-1\\k-1\end{array}\right),\end{align*}
which is the required distribution.
Fix a vertex
 $v\in [n]$
. Define the sequence of random variables
$v\in [n]$
. Define the sequence of random variables
 $X_0,\ldots, X_n$
by
$X_0,\ldots, X_n$
by
 \begin{equation*} X_0\,:\!=\,1, \qquad \text{and} \qquad X_k\,:\!=\,|\Gamma^k_{{\textbf{T}}}(v)| \text{ for all $k \in [n]$}. \end{equation*}
\begin{equation*} X_0\,:\!=\,1, \qquad \text{and} \qquad X_k\,:\!=\,|\Gamma^k_{{\textbf{T}}}(v)| \text{ for all $k \in [n]$}. \end{equation*}
From Lemma 6.1, we have
 $X_1-1\sim$
Bin
$X_1-1\sim$
Bin
 $(n-2,\frac{1}{n})$
. Notice that, for
$(n-2,\frac{1}{n})$
. Notice that, for
 $k\geqslant 1$
, the vertices of
$k\geqslant 1$
, the vertices of
 $\Gamma^{k+1}_{{\textbf{T}}}(v)$
are adjacent only to the vertices of
$\Gamma^{k+1}_{{\textbf{T}}}(v)$
are adjacent only to the vertices of
 $\Gamma^k_{{\textbf{T}}}(v)$
in
$\Gamma^k_{{\textbf{T}}}(v)$
in
 $\bigsqcup_{j\leqslant k+1}\Gamma^j_{{\textbf{T}}}(v)$
. Let
$\bigsqcup_{j\leqslant k+1}\Gamma^j_{{\textbf{T}}}(v)$
. Let
 $(x_1,\ldots,x_k)$
be a sequence of positive integers such that
$(x_1,\ldots,x_k)$
be a sequence of positive integers such that
 $1+x_1+\ldots+x_k\leqslant n$
. By Lemma 6.1, if
$1+x_1+\ldots+x_k\leqslant n$
. By Lemma 6.1, if
 $x_1+\ldots+x_k\leqslant n-3$
, then the conditional distribution of
$x_1+\ldots+x_k\leqslant n-3$
, then the conditional distribution of
 $X_{k+1}-1$
subject to
$X_{k+1}-1$
subject to
 $(X_1=x_1,\ldots,X_k=x_k)$
is binomial with parameters
$(X_1=x_1,\ldots,X_k=x_k)$
is binomial with parameters
 $n-x_1-\ldots-x_k-2$
and
$n-x_1-\ldots-x_k-2$
and
 $\frac{x_k}{n-x_1-\ldots-x_{k-1}-1}$
. If
$\frac{x_k}{n-x_1-\ldots-x_{k-1}-1}$
. If
 $x_1+\ldots+x_k=n-2$
, then
$x_1+\ldots+x_k=n-2$
, then
 $X_{k+1}=1$
. Finally, if
$X_{k+1}=1$
. Finally, if
 $x_1+\ldots+x_k=n-1$
, then
$x_1+\ldots+x_k=n-1$
, then
 $X_{k+1}=0$
.
$X_{k+1}=0$
.
Lemma 6.2. There exists a sequence
 $X_0=X^{\prime}_0,X^{\prime}_1,\ldots,X^{\prime}_n$
such that
$X_0=X^{\prime}_0,X^{\prime}_1,\ldots,X^{\prime}_n$
such that
-
•
$X^{\prime}_k\geqslant X_k$
, -
• for
$k\geqslant 0$
, the distribution of
$X^{\prime}_{k+1}-1$
subject to
$X_j=x_j,X^{\prime}_j =x^{\prime}_j $
,
$j\in[k]$
, is
\begin{equation*}\begin{cases}\rm{Bin}\left(n-\sum_{j=0}^{k-1} x_j,\frac{x^{\prime}_k}{n-\sum_{j=0}^{k-1} x_j}\right), &\text{if }n-\sum_{j=0}^{k-1} x_j\geqslant x^{\prime}_k,\\[10pt]x^{\prime}_k \text{ with probability } 1, &\text{otherwise}.\end{cases}\end{equation*}






Proof. It is straightforward since, for every k, we preserve the denominator of the second parameter of the binomial distribution but make the first one larger.
Note that
 $(X^{\prime}_k-k)_{k\in[n]}$
is a martingale sequence. Unfortunately, we can not apply Theorem 4.1 directly because every
$(X^{\prime}_k-k)_{k\in[n]}$
is a martingale sequence. Unfortunately, we can not apply Theorem 4.1 directly because every
 $X^{\prime}_k$
ranges in a large interval (mostly for small k). Instead, we cut the tails of these random variables and construct a new martingale. To do that we need the following property of binomial distributions.
$X^{\prime}_k$
ranges in a large interval (mostly for small k). Instead, we cut the tails of these random variables and construct a new martingale. To do that we need the following property of binomial distributions.
Lemma 6.3. Let N and
 $a\leqslant N$
be positive integers,
$a\leqslant N$
be positive integers,
 $\xi\sim\rm{Bin}(N,\frac{a}{N})$
. Then, for every
$\xi\sim\rm{Bin}(N,\frac{a}{N})$
. Then, for every
 $b\in\mathbb{N}$
, there exists an interval
$b\in\mathbb{N}$
, there exists an interval
 $\mathcal{I}=\mathcal{I}(N,a,b)\subset[a-b,a+b]$
such that
$\mathcal{I}=\mathcal{I}(N,a,b)\subset[a-b,a+b]$
such that
-
•
$\mathbb{P}(\xi\notin\mathcal{I})\leqslant N^2\mathbb{P}(\xi\notin[a-b,a+b])$
, -
•
$\exists c\in[a-b,a+b]$
such that the function
$f\,:\,\mathbb{R}\to\mathbb{R}$
defined by satisfies
\begin{equation*}f(x)\,:\!=\,\left\{\begin{array}{cc}x, & x\in\mathcal{I} \\ c, & x\notin\mathcal{I}\end{array}\right.\end{equation*}
$\mathbb{E}\left[{f(\xi)}\right] =a$
.





Proof. For
 $a=N/2$
, we get the result by setting
$a=N/2$
, we get the result by setting
 $\mathcal{I}=[a-b,a+b]$
and
$\mathcal{I}=[a-b,a+b]$
and
 $c=a$
. For the following, without loss of the generality, we may assume
$c=a$
. For the following, without loss of the generality, we may assume
 $a<N/2$
since the proof for
$a<N/2$
since the proof for
 $a>N/2$
is symmetric.
$a>N/2$
is symmetric.
Let us consider the set
 $\mathcal{S}$
of all integers s such that
$\mathcal{S}$
of all integers s such that
 \begin{equation} {\mathbb{E}}[\xi \mathbb{1}_{\{\xi\in[a-s,a+b]\}}]\geqslant a\mathbb{P}(\xi\in[a-s,a+b]).\end{equation}
\begin{equation} {\mathbb{E}}[\xi \mathbb{1}_{\{\xi\in[a-s,a+b]\}}]\geqslant a\mathbb{P}(\xi\in[a-s,a+b]).\end{equation}
It is clear that
 $0\in\mathcal{S}$
. However, for every
$0\in\mathcal{S}$
. However, for every
 $x\in\mathbb{N}$
,
$x\in\mathbb{N}$
,
 $\mathbb{P}(\xi=a-x)>\mathbb{P}(\xi=a+x)$
. Indeed,
$\mathbb{P}(\xi=a-x)>\mathbb{P}(\xi=a+x)$
. Indeed,
 \begin{equation*} \frac{\mathbb{P}\left(\xi=a-x\right)}{\mathbb{P}\left(\xi=a+x\right)}=\frac{\left(1+\frac{x}{a}\right)\left(1+\frac{x-1}{a}\right)\ldots\left(1-\frac{x-1}{a}\right)}{\left(1+\frac{x}{N-a}\right)\left(1+\frac{x-1}{N-a}\right)\ldots\left(1-\frac{x-1}{N-a}\right)}>1.\end{equation*}
\begin{equation*} \frac{\mathbb{P}\left(\xi=a-x\right)}{\mathbb{P}\left(\xi=a+x\right)}=\frac{\left(1+\frac{x}{a}\right)\left(1+\frac{x-1}{a}\right)\ldots\left(1-\frac{x-1}{a}\right)}{\left(1+\frac{x}{N-a}\right)\left(1+\frac{x-1}{N-a}\right)\ldots\left(1-\frac{x-1}{N-a}\right)}>1.\end{equation*}
Therefore,
 $b\notin\mathcal{S}$
. Let
$b\notin\mathcal{S}$
. Let
 $s^*$
be the maximum integer from
$s^*$
be the maximum integer from
 $\mathcal{S}$
. Then,
$\mathcal{S}$
. Then,
 $s^*\in[1,b-1]$
and
$s^*\in[1,b-1]$
and
 \begin{equation}{\mathbb{E}}[\xi \mathbb{1}_{\{\xi\in[a-s^*-1,a+b]\}}]<a\mathbb{P}(\xi\in[a-s^*-1,a+b]).\end{equation}
\begin{equation}{\mathbb{E}}[\xi \mathbb{1}_{\{\xi\in[a-s^*-1,a+b]\}}]<a\mathbb{P}(\xi\in[a-s^*-1,a+b]).\end{equation}
Let us prove that
 $\mathcal{I}=[a-s^*,a+b]$
is the desired interval. From (23), we get
$\mathcal{I}=[a-s^*,a+b]$
is the desired interval. From (23), we get
 \begin{align*} {\mathbb{E}}&[(a-s^*-1)\mathbb{1}_{\{\xi\notin\mathcal{I}\}}+\xi\mathbb{1}_{\{\xi\in\mathcal{I}\}}]\\ &={\mathbb{E}}[(a-s^*-1)] \mathbb{1}_{\{\xi\notin[a-s^*-1,a+b]\}}+\xi\mathbb{1}_{\{\xi\in[a-s^*-1,a+b]\}}]\\ &<(a-s^*-1)\mathbb{P}(\xi\notin[a-s^*-1,a+b])+a\mathbb{P}(\xi\in[a-s^*-1,a+b])<a.\end{align*}
\begin{align*} {\mathbb{E}}&[(a-s^*-1)\mathbb{1}_{\{\xi\notin\mathcal{I}\}}+\xi\mathbb{1}_{\{\xi\in\mathcal{I}\}}]\\ &={\mathbb{E}}[(a-s^*-1)] \mathbb{1}_{\{\xi\notin[a-s^*-1,a+b]\}}+\xi\mathbb{1}_{\{\xi\in[a-s^*-1,a+b]\}}]\\ &<(a-s^*-1)\mathbb{P}(\xi\notin[a-s^*-1,a+b])+a\mathbb{P}(\xi\in[a-s^*-1,a+b])<a.\end{align*}
Moreover, since (22) holds for
 $s=s^*$
,
$s=s^*$
,
 \begin{equation*} {\mathbb{E}}[a\mathbb{1}_{\{\xi\notin\mathcal{I}\}}+\xi\mathbb{1}_{\{\xi\in\mathcal{I}\}}]\geqslant a\mathbb{P}(\xi\notin\mathcal{I})+a\mathbb{P}(\xi\in\mathcal{I})=a.\end{equation*}
\begin{equation*} {\mathbb{E}}[a\mathbb{1}_{\{\xi\notin\mathcal{I}\}}+\xi\mathbb{1}_{\{\xi\in\mathcal{I}\}}]\geqslant a\mathbb{P}(\xi\notin\mathcal{I})+a\mathbb{P}(\xi\in\mathcal{I})=a.\end{equation*}
Therefore, there exists
 $c\in(a-s^*-1,a]$
such that
$c\in(a-s^*-1,a]$
such that
 ${\mathbb{E}}[cI(\xi\notin\mathcal{I})+\xi I(\xi\in\mathcal{I})]=a$
.
${\mathbb{E}}[cI(\xi\notin\mathcal{I})+\xi I(\xi\in\mathcal{I})]=a$
.
It remains to estimate
 $\mathbb{P}(\xi\notin\mathcal{I})$
from above. Notice that, from (23),
$\mathbb{P}(\xi\notin\mathcal{I})$
from above. Notice that, from (23),
 \begin{equation*} a\mathbb{P}(\xi\in[a-s^*-1,a+b])+(a-s^*)\mathbb{P}(\xi<a-s^*-1)+N\mathbb{P}(\xi>a+b)>a.\end{equation*}
\begin{equation*} a\mathbb{P}(\xi\in[a-s^*-1,a+b])+(a-s^*)\mathbb{P}(\xi<a-s^*-1)+N\mathbb{P}(\xi>a+b)>a.\end{equation*}
Therefore,
 $s^*\mathbb{P}(\xi<a-s^*-1)<N\mathbb{P}(\xi>a+b)$
. Since
$s^*\mathbb{P}(\xi<a-s^*-1)<N\mathbb{P}(\xi>a+b)$
. Since
 $2a\mathbb{P}(\xi=a-s^*-2)>\mathbb{P}(\xi=a-s^*-1)$
, we get
$2a\mathbb{P}(\xi=a-s^*-2)>\mathbb{P}(\xi=a-s^*-1)$
, we get
 \begin{equation*} \mathbb{P}(\xi<a-s^*)<(2a+1)\mathbb{P}(\xi<a-s^*-1)\leqslant N^2\mathbb{P}(\xi>a+b),\end{equation*}
\begin{equation*} \mathbb{P}(\xi<a-s^*)<(2a+1)\mathbb{P}(\xi<a-s^*-1)\leqslant N^2\mathbb{P}(\xi>a+b),\end{equation*}
and this immediately implies that
 $\mathbb{P}(\xi\notin\mathcal{I})\leqslant N^2\mathbb{P}(\xi\notin[a-b,a+b])$
.
$\mathbb{P}(\xi\notin\mathcal{I})\leqslant N^2\mathbb{P}(\xi\notin[a-b,a+b])$
.
Now, we are ready to construct a martingale sequence that coincides with
 $X^{\prime}_k-k$
with probability very close to 1, but is more suitable for applying Theorem 4.1. For every
$X^{\prime}_k-k$
with probability very close to 1, but is more suitable for applying Theorem 4.1. For every
 $k\geqslant 2$
, consider the event
$k\geqslant 2$
, consider the event
 \begin{equation*}\mathcal{B}_k\,:\!=\,\left\{n-\sum_{j=0}^{k-2}X_j\geqslant X^{\prime}_{k-1}\right\}.\end{equation*}
\begin{equation*}\mathcal{B}_k\,:\!=\,\left\{n-\sum_{j=0}^{k-2}X_j\geqslant X^{\prime}_{k-1}\right\}.\end{equation*}
For
 $\omega\in\mathcal{B}_k$
, denote
$\omega\in\mathcal{B}_k$
, denote
 \begin{align*}\mathcal{I}_k&\,:\!=\,\mathcal{I}\left(n-\sum_{j=0}^{k-2}X_j,X^{\prime}_{k-1},\sqrt{X^{\prime}_{k-1}}\,{\textrm{log}}\, n\right),\\f_k&\,:\!=\,f\left(n-\sum_{j=0}^{k-2}X_j,X^{\prime}_{k-1},\sqrt{X^{\prime}_{k-1}}\,{\textrm{log}}\, n\right).\end{align*}
\begin{align*}\mathcal{I}_k&\,:\!=\,\mathcal{I}\left(n-\sum_{j=0}^{k-2}X_j,X^{\prime}_{k-1},\sqrt{X^{\prime}_{k-1}}\,{\textrm{log}}\, n\right),\\f_k&\,:\!=\,f\left(n-\sum_{j=0}^{k-2}X_j,X^{\prime}_{k-1},\sqrt{X^{\prime}_{k-1}}\,{\textrm{log}}\, n\right).\end{align*}
Let
 \begin{equation*}\mathcal{E}_k\,:\!=\,\mathcal{B}_k\cap\left(\bigcap_{j=1}^k\{X^{\prime}_j-1\in\mathcal{I}_j\}\right).\end{equation*}
\begin{equation*}\mathcal{E}_k\,:\!=\,\mathcal{B}_k\cap\left(\bigcap_{j=1}^k\{X^{\prime}_j-1\in\mathcal{I}_j\}\right).\end{equation*}
Define the sequence
 $(Y_k)_{k\in[n]}$
as follows. Let
$(Y_k)_{k\in[n]}$
as follows. Let
 $Y_0\,:\!=\,X^{\prime}_0=1$
. For
$Y_0\,:\!=\,X^{\prime}_0=1$
. For
 $k\geqslant 1$
, set
$k\geqslant 1$
, set
 \begin{equation*}Y_k\,:\!=\,[f_k(X^{\prime}_k -1)-(k-1)]\mathbb{1}_{\mathcal{E}_k}+Y_{k-1}\mathbb{1}_{\overline{\mathcal{E}_k}}.\end{equation*}
\begin{equation*}Y_k\,:\!=\,[f_k(X^{\prime}_k -1)-(k-1)]\mathbb{1}_{\mathcal{E}_k}+Y_{k-1}\mathbb{1}_{\overline{\mathcal{E}_k}}.\end{equation*}
Using Lemmas 6.2 and 6.3, we find that
 $(Y_0,Y_1,\ldots,Y_n)$
is a martingale sequence with respect to the filtration
$(Y_0,Y_1,\ldots,Y_n)$
is a martingale sequence with respect to the filtration
 $\mathcal{F}_i = \sigma(X_j,X^{\prime}_j \mathrel{:} \,0\leqslant j\leqslant i)$
for all
$\mathcal{F}_i = \sigma(X_j,X^{\prime}_j \mathrel{:} \,0\leqslant j\leqslant i)$
for all
 $i\in\{0,1,\ldots,n\}$
.
$i\in\{0,1,\ldots,n\}$
.
Lemma 6.4. Let
 $c>0$
be a fixed constant. Then, the following bounds hold:
$c>0$
be a fixed constant. Then, the following bounds hold:
-
a.
$\mathbb{P}\left(\exists k\in[n]:\,\,Y_k>k\,{\rm{log}}^4 n\right)\leqslant e^{-\omega({\rm{log}}\, n)}$
, -
b.
$\mathbb{P}\left(\exists k\in[n]:\,\,Y_k\neq X^{\prime}_k -k\right)\leqslant e^{-\omega({\rm{log}}\, n)}$
.


Proof. For (a), we apply Theorem 4.1. First, we estimate the conditional ranges. From Lemma 6.3, we get that, for all
 $k\in[n]$
$k\in[n]$
 \begin{equation*}\textrm{ran}_k [Y_{k+1}]\leqslant 2\sqrt{X^{\prime}_k}\,{\textrm{log}}\, n\, \mathbb{1}_{\mathcal{E}_k}=2\sqrt{Y_k+k}\,{\textrm{log}}\, n \,\mathbb{1}_{\mathcal{E}_k}.\end{equation*}
\begin{equation*}\textrm{ran}_k [Y_{k+1}]\leqslant 2\sqrt{X^{\prime}_k}\,{\textrm{log}}\, n\, \mathbb{1}_{\mathcal{E}_k}=2\sqrt{Y_k+k}\,{\textrm{log}}\, n \,\mathbb{1}_{\mathcal{E}_k}.\end{equation*}
We prove by induction on k that
 ${\textsf{P}}(Y_k> k\,{\textrm{log}}^4\, n)\leqslant\exp[-c\,{\textrm{log}}^2 n]$
, where
${\textsf{P}}(Y_k> k\,{\textrm{log}}^4\, n)\leqslant\exp[-c\,{\textrm{log}}^2 n]$
, where
 $c>0$
does not depend on k and n. For
$c>0$
does not depend on k and n. For
 $k=1$
, we have
$k=1$
, we have
 $\mathbb{P}(Y_1>{\textrm{log}}^4\, n)\leqslant \mathbb{P}(Y_1>{\textrm{log}}\, n)=0$
.
$\mathbb{P}(Y_1>{\textrm{log}}^4\, n)\leqslant \mathbb{P}(Y_1>{\textrm{log}}\, n)=0$
.
Assume that
 $\mathbb{P}(Y_j> j\,{\textrm{log}}^4\, n-j)\leqslant\exp[-{\textrm{log}}^2 n(1+o(1))]$
for all
$\mathbb{P}(Y_j> j\,{\textrm{log}}^4\, n-j)\leqslant\exp[-{\textrm{log}}^2 n(1+o(1))]$
for all
 $j\leqslant k$
. Then, with a probability at least
$j\leqslant k$
. Then, with a probability at least
 $1-n\exp[{-}{\textrm{log}}^2 n(1+o(1))]=1-\exp[{-}{\textrm{log}}^2 n(1+o(1))]$
,
$1-n\exp[{-}{\textrm{log}}^2 n(1+o(1))]=1-\exp[{-}{\textrm{log}}^2 n(1+o(1))]$
,
 \begin{equation*}\sum_{j=1}^{k+1}(\textrm{ran}_{j-1}[Y_j])^2\leqslant 4\,{\textrm{log}}^2 n\sum_{j=0}^{k}(Y_j+j)\leqslant 2k^2\,{\textrm{log}}^6 n.\end{equation*}
\begin{equation*}\sum_{j=1}^{k+1}(\textrm{ran}_{j-1}[Y_j])^2\leqslant 4\,{\textrm{log}}^2 n\sum_{j=0}^{k}(Y_j+j)\leqslant 2k^2\,{\textrm{log}}^6 n.\end{equation*}
Therefore, by Theorem 4.1,
 \begin{align*}\mathbb{P}\Big(Y_{k+1}>&(k+1)\,{\textrm{log}}^4\, n-(k+1)\Big) \\[5pt] &\leqslant2\exp\!\left[-\frac{(k+1)^2}{k^2}\,{\textrm{log}}^2 n(1+o(1))\right]+2\exp\left[-{\textrm{log}}^2 n(1+o(1))\right]\\[5pt] &=\exp\!\left[-{\textrm{log}}^2 n(1+o(1))\right].\end{align*}
\begin{align*}\mathbb{P}\Big(Y_{k+1}>&(k+1)\,{\textrm{log}}^4\, n-(k+1)\Big) \\[5pt] &\leqslant2\exp\!\left[-\frac{(k+1)^2}{k^2}\,{\textrm{log}}^2 n(1+o(1))\right]+2\exp\left[-{\textrm{log}}^2 n(1+o(1))\right]\\[5pt] &=\exp\!\left[-{\textrm{log}}^2 n(1+o(1))\right].\end{align*}
This proves (a).
For (b), observe that, by the definition of
 $Y_k$
,
$Y_k$
,
 \begin{equation*}\mathbb{P}(\exists k \quad Y_k\neq X^{\prime}_k)=\mathbb{P}\left(\bigcup_k\mathcal{B}_k{\setminus}\mathcal{E}_k\right)\leqslant\sum_{k=1}^n\mathbb{P}\left(X^{\prime}_k-1\notin\mathcal{I}_k \mid \mathcal{B}_k\right).\end{equation*}
\begin{equation*}\mathbb{P}(\exists k \quad Y_k\neq X^{\prime}_k)=\mathbb{P}\left(\bigcup_k\mathcal{B}_k{\setminus}\mathcal{E}_k\right)\leqslant\sum_{k=1}^n\mathbb{P}\left(X^{\prime}_k-1\notin\mathcal{I}_k \mid \mathcal{B}_k\right).\end{equation*}
Each term in the sum above is
 $e^{-\omega({\textrm{log}}\, n)}$
by Lemma 6.5 and the difinition of
$e^{-\omega({\textrm{log}}\, n)}$
by Lemma 6.5 and the difinition of
 $X^{\prime}_k$
given in Lemma 6.2. Part (b) follows.
$X^{\prime}_k$
given in Lemma 6.2. Part (b) follows.
Lemma 6.5. For n large enough and all positive integers
 $a\leqslant N$
, a random variable
$a\leqslant N$
, a random variable
 $\xi \sim \rm{Bin}(N,a/N)$
satisfies the following:
$\xi \sim \rm{Bin}(N,a/N)$
satisfies the following:
 \begin{equation*}\mathbb{P}(|\xi-a|>\sqrt{a}\,{\rm{log}}\, n)\leqslant\rm{exp}\left(-\dfrac{1}{5}{\rm{log}}\, n\,{\rm{log}}\,{\rm{log}}\, n\right).\end{equation*}
\begin{equation*}\mathbb{P}(|\xi-a|>\sqrt{a}\,{\rm{log}}\, n)\leqslant\rm{exp}\left(-\dfrac{1}{5}{\rm{log}}\, n\,{\rm{log}}\,{\rm{log}}\, n\right).\end{equation*}
Proof. By the Chernoff bounds,
 \begin{align*}\mathbb{P}(\xi\geqslant a+\sqrt{a}\,{\textrm{log}}\, n)&\leqslant\textrm{exp}\!\left[\sqrt{a}\,{\textrm{log}}\, n-(a+\sqrt{a}\,{\textrm{log}}\, n)\ln\left(1+\frac{{\textrm{log}}\, n}{\sqrt{a}}\right)\right],\\[5pt] \mathbb{P}(\xi\leqslant a-\sqrt{a}\,{\textrm{log}}\, n)&\leqslant \textrm{exp}\!\left[-\frac{1}{2}{\textrm{log}}^2 n\right]\end{align*}
\begin{align*}\mathbb{P}(\xi\geqslant a+\sqrt{a}\,{\textrm{log}}\, n)&\leqslant\textrm{exp}\!\left[\sqrt{a}\,{\textrm{log}}\, n-(a+\sqrt{a}\,{\textrm{log}}\, n)\ln\left(1+\frac{{\textrm{log}}\, n}{\sqrt{a}}\right)\right],\\[5pt] \mathbb{P}(\xi\leqslant a-\sqrt{a}\,{\textrm{log}}\, n)&\leqslant \textrm{exp}\!\left[-\frac{1}{2}{\textrm{log}}^2 n\right]\end{align*}
It is straightforward to check that the stated bound holds for all possible values of a.





 Open access
Open access