





Introduction
Bilinguals with extensive experience in their second language (L2) often struggle to retrieve a word in their native language as effortlessly as monolingual speakers. This and other similar phenomena encompassing impaired accessibility to or the modification of the native language after substantial exposure to an L2 are commonly known as first language (L1) attrition (Schmid & Köpke, Reference Schmid, Köpke and Pavlenko2009, Reference Schmid and Köpke2017). Traditionally, lexical attrition in particular has attracted researchers’ attention, likely because of the prevalence of word usage difficulties, which are commonly observed in bilinguals experiencing L1 attrition (Gallo et al., Reference Gallo, Bermudez-Margaretto, Shtyrov, Abutalebi, Kreiner, Chitaya, Petrova and Myachykov2021; Jarvis, Reference Jarvis, Schmid and Köpke2019; Schmid & Jarvis, Reference Schmid and Jarvis2014).
In general, two main factors are thought to contribute to the relative decline of L1 linguistic abilities in bilinguals: (i) reduced L1 exposure and use, resulting in linguistic reorganisation and impairments in lexical access, and (ii) the online interference of a competing L2 (Schmid, Reference Schmid2011; Schmid & Köpke, Reference Schmid and Köpke2017). Consequently, aspects of second language experience and development, such as use, exposure, and proficiency, are deemed crucial in predicting attrition effects in the L1 (Schmid, Reference Schmid, Schmid and Köpke2019).
Nonetheless, the complexity of the bilingual experience makes examining these potential predictors a challenging and often unsatisfactory endeavour. Indeed, despite considerable scholarly efforts, the current literature on the role of experiential factors in the emergence and progression of L1 attrition still renders a blurry picture (Schmid & Köpke, Reference Schmid and Köpke2017, Reference Schmid, Köpke, Cherciov, Karayayla, Keijzer, De Leeuw, Mehotcheva, Montrul and Polinsky2019). In the case of L1 lexical attrition, this discouraging state of affairs may be partly explained by the reliance on traditional methods lacking the sensitivity required to capture subtle changes in the lexicon (Jarvis, Reference Jarvis, Schmid and Köpke2019).
In this study, we overcome these problems by employing network science tools to analyse semantic fluency data from two groups of Spanish–English bilinguals. While both groups had similarly high L2 proficiency, their exposure to the L2 differed (immersed vs non-immersed). As we will show, our results demonstrate the ability of network science tools to effectively capture the nuanced dynamics within the bilingual semantic memory system brought about by language use, underscoring their potential as powerful instruments in the study of lexical attrition. Furthermore, our data illuminate the developmental trajectory of L1 lexical attrition. Drawing from these insights, we introduce the Lexical Attrition Foundation (LeAF) framework, which aims to serve as a theoretical and methodological paradigm to investigate this evolution and its possible effects in language-related processes from a network perspective.
L1 lexical attrition and the role of immersion
As pointed out, in the definition of L1 attrition we entertain here, the role of the L2 is pivotal in prompting changes in the native language. Traditionally, extensive L2 experience has been regarded as necessary for the L2 to significantly impact the well-established L1 (but see evidence of influence after only minimal exposure during beginner L2 learning in Chang, Reference Chang2012; Levy et al., Reference Levy, McVeigh, Marful and Anderson2007; Linck et al., Reference Linck, Kroll and Sunderman2009). Therefore, immersion contexts represent ideal testing grounds for studying L1 attrition effects. Not surprisingly, inspecting immersed participants is common practice in research on lexical attrition (e.g., Casado et al., Reference Casado, Walther, Wolna, Szewczyk, Sorace and Wodniecka2023; Malt et al., Reference Malt, Li, Pavlenko, Zhu and Ameel2015; Schmid & Jarvis, Reference Schmid and Jarvis2014; Schmid & Yilmaz, Reference Schmid and Yilmaz2021; Yilmaz & Schmid, Reference Yilmaz and Schmid2012) as well as in studies focused on changes in syntactic representation and processing in the native language (e.g., Chamorro et al., Reference Chamorro, Sorace and Sturt2016; Dussias & Sagarra, Reference Dussias and Sagarra2007; Gargiulo & van de Weijer, Reference Gargiulo and van de Weijer2020; Tsimpli et al., Reference Tsimpli, Sorace, Heycock and Filiaci2004).
While a comprehensive review of the impact of length of immersion lies beyond the scope of the present work, two previous studies are particularly relevant due to their similarities with our investigation. Both studies (i) employed semantic fluency tasks, where participants generated exemplars of a given semantic category within a timeframe, and (ii) targeted late bilinguals who moved to the immersion context after puberty.
Similar to our experimental design, Linck et al. (Reference Linck, Kroll and Sunderman2009) compared two groups of L2-immersed and non-immersed English-Spanish bilinguals. In their study, however, the immersed participants had only been living in Spain for three months. Yet, even with this short duration, these individuals exhibited comparatively reduced access to their L1 during both a translation recognition and a semantic fluency task. On the other hand, Baus et al. (Reference Baus, Costa and Carreiras2013) assessed native speakers of German learning Spanish at two points: upon their arrival in Spain for a six-month immersive language learning experience; and at their departure. The participants underwent a picture-naming task and displayed a decline in performance post-immersion, taking more time to name the pictures. Notably, this decline was restricted to low-frequency non-cognate words. Most relevant to our current objectives, no significant difference emerged in the semantic fluency task results pre- and post-immersion.
What could account for these discrepancies in the semantic fluency outcomes? In the following section, we argue that the inherent limitations of the traditional approaches employed to analyse the data from this task may explain these inconsistent results. Crucially, our current network science approach offers a robust solution to these limitations, thereby enhancing the consistency and reliability of semantic fluency tasks as effective tools for capturing lexical-semantic representation.
L1 lexical attrition and methodological limitations
Verbal fluency tasks have a long-standing tradition in lexical attrition research, as they are believed to effectively capture lexical-semantic access, retrieval, and organisation (Shao et al., Reference Shao, Janse, Visser and Meyer2014). Researchers typically employ two variants: letter fluency, where participants generate words starting with a particular letter, and semantic fluency, where, as discussed above, participants provide exemplars of a particular semantic category (e.g., Mickan et al., Reference Mickan, McQueen, Brehm and Lemhöfer2023; Schmid, Reference Schmid, Köpke, Schmid, Keijzer and Dostert2007; Schmid & Jarvis, Reference Schmid and Jarvis2014; Schmid & Karayayla, Reference Schmid and Karayayla2020; Schmid & Köpke, Reference Schmid, Köpke and Pavlenko2009; Yağmur, Reference Yağmur1997). Importantly, semantic fluency is regarded as more naturalistic since it taps into the common association-based cognitive processes within the lexicon. In contrast, generating words beginning with the same letter is not a task we typically engage in during everyday conversations. This distinction potentially explains the greater involvement of inhibitory control in letter fluency tasks (e.g., Birn et al., Reference Birn, Kenworthy, Case, Caravella, Jones, Bandettini and Martin2010; Patra et al., Reference Patra, Bose and Marinis2020).
Despite its widespread use, the evidence provided by verbal fluency tasks remains somewhat inconsistent, with some studies showing attrition effects, while others do not (e.g., Luo et al., Reference Luo, Luk and Bialystok2010; Patra et al., Reference Patra, Bose and Marinis2020; Schmid & Jarvis, Reference Schmid and Jarvis2014). Moreover, even when differences are observed, the effect sizes tend to be minimal (e.g., Schmid & Jarvis, Reference Schmid and Jarvis2014).
The analysis of verbal fluency often involves counting the number of correct responses. However, this measure may not be as effective as previously assumed since it may not fully capture the nuances of lexical-semantic retrieval and organisation in bilinguals. For instance, two groups could generate a similar total number of responses simply because the task is relatively easy, potentially obscuring meaningful differences in their linguistic abilities. To address such limitations, researchers have adopted time-course analyses, in which the generated words are grouped into specific time bins, allowing for the extraction of various measures (e.g., Friesen et al., Reference Friesen, Luo, Luk and Bialystok2015; Luo et al., Reference Luo, Luk and Bialystok2010; Patra et al., Reference Patra, Bose and Marinis2020).
Still, neither response counts nor time-course analyses are informative about the structure of the semantic system, which is believed to be a significant contributor to lexical attrition (see discussion in Gallo et al., Reference Gallo, Bermudez-Margaretto, Shtyrov, Abutalebi, Kreiner, Chitaya, Petrova and Myachykov2021). Differences between monolinguals and potentially attrited bilinguals may arise from variations in the connectivity of words at different representational levels or from discrepancies in the system's overall efficiency. Traditionally, analyses exploring structural variation have employed clustering and switching techniques (e.g., Troyer, Reference Troyer2000; Troyer et al., Reference Troyer, Moscovitch and Winocur1997). Clustering helps identify the grouping of words within the network, such as farm or African animals in the animals category. In contrast, switching assesses transitions between clusters during the completion of the task. Note, however, that this type of analysis comes with its own problems, with the primary concern being the inherent subjectivity of semantic categories, which critically undermines the empirical validity of the analysis (but see potential solutions in, e.g., Taler et al., Reference Taler, Johns, Young, Sheppard and Jones2013; Voorspoels et al., Reference Voorspoels, Storms, Longenecker, Verheyen, Weinberger and Elvevåg2014).
In summary, traditional methods exhibit significant limitations when it comes to effectively analysing the impact of attrition on semantic structures. Given these constraints, it is imperative for the field to investigate innovative approaches to capture and understand these effects. To this end, we shift our focus towards recent advancements in network science, which present vast opportunities for tackling this complex endeavour.
Leveraging network science analysis for studying lexical attrition
Network science is a relatively novel discipline based on mathematical graph theory that studies the function, dynamics, and structure of complex systems (e.g., Barabási & Albert, Reference Barabási and Albert1999; Boccaletti et al., Reference Boccaletti, Latora, Moreno, Chavez and Hwang2006). This approach is particularly well-suited for investigating lexical-semantic representation and processing, as it aligns with the long-standing assumption that our lexicons function as networks (Collins & Loftus, Reference Collins and Loftus1975). Within these systems, nodes represent words or concepts, while edges signify the relationships between them (e.g., semantic, associative, or phonological). Notably, this conceptualisation has contributed significantly to our understanding of the lexicon and the cognitive mechanisms involved in its development and functioning (e.g., Castro et al., Reference Castro, Stella and Siew2020; Castro & Siew, Reference Castro and Siew2020; De Deyne et al., Reference De Deyne, Navarro, Perfors and Storms2016; Steyvers & Tenenbaum, Reference Steyvers and Tenenbaum2005; Vitevitch, Reference Vitevitch2022; see Li & Xu, Reference Li and Xu2022, for a recent review focusing on bilingual language learning).
It is important to note that many different real-world networks present a so-called small-world structure, which is characterised by having tightly-knit clusters of nodes while still maintaining relatively short pathways between any two nodes. In language networks, small-worldness is believed to emerge due to the competing aspects of language use and memory constraints (Siew et al., Reference Siew, Wulff, Beckage and Kenett2019). To investigate these structural attributes, networks are assessed using a set of global measures. For example, average shortest-path length (ASPL) indicates the average distance between each pair of nodes; clustering coefficient (CC) reflects the degree to which nodes tend to group together; and modularity (Q) quantifies the degree to which the network comprises distinct communities.
Due to its recency, one of the drawbacks of using network science approaches has been the difficulty in applying reliable and robust statistical methods (Siew et al., Reference Siew, Wulff, Beckage and Kenett2019). However, recent developments have successfully overcome this problem, allowing significance testing through comparisons with random networks and bootstrap analyses (e.g., Christensen & Kenett, Reference Christensen and Kenett2021; Kenett et al., Reference Kenett, Wechsler-Kashi, Kenett, Schwartz, Ben-Jacob and Faust2013). Recent studies have proved these approaches to be enormously efficient and insightful when examining differences in semantic memory structure across various populations. Examples include research on creativity (Kenett et al., Reference Kenett, Anaki and Faust2014), metaphor production (Li et al., Reference Li, Kenett, Hu and Beaty2021), educational experience (Denervaud et al., Reference Denervaud, Christensen, Kenett and Beaty2021), and openness to experience (Christensen et al., Reference Christensen, Kenett, Cotter, Beaty and Silvia2018), to name just a few.
For instance, within the specific domain of cognitive network science, ASPL has been shown to reflect semantic integration and efficiency of information flow, with lower values indicating faster navigability across the system (Siew & Guru, Reference Siew and Guru2023). On the other hand, high CC values signify a better semantic organisation at the local level (e.g., Christensen et al., Reference Christensen, Kenett, Cotter, Beaty and Silvia2018; Cosgrove et al., Reference Cosgrove, Kenett, Beaty and Diaz2021). Interestingly, the role of modularity (Q) remains more contentious, as existing findings are somewhat contradictory. For example, higher Q values, indicating networks with more independent modules, have been associated with fluid intelligence (Kenett et al., Reference Kenett, Beaty, Silvia, Anaki and Faust2016a). Contrary to this, a study investigating novice and expert knowledge revealed that the semantic systems of experts had lower Q values (Siew & Guru, Reference Siew and Guru2023). This finding aligns with the increased creative abilities linked to less modular networks observed in Kenett et al. (Reference Kenett, Anaki and Faust2014). Further complicating this picture, extreme modularity has been associated with rigidity of thought in individuals with Asperger syndrome (Kenett et al., Reference Kenett, Gold and Faust2016b).
Two studies deserve particular attention in this discussion given their focus on examining bilingual individuals’ networks. Borodkin et al. (Reference Borodkin, Kenett, Faust and Mashal2016) provided relevant evidence regarding the intricacies of the bilingual semantic system. They investigated the organisation of the L2 lexicon in English–Hebrew early bilinguals. Their data revealed that the L2 semantic system displayed higher CC and lower Q values compared with native language networks, while the pattern of ASPL values was inconsistent.
Previous interpretations of global network measures (particularly clustering coefficients) might suggest that the L2 network had a superior overall organisation. However, Borodkin and colleagues concluded the contrary, arguing that L1 networks yielded more differentiated communities (i.e., higher modularity). While the role of modularity in the efficiency of lexical-semantic networks may be more disputable (see our previous discussion), increased network density, as reflected by clustering coefficients, has invariably been considered a marker of greater connectivity. As such, Borodkin et al.'s conclusions are, at least partially, hard to reconcile with previous findings.
It is important to note that their study examined bilinguals exposed to L2 Hebrew at an early age, who subsequently started living in a Hebrew-dominant environment for years. When attempting to align their findings with previous reports, it is conceivable that, in fact, their participants’ L2 networks were more efficiently organised and integrated. This remains a plausible explanation despite the participants’ assumed lower proficiency in L2 Hebrew (L1 proficiencies were not provided) – which was, nevertheless, high overall – and the fact that they reported using English slightly more than Hebrew in their daily lives.
In a more recent study, Feng and Liu (Reference Feng and Liu2023) examined the L2 networks of Chinese–English late sequential bilinguals. Using a cross-sectional design, they investigated two groups of university students in China. The first group consisted of undergraduates majoring in engineering taking only one English course. In contrast, the second group included graduates with majors in either translation or interpreting, with English serving as both the target language and the language of instruction. This experimental design enabled the authors to gain insights into the changes in the non-native semantic system resulting from intensive L2 experience. Overall, they observed that graduate networks had a significantly higher clustering coefficient, while average shortest-path length did not differ across groups. It should be noted that modularity was not investigated in their study.
As this review demonstrates, network science measures have proven notably effective in investigating semantic organisation. Further, the emerging but still very limited body of research on bilingual networks underscores the suitability of this methodology for examining shifts in lexical-semantic networks resulting from varying bilingual experiences. Since lexical attrition is driven by such structural changes within the lexicon (alongside the effects of cross-linguistic influence), network science stands out as an ideal tool for delving into this phenomenon. Remarkably, to date, no attempt has been made to incorporate global network measures into L1 lexical attrition research, despite the topic being one of the most investigated areas in psycholinguistics research. The present study takes on this novel endeavour, laying the groundwork for future investigations into L1 attrition from a network science perspective.
The present study
We investigated lexical attrition effects in two groups of late L1 Spanish–L2 English bilinguals with high proficiency in their L2 English. Half of the participants were recruited from the UK, an L2-dominant environment, while the other half resided in Spain. This critical manipulation allowed us to examine how L2 immersion impacts the L1 and L2 lexical-semantic networks. Moreover, we assessed the participants’ L2 proficiencies to ensure our two groups were similar in that regard. In doing so, we effectively isolated any potential confounding effects of that factor, focusing on a more theoretically relevant construct (e.g., Chaouch-Orozco et al., Reference Chaouch-Orozco, González Alonso and Rothman2021, Reference Chaouch-Orozco, González Alonso, Duñabeitia and Rothman2023).
The subjects completed two semantic fluency tasks, one in each language. Crucially, going beyond the traditional response-count analysis, we employed a network science approach, capitalising on recent advances in network science tools that have proved highly effective in the study of semantic organisation across diverse populations.
Our predictions were straightforward: Language experience would alter the structure of the participants’ semantic lexicon. Regardless of the language in focus, higher clustering coefficient (CC) and lower average shortest-path length (ASPL) and modularity (Q) values would signify structural superiority and increased connective efficiency. Nonetheless, based on previous research, we anticipated greater variability in the ASPL and Q indices. More specifically, we expected that participants immersed in an L2 environment, despite having similar L2 proficiency levels, would display more robust, interconnected, and flexible networks in their L2 English. This hypothesis is hardly surprising, as greater exposure to a less established language should naturally foster further development. However, the significance of this prediction for our study is paramount. If confirmed, it would serve as a proof of concept for the validity of our current network science methodology as well as for the findings related to the native language. As for the predictions regarding the L1 networks, we expected the immersed participants would exhibit a decline in the quality of the overall organisation of their native semantic systems.
Anticipating our results, our network analyses reveal that L2 experience significantly impacts the network topography of both languages. Furthermore, our data shed light on the gradual unfolding of lexical attrition within the structural properties of the native semantic system. Based on these insights, we introduce the Lexical Attrition Foundation (LeAF) framework, which aims to provide a network-based guideline for studying and understanding the progressive structural transformations that result in lexical attrition, alongside its potential effects for real-time communication.
Method
Participants
Two groups of 94 immersed (69 females) and 80 non-immersed (64 females) L1 Spanish–L2 English bilinguals participated in the study. All subjects were late sequential bilinguals – that is, they were raised monolingually and started learning English in school. The immersed bilinguals were raised in Spain and were living in the L2 environment (i.e., the UK) at the time of testing for an average of 3.73 years (SD = 2.52), while the non-immersed individuals were living in Spain. All subjects were highly proficient in English as measured with the Quick Placement Test (QPT). Immersed participants had a mean QPT score of 52.66 (SD = 3.08; range = 48–60), while the non-immersed subjects’ mean was 52.43 (SD = 3.63; range = 48–60). A Mann-Whitney U test indicated that this difference was non-significant. Lastly, to confirm that our immersion manipulation was effective in ensuring differences in L2 experience, we compared (i) the English use score provided by the Bilingual Language Profile (Birdsong et al., Reference Birdsong, Gertken and Amengual2012) and (ii) self-rated L2-experience scores across groups. Mann-Whitney U tests revealed that, indeed, participants in the immersed group had significantly more experience with the L2 (ps < .001).
Semantic fluency tasks
Participants completed one semantic fluency task in each language, providing as many exemplars of a category as possible within one minute. In their L1 Spanish, the category was fruits and vegetables, whereas, in their L2 English, it was animals. Both categories are among the most commonly employed in the literature (e.g., Ardila et al., Reference Ardila, Ostrosky-Solís and Bernal2006; Borodkin et al., Reference Borodkin, Kenett, Faust and Mashal2016).
Network estimation
All data and codes generated for the analysis are publicly available in the first authors’ OSF repository (https://osf.io/wyx4j/?view_only=51bf758426e0479faf1c8887f4814f8e). Networks were created and analysed using the SemNetDictionaries, SemNetCleaner and SemNet packages developed by Christensen and Kenett (Reference Christensen and Kenett2021). Participant responses were first cleaned by performing a spell-check, converting plural forms to singular, and standardising terms referring to the same concept to the most common label. Then, for each of the four lists (i.e., immersed L1 and L2, and non-immersed L1 and L2), we created binary data matrices with columns representing each unique response and rows representing participants. Each cell indicated whether a word was generated by a participant (i.e., “1” to indicate “yes” and “0” for “no”). Finally, idiosyncratic responses given by only one participant in each group were removed. To ensure comparability across networks and to avoid confounding effects, the number of nodes in each group's matrix (i.e., immersed and non-immersed) were matched for each comparison (i.e., L1 and L2), removing nodes that appeared only in one of the lists (Borodkin et al., Reference Borodkin, Kenett, Faust and Mashal2016; Kenett et al., Reference Kenett, Wechsler-Kashi, Kenett, Schwartz, Ben-Jacob and Faust2013).
We estimated correlation-based networks from the binary matrices. The associations reflected by the edges in each network capture co-occurrences in the data. For example, if word a is frequently generated alongside word b, both will exhibit a high association degree (Kenett et al., Reference Kenett, Wechsler-Kashi, Kenett, Schwartz, Ben-Jacob and Faust2013), which is measured with cosine similarity. The triangular maximally filtered graph was applied to further filter the network, maximising associative strengths while minimising spurious connections and noise (Christensen et al., Reference Christensen, Kenett, Cotter, Beaty and Silvia2018).
Results
Number of responses
First, we aimed to compare the performance of the two groups employing more traditional indexes of semantic fluency. We calculated the average number of total responses per participant and the total number of unique responses for each semantic category and group, and performed significance tests. For the L1 fruits and vegetables category, the number of responses was remarkably similar in the two groups. On average, non-immersed participants generated 19.32 (SD = 4.30; range = 10–29) words, whereas immersed subjects produced 19.37 (SD = 4.28; range = 11–31). A Mann-Whitney U test indicated that this difference was non-significant (W = 3949, p = .86). As per the total number of unique responses, the non-immersed group produced 85 words compared to the 88 words in the immersed group. A chi-square test revealed that the difference, again, was non-significant, X 2 (1) = .05, p = .82. For the L2 animals category, participants in the non-immersed group produced an average of 15.64 (SD = 4.19; range = 9–27) responses, while subjects in the immersed group generated 18.15 (SD = 4.15; range = 10–32). This difference was significant (W = 2593, p < 0.01). The two groups also differed in the total number of unique responses generated: 126 in the non-immersed group and 170 in the immersed subjects, this difference being significant, X 2 (1) = 6.54, p < .05.
Main network analysis
For an initial qualitative assessment, we visualised the networks (Figures 1 and 2) applying the force-directed Kamada-Kawai algorithm (Kamada & Kawai, Reference Kamada and Kawai1989) with the igraph package (Csardi & Nepusz, Reference Csardi and Nepusz2006) in R (R Core Team, 2023). Consistent with established practices in network structure studies, we employed unweighted networks, which help mitigate the noise in the interpretation of structural properties (Christensen et al., Reference Christensen, Kenett, Cotter, Beaty and Silvia2018). Furthermore, results from unweighted networks are similar to those of weighted networks (e.g., Abbott et al., Reference Abbott, Austerweil and Griffiths2015; Kenett et al., Reference Kenett, Levi, Anaki and Faust2017).
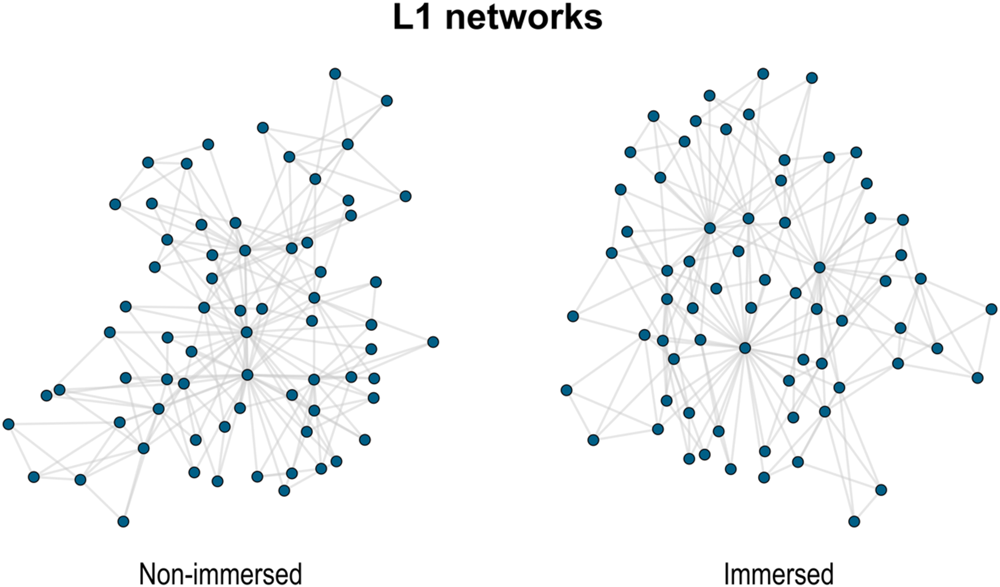
Figure 1. Visualisation of the L1 semantic networks for the immersed and non-immersed groups.
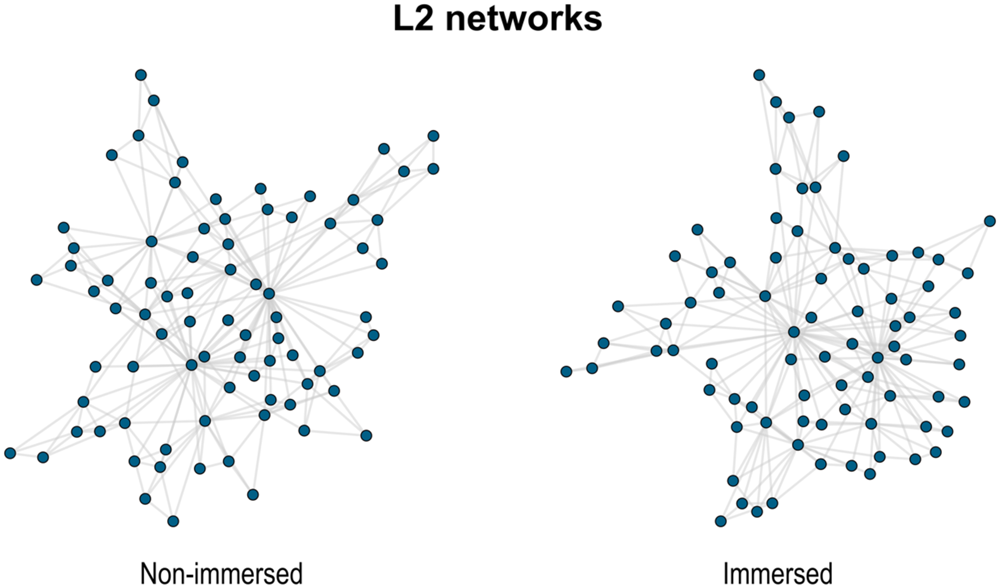
Figure 2. Visualisation of the L2 semantic networks for the immersed and non-immersed groups.
For the quantitative analysis, we first computed ASPL, CC, and Q network measures for each group's L1 and L2 networks. Following Christensen and Kenett (Reference Christensen and Kenett2021), we compared these measures from the real networks with those from random graphs to test their significance. Accordingly, for each network, we generated 1000 random networks using the Markov Chain Monte Carlo algorithm (Viger & Latapy, Reference Viger and Latapy2016), which builds graphs with the same number of nodes and edges as in the original network, but with randomised edges. This process led to a sampling distribution of the measures, which then served as a benchmark to calculate the p-values for the measures of the original networks (Table 1 presents the metrics for each network, including random networks). Our analysis confirmed that the measures from participant-derived graphs significantly deviated from those from the randomly generated networks (ps < .001).
Table 1. Network measures for the two categories and groups. Note: The random networks include the standard deviations in parentheses. ASPL, average shortest-path length; CC, clustering coefficient; Q, modularity.
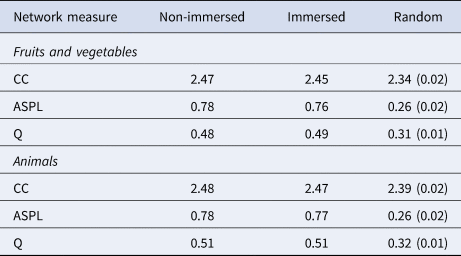
At a glance, the networks (Figures 1 and 2) and the measures presented in Table 1 might suggest minimal differences between groups. However, it is important to emphasise that these are raw averages that might not capture the full extent of variability within each group. To address this question, we next performed a bootstrap analysis to test the significance of the differences in the participants’ networks across the two groups (Christensen & Kenett, Reference Christensen and Kenett2021; Kenett et al., Reference Kenett, Gold and Faust2016b). This method allowed us to explore the distribution of these metrics within our actual data, providing a robust statistical framework to detect subtle changes in the lexicon due to language immersion.
In the bootstrap analysis, we generated partial networks by randomly selecting subsets of nodes. We repeated this process 1000 times for subsets containing 50%, 60%, 70%, 80%, and 90% of the nodes in the original networks, thus creating a sampling distribution for each measure and network. The logic behind this approach is that if two networks differ, the partial networks derived from them should also differ (Kenett et al., Reference Kenett, Gold and Faust2016b). We used analysis of covariance (ANCOVA) to test for the differences between the groups, with the percentage of nodes and edges as covariates to control for potential confounds related to the number of nodes and edges. Table 2 presents the results of the bootstrap analysis for all networks, demonstrating an effect of immersion on both the L1 and the L2.
Table 2. Bootstrap analysis results. Note: * = p < .05; ** = p < .01; *** = p < .001; t, t-statistics; d, Cohen's d values (Cohen, 1992). Negative t-statistics reflect larger means in the immersed group. Cohen's d effect sizes: 0.50, moderate; 0.80, large; 1.10, very large. ASPL, average shortest-path length; CC, clustering coefficient; Q, modularity.

The results in the L2 overwhelmingly indicated a superior structural organisation in the immersed population. All three global network measures resulted in the expected outcomes. As such, ASPL and Q values were significantly lower in the immersed group, while CC values were higher (all ps < .001). This reflects less modular and more well-connected L2 networks in the immersed group compared to the non-immersed one. More importantly, because the L2 is expected to be more susceptible to change due to increased exposure, the results with the L2 networks serve as a proof of concept, confirming the validity of the present network methodology.
Interestingly, regarding the sensitivity of the native semantic system to alterations resulting from bilingual experience, the effect of immersion was a nuanced one in the native language. Notably, clustering coefficient emerged as a robust indicator of these changes. As expected, for all partial L1 networks (i.e., 50%, 60%, 70%, 80%, 90%), clustering coefficient (CC) values were significantly higher in the non-immersed group (ps < .001), showing that the subjects with less exposure to L2 English had L1 networks that were more densely connected. On the other hand, the results for the ASPL values in the L1 were mixed, with the differences varying relative to the percentage of retained nodes. Lastly, modularity (Q) values in the L1 were significantly higher in the immersed participants’ networks, indicating more modular L1 networks. Note, however, that these effects only appeared in the partial networks where 50% and 60% of the nodes were retained (p < .01 and p < .001, respectively).
To gain further insights from our data, and to complement the results from the ANCOVA analyses with a method that focuses more on the bootstrapped distributions, we conducted Kolmogorov-Smirnov tests. Overall, the outcomes of this analysis aligned closely with those of the main one. The only minor difference occurred in the L1 network for ASPL values when 60% of the nodes were retained, revealing a non-significant difference between groups. On the whole, however, we can conclude that both approaches yielded essentially the same results.
At this point, it should be noted that while L2 immersion naturally provides more opportunities for exposure to the second language, the usage profiles among immersed individuals can vary substantially. For example, some may converse with friends in their L2, while others stick to their L1, even in immersive settings. Given this variability, one can reasonably expect divergences in the semantic systems of both languages depending on how the L2 is specifically used in different social contexts. We explore this and other related questions through a series of post-hoc analyses.Footnote 1
Post-hoc network analyses
To inspect the potential variations in L2 use among our immersed participants and to understand its impact on the bilingual lexicon, we began by assessing how these individuals employed their L2 based on their reports in the BLP. Notably, the majority of participants residing in the UK reported using L2 English for work or study at least 80% of the time. To minimise variation, we excluded participants who used their L2 for work or study less than 80% of the time, leaving us with a sample of 79 immersed subjects. Additionally, most of these remaining participants primarily communicated with their families in their native languages, using it more than 80% of the time. We consequently excluded the minority who mainly used the L2 with their families, reducing our pool to 60 individuals. Upon examining L2 use with friends, we noted considerable variation, which was normally distributed. We then performed a median split based on the percentage of L1 and L2 use with friends (median = 0.6 – i.e., 60% of L2 use). This resulted in a “High L2 use with friends” group (n = 29) and a “Low L2 use with friends” group (n = 27). We replicated our main network analysis with these two groups of participants, expecting differences in semantic organisation based on their L2 interactions with friends.
The results from this analysis were clear and aligned with those from our primary analysis. Participants who used their L2 less frequently with friends – while maintaining comparable L2 use with family and at work or in studies – exhibited L1 networks with significantly higher CC values (ps < .001 for 50%, 60%, and 70%; p < .05 for 90%) and lower Q values (ps < .001 for 50% and 60%; p < .05 for 70%), indicative of better-organised networks. Interestingly, as observed in the main analysis, ASPL values for this group were also higher (ps < .001 for 70%, 80%, and 90%).
As per the L2 networks, the results were as expected: participants who used the L2 more frequently with friends exhibited more robust and interconnected L2 networks (i.e., higher CC and lower ASPL and Q values; all ps < .001, except for ASPL values with 50% and 80% of the nodes, which yielded a non-significant result and significant result with p < .05, respectively).
Next, we further examined the impact of length of immersion (LoI) on both the L1 and the L2 semantic systems. Upon inspecting the distribution of LoI, we found that most of our immersed participants who fell below the threshold of the third quartile (n = 76) had been living in the UK for less than five years. Thus, to better understand the role of immersion, we conducted a more controlled analysis comparing this subset of immersed participants with the non-immersed group. This approach aimed to strike a balance between several factors: (i) minimising the variation in LoI within the immersed group, (ii) maintaining as large a sample size as possible, and (iii) keeping the difference in sample size between the UK and Spain groups relatively small.
Overall, the results of this analysis closely mirrored those obtained earlier, further confirming that L2 experience significantly influences the semantic organisation of the native language. In line with this, the L1 network of the non-immersed participants exhibited higher CC and lower ASPL and Q values (all ps < .001). Likewise, the L2 network of the immersed group was overall more cohesive. Intriguingly, however, these findings with the L2 networks were not as consistent as those from previous analyses. Specifically, the immersed group had higher CC values (ps < .001 and < .05 for 50%, 60%, 70% and 80%, respectively) and lower Q values (ps < .05 for 50% and 60%), in alignment with our predictions. However, the ASPL values diverged from our expectations, being higher for the immersed group; thus adding to the inconsistent pattern observed for this particular marker across the analyses (ps < .001 for 70%, 80%, and 90%).
Finally, it is worth recalling that our participants were, on the whole, highly proficient in their second language, with all QPT scores being above 48 out of 60. Nonetheless, we further explored whether the observed impact of immersion would hold across varying proficiency levels, even if the “lower” proficiencies are still relatively high. To anticipate our findings, the answer is affirmative. We examined the distribution of QPT scores among both immersed and non-immersed participants, observing that the median was 52.5 in both cases. We then performed a median split, resulting in four groups that differed in terms of immersion and proficiency. Crucially, the pattern of effects remained consistent when comparing both lower- and higher-proficiency immersed and non-immersed participants. Regardless of proficiency, the L1 networks of the immersed participants were less organised, as indicated by lower CC and higher ASPL and Q values (all ps < .001, except for ASPL at the 90% node retention level in the lower-proficiency group, which showed the opposite effect). Once again, the expected pattern was found with the L2 networks – that is, irrespective of proficiency, immersion led to better-organised, more densely connected L2 networks (i.e., higher CC and lower ASPL and Q values; all ps < .001).
Discussion
The present study set out to investigate how exposure to an L2 shapes the bilingual semantic memory system, placing a particular focus on attrition effects in the L1. We employed two semantic fluency tasks, testing bilinguals with similar L2 proficiencies but differing levels of L2 exposure. Crucially, our investigation incorporated network science tools, a novel approach that enabled us to overcome the limitations typically encountered with traditional methodologies in this field.
Our findings demonstrate that immersion in an L2-dominant environment significantly impacts the bilingual lexical-semantic system, and this effect is independent of L2 proficiency (see Chaouch-Orozco et al., Reference Chaouch-Orozco, González Alonso and Rothman2021, Reference Chaouch-Orozco, González Alonso, Duñabeitia and Rothman2023, for complementary evidence about the influence of L2 experience/use with translation priming data). Global network measures revealed that increased exposure to a second language positively influences the L2 semantic network, making it more interconnected and less modular, while the opposite is true for the L1 network. L2 immersion leads to the weakening of the native semantic system. This decline is first and most notably evidenced by a significant reduction in overall connectedness, as reflected by lower clustering coefficient (CC) values, while the effects on average shortest-path length (ASPL) and modularity (Q) values are less pronounced.
Furthermore, our post-hoc evaluations offered consistent evidence. For instance, a higher frequency of L2 use with friends was linked to better-organised L2 networks and more disrupted L1 systems, emphasising the impact of L2 experience on the bilingual lexicon. This result is particularly noteworthy. While workplace language use is often considered a primary factor in attrition (see discussion in, e.g., Schmid & Jarvis, Reference Schmid and Jarvis2014; Schmid & Köpke, Reference Schmid and Köpke2017), our data suggest that the language employed with friends is also influential. This diverges from the previously observed lack of benefit in preserving the L1 through its use in informal contexts (e.g., de Leeuw et al., Reference de Leeuw, Mennen and Scobbie2012; Schmid, Reference Schmid, Köpke, Schmid, Keijzer and Dostert2007; Schmid & Dusseldorp, Reference Schmid and Dusseldorp2010), contributing to our understanding of the complex interplay between language use and the representational dynamics within the bilingual lexicon.
Additionally, further assessments revealed that the impact of immersion remained stable regardless of proficiency – although all our participants were highly proficient, and variation was low. Moreover, L2 immersion influence persisted even when the immersion period was substantially reduced to less than five years. These observations challenge more conservative estimates suggesting that the onset of L1 attrition requires decades of limited exposure to the first language or occurs only in extreme deprivation environments (e.g., Costa & Sebastián-Gallés, Reference Costa and Sebastián-Gallés2014; Dussias & Sagarra, Reference Dussias and Sagarra2007). Contrary to this, we find that early signs of attrition can be detected in the organisation of the native semantic system, corroborating evidence about early effects in the literature (Chang, Reference Chang2012; Levy et al., Reference Levy, McVeigh, Marful and Anderson2007; Linck et al., Reference Linck, Kroll and Sunderman2009).
In sum, our analyses emphasise the impact of immersion and L2 experience on the structural dynamics of the bilingual semantic system, thereby validating the robustness and potential of the network science approach employed in this study. In the following sections, we delve into these insights and other related discussions in more detail, and introduce the Lexical Attrition Foundation (LeAF) framework, which aims to describe the manifestation and progress of L1 lexical attrition from a structural network perspective.
Network science: Overcoming limitations in traditional L1 lexical attrition research
Our primary goal was to understand how intensive exposure to an L2 results in changes in the L1 lexicon, particularly at the semantic level. Increased experience with the L2 (and/or reduced experience with the L1) is traditionally considered one of the main precursors of attrition effects through the reorganisation of the lexicon and the overall linguistic system (Schmid, Reference Schmid2011, Reference Schmid, Schmid and Köpke2019; Schmid & Köpke, Reference Schmid and Köpke2017). Crucially, we employed a novel methodology – network analysis – that nicely fits the purpose of studying semantic organisation. This allowed us to move beyond the limitations of more standard approaches in lexical attrition research. Illustrating this point, when we looked at the total number of responses in the present analysis, we did not observe any attrition effects in the L1 (i.e., the number of responses was similar for both groups). Only by examining global network measures could we identify markers signifying the onset of cohesiveness loss and structural erosion in the L1 network resulting from the reduced exposure to and use of the L1 that inevitably occurs during L2 immersion.
Importantly, considering the apparently less conclusive results for the L1 network as compared to those for the L2, some might question the validity of the network approach, the manifestation of L1 lexical attrition, or both. Nevertheless, as already pointed out, there are compelling reasons to dismiss these doubts as unfounded.
Given the well-documented representational robustness of the native language (e.g., Bahrick et al., Reference Bahrick, Hall, Goggin, Bahrick and Berger1994; Köpke & Schmid, Reference Köpke and Schmid2004), which stems from its foundational role in the bilingual's cognitive and linguistic system, it would be somewhat unreasonable to expect changes in the L1 to be as dramatic as in the still-developing L2 lexicon. Observing such shifts in the L2 networks would, therefore, serve as a proof of concept for the current methodology, affirming its suitability to study L1 lexical attrition. Crucially, that is precisely what we found across multiple analyses: the L2 network in the immersed group was consistently better organised. This finding held true despite two key conditions: (i) the participants had comparable L2 proficiency levels, and (ii) the networks contained the same number of nodes. In other words, the immersed group exhibited improved L2 semantic organisation even when all other variables remained constant across both groups. This evidence speaks to the validity and efficiency of the network science methodology, as further supported by a growing body of research successfully employing network analysis to examine semantic organisation (see Feng & Liu, Reference Feng and Liu2023, for a case in point here).
Our results, therefore, underscore that, equipped with a robust methodology, we can effectively identify not only advancements in L2 lexical development but also the early signs of L1 lexical attrition. However, this leads to a pressing question: how exactly does attrition emerge and evolve within the lexicon? To address this, we propose that these changes follow a systematic trajectory. Elaborating on this concept, the following section introduces the Lexical Attrition Foundation (LeAF) framework, which aims to aid in investigating and understanding the onset and progression of L1 lexical attrition from a network perspective.
The Lexical Attrition Foundation (LeAF) framework
In light of the present results, it can be inferred that the structural changes brought about by intensive linguistic experience (i.e., immersion in our case) are first reflected in the clustering coefficients (CC). In contrast, modularity (Q) and average shortest-path length (ASPL) appear to be less sensitive to early attrition effects. The results for the networks’ modularity are particularly interesting for two reasons. First, the existing literature on the role of the index is contradictory to some extent. Second, our data provide valuable insights into the progression of L1 attrition as reflected by modularity. Recall that, in the L1 network, this measure showed attrition effects for the immersed group (i.e., higher Q values) when 50% and 60% of the nodes were retained in the bootstrap analysis, while values remained similar for both groups when 70%, 80, and 90% of the nodes were kept. Thus, it seems reasonable to expect that, given increased exposure to the L2 and the subsequent disruption in the native system, modularity values would rise further, yielding consistency across all analyses.
Interestingly, we find a similar situation when looking at the average shortest-path length. Our data supported our hypotheses only in the analyses where 50% and 60% of the nodes were retained. There, the L1 networks of the immersed individuals had overall reduced navigability, making accessing connected words more effortful (i.e., higher ASPL values). Thus, whereas clustering coefficient is affected across all levels (i.e., independently of the number of nodes retained), modularity and average shortest-path length only reflect attrition effects when the network is more perturbed. This suggests that these particular networks’ features show greater resilience to change.
Based on these insights, we propose the Lexical Attrition Foundation (LeAF) framework, which outlines a hierarchy describing the unfolding of structural changes and lexical attrition effects in the L1 (see Jarvis, Reference Jarvis, Schmid and Köpke2019, for a review of these effects). In the LeAF framework (Figure 3), immersion-induced erosion of the L1 network begins with a reduction in connectedness (i.e., lower CC values), which results in poorer semantic organisation and the decrease of tightly-knit communities (e.g., Christensen et al., Reference Christensen, Kenett, Cotter, Beaty and Silvia2018; Cosgrove et al., Reference Cosgrove, Kenett, Beaty and Diaz2021). Consequently, words that were once readily accessible through associative and/or semantic links within the same clusters become less interconnected, hampering efficient lexical retrieval in the bilinguals’ L1s. Specifically, this decreased efficiency may manifest as hesitations and pauses during speech as individuals struggle to find the target words, or as circumlocutions when word retrieval fails.
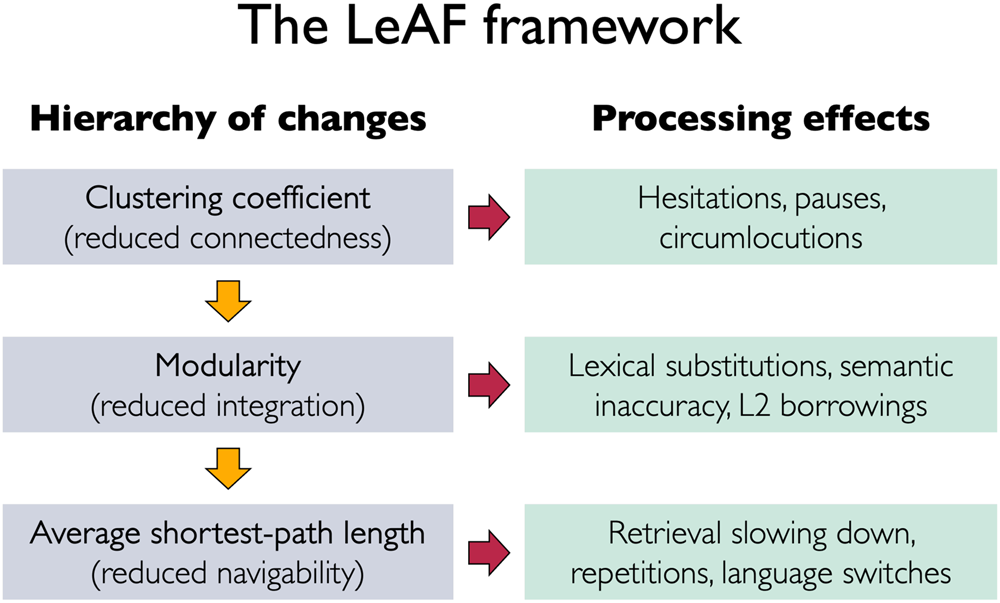
Figure 3. The Lexical Attrition Foundation (LeAF) framework. A hierarchy of structural changes is predicted to occur gradually during the onset of L1 lexical attrition as described on the left panel. Those changes are expected to lead to the processing difficulties that characterise L1 lexical attrition, indicated on the right panel.
As attrition effects continue to spread, the L1 semantic network becomes increasingly fragmented and less efficient. This is reflected by changes in modularity (Q) and average shortest-path length (ASPL), which, in turn, adversely affect overall language performance and fluency in the native language. Particularly, the fragmentation induced by changes in modularity makes retrieving words from different communities more challenging. These difficulties would lead to lexical substitutions and semantic inaccuracies where less semantically precise but more accessible words are selected, or even to L2 borrowings when L2 words come to mind more effortlessly.
Moreover, the longer paths between words in attrited L1 networks further slow down word retrieval. These effects would be intensified under conditions of high communicative demand and cognitive load, resulting in repetitions, prolonged hesitations or deliberate language switches.
Overall, the gradual deterioration of the L1 semantic network may have significant implications for L1 processing. Particularly in scenarios requiring rapid lexical access, the weakened network may lead to observable disruptions, such as hesitations or pauses. More severe attrition may drive speakers to switch to their L2s, as this may require less cognitive effort than using their increasingly elusive L1. This complexity underscores the importance of the LeAF framework in examining the nuanced effects of bilingualism on language dynamics and the structural properties of the lexicon.
Conclusion and future directions
Our data demonstrate that substantial exposure to and use of the second language significantly impacts both the L1 and L2 semantic systems, leading to enhanced organisation in L2 networks and subtle yet detectable L1 attrition effects, primarily reflected in the nodes’ interconnectivity. Crucially, these nuanced attrition effects only become evident through network analysis, revealing the potential of graph theory in this particular field.
The present study amplifies the value of network science tools in unravelling the complex nature and dynamics of semantic memory systems. Specifically, our findings highlight the differing sensitivity of network measures to L1 attrition, offering an exciting framework that can guide future research and yield valuable insights.
Thus, moving forward, it is imperative for future studies to continue exploring and refining these instruments to deepen our understanding of lexical attrition in bilingual individuals. In this context, investigating phonological-semantic L1/L2 multilayer networks throughout development emerges as a fascinating theoretical pursuit (Levy et al., Reference Levy, Kenett, Oxenberg, Castro, De Deyne, Vitevitch and Havlin2021; Siew & Vitevitch, Reference Siew and Vitevitch2019; Stella, Reference Stella2020; Stella et al., Reference Stella, Beckage, Brede and De Domenico2018). Indeed, the incorporation of phonological data into the LeAF framework is essential for it to evolve into a holistic approach capable of capturing the full scope of the lexical attrition phenomenon.
Furthermore, it should be emphasised that attrition effects are likely to be dynamic and contingent upon the degree of L2 exposure and use, which might indeed interact with other variables. The present design prevents us from ascribing the observed effects in the L1 network exclusively to either L2 development or decreased use of the L1. Instead, it is likely that both factors, among many others, contributed to the observed L1 attrition. Importantly, the exact interplay between these two factors may vary among individuals and be influenced by specific immersion contexts. This highlights the need for future studies to aim to disentangle the respective contributions of these two components to better understand the mechanisms driving L1 attrition. Consequently, longitudinal research would be especially beneficial for comprehending the long-term consequences of L2 immersion on the native lexicon, such as the potential for reversibility or stabilisation of attrition effects as L1/L2 exposure and use fluctuate over time.
In addition to the quantitative focus of the present study, future research could benefit from incorporating a more qualitative approach. Specifically, examining communities across various graphs and investigating the roles of individual nodes within those communities could offer deeper insights into the dynamics of language networks. While this qualitative perspective lies beyond the scope of our current investigation, it presents a promising avenue for upcoming studies.
Finally, to comprehensively evaluate and expand the scope of the LeAF framework, a multifaceted approach is paramount. Alongside the multilayer network perspective, which includes both phonological and semantic dimensions, this approach should also incorporate a variety of other methodologies. Particularly important are those methods that closely mirror the real-world challenges bilinguals face when using their first language. We consider this a critical path for future research to follow. By pursuing this strategy, the field would gain deeper insights into the evolving dynamics of L1 lexical attrition, thereby illuminating fundamental aspects of the complex interplay between languages in the bilingual mind.
Acknowledgements
There are no acknowledgements.






 Open access
Open access