Introduction
Comprehenders rely on various cues to interpret a referent in a discourse context. Some of these cues come from explicit linguistic devices such as gender marking (e.g., he, she); others are less explicit. The sentence fragments in (1), for example, provide no explicit information as to which protagonist in the main clause the pronoun refers to. Nevertheless, some interpretations seem more natural than others, based on probabilistic inferences about who is more likely to be responsible for the event. In case of the surprise event in (1a), Tom appears more likely to be the cause of the event than Bill, and thus a more suitable antecedent for he in the ensuing causal dependent clause. In the hate event in (1b), on the other hand, Jane seems the more likely cause of the event, and consequently the more suitable antecedent for she. This phenomenon has been called implicit causality (Brown & Fish, Reference Brown and Fish1983; Garvey & Caramazza, Reference Garvey and Caramazza1974; Au, Reference Au1986) or remention bias (Hartshorne, Reference Hartshorne2014). Verbs with a bias toward the subject as the underlying cause of the event (as determined by speakers’ referential preferences in sentences like (1)) are referred to as ‘subject-biased’ verbs, and verbs with a bias toward object as ‘object-biased’ verbs.
(1a) Tom surprised Bill because he. . .
(1b) Mary hated Jane because she. . .
Verb-induced implicit causality (IC) bias is a well-attested factor in first language (L1) reference resolution (e.g., Cozijn, Commandeur, Vonk & Noordman, Reference Cozijn, Commandeur, Vonk and Noordman2011; Ferstl, Garnham & Manouilidou, Reference Ferstl, Garnham and Manouilidou2011; Hartshorne & Snedeker, Reference Hartshorne and Snedeker2013; Itzhak & Baum, Reference Itzhak and Baum2015; Stewart, Pickering & Sanford, Reference Stewart, Pickering and Sanford2000; Pyykkönen & Järvikivi, Reference Pyykkönen and Järvikivi2010). Relative to the extensive evidence for native speakers’ use of IC bias in reference interpretation, less is known about how this information is utilized by second language (L2) speakers. To the best of our knowledge, only two studies have examined this issue (Cheng & Almor, Reference Cheng and Almor2017; Liu & Nicol, Reference Liu, Nicol, Prior, Watanabe and Lee2010). Liu and Nicol (Reference Liu, Nicol, Prior, Watanabe and Lee2010) used a self-paced reading task to investigate whether advanced Chinese learners of English show online sensitivity to mismatch between a verb's IC bias and the gender of the subject pronoun in a subordinate causal clause. They observed significant reading slowdowns in the dependent clause when the pronoun was inconsistent with verb-bias. This effect was present in both their L1 and their L2 group, albeit in slightly different regions. Notably, the slowdown occurred earlier for subject- than for object-biased verbs in the L2 group; this was not the case in the L1 group, and may indicate that L2 speakers relied more heavily on other cues creating an expectation for remention of the subject, such as the well-known subject-, first-mention, and/or parallel function preferences (see Arnold, Reference Arnold2010, for review). At the same time, Liu and Nicol's (Reference Liu, Nicol, Prior, Watanabe and Lee2010) findings provide evidence that (advanced) L2 learners are sensitive to verb-bias and use this information in referential processing in an L2.
Similar conclusions emerged from a study by Cheng and Almor (Reference Cheng and Almor2017), who investigated advanced Chinese-speaking L2 learners’ use of IC bias during referential choices in a written English sentence-completion task with items similar to those in (1). Both L2 learners and native speakers showed clear preferences for bias-consistent continuations. For subject-biased verbs, this bias was similar in both groups; for object-biased verbs, however, a significantly weaker effect was found in the L2 compared to the L1 group. Cheng and Almor suggest that this between-group difference may reflect L2 speakers’ limited ability to effectively integrate multiple sources of information, in line with Grüter, Rohde and Schafer's (2017) RAGE hypothesis, which posits that non-native speakers have reduced ability to generate expectations about upcoming referents during discourse processing. Cheng and Almor also point out that the L2 speakers’ stronger reliance on a subject- and/or first-mention bias may have been induced by the presence of an overt pronoun (e.g., Ariel, Reference Ariel1990; Gordon, Grosz & Gilliom, Reference Gordon, Grosz and Gilliom1993).
Both Liu and Nicol's (Reference Jarvis, Roberts, Howard, Laoire and Singleton2010) and Cheng and Almor's (Reference Cheng and Almor2017) findings point to the conclusion that L2 learners are sensitive to verb-related biases, but may rely more strongly on form-related constraints associated with pronouns. This interpretation is consistent with findings by Grüter et al. (Reference Grüter, Rohde and Schafer2017), who observed that Japanese- and Korean-speaking learners of English were as sensitive as native speakers to referential biases associated with referential form (pronoun vs name) in a story-completion task, but were less sensitive to verbal aspect (perfective vs imperfective), an event-level cue that influences native speakers’ referential expectations. Potential L1-L2 difference in the relative weighting of cues at various levels of linguistic representation is an interesting and relevant phenomenon worthy of further pursuit. The focus of the present study, however, is more specifically on L2 speakers’ use of verb-related IC biases, and on potential cross-linguistic influence in this regard – an issue that has not been investigated to date. Thus in order to minimize the influence of form-related constraints, we use a sentence completion task in which the subject of the subordinate clause is not provided, allowing participants to freely choose a referential form consistent with any expectations they may have created based on the previous discourse context.
Previous research of bilingual/L2 lexical processing has provided ample evidence for cross-language influence in bilinguals and L2 learners (e.g., Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002). Jarvis (Reference Jarvis and Pavlenko2009) discusses cross-linguistic influence that occurs at syntactic/semantic levels, using the term lemmatic transfer. Jarvis’ notion of lemmatic transfer includes a variety of transfer phenomena that relate to “the semantic and syntactic properties of words” (p. 102). Research on lemmatic transfer revealed several characteristics of interference between words that are semantically related or translation equivalents across languages, including that it can take place regardless of typological distance (Ringbom, Reference Ringbom2007). Lemmatic transfer is assumed to result from shared syntactic and semantic representations at the lemma level in the bilingual mental lexicon (Jarvis, Reference Jarvis and Pavlenko2009; Kroll & Stewart, Reference Kroll and Stewart1994).
While studies on lemmatic transfer provide evidence for the activation of syntactic and semantic properties of translation correspondents, potential repercussions of such lemma level transfer on language processing at higher levels have not been explored. This is because previous studies have focused largely on words in isolation. For example, most of the evidence for lemmatic transfer comes from analyses of learners’ vocabulary use in production, which concern how a learner's knowledge of lemmas in L1 affects the way that lemmas are linked to concepts in L2 (e.g., Meriläinen, Reference Meriläinen2006; Ringbom, Reference Ringbom2007). However, considering that the proposed scope of Jarvis’ notion of lemmatic transfer encompasses cross-language influence related to “the semantic and syntactic properties of words”, and that these properties, especially in verbs, make significant contributions to the structure and meaning of the whole sentence, it may be hypothesized that we should see effects of lemmatic transfer that go beyond the lemma level itself.
Here we investigate how Korean–English bilinguals are affected by parallel access to English verbs and their Korean translation counterparts when they construe causality in English. Specifically, this paper focuses on the effect of lemmatic transfer on referential choices in causal dependent clauses, where the dependent clause provides an explanation for the event in the matrix clause, as in (1). It is assumed that biases to remention an event participant from the matrix clause in a causal dependent clause are related to the matrix verb's syntactic/semantic structure (Hartshorne & Snedeker, Reference Hartshorne and Snedeker2013). As discussed below, some English predicates have different syntactic/semantic structures from their Korean translation correspondents. We hypothesize that these differences give rise to cross-linguistic differences in the strength of biases for rementioning one of the event participants in a causal dependent clause, and that lemmatic transfer arising from such cross-linguistic differences will affect Korean–English bilinguals in their referential choices in English. By looking at the effects of lemmatic transfer at the level of the matrix-clause verb on biases to remention an event participant in a causal dependent clause, this study extends the scope of research on bilingual lexical access by exploring whether the effect of lemmatic transfer goes beyond the lemma level and extends to influence bilinguals’ discourse construal as reflected in their referential choices in a separate clause.
The few previous studies that have investigated IC bias cross-linguistically have overwhelmingly observed cross-linguistic uniformity of IC biases for translational equivalents in L1 continuation tasks (e.g., Bott & Solstad, Reference Bott, Solstad, Hemforth, Schmiedtová and Fabricius-Hansen2014; Hartshorne, Sudo & Uruwashi, Reference Hartshorne, Sudo and Uruwashi2013). However, relatively little attention has been paid to variations in syntactic and semantic structures of the verbs investigated in these studies. Here we probe whether a more specific focus on cross-linguistic differences at this level can reveal differences in IC bias between Korean and English L1 speakers, and between L1 and L2 speakers of English.
Cross-linguistic differences in IC bias between English and Korean
A majority of the English predicates examined in the IC literature are interpersonal transitive verbs (Ferstl et al., Reference Ferstl, Garnham and Manouilidou2011) that convey information about causal relations between arguments in a single lexical item, as in (1). In contrast, many interpersonal predicates in Korean are realized as light verb constructions (e.g., Chae, Reference Chae1997) composed of a noun of Chinese origin and the light verb ha (‘do’; 2a, 2c), and a small number of verbs of Korean origin are, as in English, realized as a single lexical verb (2d). In addition, Korean also has a (subject-biased) (morpho)syntactic causative (SC) construction, best translated as ‘causing X to be Y’ (2b; H-S Lee, Reference Lee2017; K Lee, Reference Lee, Park and Kim1996).
(2a)

(2b)
(2c)
(2d)




A Korean SC construction (2b) is created by adding the resultative suffix –key to the adjectival predicate nolla- (‘be surprised’), and then attaching the causative verb ha- (literally ‘do’; O'Grady, Reference O'Grady1991; Park, Reference Park1994; Sohn, Reference Sohn2001). Thus, the embedded predicate nolla- (‘be surprised’) describes the caused event resulting from the action denoted by the matrix verb ha-.
English also has an SC construction where the cause and effect events are denoted by the matrix and embedded verbs respectively (e.g., “Tom caused John to be surprised”). However, there is a noticeable cross-linguistic difference between experiencer-object verbs in English and their Korean translation counterparts. Several experiencer-object verbs in English can only be translated into Korean as an SC construction, containing –keyha. For example, the Korean SC predicates, nolla-keyha- and cilwuha-keyha-, are the translation counterparts of the English verbs surprise and bore. By contrast, other English IC verbs have Korean translation equivalents which are also lexical verbs (or light verb constructions), for example, apwuha- (‘flatter’) and sakwaha- (‘apologize to’).
It has been hypothesized that explicit marking of causality may give rise to stronger IC biases than implicit causality in the lexical verbs typically examined in the literature. In particular, Hartshorne et al. (Reference Hartshorne, Sudo and Uruwashi2013), noting that some experiencer-object verbs in Japanese are realized by inserting the causative morpheme –(s)ase, conjectured that “for these verbs, causality is not implicit but actually explicit, and one may expect clearer implicit causality biases in Japanese” (p. 182). Causative markings in Korean and Japanese both change one-place and two-place experiencer-subject verbs into experiencer-object verbs. For example, the causative markers –keyha and –(s)ase can attach, respectively, to the two-place experiencer-subject verb mwuseweha- in Korean and kowagar- in Japanese (‘to fear’) and form experiencer-object verbs, mwusep-keyha- and kowagar-ase- (‘to frighten’). The same causative markers can also attach to one-place experiencer-subject verbs, such as Korean nolla and Japanese odorok-u (‘to be surprised’), to create two-place experiencer-object verbs, such as
nolla-keyha- and odorok-as- (‘to surprise [someone]’). Hartshorne and colleagues hypothesize that the Japanese causative morpheme makes the causal relation between event participants more explicit, potentially leading to clearer IC biases for these Japanese verbs relative to verbs in other languages that do not involve this affixation. To the best of our knowledge, this hypothesis has not yet been empirically tested. The Korean –keyha construction discussed above is closely related to the Japanese –(s)ase construction, thus providing a good test case. In Experiment 1, we asked Korean speakers to provide written continuations for Korean sentence fragments containing SC (–keyha) and non-SC predicates (Experiment 1a), and compared their referential choices to those from English speakers who completed the same task in English, where predicates did not contain explicit marking of causality (Experiment 1b). To foreshadow, in line with Hartshorne et al.’s hypothesis, the findings from Experiment 1 show stronger subject-bias for Korean SC (–keyha) than non-SC predicates, while no difference emerged between their (non-SC) translation counterparts in English. This allows us to investigate the consequences of these cross-linguistic differences in bias strength for bilingual processing. In Experiment 2, we employed an English continuation task with Korean learners of English to test whether the cross-linguistic difference in IC bias strength between English predicates and their Korean counterparts would affect their referential choices in English.
Experiment 1: Referential biases in L1 Korean and L1 English
Experiment 1 consists of two parallel sentence-completion experiments in Korean (Experiment 1a) and English (Experiment 1b) with the aim of testing cross-linguistic differences between predicates in the two languages in terms of IC bias. More specifically, Experiment 1a tests whether Korean SC predicates give rise to stronger subject-biases than (subject-biased) non-SC predicates among native Korean speakers. No differences in bias-strength are expected for the English translations of Korean SC vs. non-SC predicates among native English speakers (Experiment 1b), as (almost) all translations consist of lexical verbs with no explicit encoding of causality. In Experiment 1a, native speakers of Korean completed written sentence fragments containing SC and non-SC predicates in Korean. In Experiment 1b, these fragments were translated into English and completed by native speakers of English.
Experiment 1a: Method
Participants
Thirty-six adult native speakers of Korean (age 20–22 years; 10 female) participated in this experiment. All participants were recruited from a college in Korea, and received the Korean equivalent of $5 for their participation.
Materials
Eighty Korean predicates were selected based on the following steps. First, a pool of verbs was collected from previous IC studies (Garnham, Traxler, Oakhill & Gernsbacher, Reference Garnham, Traxler, Oakhill and Gernsabacher1996; Kasof & Lee, Reference Kasof and Lee1993; Long & De Ley, Reference Long and De Ley2000; Rohde & Ettlinger, Reference Rohde and Ettlinger2011; Rohde, Levy & Kehler, Reference Rohde, Levy and Kehler2011; Stewart, Pickering & Sanford, Reference Stewart, Pickering, Sanford, Gernsbacher and Derry1998). From this pool, we selected 40 verbs reported as subject-biased and 40 reported as object-biased. In the selection of subject-biased verbs, our goal was to include 20 items best translated into Korean with a lexical verb or a light verb construction (non-SC construction, e.g., hyeppakha- ‘threaten’), and 20 for which there is no direct lexical translation equivalent and which are best translated with an explicit causative construction (SC construction, e.g., culkep-keyha- ‘amuse’). We used the NAVER English–Korean dictionary (http://dic.naver.com) as our criterion for this purpose: If the first Korean entry for a given subject-biased verb in English was a lexical verb or a light verb construction, it was included as a non-SC item, if the first entry contained an explicit causative marker, it was included as an SC item. (See Supplementary Materials for the list of all 80 predicates – 20 subject-biased non-SC, 20 subject-bias SC, and 40 object-biased, Supplementary Materials.) The subject-biased predicates constitute the experimental items in this study; the object-biased verbs act as distractors.
For each predicate, a sentence fragment of the type illustrated in (3) was created, starting with an adverbial phrase, followed by a main clause containing two human referents of the same gender with nominative and accusative case marking, respectively, and the main verb in canonical SOV order (half of the items with male-male and the other half with female-female referents).Footnote 1 The relational connective nuntey, which marks the first clause as background information for the second (Lee, Reference Lee1993; Park, Reference Park1999), was attached to the verb for denoting the discourse coherence relation between the two clauses. Following the main predicate, the sentence fragment ended with the causal conjunction waynyahamyen (‘because’).
(3)

No pronoun was included in the subordinate clause because Korean is a null subject language, and the use of overt pronouns is relatively restricted and infrequent (Han, Reference Han2006; Lee, Lee & Chae, Reference Lee, Lee and Chae1997). An overt pronoun in a context like (3) would not only be somewhat unnatural, but it would disallow continuations starting with a null pronoun, which is typically the preferred option in contexts of topic continuity (Kim, Reference Kim1999; Roh & Lee, Reference Roh, Lee, Bow and Hughes2003). The absence of an overt subject prompt allowed participants to freely choose the referential form of the subject in addition to its antecedent.
Procedure
Participants completed a language background questionnaire followed by the sentence-completion task in pen-and-paper format. Participants were instructed to provide a natural continuation for each sentence in writing, avoiding humor. The entire experiment took approximately 30–40 minutes.
Coding
Continuations were coded by two native speakers of Korean blind to the purpose of the study. Coders annotated participants’ responses for referential form and intended reference of the subordinate subject. Responses that were incomplete or incoherent (e.g., reflecting misunderstanding of the main clause) were eliminated from further coding and analysis (4% of all data).
Referential form was coded as falling into one of five categories: overt pronoun, null subject, (repeated) name, full NP (an NP other than a name or pronoun), or other. Intended reference of the subordinate clause subject included the three options ‘subject’ (of the main clause), ‘object’ (of the main clause), and ‘other’, which included joint reference to both subject and object, as well as referents not mentioned in the main clause. Since intended reference could not always be determined with certainty, especially in continuations with null subjects, coders were also given the options ‘totally ambiguous’, ‘ambiguous, but more likely subject’ (ambig-subj), and ‘ambiguous, but more likely object’ (ambig-obj). For analysis purposes, ‘subject’ and ambig-subj responses, and ‘object’ and ambig-obj responses, were collapsed, respectively. Responses were excluded from further analysis if both coders annotated them as ‘totally ambiguous’ (0.03% of data), or if coders disagreed on reference (0.10%). Inter-coder reliability was high (κ = .998).
Experiment 1a: Results
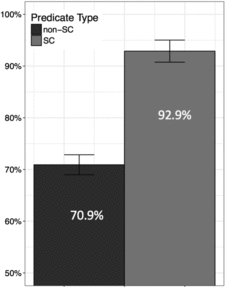
We analyzed participants’ responses in the two experimental conditions (SC, non-SC) for referential form and intended reference. For referential form, the vast majority of responses (86%) consisted of a name. This is somewhat surprising given that the antecedent was highly accessible, a context where a less marked form might be expected (Gundel, Hedberg & Zacharski, Reference Gundel, Hedberg and Zacharski1993). Previous work on Korean has shown, however, that null pronouns are not always the form of choice when a referent is highly accessible (Oh, Reference Oh2007).Footnote 2 The remaining responses contained full NPs (6%) and null subjects (8%). No overt pronouns were produced in this task, confirming their unnaturalness in this context in Korean. For intended reference, the vast majority of responses (93%) referred to either the previous subject (76%) or object (17%). Only these responses are included in the following analyses, in which the proportion of subject reference out of all responses with either subject or object reference constitutes the measure of interest. Figure 1 illustrates subject bias thus calculated for SC and non-SC predicates.

Figure 1. Mean percentage of subject bias in Experiment 1a; error bars indicate 95% CIs
Proportion of subject bias was modeled using mixed-effects logistic regression (Baayen, Reference Baayen2008; Jaeger, Reference Jaeger2008). Unless otherwise indicated, all models include the maximal random effects structure allowed by the design (Barr, Levy, Scheepers & Tily, Reference Barr, Levy, Scheepers and Tily2013). This model, which included predicate type (SC, non-SC) as a fixed effect (contrast-coded and centered) and participants and items as random effects, revealed a significant main effect of predicate type (b = 2.50, SE = 0.51, p < .001), with more subject reference following SC (M = 93%, SD = 6%) than non-SC predicates (M = 71%, SD = 6%).
Experiment 1a: Discussion
Experiment 1a tested whether SC predicates in Korean, which contain an explicit causality marker, induce a stronger IC bias toward a subject antecedent than non-SC predicates, where information pertaining to causality is only implicit. The results of the Korean sentence-completion task demonstrated that native Korean speakers did indeed refer back to the previous subject more frequently in a causal subordinate clause following SC compared to non-SC predicates. However, it remains possible that other semantic properties of the SC predicates selected for this study, rather than the explicit encoding of causality in the keyha construction, might have led to a stronger subject bias in this group of verbs. We return to this important caveat in the discussion of Experiment 1b. As a first step towards probing whether it is the explicit versus implicit encoding of causality information that drives this difference, we conducted a parallel experiment in English, with materials translated from Korean to English as closely as possible. Critically, the English translations of both SC and non-SC predicates consist almost entirely of non-SC predicates. If explicit vs. implicit marking of causality is a driving factor in the difference we observed in Experiment 1, we expect no differences in IC bias between the English translation correspondents of SC and non-SC predicates in Experiment 1b. Moreover, we predict an interaction between predicate type (SC, non-SC) and experiment/language (Korean, English). Experiment 1b was conducted to address these predictions.
Experiment 1b: Method
Participants
Thirty-five native speakers of English (age 18–29 years; 21 female) from the University of Hawai‘i student community participated in the English sentence-completion task in return for partial course credit.
Materials
To create English materials that were semantically as close as possible to the Korean materials in Experiment 1a, we asked four speakers fluent in both languages to individually translate all 80 Korean sentence fragments from Experiment 1a into English. Based on these four sets of translations, we selected items as follows. First, if the same translation was provided by at least 3 of the 4 translators, it was selected (47/80 items). When two translators agreed and the other two each provided different translations, the translation that two agreed on was selected (20/80). In the case of a two-two tie (6/80) or disagreement among all four translators (7/80), the first author used his own judgment to select among the translations provided.Footnote 3
This procedure allowed for the possibility that two different Korean verbs were translated to the same form in English, or that a verb was translated into a multi-word predicate. To keep the English translations semantically close to the Korean counterparts, we did not remove or modify any of these items. Thus 9 items were used twice (1 in SC, 2 in non-SC, 6 in object-biased predicates), and 8 were presented as multi-word predicates (3 in SC, 1 in non-SC, 4 in object-biased predicates).
As in Experiment 1a, the subject-biased predicates constitute the experimental items, while the object-biased verbs act as distractors. Note that the subject-biased predicates in English are called ‘SC’ and ‘non-SC’ based on the status of their Korean translation counterparts. The assignment of items into the two conditions was done to allow for comparisons between the Korean predicates in Experiment 1a and their English counterparts in Experiment 1b, for the purpose of testing whether the difference in IC bias strength between Korean SC and non-SC predicates found in Experiment 1a may have been due to lexico-semantic properties unrelated to implicit vs explicit expressions of causality.
Procedure
Eighty English sentence fragments were constructed analogous to the Korean stimuli in Experiment 1a. All Korean names were replaced with corresponding male/female English names. The procedure was identical to that of Experiment 1a, except that it was delivered through a web-based interface.
Coding
Two coders annotated participants’ responses for referential form and intended reference of the syntactic subject in the subordinate clause, using the same criteria as in Experiment 1a. Incomplete or incoherent responses (2% of all data), responses coded as ‘totally ambiguous’ (0.79%), and those where coders disagreed on intended reference (6%) were excluded from further analysis. Inter-coder reliability was high (κ = .902).
Experiment 1b: Results
Participants’ responses in the two experimental conditions (SC, non-SC) were analyzed as in Experiment 1a. For referential form, 61% involved a pronominal subject, 33% involved a name, 4% involved a full NP, and 2% involved other types that corresponded to none of these forms. This is in sharp contrast to Experiment 1a where there were no responses with overt pronouns and only 8% null subjects.
Turning to intended reference, a majority of referents (92%) were coded either as subject (75%) or object (17%). As in Experiment 1a, only these responses are included in the following analyses. Figure 2 illustrates subject bias for ‘SC’ and ‘non-SC’ predicates.
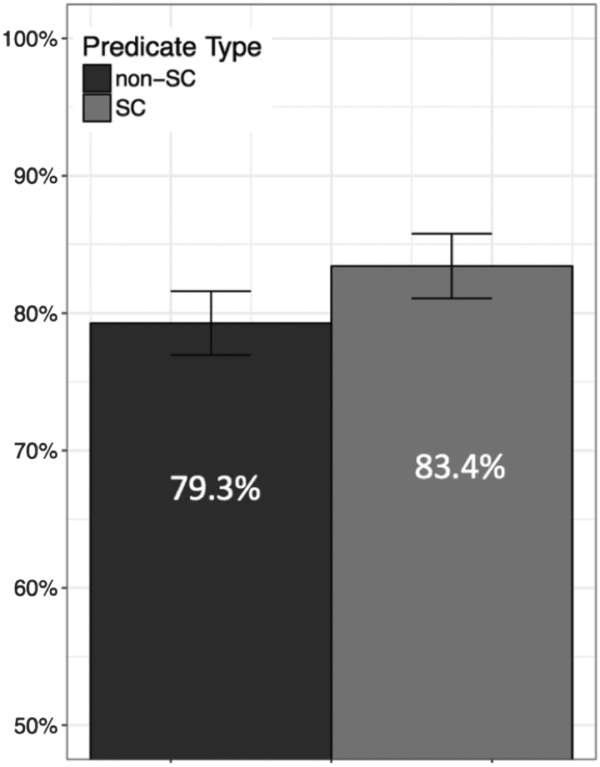
Figure 2. Mean percentage of subject bias in Experiment 1b; error bars indicate 95% CIs
A mixed-effects logistic regression model with predicate type (SC, non-SC) as a fixed effect, and participants and items as random effects, was fitted to these data. The results showed no main effect of predicate type (b = 0.23, SE = 0.39, p = .558), in contrast with the results of Experiment 1a, which exhibited a significant difference in subject bias between SC and non-SC predicates.
In order to further investigate the differences between Experiments 1a and 1b, we conducted an additional mixed-effects logistic regression analysis with predicate type (SC, non-SC) and experiment/language (1a/Korean, 1b/English) as fixed factors. This model revealed a main effect of predicate type (b = 1.24, SE = 0.31, p < .001), indicating more subject reference following SC than non-SC predicates across the experiments, no main effect of experiment (b = 0.23, SE = 0.21, p = .281), indicating that the total subject bias did not differ significantly between experiments, and critically an interaction between these two factors (b = 1.66, SE = 0.28, p < .001). This interaction between predicate type and experiment provides further support for our interpretation of the findings from Experiments 1a and 1b, namely that SC and non-SC predicates in Korean differ in the strength of their subject bias whereas their English translation equivalents do not.
Experiment 1b: Discussion
In this experiment, English speakers provided written continuations for the English sentence fragments that were translated from the Korean stimuli in Experiment 1a. No difference in bias strength was found between the English translations of SC compared to non-SC predicates. These findings are consistent with Hartshorne et al.’s (2013) conjecture that morphosyntactic causative marking, as in Japanese –(s)ase or Korean –keyha, would create stronger IC biases. However, these findings are not sufficient to conclude that explicit causative marking was the only driving force for the observed differences. In particular, it remains possible that verbs classified as SC and non-SC based on the explicitness of causality marking in Korean also differ along other dimensions that were not considered in the design of these experiments. One such dimension is the degree of intentionality associated with the events denoted by the predicates in each language and condition.Footnote 4 Verbs typically classified as subject-biased IC predicates include both Stimulus-Experiencer (SE) and Agent-Patient (AP) verbs, which critically differ in that only an Agent, but not a Stimulus, can intentionally cause an event. In a study of IC in German and Norwegian, Bott and Solstad (Reference Bott, Solstad, Hemforth, Schmiedtová and Fabricius-Hansen2014) found a significantly stronger subject bias for SE than for AP verbs, indicating that greater intentionality of the subject is associated with a weaker subject bias, a relation that was also reflected in different types of causal explanations following SE vs. AP predicates (see Bott & Solstad, Reference Bott, Solstad, Hemforth, Schmiedtová and Fabricius-Hansen2014, and Solstad & Bott, Reference Solstad, Bott and Waldmann2017, for further discussion).
These findings have important implications for the interpretation of our results. In the selection of predicates for Experiments 1a and 1b, we had not taken into consideration these subclasses of verbs, and the differential degree of intentionality associated with them. It is thus possible that SE and AP verbs were distributed unequally between (i) our SC and non-SC categories, and (ii) between our Korean and English verbs. Note that Bott and Solstad (Reference Bott, Solstad, Hemforth, Schmiedtová and Fabricius-Hansen2014) found that even cognates in typologically closely related languages like German and Norwegian can differ in terms of their status as SE or AP predicates. Such differences are thus a distinct possibility here, and present a potential confound for the interpretation of the observed effects as due to the explicitness of causative marking. In order to examine this possibility, we applied Bott and Solstad's (2014) diagnostic tests for determining whether a verb classifies as SE, AP, or both, to our experimental stimuli. Verbs were classified as allowing an AP interpretation when the insertion of the adverbial deliberately/ilpwule in the frame X Verbed Y appeared felicitous. To test whether the verb allows a Stimulus argument in the first position, we applied Bott and Solstad's ‘that clause replacement test’, where the proper name in the relevant position is replaced with a proposition that could otherwise be expressed in a subordinate because-clause (e.g., Peter annoyed Mary because he sang loudly → It annoyed Mary that Peter sang loudly). Verbs that allowed this replacement were classified as allowing an SE interpretation. Verbs that passed both tests were categorized as ambiguous (following Bott & Solstad, Reference Bott, Solstad, Hemforth, Schmiedtová and Fabricius-Hansen2014).Footnote 5 A limitation of this method is that it cannot capture preferences for Agent versus Stimulus interpretations in the case of predicates categorized as ambiguous, nor differences in the degree to which AP verbs are interpreted to be intentional, given that they allow both intentional and unintentional interpretations. Using these criteria can thus provide only a coarse approximation to the issue of intentionality in our materials. Independent rating studies (in both languages), in which speakers rate the felicity of sentences with these predicates combined with the adverb “un/intentionally”, would be needed for a more fine-grained evaluation of potential gradient differences between the predicates in each language and condition with regard to intentionality.
Table 1 summarizes the results of our analysis using Bott and Solstad's broad classification criteria (see Supplementary Materials for classification of individual items). This revealed two general patterns: (i) SE and AP verbs are indeed distributed unequally between our SC and non-SC categories, and (ii) this imbalance appears very similar in both languages. More specifically, we found that all items in the SC condition, in both languages, allow an SE interpretation (SE or AP/SE), while the majority of items in the non-SC condition, again in both languages, allow only an AP interpretation. Given Bott and Solstad's observation that SE verbs have stronger subject-bias than AP verbs, the results from Experiment 1a (Korean) could thus be explained by differences in thematic verb classes, broadly associated with different degrees of intentionality, rather than explicitness of causative marking. On this explanation, however, the results from Experiment 1b (English) remain unexplained: Despite a very similar and imbalanced distribution of AP and SE predicates, we saw no significant differences in bias strength between the two predicate types in Experiment 1b. This remains unexplained under an explanation relying on differences in intentionality, at least to the extent that we were able to capture such differences here. We therefore conclude that differences at the level of intentionality are a likely contributor to the differences observed in Experiment 1a, the pattern of results across both experiments is not fully explained by this factor alone, and that explicitness of causality marking is an additional factor, and the one responsible for the cross-linguistic difference observed here. Future work controlling more rigorously for more fine-grained differences at the level of verb semantics will be needed to further tease apart the respective roles of these factors on referential biases.
Table 1. Distribution of thematic verb types by Language/Experiment (Korean, English) and Predicate Type (SC, non-SC) following Bott and Solstad's (2014) diagnostics.

While the precise reason(s) for the cross-linguistic differences in bias strength we observed in Experiment 1 cannot be fully resolved here, what is critical for our investigation of cross-linguistic activation in bilingual processing is that these cross-linguistic differences exist. Previous cross-linguistic work on IC biases has found that differences in the direction of bias (subject- vs object-bias) align with thematic verb classes fairly consistently across languages (Hartshorne et al., Reference Hartshorne, Sudo and Uruwashi2013). More subtle differences, however, have been observed even between cognates in closely related languages (Bott & Solstad, Reference Bott, Solstad, Hemforth, Schmiedtová and Fabricius-Hansen2014). The findings from Experiment 1 present a further instance of subtle cross-linguistic differences in this domain, thereby providing an ideal scenario for investigating the effects of lemmatic transfer beyond individual words. More specifically, the observed cross-linguistic differences allow us to test whether the stronger subject-bias associated with SC predicates in Korean is activated and affects referential choices when Korean–English bilinguals read sentences in English. If this is the case, the prediction is that bilinguals, but not native English speakers, will show a stronger bias to remention the subject with English translation correspondents of Korean SC predicates than with English counterparts of Korean non-SC predicates. We test this prediction in Experiment 2.
Experiment 2: Korean learners’ referential biases in L2 English
Experiment 2 explores the effects of lemmatic transfer on L2 learners’ referential choices in English by addressing the following research questions:
RQ1) Do Korean learners of English carry over IC bias from Korean predicates while making referential choices in English causal dependent clauses? (Effects of lemmatic transfer)
RQ2) Does completing an explicit translation task preceding the sentence-completion task enhance the extent to which these learners carry over IC bias from Korean predicates? (Effects of translation priming)
A written sentence-completion task in English was conducted with two groups of Korean-speaking learners of English, and a control group of native English speakers. The L2 learners additionally completed a translation task in which they translated the English sentence fragments from the sentence-completion task into Korean. The purpose of the translation task is three-fold. First, learners’ translations provide a measure of their understanding of the stimuli (e.g., Brysbaert, van Dyck & van de Poel, Reference Brysbaert, van Dyck and van de Poel1999; Midgley, Holcomb & Grainger, Reference Midgley, Holcomb and Grainger2009); for each participant, items not correctly translated in this task were eliminated from the analysis of responses in the sentence-completion task. The second purpose of the translation task was to check whether participants’ translations aligned with our expectations with regard to whether an English predicate would be translated into a –keyha construction or not. Finally, the translation task allows us to explore the role of translation priming (see Altarriba & Basnight-Brown, Reference Altarriba and Basnight-Brown2007, for a review of translation-priming): that is, whether completing the translation task immediately before the sentence-completion task leads to stronger activation of Korean translation correspondents during the sentence-completion task, potentially inducing a stronger effect of lemmatic transfer in learners’ referential choices. To address this second research question, half of the learners completed the translation task before the sentence-completion task (‘translation-first’ group, T1), while the other half completed it after (T2).
We address the first research question by comparing referential choices in the sentence-completion task between the native English-speaking control group and the T2 group. Since the T2 group completed the sentence-completion task before the translation task, this allows for a direct comparison of referential choices between native English and Korean speakers in the absence of translation priming. The second research question and the role of translation priming is addressed by comparing the T2 with the T1 group.
Experiment 2: Method
Participants
Seventy-two adult Korean-speaking learners of English were recruited from colleges in Korea and randomly assigned to the T1 (16 female) or the T2 group (18 female). Thirty-four adult native speakers of English from the University of Hawai‘i student community (15 female) constitute the native-speaker control group (NS). The three groups did not differ in age, and the two learner groups did not differ in their English proficiency, as measured by their length of studying English, self-reported TOEIC® (Test of English for International Communication™) scores, and self-ratings of English proficiency (Table 2).
Table 2. Experiment 2: Participant information

Note. Number in parenthesis = standard deviation
Materials for sentence-completion task
Thirty-six verbs – 12 subject-biased SC, 12 subject-biased non-SC, and 12 object-biased – were selected from the 80 items in Experiment 1b according to the following criteria. No multi-word predicates, and only verbs found in the vocabulary lists in English textbooks used in Korean middle and high schools and in the vocabulary lists for the Korean SAT tests were included. An additional 12 predicates with no known IC biases were included as distractors (see Supplementary Materials).
To ensure that the subset of SC and non-SC predicates selected for Experiment 2 was representative of the items in Experiments 1a and 1b, analyses of the results from Experiments 1a and 1b limited to this subset of items were conducted. These analyses replicated the effects observed above: The Korean data showed a main effect of predicate type (b = 1.35, SE = 0.57, p = .018), with significantly stronger subject bias for SC than non-SC predicates, whereas the English counterparts of these predicate types showed no such effect (b = –0.10, SE = 0.41, p = .818).
The 48 English predicates were presented in contexts as in (4).
(4) Jacob amused Bill because ______________.
Materials for translation task
The items for the translation task consisted of the main clause portion of the 36 experimental items from the sentence-completion task. Participants were asked to provide the most natural Korean translation for each English sentence.
Procedure
Both tasks were completed via a web-based interface. Native speakers completed only the sentence-completion task. There was a 5-minute break between the two tasks for the L2 speakers. Including the language background questionnaire, the entire session took approximately 20–30 minutes for the NS and 60–80 minutes for the L2 groups.
Coding for sentence-completion task
Two coders annotated participants’ responses in the sentence-completion task following the same protocol used for Experiments 1a and 1b. Incoherent or incomplete continuations (1% of all data), responses annotated as ‘totally ambiguous’ (0.1%), and items with inter-coder disagreement (1%), were excluded from further analysis. Inter-coder reliability was high (κ = .980).
Coding for translation task
Two Korean–English bilingual coders annotated L2 participants’ translations for accuracy. Responses were removed if translations were judged as semantically inaccurate by both coders (10.2% in SC, 10.4% in non-SC) or if the coders disagreed on accuracy (1% of L2 data). In addition, all responses were annotated for the presence or absence of the explicit causality marker –keyha in the Korean translation.
Experiment 2: Results
We analyzed participants’ responses in the two experimental conditions (SC, non-SC) in terms of referential form and intended reference. For referential form, the NS group showed a pattern distinct from the L2 groups in the use of pronouns and names. While the NS group produced 61% pronouns and 33% names, the L2 groups produced proportionally many more names (T1: 83%, T2: 82%) and fewer pronouns (T1: 11%, T2: 12%), a pattern reminiscent of the results from Experiment 1a, in which the Korean speakers produced 86% names. The overwhelming use of names in the L2 data indicates that the learners transfer the preferred reference form from their L1.
For intended reference, all three groups demonstrated similar patterns overall. A majority of referents were coded as either subject or object in all groups (NS: 86%, T1: 90%, T2: 90%). As in Experiments 1a and 1b, only these responses are included in the following analyses.
Analyses of the strength of subject bias by predicate type (SC, non-SC) and group were conducted in three steps: (1) analysis of total data, (2) analysis of translation-consistent data, and (3) analysis of data by participant-driven category. The first analysis is parallel to the analyses in Experiments 1a and 1b, and does not take into consideration the individual translations provided by the L2 participants in the translation task beyond excluding items that were not translated correctly. For the second analysis, we included only those items for which the participant provided a translation consistent with expected predicate type (i.e., a keyha construction for the 12 items designated as SC, and a lexical verb or light verb construction for the 12 items designated as non-SC). Finally, in the third analysis, items were redesignated as SC and non-SC solely based on the participant's translation, ignoring the category we had originally expected the item to be in. While the first analysis is most consistent with the analyses in Experiments 1a and 1b, it ignores individual differences between learners with regard to translation equivalents, likely introducing noise in the results. The second analysis reduces this noise, but at the cost of excluding meaningful data points. The third analysis salvages these data points, but leads to greater imbalance in terms of items per condition.
To address our research questions about effects of lemmatic transfer (RQ1) and translation priming (RQ2), comparisons were made between the NS and the T2 groups (RQ1) on the one hand, and between the T2 and the T1 groups (RQ2) on the other. For each comparison and analysis, we report the output of a mixed-effects logistic regression model with group, predicate type (SC, non-SC), and their interaction as fixed effects (contrast-coded and centered), and participants and items as random effects. Since we conduct three different analyses for each comparison, the alpha level was adjusted to .017 (.05/3).
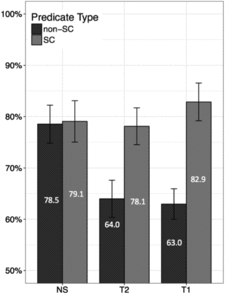
Analysis 1: Total data (Figure 3)
For the comparison between NS and T2, no effects reached significance at the adjusted alpha level (group: b = –0.69, SE = 0.31, p = .028; predicate type: b = –0.06, SE = 0.36, p = .856; interaction: b = 0.23, SE = 0.48, p = .636), although a marginal main effect of group indicates somewhat more subject reference in the NS than in the T2 group overall. Thus no evidence for lemmatic transfer emerged when all data points were included regardless of participants’ individual translation preferences.
For the comparison between T2 and T1, despite a numerical trend visible in Figure 3 towards a stronger subject bias for SC vs. non-SC type predicates in the T1 group, again no effects reached significance (group: b = 0.04, SE = 0.23, p = .847; predicate type: b = 0.31, SE = 0.28, p = .259; interaction: b = 0.56, SE = 0.34, p = .105).

Figure 3. Mean percentage of subject bias in Experiment 2 (Analysis 1: Total data); error bars indicate 95% CIs
Analysis 2: Translation-consistent data (Figure 4)
For this analysis, L2 participants’ translations were coded according to consistency with the predetermined predicate type. For SC predicates, translations were coded as “consistent” when they included –keyha (T1: 93%; T2: 91%). For non-SC predicates, “consistent” translations were those that did not contain –keyha (T1: 98%; T2: 97%). After exclusion of data from inconsistent items (5.4% of the data in analysis 1; 8.6% in SC, 2.4% in non-SC), we conducted the same between-group analyses as outlined above in this reduced dataset.
In the first model, including the data from the NS and T2 groups, despite a numerical trend towards more subject reference for SC than for non-SC predicates in the T2 but not in the NS group apparent in Figure 4, no effects reached significance at the adjusted alpha level (group: b = –0.24, SE = 0.25, p = .344; predicate type: b = 0.27, SE = 0.37, p = .468; interaction: b = 0.73, SE = 0.36, p = .042).

Figure 4. Mean percentage of subject bias in Experiment 2 (Analysis 2: Translation-consistent data); error bars indicate 95% CIs

Figure 5. Mean percentage of subject reference in Experiment 2 (Analysis of reorganized data); error bars indicate 95% CIs
Turning to the comparison between T2 and T1, the model revealed a significant effect of predicate type (b = 1.14, SE = 0.36, p = .002), and no effect of group (b = 0.18, SE = 0.22, p = .414).Footnote 6 The interaction did not reach significance at the adjusted alpha level (b = 0.70, SE = 0.35, p = .044). In light of the marginal interaction and in order to fully explore our second research question regarding translation priming, we created separate models for each group to examine potential effects of predicate type (with alpha further adjusted to .008; .017/2). A significant effect of predicate type was found for the T1 (b = 1.50, SE = 0.02, p < .001) but not the T2 (b = 0.65, SE = 0.45, p = .153) group.
Taken together, the second analysis, which included translation-consistent items only, indicated some differences between SC and non-SC predicates for the T1, but not for the T2 and the NS groups. These findings provide some indication of cross-language influence, but only when cross-language associations were primed through an immediately preceding translation task.
Analysis 3: Participant-driven analysis (Figure 5)
In this last analysis, L2 data were re-categorized into SC and non-SC depending on whether participants’ translations included an SC or non-SC construction, ignoring our original SC/non-SC categories. This process resulted in 44% of all items categorized as SC and 56% as non-SC in T1, and 45% as SC and 55% as non-SC in T2.
In the comparison between NS and T2, there was a main effect of predicate type (b = 0.80, SE = 0.23, p < .001), qualified by a significant interaction between group and predicate type (b = 0.79, SE = 0.32, p = .015). The main effect of group did not reach significance at the adjusted alpha level (b = –0.50, SE = 0.25, p = .043). Follow-up models for each group showed a main effect of predicate type for the T2 (b = 1.23, SE = 0.29, p < .001), but not for the NS group (b = 0.20, SE = 0.53, p = .700), indicating effects of lemmatic transfer even in the absence of translation priming.
In the comparison between T1 and T2, there was a main effect of predicate type (b = 1.42, SE = 0.20, p < .001) due to greater subject bias for SC than for non-SC predicates. There was no effect of group (b = 0.10, SE = 0.21, p = .664) or interaction (b = 0.32, SE = 0.29, p = .256). For comparison with Analysis 2, we created separate models for each group. These models revealed significant effects of predicate type in both the T1 (b = 1.43, SE = 0.26, p < .001) and the T2 group (b = 1.23, SE = 0.29, p < .001).
In summary, when the data was reorganized based on participant-driven categories, effects of lemmatic transfer as indicated by higher subject bias for SC than for non-SC predicates emerged in both learner groups, regardless of translation priming.
Experiment 2: Discussion
In Experiment 2, effects of lemmatic transfer and translation priming were inspected in Korean–English bilinguals’ referential choices in English causal dependent clauses. The data were analyzed in three ways. In the first analysis, no significant effects of lemmatic transfer were observed. This analysis was analogous to those in Experiments 1a and 1b, but did not take into account participants’ actual cross-linguistic associations. The second analysis, which included only those items for which participants’ cross-linguistic associations aligned with those expected by the experimental design, there was some indication of the predicted effect, but only for learners who were primed through a preceding translation task. In the third analysis, which included all data points, with items assigned to SC/non-SC categories based on participants’ individual translations in the independent translation task, the effect of lemmatic transfer emerged clearly in both L2 groups, regardless of task order, but not in the native speaker control group.
These findings suggest that properties of Korean predicates related to IC bias are activated when Korean learners of English process English translation correspondents of these predicates, leading to stronger subject bias for SC-type predicates than for non-SC-type predicates even in English. These findings indicate that cross-linguistic activation at the word level can affect learners’ processing at the discourse level, presumably through the mental models they create as a result of shared representations at a lexical level.
As in all investigations of cross-linguistic influence, it is important to ask to what extent differences observed between the performance of L2 learners and native speakers can confidently be attributed to properties of the learners’ L1, and to what extent they may be a reflection of non-native language use more generally. This question is typically addressed by including two separate L2 groups whose L1s differ with regard to the property under investigation, such that one group's L1 is similar to the L2 while the other is different (see e.g., White, Reference White and Cook1986; Grüter & Crago, Reference Grüter and Crago2012). For the linguistic phenomenon investigated here, the scenario is somewhat different, and presents an instance of what Jarvis (Reference Jarvis, Roberts, Howard, Laoire and Singleton2010) termed intralingual contrasts, where a certain feature in one language is stratified into more than one feature in the other. In this case, IC verbs in English are stratified into two types in Korean, namely those that have translation correspondents in Korean that are also IC verbs (non-SC) and those that are best translated into constructions with explicit causality marking (SC). As a consequence, the critical comparison between our L2 and L1 groups with regard to transfer does not lie in a simple main effect of group, but in the interaction between predicate type and group. The nature and significance of this interaction shows that the L2 group is making a distinction that the L1 group is not, where the only difference between the items in the two predicate-type conditions is whether or not a lexical translation correspondent is available in Korean. It is thus difficult to see how this distinction could be attributed to ‘learner-general’ factors. Further empirical support for this conclusion could come from the inclusion of an additional L2 group whose L1 has translation correspondents for items in both predicate-type conditions that are all IC verbs, as in English. Our key predictions would be a null effect for the interaction between predicate type and group when comparing that additional group to the native English group, and the same interaction effect reported here when comparing that additional group to the L2 Korean group in this study. We must leave such further exploration for future research.
General discussion and conclusion
The primary goal of this study was to investigate the effect of lemma-level transfer on Korean–English bilinguals’ referential choices in English at a discourse level. To this end, we first conducted written continuation tasks with Korean (Experiment 1a) and with English native speakers (Experiment 1b) respectively, in order to test the hypothesized cross-linguistic difference in bias strength between Korean and English IC predicates. Building on the results from these experiments, we conducted an English continuation task with Korean learners of English to test whether the established cross-linguistic difference between Korean and English predicates would influence learners’ referential choices in English (Experiment 2).
The results from Experiments 1a and 1b provided evidence for a cross-linguistic difference between (morpho)syntactic causative (SC) predicates in Korean and their English translation counterparts: Korean speakers provided more continuations with subject reference following SC than non-SC predicates, while English speakers showed little difference in the subject bias strength across the two predicate types. This finding is consistent with Hartshorne et al.’s (2013) conjecture that explicit causative marking, as in Japanese –(s)ase, will increase bias strength. Yet future work will be needed to better tease apart the roles of explicitness of causality marking and intentionality associated with the predicates involved, given that the SC predicates used here differed from the non-SC predicates along both of these dimensions. Importantly, however, we observed a difference in bias strength between the two predicate types only in Korean, not in English. Since the distribution of (broadly defined) verb classes was highly similar in the materials in both languages, we thus cautiously conclude that explicitness of causative marking is likely a contributing factor in the referential biases observed with these predicates, and a factor that should be considered alongside other known factors, such as verb semantics and thematic roles (e.g., Brown & Fish, Reference Brown and Fish1983; Hartshorne & Snedeker, Reference Hartshorne and Snedeker2013) and world knowledge (e.g., Pickering & Majid, Reference Pickering and Majid2007) in the IC literature.
With regard to bilingual processing, the primary object of investigation here, the results from Experiment 2 demonstrate that the difference between Korean and English in terms of bias strength affected Korean–English bilinguals’ referential choices in English causal dependent clauses. The effect appeared somewhat more robust when learners completed the translation task before the continuation task. This is consistent with previous research on translation priming which has shown that prior exposure to a word in one language enhances the activation of that word during the processing of the translation equivalent in another language (e.g., De Groot & Nas, Reference De Groot and Nas1991; Gollan, Forster & Frost, Reference Gollan, Forster and Frost1997; Kroll & Stewart, Reference Kroll and Stewart1994). These earlier findings indicate that translation equivalents in bilinguals’ mental lexicons are accessed in parallel and translation priming can modulate bilingual word activation. Our results confirm the effect of translation priming at the word level, and indicate furthermore that translation priming can also affect bilinguals’ referential choices at a discourse level.
Importantly, however, the predicted effect of cross-linguistic activation of IC bias strength emerged even without translation priming when the data were analyzed respecting participants’ individual cross-linguistic associations. Although this analysis led to an imbalance in the number of items per condition, we believe that it affords the most accurate picture of bilingual processing by taking into account inevitable individual differences among bilinguals with regard to the specific cross-linguistic associations in their mental lexicons. Taking such individual differences into account is particularly important when the languages involved are typologically and culturally distant, making it more difficult, and in some cases impossible, to establish uniform translation equivalents across languages. The findings from Experiment 2 thus provide evidence that lemmatic transfer at a word level can have repercussions for processing at the sentence and discourse level. We presume that these effects arise through the mental models that are created under the influence of cross-linguistic activation at the lexical level during bilingual discourse processing. We hope that future work can identify other cross-linguistic differences of this type to further investigate the scope of cross-linguistic influence and lemmatic transfer in L2 discourse processing.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S1366728918000561