





Introduction
During reading our eyes do not move smoothly through the text. Rather, we make a series of fixations (in which our eye is relatively still, and we take in information) and saccades (in which we move our eyes to the next fixation location, and do not take in information). When the eye fixates on a word during reading, it is primarily ascertaining information about the word in the fovea – the center of the retina which has the highest visual acuity, approximately 2 degrees of visual angle from the fixation. Importantly, however, it is also ascertaining information about words in the parafovea – the area outside the fovea extending to approximately 5 degrees of visual angle (e.g., Schotter et al., Reference Schotter, Angele and Rayner2012). The parafoveal area is important as it allows the readers to preprocess upcoming information that is not being directly fixated upon, thereby allowing readers to plan upcoming eye movements.
Evidence for parafoveal processing comes from, for example, the gaze-contingent boundary paradigm (GCB; Rayner, Reference Rayner1975). This paradigm involves masking a critical word of interest and embedding an invisible boundary prior to that region; when the reader makes a saccade across the invisible boundary, the masked region is unmasked. Typically, the participant is unaware of this change because of saccadic suppression (Matin, Reference Matin1974). For example, in Figure 1 the critical word (lawn) is masked with a series of Xs (therefore blocking the word from being parafoveally processed), and upon making a saccade across the invisible boundary (the dashed line) the Xs are permanently replaced with the critical word lawn (as in B).

Figure 1. Illustration of the Gaze Contingent Boundary (GCB) paradigm (taken from Fernandez et al., Reference Fernandez, Allen and Scheepers2021). The green ellipses represent hypothetical fixation points and the red dotted lines represent a pre-defined boundary that is invisible to the reader. As soon as the eye crosses the invisible boundary, the mask ‘xxxx’ in (A) is permanently replaced with the critical word ‘lawn’ in (B).
Using this paradigm, evidence for parafoveal processing has been found in the form of the parafoveal N + 1 preview effectFootnote 1. An N + 1 preview effect occurs when there are measurable reading differences on a target word (N + 1) when that word is available in the parafoveal view of N (the word prior to the critical word, as in B) compared to the same word when it is blocked in the parafoveal view of N (as in A). Traditionally this type of effect has been referred to as a preview benefit but, in line with Vasilev and Angele (Reference Vasilev and Angele2017), we refer to it as the N + 1 preview effect.
Parafoveal masks that do not share information with the critical word (e.g., the Xs in Figure 1) are uninformative and lead to an increased reading time on the critical word, or N + 1 inhibition (e.g., Fernandez et al., Reference Fernandez, Scheepers and Allen2020; Hutzler et al., Reference Hutzler, Schuster, Marx and Hawelka2019; Marx et al., Reference Marx, Hawelka, Schuster and Hutzler2015; Vasilev & Angele, Reference Vasilev and Angele2017). In their meta-analysis Vasilev and Angele found a graded effect from uninformative masks, with N + 1 inhibition increasing as a parafoveal mask becomes less word-like (i.e., identical word < unrelated word < pseudo-word < string of random letters < string of X's). However, parafoveal masks need not be uninformative; they can also be informative about certain aspects of the word. For example, the parafoveal mask can share orthographic information with the critical word (e.g., lawc; in which the first three letters are shared between the mask and critical word) or semantic information with the critical word (e.g., yard). Research has shown that when the parafoveal mask and the critical word share the first few letters, there is a large N + 1 benefit (see Schotter et al., Reference Schotter, Angele and Rayner2012, for a review).
However, the benefit from having a semantic relationship between the parafoveal mask and critical word is less consistent. Both Rayner et al. (Reference Rayner, Balota and Pollatsek1986) and Rayner et al. (Reference Rayner, Schotter and Drieghe2014) found no evidence of an N + 1 semantic benefit in English when a critical word (e.g., song) was parafoveally masked with a semantically related word (e.g., tune). More recent research has found evidence for a semantic N + 1 benefit in English, in certain situations. For example, a benefit is found when parafoveal masks are synonyms as opposed to semantic associates (Schotter, Reference Schotter2013; Schotter et al., Reference Schotter, Lee, Reiderman and Rayner2015), when some individual differences are taken into account (e.g., reading skill; Veldre & Andrews, Reference Veldre and Andrews2016a), and when the N + 1 word is capitalized thus increasing visual attention to the word (Rayner & Schotter, Reference Rayner and Schotter2014). Additionally, a preview benefit has been found in English for parafoveal masks that are plausible within the sentence context, even if the mask and the critical word do not share information (Schotter & Fennell, Reference Schotter and Fennell2019; Schotter & Jia, Reference Schotter and Jia2016; Veldre & Andrews, Reference Veldre and Andrews2016b; Wakeford & Murray, Reference Wakeford, Murray, Knauffm, Sebanz, Pauen and Wachsmuth2013). This suggests that, at least in early reading measures, semantic preview benefits may arise from the fit between the context of the sentence and the plausibility of the mask.
Semantic N + 1 effects have been more readily found in languages such as Chinese (e.g., Tsai et al., Reference Tsai, Kliegl and Yan2012; Yan et al., Reference Yan, Zhou, Shu and Kliegl2012; Yang et al., Reference Yang, Wang, Tong and Rayner2012), Korean (Yan et al., Reference Yan, Wang, Song and Kliegl2019), and German (e.g., Hohenstein & Kliegl, Reference Hohenstein and Kliegl2014). Yan et al. (Reference Yan, Richter, Shu and Kliegl2009) has proposed that properties of the written system dictate which type of information is parafoveally processed. In contrast to alphabetic scripts, meaning in the Chinese writing system is mapped more closely to orthography than to phonology. Additionally, most Chinese words consist of two characters, meaning that the N + 1 word is typically viewed with higher visual acuity than in alphabetic scripts where words have more characters. Indeed, Tsai et al. (Reference Tsai, Kliegl and Yan2012), Yan et al. (Reference Yan, Wang, Song and Kliegl2019), and Yang et al. (Reference Yang, Wang, Tong and Rayner2012) have found evidence for semantic N + 1 benefit in Chinese. Yan et al. (Reference Yan, Wang, Song and Kliegl2019) also found evidence for a semantic N + 1 benefit in Korean. Interestingly, characters in the Hangul script used for Korean represent a syllable, and words consist of only a few characters, thus providing readers with higher N + 1 visual acuity. Additionally, the spelling to sound correspondence is relatively clear in Korean, making lexical access more straightforward (unlike English).
Hohenstein and Kliegl (Reference Hohenstein and Kliegl2014) found a semantic N + 1 benefit in German, across three GCB studies. In neutral sentence contexts they found an N + 1 preview benefit when a critical word (e.g., Wolle (wool)) was masked with a related word (e.g., Seide (silk)), but not with an unrelated word (e.g., Seife (soap))Footnote 2. They also found a preview benefit for related words compared to unrelated words regardless of capitalization (the first letter of German nouns is capitalized), suggesting that this benefit was not just the result of increased parafoveal visual salience of German nouns due to capitalization. The clear semantic N + 1 benefit seen in German may result from the relatively clear spelling-to-sound correspondence in German (see, for example, Laubrock & Hohenstein, Reference Laubrock and Hohenstein2012), which may make lexical information easier to extract relative to languages like English (with an opaque spelling-to-sound correspondence).
From the L1 evidence previously outlined, the semantic N + 1 benefit seems to arise under certain conditions, and with particular languages. However, most of our understanding of reading and language processing is based on monolingual speakers, despite the reality that more than half of the world speaks more than one language (Marian & Shook, Reference Marian and Shook2012). While research investigating bilingual language processing has become more prominent, there are still relatively few studies that systematically investigate classic oculomotor behavior in L2 speakers (e.g., skipping behavior and parafoveal processing). We seek to form a more comprehensive picture of L2 reading behavior by investigating L2 parafoveal processing. In the current study, we expand on a previous “seemingly English” parafoveal processing study with L1 German–late L2 English speakers (Fernandez et al., Reference Fernandez, Allen and Scheepers2021) by presenting similar but translated items in a “seemingly German” parafoveal processing study with L1 German–L2 English.
To the knowledge of the authors, there are only a handful of published studies investigating L2 parafoveal processing. Three of these studies have focused on effects that are not semantic. First, Jouravlev and Jared (Reference Jouravlev and Jared2018) found that English–Russian bilinguals reading in English can make use of orthographic and phonological information from Russian parafoveal masks presented in Cyrillic. Second, Vaughan-Evans et al. (Reference Vaughan-Evans, Liversedge, Fitzsimmons and Jones2020) found that Welsh–English bilinguals reading in English are sensitive to English parafoveal previews that adhere to Welsh soft mutation morpho-syntactic rules (relative to those with an aberrant soft mutation). Finally, Fernandez et al. (Reference Fernandez, Scheepers and Allen2020) found that L1 English and L1 German–L2 English readers showed a graded N + 1 interference from uninformative masks, with the interference increasing the less “word-like” the masks became.
A number of other L2 studies focused on semantic N + 1 effects, but their results are somewhat mixed. Three studies show no semantic preview effect. Altarriba et al. (Reference Altarriba, Kambe, Pollatsek and Rayner2001) investigated parafoveal processing in a group of Spanish–English bilinguals while reading in both Spanish and English. They found that there was an N + 1 benefit with cognate translation masks (cream/crema (cream)) and pseudo-cognate masks (grass/grasa (grease)) relative to non-cognate translation masks (strong/fuerte (strong)). This suggests that the bilingual readers only derived a benefit when the mask shared phonological and orthographic features with the target word, and not when the mask shared only semantic information. More recently, this lack of N + 1 benefit from non-cognate translations in Spanish–English bilinguals was replicated with different materials (Hoversten & Traxler, Reference Hoversten and Traxler2020), again suggesting that bilingual readers of alphabetic languages do not access translation/semantic information parafoveally. A similar result was found with late L2 Chinese speakers (L1 Korean) reading in Chinese; Wang et al. (Reference Wang, Zhou, Shu and Yan2014) found an N + 1 preview benefit when the mask and critical word shared orthographic features but not when they shared semantic features. Interestingly, Wang et al. included a measure of L2 proficiency and found that more proficient participants were more efficient at extracting parafoveal information. They argued that less skilled readers had to devote more of their cognitive resources to the foveal word, which left fewer cognitive resources to devote to the processing of the parafoveal word. The role of proficiency was not tested in Altarriba et al., nor is it clear whether their participants were early bilinguals, late bilinguals, or heritage speakers. Proficiency was measured in the Hoversten and Traxler paper, with all participants showing similar proficiency in both English and Spanish respectively, but proficiency level was not included in their statistical models.
Three additional studies investigating semantic L2 parafoveal processing, however, did find evidence for an L2 N + 1 semantic benefit. The first investigated late L2 Chinese speakers (with a Korean L1) reading in a seemingly Chinese task where, however, the parafoveal masks were presented in Korean (Wang et al., Reference Wang, Yeon, Zhou, Shu and Yan2016). They found an N + 1 semantic benefit during reading for both cognate and non-cognate semantic masks, suggesting that the benefit was not purely orthographic in nature, but rather semantic. They argue that this benefit could be the result of the relatively transparent spelling-to-sound correspondence of Korean (which has a similar orthographic depth to German). The second study found evidence for an L2 N + 1 semantic benefit for Basque–Spanish bilinguals, although with some methodological differences from previous studies (Antúnez et al., Reference Antúnez, Mancini, Hernández-Cabrera, Hoversten, Barber and Carreiras2021). This study used Fixation-Related Potentials to measure brain activity during reading. In addition, participants did not read sentences, but rather viewed two words during a Spanish reading task; word N + 1 was masked when the participant was fixating on word N, and was replaced with the critical word when the participant made a saccade to word N + 1. Antúnez et al. found evidence for a facilitation from a non-cognate Basque translation parafoveal mask relative to an unrelated Basque parafoveal mask. This suggests that, even in alphabetic languages, word recognition is not language-selective. The third study to find some evidence for an N + 1 semantic benefit with L2 speakers investigated L1 speakers of English and L2 speakers of English (with an L1 of German) reading in an English reading task (Fernandez et al., Reference Fernandez, Allen and Scheepers2021). Given that tshe current study aims to extend the Fernandez et al. study, we devote more attention to this study.
Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) tested orthographic and semantic parafoveal processing for both L1 speakers of English (with no German knowledge) and late L2 speakers of English with German L1 (mean age of English acquisition was 10.2 years old), using the GCB. They presented neutral context sentences in English (The man found the arrow in a tree) with the critical word (arrow) masked with six different masks types: an identical word mask (arrow), an English orthographic mask (arrzm), an English string mask (xezne) in which ascending and descending letters were matched, a German translation (pfeil), a German orthographic mask (pfexk), or a German string mask (ylctb) in which ascending and descending letters were matched. Critically, the German translation mask was carefully matched in length, and the English meaning could not be guessed based on the German word (as guessed by 250 native English speakers who had never learned German or any Germanic language other than English; materials taken from Friel & Kennison, Reference Friel and Kennison2001). Therefore, L1 speakers of English were not able to extract any useful information from the German masks, while L2 speakers of English with German L1 would potentially be able to extract semantic and/or orthographic information from the German masks.
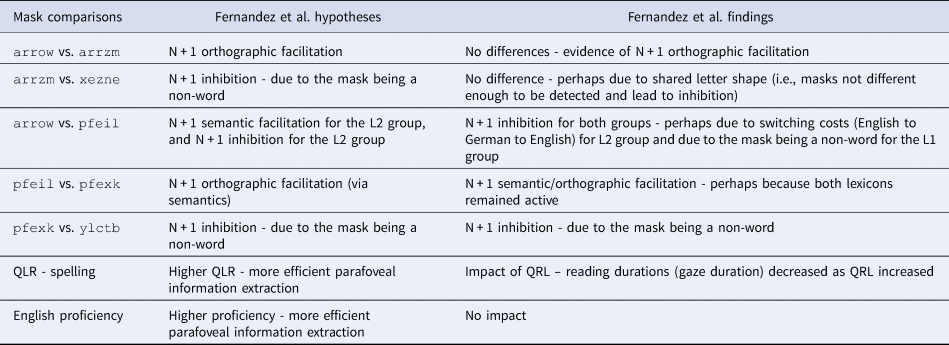
In their study, they made several comparisons, each with a specific hypothesis; see Table 1 for all comparisons, hypotheses, and findings. First, they hypothesized similar reading times between the identical (arrow) and the English orthographic mask (arrzm). They found no difference between the two mask types, suggesting that both groups showed orthographic N + 1 facilitation. Second, they hypothesized greater reading durations for the English string mask (xezne) compared to the English orthographic mask (arrzm). They found no such inhibition, which they argued may be the result of the masks being very similar (i.e., they matched in ascending and descending letter shapes), making the display change harder to detect and thus limiting inhibition. Third, they hypothesized an N + 1 semantic facilitation (with similar reading times) between the German translation mask (pfeil) compared to the identical mask (arrow) for the L2 English speakers with German L1, and an inhibition for the L1 English speakers. They found that both language groups showed an inhibition in the German translation mask condition (in terms of increased reading durations in the German mask condition), which they argued may reflect a switching cost for the L2 speakers and may reflect that the mask was less word-like for the L1 group. Fourth, they hypothesized an N + 1 orthographic benefit for L2 speakers when comparing the German mask (pfeil) to the German orthographic mask (pfexk) and no difference for L1 speakers since both should be non-words. They found an N + 1 orthographic benefit from the German orthographic mask, with L2 speakers showing shorter reading times after the pfexk relative to pfeil conditions, while L1 readers showed no such differenceFootnote 3. Fifth, they hypothesized an N + 1 inhibition for the German string mask (ylctb) compared to the German orthographic mask (pfexk). They found an N + 1 inhibition for both groups (with greater reading durations for the German string mask), suggesting that both groups showed an inhibition due to the German string mask being less word-like. In terms of individual differences, they hypothesized that participants with higher quality of lexical representation (tested via spelling skill) and with higher proficiency (tested via English morpho-syntactic knowledge) would be more efficient at extracting parafoveal information and would have shorter reading times. They found this was the case for quality of lexical representation but not for proficiency level.
Table 1. Fernandez et al. summary of hypotheses and findings.
According to the Bilingual Interactive Activation Plus (BIA+) model of word recognition (Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002), the bilingual lexicon is non-selective and integrated between languages. Within this framework, Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) argued that when a late L2 English speaker (with an L1 of German) reads in English, but views a complete German word in the parafovea (e.g., pfeil), the German language node is activated and the English language node is inhibited. This is further compounded by the fact that the word ultimately fixated on (and the continuation of the sentence) is in English, which could incur an additional language switching cost leading to N + 1 inhibition. However, when viewing an orthographic mask (but not a real word in German or English, e.g., pfexk) in the parafovea, both German and English lexicons remain active, and lexical and semantic candidates are narrowed down in both English and German, thus leading to quicker access to arrow upon foveal viewing. This leads to N + 1 facilitation and, given that both English and German remain active, few if any language switching costs are incurred. It is important to note, however, that L1 speakers showed a somewhat similar pattern (a decrease in reading time in the German orthographic condition (pfexk) relative to the German translation condition (pfeil)) and, while this effect did not reach significance, there is no reason this pattern should emerge.
The unexpected finding that the German translation mask was inhibitory while the German orthographic mask was faciliatory suggests that L2 readers are engaging in complex processing and are able to use parafoveal information to narrow down lexical candidates in a language non-specific way (much like they do for foveal processing). There are only a handful of studies investigating parafoveal processing in L2 readers and, to our knowledge, theories of eye-movements during reading do not typically consider L2 reading behavior (despite the fact that these theories account for reading behavior in other groups such as children and older adults). However, previous L2 research does not seem to support the idea that L2 readers are able to engage in such complex reading behaviors. In a recent study, Cop et al. (Reference Cop, Drieghe and Duyck2015) report a comprehensive description of both bilingual and monolingual reading behavior during the reading of a novel. Dutch L1 (late English L2) speakers and monolingual L1 English speakers read the same novel in its entirety while having their eyes tracked; the bilingual group read half in Dutch and half in English, while the monolingual group read the novel entirely in English. Analysis within the same bilingual participant (the same participant was compared reading in their L1 and their L2) showed several effects at the sentence level when reading in an L2 relative to reading in an L1: average sentence reading times were longer, there were more fixations per sentence, average fixation durations were longer, average saccade lengths were shorter, and the likelihood of skipping a word was lower. Cop et al. argue that this pattern of behavior is similar to that of 7- to 11-year-old L1 readers, and that there is an overall slowing of lexical access that drives differences between L1 and L2 reading behavior. This would suggest that L2 readers should take longer to read the foveal word and as a consequence have fewer resources to invest in parafoveal processing.
In terms of the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study, it is possible that the unexpected results (inhibition from the German translation mask but facilitation from the German orthographic mask) are in part due to the relatively low power in their study (51 L1-speakers / 51 L2-speakers, each reading 4 items per condition). Therefore, in the current registered report we increased the power with 100 L1 speakers of German (who were late English L2 speakers) reading 18 items per condition. In addition, we expanded on the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) findings by using similar materials but translated into German. This allowed us to see whether the same pattern of results holds true regardless of the language frame in which the masks were embedded. Finally, we made several changes to the designFootnote 4 that we believe allowed us to more directly test the extent to which readers are able to use L2 parafoveal information during reading (see Table 2).
Table 2. Example stimulus. The sentence frame is shown in the leftmost column where the critical word (here the underscored word Pfeil) was embedded; “ | ” indicates the position of the invisible boundary. Before crossing this boundary with an eye-movement, the critical word was masked with one of five different types of letter strings (columns 2-6).

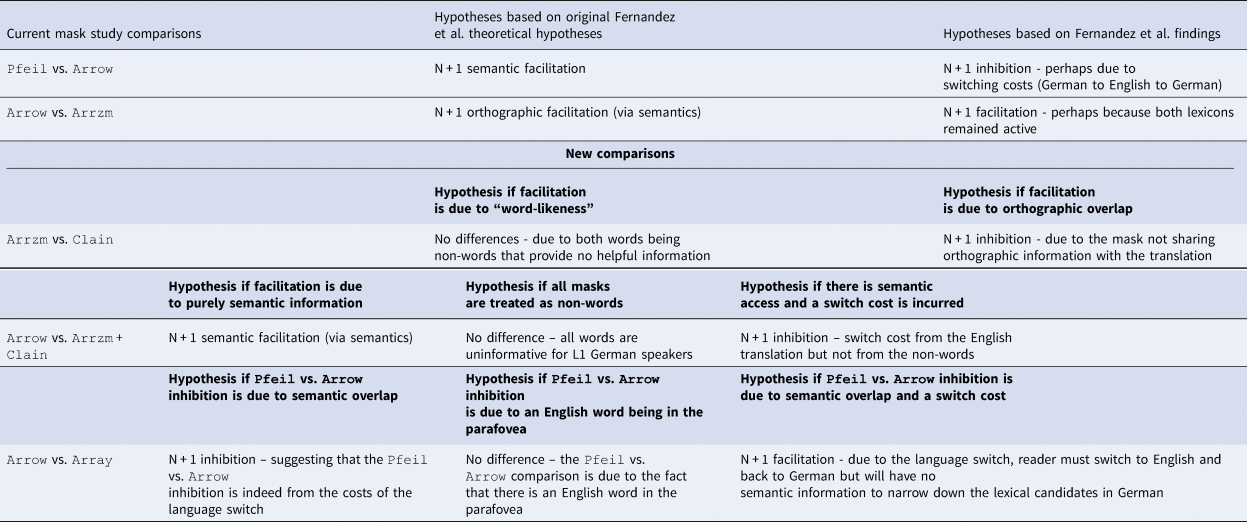
First, we removed the two string mask conditions (e.g., xezne and ylctb) as we did not have any additional theoretical questions about these conditions. We also replaced the German orthography condition (pfexk) with an English pseudo-word mask (Clain) with no orthographic overlap. It is possible that the facilitation from the orthographic-word mask (pfexk) was due to the fact that this mask happens to be “word-like”, thus evoking less interference (see Fernandez et al., Reference Fernandez, Scheepers and Allen2020; Vasilev & Angele, Reference Vasilev and Angele2017) rather than due to orthographic and semantic overlap. This allowed us to directly test whether the facilitation from the orthographic mask was due to orthographic overlap or merely to the fact that this mask is “word-like”.
Second, we added a comparison of the English translation to the two non-word masks (the English pseudo-word mask Clain and the English orthography mask Arrzm). As mentioned previously, we can expect an N + 1 inhibition effect from uninformative masks in the parafovea, and that this inhibition becomes greater the less “word-like” the mask becomes for L1 speakers. Interestingly, Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) reported the opposite for viewing words in another language parafoveally: they found a greater N + 1 inhibition effect when a complete, real-word translation equivalent of the target word (e.g., the mask pfeil for the target word arrow) was shown parafoveally to L1 German–L2 English speakers when reading in English (L2), relative to a non-word-like pfexk (which only exhibits orthographic overlap with the translation equivalent). This pattern suggests that bilingual readers benefit from a non-word relative to an L1 word in the parafovea, which suggests that there is a switching cost from the translation word, but not from the (orthographically overlapping) non-word. This finding would be in direct contrast to what is found with L1 speakers (inhibition from non-words) and would further support the idea that L2 speakers are able to extract semantic information from the parafovea.
Third, it is possible that the differences in Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) when comparing the critical word to the German translation (arrow to pfeil) were not due to the semantic activation of pfeil, but rather to the fact that arrow was the target word (while pfeil was not). In order to test this possibility, in the current study, a semantically unrelated but orthographically related English word condition is added – that is, an English word that shares the first few letters with the English translation condition, but is semantically unrelated to the English translation word; e.g., Array. By comparing Arrow to Array in the current study we test whether differences were due to the fact that there was an English word in the parafovea that shares semantic information with the target word, or whether differences were merely due to the fact that there was an English word in the parafovea. While we deviated from the original design of Fernandez et al., these changes still allowed us to replicate with greater power, as well as expand on whether bilingual readers are indeed able to derive a semantic benefit from an orthographic match in their L2.
Before outlining the current study, we briefly discuss the asymmetry associated with tasks that involve single word language switches and research with inter-sentential language switches. The asymmetry associated with switch costs and translation priming is likely to have important implications for the current study. Research has found asymmetric switch costs; that is, the cost of switching from L2 to L1 is greater than switching from L1 to L2 (for reviews see Bobb & Wodniecka, Reference Bobb2013; Declerck & Philipp, Reference Declerck and Philipp2015). Additionally, research with non-cognate translation masked priming has shown that priming effects occur from both L1 to L2 and L2 to L1. However, the effect is smaller from L2 to L1 than L1 to L2 (e.g., Schoonbaert et al., Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009). In the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study, L2 speakers read in their L2, parafoveally viewed translation masks in their L1, but ultimately viewed the critical word in their L2, which in theory should be symmetric (L1 to L2, at least in terms of the critical word pfeil to arrow). In contrast, in the current study L1 speakers read in their L1, parafoveally view translation masks in their L2, but ultimately view the critical word in their L1, which would theoretically be asymmetric (L2 to L1, at least in terms of the viewing of the critical word Arrow to Pfeil). Therefore, it stands to reason that in the current study there might be a greater likelihood for inhibition between the English translation mask and the German identical mask relative to the Fernandez et al. study. However, we believe both studies will incur similar costs, given that both studies have overall switches from L1 to L2 and from L2 to L1 (Fernandez et al. (Reference Fernandez, Allen and Scheepers2021): English (L2) to German (L1) to English (L2); current study: German (L1) to English (L2) to German (L1)).
Research investigating bilingual sentence processing in which there is a language change within a sentence has shown that the language of the sentence preceding the switch is not enough to suppress activation of the non-target language (see Lauro & Schwartz, Reference Lauro and Schwartz2017; Van Assche et al., Reference Van Assche, Duyck and Hartsuiker2012). However, whether contextual information can constrain lexical candidates is somewhat less clear. In the face of sentences with low contextual constraint, it seems that bilinguals access both languages (Duyck et al., Reference Duyck, Van Assche, Drieghe and Hartsuiker2007; Libben & Titone, Reference Libben and Titone2009; Pivneva et al., Reference Pivneva, Mercier and Titone2014; Schwartz & Kroll, Reference Schwartz and Kroll2006; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011; Van Hell & de Groot, Reference Van Hell and de Groot2008). However, in the face of high contextual constraints, language-specific lexical access may be constrained (Lauro & Schwartz, Reference Lauro and Schwartz2017). Given that our current study investigates low contextually constraining sentences (see the methods section), we will not discuss this further.
Previous research shows that sentence level processing and language switches impact bilingual lexical access. However, we believe that drawing too many parallels between word recognition research (which primarily employs masked priming and lexical decision tasks) and the current study (which employs parafoveal processing during reading) is not particularly useful since the paradigms are vastly different. The former typically involves single word presentation and a lexical decision task, while the latter involves naturalistic sentence reading within one language (and participants are not aware of any cross-language changes throughout the whole study). We also believe it is not fruitful to draw too many parallels with inter-sentential language switch research which typically involves the participant reading a sentence in one language, an obvious language switch, and sentence continuation. In the current study a language switch also occurs, but the switched word is not perceived with foveal awareness because it is never directly fixated upon. Additionally, most previous studies have investigated the role of cognates and interlingual homographs in which the critical word shares at least some orthographic characteristics across both languages (e.g., Duyck et al., Reference Duyck, Van Assche, Drieghe and Hartsuiker2007; Elston-Güttler et al., Reference Elston-Güttler, Gunter and Kotz2005; Schwartz & Kroll, Reference Schwartz and Kroll2006; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). However, in the current study the critical word shares only semantic information across languages and the participant is not aware that a language switch has occurred, meaning that any N + 1 benefit would arise solely from semantic information. Therefore, we believe this study has the potential to provide new insight into the process of bilingual lexical access.
Current study
As outlined above, in the current registered report we aimed to overcome some of the potential confounds of the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study, and expand on their findings by using more theoretically motivated masks (while at the same time increasing power) to test whether the pattern of inhibition from a translation mask and facilitation from a purely orthographic mask remains. In order to test the generalizability of response patterns in L1 versus L2 (further corroborating or indeed disconfirming the Fernandez et al. findings) we presented the sentence frames in German. In the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study, L1 German speakers read sentences in a “seemingly English” (L2) task, using both English and German-based masks, to test whether readers are able to make use of translations from their L1 while reading in their L2. In the current study, we tested L1 speakers of German reading sentences in a “seemingly German” task, i.e., they read sentences in their L1. However, we employed both German-based and English-based masks to test whether L1 speakers make use of translations from their L2 while reading in their L1. Additionally, the original Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study tested the role of English proficiency and quality of lexical representation, given previous findings which suggested that individuals are more efficient at extracting parafoveal information if they have a higher quality of lexical representation (QLR) (Veldre & Andrews, Reference Veldre and Andrews2014; L2 speakers – Whitford & Titone, Reference Whitford and Titone2015) or higher proficiency (Wang et al., Reference Wang, Zhou, Shu and Yan2014). While Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) found no impact of English proficiency on any of their measures, they did find that reading durations decreased as spelling scores increased. In the current study, we also assessed the role of QLR and English proficiency. Consistent with Fernandez et al., we tested English proficiency using a test of morphosyntactic ability (Oxford Placement Test, Part A). Given the relatively clear spelling-to-sound correspondence in German, we opted to use the German LexTale test as a measure of QLR (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012).
Given the potential confounds outlined previously, and the rather low power in Fernandez et al. (Reference Fernandez, Allen and Scheepers2021), the current study used a modified design and materials. Firstly, we removed the German orthography condition, the English string, and German string conditions, as we did not have additional theoretical questions about these conditions. Secondly, we added two new conditions: the first is an English pseudo-word condition, which allowed us to directly test whether it is the orthographic overlap between the orthographic mask and the translation that drives the facilitation, or whether it is the fact that the orthographic mask is merely more “word-like” that drives the facilitation. The second is an English word condition (the word shares orthographic overlap but no semantic overlap with the English translation), which allowed us to directly test whether any inhibition for the English translation mask (relative to the Identical mask) arises merely because there is an English word in the parafovea, or whether it is due to the semantic overlap between the Identical word and the English translation. Additionally, we compared the English translation mask to the two non-word masks (the English orthography and the English pseudo-word masks) to test whether the translation preview lead to greater N + 1 inhibition relative to the two non-word previews (this would also provide additional evidence of a parafoveal switch cost).
We summarize the hypotheses for the current study in Table 3.
Table 3. Current study hypotheses.
Methods
Participants
A total of 107 L1 speakers of German, who were late L2 learners of English, were recruited from the RPTU-Kaiserslautern, Kaiserslautern Germany. Based on our registered exclusion criterion, we removed two participants who were raised bilingually and four participants who scored 50% or below on the English proficiency test. An additional participant was removed due to a technical issue. The remaining 100 participants met our registered requirements: they were native speakers of German (between 18 and 45 years old) who grew up in Germany with only German spoken at home, and were not exposed to a second language before the age of 6 years; see Table 4. Additionally, no participants reported a language disorder and all reported having normal or corrected-to-normal vision. Their mean English acquisition age was 9.30 years of age (SD = 1.79; range: 19-44 years of age).
Table 4. Participant information (standard deviation in parentheses).
Apparatus
Eye movements were recorded using an EyeLink 1000 sampling at 1000 Hz. Stimuli were presented on a Dell P1130 19” flat screen cathode ray tube (1024 X 768 resolution; 120 Hz refresh rate) with approximately 2.65 characters subtended 1° of visual angle. The refresh rate yielded a mean display change of 8.32 msec (SD = 2.42; range: 0–13.08 msec). Participants sat approximately 65 cm away from the monitor with their head stabilized using a chin rest. Viewing was binocular but only the right eye was recorded.
Materials
The experiment consisted of 4 practice trials plus 90 critical items presented in German. An example of the critical stimuli can be seen in Table 2. Overall, the design was one-way with five levels (mask type: Identical, English translation, English orthography, English word, English pseudo-word) with mask type manipulated within subject and item.
The stimuli were taken from Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) and translated into German. Sixty-six additional items were created to match the original Fernandez et al items. The critical stimuli start with a proper noun (Sebastian) or an article and a noun denoting a human or group of humans (e.g., der Mann/die Damen), followed by a verb in the past tense (fand), an article (den) with an embedded invisible boundary (|), the critical target word (Pfeil) and parafoveal mask, and a spill over region (in einem Baum).
The critical target word and English translation were non-cognates. The German target word and its English translation did not share the same first letter (to avoid orthographic overlap) and were matched for length within item (3-11 characters). Given that the current study was run in German, the first letter of each mask was capitalized (unlike in Fernandez et al., Reference Fernandez, Allen and Scheepers2021). However, if the German word contained a letter with an umlaut or an Eszett (ß) it is respectively presented with “e” following the vowel (e.g., Jäger→ Jaeger (hunter)) or presented with “ss” (e.g., Fluß → Fluss (river)). The German target words were relatively common (mean log10 frequency of 1.15 per million) according to the TenTen German Web Corpus (Jakubíček et al., Reference Jakubíček, Kilgarriff, Kovář, Rychlý and Suchomel2013). The English translations and English orthographically (but not semantically) matched words were also reasonably frequent according to the TenTen English Web Corpus (Jakubíček et al., Reference Jakubíček, Kilgarriff, Kovář, Rychlý and Suchomel2013) (mean log10 frequency of 1.35 per million and 0.85 per million respectively). Both the English translation and English orthography masks shared the first 2-4 characters; the remainder of the letters in the English orthography mask were replaced with letters that matched in ascension and descension which overall formed a non-word (e.g., Arrow→Arrzm). The Wuggy software was used to create pronounceable length-matched English pseudo-word masks (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010)Footnote 5. See OSF (https://osf.io/vezfn/) for a complete list of critical items and masks (including the amount of letter overlap).
To ensure there was no strong semantic overlap between the English translation and English orthography words (e.g., Arrow and Array), we took the semantic similarity cosine scores from HAL (Hyperspace Analogue to Language; Lund & Burgess, Reference Lund and Burgess1996) and LSA (Latent Semantic Analysis; Landauer et al., Reference Landauer, Foltz and Laham1998) for each pair of English words per itemFootnote 6. While HAL and LSA use somewhat different methods, their scores were correlated (r = 0.8) across the word pairs, so they were combined into an average score ((HAL + LSA)/2) for greater reliability. Cosine similarities range from -1 (semantically opposite) to 1 (semantically identical); 0 means no semantic relationship whatsoever. The mean and median of the combined cosine metric (0.26 and 0.25 respectively) suggest low semantic relatedness between the two English words per item on average; we include this metric as a covariate in our model comparing these two conditions. See OSF for a complete list of the items and masks (including the cosine semantic similarity information).
An offline sentence completion task was used to test whether the target word was expected given the sentence context. Participants (20 native German speakers) were provided with the beginning of the sentences (“Der Mann fand d”) and were asked to complete the sentence with a grammatically correct article and noun (the d was provided to ensure the participants always used an article). For 88 items, the predictability of the target word was very low (0.23%). For the remaining two items, the items were completed with the critical word more than 20% of the time, and were replaced. An additional offline task of the same format was created with two additional items, and was completed by 11 L1 German speakers. For the 2 items, no participant completed the item with the target word. Therefore, it is safe to assume that participants have no prior expectations when encountering the critical word in the sentence for the first time.
Procedure
To ensure that participants believed that they are taking part in a German reading task, the first portion of the testing was conducted in German. After providing informed consent (the current study has been approved by the local Ethics Committee), participants completed the computerized German LexTale test, and then the eye-tracking main task. Following this, there was a mandatory break, and to ensure their English proficiency, the remainder of the testing took place in English: participants completed the Language Social Background Questionnaire (Anderson et al., Reference Anderson, Mak, Keyvani Chahi and Bialystok2018) and took an English proficiency test assessing morpho-syntactic knowledge (Oxford Placement Test, Part A). Participants were paid 10 Euro or given course credit for their participation.
The eye-tracking main task began with a standard EyeLink 9-point calibration. The eye-tracking study was self-paced, such that participants could take a break as needed (with subsequent recalibration), and were recalibrated following an obligatory break halfway through the experiment. The study instructions were presented on the screen and verbally explained. Participants were asked to read silently for comprehension and instructed that after some of the sentences there will be a yes/no question about the sentence they just read, which they can answer by pressing “x” for yes and “m” for no on a standard German keyboard. One third of the sentences were followed by a comprehension question; half of the questions had a correct answer of “yes” and half had a correct answer of “no”. See OSF for a copy of the data source including comprehension questions (https://osf.io/vezfn/). Participants were also given a secondary ‘glitch detection’ task combined with the following cover story: “Because we have to use a less than optimal monitor for this study, you may very occasionally experience a ‘glitch’ during text presentation. Such glitches are indeed not intended. Hence, in the unlikely event that you have noticed something weird happening on screen, please let the experimenter know after the affected trial, so that we'll be able to remove that trial from analysis.” Using this secondary task gave us some idea of conscious display-change detection per trial, while the cover story ensures that there was not too much emphasis on detecting display changes – indeed, the primary task of the study remained reading for comprehension.
Trials began with a drift correct (x-coordinate: 54, y-coordinate: 280) which corresponded to the first letter in the critical sentence. The trial proceeded after the participant fixated for 150 ms within a half-degree region surrounding the drift correct; if this criteria was not met, the participant was recalibrated. All sentences were presented in a monospaced font (Courier New) on one line in a font size of 15. When the participant finished reading the sentence, they pressed the space bar to advance to the yes/no question. The yes/no comprehension question (along with instructions to press ‘x’ for yes and ‘m’ for no below the question) was then displayed at the same coordinates as the critical sentence and in Courier New with a font size of 15. After pressing the x or m key, the next trial began with the drift correct. Presentation order was random for each participant.
Analysis
The following pre-processing steps, exclusion criteria, and analysis were registered (see https://osf.io/vezfn/ for the accepted registered steps). Prior to analysis, trials were excluded when (1) a saccade within the critical region of interest could not be calculated because it ended outside of any interest area (18.74%), (2) a saccade crossed the invisible boundary but landed on a word prior to the critical word (i.e., j-hook; 2.52%), (3) a fixation occurred on the critical word before the boundary change was triggered (0%), (4) the display change time was greater than 15ms (0%), and (5) the participant noticed something strange during text presentation (0.98%).
Comprehension accuracy was 91.10%; we did not expect any cross-condition differences and therefore do not discuss accuracy further. Two duration-based measures (first fixation duration and gaze duration) and a probability-based measure (skipping rate) were analysed. First fixation duration (FFD) is the duration of the first fixation within the critical region, while gaze duration (GD) is the sum of the duration of fixations on the critical word before the eye moves out of the region. Prior to statistical analysis, FFD and GD data were trimmed, such that all fixations under 80ms or over 1000ms (for FFD) or 1200ms (for GD) were removed (see Supplementary Material 1 for percent of data removed and the remaining data points per condition). While our primary hypotheses focus on the duration measures, we are also interested in skipping rate to see whether these readers are able to use second language bottom-up visual information from the parafoveal area to inform oculomotor planning. We calculated skipping rate as the percentage of trials in which the critical target word was skipped during the first pass (see Supplementary Material 1). This measure is binary, with the critical word being skipped (1) or fixated on (0) during the first pass.
Duration measures were analysed using generalized linear mixed-effects models (GLMM) in R (R Core Team, 2019) using the lme4 package (Bates et al., Reference Bates, Maechler and Bolker2019), and p-value estimates were derived from the lmerTest package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Bojesen2019). Given the skew in duration measures, the identity link function with a Gamma distribution was used (see Lo & Andrews, Reference Lo and Andrews2015) which takes into account the positive skew of duration data. The alpha threshold for the duration measures was set to 0.05/2 = 0.025 given the increased potential for Type I error with multiple comparisons (see von der Malsburg & Angele, Reference von der Malsburg and Angele2017). Skipping rate was analysed using a binary logistic GLMM. The skipping rate model was fit in the same way as the duration models, but the additional centred covariate of mask length (in number of characters) was added to the model as a main effect. Given that the skipping rate measure is exploratory, the alpha threshold was set to 0.05/3 = 0.016.
A custom a-priori contrast matrix (Schad et al., Reference Schad, Vasishth, Hohenstein and Kliegl2020) compared the following across two models: 1) Identical vs. English translation, 2) English translation vs. English orthography, 3) English translation vs. English pseudo-word, and 4) English translation vs. [English orthography + English pseudo-word], and 5) English translation vs. English word (see https://osf.io/vezfn/).
The first model consisted of the fixed effects of mask type (5 levels: Identical, English Translation, English Orthography, English Word, and English Pseudo-word), LexTale score, proficiency score (with the two latter being scaled to reduce collinearity), and their interaction, and included the first 4 contrasts. The second model was identical to the first model, but included the additional scaled cosine semantic similarity value, and included the 5th contrast comparing the English translation and English word mask (given that these are the two relevant conditions for the semantic similarity value). Across both models, the random effects structure was maximally specified (Barr et al., Reference Barr, Levy, Scheepers and Tily2013) with crossed random effect of participant and items. For all models, the maximal model did not converge. Therefore, as outlined in our registered statistical approach, the random slopes for the individual difference measures (LexTale Score and proficiency score) were removed (Barr et al., Reference Barr, Levy, Scheepers and Tily2013, found that it may not be essential to include random slopes for control predictors). In all cases this model converged.Footnote 7
Below t/z and p values are reported, see Table S2.1 for mean values and standard deviations, see Supplementary Material 2 for additional model information, and see (https://osf.io/vezfn/) for collected data and statistical code.
Results
First fixation duration
For a visualization of FFD see, Figure 2. The first model revealed a main effect of the Identical condition vs. the English translation condition (Pfeil vs Arrow; t = 4.71, p < .001), with FFD increasing in the English translation condition relative to the Identical condition. Both the first (t = 3.28, p < .01) and second (t = 3.04, p < .01) model revealed an interaction of German QLR (measured via the German LexTALE) and English proficiency (measured via the OPT). To explore this interaction, we split the LexTALE score into two groups (low LexTALE: n = 52 (range = 55.00-87.50)/ high LexTALE: n = 48 (range = 88.75-97.50)), see Figure 3. We found that individuals with lower German QLR scores showed decreased FFD as English proficiency increased, while individuals with high German QLR score showed increased FFD as English proficiency increased. No further effects reached significance (see Supplementary Material 2).
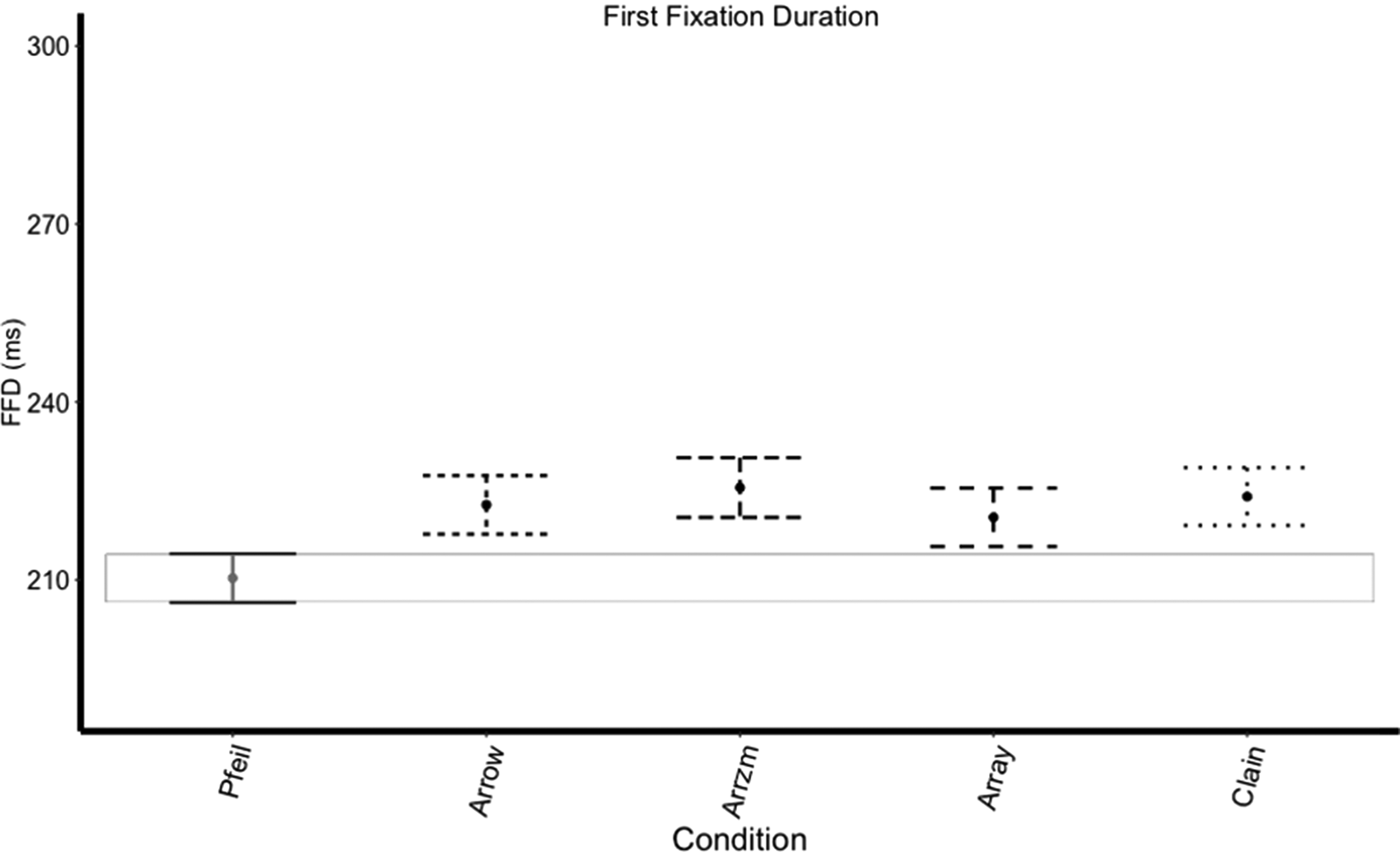
Figure 2. Mean FFD across all conditions (error bars reflect 97.5% confidence intervals)
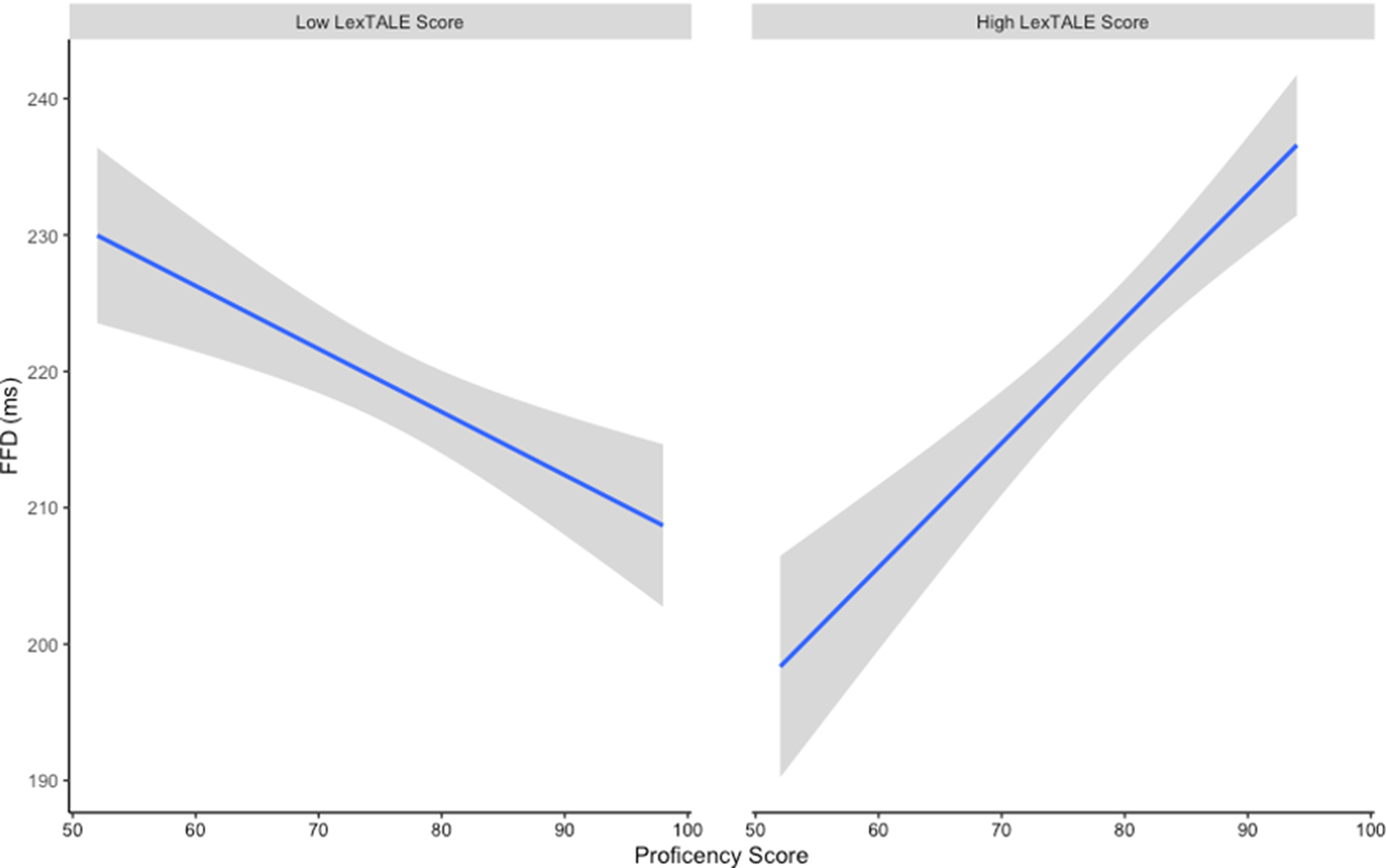
Figure 3. FFD and English proficiency split by LexTALE score (grey shading reflect 95% confidence intervals)
Gaze duration
For a visualization of GD see, Figure 4. The first model revealed a main effect of the Identical condition vs. the English translation condition (Pfeil vs Arrow; t = 3.22, p < .01) with GD increasing in the English translation condition relative to the Identical condition. Both the first (t = 2.62, p < .01) and second (t = 2.34, p < .025) model revealed an interaction between German QLR and English proficiency. As was done for FFD, we split the LexTALE to explore the interaction, see Figure 5. Again, we found the same pattern: individuals with lower German QLR scores showed decreased GD as English proficiency increased, while individuals with high German QLR score showed increased GD as English proficiency increased. No further effects reached significance (see Supplementary Material 2).

Figure 4. Mean GD across all conditions (error bars reflect 97.5% confidence intervals)
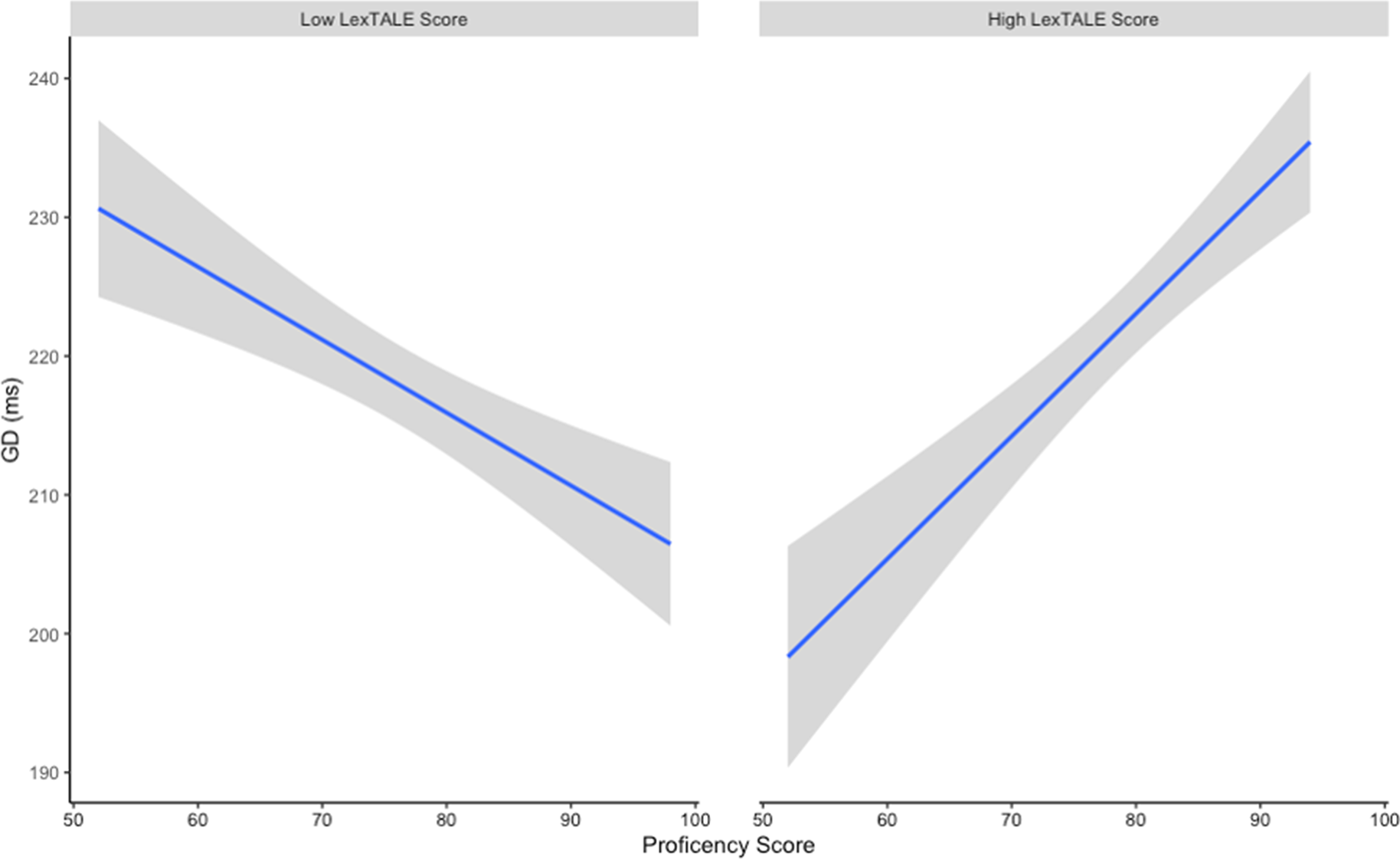
Figure 5. GD and English proficiency split by LexTALE score (grey shading reflect 95% confidence intervals)
Skipping rate
For a visualization of skipping rate see figure S3 Supplementary Material 3. No significant effects were registered in this variable (see Supplementary Material 2).
Discussion
Currently, the semantic N + 1 benefit is somewhat elusive in research on both monolingual and bilingual speakers, with some languages and language combinations showing a benefit (e.g., Chinese: Tsai et al., Reference Tsai, Kliegl and Yan2012; Yan et al., Reference Yan, Zhou, Shu and Kliegl2012; Yang et al., Reference Yang, Wang, Tong and Rayner2012; English: Schotter, Reference Schotter2013; Schotter et al., Reference Schotter, Lee, Reiderman and Rayner2015; Schotter & Fennell, Reference Schotter and Fennell2019; Schotter & Jia, Reference Schotter and Jia2016; Wakeford & Murray, Reference Wakeford, Murray, Knauffm, Sebanz, Pauen and Wachsmuth2013; Korean: Yan et al., Reference Yan, Wang, Song and Kliegl2019; German: Hohenstein & Kliegl, Reference Hohenstein and Kliegl2014; Spanish–Basque bilinguals when using Fixation-Related Potentials and using word presentation: Antúnez et al., Reference Antúnez, Mancini, Hernández-Cabrera, Hoversten, Barber and Carreiras2021; Chinese–Korean bilinguals when L1 Korean speakers read in their L2 Chinese but are presented with a mask in their L1: Wang et al., Reference Wang, Yeon, Zhou, Shu and Yan2016) and others showing no benefit (e.g., Finnish: Hyönä & Häikiö, Reference Hyönä and Häikiö2005; English: Rayner et al., Reference Rayner, McConkie and Zola1980; Chinese–Korean bilinguals: Wang et al., Reference Wang, Zhou, Shu and Yan2014; Spanish–English bilinguals: Altarriba et al., Reference Altarriba, Kambe, Pollatsek and Rayner2001; Hoversten & Traxler, Reference Hoversten and Traxler2020). Given this discrepancy and the general dearth of research on L2 parafoveal processing, in this registered report, we tested L1 German–late L2 English speakers in a “seemingly German” task with English translation masks. This study provides unique data and insight into cross-language N + 1 semantic preview effects given that L1 German speakers show an N + 1 semantic benefit (Hohenstein & Kliegl, Reference Hohenstein and Kliegl2014) and that bilingual readers are able to derive an N + 1 semantic benefit from an L1 translation mask when reading in their L2 (L1 Korean–late L2 Chinese speakers; Wang et al., Reference Wang, Yeon, Zhou, Shu and Yan2016). In addition, this study provides evidence to whether late L2 speakers are able to make use of semantic parafoveal information during reading in a seemingly monolingual task.
In the current registered report, we built upon and expanded the original Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study by increasing power, conducting the study in German, and adding additional conditions that allowed us to more directly test whether L1 speakers are able to make use of L2 words parafoveally during reading. Particularly, we were interested in replicating Fernandez et al.'s surprising finding that bilingual readers showed an inhibition from a translation mask (Pfeil vs Arrow) but a facilitation from a translation mask that shared only partial orthographic information (Arrow vs. Arrzm). In addition, we developed several other mask types and comparisons to identify the theoretical reasons why this pattern may occur.
If we replicated what was found in the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) paper, there would be an N + 1 inhibition effect (in terms of greater reading times following the English translation condition) between the German mask and English translation (Pfeil vs. Arrow), presumably arising because of costs incurred from switching from German to English and back to German. And, there would be an N + 1 facilitation effect (in terms of shorter reading times following the [semantically unrelated] English orthography condition) between the English translation and English orthography mask (Arrow vs. Arrzm), presumably because both German and English lexicons remain active, and lexical and semantic candidates are narrowed down leading to quicker access to Pfeil upon foveal viewing. When looking at the data in the current study, we replicated the N + 1 inhibition when comparing Pfeil vs. Arrow in FFD and GD. This suggests that readers fixate on the target word longer after parafoveally viewing the English translation. However, we were not able to replicate the N + 1 facilitation when comparing Arrow vs. Arrzm in any measure. Together this indicates that bilingual readers show an immediate effect when a translation mask is viewed parafoveally but they do not show a benefit from an orthographic mask. Thus, we found no evidence that bilingual readers use partial translation information to narrow down lexical candidates parafoveally.
To investigate why this pattern emerged, we first compare the English orthography mask and the English pseudo-word mask (Arrzm vs. Clain). We hypothesized two possibilities. First, a finding that there are no differences between the two conditions would be consistent with the idea that the reader is treating both the English orthography mask and the English pseudo-word mask as non-word masks that provide no helpful information. Second, a finding that there is an N + 1 inhibition effect in terms of greater reading times for Clain relative to Arrzm would indicate that the shared orthography of Arrzm and the English translation leads to a semantic facilitation when ultimately reading Pfeil. In the current study, we found no differences when comparing Arrzm vs. Clain. This suggests that bilingual readers are treating both types of masks as non-words, despite Arrzm sharing orthographic information with the English translation word.
Second, we compare the English translation and the English word (Arrow vs. Array). We considered several possible outcomes. First, an N + 1 inhibition effect (in terms of longer reading times from the English translation relative to the English word mask) would indicate that any N + 1 inhibition seen when comparing the German word and its English translation (Pfeil vs. Arrow) must be due to the semantic overlap between Arrow and Pfeil (which led to a switch cost), and not merely due to the fact that the identical word was not in the parafovea (that led to increased reading times). Second, no differences between the conditions would suggest that the German vs. English translation masks may be driven merely by the fact that there is any word in English in the parafovea. Finally, an N + 1 facilitation (in terms of shorter reading times from the English translation relative to the English word) would indicate that a language switch is occurring, and reading times would be further compounded by the fact that the English word mask shares no semantic information with the German word. In the current experiment, we found no differences between Arrow vs. Array. This lack of difference suggests that the N + 1 inhibition we found between Pfeil and Arrow stemmed merely from the fact that there was an English word in the parafovea. This would also mean that the N + 1 inhibition found by Fernandez et al. was not due to the semantic overlap between the target word and the translation, but was also due to the fact that there was an English word in the parafovea.
Lastly, when comparing the English translation and the two English non-words (Arrow vs. Arrzm + Clain), three possible outcomes seemed likely. First, an N + 1 facilitation (in terms of shorter reading times for the English translation relative to the two non-word conditions) would indicate semantic facilitation from the English translation word relative to the other uninformative masks. Alternatively, no difference between the conditions would suggest that all three mask types were treated as uninformative masks. Finally, an N + 1 inhibition (with greater reading times for the English translation relative to the two non-words) would indicate that readers incurred a switching cost from the translation but not from the non-words. Here, we found no differences between Arrow vs. Arrzm + Clain. This suggests that bilingual readers are treating all three masks as uninformative, and translation words do not incur a measurable switch cost relative to non-words. We therefore found no support for Fernandez et al.'s (2021) hypothesis that non-words evoke less interference than real words. Instead, our results support the numerous studies that have found that the less word-like the parafoveal mask, the greater the N + 1 inhibition (e.g., Fernandez et al., Reference Fernandez, Scheepers and Allen2020; Hutzler et al., Reference Hutzler, Schuster, Marx and Hawelka2019; Marx et al., Reference Marx, Hawelka, Schuster and Hutzler2015; Vasilev & Angele, Reference Vasilev and Angele2017).
We also hypothesized that individuals with higher QLR and proficiency scores would be more efficient at extracting parafoveal information, leading to shorter first fixation and gaze durations as well as to increased skipping rate. We did not find any main effects of QLR or proficiency, nor did we find interactions with the mask comparisons for any of our dependent variables. This is somewhat surprising given the importance of QLR and proficiency during reading and parafoveal processing (Veldre & Andrews, Reference Veldre and Andrews2014; Wang et al., Reference Wang, Zhou, Shu and Yan2014; Whitford & Titone, Reference Whitford and Titone2015). Given that we found very little evidence of semantic N + 1 processing, we speculate that the role of individual differences was just not apparent. Perhaps individual differences are more apparent when looking at orthographic N + 1 processing (with the mask and the target sharing orthography), given that orthographic parafoveal processing is more readily found than semantic (e.g., Schotter et al., Reference Schotter, Angele and Rayner2012). It is also possible that L2 QLR is important for parafoveal processing, but the L2 proficiency measure we used here is not a good proxy for L2 QLR. Though intuitively QLR and proficiency seem like they should go hand in hand, it may be the case that in opaque orthography languages like English, one could have high proficiency with lower QLR. So, while a bilingual reader may have high L2 comprehension, they may have poor orthographic representation, which may limit parafoveal processing. We believe that teasing apart these individual differences in bilingual readers is a compelling line for future research.
However, we did find an interaction between QLR and proficiency for FFD and GD. To interpret these interactions, we split the participants into high and low scoring QLR and visualized the dependent variables across proficiency score. We found that individuals with lower German QLR scores showed decreased FFD and GD as English proficiency increased, while individuals with high German QLR score showed increased FFD and GD as English proficiency increased. This suggests that there might be a tradeoff between L1 QLR and L2 proficiency such that if you have weaker L1 representation, an increase in L2 proficiency may facilitate the decoding of parafoveal information leading to shorter reading times on the target word (at least in the case where parafoveal masks are more L2-like than L1-like). If you have stronger L1 representation, then an increase in L2 proficiency may inhibit the decoding parafoveal of information, leading to longer reading times on the target word (at least in the case where parafoveal masks are more L2-like than L1-like). Again, we believe teasing apart these differences would be a compelling line for future research.
Overall, our data do not show evidence for either of our outlined hypotheses. While we were able to replicate the N + 1 inhibition between the identical target and the translation mask, we were not able to replicate the N + 1 facilitation between the translation mask and the orthographic mask. In terms of the replicated N + 1 inhibition, our follow-up comparisons revealed that this difference most likely stems from the fact that the parafoveal mask does not match the target word, rather than from semantic overlap between the mask and target. This suggests that bilingual readers are treating all L2 mask types similarly, and do not process any L2 semantic, L2 orthographic, or L2 pseudo-word information parafoveally. This data therefore supports previous research that has found no cross-language semantic N + 1 benefit with bilingual readers (Altarriba et al., Reference Altarriba, Kambe, Pollatsek and Rayner2001; Hoversten & Traxler, Reference Hoversten and Traxler2020; and Wang et al., Reference Wang, Zhou, Shu and Yan2014). Similarly, it fails to support previous research that has found L2 N + 1 semantic benefit from bilingual readers (Antúnez et al., Reference Antúnez, Mancini, Hernández-Cabrera, Hoversten, Barber and Carreiras2021; Fernandez et al., Reference Fernandez, Allen and Scheepers2021; Wang et al., Reference Wang, Yeon, Zhou, Shu and Yan2016).
In terms of the Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) study, their data may indeed have been spurious. There could be several reasons for this discrepancy. It is possible that their pattern of results was due to a lack of power and may have led to false positives (see, for example, Brysbaert, Reference Brysbaert2019) that could not be replicated in the current study, highlighting the importance of replication in psycholinguistic research. In their study, Fernandez et al. compared 51 L1 speakers and 51 L2 speakers in a 2 × 6 design with 4 items per condition. In the current study, we overcame some of the power issues by testing 100 participants in a 1 × 5 design (with 18 items per condition). Another possibility is that the spelling-to-sound correspondence plays a role in the ability of the participants to make use of the parafoveal information. German has a relatively clear spelling to sound correspondence, unlike English, which is relatively opaque. In the Fernandez et al. study, participants may have been able to access the semantic information of the orthographic German parafoveal mask more efficiently than when the mask was presented parafoveally in English in the current study.
Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) attempted to explain their findings within BIA+ model of word recognition, but did not provide definitive theoretical implications of parafoveal processing. In the current study we aimed to provide further insight into these potential implications. However, given that we were not able to replicate the main Fernandez et al. findings, we do not expand on this further. The findings in the current study may still easily fit within the BIA+ if, for example, L2 N + 1 semantic information does not activate the corresponding language node. Within the current study we cannot definitively say why this node is not activated, but it seems reasonable that it may be due to the opaque orthography of the English masks (making semantic access more difficult or time-consuming), a general slowing of foveal lexical access by L2 speakers (thus limiting the amount of cognitive resources available for parafoveal processing), or a combination of both.
While the main aim of the current study was not to test models of eye-movement behavior, we believe that a brief discussion is warranted in light of the findings. There is very limited research exploring L2 patterns of eye movements within the framework of eye-movement models based on L1 reading. One such study that has discussed this issue is Cop et al. (Reference Cop, Drieghe and Duyck2015); they argued that their findings fit easily within the E-Z Reader (Reichle et al., Reference Reichle, Pollatsek, Fisher and Rayner1998; Reichle & Sheridan, Reference Reichle, Sheridan, Pollatsek and Treiman2015) model of eye-movement behavior. In the current study, in contrast to Fernandez et al., but in line with Cop et al., we did not find increased skipping rates or evidence of facilitated N + 1 processing. Rather, when L1 German–L2 English speakers read a sentence in their L1, they showed little to no L2 N + 1 processing. This would fit within the E-Z reader framework, if we assume that even though there are theoretically enough resources during the familiarity check to shift attention to the N + 1 word (given the L1 sentence frame), N + 1 processing will take longer (given that the N + 1 word is in an L2) and require more resources (given the potential language switch and the slowed L2 access). As a result, bilingual readers will be less likely to process L2 N + 1 semantic information.
Conclusions
While research investigating bilingual language processing has become more prominent, there are still very few studies that systematically investigate classic oculomotor behavior patterns in L2 speakers, at least not to the extent that is seen in L1 speakers (e.g., skipping behavior and parafoveal processing). In this registered report we attempted to replicate Fernandez et al. (Reference Fernandez, Allen and Scheepers2021) with greater power and new theoretically motivated types of masks. Interestingly, we were able to replicate the semantic N + 1 inhibition between the identical mask (Pfeil) compared to the English translation (Arrow), but we were not able to replicate the orthographic N + 1 facilitation between the English translation (Arrow) and the English orthography mask (Arrzm). We further tested the potential reasons behind this semantic N + 1 inhibition and found no evidence that the inhibition stemmed from semantic processing (or incurred a switch cost). Rather, the inhibition stemmed from the mere fact that the parafoveal word did not match the target word. Unlike the findings of Fernandez et al., the current findings provide little evidence that bilingual readers are able to make use of L2 semantic and orthographic N + 1 information. Additionally, the current findings seem to fit straightforwardly within the BIA+ model of word recognition and the E-Z reader model. Overall, we were not able to replicate the findings of Fernandez et al., thus finding little evidence of L2 semantic N + 1 processing, and highlighting the growing need for high powered registered replication studies within the field of bilingualism.
Competing interests
The author(s) declare none.
Supplementary Material
For supplementary material accompanying this paper, visit https://doi.org/10.1017/S1366728923000536











