


1. Introduction
A common trait for natural languages is the ability to establish filler–gap dependencies between two elements across a distance in a sentence. For example, in (1), the wh-words what/hva ‘what’ are interpreted as the object of the verbs fix/fikse ‘fix’ in the English and Norwegian sentences.

Filler–gap dependencies are unbounded, but there are constraints that limit the establishment of a dependency across certain domains. These domains are often referred to as islands (Ross Reference Ross1967). Many researchers hold that island constraints are unlearnable from input alone, and, thus, they theorize that islands somehow arise from innate principles (either constraints or learning biases) and are therefore part of Universal Grammar (UG; Chomsky Reference Chomsky, Katz and Fodor1964, Reference Chomsky, Anderson, Paul and Morris1973, Reference Chomsky1986; Ross Reference Ross1967; Huang Reference Huang1982; Rizzi Reference Rizzi1990; Lasnik & Saito Reference Lasnik and Saito1992; Manzini Reference Manzini1992; Phillips Reference Phillips2013a:107).Footnote 1
Adjuncts were first identified as islands by Huang (Reference Huang1982). In the examples in (2), trying to link a wh-filler to a gap inside an adjunct clause renders the sentences unacceptable:
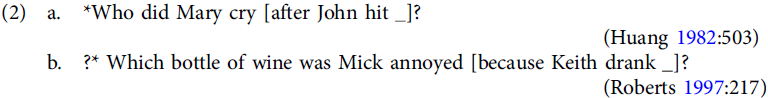
Huang (Reference Huang1982:505) posited the Condition on Extraction Domains (CED) such that both subjects and adjuncts would be considered islands for extraction:

Although the notion of proper government has been abandoned in recent theoretical frameworks, the notion that adjuncts, as a general structural class, are islands remains pervasive.
While certain non-finite adjuncts have been acknowledged to be exceptions to the CED,Footnote 2 in addition to certain complex subject clauses (Stepanov Reference Stepanov2007, Abeillé et al. Reference Abeillé, Hemforth, Winckel and Gibson2020), finite adjuncts are often considered among the strongest islands cross-linguistically (Huang Reference Huang1982, Stepanov Reference Stepanov2007, Truswell Reference Truswell2011, Sprouse & Hornstein Reference Sprouse and Hornstein2013a). However, anecdotal evidence suggests that Mainland Scandinavian (MSc) languages allow filler–gap dependencies to be formed into a tensed adjunct clause (Bermingrud Reference Bermingrud1979, Anward Reference Anward1982, Maling & Zaenen Reference Maling, Zaenen, Pauline and Pullum1982, Faarlund Reference Faarlund1992). The sentences in (4) provide examples of reportedly acceptable filler–gap dependencies into tensed adjunct clauses in MSc languages.

In (4a), the pronoun det ‘that’ appears to have been topicalized from the direct object position of the adjunct-internal verb seier ‘say’. In (4b), the definite DP den saka ‘that case’ has been topicalized from the object position of the adjunct-internal simple verb ordnar ‘fix’. Similarly, in the Swedish example in (4c), the definite DP sportspegeln ‘the sports program’ appears to have been topicalized from the object position of the adjunct-internal verb ser ‘see’.
Recent experimental evidence provides some support for the observations about MSc (e.g. Nyvad, Christensen & Vikner Reference Nyvad, Christensen and Vikner2017; Kush et al. Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019; C. Müller Reference Müller2019). In several studies, the acceptability of island extraction in MSc languages has been investigated by way of formal experiments. We focus on two studies (using the factorial design developed by Sprouse Reference Sprouse2007; see Section 2.1.1 below for details) that investigated Norwegian: (i) Kush et al. (Reference Kush, Lohndal and Sprouse2018), which tested the acceptability of wh-extraction from five islands types: ‘whether’, complex NP, subject, (conditional) adjunct, and relative clause, and (ii) Kush et al. (Reference Kush, Lohndal and Sprouse2019), which tested the acceptability of contrastive topicalization from the same five island types.
Kush et al. (Reference Kush, Lohndal and Sprouse2018) found clear evidence of subject, adjunct, complex NP, and relative clause-island effects on wh-extraction with simple (e.g. hva ‘what’) and complex (e.g. hvilken bok ‘which book’) wh-phrases.Footnote 3 The authors failed to find reliable ‘whether’-island effects, which reflected significant inter-individual variation in whether participants accepted wh-extraction from embedded polar questions. Notably, many participants did not exhibit any sensitivity to ‘whether’-island violations at all. The authors reasoned that the absence of statistically reliable ‘whether’-island effects and variability in the underlying distribution of judgments of ‘whether’-island violations was inconsistent with the conclusion that embedded questions were syntactic islands in Norwegian.
Following up on these findings, Kush et al. (Reference Kush, Lohndal and Sprouse2019) investigated the island-sensitivity of contrastive topicalization. Many of the reported naturally-occurring examples of island violations in MSc involve topicalization. As a type of A′-movement, topicalization is expected to respect the same syntactic locality conditions as wh-movement under traditional syntactic accounts (see e.g. den Dikken & Lahne Reference Dikken, Lahne and den Dikken2013; Phillips Reference Phillips2013a:68). However, topicalization is subject to different semantic and discourse-pragmatic factors. Thus, insofar as the island effects observed in Kush et al. (Reference Kush, Lohndal and Sprouse2018) reflect syntactic constraint violations, similar effects should obtain with topicalization. However, if any of the island effects observed for wh-extraction were semantic or discourse-pragmatic in origin, then a different pattern might be found for topicalization.
Kush et al. (Reference Kush, Lohndal and Sprouse2019) replicated large island effects for subjects and complex NPs, and once again failed to find a reliable ‘whether’-island effect. Relevant for our purposes, the authors unexpectedly found no island effect for dependencies like (5) in their second experiment, where an object has been topicalized from a finite conditional adjunct clause introduced by the complementizer om ‘if’.

Judgments of topicalizations from adjuncts were variable: participants rejected the dependencies on some trials, but accepted on others. On balance, participants were more likely to accept topicalizations from om-adjuncts than to reject them.Footnote 4 Tellingly, the probability of accepting topicalization from a conditional adjunct was comparable to the probability of accepting long-distance topicalization from a non-island embedded declarative clause.
The findings suggest that conditional adjuncts are not categorical islands for A′-movement in Norwegian and that the type of dependency has a significant impact on acceptability of A′-dependencies into certain islands (see also Sprouse et al. Reference Sprouse, Caponigro, Greco and Cecchetto2016). However, given the potentially large theoretical consequences of revising our standard understanding of the islandhood of adjuncts, we should be sure that the such findings can be replicated with a larger sample. A further question concerns the generality of the findings. Kush et al. (Reference Kush, Lohndal and Sprouse2019) only investigated conditional adjunct clauses. Many syntactic accounts of extraction from adjuncts predict that adjuncts should behave as a coherent class with respect to their island status (Huang Reference Huang1982; Lasnik & Saito Reference Lasnik and Saito1992; Uriagereka Reference Uriagereka, Epstein and Norbert1999, Reference Uriagereka2012; Boeckx Reference Boeckx2003, Reference Boeckx2012; Stepanov Reference Stepanov2007; G. Müller Reference Müller2011; Hunter Reference Hunter2015). We therefore ask whether similar island-insensitivity would be observed with other finite adjuncts in Norwegian. It is also possible that island effects might vary by adjunct type (a possibility hinted at in Truswell Reference Truswell2007, Reference Truswell2011, and C. Müller Reference Müller2019). Insofar as we observe variability in island-sensitivity across adjuncts, this variability might provide clues about a finer-grained set of features governing adjunct islandhood beyond the coarse cut made by conditions like the CED.
2. Experiments
To investigate these questions, we ran two acceptability judgment experiments testing the acceptability of topicalization dependencies into three different types of finite adjunct clauses, partly using the same material as in Kush et al. (Reference Kush, Lohndal and Sprouse2019).
2.1 Experimental design
2.1.1 The factorial definition of island effects
We describe common design characteristics of our experiments before discussing the specifics of each experiment individually. Our experiments adopted the general factorial definition of islands, introduced by Sprouse (Reference Sprouse2007) and used in much recent work (Sprouse et al. Reference Sprouse, Fukuda, Ono and Kluender2011, Sprouse, Wagers & Phillips Reference Sprouse, Wagers and Phillips2012, Sprouse et al. Reference Sprouse, Caponigro, Greco and Cecchetto2016). In a standard design, participants judge multi-clausal sentences with a filler–gap dependency. The two factors, Distance and Structure, determine the properties of the sentences. Distance determines whether the filler is linked to a gap in the matrix clause (Short-distance) or the embedded clause (Long-distance). Structure determines whether the embedded clause is a non-Island or (contains) an Island. Island is here used as a label for conditions that simply contain domains characterized as islands (both (6c) and (6d) in example (6) below). The factorial design crosses these factors, creating conditions that correspond to combinations of the factors’ levels, as shown in Table 1.
Table 1. A schematic of a 2 × 2 factorial design for testing for island effects.

The factorial design is illustrated with a test item that uses a ‘whether’-island below. Short-distance is realized as the movement of the wh-word from subject position in the matrix clause in (6a) and (6c). Long-distance is realized as the movement of the wh-word from object position of verb in the embedded clause in (6b) and (6d). In no-Island sentences the embedded clause is a declarative complement clause. In Island sentences, the embedded clause is a ‘whether’-clause in (6c) and (6d).

The factorial design proceeds from the assumption that linear distance and structural complexity may have effects on sentence acceptability. For example, participants might like longer dependencies less than shorter dependencies or prefer simpler structures to more complex structures due to processing burden. Such effects are, however, orthogonal to the question of whether there is an island effect. The strength of the factorial design is that it allows for the main effects that distance and complexity might have on acceptability to be isolated, so that the independent island effect (if there is one) can be isolated. The factorial definition treats island effects as the super-additive interaction of the two independent factors (Distance and Structure), independent of the main effects.
Identifying the presence or absence of an island effect within the paradigm can be done visually by plotting the acceptability of each of the four conditions with an interaction plot. If there is no island effect, we expect that the unacceptability of the Long-distance, Island condition should be equal to the linear sum of the costs of Distance and Structure. Such a state of affairs would correspond to the plot in Figure 1A. If, on the other hand, there is an island effect, we expect the unacceptability of the Long-distance, Island condition to be greater than the sum of the linear costs of Distance and Structure, we expect a super-additive interaction like Figure 1B.
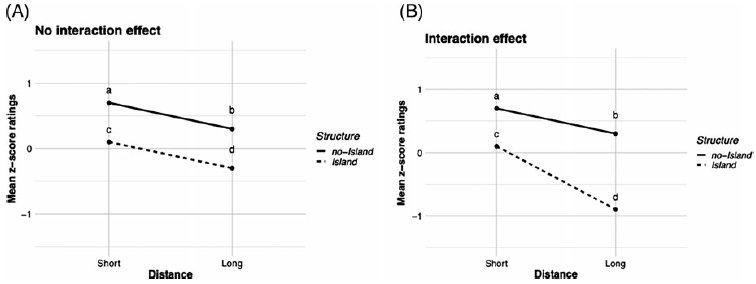
Figure 1. Example interaction plots illustrating the absence of a Distance × Structure island effect (A) or the presence of a Distance × Structure island effect (B).
The size of the Distance × Structure interaction, and hence the island effect can be quantified using a Differences-in-Differences (DD)Footnote 5 score (Maxwell & Delaney Reference Maxwell and Delaney2003). This allows (mean) effect sizes to be compared across islands and experiments.
2.1.2 Materials Footnote 6
Our experiments tested extraction from five different clause types: three adjunct clauses – om ‘if’, når ‘when’, and fordi ‘because’ – and two control islands – subject islands and ‘whether’-islands. The subject- and ‘whether’-island sub-experiments were included as baselines for comparison. Kush et al. (Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019) found very large island effects for subject islands in Norwegian, making the subject island a good baseline for a large island effect. In comparison, they found small and unreliable effects for extraction from an embedded ‘whether’-question in Norwegian. Moreover, the authors identified the variability in judgments observed with extraction from embedded ‘whether’-questions as characteristic of ‘extra-syntactic’ effects on acceptability. Thus, other island effects that exhibit similar variability might be argued to be similarly ‘extra-syntactic’ in nature.
Since we were interested in testing whether Kush et al.’s (Reference Kush, Lohndal and Sprouse2019) results can be replicated, we used the design for their test items for all our items. Each test item contained four test sentences that were different realizations of Distance × Structure. Each test sentence was preceded by a preamble that facilitated topicalization in the test sentence. Context was included because Kush and colleagues found that participants rejected indisputably grammatical contrastive topicalization dependencies presented in vacuo without supporting context at surprisingly high rates. The context sentence introduced felicitous context for topicalization. Below are example items for all the islands tested. The example items for om ‘conditional if’, ‘whether’- and subject islands are from Kush et al. (Reference Kush, Lohndal and Sprouse2019), while the items for når ‘(temporal) when’ and fordi ‘causal because’ adjunct clauses were created for the current study.




2.1.3 Procedure and analysis
Test items were distributed online on IbexFarm (Drummond Reference Drummond2012). Participants were instructed to rate the test sentences between 1 and 7, with 1 given as dårlig ‘bad’ and 7 as god ‘good’ and to imagine that the sentences were uttered in a conversation. All test items contained a context sentence in italics followed by the test sentence. Participants were instructed to base their ratings on the acceptability of the second sentence.
Before analysis, participant ratings were z-score transformed by participant to control for scale bias (e.g. Sprouse et al. Reference Sprouse, Caponigro, Greco and Cecchetto2016).Footnote 7 Analysis was conducted using linear mixed effects models using the lme4 (Bates et al. Reference Bates, Maechler, Bolker and Walker2015) and lmerTest (Kuznetsova, Brockhoff & Christensen Reference Kuznetsova, Brockhoff and Christensen2017) packages in R (R Core Team 2019). Separate models for each island type with Distance, Structure and their interaction (Distance × Structure) as the fixed effects were constructed with simple difference coding. The model included random intercepts for subject and items as well as by-subject random slopes for the fixed effects and their interaction. In the few cases when a model did not converge, the random effects structure was simplified. The Satterthwaite approximation was used to calculate p-values in the lmerTest package. We only report the size of the Distance × Structure interaction effect, as main effects are orthogonal to our questions of interest. All plots were constructed with ggplot2 (Wickham Reference Wickham2016).
2.2 Experiment 1
2.2.1 Participants
One hundred and five self-reported native Norwegian-speaking volunteers took part in Experiment 1 (66 females, mean age = 43.5 years). Participants were recruited via announcements on social media sites. Four participants were excluded for reporting a different native language than Norwegian. All speakers self-identified as native speakers of Norwegian.
2.2.2 Materials
Eight item sets were constructed for each of the five island types. The test sentences were distributed across four lists in a Latin-Square fashion, such that each participant encountered 40 test sentences – two items per condition per island. The 40 test sentences were pseudo-randomly mixed with 46 fillers, 15 acceptable fillers and 31 unacceptable. Only 10 of the 40 encountered test sentences were unacceptable sentences (i.e. sentences testing the Long-distance, Island condtion). In order to balance the experiment between unacceptable and acceptable test sentences, we included 31 unacceptable fillers. In effect, participants encountered 86 test sentences, out of which, 45 could be considered acceptable and 41 unacceptable. The order of the test items differed for each participant.
2.2.3 Results
The unacceptable fillers received a mean score of z = −0.84, whereas the good fillers received a mean of z = 0.63. Interaction plots displaying the average rating by condition and island type are presented in Figure 2. Table 2 provides a statistical summary of the Distance × Structure interaction effects for each island. As can be seen, superadditive interaction effects were observed for all islands tested (p < .001).

Figure 2. Interaction plots for Experiment 1. Error bars indicate standard error.
Table 2. Statistical summary of the Structure × Distance interaction effects for each island type in Experiment 1.
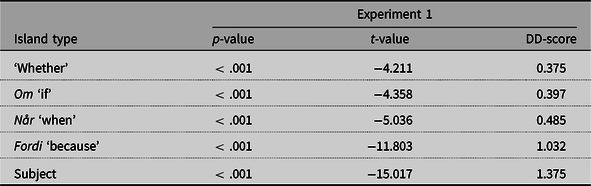
The size of the interaction effects varies by island: subject-island effects were large (DD = 1.375), while ‘whether’-island effects were considerably smaller (DD = 0.375). This replicates previous findings for these island types (Kush et al. Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019). The adjunct island effect sizes also vary: the om-, når- and fordi-islands have DD scores of 0.397, 0.485, and 1.032, respectively.
What is also evident from Figure 2 is that the mean acceptability of the island-violating sentence differs for each adjunct. On average, participants rated extraction from om-adjuncts around z = 0.25 (similar to their judgments for ‘whether’-islands) and from når-adjuncts around z = 0, but extraction from fordi-adjuncts was rated much lower: closer to z = −0.75. Kush et al. (Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019) showed that average acceptability scores that fall in the acceptable or intermediate range can conceal rather variable judgments of island-violations. To investigate the judgment pattern underlying the mean scores, we inspected the distribution of ratings by condition.
Distributions in Figure 3 show the density of ratings for each z-score by island type and by condition. If a sentence is always rated as acceptable we should see a unimodal distribution around +1, which we can see for the Short-distance, no-Island conditions. The distributions for the Short-distance, Island conditions are also unimodally distributed around +1. The distributions for the Long-distance, no-Island conditions provide a point of comparison for how ratings of acceptable long-distance topicalization pattern. Here we see a mode at or close to +1, but also a longer leftward tail. This indicates that the items in this condition are not always accepted unequivocally and are perhaps rejected at a slightly higher rate than the short conditions.
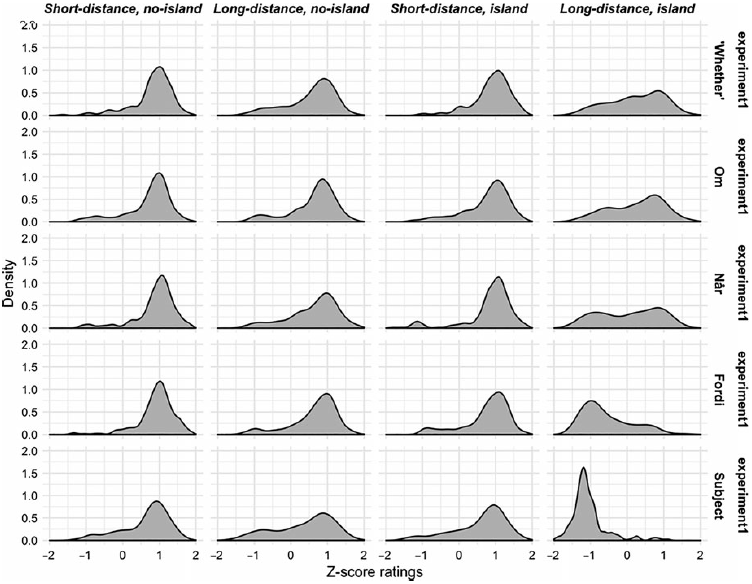
Figure 3. Distribution of z-scores for each island type tested and for each condition.
Turning to the distributions for the Long-distance, Island condition, we see great differences between island types. The two control-island types show, as expected, very different behavior: judgments of the subject island are narrowly and unimodally distributed around z = −1.5. This means that topicalization from a complex subject is always rejected. Judgments of topicalization from embedded ‘whether’-clauses largely fall, as in Kush et al. (Reference Kush, Lohndal and Sprouse2019), above z = 0. The distribution for ‘whether’ exhibits a longer, fatter left tail than seen in the corresponding Short-distance, Island condition. This left tail indicates that participants judged topicalization from a ‘whether’-embedded question as either less acceptable or wholly unacceptable on a subset of trials.
The distribution of Long-distance, Island ratings differed considerably across all three adjuncts.Footnote 8 Ratings of topicalization from a conditional adjunct, show a distribution similar to the ‘whether’-clauses, again consistent with Kush et al. (Reference Kush, Lohndal and Sprouse2019). The distribution is roughly bimodal: the majority of judgments cluster around z = 1, but there is a smaller group of judgments that cluster around z = −1. This entails that extraction from this adjunct is more often accepted than it receives intermediate or poor ratings. The fordi-island exhibits unimodal distribution on the Long-distance, Island condition, however, unlike om, the distribution patterns well below 0 around z = −0.75. Fordi-extractions pattern more like the subject island, indicating relatively consistent rejection, though there does appear to be a small number of trials where topicalization was accepted. For the temporal når-island, we see clear bimodality. Bimodal distributions entail either-or-judgment, sometimes the condition is accepted, sometimes it is rejected, but it is less often given an intermediate rating. Accordingly, the når-adjunct does not pattern like any of the other conditions, with clustering around z = −1 and z = 1.
Figure 3 above shows that there is variability in judgments, but does not allow us to distinguish between different origins of variability. Does the variability reflect inter-subject, inter-item differences, or both? We first investigate inter-subject differences using a visualization method from Kush et al. (Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019); see also Kush & Dahl (published online on 15 September 2020). Figure 4 provides scatterplots of each participant’s first and second judgment for each island type on the Long-distance, Island condition. When dots cluster in the bottom left quadrant, participants are consistently rejecting the island violating condition. Dots that lie in the top right quadrant indicate that participants are consistently accepting this condition. Dots that fall in the lower right or upper lefthand quadrant correspond to inconsistent raters, who accepted on one trial and rejected on another.
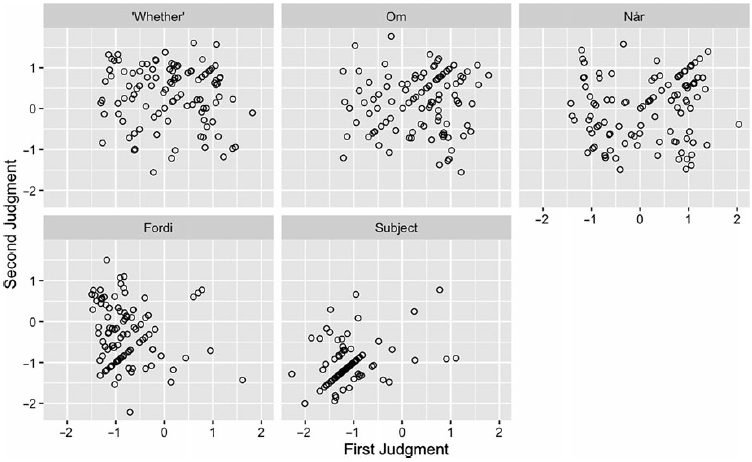
Figure 4. Each participant’s judgments split by island type in Experiment 1. Each dot represents one participant, with their first judgment (x-axis) plotted against their second judgment (y-axis) on the Long-distance, Island condition.
Almost all participants consistently rejected subject island violations, as evidenced by the preponderance of dots in the lower lefthand quadrant for subject islands in Figure 4. Many participants consistently accepted ‘whether’-island violations, though there were also many inconsistent raters. For om-adjunct violations, a substantial portion of participants were consistent accepters, judging both trials above z = 0, as seen by the large number of dots in the upper right quadrant in Figure 4 (in line with the findings of Kush et al. Reference Kush, Lohndal and Sprouse2019). A few participants consistently rejected topicalization from om, but most of the participants judged inconsistently: appearing to accept one trial and reject another.
Greater inter-participant variability is found with judgments of topicalization from når. A number of participants appear to consistently accept topicalization from når, somewhat similar to om, but there are more participants who consistently rejected når test sentences compared to om. This matches the bimodal distribution found for når in Figure 3. There are also a number of inconsistent raters. The majority of the fordi-adjunct ratings lie in the bottom left quadrant, indicating generally consistent rejection. Three participants appear to have consistently accepted the sentences, and a few more participants exhibited inconsistency.
We also inspected inter-item variability, by comparing distributions of judgments for different items separately by island type.
The plots in Figures 5–7 reveal that there is also variation between items within each adjunct type. For om, most items have ratings centered around z = 0.75. Three items show a clear single mode close to z = 1 (36, 39, 40), and three others show a bimodal or left-skewed distribution slightly favoring positive scores (34, 35, 36). Only one item (33) appears to have consistently received a negative z-score. For når-items, judgments were either clustered around z = 1 (items 10, 12), or exhibited bimodal distributions. Only one item seems to have received mostly negative z-scores. In contrast to om, six of eight fordi-items show relatively consistent ratings centered around z = −1. Two items (6, 7) have ratings centered around z = 0.5.

Figure 5. Distribution of z-scores for the Long-distance, Island condition for om-items tested. Item numbers are provided for cross-reference in the materials list.
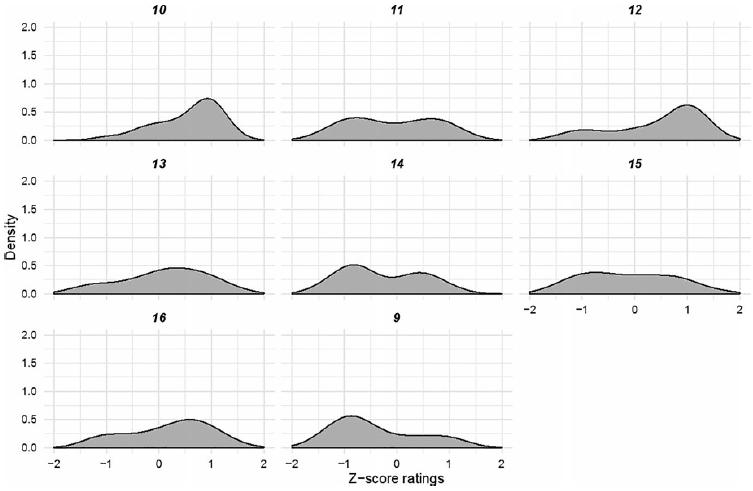
Figure 6. Distribution of z-scores for the Long-distance, Island condition for når-items tested. Item numbers are provided for cross-reference in the materials list.
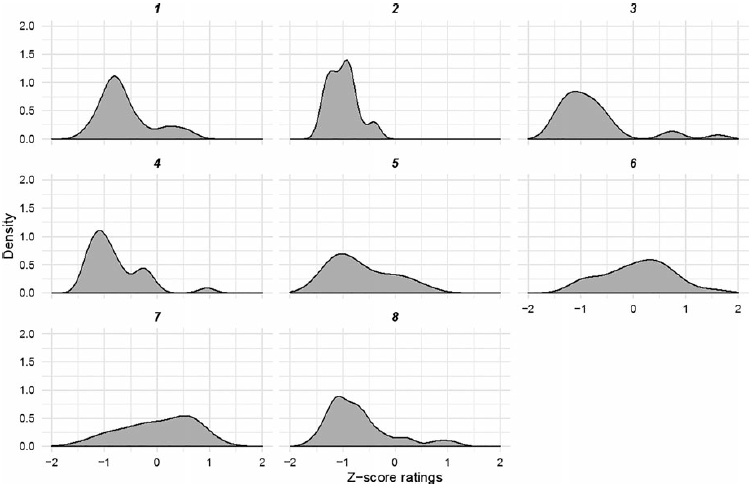
Figure 7. Distribution of z-scores for the Long-distance, Island condition for fordi-items tested. Item numbers are provided for cross-reference in the materials list.
In order to determine whether there were any features that reliably contribute to acceptable topicalization or correlate with it, we coded each item for a number of surface features, which have been proposed to affect acceptability of extraction (e.g. Truswell Reference Truswell2011, Dal Farra Reference Dal Farra2020): tense in the matrix and embedded clauses, agentivity of the matrix and embedded predicates, aspectual class of the matrix clause, telicity of the matrix VP, spatiotemporal overlap between matrix and embedded clause, direct causation between matrix and embedded clause and type of matrix verb. We also checked the definiteness of the moved constituent (Szabolcsi & Lohndal Reference Szabolcsi, Lohndal, Martin and Henk2017) and, the number of words between the filler and the gap (i.e. processing difficulty, Hofmeister, Casanto & Sag Reference Hofmeister, Casanto and Sag2013). We then compared ratings of the Long-distance, Island condition by items grouped across shared features through visual inspection of plotted ratings to investigate whether any of the om-, når-, or fordi-items that were disproportionately accepted shared any features with one another to the exclusion of the items that were rejected. We could not find any surface features that could explain the variation between items for any of the islands.
2.2.4 Discussion
The experiment roughly replicates Kush et al.’s (Reference Kush, Lohndal and Sprouse2019) findings for extraction from subject, ‘whether’- and om-clauses. Subject island effects were large, while island effects for ‘whether’-clauses and conditional om-adjuncts were considerably smaller. Though there were small differences in the significance of the interaction effect, these can be attributed to a lower sample size in Kush et al.’s (Reference Kush, Lohndal and Sprouse2019) experiment compared to this experiment, 36 versus 105, respectively. We also found that average judgments of topicalization from ‘whether’- and conditional om-islands fell in the range of ‘acceptable’ sentences (z > 0) and were roughly comparable to long-distance extractions from non-islands. Moreover, judgments of topicalization from both ‘whether’-clauses and om-adjuncts were highly variable, just as Kush et al. (Reference Kush, Lohndal and Sprouse2019) found.
Next, we turn to the two new adjunct types we investigated. The island effect size of extraction from når-adjuncts (DD = 0.485) was smaller than for subject islands (DD = 1.375), but larger than for ‘whether’-islands (DD = 0.375). Judgments of topicalization from når-adjuncts were bimodally distributed, indicating significant variation. Bimodality can partly be explained as inter-participant variation: we see some consistent accepters, some consistent rejecters and some inconsistent participants.Footnote 9 The bimodal distribution of z-scores for the Long-distance, Island condition is also partly due to variation between items.
Contrary to the pattern found for når, we found a large fordi-island effect similar in size to subject islands. Topicalization from a fordi-adjunct was almost always rejected. However, the judgments for fordi are nevertheless more variable than the subject-island judgments. Fordi-island sentences were less often categorically rejected than subject-island sentences. Still, fordi is much less accepted than når.
The variation seen within each adjunct type, as well as between the different adjuncts, is surprising. We could not find any surface features that could straightforwardly explain the variation between items or the variation between island types. We observed a large number of inconsistent participants, as in Kush et al.’s (Reference Kush, Lohndal and Sprouse2019) study, and some participants who were consistent rejectors. Inter- and intra-participant inconsistency could be explained in a number of ways. For example, observed differences could reflect meaningful differences at the population level, or could be attributed to noise. With the current design, it is difficult to tease apart various hypotheses due to lack of power at the individual participant level, given that each participant has only encountered two Long-distance, Island items per island type. To better understand the source of inconsistent ratings we ran an experiment with more observations per participant.
2.3 Experiments 2a and 2b
To better investigate the variation seen in Experiment 1, Experiments 2a and 2b were conducted. We increased the number of observations per participant per condition in the om-, når- and fordi-islands to five per participant (20 items in total). We also increased the number of subject islands to four per participant (16 items in total). To avoid participant fatigue, island types were distributed into two different experiments: Experiment 2a included items of om-, fordi-, as well as the control islands; ‘whether’- and subject islands. Experiment 2b included items of om-, når-, and the same control items as in Experiment 2a.
2.3.1 Participants
In Experiment 2a there were 28 participants (20 female, mean age = 25 years), three participants were excluded for having reported a different native language than Norwegian. In Experiment 2b there were 37 participants (27 female, mean age = 26 years); one participant was excluded for reporting a different native language than Norwegian. All speakers were self-identified native speakers of Norwegian. Participants were recruited through various social media sites or through virtual learning environments for various courses. We were careful to distribute the link for Experiment 2a and the link for Experiment 2b to different channels. In the instructions, we also added that participants who knew that they participated in Experiment 1 should not participate in Experiment 2a or 2b.
2.3.2 Materials
In Experiment 2a, participants saw 64 test sentences across all four test conditions – 5 om-adjunct items, 5 fordi-adjunct items, 4 subject island items, 2 ‘whether’-adjunct items. In Experiment 2b, participants saw 64 test sentences across all four test conditions – 5 om-adjunct items, 5 når-adjunct items, 4 subject island items, 2 ‘whether’-adjunct items. Test items in Experiments 2a and 2b were pseudo-randomly intermixed among 40 unacceptable fillers, out of which 31 were the same as in Experiment 1.Footnote 10 In addition we added four acceptable fillers featuring local topicalization to have a rough baseline of acceptability for topicalization across a single clause.
2.3.3 Results
In Experiment 2a, unacceptable fillers received a mean score of z = −0.79 and the local topicalization fillers a mean of z = 0.00. The average ratings of fillers in Experiment 2b were similar: unacceptable fillers z = −0.84; acceptable local topicalization z = −0.05. Interaction plots displaying the average rating by condition and island type are presented in Figure 8. Table 3 provides a statistical summary of the interaction effects for each island. The findings in Experiments 2a and 2b are similar to the findings in Experiment 1. Significant super-additive interaction effects were found for all clause types tested. The effect sizes (DD) are also comparable to Experiment 1.
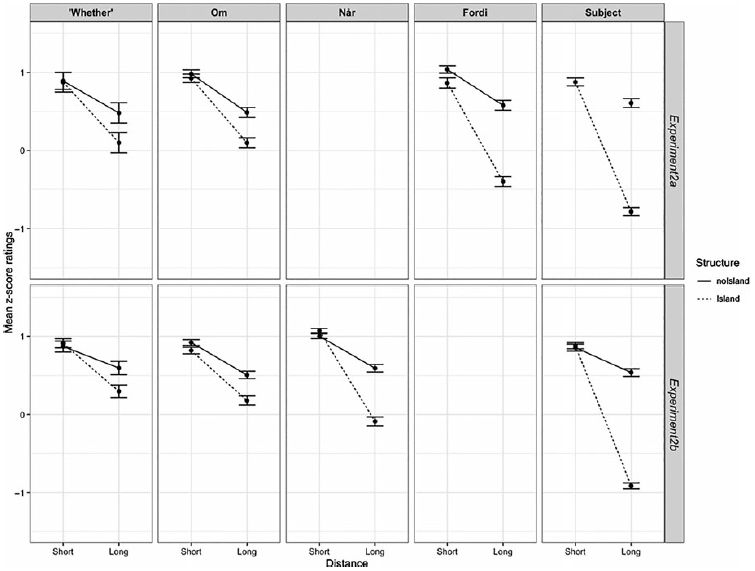
Figure 8. Interaction plots for Experiment 2a and 2b. Error bars indicate standard error.
Table 3. Statistical summary of the Distance × Structure interaction effect for each island type for each experiment.
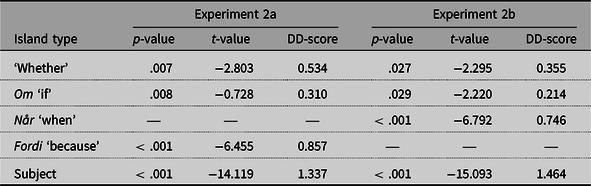
As in Experiment 1, judgments and effect sizes differ across adjunct types. Similarly, distributions of z-scores in each condition and island for Experiments 2a and 2b are comparable to what was observed in Experiment 1. This can be seen in Figure 9. Judgments of om- and når-island violations both exhibit bimodality, with a greater proportion of acceptances of extraction from om- than når-clauses. Judgments of fordi-adjunct violations cluster unimodally around z = −1, seemingly showing agreement across participants.
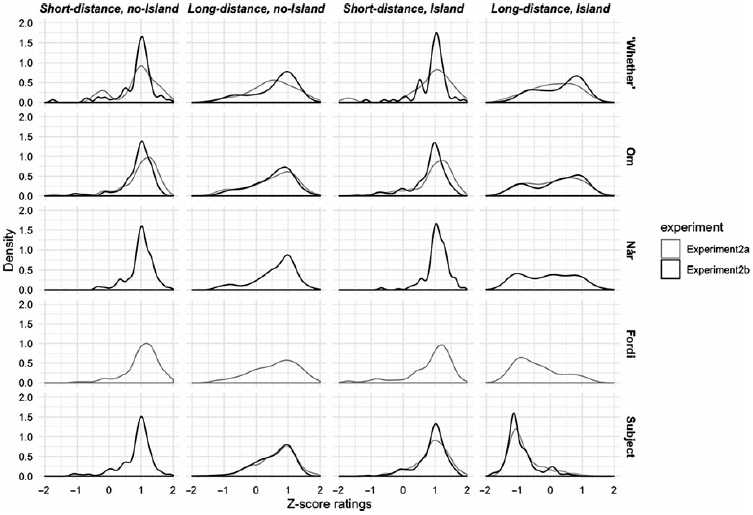
Figure 9. Distribution of z-scores for each condition in adjunct island comparisons in Experiments 2a and 2b.
Once again, we inspected the results for inter-subject variation. Figures 10 and 11 provide overviews of individual participant ratings on the Long-distance, no-Island condition in each adjunct island sub-experiment. Each column represents an individual participant. The box reports the median (black line inside the box) and the range within which 50% of the ratings lie. The top and bottom ‘whiskers’ (thin lines) report the range within which 25% of the lowest and highest ratings lie. Finally, dots represent outliers. Great variance between a participant’s ratings on the same condition can be seen in the plots as a long box and long whiskers.
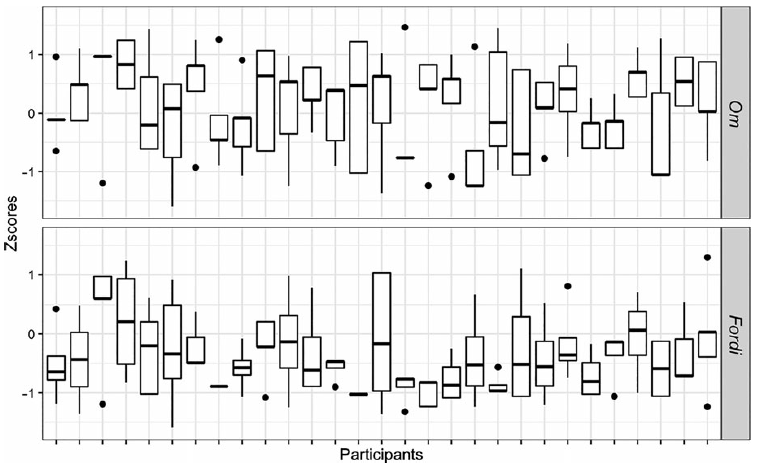
Figure 10. Overview of participant ratings of om- and fordi-adjunct items in Experiment 2a on the Long-distance, no-Island condition.
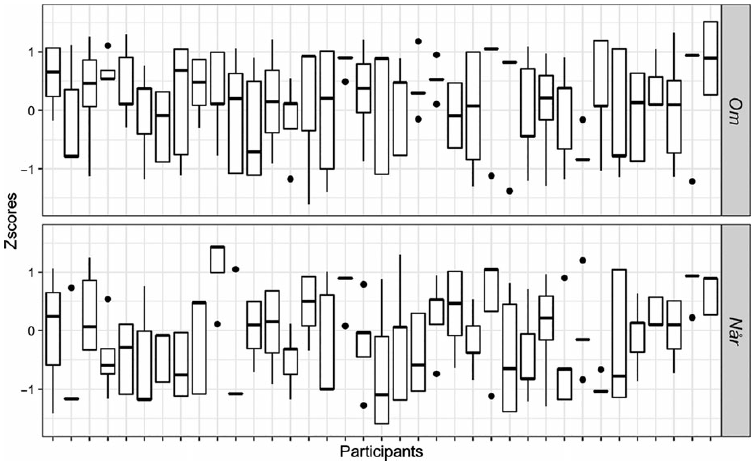
Figure 11. Overview of participant ratings of om- and når-adjunct items in Experiment 2b on the Long-distance, no-Island condition.
Participants’ judgments of extraction from om-adjuncts vary in both Experiments 2a and 2b. Nearly all participants exhibit a degree of inconsistency, but 30/37 participants in Experiment 2b exhibit a median rating above z = 0. Since we see similar variation across experiments, it is likely that some of the variability of judgments for om-adjuncts is not caused by between-participant variation. Instead, some of the variability must be attributed to between-item or within-participant variation. Figure 11 reveals that participants were not consistent in their judgments of når-adjunct island violations, though some speakers show greater consistency than others. Here, 17/37 participants had median ratings above z = 0. As in Experiment 1, most participants (27/28) consistently rejected topicalization from fordi-adjuncts showing median ratings below z = 0, however, there were a few consistent accepters and inconsistent raters.
To further address the source of the variation, we also examined the distribution of z-scores on the Long-distance, Island condition for each item of the adjunct clause types in Experiments 2a and 2b.
The distributions across adjunct types are similar to distributions across adjunct types in Experiment 1. As in Experiment 1, we also see significant variation between items within each adjunct type. Interestingly, for the items that were tested in Experiment 1 and Experiment 2a and/or 2b, we see similar variation across experiments, suggesting that the differences between items in Experiment 1 were not due to just random noise.
For om-adjuncts (see Figure 12 above), nine items in Experiment 2a and 10 in Experiment 2b show a mostly unimodal distribution around a positive z-score. Eight items in each of the two experiments have bimodal ratings or highly variable ratings across the full range. Only two items in Experiment 2a and two in 2b show a unimodal distribution around z = −1. Examining om-items based on the same surface features as in Experiment 1 (see results section in Section 2.2.3 for the list of features), we did not find any similarities across items.
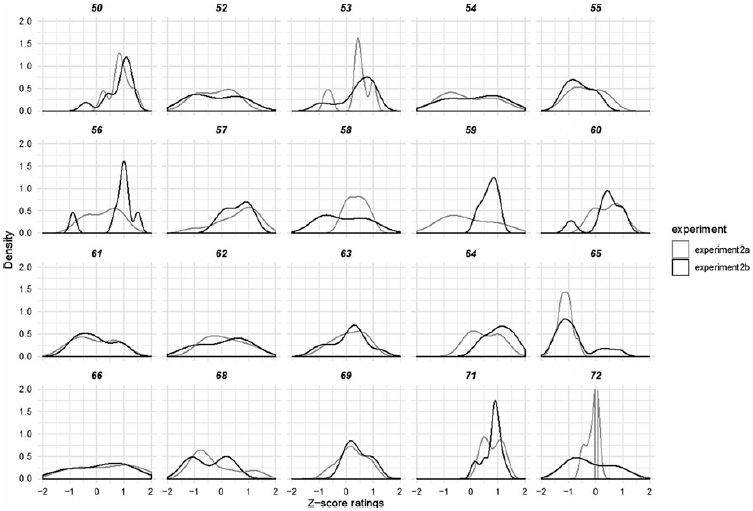
Figure 12. Distribution of z-scores in the Long-distance, Island condition for om-items tested in Experiments 2a and 2b. Item numbers are provided for cross-reference in the materials list.
The når-adjuncts (see Figure 13 above) show a large degree of variation between items: four items show a unimodal, narrow distribution around z = 0.5–0.75 and five items have a bimodal distribution. Many of the items with a bimodal distribution have a larger mode below z = 0, in contrast to om-adjuncts. Again, we could not find any shared features between items that show similar behavior.
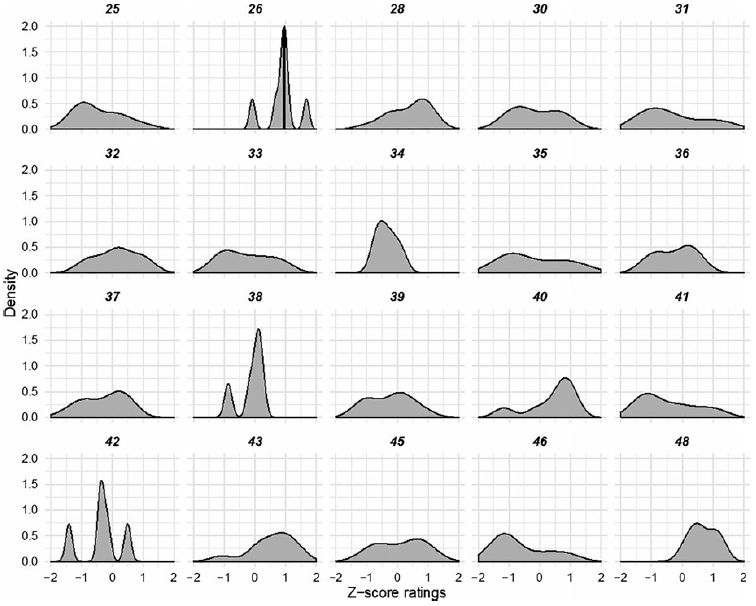
Figure 13. Distribution of z-scores in the Long-distance, Island condition for når-items tested in Experiment 2b. Item numbers are provided for cross-reference in the materials list.
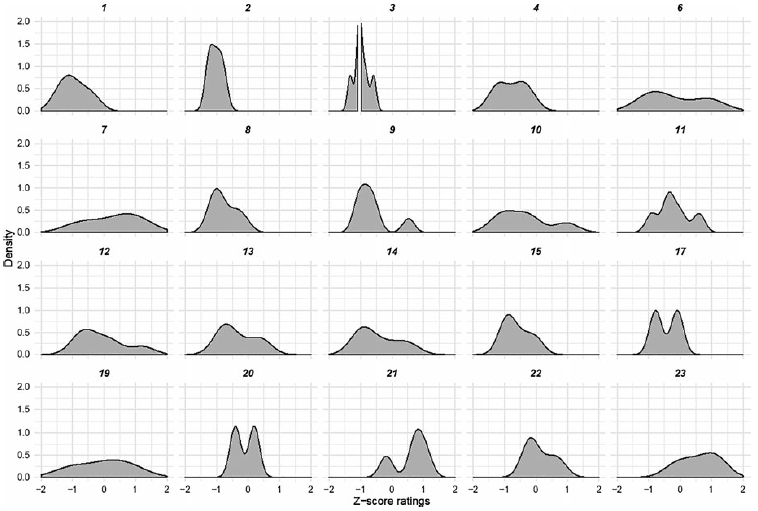
Figure 14. Distribution of z-scores in the Long-distance, Island condition for fordi-items tested in Experiment 2a. Item numbers are provided for cross-reference in the materials list.
Finally, the majority of the fordi-items (11 out of 20; see Figure 12 above) show a quite narrow unimodal distribution of z-scores centering around z = −0.75. Seven items received inconsistent ratings. Two fordi-items show ratings clustering around a positive z-score resembling the distributions of some om-items. These items do not share any surface features or feature combinations that accepted items do not have.
2.3.4 Discussion
Experiments 2a and 2b roughly replicated the findings from Experiment 1 and Kush et al. (Reference Kush, Lohndal and Sprouse2019). Island effects for topicalization from conditional om-adjuncts were comparable in size to ‘whether’-island effects, as were the average absolute judgments of such island violations. Intermediate judgments of om- and ‘whether’-island violations reflected highly variable underlying judgment distributions, in which a large number of trials represent ‘acceptable’ judgments.
As in Experiment 1, island effects were slightly larger for topicalization from når-adjuncts than om-adjuncts, but judgments of topicalization from når-adjuncts were bimodally distributed. Thus, the slightly larger island effects reflect a higher probability of rejecting topicalization from når-adjuncts than om-adjuncts. The island effects do not, however, appear to indicate that topicalization is always unacceptable from når-adjuncts (as it appears to be from subject phrases). For fordi-adjuncts, the same distribution in Experiment 1 was also seen in Experiment 2a. Topicalization from fordi-adjuncts was mostly rejected across trials, though there was a small subset of trials where such dependencies were accepted.
The fact that we observed a similar degree of variation as in Experiment 1 indicates that inconsistent judgments at an individual participant-level should not be attributed to noise. Further, the differences between the types of adjuncts were replicated across more items, indicating reliable differences between adjunct types.
3. Discussion
We investigated the acceptability of (contrastive) topicalization from three types of finite adjunct clauses om ‘if’, når ‘when’ and fordi ‘because’, in Norwegian. Our goal was to replicate Kush et al.’s (Reference Kush, Lohndal and Sprouse2019) findings of the absence of island effects with om-adjuncts and to determine whether the absence of island effects extended to other adjuncts in Norwegian. We compared the ratings of adjunct island violations to similar topicalizations from subject islands and ‘whether’-islands, as ‘anchor points’ for interpretation.
The most significant finding is the great amount of cross-trial variability in ratings both between and within adjunct types. Such variability is unexpected under most accounts of adjunct islands and has not previously been observed in formal investigations of adjunct islands. As we discuss below, this finding is at odds with established accounts of adjunct islands, which predict relatively uniform unacceptability across sentences containing the same ‘island violation’.
Before going into the variation in more detail, we point out that across the variable ratings all three adjunct clauses show super-additive interaction effects. Following the factorial definition of an island effect, all three adjunct clauses can be defined as islands for the formation of filler–gap dependencies. This entails that something causes filler–gap dependencies into these adjuncts to be judged less acceptable than might be expected based on simple considerations of distance and structural complexity alone. The mere presence of island effects alone does not tell us what the underlying cause of those effects is.
Our study shows that the type of adjunct clause impacts the acceptability of extraction to a large extent. We observed considerable variation between adjunct clauses in (i) the size of the island effect; (ii) the mean z-score rating of the Long-distance, Island condition; and (iii) the distribution of z-scores on the Long-distance, Island condition. Similarly to Kush et al. (Reference Kush, Lohndal and Sprouse2019), we found that contrastive topicalization from om-adjuncts resulted in relatively small island effects (in comparison to subject-island effects, but similar to ‘whether’-island effects), mean judgments of island violations fell in the range of acceptability (e.g. z > 0), and that judgments of such topicalizations exhibited a bimodal distribution, though the majority of judgments fell above z = 0. Topicalization from når-adjuncts also resulted in smaller island effects, higher average acceptability scores, and a bimodal rating distribution. Fordi-islands differed in that effect sizes were reliably larger and test sentences were almost consistently rejected.
Kush et al. (Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019) argued that judgment distributions could inform the theoretical interpretation of different island effects and, in particular, where to apportion responsibility for island effects. The authors argued that a high degree of variability in judgments was inconsistent with the conclusion that A′-movement was (syntactically) prohibited from that domain tout court. More specifically, Kush et al. (Reference Kush, Lohndal and Sprouse2019) suggest that small or inconsistent island effects paired with bimodal judgment distributions should be taken as evidence that a particular domain was not a syntactic island, under the assumption that syntactic islands should categorically block A′-dependency formation. Under this interpretation our results (and theirs) imply at the very least that om-adjuncts are not syntactic islands in Norwegian. The variability observed with når-adjuncts could also be interpreted as evidence against når-adjuncts being syntactic islands.
3.1 Implications for syntactic approaches to adjunct islands
Neither the fact that extraction is ever judged acceptable from any adjuncts we tested or that there is substantial variation across adjunct types is predicted under any of the syntactic theories on adjunct islands that treat adjuncts as one uniform class of island domains (e.g. Huang’s Reference Huang1982 Condition on Extraction Domains, Chomsky’s Reference Chomsky1986 Barriers; Rizzi’s Reference Rizzi1990, Reference Rizzi and Adriana2004 Relativized Minimality, or the spell-out based approach of Uriagereka Reference Uriagereka, Epstein and Norbert1999, Nunes & Uriagereka Reference Nunes and Uriagereka2000). If all of the adjuncts share the same structural feature (e.g. adjuncthood) that determines opacity for A′-dependencies, then differences are not predicted. To account for our findings within these frameworks would require a number of stipulations which have little independent justification and which would weaken their appeal, which lies in their generality. For example, to be treated as non-islands, om- and når-adjuncts would have to be properly governed, or merged in such a way to avoid early spell-out, while fordi-adjuncts should not. Furthermore, to account for the variability, proper government or evading late spell-out would have to be optionally available for om- and når-adjuncts. It is not at all clear how such optionality could be formally implemented in a principled way.
Traditional approaches to adjunct clauses appear to be too coarse in their classification to account for our data. Syntactic analyses that allow for finer–grained distinctions could, in principle, fare better. If, for example, different adjunct interpretations corresponded to different attachment heights (e.g. Ernst Reference Ernst2002), a correlation between position and extractability might be tenable. Recently, C. Müller (Reference Müller2019) proposed an analysis of extraction from adjuncts in Swedish where the height of an adjunct’s merge position determines its opacity to A′-movement (see also Truswell Reference Truswell2011). C. Müller adopts Haegeman’s (Reference Haegeman2012) distinction between central and peripheral adjunct clauses and postulates that extraction is only allowed from central adjunct clauses that are adjoined low in the structure, at TP or vP (C. Müller Reference Müller2019:42). The adjunct clauses we tested in our experiments are classified as central adjunct clauses according to Haegeman’s (Reference Haegeman2012) and C. Müller’s (Reference Müller2019) definitions: om-, når- and fordi-clauses can have both a central and a peripheral reading, but they are considered central adjunct clauses when they provide information about the condition for, the time of and the cause of the event expressed in the matrix clause, respectively (Haegeman Reference Haegeman2012:161–164). The items in (12) below provide prototypical examples of items with respect to the classification of the type of adjunct clause:

The embedded om-clause in (12a) provides the condition for why the disappointment occurs. In (12b) the adjunct clause provides the time of the event expressed in the matrix VP. In (12c) the cause of ‘the staying’ is expressed by the fordi-clause. Insofar as they are all central adjuncts, the central versus peripheral distinction cannot be the only relevant distinction for determining acceptability (if it is relevant at all).Footnote 11
More generally, any proposal that automatically maps particular adjunct types to rigid attachment positions and uses attachment position as the sole determinant of acceptability of extraction would be hard-pressed to explain the inter- and intra-participant variation we see within individual adjunct types. Whatever the ultimate explanation for adjunct island effects is, it must account for variability by presumably allowing the precondition(s) for acceptable extraction to be variably assigned within an experimental setting.
3.2 Extra-syntactic explanations
We suspect that an account of adjunct island effects will have to take seriously semantic and discourse-pragmatic factors in order to provide an explanation of the fine-grained differences that we observe. Interpretive differences between the semantics of the different adjunct types (conditional, temporal, causal) could, for example, provide a foundation for differences between adjunct types. However, once again, semantic accounts would have to provide room for inter-trial variation, so the lexical semantics of the different complementizers cannot be the only factor determining acceptability of extraction. It seems more likely that the individual lexical semantics of the complementizers interact with semantic or pragmatic properties of the larger sentence. Under some frameworks, islandhood is tied to pragmatic focus or the foreground/background distinction (e.g. Erteschik-Shir Reference Erteschik-Shir1973, Erteschik-Shir & Lappin Reference Erteschik-Shir and Lappin1979, Ambridge & Goldberg Reference Ambridge and Goldberg2008). Within these frameworks, adjuncts would be non-islands insofar as they constitute the ‘main focus’, ‘informational center’, or insofar as their content was foregrounded. This status would be influenced by a number of different factors within the clause and interactions between various features would be expected. For example, differences in how often topicalization out of different adjunct types was accepted might reflect how easy the lexical semantics of the individual complementizers make it to adopt a pragmatically central/relevant reading of the adjunct.
Moreover, the differences that we observe between dependency types might also reflect differences in how easy it is to meet the relevant information structural conditions for extraction given the discourse function of different dependency types (see also Abeillé et al. Reference Abeillé, Hemforth, Winckel and Gibson2020 for a similar idea). Kush et al. (Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019) found that topicalization is more often judged acceptable than wh-movement from adjuncts: this could reflect that the (yet-to-be determined) conditions on acceptable extraction are harder to meet with wh-movement than with topicalization. We note that, insofar as pragmatic conditions are not expected to vary across languages, we would expect differences in adjunct island effects to vary by dependency type across languages. To some extent, this prediction is borne out: Sprouse et al. (Reference Sprouse, Caponigro, Greco and Cecchetto2016) found a conditional adjunct island effect in a wh-dependency in English, but did not find one in a relative clause dependency.Footnote 12
Erteschik-Shir & Lappin (Reference Erteschik-Shir and Lappin1979) also propose that stress pattern and particularly relevant for our data, contrastive stress pattern, also influence the pragmatic focus of the sentence. They argue that extraction of an element is licit if it is contrastively paired and marked with a contrastive stress pattern with another element outside the embedded clause. Erteschik-Shir & Lappin’s (Reference Erteschik-Shir and Lappin1979) account could provide an explanation for why topicalization dependencies have been found to be accepted more often than wh-dependencies in Norwegian (see Kush et al. Reference Kush, Lohndal and Sprouse2018, Reference Kush, Lohndal and Sprouse2019). Applied to our data, all our test sentences in the Long-distance condition have contrastive topicalization, which means that the stress pattern must, in order for this account to work, interact with other features to allow extraction in some test sentences and not in others. It could perhaps also be the case that some of our items more felicitously than others encourage a contrastive reading between the preamble and the test sentence. We have not been able to identify any conditions or features that allow a contrastive reading to a larger or lesser extent in our test sentences. However, given the difference in judgments between the two Long-distance conditions, it is clear that the type of embedded clause influences acceptability to a greater extent than a contrastive stress pattern.
Truswell (Reference Truswell2011) proposes a semantic condition in which extraction is possible if the event denoted by the embedded adjunct clause and the matrix clause can be construed as a single event grouping in the Single Event Grouping Condition:

A core assumption for this condition is that it only applies to non-finite adjunct clauses (Truswell Reference Truswell2011:118), as tensed adjunct clauses will force a two-event reading.Footnote 13 Nevertheless, we will dispose of this premise to consider whether the SEGC can account for some of the patterns in our data with finite adjunct clauses.
Truswell (Reference Truswell2011:157) identifies the following conditions for a single event grouping (SEG):
-
(i) spatiotemporal overlap between events denoted by matrix and embedded clause
-
(ii) a maximum of one (maximal) event is agentive
Under this account, we would expect the distribution of SEG-items to roughly mirror the distribution of accepted items across adjunct type, such that om with the largest proportion of accepted items also would have the largest proportion of items with an SEG-reading. In fact, we do see slightly more items that, with the exception of tense, meet the criteria for being construed as an SEG in når- and om-items, compared to fordi-items. However, the proportion of SEG-items with fordi is much larger than the acceptability ratings for this adjunct type would predict.
Turning to the between-items variation, we see instances of accepted topicalization from both SEG items and non-SEG items within the same adjunct type. For example, in (14) we have one item with a single event grouping reading (14a) and one where the most natural interpretation is arguably consistent with a multiple events reading (14b) (though see endnote 10).

Both items received similar ratings (14a: mean rating z = 0.87, percentage of z > 0 = 85; 14b: mean rating z = 0.68, percentage of z > 0 = 100). The matrix and embedded clause in (14a) can be construed as a single event grouping as (i) the events overlap spatiotemorally – the activity of watching is occurring in the same space and at the same time as his interest rises; and (ii) only the embedded clause is agentive – the handball coach is deliberately watching the game, but not deliberately becoming interested in it. The reading of (14b) is ambiguous with regard to spatiotemporal overlap. The most obvious reading, when also taking into account the reading of the preamble, is one in which the item does not constitute a single event grouping as the events do not overlap spatiotemporally: the accomplishment arrangere ‘organize’ does not occur at the same time as the change in mood.Footnote 14
This implies that the patterns in our data do not match perfectly with what is predicted by the SEGC. Nevertheless, we do see that the majority of accepted items are SEG-items, particularly when we also consider items that are ambiguous with regard to spatiotemporal overlap as SEG-items. However, there is still a substantial number of SEG-items that are not accepted and a significant number of non-SEG-items that are accepted. This does not exclude the possibility that the SEGC is a precondition for extraction, but it implies that other features also interact with acceptability of extraction. Of the surface features we tracked, we could not find any shared features/combination of features between the unaccepted SEG-items.
Truswell (Reference Truswell2011:44) furthermore proposes that causation between the matrix and the embedded clause enables extractability, as it facilitates a single event reading. C. Müller (Reference Müller2019) supports this. It is interesting to note that there is a potential causative relationship between the matrix and embedded clause in all items that are accepted in our study, across adjunct type. However, this relationship alone is not enough to guarantee extraction as most items that are rejected also have a causation link between the matrix and embedded clause. Thus, it might be the case that causation is one prerequisite for extraction, but not the only one.
If relations like causation or SEG are interpretive preconditions on extraction, but those interpretations were not forced by our materials, then some variability in our data could be explained as a result of participants failing to adopt the appropriate interpretation on a given trial. Individual surface level features (e.g. tense, verb choice, plausibility, lexical semantics of individual complementizers or matrix predicates) – or their interactions – might also conspire to lead towards or away from causation readings or single event construal (Truswell Reference Truswell2011, Dal Farra Reference Dal Farra2020). As Truswell (Reference Truswell2011:124) notes, participants may differ in the probability that they will construe events into a single event grouping depending on world-knowledge and creative ability to perceive a link between two events.
4. Conclusion
Our experiments investigated the acceptability of contrastive topicalization dependencies from three adjunct types in Norwegian – om ‘if’, når ‘when’, and fordi ‘because’. Our results suggest that om-adjuncts are not categorical islands for A′-movement (replicating the findings of Kush et al. Reference Kush, Lohndal and Sprouse2019). We found island effects for når-adjuncts, but we reasoned, on the basis of judgment distributions, that these effects were also incompatible with a strict ban on movement from structural adjuncts. Participants largely rejected topicalization from fordi-adjuncts, suggesting variation in island effects between adjunct type. The large variation within each adjunct type implies that ‘adjunct’ is not a uniform group in relation to island extraction, as it has previously been treated. We also uncovered great inter-item variation, which we think implies that there are extra-syntactic conditions that govern the extraction from these adjunct clauses, as no known syntactic account can explain the variation seen in our experiments. Current extra-syntactic explanations for extraction from adjunct clauses can not, however, straightforwardly explain the pattern found for extraction from Norwegian adjunct clauses and should be addressed in future work.
Aknowledgements
The data presented in this paper was collected for and first published in Bondevik (MA thesis, NTNU, 2018). An early version of the paper was presented at MONS, 2019. We want to thank three anonymous NJL reviewers for feedback, comments and questions, as well as valuable insights for future work.



















 Open access
Open access