





Impact Statement
Integrating physical models with machine learning has many applications in prediction and forecasting tasks. In this work, we analyze a hybrid framework that combines neural network models with an incomplete partial differential equation (PDE) solver to account for the effects of unknown physics present in the system. We demonstrate the applicability of this approach to complex and practical simulations of reactive flows with unknown chemistry. Our experimental evaluation demonstrates the diverse possibilities this hybrid system entails such as performing accurate long-term predictions, generalization to unseen operating conditions, robustness to incorrect PDE parameters, and enabling flame shape control. This approach for hybrid simulation methods has the potential to be adapted to more complex, multi-physics problems for parameter identification and control.
1. Introduction
Modeling and forecasting of complex physical systems described by nonlinear partial differential equations (PDEs) are central to various domains with applications ranging from weather forecasting (Kalnay, Reference Kalnay2003), design of airplane wings (Rhie and Chow, Reference Rhie and Chow1983; Zafar et al., Reference Zafar, Choudhari, Paredes and Xiao2021), to material science (Wheeler et al., Reference Wheeler, Boettinger and McFadden1992). Typically, a chosen set of PDEs is solved iteratively until convergence of the solution. Modeling complex physical dynamics requires a good understanding of the underlying physical phenomena. For cases where the complete information on the physics of the system is missing, deep learning models can be employed to complete the physical description when additional data of the system is available. Deep learning methods have shown promise to account for these unknown components of the system (Um et al., Reference Um, Brand, Yun, Holl and Thuerey2020; Yin et al., Reference Yin, Le Guen, Dona, de Bézenac, Ayed, Thome and Gallinari2021). We consider a set of PDEs with partially unknown physics represented. The corresponding PDE model for a general state
 $ \phi $
is given by
$ \phi $
is given by
 $$ {\displaystyle \begin{array}{c}\hskip-2em \frac{\mathrm{\partial}\phi }{\mathrm{\partial}t}={\mathcal{P}}_c\left(\phi, \frac{\mathrm{\partial}\phi }{\mathrm{\partial}x},\frac{{\mathrm{\partial}}^2\phi }{\mathrm{\partial}{x}^2},\dots \right),\hskip22em \mathrm{i}\mathrm{n}\hskip1em \Omega \times (0,\mathrm{\infty})\\ {}=\mathcal{F}\left({\mathcal{P}}_i\left(\phi, \frac{\mathrm{\partial}\phi }{\mathrm{\partial}x},\frac{{\mathrm{\partial}}^2\phi }{\mathrm{\partial}{x}^2},\dots \right),{\mathcal{P}}_u\left(\phi, \frac{\mathrm{\partial}\phi }{\mathrm{\partial}x},\frac{{\mathrm{\partial}}^2\phi }{\mathrm{\partial}{x}^2},\dots \right)\right),\hskip5.00em \mathrm{i}\mathrm{n}\hskip1em \Omega \times (0,\mathrm{\infty})\\ {}\hskip-2.4em \mathcal{G}(\phi )=0,\hskip34.5em \mathrm{i}\mathrm{n}\hskip1em \mathrm{\partial}\Omega \times (0,\mathrm{\infty})\\ {}\hskip-2em \phi =h,\hskip34.5em \mathrm{i}\mathrm{n}\hskip1em \Omega \times (0),\end{array}} $$
$$ {\displaystyle \begin{array}{c}\hskip-2em \frac{\mathrm{\partial}\phi }{\mathrm{\partial}t}={\mathcal{P}}_c\left(\phi, \frac{\mathrm{\partial}\phi }{\mathrm{\partial}x},\frac{{\mathrm{\partial}}^2\phi }{\mathrm{\partial}{x}^2},\dots \right),\hskip22em \mathrm{i}\mathrm{n}\hskip1em \Omega \times (0,\mathrm{\infty})\\ {}=\mathcal{F}\left({\mathcal{P}}_i\left(\phi, \frac{\mathrm{\partial}\phi }{\mathrm{\partial}x},\frac{{\mathrm{\partial}}^2\phi }{\mathrm{\partial}{x}^2},\dots \right),{\mathcal{P}}_u\left(\phi, \frac{\mathrm{\partial}\phi }{\mathrm{\partial}x},\frac{{\mathrm{\partial}}^2\phi }{\mathrm{\partial}{x}^2},\dots \right)\right),\hskip5.00em \mathrm{i}\mathrm{n}\hskip1em \Omega \times (0,\mathrm{\infty})\\ {}\hskip-2.4em \mathcal{G}(\phi )=0,\hskip34.5em \mathrm{i}\mathrm{n}\hskip1em \mathrm{\partial}\Omega \times (0,\mathrm{\infty})\\ {}\hskip-2em \phi =h,\hskip34.5em \mathrm{i}\mathrm{n}\hskip1em \Omega \times (0),\end{array}} $$
where
 $ {\mathcal{P}}_c $
represents the physical system with complete information.
$ {\mathcal{P}}_c $
represents the physical system with complete information.
 $ \mathrm{\mathcal{F}} $
represents a potentially simple function that combines the known but incomplete PDE description,
$ \mathrm{\mathcal{F}} $
represents a potentially simple function that combines the known but incomplete PDE description,
 $ {\mathcal{P}}_i $
, and unknown physics represented by
$ {\mathcal{P}}_i $
, and unknown physics represented by
 $ {\mathcal{P}}_u $
to match the solutions of complete PDE system. We take
$ {\mathcal{P}}_u $
to match the solutions of complete PDE system. We take
 $ \mathcal{G} $
and
$ \mathcal{G} $
and
 $ h $
to be known functions appropriately defining the boundary and initial conditions respectively.
$ h $
to be known functions appropriately defining the boundary and initial conditions respectively.
 $ \Omega $
is the spatial domain over which we solve the PDE system and
$ \Omega $
is the spatial domain over which we solve the PDE system and
 $ \mathrm{\partial \Omega } $
its boundary. The term
$ \mathrm{\partial \Omega } $
its boundary. The term
 $ {\mathcal{P}}_u $
can take the form of closure terms, source terms, higher order coupling terms between state variables or terms resulting from a set of unknown ODEs/PDEs depending on the physical system under investigation.
$ {\mathcal{P}}_u $
can take the form of closure terms, source terms, higher order coupling terms between state variables or terms resulting from a set of unknown ODEs/PDEs depending on the physical system under investigation.
A commonly targeted case is when the governing equations of the complete PDE description are computationally too expensive to solve, with turbulence modeling in computational fluid dynamics (CFD) being a good example (Chen, Reference Chen1997; Pope, Reference Pope2000). In CFD, a spatial filtering is performed on the original governing PDEs in the context of large eddy simulations (LES). This step introduces unclosed terms in the model equations that correspond to unrepresented physics in equation (1), due to the effects of the filtered scales. Figure 1A shows instances of normalized vorticity for isotropic decaying turbulence. The solutions of a fully resolved direct numerical simulation (DNS) could be achieved by increasing the spatial resolution of LES. This is a widely studied problem, where the use of deep learning models is currently being explored (Lapeyre et al., Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019; Kochkov et al., Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021; List et al., Reference List, Chen and Thuerey2022; Stachenfeld et al., Reference Stachenfeld, Fielding, Kochkov, Cranmer, Pfaff, Godwin, Cui, Ho, Battaglia and Sanchez-Gonzalez2022). Several of these methods train a neural network with LES as the incomplete system to model the effects of the filtered scales and obtain the solutions of the complete DNS (Kochkov et al., Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021; List et al., Reference List, Chen and Thuerey2022). Instead, we consider a different, more challenging problem related to multi-physics, coupled systems containing dependent variables which describe different physical phenomena. In equation (1),
 $ {\mathcal{P}}_u $
contains all the terms corresponding to different physical phenomena that are not included in the PDEs represented by
$ {\mathcal{P}}_u $
contains all the terms corresponding to different physical phenomena that are not included in the PDEs represented by
 $ {\mathcal{P}}_i $
. This formulation could describe fluid–structure interactions which couple fluid mechanics with structural mechanics with
$ {\mathcal{P}}_i $
. This formulation could describe fluid–structure interactions which couple fluid mechanics with structural mechanics with
 $ {\mathcal{P}}_u $
representing the unknown coupling terms, or aeroacoustics problems which couple fluid dynamics and acoustics (Benra et al., Reference Benra, Dohmen, Pei, Schuster and Wan2011; Liu and Liu, Reference Liu and Liu2018).
$ {\mathcal{P}}_u $
representing the unknown coupling terms, or aeroacoustics problems which couple fluid dynamics and acoustics (Benra et al., Reference Benra, Dohmen, Pei, Schuster and Wan2011; Liu and Liu, Reference Liu and Liu2018).

Figure 1. (A) The normalized vorticity solutions of complete/DNS (bottom) solver can be reached by increasing the spatial resolution of the incomplete/LES (top) solver (List et al., Reference List, Chen and Thuerey2022). (B) We consider the problem of the incomplete/nonreactive (top) and complete/reactive (bottom) PDE solvers which can yield fundamentally different evolutions, as shown here for a sample temperature field over time.
However, in this work, we will focus on reactive flow simulation as the complete PDE description, while a nonreactive flow simulation will represent the incomplete PDE basis. It collects the chemical kinetic mechanisms in the unknown physics term of equation (1). In this system,
 $ {\mathcal{P}}_u $
could take the form of the source terms from unknown chemistry in the Navier–Stokes equations. A reactive flow refers to a fluid flow with chemical reactions occurring within a reacting fluid, such as combustion-related flows. A reacting fluid is a mixture of two or more species such as hydrocarbons, oxygen, water, carbon dioxide, and so forth, which undergo chemical reactions (Poinsot and Veynante, Reference Poinsot and Veynante2005). In contrast, a nonreactive flow refers to a fluid flow where no chemical reactions take place. Figure 1B shows a visual example of a nonreactive and reactive flow simulations which can be considered as an incomplete and complete PDE systems, respectively. Starting from the same initial condition, the influence of
$ {\mathcal{P}}_u $
could take the form of the source terms from unknown chemistry in the Navier–Stokes equations. A reactive flow refers to a fluid flow with chemical reactions occurring within a reacting fluid, such as combustion-related flows. A reacting fluid is a mixture of two or more species such as hydrocarbons, oxygen, water, carbon dioxide, and so forth, which undergo chemical reactions (Poinsot and Veynante, Reference Poinsot and Veynante2005). In contrast, a nonreactive flow refers to a fluid flow where no chemical reactions take place. Figure 1B shows a visual example of a nonreactive and reactive flow simulations which can be considered as an incomplete and complete PDE systems, respectively. Starting from the same initial condition, the influence of
 $ {\mathcal{P}}_u $
in this multi-physics system leads to fundamentally different solutions as reacting fluid (shown by blue color in Figure 1B) advances through the domain without reacting for the nonreactive flow simulation or forms a
$ {\mathcal{P}}_u $
in this multi-physics system leads to fundamentally different solutions as reacting fluid (shown by blue color in Figure 1B) advances through the domain without reacting for the nonreactive flow simulation or forms a
 $ \Lambda $
shaped flame with higher temperature of burned products (shown by dark red color) for the reactive flow simulation. Therefore, we are targeting a more challenging problem than those tackled in (Lapeyre et al., Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019; Kochkov et al., Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021; List et al., Reference List, Chen and Thuerey2022; Stachenfeld et al., Reference Stachenfeld, Fielding, Kochkov, Cranmer, Pfaff, Godwin, Cui, Ho, Battaglia and Sanchez-Gonzalez2022), where increasing spatial resolution and/or reducing time-scales of the incomplete PDE solver does not lead to a converged full solution. Rather, the complete and incomplete PDEs produce drastically different solutions due to the unknown physics. The central learning objective is to correct this behavior and retrieve the evolution that would be obtained with the complete PDE description.
$ \Lambda $
shaped flame with higher temperature of burned products (shown by dark red color) for the reactive flow simulation. Therefore, we are targeting a more challenging problem than those tackled in (Lapeyre et al., Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019; Kochkov et al., Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021; List et al., Reference List, Chen and Thuerey2022; Stachenfeld et al., Reference Stachenfeld, Fielding, Kochkov, Cranmer, Pfaff, Godwin, Cui, Ho, Battaglia and Sanchez-Gonzalez2022), where increasing spatial resolution and/or reducing time-scales of the incomplete PDE solver does not lead to a converged full solution. Rather, the complete and incomplete PDEs produce drastically different solutions due to the unknown physics. The central learning objective is to correct this behavior and retrieve the evolution that would be obtained with the complete PDE description.
Our work expands on the combination of incomplete PDE solvers and neural networks (NNs) (Takeishi and Kalousis, Reference Takeishi and Kalousis2021; Yin et al., Reference Yin, Le Guen, Dona, de Bézenac, Ayed, Thome and Gallinari2021) to account for the effects of an incomplete physics model. The NN aims to complete the PDE description, where the differences in complete and incomplete PDE solutions are beyond the effects of spatial and temporal scales. We showcase that combining the trained NN model with a differentiable solver for the incomplete PDE can accurately reproduce the physical solutions of the complete, multi-physics PDE solver with stable long-term rollouts.
Reactive flow modeling has applications in numerous domains such as combustion processes in gas turbines (Lieuwen, Reference Lieuwen2012; Gruber et al., Reference Gruber, Richardson, Aditya and Chen2018), climate modeling (Jacobson, Reference Jacobson1999; Rolnick et al., Reference Rolnick, Donti, Kaack, Kochanski, Lacoste, Sankaran, Ross, Milojevic-Dupont, Jaques, Waldman-Brown, Luccioni, Maharaj, Sherwin, Karthik Mukkavilli, Kording, Gomes, Ng, Hassabis, Platt, Creutzig, Chayes and Bengio2022), and astrophysics simulations (Gamezo et al., Reference Gamezo, Khokhlov, Oran, Chtchelkanova and Rosenberg2003). Resolving the Navier–Stokes equations lies at the core of these problems, where additionally the transport of different species of relevance must also be accounted for, together with their production or consumption often following complex reaction mechanisms (Poinsot and Veynante, Reference Poinsot and Veynante2005). For chemically reacting flows, the generation or consumption of multiple species via some chemical reaction is modeled using a net source term. It is a well-known fact that the incorporation of a detailed chemical kinetic mechanism in a reacting flow model can result in a stiff system of governing equations (Wanner and Hairer, Reference Wanner and Hairer1996; Najm et al., Reference Najm, Wyckoff and Knio1998; Knio et al., Reference Knio, Najm and Wyckoff1999).
We showcase the effectiveness of our approach for different cases of planar 2D premixed methane-air flames, and the varying transient evolution of Bunsen-type flames. We show that the proposed approach can handle large domains with highly resolved flames, which are closer to the practical flame domains used in many industrial applications. Specifically, we concentrate on training a NN model to correct the spatio-temporal effects of energy and species transport source terms. We show that in addition to recovering the desired solutions, this approach overcomes inherent problems of temporal stiffness due to the complex reaction mechanism. Lastly, we show that the resulting hybrid solver provides a flexible building block for adjacent tasks. Specifically, we demonstrate this for controlling the evolution of flame shapes via continuous control. The hybrid solvers can efficiently predict the states of the reactive flows and readily enable the control of the flow inlet velocities to arrive at a desired flame shape. Therefore, we employ a pre-trained hybrid solver to train a second controller network that learns to steer the flame simulation such that the observed states are matched.
This article is organized as follows. We discuss the relevant literature in Section 2. Section 3 describes the problem statement, the mathematical formulation, details of the differentiable PDE solver, and the neural network model. Discussion on data generation process is provided in Section 4. Section 5 shows the results obtained on different planar and Bunsen flame scenarios considered. Section 6 demonstrates the robustness of the proposed approach. Finally, in Section 7, we apply the proposed hybrid approach to arrive at the desired flame shape by solving an optimization problem. Section 8 concludes this article with a summary of the results and outlines future work.
2. Related work
Deep learning methods have been widely used to model the solutions of PDEs (Lagaris et al., Reference Lagaris, Likas and Fotiadis1998; Han et al., Reference Han, Jentzen and Weinan2018; Long et al., Reference Long, Lu, Ma and Dong2018; Bar-Sinai et al., Reference Bar-Sinai, Hoyer, Hickey and Brenner2019) and in particular, the Navier–Stokes equations (Guo et al., Reference Guo, Li and Iorio2016; Bhatnagar et al., Reference Bhatnagar, Afshar, Pan, Duraisamy and Kaushik2019).
2.1. Purely data-driven models
A simple approach in modeling any physical system consists of training a deep learning model using data coming from either experiments or numerical simulation (Fukami et al., Reference Fukami, Fukagata and Taira2019; Thuerey et al., Reference Thuerey, Weißenow, Prantl and Hu2020). These models solely use deep learning techniques with appropriate data to make predictions and hence are called as purely data-driven (PDD) models. Thuerey et al. (Reference Thuerey, Weißenow, Prantl and Hu2020) applied a convolutional neural network (CNN) to learn Reynolds-Averaged Navier–Stokes (RANS) solutions of airfoil flows. The proposed approach is very generic and applicable to a wide range of PDE boundary value problems on Cartesian grids. Stachenfeld et al. (Reference Stachenfeld, Fielding, Kochkov, Cranmer, Pfaff, Godwin, Cui, Ho, Battaglia and Sanchez-Gonzalez2022) demonstrate that a generic CNN-based models may predict turbulent dynamics on coarse grids more accurately than classical numerical solvers. The proposed approach is effectively applied on a wide range of physical domains which can be represented as grids. These classical neural networks map between finite-dimensional spaces and can only learn solutions tied to a specific discretization which can be excessively limiting. Therefore, approaches based on learning operators are receiving increased attention. Lu et al. (Reference Lu, Jin, Pang, Zhang and Karniadakis2021) proposed a novel architecture based on fully connected neural networks called DeepONets to learn diverse linear or nonlinear explicit and implicit operators. Neural operators (Li et al., Reference Li, Kovachki, Azizzadenesheli, Liu, Bhattacharya, Stuart and Anandkumar2020B; Bhattacharya et al., Reference Bhattacharya, Hosseini, Kovachki and Stuart2021; Patel et al., Reference Patel, Trask, Wood and Cyr2021), specifically, the Fourier neural operator (FNO) of Li et al. (Reference Li, Kovachki, Azizzadenesheli, Liu, Bhattacharya, Stuart and Anandkumar2020A) introduce an interesting line of work by learning mesh-free, infinite-dimensional operators with neural networks, but do not necessarily offer advantages for longer-term predictions. We compare the proposed approach with such data-driven models as baselines. PDD models can be very fast and may not suffer from the time-step stability issues associated with traditional numerical solvers. Nevertheless, as these PDD approaches lack the physical understanding of the system being modeled, they generally fail in generalizing to other operating conditions (Kim et al., Reference Kim, Azevedo, Thuerey, Kim, Gross and Solenthaler2019; Lapeyre et al., Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019). To leverage the potential of deep learning in physical simulations, it is therefore necessary to incorporate some physical information within the deep learning framework.
2.2. Physics-informed deep learning models
Deep learning models can enforce physical constraints partially through the loss function (Bar-Sinai et al., Reference Bar-Sinai, Hoyer, Hickey and Brenner2019; Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019; Yadav et al., Reference Yadav, Casel and Ghani2022) or changes in neural network architecture (Greydanus et al., Reference Greydanus, Dzamba and Yosinski2019). A well-known framework called Physics-Informed Neural Network (PINN) (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019) uses neural networks as methods for solving PDEs. It minimizes the residual of the underlying governing laws by taking advantage of automatic differentiation to compute exact, mesh-free derivatives. However, these approaches struggle to enforce physical constraints such as boundary conditions or predict the strong unsteadiness and chaotic nature of flows (Dwivedi and Srinivasan, Reference Dwivedi and Srinivasan2020; Fuks and Tchelepi, Reference Fuks and Tchelepi2020). PINN only learns the solution function of a single PDE instance and needs reoptimization for other instances or PDEs. To alleviate this issue, Wang et al. (Reference Wang, Wang and Perdikaris2021) extended the DeepONet framework by imposing the underlying physical laws via soft penalty constraints during training. Although physics-informed DeepONet imposes PDE losses on operator learning, they are not discretization invariant. To tackle this issue, physics-informed neural operator (PINO) framework was proposed by Li et al. (Reference Li, Zheng, Kovachki, Jin, Chen, Liu, Azizzadenesheli and Anandkumar2021) that uses available data and physics constraints to learn the solution operator of parametric PDEs. However, all these approaches require the explicit knowledge of the underlying PDEs to accurately train the network. For the physical systems described in equation (1) where only partial knowledge of their physical mechanism is known, these approaches may fail to converge to the solutions of the complete PDE solver. Minimizing the residual of only the known but incomplete PDEs will not lead to an accurate prediction of the solutions of a complete PDE system. Additionally, these approaches would need some further modifications to be implemented for the problem considered. Therefore, they are not considered as a baseline method for the present work.
2.3. Neural networks with differentiable PDE solvers
In recent years, the development of differentiable PDE solvers has led to an interesting line of research. Thuerey et al. (Reference Thuerey, Holl, Mueller, Schnell, Trost and Um2021) have developed an open-source physics simulation toolkit called PhiFlow for optimization and machine-learning applications. SU2 (Economon et al., Reference Economon, Palacios, Copeland, Lukaczyk and Alonso2016) is an open-source collection of software tools for analyzing PDEs and PDE-constrained optimization problems on unstructured meshes with state-of-the-art numerical methods. SciML (Rackauckas et al., Reference Rackauckas, Ma, Martensen, Warner, Zubov, Supekar, Skinner, Ramadhan and Edelman2020) is a collection of tools for solving equations and modeling systems. These tools provide differentiable functions for physical simulations, which enable close integration with deep learning frameworks by leveraging their automatic differentiation functionality. Hybrid approaches that combine machine learning techniques with numerical PDE solvers (Wang et al., Reference Wang, Kashinath, Mustafa, Albert and Yu2020; Illarramendi et al., Reference Illarramendi, Bauerheim and Cuenot2022), have attracted a significant amount of interest due to their capabilities for generalization (Chen et al., Reference Chen, Rubanova, Bettencourt and Duvenaud2018). In this context, neural networks are typically used to model or replace a part of the conventional PDE solver to improve aspects of the solving process. For example, Tompson et al. (Reference Tompson, Schlachter, Sprechmann and Perlin2017), Ajuria Illarramendi et al. (Reference Ajuria Illarramendi, Alguacil, Bauerheim, Misdariis, Cuenot and Benazera2020), and Özbay et al. (Reference Özbay, Hamzehloo, Laizet, Tzirakis, Rizos and Schuller2021) proposed a convolutional neural network-based approach to solve the Poisson equation in CFD simulation. In recent years, a number of deep learning-based models have been introduced to accurately model turbulent flows (Pathak et al., Reference Pathak, Mustafa, Kashinath, Motheau, Kurth and Day2020; Dresdner et al., Reference Dresdner, Kochkov, Norgaard, Zepeda-Núñez, Smith, Brenner and Hoyer2022; Stachenfeld et al., Reference Stachenfeld, Fielding, Kochkov, Cranmer, Pfaff, Godwin, Cui, Ho, Battaglia and Sanchez-Gonzalez2022). Belbute-Peres et al. (Reference Belbute-Peres, Economon and Kolter2020) and Um et al. (Reference Um, Brand, Yun, Holl and Thuerey2020) showed the advantages of training neural networks with differentiable physics to correct the numerical errors that arise in the discretization of PDEs. Sirignano et al. (Reference Sirignano, MacArt and Freund2020) introduced a deep learning PDE augmentation method. Large eddy simulation of turbulence is augmented with a deep neural network to model unresolved physics to obtain direct numerical simulation solutions. Kochkov et al. (Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021) correct for closure error by integrating a neural network with a differentiable CFD simulator. These approaches demonstrate the capabilities of neural networks to correct errors in a fast, under-resolved simulation. The unresolved physics in turbulence modeling is attributed to spatial filtering. Given additional compute resources, one can arrive at accurate solutions by running the known PDEs at higher resolution. Note that in this work we investigate a more challenging case of unknown physics in multi-physics system, where increasing the spatial or temporal resolution of the known but incomplete PDEs will not lead to the accurate solution of the complete PDEs.
Similar to the goals of our work, Takeishi and Kalousis (Reference Takeishi and Kalousis2021) and Yin et al. (Reference Yin, Le Guen, Dona, de Bézenac, Ayed, Thome and Gallinari2021) have introduced frameworks of augmenting incomplete physical dynamics with neural network models. These approaches demonstrate the applicability on ODE/PDE systems, which are weakly nonlinear and the unknown dynamics are linear combinations of the underlying flow fields. We expand on these works to explore the significantly more challenging scenario of reactive flows. These are characterized by a multi-physics system with nonlinear advective terms which models the transport of a flow state by the velocity of the flow, and strongly nonlinear dynamics, described by exponential source terms that exhibit nonlinear combinations of the flow fields. Compared to the work by Yin et al. (Reference Yin, Le Guen, Dona, de Bézenac, Ayed, Thome and Gallinari2021), we do not use an additive approach to learn the solutions of the complete PDE system. Instead, we use the output of an incomplete PDE solver as an input to the neural network model to correct for the effects of unknown terms.
3. Methodology
We consider two different sets of PDEs with their associated numerical solver, which we denote as the incomplete PDE
 $ {\mathcal{P}}_i $
and the complete PDE
$ {\mathcal{P}}_i $
and the complete PDE
 $ {\mathcal{P}}_c $
. By evaluating
$ {\mathcal{P}}_c $
. By evaluating
 $ {\mathcal{P}}_c $
on an input state
$ {\mathcal{P}}_c $
on an input state
 $ {\phi}_t $
at time
$ {\phi}_t $
at time
 $ t $
, we can compute the points of the phase space sequences;
$ t $
, we can compute the points of the phase space sequences;
 $ {\phi}_{t+\Delta t}={\mathcal{P}}_c\left({\phi}_t\right) $
. Without loss of generality, we assume a fixed time-step
$ {\phi}_{t+\Delta t}={\mathcal{P}}_c\left({\phi}_t\right) $
. Without loss of generality, we assume a fixed time-step
 $ \Delta t $
and denote a state
$ \Delta t $
and denote a state
 $ {\phi}_{t+\Delta t} $
at next time instance as
$ {\phi}_{t+\Delta t} $
at next time instance as
 $ {\phi}_{t+1} $
. Let
$ {\phi}_{t+1} $
. Let
 $ \mathcal{X} $
be a Banach space of functions taking values in a spatial domain
$ \mathcal{X} $
be a Banach space of functions taking values in a spatial domain
 $ \Omega \subset {\mathrm{\mathbb{R}}}^2 $
. Furthermore, let
$ \Omega \subset {\mathrm{\mathbb{R}}}^2 $
. Furthermore, let
 $ {C}^{\dagger }:\mathcal{X}\to \mathcal{X} $
be a nonlinear map from
$ {C}^{\dagger }:\mathcal{X}\to \mathcal{X} $
be a nonlinear map from
 $ {\phi}_t $
to
$ {\phi}_t $
to
 $ {\phi}_{t+1} $
, defined over a finite time interval
$ {\phi}_{t+1} $
, defined over a finite time interval
 $ \left[0,T\right] $
and an input flow state
$ \left[0,T\right] $
and an input flow state
 $ \phi $
. The learning objective is to find the best possible correction function
$ \phi $
. The learning objective is to find the best possible correction function
 $$ C\left(\phi; \theta \right):\mathcal{X}\to \mathcal{X},\hskip1em \theta \in \Theta $$
$$ C\left(\phi; \theta \right):\mathcal{X}\to \mathcal{X},\hskip1em \theta \in \Theta $$
for some finite-dimensional parameter space
 $ \Theta $
by choosing
$ \Theta $
by choosing
 $ {\theta}^{\dagger } $
such that
$ {\theta}^{\dagger } $
such that
 $ C\left(.;{\theta}^{\dagger}\right)\approx {C}^{\dagger } $
. The neural network models can be employed to learn such mapping as shown in Figure 2. The model parameters
$ C\left(.;{\theta}^{\dagger}\right)\approx {C}^{\dagger } $
. The neural network models can be employed to learn such mapping as shown in Figure 2. The model parameters
 $ \theta $
are estimated from the complete PDE solution trajectories
$ \theta $
are estimated from the complete PDE solution trajectories
 $ \left({\phi}_0,{\phi}_1,..,{\phi}_T\right) $
. The learned predictions obtained after repeatedly applying the corrector
$ \left({\phi}_0,{\phi}_1,..,{\phi}_T\right) $
. The learned predictions obtained after repeatedly applying the corrector
 $ C $
and invoking
$ C $
and invoking
 $ {\mathcal{P}}_i $
are denoted by
$ {\mathcal{P}}_i $
are denoted by
 $ \left({\tilde{\phi}}_0,{\tilde{\phi}}_1,..,{\tilde{\phi}}_T\right) $
.
$ \left({\tilde{\phi}}_0,{\tilde{\phi}}_1,..,{\tilde{\phi}}_T\right) $
.

Figure 2. (A) Multi-step training framework helps to learn the dynamics of complete PDE solver over longer rollouts. (B1) Details of the input flow state and predictor block used in a purely data-driven approach and (B2) the hybrid NN-PDE approach, where S denotes the concatenation of different fields to obtain the complete flow state
 $ \tilde{\phi} $
at next time step.
$ \tilde{\phi} $
at next time step.
3.1. PDEs for reactive flows
In this section, we present the basics of reactive flow simulation and underlying conservation equations. A reactive flow involves multiple species reacting through one or more chemical reactions. Different species, such as hydrocarbons (fuel), oxygen (oxidizer), water, carbon dioxide (products), are characterized through their mass fraction
 $ {Y}_k $
. The primary variables for two-dimensional (2-D) reacting flow involve density (
$ {Y}_k $
. The primary variables for two-dimensional (2-D) reacting flow involve density (
 $ \rho $
), 2-D velocity field (
$ \rho $
), 2-D velocity field (
 $ u $
), temperature
$ u $
), temperature
 $ (T) $
, and the mass fraction
$ (T) $
, and the mass fraction
 $ {Y}_k $
of the
$ {Y}_k $
of the
 $ N $
reacting species.
$ N $
reacting species.
In a premixed combustor, fuel (
 $ {Y}_F $
) and oxidizer (
$ {Y}_F $
) and oxidizer (
 $ {Y}_O $
) are mixed before they enter the combustion chamber. The computation of premixed flames with complex chemistry is possible but we consider a simplified approach. We assume that chemistry proceeds only through one irreversible reaction, that is, one-step chemistry. If
$ {Y}_O $
) are mixed before they enter the combustion chamber. The computation of premixed flames with complex chemistry is possible but we consider a simplified approach. We assume that chemistry proceeds only through one irreversible reaction, that is, one-step chemistry. If
 $ {\upsilon}_F^{\prime } $
and
$ {\upsilon}_F^{\prime } $
and
 $ {\upsilon}_O^{\prime } $
are the coefficients corresponding to fuel and oxidizer when considering a one-step reaction of type
$ {\upsilon}_O^{\prime } $
are the coefficients corresponding to fuel and oxidizer when considering a one-step reaction of type
 $ {\upsilon}_F^{\prime }F+{\upsilon}_O^{\prime }O\to \mathrm{products}, $
the mass fractions of fuel and oxidizer correspond to stoichiometric conditions. It is defined as,
$ {\upsilon}_F^{\prime }F+{\upsilon}_O^{\prime }O\to \mathrm{products}, $
the mass fractions of fuel and oxidizer correspond to stoichiometric conditions. It is defined as,
 $$ {\left(\frac{Y_O}{Y_F}\right)}_{st}=\frac{\upsilon_O^{\prime }{W}_O}{\upsilon_F^{\prime }{W}_F}=\varphi . $$
$$ {\left(\frac{Y_O}{Y_F}\right)}_{st}=\frac{\upsilon_O^{\prime }{W}_O}{\upsilon_F^{\prime }{W}_F}=\varphi . $$
This ratio
 $ \varphi $
is called the mass stoichiometric ratio.
$ \varphi $
is called the mass stoichiometric ratio.
 $ {W}_F $
and
$ {W}_F $
and
 $ {W}_O $
represent the molecular weights of the fuel and oxidizer, respectively. The equivalence ratio of a given mixture is then,
$ {W}_O $
represent the molecular weights of the fuel and oxidizer, respectively. The equivalence ratio of a given mixture is then,
 $$ E=\varphi \left(\frac{Y_F}{Y_O}\right). $$
$$ E=\varphi \left(\frac{Y_F}{Y_O}\right). $$
A common example of such reaction is
 $ {\mathrm{CH}}_4+2{\mathrm{O}}_2\to {\mathrm{CO}}_2+2{\mathrm{H}}_2\mathrm{O} $
, where
$ {\mathrm{CH}}_4+2{\mathrm{O}}_2\to {\mathrm{CO}}_2+2{\mathrm{H}}_2\mathrm{O} $
, where
 $ {\upsilon}_F^{\prime }=1,{\upsilon}_O^{\prime }=2,{W}_F=0.016\;\mathrm{kg}/\mathrm{mol},{W}_O=0.032\;\mathrm{kg}/\mathrm{mol} $
and therefore
$ {\upsilon}_F^{\prime }=1,{\upsilon}_O^{\prime }=2,{W}_F=0.016\;\mathrm{kg}/\mathrm{mol},{W}_O=0.032\;\mathrm{kg}/\mathrm{mol} $
and therefore
 $ \varphi =4 $
. The equivalence ratio is an important parameter in the design of a premixed combustion system. Rich combustion is observed for
$ \varphi =4 $
. The equivalence ratio is an important parameter in the design of a premixed combustion system. Rich combustion is observed for
 $ E>1 $
(the fuel is in excess) and lean regimes are achieved when (E < 1) (the oxidizer is in excess) (Poinsot and Veynante, Reference Poinsot and Veynante2005). Most practical premixed combustors operate at or below stoichiometry (Lieuwen and Yang, Reference Lieuwen and Yang2005).
$ E>1 $
(the fuel is in excess) and lean regimes are achieved when (E < 1) (the oxidizer is in excess) (Poinsot and Veynante, Reference Poinsot and Veynante2005). Most practical premixed combustors operate at or below stoichiometry (Lieuwen and Yang, Reference Lieuwen and Yang2005).
The physical system we investigate is a laminar premixed methane-air flame with one-step chemistry. It is governed by the following Navier–Stokes equations (Poinsot and Veynante, Reference Poinsot and Veynante2005)
 $$ {\displaystyle \begin{array}{c}\frac{\partial \rho }{\partial t}+\nabla .\left(\rho u\right)=0\hskip32em \mathrm{in}\hskip1em \Omega \times \left[0,T\right]\\ {}\frac{\partial }{\partial t}\left(\rho u\right)+\nabla .\left(\rho u\hskip0.35em \otimes \hskip0.35em u\right)=-\nabla p+\nabla .\tau \hskip25em \mathrm{in}\hskip1em \Omega \times \left[0,T\right]\\ {}\rho {C}_p\left(\frac{\partial T}{\partial t}+\nabla .\left(u\hskip0.35em \otimes \hskip0.35em T\right)\right)={\dot{\omega}}_L^{\prime }+\lambda {\nabla}^2T\hskip25.6em \mathrm{in}\hskip1em \Omega \times \left[0,T\right]\\ {}\frac{\partial \rho {Y}_k}{\partial t}+\nabla .\left(\rho u\hskip0.35em \otimes \hskip0.35em {Y}_k\right)={\dot{\omega}}_k+\rho {D}_k{\nabla}^2{Y}_k\hskip23.5em \mathrm{in}\hskip1em \Omega \times \left[0,T\right],\end{array}} $$
$$ {\displaystyle \begin{array}{c}\frac{\partial \rho }{\partial t}+\nabla .\left(\rho u\right)=0\hskip32em \mathrm{in}\hskip1em \Omega \times \left[0,T\right]\\ {}\frac{\partial }{\partial t}\left(\rho u\right)+\nabla .\left(\rho u\hskip0.35em \otimes \hskip0.35em u\right)=-\nabla p+\nabla .\tau \hskip25em \mathrm{in}\hskip1em \Omega \times \left[0,T\right]\\ {}\rho {C}_p\left(\frac{\partial T}{\partial t}+\nabla .\left(u\hskip0.35em \otimes \hskip0.35em T\right)\right)={\dot{\omega}}_L^{\prime }+\lambda {\nabla}^2T\hskip25.6em \mathrm{in}\hskip1em \Omega \times \left[0,T\right]\\ {}\frac{\partial \rho {Y}_k}{\partial t}+\nabla .\left(\rho u\hskip0.35em \otimes \hskip0.35em {Y}_k\right)={\dot{\omega}}_k+\rho {D}_k{\nabla}^2{Y}_k\hskip23.5em \mathrm{in}\hskip1em \Omega \times \left[0,T\right],\end{array}} $$
where
 $ \tau $
,
$ \tau $
,
 $ {D}_k $
, and
$ {D}_k $
, and
 $ \lambda $
are the strain rate tensor, the diffusion coefficient of species
$ \lambda $
are the strain rate tensor, the diffusion coefficient of species
 $ k $
, and the mixture thermal conductivity. In addition,
$ k $
, and the mixture thermal conductivity. In addition,
 $ {C}_p $
denotes the mixture specific heat capacity.
$ {C}_p $
denotes the mixture specific heat capacity.
 $ {\dot{\omega}}_k $
and
$ {\dot{\omega}}_k $
and
 $ {\dot{\omega}}_T^{\prime } $
are the species reaction rate and heat release rate, respectively. Boundary conditions of each flow state vary depending on the applications and are provided in detail in Section 4.
$ {\dot{\omega}}_T^{\prime } $
are the species reaction rate and heat release rate, respectively. Boundary conditions of each flow state vary depending on the applications and are provided in detail in Section 4.
 $ \Omega \subset {\mathrm{\mathbb{R}}}^2 $
represents the spatial domain.
$ \Omega \subset {\mathrm{\mathbb{R}}}^2 $
represents the spatial domain.
The reaction rate
 $ {\dot{\omega}}_k $
for each species is linked to the progress rate
$ {\dot{\omega}}_k $
for each species is linked to the progress rate
 $ {Q}_1 $
at which the single reaction proceeds, as:
$ {Q}_1 $
at which the single reaction proceeds, as:
 $ {\dot{\omega}}_k={W}_k{\upsilon}_k{Q}_1 $
. The simplifications proposed by Mitani (Reference Mitani1980) and Williams (Reference Williams1985) are used to model the reaction rates
$ {\dot{\omega}}_k={W}_k{\upsilon}_k{Q}_1 $
. The simplifications proposed by Mitani (Reference Mitani1980) and Williams (Reference Williams1985) are used to model the reaction rates
 $ {\dot{\omega}}_k $
for each species. The progress rate
$ {\dot{\omega}}_k $
for each species. The progress rate
 $ {Q}_1 $
is assumed to have the Arrhenius form and is given by,
$ {Q}_1 $
is assumed to have the Arrhenius form and is given by,
 $$ {\displaystyle \begin{array}{c}{Q}_1={B}_1{T}^{\beta_1}{\left(\frac{\rho {Y}_F}{W_F}\right)}^{n_F}{\left(\frac{\rho {Y}_O}{W_O}\right)}^{n_O}\exp \left(-\frac{E_a}{\mathrm{RT}}\right).\\ {}{\dot{\omega}}_F={\upsilon}_F^{\prime }{W}_F{Q}_1;\hskip1em {\dot{\omega}}_O={\upsilon}_O^{\prime }{W}_O{Q}_1,\end{array}} $$
$$ {\displaystyle \begin{array}{c}{Q}_1={B}_1{T}^{\beta_1}{\left(\frac{\rho {Y}_F}{W_F}\right)}^{n_F}{\left(\frac{\rho {Y}_O}{W_O}\right)}^{n_O}\exp \left(-\frac{E_a}{\mathrm{RT}}\right).\\ {}{\dot{\omega}}_F={\upsilon}_F^{\prime }{W}_F{Q}_1;\hskip1em {\dot{\omega}}_O={\upsilon}_O^{\prime }{W}_O{Q}_1,\end{array}} $$
where
 $ {\dot{\omega}}_F $
and
$ {\dot{\omega}}_F $
and
 $ {\dot{\omega}}_O $
are the reaction rates of fuel and oxidizer, respectively.
$ {\dot{\omega}}_O $
are the reaction rates of fuel and oxidizer, respectively.
 $ {\dot{\omega}}_T^{\prime } $
is the heat release due to combustion and is formulated as,
$ {\dot{\omega}}_T^{\prime } $
is the heat release due to combustion and is formulated as,
 $ {\dot{\omega}}_T^{\prime }=-{\sum}_{k=1}^N\Delta {h}_{f,k}^o{\dot{\omega}}_k $
. The formation enthalpy
$ {\dot{\omega}}_T^{\prime }=-{\sum}_{k=1}^N\Delta {h}_{f,k}^o{\dot{\omega}}_k $
. The formation enthalpy
 $ {h}_{f,k}^o $
is the enthalpy needed to form 1 kg of species
$ {h}_{f,k}^o $
is the enthalpy needed to form 1 kg of species
 $ k $
at the reference temperature
$ k $
at the reference temperature
 $ {T}_0=298.15\mathrm{K} $
. The formulation for
$ {T}_0=298.15\mathrm{K} $
. The formulation for
 $ {\dot{\omega}}_T^{\prime } $
can be further simplified as,
$ {\dot{\omega}}_T^{\prime } $
can be further simplified as,
 $$ {\dot{\omega}}_T^{\prime }=-\sum \limits_{k=1}^N\Delta {h}_{f,k}^o{W}_k{\upsilon}_k{Q}_1=-\sum \limits_{k=1}^N\Delta {h}_{f,k}^o\frac{W_k{\upsilon}_k}{W_F{\upsilon}_F}{W}_F{\upsilon}_F{Q}_1=-\sum \limits_{k=1}^N\Delta {h}_{f,k}^o\frac{W_k{\upsilon}_k}{W_F{\upsilon}_F}{\dot{\omega}}_F=-Q{\dot{\omega}}_F. $$
$$ {\dot{\omega}}_T^{\prime }=-\sum \limits_{k=1}^N\Delta {h}_{f,k}^o{W}_k{\upsilon}_k{Q}_1=-\sum \limits_{k=1}^N\Delta {h}_{f,k}^o\frac{W_k{\upsilon}_k}{W_F{\upsilon}_F}{W}_F{\upsilon}_F{Q}_1=-\sum \limits_{k=1}^N\Delta {h}_{f,k}^o\frac{W_k{\upsilon}_k}{W_F{\upsilon}_F}{\dot{\omega}}_F=-Q{\dot{\omega}}_F. $$
Therefore, the heat release source term
 $ {\dot{\omega}}_T^{\prime } $
and the fuel source term
$ {\dot{\omega}}_T^{\prime } $
and the fuel source term
 $ {\dot{\omega}}_F $
are linked by the
$ {\dot{\omega}}_F $
are linked by the
 $ Q $
, which is the heat of reaction per unit mass. Following Poinsot and Veynante (Reference Poinsot and Veynante2005), parameters corresponding to a real-world methane-air flame are chosen as:
$ Q $
, which is the heat of reaction per unit mass. Following Poinsot and Veynante (Reference Poinsot and Veynante2005), parameters corresponding to a real-world methane-air flame are chosen as:
 $ {B}_1={1.0810}^7\mathrm{uSI};\hskip1em {\beta}_1=0; $
$ {B}_1={1.0810}^7\mathrm{uSI};\hskip1em {\beta}_1=0; $
 $ \hskip1em {E}_a=83600\hskip0.35em \mathrm{J}/\mathrm{m}\mathrm{o}\mathrm{l}\mathrm{e}; $
$ \hskip1em {E}_a=83600\hskip0.35em \mathrm{J}/\mathrm{m}\mathrm{o}\mathrm{l}\mathrm{e}; $
 $ {n}_F=1;\hskip1em {n}_O=0.5; $
$ {n}_F=1;\hskip1em {n}_O=0.5; $
 $ \hskip1em Q=50100\hskip0.35em \mathrm{k}\mathrm{J}/\mathrm{k}\mathrm{g};\hskip1em {C}_p=1450\hskip0.35em \mathrm{J}/(\mathrm{k}\mathrm{g}\mathrm{K}) $
. Taken together, the system of equations above is a challenging scenario even for classical solvers, and due to its practical relevance likewise a highly interesting environment for deep learning methods.
$ \hskip1em Q=50100\hskip0.35em \mathrm{k}\mathrm{J}/\mathrm{k}\mathrm{g};\hskip1em {C}_p=1450\hskip0.35em \mathrm{J}/(\mathrm{k}\mathrm{g}\mathrm{K}) $
. Taken together, the system of equations above is a challenging scenario even for classical solvers, and due to its practical relevance likewise a highly interesting environment for deep learning methods.
3.2. Problem formulation
The incomplete PDE solver solves the set of equation (5) without the source terms and reaction rates
 $ {\dot{\omega}}_k $
and
$ {\dot{\omega}}_k $
and
 $ {\dot{\omega}}_T^{\prime } $
, while the complete PDE solver solves the full set of equation (5). The neural network model, denoted by
$ {\dot{\omega}}_T^{\prime } $
, while the complete PDE solver solves the full set of equation (5). The neural network model, denoted by
 $ C\left({\mathcal{P}}_i\left(\phi \right)|\theta \right) $
, corrects the incomplete/nonreacting flow states
$ C\left({\mathcal{P}}_i\left(\phi \right)|\theta \right) $
, corrects the incomplete/nonreacting flow states
 $ {\mathcal{P}}_i\left(\phi \right) $
to obtain the complete/reacting states
$ {\mathcal{P}}_i\left(\phi \right) $
to obtain the complete/reacting states
 $ {\mathcal{P}}_c\left(\phi \right) $
as shown in Figure 2B2. The neural network is trained to model the effects of the unknown chemistry using parameters
$ {\mathcal{P}}_c\left(\phi \right) $
as shown in Figure 2B2. The neural network is trained to model the effects of the unknown chemistry using parameters
 $ \theta $
given an input flow state,
$ \theta $
given an input flow state,
 $ \phi =\left[{u}_i,p,T,{Y}_f,{Y}_o\right] $
. As seen from equations (5)–(7), the temperature and species mass fraction fields are strongly coupled, which significantly increases the prediction problem complexity. A slight error in one of the fields will quickly propagate into the other fields, making the predictions diverge. In the following, a subscript
$ \phi =\left[{u}_i,p,T,{Y}_f,{Y}_o\right] $
. As seen from equations (5)–(7), the temperature and species mass fraction fields are strongly coupled, which significantly increases the prediction problem complexity. A slight error in one of the fields will quickly propagate into the other fields, making the predictions diverge. In the following, a subscript
 $ {C}_s\left(\circ \right) $
will denote that the neural network
$ {C}_s\left(\circ \right) $
will denote that the neural network
 $ C $
generates the field
$ C $
generates the field
 $ s $
, for example,
$ s $
, for example,
 $ {C}_T $
generating the temperature field. The update can be written as,
$ {C}_T $
generating the temperature field. The update can be written as,
 $ {\tilde{\phi}}_{t+1}=\left[{u}_{i,t+1},{p}_{t+1},{C}_T\left({\mathcal{P}}_i\left({\tilde{\phi}}_t\right)|\theta \right),{C}_{Y_f}\left({\mathcal{P}}_i\left({\tilde{\phi}}_t\right)|\theta \right),{C}_{Y_o}\left({\mathcal{P}}_i\left({\tilde{\phi}}_t\right)|\theta \right)\right] $
where
$ {\tilde{\phi}}_{t+1}=\left[{u}_{i,t+1},{p}_{t+1},{C}_T\left({\mathcal{P}}_i\left({\tilde{\phi}}_t\right)|\theta \right),{C}_{Y_f}\left({\mathcal{P}}_i\left({\tilde{\phi}}_t\right)|\theta \right),{C}_{Y_o}\left({\mathcal{P}}_i\left({\tilde{\phi}}_t\right)|\theta \right)\right] $
where
 $ \tilde{\cdot} $
indicates a corrected state.
$ \tilde{\cdot} $
indicates a corrected state.
 $ {u}_{i,t+1} $
and
$ {u}_{i,t+1} $
and
 $ {p}_{t+1} $
are the time-advanced velocity and pressure field, respectively, predicted using the incomplete PDE solver.
$ {p}_{t+1} $
are the time-advanced velocity and pressure field, respectively, predicted using the incomplete PDE solver.
3.3. Training methodology
3.3.1. Hybrid NN-PDE approach
We employ a hybrid NN-PDE approach that augments a neural network model with a PDE solver (Um et al., Reference Um, Brand, Yun, Holl and Thuerey2020; Kochkov et al., Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021). In contrast to previous work, we use the incomplete PDE solver as a basis, and hence the solver does not converge to the desired solutions under refinement, as explained in Section 1. The neural network is integrated and trained in a loop with the incomplete PDE solver using stochastic gradient descent for
 $ m $
time steps, as shown in Figure 2A, B2. Here, the number of temporal look-ahead steps,
$ m $
time steps, as shown in Figure 2A, B2. Here, the number of temporal look-ahead steps,
 $ m $
, is an important hyper-parameter of the training process. Higher
$ m $
, is an important hyper-parameter of the training process. Higher
 $ m $
provides the network with longer-term feedback at training time through the gradient roll-outs. This gives the model improved feedback on how the time dynamics of the incomplete PDE solver affect the input states, and hence which corrections need to be inferred by the model. In our framework, if an incomplete PDE solver is very close to the complete PDE solver for the given data, the NN model would learn a correction which is closer to an identity. The skip connections in the used convolutional neural network architectures (Figure 3) would readily enable such an identity operation. In contrast, when the incomplete solver contributes very little, the proposed approach would start to represent a PDD approach.
$ m $
provides the network with longer-term feedback at training time through the gradient roll-outs. This gives the model improved feedback on how the time dynamics of the incomplete PDE solver affect the input states, and hence which corrections need to be inferred by the model. In our framework, if an incomplete PDE solver is very close to the complete PDE solver for the given data, the NN model would learn a correction which is closer to an identity. The skip connections in the used convolutional neural network architectures (Figure 3) would readily enable such an identity operation. In contrast, when the incomplete solver contributes very little, the proposed approach would start to represent a PDD approach.
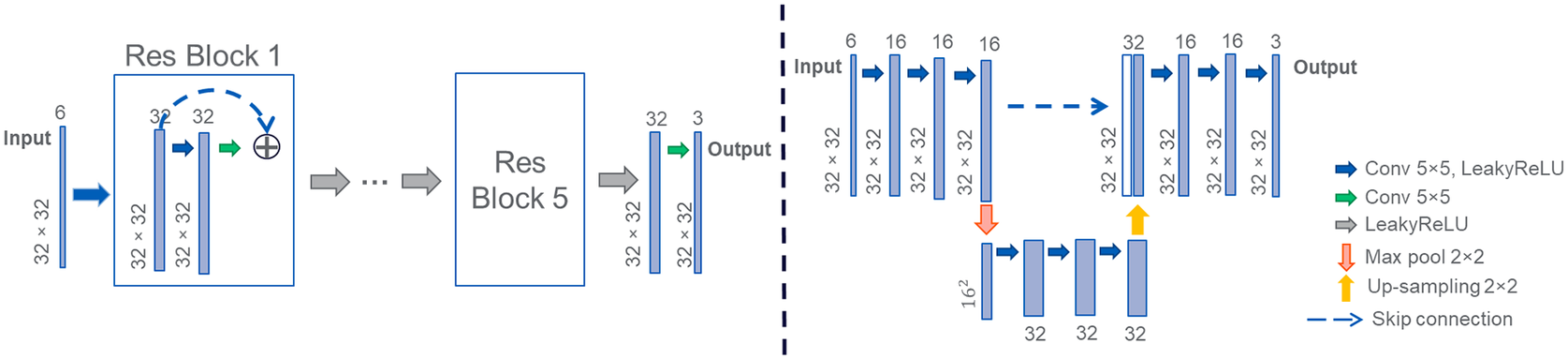
Figure 3. Schematic of the convolutional neural networks used. Left: ResNet with 5 ResBlocks, Right: UNet32 with 2 layers.
3.3.2. Differentiable PDE solver
A central component of the hybrid NN-PDE model is the differentiable solver, which allows us to embed the solver for the incomplete PDE system in the training of a neural network. The differentiable solver acts as additional nontrainable layers in the network. They provide derivatives of the outputs of the simulation with respect to its inputs and parameters. Finite differences can be used to compute the gradients of the PDE solver, but they are computationally very expensive for high-dimensional PDEs. Differentiable solvers resolve this issue by solving the adjoint problem (Pontryagin, Reference Pontryagin1987) via analytic derivatives. Here, we use the differentiable PDE solver from the phiflow framework of Thuerey et al. (Reference Thuerey, Holl, Mueller, Schnell, Trost and Um2021) in combination with Tensorflow to obtain the nonreactive flow solver and reactive flow solver solutions. The marker-and-cell method (Harlow and Welch, Reference Harlow and Welch1965) is adopted to represent temperature, pressure, density, species mass fraction fields in a centered grid, and velocities in a staggered grid. Basic differential operators such as gradient, divergence, curl, and Laplace operators are implemented in TensorFlow using basic mathematical tensor operations (Holl et al., Reference Holl, Koltun, Um and Thuerey2020). These differential operators act on a 9-point stencil of grid points and the corresponding derivatives are straight-forward to compute. Advection is implemented with a semi-Lagrangian step, while the Poisson problem for the pressure and its gradient is solved implicitly. Efficient derivatives for all these operations are then combined via back-propagation (Werbos, Reference Werbos1990).
3.3.3. PDD approach
A PDD model is used as a baseline. It employs a neural network model to learn the complete flow states
 $ {\mathcal{P}}_c\left(\phi \right) $
given an input flow state
$ {\mathcal{P}}_c\left(\phi \right) $
given an input flow state
 $ {\phi}^S $
where
$ {\phi}^S $
where
 $ {\phi}^S=\left[T,{Y}_f,{Y}_o\right] $
, as shown in Figure 2B1. The new state predicted by the trained neural network model is
$ {\phi}^S=\left[T,{Y}_f,{Y}_o\right] $
, as shown in Figure 2B1. The new state predicted by the trained neural network model is
 $ {\tilde{\phi}}_{t+1}^S=C\left({\tilde{\phi}}_t^S|\theta \right) $
. For the hybrid NN-PDE as well as PDD, the neural network part of the predictor block in Figure 2 consists of a fully convolutional neural network model.
$ {\tilde{\phi}}_{t+1}^S=C\left({\tilde{\phi}}_t^S|\theta \right) $
. For the hybrid NN-PDE as well as PDD, the neural network part of the predictor block in Figure 2 consists of a fully convolutional neural network model.
We additionally compare against the Fourier neural operator (FNO) of Li et al. (Reference Li, Kovachki, Azizzadenesheli, Liu, Bhattacharya, Stuart and Anandkumar2020A) as an example of a state-of-the-art neural operator method. The new state predicted by the trained model is given by
 $ {\tilde{\phi}}_{t+1}^S=C\left({\tilde{\phi}}_t^S|\theta \right) $
where
$ {\tilde{\phi}}_{t+1}^S=C\left({\tilde{\phi}}_t^S|\theta \right) $
where
 $ {\tilde{\phi}}^S=\left[T,{Y}_f,{Y}_o\right] $
and
$ {\tilde{\phi}}^S=\left[T,{Y}_f,{Y}_o\right] $
and
 $ C\left(\circ \right) $
represents the Fourier neural operator.
$ C\left(\circ \right) $
represents the Fourier neural operator.
3.4. Training details
All three approaches use an
 $ {L}_2 $
based loss that is evaluated for
$ {L}_2 $
based loss that is evaluated for
 $ m $
steps as
$ m $
steps as
 $$ \mathrm{\mathcal{L}}\left(\theta \right)=\sum \limits_{n=t+1}^{t+m}\sum \limits_{\phi =\left\{T,{Y}_f,{Y}_o\right\}}{\left\Vert {\tilde{\phi}}_n,{\mathcal{P}}_c\left({\phi}_n\right)\right\Vert}_2. $$
$$ \mathrm{\mathcal{L}}\left(\theta \right)=\sum \limits_{n=t+1}^{t+m}\sum \limits_{\phi =\left\{T,{Y}_f,{Y}_o\right\}}{\left\Vert {\tilde{\phi}}_n,{\mathcal{P}}_c\left({\phi}_n\right)\right\Vert}_2. $$
The network receives the input states as shown in Figure 2. The output of the neural network model is used to obtain the corrected state
 $ {\tilde{\phi}}_{t+1} $
as specified above. We constrain the mass fraction fields
$ {\tilde{\phi}}_{t+1} $
as specified above. We constrain the mass fraction fields
 $ {Y}_k $
to contain physical values in the range
$ {Y}_k $
to contain physical values in the range
 $ {Y}_f\in \left[\mathrm{0,0.05}\right] $
and
$ {Y}_f\in \left[\mathrm{0,0.05}\right] $
and
 $ {Y}_o\in \left[0,1\right] $
. All models are trained for 100 epochs with a batch size of 3 and a learning rate of 0.0001. We have used a small batch size of 3 due to the memory requirements as we unroll the NN-PDE framework over long timesteps. Our training procedure uses the Adam optimizer (Kingma and Ba, Reference Kingma and Ba2015). For all our computations, a Nvidia Quadro RTX 8000 GPU is used. Figure 4 shows the typical training loss curve over 100 epochs.
$ {Y}_o\in \left[0,1\right] $
. All models are trained for 100 epochs with a batch size of 3 and a learning rate of 0.0001. We have used a small batch size of 3 due to the memory requirements as we unroll the NN-PDE framework over long timesteps. Our training procedure uses the Adam optimizer (Kingma and Ba, Reference Kingma and Ba2015). For all our computations, a Nvidia Quadro RTX 8000 GPU is used. Figure 4 shows the typical training loss curve over 100 epochs.

Figure 4. Typical
 $ {L}_2 $
based training loss as defined in equation (8) over 100 epochs. The inset figure shows zoomed-in loss function curve for last 40 epochs.
$ {L}_2 $
based training loss as defined in equation (8) over 100 epochs. The inset figure shows zoomed-in loss function curve for last 40 epochs.
For PDD and the hybrid NN-PDE approach, we experimented with both the ResNet (He et al., Reference He, Zhang, Ren and Sun2016) and the UNet (Ronneberger et al., Reference Ronneberger, Fischer and Brox2015) architectures. Figure 3 shows the schematic of the neural network models used. We found that the ResNet performed the best for the PDD setting, while for the hybrid NN-PDE approach, the UNet performed consistently better. Hence, the following results will use a ResNet for PDD models, and a UNet for the NN-PDE hybrids. Additional details of the neural network architectures are provided in Section A.1 of the Supplementary Material as well as results comparing the UNet and ResNet architectures.
4. Numerical experiments
We consider a case of planar 2D premixed methane-air flame propagating in a quiescent mixture (Planar-v0 ) and two cases of the transient evolution of an initially planar laminar premixed flame into a Bunsen-type flame under different inlet velocity conditions (uniform-Bunsen, nonUniform-Bunsen ). We obtain the target data by considering the source terms as defined by equations (6) and (7) with the parameters mentioned in Section 3.1.
4.1. Planar-v0
For the most basic case, the planar 2D flame model setup, we consider the reacting Navier–Stokes equations described in Section 3.1 with zero inlet velocity, that is,
 $ {u}_x=0 $
,
$ {u}_x=0 $
,
 $ {u}_y=0 $
. We consider a square domain of size 0.05 m
$ {u}_y=0 $
. We consider a square domain of size 0.05 m
 $ \times $
0.05 m with 32
$ \times $
0.05 m with 32
 $ \times $
32 resolution and closed boundary conditions, as shown in Figure 5. The simulation is initialized using a steep transition between a premixed methane-air mixture and burnt gases. Our training data consists of six simulations of 300 steps created by varying the equivalence ratio
$ \times $
32 resolution and closed boundary conditions, as shown in Figure 5. The simulation is initialized using a steep transition between a premixed methane-air mixture and burnt gases. Our training data consists of six simulations of 300 steps created by varying the equivalence ratio
 $ E $
. It represents the stoichiometric mixture (
$ E $
. It represents the stoichiometric mixture (
 $ \varphi $
) of fuel
$ \varphi $
) of fuel
 $ {Y}_f $
and oxidizer
$ {Y}_f $
and oxidizer
 $ {Y}_o $
mass fractions, that is,
$ {Y}_o $
mass fractions, that is,
 $ E=\varphi \frac{Y_f}{Y_o} $
and thus fundamentally influences the dynamics of the chemical reaction. For the training data we use
$ E=\varphi \frac{Y_f}{Y_o} $
and thus fundamentally influences the dynamics of the chemical reaction. For the training data we use
 $ {E}_{\mathrm{train}}=\left\{\mathrm{1.0,0.9,0.8,0.7,0.6}\right\} $
, while the test dataset contains
$ {E}_{\mathrm{train}}=\left\{\mathrm{1.0,0.9,0.8,0.7,0.6}\right\} $
, while the test dataset contains
 $ {E}_{\mathrm{test}}=\left\{\mathrm{0.95,0.85,0.75,0.65}\right\} $
.
$ {E}_{\mathrm{test}}=\left\{\mathrm{0.95,0.85,0.75,0.65}\right\} $
.

Figure 5. Details of the boundary condition for—left: Planar flame; right: a Bunsen-type flame. n represents resolution of the domain.
4.2. uniform-Bunsen
In contrast to the planar case, the premixed methane-air mixture is now fed with a constant inlet velocity. The boundary conditions upstream, at
 $ y=0 $
, are
$ y=0 $
, are
 $ {\left({u}_x,{u}_y\right)}_{x,y=0}=\left(0,\kappa \right) $
where
$ {\left({u}_x,{u}_y\right)}_{x,y=0}=\left(0,\kappa \right) $
where
 $ \kappa $
is a
$ \kappa $
is a
 $ n $
-dimensional vector with constant amplitude. The target simulation contains a heat release rate term, and in this case, the initial temperature field evolves into different
$ n $
-dimensional vector with constant amplitude. The target simulation contains a heat release rate term, and in this case, the initial temperature field evolves into different
 $ \Lambda $
-shaped flames at the end of the 300th time step. Training and testing datasets are created by varying the equivalence ratio and inlet velocity amplitude
$ \Lambda $
-shaped flames at the end of the 300th time step. Training and testing datasets are created by varying the equivalence ratio and inlet velocity amplitude
 $ U $
:
$ U $
:
 $ {E}_{\mathrm{train}}=\left\{\mathrm{1.0,0.9,0.8}\right\} $
and
$ {E}_{\mathrm{train}}=\left\{\mathrm{1.0,0.9,0.8}\right\} $
and
 $ {U}_{\mathrm{train}}=\left\{\mathrm{0.45,0.4,0.3}\right\} $
. The test dataset uses
$ {U}_{\mathrm{train}}=\left\{\mathrm{0.45,0.4,0.3}\right\} $
. The test dataset uses
 $ {E}_{\mathrm{test}}=\left\{\mathrm{0.95,0.85}\right\} $
$ {E}_{\mathrm{test}}=\left\{\mathrm{0.95,0.85}\right\} $
 $ {U}_{\mathrm{test}}=\left\{\mathrm{0.43,0.375,0.325}\right\} $
. The length and temperature of the flame significantly vary depending on the inlet velocity and equivalence ratio provided. Figure 6A shows the temperature field evolution of the incomplete PDE solver at different time instances for 3 different operating conditions for the uniform-Bunsen case. Figure 6B shows the corresponding target training data for the uniform-Bunsen case. All the simulations are run for 300 steps. It shows the difference between nonreactive and reactive flow solver simulations for different operating conditions over 300 time-steps. Figure 6C shows the last snapshot (
$ {U}_{\mathrm{test}}=\left\{\mathrm{0.43,0.375,0.325}\right\} $
. The length and temperature of the flame significantly vary depending on the inlet velocity and equivalence ratio provided. Figure 6A shows the temperature field evolution of the incomplete PDE solver at different time instances for 3 different operating conditions for the uniform-Bunsen case. Figure 6B shows the corresponding target training data for the uniform-Bunsen case. All the simulations are run for 300 steps. It shows the difference between nonreactive and reactive flow solver simulations for different operating conditions over 300 time-steps. Figure 6C shows the last snapshot (
 $ t=300 $
) of nine training simulations and six testing datasets with operating parameters interpolated between the training data parameters for uniform-Bunsen case. These datasets are obtained by varying the equivalence ratio and the magnitude of the uniform inlet velocity. The flame temperature depends on the equivalence ratio used and the flame height depends on the inlet velocity amplitude and equivalence ratio.
$ t=300 $
) of nine training simulations and six testing datasets with operating parameters interpolated between the training data parameters for uniform-Bunsen case. These datasets are obtained by varying the equivalence ratio and the magnitude of the uniform inlet velocity. The flame temperature depends on the equivalence ratio used and the flame height depends on the inlet velocity amplitude and equivalence ratio.
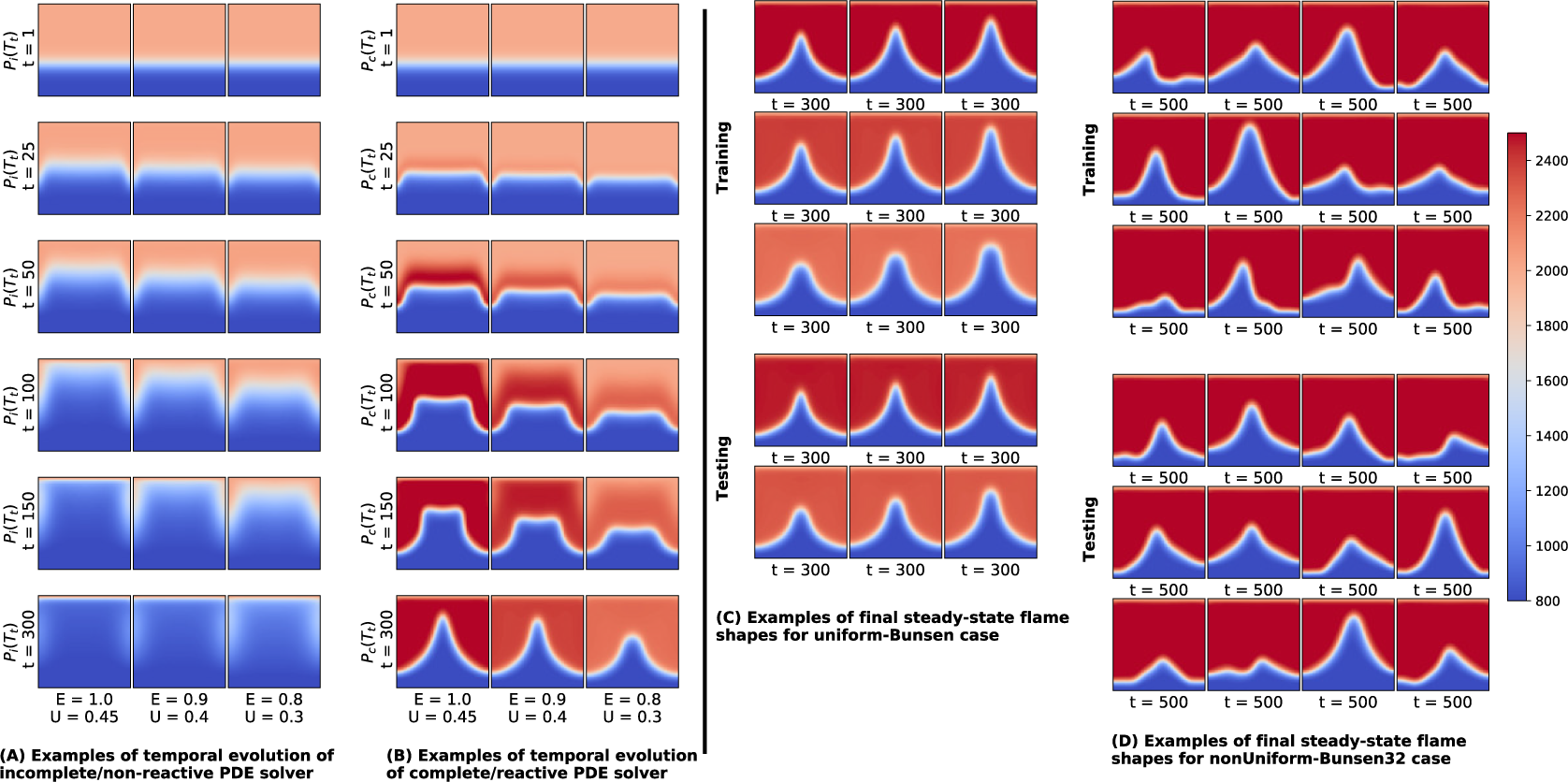
Figure 6. Instances of temporal evolution of (A) incomplete PDE solver; (B) complete PDE solver for different operating conditions. (C) Snapshot of complete PDE solver at
 $ t=300 $
for all training and testing datasets of the uniform-Bunsen case. (D) Snapshot of complete PDE solver at
$ t=300 $
for all training and testing datasets of the uniform-Bunsen case. (D) Snapshot of complete PDE solver at
 $ t=500 $
for all training and testing datasets of the nonUniform-Bunsen32 case.
$ t=500 $
for all training and testing datasets of the nonUniform-Bunsen32 case.
4.3. nonUniform-Bunsen
As a third case, we consider the transient evolution of a premixed methane-air flame with nonuniform inlet velocity. The boundary conditions upstream, at y = 0, are
 $ {\left({u}_x,{u}_y\right)}_{x,y=0}=\left(0,\kappa \right) $
where
$ {\left({u}_x,{u}_y\right)}_{x,y=0}=\left(0,\kappa \right) $
where
 $ \kappa $
is a
$ \kappa $
is a
 $ n $
-dimensional vector whose elements are each sampled from a uniform distribution from [0.2, 0.65]. We experiment with two different domain sizes, 32
$ n $
-dimensional vector whose elements are each sampled from a uniform distribution from [0.2, 0.65]. We experiment with two different domain sizes, 32
 $ \times $
32 (nonUniform-Bunsen32
) and 100
$ \times $
32 (nonUniform-Bunsen32
) and 100
 $ \times $
100 (nonUniform-Bunsen100
). The larger domain size used is closer to the practical reactive flow domain utilized in CFD applications (Jaensch et al., Reference Jaensch, Merk, Gopalakrishnan, Bomberg, Emmert, Sujith and Polifke2017) with a highly resolved flame. These inlet velocity conditions generate complex flame shapes, which increase the difficulty of the prediction problem. We consider simulation sequences with 500 steps, as it takes longer time for the flame to reach the steady-state solution. Figure 6D showcases the snapshots of training and testing dataset at
$ \times $
100 (nonUniform-Bunsen100
). The larger domain size used is closer to the practical reactive flow domain utilized in CFD applications (Jaensch et al., Reference Jaensch, Merk, Gopalakrishnan, Bomberg, Emmert, Sujith and Polifke2017) with a highly resolved flame. These inlet velocity conditions generate complex flame shapes, which increase the difficulty of the prediction problem. We consider simulation sequences with 500 steps, as it takes longer time for the flame to reach the steady-state solution. Figure 6D showcases the snapshots of training and testing dataset at
 $ t=500 $
for nonUniform-Bunsen32 case. Nonuniform variations in inlet velocity profile leads to different complex flame shapes. We use 12 datasets with 500 simulation steps to train the models and test it on 12 test cases shown in Figure 6D. For the nonUniform-Bunsen32 case with 32 unrolling steps (
$ t=500 $
for nonUniform-Bunsen32 case. Nonuniform variations in inlet velocity profile leads to different complex flame shapes. We use 12 datasets with 500 simulation steps to train the models and test it on 12 test cases shown in Figure 6D. For the nonUniform-Bunsen32 case with 32 unrolling steps (
 $ m=32 $
), training requires approximately 60 hours with approximately 1 GB of GPU memory.
$ m=32 $
), training requires approximately 60 hours with approximately 1 GB of GPU memory.
To generate input and target data for training, we simulate the temperature
 $ T $
, mass fractions
$ T $
, mass fractions
 $ {Y}_f $
,
$ {Y}_f $
,
 $ {Y}_o $
and velocity
$ {Y}_o $
and velocity
 $ {u}_x,{u}_y $
fields of all flames under study. Table 1 summarizes the boundary conditions applied for the planar and Bunsen-type flame cases discussed above. No-slip boundary conditions are used for the velocity field
$ {u}_x,{u}_y $
fields of all flames under study. Table 1 summarizes the boundary conditions applied for the planar and Bunsen-type flame cases discussed above. No-slip boundary conditions are used for the velocity field
 $ {u}_y $
to obtain the
$ {u}_y $
to obtain the
 $ \Lambda $
-shaped flames.
$ \Lambda $
-shaped flames.
Table 1. Details of the boundary conditions used for the planar flame case and various cases of Bunsen-type flames.

Note. The uniform-Bunsen case is obtained with
 $ \kappa $
= constant and nonUniform-Bunsen case is obtained with
$ \kappa $
= constant and nonUniform-Bunsen case is obtained with
 $ \kappa \in {\mathrm{\mathbb{R}}}^n $
as discussed in Section 4.
$ \kappa \in {\mathrm{\mathbb{R}}}^n $
as discussed in Section 4.
The training and test datasets are split using different initial conditions. This ensures that varied (training) and unseen (test) data are provided. For example, in the case of Planar-v0 scenario, the training data consists of five simulations of planar flame with different equivalence ratios, evolving over 300 simulation steps. During test time, only the initial state of the flow field (
 $ {\phi}_0 $
) and unseen boundary conditions (i.e., other equivalence ratios than those in the training datasets) are specified and the trained hybrid NN-PDE model is used to make predictions over 300 time steps. A similar setup is used for the baseline approaches. Multi-step training framework shown in Figure 2 demonstrates the training setup for the baseline and hybrid NN-PDE approaches. Continuous time-slices are used during training. As shown in Figure 2A, during training, the Predictor Block is unrolled for
$ {\phi}_0 $
) and unseen boundary conditions (i.e., other equivalence ratios than those in the training datasets) are specified and the trained hybrid NN-PDE model is used to make predictions over 300 time steps. A similar setup is used for the baseline approaches. Multi-step training framework shown in Figure 2 demonstrates the training setup for the baseline and hybrid NN-PDE approaches. Continuous time-slices are used during training. As shown in Figure 2A, during training, the Predictor Block is unrolled for
 $ m $
steps, that is, the network is trained using multiple “sequences” of
$ m $
steps, that is, the network is trained using multiple “sequences” of
 $ m $
consecutive snapshots (selected from the cases in the training datasets). During testing, only
$ m $
consecutive snapshots (selected from the cases in the training datasets). During testing, only
 $ {\phi}_0 $
(the initial flow state) along with unseen boundary conditions are provided and the trained predictor block is evaluated 300 times to obtain predictions from
$ {\phi}_0 $
(the initial flow state) along with unseen boundary conditions are provided and the trained predictor block is evaluated 300 times to obtain predictions from
 $ t=1,2\dots, 300 $
.
$ t=1,2\dots, 300 $
.
5. Results
We demonstrate the capabilities of the proposed learning approach to represent the complete PDE description with the aforementioned cases of increasing difficulty. We also study its ability to generalize to unseen operating conditions such as equivalence ratios, simultaneous variations in constant inlet velocity and equivalence ratio, and nonuniform inlet velocity profiles. As baselines, we compare against a PDD approach; a neural network model with exactly the same look-ahead steps, and the Fourier neural operator of Li et al. (Reference Li, Kovachki, Azizzadenesheli, Liu, Bhattacharya, Stuart and Anandkumar2020A) that likewise includes
 $ m $
look-ahead steps as discussed in Section 3.3. All the qualitative and quantitative evaluations shown in the article are performed on test datasets with unseen initial conditions.
$ m $
look-ahead steps as discussed in Section 3.3. All the qualitative and quantitative evaluations shown in the article are performed on test datasets with unseen initial conditions.
5.1. Planar-v0
Table 2 compares the mean absolute percentage errors (MAPE) and mean squared errors (MSE) of temperature field for all the cases discussed in Section 4. For Planar-v0, the FNO and PDD approaches yield large errors with a MAPE of 8.27% and 6.33%, respectively. On the other hand, the hybrid NN-PDE model trained with 32 look-ahead steps reduces the error to 1.4% and thus performs significantly better than the two baselines. This behavior is visualized in Figure 7 with a 1D transverse cut of the simulation domain over 300 time-steps. The hybrid NN-PDE approach successfully captures the propagation of the flame.
Table 2. Mean and standard deviation of errors over all time steps of all testsets.

Note. The Hybrid NN-PDE approach outperforms all other baselines considered.

Figure 7. 1D cut of the planar flame simulation over 300 steps. The initial state is plotted in red, target state in green. Hybrid NN-PDE approach predicts physically accurate results over longer rollouts.
In Figure 8, we also compare two important physical quantities: the flame temperature and relative displacement of the flame front, across different equivalence ratios. It can be seen that the hybrid NN-PDE model (green circles) accurately predicts the flame temperature for different test cases (solid green line). The relative displacement of the flame front is computed as
 $ \mid {\tilde{x}}_t-{\tilde{x}}_0\mid /\mid {x}_t-{x}_0\mid $
, where
$ \mid {\tilde{x}}_t-{\tilde{x}}_0\mid /\mid {x}_t-{x}_0\mid $
, where
 $ {x}_t $
is the position along the flame normal at time
$ {x}_t $
is the position along the flame normal at time
 $ t $
on the
$ t $
on the
 $ 1,200\mathrm{K} $
isotherm of the ground truth simulation, and
$ 1,200\mathrm{K} $
isotherm of the ground truth simulation, and
 $ \tilde{x} $
denotes the predicted position. For all test cases, the hybrid approach accurately predicts the flame displacement over
$ \tilde{x} $
denotes the predicted position. For all test cases, the hybrid approach accurately predicts the flame displacement over
 $ t $
= 300 steps, while the other approaches yield significant errors. Figure 9A shows the 2D visualization of the temperature field predictions for Planar-v0 case. As seen from the ground truth images, methane-air mixture (black color) converts into the burned products (yellow color) due to the chemical reaction at the flat flame surface (red color). The dotted, horizontal red line helps to compare the transition of the flame interface, that is, the displacement of the flame front. Due to the chemical reaction, fuel-air mixture is consumed and turns into burned product as the simulation progresses. The FNO approach completely fails to predict the propagation of the flame for the given test case. Its output does not show any evolution from the initial temperature profile for the given operating condition. The PDD approach fails to capture the flame front displacement correctly, thus leading to an inaccurate prediction with large errors. The hybrid NN-PDE model accurately captures this evolution of planar methane-air flame in a quiescent mixture. Figure 9B shows the instantaneous MAPE w.r.t. ground truth data for predictions shown in Figure 9A. The absolute error shown in Figure 9B exceeds 1,100 K for the FNO and PDD approaches as these do not predict the flame temperature and flame front displacement correctly. We use the upper limit of 1,100 K for colorbar to highlight the errors in the hybrid NN-PDE approach more clearly. Large errors in FNO and PDD results stem from their inability to reliably predict the flame temperature and flame front displacement.
$ t $
= 300 steps, while the other approaches yield significant errors. Figure 9A shows the 2D visualization of the temperature field predictions for Planar-v0 case. As seen from the ground truth images, methane-air mixture (black color) converts into the burned products (yellow color) due to the chemical reaction at the flat flame surface (red color). The dotted, horizontal red line helps to compare the transition of the flame interface, that is, the displacement of the flame front. Due to the chemical reaction, fuel-air mixture is consumed and turns into burned product as the simulation progresses. The FNO approach completely fails to predict the propagation of the flame for the given test case. Its output does not show any evolution from the initial temperature profile for the given operating condition. The PDD approach fails to capture the flame front displacement correctly, thus leading to an inaccurate prediction with large errors. The hybrid NN-PDE model accurately captures this evolution of planar methane-air flame in a quiescent mixture. Figure 9B shows the instantaneous MAPE w.r.t. ground truth data for predictions shown in Figure 9A. The absolute error shown in Figure 9B exceeds 1,100 K for the FNO and PDD approaches as these do not predict the flame temperature and flame front displacement correctly. We use the upper limit of 1,100 K for colorbar to highlight the errors in the hybrid NN-PDE approach more clearly. Large errors in FNO and PDD results stem from their inability to reliably predict the flame temperature and flame front displacement.
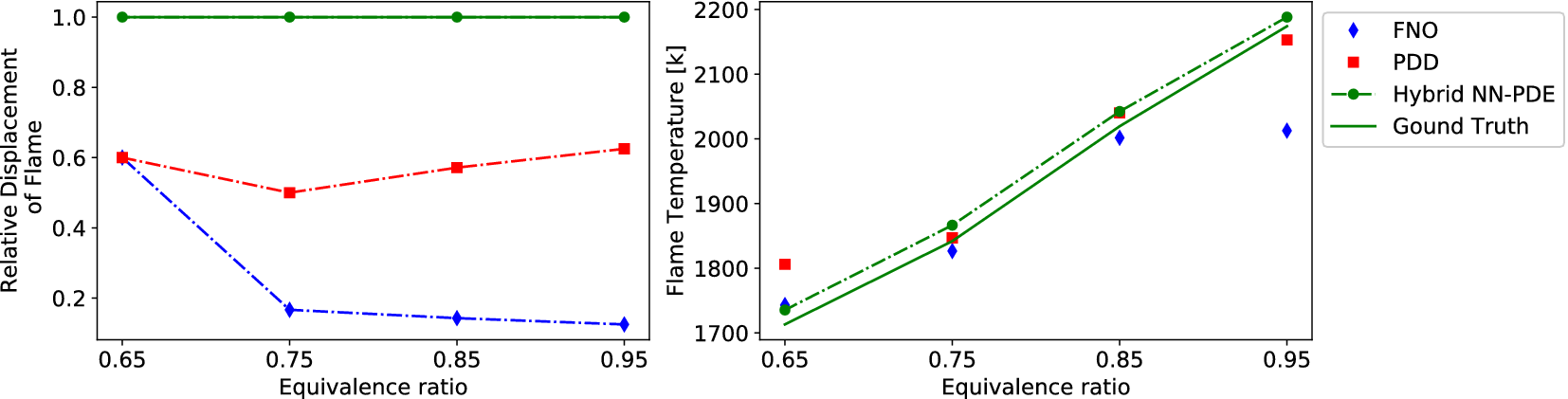
Figure 8. Hybrid NN-PDE approach predicts physically accurate results with correct flame temperature and relative displacement of flame front across different equivalence ratios.

Figure 9. Planar-v0 flame case with
 $ E $
= 0.95. (A) Temperature field predictions; (B) Absolute error between ground truth (
$ E $
= 0.95. (A) Temperature field predictions; (B) Absolute error between ground truth (
 $ {\mathcal{P}}_c\left({T}_t\right) $
) and the output predicted—from top to bottom top—by: FNO, purely data-driven approach and hybrid NN-PDE. The numbers represent instantaneous MAPE.
$ {\mathcal{P}}_c\left({T}_t\right) $
) and the output predicted—from top to bottom top—by: FNO, purely data-driven approach and hybrid NN-PDE. The numbers represent instantaneous MAPE.
5.2. Bunsen-type flame
For the uniform-Bunsen case, the PDD baseline with an error of 7.58% performs better than the FNO model which yields an error of 15.57%. However, a neural network model combined with an incomplete PDE solver for 32 look-ahead steps yields a significantly lower error of 0.72% as shown in Table 2. This means that the hybrid approach reduces the errors by a factor of 10 over the baselines considered. Figure 10A shows the temporal evolution of the hybrid NN-PDE approach predicted over 300 time steps for the uniform-Bunsen case. It shows the results for a test case with
 $ U=0.4375 $
and
$ U=0.4375 $
and
 $ E=0.95 $
. It predicts a symmetric flame with accurate flame height and achieves very low instantaneous MAPE of 0.73% at
$ E=0.95 $
. It predicts a symmetric flame with accurate flame height and achieves very low instantaneous MAPE of 0.73% at
 $ t $
=300, when compared with the ground truth data.
$ t $
=300, when compared with the ground truth data.

Figure 10. Left: Inlet velocity profile used. (a–d) Temperature field prediction by hybrid NN-PDE approach over different steps given the inlet velocity profile. (e) Ground truth data. Right: Difference between ground truth data and hybrid NN-PDE output at last snapshot. Top to bottom: 32
 $ \times $
32 resolution cases of (A) uniform-Bunsen, (B) nonUniform-Bunsen32, and (C) 100
$ \times $
32 resolution cases of (A) uniform-Bunsen, (B) nonUniform-Bunsen32, and (C) 100
 $ \times $
100 testcase nonUniform-Bunsen100.
$ \times $
100 testcase nonUniform-Bunsen100.
 $ \varepsilon $
represents the instantaneous MAPE.
$ \varepsilon $
represents the instantaneous MAPE.
Next, we study a complex scenario of nonUniform-Bunsen flame with 32
 $ \times $
32 resolution. The hybrid NN-PDE approach outperforms the PDD approach and FNO with an improvement of
$ \times $
32 resolution. The hybrid NN-PDE approach outperforms the PDD approach and FNO with an improvement of
 $ \sim 80\% $
. We also include variant of the PDD approach (PDD-5) which is trained to predict all quantities (
$ \sim 80\% $
. We also include variant of the PDD approach (PDD-5) which is trained to predict all quantities (
 $ {\phi}^S=\left[T,{Y}_f,{Y}_o,u,p\right] $
) of the flow state (details in Section A.2 of the Supplementary Material). The hybrid NN-PDE model achieves a low MAPE of 2.04% compared to the higher errors of 23.45% and 12.48% predicted by the PDD-5 and the PDD approach, respectively. The MSE values show this trend even more clearly. The large standard deviations of the MSE numbers indicate that the predictions made by the baseline approaches contain substantial deviations from the target values. It is important to highlight that despite using the same training data and a similar neural network architecture with same number of look-ahead steps, the hybrid approach outperforms the PDD approach due to its learned collaboration with the incomplete PDE solver. It accurately reproduces the complete PDE behavior. Figure 10B highlights this with a visualization of the hybrid NN-PDE model predictions for nonUniform-Bunsen32 case. The trained model accurately predicts the flame simulation over long roll-outs of 500 steps and achieves the complex flame shape with a low, instantaneous MAPE of 2.38%.
$ {\phi}^S=\left[T,{Y}_f,{Y}_o,u,p\right] $
) of the flow state (details in Section A.2 of the Supplementary Material). The hybrid NN-PDE model achieves a low MAPE of 2.04% compared to the higher errors of 23.45% and 12.48% predicted by the PDD-5 and the PDD approach, respectively. The MSE values show this trend even more clearly. The large standard deviations of the MSE numbers indicate that the predictions made by the baseline approaches contain substantial deviations from the target values. It is important to highlight that despite using the same training data and a similar neural network architecture with same number of look-ahead steps, the hybrid approach outperforms the PDD approach due to its learned collaboration with the incomplete PDE solver. It accurately reproduces the complete PDE behavior. Figure 10B highlights this with a visualization of the hybrid NN-PDE model predictions for nonUniform-Bunsen32 case. The trained model accurately predicts the flame simulation over long roll-outs of 500 steps and achieves the complex flame shape with a low, instantaneous MAPE of 2.38%.
Finally, we showcase the ability of the hybrid approach to predict the temporal evolution of highly resolved flames with the nonUniform-Bunsen100 scenario. Despite the increased complexity of the larger resolution, it achieves a very good overall MAPE of 3.23% over 12 test cases of 500 simulation steps. Figure 10C shows an example of physically accurate predictions made by the hybrid NN-PDE model. We omit the evaluation of baselines for high-resolution cases as they do not succeed to model the flame dynamics for low-resolution cases.
In the following subsections, we present additional visualizations and a detailed comparison of the hybrid NN-PDE model against baseline approaches for different scenarios of Bunsen-type flames.
5.2.1. uniform-Bunsen
Figure 11 shows an example of the uniform-Bunsen case: a test case with
 $ {u}_y=0.375 $
and
$ {u}_y=0.375 $
and
 $ E=0.95 $
. The constant inlet velocity results in a symmetric,
$ E=0.95 $
. The constant inlet velocity results in a symmetric,
 $ \Lambda $
-shaped flame. Vertical, dotted, red line in Figure 11A helps to assess the symmetric nature of the flame. The PDD model predicts a thicker flame (
$ \Lambda $
-shaped flame. Vertical, dotted, red line in Figure 11A helps to assess the symmetric nature of the flame. The PDD model predicts a thicker flame (
 $ t=50 $
) or a flame with a spurious tip (
$ t=50 $
) or a flame with a spurious tip (
 $ t=172 $
) or an asymmetric flame (
$ t=172 $
) or an asymmetric flame (
 $ t=225 $
). Snapshots of the hybrid NN-PDE model predictions in Figure 11A show that it adapts to this scenario very well and succeeds in obtaining the correct results for long-term forecasts of the temperature field. Furthermore, the flame shape and height are also better predicted, as shown in Figure 11A. Very low error levels in Figure 11B, such as
$ t=225 $
). Snapshots of the hybrid NN-PDE model predictions in Figure 11A show that it adapts to this scenario very well and succeeds in obtaining the correct results for long-term forecasts of the temperature field. Furthermore, the flame shape and height are also better predicted, as shown in Figure 11A. Very low error levels in Figure 11B, such as
 $ \unicode{x025B} =1.26 $
at
$ \unicode{x025B} =1.26 $
at
 $ t=300 $
, indicate that the hybrid model recovers the temperature field well.
$ t=300 $
, indicate that the hybrid model recovers the temperature field well.

Figure 11. uniform-Bunsen case with constant inlet velocity
 $ U $
= 0.375 and
$ U $
= 0.375 and
 $ E $
= 0.95. (A) Temperature field predictions; (B) Absolute error between ground truth (
$ E $
= 0.95. (A) Temperature field predictions; (B) Absolute error between ground truth (
 $ {\mathcal{P}}_c\left({T}_t\right) $
) and the output predicted—from top to bottom top—by: FNO, purely data-driven approach and hybrid NN-PDE. Hybrid NN-PDE model predicts physically accurate evolution of the flame cases under study.
$ {\mathcal{P}}_c\left({T}_t\right) $
) and the output predicted—from top to bottom top—by: FNO, purely data-driven approach and hybrid NN-PDE. Hybrid NN-PDE model predicts physically accurate evolution of the flame cases under study.
5.2.2. nonUniform-Bunsen
Figure 12 compares the temporal predictions made by FNO, PDD, and the hybrid NN-PDE model with ground truth data for nonUniform-Bunsen32 case. Compared to Planar-v0 and uniform-Bunsen case, FNO predicts qualitatively better results for this case. Although still highly inaccurate, it predicts shapes that come closer to the target flame shapes for the later part of the simulation (for
 $ t>300 $
). This improvement might be due to the larger training dataset used for this scenario compared to the previous two scenarios. However, it fails to predict accurate temporal predictions over the entire simulation. The hybrid NN-PDE approach predicts the accurate flame evolution well. Additionally, we showcase the performance of the hybrid NN-PDE approach on two different test cases with complex flame shapes in Figure 13. The neural network model along with incomplete PDE solver reconstructs these complex flame shapes in an accurate manner.
$ t>300 $
). This improvement might be due to the larger training dataset used for this scenario compared to the previous two scenarios. However, it fails to predict accurate temporal predictions over the entire simulation. The hybrid NN-PDE approach predicts the accurate flame evolution well. Additionally, we showcase the performance of the hybrid NN-PDE approach on two different test cases with complex flame shapes in Figure 13. The neural network model along with incomplete PDE solver reconstructs these complex flame shapes in an accurate manner.

Figure 12. nonUniform-Bunsen32: Comparison between different approaches—from top to bottom—FNO, PDD, hybrid NN-PDE for a test case. Hybrid approach predictions accurately match with the ground truth data over long-rollouts of 500 time steps.

Figure 13. nonUniform-Bunsen32: Visualization of reactive flow trajectories predicted by the hybrid approach for different test case.
For the nonUniform-Bunsen100 case, Figure 14 compares the predictions made by hybrid NN-PDE over
 $ \left\{\mathrm{0,100,200,250,300,325,350,400,450,500}\right\} $
simulation steps with the ground truth data. It also shows the absolute difference between them. As the simulation progresses, higher errors are observed around the flame front. However, the hybrid NN-PDE approach captures the flame shape very accurately for longer roll-outs of 500 simulation steps. Currently, this approach uses training dataset similar to nonUniform-Bunsen32. Further improvements in accuracy can be achieved by increasing the training dataset size or training the hybrid model with longer look-ahead steps.
$ \left\{\mathrm{0,100,200,250,300,325,350,400,450,500}\right\} $
simulation steps with the ground truth data. It also shows the absolute difference between them. As the simulation progresses, higher errors are observed around the flame front. However, the hybrid NN-PDE approach captures the flame shape very accurately for longer roll-outs of 500 simulation steps. Currently, this approach uses training dataset similar to nonUniform-Bunsen32. Further improvements in accuracy can be achieved by increasing the training dataset size or training the hybrid model with longer look-ahead steps.

Figure 14. nonUniform-Bunsen100: Comparison between ground truth data (
 $ {\mathcal{P}}_c\left({T}_t\right) $
) and hybrid NN-PDE approach predictions (
$ {\mathcal{P}}_c\left({T}_t\right) $
) and hybrid NN-PDE approach predictions (
 $ {\tilde{T}}_t $
) for a different test case of complex, high-resolution scenario.
$ {\tilde{T}}_t $
) for a different test case of complex, high-resolution scenario.
6. Discussion
In this section, we study the effect of temporal coarsening, incorrect PDE parameters, and longer look-ahead steps on predictions made by the hybrid NN-PDE solver.
6.1. Relaxing temporal stiffness in the PDE solver
Traditionally, the source terms and reaction rate terms involved in modeling the fast chemistry of reacting flows require the use of very small time-steps in simulations due to the stiffness of the chemical mechanisms. The incomplete PDE solver used in the hybrid NN-PDE approach, does not contain the source terms and reaction rate terms. Therefore, the time scales associated with the chemical reactions play a less important role in maintaining numerical stability, and it becomes possible for the solver to employ larger time steps. To illustrate this advantage, we train the neural network model with a time-step that is twice as large as the largest time-step
 $ \Delta {t}_c $
required for the complete PDE solver to yield a numerically stable result.
$ \Delta {t}_c $
required for the complete PDE solver to yield a numerically stable result.
We mimic the setup described in Section 4, but now the incomplete PDE solver uses a time-step of
 $ 2\Delta {t}_c $
, which is too large for the complete PDE solver by itself to converge to a solution. Figure 15 shows the results obtained from the models trained with a larger time-step are in good agreement with the target data for four different scenarios considered. The flame dynamics are predicted accurately while using less simulation steps. For the uniform-Bunsen case, the hybrid approach takes
$ 2\Delta {t}_c $
, which is too large for the complete PDE solver by itself to converge to a solution. Figure 15 shows the results obtained from the models trained with a larger time-step are in good agreement with the target data for four different scenarios considered. The flame dynamics are predicted accurately while using less simulation steps. For the uniform-Bunsen case, the hybrid approach takes
 $ 8.23\pm 0.011\mathrm{s} $
to infer one simulation run, whereas the complete PDE solver requires
$ 8.23\pm 0.011\mathrm{s} $
to infer one simulation run, whereas the complete PDE solver requires
 $ 15.21\pm 0.003\mathrm{s} $
. Similar performance gains are observed across the other cases studied. Note that for the previous cases with a timestep size of one
$ 15.21\pm 0.003\mathrm{s} $
. Similar performance gains are observed across the other cases studied. Note that for the previous cases with a timestep size of one
 $ \Delta {t}_c $
, the trained model incurs a negligible runtime overhead. Even though incomplete PDE solvers are cheaper to run, as mentioned in Section 1, increasing the spatial or temporal resolution of the incomplete PDE solver would not converge to the solutions of the complete description.
$ \Delta {t}_c $
, the trained model incurs a negligible runtime overhead. Even though incomplete PDE solvers are cheaper to run, as mentioned in Section 1, increasing the spatial or temporal resolution of the incomplete PDE solver would not converge to the solutions of the complete description.

Figure 15. Predictions made by hybrid NN-PDE model (
 $ {\tilde{T}}_t $
) with an incomplete PDE solver at twice the time-step of 2
$ {\tilde{T}}_t $
) with an incomplete PDE solver at twice the time-step of 2
 $ \Delta {t}_c $
, are compared with the ground truth solutions coming from the complete PDE solver at time-step of
$ \Delta {t}_c $
, are compared with the ground truth solutions coming from the complete PDE solver at time-step of
 $ \Delta {t}_c $
. We showcase the effectiveness of hybrid approach in relaxing temporal stiffness of the complete PDE solver on reactive flow cases of—from top to bottom—Planar-v0, uniform-Bunsen, nonUniform-Bunsen32 and nonUniform-Bunsen100 for different test cases.
$ \Delta {t}_c $
. We showcase the effectiveness of hybrid approach in relaxing temporal stiffness of the complete PDE solver on reactive flow cases of—from top to bottom—Planar-v0, uniform-Bunsen, nonUniform-Bunsen32 and nonUniform-Bunsen100 for different test cases.
The last column of Table 2 (Hybrid NN-PDE-dt) summarizes the errors of the large time-step approach for all four reactive cases considered. Despite an effectively doubled computational performance, this model achieves similar errors to the hybrid NN-PDE approach. This highlights the capabilities of learned, hybrid PDE solvers, which can produce these solutions without the stability problems exhibited by the complete PDE solver, while at the same time being more accurate than pure data-driven predictions.
6.2. Robustness of the hybrid solver
6.2.1. Generalization to incorrect PDE parameters
In real-world scenarios, even if the incomplete PDE system is observable, one may have only an approximate understanding of the physics behind it. This may lead to incorrect estimation of the parameters in the incomplete PDE solver. The proposed hybrid NN-PDE model is capable of completing the PDE description even if the underlying incomplete PDE solver has incorrect parameters. We refer to the incomplete solver with incorrect parameters as “incomplete, incorrect PDE.” We experiment with a modified hybrid NN-PDE approach wherein we combine an incomplete, incorrect PDE solver with a neural network model. We assume that the known values of the incomplete PDE parameters in equation (5), strain rate tensor (
 $ \tau $
), the diffusion coefficient of species
$ \tau $
), the diffusion coefficient of species
 $ k $
(
$ k $
(
 $ {D}_k $
), and mixture thermal conductivity (
$ {D}_k $
), and mixture thermal conductivity (
 $ \lambda $
), are incorrect. Figure 16A shows the difference between the temperature field evolution of the incomplete PDE solver with correct parameters (
$ \lambda $
), are incorrect. Figure 16A shows the difference between the temperature field evolution of the incomplete PDE solver with correct parameters (
 $ \left[\tau, {D}_k,\lambda \right]=\left[\mathrm{0.1,0.1,0.1}\right] $
) and incorrect parameters (
$ \left[\tau, {D}_k,\lambda \right]=\left[\mathrm{0.1,0.1,0.1}\right] $
) and incorrect parameters (
 $ \left[\tau, {D}_k,\lambda \right]=\left[\mathrm{0.05,0.05,0.05}\right] $
) at different time-steps. The hybrid NN-PDE combines this incomplete, incorrect PDE solver with the neural network model to obtain the solutions of the complete PDE solver with correct parameters. Figure 16B compares the flame dynamics predicted by this hybrid NN-PDE model with that of the complete, correct PDE solver. A good match is observed over various test cases. The hybrid model with incomplete, incorrect solver achieves an overall MAPE of 2.48
$ \left[\tau, {D}_k,\lambda \right]=\left[\mathrm{0.05,0.05,0.05}\right] $
) at different time-steps. The hybrid NN-PDE combines this incomplete, incorrect PDE solver with the neural network model to obtain the solutions of the complete PDE solver with correct parameters. Figure 16B compares the flame dynamics predicted by this hybrid NN-PDE model with that of the complete, correct PDE solver. A good match is observed over various test cases. The hybrid model with incomplete, incorrect solver achieves an overall MAPE of 2.48
 $ \pm $
1.20%, compared to the MAPE of 2.04
$ \pm $
1.20%, compared to the MAPE of 2.04
 $ \pm $
1.39% for hybrid model with incomplete, correct PDE.
$ \pm $
1.39% for hybrid model with incomplete, correct PDE.

Figure 16. Generalization to incorrect PDE parameters (A) visualization of differences in temperature fields due to incorrect parameters in incomplete PDE description. (B) Modified hybrid NN-PDE model, which combines the incomplete, incorrect PDE solver with neural network model is able to recover solutions of complete, correct PDE.
6.2.2. Effect of longer look-ahead steps
We evaluate the effect of varying look-ahead steps on the performance of the hybrid model. We show the comparison of models trained with
 $ m=\left\{\mathrm{2,4,8,16,32}\right\} $
for different cases in Figure 17. Models with smaller
$ m=\left\{\mathrm{2,4,8,16,32}\right\} $
for different cases in Figure 17. Models with smaller
 $ m\;(2) $
do not learn to accurately correct the fields over long time and quickly diverge from the target simulation. Using larger
$ m\;(2) $
do not learn to accurately correct the fields over long time and quickly diverge from the target simulation. Using larger
 $ m $
improves the quality of prediction drastically as the model learns the correction via the gradients over longer simulation steps. For Planar-v0 and uniform-Bunsen cases, iterating the NN and PDE solver for 32 time-steps improves the accuracy by 81.7% and 94%, respectively compared to the
$ m $
improves the quality of prediction drastically as the model learns the correction via the gradients over longer simulation steps. For Planar-v0 and uniform-Bunsen cases, iterating the NN and PDE solver for 32 time-steps improves the accuracy by 81.7% and 94%, respectively compared to the
 $ m=2 $
model. For nonUniform-Bunsen32 and nonUniform-Bunsen100, the model performance improves by 84.2% and 70.9%, respectively, by using
$ m=2 $
model. For nonUniform-Bunsen32 and nonUniform-Bunsen100, the model performance improves by 84.2% and 70.9%, respectively, by using
 $ m=32 $
instead of
$ m=32 $
instead of
 $ m=2 $
model.
$ m=2 $
model.

Figure 17. Effect of longer look-ahead steps. MAPE of temperature field predictions by hybrid NN-PDE model, over all testsets. Models trained with higher look-ahead steps
 $ m $
accurately predict the temporal evolution of dynamics for longer duration across all cases considered.
$ m $
accurately predict the temporal evolution of dynamics for longer duration across all cases considered.
For some of error curves in Figure 17, significant error fluctuations are observed for lower simulation steps followed by recovery as the simulation progresses (e.g., Figure 17C,
 $ m=4 $
). The evolution of the flame dynamics over time is highly nonlinear owing to the strong nonlinearity of the system where the premixed fuel and air mixture reacts to form the products. During the initial steps of this transient behavior, the distribution of flame temperature and flame interface varies rapidly. This leads to steep temperature gradients across the computational domain. As the simulation approaches toward the steady-state flame shape, the temperatures across the domain are in a similar range across different datasets. Therefore, small errors in flame temperature predictions and flame velocity predictions may lead to larger errors during the transient phase of the flame before it reaches a steady state.
$ m=4 $
). The evolution of the flame dynamics over time is highly nonlinear owing to the strong nonlinearity of the system where the premixed fuel and air mixture reacts to form the products. During the initial steps of this transient behavior, the distribution of flame temperature and flame interface varies rapidly. This leads to steep temperature gradients across the computational domain. As the simulation approaches toward the steady-state flame shape, the temperatures across the domain are in a similar range across different datasets. Therefore, small errors in flame temperature predictions and flame velocity predictions may lead to larger errors during the transient phase of the flame before it reaches a steady state.
6.2.3. Effect of training dataset size
We study the effect of training dataset size on the accuracy of PDD predictions. We train PDD models with different numbers of simulations in the training dataset. Each simulation contains 500 time-steps. Figure 18A shows the MAPE of PDD models trained with
 $ \left\{\mathrm{4,8,12,16,24,32}\right\} $
training datasets, over a fixed testset. We compare the performance of these PDD models with an equivalent (trained with same look-ahead steps
$ \left\{\mathrm{4,8,12,16,24,32}\right\} $
training datasets, over a fixed testset. We compare the performance of these PDD models with an equivalent (trained with same look-ahead steps
 $ m=2 $
) hybrid NN-PDE model, trained with 12 simulation sets. Figure 18A shows increasing the number of training sets has little or no effect on the prediction capabilities of the PDD models for nonUniform-Bunsen32 case. The hybrid model with 12 training sets achieves a MAPE of 12.49
$ m=2 $
) hybrid NN-PDE model, trained with 12 simulation sets. Figure 18A shows increasing the number of training sets has little or no effect on the prediction capabilities of the PDD models for nonUniform-Bunsen32 case. The hybrid model with 12 training sets achieves a MAPE of 12.49
 $ \pm $
4.17%, an improvement of 38% over the PDD model with 32 training sets. The PDD models cannot achieve the same level of accuracy even in the presence of large amounts of data. This result strengthens the hypothesis that integrating the incomplete PDE solver into the neural network training yields a learning signal that fundamentally differs from that produced by training with precomputed data. The PDD models cannot achieve the same level of accuracy even in the presence of large amounts of data.
$ \pm $
4.17%, an improvement of 38% over the PDD model with 32 training sets. The PDD models cannot achieve the same level of accuracy even in the presence of large amounts of data. This result strengthens the hypothesis that integrating the incomplete PDE solver into the neural network training yields a learning signal that fundamentally differs from that produced by training with precomputed data. The PDD models cannot achieve the same level of accuracy even in the presence of large amounts of data.

Figure 18. (A) The effect of increasing training dataset size for the PDD approach, over fixed testsets, is compared with equivalent (trained with same look-ahead steps
 $ m=2 $
) hybrid NN-PDE model. (B) Effect of temporal coarsening on PDD models trained with
$ m=2 $
) hybrid NN-PDE model. (B) Effect of temporal coarsening on PDD models trained with
 $ m=32 $
look-ahead steps.
$ m=32 $
look-ahead steps.
6.2.4. Effect of temporal coarsening
Table 2 compares the MAPE of temperature field predictions at time-step
 $ \Delta {t}_c $
, for all three scenarios. The hybrid NN-PDE approach consistently performs better than both the baselines for all three scenarios considered. Higher standard deviations in Table 2 indicate the large differences in the prediction of flame temperatures for baseline approaches. The multi-physics systems we study provide a substantially more difficult environment than regular fluids: the chemical reactions are numerically very stiff, and the resulting dynamic interactions are difficult to capture by numerical solvers. To further illustrate the temporal behavior of the simulations, we perform additional experiments with the baseline approaches using twice the time-step size of the complete solver (
$ \Delta {t}_c $
, for all three scenarios. The hybrid NN-PDE approach consistently performs better than both the baselines for all three scenarios considered. Higher standard deviations in Table 2 indicate the large differences in the prediction of flame temperatures for baseline approaches. The multi-physics systems we study provide a substantially more difficult environment than regular fluids: the chemical reactions are numerically very stiff, and the resulting dynamic interactions are difficult to capture by numerical solvers. To further illustrate the temporal behavior of the simulations, we perform additional experiments with the baseline approaches using twice the time-step size of the complete solver (
 $ 2\Delta {t}_c $
). As shown in Figure 19, for the Planar-v0 and uniform-Bunsen case, PDD catches up with the hybrid approach whereas the PDD approach completely fails to predict the dynamics of the nonUniform-Bunsen32 case. We further investigate the performance of the PDD approach on the nonUniform-Bunsen32 case with larger time-steps (2 times, 4 times, and 8 times) as shown in Figure 18B. PDD achieves higher MAPE of 22.44% for 8
$ 2\Delta {t}_c $
). As shown in Figure 19, for the Planar-v0 and uniform-Bunsen case, PDD catches up with the hybrid approach whereas the PDD approach completely fails to predict the dynamics of the nonUniform-Bunsen32 case. We further investigate the performance of the PDD approach on the nonUniform-Bunsen32 case with larger time-steps (2 times, 4 times, and 8 times) as shown in Figure 18B. PDD achieves higher MAPE of 22.44% for 8
 $ \Delta {t}_c $
setup as compared to the MAPE of 12.48% for
$ \Delta {t}_c $
setup as compared to the MAPE of 12.48% for
 $ \Delta {t}_c $
setup. The PDD approach does not predict the dynamics accurately for any of the larger time-steps considered. We cannot showcase the performance of the hybrid NN-PDE solver for time steps greater than
$ \Delta {t}_c $
setup. The PDD approach does not predict the dynamics accurately for any of the larger time-steps considered. We cannot showcase the performance of the hybrid NN-PDE solver for time steps greater than
 $ 2\Delta {t}_c $
as it is restricted by the underlying incomplete PDE solver. Figure 20 visualizes these results over different time-steps for one of the test cases. The predictions made by FNO, PDD, and hybrid NN-PDE model for nonUniform-Bunsen32 case at twice the time-step of
$ 2\Delta {t}_c $
as it is restricted by the underlying incomplete PDE solver. Figure 20 visualizes these results over different time-steps for one of the test cases. The predictions made by FNO, PDD, and hybrid NN-PDE model for nonUniform-Bunsen32 case at twice the time-step of
 $ 2\Delta {t}_c $
, are compared with the ground truth solutions coming from the complete PDE solver at time-step of
$ 2\Delta {t}_c $
, are compared with the ground truth solutions coming from the complete PDE solver at time-step of
 $ \Delta {t}_c $
. FNO and PDD (upper two rows) fail to recover the correct flame shapes over 250 simulation steps. The hybrid NN-PDE model (second row from below) predicts the flame shape accurately, thus relaxing the temporal stiffness of the complete PDE solver.
$ \Delta {t}_c $
. FNO and PDD (upper two rows) fail to recover the correct flame shapes over 250 simulation steps. The hybrid NN-PDE model (second row from below) predicts the flame shape accurately, thus relaxing the temporal stiffness of the complete PDE solver.

Figure 19. Bar plot of MAPE of temperature field predictions by FNO, PDD, and hybrid NN-PDE model at time-step
 $ 2\Delta {t}_c $
, for different testcases.
$ 2\Delta {t}_c $
, for different testcases.

Figure 20. Comparison between different approaches at time-step
 $ 2\Delta {t}_c $
—from top to bottom—FNO, PDD, hybrid NN-PDE for nonUniform-Bunsen32 test case. Hybrid approach predictions accurately match with the ground truth data over long roll-outs.
$ 2\Delta {t}_c $
—from top to bottom—FNO, PDD, hybrid NN-PDE for nonUniform-Bunsen32 test case. Hybrid approach predictions accurately match with the ground truth data over long roll-outs.
7. Flame shape control
To demonstrate the flexibility of the hybrid NN-PDE solver of the previous sections we consider a multi-physics system control problem. We test the joint applicability of a neural network with a pre-trained hybrid reactive flow solver to obtain a desired flame shape. We integrate the hybrid solver as a layer into the neural network model to enable the training of a flame shape controller. As a result, physics knowledge from the hybrid solver can be embedded into the optimization problem, by matching observations coming from the solver. The hybrid solver provides the agent with feedback of how interactions at any point in time affect the flame shape. We consider a physical system of reactive flows where the agent can interact with the system by controlling the inlet velocity of fuel-air flow.
We use a predictor–corrector approach (Holl et al., Reference Holl, Thuerey and Koltun2020) with a supervised loss function and control sequence refinement for the nonUniform-Bunsen case with 32
 $ \times $
32 resolution. A pre-trained hybrid solver from Section 5.2.2 is used as a reactive flow solver. This hybrid model consists of incomplete PDE solver along with an UNet model detailed in Sections 3.3 and 3.4 and Figures 2 and 3. It is first trained using training instances of the uniform-Bunsen32 case described in Section 4. Additionally, it is further trained on the training data of flame shape transitions from an arbitrary flame shape to any other arbitrary flame shape. Once trained, the weights of the hybrid solver are frozen and used as a layer into the predictor–corrector approach. It is differentiable by construction, when combined with the deep neural networks is shown to learn a policy to control flame shapes. The learning objective is to arrive at a target temperature field (
$ \times $
32 resolution. A pre-trained hybrid solver from Section 5.2.2 is used as a reactive flow solver. This hybrid model consists of incomplete PDE solver along with an UNet model detailed in Sections 3.3 and 3.4 and Figures 2 and 3. It is first trained using training instances of the uniform-Bunsen32 case described in Section 4. Additionally, it is further trained on the training data of flame shape transitions from an arbitrary flame shape to any other arbitrary flame shape. Once trained, the weights of the hybrid solver are frozen and used as a layer into the predictor–corrector approach. It is differentiable by construction, when combined with the deep neural networks is shown to learn a policy to control flame shapes. The learning objective is to arrive at a target temperature field (
 $ {T}_{\ast } $
) with the desired flame shape from an arbitrary, given initial configuration (
$ {T}_{\ast } $
) with the desired flame shape from an arbitrary, given initial configuration (
 $ {T}_0 $
) by controlling the velocity field (
$ {T}_0 $
) by controlling the velocity field (
 $ {u}_i^c $
). We consider a real-world setting where only few states of the reactive flow system are observable and controllable: the temperature and mass-fraction fields are observable, and only the inlet of the velocity field is controllable. The predictor–corrector approach consists of two neural network models. First, an observation predictor network (OP), predicts the intermediate states of the observable quantity, that is, temperature in this case (
$ {u}_i^c $
). We consider a real-world setting where only few states of the reactive flow system are observable and controllable: the temperature and mass-fraction fields are observable, and only the inlet of the velocity field is controllable. The predictor–corrector approach consists of two neural network models. First, an observation predictor network (OP), predicts the intermediate states of the observable quantity, that is, temperature in this case (
 $ {T}_i^p $
). The corrector (CFE) network predicts the control force (
$ {T}_i^p $
). The corrector (CFE) network predicts the control force (
 $ {u}_i^c $
) required to follow the trajectory predicted by OP network. The inlet velocity field predicted by the CFE network is used by the pre-trained hybrid solver to compute the corrected temperature field (
$ {u}_i^c $
) required to follow the trajectory predicted by OP network. The inlet velocity field predicted by the CFE network is used by the pre-trained hybrid solver to compute the corrected temperature field (
 $ {T}_i^c $
). Figure 21 shows the sequence of OP-CFE network used to control the flame shape
$ {T}_i^c $
). Figure 21 shows the sequence of OP-CFE network used to control the flame shape
 $ {T}_{\ast } $
given the initial flame shape
$ {T}_{\ast } $
given the initial flame shape
 $ {T}_0 $
, over the trajectory of four time-steps. The OP network is modeled as a temporal hierarchical process to incorporate the knowledge about longer time spans. Therefore, OP networks are trained to predict the optimal center point between two time-steps instead of predicting the state of the next time step. The recursive call to the OP network enables the prediction of observable quantities at every time step (
$ {T}_0 $
, over the trajectory of four time-steps. The OP network is modeled as a temporal hierarchical process to incorporate the knowledge about longer time spans. Therefore, OP networks are trained to predict the optimal center point between two time-steps instead of predicting the state of the next time step. The recursive call to the OP network enables the prediction of observable quantities at every time step (
 $ {T}_i^p $
). Using
$ {T}_i^p $
). Using
 $ {T}_{i-1} $
and OP prediction at step i, that is,
$ {T}_{i-1} $
and OP prediction at step i, that is,
 $ {T}_i^p $
, CFE network predicts the control force at step i,
$ {T}_i^p $
, CFE network predicts the control force at step i,
 $ {u}_i^c $
. Once
$ {u}_i^c $
. Once
 $ {u}_i^c $
is predicted, learned hybrid solver can be used to advance the simulation to next time step and obtain the actual state
$ {u}_i^c $
is predicted, learned hybrid solver can be used to advance the simulation to next time step and obtain the actual state
 $ {T}_i^c $
. Using this sequence of OP-CFE network, we can obtain
$ {T}_i^c $
. Using this sequence of OP-CFE network, we can obtain
 $ {T}_n^c $
with
$ {T}_n^c $
with
 $ n $
CFE evaluations, which matches target flame shape
$ n $
CFE evaluations, which matches target flame shape
 $ {T}_{\ast } $
very closely. This sequence can be generalized to any arbitrarily long length of sequences. OP-CFE networks are trained using the supervised loss function on the target temperature field achieved and inlet velocity predicted, respectively. The loss function formulations for OP and CFE networks are,
$ {T}_{\ast } $
very closely. This sequence can be generalized to any arbitrarily long length of sequences. OP-CFE networks are trained using the supervised loss function on the target temperature field achieved and inlet velocity predicted, respectively. The loss function formulations for OP and CFE networks are,
 $$ {L}_{\mathrm{op}}={\left|\mathrm{OP}\left[{T}_i,{T}_j\right]-{T}^{GT}\left(\frac{i+j}{j}\right)\right|}^2\hskip2em {L}_{\mathrm{CFE}}=\sum \limits_{i=1}^n{\left|{u}_i^c-{u}_i^{\ast}\right|}^2, $$
$$ {L}_{\mathrm{op}}={\left|\mathrm{OP}\left[{T}_i,{T}_j\right]-{T}^{GT}\left(\frac{i+j}{j}\right)\right|}^2\hskip2em {L}_{\mathrm{CFE}}=\sum \limits_{i=1}^n{\left|{u}_i^c-{u}_i^{\ast}\right|}^2, $$
where
 $ {T}^{\mathrm{GT}} $
and
$ {T}^{\mathrm{GT}} $
and
 $ {u}^{\ast } $
indicate the ground truth temperature field and inlet velocity, respectively. The simplest technique to obtain the optimal trajectory, given an initial state is to use the chain of CFE networks followed by the solver. CFE, modeled using deep neural network, predicts the control force required to predict the transition to next observable state. Therefore, as a baseline model, we consider the CFE only approach. All neural networks used in this work are modified UNet architectures (Ronneberger et al., Reference Ronneberger, Fischer and Brox2015).
$ {u}^{\ast } $
indicate the ground truth temperature field and inlet velocity, respectively. The simplest technique to obtain the optimal trajectory, given an initial state is to use the chain of CFE networks followed by the solver. CFE, modeled using deep neural network, predicts the control force required to predict the transition to next observable state. Therefore, as a baseline model, we consider the CFE only approach. All neural networks used in this work are modified UNet architectures (Ronneberger et al., Reference Ronneberger, Fischer and Brox2015).

Figure 21. Details of the OP-CFE prediction sequence.
Figure 22b–E shows examples of the transition achieved and compares the target flame shape obtained using the neural network model with the target flame shape (
 $ {T}_{\ast } $
). All three cases are test cases, that is, were not seen at training time, and have a sequence length of 64 simulation steps. It is visible that the neural network model succeeds at controlling the inlet velocity of fuel-air mixture flow to obtain the desired flame shapes. To quantify these results, the learned model achieves MAPE of 1.34
$ {T}_{\ast } $
). All three cases are test cases, that is, were not seen at training time, and have a sequence length of 64 simulation steps. It is visible that the neural network model succeeds at controlling the inlet velocity of fuel-air mixture flow to obtain the desired flame shapes. To quantify these results, the learned model achieves MAPE of 1.34
 $ \pm $
0.41% over 50 test cases considered. It achieves an improvement of 65.7% compared to a baseline model of the CFE only approach, without a predictor network for the long-term prediction of temperature fields. This baseline model has a MAPE of 3.91
$ \pm $
0.41% over 50 test cases considered. It achieves an improvement of 65.7% compared to a baseline model of the CFE only approach, without a predictor network for the long-term prediction of temperature fields. This baseline model has a MAPE of 3.91
 $ \pm $
2.19%. This case highlights the capabilities of differentiable hybrid NN-PDE multi-physics solvers. Specifically, the hybrid solver helps the OP-CFE networks to yield controllers that steer the complex physics of the reactive flow over long time spans.
$ \pm $
2.19%. This case highlights the capabilities of differentiable hybrid NN-PDE multi-physics solvers. Specifically, the hybrid solver helps the OP-CFE networks to yield controllers that steer the complex physics of the reactive flow over long time spans.

Figure 22. Temperature field predictions are achieved by the neural network model
 $ {\tilde{T}}_{\ast}^{\mathrm{NN}} $
from given initial flame shape
$ {\tilde{T}}_{\ast}^{\mathrm{NN}} $
from given initial flame shape
 $ {T}_0 $
to achieve target flame shape
$ {T}_0 $
to achieve target flame shape
 $ {\tilde{T}}_{\ast } $
by controlling flow velocity.
$ {\tilde{T}}_{\ast } $
by controlling flow velocity.
8. Conclusion
In this work, we proposed a hybrid NN-PDE solver which learns to complete an incomplete PDE solver in the context of a multi-physics system, namely the case of a reacting flow. The trained neural network model works alongside an incomplete solver to accurately account for and predict the effects of unknown physics. We compare its performance with two baselines—a PDD approach and state-of-the-art FNO approach. We test it on the cases of reacting flows of increasing complexity. The qualitative and quantitative performance of the presented hybrid NN-PDE approach is found to be superior compared to these baselines to predict the long-term temporal evolution of the reactive flows. The incomplete PDE description helps the neural network model recover the target simulation with a significantly improved accuracy. This hybrid NN-PDE model is able to predict the correct evolution of the important features of the multi-physics system (in our case, the flame interface and flame shape) for longer simulation steps in all scenarios and is able to generalize to other (initial and boundary) conditions of the system. This is demonstrated by variations in the equivalence ratio and inlet velocity forcing. We also show that such hybrid approach may have the added benefits of allowing to relax numerical constraints linked to the potential stiffness of the unknown physics. The learned hybrid NN-PDE solver is successfully adapted to enable flame shape control by combining with deep neural networks.
Our work represents a stepping stone for numerous avenues of future work. While we demonstrated the applicability of the proposed approach to the complex case of a reacting flow (with strong nonlinear interactions between chemistry and velocity), the proposed hybrid NN-PDE solver could be further utilized to predict and control the dynamics of other tightly coupled multi-physics systems (Levy, Reference Levy1999; Dowell and Hall, Reference Dowell and Hall2001). In addition, applying the proposed approach to other cases, where a limited amount of real data is available would be a very interesting step. Especially if the data is very sparse and contains noise, learning meaningful corrections could become excessively challenging. Performing such an assessment will be explored in future work. We note that the proposed approach does not seek to replace the classical physical simulation approaches. However, it is an important step in the direction of harnessing the capabilities of neural network models using the knowledge of PDEs for complex multi-physical systems.
Author contribution
Conceptualization: N.T.; Data curation: N.N.T.; Formal analysis: N.N.T.; Investigation: N.N.T.; Methodology: N.N.T.; Software: N.N.T.; Supervision: N.T., N.A.K.D., C.F.S.; Validation: N.N.T.; Visualization: N.N.T.; Writing—original draft: N.N.T.; Writing—review and editing: N.N.T., N.A.K.D., C.F.S., N.T. All authors approved the final submitted draft.
Competing interest
The authors declare no competing interests.
Data availability statement
The code to generate the data and train models that support the findings of this study are openly available at https://github.com/tum-pbs/Hybrid-Solver-for-Reactive-Flows.
Funding statement
N.N.T acknowledges the financial support of the European Union’s Horizon 2020 research and innovation program under the Marie Sklodowska-Curie grant agreement No. 766264 and the ERC Consolidator Grant SpaTe (CoG-2019-863850).
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/dce.2023.20.




















































 Open access
Open access
Comments
No Comments have been published for this article.