


How well do qualifications measures capture judicial nominees’ “quality”? How does “quality” affect potential judges at different stages in their careers (e.g., during their selection, nomination, confirmation, and while they are on the bench)? Existing research is equivocal about the effect of qualifications. Some studies find that highly qualified judges are more likely to earn promotion (Savchack et al. 2006), get through the nomination process more quickly (Allison Reference Allison1996; Martinek, Kemper, and Van Winkle Reference Martinek, Kemper and Van Winkle2002; Stratmann and Garner Reference Stratmann and Garner2004; Hendershot Reference Hendershot2010), and be influential (Landes, Lessig, and Solimine Reference Landes, Lessig and Solimine1998; Black and Owens Reference Black and Owens2013). Yet other studies find qualifications to have no effect on the length of the nomination process (Binder and Maltzman Reference Binder and Maltzman2002), whether senators deploy institutional delay tactics against the nominee (Black, Madonna, and Owens Reference Black, Madonna and Owens2014), or the likelihood of confirmation (Scherer, Bartels, and Steigerwalt Reference Scherer, Bartels and Steigerwalt2008; Steigerwalt Reference Steigerwalt2010). Moreover, highly qualified judges work harder (Choi, Gulati, and Posner Reference Choi, Gulati and Posner2013) and more efficiently (Christensen and Szmer Reference Christensen and Szmer2012). But a negative relationship exists between productivity and influence, on the one hand, and time to confirmation, on the other (Lott Reference Lott2005).
The puzzling pattern of results might arise from an imperfect measure of qualifications: American Bar Association (ABA) ratings. The inadequacy of the ABA rating measure leads researchers to come up with alternative operationalizations that muddle findings and stymie the development of a coherent body of knowledge. This study aims to develop a better measure of judicial qualifications by improving ABA ratings for US Courts of Appeals (i.e., circuit court) nominees in a valid and reliable way.
Despite their well-documented problems, ABA ratings provide a useful starting point for the creation of the new measure. Indeed, the fact that researchers have documented the problems with ABA ratings so well leads to a straightforward improvement. Briefly, the study leverages new data on the people who produce ABA ratings to indirectly minimize unwarranted biases in the ratings, especially biases stemming from partisan, gender, and racial identities. To show its benefits, I then test the adjusted measure in an empirical context: the word choices senators make at the nominee’s confirmation hearing.
The results are promising. The adjusted ABA ratings measure corrects many of the problems of raw ABA ratings, most importantly their questionable construct validity and reliability. The raw measure assigns 56.5 percent of all circuit court nominees between 1958 and 2020 the highest possible rating: “well qualified.” Empirically, nominees’ backgrounds are more continuous than categorical – a difference that the adjusted measure captures well. It also reliably assigns similar ratings to nominees with similar backgrounds.
Turning to the empirical example, adjusted ABA ratings change the analysis of confirmation hearing word choice. The qualifications word choice analysis using raw ABA ratings finds few substantively significant differences between low- and high-quality nominees, observations consistent with the argument that the hearings are “not personal” (Dancey, Nelson, and Ringsmuth Reference Dancey, Nelson and Ringsmuth2014, Reference Dancey, Nelson and Ringsmuth2020). But the analysis using the adjusted measure demonstrates that the difference in senators’ use of qualifications-related words between low- and high-quality nominees can be as much as 69 percent. Thus, the study presents evidence that the hearings are personal in part, so long as researchers measure nominees’ personal backgrounds accurately.
The main contribution of the study is the new measure of qualifications for circuit court nominees. Wide adoption of the measure will allow for comparable findings across independent studies, which will in turn lead to a coherent body of knowledge about the role of qualifications in nomination politics and a judge’s behavior once on the bench. In the empirical example, I contribute a new machine-coded dataset on the content of circuit court confirmation hearings. Additionally, the findings speak to a wider discussion about the ABA’s role in vetting candidates for federal judicial office. Recent research that ties ABA ratings to performance (e.g., citation (Lott Reference Lott2013) and reversal rates (Sen Reference Sen2014)) finds no relationship between the two. However, in muting some of the ratings’ considerable “noise” – a heavily left-skewed distribution, partisan bias, and demographic bias – the study tries to recover from them a useful “signal” about the nominee’s qualifications (Silver Reference Silver2012). Given the exposure of ABA research in popular media (Lott Reference Lott2006; Voeten Reference Voeten2013), the results could have real implications for the policy choices presidents make with respect to the ABA’s continued involvement in the judicial nomination process.
The next section documents the problems with ABA ratings and how scholars have tried to deal with them as both independent and dependent variables. Then, I present the adjusted measure of qualifications and describe some of its beneficial qualities. I end the empirical discussion with an analysis of confirmation hearing word choice. The analysis compares ABA ratings, the adjusted measure, and a proxy indicators approach to demonstrate the problems and promise in studying the role of qualifications in judicial politics.
Problems with ABA ratings: Heterogeneity in lower court qualifications measures
Unfortunately for scholars of judicial politics, the relatively minor salience of lower court nominations precludes the application of the standard method used to create an exogenous measure of qualifications for Supreme Court nominees. Cameron, Segal, and Songer (Reference Cameron, Cover and Segal1990) analyzed editorial content discussing nominees’ qualifications in four national newspapers, two liberal and two conservative, to create the standard qualifications variable for the Supreme Court. But editorial writers for national newspapers do not, for the most part, write about specific circuit or district judge nominations. To be sure, lower court nominations generate editorial attention at the regional level, but reliance on regional newspapers introduces a host of confounds. Most prominently, the difficulty in scaling editorial ideology for newspapers across circuits unfavorably contrasts with the simplicity of using the same four newspapers for every nominee. The difficulty notwithstanding, there should be a single measure of lower court nominees’ qualifications that is both valid and reliable. The current standard measurement of qualifications in research on lower courts now, however, is that there is no standard.
Broadly, studies that use a measure of qualifications fit into three categories. First, studies in the proxy indicators approach use a series of variables designed to represent the underlying qualifications construct. Second, the modified ABA ratings approach uses simplified versions of the ordinal scale, “not qualified” to “well qualified,” on which the ABA rates nominees. Finally, some studies use the raw ABA rating as a measure of qualifications. Table 1 categorizes several studies over a recent two-decade span on their approaches to measurement of qualifications.
Table 1. Existing Approaches to Qualifications Measurement
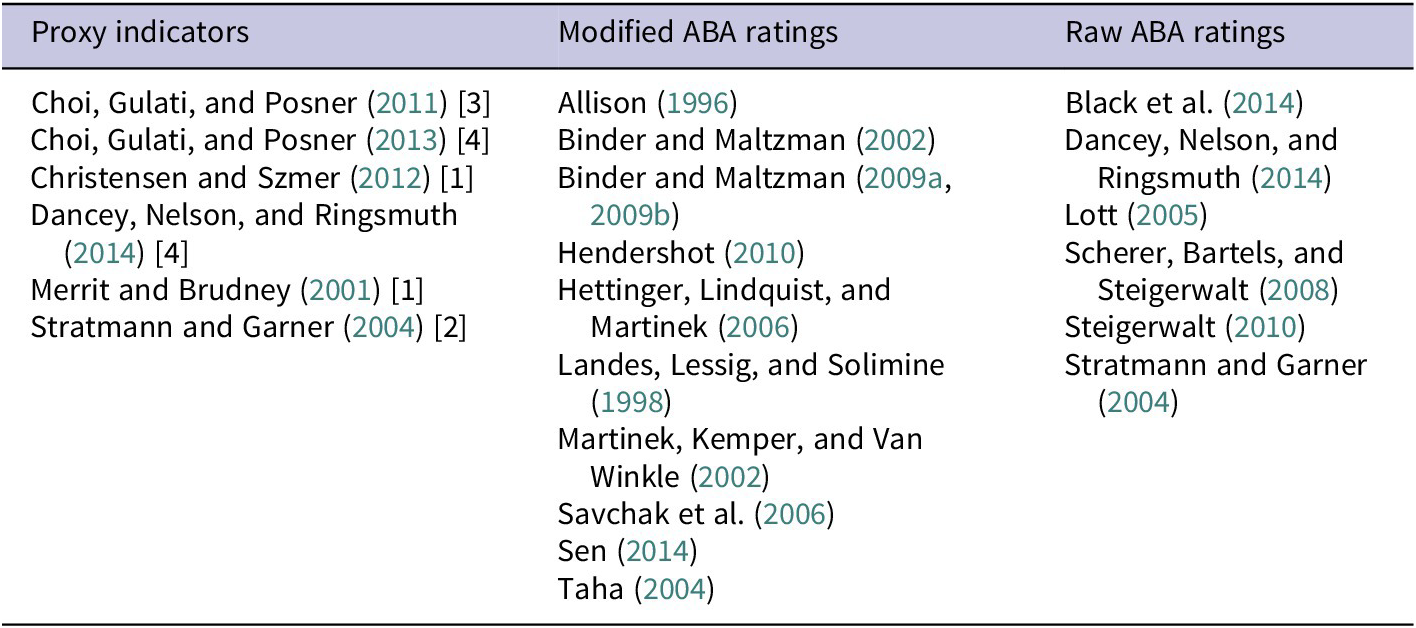
Note: The number of indicators used in each of the proxy indicators studies appears in brackets after the citation. The 11 studies in the modified ABA ratings approach used seven distinct modifications.
The heterogeneity in how researchers measure qualifications – there are almost as many ways to operationalize the construct as there are studies that include some measurement of qualifications – makes it difficult to compare results across studies.Footnote 2 With uncomparable results, knowledge about the role of qualifications does not accumulate; that is, the field of judicial politics does not have much concrete to say about the role of qualifications in the stages of a (potential) judge’s career.
Moreover, both the proxy indicators and modified ABA ratings approaches make the falsification of a qualifications-related theory a shifting target. For example, consider a situation in which the inclusion of variables measuring private practice experience, judicial experience, and elite law school produces no significant results in a multiple regression analysis, yet the inclusion of prosecutorial experience and clerkship experience variables do produce significant results. Given the pronounced publication bias in the social sciences, a researcher is far more likely to write up and publish the latter output (Franco, Malhotra, and Simonovits Reference Franco, Malhotra and Simonovits2014). So not only does knowledge not generally accumulate, at least some of the knowledge that does build up reflects a skewed sample of all possible results.
If researchers treat the raw ABA rating consistently, the epistemological problems of the proxy indicators and modified ABA ratings approaches do not arise. The raw scale is reliable from study to study. However, its validity is questionable. The hodgepodge of relationships, some diametrically opposed, between the ABA rating and various outcomes calls its face and construct validity into question. With respect to unbiasedness, the ABA rating fares no better. Political elites have asserted at different times that liberal or conservative nominees receive lower ratings because of the nominees’ ideology or background (Slotnick Reference Slotnick1983; Kamenar Reference Kamenar, Abraham, Bell, Grassley, Hickok, Kern, Markman and Reynolds1990; ABA Watch 2006). And the balance of social scientific research finds strong evidence for ideologically biased ratings for circuit court nominees (e.g., Smelcer, Steigerwalt, and Vining Reference Smelcer, Steigerwalt and Vining2012; Sieja Reference Sieja2023a; see Sen Reference Sen2014 for gender and racial bias at the district court level).
Biased measures are not necessarily useless, especially if, as is true with ABA ratings, researchers know the bias’s direction. Using a biased measure ordinarily induces a researcher to note that the results represent a “conservative estimate” or the “ceiling” of the actual effect size. Yet, ideologically biased ratings present real problems as a measure of qualifications in multiple regression analyses. Specifically, the correlation between two independent variables – ABA rating and ideology – could affect the estimation of the effect of one or both. Determining the actual presence, size, and direction of any potential effect is difficult.
As researchers presently treat it, the ABA rating both induces heterogeneity in scientific measurement of qualifications and potentially biases the results of studies that use it unaltered. Despite its problems, though, the ABA rating is a useful starting point for the creation of a reliable and valid measure of nominee qualifications. The ABA rating’s wide recognition and basic reliability are positives. Another plus is that it is the product of an extensive investigation into a nominee’s background (American Bar Association 2020, 1–9).Footnote 3 Given general agreement that judges ought to have traits like integrity and an even temperament, in addition to law degrees and experience in the courtroom or classroom, researchers using ABA ratings have a richer measure of qualifications. The biases remain, though, and expunging them is not a simple task. What follows is an attempt to purge the ratings of the unwarranted biases in a valid and reliable way.
Adjusting the ratings
Data and methods
To adjust ABA ratings, I used a dataset that began with demographic, background, and partisanship information on the 643 nominees to the circuit courts and the 250 ABA Standing Committee on the Federal Judiciary (SCFJ) members whose investigations produced the nominees’ ratings from 1958 to 2020.Footnote 4 Using a genetic matching algorithm, I matched nominees on race, gender, age, years as a federal judge, years as a state judge, years as a government attorney, years in private practice, whether they taught law school, whether they were a federal clerk, whether they had political experience, and whether they graduated from a Top 14 law school (Diamond and Sekhon Reference Diamond and Sekhon2013; Ho et al. Reference Ho, Imai, King and Stuart2011). Party of the appointing president was the treatment variable. The preprocessing left 562 observations, evenly split between Republican and Democratic nominees, investigated by 188 SCFJ members.
In addition to balancing the data, matching is particularly useful for adjusting ABA ratings. This is because it restricts the data for producing the adjustment coefficients to a portion of the set, yet all nominees will receive an adjusted rating based on the results of the restricted estimation. If the new measure performs better than raw ABA ratings for the whole population, including out-of-matched observations, the improved performance would be solid evidence that the adjustment is worthwhile.Footnote 5
There are at least two ways to adjust ABA ratings. First, consider a less-valid adjustment: Taking the estimated coefficients on the partisanship variable from Smelcer, Steigerwalt, and Vining’s (Reference Smelcer, Steigerwalt and Vining2012) model, one could simply “zero-out” the partisan bias by generating a predicted rating for the nominees with their partisanship set at “Democratic.” But the assumption of uniform bias from the ABA is incorrect. Indeed, Republican nominees suffer from lower ABA ratings on average, but the estimated effect for or against Republican and Democratic nominees varies with the partisanship of the investigating member and different levels of partisanship on the SCFJ as a whole. Therefore, the naïve adjustment would unduly punish (reward) nominees who were (not) exposed to bias. In effect, the zero-out approach to adjustment would trade one form of construct invalidity for another.
Instead, the more-valid approach focuses primarily on the adjustment for the SCFJ investigator and committee composition and secondarily on the effects of race and gender, all variables over which the nominee has no control. Sieja (Reference Sieja2015, Reference Sieja2023a) demonstrates that the individual member primarily and the committee secondarily interact to have significant effects on the nominee’s final rating, after controlling for other potential covariates. Therefore, to produce the adjusted rating, I first estimated an ordered logit model with the matched sample that included a three-way interaction term between the partisanship of the nominee, the SCFJ investigator, and the committee as a whole. The dependent variable was the nominee’s ABA rating, preserving split ratings but collapsing all “well-qualified” and above ratings to “well-qualified” (Martinek, Kemper, and Van Winkle Reference Martinek, Kemper and Van Winkle2002). I also included experience controls for years as a federal judge, years as a state judge, years in private practice, years as a government attorney, graduation from a Top 14 law school, having taught law, holding a clerkship for a federal judge, and participating in partisan political activity; demographic controls for minority status, gender, age, and the square of age; and an “era” control for the existence of publicly available split votes. With the exception of the SCFJ-related variables, the model is the same as Smelcer, Steigerwalt, and Vining’s (Reference Smelcer, Steigerwalt and Vining2012) model.
The results in Table 2 provide estimates for the relative weight that the ABA places on each element that goes into the rating decision. Some elements, such as experience as a federal judge, as a state judge, in private practice, as a government attorney, and as a federal clerk, seem appropriate as positive predictors of a qualified nominee. The effects of elite law school attendance and law professorship are substantively negligible, and the ABA itself explicitly discounts prior political experience (American Bar Association 2020, 4). Minority and female identifiers have a lower probability of a high rating. Though it is not statistically significant overall, the committee proportion variable is substantively important over certain values.
Table 2. Ordered Logit Results Used for Adjusted ABA Measure Creation. The dependent variable is a six-point ordinal measure of the nominee’s ABA rating

Notes: *: p<0.05 **: p<0.01 (two-tailed)
After model estimation, I duplicated all observations in the dataset and then set the duplicated observations’ values for SCFJ investigator partisanship to 1 (Republican), minority status, gender, and “no split vote” era to 0 (white, male, and exposed to split vote possibility, respectively), and proportion of Republicans on the SCFJ to 0.647. Empirically, this proportion is the point at which the predicted probability of a “well-qualified” rating for Republican SCFJ investigators is equal for both Republican and Democratic nominees (0.54). In effect, this made all the duplicated observations white male nominees investigated by a Republican SCFJ member when the committee was about two-thirds Republicans and one-third Democrats. The observed values for all other variables, such as party of the nominating president, years of judicial or litigation experience, and whether the nominee was a law professor, remained the same in the duplicated observations.
Finally, I created the linear prediction from the model as each nominee’s adjusted ABA rating, rounded it to the nearest 0.1, and standardized the resulting distribution (i.e., subtracted the mean and divided by the standard deviation). Predictions to derive a single measure of a complex underlying construct are, of course, not unknown to scholars of judicial politics. For example, Black and Boyd (Reference Black and Boyd2011) used a model of certiorari grants to derive a case-level measure of certworthiness, an approached followed by others in the field (e.g., Benesh, Armstrong, and Wallander Reference Benesh, Armstrong and Wallander2020).
Properties of adjusted ABA ratings: Less bias and increased face validity
The adjusted ABA ratings are attractive for several reasons. First, they adjust for the partisan and demographic biases in the existing ratings. In the case of partisan bias, the measure reduces the connection between nominee partisanship and ABA ratings without changing the partisanship of any nominee. The adjustment altered only SFCJ investigators’ partisanship, the level of partisanship on the SCFJ committee, and nominees’ race and gender. Nevertheless, the bivariate correlation between the party of appointing president and qualifications went down from the raw ABA rating’s r = -0.129 to the adjusted rating’s r = -0.056, a 57 percent reduction. At the same time, the magnitudes of the bivariate correlations between the adjusted measure and other non-adjusted variables increased for all but one covariate (law professor). In most cases, the increases were well over 100 percent.
Second, in addition to its increased unbiasedness, the adjusted ABA rating is a more facially valid measure of qualifications. That is, it generates similar values for nominees with similar backgrounds. Consider the case of Goodwin Liu, a University of California law professor nominated to the Ninth Circuit by President Obama in 2010. The ABA rated Professor Liu unanimously “well-qualified” even though he had no judicial experience and only two years of experience in private practice, a full decade less than the ABA recommended at the time (American Bar Association 2009, 3). Critics railed against the “ridiculous” rating, comparing it unfavorably to the split “qualified-not qualified” rating given to Reagan Seventh Circuit nominee Frank Easterbrook, who had a similar résumé to Liu at the time of his appointment (Whelan Reference Whelan2010). The adjusted ABA rating for Liu is -1.30 and -1.00 for Easterbrook. Although these ratings are both substantively low – they reflect nominees with qualifications about one standard deviation below the mean – they are nevertheless consistent.
The adjusted measure’s improved consistency applies to more than the high-profile Liu and Easterbrook pairing. Consider further 39-year-old Clinton DC Circuit nominee Elena Kagan, “qualified-well qualified” according to the ABA, and 35-year-old Reagan Ninth Circuit nominee Alex Kozinski, whom the ABA rated “qualified-not qualified.” Both lacked previous Article III federal or state judicial experience and did not meet the 12-year benchmark as a practicing attorney (three years and six years of experience, respectively), yet they clerked for federal judges. Kagan’s law degree came from a Top 14 institution, Harvard, but Kozinski’s came from UCLA, just outside the upper echelon. Of course, Kagan was female and Kozinski male, which advantaged Kozinski. The adjusted measure assigns both nominees essentially the same rating, -1.42 for Kagan and -1.41 for Kozinski, again reflecting their similarly thin legal résumés at the time of their nominations.
The adjusted measure benefits not just Republican nominees. Consider finally Obama Second Circuit nominee Susan Carney – a Harvard Law School graduate and former federal clerk with 2.5 times the ABA’s suggested amount of experience as a lawyer – whom the ABA nevertheless rated only “qualified.” Carney’s background compares well with Trump Fifth Circuit nominee Halil Ozerden – a Stanford Law School graduate and former federal clerk with a decade less overall legal experience than Carney. But Ozerden served 12 years as a federal district court judge. The ABA rated Ozerden “well qualified.” The adjusted measure, though, assigns Carney and Ozerden the same 1.08 score – both are one standard deviation above the mean in overall qualifications – which suggests the ABA may have unduly discounted, relative to other nominees, Carney’s prodigious private practice experience or unfairly downgraded her due to her gender.
Third, as Figure 1 shows, the adjusted measure is more fine-grained than the categories of the raw ABA ratings. ABA ratings skew drastically to the left, with over 56 percent of the rated nominees receiving the top possible rating. The adjusted ratings approximate a normal curve, which is a function not of model estimation but rather the combinations of over 600 unique backgrounds. Practically, the distribution comports with expectations for circuit court nominees.Footnote 6 Most are professionally competent, and there are a few outstanding nominees. And there are others whose résumés show promise but lack much objectively measurable experience. Table 3 compares the summary statistics for raw and adjusted ABA ratings.
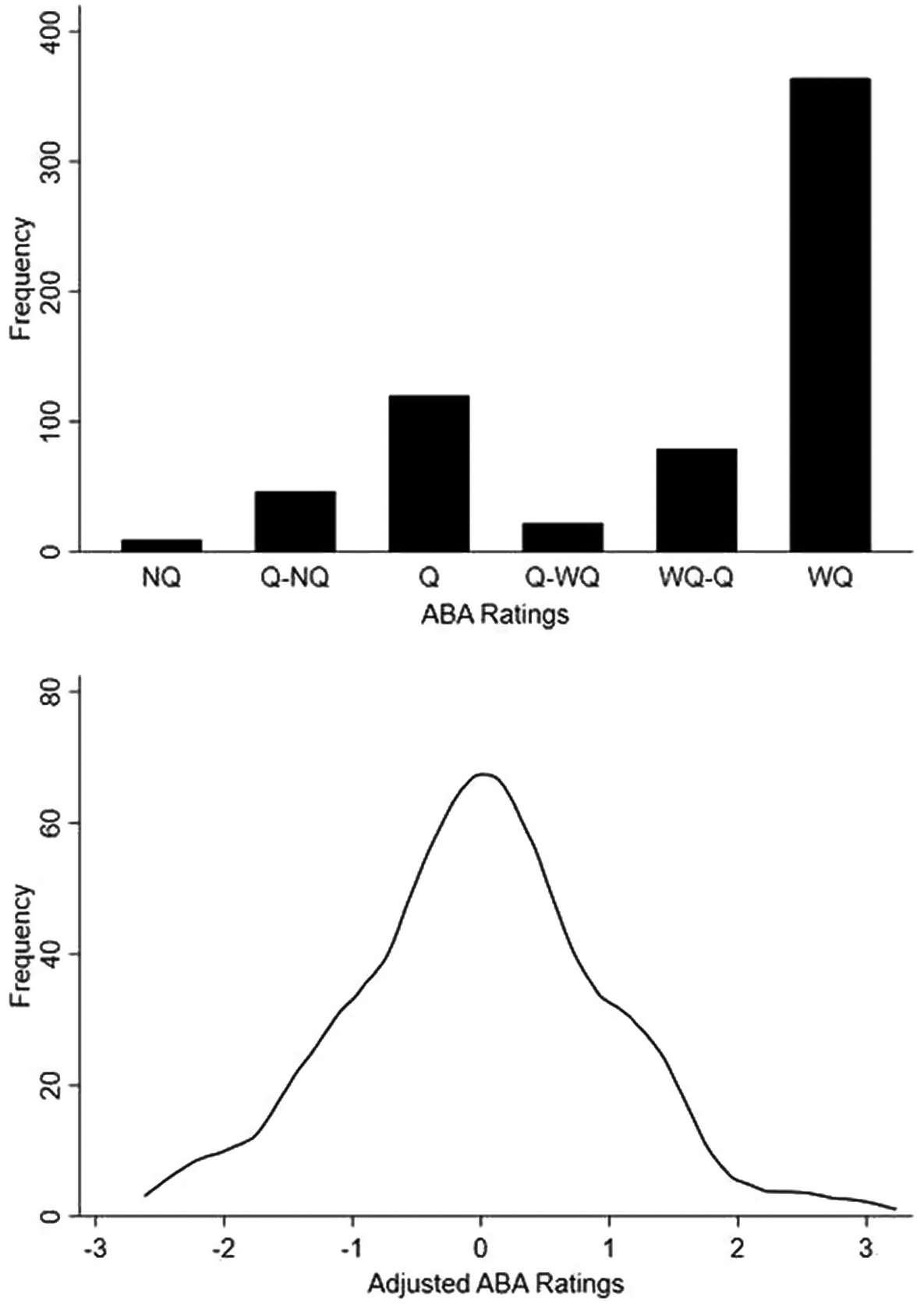
Figure 1. Distributions of Qualifications Measures. The top panel shows the distribution of raw ABA ratings. The bottom panel displays the distribution of adjusted ABA ratings.
Table 3. Summary Statistics of Qualifications Measures
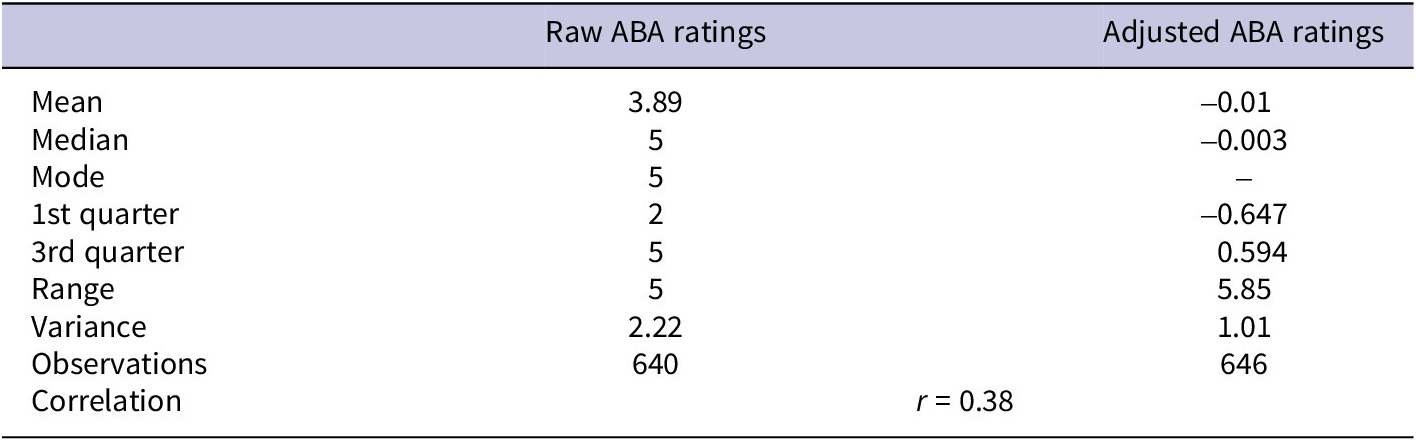
Note: The number of observations for adjusted ABA ratings includes nominees whom the ABA did not officially rate. The method of adjustment creates ratings for these nominees. None of the nominees who did not have an official ABA rating appears in the data for the empirical example.
In sum, the adjusted measure is less biased as a measurement of the underlying qualifications construct, valid on its face, and reliably assigns values to nominees with similar backgrounds. In short, adjusted ABA ratings correct many of the ABA ratings’ measurement problems. However, empirical demonstration shows the ultimate usefulness of the adjustment. The three attractive qualities of adjusted ABA scores are not much help if the measure does not have a fourth quality: improving a researcher’s ability to model real-world political behavior.
Empirical example: Senators’ confirmation hearing word choice
I now turn to an empirical example in which qualifications may influence the behavior of institutional actors in the nomination and confirmation process. The example, a quantitative analysis of senators’ word choice at confirmation hearings for circuit court nominees over a 15-year period, builds directly on the foundation that Dancey, Nelson, and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2014, Reference Dancey, Nelson and Ringsmuth2020) laid. Using adjusted ABA ratings leads to a materially different understanding of the role nominees’ qualifications play in the hearings.
In the example, I estimate three models. The first model uses raw ABA ratings as its measure of qualifications. The second model replaces raw ABA ratings with adjusted ABA ratings. The third model drops any form of ABA rating in favor of a proxy indicators approach. The estimation strategy generates a working hypothesis to test whether the adjusted measure works well. If adjusted ABA ratings perform as expected, the model with adjusted ratings should improve the overall model fit: Concretely, the second model should have a lower AIC and BIC than the other models.
AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) allow for the comparison of non-nested models, so they are useful for swapping out variables with others. BIC tends to favor more parsimonious models, whereas AIC values reducing the log-likelihood. For both information criteria, a difference in value less than two between models suggests their equality (i.e., evidence for the null hypothesis). A difference greater than four suggests the model with the lower value is “considerably” better (Fabozzi, Focardi, Rachev, and Arshanapalli Reference Fabozzi, Focardi, Rachev and Arshanapalli2014, 401–403).
Senatorial word choice: The qualifications and non-qualifications frames
Do senators speak differently in confirmation hearings because of who the nominee is? Dancey, Nelson, and Ringsmuth’s (Reference Dancey, Nelson and Ringsmuth2014, Reference Dancey, Nelson and Ringsmuth2020) work on lower court hearings suggests the answer is no: It’s Not Personal; it’s politics. While altering some of Dancey, Nelson, and Ringsmuth’s research design, I retain their basic approach, including their theoretical logic and independent variables of interest. The results point to senators’ adoption of more personalized approaches to nominees than Dancey, Nelson, and Ringsmuth’s findings suggest.
Why do senators mention a particular topic more often in a confirmation hearing as opposed to another? I contend that there are two frames – alternative sets of “terms in which equivalent choices are described” (Iyengar Reference Iyengar1987, 11; Kahneman and Tversky Reference Kahneman and Tversky1984) – that senators can use in their hearing speech. One frame more heavily emphasizes nominee qualifications – even if qualifications are not the main thrust of the questioning. The other frame de-emphasizes qualifications talk in favor of other politically salient terms. The contention is broadly consistent with Dancey, Nelson, and Ringsmuth’s (Reference Dancey, Nelson and Ringsmuth2014, Reference Dancey, Nelson and Ringsmuth2020) and Collins and Ringhand’s (Reference Collins and Ringhand2013) question coding schemes.
First, in the qualifications frame, senators exercise their advice and consent role by mentioning the nominees’ professional backgrounds and temperaments. In both their preliminary comments and direct questions, the senators will talk about the nominees’ experiences, making references to their legal training, academics, intellect, compassion, and courtesy. The ostensible motivation behind this type of talk is to establish the nominees’ fitness for judicial office, independent of the decisions they will make once on the bench. Given that every nominee to the federal bench has a law degree and some further legal experience, senators will more likely use qualifications words to bolster nominees than denigrate them, all else equal. Indeed, Dancey, Nelson, and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2020, 81) observe, “senators from the president’s party can facilitate the confirmation of … policy allies by highlighting nominees’ qualifications.”Footnote 7 Senators thus use the frame to achieve indirectly their goal of good public policy (Fenno Reference Fenno1978). Hypothetically, senators ideologically proximate to the nominee will use more qualifications frame words than senators who are ideologically distant.
Second, in the non-qualifications frame, senators talk to nominees about anything but qualifications. Typically, they focus on hot-button judicial issues (e.g., the death penalty or the Violence Against Women Act in the late-1990s to the rights of detainees or disadvantaged groups in the 2000s). Through the non-qualifications frame, senators view the confirmation hearing as both a platform to espouse their reading of the law (i.e., position-taking) and a last-ditch effort to paint nominees as “outside the mainstream,” claiming credit if nominees ultimately do not move forward in the process (Mayhew Reference Mayhew2004; Steigerwalt Reference Steigerwalt2010). Thus, senators ideologically farthest away from the nominee will use fewer qualifications words.
Although the sincere qualifications and non-qualifications frame hypotheses are straightforward, they ignore the potential influence nominees’ actual qualifications might play in altering senators’ word choices. Put simply, highly qualified nominees’ résumés might force senators to take notice of them, thereby drawing senators from the non-qualifications frame into the qualifications frame. Senators already opposed to confirmation can easily ignore less-qualified nominees’ résumés. Informing this logic, Dancey, Nelson and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2020, 105) present results “consistent with a staffer who told us that objections to lower court nominees are ‘very rarely on the merits’” (i.e., qualifications-driven). Ideologically opposed senators may also look at nominees with thin credentials as especially good targets for issue-based questioning. Not providing adequate answers to salient legal questions embarrasses nominees who lack extensive legal backgrounds to bolster their prima facie case for confirmation. So, there is good reason to believe that ideological distance and nominee qualifications interact in a specific way: Ideologically distant senators will use fewer qualifications words with less-qualified nominees than they will with highly qualified nominees.
Note that the theory does not imply the converse conditional effect. Nominee qualifications should not affect ideologically close senators’ word choice. Consider the upside of talking about technical legal matters with less-qualified nominees if senators want the nominees confirmed: At best, the nominees show that they are conversant on legal topics. But, given that an ideologically proximate senator engages the nominees, the conversation will not likely impress any undecided senators necessary for confirmation. The downside is steep: Nominees flub “softball” questions on the law from friendly senators, effectively “striking out” at their confirmation chance. The safest play is for ideologically close senators to mention qualifications no matter the nominees’ backgrounds, reiterating the prima facie confirmation case for highly qualified nominees and bolstering less-qualified nominees. Therefore, the null hypothesis – no difference in the number of qualifications words for ideologically close senators across levels of nominee qualifications – should find support.
Though they were for district court seats, two recent SJC hearings, both featuring Senator John Kennedy (R-LA), illustrate the different expectations well. In 2017, faced with a panel of five Trump nominees, Senator Kennedy began his questioning by probing their backgrounds. Matthew Petersen was the only nominee who answered that he had not tried a case to verdict. After 12 more questions about Petersen’s background, Kennedy then asked three questions about judicial decision making – what the Daubert standard for expert witnesses was, what a motion in limine was, and what the Younger and Pullman abstention doctrines were – that Petersen utterly failed to address (NOLA.com 2017).
In contrast, Kennedy began a 2023 hearing with five Biden nominees by bypassing any questions about their qualifications. After perfunctorily addressing her as “judge,” Kennedy asked Washington state court Judge Charnelle Bjelkengren what Articles V and II of the Constitution covered and what “purposivism” in judging was. Judge Bjelkengren, like Petersen, did not attempt to explain or define the passages and concepts Kennedy asked about.
Several important facets of the two hearings deserve highlighting. First, consistent with the theoretical expectations, Kennedy spent ample time talking about the qualifications of the eventually embattled Trump nominee Petersen. Only after firmly establishing the nominee’s background did Kennedy ask the procedural questions, and Petersen could have coasted to confirmation if he had been able to answer them. Second, and also consistent with expectations, Kennedy did not spend any time on the Biden nominees’ backgrounds; rather, he presented them with questions about conservative judicial priorities right away, including the difference between purposivism and originalism. Finally, all nominees in the two hearings who engaged with Kennedy – Petersen, Bjelkengren, Matthew Brookman, and Oriela Eleta Merchant – consistently referred to their own qualifications in their responses, again demonstrating that, in SJC hearings, qualifications talk is overwhelmingly more often a shield than a sword.
Data and measures
To determine why senators mention qualifications-related words, I machine coded all of the confirmation hearings for circuit court nominees held between 1997 and 2012.Footnote 8 The dependent variable is a count of the qualifications-related words a senator spoke in a hearing. I identified terms related to judicial qualifications and experience in part by taking the beginning fragments of words from the ABA’s backgrounder on how it rates nominees (American Bar Association, 2020). I included some word fragments inductively after reading several presentations of nominees.Footnote 9
Following Dancey, Nelson, and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2020), I split the independent variables of theoretical interest into two groups: nominee-specific factors and contextual factors.Footnote 10 Nominee-specific factors begin with ideological distance, which is the absolute value of distance between the speaking senator’s Common Space score (Poole Reference Poole1998) and the nominee’s Common Space score, calculated using the method Giles, Hettinger, and Peppers (Reference Giles, Hettinger and Peppers2001) suggest. The GHP method leverages the norm of senatorial courtesy in nominations by assigning nominees the Common Space of their home-state senator if the senator is a member of the president’s party – or the average of the two home-state senators if both are members of the president’s party. If both home-state senators are of the party opposite the president, then the nominee receives the president’s Common Space score. Because theory suggests that senators will use fewer qualifications words with any ideologically distant nominee, regardless of direction of the distance, the absolute value is appropriate.
The second nominee specific factor, qualifications, includes three distinct measurements, each estimated in a separate model. The first is raw ABA rating, which ranges from 1 (“qualified-not qualified”) to 5 (“well-qualified”) in the analysis because I exclude the Wallace hearing. Second is the adjusted ABA rating, which ranges from -2.24 to 3.23. Third, proxy indicators can represent qualifications. For this approach, I include the same experience variables – years as a federal judge, state judge, private practice, and government attorney; experience as a law professor, federal clerk, and in partisan politics; and graduation from a Top 14 law school – used to derive the adjusted ABA ratings. To test the conditional hypotheses, I interact each qualifications measure with ideological distance.
The remaining nominee-specific and contextual factors are of less importance to demonstrating the usefulness of adjusted ABA ratings, so I condense their discussion. The third nominee-specific factor is whether there is at least one senator of the opposition party to the president representing the nominee’s home state. Dancey, Nelson, and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2020) argue that the presence of an opposition party home state senator can moderate the nominee’s ideology; therefore, senators will use more qualifications frame words with such nominees. Demographic variables round out the nominee-specific factors. I include indicators for non-white or female identity, as well as nominees’ age and the square of age.
The contextual factors are the same four variables that Dancey, Nelson, and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2020) use, plus an additional one due to this study’s slightly wider scope. Whether the hearing occurs during a presidential election year or divided government should reduce the number of qualifications words, given that both contexts heighten senators’ ideological concerns. Panel balance – the existing difference between the fraction of active judges on the circuit appointed by Democratic presidents and the fraction appointed Republican presidents (Binder and Maltzman Reference Binder and Maltzman2009a) – can affect the number of qualifications words. As panel balance approaches zero (i.e., a 50–50 split), a new judge will tip the panel in one party’s favor. Hence, in this ideologically charged context, qualifications talk will likely recede. Dancey, Nelson, and Ringsmuth (Reference Dancey, Nelson and Ringsmuth2020) also include the interaction between divided government and panel balance to capture particularly intense ideological contexts. The two other contextual variables are indicators for nominees to the DC and Federal Circuits, both due to the unique nature of their circuits: the “prestige and salience” of the DC Circuit (Dancey, Nelson, and Ringsmuth Reference Dancey, Nelson and Ringsmuth2020, 85) and the technical backgrounds of Federal Circuit judges (Handler Reference Handler2022).
For pure controls, I include first whether the speaker is in the majority party of the Senate at the time of the hearing. The presenter, often a senator, introduces the nominee to the committee by recounting the nominee’s biography, thus increasing the number of qualifications-related words used. The chair of the hearing, as identified by the hearing transcript, presides over the hearing, recognizing the order of speakers and keeping time. I include the log of the total words spoken by a senator during a hearing and whether it was the second hearing for the nominee. The former variable ensures that verbose senators, who in their logorrhea happen to use some qualifications-related words as well, do not produce spurious results. The latter variable is important because the senators may dispense with many qualifications references in a second hearing, having already heard them in the first.
Methods and results
Because the dependent variable is a count, I estimate three negative binominal regressions, replacing different measures of qualifications in each. The first model uses raw ABA ratings, the second uses adjusted ABA ratings, and the third uses proxy indicators. In all models, I clustered standard errors on the date of the hearing. In some cases, the SJC considered and questioned multiple nominees in the same hearing, though each nominee counted as a separate set of observations. Thus, the errors in qualifications-related words are likely correlated within the hearing itself. Table 4 displays the regression estimates for the different qualifications measures and ideological distance.Footnote 11
Table 4. Negative Binomial Regression Results, Limited to Qualifications Measures. The dependent variable is a count of the number of qualifications-related words a senator used in a nominee’s hearing. Model I uses unadjusted ABA ratings. Model II uses adjusted ABA ratings. Model III uses multiple measures of nominee qualifications

Notes: *: p<0.05 **: p<0.01 (two-tailed)
Before discussion of the independent variables’ effects, a comparison of the models is necessary to see which approach to modeling qualifications best fits the data. The proxy indicators model (Model III) has the lowest AIC, suggesting the best model fit. However, the adjusted ABA ratings model (Model II) fares best under BIC, the information criterion that favors more parsimonious models. Indeed, with respect to BIC, Model III is the worst-fitting model. Both the AIC and BIC difference between Models I and II is greater than four, which is “considerabl[e]” and positive evidence that Model II fits better than Model I (Fabozzi et al. Reference Fabozzi, Focardi, Rachev and Arshanapalli2014, 401–403). Model II is not the worst-fitting model under either criterion. It is distinguishably the best under the more exacting BIC.
Though they fit the data best, do adjusted ABA ratings change anything substantive about the interpretation of qualifications’ role in the confirmation process? They do, considering the difference in effects displayed in Figure 2. While the sincere qualifications frame and non-qualifications frame hypotheses find support in Model I – the effect of ideological distance is negative and statistically significant – the conditional hypothesis finds barely marginal support. The interaction between qualifications and ideological distance is not statistically significant.Footnote 12 Yet, in Model II, both the sincere and conditional hypotheses find clear and strong support. The effect of ideological distance is effectively the same in both models; however, the interaction between ideological distance and qualifications is positive and statistically significant in the adjusted ABA ratings model.Footnote 13 The results suggest that the background of highly qualified nominees can, in fact, influence senators’ speech in the confirmation hearing. The finding contrasts with Dancey, Nelson, and Ringsmuth’s (Reference Dancey, Nelson and Ringsmuth2014, Reference Dancey, Nelson and Ringsmuth2020) findings that individual nominees’ characteristics do not influence senators’ questioning.
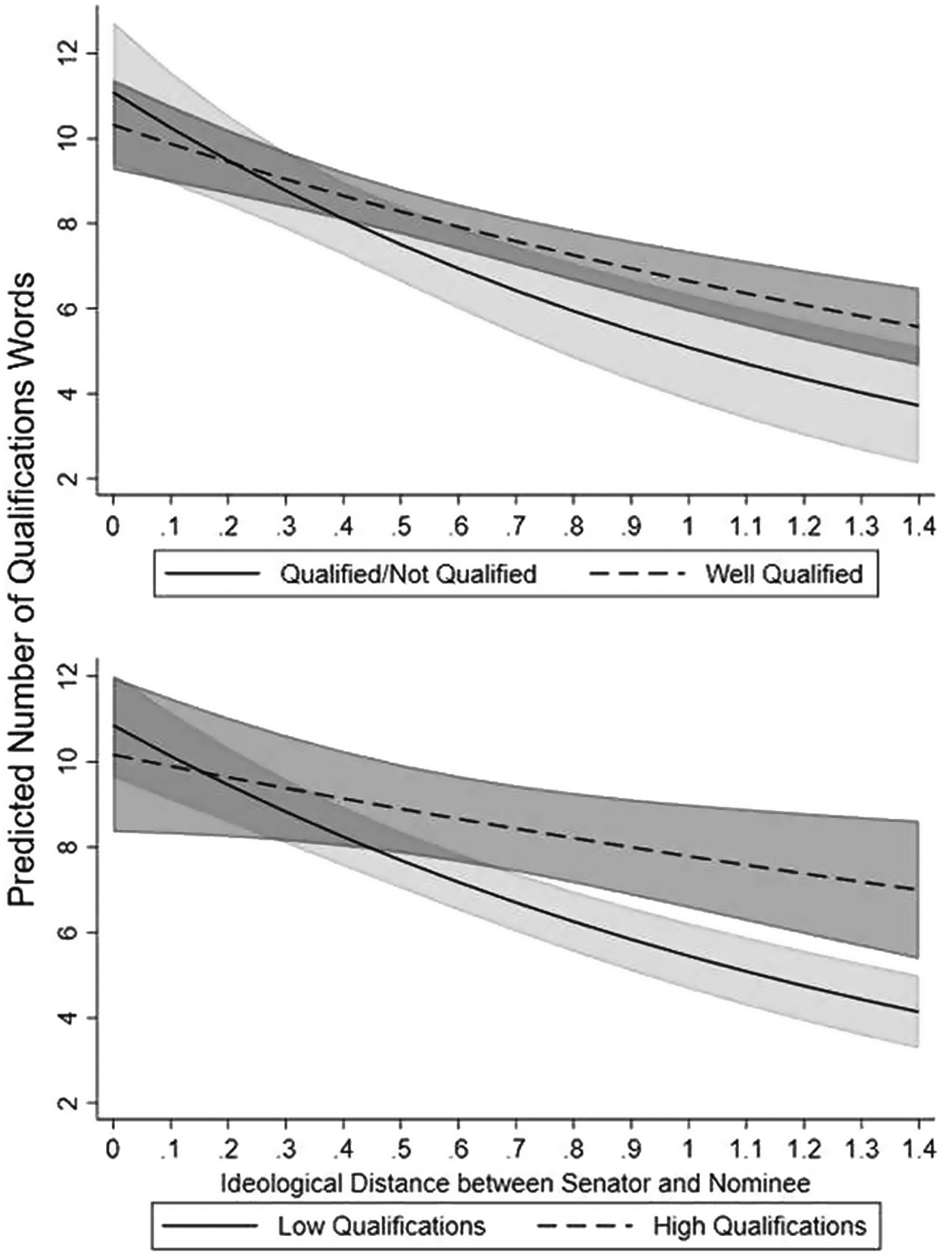
Figure 2. Comparison of the Substantive Effect of Qualifications and Ideological Distance. The top panel displays the substantive change in ideological distance for “well qualified” (dashed line) and “qualified-not qualified” (solid line) qualified nominees from Model I. The bottom panel shows the same for high (+2 standard deviations) and low (-1 standard deviation) qualified nominees from Model II. The shaded regions represent the predictions’ 95% confidence intervals.
Figure 2 shows how the introduction of adjusted ABA ratings changes the substantive interpretation of qualifications’ role in SJC hearings. In both panels, the predicted number of qualifications-related terms are plotted against increasing ideological distance between the senator and the nominee. To provide some context for the substantive discussion, the model predicts that nominee presenters – ordinarily home-state senators whose one job is to provide the SJC with background information on the nominee – will use 12.8 qualifications words. The ideologically closest presenters, senators whom the GHP measure assumes have essentially made the nomination themselves, will use 16.5 qualifications words, while the ideologically farthest presenters, senators from the nominee’s home state but not of the president’s party, will use 8.7 qualifications words.Footnote 14
In the top panel of Figure 2, the dashed line represents the predictions for a “well qualified” nominee, and the solid line represents a “qualified-not qualified” nominee, the lowest ABA category used in Model I’s estimation. A senator at minimal ideological distance is expected to use 10.31 qualifications-related words for a “well qualified” nominee and 11.08 for a “qualified-not qualified” nominee. The difference is not statistically significant (
 $ {X}_{(1)}^2 $
= 0.51, p>0.47). At maximum ideological distance, a senator will use 5.57 qualifications words for a “well qualified” nominees and 3.72 for “qualified-not qualified” nominees. The 40 percent difference reaches conventional levels of statistical significance (
$ {X}_{(1)}^2 $
= 0.51, p>0.47). At maximum ideological distance, a senator will use 5.57 qualifications words for a “well qualified” nominees and 3.72 for “qualified-not qualified” nominees. The 40 percent difference reaches conventional levels of statistical significance (
 $ {X}_{(1)}^2 $
= 4.12, p<0.05). The differences between minimum and maximum levels of ideological distance within each ABA rating are statistically significant (
$ {X}_{(1)}^2 $
= 4.12, p<0.05). The differences between minimum and maximum levels of ideological distance within each ABA rating are statistically significant (
 $ {X}_{(1)}^2 $
= 30.13, p<0.01 for “well qualified”;
$ {X}_{(1)}^2 $
= 30.13, p<0.01 for “well qualified”;
 $ {X}_{(1)}^2 $
= 29.50, p<0.01 for “qualified-not qualified”). Thus, individual nominees matter mostly to the extent that their ideology diverges from the senator, a finding consistent with the It’s Not Personal argument.
$ {X}_{(1)}^2 $
= 29.50, p<0.01 for “qualified-not qualified”). Thus, individual nominees matter mostly to the extent that their ideology diverges from the senator, a finding consistent with the It’s Not Personal argument.
In contrast, the bottom panel, created using estimates from Model II, shows strong support for the conditional hypothesis. Because the adjusted ABA ratings do not fall into discrete categories, the dashed line represents a nominee one standard deviation below the mean qualifications. The solid line represents a nominee two standard deviations above the mean.Footnote
15 At the minimum of ideological distance, there is still no statistically significant difference between higher- and lower-qualified nominees. With highly qualified nominees, senators use 10.16 qualifications-related words, and they use 10.85 words with low-qualified nominees (
 $ {X}_{(1)}^2 $
= 0.29, p>0.58). Like Model I, ideologically close senators mention qualifications almost as much as the average presenter does.
$ {X}_{(1)}^2 $
= 0.29, p>0.58). Like Model I, ideologically close senators mention qualifications almost as much as the average presenter does.
But, at maximum ideological distance, there is a statistically and substantively significant difference between high and low qualifications. While an ideologically distant senator uses 4.13 qualifications-related words – about 47.5 percent of an ideologically-distant presenter – with nominees who have relatively thin résumés, the same senator uses 7.00 qualifications words with highly qualified nominees. The 69 percent increase in qualifications word usage is statistically significant (
 $ {X}_{(1)}^2 $
= 7.74, p<0.01). Substantively, the 2.87-word increase makes the ideologically distant senator’s speech resemble 80.5 percent of an ideologically distant presenter’s speech in terms of qualifications mentions.Footnote
16 The differences between highly- and low-qualified nominees are statistically significant for all values of ideological distance greater than 0.60, which account for 47 percent of all observations.
$ {X}_{(1)}^2 $
= 7.74, p<0.01). Substantively, the 2.87-word increase makes the ideologically distant senator’s speech resemble 80.5 percent of an ideologically distant presenter’s speech in terms of qualifications mentions.Footnote
16 The differences between highly- and low-qualified nominees are statistically significant for all values of ideological distance greater than 0.60, which account for 47 percent of all observations.
For highly qualified nominees, the 3.18-word decline in qualifications frame mentions between an ideologically proximate senator and an ideologically distant senator is statistically significant (
 $ {X}_{(1)}^2 $
= 4.86, p<0.05).Footnote
17 For low-qualified nominees, the difference is also statistically significant (
$ {X}_{(1)}^2 $
= 4.86, p<0.05).Footnote
17 For low-qualified nominees, the difference is also statistically significant (
 $ {X}_{(1)}^2 $
= 60.88, p<0.01), but the magnitude of the decline is over 110 percent larger: 6.72 words.Footnote
18 Substantively, the decline represents moving from 85 percent to under one-third of the average presenter’s speech. In short, the Model II results demonstrate that nominees’ backgrounds can influence the frame senators use, a clear contrast to Dancey, Nelson, and Ringsmuth’s (Reference Dancey, Nelson and Ringsmuth2020) conclusions.Footnote
19
$ {X}_{(1)}^2 $
= 60.88, p<0.01), but the magnitude of the decline is over 110 percent larger: 6.72 words.Footnote
18 Substantively, the decline represents moving from 85 percent to under one-third of the average presenter’s speech. In short, the Model II results demonstrate that nominees’ backgrounds can influence the frame senators use, a clear contrast to Dancey, Nelson, and Ringsmuth’s (Reference Dancey, Nelson and Ringsmuth2020) conclusions.Footnote
19
Discussion
This study makes two substantive contributions to the study of lower courts and the lower court confirmation process. First, it created a single valid and reliable measure of qualifications for nominees to the circuit courts. It then tested the measure against two alternative operationalizations of qualifications: the existing raw ABA ratings and a proxy indicators approach. The adjusted ABA ratings fit the data better on balance than either of the other two approaches. In future studies, when appropriate, researchers can use the adjusted ABA ratings as a common, consistent measure of qualifications, which will allow studies to build on each other directly.
Second, the study contributes the data and findings with respect to the content of confirmation hearings. It showed that ideology is a driving force behind the choice senators make to mention qualifications. It further showed that nominees’ backgrounds, if sufficiently impressive, could induce senators to mention their qualifications. Moving from a low-qualified nominee to a highly qualified nominee results in a 69 percent increase in the number of qualifications-related words used by each senator in the hearing. A finding of this magnitude does not appear using raw ABA ratings. The significant left-skew and blunt categorization of ABA ratings obscure the actual information transmitted to senators. The adjusted ratings strip the noise related to ideology and skewness, leaving a signal that is closer to the information gathered by senators and their staff while evaluating nominees. The findings also contrast with the notion that lower court confirmation hearings are not personal (Dancey, Nelson, and Ringsmuth Reference Dancey, Nelson and Ringsmuth2014, Reference Dancey, Nelson and Ringsmuth2020).
On a higher level, the research highlights the close connection between qualifications and politics. Political considerations characterize the path to a seat on the lower federal courts. The equivocal findings of research into qualification effects in the confirmation process and on judicial behavior reinforce the link between ideology and qualifications. Disentangling qualifications and politics is key to doing methodologically sound social science to answer questions about the federal judiciary. Although a disentangled measure exists for Supreme Court justices and nominees (Cameron, Segal, and Songer Reference Cameron, Cover and Segal1990), none existed for judges on the circuit courts. None still exists for the district court.
Adjusted ABA ratings do not reveal the content of the confidential interviews that apparently can cause members of the SCFJ to switch their votes on nominees (Tober Reference Tober2006). Knowing the factors and personalities that enter the ratings’ formulation can lead to their better consumption by journalists, senators, and presidents. Because it appears that the original investigator, along with the committee, influence the rating, the research can lead to better procedures within the SCFJ itself, which are already under discussion (Little Reference Little2001; Sieja Reference Sieja2023b). If “the quality of our judges … is … the quality of our civilization,” then we should know “the significance of” the quality “measures which are taken” (Leflar Reference Leflar1960, 305; Mott Reference Mott1948, 262).
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/jlc.2023.19.
Acknowledgements
I thank Brad M. Jones for his programming expertise. I thank Ronnie Olesker, Nancy Scherer, Justin Wedeking, Steve Wasby, Logan Dancey, Ken Mayer, Alex Tahk, Ryan Owens, Ellie Powell, Sida Liu, and anonymous reviewers at this and other journals for their encouragement, insight, and suggestions. I presented earlier versions of this research at the 2014 and 2015 Midwest Political Science Association Meetings and the 2014 American Political Science Association Meeting.
Funding declaration
The author received no financial support for the research, authorship, and/or publication of this article.
Competing interest declaration
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All data to reproduce the tables and figures in this publication will be available on the author’s website and the Journal’s Dataverse archive.








