


1 Introduction
Modality in English language studies is by now a well-established field of linguistic enquiry. A canon of research exists that documents functional categorisations, formal properties and ongoing change in the expression of modality. Such research centres on the semantic functions of modality, which some researchers (e.g. Krug Reference Krug2000; Palmer Reference Palmer2001, Reference Palmer2003; Facchinetti & Palmer Reference Facchinetti, Krug and Palmer2003; Leech Reference Leech2003; Collins Reference Collins2009; Marín Arrese et al. Reference Marín Arrese, Carretero, Hita and van der Auwera2013) categorise as epistemic, deontic and dynamic. Categorically, modality in English is usually conceptualised as pertaining to the core modal auxiliaries (e.g. can), semi-modals (e.g. ought to) and lexical modals (e.g. certainly); although, of these sets of modal expressions, only the core modal auxiliaries are consistently categorised as such in the literature. These sets of modal expressions have been at the centre of studies of language and language change, with seminal research debating whether the core modal auxiliaries are in decline (e.g. Leech Reference Leech2003, Reference Leech2011, Reference Leech2013; Millar Reference Millar2009). Yet, as a linguistic phenomenon, modality remains relevant and pertinent, with many avenues for further research, not least because of the ongoing technical and theoretical developments in the field of corpus linguistics.
Typically, research on modality has centred on written language, owing to the limited availability of representative spoken language data. However, with the advent of new spoken corpora, such as The Spoken British National Corpus 2014 (Spoken BNC2014, Love et al. Reference Love, Dembry, Hardie, Brezina and McEnery2017; McEnery et al. Reference McEnery, Love, Hardie, Brezina, Dembry and Timperley2017) and The London–Lund Corpus 2 (Põldvere et al. Reference Põldvere, Johansson and Paradis2021), there is further scope to better understand and document spoken modality in British English as well as diachronic changes when compared to the Spoken BNC1994 (BNC Consortium 2007), for example. Such a diachronic perspective will offer an important contribution to research on modality, as there is an evident dearth in knowledge surrounding contemporary spoken use of modality in British English, as well as an understanding of how this use may have changed over time. Moreover, while it has long been recognised that modality can be classified according to semantic function (von Wright Reference von Wright1951), research in the field tends to formally group and classify modality into sets on lexical syntactic grounds (core modal auxiliary, semi-modal, lexical modal; Leech Reference Leech2003, Reference Leech2013). Consequently, such studies of modality typically make claims surrounding modal behaviour and change with reference to these sets, which may limit our understanding of general functional behaviour and change in English modality. Advances in corpus pragmatics encourage researchers to consider both form–function and function–form relationships (Aijmer & Rühlemann Reference Aijmer and Rühlemann2014a; O'Keeffe Reference O'Keeffe, Jucker, Schneider and Bublitz2018; Curry Reference Curryforthcoming) in order to gain a more nuanced perspective on the language being studied. To date, a comprehensive perspective on both formal and functional change in modality in contemporary British English is absent from the literature.
This study seeks to contribute such a perspective through a diachronic investigation of modality using a relatively new corpus of contemporary spoken British English, the Spoken BNC2014. The Spoken BNC2014 comprises 11.5 million tokensFootnote 2 of transcribed informal spoken British English, as recorded by hundreds of participating members of the public in the UK (mainly in England) (Love Reference Love2020). By comparing the Spoken BNC2014 to its predecessor, the Spoken BNC1994 (BNC Consortium 2007), it is possible to explore recent change in modality in informal British English between the 1990s and 2010s.
To do this, this article presents a literature review underpinning our theoretical perspective on modality, research on documented change in written and spoken modality, and the current state of the art of modality research in spoken British English (section 2). Subsequently, section 3 presents the data and methodology, outlining the corpus data, the modality-indicating devices studied, and the methodology for analysing the modal expressions in terms of their frequency and modal function (epistemic, deontic, dynamic). Section 4 presents our findings regarding changes in the use of the modal expressions, which suggest that changes in modality are not consistent within formal sets, and that by considering modals on a case-by-case basis, it is possible to see more coherent trends in modal function use. These findings are discussed in section 5 together with a brief conclusion outlining the empirical and methodological contributions of this article and highlighting future directions for the study of modality.
2 Literature review
In this section, we discuss a range of definitions for modality and its classifications, leading us to make the case that conceptual inconsistency in the literature creates a challenge for diachronic studies of modality such as the present one. We then survey corpus research into modality in written and spoken English, before presenting our research questions.
2.1 Modality in English: forms and functions
Modality is the linguistic means of indicating a speaker's attitude or point of view on a state of the world (Carter & McCarthy Reference Carter and McCarthy2006: 638). It is widely considered to have two subtypes: grammatical mood (verb inflections) and a lexical ‘modal system’ (Palmer Reference Palmer2003: 2–3); Present-day English (PDE) is considered not to have a grammatical mood, but rather a modal system (Palmer Reference Palmer2003: 3). While several members of the English modal system – modal auxiliaries and clitics – ‘enjoy a rather advanced grammaticalized status’ (Krug Reference Krug2000: 40), and have received a lot of attention in research, there are also the less grammaticalised (i.e. lexical) ‘modal constructions’ (Krug Reference Krug2000: 40) (e.g. I think) as well as the so-called ‘semi-modals’ (Leech Reference Leech2003: 229) (e.g. used to). In this article, we refer to any item that functions to express modality, regardless of form, as a modality-indicating device (MID), a term we adopt from Mubarak (Reference Mubarak2015).
Modality is typically classified according to function; this convention can be attributed to von Wright (Reference von Wright1951), who proposed four categories of ‘modal logic’ (Reference von Wright1951: 1): alethic, epistemic, deontic and existential. Alethic modality is concerned with ‘the modes in which a proposition is (or is not) true’; epistemic modality concerns ‘the modes of knowing’; deontic modality the ‘modes of obligation’; and existential modality ‘the modes of existence’ (von Wright Reference von Wright1951: 1–2). In subsequent research, the ‘major distinction’ came to be between epistemic and deontic modality (Krug Reference Krug2000: 41), with the other two categories receiving less attention, possibly because epistemic modality could be said to have subsumed alethic modality, and because existential modal expressions are less common. This approach can also be seen in work by Coates (Reference Coates1983), Perkins (Reference Perkins1983), Nordlinger & Traugott (Reference Nordlinger and Traugott1997), Palmer (Reference Palmer2001) and Fairclough (Reference Fairclough2003).
According to Palmer (Reference Palmer2003: 7), epistemic modality ‘is concerned solely with the speaker's attitude to [the] status of the proposition’ (e.g. They may be in the office), while deontic (root) modality is concerned with the subject's ability to do something as permitted by an external source (e.g. They can come in now). Palmer (Reference Palmer2001: 24) classifies epistemic modality as a type of ‘propositional modality’; this is contrasted to ‘event modality’ (Palmer Reference Palmer2001: 70), which comprises deontic modality and another type, dynamic modality, which is concerned with ‘the subject's own (internal) ability’ (e.g. They can run very fast) (Palmer Reference Palmer2003: 7).
An alternative framework for modality is described by Bybee et al. (Reference Bybee, Pagliuca and Perkins1991: 23), who distinguish three types of modality: agent-oriented, epistemic and speaker-oriented, but exclude deontic modality, as it ‘cuts across the modality domain in a way that is not cross-linguistically valid’. Despite this framework appearing to represent a different view of modality, Krug (Reference Krug2000: 42) suggests that Bybee et al.'s framework does, nonetheless, adhere to the traditional view of the modal system, since ‘the concept of agent-oriented modality overlaps to a great extent with the concept of deontic modality’.
How modality research has addressed and labelled such functions has been inconsistent, with a range of terminology with overlapping senses used to categorise modal function. On the other hand, generally speaking, it appears that epistemic, deontic and dynamic modalities are accounted for in some way across most studies. Furthermore, there is similar inconsistency when it comes to the categorisation of MIDs across the three formal categories of core modal auxiliary, semi-modal and lexical modal expression. For example, those who follow Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985) might draw distinctions between semi-modals and lexical modals by arguing that the likes of marginal modals, semi-auxiliaries and modal idioms are not lexical items and therefore would not be considered lexical MIDs. A similar view is shared by Bolinger (Reference Bolinger, Brettschneider and Lehmann1980: 297), who argues that verbs that perform modality (e.g. need) and have some form of infinitive complement can be seen as modal auxiliaries or semi-modals. However, Carter & McCarthy (Reference Carter and McCarthy2006) do not share this view, and instead draw a distinction between semi-modals and lexical modal verbs by identifying shared syntactic features between core modal verbs and semi-modals (e.g. the lack of auxiliaries in forming negatives or questions). Moreover, Leech (Reference Leech2013) identifies categories such as ‘emergent’ modals; includes need and ought to among core modals; and includes a range of lexical modal verbs among his set of lexical modal expressions. Making sense of these varied categorisations has proven difficult, and the incoherence between the ways in which MIDs are formally grouped poses challenges for comparing findings across a range of studies. In this article, we endeavour to consider both formal and functional categorisations of MIDs, and ultimately argue that functional perspectives may better serve to avoid such incoherence. We discuss our approach to the categorisation of both modal forms and functions in section 3.
2.2 Corpus research on modality in British English
The following section reviews several corpus studies that have investigated modality in recent British English.
2.2.1 Modality in written British English
Due to the wider availability of written (as opposed to spoken) English corpora, corpus-based research into change in modality in contemporary British English has been concerned mostly with written English. The research in this area points towards a general pattern of decline from the middle of the twentieth century. Leech (Reference Leech2003) examined change in the use of modal auxiliaries (e.g. may, should, must) and semi-modals/‘emergent’ modals (e.g. be able to, be going to, have got to) in British and American written English between the 1960s and 1990s, using four corpora: LOB, Brown, FLOB and Frown (the ‘Brown quartet’, Bowie et al. Reference Bowie, Wallis and Aarts2013: 58). Leech found that modal auxiliaries had decreased significantly in frequency in written British English and that, simultaneously, semi-modals had increased significantly. This finding was questioned by Millar (Reference Millar2009) who, by investigating the much larger TIME Magazine Corpus (Davies Reference Davies2007), found an overall pattern in growth between the 1920s and the 2000s. In response to Millar (Reference Millar2009), Leech (Reference Leech2011) asserted that the variation observed in the TIME Magazine Corpus (comprising just one genre of written American English) could not be assumed to be representative of English in general, and (using newly compiled Brown Family corpora from the 1900s and 1930s) argued that modal verbs had decreased in usage in British and American English during the latter half of the twentieth century, having peaked somewhere between the 1930s and 1960s. In addition, beyond the core modals and semi-modals, Leech (Reference Leech2013: 108) provided further evidence of a decline in modality by examining a set of nearly 40 ‘lexical expressions of modality’ (e.g. be obliged to, certainly, perhaps, seem), observing a decrease of almost 12 per cent over a 75-year period.
In offering possible explanations for the decline of core and lexical modality (and the rise of semi-modals) in written English, Leech (Reference Leech2003) demonstrates that modal semantics is often involved in frequency change (i.e. the change in frequency of a particular semantic function drives an overall change in frequency). For example, the decline of may and should can be explained by ‘a trend towards monosemy’, whereby the dominant function becomes even more dominant and the minor functions become less frequent (Leech Reference Leech2003: 234). Furthermore, Leech (Reference Leech2013) draws upon the theories of colloquialisation (e.g. Mair Reference Mair and Ljung1997; Hundt & Mair Reference Hundt and Mair1999; Leech et al. Reference Leech, Hundt, Mair and Smith2009) and grammaticalisation (e.g. Hopper Reference Hopper1991; Rohdenburg Reference Rohdenburg1995; Krug Reference Krug2000) to present
the most plausible explanation … that grammaticalization of the emergent modals in speech has been associated with increasing frequency, progressively leading to competition with the core modals, which consequently have been undergoing decline in recent English. (Leech Reference Leech2013: 114)
Although we are only interested in spoken (and not written) British English in this article, our brief review of research on modality in written English suggests, through the theory of colloquialisation, that changes in spoken English modality may lead the way for changes in written modality. Therefore, the overall trends observed in written British English are worth discussing, as the changes we observe in present-day spoken English may serve to predict near-future developments in written English. However, it is worth remembering that the verbs that Leech includes in these formal sets of semi-modals and lexical expressions of modality differ from those used in other research on modal forms, rendering much of the literature in this area difficult to compare.
2.2.2 Modality in spoken British English
Although most of Leech's (Reference Leech2003) research focused on written English, he also conducted an analysis of modality in spoken British English, using two 80,000-word samples from the Diachronic Corpus of Present-day Spoken English (DCPSE; Aarts et al. Reference Aarts, Wallis, Bury, Kirk, Kostadinova–Kavalova, Law and Ozón2002), one each from the first London–Lund Corpus (LLC–1; Svartvik Reference Svartvik1990) and ICE-GB (Nelson et al. Reference Nelson, Wallis and Aarts2002) subcorpora. Considering the dearth of available spoken data from time periods comparable to the LOB/Brown (1960s) and F-LOB/Frown (1990s) corpora, the use of such small datasets is understandable; nonetheless, the extent to which we ought to generalise Leech's (Reference Leech2003: 231) finding – a 17.3 per cent decrease in the use of core modals between the DCPSE samples – should be considered. This limitation is discussed by Leech (Reference Leech2013), who shows that, when frequencies of the core modals and semi-modals are combined, there is only a non-significant decrease in overall modal frequency between the DCPSE samples, ‘so we must assume that the case for a “modality deficit” in the spoken data … is unproven’ (Leech Reference Leech2013: 107). The same caution can be applied to the claims of Smith (Reference Smith2003), who used the same corpus samples to analyse the use of the ‘obligation/necessity markers’ (i.e. deontic modality): must, need, (have) got to, have to and need to; in the spoken data, Smith (Reference Smith2003) reports a decrease of 11.7 per cent between the DCPSE samples. Leech's recognition of the impact of formal groupings on observable trends is important, as the MIDs that constitute these formal sets may not behave homogeneously.
A much larger sample of spoken British English from the early 1990s was made available in the form of the Spoken BNC1994 (BNC Consortium 2007), facilitating fresh studies of modality with a more solid empirical foundation. Paradis (Reference Paradis2003), for example, examined the functions of adverb really in the LLC–1 and in COLT (the Bergen Corpus of London Teenage Language, Haslerud & Stenström Reference Haslerud, Stenström, Leech, Myers and Thomas1995), which is a subcorpus of the Spoken BNC1994. She finds that ‘really is pragmatically conditioned by the speaker's wish to qualify an expression epistemically with judgements of truth’ (Paradis Reference Paradis2003: 214). Nokkonen (Reference Nokkonen2006) also used COLT, in comparison with the LLC–1 (spoken) and LOB and FLOB (written) corpora, to examine the semantic functions of the semi-modal need to. She found that, of the four corpora, COLT had the strongest deontic examples of need to and also the most examples of the newly emerging epistemic function. Another example is Verhulst et al. (Reference Verhulst, Depraetere and Heyvaert2013), who used random samples of should, ought to and be supposed to from the BNC1994 to refine theoretical approaches to root necessity.
Leech (Reference Leech2013) used the demographically sampled subcorpus of the Spoken BNC1994 and the Santa Barbara Corpus of Spoken American English (SBCSAE; Du Bois et al. Reference Du Bois, Chafe, Meyer, Thompson, Englebretson and Martey2000–5) to compare modality in 1990s British and American English conversation. He found ‘a much higher incidence’ (Leech Reference Leech2003: 111) of semi-modals in these corpora compared to the much smaller DCPSE samples; this adds considerable weight to the observed pattern of increasing competition between the core and semi-modals. Leech (Reference Leech2013: 113) also conducted an apparent-time analysis of modals in the BNC data (using the age groups in the speaker metadata), which very clearly shows a rise in usage of semi-modals from the oldest to the youngest speakers, suggesting that the semi-modals have become more popular over time. Of course, it is worth noting that among Leech's semi-modals are forms such as going to, have to, need to, got to, be supposed to, be able to, while his core modals include the typical nine auxiliary verbs we might expect as well as ought and need (see table 2 in section 3.2.1 below).
Due to a dearth of available data, few studies have investigated modality in British English as spoken any later than the early 1990s, and most of those that have done so (e.g. Tagliamonte Reference Tagliamonte, Lindquist and Mair2004; Fehringer & Corrigan Reference Fehringer and Corrigan2015) have investigated a specific regional dialect of British English (York and Tyneside, respectively) rather than a national sample. However, Baker & Heritage (Reference Baker, Heritage, O'Keefe and McCarthyforthcoming) conduct a diachronic analysis of the modal may by comparing the Spoken BNC1994 and the Spoken BNC2014 (Love et al. Reference Love, Dembry, Hardie, Brezina and McEnery2017). They find that the overall usage of may is lower in the 2010s data, but that frequency is highly variable across speaker age groups. They also find some evidence of a functional shift in may, where polite requests (e.g. may I have some milk) have given way to hedging propositions (e.g. you may want to go).
In summary, it seems certain that there has been a decline in the usage of core and lexical MIDs, and a rise in semi-modals, in written British English, over the course of the twentieth century. There is some evidence of a more extreme version of this pattern in conversational British English (Leech Reference Leech2013), and there appear to be other functional effects that are most salient in speech (e.g. Nokkonen Reference Nokkonen2006). While some research has been conducted on modality in regional varieties of twenty-first-century spoken British English (e.g. Fehringer & Corrigan Reference Fehringer and Corrigan2015), or on a specific modal in national corpora (Baker & Heritage Reference Baker, Heritage, O'Keefe and McCarthyforthcoming), what is lacking is a general perspective on how modality in spoken British English has changed since the 1990s, and whether the attested patterns of the 1960s–90s have continued since then. The aim of this article is to investigate the expression of modality in spoken British English in the 1990s and 2010s. The release of the Spoken BNC2014 (Love et al. Reference Love, Dembry, Hardie, Brezina and McEnery2017) facilitates the comparison of informal spoken British English with its spoken counterpart from the BNC1994 (BNC Consortium 2007), affording a comparison of data from the 1990s and 2010s. By isolating one register of speech, we minimise unwanted variation that may be caused by genre differences (cf. Bowie et al. Reference Bowie, Wallis and Aarts2013). The trade-off of this approach is a sacrifice of genre representativeness; we acknowledge that we are not speaking of ‘spoken English’ in general but of a specific register – informal spoken British English (as spoken mainly in England; Love Reference Love2020).
2.3 Research questions
This study aims to provide a broad perspective on how modality may have changed in informal spoken British English since the 1990s. We explore this using the following research questions:
• RQ1. How has the frequency of modality-indicating devices (MIDs), categorised into three sets (core modal auxiliaries, semi-modals and lexical MIDs), changed in informal spoken British English between the 1990s and 2010s?
• RQ2. How have the modal functions of the core modal auxiliaries in informal spoken British English changed between the 1990s and 2010s?
RQ1 aims to explore how the frequencies of core modals, semi-modals and lexical expressions of modality have changed between the two sampling points. RQ2 is intended to set in motion a body of work exploring the functional factors which may be at play in explaining any observed frequency changes; our starting point in this article is to explore the modal functions of the core modal auxiliaries, with a view to expanding our functional approach to other MIDs in future research (e.g. Love & Curry Reference Love and Curryforthcoming). From a macro-perspective, our approach to RQ2 is onomasiological in that we are interested in how the function(s) of modality are expressed through the modal auxiliaries and how this may have changed between the 1990s and 2010s in informal spoken British English.
At this stage, we wish to acknowledge the limitations of our approach, much in the same way as we seek to interrogate and problematise prior approaches to the formal and functional investigation of modality. Firstly, it should be noted that we do not consider how the three sets of modality-indicating devices (modal auxiliary, semi-modal and lexical MID) correspond with one another. In future studies, engaging with any such correspondences would offer a more comprehensive onomasiological approach. Secondly, by only considering the core modal auxiliaries in our functional analysis, we are necessarily restricting the observations we can make about how modality is expressed, and how it may have changed, in recent spoken British English.
To summarise, RQ1 is concerned with formally analysing three sets of MIDs in terms of frequency differences between the Spoken BNC1994 and the Spoken BNC2014. RQ2 is concerned with modal function; but, for reasons of space, and our desire to ensure ample opportunity to problematise the treatment of MIDs as ‘sets’ in our own and others’ research, we only consider the functions of the core modal auxiliaries. As mentioned, we aim to complement the analysis of core modal auxiliary functions in future work by investigating the functions of semi-modals and other lexical expressions of modality, in order to gain a fuller understanding of the semantics of modality in twenty-first-century informal British English conversation.
3 Data and methodology
In this section, we discuss our use of the Spoken BNC corpora and our procedure for selecting and analysing the MIDs investigated in this study.
3.1 Corpus data
The corpora used in this study are the spoken components of the two British National Corpora, which were sampled from the 1990s and 2010s, respectively. The first is the demographically sampled subcorpus of the Spoken BNC1994 (BNC Consortium 2007), which was recorded in 1991–3 among 1,408 speakers across 153 texts. The second is the Spoken BNC2014 (Love et al. Reference Love, Dembry, Hardie, Brezina and McEnery2017; McEnery et al. Reference McEnery, Love, Hardie, Brezina, Dembry and Timperley2017), which was recorded in 2012–16 among 668 speakers across 1,251 texts. Both corpora comprise solely informal conversational data, recorded mostly among family and friends, and can be said to represent informal spoken British English as spoken mostly in England (the representativeness of both corpora is discussed in detail by Love Reference Love2020).
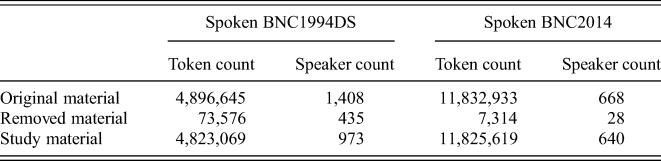
The corpora were accessed and analysed using Sketch Engine (Kilgarriff et al. Reference Kilgarriff, Baisa, Bušta, Jakubíček, Kovář, Michelfeit, Rychlý and Suchomel2014). In Sketch Engine, the Spoken BNC1994DS (demographically sampled part) comprises 4,896,645 tokens, while the Spoken BNC2014 comprises 11,832,933 tokens. Both corpora are tagged using the English Penn Treebank tagset (Marcus et al. Reference Marcus, Santorini and Marcinkiewicz1993).
In our analysis, we sought to mitigate against a known limitation of both the Spoken BNC1994DS and the Spoken BNC2014, which is the presence of speaker IDs that contribute a very small or very large number of tokens to the corpora. This issue is discussed in detail by Sönning & Krug (Reference Sönning, Krug, Schützler and Schlüterforthcoming), who clearly illustrate the challenges that individual speaker under- and over-representations can create. To mitigate against this limitation, we firstly identified and excluded speakers in both corpora who contributed fewer than 500 tokens each. The arbitrary cut-off point of 500 tokens was chosen to maximise the opportunity for each speaker to make a meaningful individual contribution to the data, while avoiding the removal of a substantial portion of each corpus. We identified and excluded a total of 435 speaker IDs in the Spoken BNC1994DS that contribute fewer than 500 tokens each. By contrast, in the Spoken BNC2014, only 28 speaker IDs of this type were found and excluded. Secondly, we used Welch's t-test to account for individual variation among the remaining speakers (Brezina Reference Brezina2018), including those who contribute relatively large token counts. The application of Welch's t-test is discussed in more detail later in the article. Table 1 summarises the data used in this study.
Table 1. Token and speaker counts for the corpora before and after removal of speakers accounting for fewer than 500 tokens each
3.2 Methodological approach
Owing to the diachronic nature of this study, we adopted an integrated horizontal and vertical reading of the corpus data to allow for the effective investigation of language within clearly defined and temporally situated data (cf. Kohnen Reference Kohnen2014). We conducted a quantitative analysis of the usage of core modals, semi-modals and a sample of lexical MIDs in both corpora. Then, we conducted a detailed, qualitative corpus study (cf. Verhulst et al. Reference Verhulst, Depraetere and Heyvaert2013) of the functions of the core modals in both corpora, which allowed us to explore the relationship between shifts in frequency and shifts in the functional use of these forms.
3.2.1 Selecting the modality-indicating devices
To address RQ1, we first identified the three categories of MID, (1) core modals, (2) semi-modals and (3) lexical modal expressions and created lists of members of each category (see table 2). For all MIDs listed in the table, we searched for any morphologically related forms (e.g. when searching for possible, we retrieved the forms impossibility, impossible, impossibly, possibilities, possibility, possible and possibly). We also retrieved any negative forms (e.g. oughtn't).
Table 2. The modality-indicating devices (MIDs) examined in the study

In deciding which forms to assign to each category, we noted the inconsistency with which these distinctions have been made in the literature. Although the nine core modal auxiliaries are fairly consistently reported as such, other forms have also been considered as core modals. Leech (Reference Leech2003: 226), for example, includes ought to and need among the core modals in his study, on the basis that they are identified as such in the Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985) grammar. However, a more recent corpus-based grammar (Carter & McCarthy Reference Carter and McCarthy2006: 657) lists ought to and need as semi-modals (alongside dare and used to). In this article, we adopt Carter & McCarthy's (Reference Carter and McCarthy2006) categorisations as, when compared to those of Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985), Carter & McCarthy's (Reference Carter and McCarthy2006) categorisations, arguably, better suit our data. This is because Carter & McCarthy's (Reference Carter and McCarthy2006) categorisations are based on an analysis of larger and more recently compiled corpora of spoken English than Quirk et al. (Reference Quirk, Greenbaum, Leech and Svartvik1985), e.g. CANCODE (Carter & McCarthy Reference Carter and McCarthy2006).
As for the lexical MIDs, we noted Leech's observation that ‘lexical modality devices are so numerous that it is scarcely possible to list them exhaustively’ (Reference Leech2013: 108). This meant that certain decisions had to be made in order to identify a reasonable selection of lexical MIDs to analyse and present herein. Given the claim that modality is largely identified by its function, and that lexical MIDs can take the form of verbs, verb constructions, nouns, adjectives and adverbs (Carter & McCarthy Reference Carter and McCarthy2006), the ten lexical MIDs were chosen to reflect a range of epistemic and root modality as well as a range of forms. These MIDs are also frequent in both corpora and have been studied elsewhere (Carter & McCarthy Reference Carter and McCarthy2006; Leech Reference Leech2013; Keizer Reference Keizer2018), offering sufficient data to analyse and contextualise them with previous studies. This reduced focus does make it impossible to talk generally about changes in lexical modality, and so there is an evident need to expand the study of lexical MIDs to dig more deeply into contemporary usage of modal expressions. This is an issue to which we return in section 4.1.
3.2.2 Frequency comparison of MIDs across corpora
For the core modals, we used part-of-speech (POS) tagging to assist our retrieval, by searching for each form tagged as modal (tag: MD). Each core modal was sampled using a 95 per cent confidence (+/–5%) sample (Israel Reference Israel1996; Moinester & Gottfried Reference Moinester and Gottfried2014)Footnote 3 to avoid arbitrary selection of sample sizes, and the samples were analysed to distinguish core-modals from items erroneously tagged as modal.
For the semi-modals, we followed Carter & McCarthy (Reference Carter and McCarthy2006) and searched for ought to, need, dare and used to in their various forms and syntactic positions. As with core modals, semi-modals were analysed to distinguish semi-modals from lexical modals (in the case of need and dare) and to determine any non-modal forms retrieved in the search. In the case of dare, which was very infrequent, it was possible to analyse all examples in both corpora. For the remaining items, 95 per cent confidence (+/–5%) samples were extracted and analysed. As noted in table 2, need is included in our study as both a semi-modal and a lexical MID. In our analysis, this distinction was made based on syntactic behaviour. Instances of need were categorised as semi-modal when they act as an auxiliary to a main verb (e.g. I needn't go round that way), while instances where need is the main verb were categorised as lexical (e.g. we need some bananas). In addition, nominal uses of need were classed as lexical MIDs, although these are very rare (e.g. he has no need to).
For lexical modal expressions, a function-to-form approach was necessary to identify relevant forms. Following Aijmer & Rühlemann (Reference Aijmer and Rühlemann2014a), O'Keeffe (Reference O'Keeffe, Jucker, Schneider and Bublitz2018) and Curry (Reference Curryforthcoming), for this initial study of lexical modality, we identified lexical MIDs based on the formal findings from previous analyses (Carter & McCarthy Reference Carter and McCarthy2006; Leech Reference Leech2013; Keizer Reference Keizer2018).
As mentioned, we endeavoured to ensure that we investigated forms that are heavily associated with the expression of modality. For the core modal auxiliaries, we relied on part-of-speech tagging to isolate modal-functioning forms. For the semi-modals and lexical MIDs, 95 per cent confidence (+/–5%) samples were extracted and analysed to distinguish between MID and non-MID forms. We found that, for both sets, the forms functioned modally to a very high extent. For the semi-modals, 99.4 per cent (1990s) and 99.5 per cent (2010s) of cases in our samples were found to express modality. For the lexical MIDs, 99.2 per cent (1990s) and 98.2 per cent (2010s) of cases in our samples were found to express modality. Across the two sets, this sampling procedure involved the qualitative coding of a total of 1,429 concordance lines. Given that (a) the proportion of non-modal usage (e.g. I dare you) is so low across all samples, and (b) adjusting the relative frequency per speaker for each form to remove the small proportion of non-modal usage would be methodologically challenging, we decided not to adjust the frequencies. In making this decision, we acknowledge the presence of a very small proportion of non-modal usage within our reported findings.
The relative frequency of each of the MIDs (per speaker) was retrieved from both corpora and then compared statistically using Welch's independent samples t-test (Welch Reference Welch1947) and the Cohen's d effect size measure (Cohen Reference Cohen1988). Welch's t-test was used to compare the mean relative frequency of each MID across all speakers in each corpus, thus taking into account individual speaker variation (Brezina Reference Brezina2018: 187); this approach has been shown to better reflect the reality of the data when compared to an aggregate data methodology that analyses the data wholesale and uses a statistic like log-likelihood (Brezina & Meyerhoff Reference Brezina and Meyerhoff2014). Cohen's d was then used to evaluate the size of the frequency difference between the corpora (Brezina Reference Brezina2018: 190). The combination of Welch's t-test and Cohen's d is recommended by Brezina (Reference Brezina2018) for comparing the occurrence of linguistic variables between two groups of speakers (or corpora).
3.2.3 Semantic function analysis of core modal auxiliaries
To address RQ2, we manually categorised random samples of each of the core modals in both corpora according to modal function. The size of the sample taken for each core modal (table 3) was determined by 95 per cent confidence samples (+/–5%).
Table 3. Sizes of each random sample of the core modals

The samples were categorised qualitatively according to modal function via close inspection of concordance lines, which were used to gain an understanding of the immediate linguistic context in which each MID occurred. Simple category labels, which conveyed the basic modal sense of the MID (e.g. permission), were used during the analysis, and later attributed to the three broad modality types discussed in section 2.2.1 (epistemic, deontic and dynamic modality). Table 4 shows each of the modal function categories used in the analysis and their corresponding definition that guided our categorisation.
Table 4. Category labels and corresponding modality types used in the qualitative semantic analysis

The N/A (not applicable) label was used for instances where tagging errors introduced non-modal forms (e.g. the month of May). The unclear label was used for cases where the immediate linguistic context afforded by the concordance lines was not sufficient to determine the modal function.
The qualitative analysis was split evenly between co-authors, with regular reviewing of each other's categorisations used to maximise inter-rater reliability. An inter-rater reliability test was also conducted, with both raters categorising the same set of 600 concordance lines, containing an approximately even number of core modals from both corpora. Across all samples, the mean rate of agreement for the broad modal function was 94.42 per cent (kappa coefficient = 0.93, Cohen Reference Cohen1960; this indicates ‘almost perfect’ agreement; Landis & Koch Reference Landis and Koch1977: 165).
For each core modal, we conducted two measures of the distribution of modality type. The first follows Leech (Reference Leech2003) and reports the percentage of each modal function as a proportion of the total sample of the core modals. However, this alone can be misleading, as such an approach does not take into account changes in the overall usage of the functions in the corpora. For example, Leech (Reference Leech2003: 232) reports that, between the LLC–1 and ICE-GB samples of spoken British English, the epistemic function of may increases from 45 to 82 per cent as a proportion of all instances of may. This, according to Leech (Reference Leech2003: 234), is evidence of ‘a common tendency for the dominant sense in the early 60s to be even more dominant in the early 90s’. However, if instead of only considering the internal distribution of the functions, we consider the corpus frequency of the functions (i.e. the relative frequency of the function as a proportion of the entire corpus size, per million tokens), then it is revealed that the epistemic function of may actually decreases from a relative frequency of 488 per million tokens (LLC–1) to 388 per million tokens (ICE-GB), as part of an overall decrease in the usage of may between the two corpora. In real terms, speakers use the epistemic function of may less, not more, because they utter the word may less frequently overall. This approach provides an alternative view of the functional patterns of the modals, which, we argue, is as important to the interpretation of the functions as the internal distribution. Therefore, we report both types of findings in our analysis. In our case, the corpus frequency of the core modal functions is determined by scaling up the proportions observed in the random samples to extrapolate their frequency across all instances.
4 Findings
In this section, we present the findings of our analysis, starting with the formal analysis of the core modals, semi-modals and lexical MIDs, before turning to the functional analysis of the core modals.
4.1 Frequency analysis of the core modals, semi-modals and lexical MIDs
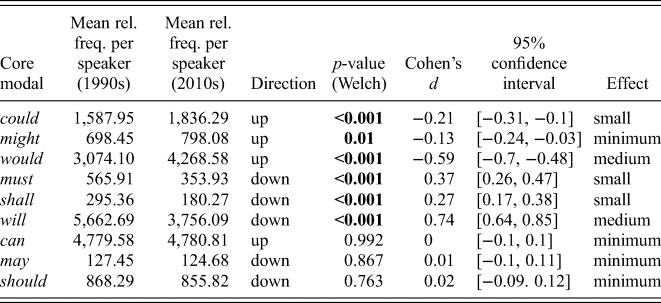
Between the corpora, there is a statistically significant difference in the use of the core modals (as a set), t(1422.7) = 2.82, p = 0.005, with the Spoken BNC2014 (mean: 16,954.5 per million tokens) containing relatively fewer instances than the Spoken BNC1994DS (mean: 17,695.8 per million tokens). The size of the effect is minimal, d = 0.15, 95 per cent CI [0.04, 0.25]. This appears to provide evidence that the occurrence of the core modals has decreased in informal spoken British English between the 1990s and 2010s.
Individually, six out of the nine core modals differ significantly in frequency between the corpora (table 5). Core modals could, might and would have a significantly higher frequency in the Spoken BNC2014, whereas must, shall and will have a significantly lower frequency. The core modals can, may and should do not differ significantly in frequency between the corpora; the frequency of these core modals appears to have remained stable over time. The most substantial differences among the core modals are the increase of would and the decrease of will, the latter of which has the highest effect size (d = 0.74), and appears to be the driver behind the overall decrease of the core modals as a set.
Table 5. Comparing frequency (per million tokens) of the core modals between the Spoken BNC1994DS (‘1990s’) and Spoken BNC2014 (‘2010s’) (significant p-values in bold)
With regards to the semi-modals, table 6 shows that two of the four semi-modals differ in frequency significantly between the corpora; both ought to and need have a significantly lower frequency in the Spoken BNC2014 compared to the Spoken BNC1994DS. In contrast, there is not a significant difference in frequency for dare and used to between the corpora.
Table 6. Comparing frequency (per million tokens) of the semi-modals between the Spoken BNC1994DS (‘1990s’) and Spoken BNC2014 (‘2010s’) (significant p-values in bold)

a These values were extrapolated from the sample data for need.
b This p-value was calculated using log-likelihood,Footnote 4 rather than Welch's t-test, since individual speaker frequencies were not available, due to some instances of need being classified as lexical.
As a set, the semi-modals have a slightly higher frequency in the Spoken BNC2014 (689.14 per million tokens) compared to the Spoken BNC1994DS (685.8 per million tokens). This difference is not significant (t(4257.17) = –0.44, p = 0.663; excluding need, the frequencies of which were extrapolated from samples), so there is not enough evidence to suggest that the semi-modals as a set have risen in usage over time.
Turning to the lexical MIDs (table 7), seven MIDs have significantly different frequencies between the corpora. Five MIDs (able to, need, possible, probable and sure) show evidence of a significant increase in usage over time, while the MIDs have to and want to have decreased significantly. The difference with the largest effect size is the increase in usage of probabl*, the frequency of which (per speaker) in the Spoken BNC2014 is almost double its frequency in the Spoken BNC1994DS.
Table 7. Comparing frequency (per million tokens) of the lexical MIDs between the Spoken BNC1994DS (‘1990s’) and Spoken BNC2014 (‘2010s’) (significant p-values in bold)

a These values were extrapolated from the sample data for need.
b This p-value was calculated using log-likelihood, rather than Welch's t-test, since individual speaker frequencies were not available, due to some instances of need being classified as semi-modal.
As a set, the lexical MIDs have a higher frequency in the Spoken BNC2014 (10130.76 per million tokens) compared to the Spoken BNC1994DS (9758.96 per million tokens). This difference is not significant (t(12823.48) = 0.95, p = 0.341; excluding need, the frequencies of which were extrapolated from samples), so there is not enough evidence to suggest that the lexical MIDs as a set have risen in usage over time. As will be discussed, the divergent trends observed among these items leads us to suggest that grouping the lexical MIDs in this way may not be helpful for investigating change in modality.
4.2 Functional analysis of the core modals
This section reports on the overall functional findings for the core modals as a set (see Appendix for functional data for each individual core modal). Starting with the internal distribution of modal functions (figure 1), there appears to be a divergence between epistemic and deontic modality; between the 1990s and 2010s, epistemic modality rises from 50.9 to 52.8 per cent, while deontic modality falls from 40.9 to 38.8 per cent (dynamic modality remains stable at 8.2 and 8.3 per cent, respectively). However, these differences are not significant (epistemic: t(15.56) = –0.14, p = 0.89; deontic: t(15.37) = 0.15, p = 0.881; dynamic: t(15.78) = –0.02, p = 0.982), so there is not enough evidence to claim that the internal distribution of modal functions has changed between the 1990s and 2010s. Despite this, it should be noted that this pattern is replicated by five of the modals (can, may, might, must, will; see Appendix).

Figure 1. Internal distribution (percentage) of modal functions across all core modal samples
As discussed in section 3.2.3, considering the internal distribution of functions alone has the potential to be misleading, so we also calculated the mean relative frequency of modality types across all core modals (figure 2). In this case, taking into account relative frequency (i.e. a normalised frequency that allows the comparison of findings from corpora of different sizes) appears to support and amplify the divergence between epistemic and deontic modality. However, once again, these differences are not significant (epistemic: t(15.67) = –0.28, p = 0.78; deontic: t(13.8) = 0.25), p = 0.808; dynamic: t(15.97) = –0.24, p = 0.81).
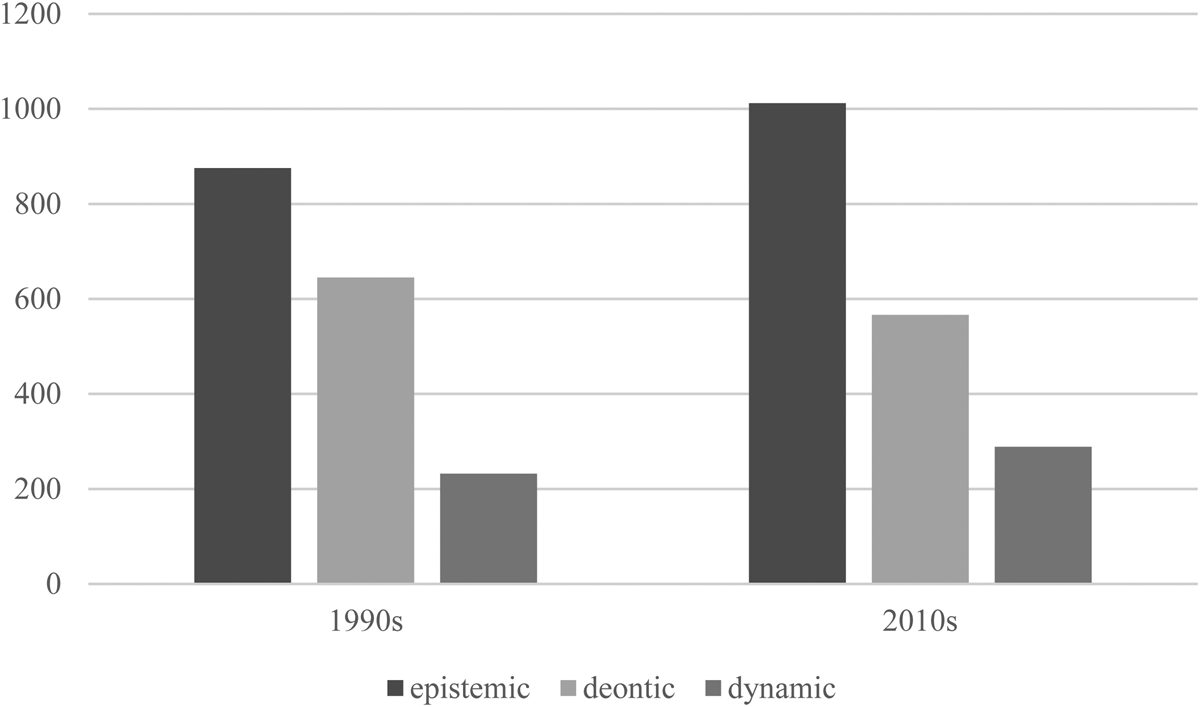
Figure 2. Mean relative corpus frequency (per million tokens) of modal functions across the core modals (extrapolated from samples)
5 Discussion and conclusion
In discussing the results, section 5.1 addresses the findings of the frequency analysis of core modal auxiliaries, semi-modals and lexical MIDs (RQ1), with a view to interrogating how these findings may reflect changes (and lack thereof) in modality in spoken British English. Secondly, the findings of the functional analysis of core modals (RQ2) are discussed, considering both formally constrained functional changes and more general changes in the functional behaviour of modality in the core modal auxiliaries. Finally, in section 5.2, we discuss how this research could be extended in future work.
5.1 Discussion of findings
Generally, the presence of core modal forms in informal spoken British English has decreased between the 1990s and 2010s. This decrease is significant and would appear to support Leech's view that core modal auxiliaries are in decline (Reference Leech2003, Reference Leech2011). Arguably, such a view may not be surprising, as with the decline of core modal auxiliaries in a range of written genres and registers (Leech Reference Leech2013), the theory of colloquialisation would have predicted that this decline had already been taking place in informal spoken English. However, this argument appears only to be valid when considering the core modal auxiliaries as a homogeneous set. Interestingly, our findings illustrate clear divergences within this set, rendering a claim of declining core modal auxiliaries somewhat problematic. While the overall trend of formal decline is significant, the modal forms could, might and would have significantly increased over time. Similarly, the forms must, shall and will have significantly decreased, while the remaining core modal auxiliary forms appear to be stable. Therefore, could, might and would better reflect Millar's (Reference Millar2009) proposition of increase, while must, shall and will support Leech's stance on core modal auxiliaries in decline (Reference Leech2003, Reference Leech2011). Furthermore, it appears that the modal will plays a key role in determining this general state of decline in core modal auxiliaries, given its large effect size. Essentially, our findings problematise the treatment of core modal auxiliaries as a homogeneous set, bound by formal and grammatical categorisation, given that their semantic function arguably plays a more important role in determining their use. We shall return to this issue later in this section.
With regards to the semi-modals, our results indicate that, as a set, there is not sufficient evidence to suggest that they have changed in frequency over time. However, within the set, both the forms ought to and need have decreased significantly. This reflects Carter & McCarthy's (Reference Carter and McCarthy2006: 657–60) observation that both forms occur rather infrequently. Evidently, these forms are continuing to decline, according to our results. Conversely, there does not appear to be a significant difference in the frequency of dare and used to between the 1990s and 2010s. While the wholesale comparison of the set of four semi-modals reflects a very slight increase, this increase is not significant. Leech (Reference Leech2003) discusses the increase in semi-/‘emergent’ modals, which our findings may appear to contradict. However, the issue here pertains to the label of semi-modals, which is inconsistent in the literature. For the sake of comparability elsewhere, it is important to keep in mind that, while Leech (Reference Leech2003: 229) included a range of forms, including be going to, be to, (had) better, (have) got to, have to, need to, want to and used to, the semi-modals in our study encapsulate only dare, need, ought to and used to. Therefore, it is challenging to discuss this formal set, and it would be better to consider these four forms independently. Further, Leech's focus (predominantly) on written English renders comparability of the findings incommensurable.
For lexical modality, the significant increase in the usage of able, need (to), possible, probable and sure is noteworthy. In Leech (Reference Leech2013), lexical modality saw a decline of 11.93 per cent, to which Leech attributed a cause of ‘modality deficit’. For Leech, this deficit was potentially owing to colloquialisation, with the implication that spoken language would also reflect a decrease in lexical modality. However, according to our data, this does not appear to be the case. That being said, it must be noted that our study is based on only ten lexical MIDs and is by no means exhaustive. Nonetheless, this contrast is an interesting observation. While five lexical MIDs significantly increased, two (have to and want to) decreased significantly. Therefore, as with the core modal auxiliaries and semi-modals, the set of lexical MIDs is not homogeneous and while, on a case-by-case basis, individual lexical MIDs reflect significant changes over time, the overall use of lexical MIDs studied herein does not appear to have changed significantly. This further challenges the view of lexical MIDs as a homogeneous group, defined by their alignment with degrees of grammaticality and lexicality.
Overall, a key problematisation that has emerged in this discussion pertains to the issue of the lack of homogeneity in the literature in the conception of modals as forming sets. In considering MIDs individually, there is evidence of significant increases and decreases in core modal auxiliaries, semi-modals and lexical MIDs. However, in trying to align our findings on modality to a range of studies, the lack of homogeneity in approaches to categorising modal forms in the literature, and within our own study, means that it is challenging to bring together a wide collection of studies to underpin the discussion of modality and language change in informal spoken British English. Arguably, making general observations about changes in core, semi- and lexical modality ‘sets’ can obfuscate and distort changes that occur on a case-by-case basis, formally, and on a functional basis, more generally. Given that modality is a semantic phenomenon (von Wright Reference von Wright1951), a functional perspective – not only semantic but also morphosyntactic – may better serve to offer insight into whether change in the use of modality is taking place. Therefore, a clear question emerges as to whether a comparison of the use of modal function might produce a more coherent understanding of the behaviour of modals in contemporary British English; based on our initial findings regarding core modal forms, we suggest that future studies move away from the formal categories (core, semi- and lexical MIDs) and instead adopt functional categorisations of modal forms.
In the case of the core modal auxiliaries, the functional analyses revealed a number of shifts in functional distribution. For can, may, might, must and will, there appears to be a slight shift in modal function, with a greater proportion of each verb performing epistemic modality and a lesser proportion reflecting deontic modality. For the remaining core modal auxiliaries (could, shall, should and would), there are only marginal differences in the proportional distribution of function. Among these, shall is noteworthy in that it appears to resist the possible trend towards epistemicity that we have noted above. In the 1990s data, shall is almost exclusively used in deontic functions (92.4 per cent of our sample), and this remains the case in the 2010s data (98.2 per cent). Likewise, should shifts towards a higher proportion of deontic usage (from 74.0 to 87.9 per cent). Given the high (and apparently increasing) proportion of a single modal function in both shall and (to a lesser extent) should, an argument could be made for a movement towards monosemy in both cases (Leech Reference Leech2003) – at least in terms of their broad modal function. However, overall (shall notwithstanding), there is no evidence of a general shift towards monosemy in core modal auxiliaries, as Leech (Reference Leech2003) suggests there is, given that most of the modal auxiliaries are observed to perform a range of modal functions.
When considering changes in epistemic, deontic and dynamic modality in core modal auxiliaries in general, our results show a slight increase in epistemic modality and a slight decrease in deontic. While neither trend is significant, this does remain of interest. At a functional level, it is possible to observe a more coherent trend in modality than the analysis of formal sets affords. For example, although this study's semantic analysis centred on the core modals only, the semi-modals and lexical MIDs that significantly increased (excluding need) all show a tendency to reflect meanings attributed to epistemic modality (Carter & McCarthy Reference Carter and McCarthy2006). Similarly, those semi-modals and lexical MIDs that have significantly declined typically reflect deontic modality meanings, according to Carter & McCarthy (Reference Carter and McCarthy2006); this is a claim we intend to investigate in future. Therefore, while the change in modal function is not significant, the functional perspective offers a coherent overview of modal functions in contemporary British English. It is possible that what we are observing is a change in process with a potential for increased use of epistemic modality over time. Therefore, future studies of British English modality may benefit from focusing more (or even exclusively) on functional categories instead of formal categories to understand changes in the use of modality over time.
5.2 Future directions
This article represents the first stage of a body of work (e.g. Love & Curry Reference Love and Curryforthcoming) that aims to provide a rigorous, inclusive and functional description of recent changes in modality, however expressed, in conversational British English. The contributions that this article makes towards this goal are:
• a description of frequency differences among core, semi- and a selection of lexical MIDs between the 1990s and 2010s;
• a description of the modal functions of the core modal auxiliaries in the 1990s and 2010s.
The next stage of this work involves:
• extending the frequency analysis of lexical MIDs to include a larger and more representative number of forms;
• conducting apparent-time frequency analyses of all MIDs to complement the real-time analysis presented in this article (cf. Leech Reference Leech2013 and Baker & Heritage Reference Baker, Heritage, O'Keefe and McCarthyforthcoming);
• extending the functional analysis of MIDs to include semi-modals and lexical MIDs.
Beyond this, further work should consider changes in the distribution of modalised and non-modalised utterances over time (cf. Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan1999: 456). In addition, it should provide a complementary functional analysis of changes in the expression of modality between the 1990s and 2010s among other registers of British English, including various genres of writing and e-language. To facilitate this, we anticipate the public release of the written component of the BNC2014, which complements the spoken component used in this study and provides a point of comparison for the written component of the BNC1994.Footnote 5
Appendix
Table A1 Internal distribution and relative frequency of the modality types among the core modals in the Spoken BNC1994DS and Spoken BNC2014












 Open access
Open access