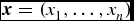1 INTRODUCTION
With the rapid development of both the astronomical instruments and various machine learning algorithms, we can apply the spectral characteristics of stars to classify the stars. A great quantity of astronomical observatories have been built to get the spectra, such as the Large Sky Area Multi-Object Fibre Spectroscopic Telescope (LAMOST) in China. A variety of machine learning methods, e.g., principal component analysis (PCA), locally linear embedding (LLE), artificial neural network (ANN), and decision tree etc., have been applied to classify these spectra in an automatic and efficient way. In this study, we apply a novel machine learning method, restricted Boltzmann machine (RBM), to classify the cataclysmic variables (CVs) and non-CVs.
CVs are composed of the close binaries that contain a white dwarf accreting material from its companion (Warner Reference Warner2003). Generally, they are small with an orbital period of 1–10 h. The white dwarf is often called ‘primary’ star, whereas the normal star is called the ‘companion’ or the ‘secondary’ star. The companion star, which is ‘normal’ like our Sun, usually loses its material onto the white dwarf via accretion.
The three main types of CVs are novae, dwarf novae, and magnetic CVs. Magnetic CVs (mCVs) are binary star systems with low mass and also with a Roche lobe-filling red dwarf, which ‘gives’ material to a magnetic white dwarf. Polars (AM Herculis systems) and Intermediate Polars (IPs) are two major subclasses of mCVs (Wu Reference Wu2000). More than a dozen of objects have been classified as AM Her systems. Most of the objects were found to be X-ray sourcesFootnote 1 before classified as AM Her’s resorting to optical observations.
Besides, Muno et al. (Reference Muno2009) presented a catalogue of 9017 X-ray sources identified in Chandra observations of a 2 × 0.8° field around the Galactic center. And they found that the detectable stellar population of external galaxies in X-rays was dominated by accreting black holes and neutron stars, while most of their X-ray sources may be CVs.
1.1 Previous work in spectral classification in astronomy
Singh, Gulati, & Gupta (Reference Singh, Gulati and Gupta1998) applied PCA and ANN to stellar spectral classification on O- to M-type stars, where O-type stars are the hottest and the letter sequence (O to M) indicates successively cooler stars up to the coolest M-type stars. They adopted PCA for dimension reduction firstly, in which they reduced the dimension to 20, with the cumulative percentages larger than 99.9%. Then, they used multi-layer back propagation (BP) neural network for classification.
Sarty and Wu (Reference Sarty and Wu2006) applied two well-known multivariate analysis methods, i.e., PCA and discriminant function analysis, to analyse the spectroscopic emission data collected by Williams (Reference Williams1983). By using the PCA method, they found that the source of variation had correlation to the binary orbital period. With the discriminant function analysis, they found that the source of variation was connected with the equivalent width of the Hβ line (Sarty & Wu Reference Sarty and Wu2006).
McGurk et al. (Reference McGurk, Kimball and Ivezić2010) applied PCA to analyse the stellar spectra obtained from SDSS (Sloan Digital Sky Survey) DR6. They found that the first four principal components (PCs) could remain enough information of the original data without overpassing the measurement noise. Their work made classifying novel spectra, finding out unusual spectra, and training a variety of spectral classification methods, etc., not as hard as before.
Bazarghan (Reference Bazarghan2012) applied self-organising map (SOM, a kind of unsupervised ANN algorithm) to stellar spectra obtained from the Jacoby, Hunter, and Christian (JHC) library, and the author obtained the accuracy of about 92.4%. In the same year, Navarro, Corradi, & Mampaso (Reference Navarro, Corradi and Mampaso2012) used the ANN method to classify the stellar spectra with low signal-to-noise ratio (S/N) on the samples of field stars, which were along the line of sight towards NGC 6781 and NGC 7027 etc.,. They not only trained but also tested the ANNs with various S/N levels. They found that the ANNs were insensitive to noise and the ANN’s error rate was smaller, when there were two hidden layers in the architecture of the ANN in which there were more than 20 hidden units in each hidden layer.
In the above, some applications of PCA for dimension reduction and ANN for spectral classification were reviewed in astronomy. Furthermore, support vector machine (SVM) and decision trees have also been used for spectral classification in astronomy.
Zhang and Zhao (Reference Zhang and Zhao2004) applied single-layer perceptron (SLP) and SVMs etc., for the binary classification problem, i.e., the classification of AGNs (active galactic nucleus) and S & G (stars and normal galaxies), in which they first selected features using the histogram method. They found that SVM’s performance was as good as or even better than that of the neural network method when there were more features chosen for classification. Ball et al. (Reference Ball, Brunner, Myers and Tcheng2006) applied decision trees to SDSS DR3. They investigated the classification of 143 million photometric objects and they trained the classifier with 477 068 objects. There were three classes, i.e., galaxy, star, and neither of the former two classes, in their experiment.
From the perspective of feature extraction methods, some researches in spectral classification based on linear dimension reduction technique, e.g., PCA, have been reviewed. Except from linear dimension reduction method, nonlinear dimension reduction technique has also been applied in spectral classification for feature extraction.
Daniel et al. (Reference Daniel, Connolly, Schneider, Vanderplas and Xiong2011) applied locally linear embedding (LLE, a well known nonlinear dimension reduction technique) to classify the stellar spectra coming from the SDSS DR7. There were 85 564 objects in their experiment. They found that most of the stellar spectra was approximately a one-dimensional (1D) sequence lying in a three-dimensional (3D) space. Based on the LLE method, they proposed a novel hierarchical classification method being free of the feature extraction process.
1.2 Previous application of RBM
In this subsection, we present some representative applications of the RBM algorithm so far.
Salakhutdinov, Mnih, & Hinton (Reference Salakhutdinov, Mnih, Hinton and Ghahramani2007) applied RBM for collaborative filtering, which is closely related to recommendation system in machine learning community. Gunawardana & Meek (Reference Gunawardana, Meek, Pu, Bridge, Mobasher and Ricci2008) applied RBM for cold-start recommendations. Taylor & Hinton (Reference Taylor, Hinton, Danyluk, Bottou and Littman2009) applied RBM for modeling motion style. Dahl et al. (Reference Dahl, Mohomed and Hinton2010) applied RBM to phone recognition on the TIMIT data set. Schluter & Osendorfer (Reference Schluter, Osendorfer, Chen, Dillon, Ishbuchi, Pei, Wang and Wani2011) applied RBM to estimate music similarity. Tang, Salakhutdinov, & Hinton (Reference Hinton, Montavon, Orr and Müller2012) applied RBM for recognition and de-noising on some public face databases.
1.3 Our work
In this study, we applied the binary RBM algorithm to classify spectra of CVs and non-CVs obtained from the SDSS.
Generally, before applying a classifier for classification, the researchers always preprocess the original data, for example, normalisation to get better features and thus to get better performance. Thus, firstly, we normalise the spectra with unit normFootnote 2 . Then, to apply binary RBM for spectral classification, we binarise the normalised spectra by some rule, which we will discuss in the experiment. Finally, we use the binary RBM for classification of the data, one-half of all the given data for training and the other half for testing. The experiment result shows that the classification accuracy is 100%, which is state-of-the-art. And RBM outperforms the prevalent classifier, SVM, with accuracy of 99.14% (Bu et al. Reference Bu, Pan, Jiang, Chen and Wei2013).
The rest of this paper is organised as follows. In Section 2, we review the prerequisites for training RBM. In Section 3, we introduce the binary RBM and the training algorithm for RBM. In Section 4, we present the experiment result. Finally, in Section 5, we conclude our work in this study and also present the future work.
2 PREREQUISITES
2.1 Markov chain
A Markov chain is a sequence composed of a number of random variables. Each element in the sequence can transit from one state to another one randomly. Indeed, a Markov chain belongs to a stochastic process (Andrieu et al. Reference Andrieu, De Freitas and Doucet2003). In general, the number of possible states for each element or random variable in a Markov chain is finite. And a Markov chain is a random process without memory. It is the current state rather than the states preceding the current state that can influence the next state of a Markov chain. This is the well-known Markov Property (Xiong, Jiang, & Wang Reference Xiong, Jiang, Wang, Min, Wu, Liu, Jin, Jarvis and Al-Dubai2012).
Mathematically, a Markov chain is a sequence, X 1, X 2, X 3,. . ., with the following property:
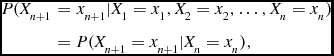 \begin{eqnarray*}
P(X_{n+1}&=&x_{n+1}|X_1=x_1, X_2=x_2, \ldots , X_n=x_n)\\
&=&{P(X_{n+1}=x_{n+1}|X_n=x_n),}
\end{eqnarray*}
\begin{eqnarray*}
P(X_{n+1}&=&x_{n+1}|X_1=x_1, X_2=x_2, \ldots , X_n=x_n)\\
&=&{P(X_{n+1}=x_{n+1}|X_n=x_n),}
\end{eqnarray*}
Generally, all the probabilities of the transition from one state to another one can be represented as a whole by a transition matrix. And the transition matrix has the following three properties:
-
• square: both the row number of the matrix and the column number of the matrix equal the total number of the states that the random variable in the Markov chain can take on;
-
• the value of a specific element is between 0 and 1: it represents the transition probability from one state to another one;
-
• all the elements in each row sum to 1: the sum of the transition probabilities from any specific one state to all the states equals 1.
If the initial vector, a row vector, is
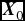 $\textbf {\textit {X}}_0$
, and the transition matrix is
$\textbf {\textit {X}}_0$
, and the transition matrix is
 $\textbf {\textmd {T}}$
, then after n steps of inference, we can get the final vector
$\textbf {\textmd {T}}$
, then after n steps of inference, we can get the final vector
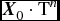 $\textbf {\textit {X}}_0\cdot \textbf {\textmd {T}}^n$
.
$\textbf {\textit {X}}_0\cdot \textbf {\textmd {T}}^n$
.
Then, we introduce the equilibrium of a Markov chain. If there exists an integer
 $\tilde{N}$
, which renders all the elements in the resulting matrix
$\tilde{N}$
, which renders all the elements in the resulting matrix
 $\textbf {\textmd {T}}^{\tilde{N}}$
nonzero, or rather, greater than 0, then we say that the transition matrix is a regular transition matrix (Greenwell, Ritchey, & Lial Reference Greenwell, Ritchey and Lial2003). If the transition matrix
$\textbf {\textmd {T}}^{\tilde{N}}$
nonzero, or rather, greater than 0, then we say that the transition matrix is a regular transition matrix (Greenwell, Ritchey, & Lial Reference Greenwell, Ritchey and Lial2003). If the transition matrix
 $\textbf {\textmd {T}}$
is a regular transition matrix, and there exists one and only one row vector
$\textbf {\textmd {T}}$
is a regular transition matrix, and there exists one and only one row vector
 $\textbf {\textit {V}}$
satisfying the condition that
$\textbf {\textit {V}}$
satisfying the condition that
 $\textbf {\textit {v}}\cdot \textbf {\textmd {T}}^n$
approximately equals
$\textbf {\textit {v}}\cdot \textbf {\textmd {T}}^n$
approximately equals
 $\textbf {\textit {V}}$
, for any probability vector
$\textbf {\textit {V}}$
, for any probability vector
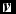 $\textbf {\textit {v}}$
and large enough integer n, then we call the vector
$\textbf {\textit {v}}$
and large enough integer n, then we call the vector
 $\textbf {\textit {V}}$
as the equilibrium vector of the Markov chain.
$\textbf {\textit {V}}$
as the equilibrium vector of the Markov chain.
2.2 MCMC
Markov chain Monte Carlo (MCMC) is a sampling algorithm from a specific probability distribution. For the detailed information of MCMC, the readers are referred to Andrieu et al. (Reference Andrieu, De Freitas and Doucet2003). The sampling process proceeds in the form of a Markov chain and the goal of MCMC is to get a desired distribution, or rather, the equilibrium distribution via running many inference steps. The larger the number of iterations is, the better the performance of the MCMC is. And MCMC can be applied for unsupervised learning with some hidden variables or maximum likelihood estimation (MLE) learning of some unknown parameters (Andrieu et al. Reference Andrieu, De Freitas and Doucet2003).
2.3 Gibbs sampling
Gibbs sampling method can be used to obtain a sequence of approximate samples from a specific probability distribution, in which sampling directly is usually not easy to implement. For the detailed information of the Gibbs sampling, the readers are referred to Gelfand (Reference Gelfand2000). The sequence obtained via the Gibbs sampling method can be applied to approximate the joint distribution and the marginal distribution with respect to (w.r.t.) one of all the variables etc. In general, the Gibbs sampling method is a method for probabilistic inference.
The Gibbs sampling method can generate a Markov chain of random samples under the condition that each of the sample is correlated with the nearby sample, or rather, the probability of choosing the next sample equals to 1 in the Gibbs sampling (Andrieu et al. Reference Andrieu, De Freitas and Doucet2003).
3 RBM
Considering that RBM is a generalised version of Boltzmann Machine (BM), we first review BM in this section. For the detailed information of BM, the readers are referred to Ackley, Hinton, & Sejnowski (Reference Ackley, Hinton and Sejnowski1985).
BM can be regarded as a bipartite graphical generative model composed of two layers in which there are a number of units with both inter-layer and inner-layer connections. One layer is a visible layer
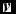 $\textbf {\textit {v}}$
with m binary visible units vi
, i.e.,
$\textbf {\textit {v}}$
with m binary visible units vi
, i.e.,
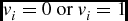 $v_i=0 \textrm { or } v_i=1$
(i = 1, 2, . . ., m). For each unit in the visible layer, the corresponding value is observable. The other layer is a hidden (latent) layer
$v_i=0 \textrm { or } v_i=1$
(i = 1, 2, . . ., m). For each unit in the visible layer, the corresponding value is observable. The other layer is a hidden (latent) layer
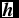 $\textbf {\textit {h}}$
with n binary hidden units hj
. As in the visible layer,
$\textbf {\textit {h}}$
with n binary hidden units hj
. As in the visible layer,
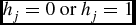 $h_j=0 \textrm { or } h_j=1$
(j = 1, 2, . . ., n). For each unit or neuron in the hidden layer, the corresponding value is hidden, latent or unobservable, and it needs to be inferred.
$h_j=0 \textrm { or } h_j=1$
(j = 1, 2, . . ., n). For each unit or neuron in the hidden layer, the corresponding value is hidden, latent or unobservable, and it needs to be inferred.
The units coming from the two layers of a BM are connected with weighted edges completely, with the weights wij (vi ↔ hj ) (i = 1, 2, . . ., m, j = 1, 2, . . ., n). For the two layers, the units within each specific layer are also connected with each other, and also with weights.
For a BM, the energy function can be defined as follows:
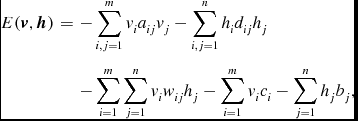 \begin{eqnarray}
E(\textbf {\textit {v}},\textbf {\textit {h}})&=&-\sum _{i,j=1}^{m}v_ia_{ij}v_j-\sum _{i,j=1}^{n}h_id_{ij}h_j \nonumber\\
&&{-\sum _{i=1}^{m}\sum _{j=1}^{n}v_iw_{ij}h_j-\sum _{i=1}^{m}v_ic_i-\sum _{j=1}^{n}h_jb_j,}
\end{eqnarray}
\begin{eqnarray}
E(\textbf {\textit {v}},\textbf {\textit {h}})&=&-\sum _{i,j=1}^{m}v_ia_{ij}v_j-\sum _{i,j=1}^{n}h_id_{ij}h_j \nonumber\\
&&{-\sum _{i=1}^{m}\sum _{j=1}^{n}v_iw_{ij}h_j-\sum _{i=1}^{m}v_ic_i-\sum _{j=1}^{n}h_jb_j,}
\end{eqnarray}
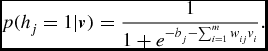 \begin{equation*}
p(h_j=1|\textbf {\textit {v}})=\frac{1}{1+e^{-b_j-\sum _{i=1}^{m}w_{ij}v_i}}.
\end{equation*}
\begin{equation*}
p(h_j=1|\textbf {\textit {v}})=\frac{1}{1+e^{-b_j-\sum _{i=1}^{m}w_{ij}v_i}}.
\end{equation*}
And in a RBM, the ci is the bias for the visible unit vi in the following formula:
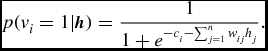 \begin{equation*}
p(v_i=1|\textbf {\textit {h}})=\frac{1}{1+e^{-c_i-\sum _{j=1}^{n}w_{ij}h_j}}.
\end{equation*}
\begin{equation*}
p(v_i=1|\textbf {\textit {h}})=\frac{1}{1+e^{-c_i-\sum _{j=1}^{n}w_{ij}h_j}}.
\end{equation*}
Then, for each pair of a visible vector and a hidden vector
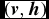 $(\textbf {\textit {v}},\textbf {\textit {h}})$
, the probability of this pair can be defined as follows:
$(\textbf {\textit {v}},\textbf {\textit {h}})$
, the probability of this pair can be defined as follows:
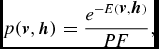 \begin{equation*}
p(\textbf {\textit {v}},\textbf {\textit {h}})=\frac{e^{-E(\textbf {\textit {v}},\textbf {\textit {h}})}}{PF},
\end{equation*}
\begin{equation*}
p(\textbf {\textit {v}},\textbf {\textit {h}})=\frac{e^{-E(\textbf {\textit {v}},\textbf {\textit {h}})}}{PF},
\end{equation*}
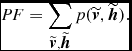 \begin{equation}
PF=\sum _{\widetilde{\textbf {\textit {v}}},\widetilde{\textbf {\textit {h}}}}p(\widetilde{\textbf {\textit {v}}},\widetilde{\textbf {\textit {h}}}).
\end{equation}
\begin{equation}
PF=\sum _{\widetilde{\textbf {\textit {v}}},\widetilde{\textbf {\textit {h}}}}p(\widetilde{\textbf {\textit {v}}},\widetilde{\textbf {\textit {h}}}).
\end{equation}
Besides, a RBM is a graphical model with the units for both layers not connected within a specific layer, i.e., there are only connections between the two layers for the RBM (Hinton & Salakhutdinov Reference Hinton and Salakhutdinov2006). Mathematically, for a RBM, aij
= 0 for i, j = 1, 2, . . ., m and dij
= 0 for i, j = 1, 2, . . ., n. Thus, the states of all the hidden units hj
’s are independent given a specific visible vector
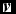 $\textbf {\textit {v}}$
and so are the visible units vi
’s given a specific hidden vector
$\textbf {\textit {v}}$
and so are the visible units vi
’s given a specific hidden vector
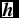 $\textbf {\textit {h}}$
. Then, we can obtain the following formula:
$\textbf {\textit {h}}$
. Then, we can obtain the following formula:
 \begin{equation*}
p(\textbf {\textit {h}}|\textbf {\textit {v}})=\prod _j p(h_j|\textbf {\textit {v}}) \textrm { and } p(\textbf {\textit {v}}|\textbf {\textit {h}})=\prod _ip(v_i|\textbf {\textit {h}}).
\end{equation*}
\begin{equation*}
p(\textbf {\textit {h}}|\textbf {\textit {v}})=\prod _j p(h_j|\textbf {\textit {v}}) \textrm { and } p(\textbf {\textit {v}}|\textbf {\textit {h}})=\prod _ip(v_i|\textbf {\textit {h}}).
\end{equation*}
3.1 Contrastive divergence
Contrastive divergence (CD) is proposed by Hinton and it can be used to train RBM (Hinton, Osindero, & Teh Reference Hinton, Osindero and Teh2006). Initially, we are given vi
(i = 1, 2, . . ., m), then we can obtain hj
(j = 1, 2, . . ., n) by the sigmoid function given in the above. And the value of hj
is determined by comparing a random value r ranging from 0 to 1 with the probability
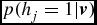 $p(h_j=1|\textbf {\textit {v}})$
. Then, we can reconstruct
$p(h_j=1|\textbf {\textit {v}})$
. Then, we can reconstruct
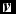 $\textbf {\textit {v}}$
by
$\textbf {\textit {v}}$
by
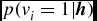 $p(v_i=1|\textbf {\textit {h}})$
.
$p(v_i=1|\textbf {\textit {h}})$
.
We can repeat the above process backward and forward until the reconstruction error is small enough or it has reached the maximum number of iterations, which is set beforehand. To update the weights and biases in a RBM, it is necessary to compute the following partial derivative:
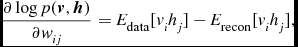 \begin{equation}
\frac{\partial \log p(\textbf {\textit {v}},\textbf {\textit {h}})}{\partial w_{ij}}=E_{\text{data}}[v_ih_j]-E_{\text{recon}}[v_ih_j],
\end{equation}
\begin{equation}
\frac{\partial \log p(\textbf {\textit {v}},\textbf {\textit {h}})}{\partial w_{ij}}=E_{\text{data}}[v_ih_j]-E_{\text{recon}}[v_ih_j],
\end{equation}
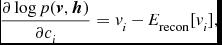 \begin{equation}
\frac{\partial \log p(\textbf {\textit {v}},\textbf {\textit {h}})}{\partial c_i}=v_i-E_{\text{recon}}[v_i],
\end{equation}
\begin{equation}
\frac{\partial \log p(\textbf {\textit {v}},\textbf {\textit {h}})}{\partial c_i}=v_i-E_{\text{recon}}[v_i],
\end{equation}
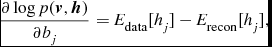 \begin{equation}
\frac{\partial \log p(\textbf {\textit {v}},\textbf {\textit {h}})}{\partial b_j}=E_{\text{data}}[h_j]-E_{\text{recon}}[h_j],
\end{equation}
\begin{equation}
\frac{\partial \log p(\textbf {\textit {v}},\textbf {\textit {h}})}{\partial b_j}=E_{\text{data}}[h_j]-E_{\text{recon}}[h_j],
\end{equation}
Then, the weight can be updated according to the following rule:
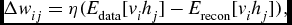 \begin{equation*}
\Delta w_{ij}=\eta (E_{\text{data}}[v_i h_j]-E_{\text{recon}}[v_i h_j]),
\end{equation*}
\begin{equation*}
\Delta w_{ij}=\eta (E_{\text{data}}[v_i h_j]-E_{\text{recon}}[v_i h_j]),
\end{equation*}
In Equations (3)–(5),
 $E_{\text{data}}[\star ]$
’s are easy to compute. To compute or inference the latter term
$E_{\text{data}}[\star ]$
’s are easy to compute. To compute or inference the latter term
 $E_{\text{recon}}[\star ]$
, we can resort to MCMC.
$E_{\text{recon}}[\star ]$
, we can resort to MCMC.
3.2 Free energy and soft-max
To apply RBM for classification, we can resort to the following technique. We can train a RBM for each specific class. And for classification, we need the free energy and the soft-max function for help. For a specific visible input vector
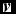 $\textbf {\textit {v}}$
, its free energy equals to the energy that a single configuration must own and it equals the sum of the probabilities of all the configurations containing
$\textbf {\textit {v}}$
, its free energy equals to the energy that a single configuration must own and it equals the sum of the probabilities of all the configurations containing
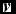 $\textbf {\textit {v}}$
. In this study, the free energy (Hinton Reference Hinton, Montavon, Orr and Müller2012) for a specific visible input vector
$\textbf {\textit {v}}$
. In this study, the free energy (Hinton Reference Hinton, Montavon, Orr and Müller2012) for a specific visible input vector
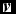 $\textbf {\textit {v}}$
can be computed as follows:
$\textbf {\textit {v}}$
can be computed as follows:
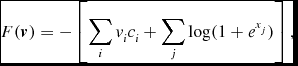 \begin{equation}
F(\textbf {\textit {v}})=-\left[\sum _iv_ic_i+\sum _j\log (1+e^{x_j})\right],
\end{equation}
\begin{equation}
F(\textbf {\textit {v}})=-\left[\sum _iv_ic_i+\sum _j\log (1+e^{x_j})\right],
\end{equation}
For a given specific test vector
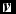 $\textbf {\textit {v}}$
, after training the RBMc
on a specific class c, the log probability that RBMc
assigns to
$\textbf {\textit {v}}$
, after training the RBMc
on a specific class c, the log probability that RBMc
assigns to
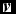 $\textbf {\textit {v}}$
can be computed according to the following formula:
$\textbf {\textit {v}}$
can be computed according to the following formula:
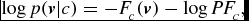 \begin{equation*}
\log p(\textbf {\textit {v}}|c)=-F_c(\textbf {\textit {v}})-\log PF_c,
\end{equation*}
\begin{equation*}
\log p(\textbf {\textit {v}}|c)=-F_c(\textbf {\textit {v}})-\log PF_c,
\end{equation*}
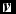 $\textbf {\textit {v}}$
resorting to the free energies of all the class-dependent RBMc
’s:
$\textbf {\textit {v}}$
resorting to the free energies of all the class-dependent RBMc
’s:
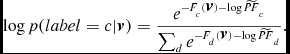 \begin{equation}
\log p(label=c|\textbf {\textit {v}})=\frac{e^{-F_c(\textbf {\textit {v}})-\log \widetilde{PF}_c}}{\sum _de^{-F_d(\textbf {\textit {v}})-\log \widetilde{PF}_d}}.
\end{equation}
\begin{equation}
\log p(label=c|\textbf {\textit {v}})=\frac{e^{-F_c(\textbf {\textit {v}})-\log \widetilde{PF}_c}}{\sum _de^{-F_d(\textbf {\textit {v}})-\log \widetilde{PF}_d}}.
\end{equation}
In Equation (7), all the partition functions
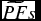 $\widetilde{PF}s$
can be learned by maximum likelihood (ML) training of the ‘soft-max’ function, where the maximum likelihood method is a kind of parameter estimation method generally with the help of the log probability. Here, the ‘soft-max’ function for a specific unit is generally defined in the following form:
$\widetilde{PF}s$
can be learned by maximum likelihood (ML) training of the ‘soft-max’ function, where the maximum likelihood method is a kind of parameter estimation method generally with the help of the log probability. Here, the ‘soft-max’ function for a specific unit is generally defined in the following form:
 \begin{equation*}
p_j=\frac{e^{x_j}}{\sum _{i=1}^{k} e^{x_i}},
\end{equation*}
\begin{equation*}
p_j=\frac{e^{x_j}}{\sum _{i=1}^{k} e^{x_i}},
\end{equation*}
For clarity, we show the complete RBM algorithm in the following. The RBM algorithm as a whole based on the CD method can be summarised as follows:
-
• Input: a visible input vector
 $\textbf {\textit {v}}$
, the size of the hidden layer nh
, the learning rate η, and the maximum epoch Me
;
$\textbf {\textit {v}}$
, the size of the hidden layer nh
, the learning rate η, and the maximum epoch Me
; -
• Output: a weight matrix
$\textbf {\textmd {W}}$
, a biases vector for the hidden layer
$\textbf {\textit {b}}$
, and a biases vector for the visible layer
$\textbf {\textit {c}}$
; -
• Training:
Initialisation: Set the visible state with
$\textbf {\textit {v}}_1=\textbf {\textit {x}}$
, and set
$\textbf {\textmd {W}}$
,
$\textbf {\textit {b}}$
, and
$\textbf {\textit {c}}$
with small (random) values,For t = 1, . . ., Me ,
For j = 1, . . ., nh ,
Compute the following value:
$p(h_{1j}=1|\textbf {\textit {v}}_1)=sigmoid(b_j+\sum _iv_{1i}W_{ij})$
;Sample h 1j from the conditional distribution
$P(h_{1j}|\textbf {\textit {v}}_1)$
with the Gibbs sampling method;End
For i = 1, 2, . . ., nv , //Here, the nv is the size of the visible input vector
$\textbf {\textit {v}}$
Compute the following value:
$p(v_{2j}=1|\textbf {\textit {h}}_1)=sigmoid(c_i+\sum _jW_{ij}h_{1j})$
;Sample v 2i from the conditional distribution
$P(v_{2i}|\textbf {\textit {h}}_1)$
with the Gibbs sampling method;End
For j = 1, . . ., nh ,
Compute the following value:
$p(h_{2j}=1|\textbf {\textit {v}}_2)=sigmoid(b_j+\sum _iv_{2i}W_{ij})$
;End
Update the parameters:
$\textbf {\textmd {W}}=\textbf {\textmd {W}}+\eta [P({h_1=1}|\textbf {\textit {v}}_1)\textbf {\textit {v}}_1-P({h_2=1}|\textbf {\textit {v}}_2)\textbf {\textit {v}}_2]$
;
$\textbf {\textit {c}}=\textbf {\textit {c}}+\eta (\textbf {\textit {v}}_1-\textbf {\textit {v}}_2)$
;
$\textbf {\textit {c}}=\textbf {\textit {c}}+\eta [P({h_1=1}|\textbf {\textit {v}}_1)-P({h_2=1}|\textbf {\textit {v}}_2)]$
;End

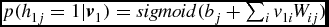
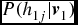
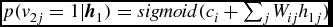
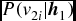
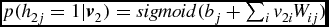
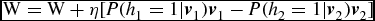
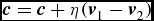
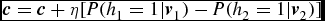
For classification, after training the RBM using the above algorithm, we need to compute the free energy function by Equation (6) and then we can assign a label for the sample
 $\textbf {\textit {v}}$
with Equation (7).
$\textbf {\textit {v}}$
with Equation (7).
4 EXPERIMENT
4.1 Data description
There have been a large amount of surveys in astronomy. SDSS is one of those surveys and it is one of the most not only ambitious but also influential ones (The official website of SDSS is http://www.sdss.org/). The SDSS has begun collecting data since 2000. From 2000 to 2008, the SDSS collected deep and multi-colour images containing no less than a quarter of the sky and it also created 3D maps for over 930 000 galaxies and also for over 120 000 quasars. Data Release 7 (DR7) is the seventh major data release and it provides spectra and redshifts etc., for downloading.
All the data used in our experiment are coming from the SDSS. All the samples in the entire data set are divided into two classes, one class composed of non-CVs whereas the other class composed of CVs. There are totally 6 818 non-CVs and 208 CVs in our data set. Each sample is composed of 3 522 variables, or rather, spectral components. Among the total 6 818 non-CVs, there are 1 559 belonging to Galaxies, 3 981 belonging to Stars, and the remaining 1 278 belonging to QSOs (Quasi-stellar objects)Footnote 3 .
In the following, we show the CVs in detail in our experiment. It is common that there will be transparent Balmer absorption lines in their spectra when the CVs outburst. A representative spectrum of the CV from the SDSS is shown in Figure 1. Much work has been done on the CVs for ages. Without high-tech, the earlier researches are focused on the optical characteristics of the spectrum. Then, with the help of the high-tech astronomical instruments, the multi-wavelength studies of the spectrum become to be true and the astronomers can obtain much more information about the CVs than before (Bu et al. Reference Bu, Pan, Jiang, Chen and Wei2013). From 2001 to 2006, Szkody et al. had been using the SDSS to search for CVs. The CVs in our data set are from their studies (Szkody et al. Reference Szkody2002, Reference Szkody2003, Reference Szkody2004, Reference Szkody2005, Reference Szkody2006, Reference Szkody2007), and we are deeply grateful to their researches. For clarity, we show the number of the CVs they found using the SDSS in Table 1. And the spectrum of a CV in our data set is shown in Figure 2.

Figure 1. Spectrum of a cataclysmic variable star. The online version is available at: http://cas.sdss.org/dr7/en/tools/explore/obj.asp?id=587730847423725902.

Figure 2. Spectrum of a cataclysmic variable star in our data set.
Table 1. The number of the CVs that Szkody et al. searched using the SDSS.

In our experiment, we chose randomly half of the whole data for training and the remaining half for testing for both non-CVs and CVs. In detail, for non-CVs, half of the total 6 818 samples (i.e. 3 409) were randomly chosen to train the RBM classifier and the remaining half to test the RBM classifier. Similarly, for CVs, half of all the 208 samples (i.e. 104) were randomly chosen to train the RBM classifier and the remaining half to test the RBM classifier. To explain it clearly, we showed the data used for training and testing the RBM classifier in Table 2.
Table 2. The number of the original data for training and for testing respectively, where the number 3 522 is the dimension of the original data.

4.2 Parameter chosen
In this subsection, we present the parameters in our experiment. We chose all the parameters referring to Hinton (Reference Hinton, Montavon, Orr and Müller2012). The learning rate in the process of updating was set to be 0.1. The momentum for smoothness and to prevent over-fitting was chosen to be 0.5. The maximum number of epochs was chosen to be 50. The weight decay factor, penalty, was chosen to be 2 × 10−4. The initial weights were randomly generated from the standard normal distribution, while the biases vectors
 $\textbf {\textit {b}}$
and
$\textbf {\textit {b}}$
and
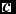 $\textbf {\textit {c}}$
were initialised with
$\textbf {\textit {c}}$
were initialised with
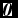 $\textbf {\textit {0}}$
. For clarity, we present them in Table 3.
$\textbf {\textit {0}}$
. For clarity, we present them in Table 3.
Table 3. The parameters in our experiment.

4.3 Experiment result
We first normalised the data to make it have unit l
2 norm, i.e. for a specific vector
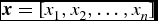 $\textbf {\textit {x}}=[x_1,x_2,\ldots ,x_n]$
, the l
2 norm of the vector satisfies ∑
i
x
2
i
= 1. Then, we could get two matrixes, one was
$\textbf {\textit {x}}=[x_1,x_2,\ldots ,x_n]$
, the l
2 norm of the vector satisfies ∑
i
x
2
i
= 1. Then, we could get two matrixes, one was
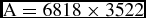 $\textbf {\textmd {A}}=6 818\times 3 522$
and the other was
$\textbf {\textmd {A}}=6 818\times 3 522$
and the other was
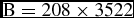 $\textbf {\textmd {B}}=208\times 3 522$
. Then, we found out the maximum element and the minimum element for CVs and non-CVs, respectively. Finally, to apply binary RBM for classification, we found a parameter to assign the value of the variable in our experiment with 0 or 1, or rather, binarisation.
$\textbf {\textmd {B}}=208\times 3 522$
. Then, we found out the maximum element and the minimum element for CVs and non-CVs, respectively. Finally, to apply binary RBM for classification, we found a parameter to assign the value of the variable in our experiment with 0 or 1, or rather, binarisation.
Mathematically, if
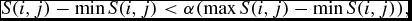 \begin{equation*}
S(i,j)-\min S(i,j)<\alpha (\max S(i,j)-\min S(i,j)),
\end{equation*}
\begin{equation*}
S(i,j)-\min S(i,j)<\alpha (\max S(i,j)-\min S(i,j)),
\end{equation*}
 $\textbf {\textmd {A}}$
and
$\textbf {\textmd {A}}$
and
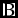 $\textbf {\textmd {B}}$
in the ith row and the jth column. The parameter α satisfied 0<α<1. To investigate the influence of the parameter α on the final performance of the binary RBM algorithm, we first chose it to be 1/2 heuristically. Then, we chose it to be 1/3. The experiment result shows that the classification accuracy is 100%, which is state-of-the-art and it outperforms the prevalent classifier SVM (Bu et al. Reference Bu, Pan, Jiang, Chen and Wei2013).
$\textbf {\textmd {B}}$
in the ith row and the jth column. The parameter α satisfied 0<α<1. To investigate the influence of the parameter α on the final performance of the binary RBM algorithm, we first chose it to be 1/2 heuristically. Then, we chose it to be 1/3. The experiment result shows that the classification accuracy is 100%, which is state-of-the-art and it outperforms the prevalent classifier SVM (Bu et al. Reference Bu, Pan, Jiang, Chen and Wei2013).
For clarity, we show the result in Table 4, in which we also show the performance the binary RBM algorithm based on other values for the variable α. From Table 4, we can see that the classification accuracy is 97.2%, when α = 1/2. However, almost all of the CVs for testing is labelled as non-CVs.
Table 4. The classification accuracy with different α′s.

Table 4 shows the classification accuracy computed by the following formula:
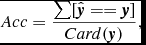 \begin{equation}
Acc=\frac{\sum [\hat{\textbf {\textit {y}}}==\textbf {\textit {y}}]}{Card(\textbf {\textit {y}})},
\end{equation}
\begin{equation}
Acc=\frac{\sum [\hat{\textbf {\textit {y}}}==\textbf {\textit {y}}]}{Card(\textbf {\textit {y}})},
\end{equation}
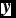 $\textbf {\textit {y}}$
is a vector, denoting the label of all the test samples. In our experiment, there are 3 413 (3 409 non-CVs + 104 CVs) test samples. And ‘Card(
$\textbf {\textit {y}}$
is a vector, denoting the label of all the test samples. In our experiment, there are 3 413 (3 409 non-CVs + 104 CVs) test samples. And ‘Card(
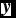 $\textbf {\textit {y}}$
)’ represents the number of elements in vector
$\textbf {\textit {y}}$
)’ represents the number of elements in vector
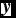 $\textbf {\textit {y}}$
. In Equation (8), the denominator
$\textbf {\textit {y}}$
. In Equation (8), the denominator
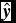 $\hat{\textbf {\textit {y}}}$
is the label of all the test samples predicted by Equation (7), in which c = +1 or c = −1. In this paper, c = +1 means that the sample belongs to non-CVs, whereas c = −1 means that the sample belongs to CVsFootnote
4
. And
$\hat{\textbf {\textit {y}}}$
is the label of all the test samples predicted by Equation (7), in which c = +1 or c = −1. In this paper, c = +1 means that the sample belongs to non-CVs, whereas c = −1 means that the sample belongs to CVsFootnote
4
. And
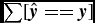 $\sum [\hat{\textbf {\textit {y}}}==\textbf {\textit {y}}]$
means the total number of equal elements in vector
$\sum [\hat{\textbf {\textit {y}}}==\textbf {\textit {y}}]$
means the total number of equal elements in vector
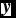 $\textbf {\textit {y}}$
and vector
$\textbf {\textit {y}}$
and vector
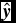 $\hat{\textbf {\textit {y}}}$
.
$\hat{\textbf {\textit {y}}}$
.
5 CONCLUSION AND FUTURE WORK
RBM is a bipartite generative graphical model, which can extract features representing the original data well. By introducing free energy and soft-max function, RBM can be used for classification. In this paper, we apply RBM for spectral classification of non-CVs and CVs. And the experiment result shows that the classification accuracy is 100%, which is the state-of-the-art and outperforms the rather prevalent classifier, SVM.
Since RBM is the building block of deep belief nets (DBNs) and deep Boltzmann machine (DBM), then we can infer that DBM (Salakhutdinov & Hinton Reference Salakhutdinov and Hinton2009) and DBN can also perform well on spectral classification, which is our future work.
ACKNOWLEDGEMENTS
The authors are very grateful to the anonymous reviewer for a thorough reading, many valuable comments, and rather helpful suggestions. The authors thank the editor Bryan Gaensler a lot for the helpful suggestions on the organisation of the manuscript. The authors also thank Jiang Bin for providing the CV data.