

I. INTRODUCTION
Figure 1 illustrates the evolution of visual media types in terms of image quality (SD → HD → 4K), realism, depth sensation, and interactivity (2D → 3D → 4D). A key characteristic of earlier systems is that a desired two-dimensional/three-dimensional (2D/3D) scene can only be viewed from a fixed viewpoint and they usually lack the capability to manipulate interactively the viewpoints of captured 2D/3D scene.

Fig. 1. Evolution of video capture and display system.
For the past several years and because of advances made in computer graphics, computer vision and multi-view/3D multimedia technologies, a new type of interactive video navigation and visualization has been gaining popularity and is becoming available in the professional and consumer markets (e.g. bullet time movie and 360° panoramic video for VR head-mount (https://www.youtube.com/watch?v=82mXrQWlW38 https://www.youtube.com/watch?v=zKtAuflyc5w https://www.oculus.com/gear-vr/).) Navigation range offered by initial commercial products has been limited to a simple linear/angular change along the linear trajectory between capturing devices (e.g. camera array). Modern professional systems have however started to demonstrate a more flexible range of viewpoint navigation, independent of capturing device placements (e.g. sportscast, immersive concert streaming as shown in (https://www.youtube.com/watch?v=l_TxrOxCPSg&feature=youtu.be https://www.youtube.com/watch?v=h-7UPZg_qOM).) International Standardization Organizations, ISO-MPEG, and ITU-T VCEG, have also been working on various aspects of free viewpoint visual media technology, known as Free Viewpoint Television (FTV) standardization [Reference Lafruit, Wegner and Tanimoto1–Reference Tanimoto, Tehrani, Fujii and Yendo5]. More specifically, Multi-view Video Coding (MVC) [6] is developed for efficient compression of multi-view cameras in phase 1 of FTV standardization activity. Phase 2 of FTV standardization, called 3DV, supports generation of virtual view(s) from small number of coded camera views together with their associated depth map(s) [7]. MPEG is currently considering the third phase of FTV standardization and is planning to issue CfE (Call for Evidence) in June 2015 [Reference Lafruit, Wegner and Tanimoto1].
A) Free viewpoint video (FVV)
As mentioned earlier, FVV is an advanced visual media type that offers flexible viewpoint navigation in 3D space and time (4D video) from multi-view captured video. The key benefit of FVV is interactivity allowing users, rather than broadcasters or content creators, to control the desired viewing angles and positions. A description of FVV system is given below.
B) FVV system
As described in [Reference Smolic8] and shown in Fig. 2, a typical FVV system is composed of the following modules:
• Acquisition module: Main functionality is to capture the 3D scene. It consists, in general, of multiple capture devices (e.g. sensors and camera arrays.)
• Processing module: It is used to convert captured data signals (e.g. image data) into a data format suitable for 3D scene representation (i.e. volumetric shape and texture) (Table 1).
• Transmission module: It provides a compact representation format of the 3D data for streaming and/or storage.
• Rendering module: It synthesizes the decoded 3D data for visualization and navigation at a desired scale in viewing and time.
• Display module: It presents rendered video to enhance user's scene immersive experience. It also provides user interface (UI) tools for viewpoint navigation.
Fig. 2. FVV system overview (Smolic [8]).
Table 1. Comparison of different 3D scene representations (Smolic [Reference Smolic8])
A brief description of each module follows.
II. SYSTEM MODULE OVERVIEW
A) Acquisition module
Acquisition module consists of a number of capturing devices (e.g. camera array) characterized generally by three key configuration parameters: (1) topology, (2) synchronization, and (3) calibration.
1. TOPOLOGY (INWARD VERSUS OUTWARD)
The choice of topology depends largely on the goal of the target viewing content in scene production i.e. whether the main target and focus of immersive viewing is on the background (BG) or on the foreground (FG).
In case of BG viewing target, capturing devices are placed in an outward looking manner, as shown in Fig. 3. Scene capture in this case is typically done by a 360° spherical camera that consists of multiple sensors and optical modules.
Fig. 3. Outward FVV.
For FG target viewing, capturing devices are instead placed in an inward looking manner, as shown in Fig. 4. Scene capture is typically done by either dense or sparse capturing devices such as camera array.
Fig. 4. Inward FVV.
2. SYNCHRONIZATION
In order to capture dynamically moving or non-rigid targets, from multiple cameras, it is essential to maintain a degree of synchronization between cameras.
Wilburn et al. [Reference Wilburn9], for example, has shown that it is possible to maintain 1.2 μs synchronization accuracy between 100 cameras, by a single source of hardware trigger. Since synchronization is performed by wired connection between cameras, this approach may not be practical for consumer applications. An alternative and more cost-effective approach is based on GigE-Vision2 industry standard [59], which has an optional support for Precision Time Protocol (PTP, IEEE 1588). It has however some difficulties to guarantee predictable trigger latency and it is also necessary to have wired Ethernet connection between capturing devices. To eliminate the need for wired connections, Meyer et al. [Reference Meyer10] has proposed a wireless and cost-effective approach that can achieve 0.39 μs synchronization accuracy by using GPS time sync via Wi-Fi. Use of audio information [Reference Lichtenauer11], is another way by which the need for wired trigger can be eliminated.
3. CALIBRATION
With any multi-capturing devices, intrinsic and extrinsic camera calibrations are required, for 3D shape reconstructions and wider viewpoint navigation. Various calibration approaches are available in public domain and the detail survey of these approaches is out of the scope of this paper.
It should be noted that there are certain approaches for which it is possible to avoid calibration step. For instance, if view interpolation is expected along the physical boundary of camera arrays rather than 3D shape reconstruction, then calibration can be avoided. A second approach to avoid calibration is to apply structure from motion (SfM) (e.g. [Reference Tomasi and Kanade12,Reference Snavely, Seitz and Szeliski13]). SfM can estimate, over time, poses and positions of capturing device as well as 3D structure of the scene from captured trajectories. This approach is appropriate if the target object remains static/rigid. It cannot however be easily applied to dynamically moving or non-rigid objects that are typical of FVV applications.
It should also be emphasized that camera calibration error greatly affects the quality of 3D shape reconstruction. Furukawa and Ponse [Reference Furukawa and Ponse14] have proposed a method to refine camera calibration from the multi-view stereo (MVS) system. A possible shortcoming of this approach is that it may have some difficulties dealing with sparse camera array.
In summary, camera calibration complexity due to high setup and installation cost is one of the main reasons that current applications of FVV have been limited to professional domain, only.
B) Processing module
1. IMAGE-BASED VERSUS MODEL-BASED
In general, for an FVV system, with dense camera array, one can reduce computational complexity by applying image-based approaches (e.g. image stitching and view interpolation). In contrast, an FVV system with sparse camera array, tends to be model-based because of low correlation that exists between widely separated base-line of cameras [Reference Lafruit, Wegner and Tanimoto1,Reference Smolic8,Reference Kanade and Narayanan56,Reference Chan, Shum and Ng57] (Table 1).
a) Image-based
In outward FVV systems, it is common practice to use image-based view interpolation methods to create 360° panoramic and photorealistic BG scene views. In such case, flexibility of viewpoint navigation will be limited to angular viewing only due to the lack of 3D scene geometry.
The inward FVV system, with dense camera array, can offer view interpolation with high image quality. However, if the target virtual viewpoint moves further, relative to capturing device, image quality could suffer due to limited 3D scene geometry information. Inward FVV systems incorporating depth (e.g. RGB{_}D or time-of-flight depth-camera) can reduce density of camera array and extends the potential range of viewpoint navigation [Reference Smolic8,Reference Zitnick15,Reference Zollhofer16]. Use of such depth cameras is limited to indoor scenes due to the use of near-infrared active sensing.
b) Model-based
In contrast with image-based approaches, model-based or geometry-based approaches offer a wider viewpoint navigation range.
For dense number of capturing devices, multi-view stereo (MVS) is a common technology that utilizes silhouette, texture, and shading (e.g. occluding contour) cues for 3D shape and texture reconstruction [Reference Shan, Curless, Furukawa, Hernandez and Seitz17,Reference Furukawa61]. However, effective application of the MVS system requires much shorter camera base-line for feature matching.
Whereas for sparse number of capturing devices one needs to exploit 3D reconstruction beyond stereo matching algorithm, due to low correlation between captured views.
We elaborate further about the 3D shape reconstruction and texture mapping.
2. 3D SHAPE RECONSTRUCTION
The general approach for 3D shape reconstruction is to use a number of visual cues, known as “Shape from X”, in computer vision literature. It includes shape from silhouette (SfS) (silhouette cue), shape from texture (texture cue), and shape from shading (shade cue). Moreover, if the target shape is known as a priori, 3D priori model can also be applied. We will discuss briefly about each approach.
a) Silhouette cue
Visual hull (VH) or SfS is a commonly used method for 3D shape reconstruction [Reference Matusik, Buehler and Raskar18–Reference Furukawa and Ponce21]. As mentioned earlier, this is mainly due to lack of correlation between widely separated views that could cause breakdown of feature-based matching methods. The first step in SfS is to extract silhouette(s) of the target FG object(s) from BG. This is usually done based on priori modeling of BG and by its subtraction from captured image. This process is known as background subtraction (BGS) and various algorithms have been proposed for both indoor and outdoor scenes [Reference Sobral22]. Although extracted silhouette may be sufficient for FG detection, it may not be precise for 3D shape reconstruction due to the outliners of silhouette detection (e.g. excessive or missing body parts) and the low-pass filtering nature of BGS. To simplify the process of BGS, typical FVV capture systems place uniform color BG (e.g. green BG as shown in Fig. 4). This kind of simplification is not always possible in an outdoor scene. In [Reference Landabaso, Pardas and Casas23,Reference Haro24], a more robust SfS algorithms have been proposed. The goal is to improve silhouettes due to errors in camera calibration or inconsistent silhouettes.
Besides, silhouette-based VH produce low shape surface details due to its inability to recover concavity [Reference Laurentini19].
b) Texture cue
To address lack of surface details associated with SfS, photo consistency-based approach, as a complement to SfS, has been proposed [Reference Seitz and Dyer25–Reference Yezzi27] (Fig. 5). The general idea behind photo consistency is to enforce color consistency across views in addition to application of SfS or feature matching (e.g. SIFT [Reference Lowe28] and SURF [Reference Bay, Tuytelaars and Gool29]) due to low feature correlation between sparse views. Surface detail refinement can be performed based on joint optimization of silhouette and photo consistency using Graph cut or Level-set [Reference Vogiatzis30,Reference Esteban and Schmitt31]. It should be pointed out that despite of its simple algorithm photo consistency has nevertheless high computational run-time due to many repetitive operations.
Fig. 5. VH(silhouette only) and improvement by joint-optimization of silhouette + photoconsistency (Esteban and Schmitt [31]). Left: silhouette based visual hull (low concavity). Middle: Silhouette and photoconsistency joint optimization by level-set. Right: Original input image.
Standard SfM tends to rely on spatially robust texture and corner feature points associated primarily with static or rigid objects [Reference Tomasi and Kanade12,Reference Snavely, Seitz and Szeliski13]. Torresani et al. [Reference Torresani, Hertzmann and Bregler32] have proposed non-rigid SfM by learning temporal dynamics of object shape. In his approach, temporally robust feature points are manually assigned. For estimation of 3D shape deformation, automatic detection of sufficient number of such feature points becomes a challenging task, however.
c) Shading cue
Traditional shape from shading assumes the existence of a calibrated light source or a known surface material with no color or texture [Reference Dovgard and Basri33,Reference Tankus, Sochen and Yeshurun34]. Recently, Barron and Malik have proposed SIRFS model [Reference Barron and Malik35] with no priori assumption about shading, shape, light, and reflectance and has applied it to a single image. With the availability of RGB-D, the quality of shading and shape can be further refined for higher accuracy [Reference Barron and Malik36]. This state-of-the-art technique has nevertheless some difficulties in dealing with textured objects in natural light and outdoor conditions (Fig. 6).
Fig. 6. SIRFS model for Shape from Shading (Barron and Malik [35]).
d) 3D Priori Model
Presumably, with the target shape known as a priori, a more robust 3D shape reconstruction is possible. With the exception of human body model, there is however a limited number of priori 3D shape available. FVV application would typically require realistic surface-level reconstruction (e.g. skin and clothing) going beyond the skeleton model.
Various realistic and morphable 3D human body models have been proposed in the literature [Reference Anguelov, Srinivasan, Koller, Thrun, Rodgers and Davis37–Reference Chen, Liu and Zhang39]. Anguelov et al. [Reference Anguelov, Srinivasan, Koller, Thrun, Rodgers and Davis37] have proposed a popular SCAPE model. It is based on the 3D scanned human body template model for estimation of the articulated pose and non-rigid shape deformation.
Using SCAPE or other 3D morphable models, various researchers have addressed non-linear 3D deformation and registration algorithm from 3D to multi-view 2D images [Reference Balan, Sigal, Black, Davis and Haussecker40–Reference Aguiar, Stoll, Theobalt, Ahmed, Seidel and Thrun45]. Main advantage with these approaches is to provide temporally robust shape, particularly on non-rigid body parts (e.g. arms and legs) as shown in Figs 7 and 8 [Reference Vlasic, Baran, Matusik and Popovic41] and Fig. 9 [Reference Gall, Stoll, Aguiar, Theobalt, Rosenhahn and Seidel42]. Main remaining challenge include scalability of the model: a typical non-scalable system requires generating a new, non-trivial 3D template per each subject for the specific type of activities. Use of generic 3D template model tends to lose specifics of individuals with minimum shape surface details and they tend to look rather graphic-like than photorealistic.
Fig. 7. 3D priori model improves non-rigid body parts. (Left: visual hull, Right: 3D priori model) (Vlasic et al. [41]).
Fig. 8. Visual quality of shape reconstruction by Visual hull (Left), linear articulation of 3D model (Middle), and non-rigid deformation of 3D model (Right) (Vlasic et al. [41]).
Fig. 9. Gall [42] captures the motion of animals and humans accurately by non-linear surface deformation of 3D priori model.
3. TEXTURE MAPPING
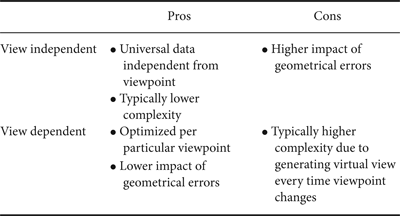
In addition to 3D shape, texture mapping is a critical factor affecting the visual quality of the reconstructed 3D scene and it is often the source of computational bottle-neck in the computer graphics (CG) processing flow [Reference Akenine-Moller, Haines and Hoffman46]. In a typical CG processing chain, the texture is projected from multiple cameras' pixel data to the entire surface of the model using proximity or directional optimization between cameras and surface normal. This view-independent texture mapping can generate universal dataset, independent of virtual viewpoint. For potentially higher texture quality optimized per particular viewpoint, texture map can be generated in a view-dependent context [Reference Matusik, Buehler and Raskar18,Reference Casas47–Reference Nobuhara, Ning and Matsuyama49]. Hisatomi [Reference Hisatomi60] shows that view-dependent approach can suppress the impact of geometrical errors by processing images of cameras visible and close to the viewpoint. However, view-dependent texture mapping typically requires higher computational complexity due to the need for generating new virtual view every time viewpoint changes.
The key challenges with texture mappings are occlusion [Reference Smolic8] and texture seam [Reference Casas47,Reference Takai, Hilton and Matsuyama48,Reference Eisemann50]. It is worth to note that unless proper texture synthesis approaches are applied, occlusion and texture seam could cause further degradation in visual quality, as the camera array becomes sparser (Table 2).
Table 2. Comparison of texture-mapping approach
a) Occlusion
Some parts of the target object may be invisible by all capturing devices. In that case, the texture needs to be filled by in-painting or some other type of image completion [Reference Smolic8] to allow 360° virtual viewpoint. Occlusion also needs to be handled in a temporally consistent manner for video, unless the time is stopped during the viewpoint navigation (e.g. bullet time movie).
b) Texture seam
Since texture on the target object is projected from multiple camera views and due to potential camera calibration and estimated shape errors, a globally mapped texture becomes blurry or duplicated near border lines (i.e. contribution of texture projection switches from one camera to another).
Various approaches have been proposed to minimize texture seam. Eisemann [Reference Eisemann50] and Casas et al. [Reference Casas47] (Fig. 10) have proposed local texture alignment using optical flow. Takai et al. [Reference Takai, Hilton and Matsuyama48] deform the multi-view images based on the virtual camera position to harmonize the texture mapping while maintaining the 3D shape and camera calibration.
Fig. 10. Texture local alignment by optical flow (Casas et al. [47]). (a, b) camera captured walk and run views; (c) naïve direct blend of textures to a geometric proxy at virtual view; (d) optical flow and (e) proposed alignment.
C) Transmission
For smooth rendering of virtual views and scene navigation, a traditional multi-view system consists of a large number of sensor (camera) views. In [Reference Wilburn9], for example, a custom array of 100 cameras is constructed, where each three cameras are connected to PC for handling high bandwidth video data. From cost and efficiency point of view it is therefore necessary to develop appropriate visual coding and representation formats for efficient transmission and rendering of arbitrary views.
ISO/IEC MPEG and ITU-T VCEG International standard bodies have been engaged in the development of efficient representation and compression of such data as early as 1996 [51]. More recent activities include phase 1 of FTV (MVC) which started in March of 2004 and was completed in May of 2009 and it is based on the extension of H.264/MPEG-4 AVC [6]. Subsequently, in phase 2 of FTV, multi-view extension of HEVC, known as MV-HEVC [7], was developed and completed in July of 2014, by JCT-3 V. Compared with MVC, MV-HEVC has a higher coding efficiency and provides means for optional coding of depth data associated with each view – see Fig. 12. MV-HEVC is in particular well suited for delivery of 3D content for auto-stereoscopic displays for which many views are needed for scene immersive visual experience and sensation.
As illustrated in Fig. 11, in either MVC or MV-HEVC correlation across views and time are used for better prediction; thus, providing an efficient compression of multi-view video.
Fig. 11. Temporal/inter-view prediction for MV-HEVC. (Smolic [8]).
Fig. 12. Simplified block diagram of MV-HEVC [52].
For coding of 3D model data, MPEG-4 provides a process by which 3D (graphics) content is represented and coded. It is known as Animation Framework eXtension (AFX) [53]. Similarly, MPEG has also specified a model for interfacing AFX 3D graphics compression tools to graphics primitives defined in other standards referred to as 3DCG [54].
ISO/IEC MPEG is currently in phase 3 of FTV targeting free navigation (walk-through or flying through experience) and super multi-view (ultra-realistic 3D viewing) [Reference Tanimoto58].
D) Display
It should be emphasized that a key feature of FVV is to gain control over virtual view point and direction, based on personal preferences. A side effect of increased viewing controllability is higher viewing complexity. This is because the FVV system can generate infinite number of views despite the fact that human eyes can only see one to two views at a given time instant [Reference Tanimoto, Tehrani, Fujii and Yendo5]. A key challenge is therefore to provide users with natural and user friendly UI for viewpoint navigation by taking into account the above property of human visual system.
Various types of display devices can present FVV video content [Reference Tanimoto2]. Display devices of first type include traditional 2D/3D monitors (e.g. TV, laptop, smartphone, and VR head-mount display), which could be equipped with UI for viewpoint navigation (e.g. joystick, mouse, head/eye-tracker, remote controller, and touch panel). This type of display devices provide single user interface. Second type of display devices provide all the 360° views and multiple users are able to see any views by changing their locations. Yendo [Reference Yendo, Fujii, Tanimoto and Tehrani55] proposed 360° ray-producing display that allows multiple viewing of FVV videos.
III. APPLICATION EXAMPLES
As part of current MPEG FTV activities and discussions, two application scenarios are being considered: super multi-view display (SMV) and free navigation (FN) [Reference Lafruit, Wegner and Tanimoto1].
A) Super multi-view display
The system is constructed by 1D or 2D dense camera array (typically 80 cameras.) The main challenge here is to address high bandwidth transmission. Video synthesis technology is an image-based approach (e.g. view interpolation), and therefore, the system requires a large number of cameras, and the viewpoint change is typically limited around physical camera array (e.g. angular viewpoint change, if the camera topology is 1D arc) (Fig. 13).
Fig. 13. 1D arc dense camera array for SMV (Lafruit et al. [1]).
B) Free navigation
The system is constructed by sparse number of cameras (typically 5–10 cameras.) Due to a low correlation between widely separated views, the view synthesis technology is based on geometry or model-based approach (e.g. 3D reconstruction). Emphasis of FN is on visual quality of CG rendering and view synthesis (Fig. 14).
Fig. 14. Sparse camera array for FN (Lafruit et al. [1]).
IV. DISCUSSION
Generally, the key issue that could cause barriers to wide market penetration and roll-out of FVV system can be summarized as high set-up cost and difficulty in system operation. In other words, it is the burden of installing and calibrating multiple cameras and performing non-trivial video operations at high bandwidth. Innovative solution(s) to this issue calls for collective efforts across industry (i.e. capture, authoring, and display), standardization (interoperability, transmission, and storage format), and academic research (processing and rendering). Herewith, we are listing some of the technical challenges that need to be overcome and for which new technologies and standards need to be introduced:
• Automated or dynamic calibration of capture devices: Time-consuming multi-view camera calibration is key bottle-neck for the consumer. For example, recalibration becomes necessary, if any camera is moved.
• Photorealistic view synthesis by sparse camera array: Focus of standard activities has been mostly on image-based view interpolation with dense camera array and point-cloud data representation, for higher visual quality. Due to a large number of capturing devices, the set-up cost is high. Accordingly, in an effort to reduce number of capturing devices and set-up cost, current academic trend of FVV research is model-based 3D reconstruction. In spite of these efforts, generation of photorealistic view synthesis of shape and texture that fits within a reasonable computational complexity is still a major challenge (e.g. challenges for texture mapping, namely occlusion and texture seam, become critical, as the camera array becomes sparser).
• Establishing of a ground truth: Due to the nature of arbitrary virtual viewpoint, it is also difficult to define the ground truth for quality measure that correlates well with user viewing experience. In the absence of a well-established quality measure it will be a major challenge to compare the quality performance of one system versus another.
• Robust FG extraction from general indoor/outdoor BG: Automatic and robust extraction of high-quality FG objects from general BG scene remains challenging in an uncontrolled indoor/outdoor environment. Multimodal sensing approach (e.g. silhouette, texture, motion, and depth) is needed with less reliance on BG priors (e.g. natural BG versus green screen).
• Easy and intuitive mean of view point navigation: User experience will suffer, if viewpoint navigation is not easy. TV and head-mount devices with eye-tracker have been proposed for the direct UI. This is nevertheless not at practical level to create immersive user experience.
ACKNOWLEDGEMENT
This work is supported by Naofumi Yanagihara, Visual Technology Development Department of Sony, Corp. We also would like to thank Ken Tamayama who provided technical insight and expertise that have greatly assisted in the drafting of the paper.
Chuen-Chien Lee is senior Vice President at Sony Electronics in charge of US Research Center based in San Jose, California. He is responsible for overseeing research in basic science as well as research and development of emerging technologies for the next-generation products and new businesses. He has accordingly led US Research Center in a wide range of research and development activities, including: advanced camera signal processing, computational intelligence, video codec standardization, 3D visualization and interactivity, medical imaging, media streaming & indexing, wireless technology and standardization, smart energy, and green nanotechnologies. These technologies have been deployed in many Sony consumer products including: digital cameras and camcorders, Bravia TVs, mobile phones, and image sensors. Dr. Lee received his Bachelor degree in Electrical Engineering from National Chiao-Tung University in Taiwan and he holds a Ph.D. & Master of Science in Electrical Engineering and Computer Sciences from the University of California, Berkeley.
Ali Tabatabai is a Director and IEEE Fellow at Sony US Research Center, San Jose, California. He started his professional career with Bell Laboratories and later Bell Communication Research where he worked on algorithmic research and on the application of sub-band techniques for still image coding for which he was the co-winner of the IEEE CSVT Best Paper Award. He later joined Tektronix as the manager of digital video research group where his responsibilities included algorithmic research and development of video compression techniques for studio and production quality applications. He chaired AdHoc group in MPEG-2 whose work resulted in the standardization of a highly successful MPEG-2 4:2:2 Profile & Main Level. In his current work at Sony, he is responsible for managing R&D activities in 3D visualization and next generation video codec. He obtained his bachelor degree from Tohoku University and Ph.D. degree from Purdue University both in Electrical Engineering.
Kenji Tashiro is a manager of 3D visualization group at Sony US Research Center, San Jose, California. He started his professional career at PULNiX (later JAI) as a research & development engineer for industrial and traffic capture & vision processing systems. He later joined Teledyne Scientific as a senior research scientist to research neuromorphic vision processing algorithms and hardware architecture for defense applications. In his current work at Sony, he is responsible for managing the 3D visualization group. His main research interests are 3D modeling, texture synthesis, and video processing & codec. He received his bachelor's and master's degrees in Precision Machinery from the University of Tokyo, Japan.



 Open access
Open access