



1. Introduction
Making choices and expressing preference is an inherent part of being human. Many choices, such as what to eat for breakfast or whether to have our morning coffee hot or iced, are ones that we make unconsciously and that have little long-term impact. But other choices have far-ranging effects, such as planning the direction of a business, or choosing a profession, where to live, or what to study. While the psychological processes involved in decision-making are largely the purview of the behavioral sciences (e.g., Brocas & Carrillo, Reference Brocas and Carrillo2014; Fellows, Reference Fellows2004; Kahneman & Tversky, Reference Tversky and Kahneman1981), how people communicate their preferences is fundamentally a linguistic phenomenon. Speakers convey their decision-making process and their final preferences through an array of word choices and morphosyntactic constructions appropriate to the context. For example, in response to the standard question when buying a morning coffee – “Is that for here or to go?” – the addressee might simply respond with “to go”. When selecting fruit at the grocery store, a speaker might state a preference by setting up a contrast using demonstrative pronouns this and that, as in “This one looks fresher than that one”. As speakers, we also move our bodies in ways that are aligned with speech. For example, when talking about the evaluation process for what university program to attend, a speaker might place both hands in a palm-up orientation as if holding objects, then perform a gesture that enacts the assessment of their relative weight.
Despite the staggering array of choices speakers make daily, the linguistic tools and coordinated kinesic expression of marking preference have received little explicit attention. Recent research in psychology, the cognitive sciences, cognitive linguistics, and gesture studies has shown that speech and the gestures that accompany speech, known as speech-accompanying or co-speech gesture (Kendon, Reference Kendon2004; McNeill, Reference McNeill1992, Reference McNeill2005; Zima & Bergs, Reference Zima and Bergs2017) are tightly coordinated. The two channels are very closely integrated both temporally and semantically (Church et al., Reference Church, Kelly and Holcombe2014; Kelly et al., Reference Kelly, Healey, Özyürek and Holler2015; Kelly et al., Reference Kelly, Özyürek and Maris2010). We know that when people talk about weighing options and making decisions, they use gestures and other body movements (such as head tilts) to signal their mental construal of a contrastive set-up. For instance, the prototypical gesture for the idiomatic English expression on the one hand … on the other hand … is a bilateral gesture with each palm facing upwards (Hinnell, Reference Hinnell2019). Comparing hypothetical options with should I or shouldn’t I …, speakers tend to enact similar bilateral gestures in combination with head tilts or simply perform a head tilt first to one side and then the other in coordination with the utterance (Hinnell, Reference Hinnell2019). Research has also shown that speakers tend to produce gestures with alternate hands and anchor these in the gesture space around their body when they are comparing both concrete and abstract referents (Parrill & Stec, Reference Parrill and Stec2017). While these findings illuminate how speakers enact contrast, we know very little about the effect that these gestures have on the interlocutor, addressee, or observer. In the studies presented here, we address whether observers use a speaker’s gesture to discern that speaker’s preference between two possibilities.
A number of papers have shown that interlocutors track the spatial locations of gestures and use them to understand a discourse (Sekine & Kita, Reference Sekine and Kita2015, Reference Sekine and Kita2017; Sekine et al., Reference Sekine, Sowden and Kita2015; So et al., Reference So, Kita and Goldin-Meadow2009). These studies have focused on concrete entities (characters in a story, typically). Researchers have explained these findings by arguing that listeners create mental images of a discourse, encoding the spatial locations of entities in memory. That is, mental models of a discourse are embodied, in the sense that they include visual and motoric simulations (or partial reconstructions) of images and actions (Hostetter & Alibali, Reference Hostetter and Alibali2008, Reference Hostetter and Alibali2019). While claims about mental simulation have been most fully developed for the production side (see Hostetter and Alibali’s Gestures as Simulated Action model), Sekine and Kita’s active gestural discourse representation hypothesis makes a related argument for the comprehension side. According to these theories, observers should mentally simulate content they are encoding, thus linking the spatial location of a gesture to its referent in their mental model. Gestures in those locations can therefore help with retrieval. For example, if a speaker is describing a cat sitting on a fence, listeners will form a mental image of the locations of the cat and fence. Gestures can reinforce and elaborate that mental image.
But the same case has only recently (Hinnell & Parrill, Reference Hinnell and Parrill2020) been made for abstract entities (e.g., arguments and ideas), which do not have spatial locations. While theories of embodiment have argued that abstract content is also simulated, findings from experimental studies have been inconsistent (for a valuable summary of the general logic, see Diefenbach et al., Reference Diefenbach, Rieger, Massen and Prinz2013). If a speaker is talking about two relationships and gestures to each side, is that because she is actively maintaining a mental image with different spatial locations assigned to those relationships? Does her listener form a mental image that includes the locations of those abstract entities? Does that mental image become part of a discourse model in a way that facilitates comprehension? If observers use the spatial location of a gesture produced with an opinion to understand later discourse about that opinion, this finding would provide some evidence that we do indeed form such mental images and use gesture location to track abstract discourse referents. In short, the key contribution of our studies is the potential to extend arguments about embodied cognition beyond concrete reference into the domain of abstract reference.
In the next section, we contextualize the current study by reviewing relevant findings on anaphora resolution in sentence processing, on the use of gesture to track concrete referents in a discourse, and, finally, on the role of gesture in resolving ambiguous anaphora. We then describe two experiments that examine how observers respond to ambiguous expressions of preference and what role gesture plays in those responses. We close with implications for the field and areas of future research.
2. Background
In the current study, we explore how participants resolve ambiguous discourse reference in both a monomodal and multimodal context. The stimuli consist of scenarios with a pair of statements of preference (e.g., Toni says pizza is best with pineapple. Marco really prefers more traditional pizza), followed by one of the following ambiguous statements: I agree with her/him/them, I’d prefer that, that makes more sense, that’s more important to me, or s/he’s/they’re right. In these statements, the personal or demonstrative pronouns are ambiguous in terms of which statement they refer to. Scenarios will be introduced in more detail below. We introduce them here to illustrate the relevance of several bodies of literature, namely, what we know about anaphora resolution in sentence processing, multimodal (i.e., gestural) reference tracking, and the multimodal depiction of contrast.
2.1. Sentence processing and anaphora resolution
Monomodal studies have shown that the resolution of anaphoric reference (e.g., pronouns that refer back to a previous noun phrase) relies on a very wide set of linguistic variables in the speech context. These include the linguistic salience or accessibility of the referent, which have been shown to be related to subject position (Gernsbacher & Hargreaves, Reference Gernsbacher and Hargreaves1988; Nappa & Arnold, Reference Nappa and Arnold2014), givenness (Gundel et al., Reference Gundel, Hedberg and Zacharski1993), and thematic roles (e.g., the stimulus role; Arnold, Reference Arnold2001).
Subject, or first-mention bias, is exemplified in the sentence pair My mom went shopping with my sister. She bought shoes, in which the ambiguous pronoun she will most frequently be interpreted as referring back to my mom. There is also evidence for a recent mention bias over clause boundaries. For example, Arnold (Reference Arnold2010) demonstrated in a corpus study that “reference to information mentioned in recent clauses is more likely to be pronominal than less recent information” (Arnold Reference Arnold2010, p. 189). In a later study, Arnold summarized these findings by saying that listeners build assumptions based on their linguistic experience. Arnold argues “that speakers tend to continue talking about recently mentioned entities especially subjects” (Arnold et al., Reference Arnold, Strangmann, Hwang, Zerkle and Nappa2018, p. 42).
While these findings are from studies using concrete referents (e.g., characters), there is also an extant body of work on the resolution of abstract antecedents in anaphora resolution. This is often referred to as discourse deixis, defined as anaphoric reference that involves reference to abstract entities such as events and states (Asher, Reference Asher1993). Discourse deixis is exemplified in the clause pair Max destroyed his leaf collection last night. That was dumb (Hegarty et al., Reference Hegarty, Gundel and Borthen2001, p. 138), where that refers to the whole event in the first clause. Much of this research relates specifically to discourse status (e.g., given vs. new information; Gundel et al., Reference Gundel, Hedberg and Zacharski1993), rather than to differences between abstract vs. concrete entities, which is a distinction we make here.
Both the recent mention bias found for concrete entities and the research on discourse deixis are important factors in the studies presented here. We argue that the recent-mention bias explains the overall patterns in both Study 1 and Study 2. We specifically argue that gesture is being used to override this bias for some trials. Discourse deixis is relevant in that the demonstrative pronoun that appears in one of the (ambiguous) constructions in our stimuli: I guess I agree more with that.
2.2. Multimodal reference tracking in production
Studies of multimodal (i.e., embodied) behavior are also relevant to anaphora resolution since speakers and signers make use of gesture space (the area directly around their torso where co-speech gesture generally occurs) to anchor referents in space. For example, when participants retold stories they were shown in a series of vignettes, speakers used the location of their gestures to identify characters in the story, in addition to specifying them in their speech (So et al., Reference So, Kita and Goldin-Meadow2009). Sekine and Kita (Reference Sekine and Kita2017) found that if a speaker produced gestures in particular locations for story characters, observers used those locations to resolve reference, even when no further gestures were produced (see also Sekine & Kita, Reference Sekine and Kita2015; Sekine et al., Reference Sekine, Sowden and Kita2015). They termed this the ‘active gestural discourse representation hypothesis’, which proposes that gesture serves as part of a mental model of discourse entities and events in short-term memory. Parrill and Stec (Reference Parrill and Stec2017) found that gesture space is also used in a consistent way for gestures about abstract referents.
The use of space around the body to anchor ideas is also a known feature of sign languages. In outlining the spatial mapping strategies of American Sign Language, Winston (Reference Winston, Emmorey and Reilly1995, Reference Winston1996) describes how signers construct a spatial map by anchoring entities on either side of the signing space through pointing in sequence to each side. The signer then continues to refer to the two entities throughout the discourse by pointing to the two spaces in which these entities are anchored (Janzen, Reference Janzen, Dancygier and Sweetser2012). Some research has explicitly investigated differences between the use of referential space in sign versus spoken language. For example, in an investigation of the marking of referential space in both German Sign Language and in co-speech gesture accompanying German in elicited narratives, Perniss and Ozyürek (Reference Perniss and Ozyürek2015, p. 36) found that “the configuration of referent locations in sign space and gesture space corresponds in an iconic and consistent way to the locations of referents in the narrated event”. They go on to describe how the use of space is modified in specific contexts for sign and co-speech gesture modalities depending on whether referents were re-introduced in a discourse or maintained across consecutive clauses.
2.3. Multimodal reference tracking in perception
The research cited above demonstrates how speakers consistently produce gestures and use gestures referentially. However, it is also important to know what information the interlocutor is gaining from these gestures. We know that addressees pay attention to co-speech gestures and use semantic information to improve understanding (e.g., Beattie & Shovelton, Reference Beattie and Shovelton2002). When observing gestures that do not match someone’s speech, gestural details are incorporated into our representations (Broaders & Goldin-Meadow, Reference Broaders and Goldin-Meadow2010; McNeill et al., Reference McNeill, Cassell and McCullough1994). In more recent research, a study of pointing gestures with non-present referents (i.e., pointing to empty space, rather than at an object) found that inconsistent use of gesture space impaired language processing (Gunter et al., Reference Gunter, Weinbrenner and Holle2015). In an experimental set-up featuring a mismatch paradigm, participants watched a video in which a woman being interviewed anchored referents such as Donald Duck and Mickey Mouse in gesture space. In scenarios in which the pointing gesture accompanied a target word that was not consistent with a previously established location in gesture space, participants exhibited a larger N400, a neural measure of language processing that has a higher amplitude when an element is unexpected or harder to process. Finally, a qualitative study of dyadic interaction showed that the speaker and addressee co-construct spatial reference even across longer periods of time (Stec & Huiskes, Reference Stec and Huiskes2014).
Specific to perception studies of reference resolution, when addressees track a referent in discourse, they appear to be sensitive to the presence of gesture; however, studies of anaphora resolution diverge widely in the effect found. In a study based on a series of reaction time experiments, Debreslioska and colleagues (Reference Debreslioska, van de Weijer and Gullberg2019) explored localizing anaphoric gestures in gesture-congruent and gesture-incongruent conditions. In their reaction time tasks, participants watched videos of narratives involving two (or more) characters. Participants were instructed that the first-mentioned entity was the main protagonist and were shown stimuli with video such as the following narrative: There was a woman. And her husband couldn’t repair the engine of his car by himself. So, the woman decided to call/write to her brother. He should come to help him out, in which gestures to left/right gesture space aligned with the underlined segments. Debreslioska and colleagues predicted that participants would be faster to respond to the question Did the main protagonist call for help? in the gesture congruent condition – a prediction that was not, in fact, borne out in their two studies. While this study tracked only one referent through the short narrative, others (Nappa & Arnold, Reference Nappa and Arnold2014; Sekine & Kita, Reference Sekine and Kita2017) have examined contrasted entities, i.e., by localizing two referents in opposite gesture spaces, as our stimuli do. Nappa and Arnold (Reference Nappa and Arnold2014) reported no difference between the incongruent and no-gesture conditions in their study, while Sekine and Kita (Reference Sekine and Kita2017) showed slower reaction times in the incongruent condition in their study.Footnote 1
In an experiment using taped narratives in which the speaker used a pronoun that could refer to either of the previously mentioned same-gender referents, and in which a gesture co-occurred with one of the two possible referents, Goodrich Smith and Hudson Kam (Reference Goodrich Smith and Hudson Kam2012) replicated the first-mention bias discussed above. However, in a finding replicated in Study 2 presented here, when a localizing gesture co-occurred with the second-mentioned referent, participants chose that referent more often than a referent with no gesture. (However, they still chose the first referent more often overall.) An important distinction is that Goodrich Smith and Hudson Kam (Reference Goodrich Smith and Hudson Kam2012) and the other perception studies cited here involve concrete entities, i.e., characters in a narrative, rather than gestures that localize abstract referents (e.g., opinions, statements) as in the studies presented here.
2.4. Gestures depict mental structures of contrast
Given our focus on contrastive statements of preference, studies on the multimodal expression of contrast are relevant here as well. A recent corpus study of expressions of contrast in North American English using the Red Hen multimedia archive (Steen & Turner, Reference Steen, Turner, Borkent, Dancygier and Hinnell2013; www.redhenlab.org) showed that speakers consistently use a subset of hand shapes anchored on either side of the body to gesture contrast (Hinnell, Reference Hinnell2019, Reference Hinnell2020). This was true of comparisons of objects and abstract notions in the real world, as well as in comparisons of two hypothetical situations (e.g., If X / if Y, and should I / shouldn’t I). Findings suggest that contrast is systematically expressed through lateral and symmetrical manual gestures (e.g., bilateral palm-up open-hand). Enactments of contrast that were aligned with hypothetical expressions (i.e., in the irrealis domain, marked linguistically by conditionals and modal verbs) featured either head tilts (i.e., first to one side then the other) or head tilts in coordination with manual gesture (Hinnell, Reference Hinnell2019, Reference Hinnell2020). The following examples (drawn from Hinnell, Reference Hinnell2019) illustrate these patterns. The prototypical expression of contrast using the palm-up open-hand gesture form (PUOH; Müller, Reference Müller, Cienki and Müller2008) in conjunction with on the one hand / on the other hand, is shown in Figure 1. In Figure 2, two abstract entities (Republican news network and Republican presidential candidates) are anchored on alternate sides of the speaker’s gesture space using a container gesture, in which the hands are seen to hold a metaphorical object between them, while Figure 3 shows a head tilt accomplishing the same general function of placing objects on either side of the gesture space.

Fig. 1. Palm-up open-hand gesture: ‘weighing options’.

Fig. 2. Container gesture: ‘placing options in space’.

Fig 3. Head tilt: ‘placing options in space’.
While these examples show contrast being expressed through phrasal expressions and antonymic noun and adverbial phrases, contrast can also be expressed at a discourse level through concessive markers such as anyhow, anyways, but, though, and nevertheless, and phrasal markers with the same function such as at the same time (Biber et al., Reference Biber, Johansson, Leech, Conrad and Finegan1999; cf. Barth, Reference Barth, Couper-Kuhlen and Kortmann2000; Couper-Kuhlen & Thompson, Reference Couper-Kuhlen, Thompson, Couper-Kuhlen and Kortmann2000; Ford, Reference Ford, Couper-Kuhlen and Kortmann2000). The corpus study referenced earlier (Hinnell, Reference Hinnell2019) showed that this type of discourse-level contrast is also marked in the body, via body lean, gesture, and head tilts. Given their role in marking contrast, concessive markers were used for the stimuli in the studies presented here.
Why do speakers gesture, lean, or tilt their heads to different sides, and produce gestures as though they are holding or placing objects to one side or the other? According to conceptual metaphor theory (Johnson, Reference Johnson1987, Reference Johnson2017; Lakoff & Johnson, Reference Lakoff and Johnson1980, Reference Lakoff and Johnson1999), humans conceptualize decision-making or preference as balance or weight to one side or the other. Some experimental support for this claim comes from a study showing that manipulating participants’ body position impacts their preferences (Dijkstra et al., Reference Dijkstra, Eerland, Zijlmans and Post2012). Gestures reflect imagery and motor representations (Hostetter & Alibali, Reference Hostetter and Alibali2008, Reference Hostetter and Alibali2019), thus we may see lateral gestures during expressions of contrast because humans conceptualize the ideas that they are talking about as objects that can be placed or held (see for example Parrill, Reference Parrill, Cienki and Müller2008). On the other hand, PUOH gestures are so common in discourse that some authors have argued that they are conventionalized (Müller, Reference Müller, Cienki and Müller2008), rather than reflecting active metaphoric imagery or mental simulation.
The literature cited here shows how speakers and signers organize sign and gesture space to anchor concrete references. It also suggests that observers perceive gestures as conveying meaningful information, though the findings from perception studies of anaphora resolution are mixed. Our study goes beyond the question of whether speakers use gesture to help resolve reference for concrete referents (characters, objects, spatial locations). We ask whether observers will use gesture to resolve reference when the entity being talked about is abstract, i.e., What is the effect of gesture on an observer’s perception of a speaker’s preferences for one possibility over another? The referents in our study are discourse deictic elements (Levinson, Reference Levinson1983; Webber, Reference Webber1991). That is, rather than a person or object or spatial location, the referents that observers must track are what the speaker has said. There is good reason to expect that gesture will be valuable here as well, based on previous reference-tracking studies and corpus studies of naturalistic behavior. However, to our knowledge the only study showing that observers use gesture to resolve ambiguous pronouns that have abstract antecedents is an experiment conducted by the authors (Hinnell & Parrill, Reference Hinnell and Parrill2020), which we comment on in the discussion (Section 5).Footnote 2 For concrete referents, the argument is that listeners form a mental image of what they are hearing, thus incorporating spatial locations into that mental image (Perniss & Özyürek, Reference Perniss and Ozyürek2015), as the active gestural discourse representation hypothesis (Sekine & Kita, Reference Sekine and Kita2017) would presumably also argue. That listeners do something similar for abstract referents needs to be established with experimental data. As noted in the introduction (Section 1), while people gesture in ways that maintain the spatial relationships between concrete entities, presumably because they form mental images of those relationships (Hostetter & Alibali, Reference Hostetter and Alibali2008, Reference Hostetter and Alibali2019), only limited evidence is available for abstract entities (Hinnell & Parrill, Reference Hinnell and Parrill2020). Language users do seem to use space consistently for abstract reference (Parrill & Stec, Reference Parrill and Stec2017), but these patterns and those found in work by Hinnell may be the result of convention rather than mental imagery or simulation. If observers use the spatial location of a gesture produced with an opinion to understand later discourse about that opinion, this finding would support the claim that listeners are also forming mental images that include the locations of abstract entities. Furthermore, even the findings from perception studies regarding concrete referents are unclear.
We present two studies that explore how participants respond to ambiguity when a speaker is expressing a preference. The first study establishes a baseline by asking how speakers respond in a monomodal environment (i.e., reading a speaker’s words as text). Based on pilot work, we anticipated that, in the absence of any information, participants will choose the last thing read or heard as the speaker’s preference (a recent mention bias). In the second study, we investigate the role of gesture in disambiguating the speaker’s preference.
3. Study 1: How do observers respond to ambiguous statements of preference?
Study 1 asked how participants respond to an ambiguous expression of preference when reading text.
3.1. Method
3.1.1. Participants
Thirty students from a private university in the northeastern US took part in the study for course extra credit. Twenty identified as female, none identified as non-binary. The mean age was 20, and the range was 18–21. All were native speakers of American English.
3.1.2. Materials
We created 59 scenarios that contained the following elements:
-
1. An attitude about a topic (this will be referred to as the A statement)
-
2. A concessive
-
3. A differing attitude about the topic (referred to as the B statement)
-
4. A hedge indicating uncertainty
-
5. An ambiguous statement that used a pronoun to indicating a preference for either the A or B (referred to as the preference statement).
For example, one scenario was as follows: Toni says pizza is best with pineapple (A statement). On the other hand (concessive), Marco really prefers more traditional pizza (B statement). I’m not sure (hedge), but I think he’s right (preference statement). The preference statement is ambiguous because he could refer to either Toni or Marco. We used five different concessive expressions: but, but also, but then, but at the same time, and on the other hand. These concessives were selected because a corpus study of contrast (Hinnell, Reference Hinnell2020) indicated that they are frequently used in contrastive speech. The preference statements contained one of the following: I agree with her/him/them, I’d prefer that, that makes more sense, that’s more important to me, or s/he’s/they’re right.
3.1.3. Procedure
Participants were presented with these scenarios in random order using Qualtrics survey software. After an informed consent screen, participants were presented with a scenario as text. After reading the scenario, participants responded to a question asking for their judgment about the stimulus speaker’s preference on a new screen. The exact question was matched to the preference statement, so that, for example, a preference statement ending with I’d prefer that would be followed by the question What does the speaker prefer? In the example scenario above, the question would be Who does the speaker think is right? Participants chose between options matched to the scenario, such as pineapple pizza and traditional pizza. Options were presented horizontally, and their locations were random (thus, the option appearing to the left was random for each trial so that the choice options did not necessarily match the spatial location of the A and B statements from the participant’s point of view). The A and B statements were not counterbalanced. That is, for the previous example, all participants saw pineapple pizza in the A statement, and traditional pizza in the B statement.
Second, a new screen asked participants to respond to the question What is your personal opinion/preference?, and they were presented with the same options as in the previous question (e.g., pineapple pizza, traditional pizza). The location of options was also randomized with respect to location. Participants answered these questions for each of the 36 scenarios, then completed a demographic survey asking about age and sex/gender (male, female, non-binary).
The key dependent variable for our study is the participant’s judgment about the stimulus speaker’s preference. We refer to this as ‘stimulus speaker’s preference’. The variable describing what participants chose for their own preference is referred to as ‘participant preference’. The A and B statements were not counterbalanced, so we collected this information in case it turned out that participants tended to prefer one of the two options above chance (e.g., traditional pizza is more popular).
Because our pilot work indicated that participants would choose the B statement more often than the A statement for stimulus speaker’s preference, we coded the choice of the A statement as 0 and the choice of the B statement as 1. We hypothesized that we would see a proportion higher than .50 for B statement responses.
3.2. Results
One scenario was removed due to a data collection error leaving a total of 58. Data have been uploaded to Open Science framework and can be found here at <https://osf.io/fzhwj/>. Data were analyzed using R version 4.0.0 (R Core Team, 2020). Utility packages used for data manipulation, cleaning, and analysis include tidyverse (Wickham et al., Reference Wickham2019; Wickham & Henry, Reference Wickham and Henry2020), dplyr (Wickham et al., Reference Wickham, François, Henry and Müller2020), broom (Robinson et a., Reference Robinson, Hayes and Couch2020), lme4 (Bates et al., Reference Bates, Maechler, Bolker and Walker2015), and afex (Singmann et al., Reference Singmann, Bolker, Westfall, Aust and Ben-Shachar2020).
Figure 4 shows a boxplot for the proportion of participants choosing the B statement across the two dependent variables. Our analyses are designed to answer two separate questions: (1) Do participants choose the B statement at a rate higher than chance; and (2) Do participants choose the B statement more often for the stimulus speaker’s preference compared to their own preference?
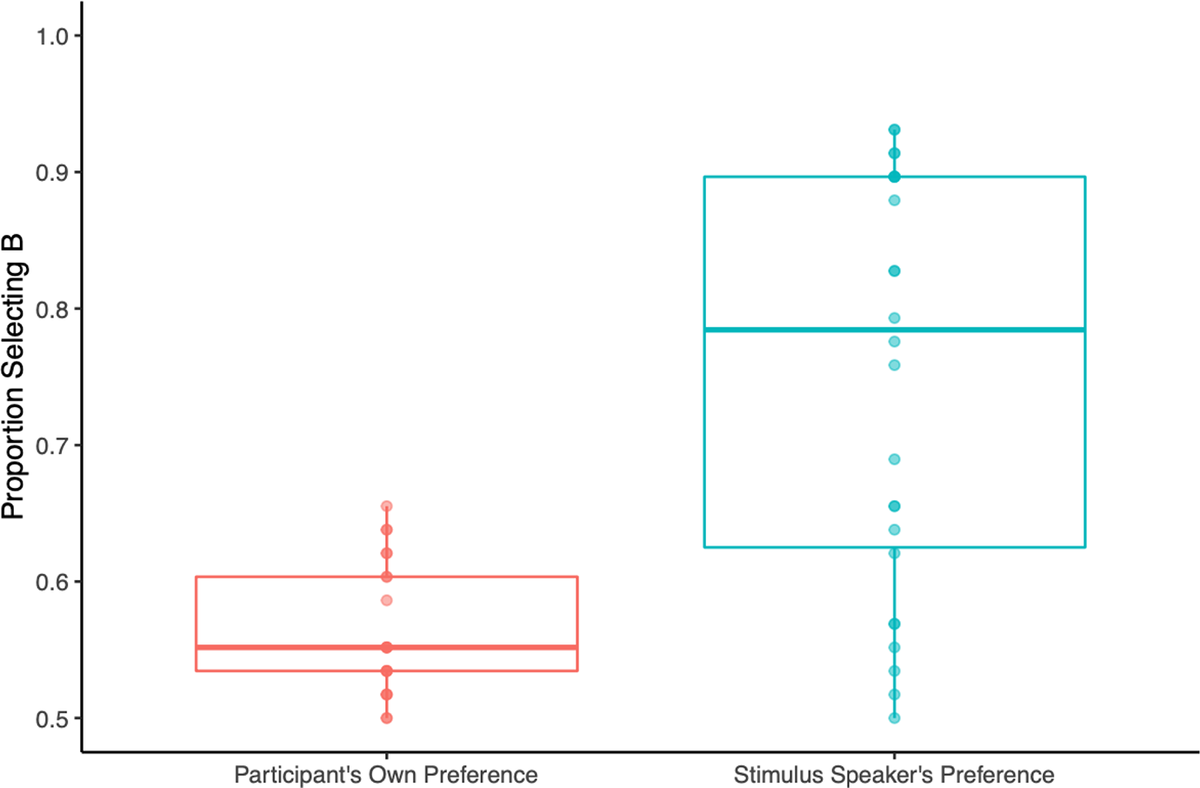
Fig. 4. Boxplot showing proportion choosing the B statement.
3.2.1. Do participants choose the B statement at a rate higher than chance?
We carried out a Shapiro–Wilk normality test, finding that stimulus speaker data were non-normal (W = 0.90624, p = .01197), so a non-parametric test should be used. Participant preference data were roughly normally distributed (W = 0.96242, p = .3566), so a parametric or a non-parametric test could be used. We opted to use a Wilcoxon test to compare the proportion choosing B to chance (.5). We calculated the proportion of B choices for each participant, created a column that has .50 (the chance level) for each participant, and compared the two columns. We did this for both dependent variables separately. The Wilcoxon signed rank test for stimulus speaker preference versus chance (0.5) showed a statistically significant difference (V = 414, p < .00001). Individuals did not appear to be randomly selecting ‘A’ vs. ‘B’ when asked for the stimulus speaker’s preferences, with participants choosing B an average of 71% of the time (M = 0.71, SD = 0.18). The Wilcoxon signed rank test for the participants’ own preference versus chance (0.5) also showed a marginally significant difference (V = 324, p = .06). Individuals did not appear to be randomly selecting ‘A’ vs. ‘B’ by chance when asked for their own preferences, with participants choosing B an average of 54% of the time (M = 0.54, SD = 0.06).
Consistent with findings from the recent mention bias literature, participants chose the B statement more often for stimulus speaker preference (about 70% of the time). For participant’s own preference, because the A and B statement were not counterbalanced, we saw a proportion much closer to chance (54%), indicating that some participants preferred A and some preferred B. This difference was also statistically different from chance, indicating a bias towards the B statement overall. This pattern is considered in greater detail in the general discussion (Section 5).
3.2.2. Do participants choose the B statement more often for stimulus speaker’s preference compared to their own preference?
In our study design, 30 participants responded to 58 scenarios. For each scenario, the participant answered two questions: What does the speaker prefer? (stimulus speaker preference) and What is your personal opinion/preference? (participant’s preference). To see whether the rate of choosing the B statement was any different for the two questions, we ran a mixed-model logistic regression (logit) model with participant and scenario as random effects, and fixed effect of ‘Whose Preference’ (stimulus speaker or participant’s own). The dependent variable was choosing the B statement as preference, with a score of 0 if the individual chose the A statement, and 1 if they chose the B statement. The model was fit using maximum likelihood (Laplace Approximation), with a random effect of scenario (Intercept Variance = 0.595, SD = 0.77) and a random effect of participant (Intercept Variance = 0.1941, SD = 0.44). The fixed effect of ‘Whose Preference’ was statistically significant (ß = 0.87, SE = 0.077, z = 11.263, p < .0001), with participants being 1.4 times more likely to respond ‘B’ when asked the stimulus preference than when asked their own preference. The model has a residual error of 4174.2 on 3476 degrees of freedom; an Akaike’s information criterion (AIC) of 4182.2; and fixed intercept values as follows: ß = 0.16970, SE = 0.13950, z = 1.216, p = .224.
Finally, although our research question was not concerned with the influence of different concessives, we include brief analyses exploring the impact of concessive in the Appendix. Broadly speaking, the pattern was the same regardless of which concessive appeared in the scenario.
3.3. Discussion
Taken together, these analyses indicated that participants tended to think the stimulus speaker preferred the B option (whatever was expressed last) in the absence of any disambiguating information. These findings are consistent with the literature on recent mention as a factor in reference resolution (e.g., Arnold, Reference Arnold2010). They also had a slight bias towards the B statement for their own preference, which we will comment on in greater detail in the general discussion (Section 5).
4. Study 2: How does gesture affect observers’ responses to ambiguous statements of preference?
Having established how participants respond to ambiguous text scenarios, in Study 2 we asked whether participants will use gesture to disambiguate these kinds of scenarios. We first created an audio version of our scenarios. Comparing audio to video will allow us to rule out the possibility that intonation explains some part of our findings. In our main study, we presented participants with video versions of scenarios in which the speaker performed gestures with the A and B statements. In some trials, a gesture also occurred with the preference statement. This gesture was always in the same location as the gesture co-occurring with the A statement. We asked: Given that participants tend to choose the B statement for the stimulus speaker’s preference, are they less likely to do so if the ambiguous preference statement is accompanied by a gesture in a location previously established as the ‘A statement location”? (That is, if the gesture is performed in the same location as a previous gesture that co-occurred with the A statement.)
4.1. Method
4.1.1. Participants
150 participants were recruited using the online data collection platform Amazon Mechanical Turk. Mechanical Turk data have been shown to be comparable to data collected in academic research studies, but the Mechanical Turk population is more diverse in age, education, and race/ethnicity than most typical university research populations (Buhrmester et al., Reference Buhrmester, Kwang and Gosling2011). Participants were required to be within the United States to take part and were compensated with three dollars (the study took about half an hour).
4.1.2. Materials
We identified the 36 scenarios from Study 1 that had the highest proportion of participants choosing the B statement for the stimulus speaker’s preference. These ranged from .68 to .98. Scenarios (and proportions choosing B for both variables) can be found in the Appendix.
We first recorded audio for each scenario. A female research assistant was trained on the intonational properties of the scenarios by the second author. Peak prosodic emphasis was on the subject noun phrase of the statements (e.g., Toni, Marco), and the ambiguous noun phrase of the preference statement (e.g., he’s). After this training, the research assistant was instructed to read each scenario as naturally as possible. We next recorded video for each scenario. The same research assistant was instructed to sit in a comfortable posture, and to perform several scenarios as naturally as possible. Scenarios were performed in two different ways, a gesture-disambiguating version (GD) and a gesture non-disambiguating version (GND).
Both versions used palm-up open-hand gestures. These were performed with the A and B statements. The research assistant performed versions with the left hand first and with the right hand first. For the GND version, the speaker sat still during the preference statement. For the GD version, the speaker performed a final palm-up open-hand gesture with the preference statement. The final gesture always occurred in the location where the A statement gesture had been performed. For example, if the first gesture was on the left, the final gesture would be performed on the left as well.
We selected the best videos to create four categories: (1) right hand first, left hand second, final gesture with right hand; (2) left hand first, right hand second, final gesture with left hand; (3) right hand first, left hand second, no third gesture; and (4) left hand first, right hand second, no third gesture. These were used to create final videos for all scenarios. Using Final Cut Pro, we matched audio files to these four different videos to create two stimulus lists. Stimulus lists counterbalanced trial type (GD, GND) across specific scenarios. That is, a scenario about pizza preference would be matched with GD video for list 1 and GND video for list 2. We also counterbalanced which hand gestured first for each scenario across lists. This use of lists was intended to minimize the chances that specific properties of the scenarios would interfere with our results. Due to an error (discussed below) scenarios were assigned unevenly, with 17 assigned as GD trials, and 19 assigned as GND trials. We next used Final Cut Pro to align gesture strokes (the effortful, meaningful portion of a gesture; McNeill, Reference McNeill1992) with the subject noun phrases (e.g., Toni, Marco), by adding or removing slices of audio or video. We edited the video so that the gesture was held until the end of the statement, then edited the video so that the gesture retraction (return to rest) occurred after the end of the statement. We also edited the video so that the stroke of the final gesture (for GD stimuli) was aligned with the ambiguous noun phrase (e.g., he’s), held for the rest of the statement, and the retraction occurred after the end of the statement.
We used Final Cut Pro to blur the speaker’s face and upper shoulders so that mouth movements did not reveal the fact that audio and video had been edited, as shown in Figure 5. We also did this masking so that variability in facial expressions and head movements would not affect participants’ judgments. There was some variation in intonational contours and in the research assistant’s posture across each scenario. This was desirable, as it made the scenarios appear more natural. Once the videos were completed, we exported the audio tracks. These audio tracks were used for an audio-only condition.

Fig. 5. Example stimulus.
To recapitulate: the outcome of the audio/video editing was to create two versions of each scenario, with scenarios paired to GD and GND videos in a counterbalanced way. Within those categories, scenarios were paired in a counterbalanced way with videos in which the right versus left hand was used first. Audio and video were carefully aligned to preserve the systematicity of auditory and gestural cues, and the audio-only condition used exactly the same audio as the gesture condition. Participants saw only one version of each scenario (either as a GD or a GND video).
4.1.3. Procedure
Participants received a link to access the study and were randomly directed to one of three versions: audio only, gesture version list 1, or gesture version list 2. The surveys were presented using Qualtrics survey software. After an informed consent screen, participants were presented with a stimulus (audio or video), then answered the questions described above (the participant’s judgment about the stimulus speaker’s preference and the participant’s own preference). Each element (audio/video, first question, second question) was presented on a separate screen. As with Study 1, the location (left, right) of the options was randomized. This ensured that, for example, when a gesture was performed on the speaker’s left in a video, the location of the option associated with the co-occurring NP would be on the left for approximately half the participants and on the right for approximately half. Participants answered these questions for each of the 36 scenarios, then completed a demographic survey asking about age, sex (male, female, non-binary), race/ethnicity, and what the participant thought the study was about.
4.2. Results
Data have been uploaded to Open Science framework and can be found here at <https://osf.io/fzhwj/>. Data were analyzed using R version 4.0.0. Details on specific packages can be found in the results section for Study 1 (Section 3.2). Data were removed if the participant did not answer all questions or completed the study too quickly to have done the task correctly (7 participants were removed; thus the final number of participants was as follows: audio only = 45, gesture version list 1 = 46, and gesture version list 2 = 52). Demographic details are presented in the Appendix. The dependent variables for study 2 are the same as for study 1, namely stimulus speaker’s preference and participant preference.
4.2.1. Audio results
Figure 6 shows a boxplot for the proportion of participants choosing the B statement across the two dependent variables. The audio version of the scenarios was intended to rule out the possibility that intonation explained some part of potential differences we saw when gesture was added. Because the audio condition is not comparable to the video condition (it has no disambiguating and non-disambiguating trials), we analyzed it separately.
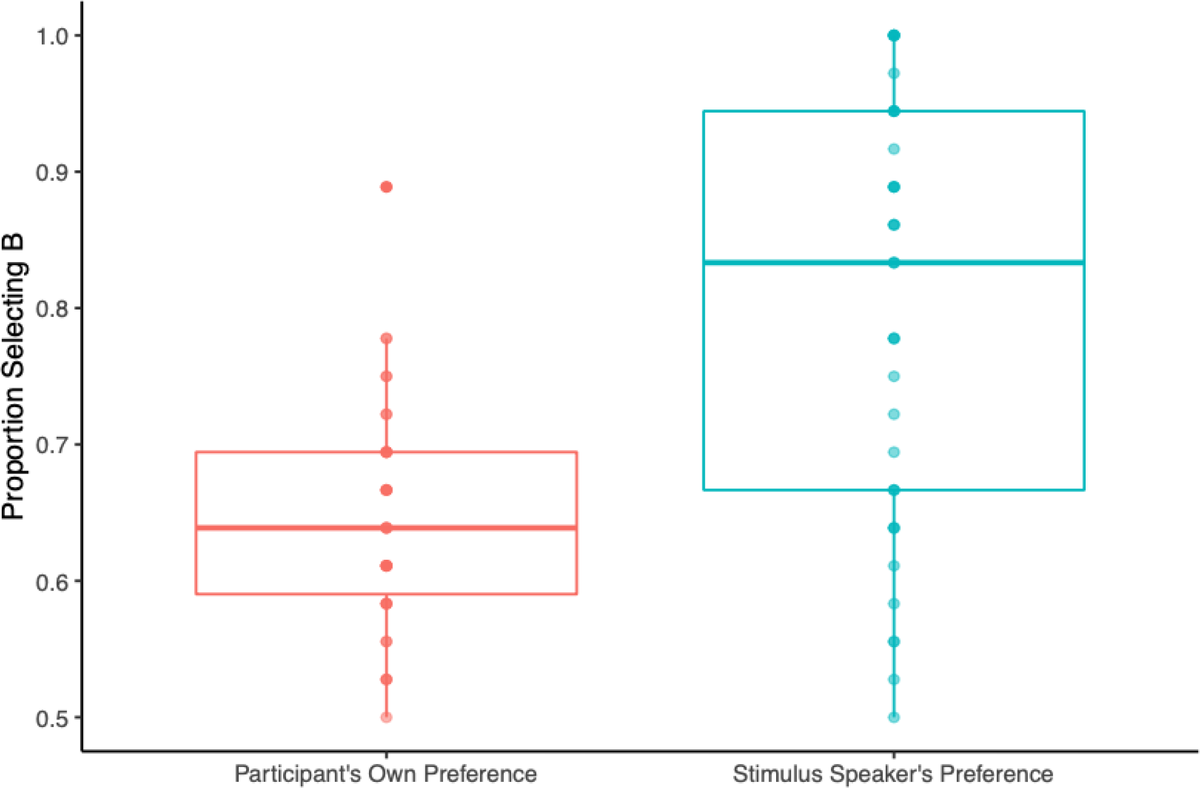
Fig. 6. Proportion choosing the B statement for audio condition.
As with study 1, our analyses answer two different questions: (1) Do participants choose the B statement at a rate higher than chance? and (2) Do participants choose the B statement more often for the stimulus speaker’s preference compared to their own preference? To answer the first question, we carried out a Shapiro–Wilk normality test, finding that stimulus speaker audio data were non-normal (W = 0.927, p = .0078), so a non-parametric test should be used. Participant preference audio data were roughly normally distributed (W = 0.982, p = .732), so a parametric or a non-parametric test could be used. As with Study 1, we used a Wilcoxon test to compare the proportion choosing B to chance (.50). We calculated the proportion of B choices for each participant, created a column that had .50 (the chance level) for each participant, and compared the two columns. We did this for both dependent variables separately. The Wilcoxon signed rank test for stimulus speaker preference vs. chance (0.5) showed a statistically significant difference (V = 972, p < .00001). Individuals did not appear to be randomly selecting ‘A’ vs. ‘B’ by chance when asked the stimulus speaker’s preferences, with participants choosing B an average of 77% of the time (M = 0.77, SD = 0.18). The Wilcoxon signed rank test for the participants’ own preference vs. chance (0.5) also showed a statistically significant difference (V = 923, p < .0001). Individuals did not appear to be randomly selecting ‘A’ vs. ‘B’ by chance when asked for their own preferences, with participants choosing B an average of 54% of the time (M = 0.54, SD = 0.10).
To answer our second question (Is the rate of choosing the B statement different for the two questions?), we ran a mixed-model logistic regression (logit) model with participant and scenario as random effects, and fixed effect of ‘Whose Preference’ (stimulus speaker or participant’s own). We included participant and scenario as random intercepts with the goal of increasing the generalizability of the findings outside the specific group of people and scenarios (see, e.g., Bresnan, Reference Bresnan, Featherston and Sternefeld2007; Quené & van den Burgh, Reference Quené and den Burgh2008). We did not fit random slopes because there is a limited number of possible slopes for these data, thus no theoretically motivated reason for including this term. The dependent variable was choosing the B statement as the preference, with a score of 0 if the individual chose the A statement, and 1 if they chose the B statement. The model was fit using maximum likelihood (Laplace Approximation), with a random effect of scenario (Intercept Variance = 0.32, SD = 0.568) and a random effect of participant (Intercept Variance = 0.434, SD = 0.659). The fixed effect of ‘Whose Preference’ was statistically significant (ß = 0.869, SE = 0.083, z = 10.354, p < .0001), with participants being 1.38 times more likely to respond ‘B’ when asked for the stimulus preference compared to when asked for their own preference. The model has a residual error of 3633.3 on 3236 degrees of freedom; an AIC of 3641.3.
4.2.2. Video results
Because the only purpose of our two stimulus lists was to counterbalance trial type across different scenarios, we collapsed over the two lists. Thus, 98 participants responded to 36 scenarios. As with previous analyses, we started by asking whether participants chose the B statement at a rate higher than chance for the two questions (what does the speaker prefer, stimulus speaker preference, and what is your personal preference, participant preference). We examined this separately for the two kinds of trial types (GD, GND). Again, we carried out a Shapiro–Wilk normality test for each grouping, which generally indicated that data were non-normal, suggesting a non-parametric test should be used. Test statistics for each individual test can be found in the Appendix. We then carried out Wilcoxon signed rank tests, all of which showed a statistically significant difference from chance. Individuals did not appear to be randomly selecting ‘A’ vs. ‘B’. Table 1 shows means, SDs, V values, and p values for individual tests, and Figure 7 shows a boxplot by response and trial type.
Table 1. Results of Wilcoxon tests comparing each grouping to chance


Fig. 7. Boxplot for video data.
Our main research question was whether the rate of choosing the B statement for stimulus speaker preference was lower for gesture disambiguating trials compared to gesture non-disambiguating trials. To see whether the rate of choosing the B statement was different for the two questions, we ran a mixed model logistic regression (logit) model with participant and scenario as random effects (again fitting no random slopes). Fixed effects were trial type (GD vs. GND) and ‘Whose Preference’ (stimulus speaker or participant’s own), and their interaction. The dependent variable was choosing the B statement as a preference, with a score of 0 if the individual chose the A statement, and 1 if they chose the B statement. The model was fit using maximum likelihood (Laplace Approximation). Table 2 shows the model summary for change scores, including z values and p values. With GD trials set as the comparison, we found a statistically significant difference in the selection of the B statement across trial type. With stimulus speaker preference set as the comparison, we found a statistically significant effect of ‘Whose Preference’, and a significant interaction between trial type and ‘Whose Preference’, AIC = 8390.5 on 7050 degrees of freedom.
Table 2. Logistic regression model for summary for trial type and whose preference, comparison group in parentheses

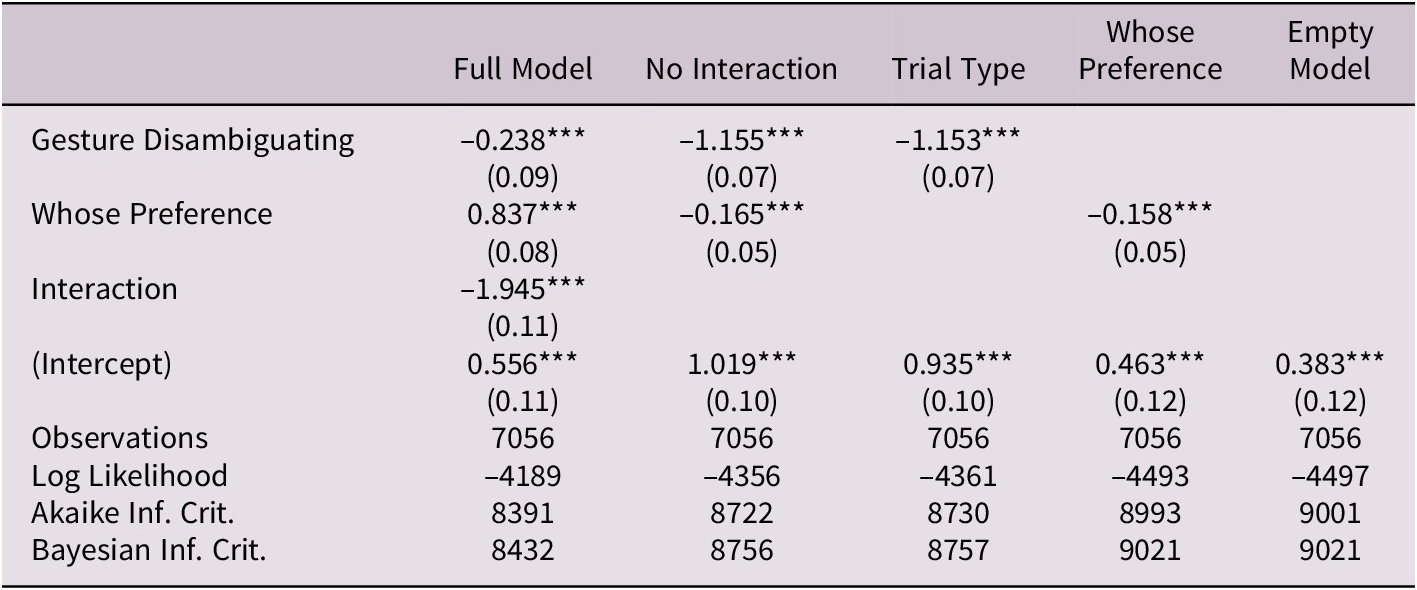
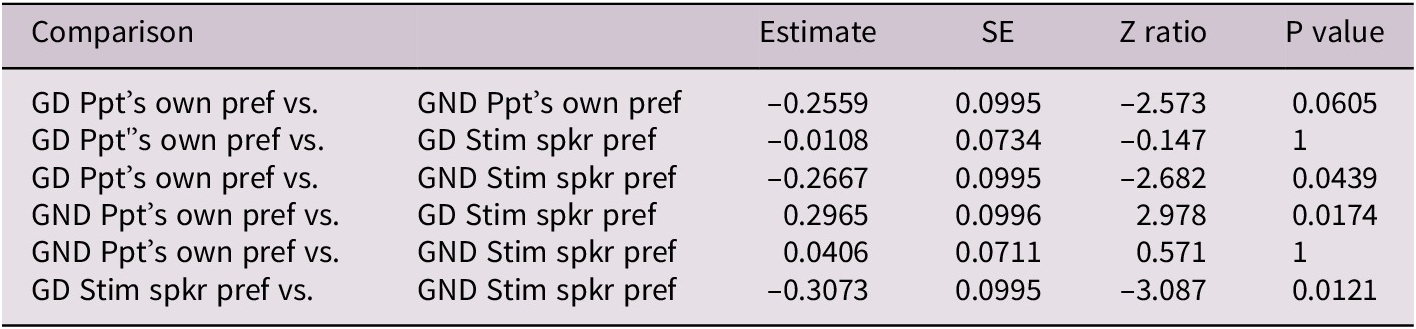
Table 3 shows a comparison between the model with the interaction, one with no interaction, models with only one fixed effect (trial type or ‘Whose Preference’) and an empty model. The decrease in AIC across the models suggests that the full model performs best. Finally, we used the emmeans package to perform pairwise comparisons for Trial Type and ‘Whose Preference’. Table 4 shows these contrasts. Because participants were more likely to choose the B statement for all trial types, there are multiple significant contrasts. The most theoretically relevant contrasts are those between the different trial types (GD, GND) for stimulus speaker preference, which is statistically different, versus that same difference across trial types for participant’s own preference, which is not statistically different.
Table 3. Model comparison, Study 2 video data
Note: *p, **p, ***p < .01.
Table 4. Pairwise comparisons
4.3. Discussion
The results of Study 2 suggest that participants chose the B statement at a rate higher than chance for both stimulus speaker preference, and the participant’s own preference, when listening to audio scenarios. This pattern remained true when presented with video scenarios in which the speaker performed gestures only while voicing the A and B statements. The pattern was different when the speaker performed a third gesture while voicing the preference statement. Because this gesture occurred in the same spatial location as the previously uttered A statement, in this case only participants were more likely to choose the A statement for stimulus speaker’s preference (chose A about 70% of the time on average). This pattern suggests that observers maintained an association between the side of space where a gesture had previously occurred during the A statement, and the option voiced along with that gesture. Observers then used that association to interpret the ambiguous preference statement.
5. General discussion
This project is grounded in a corpus study showing that expressions of contrast are consistently accompanied by gestures anchored on either side of the body (Hinnell, Reference Hinnell2019). We extended these findings by showing that the occurrence of a gesture changes the way an observer interprets the speaker’s preference. That is, an ambiguous expression of preference without gesture is interpreted differently than one with gesture. This is consistent with a body of research indicating that observers track the spatial locations of gestures and integrate them into their representations of what the speaker is saying. We were also able to show that spatial location tracking occurs with abstract references (discourse-deictic elements), as other studies have shown for concrete referents. The results of Study 1 indicate that, when responding to an ambiguous scenario presented as text, participants will choose the last thing they encountered as the speaker’s preference, about 70% of the time. Our participants also tended to choose the last thing they read as their own preference, about 54% of the time. When presented with audio scenarios (Study 2), participants also chose the B statement for the stimulus speaker’s preference more often than chance. The rate for audio was slightly higher (77% of responses) compared to text. Participants also continued to choose the B statement at a rate slightly higher than chance for their own preference (54%).
When presented with video scenarios, we saw a similar pattern if there was no gesture occurring with the preference statement. For those trials (gesture non-disambiguating, GND), participants chose the B statement about 80% of the time on average for the stimulus speaker’s preference. They chose B for their own preference about 60% of the time. However, when a gesture occurred in the same spatial location as a previously uttered referent, participants chose the B statement only 30% of the time as the stimulus speaker’s preference. When gesture occurred with the preference statement in a location previously associated with the A statement, participants chose the B statement for their own preference 63% of the time on average.
Taken together, these findings are consistent with the literature on recent mention as a factor in reference resolution (e.g., Arnold, Reference Arnold2010). People will assume that the last thing said is what the speaker is referring to. But, crucially, gesture can be used to weaken that assumption.
5.1. Limitations
Several limitations arose from design choices we made in creating experimentally controlled videos. Our participants were presented with a series of statements from the same (face-less) speaker, and their response is doubtless rather different from the way gesture is integrated into mental representations during dynamic, real-life interactions. Although only 20 to 30 percent of our participants mentioned gesture or body language when asked what they thought the study was about, the artificial nature of the stimuli presumably directed attention to gesture in ways that only generally reflect typical processing. We did not perform any analyses asking whether guessing the purpose of the study predicted response, but this could be explored in future work. Next steps might vary the handshape of the gestures, the prosody, involve more speakers and naturalistic settings, and generally increase the extent to which the stimuli represent real discourse. In addition, because we chose to match audio and video features (gesture strokes and peak prosodic emphasis for noun phrases), the audio for gesture disambiguating and non-disambiguating versions of each scenario differed slightly. These differences were millisecond differences in the length of pauses, rather than differences in intonation. It is possible that these minute audio differences actually explain our findings.Footnote 3 We think this is unlikely: the variability in audio editing was not constant across trials because the length of each noun phrase varied. That is, as far as we know there is no systematic feature in the audio that could be tied to a theoretically relevant phenomenon. That said, we cannot rule it out.
An unexpected finding was that participants also chose the B statement as their own preference more frequently than chance. This occurred for all versions of our scenarios, ranging from 54% to 63%. A simple explanation for this phenomenon is that, because we did not counterbalance the order of the statements, the more popular choice (on average) was B. For example, traditional pizza was always the B statement in our scenarios, and perhaps more of our participants prefer traditional pizza. Based on responses from Study 1, the average for participant preference across all scenarios was 60% (see proportions by scenario in the Appendix). This may mean that the overall tendency to choose B was amplified. This is not problematic for our findings, because the same logic would not apply to the selection of stimulus speaker preference. In Study 2, we saw that both fixed effects (trial type, ‘Whose Preference’) predicted the choice of A or B, and their interaction also predicted the choice of A or B. But while the contrast between the two trial types was statistically different for stimulus speaker preference, it was not for participants’ own preference.
Although we feel that this is a good explanation for the patterns we observed, it is also possible that a recent mention bias impacted participants’ choices for their own preference, possibly because this was an experimental situation with zero stakes. That is, when pressing a button to decide which kind of pizza you prefer, absent a strong feeling, you may choose whatever you heard last. Our study was not designed to separate these possibilities. Future work could ensure the study begins with a set of normed options with preferences balanced, or the statements could be counterbalanced. But the neutrality of the scenarios does raise an interesting question about whether the relative plausibility of the two options shapes the role played by gesture. That is, if listeners find it highly implausible that the speaker could actually take the ‘A’ position, will gesture still perform a disambiguating function when it occurs in the ‘A statement’ location? We recently extended our paradigm by comparing neutral to moral scenarios (for example, a neutral scenario such as buying pink sandals versus an evaluation of human cloning, which the majority of Americans consider to be immoral: Gallup, 2017). We found that participants did not respond differently to morally charged scenarios (Hinnell & Parrill, Reference Hinnell and Parrill2020). When a speaker’s gesture co-occurred with a statement about a very unpopular position (e.g., human cloning is good), a gesture in the same spatial location co-occurring with an ambiguous statement was still used to disambiguate the statement.
5.2. Future directions
The key finding of our study is that the presence of a gesture changed how participants interpreted a speaker’s statements. A number of questions remain. First, our study does not explain why participants choose the last thing they encountered as the stimulus speaker’s preference. Our argument is that this is the general function of concession (that is, concession allows speakers to negate the first discourse element and align themselves with the second), and that this pattern reflects a general tendency to choose the most recent referent in resolving an ambiguous pronoun (e.g., Arnold, Reference Arnold2010).
A second question raised by our findings concerns the fact that, even when seeing a disambiguating gesture, participants did not always choose the statement that the gesture occurred with. Participants still chose the B statement around 30 percent of the time (decreasing from around 70% without disambiguating gesture). This pattern indicates that the information coming from the gestural modality is balanced against the discourse function of a concessive (the speaker believes whatever she says last), and recent mention biases. Previous studies have also found that gesture interacts with other factors in a more nuanced way than might be expected. Debreslioska and colleagues (Reference Debreslioska, van de Weijer and Gullberg2019) discuss the fact that results of studies on localizing gestures for concrete referents do not always converge. This is perhaps not surprising given that gesture is expected to be the less-attended channel of information, thus it is unlikely to completely override other factors such as the recent mention bias.
In addition, it is important to understand the role of gesture in statements of preference that are not ambiguous. Several studies have found no facilitatory effect of gesture on response time in gesture-congruent conditions (Sekine & Kita, Reference Sekine and Kita2017), but Gunter and Weinbrenner (Reference Gunter and Weinbrenner2017) suggest that gestures must be valid cues for a task in order to facilitate comprehension. One possible extension of the study presented here is to examine whether gestures facilitate comprehension of statements of preference that are not ambiguous and to investigate the degree to which observers attend to gestures in non-ambiguous linguistic contexts (i.e., those that are disambiguated entirely in the speech to prevent an unnatural focus on gesture).
Gestures that mark preference display an embodied grounding in our experience of contrast in the real world. We weigh ideas or objects against each other and we refer to these in the ongoing discourse by indexing these options in the gesture space, most frequently to either side of our body (Hinnell, Reference Hinnell2019, Parrill & Stec, Reference Parrill and Stec2017). While gesture has been referred to as an ‘unwitting’ window into the mind of the speaker/gesturer (McNeill, Reference McNeill1992), in this study, we reversed the question. Rather than exploring how preferences are enacted by speakers, we investigated the effect of a speaker’s gesture on an observer. Findings showed that gestures can shift an observer’s interpretation of speaker preference. These findings go beyond previous studies of cohesive and referential gestures by using abstract referents (i.e., discourse deictic elements) rather than concrete ones. More broadly, these findings provide supporting evidence for the tight integration of speech and gesture (Church et al., Reference Church, Kelly and Holcombe2014; Kelly et al., Reference Kelly, Healey, Özyürek and Holler2015; Kelly et al., Reference Kelly, Özyürek and Maris2010), for the activation of gesture throughout a discourse, and for the role of gesture in an observer’s comprehension of discourse (Sekine & Kita, Reference Sekine and Kita2017). The findings also provide perception evidence that humans conceptualize decision making or preference as balance or weight to one side or the other (e.g., Hinnell, Reference Hinnell2019, Reference Hinnell2020; Johnson, Reference Johnson1987, Reference Johnson2017; Turner, Reference Turner1991), thereby extending arguments about embodied cognition beyond concrete reference into the domain of abstract reference. While some proponents of embodied theories of cognition suggest there is no great difference between a concrete object (a cat) and an abstract object (the right way to stay mentally sharp), the literature on the comprehension of abstract language has not always found the same patterns for the two types of language (see Diefenbach et al., Reference Diefenbach, Rieger, Massen and Prinz2013). In addition, the arguments about visual and motor simulation (Hostetter & Alibali, Reference Hostetter and Alibali2008, Reference Hostetter and Alibali2019) – and how such putative processes connect to co-speech gestures – are not as straightforward for abstract speech. Abstract referents do not have spatial locations until a conceptualizer creates them. It is important and worthwhile to show that gestures accompanying speech about ideas can serve similar discourse functions to gestures accompanying speech about objects.
Acknowledgements
We thank Raedy Ping for advice on statistical procedures and Nicole Baumgartner for assistance with stimulus preparation.
Conflicts of Interest
We have no conflicts of interest to declare.
Appendix
Study 2 scenarios
Table A1 presents the scenarios used in Study 2. Columns three and four show the mean proportion choosing B. These were selected from the Study 1 scenarios because they had the highest proportion of participants choosing the B statement for the stimulus speaker’s preference.
Table A1. Study 2 scenarios

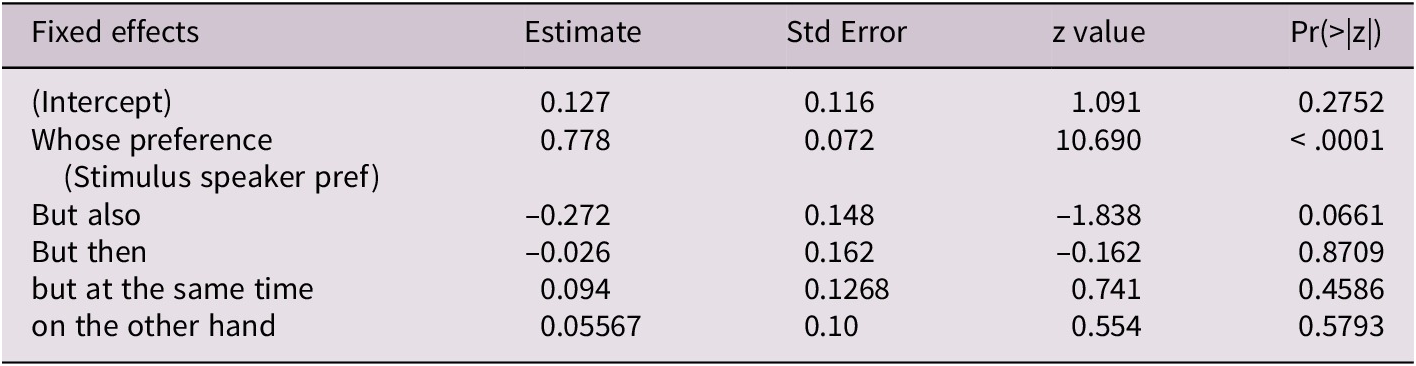
Analyses by concessive
We did not design our scenarios to test the impact of different concessives but, to explore their possible impact we used a mixed model logistic regression (logit) model with participant as random effect, and fixed effects of ‘Whose Preference’ (stimulus speaker or participant’s own) and concessive. The dependent variable was choosing the B statement as preference, with a score of 0 if the individual chose the A statement, and 1 if they chose the B statement. With ‘but’ as the comparison level, we found a marginally significant effect for ‘but also’, but no other differences as a function of concessive. For Study 2, we chose the Study 1 scenarios that had the highest proportion of participants choosing the B statement for the stimulus speaker’s preference. None of these scenarios used ‘but also’.
Table A2. Model summary for choice of A versus B by concessive
Shapiro–Wilk test results for Study 2 video version
To assess the normality of the video data, we carried out Shapiro–Wilk tests. They are included here to make the main text more readable.
Table A3. Study 2 Shapiro–Wilk test results

Study 2 demographic information
Demographic data were collected to allow for the possibility of exploratory analyses that could be used in designing future studies. We had no theoretical questions about age, race, or sex/gender so do not conduct any analyses here.
Table A4. Study 2 demographic information
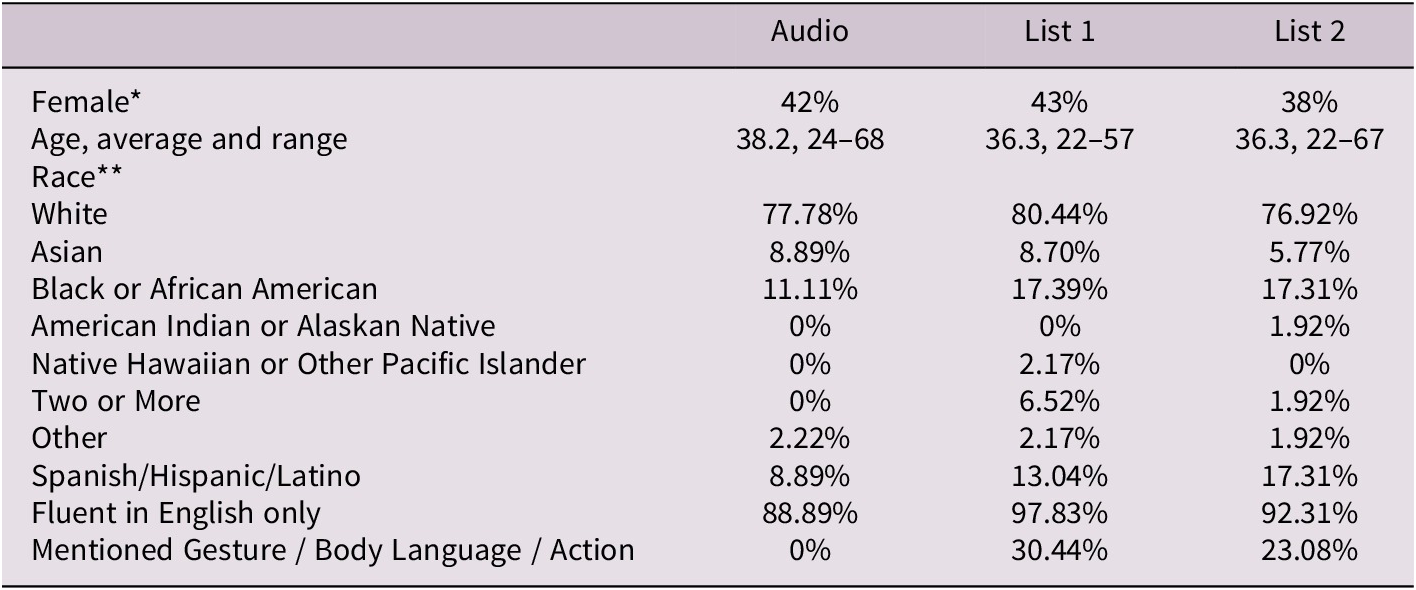
Notes: * Choices were Male/Female/Other, no participant identified as other; **Participants were asked “Do you identify as …?”.
















 Open access
Open access