


Anxiety disorders in later life are highly prevalent (Reference FlintFlint, 1994; Reference Beekman, Bremmer and DeegBeekman et al, 1998; Reference JormJorm, 2000), compromise quality of life (Reference De Beurs, Beekman and Van BalkomDe Beurs et al, 1999; Reference Mendlowicz and SteinMendlowicz & Stein, 2000), are associated with excess mortality (Reference Van Hout, Beekman and De BeursVan Hout et al, 2004) and generate substantial economic costs to society (Reference Greenberg, Sisitsky and KesslerGreenberg et al, 1999; Reference LöthgrenLöthgren, 2004; Reference Smit, Cuijpers and OostenbrinkSmit et al, 2006a ). Prevention of anxiety might thus be a means of generating health gains in the population and reducing future costs. To maximise the impact of prevention strategies on patient outcomes and costs, evidence of target groups is needed (cf. Reference Schoevers, Smit and DeegSchoevers et al, 2006; Reference Smit, Ederveen and CuijpersSmit et al, 2006b ). We report the results of an analysis of longitudinal epidemiological data to identify groups at increased risk of developing anxiety in later life who might benefit from targeted prevention strategies. This would help to set a rational agenda for preventive psychiatry.
METHOD
The analyses were based on data derived from the first two waves of the Longitudinal Aging Study Amsterdam (LASA). The sampling method and procedures of this study have been described elsewhere in detail (Reference Beekman, Geerlings and DeegBeekman et al, 2002). At baseline a population-based sample was obtained comprising 3107 persons in the age group 55-85 years. Participants had given their informed consent and underwent face-to-face interviews at home. The random sample was stratified by age and gender. The older age strata and men were over-sampled in anticipation of their higher attrition rates. After 3 years (mean=1115 days, s.d.=59) a total of 2164 (69.6%) participants were successfully re-interviewed and had complete data on their anxiety status. Loss to follow-up (n=943) occurred mainly because the individuals were too ill or were no longer alive at the time of the first follow-up. Predictors of loss to follow-up were older age, male gender, lower educational level, functional limitations, chronic diseases and cognitive decline, but not anxiety status at baseline (Reference Beekman, Geerlings and DeegBeekman et al, 2002). Corrective weights were used to account for the joint effect of intentional over sampling and attrition.
Measures
Anxiety
Anxiety was measured with the anxiety sub-scale of the Hospital Anxiety and Depression Scale (HADS; Reference Zigmond and SnaithZigmond & Snaith, 1983). The HADS was constructed with the aim of avoiding overlap between symptoms of anxiety, depression and physical illness. Its anxiety sub-scale (HADS-A) consists of seven items, for example ‘Lately, worrying thoughts go through my mind’. Each answer is rated on a four-point scale, ranging from 0 (rarely or never) to 3 (mostly or always). The scale scores range from 0 to 21, with higher scores reflecting higher anxiety levels. The HADS-A has good psychometric properties (Reference Mykletun, Stordal and DahlMykletun et al, 2001). The scores were dichotomised at the cut-off score of ⩾8 (Reference SnaithSnaith, 2003). In this paper a HADS-A score equal to or greater than 8 is referred to as ‘anxiety’. Measurements were taken at baseline (t 0) and at first follow-up (t 1). Incident cases were identified when two criteria were met: absence of anxiety at t 0 (HADS-A <8) and presence of anxiety at t 1 (HADS-A ⩾8).
Risk indicators
It is appropriate to conduct indicated prevention, or early intervention, in people who have some symptoms of anxiety but who do not yet meet the diagnostic criteria of the full-blown disorder (Reference Mrazek and HaggertyMrazek & Haggerty, 1994). Therefore, sub-threshold anxiety is a relevant risk indicator. Sub-threshold anxiety was defined as an HADS-A score above the population mean of 3 and below the cut-off of 8. Furthermore, it is appropriate to conduct selective prevention in people who are at a higher risk of anxiety because they are vulnerable and exposed to risk factors. Following the vulnerability-stress theory (Reference Brown and HarrisBrown & Harris, 1978) and pertinent research (Reference De Beurs, Beekman and GeerlingsDe Beurs et al, 2001; Schoevers et al, Reference Schoevers, Beekman and Deeg2003, Reference Schoevers, Deeg and Van Tilburg2005), the following risk indicators were included.
Depressive symptoms. Depressive symptoms were ascertained with the Center for Epidemiological Studies Depression scale (CES-D; Reference RadloffRadloff, 1977). The CES-D consists of 20 items and its total score has a range between 0 and 60. Scores of 16 or over indicate clinically significant levels of depressive symptoms (Reference Berkman, Berkman and KarlBerkman et al, 1986). At this cut-off score sensitivity is 100% and specificity is 88% for DSM-IV Axis I depressive disorder (American Psychiatric Association, 1994) in the Dutch population older than 55 years (Reference Beekman, Deeg and Van LimbeekBeekman et al, 1997). In this paper CES-D scores of 16 or over are referred to as ‘depression’.
Chronic illness. Chronic illness refers to the most prevalent chronic physical disorders among older people, such as diabetes mellitus, chronic obstructive pulmonary disease, cardiovascular disease, arthritis and cancer (Reference Kriegsman, Penninx and Van EijkKriegsman et al, 1996). The chronic illness variable was dichotomised as 0 (no illness or one illness) or 1 (two or more illnesses); because the majority of older people have a least one chronic illness, dichotomising at one illness would be unlikely to have much discriminatory or predictive power. It is worth noting that the physical disorders were reviewed in detail during the interview: symptoms were checked, and it was ascertained whether the participant was receiving medical attention for that particular physical disorder. In addition, the congruence between the self-reports and the medical files of the general practitioners was checked, and found satisfactory. Moreover, concordance between self-reports and general practitioners' data did not depend on depression or anxiety status (Reference Kriegsman, Penninx and Van EijkKriegsman et al, 1996).
Functional limitations. Functional limitations were measured with an adaptation of the Organisation for Economic Cooperation and Development (OECD) indicator for functional limitations (Reference Van SonsbeekVan Sonsbeek, 1988); this variable was coded as 0 (none or one limitation) or 1 (two or more limitations).
Self-rated health. Answers to the question, ‘How do you rate your health?’ were coded as 1 (poor health, sometimes good/sometimes bad, fair) or 0 (good or excellent health).
Mastery. Low mastery was measured using the abbreviated (five-item) version of the (seven-item) Pearlin Mastery Scale (Reference Pearlin and SchoolerPearlin & Schooler, 1978) and dichotomised at the median (1, score below the 50th percentile on the scale; 0, score above 50th percentile).
Other variables. The following socio-demographic variables were also included in the analyses: male gender (1, female; 0, male), old age (1, older than 75 years; 0, younger), low educational level (1, elementary or less; 0, more than elementary), living in an urban environment (1, living in Amsterdam; 0, living elsewhere) and small social network (1, fewer than 13 persons; 0, 13 or more persons).
It should be noted that all risk indicators were measured at t 0, thus well before the outcomes at t 1, and were dichotomised prior to the analysis, such that the index category (coded 1) was the assumed higher risk compared with the reference category (coded 0).
Analysis
All analyses took into account that the data were generated by a sampling design with intentional oversampling of the male and older age strata, and some amount of loss to follow-up. Therefore, the data were weighted such that the multivariate sample distribution over gender and age was exactly the same as in the general Dutch population in the age range of 55-85 years as reported by Statistics Netherlands (http://www.cbs.nl). In order to obtain correct 95% confidence intervals and probability values under weighting, all variance-related statistics were obtained with the help of the first-order Taylor series linearisation method as implemented in Stata version 9.0 for Windows. Weighted numbers are reported, rounded to the nearest integer, throughout the remainder of this paper. The subsequent analyses were carried out in several steps.
Analysis of incidence
Incidence was calculated in the cohort of the population at risk - that is, among those who were not categorised as HADS-A anxiety cases at baseline, and for whom the HADS-A anxiety status was available at follow-up after 3 years (n=1931). The incidence rate was obtained with the help of a weighted Poisson model which was regressed on the HADS-A anxiety status at follow-up, while taking into account that not all participants had equal follow-up times.
Analysis of risks
The incidence rate ratio (IRR) helps to identify high-risk groups. For each risk indicator the IRR was obtained by regressing the outcome (1, incident case; 0, not an incident case) on the risk indicator in a weighted Poisson regression model, while adjusting for all other variables in the risk set. The IRR describes how much larger the incidence rate is in the exposed group relative to the incidence rate in the unexposed group, controlling for competing risks. Incidence rate ratio values larger than 1 signify an increased risk and values smaller than 1 indicate a lower risk in the exposed group.
For each of the risk indicators (or combinations thereof) exposure rates were calculated. The exposure rate gives the percentage of the population exposed to a risk indicator, or to a combination of risk indicators. Finally, the attributable fraction was calculated for risk indicators and combinations thereof. This indicates by how many percentage points the incidence of anxiety will be reduced when the adverse effect of the risk indicators is completely blocked (Reference MiettinenMiettinen, 1974; Reference Rothman and GreenlandRothman & Greenland, 1998). In other words, the attributable fraction puts an upper limit to the achievable health gain in the population when prevention is successful in containing the adverse effects of the risk indicators. A maximum likelihood estimate of attributable attributable fraction was obtained with the aflogit-procedure in Stata for each of the risk profiles under a Poisson regression while adjusting for competing risks (Reference Greenland and DrescherGreenland & Drescher, 1993).
These statistics indicate the size of the group to be targeted (exposure rate), their risk (IRR) and the expected maximum number of preventable cases (attributable fraction). The last can also be used to quantify the economic benefits of avoiding the onset of new cases. Together, these indices of health gain and effort allow us to select high-risk groups for whom prevention is likely to be most cost-effective.
Identification of small, high-risk groups
Starting from the ‘long list’ of available risk indicators (see Table 1), a ‘short-list’ was compiled (see Table 2) using a conventional back-stepping procedure in a multivariate Poisson model. Only statistically significant risk indicators were retained in the model. There are two reasons to take this approach. First, the number of tests (in the subsequent analysis) increases exponentially with the number of risk indicators, and extensive multiple testing would increase the likelihood of committing a type I error, i.e. incorrectly assuming that some associations are significant when in fact they are not. Second, extensive multiple testing would soon become very time-consuming and make the method less attractive for use.
Table 1 Complete multivariate model of the risk indicators: exposure rates, incidence rate ratios and population attributable fractions (n=1931, weighted analysis)

| Risk indicator 1 | Exposure rate, % (95% CI) | IRR (95% CI) | Attributable fraction, % (95% CI) |
|---|---|---|---|
| Female gender | 52.3 (50.0 to 54.6) | 1.37 (0.87 to 2.15) | 18.4 (–10.0 to 38.9) |
| Age > 75 years | 20.6 (18.9 to 22.2) | 0.77 (0.50 to 1.18) | |
| Elementary education only | 37.0 (34.8 to 39.2) | 1.63 (1.08 to 2.46) * | 22.0 (4.8 to 37.0) * |
| Urban environment | 25.0 (23.1 to 27.0) | 1.44 (0.97 to 2.13) | 11.7 (–0.2 to 23.2) |
| Network <13 people | 46.4 (44.1 to 48.7) | 1.27 (0.86 to 1.86) | 9.5 (–8.3 to 29.0) |
| Ever widowed | 20.8 (19.0 to 22.5) | 1.28 (0.70 to 2.32) | 7.6 (–10.0 to 22.3) |
| No current partner | 26.8 (24.9 to 28.8) | 0.86 (0.46 to 1.62) | |
| Sub-threshold anxiety | 32.0 (29.8 to 34.0) | 4.11 (2.59 to 6.54) * | 55.9 (39.4 to 67.8) * |
| Depression | 6.9 (5.8 to 8.1) | 1.72 (1.12 to 2.63) * | 11.2 (0.0 to 19.5) * |
| Two or more chronic diseases | 19.4 (17.7 to 21.2) | 1.54 (1.04 to 2.30) * | 13.7 (0.0 to 24.9) * |
| Two or more functional limitations | 13.3 (11.9 to 14.8) | 0.93 (0.60 to 1.45) | |
| Self-rated ill health | 31.4 (29.3 to 33.5) | 1.65 (1.08 to 2.52) * | 23.4 (3.8 to 39.0) * |
| Low mastery | 54.8 (52.5 to 57.1) | 1.65 (1.06 to 2.58) * | 30.3 (3.5 to 49.6) * |
| Total attributable fraction 2 | 87.9 (79.3 to 93.0) * |
IRR, incidence rate ratio
1. Risk indicator at t 0
2. Obtained for all risk indicators with IRR > 1.00
* P<0.05
Table 2 Parsimonious multivariate model of the risk indicators (n=1931, weighted analysis)
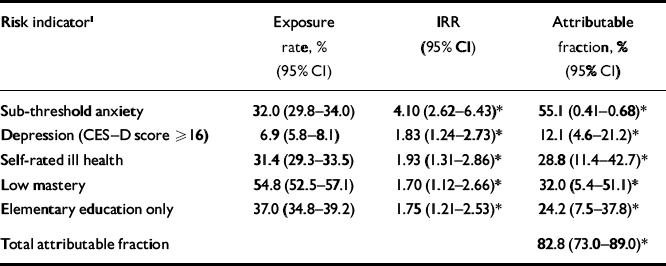
| Risk indicator1 | Exposure rate, % (95% CI) | IRR (95% CI) | Attributable fraction, % (95% CI) |
|---|---|---|---|
| Sub-threshold anxiety | 32.0 (29.8–34.0) | 4.10 (2.62–6.43) * | 55.1 (0.41–0.68) * |
| Depression (CES–D score ≥ 16) | 6.9 (5.8–8.1) | 1.83 (1.24–2.73) * | 12.1 (4.6–21.2) * |
| Self-rated ill health | 31.4 (29.3–33.5) | 1.93 (1.31–2.86) * | 28.8 (11.4–42.7) * |
| Low mastery | 54.8 (52.5–57.1) | 1.70 (1.12–2.66) * | 32.0 (5.4–51.1) * |
| Elementary education only | 37.0 (34.8–39.2) | 1.75 (1.21–2.53) * | 24.2 (7.5–37.8) * |
| Total attributable fraction | 82.8 (73.0–89.0) * |
CES–D, Center for Epidemiological Studies–Depression scale; IRR, incidence rate ratio
* P<0.05
The short-list of competitive risk indicators was then used as a starting point for generating risk profiles. Each risk profile contains at least one risk indicator and often a combination of risk indicators. For each risk profile the corresponding IRR, exposure rate and attributable fraction values were calculated. Therefore it is also possible to identify risk profiles that are associated with the best values for the IRR, exposure rate and attributable fraction overall.
For the selection of the ‘best’ risk profiles, we used the following criteria. First, we selected only risk profiles with an IRR of 5.00 or more - population segments with at least a five-fold risk of becoming anxiety cases. This was done for ethical reasons: we wanted to select only groups with seriously elevated risk levels. Second, we decided to target only population segments that formed 10% or less of the older population (i.e. where the exposure rate is 10% or less). This criterion was invoked in order to make future preventive interventions logistically and economically more feasible. When several risk profiles met these criteria, we opted for the risk profile associated with the highest attributable fraction value; that is, where we might expect the largest health gain. Here we need to point out that the criteria were arbitrary, and other thresholds could have been chosen; however, choosing other thresholds does not affect the principle of the methodology.
Systematic application of these criteria can be graphically depicted as tree-like structures (Reference Lemon, Roy and ClarkLemon et al, 2003; see Figs 1 and 2). At the top of the tree we place the risk indicator which has the best starting values of IRR, exposure rate and attributable fraction. The risk indicator with the starting values is called the ‘parental’ node. ‘Child’ nodes can appear below the ‘parental’ node; in a ‘child’ node the ‘parental’ risk indicator is combined with the risk indicator of the ‘child’ node. At the level of the ‘child’ nodes the risk indicators are selected such that the IRR remains equal to or above 5.00 and the exposure rate drops below 10%. This process can be continued by adding more nodes to a branch. At the end of a branch one finds a ‘terminal’ node that satisfies the pre-set criteria (IRR ⩾5.00 and exposure rate ⩽10%). If there is a choice among several terminal nodes, then one selects the node associated with the highest attributable fraction value; that is, where the health gain at population level is more substantial.
These data-analytical strategies were pioneered by Smit et al (Reference Smit, Beekman and Cuijpers2004) in the field of depressive disorder among people aged 18-65 years then improved and applied to late-life depression (Reference Smit, Ederveen and CuijpersSmit et al, 2006b ) and cross-validated by using a different dataset and following a different analytical approach (Reference Schoevers, Smit and DeegSchoevers et al, 2006).
RESULTS
Characteristics of the sample
The cohort at risk (n=1931) can be described as follows: 52.3% were female, 20.6% were older than 75 years, 37.0% had elementary education or less, 26.8% lived without a partner and 46.4% had a personal network of fewer than 13 people. In clinical terms the sample was characterised by presence of anxiety symptoms (32.0%), CES-D depression (6.9%), presence of two or more chronic illnesses (19.4%), two or more functional limitations (13.3%), poor self-rated health (31.4%) and a below-average sense of internal locus of control, i.e. low mastery (54.8%).
Incidence
In the cohort at risk (n=1931) the incidence rate was 1.82 new cases per 100 person-years (95% CI 1.51-2.19). Accordingly, if we were to follow 100 people at risk of developing anxiety over 1 year, we would be likely to observe 1.82 new cases. The incidence rate is higher in women (2.45, 95% CI 1.97-3.05) than in men (1.12, 95% CI 0.79-1.60).
Model with all risk indicators
Table 1 shows the exposure rate, incidence rate ratio, and the population attributable fraction for each of the risk indicators, after adjusting for the effects of all other risks in the model. In this multivariate model six risk indicators reached statistical significance for their respective IRRs. These were low education, sub-threshold anxiety, history of depression, presence of two or more chronic illnesses, low self-rated health and below-average levels of mastery. The attributable fraction of sub-threshold anxiety is large, and indicates that 55.9% of new cases of anxiety can be prevented when all cases of sub-threshold anxiety can be identified and receive an adequate early intervention. It is worth noting that all the risk indicators account for 87.9% of future anxiety cases (‘total attributable fraction' in Table 1). We will return to this point shortly.
Selecting a smaller set of risk indicators
In the next step we obtained a parsimonious multivariate model with fewer risk indicators (Table 2). This model is based on the smallest subset of statistically significant risk indicators (at P<0.05). Five risk indicators were retained: sub-threshold anxiety, depression, self-reported poor health, low mastery and elementary education only. Using the five selected risk indicators, 82.8% of future cases of clinically relevant anxiety can be identified (‘total attributable fraction' in Table 2). In the complete model with all risk indicators (Table 1) this percentage was only marginally higher. The implication is that the parsimonious model is nearly as good for predictive purposes as the one that contained all available risk indicators. It should be noted that we obtained nearly identical results for a parsimonious model in which the indicator ‘poor self-rated health’ was replaced by ‘presence of at least two chronic illnesses’, but then both variables are highly correlated (OR=5.70; s.e.=0.67; P<0.001). For that reason we also included ‘presence of at least two chronic illnesses’ in the subsequent analyses.
Selecting ‘optimal’ risk profiles for indicated prevention
As is evident from Table 2, there is some benefit in selecting sub-threshold anxiety as a starting point for identifying the ‘best’ high-risk group for prevention. This group is certainly associated with a high risk; the drawback is that the corresponding group is large (32% of the population of older people) and it is difficult to see how prevention could be delivered to such a large population segment. Now a number of risk indicators can be added to the risk profile (Fig. 1). Adding depression offers a good solution: the IRR is still larger than 5, but the exposure rate has now dropped to 5.4%. Thus the combination of sub-threshold anxiety and depression can be seen as a risk profile that meets the pre-set criteria. Figure 1 also shows that adding ‘low mastery’ to ‘sub-threshold anxiety’ is a good step in building a risk profile, but the size of the corresponding target group is still too large, and a third risk indicator must be added. This results in four terminal nodes, all satisfying the pre-set criteria. Among these terminal nodes, it can be seen that joint exposure to ‘sub-threshold anxiety’, plus ‘low mastery’, plus ‘low self-rated health’ yields the best attributable fraction value, indicating a larger health gain at population level compared with the alternative risk profiles.
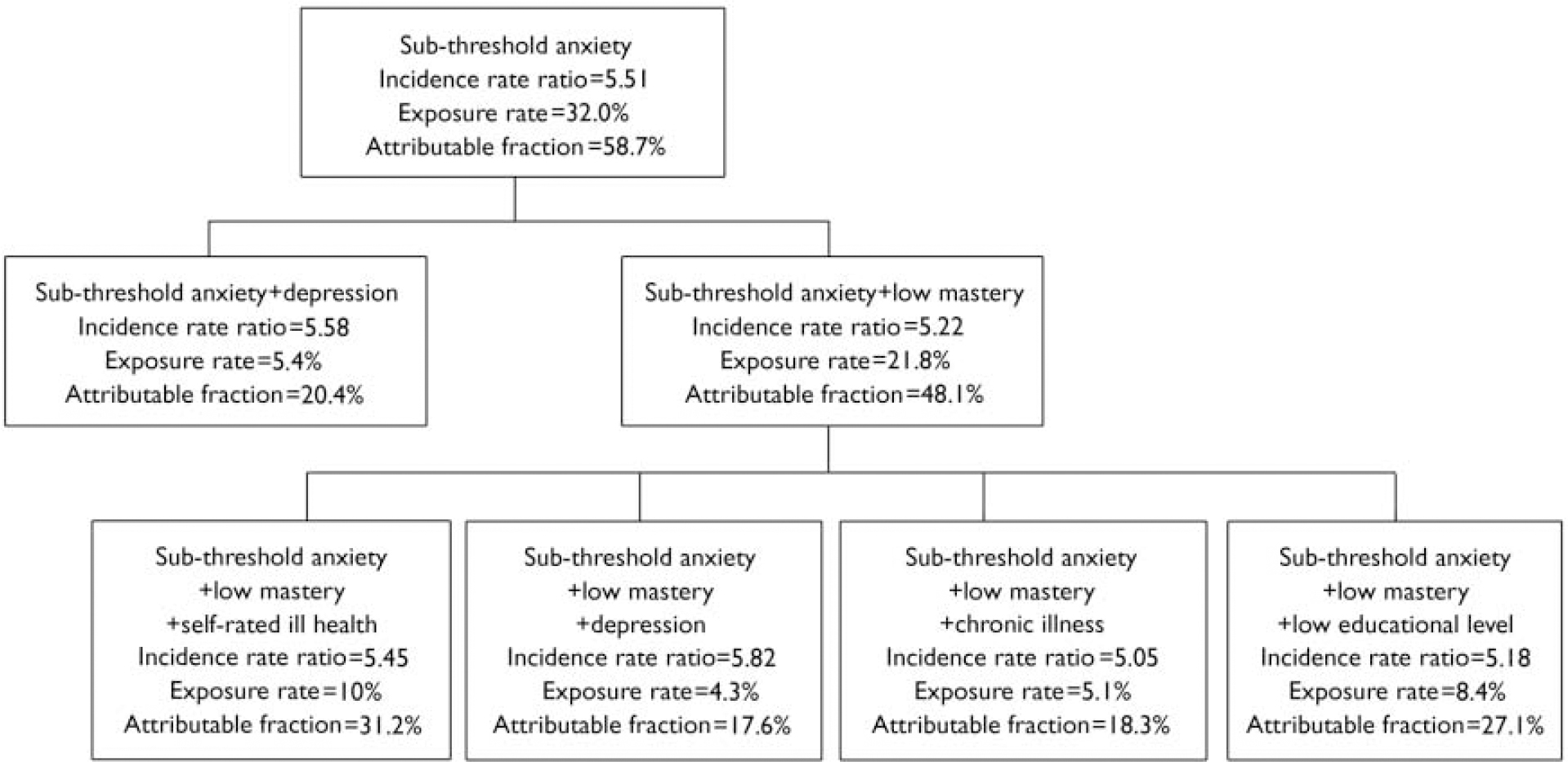
Fig. 1 Selecting combinations of risk indicators where the incidence rate ratio is greater than 5 and the exposure rate is below 10% while maintaining the attributable fraction as high as possible, starting with the group of people with sub-threshold anxiety (i.e. indicated prevention).
Selecting ‘optimal’ risk profiles for selective prevention
In the previous section we started with ‘sub-threshold anxiety’. This approach corresponds to indicated prevention (early intervention) in groups that already have some anxiety symptoms and are therefore at risk of developing the full-blown disorder. However, sometimes it may be impossible (or too complex) to identify sub-threshold cases for the purpose of prevention. Then one would like to conduct ‘selective prevention’ directed at people without symptoms but exposed to easily recognised risk indicators, for example risk indicators that are known to general practitioners, or can be retrieved from patient files. Ruling out ‘sub-threshold anxiety’ as a starting point, the next best candidate is ‘antecedent depression’ (Fig. 2). The corresponding population segment is not too large (exposure rate 6.9%), but the IRR falls below the pre-set criteria. The remaining risk indicators can then be added to the risk profile and the IRRs are increased to a level that meets the criteria. Most of the risk indicators in Fig. 2 are likely to be known by a general practitioner, whereas ‘mastery’ can be measured quickly with the help of a five-item scale and ‘self-rated health’ with only one question.
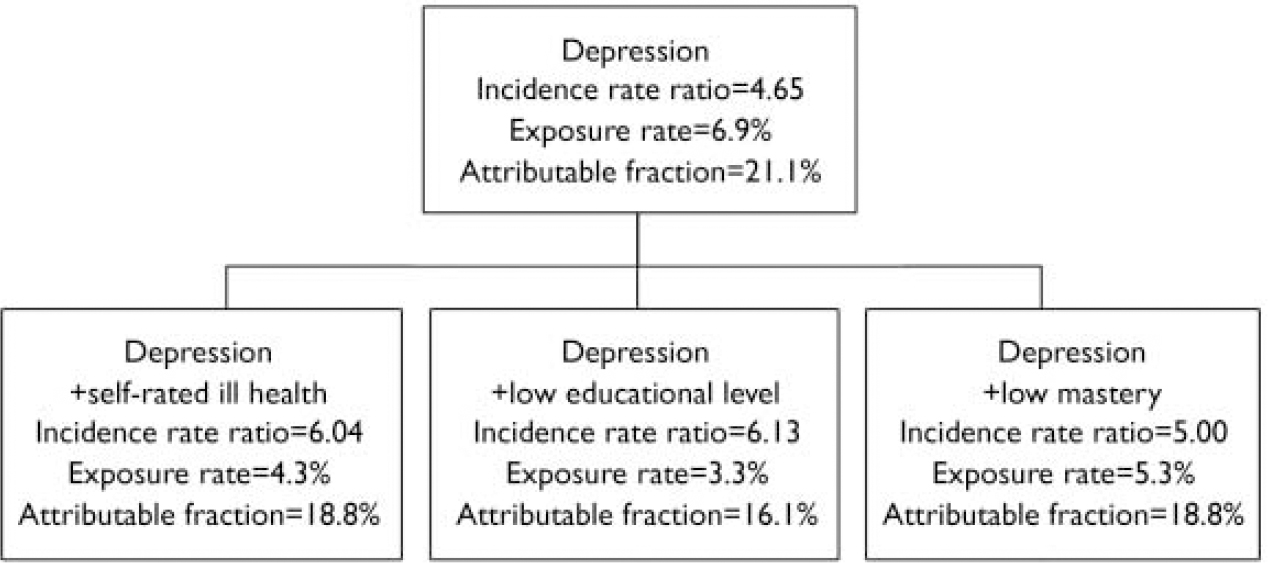
Fig. 2 Selecting combinations of risk indicators where the incidence rate ratio is greater than 5 and the exposure rate is below 10% while maintaining the attributable fraction as high as possible, not starting from people with sub-threshold anxiety (i.e. selective prevention).
DISCUSSION
We wanted to identify population segments in whom prevention of late-life anxiety would stand the best chances of generating health gains at population level. This would help to guide research towards promising areas in preventive psychiatry. This is important because anxiety disorders are prevalent and diminish quality of life, but there is no empirically validated intervention for preventing onset of anxiety disorders in later life (Reference Feldner, Zvolensky and SchmidtFeldner et al, 2004).
Main findings
Our study shows that it is possible to use longitudinal epidemiological data to select risk indicators that warrant interest from the prevention perspective. These are risk indicators that are associated with a low exposure rate, representing small groups, high incidence rate ratios (IRR), indicating seriously elevated risk levels; and high population attributable fractions, indicating substantial health gains at population level. The methodology of identifying risk indicators for prevention is not new (Reference MiettinenMiettinen, 1974; Reference Morgenstern and BursicMorgenstern & Bursic, 1982), but in the field of psychiatric epidemiology and prevention research it has rarely been applied. In this study, we applied it to late-life anxiety and came up with the following key findings.
First, the incidence of clinically relevant late-life anxiety is 1.82 new cases per 100 person-years, representing a substantial annual influx of new cases. Second, starting from a list of putative risk indicators, only a few were identified as interesting from the prevention perspective when the effects of the risk indicators were adjusted for competing risks. These are sub-threshold anxiety, depression, having a below-average sense of mastery, low self-rated health and having had only elementary education. It is worth noting that poor self-rated health and having two or more chronic illnesses are correlated variables that appear interchangeable. Third, the combined effect of being exposed to two, three or four selected risk indicators yields statistically significant and substantially interesting values on measures of potential health gain (IRR, attributable fraction) and effort (exposure rate). It is worth noting that the joint exposure to more risk indicators implies a smaller population segment. The intervention thus has a narrow focus, and the corresponding number of people who are the intended recipients of prevention becomes logistically manageable.
Economic ramifications
Once the costs of the disorder are known from a cost-of-illness study, then it is possible to combine the indices of effect and effort with the costs into an ante hoc cost-effectiveness analysis (Smit et al, Reference Smit, Beekman and Cuijpers2004, Reference Smit, Ederveen and Cuijpers2006b ). Here we will make the corresponding calculations for two hypothetical preventive scenarios: a ‘do nothing’ scenario, and a scenario in which people are targeted for prevention when they are depressed and have some anxiety symptoms.
In the ‘do nothing’ scenario (without any preventive intervention) one would see 18 200 new anxiety cases per 1 million people in a given year, because the incidence rate is 1.82 new anxiety cases per 100 person-years. A study carried out in the USA conservatively estimated that the direct medical per-patient costs of anxiety disorders were equivalent to £844 in UK currency. In a source population of 1 million people, the ‘do nothing’ scenario would thus entail a cost of £844×18 200 =£15 360 800 annually per 1 million source population. Now suppose that a preventive intervention is developed to contain the adverse effects of sub-threshold anxiety in people with depression. This intervention could be based, for example, on cognitive-behavioural therapy. To reduce intervention costs, it could be offered as self-help with minimal guidance. From Fig. 1 we now know that a completely successful intervention delivered to all people with depression and with sub-threshold anxiety (5.4% of the older population) would reduce the incidence of anxiety by 20.4%. In a hypothetical scenario in which 100% of the target group is reached and all receive a 100% effective intervention, then 3713 (20.4%) of the new cases would have been avoided. In a more realistic scenario of 60% coverage and a 30% success rate for the intervention (cf. Reference Cuijpers, Van Straten and SmitCuijpers et al, 2005), this would result in 3713×0.60×0.30= 688 avoided onsets. Avoiding 688 onsets would thus save £844×688=£580 700 per 1 million source population.
Clearly, the intervention would introduce costs of its own. We have calculated these as £285 per recipient of a preventive intervention of the type described above (Reference Smit, Willemse and KoopmanschapSmit et al, 2006c ). Again assuming a coverage rate of 60%, this would entail 3713×0.60×285=£635 000. The averted costs (£580 700 per 1 million people) may not completely offset the costs of a preventive intervention (£635 000 per 1 million people); nevertheless, the savings form a good starting point for cost-effective prevention of late-life anxiety. In short, we have a method at our disposal that could help to direct attention to high-risk groups in which preventive interventions are likely to become cost-effective. This is achieved at an early stage of the expensive and time-consuming cycle of development and evaluation of preventive interventions. Having said this, we need to add that ultimately the cost-effectiveness of a preventive intervention has to be established in a cost-effectiveness analysis alongside a randomised trial.
Strengths and limitations
Our findings have to be placed in the context of the strengths and limitations of this study. Its strengths are the use of population-based data; the prospective design, which enables the study of incidence and facilitates aetiological inference; and the measurement of exposures, which is not biased through post hoc rationalisation on the part of the participants because at t 0 they could not have any knowledge about their future health status at t 1. Furthermore, this study is among the first to show how a statistical technique can be applied to quantify potential health benefits and the effort required to generate these health gains. It thus supplies the sort of methodology which is of importance for setting a rational ‘research and development agenda’ for preventive psychiatry.
The limitations of this study consist in the not very detailed measurement of the exposures. We do not know for how long and how intensively the individuals were exposed. Moreover, the number of studied risk indicators is limited in that, for example, genetic and other biological risk indicators were not included. Another limitation is the measurement of anxiety with the HADS-A. This is not a diagnostic instrument. However, it has good psychometric properties (Reference Mykletun, Stordal and DahlMykletun et al, 2001), and it may be valuable as a screening instrument, especially because anxiety disorders in older people are not well recognised.
Conceptually, it would be useful to distinguish between risk indicators that are amenable to change, such as anxiety and depressive symptoms, and those that are not. It should be noted that some risk indicators are not modifiable, such as chronic illness. However, their adverse psychological effects might be contained. Finally, there are risk indicators that are not modifiable and that have effects that cannot be brought under control through preventive interventions (such as gender); however, these risk indicators are valuable from the perspective of identifying groups at risk - which was the principal aim of this paper.
Currently there is no empirical evidence that prevention of anxiety can be successful in older people, but there are examples of effective prevention of anxiety in younger age groups (see Reference Feldner, Zvolensky and SchmidtFeldner et al, 2004) and in unipolar depression (Reference Cuijpers, Van Straten and SmitCuijpers et al, 2005). In this Journal we have presented data on the effectiveness of preventing depression in adults (Reference Willemse, Smit and CuijpersWillemse et al, 2004) and on its cost-effectiveness (Reference Smit, Willemse and KoopmanschapSmit et al, 2006c ). We believe that developing and testing preventive interventions of anxiety disorders across the lifespan is an important and emerging research field, and this calls for a rational research agenda for the future, based on the data that we now have (cf. Reference Smit, Ederveen and CuijpersSmit et al, 2006b ).
This study and related studies (Smit et al, Reference Smit, Beekman and Cuijpers2004, Reference Smit, Ederveen and Cuijpers2006b ; Reference Schoevers, Smit and DeegSchoevers et al, 2006) were conducted in an attempt to answer the question of whether it is possible to reduce the incidence of common, disabling and costly mental disorders in a cost-effective way. Our answers are only tentative and are best regarded as working hypotheses about directions where efforts to develop preventive interventions and to test these interventions in empirical cost-effectiveness studies are likely to stand the best chances of becoming fruitful. In a next step these hypotheses have to be tested in randomised prevention trials and cost-effectiveness studies. As yet, we are only beginning to see how prevention can be directed to high-risk groups such that the health gains are maximised, while the efforts and costs to generate these health gains are minimised.
Acknowledgements
This study is based on data collected in the context of the Longitudinal Aging Study Amsterdam, financed by The Netherlands Ministry of Public Health. The work done for the current paper was financed by The Netherlands Health Research Council (ZonMw) grant 1360.0008.





eLetters
No eLetters have been published for this article.