


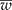 ) is narrower than the desired width (ω); and (2) iteratively increase the sample size until
) is narrower than the desired width (ω); and (2) iteratively increase the sample size until 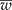 is smaller than the desired width (ω) with a specified degree of certainty (γ). Simulated data were created and tables are presented showing the different possible scenarios that a researcher may encounter. An R program is given and explained that will reproduce the results and make it easy for the researcher to create other scenarios.
is smaller than the desired width (ω) with a specified degree of certainty (γ). Simulated data were created and tables are presented showing the different possible scenarios that a researcher may encounter. An R program is given and explained that will reproduce the results and make it easy for the researcher to create other scenarios.Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Galeano, Pablo
Debat, Claudio Martínez
Ruibal, Fabiana
Fraguas, Laura Franco
and
Galván, Guillermo A.
2010.
Cross-fertilization between genetically modified and non-genetically modified maize crops in Uruguay.
Environmental Biosafety Research,
Vol. 9,
Issue. 3,
p.
147.
Brera, C.
De Santis, B.
Prantera, E.
De Giacomo, M.
and
Onori, R.
2011.
Food Chain Integrity.
p.
214.
Montesinos-López, Osval Antonio
Montesinos-López, Abelardo
Crossa, José
Eskridge, Kent
and
Sáenz, Ricardo A.
2011.
Optimal sample size for estimating the proportion of transgenic plants using the Dorfman model with a random confidence interval.
Seed Science Research,
Vol. 21,
Issue. 3,
p.
235.
Montesinos-López, Osval Antonio
Montesinos-López, Abelardo
Crossa, José
Eskridge, Kent
and
Duffy, Ken R.
2012.
Sample Size under Inverse Negative Binomial Group Testing for Accuracy in Parameter Estimation.
PLoS ONE,
Vol. 7,
Issue. 3,
p.
e32250.
Cisneros-López, Ma. Eugenia
Mendoza-Onofre, Leopoldo E.
González-Hernández, Víctor E.
and
Montes-García, Noé
2012.
Male to female row ratio and fungicide application during panicle development to control sorghum ergot in the Mexican Highlands.
Australasian Plant Pathology,
Vol. 41,
Issue. 4,
p.
389.
Montesinos-López, Osval Antonio
Montesinos-López, Abelardo
Crossa, José
and
Eskridge, Kent
2013.
Sample size for detecting transgenic plants using inverse binomial group testing with dilution effect.
Seed Science Research,
Vol. 23,
Issue. 4,
p.
279.
Hepworth, Graham
2013.
Improved Estimation of Proportions Using Inverse Binomial Group Testing.
Journal of Agricultural, Biological, and Environmental Statistics,
Vol. 18,
Issue. 1,
p.
102.
Montesinos-López, Osval Antonio
Eskridge, Kent
Montesinos-López, Abelardo
and
Crossa, José
2015.
Optimal sample sizes for group testing in two-stage sampling.
Seed Science Research,
Vol. 25,
Issue. 01,
p.
12.