



1. Introduction
Computer-assisted pronunciation training (CAPT) has emerged as a promising tool for enhancing second language (L2) learners’ pronunciation skills, potentially overcoming some of the limitations of conventional instruction. Today, a variety of commercial and open-source CAPT systems are increasingly available on desktop and mobile devices (Bajorek, Reference Bajorek2017). These systems promise L2 learners rich pronunciation input, self-paced practice, and immediate feedback (Neri, Cucchiarini, Strik & Boves, Reference Neri, Cucchiarini, Strik and Boves2002). Input in CAPT ranges from natural speech models produced by first language (L1) speakers to manipulated speech emphasizing specific pronunciation features, as well as synthetic computer-generated speech that models human pronunciation (Wang & Munro, Reference Wang and Munro2004). Such forms of input are particularly valuable when presented through high variability phonetic training (HVPT), which exposes learners to a wide range of pronunciation models presented by different speakers in different phonetic contexts (Thomson, Reference Thomson2012). CAPT systems are further enhanced with automatic speech recognition (ASR), which provides learners with instantaneous speech-to-text conversion, error detection, and personalized feedback (Henrichsen, Reference Henrichsen2021).
The effectiveness of CAPT has been highlighted in a number of metanalyses. Mahdi and Al Khateeb (Reference Mahdi and Al Khateeb2019), for example, reviewed 20 studies investigating the effectiveness of CAPT applications in developing L2 learners’ pronunciation. The results indicated that CAPT systems are effective in enhancing L2 learners’ pronunciation, particularly those at beginner or intermediate levels. In a more recent metanalysis of 15 empirical studies, Ngo, Chen and Lai (Reference Ngo, Chen and Lai2024) found ASR-based CAPT to be more effective in developing English as a second/foreign language (ESL/EFL) learners’ segmental accuracy (i.e. vowels and consonants) than suprasegmental accuracy (i.e. stress, intonation, and rhythm), with explicit feedback systems being the most effective. However, while these studies provide systematic evidence for the effectiveness of CAPT, little is known about the pedagogical practices and learning measures employed in CAPT research. The next section provides a background about the current practices in L2 pronunciation instruction, including pedagogical goals, training, and assessment.
1.1 Important concepts in L2 pronunciation teaching
An often neglected area of L2 teaching, pronunciation has witnessed increased attention in the last two decades (Thomson & Derwing, Reference Thomson and Derwing2015). This is largely due to a shift from a “nativist” approach aiming at achieving L1-like pronunciation to teaching approaches that prioritize attainable learning goals like intelligibility and comprehensibility (Munro & Derwing, Reference Munro and Derwing1995). In this context, “intelligibility refers to the actual understanding of the utterance by the listener” and “comprehensibility denotes the ease or difficulty of understanding on the part of the listener” (Kang, Thomson & Moran, Reference Kang, Thomson and Moran2018: 117). Since these partially independent measures of pronunciation serve communicative goals, contemporary pronunciation practices increasingly focus on teaching phonetic features that contribute to intelligibility and comprehensibility. In this regard, empirical studies (e.g. Kang, Reference Kang2010; Saito, Trofimovich & Isaacs, Reference Saito, Trofimovich and Isaacs2016) have shown that a comprehensible pronunciation requires a focus on both segmental and suprasegmental features.
The practice of pronunciation requires different types of activities depending on the target phonetic features (i.e. segmental/suprasegmental features) or phonetic skill (i.e. perception/production). Explicit pronunciation instruction, for example, focuses on increasing L2 learners’ awareness of the target language features, as perception is considered a precursor to pronunciation production (Lee, Plonsky & Saito, Reference Lee, Plonsky and Saito2020; Nagle, Reference Nagle2021). It relies heavily on controlled speech activities, where the target pronunciation features are predetermined and elicited through phonetic notation, listen-and-repeat, or read-aloud activities. Such forms of pronunciation practice are particularly beneficial when targeting discrete (i.e. specific) phonetic features (e.g. vowels, consonants, stress, intonation) (Immonen, Alku & Peltola, Reference Immonen, Alku and Peltola2022). Alternatively, communicative teaching tackles pronunciation through a more implicit approach by employing activities that elicit spontaneous natural speech, such as open questions, discourse completion, or picture description tasks (Derwing & Munro, Reference Derwing and Munro2015: 111).
Corrective feedback (CF), defined by Lightbown and Spada (Reference Lightbown and Spada1999) as “any indication to the learners that their use of the target language is incorrect” (p. 172), is another necessary pedagogical component of pronunciation training. CF can either be implicit, where errors are subtly addressed through recasts, clarification requests, and elicitation, or it can be explicit, where errors are overtly demonstrated and corrected (Engwall & Bälter, Reference Engwall and Bälter2007). Empirical evidence indicates that optimal pronunciation learning outcomes are achieved through a combination of implicit feedback and explicit instruction (Saito & Lyster, Reference Saito and Lyster2012). To align with the current pedagogical consensus, feedback should prioritize addressing pronunciation errors that are most likely to impact intelligibility and comprehensibility.
Assessment constitutes another facet of pronunciation instruction pedagogy, encompassing a range of concepts, methodologies, and measures. In a meta-analysis of 77 L2 pronunciation studies, Saito and Plonsky (Reference Saito and Plonsky2019) provided a comprehensive framework of key concepts in assessment encompassing constructs (i.e. global/discrete pronunciation features), speech elicited (i.e. controlled/spontaneous), and rating method (i.e. human listeners/acoustic analysis). In line with pedagogical goals, contemporary pronunciation assessment practices ideally focus on “what matters for communication” (Derwing & Munro, Reference Derwing and Munro2015: 110). This can be manifested in assessment practices that prioritize evaluating global pronunciation qualities (e.g. intelligibility/comprehensibility) or specific phonetic features that contribute to it. The nature of the pronunciation assessment tasks largely depends on the pronunciation features being evaluated. For example, controlled speech activities, such as reading, are ideal when assessing phonemic accuracy because they offer control over what the learner produces. Alternatively, activities eliciting more natural spontaneous or extemporaneous speech are more suitable for assessing global pronunciation. Conversely, perception can be assessed through phonetic identification (e.g. audio recording: /naɪt/, did you hear night or light?) or discrimination tasks (e.g. are these words identical or different? /bɪt/, /biːt/).
Due to their subjective nature, global pronunciation learning measures like accent and comprehensibility tend to be evaluated using scalar ratings (e.g. 1 = extremely easy to understand; 9 = impossible to understand) (Munro & Derwing, Reference Munro and Derwing1995). Discrete features, on the other hand, are often evaluated through criterion-based measures, where phonemic accuracy is determined by the number of phonemic substitutions or deletions and prosodic accuracy by absence, misplacement, or misuse of stress, intonation, or rhythm (Saito, Suzukida & Sun, Reference Saito, Suzukida and Sun2019). However, some studies (e.g. Isaacs & Thomson, Reference Isaacs and Thomson2013; Lee et al., Reference Lee, Plonsky and Saito2020) still employ scalar ratings to evaluate discrete features (e.g. 1 = utterly inaccurate; 9 = perfectly accurate). Recent pronunciation research also suggests that global pronunciation measures like intelligibility can be accurately assessed through criterion-based measures such as transcription of speech or non-sense sentences (e.g. Kang et al., Reference Kang, Thomson and Moran2018). Pronunciation can be assessed by human raters or computer-based acoustic measures. However, despite the significant advances in automatic speech assessment, it is still far from achieving human-like assessment capabilities (Isaacs, Reference Isaacs and Kunnan2013).
1.2 The pedagogy–technology conflict in CAPT
Despite technological innovation, many researchers remain skeptical about the extent to which CAPT delivers effective pronunciation training. This has originally stemmed from the observed discrepancies between CAPT systems’ design and pronunciation instruction pedagogy (Levis, Reference Levis2007; Neri, Cucchiarini, Strik & Boves, Reference Neri, Cucchiarini, Strik and Boves2002). While modern language teaching approaches strive for more attainable goals, such as comprehensibility and intelligibility, numerous CAPT systems are still built on comparing L2 learners’ pronunciation to that of adult L1 speakers (O’Brien et al., Reference O’Brien, Derwing, Cucchiarini, Hardison, Mixdorff, Thomson, Strik, Levis, Munro, Foote and Levis2018). This often results in ASR failures with accented L2 pronunciation (e.g. Henrichsen, Reference Henrichsen2021; Martin & Wright, Reference Martin and Wright2023) and with children’s speech (e.g. Gelin, Pellegrini, Pinquier & Daniel, Reference Gelin, Pellegrini, Pinquier and Daniel2021). This led to skepticism about the efficacy of ASR in assessing L2 speech and encouraged attempts at using non-ASR tools (Fontan, Kim, De Fino & Detey, Reference Fontan, Kim, De Fino and Detey2022; Fontan, Le Coz & Detey, Reference Fontan, Le Coz and Detey2018). CAPT feedback is also often perceived as a technological innovation rather than a pedagogically informed feature, hindering its reliability in detecting L2 pronunciation issues and adapting to learners.
Given this pedagogy–technology conflict, it is necessary to map pronunciation teaching practices in empirical studies investigating the effectiveness of CAPT. This is particularly important because although previous reviews have demonstrated evidence for the effectiveness of CAPT (e.g. Mahdi & Al Khateeb, Reference Mahdi and Al Khateeb2019; Ngo et al., Reference Ngo, Chen and Lai2024), they did not shed enough light on the pedagogical practices. Therefore, it remains unclear how CAPT studies approached pronunciation training and measured learning. Further uncertainty arises about findings in the literature due to insufficient details about the methodology and CAPT systems used. This study presents a pedagogically informed systematic review that aims to categorize and evaluate the methodology, CAPT systems, pronunciation training scopes and approaches, and assessment practices in the CAPT literature. This review seeks to answer the following research questions:
-
1. What are the most researched L2 communities in CAPT research?
-
2. What are the methodological designs employed in CAPT research?
-
3. What systems are used in CAPT research?
-
4. What are the pedagogical scopes of pronunciation teaching in CAPT research?
-
5. How is pronunciation practiced in CAPT research?
-
6. What are the pedagogical pronunciation assessment practices in CAPT research?
-
7. How is pronunciation learning measured in CAPT research?
2. Method
2.1 Inclusion and exclusion criteria
This systematic review employed a set of inclusion and exclusion criteria to filter the relevant sources (see Table 1). The review was limited to peer-reviewed journal articles on the topic of CAPT. To ensure a minimum quality standard for the retrieved sources, the following academic databases were used: Education Resources Information Center (ERIC), ProQuest, Scopus, and PubMed. The search was also limited to the articles published between 1999 and 2022. This is primarily because the pedagogical criteria used to extract and classify the instruction and assessment practices were established during the late 1990s and early 2000s. Moreover, the studies conducted before 1999 mostly relied on CAPT systems that are vastly different from those available on the market today. Given that most research on CAPT is published in English, only studies written in this language were reviewed.
Table 1. Inclusion and exclusion criteria

In terms of research design, this review was limited to experimental and quasi-experimental studies investigating the effectiveness of CAPT in improving L2 pronunciation. Non-experimental studies, such as viewpoint articles and reviews, were excluded. The review focused on the studies involving commercial, free open-source, or prototype CAPT systems that are specifically designed for L2 pronunciation training. The search was limited to studies involving healthy language learners with no exclusion criteria for context, age, L1, or target language. However, studies with speech- or hearing-impaired participants were not included, as they go beyond the scope of the current review. As for data collection, the review was limited to studies that measured participants’ pronunciation learning after a CAPT treatment. To assess the consistency of the inclusion and exclusion criteria, an interrater reliability test (Cohen’s kappa) was conducted with a second coder, who made decisions on the inclusion or exclusion of 25 publications. The results showed substantial agreement (κ = .73, percentage agreement = 88%) with the main author.
2.2 Search process
To find the relevant sources, in addition to the academic search engines ERIC, ProQuest, Scopus, and PubMed, a manual search was also conducted using the search engines of seven major journals in the field of technology and language learning: Computer Assisted Language Learning, CALICO Journal, The JALT CALL Journal, Language Learning & Technology, ReCALL, Speech Communication, and System. The review employed three main search keywords to generate relevant search results (see Table 2). The keywords were used to identify studies investigating the effects of CAPT systems on L2 learners’ pronunciation.
Table 2. Search keywords

To ensure that the review includes all of the possible relevant publications, the search process was carried out on four different occasions. The first search was conducted on 14 November 2019, the second on 4 October 2020, the third on 10 December 2021, and the final search on 18 December 2022. The search process yielded 256 publications, 180 of which were generated using academic search engines, while 76 publications were the result of a manual search in reputable CALL journals. As a first step, 81 publications were deleted due to duplication. This was followed by a title and abstract screening that resulted in the removal of 100 publications due to their incompatibility with the inclusion criteria of the review. Finally, an in-depth reading of the remaining 75 sources resulted in the exclusion of 45 publications, which were either irrelevant or missing key information, leaving 30 publications for the main review and data extraction.
2.3 Data extraction
A codebook was created to manually extract and classify the necessary information from the relevant studies (see the supplementary material for the complete codebook). The codebook is divided into four main sections, namely: (1) Methodology, (2) CAPT System, (3) Training, and (4) Assessment. The first section was used to extract ethnographic information, including participants’ educational level, target language, language proficiency, and age range. This helped in methodically classifying the participants of the various studies. The methodology section was used to classify the studies’ experimental designs, particularly with regard to the sampling approach, group design, and pre-/post-treatment testing.
The CAPT section of the codebook was used to categorize the systems based on their access type (i.e. commercial, open source, or prototype) and their technological basis (ASR/non-ASR based). CAPT input was classified into three different types of speech: natural speech, which refers to unaltered human pronunciation; manipulated speech, which is edited to emphasize certain pronunciation features; and synthetic speech, which is artificial computer-generated speech. As for the scope of training, studies were categorized based on the target phonetic level (i.e. segmental/suprasegmental), phonetic skill (i.e. perception/production), and whether the activities elicited controlled speech (e.g. listen and repeat) or spontaneous speech (e.g. picture description). The feedback was classified as implicit, in cases of simple spectrograms without error detection, or explicit, in cases where systems visually highlight specific pronunciation errors and provide a correction.
The codebook was also employed to classify the pronunciation learning assessment practices in the CAPT literature based on L2 pronunciation research consensus. This allowed coders to categorize the pronunciation production elicitation tasks into controlled speech or spontaneous speech tasks, along with discerning whether they were rated by human listeners or acoustic measures. In studies investigating participants’ perception, the scheme was used to classify the assessment tasks into identification or discrimination activities. Finally, the codebook was used to classify whether the studies employed discrete pronunciation learning measures targeting phonological accuracy or global measures such as comprehensibility or accent.
The primary data extraction and coding was carried out by the main author of the study. To address the research questions, data concerning various features within each category (i.e. Methodology, CAPT System, Training, and Assessment) were classified and reported in the form of frequencies and percentages in an Excel spreadsheet. Through systematic categorization and quantification of these features, key trends, patterns, and relationships were identified in the field of CAPT research (see section 3. Results). This analysis enabled the identification of insights into extensively studied L2 communities, methodological designs, CAPT system types, the scopes of pronunciation training, assessment practices, and measures of pronunciation learning.
To evaluate the dependability of the coding scheme, an interrater reliability test was performed with a second researcher, who coded 12 out of the 30 studies. The results showed a significant agreement with the main author (κ = .75, percentage agreement = 82.20%). On an item level, the two researchers reached an agreement percentage of 82% (κ = 0.75) in coding the methods data, 81% (κ = 0.74) in coding the CAPT system data, 88% (κ = 0.77) in coding the training data, and 79% (κ = 0.64) in coding the assessment data. While disagreements among coders were resolved through discussion, readers are advised to interpret findings with caution, as coding is subject to individual variation and minor discrepancies are inevitable.
3. Results
In this section, the information extracted using the codebook is displayed in a categorical format and conveyed through measures of frequency. Table 3 provides a data extraction summary of the studies reviewed in terms of the sample size, CAPT systems, target languages, training durations, scopes of training and assessment, and pronunciation learning measures. To facilitate readability, the studies in the table are arranged based on target language, scope of training, and assessed skills.
Table 3. Data extraction summary

Note. EFL = English as a foreign language; ESL = English as a second language; CAPT = computer-assisted pronunciation training; ASR = system employs automatic speech recognition; Non-ASR = system does not employ automatic speech recognition.
3.1 Methodological characteristics
Table 4 provides a general summary of the contexts and participants in the reviewed CAPT literature. The great majority of studies were conducted with adult learners of English at a higher educational level. While a few studies were conducted with language learners in primary (n = 3) and secondary (n = 2) schools, many more were conducted in higher education institutions (n = 22). Furthermore, very few CAPT studies were conducted with professional participants (n = 1) or non-student participants (n = 2). This means that the great majority of studies were conducted with young adults aged between 18 and 33 years old (n = 22), while fewer studies involved children, teenagers, or older adults.
Table 4. Summary of profile information in the reviewed CAPT literature
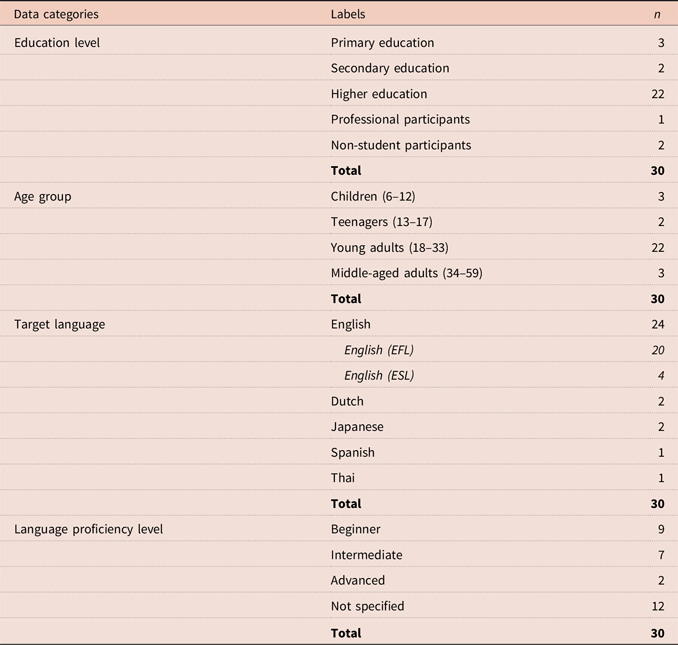
In terms of the target language in these CAPT studies, English was by far the most frequent (n = 24). Meanwhile, the few remaining studies targeted other languages like Dutch (n = 2), Japanese (n = 2), Spanish (n = 1), and Thai (n = 1). As for the language proficiency of the participants, many studies did not specify the level of the participants (n = 12). Of the remaining 18 studies, nine were conducted with beginners and seven with intermediate learners, while only two studies were conducted with advanced learners.
Figure 1 provides an overview of the target languages and participants’ language proficiency levels in the studies reviewed. As noted, the majority of studies were conducted with learners of English and with intermediate-level learners (n = 7). The studies conducted with other languages were either with beginners or did not specify the level.

Figure 1. Target language vs. language proficiency level in CAPT research.
Table 5 details the experimental designs employed in the 30 studies. Since most employed a quasi-experimental approach, the research design criteria were categorized based on the group design, measurement of effects, and sampling approach. Most CAPT studies employed a pre-test/post-test control group design with random recruitment of participants (n = 8). Overall, the control group design was the most common design in CAPT studies (n = 20), while fewer studies employed a comparison group design (n = 4) or a single group design (n = 6). As for measuring effects, most of the studies made use of a pre-test/post-test design, while fewer studies used a post-test only or a time series design. As for sampling, more studies reported using random sampling approaches (n = 10) than those reporting non-randomized sampling (n = 6). Many studies, however, did not specify their sampling approach (n = 14). Table 6 provides descriptive statistics about the sample sizes and treatment durations in the studies reviewed.
Table 5. Experimental designs in CAPT research

Table 6. Overview of sample sizes and treatment durations in CAPT research

The sample sizes in the studies reviewed ranged from a minimum of five participants to a maximum of 132 participants, and the overall average sample size was 47.47. As for the duration of interventions, training ranged from a minimum of one week to a maximum of 32 weeks, while the average study lasted seven weeks.
3.2 CAPT systems
Table 7 summarizes key details about the CAPT systems used in the studies reviewed. The systems were categorized according to their access type (i.e. commercial, free open-source, software prototype) and their use of ASR technology.
Table 7. Type and technology basis of systems in CAPT research

The studies reviewed used commercial CAPT applications (n = 16) as well as software prototypes that are designed for specific L2 populations (n = 14) almost equally. As for the use of ASR technology, just over half of the studies reviewed employed ASR-based CAPT systems (n = 16), while 14 studies employed non-ASR-based CAPT systems.
3.3 Pronunciation training
Table 8 details the pronunciation training scopes and approaches adopted in the studies reviewed.
Table 8. Pronunciation training scopes and approaches in CAPT research

Overall, Table 8 shows that most of the studies reviewed focused on the practice of segmental features (n = 14) rather than suprasegmental features (n = 6), with a specific focus on pronunciation production (n = 15) rather than perception (n = 6). Natural speech was the most frequently used input modeling tool (n = 23), while very few studies made use of HVPT, manipulated speech, synthetic speech, or orthography. As for the type of speech practiced, all of the studies reviewed employed a controlled speech practice (n = 30), mostly through listen-and-repeat activities. Furthermore, most of the studies used explicit feedback (n = 11), where the system specifically highlighted pronunciation errors. Conversely, fewer studies employed implicit feedback (n = 6), by using speech visualization spectrograms without error detection. Interestingly, many studies used a combination of implicit and explicit feedback types (n = 11), while very few studies did not provide any type of feedback (n = 2).
Figure 2 visualizes the scopes of training in the studies reviewed. Pronunciation training in most of the studies targeted the production (n = 6) and perception (n = 6) of segmental features. Conversely, suprasegmental features were explored in production more than in perception. When targeting both phonetic levels, CAPT studies particularly focused on production (n = 7).

Figure 2. Scopes of pronunciation training in CAPT research.
3.4 Pronunciation assessment
Table 9 summarizes key information about the pronunciation assessment scopes, tasks, rating methods, and learning measures in the studies reviewed. As with training, pronunciation assessment mainly focused on production (n = 21) rather than perception (n = 4). Another similarity with the training trends was evident in the choice of production tasks, where most studies opted for controlled speech tasks (n = 19). Other studies used a combination of controlled and spontaneous speech elicitation activities (n = 5) and only a few studies relied solely on spontaneous speech elicitation (n = 2). Perception activities, on the other hand, mostly used identification tasks (n = 5) or a combination of identification and discrimination tasks (n = 4).
Table 9. Pronunciation assessment in CAPT research

Table 10 shows the scope of pronunciation assessment in relation to the rating methods and learning measures in the studies reviewed.
Table 10. Assessment scopes vs. ratings methods vs. learning measures

Overall, most of the studies reviewed employed discrete pronunciation learning measures (n = 21) rather than global pronunciation learning measures (n = 4). In other words, researchers were mainly interested in evaluating learners’ segmental or suprasegmental accuracy, rather than broader measures such as accent, intelligibility, or comprehensibility. In both cases, human listeners’ ratings were prioritized over acoustic measures in evaluating both discrete and global measures. In Figure 3, the proportion of specific discrete and global pronunciation learning measures in the data set is represented by cell size.

Figure 3. Discrete and global measures of pronunciation production improvement.
Figure 3 shows that the discrete measures employed in the studies were more directed at assessing L2 learners’ segmental quality (n = 12) than suprasegmental quality (n = 7). When it comes to global measures, only a small number of studies measured comprehensibility, accentedness, communicative competence, and intelligibility. Notably, two studies evaluated pronunciation globally without specifying the criteria used for assessment.
4. Discussion
4.1 Methodological trends in CAPT research
Overall, the studies reviewed showed that CAPT research is mostly conducted with adult learners of English at a higher education level. Such results are in line with Mahdi and Al Khateeb’s (Reference Mahdi and Al Khateeb2019) review showing the predominance of English as the target language in empirical CAPT studies. The emphasis on the English language is unsurprising, considering its growing popularity and significant role as a lingua franca. However, this does not justify the significant lack of CAPT research for the learning of other languages. Currently, little is known about how the capabilities of ASR in pronunciation training can be harnessed for languages other than English. Such a knowledge gap can lead to a limited applicability of CAPT research findings and missed opportunities to optimize CAPT systems that could be effective with other languages.
With the exception of a few studies (e.g. Elimat & AbuSeileek, Reference Elimat and AbuSeileek2014; Gao & Hanna, Reference Gao and Hanna2016; Neri, Mich, Gerosa & Giuliani, Reference Neri, Mich, Gerosa and Giuliani2008), the review showed that little work is done with children or teenage L2 learners. This is probably because many of the studies used CAPT applications that employ advanced ASR and speech visualization systems that are designed for adult learners (Gelin et al., Reference Gelin, Pellegrini, Pinquier and Daniel2021). To tackle this issue, future systems should integrate simplified user interfaces and be trained to recognize young L2 learners’ speech. Alternatively, studies with young participants can engage learners in collaborative CAPT, where they can receive technical assistance from teachers or peers (e.g. Amrate, Reference Amrate2022; Elimat & AbuSeileek, Reference Elimat and AbuSeileek2014; Tsai, Reference Tsai2015). This would shed more light on the potential of CAPT with wider L2 populations.
Most of the studies reviewed employed the quasi-experimental control group design, while only a few studies used a comparison group design or a single group design. This demonstrates that the authors of these studies were keen to highlight the extent to which CAPT systems are responsible for pronunciation learning gains. Despite this, the generalizability of the results may be compromised due to the sampling approaches used in many studies. While the studies used various sample sizes and treatment durations (see Table 6), many did not specify the sampling approach or employed non-random sampling (see Table 5). The generalizability of the results obtained in future CAPT studies is, therefore, highly dependent on specific and detailed explanations of the sampling and group assignment approaches.
4.2 The nature of training systems in CAPT research
The studies reviewed used both commercial and prototype CAPT systems (see Table 7). Commercial systems were likely used due to their accessibility and availability on most devices (Bajorek, Reference Bajorek2017). Sometimes, however, commercial systems fail to deliver effective training, as they have traditionally focused on presenting technological innovations rather than following established pedagogical guidelines (Neri, Cucchiarini & Strik, Reference Neri, Cucchiarini and Strik2002). Moreover, commercial systems are designed with a broad audience in mind and thus fail to meet the specific pronunciation needs of different L2 groups. Alternatively, prototypes (e.g. Neri, Mich, et al., Reference Neri, Mich, Gerosa and Giuliani2008; Thomson, Reference Thomson2011) are often more pedagogically appropriate because they are designed with specific L2 groups in mind. If future commercial systems are audience-specific and adhere to sound pedagogical principles, they would have the potential to be more effective.
The studies reviewed also involved both ASR and non-ASR systems almost equally. This means that many studies utilized CAPT systems that were developed specifically for pronunciation training but lacked ASR features like instant speech-to-text representation, error detection, or immediate personalized feedback on learners’ output. Instead, they employed systems that simply recorded learners’ speech and provided informative spectrographic visualization. Other non-ASR-based CAPT systems were also focused on providing perceptual training through phonetic identification and discrimination activities. Despite the prevalent challenge of accurately recognizing accented L2 pronunciation (e.g. Henrichsen, Reference Henrichsen2021; Martin & Wright, Reference Martin and Wright2023), the integration of well-trained ASR-based CAPT systems is still important in future studies, as they can deliver personalized error detection and feedback.
4.3 Pronunciation training in CAPT research
The review shows that CAPT studies are mostly focused on the production of segmental features, while suprasegmentals and perception are considerably understudied. This is similar to the patterns observed in conventional pronunciation instruction (Thomson & Derwing, Reference Thomson and Derwing2015). A possible explanation for the overemphasis on segmental features could be the primary influence of these features on pronunciation intelligibility. Another factor might be that segmental features can be more easily assessed with ASR technology than suprasegmental features (Isaacs, Reference Isaacs and Kunnan2013). However, this does not detract from the need for more CAPT research focusing on suprasegmental features, since these are highly correlated with pronunciation comprehensibility (Saito et al., Reference Saito, Trofimovich and Isaacs2016). Such features could also be targeted through perceptual training, which has been consistently shown to have a positive correlation with production (e.g. Nagle, Reference Nagle2021; O’Brien et al., Reference O’Brien, Derwing, Cucchiarini, Hardison, Mixdorff, Thomson, Strik, Levis, Munro, Foote and Levis2018).
This review also showed an overwhelming use of controlled practice through listen-and-repeat or read-aloud activities. This is likely a side effect of the focus on segmental features in CAPT research, which can require the drilling of specific sounds in an attempt to match the models (e.g. Immonen et al., Reference Immonen, Alku and Peltola2022). This drilling approach, however, does not guarantee the transfer of the learning gains to the untrained contexts or features (e.g. Qian, Chukharev-Hudilainen & Levis, Reference Qian, Chukharev-Hudilainen and Levis2018). The generalizability of the learning gains can also be negatively affected by the lack of input variability, as most studies relied on natural speech recordings of L1 speakers. This stems from a belief that considers natural L1 speech models as sufficient input (Thomson & Derwing, Reference Thomson and Derwing2015). However, to emphasize the diverse uses of pronunciation features, it is essential to have a range of raw and manipulated input forms, including different kinds of voice, gender, accent, and context (e.g. Qian et al., Reference Qian, Chukharev-Hudilainen and Levis2018; Thomson, Reference Thomson2011).
As for feedback, most of the studies integrated systems that provide explicit feedback, including error detection and visualization. However, while important advances have been made in automated feedback, CAPT systems still struggle to accurately evaluate L2 speech (Henrichsen, Reference Henrichsen2021). This can lead to erroneous feedback on pronunciation that is perfectly comprehensible, negatively impacting the learning process. CAPT feedback is also criticized for being difficult to interpret, as it often highlights errors without further clarification. To address this, developers can train future systems on a variety of L2 corpora to minimize L2 speech recognition failures. Alternatively, practitioners can engage learners in collaborative or supervised CAPT, where peers can compensate for erroneous feedback (e.g. Amrate, Reference Amrate2022; Elimat & AbuSeileek, Reference Elimat and AbuSeileek2014; Tsai, Reference Tsai2015).
4.4 Pronunciation assessment in CAPT research
The review found that most CAPT studies were interested in employing discrete learning measures to assess pronunciation production accuracy, mostly relying on controlled speech elicitation tasks. This aligns with trends observed in conventional pronunciation instruction research (e.g. Saito & Plonsky, Reference Saito and Plonsky2019; Thomson & Derwing, Reference Thomson and Derwing2015). These results indicate that the studies were attentive to evaluating the outcomes of their training, which concentrated on specific segmental and suprasegmental features. However, with few studies employing global measures, it is difficult to determine the extent to which phonetic accuracy gains in CAPT translate into a comprehensible or intelligible pronunciation. Furthermore, as argued by Saito and Plonsky (Reference Saito and Plonsky2019), the predominance of controlled speech elicitation tasks in assessment can give an unclear image about the transferability of the learning gains to untrained contexts. Therefore, future research can shed light on the effectiveness of CAPT in improving L2 learners’ pronunciation by employing both discrete- and global-level measures using elicitation tasks that can function as a better predictor for the transferability of the learning gains.
Pronunciation ratings in the studies reviewed mostly relied on human rating rather than acoustic measurements in assessing both discrete and global features. As noted by Saito and Plonsky (Reference Saito and Plonsky2019) and Thomson and Derwing (Reference Thomson and Derwing2015), pronunciation researchers likely lean towards human evaluations because of their interest in identifying pronunciation enhancements that are perceptible to listeners, as opposed to subtle acoustic refinements that might only be detectable through acoustic analysis. Moreover, acoustic measurements can require resources and expertise in acoustic analysis to guarantee accurate pronunciation evaluation. Nevertheless, future CAPT studies can shed more light on the correlation between learning improvements detected by acoustic measures and human rating by employing a combination of both rating methods.
5. Conclusion
The aim of the study was to conduct a pedagogically informed systematic review that maps the pronunciation training and assessment practices in empirical studies investigating the effectiveness of CAPT. Overall, the studies reviewed showed that research in this area is mostly conducted with adult intermediate learners of English. On a methodological level, the studies mostly took the form of randomized controlled trials with a pre-test/post-test design. These studies employed both ASR and non-ASR commercial as well as software prototypes equally. The scope of training was mostly focused on the controlled production of segmental features. As for the training approach, the studies were entirely reliant on the controlled practice with natural speech models and a combination of implicit and explicit feedback. Meanwhile, assessment mostly targeted the production of discrete features through the use of controlled speech elicitation. As for the learning measures, the studies mostly employed human listeners to assess discrete phonetic accuracy, with few studies addressing global pronunciation quality.
The findings underscore the need for methodologically diverse and pedagogically informed CAPT research to harness the full potential of this technology. On a methodological level, CAPT research should target wider L2 populations of different proficiency levels and ages using designs that generate generalizable results. This can be made easier if future CAPT systems are trained with larger and more diverse corpora to be optimized for such populations. As for training, future research must also target pronunciation features that directly enhance learners’ comprehensibility and intelligibility instead of accent. To do this, equal attention should be given to the perception and production of segmental as well as suprasegmental features through innovative training approaches beyond drilling. When assessing learning, future studies should employ discrete as well as global pronunciation measures equally with speech elicitation tasks that simulate real-life use of pronunciation and better predict the transferability of the learning gains.
Several limitations should be considered when interpreting the findings of this study. Although the review focused solely on empirical studies of CAPT systems, the field encompasses diverse research areas, from software testing to teacher and learner perceptions. Therefore, the findings may not fully represent the entire CAPT literature. Furthermore, although coder disagreements in data extraction were resolved through discussion, readers need to recognize that minor individual variations in coding are inevitable, potentially impacting the interpretation of findings. The variability in systems and training, combined with the absence of key methodological details in some of the studies reviewed, further hindered the possibility of conducting advanced statistical analyses. Despite these constraints, the review provides a critical roadmap, pinpointing gaps and setting the stage for future research to enhance CAPT efficacy and applicability, ultimately advancing L2 pronunciation teaching and learning.
Supplementary material
To view supplementary material referred to in this article, please visit https://doi.org/10.1017/S0958344024000181
Acknowledgements
We extend our sincere gratitude to the anonymous reviewers who provided valuable feedback contributing to the enhancement of the manuscript.
Ethical statement and competing interests
This study did not involve human participants. All the reviewed papers are publicly available online. The authors ensured adherence to ethical research practices in their respective countries. The authors declare no competing interests. The authors also declare no use of generative AI.
About the authors
Moustafa Amrate is a lecturer in applied linguistics and TEFL at the Department of English, University of Biskra. He holds an MA in applied linguistics from the University of Biskra and a PhD in education from the University of York, United Kingdom. His research interests revolve around second language speech and computer-assisted pronunciation training.
Pi-hua Tsai, MA in linguistics and PhD in TESOL, brings over 34 years of English teaching experience. Her interdisciplinary research spans computer-assisted pronunciation training, discourse analysis, and medical humanities. Published in esteemed journals like Computer Assisted Language Learning, her work reflects her passion for educational technology and linguistic inquiry.
















 Open access
Open access