



No CrossRef data available.
Published online by Cambridge University Press: 28 November 2023
Very metal-poor (VMP, [Fe/H]<-2.0) stars serve as invaluable repositories of insights into the nature and evolution of the first-generation stars formed in the early galaxy. The upcoming China Space Station Telescope (CSST) will provide us with a large amount of spectral data that may contain plenty of VMP stars, and thus it is crucial to determine the stellar atmospheric parameters (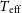 $T_{\textrm{eff}}$,
$T_{\textrm{eff}}$, 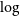 $\log$ g, and [Fe/H]) for low-resolution spectra similar to the CSST spectra (
$\log$ g, and [Fe/H]) for low-resolution spectra similar to the CSST spectra ( $R\sim 200$). This study introduces a novel two-dimensional Convolutional Neural Network (CNN) model, comprised of three convolutional layers and two fully connected layers. The model’s proficiency is assessed in estimating stellar parameters, particularly metallicity, from low-resolution spectra (
$R\sim 200$). This study introduces a novel two-dimensional Convolutional Neural Network (CNN) model, comprised of three convolutional layers and two fully connected layers. The model’s proficiency is assessed in estimating stellar parameters, particularly metallicity, from low-resolution spectra (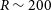 $R \sim 200$), with a specific focus on enhancing the search for VMP stars within the CSST spectral data. We mainly use 10 008 spectra of VMP stars from LAMOST DR3, and 16 638 spectra of non-VMP stars ([Fe/H]>-2.0) from LAMOST DR8 for the experiments and apply random forest and support vector machine methods to make comparisons. The resolution of all spectra is reduced to
$R \sim 200$), with a specific focus on enhancing the search for VMP stars within the CSST spectral data. We mainly use 10 008 spectra of VMP stars from LAMOST DR3, and 16 638 spectra of non-VMP stars ([Fe/H]>-2.0) from LAMOST DR8 for the experiments and apply random forest and support vector machine methods to make comparisons. The resolution of all spectra is reduced to 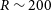 $R\sim200$ to match the resolution of the CSST, followed by pre-processing and transformation into two-dimensional spectra for input into the CNN model. The validation and practicality of this model are also tested on the MARCS synthetic spectra. The results show that using the CNN model constructed in this paper, we obtain Mean Absolute Error (MAE) values of 99.40 K for
$R\sim200$ to match the resolution of the CSST, followed by pre-processing and transformation into two-dimensional spectra for input into the CNN model. The validation and practicality of this model are also tested on the MARCS synthetic spectra. The results show that using the CNN model constructed in this paper, we obtain Mean Absolute Error (MAE) values of 99.40 K for 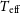 $T_{\textrm{eff}}$, 0.22 dex for
$T_{\textrm{eff}}$, 0.22 dex for 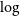 $\log$ g, 0.14 dex for [Fe/H], and 0.26 dex for [C/Fe] on the test set. Besides, the CNN model can efficiently identify VMP stars with a precision rate of 94.77%, a recall rate of 93.73%, and an accuracy of 95.70%. This paper powerfully demonstrates the effectiveness of the proposed CNN model in estimating stellar parameters for low-resolution spectra (
$\log$ g, 0.14 dex for [Fe/H], and 0.26 dex for [C/Fe] on the test set. Besides, the CNN model can efficiently identify VMP stars with a precision rate of 94.77%, a recall rate of 93.73%, and an accuracy of 95.70%. This paper powerfully demonstrates the effectiveness of the proposed CNN model in estimating stellar parameters for low-resolution spectra (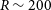 $R\sim200$) and recognizing VMP stars that are of interest for stellar population and galactic evolution work.
$R\sim200$) and recognizing VMP stars that are of interest for stellar population and galactic evolution work.
 $left[alpha/ext{Fe} ight]$
from gaia low-resolution bp/rp spectra using the extratrees algorithmCrossRefGoogle Scholar
$left[alpha/ext{Fe} ight]$
from gaia low-resolution bp/rp spectra using the extratrees algorithmCrossRefGoogle Scholar