



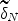


Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Lin, Miao-Hsiang
Hsiung, Chao A.
and
Hsiao, Chin-Fu
1994.
A Program for Monotonizing Two Empirical Bayes Estimators in Binomial and Hypergeometric Data Distributions.
Psychometrika,
Vol. 59,
Issue. 3,
p.
423.
Bock, R. Darrell
Thissen, David
and
Zimowski, Michele F.
1997.
IRT Estimation of Domain Scores.
Journal of Educational Measurement,
Vol. 34,
Issue. 3,
p.
197.
Pommerich, Mary
2006.
Validation of Group Domain Score Estimates Using a Test of Domain.
Journal of Educational Measurement,
Vol. 43,
Issue. 2,
p.
97.
Fox, Jean‐Paul
2008.
Beta‐binomial ANOVA for multivariate randomized response data.
British Journal of Mathematical and Statistical Psychology,
Vol. 61,
Issue. 2,
p.
453.
Wang, Yuan-Quan
Zhang, Ying-Ying
and
Liu, Jia-Lei
2023.
Expectation identity of the hypergeometric distribution and its application in the calculations of high-order origin moments.
Communications in Statistics - Theory and Methods,
Vol. 52,
Issue. 17,
p.
6018.