This journal utilises an Online Peer Review Service (OPRS) for submissions. By clicking "Continue" you will be taken to our partner site https://mc.manuscriptcentral.com/probengsci. Please be aware that your Cambridge account is not valid for this OPRS and registration is required. We strongly advise you to read all "Author instructions" in the "Journal information" area prior to submitting.
This paper defines and studies the down entrance state (DES) and the restart entrance state (RES) classes of quasi-skip free (QSF) processes specified in terms of the nonzero structure of the elements of their transition rate matrix Q. A QSF process is a Markov chain with states that can be specified by tuples of the form (m, i), where 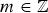 $m \in {\open Z}$ represents the “current” level of the state and
$m \in {\open Z}$ represents the “current” level of the state and 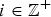 $i \in {\open Z}^{+}$ the current phase of the state, and its transition probability matrix Q does not permit one-step transitions to states that are two or more levels away from the current state in one direction of the level variable m. A QSF process is a DES process if and only if one step “down” transitions from a level m can only reach a single state in level m − 1, for all m. A QSF process is a RES process if and only if one step “up” transitions from a level m can only reach a single set of states in the highest level M2, largest of all m.
$i \in {\open Z}^{+}$ the current phase of the state, and its transition probability matrix Q does not permit one-step transitions to states that are two or more levels away from the current state in one direction of the level variable m. A QSF process is a DES process if and only if one step “down” transitions from a level m can only reach a single state in level m − 1, for all m. A QSF process is a RES process if and only if one step “up” transitions from a level m can only reach a single set of states in the highest level M2, largest of all m.
We derive explicit solutions and simple truncation bounds for the steady-state probabilities of both DES and RES processes, when in addition Q insures ergodicity. DES and RES processes have applications in many areas of applied probability comprising computer science, queueing theory, inventory theory, reliability, and the theory of branching processes. To motivate their applicability we present explicit solutions for the well-known open problem of the M/Er/n queue with batch arrivals, an inventory model, and a reliability model.
