


1 Introduction
Researchers conducting experiments about racial discrimination typically manipulate the apparent race or ethnicity of persons whom a decision-maker is asked to serve or choose among. How the researcher signals race/ethnicity varies considerably from study to study. Sometimes the treatments consist of real people, or photographs of people (Terkildsen Reference Terkildsen1993; Yinger Reference Yinger1995; Ondrich, Ross, and Yinger Reference Ondrich, Ross and Yinger2003; Pager Reference Pager2007; Iyengar et al. Reference Iyengar, Messing, Bailenson and Hahn2010; Weaver Reference Weaver2012; Doleac and Stein Reference Doleac and Stein2013; Stephens Reference Stephens2013; Moehler and Conroy-Krutz Reference Moehler and Conroy-Krutz2016; Visalvanich Reference Visalvanich2016); sometimes the researcher employs racially or ethnically identifiable names (e.g., Bertrand and Mullainathan Reference Bertrand and Mullainathan2004; McConnaughy et al. Reference McConnaughy, White, Leal and Casellas2010; Butler and Broockman Reference Butler and Broockman2011; DeSante Reference DeSante2013; Agan and Starr Reference Agan and Starr2016); and sometimes researchers use explicit labels, such as the words “African-American” and “White” (e.g., Hainmueller, Hopkins, and Yamamoto Reference Hainmueller, Hopkins and Yamamoto2014; Hainmueller and Hopkins Reference Hainmueller and Hopkins2015; Sen Reference Sen2015; see also Sigelman et al. Reference Sigelman, Sigelman, Walkosz and Nitz1995; Philpot and Walton Reference Philpot and Walton2007).
The tacit assumption underlying much of this work is that the form of the race/ethnicity treatment is not important. Names, photographs, and labels are largely interchangeable (but see Sen and Wasow Reference Sen and Wasow2016). The strong grip of this assumption is reflected in the lack of research on treatment-mode differences. To the best of our knowledge, not a single choice-object experiment in any social scientific discipline has investigated whether these treatment modes make a difference.Footnote 1 There are reasons to expect the effects to diverge. Racial and ethnic labels seem likely to elicit cognitive reactions (“Do I, or should I, value the labeled characteristic positively or negatively, and to what extent?”), whereas pictures may elicit more automatic or emotional reactions (“I feel more comfortable with her”; or, “That guy looks untrustworthy.”). A substantial body of work in psychology and neuroscience suggests that whites who are committed in principle to antidiscrimination norms may nonetheless have aversive, gut-level reactions to racial and ethnic minorities (e.g., Blair and Banaji Reference Blair and Banaji1996; Kubota, Banaji, and Phelps Reference Kubota, Banaji and Phelps2012; Perez Reference Perez2015). The same intuition undergirds political science research on racial campaign appeals, which posits and has often found that relatively subtle, “implicit” appeals to racial sentiments are more effective than “explicit” appeals (e.g., Mendelberg Reference Mendelberg2001; Huber and Lapinski Reference Huber and Lapinski2006; Hutchings and Jardina Reference Hutchings and Jardina2009; McIlwain and Caliendo Reference McIlwain and Caliendo2011).Footnote 2 One might therefore surmise that the treatment effect of race/ethnicity conveyed by images will be larger than the corresponding effect of written labels.
This conjecture—if borne out—would have important implications for the burgeoning body of research using conjoint experimental designs (e.g., Bechtel, Hainmueller, and Margalit Reference Bechtel, Hainmueller and Margalit2015; Carlson Reference Carlson2015; Crowder-Meyer et al. Reference Crowder-Meyer, Gadarian, Trounstine and Vue2015; Franchino and Zucchini Reference Franchino and Zucchini2015; Hainmueller, Hangartner, and Yamamoto Reference Hainmueller, Hangartner and Yamamoto2015; Hainmueller and Hopkins Reference Hainmueller and Hopkins2015; Sen Reference Sen2015; Bansak, Hainmueller, and Hangartner Reference Bansak, Hainmueller and Hangartner2016; Bechtel, Genovese, and Scheve Reference Bechtel, Genovese and Scheve2016; Brown et al. Reference Brown, Carey, Horiuchi and Martin2016; Carnes Reference Carnes2016; Gallego and Marx Reference Gallego and Marx2016; Horiuchi, Smith, and Yamamoto Reference Horiuchi, Smith and Yamamoto2016; Ono and Yamada Reference Ono and Yamada2016; Wright, Levy, and Citrin Reference Wright, Levy and Citrin2016)—nearly all of which represent choice objects (typically persons) with a table of written attributes.Footnote 3
We implement a vote-choice experiment informed by the standard conjoint design. Our respondents, a nationally representative sample of white voting-age citizens, evaluate six pairs of hypothetical candidates. One candidate in each pair is depicted as Latino and the other as white. The candidates in our experiment are designed to be roughly equally appealing in other respects. Candidate attributes apart from ethnicity are presented in the tabular form used in conjoint studies. We randomize which candidate in each pair is Latino, and, at the level of the respondent, whether candidate race/ethnicity is conveyed using names and a Race/Ethnicity row in the table of the candidate attributes, or names and photographs.
We hypothesized that the candidates depicted as Latino would receive less voter support when race/ethnicity was communicated using photographs as opposed to written labels, and we expected the differential treatment to be most pronounced among respondents who, by standard social-psychology metrics, are “internally motivated to control stereotyping” (Plant and Devine Reference Plant and Devine1998).Footnote 4 Such people try to avoid treating minorities badly because they think it is wrong. By contrast, people who are “externally motivated to control stereotyping” check themselves because they do not want others to think poorly of them.
Contrary to our main hypothesis, our findings reveal that white respondents who are internally motivated to control stereotyping gave almost exactly the same vote share to Latino candidates in the “labels” and “pictures” branches of our study. Yet respondents who are not so motivated chose the white candidate by landslide margins in the labels condition, while giving only slightly more support to white candidates than Latino candidates in the pictures condition. Overall, Latino candidates fared significantly worse when their ethnic identity was conveyed via labels rather than pictures. These findings confirm that treatment-mode differences do exist where the focal attribute is race/ethnicity, and reinforce the need for additional research on the subject matter.
The hypotheses and principal data analysis presented in this paper follow a preanalysis plan registered with Evidence in Governance and Politics prior to fielding the experiment.Footnote 5 See Abrajano, Elmendorf, and Quinn (Reference Abrajano, Christopher and Kevin2017) for replication data.
2 Study Design
Our study builds on Hainmueller, Hopkins, and Yamamoto (Reference Hainmueller, Hopkins and Yamamoto2014)’s conjoint design for stated-preference experiments. Respondents are presented with six candidate matchups. Each candidate is defined by five discrete-valued attributes: Race/Ethnicity, Education, Military Service, Political Party, and Other Information. The choice task is, “If you were voting in this election, which candidate do you think you would prefer?”
Respondents are randomly assigned to the “labels” or “pictures” branch of the study. In the labels condition, Race/Ethnicity is very explicitly signaled. It is presented as a row in the table of candidate attributes, with labels “Latino/Hispanic” and “White.” In the pictures branch, the Race/Ethnicity row is omitted, and a photograph of the candidate is included at the top of his column in the table. In both branches, the candidates are referred to by name, and the names are ethnically identifiable.
We include ethnically identifiable names in both branches of the study for realism and to minimize the risk of differential treatment effects due to variation in the clarity of the signal of ethnicity. Although the photographs we employ are meant to be ethnically unambiguous (more on this below), we thought some respondents might fail to perceive ethnicity from photographs alone. We use the same ethnically identifiable names in both branches of the study, so that any differential effect of the pictures treatment relative to labels can be interpreted as the marginal effect of pictures, rather than the compound effect of pictures-plus-names relative to labels-without-names. Pretests with Amazon Mechanical Turk (“MTurk”) workers yielded similar, very high rates of “correct” classification of ethnicity for both the white-photo-plus-name and the Latino-photo-plus-name profiles in our study.Footnote 6
The screen shots in Figures 1 and 2 show how we presented candidates to respondents in, respectively, the labels and pictures conditions.

Figure 1. Presentation of candidate profiles to respondents: “labels” condition.

Figure 2. Presentation of candidate profiles to respondents: “pictures” condition.
In pretests with inexpensive MTurk samples, we followed Hainmueller, Hopkins, and Yamamoto (Reference Hainmueller, Hopkins and Yamamoto2014) and randomized all candidate attributes. The fully randomized design is, however, a low-power design for detecting differences between pictures and labels Race/Ethnicity treatments. It is often the case that one candidate in a pair ends up being much more desirable than the other candidate on non-ethnic grounds. These differences dampen the average treatment effect of race/ethnicity and introduce additional estimation uncertainty.
Before fielding our study on a nationally representative sample of voting-age citizens, we modified the standard conjoint design to obtain more power. Using data from MTurk pretests, we preselected six pairs of candidate profiles, fixing all attribute levels other than Race/Ethnicity for each profile. The profiles were chosen so that each candidate in a pair would be roughly equally attractive in terms of his valence traits. To ensure that party effects would not swamp race effects, we also made all matchups intraparty—Democrat vs. Democrat or Republican vs. Republican.Footnote 7 This modified design retains what is for our purpose the most important feature of the conjoint setup: the candidates in a pair differ from one another in several respects other than Race/Ethnicity, such that the respondent’s choice of (say) the white candidate over the Latino candidate does not necessarily mean that the respondent preferred the chosen candidate on the basis of ethnicity. This should tend to limit social desirability effects.Footnote 8
For each respondent, we randomized (1) the order of presentation of the six candidate pairs, (2) which candidate in each pair is shown in the left column of the table of candidate profiles, (3) which candidate in each pair is Latino (the other candidate is always white), and (4) conditional on candidate ethnicity, the assignment of names to candidates. In the pictures branch of the survey, we also randomized the assignment of photographs to candidates, again conditional on candidate ethnicity. Finally, in the labels branch of the survey, we randomized at the level of the respondent the position of the Race/Ethnicity row in the table of candidate attributes.
After voting on the six candidate matchups, respondents answered a few demographic questions, and a battery of ten questions developed by social psychologists to measure internal and external motivations to control stereotyping of racial and ethnic minorities (Plant and Devine Reference Plant and Devine1998).Footnote 9 We considered several more general measures of social sensitivity, but because there appears to be no consensus in the political science or psychology literature about the best such measure, we opted for a measure that targets racial/ethnic stereotyping. The distributions of the motivation-to-control-stereotyping variables, summarized in the Supplementary Information available at https://doi.org/10.1017/pan.2017.36, are similar across the photos-and-labels treatment arms, alleviating possible concerns about posttreatment bias.Footnote 10
2.1 Choice of photos and names
We designed a photo-selection protocol to obtain several typical yet clearly ethnically identifiable photos of serious candidates, while minimizing researcher discretion. Choosing photos presents a dilemma. On the one hand, there is a risk that the white and Latino photos will differ from one another in some vote-relevant dimension apart from ethnicity, such as perceived attractiveness or seriousness. On the other hand, if the minority is negatively stereotyped, precoding photographs for similarity on such dimensions may result in a minority treatment condition that includes only visually extraordinary candidates.
The best solution would be to use photographs drawn from the pool of “potential candidates,” defined as people who might run for office in a world without race discrimination, but that population is unobservable. We use an imperfect but observable proxy: currently serving state legislators.
We hired MTurk workers to precode male state legislator photographs for age, race/ethnicity, and quality as a campaign photo.Footnote 11 We asked for campaign-photo-quality ratings as a way to minimize the risk of imbalance with respect to non-racial signals about professionalism, seriousness, or competence communicated by the photographs.Footnote 12 Each image was rated by an average of 37 MTurk workers. On the basis of the codings we excluded very young and very old legislators, as well as legislators who were not clearly identified as Latino or white. We then used the GenMatch package in R to find white matches for the remaining Latinos, matching on perceived age and photo quality and winnowing the pool down to eight well-matched whites and Latinos (16 photos in all).
To select the names, we matched the surnames of current state legislators to the 1,000 most common surnames in the United States, excluded non-matches, and selected from the remaining surnames the eight most ethnically unique Anglo and Latino names.Footnote 13 We then created two pools of presumptively ethnic first names, selecting for each pool the first names of all state legislators whose surnames matched one of the eight we had chosen for the ethnic group in question.Footnote 14 We randomly assigned first names to surnames (within ethnic groups), subject to the constraint that no first-name/surname pair match an actual legislator’s name. This protocol was designed to ensure that the names were ethnically identifiable without also being highly improbable for a serious candidate for elective office.
We then administered a conjoint survey to MTurk workers, using photographs to represent the candidates, and after the final matchup, we asked respondents which candidate in that matchup had the higher quality campaign photo. This choice task departs from our photo prescreening surveys in a couple of respects: respondents make relative rather than absolute judgments of photo quality, and each picture comes with a candidate profile including an ethnically identifiable name. We discovered that Latino candidates’ photos were picked as higher quality somewhat less often than white candidates’ photos. Though this might be a race-discrimination effect, it could also reflect a problem with our prescreening survey.Footnote 15 To assuage concerns that any race-treatment effect documented in our study might really be a photo-quality treatment effect, we dropped two relatively unfavorable Latino photos and two relatively favorable white photos. This restores balance in average photo quality across racial groups, per the “matchup” measure of photo quality.
Two potential sources of bias should be acknowledged. First, because we used only clearly ethnically identifiable photos, the Latino candidates shown in the photos condition may be darker-skinned and more stereotypically Latino in appearance than the Latinos in the unobserved potential-candidate population. To the extent that discrimination varies with phenotypic prototypicality, our estimated “pictures” treatment effects may overstate the average level of discrimination against a more phenotypically representative sample. Cutting the other way, if Latinos seeking elective office do face discrimination, the Latinos elected to a state legislature may be visually extraordinary relative to the unobserved population of potential Latino candidates. If so, our estimated “pictures” treatment effect of Latino ethnicity is probably upwardly biased. However, these potential sources of bias are unlikely to affect our investigation of the difference in the pictures vs. labels treatment effects across respondents who are/are not internally motivated to control stereotyping. We have no a priori reason to think that voters in one of these groups would value extraordinary (versus ordinary) Latino potential candidates differently than voters in the other group.
2.2 The experimental population, and relevant subgroups
Our experimental population consists of a probability sample of 1,617 white voting-age citizens, provided by GfK. Constructed using address-based sampling of U.S. Postal Service files, GfK’s panel is generally regarded as among the highest quality for online surveys.Footnote 16 Our survey was fielded from August 16, 2016 to August 22, 2016. A random sample of 2,666 panel members was drawn from GfK’s KnowledgePanel®. A total of 1,617 (excluding breakoffs) members responded to the invitation and 1,617 qualified for the survey, yielding a final stage completion rate of 60.7% and a qualification rate of 100.0%.Footnote 17
Following Plant and Devine (Reference Plant and Devine1998), we create additive indices for internal and external motivation-to-control stereotyping, summing responses to the five Likert-type questions for each motivation. We use median splits to classify respondents as “high” or “low” for each motivation.
The results reported below are unweighted, as the estimands of interest are sample average treatment effects (Franco et al. Reference Franco, Malhotra, Simonovits and Zigerell2016).
3 Notation and Estimands
Let
 $i\in {\mathcal{I}}$
index survey respondents. Three subsets of respondents are of interest to us. First is the set of respondents who are internally motivated to control stereotyping of Latinos/Hispanics. We use
$i\in {\mathcal{I}}$
index survey respondents. Three subsets of respondents are of interest to us. First is the set of respondents who are internally motivated to control stereotyping of Latinos/Hispanics. We use
 ${\mathcal{I}}_{I}$
to denote this subset of respondents. Second we are interested in respondents who are not internally motivated to control stereotyping of Latinos/Hispanics. These are simply all respondents in
${\mathcal{I}}_{I}$
to denote this subset of respondents. Second we are interested in respondents who are not internally motivated to control stereotyping of Latinos/Hispanics. These are simply all respondents in
 ${\mathcal{I}}$
who are not in
${\mathcal{I}}$
who are not in
 ${\mathcal{I}}_{I}$
. We use
${\mathcal{I}}_{I}$
. We use
 ${\mathcal{I}}_{\setminus I}$
to denote this set of respondents. Third, we are interested in those respondents who are externally, but not internally, motivated to control stereotyping of Latinos/Hispanics.Footnote
18
We use
${\mathcal{I}}_{\setminus I}$
to denote this set of respondents. Third, we are interested in those respondents who are externally, but not internally, motivated to control stereotyping of Latinos/Hispanics.Footnote
18
We use
 ${\mathcal{I}}_{E\setminus I}$
to denote this subset of respondents.
${\mathcal{I}}_{E\setminus I}$
to denote this subset of respondents.
Let
 $p\in {\mathcal{P}}$
index pairs of candidate profiles. Each candidate profile is defined by these attributes (apart from race/ethnicity): military service, education, political party, and other information. As noted above, attribute levels for the profiles in each pair were selected to make the profiles roughly equally appealing to respondents. We make use of six pairs of candidates in this experiment, i.e.
$p\in {\mathcal{P}}$
index pairs of candidate profiles. Each candidate profile is defined by these attributes (apart from race/ethnicity): military service, education, political party, and other information. As noted above, attribute levels for the profiles in each pair were selected to make the profiles roughly equally appealing to respondents. We make use of six pairs of candidates in this experiment, i.e.
 $|{\mathcal{P}}|=6$
. We adopt the convention of referring to one of the candidates in a pair as “candidate
$|{\mathcal{P}}|=6$
. We adopt the convention of referring to one of the candidates in a pair as “candidate
 $A$
” and the other as “candidate
$A$
” and the other as “candidate
 $B$
.”
$B$
.”
We consider two manipulations, which are randomly assigned to respondents and candidate pairs. The first intervention is the depiction of candidate ethnicity via textual labels (“Latino/Hispanic” or “White”) and first and last names. We use
 $T$
to denote this first textual manipulation. Let
$T$
to denote this first textual manipulation. Let
 $T_{ip}$
denote the manipulation applied to respondent
$T_{ip}$
denote the manipulation applied to respondent
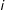 $i$
when viewing candidate pair
$i$
when viewing candidate pair
 $p$
.
$p$
.
 $T_{ip}$
can take two values: 0 and 1:
$T_{ip}$
can take two values: 0 and 1:
 $$\begin{eqnarray}T_{ip}=\left\{\begin{array}{@{}ll@{}}1\quad & \text{if }i\text{ receives textual information that candidate }A\text{ in }p\text{ is Latino/Hispanic and }\\ \quad & ~~~i\text{ receives textual information that candidate }B\text{ in }p\text{ is white}\\ 0\quad & \text{if }i\text{ receives textual information that candidate }A\text{ in }p\text{ is white and }\\ \quad & ~~~i\text{ receives textual information that candidate }B\text{ in }p\text{ is Latino/Hispanic.}\end{array}\right.\end{eqnarray}$$
$$\begin{eqnarray}T_{ip}=\left\{\begin{array}{@{}ll@{}}1\quad & \text{if }i\text{ receives textual information that candidate }A\text{ in }p\text{ is Latino/Hispanic and }\\ \quad & ~~~i\text{ receives textual information that candidate }B\text{ in }p\text{ is white}\\ 0\quad & \text{if }i\text{ receives textual information that candidate }A\text{ in }p\text{ is white and }\\ \quad & ~~~i\text{ receives textual information that candidate }B\text{ in }p\text{ is Latino/Hispanic.}\end{array}\right.\end{eqnarray}$$
The second intervention is the depiction of candidate ethnicity via photographs and first and last names. We use
 $V$
to denote this second visual manipulation and let
$V$
to denote this second visual manipulation and let
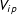 $V_{ip}$
denote the manipulation applied to respondent
$V_{ip}$
denote the manipulation applied to respondent
 $i$
when viewing candidate pair
$i$
when viewing candidate pair
 $p$
.
$p$
.
 $V_{ip}$
can take two values: 0 and 1:
$V_{ip}$
can take two values: 0 and 1:
 $$\begin{eqnarray}V_{ip}=\left\{\begin{array}{@{}ll@{}}1\quad & \text{if }i\text{ receives visual information that candidate }A\text{ in }p\text{ is Latino/Hispanic and }\\ \quad & ~~~i\text{ receives visual information that candidate }B\text{ in }p\text{ is white}\\ 0\quad & \text{if }i\text{ receives visual information that candidate }A\text{ in }p\text{ is white and }\\ \quad & ~~~i\text{ receives visual information that candidate }B\text{ in }p\text{ is Latino/Hispanic.}\end{array}\right.\end{eqnarray}$$
$$\begin{eqnarray}V_{ip}=\left\{\begin{array}{@{}ll@{}}1\quad & \text{if }i\text{ receives visual information that candidate }A\text{ in }p\text{ is Latino/Hispanic and }\\ \quad & ~~~i\text{ receives visual information that candidate }B\text{ in }p\text{ is white}\\ 0\quad & \text{if }i\text{ receives visual information that candidate }A\text{ in }p\text{ is white and }\\ \quad & ~~~i\text{ receives visual information that candidate }B\text{ in }p\text{ is Latino/Hispanic.}\end{array}\right.\end{eqnarray}$$
Our outcome variable is the revealed preference for either candidate
 $A$
or
$A$
or
 $B$
in each candidate pair by each respondent. Using potential outcomes notation, we let
$B$
in each candidate pair by each respondent. Using potential outcomes notation, we let
 $Y_{ip}(T_{ip}=t)$
denote the choice of respondent
$Y_{ip}(T_{ip}=t)$
denote the choice of respondent
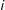 $i$
when viewing candidate pair
$i$
when viewing candidate pair
 $p$
and
$p$
and
 $T_{ip}$
is set equal to
$T_{ip}$
is set equal to
 $t$
by our intervention. We adopt the convention that
$t$
by our intervention. We adopt the convention that
 $Y_{ip}(T_{ip}=t)=1$
denotes a choice of candidate
$Y_{ip}(T_{ip}=t)=1$
denotes a choice of candidate
 $A$
and
$A$
and
 $Y_{ip}(T_{ip}=t)=0$
is a choice of candidate
$Y_{ip}(T_{ip}=t)=0$
is a choice of candidate
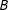 $B$
. We define
$B$
. We define
 $Y_{ip}(V_{ip}=v)$
analogously. We let
$Y_{ip}(V_{ip}=v)$
analogously. We let
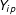 $Y_{ip}$
denote the observed choice behavior of respondent
$Y_{ip}$
denote the observed choice behavior of respondent
 $i$
when evaluating candidate pair
$i$
when evaluating candidate pair
 $p$
and let
$p$
and let
 $Y_{ip}=1$
denote a choice of
$Y_{ip}=1$
denote a choice of
 $A$
and
$A$
and
 $Y_{ip}=0$
a choice of
$Y_{ip}=0$
a choice of
 $B$
.
$B$
.
We are interested in the following sample average treatment effects.
 $$\begin{eqnarray}\unicode[STIX]{x1D70F}=\frac{1}{|{\mathcal{I}}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70F}=\frac{1}{|{\mathcal{I}}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
and
 $$\begin{eqnarray}\unicode[STIX]{x1D708}=\frac{1}{|{\mathcal{I}}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)].\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D708}=\frac{1}{|{\mathcal{I}}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)].\end{eqnarray}$$
The sample average treatment effect
 $\unicode[STIX]{x1D70F}$
is the effect of candidate ethnicity conveyed by textual labels on choice behavior. It can be interpreted as the expected change in the vote margin of a white candidate matched up against a copartisan Latino opponent (of similar quality) that would occur if the candidates’ ethnicities were transposed while holding constant the other candidate attributes, that is, if the white candidate were Latino and the Latino candidate were white. A negative value of
$\unicode[STIX]{x1D70F}$
is the effect of candidate ethnicity conveyed by textual labels on choice behavior. It can be interpreted as the expected change in the vote margin of a white candidate matched up against a copartisan Latino opponent (of similar quality) that would occur if the candidates’ ethnicities were transposed while holding constant the other candidate attributes, that is, if the white candidate were Latino and the Latino candidate were white. A negative value of
 $\unicode[STIX]{x1D70F}$
implies that voters, on average, disfavor Latino/Hispanic candidates relative to white candidates when the ethnicity of candidates is conveyed via textual labels. The interpretation of
$\unicode[STIX]{x1D70F}$
implies that voters, on average, disfavor Latino/Hispanic candidates relative to white candidates when the ethnicity of candidates is conveyed via textual labels. The interpretation of
 $\unicode[STIX]{x1D708}$
is similar except for the fact that the intervention here is the provision of photographic information regarding candidate ethnicity.
$\unicode[STIX]{x1D708}$
is similar except for the fact that the intervention here is the provision of photographic information regarding candidate ethnicity.
We are also interested in the analogous effects defined for subsets of
 ${\mathcal{I}}$
corresponding to those who are internally motivated to control stereotyping of Latinos/Hispanics:
${\mathcal{I}}$
corresponding to those who are internally motivated to control stereotyping of Latinos/Hispanics:
 $$\begin{eqnarray}\unicode[STIX]{x1D70F}_{I}=\frac{1}{|{\mathcal{I}}_{I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70F}_{I}=\frac{1}{|{\mathcal{I}}_{I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
and
 $$\begin{eqnarray}\unicode[STIX]{x1D708}_{I}=\frac{1}{|{\mathcal{I}}_{I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D708}_{I}=\frac{1}{|{\mathcal{I}}_{I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)]\end{eqnarray}$$
those not internally motivated to control stereotyping of Latinos/Hispanics:
 $$\begin{eqnarray}\unicode[STIX]{x1D70F}_{\setminus I}=\frac{1}{|{\mathcal{I}}_{\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70F}_{\setminus I}=\frac{1}{|{\mathcal{I}}_{\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
and
 $$\begin{eqnarray}\unicode[STIX]{x1D708}_{\setminus I}=\frac{1}{|{\mathcal{I}}_{\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D708}_{\setminus I}=\frac{1}{|{\mathcal{I}}_{\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)]\end{eqnarray}$$
and those who are externally motivated to control stereotyping of Latinos/Hispanics but not internally motivated:
 $$\begin{eqnarray}\unicode[STIX]{x1D70F}_{E\setminus I}=\frac{1}{|{\mathcal{I}}_{E\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{E\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70F}_{E\setminus I}=\frac{1}{|{\mathcal{I}}_{E\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{E\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(T_{ip}=1)-Y_{ip}(T_{ip}=0)]\end{eqnarray}$$
and
 $$\begin{eqnarray}\unicode[STIX]{x1D708}_{E\setminus I}=\frac{1}{|{\mathcal{I}}_{E\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{E\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)].\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D708}_{E\setminus I}=\frac{1}{|{\mathcal{I}}_{E\setminus I}|}\frac{1}{|{\mathcal{P}}|}\mathop{\sum }_{i\in {\mathcal{I}}_{E\setminus I}}\mathop{\sum }_{p\in {\mathcal{P}}}[Y_{ip}(V_{ip}=1)-Y_{ip}(V_{ip}=0)].\end{eqnarray}$$
4 Hypotheses
Our first primary hypothesis is that
 $(\unicode[STIX]{x1D70F}-\unicode[STIX]{x1D708})>0$
. In words, candidate profiles assigned Latino ethnicity are expected to be chosen more often when ethnicity is represented textually rather than visually. This motivating assumption is that some “ethnically ambivalent” respondents will choose the Latino candidate when his ethnicity is conveyed with labels (triggering cognitive processing), but not when his ethnicity is conveyed via photographs, which are expected to induce more of a gut-level reaction.
$(\unicode[STIX]{x1D70F}-\unicode[STIX]{x1D708})>0$
. In words, candidate profiles assigned Latino ethnicity are expected to be chosen more often when ethnicity is represented textually rather than visually. This motivating assumption is that some “ethnically ambivalent” respondents will choose the Latino candidate when his ethnicity is conveyed with labels (triggering cognitive processing), but not when his ethnicity is conveyed via photographs, which are expected to induce more of a gut-level reaction.
Our second primary hypothesis is that
 $(\unicode[STIX]{x1D70F}_{I}-\unicode[STIX]{x1D708}_{I})>(\unicode[STIX]{x1D70F}_{\setminus I}-\unicode[STIX]{x1D708}_{\setminus I})$
. In words, the difference between the label and photo variants of the Latino-ethnicity treatment effect is expected to be larger for respondents who are more-internally motivated to control stereotyping of Latinos.
$(\unicode[STIX]{x1D70F}_{I}-\unicode[STIX]{x1D708}_{I})>(\unicode[STIX]{x1D70F}_{\setminus I}-\unicode[STIX]{x1D708}_{\setminus I})$
. In words, the difference between the label and photo variants of the Latino-ethnicity treatment effect is expected to be larger for respondents who are more-internally motivated to control stereotyping of Latinos.
Our third primary hypothesis is that
 $(\unicode[STIX]{x1D70F}_{E\setminus I}-\unicode[STIX]{x1D708}_{E\setminus I})=0$
. That is, among respondents who are motivated to control stereotyping to maintain their reputation, but not for internal reasons, we expect the label and picture versions of the Latino-ethnicity treatment to have the same effect. These respondents are not thought to experience dissonance between their gut-level and cognitive reactions to Latino ethnicity, dissonance that in other respondents may cause the treatment effects of labels and pictures to diverge. To be sure, externally motivated respondents may be reluctant to say publicly they prefer candidates labeled white to roughly similar candidates labeled Latino, but in the context of an anonymous online survey—especially where the candidate profiles list several attributes other than Race/Ethnicity—we expect no dissembling from these respondents, and thus similar treatment effects from labels and pictures.
$(\unicode[STIX]{x1D70F}_{E\setminus I}-\unicode[STIX]{x1D708}_{E\setminus I})=0$
. That is, among respondents who are motivated to control stereotyping to maintain their reputation, but not for internal reasons, we expect the label and picture versions of the Latino-ethnicity treatment to have the same effect. These respondents are not thought to experience dissonance between their gut-level and cognitive reactions to Latino ethnicity, dissonance that in other respondents may cause the treatment effects of labels and pictures to diverge. To be sure, externally motivated respondents may be reluctant to say publicly they prefer candidates labeled white to roughly similar candidates labeled Latino, but in the context of an anonymous online survey—especially where the candidate profiles list several attributes other than Race/Ethnicity—we expect no dissembling from these respondents, and thus similar treatment effects from labels and pictures.
A fourth, exploratory hypothesis is that
 $\unicode[STIX]{x1D70F}<0$
. That is, Latino ethnicity is dispreferred in biethnic matchups between copartisan candidates of similar quality when ethnicity is labeled.
$\unicode[STIX]{x1D70F}<0$
. That is, Latino ethnicity is dispreferred in biethnic matchups between copartisan candidates of similar quality when ethnicity is labeled.
A fifth, exploratory hypothesis is that
 $\unicode[STIX]{x1D708}<0$
. That is, Latino ethnicity is dispreferred in biethnic matchups between copartisan candidates of similar quality when ethnicity is represented visually.
$\unicode[STIX]{x1D708}<0$
. That is, Latino ethnicity is dispreferred in biethnic matchups between copartisan candidates of similar quality when ethnicity is represented visually.
5 Analysis and Results
Given the random assignment of the manipulations to respondents and candidate pairs, unbiased estimators of all estimands can be constructed from sample averages. Consequently, we test the above hypotheses using linear regression with clustered standard errors in a manner consistent with Hainmueller, Hopkins, and Yamamoto (Reference Hainmueller, Hopkins and Yamamoto2014).
To maximize the power of our tests, we would like to pool across the six choice tasks given to each respondent, on the assumption that respondents’ preference as between any two candidate profiles is independent of where that matchup occurs in the sequence of six matchups presented to the respondent. It turns out, however, that the behavior of one class of respondents (those who are internally motivated to control stereotyping) assigned to one treatment arm (the photos condition) varies significantly across the six matchups. See the Supplemental Information for details. For now, we report the tests of our primary hypotheses in three ways: first, pooling across all six matchups (see Table 1); second, using data only from the first matchup (see Table 2); and finally, for completeness, using data from matchups two through six (see Table 3). By construction, choices made in the first matchup are free of spillover effects from the later matchups.
Table 1. Results based on all 6 matchups. The
 $p$
-value column gives the
$p$
-value column gives the
 $p$
-values from
$p$
-values from
 $z$
-tests of the null hypothesis that the estimand in question is equal to 0.
$z$
-tests of the null hypothesis that the estimand in question is equal to 0.

Table 2. Results based on just the first matchup. The
 $p$
-value column gives the
$p$
-value column gives the
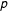 $p$
-values from
$p$
-values from
 $z$
-tests of the null hypothesis that the estimand in question is equal to 0.
$z$
-tests of the null hypothesis that the estimand in question is equal to 0.

Table 3. Results using data from matchups 2 through 6. The
 $p$
-value column gives the
$p$
-value column gives the
 $p$
-values from
$p$
-values from
 $z$
-tests of the null hypothesis that the estimand in question is equal to 0.
$z$
-tests of the null hypothesis that the estimand in question is equal to 0.

Our results contradict our first hypothesis, namely, that Latino candidates are more likely to be chosen when ethnicity is conveyed by labels and names rather than pictures and names
 $(\unicode[STIX]{x1D70F}-\unicode[STIX]{x1D708}>0)$
. We find instead that being Latino is a significant disadvantage when ethnicity is represented by labels, but irrelevant when ethnicity is represented through photos. The difference between the labels and pictures treatments is statistically significant at the 0.014 level. If we look only at data from the first matchup, we see that
$(\unicode[STIX]{x1D70F}-\unicode[STIX]{x1D708}>0)$
. We find instead that being Latino is a significant disadvantage when ethnicity is represented by labels, but irrelevant when ethnicity is represented through photos. The difference between the labels and pictures treatments is statistically significant at the 0.014 level. If we look only at data from the first matchup, we see that
 $(\unicode[STIX]{x1D70F}-\unicode[STIX]{x1D708})$
is again estimated to be negative. This difference is significantly different from 0 at the 0.011 level. In the first matchup
$(\unicode[STIX]{x1D70F}-\unicode[STIX]{x1D708})$
is again estimated to be negative. This difference is significantly different from 0 at the 0.011 level. In the first matchup
 $\unicode[STIX]{x1D70F}$
is not significantly different from 0 at conventional levels while
$\unicode[STIX]{x1D70F}$
is not significantly different from 0 at conventional levels while
 $\unicode[STIX]{x1D708}$
is significantly different from 0.
$\unicode[STIX]{x1D708}$
is significantly different from 0.
Our second primary hypothesis concerns the relative size of the labels/pictures treatment gap, for respondents who are “high” and “low” in internal motivation-to-control stereotyping:
 $(\unicode[STIX]{x1D70F}_{I}-\unicode[STIX]{x1D708}_{I})>(\unicode[STIX]{x1D70F}_{\setminus I}-\unicode[STIX]{x1D708}_{\setminus I})$
. When we pool the data for statistical power this hypothesis is confirmed (
$(\unicode[STIX]{x1D70F}_{I}-\unicode[STIX]{x1D708}_{I})>(\unicode[STIX]{x1D70F}_{\setminus I}-\unicode[STIX]{x1D708}_{\setminus I})$
. When we pool the data for statistical power this hypothesis is confirmed (
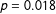 $p=0.018$
), but not in the way we expected.Footnote
19
We hypothesized that
$p=0.018$
), but not in the way we expected.Footnote
19
We hypothesized that
 $(\unicode[STIX]{x1D70F}_{I}-\unicode[STIX]{x1D708}_{I})$
would be positive, in line with our rationale for our first hypothesis. But as Table 1 shows, this expression is estimated to be almost exactly equal to zero, while
$(\unicode[STIX]{x1D70F}_{I}-\unicode[STIX]{x1D708}_{I})$
would be positive, in line with our rationale for our first hypothesis. But as Table 1 shows, this expression is estimated to be almost exactly equal to zero, while
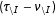 $(\unicode[STIX]{x1D70F}_{\setminus I}-\unicode[STIX]{x1D708}_{\setminus I})$
is strongly negative. Transposing the candidates’ ethnicities (candidate
$(\unicode[STIX]{x1D70F}_{\setminus I}-\unicode[STIX]{x1D708}_{\setminus I})$
is strongly negative. Transposing the candidates’ ethnicities (candidate
 $A$
from white to Latino, and candidate
$A$
from white to Latino, and candidate
 $B$
from Latino to white) increases candidate
$B$
from Latino to white) increases candidate
 $A$
’s vote share among the more-internally motivated half of the sample by 6.5 percentage points regardless of whether ethnicity is conveyed by pictures or labels. The same transposition of racial/ethnic cues reduces candidate
$A$
’s vote share among the more-internally motivated half of the sample by 6.5 percentage points regardless of whether ethnicity is conveyed by pictures or labels. The same transposition of racial/ethnic cues reduces candidate
 $A$
’s vote share among the less-internally motivated half of the sample by about the same margin when ethnicity is signaled via photos. Yet among these less-internally motivated respondents the reduction in support for candidate
$A$
’s vote share among the less-internally motivated half of the sample by about the same margin when ethnicity is signaled via photos. Yet among these less-internally motivated respondents the reduction in support for candidate
 $A$
under the counterfactual scenario that he is Latino is 2.5 times as large (a 16.7 percentage-point vs. a 6.6 percentage-point shock to his vote margin) when ethnicity is conveyed with labels rather than photos. This result confirms our expectation that variations in the way the racial/ethnic cue is signaled can lead to substantively different outcomes, though not for the specific group we hypothesized.
$A$
under the counterfactual scenario that he is Latino is 2.5 times as large (a 16.7 percentage-point vs. a 6.6 percentage-point shock to his vote margin) when ethnicity is conveyed with labels rather than photos. This result confirms our expectation that variations in the way the racial/ethnic cue is signaled can lead to substantively different outcomes, though not for the specific group we hypothesized.
Our third primary hypothesis concerns the behavior of respondents whose gut-level and cognitive reactions to Latino ethnicity were expected to be similar, yet who acknowledge misrepresenting their ethnic preferences in public settings—those who are externally but not internally motivated to control stereotyping. Given the anonymous, online nature of our survey, and the fact that the candidate profiles featured several attributes other than ethnicity, we expected no dissembling, i.e.,
 $(\unicode[STIX]{x1D70F}_{E\setminus I}-\unicode[STIX]{x1D708}_{E\setminus I})=0$
.
$(\unicode[STIX]{x1D70F}_{E\setminus I}-\unicode[STIX]{x1D708}_{E\setminus I})=0$
.
Looking at the results in Table 1 we see that both
 $\unicode[STIX]{x1D70F}_{E\setminus I}$
and
$\unicode[STIX]{x1D70F}_{E\setminus I}$
and
 $\unicode[STIX]{x1D708}_{E\setminus I}$
are estimated to be negative and significantly different from 0 at conventional levels. However, the effect of conveying racial/ethnic cues via labels is about 2.5 times larger than the photos effect (a
$\unicode[STIX]{x1D708}_{E\setminus I}$
are estimated to be negative and significantly different from 0 at conventional levels. However, the effect of conveying racial/ethnic cues via labels is about 2.5 times larger than the photos effect (a
 $22.7$
percentage-point change in vote share vs. a
$22.7$
percentage-point change in vote share vs. a
 $9.2$
percentage-point change in vote share). The difference between these two effects is significantly different from 0 at the 0.001 level. Many of our more socially sensitive respondents were clearly willing to express their preference for white candidates in the labels condition. And rather surprisingly, these same respondents were not equally hostile to Latinos when ethnicity was conveyed visually rather than textually.
$9.2$
percentage-point change in vote share). The difference between these two effects is significantly different from 0 at the 0.001 level. Many of our more socially sensitive respondents were clearly willing to express their preference for white candidates in the labels condition. And rather surprisingly, these same respondents were not equally hostile to Latinos when ethnicity was conveyed visually rather than textually.
6 Discussion
Our results defy conventional wisdom about white voters’ responses to racial/ethnic images and written labels. The absence of race/ethnicity labels in the pictures condition makes this treatment more implicit than the other, so we expected a more negative Latino-ethnicity treatment effect in this condition, especially among respondents who are internally motivated to control stereotyping. What we found suggests that internally motivated respondents have the same reaction to photographic and labeled signals of ethnicity, but that respondents who are not so motivated react much more strongly—and more negatively—to the Latino labels-and-names treatment than to the corresponding photos-and-names treatment. Pooling across all respondents and all six matchups, Latino ethnicity was not a statistically significant disadvantage unless it was labeled (
 $\unicode[STIX]{x1D708}=-0.002\text{ with }p=0.882;\unicode[STIX]{x1D70F}=-0.059\text{ with }p<0.001$
).
$\unicode[STIX]{x1D708}=-0.002\text{ with }p=0.882;\unicode[STIX]{x1D70F}=-0.059\text{ with }p<0.001$
).
What could explain the attenuation of discrimination against Latinos in the photos condition among these voters whom we categorize as not internally motivated to control stereotyping (the respondents in
 ${\mathcal{I}}_{\setminus I}$
and
${\mathcal{I}}_{\setminus I}$
and
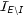 ${\mathcal{I}}_{E\setminus I}$
)? One possibility is that the Latino candidates depicted in the treatment photos are visually extraordinary relative to the white candidates depicted in the photos. As we explained above, selection effects in a world in which most voters discriminate against Latino candidates could result in Latino state legislators being visually exceptional relative to white state legislators. (Recall that our treatment photos are drawn from the population of state legislators.) As a further check, we had MTurk workers rate the treatment photos for attractiveness. It turns out that our Latino and white photos are well-balanced on this dimension, except for one Latino who appears significantly less attractive than he “should” be (for balance). So any bias from the correlation between attractiveness and ethnicity in the treatment photos should make more negative the estimated effect of Latino ethnicity in the photos condition.Footnote
20
${\mathcal{I}}_{E\setminus I}$
)? One possibility is that the Latino candidates depicted in the treatment photos are visually extraordinary relative to the white candidates depicted in the photos. As we explained above, selection effects in a world in which most voters discriminate against Latino candidates could result in Latino state legislators being visually exceptional relative to white state legislators. (Recall that our treatment photos are drawn from the population of state legislators.) As a further check, we had MTurk workers rate the treatment photos for attractiveness. It turns out that our Latino and white photos are well-balanced on this dimension, except for one Latino who appears significantly less attractive than he “should” be (for balance). So any bias from the correlation between attractiveness and ethnicity in the treatment photos should make more negative the estimated effect of Latino ethnicity in the photos condition.Footnote
20
Another possibility is that the photos-and-names treatment conveyed a less precise signal of ethnicity than the textual labels. But in our pretests, MTurk workers had no trouble correctly inferring candidate ethnicity in the pictures condition. The fuzzy-signal hypothesis is also hard to square with the behavior of internally motivated respondents, who gave the same bonus to Latino ethnicity in the labels and pictures conditions. If the signal were fuzzy in the pictures condition, the treatment effect of Latino identity represented visually should be biased toward zero among internally motivated respondents too.
Third, there may be something humanizing about the candidates’ faces. Perhaps discriminatory sentiments have less effect on vote choice when candidates are seen as real people rather than as abstractions.Footnote 21
A final interpretation is that many white voters, even those predisposed to vote against Latino candidates on the basis of the candidate’s ethnicity, do not dwell on ethnicity unless it is explicitly primed. The 2016 presidential election engendered much discussion of “white identity politics,” and it may be the case that white voters at the low end of the motivation-to-control-stereotyping scale simply respond more negatively to minority race/ethnicity the more they are encouraged to consider it.Footnote 22
Whatever may prove to be best explanation for our results, they clearly do not support the idea that the choice of treatment mode (labels & names vs. photos & names) is of no consequence in studies of racial and ethnic discrimination. In this paper, we have made the case that researchers need to be cognizant of how race/ethnicity is conveyed in conjoint studies conducted in the United States. Scholars employing conjoint studies in contexts outside of the United States to study racial/ethnic politics would be wise to do the same.
While we have demonstrated that the way in which ethnicity is signaled matters, more work needs to be done to understand the mechanisms behind these treatment-mode effects. We would not be surprised if multiple mechanisms are at work—some of which may be contextually dependent. We strongly encourage future researchers to explore the mechanisms underlying treatment-mode differences, such as those described in this study.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2017.36.










 Open access
Open access