





Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Rasoamanalina, Rivo Onisoa Léa
Mirzaei, Khaled
El Jaziri, Mondher
Rasamiravaka, Tsiry
Ramarosandratana, Aro Vonjy
and
Bertin, Pierre
2024.
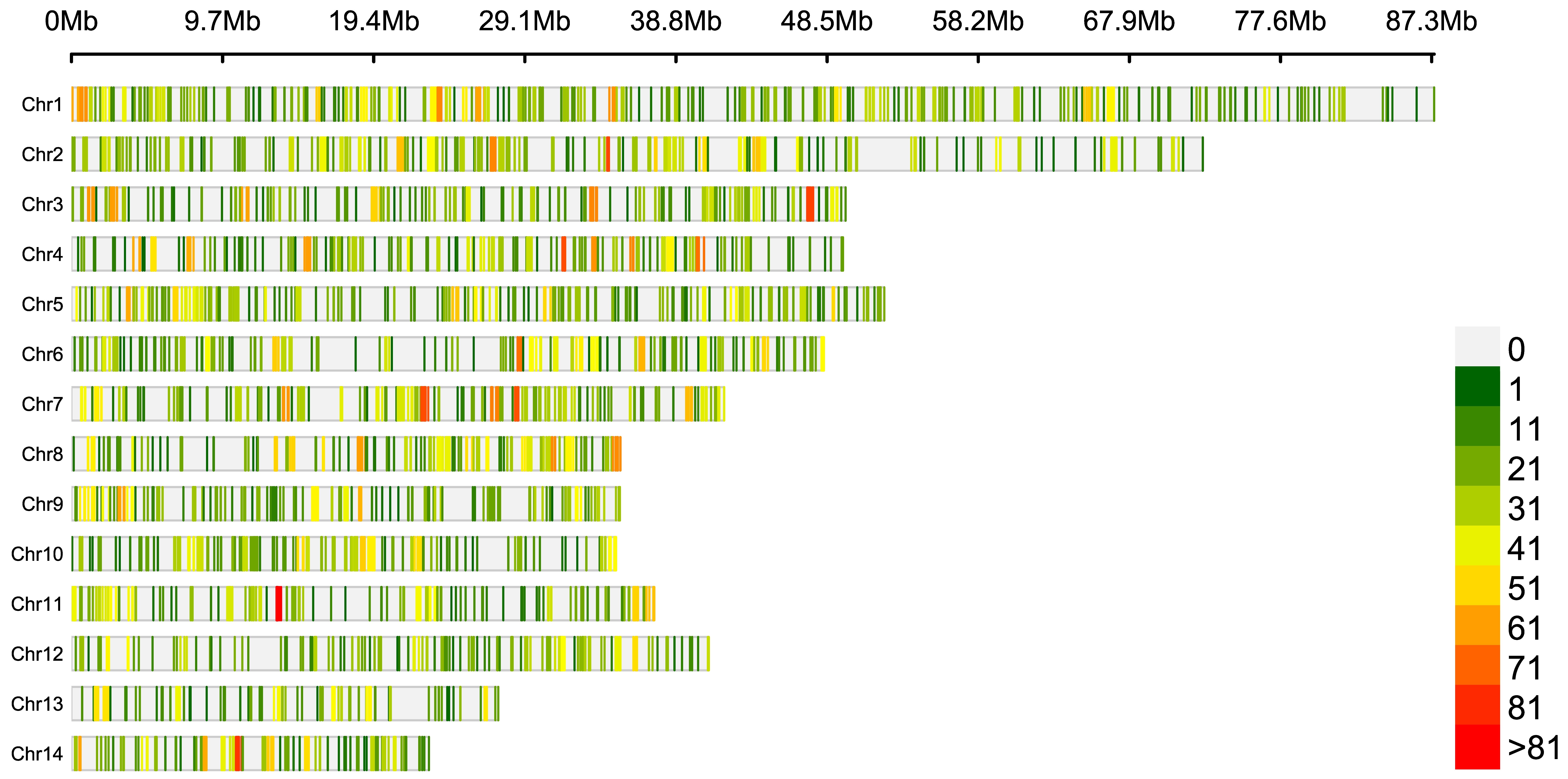
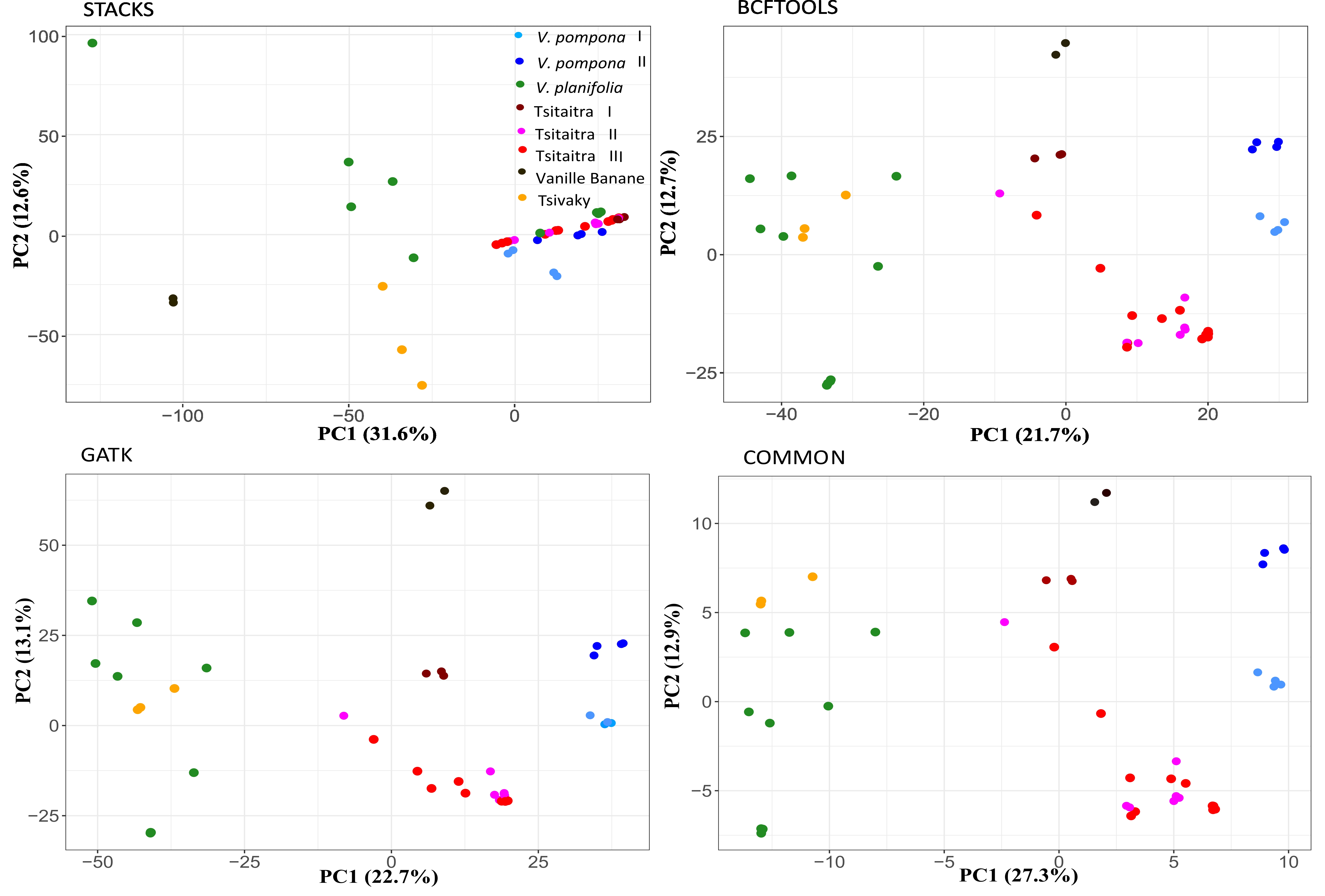
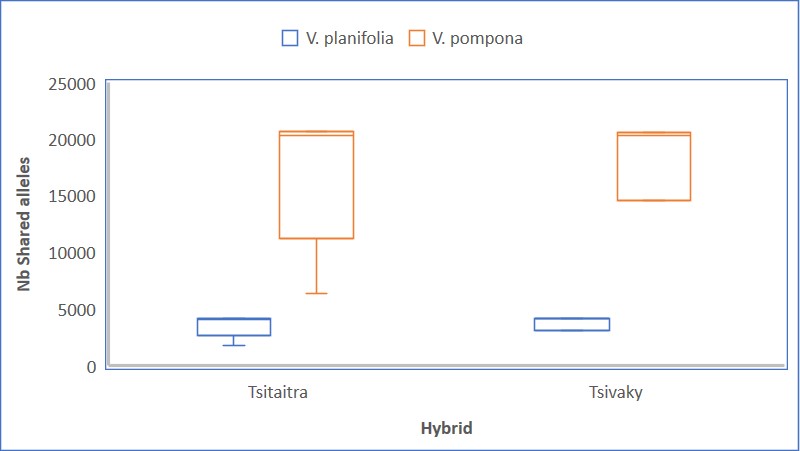
Genome-wide assessment of genetic variation and population structure in cultivated vanilla from Madagascar.
Genetic Resources and Crop Evolution,
Gastelbondo, Manuel
Micheal, Vincent
Wang, Yu
Chambers, Alan
and
Wu, Xingbo
2025.
Comparative transcriptome profiling of vanilla (Vanilla planifolia) capsule development provides insights of vanillin biosynthesis.
BMC Plant Biology,
Vol. 25,
Issue. 1,