


1. Introduction
Some phonological patterns are harder to learn than others. When a phonological rule is imperfectly learned and speakers apply it variably, what might be the causes? One proposal is that alternation learning is facilitated if there is a phonotactic generalisation that aligns with the alternation pattern (Hayes Reference Hayes, Kager, Pater and Zonneveld2004; Pater & Tessier Reference Pater, Tessier, Slabakova, Silvina and Prévost2006; Tesar & Prince Reference Tesar and Prince2007; Chong Reference Chong2019, Reference Chong2021) and that a mismatch between the lexicon and the alternation makes alternation learning harder. The present study tests the claim that lack of phonotactic support for an alternation makes it difficult to learn the alternation with the case of Korean vowel harmony in verbal inflection, a process that is arguably losing its productivity.
Different phonological theories have proposed different views on the effect of phonotactics on alternation learning; some posit that the two types of generalisations are learned using a single mechanism and that phonotactic knowledge aids alternation learning (Matthews Reference Matthews1972; Sommerstein Reference Sommerstein1974; Hayes Reference Hayes, Kager, Pater and Zonneveld2004; Pater & Tessier Reference Pater, Tessier, Slabakova, Silvina and Prévost2006; Tesar & Prince Reference Tesar and Prince2007; Chong Reference Chong2019, Reference Chong2021), while others do not posit such a link between phonotactics and alternation (Hale & Reiss Reference Hale and Reiss2008; Paster Reference Paster2013). These diverging views predict different learning outcomes for the class of phenomena commonly described as derived environment effects (DEEs; also known as non-derived environment blocking), rules that apply across morpheme boundaries but not within morphemes. While the single-mechanism view would predict that these rules are harder to learn because generalisations in the lexicon do not align with alternation patterns, the dual-mechanism view would predict that the facility with which alternation learning proceeds is not dependent on whether there is a matching phonotactic generalisation, because the two generalisations are governed by separate modules.
In recent research, the concept of the derived environment rule itself has become more nuanced, with a gradient connection between alternations and stem behaviour. Chong (Reference Chong2017, Reference Chong2019) has found that when quantitative patterns of alternation and phonotactics are considered, a derived environment effect might actually have statistical support in the lexicon. Using artificial learning experiments, Chong (Reference Chong2021) further claims that it is hard to learn an alternation that is not supported by phonotactic generalisations, and that alternation is productive to the extent that patterns in the lexicon support it.
With this background, the present study considers a mismatch between alternation and phonotactics as a reason for loss of productivity of a phonological rule. It has been argued that a receding phonological rule often goes through the stage of being confined to derived environments (Kiparsky Reference Kiparsky and Fujimura1973). That is, it is common for a phonological rule to apply initially both within morphemes and across morpheme boundaries, but later operate only across morpheme boundaries. Korean vowel harmony may be considered such a case. In Middle Korean, harmony applied both root-internally and across morpheme boundaries (detailed discussion will be provided in §2.2), while in Contemporary Korean, it still applies in verbal inflections but the trace of harmony in the lexicon is relatively weak. Given the relationship between the extent to which the lexicon and the alternation (mis-)match, on the one hand, and the productivity of the alternation, on the other, it is imaginable that loss of productivity in Korean vowel harmony in suffix alternation may be attributed to lack of phonotactic support.
To test the hypothesis that such loss of productivity may be ascribed to an incongruity between alternation and phonotactics, I investigate Korean vowel harmony variably applying in verbal suffix alternation and gradient phonotactic restrictions that reflect the harmony. In line with Chong’s claim, Korean vowel harmony turns out to be a case where an alternation with a weak phonotactic support loses productivity. Only a moderate tendency for harmony was attested in the lexicon, lending feeble support for the harmony in alternation, which may be one of the causes of rule breakdown. Further, I investigate whether phonological and morphological environments in which the alternation harmony is observed more robustly tend to have stronger phonotactic support. In general, the findings support the idea that patterns of alternation are productive to the extent that they are motivated by phonotactics.
1.1. Derived environment effects
It has long been acknowledged that similar phonological generalisations are found across morpheme boundaries and within morphemes (Chomsky & Halle Reference Chomsky and Halle1968). For instance, English bans a sequence of coda obstruents that differ in voicing both at the level of phonotactics and alternation. Within morphemes, sequences such as *[tz] and *[gt] are not found. Aligning with this phonotactic generalisation, the plural morpheme /-z/ undergoes a voicing alternation [-z]\textasciitilde[-s] to agree with the voicing feature of the preceding consonant, and the past tense morpheme /-d/ similarly shows a voicing alternation [-d]\textasciitilde[-t]. In the rule-based approach, phonotactic generalisations are explained by morpheme structure constraints (MSCs; Halle Reference Halle1959; Stanley Reference Stanley1967; Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977), and alternation by regular phonological rules. Cases in which the same generalisation was captured by two distinct devices (MSCs and rules) without any formal encoding of this commonality in the grammar were described as instances of the ‘Duplication Problem’ (Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977). The recognition of such redundancy was one of the driving forces behind the development of constraint-based frameworks such as Optimality Theory (OT; Prince & Smolensky Reference Prince and Smolensky1993, Reference Prince and Smolensky2004), in which a single mechanism (i.e., output constraints) is posited to account for generalisations both within morphemes and across morpheme boundaries.
However, it is not uncommon to find cases in which a phonological generalisation holds only in alternations. In the category of processes known as DEEs, a phonological rule applies across morpheme boundaries, but is blocked within morphemes. A well-known example is Korean palatalisation. In Korean, /th, t/ palatalise to [ch, c] before [i] across a morpheme boundary (as in (1a) and (1c)), while [thi] and [ti] sequences are attested within stems (as in (1b) and (1d)).
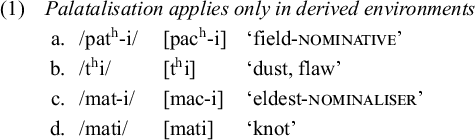
I refer to the consonants and vowels of Korean throughout this article, so I provide the inventories in Tables 1 and 2.Footnote 1
Table 1 Consonants in Korean.

Table 2 Vowels in Korean (shaded cells = [ATR] vowels, unshaded cells = [RTR] vowels; see §2.1 for discussion on the use of these features).
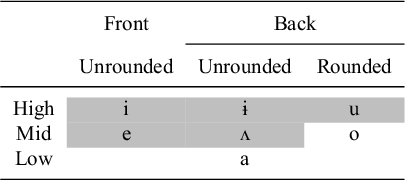
Previous accounts of DEEs have sought to characterise rules that apply only across morpheme boundaries or when fed by another phonological rule, among which I name only a few. Kiparsky (Reference Kiparsky and Fujimura1973) argued that the rules which apply only in derived environments are non-automatic neutralizing rules. Mascaró (Reference Mascaró1976) appealed to the Strict Cycle Condition, arguing that cyclic rules only apply in derived environments. Kiparsky (Reference Kiparsky, Kaisse and Hargus1993) claimed that DEEs arise as the result of structure-building rules applying to underspecified representations. Within the framework of OT, Łubowicz (Reference Łubowicz2002) adopted a constraint conjunction approach, while McCarthy (Reference McCarthy2003) introduced comparative markedness constraints.
Paster (Reference Paster2013) provides a diachronic account, arguing that alternation and phonotactics are free to differ. The claim is that if alternation and phonotactics happened to be affected by the same factors diachronically, they will match; if they have undergone changes independently of each other, they will not. Under this account, separate learning mechanisms are posited for alternation and phonotactics, and the same generalisation being redundantly stated in the grammar is not necessarily a ‘problem’, an idea dating back to Anderson (Reference Anderson1974) (see Kiparsky Reference Kiparsky and Peters1972 for a similar argument.)
In contrast, Chong (Reference Chong2019) suggests that there is, in fact, a link between phonotactics and alternation in several well-known cases of DEEs when the degree to which they (mis-)match is examined quantitatively. For instance, it was found that the Korean palatalisation exemplified in (1a) and (1c) is supported by a gradient phonotactic constraint by which [thi] and [ti] are severely underrepresented in the lexicon, although not totally illicit (see (1b) and (1d)). In other recent studies quantitatively investigating the extent to which phonotactics aligns with alternation, evidence is accumulating showing that generalisations that drive the alternation have echoes in the lexicon (Stanton Reference Stanton2020; Jun et al. Reference Jun, Byun, Park and Yeeto appear). Often, it is hard to make a clear-cut binary judgement as to whether or not there is phonotactic support. For instance, Jun et al. (Reference Jun, Byun, Park and Yeeto appear) report that three morphophonological processes in Korean show varying degrees of support in the lexicon. Given that the phonotactic well-formedness judgement itself is gradient (Coetzee & Pater Reference Coetzee and Pater2008; Hayes & White Reference Hayes and White2013) and that some DEEs apply only in specific affixes (see cases cited in Chong Reference Chong2017), it is important to investigate the tightness of the alternation–phonotactics link using quantitative and statistical methods.
In addition to examining the degree to which alternation and phonotactics match, studies have also investigated the impact of their correlation on the learning of alternations. Different theories make different predictions regarding the impact of an alternation–phonotactics link on the learnability or productivity of the alternation. Formal frameworks that posit a single learning mechanism for alternation and phonotactics (Matthews Reference Matthews1972; Sommerstein Reference Sommerstein1974; Hayes Reference Hayes, Kager, Pater and Zonneveld2004) predict that phonotactic learning facilitates alternation learning and that alternation learning is difficult when the patterns in the lexicon do not match those of the alternation. In contrast, models that posit distinct mechanisms for the two types of generalisations do not predict differences in the learnability of alternation as a function of phonotactic support (Hale & Reiss Reference Hale and Reiss2008). In general, findings from experimental studies (Pater & Tessier Reference Pater, Tessier, Solé, Recasens and Romero2003, Reference Pater and Tessier2005, Reference Pater, Tessier, Slabakova, Silvina and Prévost2006; Chong Reference Chong2021) and computational studies (Hayes Reference Hayes, Kager, Pater and Zonneveld2004; Prince & Tesar Reference Prince, Tesar, Kager, Pater and Zonneveld2004; Jarosz Reference Jarosz2006, Reference Jarosz2011; Tesar & Prince Reference Tesar and Prince2007; Hayes & Wilson Reference Hayes and Wilson2008) suggest that phonotactic knowledge aids alternation learning. However, two recent experimental studies report somewhat conflicting results; while Chong (Reference Chong2021) argues that learning of alternation is facilitated by a matching phonotactic generalisation, aligning with many previous studies mentioned above, Do & Yeung (Reference Do and Yeung2021) suggest that the learning of phonotactics has no effect on alternation learning. Do & Yeung (Reference Do and Yeung2021) point out that most experiments probing the effect of phonotactic knowledge on alternation learning have been conducted with English native speakers, who do find at least some phonotactically motivated alternations in their language (e.g., the voicing alternation in the past tense morpheme mentioned earlier this section). When tested with Cantonese speakers, who do not have experience with phonotactically motivated alternations in their first language, phonotactic knowledge did not have an effect on alternation learning. Therefore, the effect of phonotactic support on alternation learning is still subject to investigation. I refer readers to these two studies for a more thorough review of the previous studies on learnability of an alternation as a function of matching phonotactic pattern.
1.2. The current study
The present study aims to investigate the relationship between alternation and phonotactics using the case of Korean vowel harmony, a process that is known to apply across morpheme boundaries. The first contribution of this study to the literature is a quantitative comparison between alternation and phonotactics with another case of DEE. While Chong studied the link between alternation and phonotactics using rigorous statistical methods, the claims have not been tested in a sufficient number of cases. As Chong notes, it is necessary to consider quantitative patterns of alternation and phonotactics in many more cases described as DEEs, since each case might differ in terms of the degree to which phonotactic generalisations match alternation patterns and how it affects productivity of the alternation.
Second, by examining the reportedly decreasing productivity of Korean vowel harmony in suffix alternation and how it might be affected by the strength of matching phonotactic patterns, the findings can have implications for the debate on whether a single mechanism can account for both alternation and phonotactics. To this end, I first provide evidence that the harmony is retreating in specific phonological and morphological environments based on a corpus study, and relate the findings to two wug tests reported in previous studies (Kang Reference Kang2012; Jang Reference Jang and Erlewine2017). Then I examine whether each of the factors that modulate the nuanced pattern of harmony has matching phonotactic patterns in the lexicon to test the alternation-phonotactic link at a more detailed level. The findings generally support the hypothesis that there is weaker phonotactic support for the harmony in contexts in which it is more severely breaking down. The findings will also help understand why Korean vowel harmony is receding in particular contexts.
The remainder of the article is organised as follows. §2 describes the pattern of Korean vowel harmony, focusing on its productivity. §3 examines variable patterns of harmony in suffix alternations, and §4 compares the harmony in alternations with that found in the lexicon. The alternation and phonotactic patterns are modelled using Maximum Entropy grammar (Smolensky Reference Smolensky, Rumelhart and McClelland1986; Goldwater & Johnson Reference Goldwater and Johnson2003) in §5. §6 then reviews the results of phonotactic judgement experiments and nonce word tests conducted in previous studies. §7 summarises the findings of this study and discusses its implications for the link between alternation and phonotactics. §8 concludes the article.
2. Background: Korean vowel harmony
2.1. Basic patterns of Korean vowel harmony
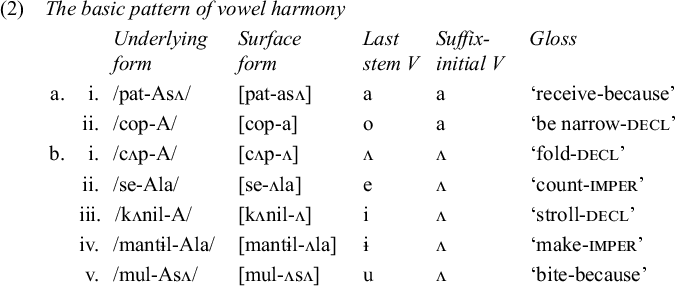
In Korean verbal inflection, certain vowel-initial suffixes have two allomorphs, one of which has [a] as its first vowel and the other [ʌ]. The suffix-initial vowel is determined by the last vowel of the verb or adjective stem (henceforth, verbal stem).Footnote 2 The initial suffix vowel is [a] if the last stem vowel is /a/ or /o/, as in (2a); otherwise, it is [ʌ], as in (2b). (The uppercase A represents the underlying form of the suffix vowel.)
The Korean vowel inventory presented in Table 2 assumes seven contrasting vowel phonemes. The vowels /a, o/, traditionally termed ‘light’ vowels, do not form a natural class, nor do the ‘dark’ vowels /i, ɨ, u, e, ʌ/.Footnote 3 Some studies propose backness as the harmonic feature (Kim Reference Kim, Kenstowicz and Kisseberth1973), while others suggest lowness (McCarthy Reference McCarthy, Richardson, Mitchell and Chukerman1983; Ahn Reference Ahn1985; Kim Reference Kim2007). However, neither [back] nor [low] distinguishes /a, o/ from other vowels (see Table 2). A number of studies adopt [±ATR] or [±RTR] (Kim Reference Kim1984; Lee Reference Lee1992; Cho Reference Cho1994; Chung Reference Chung2000; Hong Reference Hong2008; Kang Reference Kang2012). For concreteness, I will follow the latter set of studies and use [ATR] (for /i, ɨ, u, e, ʌ/) and [RTR] (for /a, o/), rather descriptively, noting that this choice remains controversial on phonetic grounds. It is beyond the scope of this article to figure out which feature best divides the two harmonic groups, and the main claim of the article about the link between alternation and phonotactics will be unaffected even if some other feature than [ATR]/[RTR] is used.
One class of verbal stems, the so-called p-irregular stems, systematically resist harmony when the last stem vowel is [RTR]. P-irregular stems are stems whose stem-final /p/ surfaces as [w] when followed by a vowel-initial suffix, as illustrated in (3) and (4). The forms with the consonant-initial suffix /-ciman/ ‘but’ show that these are stems with underlying /p/. It is shown in (3a) and (3b) that when the last stem vowel is [ATR], the suffix vowel is [ʌ], as expected. However, as (3c) and (3d) show, p-irregular stems whose last vowel is /a/ or /o/ typically take the disharmonic [ʌ] suffix forms, although the harmonic variant does arise (Hong Reference Hong2008; Kang Reference Kang2012). Exceptions to this disharmonic behaviour of p-irregular /a/- and /o/-stems are monosyllabic /o/-stems, illustrated in (4), which still take harmonic suffix allomorphs. (Monosyllabic p-irregular /a/-stems do not exist.)


In Korean verbal paradigms, /o/ and /u/ may surface as [w] when followed by vowel-initial suffixes. For instance, /po-A/ ‘to see-declarative’ can be realised as either [poa] or [pwa], and /cu-A/ ‘to give-declarative’ as either [cuʌ] or [cwʌ]. As far as p-irregular stems are concerned, it is plausible to think that [w] behaves more like the [ATR] vowel [u] at least in multisyllabic /a/- or /o/-stems, such that it is frequently followed by [ʌ]-initial suffix forms.
As mentioned in §1, vowel harmony in Contemporary Korean is arguably a case of DEE, once we set aside the special case of p-irregular stems. The harmony rule of suffix alternation has been studied extensively in the literature (Kim Reference Kim, Kenstowicz and Kisseberth1973; Kim-Renaud Reference Kim-Renaud1976; Ahn Reference Ahn1985; Cho Reference Cho1994, Reference Cho2001; Kim Reference Kim2007; Hong Reference Hong2008; Kang Reference Kang2012, among others), and harmony applies fairly regularly in alternation (although variations and exceptions exist, as will be discussed in §2.3). In stems, by contrast, disharmonic patterns are common, as illustrated by (5). An [ATR] vowel can be followed by an [RTR] vowel as in (5a)–(5c), and an [RTR] vowel may be followed by an [ATR] vowel as in (5d)–(5f).
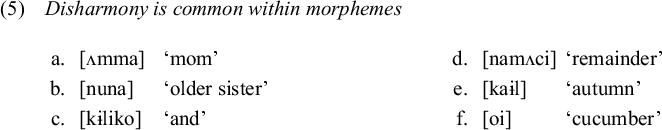
Phonotactic generalisations in the lexicon that might reflect the harmony pattern of verbal inflection have not been studied extensively. A few studies suggest that the Korean lexicon has gradient phonotactic restrictions that reflect the harmony pattern of ideophones, another class of words in Korean in which harmony is observed (Hong Reference Hong2010; Park Reference Park2020). However, the grouping of harmonic vowels in ideophones is different from that of verbal inflections (see Hong Reference Hong2010 and Jun Reference Jun and Aronoff2018 for details; see also Nuckolls et al. Reference Nuckolls, Nielsen, Stanley and Hopper2016 and the references therein for studies on many other languages whose ideophonic stratum shows distinct phonology from other strata in the lexicon). The present study aims to investigate the vowel co-occurrence restrictions in the lexicon that directly reflect the harmony pattern of verbal inflection, following the research program of Chong (Reference Chong2019) (see §4).
2.2. Productive harmony in Middle Korean
For purposes of documenting gradual retreat of the harmony, it is useful to review vowel harmony in Middle Korean. The discussion of this section follows Kim (Reference Kim1978), Ko (Reference Ko2018), Lee (Reference Lee1947) and Lee (Reference Lee1998) among others. In Middle Korean, the ancestor of the present-day Korean spoken from the 10th century to the 16th century, the vowel system was symmetrical with regard to the number of vowels in each harmony group; the alternating vowel pairs were [a]\textasciitilde[ʌ], [ə]\textasciitilde[ɨ] and [o]\textasciitilde[u], while [i] was neutral. The vowels [a], [ə] and [o] were the ‘light’ vowels, and [ʌ], [ɨ] and [u] were the ‘dark’ vowels. Vowel harmony in Middle Korean was far more productive than Contemporary Korean and applied in broader morphological and phonological environments, although it was not without exceptions (see Han Reference Han1996 and Park Reference Park2016 for a quantitative analysis of the decline of harmony). First, whereas vowel harmony in Contemporary Korean applies only across a verbal stem and a suffix, it was obeyed even within (native) roots in Middle Korean, as shown in (6). A root consisted of vowels from the same harmonic group, with the possible addition of the neutral [i]. Note that the Contemporary Korean forms of each root in (6) contain vowels from the different harmonic groups.

Moreover, while [a]/[ʌ]-initial suffixes are the only ones eligible for harmony in Contemporary Korean, suffixes that began with other vowels also participated in harmony in Middle Korean, as illustrated in (7). For example, [o]-initial suffixes alternated with [u]-initial ones, as shown in (7a). The accusative marker (which has the invariant form [-ɨl] in Contemporary Korean) alternated between [-əl] and [-ɨl], as in (7c).

Even the p-irregular /a/- and /o/-stems, which frequently take disharmonic [ʌ]-initial forms in Contemporary Korean, were followed by the [a]-initial suffix forms in Middle Korean, as illustrated in (8).

However, a number of diachronic changes led to the disruption of the vowel harmony system, including vowel loss and the adoption of Sino-Korean words. Breakdown of the harmony system is most attributed to loss of [ə] (resulting from a vowel-shift-like process, not detailed here), which was replaced with [ɨ] in non-initial syllables and with [a] in initial syllables. Let us take [kaɨl] ‘autumn’ in (6e) as an example. The 16th century form of this word was [kəəl]. In the 17th century, the second [ə] was replaced with [ɨ], giving rise to [kəɨl]. In the 18th century, [ə] in the initial syllable was transformed into [a], hence the present form [kaɨl]. Crucially, the change from [ə] to [ɨ] disrupted the harmony, since the two vowels belonged to different harmony groups. In addition, a significant amount of Sino-Korean vocabulary, which did not conform to the harmony, was brought into Korean over the period of Middle Korean. This is illustrated by the Sino-Korean words like [sonjʌ] ‘girl’ which contains two disharmonic vowels. As a result, Korean became abundant with forms that did not follow the harmony.
For these reasons, the vowel harmony that was once productive in Middle Korean now applies in limited contexts in Contemporary Korean. Harmony is not fully active within morphemes, and the only affixes that harmonise are those that begin with [a]/[ʌ], which all happen to be verb suffixes. From the viewpoint of Chong (Reference Chong2019), we could also say that the harmony in alternation was productive in Middle Korean because it had phonotactic support in the lexicon. After a number of changes, the phonotactic harmony was disrupted while still leaving some of the alternation behind.
2.3. Limited productivity of harmony in Contemporary Korean
Several characteristics of Korean vowel harmony of the present day converge to demonstrate its limited productivity. First, it is limited to [a]/[ʌ]-initial affixes. Strikingly, the process is not iterative – it fails to self-feed – so that the harmony does not apply to the second vowel of the suffix in [pat-asʌ] ‘receive-because’ (2a-i) and [mantɨl-ʌla] ‘make-imper’ (2b-iv); if it applied iteratively, we would expect *[pat-asa] and *[mantɨl-ʌlʌ], respectively. The latter of these examples also shows that only the last stem vowel can be the trigger; other vowels in the stem do not affect harmony.
Moreover, there is indication that the harmony is receding. When the last stem vowel is [RTR], variation is shown in the selection of the suffix vowel; that is, the disharmonic [ʌ] suffix allomorph is often observed, as shown in (9). Considering that [ʌ] shows a wider distribution than [a], and that suffixes surface with [ʌ] when not eligible for harmony (e.g., the second suffix in /pat-As*-A/ ‘receive-past-decl’, which is not subject to harmony, surfaces as [ʌ], as in [pat-as*-ʌ], cf. *[pat-as*-a]), it is plausible to think of the default as [ʌ], so that the variation represents regularisation to the default.Footnote 4

When the stem vowel is [ATR], only the expected [ʌ]-initial forms are observed (i.e., a perfect harmony).
In judgement surveys in which younger and older speakers’ well-formedness ratings were compared (Kang Reference Kang2012, Reference Kang2016), it was found that younger speakers were more flexible in allowing variation compared to older speakers, also suggesting a loss of productivity over time. In addition, Jo (Reference Jo2020) reports that the disharmonic forms are more frequently observed in the spoken corpus than the newspaper corpus; given that innovative forms arise first in more casual and vernacular styles of speech (Labov Reference Labov1966, Reference Labov1972), the finding suggests that Korean vowel harmony is following the typical stages of rule loss.
Furthermore, the harmony pattern is not fully reproduced in wug tests reported in previous studies (discussed in detail in §6). Kang (Reference Kang2012) conducted a production experiment using real and nonce stems to test the speakers’ intuition on the harmony pattern. When the last stem vowel was /a/ or /o/, the proportion of harmonic suffix forms was only 32.0% for nonce stems, as compared to 76.7% for real stems. The result is striking in that the dominant pattern in the speakers’ response for wug words was the disharmonic one.
One reason for the loss of productivity would be, as discussed in §2.1, that there is no single phonetically transparent feature that governs the harmony.Footnote 5 The present study suggests yet another cause of the decreasing productivity: stem phonotactics matches the alternation pattern only weakly. Looking ahead, the corpus study presented in §3 also provides evidence that the harmony rule has begun to break down in specific phonological and morphological contexts, and an examination of gradient vowel co-occurrence restrictions in the lexicon in §4 suggests that the rule breakdown tends to be more pronounced in contexts for which there is weak phonotactic support.
3. A corpus study of suffix alternation
I first examined the pattern of alternation in Contemporary Seoul Korean using the Sejong text corpus.Footnote 6 The orthography indicates whether the suffix vowel was realised as [a] or [ʌ]. A subset of the corpus is morphologically tagged, among which the speech data (805,652 words) were subject to analysis. The reason for using only the speech data was that the spoken register was considered to contain more disharmonic forms than written registers (see also Jo Reference Jo2020), serving as a useful resource for testing whether the contexts in which alternation is less productive are precisely the ones that lack phonotactic motivation. The spoken data, recorded between 2001 and 2005, featured many different types of speech styles, including lectures, TV shows and daily conversation. The majority of the speakers were in their 20s at the time of recording.
I extracted words consisting of a verbal stem followed by a V-initial suffix that participates in harmony, using the tags present in the corpus. The supplemental materials of the present study, including the list of target words extracted from the corpus, are available on the following OSF page: https://osf.io/tjcqr/?view_only=9e6077702ee44344b449459c9a415f14. I consulted Kang & Kim (Reference Kang and Kim2004) and Kang (Reference Kang2012) to identify the harmonizing suffixes, the list of which is provided in (10). The uppercase letter A represents the harmonizing vowel that surfaces as either [a] or [ʌ].
It should be noted that the suffix /-A/ (‘declarative, interrogative, imperative (intimate)’; henceforth /-A/ ‘decl’), is a sentence-ending suffix that encodes an intimate speech level, used only in vernacular speech in which two intimate speakers converse informally. In comparison, most of the other suffixes are exclusively used in a polite speech level, e.g., /-Asʌjo/ ‘because (polite)’, or can be used in various speech levels as they do not encode politeness of the utterance, e.g., /-As*/ ‘past’, /-Aja/ ‘should’ (Seo Reference Seo1984; Sohn Reference Sohn1999). It is reported that /-A/ ‘decl’ surfaces frequently as the disharmonic [-ʌ] when the harmonic [-a] is expected (Kang Reference Kang2012). The suffix type effect is presented in more detail in §3.1.1.

A total of 21,796 target tokens were found, with 13,503 tokens (1,200 word types and 560 stem types) having an [ATR] vowel as the last stem vowel. Not surprisingly, all except six tokens take the harmonic suffix forms, suggesting a categorical harmony for [ATR] stem vowels. In the following section, I focus only on /a/- and /o/-stems of 8,293 tokens (604 word types and 215 stem types), which are subject to exceptions and variation, and demonstrate phonological and morphological factors that condition the variable harmony. The harmony for [ATR] stem vowels is briefly discussed again in §4.1.
3.1. The factors influencing variation
The variable harmony of /a/-stems and /o/-stems is conditioned by various phonological and morphological factors. This section focuses on four factors, namely the effect of suffix type, stem vowel quality, the number of intervening consonants between the two vowels and stem type. A subset of these factors were already investigated using the spoken data of the Sejong text corpus in Hong (Reference Hong2008). He reported that p-irregular stems generally prefer disharmonic suffix forms and that regular stems show variation when (i) the last stem vowel is /a/ and (ii) the stem ends in a consonant. In this section, I additionally show that those two effects that emerged in regular stems are strongest for the /-A/ ‘decl’ suffix. I eventually aim to test, in §4, whether these effects are phonotactically motivated.
I first calculated harmony rate for each word by dividing the number of tokens in which the stem took a harmonic suffix by the total number of tokens employing either of the suffix allomorphs. For instance, if the word /pat-A/ ‘receive-decl’ appears 51 times as [pat-a] and 152 times as [pat-ʌ], its harmony rate was calculated as
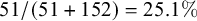 $51/(51+152) = 25.1\%$
. Then I calculated the average harmony rate of words that belong to each category of interest. To illustrate, if there were three words in the corpus that have /a/ as the last stem vowel and /-A/ ‘decl’ as the suffix (e.g., /pat-A/), whose harmony rate is 25%, 50% and 100%, respectively, the mean harmony rate for words that have /a/ stem vowel and /-A/ ‘decl’ would be
$51/(51+152) = 25.1\%$
. Then I calculated the average harmony rate of words that belong to each category of interest. To illustrate, if there were three words in the corpus that have /a/ as the last stem vowel and /-A/ ‘decl’ as the suffix (e.g., /pat-A/), whose harmony rate is 25%, 50% and 100%, respectively, the mean harmony rate for words that have /a/ stem vowel and /-A/ ‘decl’ would be
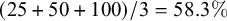 $(25+50+100)/3 = 58.3\%$
.
$(25+50+100)/3 = 58.3\%$
.
A logistic regression analysis was conducted to statistically test the effects of the four factors mentioned above. The results are provided in §3.2.
3.1.1. The /-A/ ‘decl’ suffix discourages harmony
It has been noted in Kang (Reference Kang2012) that the proportion of the [ʌ]-initial forms is the highest for the /-A/ ‘decl’ suffix. The representative data are in (11). While /-A/ ‘decl’ frequently surfaces with the disharmonic vowel (11a–11c), other suffixes show little variation, as shown in (11d–11f). Interestingly, we can see in (11c) and (11f) that although /-A/ ‘decl’ and the connective suffix are phonologically the same, only the former is subject to variation, suggesting that it is the morphological identity of /-A/ ‘decl’ that lowers the harmony rate, rather than its phonological characteristics.

The effect of suffix type on the harmony in the current data is shown in Figure 1. The numbers at the top of each bar indicate the number of words that belong to each category. Confirming the finding of Kang (Reference Kang2012), the average harmony rate of words with the /-A/ ‘decl’ suffix is substantially lower (43.9%) compared to that of other suffixes aggregated (93.2%). Considering that /-A/ ‘decl’ represents casual and vernacular styles of speech, as mentioned earlier, we can say that the innovative disharmonic forms are more frequently observed in informal speech. The finding suggests another piece of evidence showing that Korean vowel harmony is retreating, beginning from the more informal register, as is typical of a receding rule (Labov Reference Labov1966, Reference Labov1972).

Figure 1 The effect of suffix type. Numbers at the top of each bar indicate the number of words in that category.
I further show below that /-A/ ‘decl’ and the other suffixes behave differently with respect to some phonological factors that modulate the harmony. I present the results by dividing the data into two parts – declarative and non-declarative – based on the suffix type.
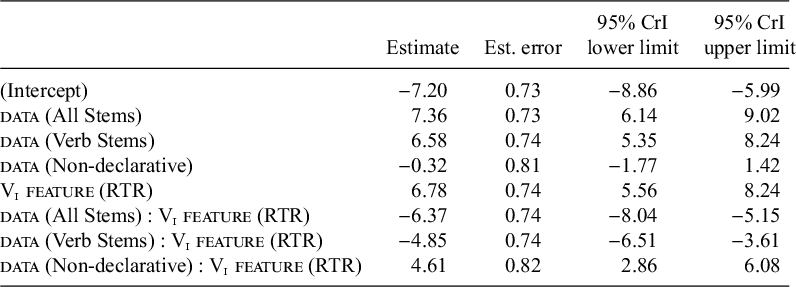
3.1.2. /o/ is a stronger trigger than /a/
The quality of the last stem vowel conditions the harmonic pattern (Kim-Renaud Reference Kim-Renaud1976; Cho Reference Cho1994; Hong Reference Hong2008; Kang Reference Kang2012), illustrated in (12). If the last vowel of the stem is /a/, and the stem ends in a consonant, as in (12a–12c), both the harmonic [a]-initial forms and the disharmonic [ʌ]-initial forms can surface. In comparison, /o/ stem vowel is more likely than /a/ to take the harmonic suffix forms, as illustrated in (12d–12f).Footnote 7

This trigger vowel effect is confirmed in the current data, but in a way that interacts with the suffix type (declarative, non-declarative) and the stem type (regular, p-irregular). As shown in Figure 2, /o/-stems, represented by the right-hand bar in each pair, exhibit categorical harmony unless they are p-irregular (in both the declarative and the non-declarative). In the declarative, /o/-stems showed a higher rate of harmony than /a/-stems regardless of the stem type. In the non-declarative, this trigger vowel effect is observed in the p-irregular stems, and the regular stems exhibited a ceiling effect in which both /a/-stems and /o/-stems had a 100% harmony rate. Regarding the stem type effect, which will be discussed further in §3.1.3, p-irregular stems had a lower harmony rate than regular stems (e.g., Hong Reference Hong2008; Kang Reference Kang2012).
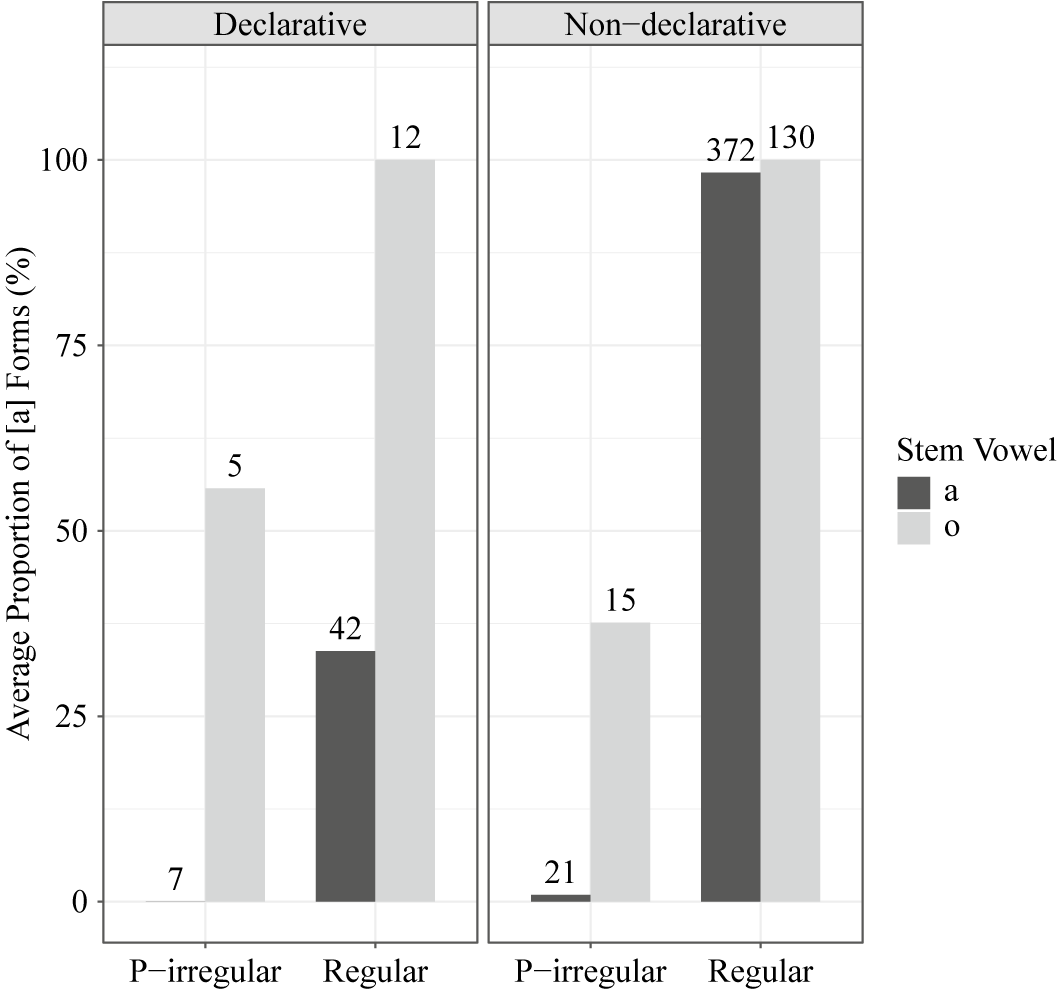
Figure 2 The effect of stem vowel. Numbers at the top of each bar indicate the number of words in that category.
In sum, /o/-stems show a higher rate of harmony than /a/-stems in the suffix alternation, confirming the findings of previous studies, but the difference between /a/ and /o/ was only observed in the declarative data and in the p-irregulars of the non-declarative data. In §4, I examine the possibility that this trigger vowel effect is motivated by phonotactic patterns in the lexicon.
3.1.3. Hiatus encourages harmony, p-irregular stems discourage it
It has been reported that the variation arises only when the /a/-stems end in a consonant (Cho Reference Cho1994; Kang Reference Kang2012). As (13) shows, if there is no intervening consonant between the last stem vowel and the suffix-initial vowel in the surface form (i.e., hiatus context), only the harmonic [a]-initial form is possible. (13b) and (13c) show that whether there is an intervening consonant or not should be evaluated at the surface level. When the stem-final /h/ deletes (due to an independent deletion process) to create a hiatus context in the surface form, only the harmonic form is possible.

If this hiatus effect is present in the current data, we expect to see variation only in the non-hiatus context, or at least observe that the harmony rate is higher in the hiatus context. Crucially, it is necessary to test if the apparent hiatus effect is an artefact of the stem type effect, since all the p-irregular stems, which are reported to resist harmony, are in the non-hiatus due to the [w] (i.e., /p/) that intervenes between the two vowels. Figure 3 shows that the hiatus effect emerged in the declarative data, even in regular stems, suggesting that the hiatus effect is observed independent of the stem type effect.Footnote 8 As we already saw in §3.1.2, the regular stems in the non-declarative data show a categorical harmony. Based on the findings of §3.1.2 and this section, we can say that the difference in the harmony rate between the declarative and the non-declarative (see Figure 1) is largely driven by regular /a/-stems with at least one intervening consonant between the stem vowel and the suffix vowel.Footnote 9
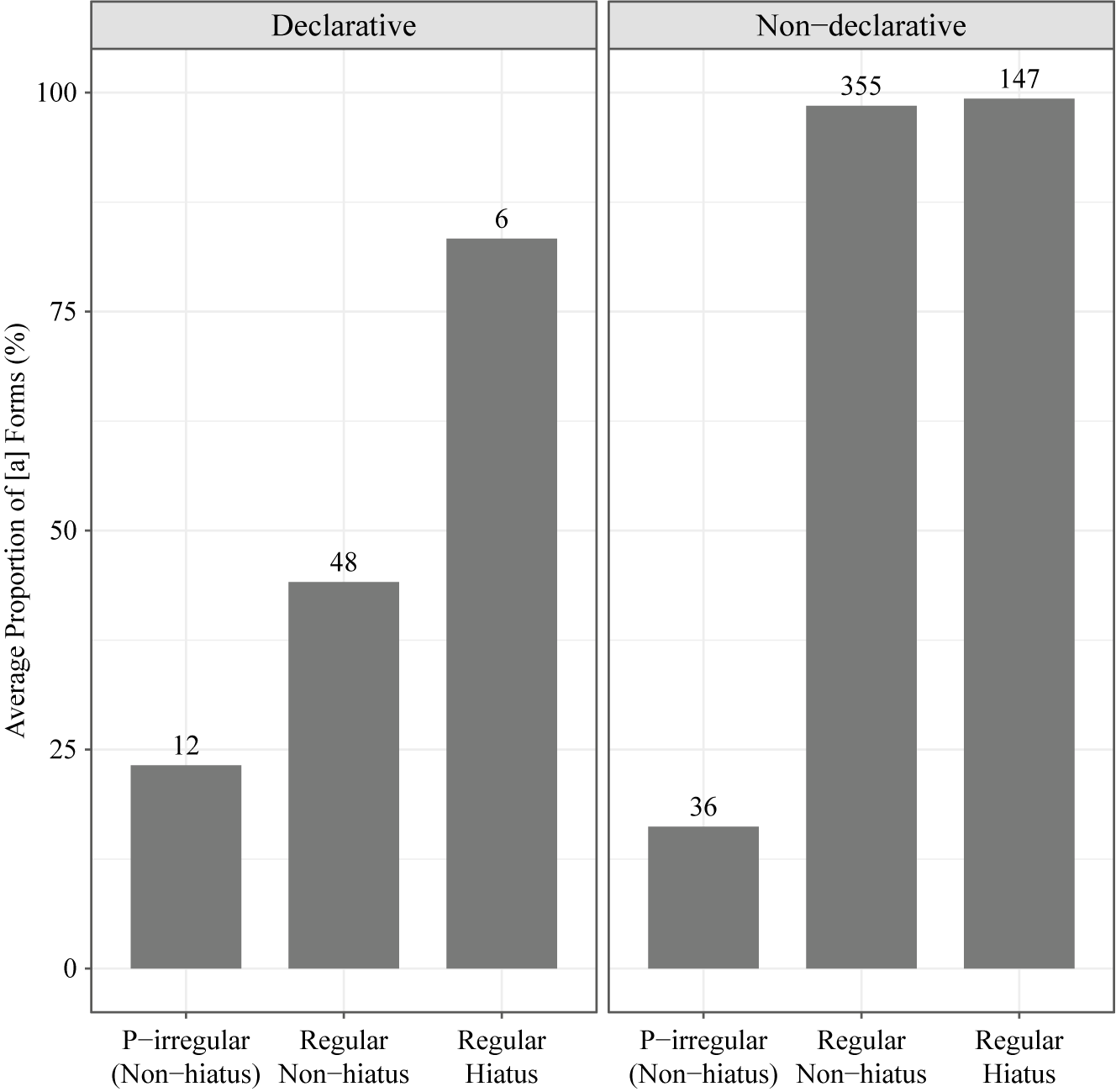
Figure 3 The effect of number of intervening consonants and the stem type. Numbers at the top of each bar indicate the number of words in that category.
The effect of p-irregular stems and its interaction with the stem length confirmed findings of previous studies, summarised in (3) and (4). Figure 3 shows that the p-irregular stems were more disharmonic than regular stems, in both the declarative and the non-declarative data. Although not separately presented in Figure 3, it was confirmed that monosyllabic /o/-stems showed categorical harmony.
To sum up, the findings are in line with those of previous studies in that harmony was encouraged when the stem vowel and the suffix vowel are adjacent to each other, and that p-irregular stems discouraged harmony. The hiatus effect was only observed in the declarative data, while the stem type effect was observed in both the declarative and the non-declarative data. In §4, I test the hypothesis that the hiatus effect and the stem type effect have phonotactic grounds in the lexicon.
3.2. Statistical testing of conditioning factors in alternation
In order to test whether the generalisations described so far are statistically valid, I ran a Bayesian logistic regression model. The dependent variable was the suffix form, which was binary-coded with harmonic [a] or disharmonic [ʌ] (baseline). Independent variables are presented in (14). All the predictor variables were sum-coded, which means that the reference level (underlined) is coded as
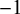 $-1$
and the other value is coded as
$-1$
and the other value is coded as
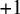 $+1$
. In addition to these predictors, random intercepts for word and speaker were also included.
$+1$
. In addition to these predictors, random intercepts for word and speaker were also included.

The model was fit using the brms package (Bürkner Reference Bürkner2017, Reference Bürkner2018, Reference Bürkner2021) in R (R Core Team 2018). A total of 10,000 samples were drawn in each of four chains from the posterior distribution over parameter values. The first 1,000 samples were discarded for warm-up. A weakly informative Student-t prior with 5 degrees of freedom was used for the intercept and all coefficients, following recommendations of Ghosh et al. (Reference Ghosh, Li and Mitra2018) for Bayesian logistic regression. There were no divergent transitions. The R-hat value was 1 for all parameters presented in Table 3, indicating that the model has converged. More details about the model, including a sensitivity analysis, are available on the following OSF page: https://osf.io/tjcqr/?view_only=9e6077702ee44344b449459c9a415f14. The sensitivity analysis suggested that the choice of priors does not substantially affect the posterior estimates.
Table 3 presents coefficient estimates along with their 95% Credible Interval (CrI) for each independent variable. In Bayesian analyses, 95% CrI is the range within which we can be 95% certain that the true value of a parameter lies (see Nicenboim & Vasishth Reference Nicenboim and Vasishth2016; Vasishth et al. Reference Vasishth, Nicenboim, Beckman, Li and Kong2018 for interpretation of CrI and a general introduction to the Bayesian framework). When the CrI included zero, I also report the probability of an effect in the direction of the sign of the coefficient (p-direction; the proportion of the posterior distribution of the coefficient values that is of the median’s sign). This value typically ranges between 50%, that is, the posterior distribution is centred around zero (indicating no evidence for an effect of either direction), and 100%, that is, the whole posterior distribution lies to either positive or negative side (indicating strong evidence for an effect in that direction).
Table 3 Results for the logistic regression analysis: harmony in suffix alternation.
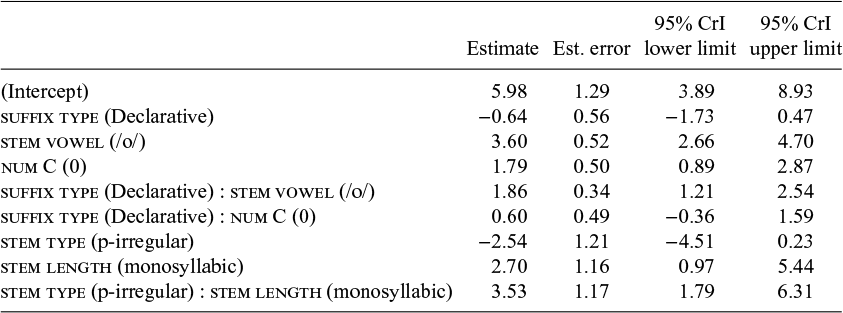
First, the negative coefficient for suffix type suggests that the declarative portion of the data had a lower harmony rate than the non-declarative data. The 95% CrI included zero, and the p-direction was 87.4%, indicating that the declarative suffix is probably associated with less harmony. The coefficient for stem vowel was positive with 95% CrI not including zero, so we can be confident that harmony was encouraged for /o/-stems. The positive coefficient for num C indicates that the hiatus context is associated with increased harmony. The 95% CrI did not include zero, so we can be confident about the effect of the number of intervening consonants. The analysis also confirmed that the trigger vowel effect was stronger in the declarative data, compared to the non-declarative data, represented by the positive coefficient of the suffix type (Declarative) : stem vowel (/o/), whose 95% CrI did not include zero. For the positive coefficient for suffix type (Declarative) : num C (0), 95% CrI included zero and the p-direction was 89.5%, suggesting that the hiatus effect is likely to be stronger in the declarative data. The negative coefficient for stem type suggests that p-irregular stems resisted harmony; the 95% CrI included zero, but the p-direction of 96.6% indicates that p-irregular stems are likely to be associated with less harmony. The positive coefficient for stem length, whose 95% CrI did not include zero, indicates that monosyllabic stems are more harmonic than multisyllabic stems. Last, consistent with previous studies (see (4)), the interaction between stem type and stem length had a positive coefficient and the 95% CrI did not include zero, confirming that despite the tendency of p-irregular stems to discourage harmony, monosyllabic p-irregular stems still had a high harmony rate.
To sum up the results of the corpus study for suffix alternation, harmony is retreating in particular phonological and morphological contexts, while others are more resistant to rule breakdown. The non-declarative portion of the corpus exhibited a higher harmony rate than the declarative data, suggesting that the vowel harmony is observed less strictly for the /-A/ ‘decl’ suffix. Further, the trigger vowel effect whereby the suffix vowel was more likely to be harmonic for /o/-stems was stronger in the declarative data. The hiatus effect was observed, with moderate statistical evidence suggesting that the effect was stronger in the declarative data. It thus seems that the /-A/ ‘decl’ suffix is leading the breakdown of the harmony process, first in the /a/-stems and in non-hiatus contexts. The stem type effect (i.e., p-irregular stems discourage harmony) is robust, confirming findings of the previous studies.
In the next section, I first investigate whether vowels in the lexicon show a tendency to harmonise at all, in order to explore the possibility that the loss of productivity in alternation may be attributed to lack of matching phonotactic generalisations. Then I assess whether the phonotactic harmony, if any, is modulated by three factors, that is, the trigger vowel, the number of intervening consonants and the type of intervening consonant ([w] vs. non-[w]) that is analogous to the effect of stem type in suffix alternation. By testing whether the alternation and the phonotactic harmony are regulated by the same factors, I aim to investigate the link between alternation and phonotactics at a more detailed level. If the two types of generalisations are closely related, the conditioning effects that are observed robustly in alternation are expected to have a strong phonotactic support; conversely, the relatively weak effects are expected to have feeble phonotactic support.
4. A comparison between alternation and phonotactics
As reviewed in §1, previous studies have proposed that alternation learning is facilitated by matching phonotactic generalisations (Hayes Reference Hayes, Kager, Pater and Zonneveld2004; Pater & Tessier Reference Pater, Tessier, Slabakova, Silvina and Prévost2006; Tesar & Prince Reference Tesar and Prince2007; Chong Reference Chong2019, Reference Chong2021). In the case of Korean vowel harmony, if there is indeed a link between alternation and phonotactics, we would expect to find that the Korean lexicon has gradient vowel co-occurrence restrictions that align with the harmony. However, the phonotactic constraints might be weak, which may be one of the reasons for the retreat of the harmony in the alternation. Further, if it is found that the harmony in alternation is dying precisely in contexts for which there are no (or weak) matching phonotactic patterns, the finding would suggest that the alternation and phonotactics are tightly linked. In §4.1, I compare the harmony gradiently observed in the lexicon against the alternation harmony, and I statistically test the difference between alternation and phonotactics in §4.2.
To analyze phonotactics in the lexicon, two subsets of the frequency data of Korean (Kang & Kim Reference Kang and Kim2004) were used: the list of content morphemes with a frequency of 10 or higher (henceforth referred to as the all-stems data) and that of verbal and adjectival morphemes with the same frequency cutoff (henceforth the verb-stems data). Stems included in the verb-stems data were mostly native Korean, and hence were expected to retain traces of the productive harmony of Middle Korean (see §2.2). Sino-Korean verbal stems are inflected with the suffix /-ha/ ‘do’, which shows a unique alternation, e.g., /ha-A/
 $\rightarrow $
[h
$\rightarrow $
[h![]() ] ‘do-decl’; thus, they are not subject to harmony and are excluded from the analysis. As will be shown below, the verb-stems data indeed pattern more similarly to alternation than the all-stems data do.
] ‘do-decl’; thus, they are not subject to harmony and are excluded from the analysis. As will be shown below, the verb-stems data indeed pattern more similarly to alternation than the all-stems data do.
It should be noted that all-stems data included polysyllabic Sino-Korean stems. Whether polysyllabic Sino-Korean stems should be treated as monomorphemic or polymorphemic can be controversial. Etymologically, each Sino-Korean syllable has meaning, and thus constitutes a morpheme. However, for many polysyllabic Sino-Korean stems, native speakers are often unaware that they contain several morphemes (Bae et al. Reference Bae, Yi and Masuda2016). For instance, [ca![]() mi] ‘rose’ has two Sino-Korean morphemes [ca
mi] ‘rose’ has two Sino-Korean morphemes [ca![]() ] and [mi], each of which means ‘rose’. But because these two morphemes are rarely used outside [ca
] and [mi], each of which means ‘rose’. But because these two morphemes are rarely used outside [ca![]() mi] (e.g., it is hard to think of other words in which [ca
mi] (e.g., it is hard to think of other words in which [ca![]() ] ‘rose’ appears), it is implausible for Korean speakers to know that they are distinct morphemes. For this reason, I included both native Korean and Sino-Korean stems in the analysis.
] ‘rose’ appears), it is implausible for Korean speakers to know that they are distinct morphemes. For this reason, I included both native Korean and Sino-Korean stems in the analysis.
From the all-stems and verb-stems data, I first extracted all the vowel sequences V1C0V2 to see if [RTR] V1s are more likely to be followed by [RTR] V2s than by [ATR] V2s. This resulted in a total of 77,652 stems in the all-stems data and 5,559 stems in the verb-stems data. I also identified the type and the number of consonants intervening between the two vowels. As will be shown below, the harmony in this set of phonotactic data was feeble. In a subsequent analysis, I narrowed down the scope of V2 to only [a] and [ʌ] to investigate whether [RTR] V1s are more likely to be followed by [a] than by [ʌ]. The intent was to test whether the harmony pattern is found in the lexicon when the phonotactic data was given the best possible chance to match the alternation (note that it is only those two vowels that alternate in the suffixes). This smaller phonotactic data consisted of 30,679 stems in the all-stems data and 2,355 stems in the verb-stems data.
4.1. Gradient harmony in phonotactics
As a first step towards comparing phonotactic patterns against alternation patterns, I examined how V2 is realised depending on the [ATR]/[RTR] specification of V1. For phonotactic data, I first consider all seven vowels as candidates for V2. If the tendency for harmony is present in the lexicon, it is expected that the proportion of [RTR] in V2 will be higher after [RTR] V1 than after [ATR] V1. Figure 4 compares the proportion of [RTR] in V2 in the two sets of alternation data (declarative and non-declarative) with the two sets of phonotactic data (all stems and verb stems). For the alternation data, V1 corresponds to the last stem vowel and V2 to the suffix-initial vowel, and the [RTR] V2 is [a]. As mentioned in §3, when the last stem vowel is [ATR], the suffix vowel shows categorical harmony; for both the declarative and the non-declarative portion of the alternation data, the proportion of [RTR]/[a] in V2 is shown to be near zero, meaning that the proportion of [ATR]/[ʌ] is near 100%. The grey bars for these two datasets, for which the stem vowel was either /a/ or /o/, were already presented in Figure 1. The alternation data, then, show a huge discrepancy in the proportion of [a] in V2 between [ATR] and [RTR] V1, confirming the harmony in suffix vowels.
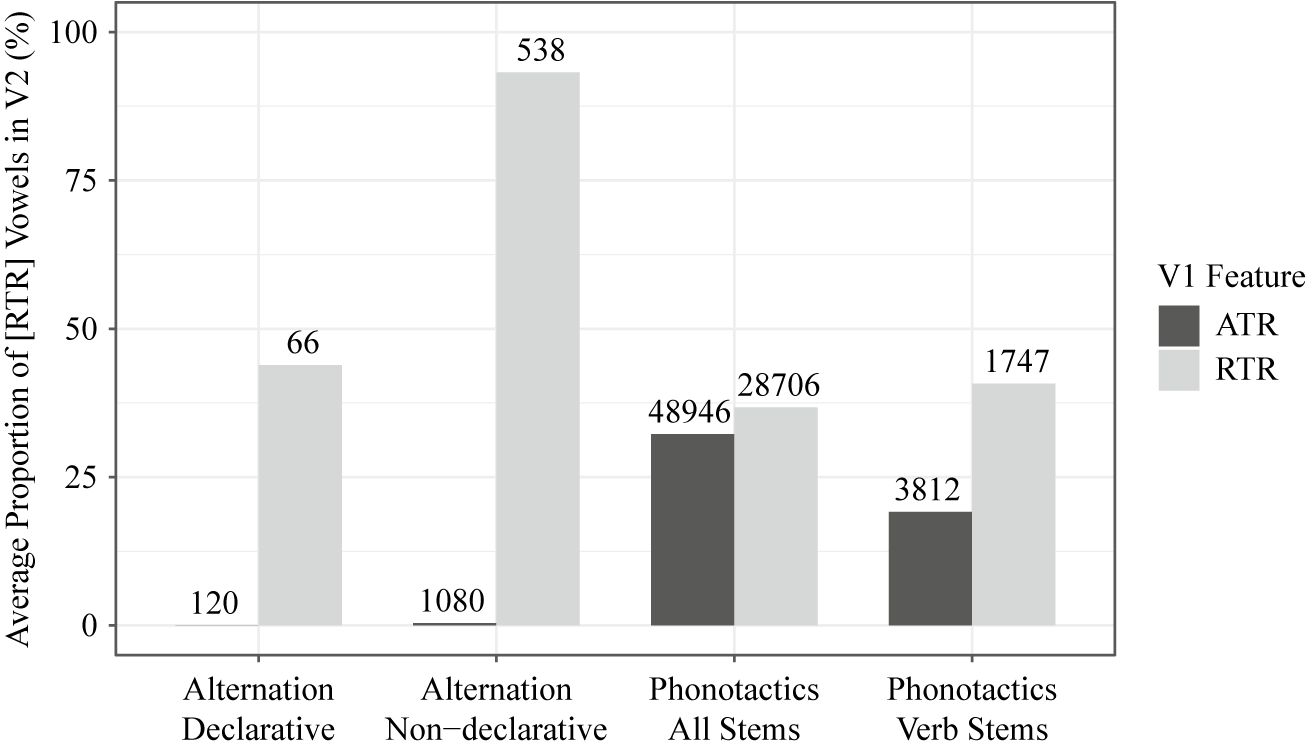
Figure 4 The percentage of [RTR] in V2 in alternation and phonotactics. Numbers at the top of each bar indicate the number of V1C0V2 sequences in that category.
In the phonotactic data, the tendency towards harmony is at best moderate. In the all-stems data, it can be seen that the proportion of [RTR] in V2 is only slightly higher when preceded by [RTR] vowels, compared to when preceded by [ATR] vowels. In other words, [ATR] V1 and [RTR] V1 do not differ in their probability of being followed by [RTR] V2. In the verb-stems data, we see that [RTR] V1 is more likely than [ATR] V1 to be followed by an [RTR] V2, suggesting phonotactic harmony. This confirms the hypothesis laid out earlier that phonotactic harmony, if any, may be stronger in the verb stems than other parts of the lexicon. However, the harmony shown in the verb-stems data is still weaker than that of the alternation data. Whereas the suffix vowel is rarely realised as [RTR]/[a] when the stem vowel is [ATR], V2 is realised as [RTR] to a fair degree after [ATR] V1 in verbal stems. In short, when all the seven vowels are considered for the V2, the harmony is nearly absent in the all-stems data, and is observed in the verb-stems data to some degree.
Could it be that the harmony in the lexicon looks feeble because the alternation data and the phonotactic data are not perfectly parallel, that is, all seven vowels are considered as candidates for V2 in the phonotactic data, whereas [a] and [ʌ] are the only vowels that participate in the alternation harmony? In what follows, I only included [a] and [ʌ] as V2 in the phonotactic data, trying to allow maximum room for phonotactics to match the alternation.
For phonotactic data that have only [a] and [ʌ] as V2, simply speaking, if there is no harmony at all, we would expect to see 50% [a] in V2 (i.e., chance level) both after [ATR] V1 and [RTR] V1. It can be seen in Figure 5 that for both sets of phonotactic data, the proportion of [a] in V2 is higher when preceded by [RTR] vowels, suggesting a tendency towards harmony. However, it is not as strong as what is found in alternation. In the all-stems data, the proportion of [a] in V2 is around 50% when V1 is [ATR], contrasting with the near 0% in the same context in the two sets of alternation data. The proportion of [a] in V2 after [RTR] V1 (which can be said to be intermediate, in the sense that it is higher than the declarative data but lower than the non-declarative data) is slightly higher compared to [ATR] V1, suggesting that there is a weak tendency for V2 to harmonise with V1. Overall, the strength of harmony, as may be indicated by the difference in the proportion of [a] in V2 between [ATR] V1 and [RTR] V1, is much weaker in the all-stems data than in the alternation data. Such difference between alternation and phonotactics is statistically supported (see the regression analysis in §4.2.)

Figure 5 The percentage of [a] forms in V2 in alternation and phonotactics. Numbers at the top of each bar indicate the number of V1C0V2 sequences in that category.
In the verb-stems data, we again find a stronger harmony than the all-stems data, indicated by the larger gap between [ATR] V1 and [RTR] V1. However, the harmony shown in the verb-stems data is still weaker than that seen in the alternation data. Whereas the proportion of [a] in V2 after [ATR] V1 is (near-)zero in the alternation data, V2 following [ATR] V1 is realised as [a] 34.9% of the time in verbal stems. Similar to the all-stems data, the proportion of [a] in V2 after [RTR] V1 was intermediate between the declarative data and the non-declarative data. The harmony in the verb-stems data, then, is stronger than the all-stems data, but still not as robust as in the alternation data, even when the phonotactic data was given its best possible chance to match the alternation data.
In sum, an investigation of phonotactic data revealed that the Korean lexicon shows at least a tendency towards harmony. Comparing alternation and stem phonotactics, however, the harmony is stronger in alternation. Within phonotactics, verbal stems show a stronger harmony than the entire lexicon. We can thus say that the harmony has varying strengths in different parts of the language. In the broader context of the link between phonotactics and alternation, we can infer that the harmony in suffix alternation is losing its productivity because it is only weakly supported by the lexicon.
4.2. Statistical testing of harmony in alternation vs. phonotactics
To assess the amount of credence we should give to the data patterns observed above, a Bayesian logistic regression analysis was implemented, with the alternation data and the smaller version of the phonotactic data (only [a] and [ʌ] considered for V2). The dependent variable was binary-coded V2, [a] vs. [ʌ] (baseline). The model included two independent variables, both of which were dummy-coded. The first was data with four levels, declarative (baseline), non-declarative, all stems and verb stems. The other independent variable was V1 feature with two levels, ATR (baseline) and RTR. Crucially, interaction terms between data and V1 feature were included to test whether the effect of V1 feature on the realisation of V2 is stronger in the declarative compared to the phonotactic data. Specifics of the model implementation are the same as those of §3.2 such as the number of samples and the priors. There were no divergent transitions. All parameters had an R-hat value of 1, suggesting model convergence. A sensitivity analysis showed that the posterior distribution of the parameters is not substantially aff ected by the prior specification. More details of the model can be found on the following OSF page, inc luding the sensitivity analysis: https://osf.io/tjcqr/?view_only=9e6077702ee44344b449459c9a415f14.
The results of the analysis are provided in Table 4. As expected, the coefficient of V1 feature was positive and the 95% CrI did not include zero, indicating that V2 is more likely to be [a] in V1=[RTR] context compared to V1=[ATR], when the data are declarative (i.e., the baseline level of data). Importantly, the interaction between data (All Stems) and V1 feature (RTR) had a negative coefficient, with the 95% CrI below zero, indicating that an [RTR] V1 enhanced the proportion of [a] in V2 to a greater degree in the declarative data relative to the all-stems data. Similarly, the interaction between data (Verb stems) and V1 feature (RTR) also had a negative coefficient and the 95% CrI below zero, suggesting that the effect of V1 feature was stronger in the declarative data compared to the verb-stems data. Finally, the interaction between data (Non-declarative) and V1 feature (RTR) had a positive coefficient and 95% CrI above zero, confirming that the effect of V1 feature is stronger in the non-declarative compared to the declarative.
Table 4 Results for the logistic regression analysis: harmony in alternation vs. phonotactics.
In sum, a comparison between alternation and stem phonotactics revealed that although tendency to harmonise is observed in both, it is more robust in alternation, specifically in suffixes other than the /-A/ ‘decl’. Therefore, we can conclude that the harmony shown in alternation is partly supported by phonotactics in the lexicon. In the following section, I investigate whether the trigger vowel effect, the hiatus effect and the effect of intervening consonant (analogous to the stem type effect in alternation; see below) are present in the lexicon by comparing the two sets of phonotactic data against the alternation data.
4.3. Trigger vowel effect in the lexicon
Recall from §3.1.2 that /o/ is a stronger trigger than /a/ in the suffix alternation (also presented in Figure 6, with all categories aggregated). Such a trigger vowel effect was rarely observed in the two sets of phonotactic data; Figure 6 demonstrates that the proportion of [a] in V2 was very similar whether V1 was [a] or [o]. Therefore, the effect of trigger vowel in alternation is not supported by generalisations in the lexicon, indicating a mismatch between alternation and phonotactics. In §5, I statistically test whether there is really no difference between V1=[a] and V1=[o] as a harmony trigger in the lexicon, because it is possible that [a] and [o] are skewed with respect to some other factors that affect the harmony.
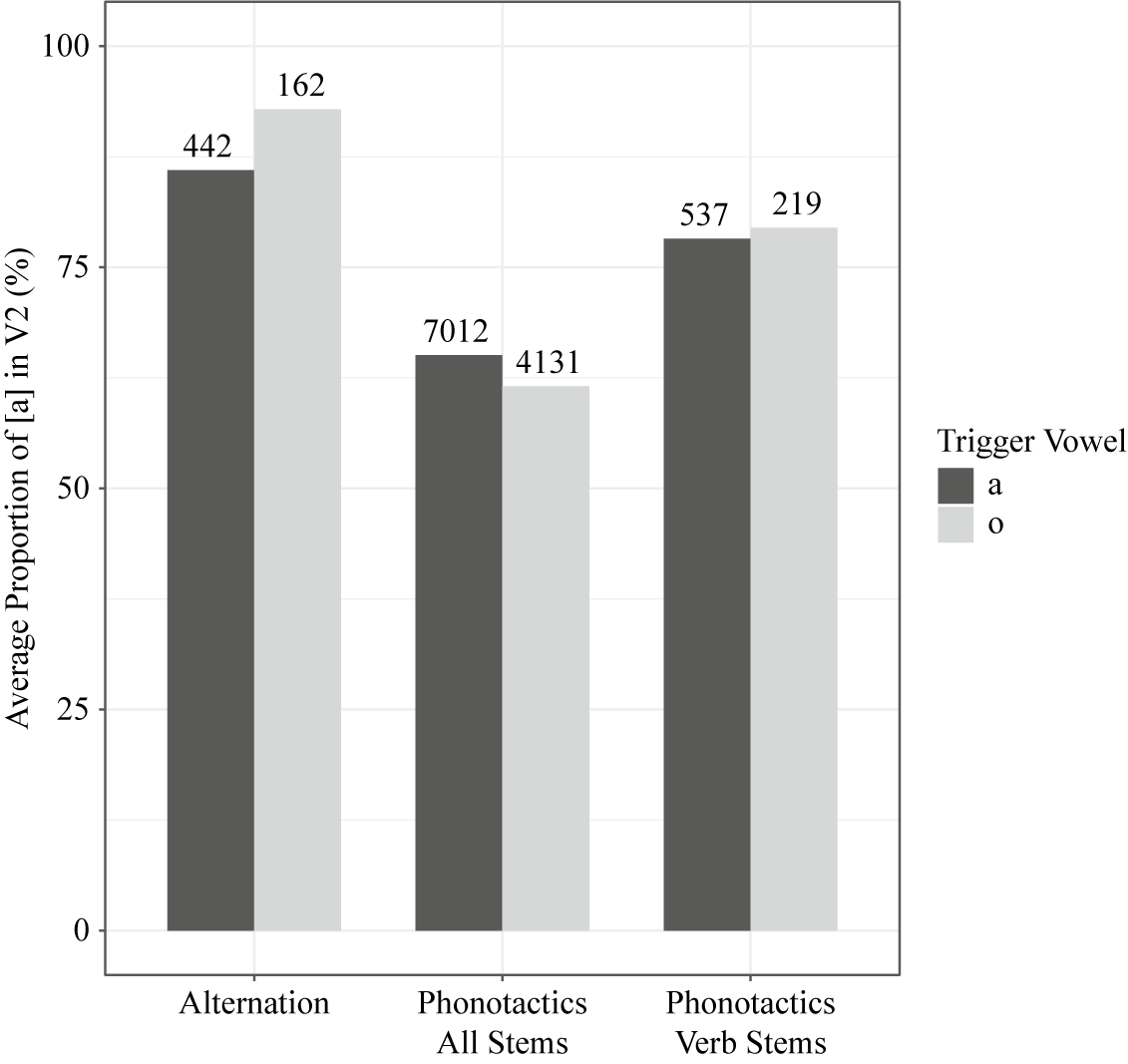
Figure 6 The trigger vowel effect in alternation and phonotactics, in which V1 (or stem vowel) = [a, o], V2 (or suffix vowel) = [a, ʌ]. Numbers at the top of each bar indicate the number of V1C0V2 sequences in that category.
4.4. The effect of intervening consonants in the lexicon
I then examined whether the hiatus effect and the stem type effect observed in the alternation have phonotactic support. For the latter, once we set aside the special case of the monosyllabic /o/-stems that always conform to harmony (see (4)),Footnote 10 a matching phonotactic pattern for the general tendency of p-irregular stems to take the disharmonic [ʌ]-initial suffix forms (e.g., [komaw-ʌ] ’to be thankful-decl’) rather than [a]-initial forms (e.g., [komaw-a]) would be that [wa] is dispreferred in the lexicon; that is, [w] would be followed by [a] less frequently than non-[w] consonants are.
It is necessary to tease apart the effect of an intervening [w] from the effect of the number of intervening consonants, because it is possible that the lower harmony rate in the non-hiatus context in the lexicon, if any, might be solely driven by the (potential) effect of [w] in lowering the proportion of [a] in V2. Figure 7 thus compares three categories, namely [w], other C(s) and hiatus, in which ‘other C(s)’ represents one or more non-[w] consonants between the vowels. The three-way contrast made here is analogous to that of Figure 3 (recall that words with a p-irregular stem are always in the non-hiatus category, due to the intervening [w] between the stem vowel and the suffix vowel that is derived from the stem-final /p/.) The [w] category in the alternation data in Figure 7 represents p-irregular verbs.
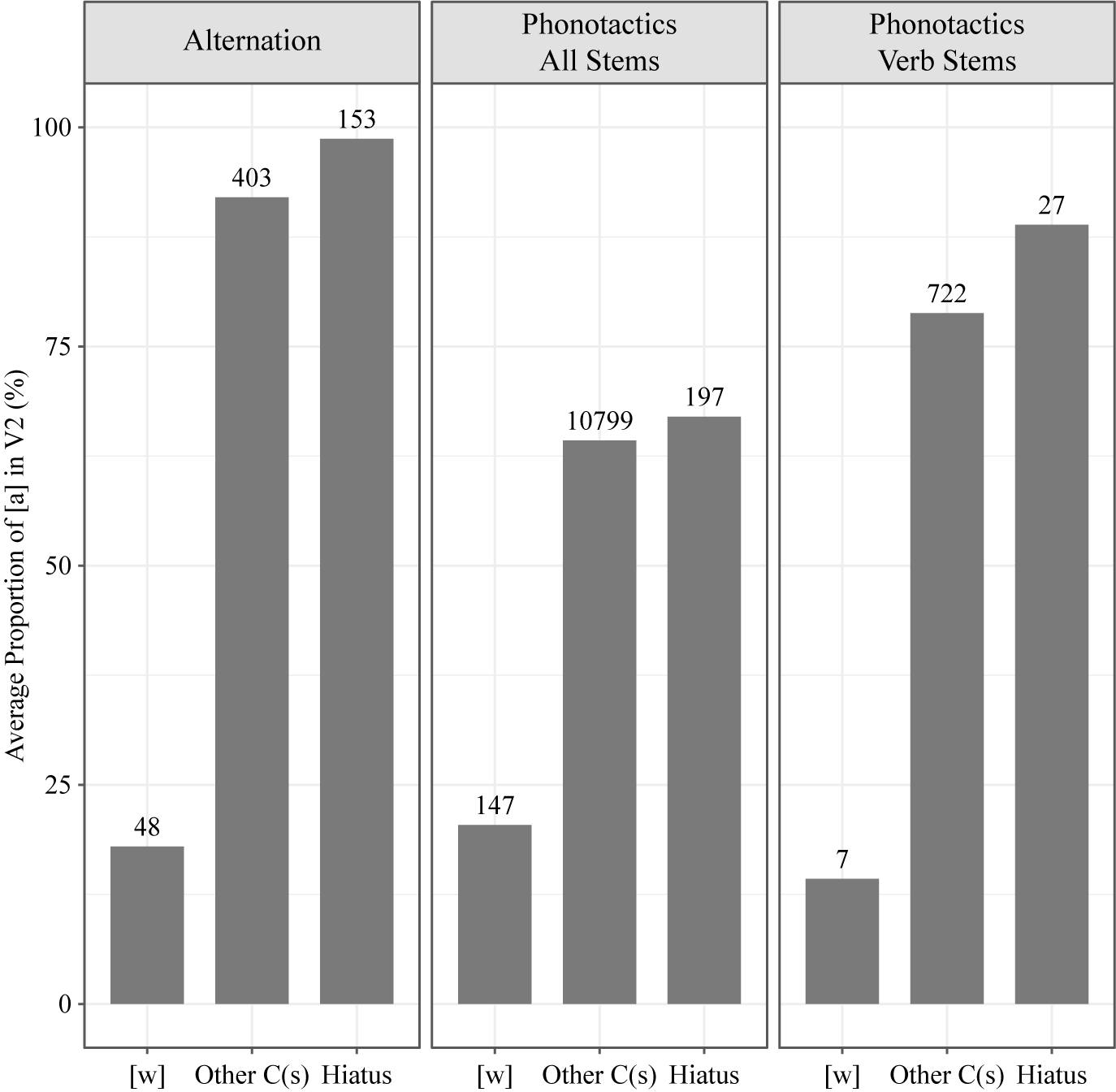
Figure 7 The effect of intervening consonants in alternation and phonotactics, in which V1 (or stem vowel) = [a, o], V2 (or suffix vowel) = [a, ʌ]. Numbers at the top of each bar indicate the number of V1C0V2 sequences in that category.
A comparison between ‘other C(s)’ and ‘hiatus’ reveals that the hiatus effect is weakly observed in the all-stems data, and a bit more clearly in the verb-stems data. This finding indicates that there is a hiatus effect that is independent of the [w] effect. In a more rigorous test of the conditioning effects in the lexicon using a Maximum Entropy grammar learner (see §5), it was found that the hiatus effect is present in both the all-stems and the verb-stems data when all other irrelevant factors are controlled for, despite the small difference between ‘other C(s)’ and ‘hiatus’ in the all-stems data shown in Figure 7. Thus, one can say that the hiatus effect in the suffix alternation, presented earlier in Figure 3 and again in Figure 7 with all categories aggregated, has a matching phonotactic generalisation.
Comparing ‘[w]’ and ‘other C(s)’, we see that the effect of intervening [w] in discouraging harmony is clear in the alternation data (as we already saw in Figure 3) and in the two sets of phonotactic data. Then, regardless of the type of data, [a] is disfavoured after [w], compared to after non-[w] consonants. Therefore, the behaviour of p-irregular stems dispreferring [a]-initial suffix forms align with the gradient phonotactic constraint that disprefers [wa] in the lexicon. One caveat is that only a small number of stems in the phonotactic data had [w] as the intervening consonant, especially in the verb-stems data, where only seven stems were found for the category [w]. This might explain why the observed tendency of [w] to discourage harmony is not reliably supported by the statistical testing, as will be reported shortly.
5. A Maximum Entropy grammar learning model
5.1. Maximum Entropy grammar
The variable harmony of the suffix alternation and of the lexicon was analyzed within the framework of Maximum Entropy (MaxEnt) grammar (Smolensky Reference Smolensky, Rumelhart and McClelland1986; Goldwater & Johnson Reference Goldwater and Johnson2003) in order to formalize the harmony and to statistically test whether the same factors that condition the alternation harmony also modulate the phonotactic harmony. In phonological variation, a MaxEnt grammar can model statistical tendencies observed in a variable pattern by assigning numerical weights to Optimality-Theoretic (OT) constraints, each of which encodes some factor that regulates the variation. The weights are calculated to maximise the probability of the observed frequencies in the data. For phonotactic data, specifically, I adopted a MaxEnt theory of phonotactics proposed in Hayes & Wilson (Reference Hayes and Wilson2008).
A conditioning factor of the variable harmony was regarded as having a significant effect when the relevant constraint was assigned a non-zero (positive) weight and determined to significantly improve the model fit to the data. To find the constraints that significantly improve the model fit, I first constructed models with all possible combinations of constraints. For instance, there are four test constraints in the alternation learning (see (15)), and each constraint can either be included in the model or excluded, resulting in 16 (
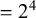 $= 2^4$
) models that differ in the set of test constraints they include. Then I selected the model with the lowest Akaike Information Criterion (AIC), a measure that takes into account both the goodness of the fit to the data and the simplicity of the model (i.e., the number of free parameters). Constraints included in this minimal adequate model were considered to significantly improve the model performance.
$= 2^4$
) models that differ in the set of test constraints they include. Then I selected the model with the lowest Akaike Information Criterion (AIC), a measure that takes into account both the goodness of the fit to the data and the simplicity of the model (i.e., the number of free parameters). Constraints included in this minimal adequate model were considered to significantly improve the model performance.
All the learning simulations were conducted in maxent.ot package in R (Mayer et al. Reference Mayer, Tan and Zuraw2022). For all constraints, the default or expected weight μ was set at 0, meaning that no prior bias was given to the weights, and σ was assigned a large value of 100,000, meaning that the constraint weights are allowed to deviate from the default weight with little penalty. The upper bound of each weight was set at 50. The materials for the learning simulation can be obtained from the OSF page https://osf.io/tjcqr/?view_only=9e6077702ee44344b449459c9a415f14.
5.2. Learning data
The corpus frequencies reported above in §§3 and 4 were used as learning data. For the alternation learning, there were a total of 12 types of input forms for [RTR] stem vowels, resulting from all possible combinations of the conditioning factors, that is, suffix type (/-A/ ‘decl’ vs. other suffixes), stem vowel (/a/ vs. /o/), the number of intervening consonants (0 vs. 1 or more) and the stem type (regular vs. p-irregular). The observed frequencies of a single input type fed to the model was split based on the ratio between the harmonic and disharmonic forms. Let us take as an example the input type with the /-A/ ‘decl’ suffix, stem vowel /a/, one or more consonants and a regular stem. There were 38 such words in the corpus, and the average harmony rate of these words was 0.29; thus, the frequency for the harmonic form was entered as
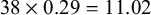 $38 \times 0.29=11.02$
, and that of the disharmonic form as
$38 \times 0.29=11.02$
, and that of the disharmonic form as
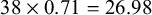 $38 \times 0.71=26.98$
. For [ATR] stem vowels, which exhibited a categorical harmony regardless of the phonological (e.g., stem vowel type) or morphological (e.g., suffix type) environments, there was only one input type with two outcomes [a] and [ʌ], that is, the input type was not divided into subtypes according to the properties of the word.
$38 \times 0.71=26.98$
. For [ATR] stem vowels, which exhibited a categorical harmony regardless of the phonological (e.g., stem vowel type) or morphological (e.g., suffix type) environments, there was only one input type with two outcomes [a] and [ʌ], that is, the input type was not divided into subtypes according to the properties of the word.
The phonotactic learning data included stems that have V1 as any of the seven vowels, and V2 as either [a] or [ʌ]. I performed two separate sets of learning simulations: one for the all-stems data and the other for the verb-stems data. The learning data consisted of 42 types of V1C0V2 sequences, that is, all possible combinations of V1, V2, the number of intervening consonants (0 vs. 1 or more) and the type of consonant ([w] vs. others).
5.3. Constraint set
The constraints included in the alternation modelling are presented in (15). There were two types of constraints: baseline constraints and test constraints. The test constraints were those listed in (15b), each of which accounts for some factor that affects the harmony, and the primary goal of the modelling was to test whether each can explain a significant amount of variance in the harmony. The baseline constraints, shown in (15a), explain the general tendency to harmonise. When these baseline constraints are included in the model, we are able to assess the explanatory power of the test constraints above and beyond the general harmony, and test whether the harmony is especially encouraged in specific contexts. The baseline constraints were included in every model that was compared against each other (following the model comparison method explained in §5.1); it is only the test constraints that were tested for their significance in improving the model.

Two things should be noted about the constraints in (15). First, they are in large part segment-based. That is, rather than defining Agree as ‘An [RTR] vowel is followed by an [RTR] vowel, and an [ATR] vowel is followed by an [ATR] vowel’, I defined it as ‘An [RTR] vowel is followed by [a], and an [ATR] vowel is followed by [ʌ]’. These more specific, segmental constraints align better with the unique properties of the Korean vowel harmony, in which only two vowels participate, although their definitions may seem somewhat ad hoc. The same constraints are used in the phonotactic learning as well (see (16)). Given the analytic choice made in §4 that the phonotactic data including only [a] and [ʌ] in V2 should be used to be compared against the alternation, employing the segment-based constraints makes more sense in this regard, too.
Second, the constraints are rather descriptive. Notably, the constraint in (15b-iv) explains the effect of stem type by militating against [RTR][wa] sequence, with an additional note that this constraint penalises only those cases in which [w] is derived from /p/ (of a p-irregular stem). Previous studies have employed different mechanisms within the framework of OT to account for the effect of p-irregular stems (e.g., cophonology in Kang Reference Kang2012; lexically indexed constraints in Hong Reference Hong2008). In the current discussion, I abstract away from choosing the exact formalisation of the phenomenon and introduce a rather ad hoc constraint *[RTR][wa]. One advantage of employing this constraint is that the same constraint can be used in explaining the harmony in the lexicon with a minimal change in its definition (see (16b-v)), as one of the claims the current study tests is that some trends in the alternation are aligned with those of phonotactics.
The constraints used to model the phonotactic data are presented in (16). As was the case in alternation learning, the phonotactic model also includes baseline constraints. First, the unigram constraints in (16a-i–16a-ix) penalise each vowel in each position.Footnote 13 The constraints in (16a-x–16a-xiii) and (16a-xx) and (16a-xxi) militate against the contexts in which the strength of (dis-)harmony is tested, and (16a-xiv) accounts for the potential preference for two identical vowel sequences. These constraints, along with the more general Agree constraints in (16a-xv–16a-xix) are included to test whether the observed harmony in specific environments is simply a phonotactic pattern; for instance, in testing whether the harmony is significantly encouraged in hiatus context when V1 is [RTR] (i.e., Agree(RTR)-VV in (16b-iii)), we want to make sure that the preference for VRTRVRTR, if any, is not merely a preference for VV sequences in the lexicon, prevalence of [a] in V1 or in V2, and so on.

Note that for an effect of interest (e.g., trigger vowel effect), there is only one test constraint in the alternation analysis (e.g., Agree(RTR)-/o/; see (15b-ii)) but two relevant test constraints in the phonotactic analysis (e.g., Agree(RTR)-/a/ and Agree(RTR)-/o/; see (16b-i) and (16b-ii)). This is because in alternation learning, Agree(RTR)-/a/ and Agree(RTR)-/o/ interact with all other constraints in exactly the same way; two forms that differ only in their trigger vowel will be penalised by the same set of constraints except Agree(RTR)-/a/ and Agree(RTR)-/o/.Footnote 14 This is not true in the phonotactic model. For instance, the forms that are penalised by Agree(RTR)-/a/ will also be penalised by *[a] in V1, while those that are penalised by Agree(RTR)-/o/ will also be penalised by *[o] in V1. It is therefore necessary to include both Agree(RTR)-/a/ and Agree(RTR)-/o/ in the constraint set to test which of them gets a positive weight.
5.4. Learning results
The results of the learning simulations are presented in Table 5, which shows the learned weights for constraints that were retained in the model with the lowest AIC value. For the alternation data, it was found that the best model was the one that includes all of the four test constraints. Thus, the modelling results suggest that all four factors – that is, suffix type, stem vowel, number of intervening consonants and the stem type – significantly improve the model fit.
Table 5 Results of the learning simulation: the models with the lowest AIC values (an empty cell indicates that the constraint is not included in the learning data).
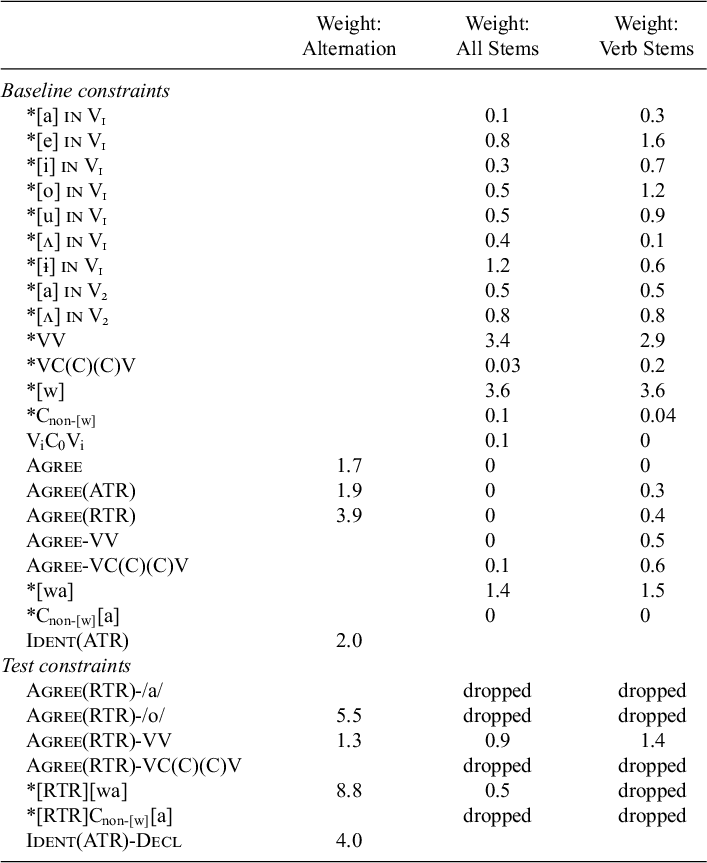
For the all-stems data, Agree(RTR)-/a/ and Agree(RTR)-/o/ were not included in the best model identified, suggesting that the lexicon does not show a preference for [aa] or [oa] sequences. This result confirms what was observed in Figure 6, that is, no difference between [a] and [o] in triggering the harmony. This result does not support the hypothesis that the trigger vowel effect that was shown to significantly improve the alternation model has a matching phonotactic pattern (but see §§6 and 7 for an alternative view). Regarding the hiatus effect, Agree(RTR)-VV was assigned a positive weight, while Agree(RTR)-VC(C)(C)V was omitted in the model, suggesting that there is a trend in the lexicon to prefer harmony in the hiatus context. This was not obvious in Figure 7; it seems that the preference for harmony in the hiatus context in the lexicon was masked by some other confounding factors. Because the constraint that enforces harmony in the hiatus context significantly improved both the alternation model and the phonotactic model, we can conclude that the alternation and phonotactic patterns match in terms of the hiatus effect. Finally, comparing *[RTR][wa] and *[RTR]Cnon-[w][a], only the former was judged to significantly improve the model. This is in line with the observation in Figure 7 that [a] is disprefered only after [w] when V1 is [a] or [o].
The learning results for the verb-stems data were similar to those of the all-stems data. The only difference was that the *[RTR][wa] was dropped in the verb-stems model. This seems to be because the number of stems in the verb-stems data that had [w] between the two vowels was very small (
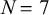 $N=7$
; see Figure 7). Otherwise, we can draw similar conclusions as we did for the all-stems data.
$N=7$
; see Figure 7). Otherwise, we can draw similar conclusions as we did for the all-stems data.
5.5. Summary
In sum, the learning simulation results generally support the claim that alternation is productive to the extent that it is supported by phonotactic patterns. We first observed that the harmony in suffix alternations is supported by a feeble tendency of harmony in the lexicon (§4), which might explain why the harmony is losing productivity. Further, we found a fair degree of, although not perfect, correlation between factors that modulate the harmony in alternation and those of the lexicon. The hiatus effect improved the model performance in both the alternation learning and the two sets of phonotactic learning. Similarly, the effect of [w] was significant in both the alternation model and the all-stems model. The trigger vowel effect, however, improved the model fit to the alternation data but did not significantly improve any of the phonotactic models. (The lack of phonotactic support for the trigger vowel effect is further discussed in §§6 and 7.) Thus, the findings suggest that (i) there is a link between alternation and phonotactics at the level of the general harmony, and (ii) for some factors that regulate the variable harmony in alternation, matching phonotactic generalisations emerge in the lexicon.
6. Productivity tests in previous research
In this section, I review a phonotactic judgement rating experiment that tested Korean speakers’ knowledge about the morpheme-internal harmony pattern and productivity tests of the harmony in verbal inflection, and discuss how findings of the present study could relate to the findings of these previous studies. The phonotactic judgement test showed that the native speakers have not internalised the feeble tendency towards harmony in the lexicon (Jun et al. Reference Jun, Byun, Park and Yeeto appear), and productivity tests showed that they do not reproduce harmony with wug stems (Kang Reference Kang2012; Jang Reference Jang and Erlewine2017). To the best of my knowledge, there is no study which has tested the same speakers’ intuition about the harmony pattern both within morphemes and in verbal inflection.
Jun et al. (Reference Jun, Byun, Park and Yeeto appear) conducted a phonotactic judgement experiment by asking Korean speakers to rate nonce harmonic and disharmonic forms on a Likert scale of 1 (unlikely as a Korean word) to 6 (likely as a Korean word). It was found that the mean rating of harmonic forms was not higher than that of disharmonic forms, suggesting little evidence that harmonic forms were more acceptable than disharmonic ones. They also report that disharmonic vowel sequences are not underrepresented in the Korean lexicon, since their MaxEnt simulation learned no constraints against disharmonic vowel sequences from the lexicon. Their findings are in line with the results of the current corpus study that the phonotactic harmony is only moderate.
Productivity tests reported in Kang (Reference Kang2012) and Jang (Reference Jang and Erlewine2017) demonstrated that the harmony pattern is not fully reproduced in wug tests. In the production experiment in Kang (Reference Kang2012), two striking results were found. First, when the /-A/ ‘decl’ suffix was employed, the proportion of harmonic forms was only 32.0% for nonce /a/- and /o/- stems, as compared to 76.7% for real stems. The proportion of [a] response did differ between [ATR] and [RTR] stem vowels (32.0% vs. 0%), so harmony is active to some extent, but the results suggest a limited productivity. Given the finding of the present study that harmony in the stem phonotactics is rather weak, and Jun et al.’s (Reference Jun, Byun, Park and Yeeto appear) finding that such weak phonotactic harmony is not internalised by the native speakers, one possible cause of underlearning of alternation harmony reported in Kang (Reference Kang2012) may be the lack of phonotactic support for the harmony in alternation.
Second, in the same study, unlike in real stems where a trigger vowel effect emerged, nonce /a/- and /o/-stems were very similar in their probability of taking a harmonic suffix (although this result might not be as reliable due to the small number of stimuli – 15 /a/-stems and 5 /o/-stems). We have seen that the trigger vowel effect was very weak in phonotactics, which leads to the conjecture that the lack of difference between /a/ and /o/ as a trigger vowel in the lexicon may be one factor that accounts for the absence of the trigger vowel effect in nonce stems. The effect of the number of intervening consonants between the trigger and the target vowel was not tested. Given the significant hiatus effect in the lexicon (§5), if the productivity of an alternation indeed increases when there is a matching phonotactic pattern, we expect that speakers in a wug test would produce more harmonic forms in hiatus contexts than in non-hiatus ones.
Another wug test, presented in Jang (Reference Jang and Erlewine2017), also demonstrates low productivity of harmony. In this experiment, as in Kang’s experiment, speakers frequently produced disharmonic suffixes for /a/- and /o/-stems. What is striking is that a few speakers even volunteered the disharmonic [a]-form for [ATR] stem vowels, despite the exceptionless harmony pattern for [ATR] stem vowels in real words. Once we consider that the [ATR] harmony is maintained only weakly in the lexicon (see §4), however, such aberrant behaviour by the speakers may not be very surprising; lack of phonotactic grounds for perfect [ATR] harmony might have led some speakers to depart from it.
In sum, an existing phonotactic well-formedness rating experiment and wug tests on the harmony pattern demonstrate that the harmony is not very productive in the alternation, and the speakers are not fully aware of the harmony pattern in the lexicon. Taken together with the findings of §4, we can infer that the low productivity of suffix alternation might be ascribed to the lack of robust phonotactic support. A more rigorous test of the link between alternation and phonotactics would be to test the same speakers’ phonotactic well-formedness judgements and their intuitions about suffix alternations in nonce verbs to see whether the two types of generalisations are correlated.
7. Discussion
The current study investigated the variable pattern of vowel harmony in Contemporary Korean in a spoken corpus and compared gradient vowel co-occurrence restrictions in the lexicon to the harmony pattern. This study, therefore, adds to existing body of research on correlation between productivity of alternation and the degree to which phonotactics and alternation match. Table 6 summarises the results of this study and previous findings for cases in which the trigger vowel (or V1 for phonotactics) is [a] or [o].
Table 6 Summary of the harmony pattern in alternation and phonotactics (* indicates that the effect was not statistically tested using a regression analysis or a MaxEnt analysis).
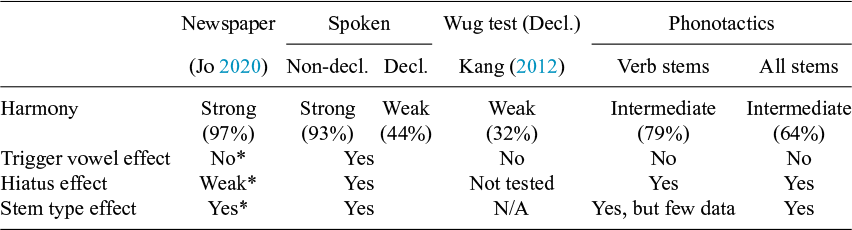
The overall harmony rate was highest in the suffix alternation in the newspaper corpus (Jo Reference Jo2020), which is presumably the most formal and conservative register in Korean. The harmony rate was slightly lower in the non-declarative portion of the spoken data, but harmony still applied quite regularly; in comparison, the declarative portion had a significantly lower rate of harmony, suggesting that harmony has begun to retreat in the /-A/ ‘decl’ suffix. As mentioned earlier, the /-A/ ‘decl’ portion represents data that are exclusively casual, while other suffixes are either only used in a polite speech level or can be used in various speech levels as they do not encode politeness of the utterance. Given that in typical stages of rule death, the breakdown of a phonological process begins in the most vernacular register of the language (Labov Reference Labov1966, Reference Labov1972), Korean vowel harmony seems to be at the beginning stage of rule breakdown in which the harmony rate was highest in the newspaper data and lowest in the spoken data with /-A/ ‘decl’.Footnote 15 In the wug test reported in Kang (Reference Kang2012), as reviewed in §6, the harmony rate was even lower. The continuum of harmony rate conditioned by register, suffix type and the real/nonce status of the stem adds another piece of evidence to the existing literature on decay of the harmony.
The harmony rates in phonotactics were intermediate, falling between harmony rates of highly harmonic alternation data (i.e., the non-declarative data) and those of weakly harmonic alternation data (i.e., the declarative data) (§4). The phonotactic restrictions in the lexicon, therefore, support the standard pattern of harmony of the suffix alternation only moderately. I suggest that the loss of productivity in alternation is (at least partially) attributable to the fact that stem phonotactics matches the alternation pattern only weakly. One caveat is that the findings do not provide evidence that lack of phonotactic support is the sole or primary cause of the decline of the harmony. There may be other factors that contribute to the rule breakdown. First, the harmony is a formally complex pattern, having no single distinctive feature that governs it (see §2.1), which makes the pattern difficult to learn. Further, only a subset of the vowels participate in the harmony, which makes the process rather marginal in the language and thus prone to erasure. The present study found another possible cause of the retreat of the harmony, that is, a mismatch between phonotactics and alternation, which does not preclude other hypotheses about the cause of the rule breakdown, but which may serve as one of the contributing factors.
Moreover, this study replicated the effects of the phonological and morphological factors that have been reported to regulate harmony in alternations, that is, the trigger vowel effect, the hiatus effect and the stem type effect (Kim-Renaud Reference Kim-Renaud1976; Cho Reference Cho1994; Hong Reference Hong2008; Kang Reference Kang2012). In the MaxEnt learning of the alternation data (§5), all three of these factors were found to significantly affect the harmony pattern. I also investigated whether there is phonotactic support for each of these effects. It turns out that alternation that takes place in the contexts for which there is a matching phonotactic pattern tends to be more productive. As for the trigger vowel effect, it is not phonotactically motivated, since neither set of phonotactic data showed a difference in the harmony rate between V1=[a] and V1=[o]. At first glance, given the significant effect of the trigger vowel in alternation, this finding seems to be at odds with the hypothesis that alternation is productive (only) when there is a matching phonotactic pattern. However, once we consider the wug test result in Kang (Reference Kang2012), the trigger vowel effect is not fully productive in the language, in fact supporting the hypothesis that alternation learning is limited when there is no matching phonotactic generalisation. An effect of the number of intervening consonants was found in the phonotactic learning simulation, aligning with the hiatus effect in the alternation. The hiatus effect was not tested in Kang’s wug test. If, in future wug tests, speakers show the (phonotactically supported) hiatus effect while not showing the (phonotactically unsupported) trigger vowel effect, it would suggest another strong piece of evidence for the link between alternation and phonotactics. The relationship should be further tested by examining the productivity of an alternation in wug tests and phonotactic judgement for nonce stems in the same individuals. The effect of intervening [w] between two vowels in the lexicon was very clear, except that it was statistically non-significant in the verb stems, probably due to the small number of cases with an intervening [w].
Overall, the findings suggest that the alternation is more likely to be productive when there is phonotactic support. Further, I propose that the reason for the correlations between strength of phonotactic support and alternation productivity shown in this study and Chong (Reference Chong2019) may be a causal relationship, that is, matching phonotactics facilitates alternation learning (Chong Reference Chong2021).
7.1. Single or dual mechanism?
The findings of the present study suggest that even stem phonotactics exhibits harmony in Korean, albeit gradient and weak, echoing findings of previous research (Hong Reference Hong2010). And, we can reasonably think that the alternation is losing productivity because the support from the stem phonotactics is only moderate. If lack of phonotactic support is the reason the alternation is losing productivity, this is inconsistent with phonological models that posit no link between the two levels of generalisations (Hale & Reiss Reference Hale and Reiss2008; Paster Reference Paster2013). As reviewed in §1, some theories posit a single component for both generalisations, such as a basic OT model in which a single output constraint accounts for both within-morpheme and across-morpheme generalisations. In this section, I show that a single constraint that enforces harmony in both alternation and phonotactics is enough to explain the link between phonotactics and alternation in a toy version of Korean vowel harmony. The constraint weights and output probabilities are calculated using the Solver utility of Microsoft Excel (Fylstra et al. Reference Fylstra, Lasdon, Watson and Waren1998), which transparently displays calculations and especially comes in handy when there are a small number of constraints. The Excel spreadsheet may be obtained from the OSF page https://osf.io/tjcqr/?view_only=9e6077702ee44344b449459c9a415f14. In a nutshell, when the lexicon is harmonic, the weight of the harmony constraint goes up, which increases the predicted probability of harmonic forms in the alternation; conversely, when the lexicon is unbiased with regard to harmony, the weight of this constraint is lower, and the probability of harmonic forms in alternation is dragged down.
I use three constraints in (17) to model two types of toy Korean data, one with a perfectly harmonic lexicon and the other with an unbiased lexicon, the latter of which is more similar to the real Korean lexicon. For expository purposes, constraints (17a) and (17b) are simplified versions of those used in §5. Also, note that a new Ident constraint (17c) is used here to prevent the change of [ATR]/[RTR] specification of vowels in disharmonic stems (e.g., [namu] ‘tree’, [ʌmma] ‘mom’) and non-harmonizing suffixes (e.g., [mak-ɨni] ‘block-as’). This contraint is lexically indexed (Pater Reference Pater2000, Reference Pater2007) to the forms that do not alternate for harmony.

In each model presented below, the default weight μ is always set as zero for all constraints. The σ of the weights, which indicates how closely the model fits the data, was assigned a relatively small value of 10.Footnote 16 In Table 7, the lexicon is equally divided between harmonic forms (stems with an [RTR][RTR] sequence, represented in the tableau by [op*a] ‘older brother’, and stems with [ATR][ATR], represented by [uri] ‘we’) and disharmonic ones (stems with an [RTR][ATR] sequence, represented by [namu] ‘tree’, and stems with [ATR][RTR], represented by [ʌmma] ‘mom’). This dataset resembles the actual Korean lexicon in that the stem portion of the learning data contains many disharmonic forms. The (inflected) verb portion of the mini data, presented in the bottom half of the tableau, also resembles the Korean data – both harmonizing suffixes (represented by /-ʌjo/ ‘declarative (polite)’) and non-harmonizing suffixes (represented by /-ɨni/ ‘as’) are included. The ratio between the sizes of the stem portion and the verb portion is set as 50:1 to reflect that stems far outnumber suffixed words.
Table 7 Modelling Mini-Korean: unbiased lexicon.

In Table 8, the stem portion consists only of harmonic forms, and non-harmonizing suffixes are also removed from the dataset to represent a hypothetical, perfectly harmonic Korean. Although in the actual Korean data harmony is retreating in the /mak-ʌjo/-type verbs, the proportion of harmonic forms is entered as 100% in the input (‘observed frequency’ of harmonic forms is 1 and that of disharmonic forms is 0) to see if the models are able to underpredict the probability of the harmonic form. This serves as a simple simulation of the retreat of the Korean vowel harmony over time.
Table 8 Modelling Mini-Korean: harmonic lexicon.

Comparing the results of Tables 7 and 8, the probability of the harmonic suffix forms goes down when the lexicon is less harmonic (see the shaded cells in each tableau). This is because the weight of Agree is relatively low when the lexicon is less harmonic, leading to a lower probability of harmonic forms in alternation as well. As can be seen in the shaded cells, the probability of harmonic forms for the verbal suffixes in question is only 0.90 when the lexicon has equal numbers of harmonic and disharmonic forms, whereas it is 0.98 when the lexicon contains only harmonic forms. Note that in the unbiased lexicon in Table 7, the predicted probability of the harmonic form for /mak-ʌjo/ is 0.90, even though the learning data exhibit a perfectly harmonic alternation (1.0). This learning result indicates that the grammar underlearns the alternation harmony and further suggests the decline of harmony over time. The model simulates, for example, a situation in which speakers of one generation produce only harmonic forms for the verbal suffixes (similar to the harmony in Middle Korean) but the next generation produces about 90% of what the previous generation did (similar to the harmony in Contemporary Korean). The rate of decay would depend on the proportion of harmonic forms in the lexicon and other parameters of the model such as σ.Footnote 17
We have observed that with a single structure-blind Agree constraint that enforces harmony in both phonotactics and in alternation, it was possible to model the link between the two levels of generalisation. When the lexicon is harmonic, the weight of the Agree constraint goes up, which in turn raises the probability of harmonic forms in the alternation, and conversely, when the lexicon is not particularly harmonic, Agree receives a relatively low weight, hence a lower probability for harmonic forms in the alternation. How would the learning results turn out if the grammar had a structure-sensitive Agree suffix constraint that boosts harmony only in alternation, in addition to the general Agree constraint already included in the model above? A series of analysesFootnote 18 indicated that when Agree suffix is added to the grammar, the gap between the unbiased lexicon and the harmonic lexicon becomes smaller, that is, 95% vs. 99%. This is because as the lexicon gets more harmonic, the weight of structure-blind Agree does go up, but then the weight of Agree suffix is able to go down. Because the work of Agree suffix only cancels out the effect of Agree, having only structure-blind Agree in the grammar is sufficient to model the effect of lexicon harmony on the alternation harmony. The analysis proposed here, therefore, is in line with previous studies that suggest a single mechanism for both phonotactic and alternation learning (Matthews Reference Matthews1972; Sommerstein Reference Sommerstein1974; Hayes Reference Hayes, Kager, Pater and Zonneveld2004; Pater & Tessier Reference Pater, Tessier, Slabakova, Silvina and Prévost2006; Tesar & Prince Reference Tesar and Prince2007).
Having established a link between phonotactics and alternation, it is worthwhile to discuss the artificial grammar learning experiments in Chong (Reference Chong2021). Experiment 1 showed that alternation learning was successful when the phonotactics matched the alternation, but was hindered when it was not supported by phonotactics. Experiments 2 and 3, however, suggested that the effect of phonotactic knowledge on alternation learning is somewhat limited; the learners were unwilling to extend learned phonotactic knowledge to alternation if they had not seen it in the training. Based on these findings, Chong suggests that phonotactic and alternation learning mechanisms are unlikely to be completely isomorphic and that models with a single mechanism may not be enough to explain the nuanced relationship between phonotactics and alternation. The proposal of the present article, in which only a single constraint was sufficient to explain the harmony at both levels of generalisation and the link between the two, may not be able to fully explain the results of the artificial grammar learning experiments. The question of whether the (limited) effect of phonotactics on alternation learning of an artificial language parallels what actually happens in learning alternations in a natural language is left for future research.
7.2. Implications for DEEs
Previous accounts of DEEs mentioned in §1.1 (Kiparsky Reference Kiparsky and Fujimura1973; Mascaró Reference Mascaró1976; Kiparsky Reference Kiparsky, Kaisse and Hargus1993; Łubowicz Reference Łubowicz2002; McCarthy Reference McCarthy2003) have mostly focused on explaining the discrepancy between alternation and stem phonotactics and proposed different mechanisms by which a phonological process applies only across morpheme boundaries. Most of these frameworks cannot capture the observation that phonological generalisations that hold in the lexicon could align with those of the alternation, or how this link could affect learning of the alternation. These frameworks may capture the mismatch between the static and the dynamic generalisations of the Korean vowel harmony, but they are unlikely to attribute the declining productivity of alternation harmony to the lack of phonotactic support. Further, while most of these accounts do not deal with gradient patterns of stem phonotactics and alternation, the present study concerns a case in which both phonotactics and alternation are probabilistic.
Chong (Reference Chong2019), by contrast, argues that in some of the known cases of DEEs, the reported mismatches between phonotactics and alternations are only superficial once we look at the quantitative patterns (as exemplified by Korean palatalisation mentioned in §1.1). He also argues that when the phonotatics–alternation mismatch is real, as in Turkish velar deletion, the alternation actually occurs in limited contexts, evidenced by the finding that Turkish velar deletion applies productively only in polysyllabic nouns. Based on a few case studies including these two processes, Chong argues that the phonological processes labelled as DEE are variegated in terms of how productive the alternation is and how strong the phonotactic support for the alternation is, and suggests that a derived environment rule is productive to the extent that it is supported by phonotactics.
The findings of the present study are generally in line with Chong’s prediction. Korean vowel harmony turns out to be a case in which phonotactics matches alternation only moderately, and the alternation is productive in restricted contexts, that is, [a]/[ʌ]-initial suffixes. This is similar to the case of Turkish velar deletion in that alternation with weak phonotactic support occurs in limited contexts, although the Korean case presents yet another unique case of DEE; while Turkish velar deletion is morphologically conditioned, Korean vowel harmony can be viewed as phonologically conditioned, since it applies to all [a]/[ʌ]-initial suffixes (which all happen to be verbal suffixes). The present study shows that the phonotactics–alternation link in Korean vowel harmony can be explained by a single OT constraint and that less harmony in the lexicon lowers the harmony in alternation. A DEE in which the alternation has weak phonotactic support can be explained by a similar mechanism.
8. Conclusion
The present study investigated Korean vowel harmony in suffix alternation and gradient harmony patterns in the lexicon, and argued that the loss of productivity of the alternation harmony may be attributed to weak phonotactic support for the harmony. The findings of the present study enrich our understanding of the link between alternation and phonotactic patterns in another process described as a DEE, using statistical and quantitative approaches. At the broader level, the overall weakness of phonotactic harmony was proposed to drive the weakening of suffix harmony currently underway. At the more specific level, phonotactics tends to affect which environments the harmony remains strong in. The present study, therefore, advances our understanding of how closely alternation and phonotactics are related and takes a step further in fleshing out the typology of DEEs.
Acknowledgements
I would like to thank three anonymous reviewers and editors for their comments on previous versions of this work. I would also like to thank Bruce Hayes, Kie Zuraw and Claire Moore-Cantwell for their guidance and advice. Thanks also to Thomas Bye, Mi-Hui Cho, Jongho Jun, Ji-eun Kim, UCLA’s statistical consulting group, as well as audiences at the 2020 Annual Meeting on Phonology, the Linguistic Society of America 2021 Annual Meeting and the UCLA phonology seminar for their invaluable input. All remaining errors are my own.
Competing interests
The author declares no competing interests.
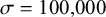
















 Open access
Open access