



1. Introduction
Question answering (QA) (Mishra and Jain Reference Mishra and Jain2016) extracts accurate, relevant, and factual information (in any natural language) from various sources, such as web pages, natural language documents, or structured databases, to provide answers to user queries. Information extraction (IE) (Chang et al. Reference Chang, Kayed, Girgis and Shaalan2006), information retrieval (IR) (Singhal et al. Reference Singhal2001), and many related natural language processing (NLP) tasks get benefits from QA. Traditional search engines focus on identifying relevant documents, and QA system aims to deliver precise answers within those documents. Multilingual question answering (MQA) (García-Cumbreras et al. Reference García-Cumbreras, Martínez-Santiago and Ureña-López2012) broadens QA for multiple languages, allowing users to communicate with the system using their native language and retrieve information from multilingual documents. While monolingual QA systems are prevalent, the growing volume of multilingual content on the internet necessitates the development of robust MQA systems. MQA systems aim to overcome the challenges posed by typological, grammatical, and syntactical differences between languages (Clark et al. Reference Clark, Choi, Collins, Garrette, Kwiatkowski, Nikolaev and Palomaki2020) to provide accurate answers across different languages.
The research community has made progress in developing MQA models. However, the development of MQA systems requires adequate linguistic resources. Currently, English has abundant NLP resources, whereas Hindi and Marathi (ranks third and fifteenth in the world,Footnote a respectively), despite being widely spoken languages, lack sufficient resources and tools. The research community has made efforts to develop datasets for English and Hindi languages, including the MMQA (Gupta et al. Reference Gupta, Kumari, Ekbal and Bhattacharyya2018), Translated SQuAD (Gupta, Ekbal, and Bhattacharyya Reference Gupta, Ekbal and Bhattacharyya2019), XQuAD (Artetxe, Ruder, and Yogatama Reference Artetxe, Ruder and Yogatama2020), and MLQA (Lewis et al. Reference Lewis, Oguz, Rinott, Riedel and Schwenk2020) datasets with a maximum sample of 18,454 in the Translated SQuAD dataset. For the Marathi language, no such efforts have been made to construct the dataset. Therefore, there is a need for an MQA benchmark dataset specifically tailored for the English-Hindi-Marathi language. To address these limitations, a comprehensive dataset for English, Hindi, and Marathi languages is created, employing a synthetic corpus generation approach leveraging the characteristics of Hindi and Marathi languages.
Additionally, the existing approaches for designing an MQA system use zero-shot/few-shot, translate-train, and translate-test to transfer knowledge from English to other languages. These approaches were inefficient in developing a unified QA system to understand the various languages. This motivates us to develop a unified MQA framework for English, Hindi, and Marathi languages. The proposed framework is an abstract structure that adapts to many different languages. The proposed model, EHMMQA, utilizes a deep learning approach with an attention-based recurrent neural network (RNN) to generate representations of questions and context in multiple languages. The model is trained on the proposed EHMQuAD dataset and evaluated on numerous benchmark datasets. The result outperforms baseline models in monolingual and multilingual settings and demonstrates its effectiveness and superiority, emerging as a state-of-the-art model for Hindi and Marathi languages.
For a given question
 $q$
, written in English, Hindi, or Marathi, the MQA system will return the precise answer from comparable documents
$q$
, written in English, Hindi, or Marathi, the MQA system will return the precise answer from comparable documents
 $\big\{D_i^N\big\}$
. The key contributions of the proposed model are highlighted as follows:
$\big\{D_i^N\big\}$
. The key contributions of the proposed model are highlighted as follows:
-
(1) Developed an MQA benchmark dataset for Indian languages accompanying the English language to access multilingual information.
-
(2) Designed and implemented an end-to-end MQA model employing an RNN and attention mechanism.
-
(3) Evaluated the proposed EHMQuAD dataset on the EHMMQA model, and a comparative analysis was conducted to assess the EM and F1-score results compared to several baseline models.
The remainder of the paper is structured as follows. Section 2 reviews related work on monolingual and multilingual QA systems. Section 3 presents the methodology, including dataset development, error analysis of the proposed dataset, and the proposed end-to-end MQA system. Section 4 describes the evaluation metrics and experimental setup for monolingual and multilingual settings. Section 5 analyses the results and conducts an ablation study of the proposed work. Finally, Section 6 presents the conclusion and future work.
2. Related work
MQA has gained popularity since the track’s inception by the Cross-Language Evaluation Forum (CLEFFootnote b). Although most of the MQA systems came up with the machine translation of either of the languages to obtain the answer from the context, the translated results were less accurate (García Santiago and Olvera-Lobo, Reference García Santiago and Olvera-Lobo2010), which deteriorated the system’s performance as the capability of machine translation was low before the evolution of Deep Learning (DL) models (Türe and Boschee, Reference Türe and Boschee2016). Recent advancement in the field of DL enhances the accuracy of machine translation for MQA systems; however, the accuracy is still low due to the limited resources for various languages. The summary of the recent work on multilingual QA systems for Indic and non-Indic languages is described in the following subsections.
2.1 Multilingual QA systems for Indic languages
There is a noticeable scarcity of research in the literature pertaining to the application of MQA tasks specifically for Indic languages. Gupta et al. (Reference Gupta, Kumari, Ekbal and Bhattacharyya2018) initiated the development of MQA for the Indic language considering only the Hindi-English language. In this work, the author has proposed an MQA system that answers the user’s question by identifying the probable snippets from the context and also developed the Multilingual & Multi-domain QA (MMQA) dataset for six domains. MMQA dataset was developed from 500 documents in English and Hindi language containing, 5,495 QA pairs. The author combined the Boolean and BM25 vector space models to retrieve and rank the top 30 passages from which the snippets are extracted to get accurate answers. The proposed dataset solely comprises factoid and short-descriptive question-answer pairs without incorporating any complex questions. To extend this work, Gupta et al. (Reference Gupta, Ekbal and Bhattacharyya2019) proposed a Deep Neural Network (DNN) based MQA model to generate snippets from passages irrespective of the language. This developed model inputs a factoid question and text from a multilingual passage in either English or Hindi and returns an answer based on the context. In this work, a shared representation of the question is learned using soft alignment between the words from both languages. This shared question representation and the original snippet are received as input to the answer extraction layer to generate the answer span. This extraction process considers the relevance of the question and snippet.
In addition, Gupta et al. (Reference Gupta, Ekbal and Bhattacharyya2019) developed a Translated SQuAD dataset to train the model and evaluated it on the Translated SQuAD and MMQA datasets. For evaluating the MMQA dataset, a novel snippet generation algorithm is proposed that takes questions and multiple documents as input and extracts a snippet that supports evidence containing the answer(s). During this process, a semantic graph for each document is generated (accounting WordNet dictionary and word embeddings) that possesses a lexico-semantic relationship between the pairs of sentences. The model cannot predict the correct answer for various reasons such as anaphora resolution problem, NER proximity error, and translation errors.
Lewis et al. (Reference Lewis, Oguz, Rinott, Riedel and Schwenk2020) presented the MLQA evaluation benchmark dataset, which uses a multiway aligned extractive technique to evaluate the QA system. It is created for seven languages: English (en), Arabic(ar), German (de), Hindi(hi), Simplified Chinese(zh), Spanish (es), and Vietnamese (vi). The author employed fine-tuning, translate-train, and translate-test approach to design an MQA system where the MLQA dataset is fine-tuned on BERT-Large (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), mBERT, and Cross-lingual Language Model (XLM) (Conneau and Lample, Reference Conneau and Lample2019) word representation models. While constructing QA pairs, the annotator focuses on a single sentence rather than multiple sentences. This leads to a reduction in sample size for languages other than English.
Another MQA dataset covering typologically diverse languages worldwide named TyDiQA (Clark et al. Reference Clark, Choi, Collins, Garrette, Kwiatkowski, Nikolaev and Palomaki2020) is created covering typological features of these languages. It comprises 204K QA pairs for 11 languages, including Telugu (te) and Bengali (bn) as Indic languages. The dataset is prepared using a crowd-sourced method instead of a machine translation approach. The qualitative analysis evaluates the linguistic phenomenon of these diverse languages in terms of data quality and example-level quality. The dataset’s quality is evaluated using a first passage baseline, mBERT model, and a human evaluator for the passage selection task. In contrast, only mBERT and human evaluation are used for minimal answer span.
2.2 Multilingual QA systems for non-Indic languages
Extensive research has also been conducted for non-Indic languages, employing diverse approaches. The subsequent section provides a detailed examination of their endeavors. The work of Chandra et al. (Reference Chandra, Fahrizain and Laufried2021) presents a thorough analysis of the advancements made in non-English Machine Reading Comprehension (MRC) and open-domain question answering (QA) datasets. The researchers reviewed QA datasets comprehensively across 14 prominent languages. In a notable study by Rogers et al. (Reference Rogers, Gardner and Augenstein2023), significant contributions of monolingual and multilingual QA/RC resources beyond the English language are surveyed, offering valuable insights into their typology, scope, and language coverage.
Carrino et al. (Reference Carrino, Costa-jussà and Fonollosa2020) proposed the Translate Align Retrieve (TAR) method to translate the SQuAD v1.1 dataset to the Spanish (es) language automatically. The author has developed SQuAD-es v1.1 (87595 QA pair) and SQuAD-es-small (46260 QA pair), where the first dataset contains all the translated examples with alignment, and the latter one keeps only those QA pairs without alignment. The author trained the Spanish QA systems by fine-tuning an mBERT model on these datasets. Experiments were performed on the MLQA and XQuAD benchmark datasets to evaluate this QA model.
MKQA-Multilingual Knowledge Question Answering (Longpre, Lu, and Daiber Reference Longpre, Lu and Daiber2021) is a large MQA dataset containing 260K QA pairs for 26 typologically diverse languages. The author used zero-shot and translation methods to extract the answers. During the experiment, the MKQA dataset is fine-tuned by various word representation models such as mBERT, RoBERTa (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019), XLM-R (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2020), and mT5 (Xue et al. Reference Xue, Constant, Roberts, Kale, Al-Rfou, Siddhant, Barua and Raffel2021). During the analysis of the MKQA dataset, it was observed that a few answers were missing from QA pairs. This issue arose due to challenges associated with the Retrieval-Independence problem and the re-annotation process. This led to difficulty capturing and including all answers in the dataset.
SK-QuAD (Hládek et al. Reference Hládek, Staš, Juhár and Koctúr2023) is a human-annotated MQA dataset for the Slovak (sk) language comprising 91K QA pairs from various domains. This dataset follows the structure of SQuADv2.0 (Rajpurkar, Jia, and Liang Reference Rajpurkar, Jia and Liang2018) dataset, where some QA pairs are unanswerable. The zero-shot approach is used along with the mBERT word representation model to evaluate the performance of the developed dataset. For annotation purposes, only two annotators were used instead of an odd number of annotators, which can cause ambiguity in selecting QA pairs. The comprehensive literature review witnessed that most of the MQA datasets and developed MQA system comprise only one language apart from English. This makes these systems either bilingual or cross-lingual but not multilingual.
3. Proposed methodology
To overcome the drawbacks found in the literature, a novel methodology is adopted for developing the EHMQuAD dataset (Section 3.1) and end-to-end MQA system (Section 3.3), considering English, Hindi, and Marathi languages. The following subsections elaborate the methodology including dataset development, error analysis of the proposed dataset, and the proposed end-to-end MQA system. Table 1 sums up the acronym and notation used in work for readability purposes.
Table 1. List of acronyms and notations used in the work

3.1 EHMQuAD dataset
As a classical probe to assess a machine’s ability to understand natural language, QA is an essential and challenging task for Machine Reading Comprehension (MRC) (Hermann et al. Reference Hermann, Kocisky, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015; Gupta and Khade Reference Gupta and Khade2020; Baradaran, Ghiasi, and Amirkhani Reference Baradaran, Ghiasi and Amirkhani2022). QA has made many advances in recent years, primarily by fine-tuning the deep pre-trained architectures and creating large-scale datasets (Pires, Schlinger, and Garrette Reference Pires, Schlinger and Garrette2019; Conneau and Lample Reference Conneau and Lample2019; Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2020). However, regarding MQA, the scarcity of annotated corpora for languages other than English poses a significant challenge. Hence, there is a need to develop an MQA dataset for low-resource language. There are two main approaches for creating an MQA dataset: Synthetic corpus generation and Cross-lingual learning methods. Synthetic corpus generation involves leveraging machine translation techniques to generate language-specific QA datasets (Carrino et al. Reference Carrino, Costa-jussà and Fonollosa2020), while the cross-lingual learning method uses few-shot and zero-shot (Lee and Lee Reference Lee and Lee2019; Zhou et al. Reference Zhou, Geng, Shen, Zhang and Jiang2021) strategies to transfer knowledge between two languages with minimal training samples.
EHMQuAD is a large-scale multilingual QA dataset that was developed using a modified version of the Translate-Align-Retrieve (TAR) method (Carrino et al. Reference Carrino, Costa-jussà and Fonollosa2020), which falls under the category of synthetic corpora generation techniques. The TAR method involves translating sentences from the widely used English SQuAD v1.1 (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) dataset into Hindi and Marathi languages. The translated sentences are aligned through a supervised alignment approach (Shi et al. Reference Shi, Huang, Jian and Tang2021). The English SQuAD v1.1 dataset is the primary source for generating the multilingual EHMQuAD dataset. SQuAD v1.1 is a well-known large-scale MRC dataset that consists of 87,599 question-answer pairs along with their corresponding context. Each sample in the SQuAD dataset is represented as a tuple
 $(q_{en},c_{en}, a_{en})$
, where
$(q_{en},c_{en}, a_{en})$
, where
 $q_{en}$
represents the question,
$q_{en}$
represents the question,
 $c_{en}$
represents the context, and
$c_{en}$
represents the context, and
 $a_{en}$
represents the answer. Additionally, the dataset includes
$a_{en}$
represents the answer. Additionally, the dataset includes
 $a^{begin}$
, which indicates the starting index of the answer within the context.
$a^{begin}$
, which indicates the starting index of the answer within the context.
Algorithm 1. Pseudo Code for modified TAR methodology.

The objective is to utilize the SQuAD dataset as an input and subsequently apply the TAR method to obtain corresponding samples in the target languages, specifically
 $(q_{hi},c_{hi}, a_{hi})$
for Hindi and
$(q_{hi},c_{hi}, a_{hi})$
for Hindi and
 $(q_{mr},c_{mr}, a_{mr})$
for Marathi, along with their respective answer’s start and end positions
$(q_{mr},c_{mr}, a_{mr})$
for Marathi, along with their respective answer’s start and end positions
 $a^{begin}_{hi/mr}$
and
$a^{begin}_{hi/mr}$
and
 $a^{end}_{hi/mr}$
, respectively, for both the languages. The TAR method encompasses two distinct sub-tasks discussed in the following sections, and a comprehensive understanding of the TAR method is presented in Algorithm 1.
$a^{end}_{hi/mr}$
, respectively, for both the languages. The TAR method encompasses two distinct sub-tasks discussed in the following sections, and a comprehensive understanding of the TAR method is presented in Algorithm 1.
-
(1) NMT training and translation using Sentence alignment: In this step, a Neural Machine Translation (NMT) model is trained to translate sentences from the source language
 $(q_{en}, c_{en}, a_{en})$
to the target language
$(q_{hi}, c_{hi}, a_{hi})$
and
$(q_{mr}, c_{mr}, a_{mr})$
using a sentence alignment mechanism.
$(q_{en}, c_{en}, a_{en})$
to the target language
$(q_{hi}, c_{hi}, a_{hi})$
and
$(q_{mr}, c_{mr}, a_{mr})$
using a sentence alignment mechanism. -
(2) Retrieval of correct answer: This strategy filters out target samples where the translated answer does not lie in the translated context.



3.1.1 NMT training and translation using sentence alignment
There are two main methods to translate the dataset: Statistical Machine Translation (SMT) and NMT. NMT is preferred due to its lower memory requirements and improved translation accuracy. NMT uses an attention mechanism that considers sentences’ semantic and syntactic contributions, making it more effective in maximizing translations. However, ensuring accurate sentence alignment between the source and target languages is challenging. To address this, a mechanism called sentence alignment (Shi et al. Reference Shi, Huang, Jian and Tang2021) is used, which aligns the sentences during the decoding phase using a beam search algorithm. This approach helps mitigate translation inaccuracies and ensures better overall translation quality. By employing NMT and sentence alignment, the dataset can be effectively translated while maintaining the integrity and accuracy of the data.
A large parallel corpus of en-hi and en-mr parallel text is used to train the NMT model for English-Hindi (en-hi) and English-Marathi (en-mr) translation. For this purpose, the Samanantar dataset (Ramesh et al. Reference Ramesh, Doddapaneni, Bheemaraj, Jobanputra, R., Sharma, Sahoo, Diddee, Kakwani and Kumar2022) is utilized, which is a significant publicly available parallel corpus of English-Indic, Indic-English, and Indic-Indic language pair sentences. This corpus contains 10.126M parallel sentences for en-hi and 3.627M parallel sentences for en-mr languages. From this corpus, 10.12 million en-hi parallel sentences and 3.621 million en-mr parallel sentences are used for training the NMT model. Additionally, 5K parallel sentences are used for validation, and 1K parallel sentences are used for testing. To ensure a balanced dataset, simple random sampling is employed. The NMT model is then trained using this dataset, enabling it to learn the translation patterns and improve its performance.
NMT model is trained using three different NMT architectures: Stacked-LSTM (Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao and Macherey2016; Johnson et al. Reference Johnson, Schuster, Le, Krikun, Wu, Chen, Thorat, Viégas, Wattenberg and Corrado2017), Stacked-Bi-LSTM (Hasan et al. Reference Hasan, Alam, Chowdhury and Khan2019), and Transformer (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). These architectures are selected to explore different approaches for NMT. The training and implementation of these models are carried out using the OpenNMT-py 2.0 toolkit (Klein et al. Reference Klein, Kim, Deng, Senellart and Rush2017), which provides a reliable framework for building and training NMT models. In the experimental setting, each architecture is configured with specific hyperparameters, such as the number of layers, hidden units, and attention mechanisms, to optimize their performance. The training process involves feeding the parallel training data from the Samanantar dataset into the models and iteratively updating the model parameters using optimization techniques like stochastic gradient descent. During training, the models learn the input–output pairs’ statistical patterns and linguistic features, enabling them to generate accurate translations. The additional experimental setting for all these models is given below:
-
(1) Stacked-LSTM model: The Stacked-LSTM model (see Figure 1(a)) is composed of an encoder and decoder, each consisting of three stacked LSTM layers. During the training process, a pretrained word vector, specifically fastText (Grave et al. Reference Grave, Bojanowski, Gupta, Joulin and Mikolov2018), is used as input to the model. This choice of word vector assists in addressing the Out-Of-Vocabulary (OOV) issue that may arise. The model dimensions for the LSTM, Bi-LSTM, and attention models are 512. The Adam optimizer is employed, with a smoothing label value of 0.1 and gradient clipping set to 1.0. The learning rate is configured to 0.005, while the dropout rate is set to 0.3 for Hindi and 0.1 for Marathi, respectively.
-
(2) Stacked-Bi-LSTM model: The Stacked-Bi-LSTM model (see Figure 1(b)) follows the same experimental setup as the Stacked-LSTM model. Still, it uses bidirectional LSTM instead of unidirectional LSTM. This modification allows the model to consider past and future contexts when making predictions.
-
(3) Transformer model: This model (see Figure 1(c)) follows the experimental setup of (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). It incorporates 16 attention heads, with input and output vectors of dimension 1024. The feed-forward network in the inner layer has a dimension of 4096. For the Hindi language, a dropout rate of 0.3 is applied, while for the Marathi language, a dropout rate of 0.1 is utilized. The hyperparameter settings include an Adam optimizer with a smoothing label value of 0.1 to improve optimization stability. The learning rate is set to 0.003, ensuring an appropriate adjustment rate during training.

Figure 1. NMT Architecture (a) LSTM based model, (b) bi-LSTM based model, (c) transformer based model (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017).
The effectiveness of translation is measured using the BLEU metric (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), which quantifies the similarity between the translated output and reference translations. BLEU is calculated using equation (1). This metric provides a quantitative measure of translation quality.
 \begin{equation} BLEU = \exp \left({\sum _{n=1}^{ng} w_nlogpr_{n}}\right) \cdot BP \end{equation}
\begin{equation} BLEU = \exp \left({\sum _{n=1}^{ng} w_nlogpr_{n}}\right) \cdot BP \end{equation}
where
 $pr_{n}$
is n-gram precision, and BP is Brevity Penalty, refer equation (2)
$pr_{n}$
is n-gram precision, and BP is Brevity Penalty, refer equation (2)
 \begin{equation} BP= \begin{cases} 1, & \text{if}\ len(\hat{y}) \gt len(y) \\[5pt] \exp \Bigl (1 - \frac{len(y)}{len(\hat{y})}\Bigl ), & \text{if}\ len(\hat{y}) \leq len(y) \end{cases} \end{equation}
\begin{equation} BP= \begin{cases} 1, & \text{if}\ len(\hat{y}) \gt len(y) \\[5pt] \exp \Bigl (1 - \frac{len(y)}{len(\hat{y})}\Bigl ), & \text{if}\ len(\hat{y}) \leq len(y) \end{cases} \end{equation}
where
 $\hat{y}$
represents the predicted translated sentence while
$\hat{y}$
represents the predicted translated sentence while
 $y$
is the gold standard alignment sentence. Table 2 reports the accomplished BLEU score for all three models. The transformer model outperforms the other models with a BLEU score of 51.74 for en-hi translation and 41.07 for en-mr translation on the test set. This score is considered a good BLEU score and can be used for en-hi and en-mr translation. The transformer model effectively produces accurate and fluent translations for the en-hi and en-mr language pairs.
$y$
is the gold standard alignment sentence. Table 2 reports the accomplished BLEU score for all three models. The transformer model outperforms the other models with a BLEU score of 51.74 for en-hi translation and 41.07 for en-mr translation on the test set. This score is considered a good BLEU score and can be used for en-hi and en-mr translation. The transformer model effectively produces accurate and fluent translations for the en-hi and en-mr language pairs.
Table 2. BLEU score of en-hi and en-mr translation

The trained NMT model is utilized to translate the entire SQUAD dataset, with each tuple being translated into Hindi and Marathi languages. During this translation process, it is observed that for certain tuples, the generated translated answer does not appear in the translated context. This occurrence is particularly noticeable for verbs, abbreviations (such as US, U.S., USA, America for the United States of America), numbers (specifically for the Marathi language), and other similar cases. This situation arises because the NMT model translates the same word differently based on the context. For example, if the translated context contains information about the “Bank of River," indicating that the context is about the river, but the translated answer outputs “Financial Institution Bank," which is unrelated to the context, then the answer is considered inaccurate. In such cases, the tuple consisting of the translated question, context, and answer will not be considered for training the model. To address this problem, retrieving the correct answer is necessary even when its translation is not explicitly present in the context. The process of retrieving the correct answer is discussed in Section 3.1.2.
3.1.2 Retrieval of correct answer
The retrieval of accurate answers is performed to obtain the complete translated version of the SQuAD dataset in both languages for cases where the translated answer (
 $a_{hi}$
and
$a_{hi}$
and
 $a_{mr}$
) is not present in the translated context. To ensure the retrieval of correct answers, the best strategy involves utilizing Hindi and Marathi WordNet (Bhattacharyya Reference Bhattacharyya2017), which serves as a thesaurus available for various languages. WordNet is used to acquire different synsets (i.e., sets of synonymous words) for a given word (lemma). It aids in replacing the existing translated answer (
$a_{mr}$
) is not present in the translated context. To ensure the retrieval of correct answers, the best strategy involves utilizing Hindi and Marathi WordNet (Bhattacharyya Reference Bhattacharyya2017), which serves as a thesaurus available for various languages. WordNet is used to acquire different synsets (i.e., sets of synonymous words) for a given word (lemma). It aids in replacing the existing translated answer (
 $a_{hi/mr}$
) with an appropriate alternative found within the translated context (
$a_{hi/mr}$
) with an appropriate alternative found within the translated context (
 $c_{hi/mr}$
).
$c_{hi/mr}$
).
In this strategy, the word in the translated answer (
 $a_{hi/mr}$
) is searched within WordNet to obtain its various senses. The process provides a pool of searched senses and their matches for a word in the translated context (
$a_{hi/mr}$
) is searched within WordNet to obtain its various senses. The process provides a pool of searched senses and their matches for a word in the translated context (
 $c_{hi/mr}$
). The translated answer is replaced with the corresponding word from the translated context if a match is found. This ensures that the retrieved answer accurately reflects the information present within the context. By applying this approach, the translated NMT model can effectively retrieve the correct answers, enhancing the overall accuracy and reliability of the translated SQuAD dataset.
$c_{hi/mr}$
). The translated answer is replaced with the corresponding word from the translated context if a match is found. This ensures that the retrieved answer accurately reflects the information present within the context. By applying this approach, the translated NMT model can effectively retrieve the correct answers, enhancing the overall accuracy and reliability of the translated SQuAD dataset.
The two subtasks described above have resulted in the creation of two versions of the EHMQuAD dataset. The first version consists of translating the original SQuAD dataset with sentence alignment. This version includes 48,769 translated samples in Hindi and 42,192 translated samples in Marathi. On the other hand, the second version incorporates the translation of the dataset with sentence alignment, along with retrieving the correct answer (Section 3.1.2). This version comprises 63,298 translated samples in Hindi and 51,359 translated samples in Marathi. The second version demonstrates an improvement in the number of tuples available in the EHMQuAD dataset. Table 3 presents the statistical details of both versions of the dataset, which were derived from the original 87,599 samples of the SQuADv1.1 dataset.
Table 3. Statistics of EHMQuAD dataset over SQuADv1.1

The proposed work utilizes the second version of the EHMQuAD dataset to develop an MQA framework, leveraging the enhanced quality and accuracy achieved through answer retrieval. Figure 2 provides a visual representation of a sample from the EHMQuAD dataset, showcasing the structure and format of the translated tuples. In the second version of the dataset, the start position (
 $a^{begin}{hi/mr}$
) and end position (
$a^{begin}{hi/mr}$
) and end position (
 $a^{end}{hi/mr}$
) of the translated answer are determined by searching for the answer span within the translated context. These positions provide the necessary information to accurately locate the corresponding answer within the translated context. A comprehensive and enriched multilingual question-answering dataset is constructed through these steps, facilitating the development and evaluation of MQA models for Hindi and Marathi languages.
$a^{end}{hi/mr}$
) of the translated answer are determined by searching for the answer span within the translated context. These positions provide the necessary information to accurately locate the corresponding answer within the translated context. A comprehensive and enriched multilingual question-answering dataset is constructed through these steps, facilitating the development and evaluation of MQA models for Hindi and Marathi languages.

Figure 2. An example of the EHMQuAD dataset.
3.2 Error analysis
A detailed error analysis is done on the second version of the EHMQuAD dataset to validate the quality of translated data. There were some translated errors in the first version; hence, the retrieval of the correct answer approach (Section 3.1.2) is applied to generate the second version. But still, some errors are identified in the samples, and hence, there is a need for a qualitative analysis wherein the produced error and the reason behind these errors are detected and rectified accordingly. To get a better understanding of the answers generated from the context, we concluded a set of observations:
-
• Type I error: Sometimes, the translator cannot identify “Noun” in the context and wrongly translate it into another word. This is due to the part-of-speech (POS) tagging error proximity.
-
• Type II error: Some words in the dataset are represented in the form of orthographic variants, i.e., similar words having different writing styles due to language, regional, and personal preferences.
-
• There are some translation errors (Type III error and Type IV error) that occur during the translation process which affects the quality of the dataset. The Type III error is due to the year’s translation into an unstructured number, while the Type IV error is due to translating the numbers into Devanagari script instead of Latin script, which confuses the model to identify the numerical data from the translated context.
The detailed description of these errors and the example are presented in Figure 3. Although these errors are responsible for downgrading the dataset’s quality, we have corrected these errors, and encouragingly, there were only a few such contexts.

Figure 3. Examples showing type of errors.
3.3 Proposed MQA framework
The proposed MQA framework (EHMMQA) is based on DNN architecture (see Figure 4). It is designed to handle MQA tasks in English, Hindi, and Marathi. The model is trained using
 $\lt q, c, a\gt$
samples from the EHMQuAD dataset, allowing it to acquire knowledge for each language. The model is evaluated on various datasets, including MMQA, Translated SQuAD, XQuAD, MLQA, and the proposed EHMQuAD datasets. The EHMMQA model accepts multilingual input through the Question and Context Encoding layer. The Shared encoding layer enables the model to process multilingual input by creating separate shared representations for the question and context. The Question-Context Attention layer performs question-context matching using attention-based RNN, generating a question-aware representation of the context. However, RNNs have limitations in capturing extensive context information, particularly when candidate answers are scattered. To address this, the Context-Context Attention layer dynamically refines the context representation by incorporating aggregated question information. This refinement process enhances the network’s ability to extract the exact answer. Finally, the Answer Extraction layer employs a pointer network to determine the start (
$\lt q, c, a\gt$
samples from the EHMQuAD dataset, allowing it to acquire knowledge for each language. The model is evaluated on various datasets, including MMQA, Translated SQuAD, XQuAD, MLQA, and the proposed EHMQuAD datasets. The EHMMQA model accepts multilingual input through the Question and Context Encoding layer. The Shared encoding layer enables the model to process multilingual input by creating separate shared representations for the question and context. The Question-Context Attention layer performs question-context matching using attention-based RNN, generating a question-aware representation of the context. However, RNNs have limitations in capturing extensive context information, particularly when candidate answers are scattered. To address this, the Context-Context Attention layer dynamically refines the context representation by incorporating aggregated question information. This refinement process enhances the network’s ability to extract the exact answer. Finally, the Answer Extraction layer employs a pointer network to determine the start (
 $a^{begin}$
) and end (
$a^{begin}$
) and end (
 $a^{end}$
) positions of the answers in all three languages. Each language has its pointer-based network. Details of each layer are elaborated in subsequent sections.
$a^{end}$
) positions of the answers in all three languages. Each language has its pointer-based network. Details of each layer are elaborated in subsequent sections.

Figure 4. Proposed unified model of MQA.
3.3.1 Question & Context encoding layer
Let us consider the English question
 $q_{en} = \big\{qw^{q_{en}}_1, qw^{q_{en}}_2,\ldots, qw^{q_{en}}_{x_{en}}\big\}$
and context
$q_{en} = \big\{qw^{q_{en}}_1, qw^{q_{en}}_2,\ldots, qw^{q_{en}}_{x_{en}}\big\}$
and context
 $c_{en} = \big\{cw^{c_{en}}_1, cw^{c_{en}}_2,\ldots, cw^{c_{en}}_{y_{en}}\big\}$
, Hindi question
$c_{en} = \big\{cw^{c_{en}}_1, cw^{c_{en}}_2,\ldots, cw^{c_{en}}_{y_{en}}\big\}$
, Hindi question
 $q_{hi} = \big\{qw^{q_{hi}}_t\big\}^{x_{hi}}_{t=1}$
and context
$q_{hi} = \big\{qw^{q_{hi}}_t\big\}^{x_{hi}}_{t=1}$
and context
 $c_{hi} = \big\{cw^{c_{hi}}_t\big\}^{y_{hi}}_{t=1}$
, and Marathi question
$c_{hi} = \big\{cw^{c_{hi}}_t\big\}^{y_{hi}}_{t=1}$
, and Marathi question
 $q_{mr} = \big\{qw^{q_{mr}}_t\big\}^{x_{mr}}_{t=1}$
and context
$q_{mr} = \big\{qw^{q_{mr}}_t\big\}^{x_{mr}}_{t=1}$
and context
 $c_{mr} = \big\{cw^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}$
. This layer is responsible for obtaining the encoding of the questions and contexts. From the given question and context, word embedding
$c_{mr} = \big\{cw^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}$
. This layer is responsible for obtaining the encoding of the questions and contexts. From the given question and context, word embedding
 $\big(\big\{e^{q_{en}}_t\big\}^{x_{en}}_{t=1}$
,
$\big(\big\{e^{q_{en}}_t\big\}^{x_{en}}_{t=1}$
,
 $\big\{e^{c_{en}}_t\big\}^{y_{en}}_{t=1}$
,
$\big\{e^{c_{en}}_t\big\}^{y_{en}}_{t=1}$
,
 $\big\{e^{q_h}_t\big\}^{x_h}_{t=1}$
,
$\big\{e^{q_h}_t\big\}^{x_h}_{t=1}$
,
 $\big\{e^{c_h}_t\big\}^{y_h}_{t=1}$
,
$\big\{e^{c_h}_t\big\}^{y_h}_{t=1}$
,
 $\big\{e^{q_{mr}}_t\big\}^{x_{mr}}_{t=1}$
, and
$\big\{e^{q_{mr}}_t\big\}^{x_{mr}}_{t=1}$
, and
 $\big\{e^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}\big)$
are generated from the pre-trained word embedding model. According to (Lee, Cho, and Hofmann Reference Lee, Cho and Hofmann2017; Xia, Ding, and Liu Reference Xia, Ding and Liu2020), character embedding is an extension of word embedding as it deals with OOV words. Hence, character-level embedding
$\big\{e^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}\big)$
are generated from the pre-trained word embedding model. According to (Lee, Cho, and Hofmann Reference Lee, Cho and Hofmann2017; Xia, Ding, and Liu Reference Xia, Ding and Liu2020), character embedding is an extension of word embedding as it deals with OOV words. Hence, character-level embedding
 $\big(\big\{c^{q_{en}}_t\big\}^{x_{en}}_{t=1}$
,
$\big(\big\{c^{q_{en}}_t\big\}^{x_{en}}_{t=1}$
,
 $\big\{c^{c_{en}}_t\big\}^{y_{en}}_{t=1}$
,
$\big\{c^{c_{en}}_t\big\}^{y_{en}}_{t=1}$
,
 $\big\{c^{q_{hi}}_t\big\}^{x_{hi}}_{t=1}$
,
$\big\{c^{q_{hi}}_t\big\}^{x_{hi}}_{t=1}$
,
 $\big\{c^{c_{hi}}_t\big\}^{y_{hi}}_{t=1}$
,
$\big\{c^{c_{hi}}_t\big\}^{y_{hi}}_{t=1}$
,
 $\big\{c^{q_{mr}}_t\big\}^{x_{mr}}_{t=1}$
, and
$\big\{c^{q_{mr}}_t\big\}^{x_{mr}}_{t=1}$
, and
 $\big\{c^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}\big)$
is also employed in this work. These character-level embeddings are produced as the final output of a bi-directional gated recurrent unit (Bi-GRU), employed for the token’s character embeddings. The word embeddings and character-level embeddings are concatenated to enhance the word representation.
$\big\{c^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}\big)$
is also employed in this work. These character-level embeddings are produced as the final output of a bi-directional gated recurrent unit (Bi-GRU), employed for the token’s character embeddings. The word embeddings and character-level embeddings are concatenated to enhance the word representation.
 \begin{equation*} E_i = concat \left(e^{q_k}_t,c^{q_k}_t\right) \end{equation*}
\begin{equation*} E_i = concat \left(e^{q_k}_t,c^{q_k}_t\right) \end{equation*}
For each question and context, the final word representations
 $u^{q_k}_t$
and
$u^{q_k}_t$
and
 $u^{c_k}_t$
are computed using Bi-GRU as follows:
$u^{c_k}_t$
are computed using Bi-GRU as follows:
 \begin{equation} \begin{aligned} u^{q_k}_t = Bi\text{-}GRU \left(u^{q_k}_{t-1},[E_i]\right)\\[4pt] u^{c_k}_t = Bi\text{-}GRU \left(u^{c_k}_{t-1},[E_i]\right) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} u^{q_k}_t = Bi\text{-}GRU \left(u^{q_k}_{t-1},[E_i]\right)\\[4pt] u^{c_k}_t = Bi\text{-}GRU \left(u^{c_k}_{t-1},[E_i]\right) \end{aligned} \end{equation}
where
 $k \in \{en, hi, mr\}$
denotes the English(en), Hindi(hi), and Marathi(mr) languages. Bi-GRU is chosen over LSTM due to its computational efficiency.
$k \in \{en, hi, mr\}$
denotes the English(en), Hindi(hi), and Marathi(mr) languages. Bi-GRU is chosen over LSTM due to its computational efficiency.
3.3.2 Shared encoding layer
The shared representation of the question and context is obtained separately for each language from the encoding of the previous layer. This shared representation improves the representation of question–question and context–context relationships. Since the dataset contains the same information for every question and context, this shared representation is achieved through soft alignment between words. A single separate representation of question and context is formed by combining the representation of individual languages.
 $\big(R^{q_{en}}_t, \text{ } R^{q_{hi}}_t \text{and }R^{q_{mr}}_t\big)$
and
$\big(R^{q_{en}}_t, \text{ } R^{q_{hi}}_t \text{and }R^{q_{mr}}_t\big)$
and
 $\big(R^{c_{en}}_t, \text{ } R^{c_{hi}}_t \text{and } R^{c_{mr}}_t\big)$
are the English, Hindi, and Marathi question and context representations, with the awareness of other two languages. The English question representation, taking into account the Hindi and Marathi question representations, is computed using a Bi-GRU as shown in equation (4):
$\big(R^{c_{en}}_t, \text{ } R^{c_{hi}}_t \text{and } R^{c_{mr}}_t\big)$
are the English, Hindi, and Marathi question and context representations, with the awareness of other two languages. The English question representation, taking into account the Hindi and Marathi question representations, is computed using a Bi-GRU as shown in equation (4):
 \begin{equation} R^{q_{en}}_t = Bi\text{-}GRU\left(R^{q_{en}}_{t-1}, v^{q_{hi}}_t, v^{q_{mr}}_t\right) \end{equation}
\begin{equation} R^{q_{en}}_t = Bi\text{-}GRU\left(R^{q_{en}}_{t-1}, v^{q_{hi}}_t, v^{q_{mr}}_t\right) \end{equation}
 \begin{align} l^t_j & = N^T tanh\left(\left[W^{q_{hi}}_u, u^{q_{hi}}_j\right] \left[W^{q_{mr}}_u, u^{q_{mr}}_j\right]\left[W^{q_{en}}_u, u^{q_{en}}_t\right]\left[W^{q_{en}}_r, R^{q_{en}}_{t-1}\right]\right)\nonumber\\[5pt] v^{q_{hi}}_t & = \sum _{i=1}^{x_{hi}}\left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{hi}} exp\big(l^t_j\big)}\right)\cdot u^{q_{hi}}_i\nonumber\\[5pt] v^{q_{mr}}_t & = \sum _{i=1}^{x_{mr}}\left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{mr}} exp\big(l^t_j\big)}\right)\cdot u^{q_{mr}}_i \end{align}
\begin{align} l^t_j & = N^T tanh\left(\left[W^{q_{hi}}_u, u^{q_{hi}}_j\right] \left[W^{q_{mr}}_u, u^{q_{mr}}_j\right]\left[W^{q_{en}}_u, u^{q_{en}}_t\right]\left[W^{q_{en}}_r, R^{q_{en}}_{t-1}\right]\right)\nonumber\\[5pt] v^{q_{hi}}_t & = \sum _{i=1}^{x_{hi}}\left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{hi}} exp\big(l^t_j\big)}\right)\cdot u^{q_{hi}}_i\nonumber\\[5pt] v^{q_{mr}}_t & = \sum _{i=1}^{x_{mr}}\left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{mr}} exp\big(l^t_j\big)}\right)\cdot u^{q_{mr}}_i \end{align}
where
 $N^T$
is a weight vector,
$N^T$
is a weight vector,
 $W^{q_{en}}_u, W^{q_{hi}}_u, W^{q_m}_u, W^{q_{en}}_r$
are the learnable weight matrices, and
$W^{q_{en}}_u, W^{q_{hi}}_u, W^{q_m}_u, W^{q_{en}}_r$
are the learnable weight matrices, and
 $\lt v^{q_{hi}}_t$
&
$\lt v^{q_{hi}}_t$
&
 $v^{q_{mr}}_t\gt$
are attention-based pooling vectors. The English question representation
$v^{q_{mr}}_t\gt$
are attention-based pooling vectors. The English question representation
 $\big(R^{q_{en}}_t\big)$
is computed using Bi-GRU by concatenating the pooling vector
$\big(R^{q_{en}}_t\big)$
is computed using Bi-GRU by concatenating the pooling vector
 $v^{q_{hi}}_t$
&
$v^{q_{hi}}_t$
&
 $v^{q_{mr}}_t$
with the previous (t-1) representation of
$v^{q_{mr}}_t$
with the previous (t-1) representation of
 $\big(R^{q_{en}}_t\big)$
. Equation (5) computes the pooling vector
$\big(R^{q_{en}}_t\big)$
. Equation (5) computes the pooling vector
 $v^{q_{hi}}_t$
&
$v^{q_{hi}}_t$
&
 $v^{q_{mr}}_t$
of English question representation
$v^{q_{mr}}_t$
of English question representation
 $u^{q_{hi}}_t$
&
$u^{q_{hi}}_t$
&
 $u^{q_{mr}}_t$
at time t. Likewise, the other two question representations, i.e.,
$u^{q_{mr}}_t$
at time t. Likewise, the other two question representations, i.e.,
 $R^{q_{hi}}_t$
and
$R^{q_{hi}}_t$
and
 $R^{q_{mr}}_t$
are computed in the similar manner. In the end, the single shared question representation is computed by combining the individual question representations from all three languages as shown in equation (6):
$R^{q_{mr}}_t$
are computed in the similar manner. In the end, the single shared question representation is computed by combining the individual question representations from all three languages as shown in equation (6):
 \begin{equation} \big\{R^{q}_t\big\}^{(x_{en}+x_{hi}+x_{mr})}_{t=1} = \big\{R^{q_{en}}_t\big\}^{x_{en}}_{t=1} \oplus \big\{R^{q_{hi}}_t\big\}^{x_{hi}}_{t=1} \oplus \big\{R^{q_{mr}}_t\big\}^{x_{mr}}_{t=1} \end{equation}
\begin{equation} \big\{R^{q}_t\big\}^{(x_{en}+x_{hi}+x_{mr})}_{t=1} = \big\{R^{q_{en}}_t\big\}^{x_{en}}_{t=1} \oplus \big\{R^{q_{hi}}_t\big\}^{x_{hi}}_{t=1} \oplus \big\{R^{q_{mr}}_t\big\}^{x_{mr}}_{t=1} \end{equation}
Similarly, the shared context representation is computed by concatenating the context representations from all three languages, as indicated in equation (7):
 \begin{equation} \big\{R^{c}_t\big\}^{(y_{en}+y_{hi}+y_{mr})}_{t=1} = \big\{R^{c_{en}}_t\big\}^{y_{en}}_{t=1} \oplus \big\{R^{c_{hi}}_t\big\}^{y_{hi}}_{t=1} \oplus \big\{R^{c_{mr}}_t\big\}^{y_{mr}}_{t=1} \end{equation}
\begin{equation} \big\{R^{c}_t\big\}^{(y_{en}+y_{hi}+y_{mr})}_{t=1} = \big\{R^{c_{en}}_t\big\}^{y_{en}}_{t=1} \oplus \big\{R^{c_{hi}}_t\big\}^{y_{hi}}_{t=1} \oplus \big\{R^{c_{mr}}_t\big\}^{y_{mr}}_{t=1} \end{equation}
In equations (6) and (7),
 $\oplus$
denotes the concatenation operation, resulting in a unified representation encompassing information from all three languages.
$\oplus$
denotes the concatenation operation, resulting in a unified representation encompassing information from all three languages.
3.3.3 Question-context attention layer
The question-aware-context representation is computed in this layer using an attention-based RNN mechanism. This approach captures the relevance and significance of context information given a specific question. The question-aware-context representation is computed separately for all three languages, considering the shared question representation and shared context representation. Since the shared question representation only includes a limited number of words, it provides a condensed representation. On the other hand, the shared context representation incorporates a larger number of words, as the context vocabulary is generally more extensive than that of the corresponding question. This facilitates a more comprehensive and enriched question-aware-context representation. The English question-aware-context representation is denoted by equation (8):
 \begin{equation} S^{c_{en}}_t = Bi\text{-}GRU\left(S^{c_{en}}_{t-1}, z^{c_{en}}_t\right) \end{equation}
\begin{equation} S^{c_{en}}_t = Bi\text{-}GRU\left(S^{c_{en}}_{t-1}, z^{c_{en}}_t\right) \end{equation}
 \begin{align} l^t_j & = N^T tanh \left( \left[W^{q}_r, R^{q}_j \right] \left[W^{c}_r, R^{c}_j \right] \left[W^{c_{en}}_u, u^{c_{en}}_t \right] \left[W^{c_{en}}_s, S^{q_{en}}_{t-1} \right] \right)\nonumber\\[5pt] z^{c_{en}}_t & = \sum _{i=1}^{x_{en}+x_{hi}+x_{mr}} \left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{en}+x_{hi}+x_{mr}} exp\big(l^t_j\big)} \right)\cdot R^{q}_i + \sum _{i=1}^{x_{en}+x_{hi}+x_{mr}} \left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{en}+x_{hi}+x_{mr}} exp\big(l^t_j\big)} \right)\cdot R^{c}_i \end{align}
\begin{align} l^t_j & = N^T tanh \left( \left[W^{q}_r, R^{q}_j \right] \left[W^{c}_r, R^{c}_j \right] \left[W^{c_{en}}_u, u^{c_{en}}_t \right] \left[W^{c_{en}}_s, S^{q_{en}}_{t-1} \right] \right)\nonumber\\[5pt] z^{c_{en}}_t & = \sum _{i=1}^{x_{en}+x_{hi}+x_{mr}} \left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{en}+x_{hi}+x_{mr}} exp\big(l^t_j\big)} \right)\cdot R^{q}_i + \sum _{i=1}^{x_{en}+x_{hi}+x_{mr}} \left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{x_{en}+x_{hi}+x_{mr}} exp\big(l^t_j\big)} \right)\cdot R^{c}_i \end{align}
where
 $W^{q}_r, W^{c}_r, W^{c_{en}}_u, W^{c_{en}}_s$
are the learnable weight matrices and
$W^{q}_r, W^{c}_r, W^{c_{en}}_u, W^{c_{en}}_s$
are the learnable weight matrices and
 $z^{c_{en}}_t$
is an attention-based pooling vector (equation (9)). Likewise, the Hindi question-aware-context representation
$z^{c_{en}}_t$
is an attention-based pooling vector (equation (9)). Likewise, the Hindi question-aware-context representation
 $\big(S^{c_{hi}}_t\big)$
and Marathi question-aware-context representation
$\big(S^{c_{hi}}_t\big)$
and Marathi question-aware-context representation
 $\big(S^{c_{mr}}_t\big)$
are derived by applying the same principles as the English representation.
$\big(S^{c_{mr}}_t\big)$
are derived by applying the same principles as the English representation.
3.3.4 Context-context attention layer
In the previous layer, the question-aware-context representation highlights the important features of the context, but the problem with this representation is that it handles very limited information. Hence, one potential answer fails to overlook the significant information in the context beyond its window. This approach is designed to address lexical or syntactical differences between the question–answer pairs in the SQuAD and EHMQuAD datasets. By dynamically matching the question-aware-context representation with the original context, the model can capture the relevant information from the context and encode it appropriately with the corresponding question, resulting in a more comprehensive and accurate context representation. For the English context, the final context representation is computed using the following equation (10):
 \begin{equation} B^{c_{en}}_t = Bi\text{-}GRU\left(B^{c_{en}}_{t-1}, S^{c_{en}}_{t}, z^{c_{en}}_t\right) \end{equation}
\begin{equation} B^{c_{en}}_t = Bi\text{-}GRU\left(B^{c_{en}}_{t-1}, S^{c_{en}}_{t}, z^{c_{en}}_t\right) \end{equation}
 \begin{align} l^t_j & = N^T tanh\left(\left[W^{c_{en}}_{b'},W^{c_{en}}_{b''}\right]\left[S^{c_{en}}_j, S^{c_{en}}_{t}\right]^T\right)\nonumber\\[5pt] z^{c_{en}}_t & = \sum _{i=1}^{y_{en}}\left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{y_{en}} exp\big(l^t_j\big)}\right)\cdot S^{c_{en}}_i \end{align}
\begin{align} l^t_j & = N^T tanh\left(\left[W^{c_{en}}_{b'},W^{c_{en}}_{b''}\right]\left[S^{c_{en}}_j, S^{c_{en}}_{t}\right]^T\right)\nonumber\\[5pt] z^{c_{en}}_t & = \sum _{i=1}^{y_{en}}\left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{y_{en}} exp\big(l^t_j\big)}\right)\cdot S^{c_{en}}_i \end{align}
where
 $W^{c_{en}}_{b'}$
and
$W^{c_{en}}_{b'}$
and
 $W^{c_{en}}_{b''}$
are the learnable weight matrices. Similarly, the final context representation of Hindi
$W^{c_{en}}_{b''}$
are the learnable weight matrices. Similarly, the final context representation of Hindi
 $\big(\big\{B^{c_{hi}}_t\big\}^{y_{hi}}_{t=1}\big)$
and Marathi
$\big(\big\{B^{c_{hi}}_t\big\}^{y_{hi}}_{t=1}\big)$
and Marathi
 $\big(\big\{B^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}\big)$
is computed in the same fashion by equations (10) and (11).
$\big(\big\{B^{c_{mr}}_t\big\}^{y_{mr}}_{t=1}\big)$
is computed in the same fashion by equations (10) and (11).
3.3.5 Answer layer
A pointer network is employed to handle the multilingual nature of the MQA framework and generate answers in multiple languages. The pointer network is based on the seq-to-seq pointer network (Chen et al. Reference Chen, Zhang, Hu and Huang2021), which is responsible for extracting the start position
 $\big(a^{begin}\big)$
and end position
$\big(a^{begin}\big)$
and end position
 $\big(a^{end}\big)$
of the answer from either the English, Hindi, or Marathi context. Given the context in any language as input, the answer layer’s objective is to determine the appropriate start and end positions within the context that correspond to the answer. This is achieved by computing the following equation (12):
$\big(a^{end}\big)$
of the answer from either the English, Hindi, or Marathi context. Given the context in any language as input, the answer layer’s objective is to determine the appropriate start and end positions within the context that correspond to the answer. This is achieved by computing the following equation (12):
 \begin{align} l^t_j & = N^T tanh \left( \left[W^{c_{en}}_{p},B^{c_{en}}_j \right] \left[W^{a_{en}}_{h},h^{a_{en}}_{t-1} \right] \right)\nonumber\\[4pt] a^t_i & = \left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{y_{en}} exp\big(l^t_j\big)} \right) \end{align}
\begin{align} l^t_j & = N^T tanh \left( \left[W^{c_{en}}_{p},B^{c_{en}}_j \right] \left[W^{a_{en}}_{h},h^{a_{en}}_{t-1} \right] \right)\nonumber\\[4pt] a^t_i & = \left(\frac{exp\big(l^t_i\big)}{\sum _{j=1}^{y_{en}} exp\big(l^t_j\big)} \right) \end{align}
where
 $h^{a_{en}}_{t-1}$
is the last hidden state of the answer layer. The attention pooling vector
$h^{a_{en}}_{t-1}$
is the last hidden state of the answer layer. The attention pooling vector
 $a^t_i$
depends on the recently predicted probability
$a^t_i$
depends on the recently predicted probability
 $a^t$
, which serves as an input to this layer. The hidden state of the answer layer is computed by equation (13):
$a^t$
, which serves as an input to this layer. The hidden state of the answer layer is computed by equation (13):
 \begin{align} h^{a_{en}}_{t} & = Bi\text{-}GRU \left(h^{a_{en}}_{t-1}, z^{c_{en}}_t\right)\nonumber\\[4pt] z^{c_{en}}_t & = \sum _{i=1}^{y_{en}}\left( a^t_i B^{c_{en}}_i\right) \end{align}
\begin{align} h^{a_{en}}_{t} & = Bi\text{-}GRU \left(h^{a_{en}}_{t-1}, z^{c_{en}}_t\right)\nonumber\\[4pt] z^{c_{en}}_t & = \sum _{i=1}^{y_{en}}\left( a^t_i B^{c_{en}}_i\right) \end{align}
The answer for the English language is obtained from the answer network by predicting the start position at time step
 $t=1$
, and subsequently predicting the end position at the next time step. This prediction is based on the probabilities assigned to each position in English. The prediction of the answer is determined by selecting the maximum probability among the predicted positions.
$t=1$
, and subsequently predicting the end position at the next time step. This prediction is based on the probabilities assigned to each position in English. The prediction of the answer is determined by selecting the maximum probability among the predicted positions.
 \begin{equation} a^t_{en} = argmax\left(a^t_{1}, a^t_{2},\ldots, a^t_{y_{en}}\right) \end{equation}
\begin{equation} a^t_{en} = argmax\left(a^t_{1}, a^t_{2},\ldots, a^t_{y_{en}}\right) \end{equation}
For Hindi and Marathi languages, the answer’s start and end positions are also predicted from their corresponding context using equation (14). This approach allows the answer network to identify the most likely start and end positions of the answer for each language, facilitating the generation of language-specific answers tailored to the corresponding context.
4. Experiments
4.1 Datasets
The performance of the proposed model is evaluated using five different MQA datasets, which consist of multilingual question-answer pairs along with their corresponding contexts. These datasets provide valuable resources for assessing the model’s ability to handle multiple languages. Among these datasets, MMQA, Translated SQuAD, XQuAD, and MLQA contain samples in the format of
 $\lt q,c,a,a^{begin}\gt$
for two languages, namely English and Hindi. On the other hand, the proposed EHMQuAD dataset is unique as it provides samples in all three languages. Table 4 shows the statistics of these datasets. This comprehensive evaluation using diverse, multilingual datasets thoroughly assesses the model’s performance across different language pairs.
$\lt q,c,a,a^{begin}\gt$
for two languages, namely English and Hindi. On the other hand, the proposed EHMQuAD dataset is unique as it provides samples in all three languages. Table 4 shows the statistics of these datasets. This comprehensive evaluation using diverse, multilingual datasets thoroughly assesses the model’s performance across different language pairs.
Table 4. Statistics of MQA dataset

4.1.1 MMQA
MMQAFootnote c dataset (Gupta et al. Reference Gupta, Kumari, Ekbal and Bhattacharyya2018) is an MQA dataset for English and Hindi languages. This dataset has comparable corpora of 500 documents for both English and Hindi languages but not the parallel corpora along with the sample of
 $\lt q, c, a\gt$
. Gupta et al. (Reference Gupta, Ekbal and Bhattacharyya2019) proposed a novel algorithm that uses the MMQA dataset of 5,495 QA pairs to evaluate and create a snippet for each pair. These selected QA pairs and their corresponding created snippets are used to evaluate the EHMMQA model. This dataset is converted into SQuAD-like sample instances.
$\lt q, c, a\gt$
. Gupta et al. (Reference Gupta, Ekbal and Bhattacharyya2019) proposed a novel algorithm that uses the MMQA dataset of 5,495 QA pairs to evaluate and create a snippet for each pair. These selected QA pairs and their corresponding created snippets are used to evaluate the EHMMQA model. This dataset is converted into SQuAD-like sample instances.
4.1.2 Translated SQuAD
The Translated SQuADFootnote d dataset (Gupta et al. Reference Gupta, Ekbal and Bhattacharyya2019) is derived from the original SQuAD dataset and involves the translation (using Google Translate API) of 18,454 samples from English to the Hindi language. For each context available in the original SQuAD dataset, a sample consisting of the question (
 $q$
), context (
$q$
), context (
 $c$
), and answer (
$c$
), and answer (
 $a$
) is selected and transformed into the format of
$a$
) is selected and transformed into the format of
 $\lt q,c,a,a_{start}, a_{end}\gt$
for both English and Hindi languages. This ensures that the translated dataset covers all the contexts present in the SQuAD dataset while providing bilingual information, which undergoes a preprocessing step to address any discrepancies that may arise from the direct translation between languages. These discrepancies are likely due to the inherent syntax, grammar, and language structure differences between English and Hindi. The preprocessing step helps mitigate these issues, ensuring the dataset’s quality and reliability for training and evaluation purposes.
$\lt q,c,a,a_{start}, a_{end}\gt$
for both English and Hindi languages. This ensures that the translated dataset covers all the contexts present in the SQuAD dataset while providing bilingual information, which undergoes a preprocessing step to address any discrepancies that may arise from the direct translation between languages. These discrepancies are likely due to the inherent syntax, grammar, and language structure differences between English and Hindi. The preprocessing step helps mitigate these issues, ensuring the dataset’s quality and reliability for training and evaluation purposes.
4.1.3 XQuAD
DeepMind has developed a Cross-lingual Question Answering Dataset (XQuAD)Footnote e (Artetxe et al. Reference Artetxe, Ruder and Yogatama2020) for MQA tasks. XQuAD covers 12 languages, including Hindi, and is a reliable benchmark for evaluating MQA models. The dataset consists of 1,190 question–answer pairs for each of the 12 languages. These pairs are derived from 240 contexts originally found in the SQuAD dataset. XQuAD is particularly valuable for evaluating English-Hindi Machine Reading Comprehension (MRC) tasks since it has been translated by linguistic experts, making this dataset more reliable for evaluating MQA models. XQuAD is a monolingual variant of the SQuAD dataset allowing, it to be utilized for evaluating the monolingual settings of the EHMMQA model in monolingual settings, such as English-English (
 $Q_{en}-C_{en}$
) and Hindi-Hindi (
$Q_{en}-C_{en}$
) and Hindi-Hindi (
 $Q_{hi}-C_{hi}$
) scenarios.
$Q_{hi}-C_{hi}$
) scenarios.
4.1.4 MLQA
MLQAFootnote f (Lewis et al. Reference Lewis, Oguz, Rinott, Riedel and Schwenk2020) is an MQA dataset containing QA pairs along with the context in seven languages, including Hindi. MLQA is a comprehensive and widely used benchmark for evaluating multilingual and cross-lingual QA models. This dataset contains 5,425 QA pairs and follows a structure similar to SQuAD, ensuring familiarity and compatibility with existing MQA models. The inclusion of Hindi in MLQA enables the specific evaluation of MQA models within the context of this language. By leveraging MLQA, researchers can conduct rigorous and reliable evaluations of multilingual and cross-lingual QA models, facilitating advancements in the field.
4.2 Experimental setup
The EHMMQA framework is designed in two different experimental setups.
-
(1) Setup-I: In Setup-I, the training focuses on the language pair of English and Hindi, excluding the Marathi sub-module of the EHMMQA framework. The model is trained using triplets consisting of an English question
$\lt q_{en}\gt$
, English context
$\lt c_{en}\gt$
, and English answer
$\lt a_{en}\gt$
, as well as Hindi counterparts
$\lt q_{hi}, c_{hi}, a_{hi}\gt$
. The entire EHMQuAD dataset is used for training and validation, while evaluation is performed on multiple datasets, including MMQA, Translated SQuAD, XQuAD, MLQA, and EHMQuAD itself. For the experiment, the EHMQuAD dataset is split into training (consisting of 54,298 QA pairs), validation (consisting of 3,000 QA pairs), and test (consisting of 6,000 pairs) sets. -
(2) Setup-II: In Setup-II, the EHMMQA model is trained using triplets of all three languages, including English (
$\lt q_{en}, c_{en}, a_{en}\gt$
), Hindi (
$\lt q_{hi}, c_{hi}, a_{hi}\gt$
), and Marathi (
$\lt q_{mr}, c_{mr}, a_{mr}\gt$
). The model is trained, validated, and tested on the proposed EHMQuAD dataset. The total number of common samples in all three languages is 46,489. Therefore, the EHMQuAD dataset is split into training (37,489 QA pairs), validation (3,000 QA pairs), and test (6,000 pairs) sets for experimental purposes.







The EHMMQA model is trained on the EHMQuAD dataset to reduce the summation of the negative log probabilities of the gold answer’s start and end positions for all three languages. For evaluating the proposed framework, the predicted answer should be in all three languages, regardless of the question and context language. To conduct the experiment, IndicFT (Kakwani et al. Reference Kakwani, Kunchukuttan, Golla, G., Bhattacharyya, Khapra and Kumar2020) and fastText (Grave et al. Reference Grave, Bojanowski, Gupta, Joulin and Mikolov2018), a publicly available pretrained word embeddings of dimension 300 is used for Hindi and Marathi language and English language, respectively. Multilingual word embedding is done by aligning the monolingual word vectors of all these languages in a single vector space. Tables 5 and 6 show the various monolingual and multilingual settings for the proposed MQA framework for two different experimental setups, respectively.
Table 5. Details of monolingual and multilingual settings for experimental setup-I

Table 6. Details of monolingual and multilingual settings for experimental setup-II

4.3 Evaluation metrics
The performance metrics used to evaluate the MQA model include Recall, Precision, F1-score, Accuracy, and Exact Match (EM). Accuracy measures the proportion of correctly identified answers from the total number of answers in the dataset. In the context of MQA, which is based on MRC, where the answer is extractive, accuracy is equivalent to EM (Dzendzik, Foster, and Vogel Reference Dzendzik, Foster and Vogel2021). EM is calculated by comparing the extracted answer with the pool of ground truth answers for a given QA pair. If the extracted answer matches any ground truth answers, EM is set to 1; otherwise, it is set to 0. Since MQA is an extractive task, the model may provide ambiguous, partial, or redundant responses. Hence, Precision, Recall, and F1-score are used to evaluate the model’s performance, even if the extracted answer does not exactly match the ground truth answer. These metrics consider the closeness between the extracted and the ground truth answers, even if they are not an exact match. EM measures the exact match between the extracted answer and the gold answer, while the F1-score quantifies the closeness between the extracted answer and the gold answer. In the monolingual settings
 $(Q_{en} - C_{en},Q_{hi} - C_{hi}$
and
$(Q_{en} - C_{en},Q_{hi} - C_{hi}$
and
 $Q_{mr} - C_{mr})$
, the predicted answer is considered correct if the model extracts the accurate answer in the same language as the question. In the case of multilingual settings, the predicted answer is accepted only if the model extracts the accurate answer in all three languages or in any two languages depending on multiple settings.
$Q_{mr} - C_{mr})$
, the predicted answer is considered correct if the model extracts the accurate answer in the same language as the question. In the case of multilingual settings, the predicted answer is accepted only if the model extracts the accurate answer in all three languages or in any two languages depending on multiple settings.
Table 7. Details of monolingual model

5. Results and discussion
The performance of an EHMMQA model is evaluated and compared with various baseline models, including an IR-based model (Gupta et al. Reference Gupta, Kumari, Ekbal and Bhattacharyya2018), monolingual (English, Hindi, and Marathi) models (refer Table 7 for more details), deep canonical correlation analysis (Deep CCA) model (Andrew et al. Reference Andrew, Arora, Bilmes and Livescu2013) and deep neural network (DNN) model (Gupta et al. Reference Gupta, Ekbal and Bhattacharyya2019). The details of these models are discussed as follows:
-
IR Model: This translation-based model consists of four steps: Document Processing, Question Processing, Candidate Answer Extraction, and Candidate Answer Scoring. The context is processed in the Document Processing step to generate snippets for each question. The Question Processing step involves Question Classification (QC) and query formulation. QC categorizes the question into different classes, while query formulation identifies nouns, verbs, and adjectives in the question to create a query. The output of QC plays a crucial role in extracting the candidate answer, where the passage is tagged with a named entity tagger to generate a list of candidate answers. Each candidate answer is assigned a score in the Candidate Answer Scoring step based on the relevance of its corresponding sentence.
-
Deep CCA Model: Deep CCA is a multivariate statistical technique used for learning and extracting highly correlated representations between two sets of variables or views. It extends the traditional CCA method by incorporating DNN to capture nonlinear and complex relationships between the views. Deep CCA optimizes the model’s parameters to ensure maximum correlation between the final representations of the two views. This is typically done by minimizing a loss function to quantify the disparity between the original views’ correlations and their mapped representations’ correlations.
-
DNN Model: In this model, a shared representation of the question is learned using soft alignment between the words from both languages. This shared question representation and the original context are received as input to the answer extraction layer to generate the answer span. This answer extraction process considers the question and context’s relevance. In addition, the pointer network is used to get the answer span’s start and end position from the context.
In experimental setup-I, the MQA model’s monolingual and multilingual settings results on all datasets are presented in Tables 8 and 9, respectively. For experimental setup-II, the results of the MQA model for monolingual and multilingual settings on the proposed EHMQuAD dataset are reported in Tables 10 and 11, respectively. It is evident from the results that the EHMMQA framework outperforms all baseline models, demonstrating its superiority in handling the MQA task.
Table 8. Performance analysis of proposed model (monolingual settings—experimental setup-I) with the other various models

Table 9. Performance analysis of proposed model (multilingual settings—experimental setup-I) with the other various models
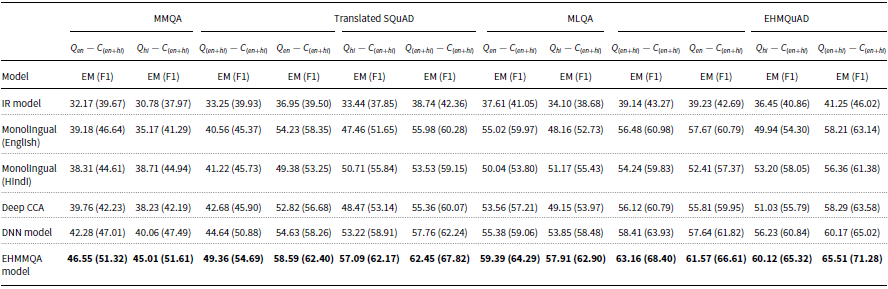
Table 10. Performance analysis of proposed model (monolingual settings—experimental setup-II) with the other various models

Table 11. Performance analysis of proposed model (multilingual settings—experimental setup-II) with the other various models

Table 12. Statistical test results showing the comparison between the proposed model and the baseline model
5.1 Result analysis
The results of the experiments are analyzed to see the impact of shared context representation and various word representations. The overall observations have been made based on the impact of the shared context representation:
-
(1) Improved Performance: The inclusion of the shared context representation in the EHMMQA model has shown a notable enhancement in performance compared to the baseline models. This suggests that the shared context representation enables better cross-lingual understanding and information integration.
-
(2) Enhanced Cross-Lingual Capability: The shared context representation facilitates effective information exchange between different languages. This enables the model to leverage relevant information from multiple languages, improving accuracy and coverage in generating answers.
-
(3) Language-Agnostic Context Understanding: The shared context representation allows the model to capture language-agnostic aspects of the context, enabling a more comprehensive understanding of the information. This is particularly beneficial in multilingual settings where the context can be in different languages.
-
(4) Robustness to Language Variations: The shared context representation helps the model handle language variations within the context more effectively. This is crucial in scenarios where the context may contain linguistic differences or code-switching between multiple languages.
Overall, the shared context representation in the EHMMQA model has proven advantageous, leading to improved performance and robustness in MQA tasks. The results of the shared context representation for two experimental setups are discussed in the following section. The results of the EHMMQA model on all five datasets are presented in Tables 8, 9, 10 and 11.
-
• Monolingual and Multilingual Settings-Experimental Setup-I: For the monolingual settings, the EHMMQA model outperforms the baseline model for the EHMQuAD dataset exhibiting the highest EM (F1) values, achieving 64.48 (69.72) for English and 59.69 (64.93) for Hindi. Conversely, the MMQA dataset exhibited the lowest EM (F1) scores for both English and Hindi, with values of 47.86 (53.19) and 44.11 (50.60), respectively. This can be attributed to the fact that these four datasets apart from MMQA, have larger contexts, allowing the model to capture a more comprehensive question-aware-context representation. The proposed EHMMQA model showcased significant improvements in both EM and F1-score compared to the baseline models for multilingual settings. Among all four datasets, the EHMMQA model achieved the best results on the EHMQuAD dataset, while the MMQA dataset recorded the lowest performance.
-
• Monolingual and Multilingual settings-Experimental Setup-II: In this setup, the EHMMQA model incorporates the Marathi language, alongside English and Hindi, to enhance its multilingual capabilities. The model is trained and validated on the EHMQuAD dataset, which comprises samples in all three languages. The trained model is then evaluated on the test set of 6K QA pairs to measure the performance of the proposed model. Remarkably, the EHMMQA model surpasses all baseline models in monolingual and multilingual settings, exhibiting superior results. Compared to the DNN model, the proposed framework exhibits significant improvements, achieving an average increase of 4.5 points in settings where the Marathi language is absent. However, in settings involving the Marathi language, the average increase is only 2.8 points. This can be attributed to certain challenges encountered while translating Marathi instances. It should be noted that certain inconsistencies slightly hamper the performance of the EHMMQA model. For example, during translation, spaces within a year might be incorrectly separated (e.g., 1986 becomes 1 98 6). Additionally, numerical values may be converted into the Devanagari script but not properly back-translated into the Latin script (e.g.,
$23$
is translated as ). These discrepancies contribute to a slight degradation in performance.

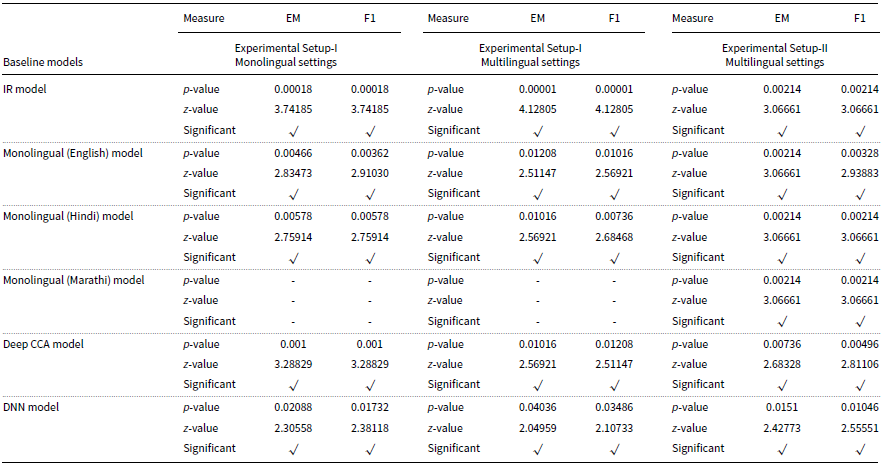
5.1.1 Statistical test results
The statistical test results confirm whether the improvement of the EHMMQA model over the baseline models is statistically significant or not significant. The improvement of the result is confirmed by using the Mann–Whitney U Test based on a significant level of 95% (i.e., 0.05) and a two-tailed hypothesis. The statistical results of the EHMMQA model over baseline models in terms of the EM and F1-score are presented in Table 12. The table has
 $p$
-value and
$p$
-value and
 $z$
-score information, where two sample sets are significant if
$z$
-score information, where two sample sets are significant if
 $p$
-value is less than 0.05, and therefore, the null hypothesis is rejected. For monolingual settings of experimental setup-II, statistical significance between the EHMMQA model over the baseline model is not calculated because the number of samples is only three, and this test required at least five samples. However, it can be observed from the results obtained for monolingual settings of experimental setup-II that the proposed model has significant improvement (for EM) of around 10.84%, 10.08%, and 8.72% for English, Hindi, and Marathi languages, respectively. In all other cases, the model has significantly improved compared to all baseline models.
$p$
-value is less than 0.05, and therefore, the null hypothesis is rejected. For monolingual settings of experimental setup-II, statistical significance between the EHMMQA model over the baseline model is not calculated because the number of samples is only three, and this test required at least five samples. However, it can be observed from the results obtained for monolingual settings of experimental setup-II that the proposed model has significant improvement (for EM) of around 10.84%, 10.08%, and 8.72% for English, Hindi, and Marathi languages, respectively. In all other cases, the model has significantly improved compared to all baseline models.
5.2 Ablation study
A comprehensive evaluation of different word representation models, including FT + W (Bojanowski et al. Reference Bojanowski, Grave, Joulin and Mikolov2017), FT + WC (Grave et al. Reference Grave, Bojanowski, Gupta, Joulin and Mikolov2018), mBERT (Pires et al. Reference Pires, Schlinger and Garrette2019), and the IndicFT (Kakwani et al. Reference Kakwani, Kunchukuttan, Golla, G., Bhattacharyya, Khapra and Kumar2020) model, is done to assess their performance on MQA datasets in the context of the Indic language. The IndicFT model stood out with its superior performance, demonstrating its potential for effectively representing and understanding the Indic language. The underlying reasons for this superior performance can be attributed to multiple factors.
-
• Language-specific training: The IndicFT model is specifically designed and trained for the Indic language. It is trained on IndicCorp, the largest publicly available monolingual corpora of the Indic language. This language-specific training allows the model to capture the unique linguistic patterns, semantic nuances, and syntactic structures specific to the Indic language. In contrast, the other models have been trained on more general or diverse datasets, which might not adequately capture the intricacies of the Indic language.
-
• Corpus size: The size of the training corpus plays a crucial role in the performance of word representation models. IndicFT benefits from being trained on large monolingual corpora, IndicCorp. The larger the training corpus, the more exposure the model has to a wide range of language contexts and variations, leading to better representation learning.
-
• Fine-tuning: It refers to adapting a pretrained model to a specific task or domain. The IndicFT model might have undergone fine-tuning specifically for the MQA datasets or the Indic language tasks, allowing it to better align with the requirements of the evaluation task. The other models, such as mBERT, FT + W, and FT + WC, are not fine-tuned specifically for the MQA datasets or the Indic language, leading to a potential performance gap.
-
• Model architecture and training techniques: The differences in model architecture and training techniques can also contribute to the performance variations. The IndicFT model employs specific architectural choices or training strategies better suited for capturing the complexities of the Indic language. These choices could include attention mechanisms, contextual embeddings, or optimization methods specifically tailored to the Indic language.
Overall, the better performance of the IndicFT model compared to mBERT, FT + W, and FT + WC models can be attributed to its language-specific training on a large monolingual corpus, potential fine-tuning on the evaluation task, and architectural and training choices that are specifically optimized for the Indic language. Table 13 reports the ablation study of the various word representation models on the MQA system.
Table 13. Ablation study of various word representations

6. Conclusion and future scope
MQA is an application of NLP that answers the user’s question irrespective of the language. Although the MQA systems used zero-shot/few-shot, translate-train, and translate-test approaches to transfer knowledge from English to other languages, these systems do not provide the abstract structure to understand multiple languages. Also, the lack of benchmark datasets for low-resource languages hinders the growth of MQA systems. To overcome these challenges, the proposed EHMQuAD dataset is created for English, Hindi, and Marathi languages using the TAR approach, and the proposed EHMMQA model is developed. This framework is an abstract structure that can be adaptable to any number of different languages. The EHMMQA model employs a deep neural network approach considering English, Hindi, and Marathi languages. The results obtained are significant on the MQA datasets and are considered state-of-the-art performance. The specific concern regarding the improvement in the performance of the system is to be addressed in the future. Multilingual complex, descriptive, and reasoning questions are a QA system’s major concern and can be handled in the future.
Competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.



















 Open access
Open access