
Natural Language Engineering, Volume 30 - Issue 2 - March 2024
- This volume was published under a former title. See this journal's title history.
Contents
Editorial Note
Editorial Note
-
- Published online by Cambridge University Press:
- 01 April 2024, pp. 215-216
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Article
Quinductor: A multilingual data-driven method for generating reading-comprehension questions using Universal Dependencies
-
- Published online by Cambridge University Press:
- 27 February 2023, pp. 217-255
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Determining sentiment views of verbal multiword expressions using linguistic features
-
- Published online by Cambridge University Press:
- 15 May 2023, pp. 256-293
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What should be encoded by position embedding for neural network language models?
-
- Published online by Cambridge University Press:
- 10 May 2023, pp. 294-318
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Towards diverse and contextually anchored paraphrase modeling: A dataset and baselines for Finnish
-
- Published online by Cambridge University Press:
- 16 March 2023, pp. 319-353
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Urdu paraphrase detection: A novel DNN-based implementation using a semi-automatically generated corpus
-
- Published online by Cambridge University Press:
- 29 May 2023, pp. 354-384
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Automatic paraphrase detection is the task of measuring the semantic overlap between two given texts. A major hurdle in the development and evaluation of paraphrase detection approaches, particularly for South Asian languages like Urdu, is the inadequacy of standard evaluation resources. The very few available paraphrased corpora for these languages are manually created. As a result, they are constrained to smaller sizes and are not very feasible to evaluate mainstream data-driven and deep neural networks (DNNs)-based approaches. Consequently, there is a need to develop semi- or fully automated corpus generation approaches for the resource-scarce languages. There is currently no semi- or fully automatically generated sentence-level Urdu paraphrase corpus. Moreover, no study is available to localize and compare approaches for Urdu paraphrase detection that focus on various mainstream deep neural architectures and pretrained language models.
This research study addresses this problem by presenting a semi-automatic pipeline for generating paraphrased corpora for Urdu. It also presents a corpus that is generated using the proposed approach. This corpus contains 3147 semi-automatically extracted Urdu sentence pairs that are manually tagged as paraphrased (854) and non-paraphrased (2293). Finally, this paper proposes two novel approaches based on DNNs for the task of paraphrase detection in Urdu text. These are Word Embeddings n-gram Overlap (henceforth called WENGO), and a modified approach, Deep Text Reuse and Paraphrase Plagiarism Detection (henceforth called D-TRAPPD). Both of these approaches have been evaluated on two related tasks: (i) paraphrase detection, and (ii) text reuse and plagiarism detection. The results from these evaluations revealed that D-TRAPPD (
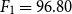 $F_1 = 96.80$ for paraphrase detection and
$F_1 = 96.80$ for paraphrase detection and 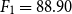 $F_1 = 88.90$ for text reuse and plagiarism detection) outperformed WENGO (
$F_1 = 88.90$ for text reuse and plagiarism detection) outperformed WENGO (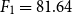 $F_1 = 81.64$ for paraphrase detection and
$F_1 = 81.64$ for paraphrase detection and 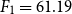 $F_1 = 61.19$ for text reuse and plagiarism detection) as well as other state-of-the-art approaches for these two tasks. The corpus, models, and our implementations have been made available as free to download for the research community.
$F_1 = 61.19$ for text reuse and plagiarism detection) as well as other state-of-the-art approaches for these two tasks. The corpus, models, and our implementations have been made available as free to download for the research community.
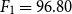
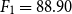
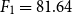
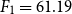
Polish natural language inference and factivity: An expert-based dataset and benchmarks
-
- Published online by Cambridge University Press:
- 01 June 2023, pp. 385-416
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Despite recent breakthroughs in Machine Learning for Natural Language Processing, the Natural Language Inference (NLI) problems still constitute a challenge. To this purpose, we contribute a new dataset that focuses exclusively on the factivity phenomenon; however, our task remains the same as other NLI tasks, that is prediction of entailment, contradiction, or neutral (ECN). In this paper, we describe the LingFeatured NLI corpus and present the results of analyses designed to characterize the factivity/non-factivity opposition in natural language. The dataset contains entirely natural language utterances in Polish and gathers 2432 verb-complement pairs and 309 unique verbs. The dataset is based on the National Corpus of Polish (NKJP) and is a representative subcorpus in regard to syntactic construction [V][że][cc]. We also present an extended version of the set (3035 sentences) consisting more sentences with internal negations. We prepared deep learning benchmarks for both sets. We found that transformer BERT-based models working on sentences obtained relatively good results (
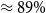 $\approx 89\%$ F1 score on base dataset). Even though better results were achieved using linguistic features (
$\approx 89\%$ F1 score on base dataset). Even though better results were achieved using linguistic features (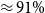 $\approx 91\%$ F1 score on base dataset), this model requires more human labor (humans in the loop) because features were prepared manually by expert linguists. BERT-based models consuming only the input sentences show that they capture most of the complexity of NLI/factivity. Complex cases in the phenomenon—for example, cases with entitlement (E) and non-factive verbs—still remain an open issue for further research.
$\approx 91\%$ F1 score on base dataset), this model requires more human labor (humans in the loop) because features were prepared manually by expert linguists. BERT-based models consuming only the input sentences show that they capture most of the complexity of NLI/factivity. Complex cases in the phenomenon—for example, cases with entitlement (E) and non-factive verbs—still remain an open issue for further research.
Emerging Trends
Emerging trends: When can users trust GPT, and when should they intervene?
-
- Published online by Cambridge University Press:
- 16 January 2024, pp. 417-427
-
- Article
-
- You have access
- Open access
- HTML
- Export citation