



1. Introduction
The ability to model lexical entailment is a test of the adequacy of any theory of lexical semantics. We study lexical entailment not merely as another engineering task in the field of natural language processing (NLP), but as a central goal of our efforts towards building generic and actionable representations of natural language semantics. We present a rule-based, language-independent system for detecting entailment between pairs of words using 4lang semantic graphs (Kornai et al. Reference Kornai, Ács, Makrai, Nemeskey, Pajkossy and Recski2015; Recski Reference Recski2018) built from dependency parses of dictionary definitions. We also present a novel architecture for constructing and manipulating graphs with synchronous grammars and use it to implement improvements of previous methods for building and expanding concept graphs from dictionaries. Our goal is to establish symbolic representations of lexical semantics that allow us to model entailment stragihtforwardly, as overlaps between premise and hypothesis graphs.
Stopping conditions of our system can be adjusted to multiple formulations of the entailment task. We present experiments on two substantially different datasets, the Semeval-2020 task “Predicting Multilingual and Cross-lingual (graded) Lexical Entailment’’ (Glavaš et al. Reference Glavaš, Vulić, Korhonen and Ponzetto2020) and the SherLIiC benchmark for context aware-typed lexical inference (Schmitt and Schütze Reference Schmitt and Schütze2019). On the Semeval task of detecting binary lexical entailment, we achieve new state-of-the- art results on three languages, two of which were held by our earlier system (Kovács et al. Reference Kovács, Gémes, Kornai and Recski2020). On the second, more challenging benchmark, our method outperforms all rule-based baselines and also allows for a slight improvement over the top-performing system. Perhaps more importantly, the high precision of our method makes it possible to combine it with a neural NLI system based on RoBERTa (Zhuang et al. Reference Zhuang, Wayne, Ya and Jun2021), improving its overall performance. As our grounds for establishing entailment between a pair of lexical entries is always some overlap between two concept graphs, predictions made by our system are all directly explainable as common subgraphs of premise and hypothesis definitions, providing an example of transparent, trustworthy, and explainable AI (xAI).
The article is structured as follows. Section 2.1 reviews the formulations of the lexical entailment task and corresponding datasets, with special emphasis on the two datasets used in our work. Then in Section 2.2, we survey recent approaches to entailment and inference tasks. We then provide a short overview of common approaches to semantic parsing in Section 2.3 and review approaches to modeling entailment with semantic graphs in Section 2.4. Section 3 describes our pipeline for building 4lang semantic graphs from Wiktionary entries and for obtaining additional synonyms both from Wiktionary and WordNet. The section also provides an overview of our method of using graph grammars to transform dependency trees to 4lang graphs, and finally describes our method for establishing entailment over pairs of 4lang graphs. Section 4 evaluates our method on two recent benchmarks and compares their performance to previous systems, also experimenting with simple strategies for combining them with the output of state-of-the art NLI systems for improved performance. Finally, Section 5 presents the results of manual error analysis on both datasets, providing insight about the differences between the two formulations of the entailment task and identifying current shortcomings of our approach, along with possible solutions. All software described in this article is open-source, released under an MIT license.Footnote a, Footnote b, Footnote c
2. Related work
2.1 Tasks and datasets
Entailment between pairs of words has been studied extensively both as one of the fundamental relationships in the lexicon and as an essential building block of models of natural language inference. Several recent task formulations equate lexical entailment with hypernymy/hyponymy or the IS_A relationship (Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017; Vulić, Ponzetto, and Glavaš Reference Vulić, Ponzetto and Glavaš2019), treating it as a relationship between two entries in a lexicon and creating datasets of labeled pairs of words such as Hyperlex (Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017). Other works are concerned with the entailment relationship between two words in their respective contexts. Pointing out that eliminate entails treat in Aspirin eliminates headaches but not in Aspirin eliminates patients, Levy and Dagan (Reference Levy and Dagan2016) introduce a dataset of annotated relation pairs. This dataset uses question–answer pairs as context for lexical entailment, other approaches involve providing context as pairs of arguments (Zeichner, Berant, and Dagan Reference Zeichner, Berant and Dagan2012) or pairs of argument types (Berant, Dagan, and Goldberger Reference Berant, Dagan and Goldberger2011; Schmitt and Schütze Reference Schmitt and Schütze2019). Lexical entailment can also be viewed as a special case of natural language inference (NLI), modern systems for this task are commonly trained and evaluated on the Stanford Natural Language Inference (SNLI) (Bowman et al. Reference Bowman, Angeli, Potts and Manning2015) dataset and the Multi-Genre NLI Corpus (MultiNLI) (Williams, Nangia, and Bowman Reference Williams, Nangia and Bowman2018) dataset.
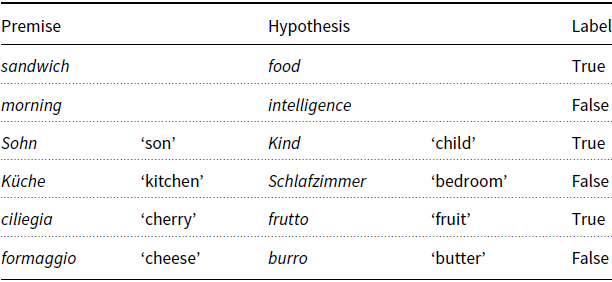
The approach taken in this article, outlined in Section 3.2, is based on the 4lang formalism for representing (lexical) semantics and is capable of inspecting the relationship between the meaning of any two utterance fragments. We will evaluate our system on two recent benchmarks. The datasets used in the 2020 Semeval task “Predicting Multilingual and Cross-lingual (graded) Lexical Entailment’’ (Glavaš et al. Reference Glavaš, Vulić, Korhonen and Ponzetto2020) are derived from HyperLex (Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017), a dataset of monolingual and cross-lingual–graded lexical entailment. Candidate word pairs for human annotation were gathered from the USF (Nelson, McEvoy, and Schreiber Reference Nelson, McEvoy and Schreiber2004) and WordNet (Miller Reference Miller1995) databases. For our experiments, we will use the binary labels of the monolingual subsets for English, German, and Italian. Some examples for each language are shown in Table 1. On this dataset, we will compare our method to the GLEN system for measuring multilingual and cross-lingual lexical entailment using specialized word embeddings (Vulić et al. Reference Vulić, Ponzetto and Glavaš2019), which outperforms previous baselines in Upadhyay et al. (Reference Upadhyay, Vyas, Carpuat and Roth2018), and also to the other systems participating in the shared task, including our own earlier system presented in Kovács et al. (Reference Kovács, Gémes, Kornai and Recski2020).
Table 1. Example entries of the monolingual binary portion of the Semeval lexical entailment dataset (Glavaš et al. Reference Glavaš, Vulić, Korhonen and Ponzetto2020)
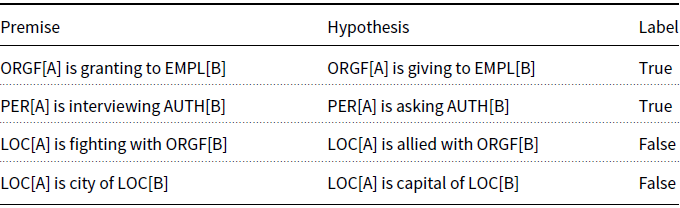
A more challenging task formulation is provided by the SherLlic dataset of lexical inference in context (Schmitt and Schütze Reference Schmitt and Schütze2019), which was built by extracting inference candidates from an entity-linked portion of the ClueWeb corpus (Gabrilovich, Ringgaard, and Subramanya Reference Gabrilovich, Ringgaard and Subramanya2013) and using them as input to human annotation. Because annotation candidates were chosen based on distributional evidence, many entailment pairs in the final dataset are completely novel, missing from existing knowledge bases such as WordNet. Argument types for event pairs are necessary to disambiguate between word senses. For example, run entails lead if its arguments are of type PERSON and COMPANY (e.g., Bezos runs Amazon) but not if they are COMPUTER and SOFTWARE, as in my mac runs macOS. Table 2 shows further examples of entries in the SherLlic dataset. An extensive evaluation of various LE systems on this dataset presented in Schmitt and Schütze (Reference Schmitt and Schütze2019) will serve as the starting point for our evaluations in Section 4.
Table 2. Example entries of the SherLlic dataset (Schmitt and Schütze Reference Schmitt and Schütze2019). Argument labels indicate entity types: PER – person, LOC – location, ORGF – organization_founder, EMPL – employer, AUTH – book_author
The need for such novel datasets has been made clear by several recent experiments that point out the biases of deep learning based models of NLI. Glockner, Shwartz, and Goldberg (Reference Glockner, Shwartz and Goldberg2018) constructed a new NLI test set from SNLI by replacing a single word in sentences from the training set, and used this new benchmark to expose top NLI systems’ inability to perform true lexical inference. The only model in their evaluation not showing a major drop in performance was the one incorporating lexical knowledge (Chen et al. Reference Chen, Cui, Ma, Wang, Liu and Hu2018). The inability of deep learning based NLI models to generalize across datasets was also shown in a more recent study across six systems and three datasets (Talman and Chatzikyriakidis Reference Talman and Chatzikyriakidis2019). These findings call into question whether black box models trained for high performance on any single NLI benchmark can be regarded as true models of inference. We believe that rule-based models such as the one proposed in this paper can facilitate further qualitative analysis of deep learning models by providing strong explainable baselines on multiple tasks and datasets.
2.2 Approaches to entailment and inference
When seen as a task of detecting hypernymy, lexical entailment is most often addressed using distributional methods. Hypernymy candidates are encoded using word embeddings and classified by either neural networks (Nguyen et al. Reference Nguyen, Köper, Schulte im Walde and Vu2017; Shwartz, Goldberg, and Dagan Reference Shwartz, Goldberg and Dagan2016; Yu et al. Reference Yu, Wang, Lin and Wang2015) or non-neural classifiers such as Support Vector Machines (SVMs) and logistic regression (Baroni et al. Reference Baroni, Bernardi, Do and Shan2012; Levy et al. Reference Levy, Remus, Biemann and Dagan2015; Roller, Erk, and Boleda Reference Roller, Erk and Boleda2014). Yu et al. (Reference Yu, Wang, Lin and Wang2015) proposes a neural model for supervised learning of hypernymy-specific embeddings. Nguyen et al. (Reference Nguyen, Köper, Schulte im Walde and Vu2017) argues that standard distributional models cannot account for the asymmetric property of hypernymy, and introduces HyperVec, a hierarchical approach to learning hypernymy embeddings that allowed for significant improvement over the state-of-the-art on the HyperLex dataset. Glavaš and Ponzetto (Reference Glavaš and Ponzetto2017) proposes Dual Tensor, an approach based on neural models to explicitly model the asymmetric nature of the hypernymy relation. Dual Tensor transforms generic embeddings into specialized vectors for scoring concept pairs based on whether the asymmetric relation holds. A different approach is taken by HypeNET (Shwartz et al. Reference Shwartz, Goldberg and Dagan2016), a method based on extracting paths between premise and hypothesis from dependency trees and using them as inputs to Long Short-term Memory Networks (LSTMs). Fine-tuning generic word vectors using external knowledge such as WordNet (Miller Reference Miller1995) has improved performance on a range of language understanding tasks (Glavaš and Vulić Reference Glavaš and Vulić2018). To extend this method to unseen words, Kamath et al. (Reference Kamath, Pfeiffer, Ponti, Glavaš and Vulić2019) introduced POSTLE (post-specialization for LE), a model that learns an explicit global specialization function captured with feed forward neural networks.
Inference systems trained on the SNLI and MultiNLI datasets mostly use neural language models based on the Transformer architecture (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017), in particular BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). SemBERT (Zhang et al. Reference Zhang, Wu, Zhao, Li, Zhang, Zhou and Zhou2020) uses a BERT backbone enhanced with a Semantic Role Labeler (SRL), MT-DNN (Liu et al. Reference Liu, He, Chen and Gao2019) enhances the system presented in Liu et al. (Reference Liu, Gao, He, Deng, Duh and Wang2015) with BERT. Top results on the MultiNLI benchmark were achieved by optimized, pretrained, and finetuned versions of BERT, RoBERTa (Zhuang et al. Reference Zhuang, Wayne, Ya and Jun2021), and ALBERT (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020). Using rule-based models in NLI and combining them with deep learning based language models (BERT, ALBERT, RoBERTa) has recently also led to competitive results (Haruta, Mineshima, and Bekki Reference Haruta, Mineshima and Bekki2020; Kalouli, Crouch, and de Paiva Reference Kalouli, Crouch and de Paiva2020). In this article, we will also present an improvement over such a model using our fully rule-based method for detecting entailment between pairs of words.
2.3 Semantic parsing
Semantic parsing is the task of mapping natural language text to some model of its meaning, and as a language processing step it can only be defined with respect to a particular system of semantic representation. As interest in symbolic representations has increased, so has the variety of such systems. Most practical frameworks link to lexical databases, including the graph of synonym sets in WordNet (Miller Reference Miller1995), the semantic role inventory in VerbNet (Kipper et al. Reference Kipper, Korhonen, Ryant and Palmer2008), or the ontology of semantic frames in FrameNet (Ruppenhofer et al. Reference Ruppenhofer, Ellsworth, Petruck, Johnson and Scheffczyk2006). Abstract meaning representations (AMR) (Banarescu et al. Reference Banarescu, Bonial, Cai, Georgescu, Griffitt, Hermjakob, Knight, Koehn, Palmer and Schneider2013), which became one of the most widely used representations in semantic parsing, is based on the PropBank database (Palmer, Gildea, and Kingsbury Reference Palmer, Gildea and Kingsbury2005). AMR handles a range of phenomena in the semantics of English but does not provide any treatment of word meaning and is also not intended as a universal representation of natural language semantics, despite some early efforts in Xue et al. (Reference Xue, Bojar, Hajič, Palmer, Urešová and Zhang2014) and the release of a Chinese AMR bank (Li et al. Reference Li, Wen, Qu, Bu and Xue2016). Automatic construction of AMR graphs from text is usually performed using deep neural models (Konstas et al. Reference Konstas, Iyer, Yatskar, Choi and Zettlemoyer2017; Lyu and Titov Reference Lyu and Titov2018; Zhang et al. Reference Zhang, Ma, Duh and Van Durme2019) trained on AMR banks. A language-agnostic approach to meaning representation is taken by Universal Conceptual Cognitive Annotation (UCCA) (Abend and Rappoport Reference Abend and Rappoport2013), which abstracts away from syntax by representing words of a sentence as leaf nodes of directed acyclic graphs (DAGs) representing scenes evoked by predicates. As in the case of AMRs, top-performing parsers for UCCA all employ neural networks trained on manually annotated sentences (Hershcovich, Abend, and Rappoport Reference Hershcovich, Abend and Rappoport2017, Reference Hershcovich, Abend and Rappoport2018; Ozaki et al. Reference Ozaki, Morio, Koreeda, Morishita and Miyoshi2020; Samuel and Straka Reference Samuel and Straka2020). Not only are these formalisms often dependent on large manually built databases, existing parsing systems also rely on large datasets of hand-crafted representations (sembanks) for training. Transferring such systems across domains and languages therefore requires a considerable amount of expert human labor. In this article, we will use a meaning representation formalism designed to enable robust rule-based parsing and relying only on language-agnostic resources. Here we provide an overview only, our extensions and modifications shall be presented in Section 3.
4lang is a theory and formalism for representing the semantics of natural language, developed in Kornai (Reference Kornai2012, Reference Kornai2019), Kornai et al. (Reference Kornai, Ács, Makrai, Nemeskey, Pajkossy and Recski2015), and partially implemented in Recski (Reference Recski2016, Reference Recski2018). 4lang concept graphs represent meaning as directed graphs of language-independent concepts. Edges connecting concepts have one of three labels. Predicates are connected to their arguments via edges labeled 1 and 2, for example, cat
 $\xleftarrow1$
catch
$\xleftarrow1$
catch
 $\xrightarrow2$
mouse, while 0-edges represent all relationships involving inheritance, including not only hypernymy (dog
$\xrightarrow2$
mouse, while 0-edges represent all relationships involving inheritance, including not only hypernymy (dog
 $\xrightarrow0$
mammal) but also attribution (dog
$\xrightarrow0$
mammal) but also attribution (dog
 $\xrightarrow0$
four-legged), and unary predication (dog
$\xrightarrow0$
four-legged), and unary predication (dog
 $\xrightarrow0$
bark). This implies a broad definition of lexical entailment: unless explicitly overridden, dog entails not only mammal, but also bark and four-legged. In its current implementations, 4lang concepts have no grammatical attributes and no event structure, for example, the phrases water freezes and frozen water would both be represented as water
$\xrightarrow0$
bark). This implies a broad definition of lexical entailment: unless explicitly overridden, dog entails not only mammal, but also bark and four-legged. In its current implementations, 4lang concepts have no grammatical attributes and no event structure, for example, the phrases water freezes and frozen water would both be represented as water
 $\xrightarrow0$
freeze. Figure 2 shows the 4lang definition of the concept jewel obtained by processing the dependency parse in Figure 1 of the Wiktionary definition A precious or semi-precious stone; gem, gemstone.
$\xrightarrow0$
freeze. Figure 2 shows the 4lang definition of the concept jewel obtained by processing the dependency parse in Figure 1 of the Wiktionary definition A precious or semi-precious stone; gem, gemstone.
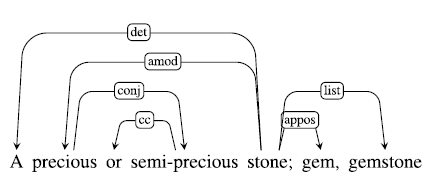
Figure 1. Dependency parse of the definition of jewel.
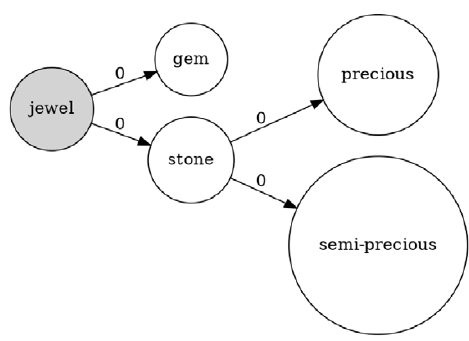
Figure 2. 4lang definition graph of jewel.
Optionally, the 4lang system allows us to expand graphs, a process which unifies one graph with the definition graphs of the concepts within that graph. For example, a graph containing the node jewel will be expanded to include as a subgraph the entire definition graph in Figure 2. This step will be essential to our method presented in Section 3.2. 4lang graphs can be built automatically from Universal Dependencies (Nivre et al. Reference Nivre, Abrams and Agić2018) using the rule-based dep_to_4lang module, which we extend to improve performance across languages. Section 3 will describe these changes, as well as our reimplementation of the parsing algorithm using Interpreted Regular Tree Grammars (IRTGs) (Koller Reference Koller2015). While in the present work this method is used to map natural language definitions to concept graphs representing the meaning of individual words, the system is capable of processing any UD graph and can be used to construct the 4lang semantic representation of any text.
2.4 Entailment in semantic graphs
Lexical entailment is explicitly encoded by several semantic formalisms. The hyponymy/ hypernymy relation, the narrow interpretation of lexical entailment used for example in the Semeval 2020 shared task, is represented directly by WordNet. The 0-edge in 4lang graphs is a more generic relation that subsumes the hypernymy relation along with all other types of predication, and accessibility of one concept from another in a 4lang graph can be seen as a broad definition of lexical entailment. Recently, we have shown (Kovács et al. Reference Kovács, Gémes, Kornai and Recski2020) the direct applicability of such semantic graphs to hypernymy detection task by using them in a competitive system at the Semeval entailment task (Glavaš et al. Reference Glavaš, Vulić, Korhonen and Ponzetto2020). When using 4lang definition graphs, we defined entailment to hold between a pair of premise and hypothesis words if and only if in the twice-expanded definition graph of the premise there is a directed path of 0-edges leading from the premise word to the hypothesis word (the maximum number of expansions was chosen arbitrarily). Because entailment does not flow through locative and negative modifier clauses, inference had to be blocked explicitly where the path would go through prepositions (e.g. English in, of, on, German in, auf, Italian di, su, il) or words conveying negation (English not, German keine, etc.). For example, where nose is defined as “a protuberance on the face’’, 4lang graphs would contain a path of 0-edges from nose to face, falsely representing entailment. One of the modifications of the parsing algorithm to be presented in this article will ensure that subgraphs representing such relations do not contain 0-paths.
On the Semeval dataset of word-level entailment, the above method detected only about one-third of all true entailments in the dev dataset but achieved nearly perfect precision. On well-resourced languages such as English, WordNet was shown to be a very strong baseline both in terms of precision and recall, and the main contribution of 4lang was its ability to increase recall without hurting precision, increasing the performance of strong WordNet-based baselines on three languages, ranking first in English and Italian and second-best on German, see Table 3. For English and Italian official WordNet releases were accessed via the nltk Footnote d package. In Kovács et al. (Reference Kovács, Gémes, Kornai and Recski2020) for German, we did not have access to a high-coverage WordNet release, word pairs were therefore translated from German to English using the wikt2dict system (ács, Pajkossy, and Kornai Reference Ács, Pajkossy and Kornai2013) to enable the use of English WordNet on the German task. In Section 4, when evaluating the methods presented in this article and comparing them to previous methods, we include a variant of this system using a recent German WordNet release, GermaNet (Hamp and Feldweg Reference Hamp and Feldweg1997; Henrich and Hinrichs Reference Henrich and Hinrichs2010).
Table 3. Official monolingual LE results on the ANY track (F-scores)
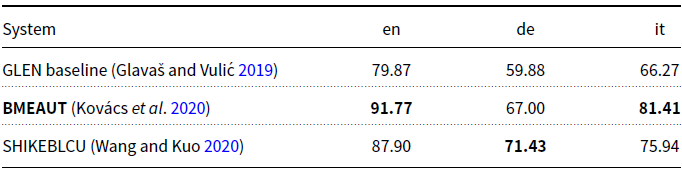
Bold values represents best scores.
3. Semantic parsing and representation
Our method for establishing entailment between pairs of words requires that we create 4lang semantic graphs for each word. Using a modified version of the pipeline described in Recski (Reference Recski2016), we process dictionary definitions with Universal Dependency (UD) (Nivre et al. Reference Nivre, Abrams and Agić2018) using the stanza library (Qi et al. Reference Qi, Zhang, Zhang, Bolton and Manning2020) and transform the resulting dependency trees using rules from the dep_to_4lang (Recski Reference Recski2018) module. In this section, we present our modified version of this pipeline, for which we reimplement the transformation of dependency trees into 4lang graphs using Interpreted Regular Tree Grammars (IRTGs) (Koller Reference Koller2015) generated dynamically using a lexicon of rule templates. Then we present our method for detecting entailment over pairs of semantic graphs corresponding to premise and hypothesis.
3.1 Semantic parsing with Interpreted Regular Tree Grammars
Many NLP tasks involve constructing or transforming graphs that represent syntax and/or semantics. Interpreted Regular Tree Grammars (IRTGs) (Koller Reference Koller2015) can be used to encode the correspondence between sets of such structures and have in recent years been used to perform syntactic parsing (Koller and Kuhlmann Reference Koller and Kuhlmann2012), generation (Koller and Engonopoulos Reference Koller and Engonopoulos2017), semantic parsing (Groschwitz, Koller, and Teichmann Reference Groschwitz, Koller and Teichmann2015; Groschwitz et al. Reference Groschwitz, Lindemann, Fowlie, Johnson and Koller2018), and surface realization (Kovács et al. Reference Kovács, Ács, Ács, Kornai and Recski2019; Recski et al. Reference Recski, Kovács, Gémes, Ács and Kornai2020). The system presented in this article uses an IRTG for transforming UD trees into 4lang graphs.
An IRTG rule is a (possibly weighted) rewrite rule of a Regular Tree Grammar that is mapped to an arbitrary number of named interpretations, each of which are operations of an algebra with the same arity as the RTG rule. Thereby any particular derivation of an IRTG grammar deterministically maps to a sequence of operations in each of the interpretation algebras. Parsing an object of one algebra involves finding the IRTG derivation(s) of the highest likelihood that would generate this object, while decoding is the subsequent construction of an object in another algebra using this sequence. The grammars used by our system establish a mapping between operations of two algebras of directed graphs, one for constructing UD representations and another for constructing 4lang graphs. The overall structure of an IRTG rule with two interpretations is shown in Figure 3. The graph operations used in this example will now be introduced.

Figure 3. Example of an IRTG rule.
Following the practice of Koller and Kuhlmann (Reference Koller and Kuhlmann2011), we use s-graph algebras. We give an informal overview of its operations, see Courcelle and Engelfriet (Reference Courcelle and Engelfriet2012) for a more formal explanation. S-graphs are graphs whose vertices may be labeled by one of a countable set of sources, which are essentially special node labels accessible by operations of the algebra. The binary merge operation creates an s-graph by taking the union of its argument graphs and merging nodes with identical sources. In other words, when two s-graphs
 $G_1$
and
$G_1$
and
 $G_2$
are merged, the resulting s-graph G’ will contain all nodes of
$G_2$
are merged, the resulting s-graph G’ will contain all nodes of
 $G_1$
and
$G_1$
and
 $G_2$
, and when a pair of nodes
$G_2$
, and when a pair of nodes
 $(v_1,v_2) \in V(G_1) \times V(G_2)$
have the same source name, they will be mapped to a single node v’ in G’ that has all adjacent edges of
$(v_1,v_2) \in V(G_1) \times V(G_2)$
have the same source name, they will be mapped to a single node v’ in G’ that has all adjacent edges of
 $v_1$
and
$v_1$
and
 $v_2$
. Sources can be manipulated by the rename and forget operations for changing or deleting a given source label from all nodes of an s-graph.
$v_2$
. Sources can be manipulated by the rename and forget operations for changing or deleting a given source label from all nodes of an s-graph.
We illustrate the algebra operations and the structure of an IRTG using a simple example. Figure 3 shows an IRTG rule encoding the correspondence between two operations: one that adds a directed amod edge between the root nodes of two UD graphs, and another that adds a directed 0 edge between the root nodes of two 4lang graphs. The first line in the example is the IRTG rule, specifying that an operation called NOUN_AMOD_ADJ takes as its arguments two objects of type NOUN and ADJ. The second and third lines are the interpretations, each specifying the same sequence of operations: the first argument is merged with a graph consisting of a single directed edge, the second argument is merged with the resulting graph after its root source has been changed to dep1 using the rename operation. Finally, the dep1 source is deleted, using the forget operation. This sequence of operations is equivalent to adding a single directed edge between the root nodes of the two argument graphs, ensuring that the root of the first becomes the root of the new graph. The syntax used in this example is specified by the Algebraic Language Toolkit, or alto Footnote e (Gontrum et al. Reference Gontrum, Groschwitz, Koller and Teichmann2017), an open-source parser for IRTGs that implements a variety of algebras, including the s-graph algebras used in this article. Graph literals in each interpretation are given using the PENMAN notation,Footnote f in this simple case the only difference between the two strings is the edge label. The correspondence expressed by the rule in Figure 3 can also be represented by the pair of graph templates in Figure 4, we will use this simplified format in future examples.
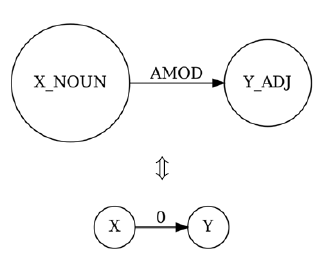
Figure 4. Graph representation of sample rule in Figure 3.
Parsing UD graphs and transforming them into 4lang graphs on a large scale would be possible using a single grammar with terminal rules corresponding to each word of the input graph. But since building and continuously extending such a large set of rules would be inefficient, we instead chose to dynamically generate individual grammars for each input UD graph, a process that makes it possible to use sets of rule templates for generating similar rules, and to organize them into configurable, application-specific rule lexica. We then construct IRTG grammars for individual UD trees by looking up their edges in such lexica, for example, the UD edge NOUN
 $\xrightarrow{amod}$
ADJ will always warrant an IRTG rule that maps this edge to the 4lang edge NOUN
$\xrightarrow{amod}$
ADJ will always warrant an IRTG rule that maps this edge to the 4lang edge NOUN
 $\xrightarrow{0}$
ADJ. Other patterns require the lexicon to reference additional nodes in the input graph, we discuss some examples below. Terminal rules that map POS-tags to words in both interpretations are added to each grammar in a trivial step. The grammar generation framework described here is available as open-source software as part of the tuw-nlp
Footnote g Python package, and is a core dependency of the system presented in this article, which is also available as part of an open-source library.Footnote h
$\xrightarrow{0}$
ADJ. Other patterns require the lexicon to reference additional nodes in the input graph, we discuss some examples below. Terminal rules that map POS-tags to words in both interpretations are added to each grammar in a trivial step. The grammar generation framework described here is available as open-source software as part of the tuw-nlp
Footnote g Python package, and is a core dependency of the system presented in this article, which is also available as part of an open-source library.Footnote h
The starting point for creating rule lexica was the mapping of the original dep_to_4lang paper (Recski Reference Recski2018), which establishes all trivial 1-to-1 mappings between pairs of UD and 4lang relations. For example, all UD relations representing modification (amod, advmod, nummod) are mapped to 0-edges, while relations between predicates and their objects (obj, nsubj:pass) become 2-edges. Subjects relations (nsubj, csubj) are mapped to a pair of 0- and 1-edges; in the sentence John is supporting Bill, the UD relation support
 $\xrightarrow{nsubj}$
John becomes support
$\xrightarrow{nsubj}$
John becomes support
 $\overset{1}{\underset{0}{\rightleftharpoons}}$
John. Clausal modifiers (acl, advcl) are generally also mapped to 0-edges, some newly introduced exceptions will be discussed below. Additionally, we introduce a new mechanism for non-core (oblique) arguments marked by the obl relation.
$\overset{1}{\underset{0}{\rightleftharpoons}}$
John. Clausal modifiers (acl, advcl) are generally also mapped to 0-edges, some newly introduced exceptions will be discussed below. Additionally, we introduce a new mechanism for non-core (oblique) arguments marked by the obl relation.
Consider the Wiktionary definition of teacher: someone who teaches, especially in a school. The UD edge teach
 $\xrightarrow{obl}$
school does not in itself reveal the semantic relationship between the two concepts, thus we introduce a pattern that will also take into account the case relation marking the argument: the full UD analysis of this sentence contains the subgraph teach
$\xrightarrow{obl}$
school does not in itself reveal the semantic relationship between the two concepts, thus we introduce a pattern that will also take into account the case relation marking the argument: the full UD analysis of this sentence contains the subgraph teach
 $\xrightarrow{obl}$
school
$\xrightarrow{obl}$
school
 $\xrightarrow{case}$
in, allowing us to build the 4lang graph teach
$\xrightarrow{case}$
in, allowing us to build the 4lang graph teach
 $\xleftarrow1$
in
$\xleftarrow1$
in
 $\xrightarrow2$
school using an IRTG rule represented in Figure 5. We also implemented an English-specific exception to this rule: the preposition by will trigger the configuration for the predicate–subject relation, so that the UD analyses of the sentences John is supported by Bill and Bill is supporting John shall both be mapped to the same 4lang graph (see Figure 6).
$\xrightarrow2$
school using an IRTG rule represented in Figure 5. We also implemented an English-specific exception to this rule: the preposition by will trigger the configuration for the predicate–subject relation, so that the UD analyses of the sentences John is supported by Bill and Bill is supporting John shall both be mapped to the same 4lang graph (see Figure 6).
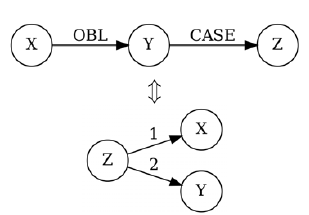
Figure 5. Obliques in UD and 4lang.

Figure 6. 4lang definition graph of John is supported by Bill and Bill is supporting John.
Another shortcoming of the original algorithm for mapping dependency graphs to 4lang representations is its treatment of coordination. The strategy introduced in Section 3.4.1 of Recski (Reference Recski2018) simply copied all semantic relations between all elements of coordinating constructions, which has proved practical for downstream applications despite introducing some erroneous edges. Our system replicates this behavior in its mapping from UD to 4lang. Some simple patterns over specific conjunctions (and, or, etc.) could be used to differentiate between occurrences of the conj dependency, similar to the approach of Enhanced Universal Dependencies (Schuster and Manning Reference Schuster and Manning2016), but modeling the semantics of coordinating conjunctions would nevertheless require considerable language-specific effort (see Gerdes and Kahane Reference Gerdes and Kahane2015; Kanayama et al. Reference Kanayama, Han, Asahara, Hwang, Miyao, Choi and Matsumoto2018).
Perhaps the most significant limitation of the original system was its lack of treatment for relationships between clauses. This is partly due to the fact that the type of the UD relation connecting the heads of two clauses often reveals very little about the semantic function of the dependent clause. The UD relation acl is definedFootnote i as clausal modifier of noun (adjectival clause), and indeed the general case can be handled by 0-edges, but this rule will currently create erroneous edges for sentences such as I have a parakeet named Cookie, since there is no mechanism to detect that in this case parakeet is the object of named. Another issue is posed by the UD relation acl:relcl (relative clause modifier of a noun), which is used both in an animal that moves and the man you love, constructions that would warrant the edges animal
 $\xrightarrow{0}$
move and man
$\xrightarrow{0}$
move and man
 $\xleftarrow{2}$
love, respectively. The first of these two examples can receive the correct treatment based on the presence of the nsubj edge between move and that, thus we introduce a rule that implements the correspondence in Figure 7. Other occurrences of acl:relcl are currently not processed. For the full mapping between UD and 4lang structures see Table 4.
$\xleftarrow{2}$
love, respectively. The first of these two examples can receive the correct treatment based on the presence of the nsubj edge between move and that, thus we introduce a rule that implements the correspondence in Figure 7. Other occurrences of acl:relcl are currently not processed. For the full mapping between UD and 4lang structures see Table 4.
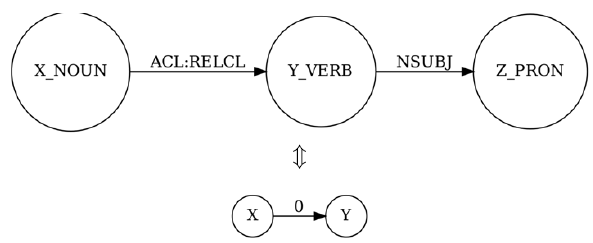
Figure 7. Relative clause modifier of a noun in UD and 4lang.
Table 4. Mapping from UD relations to 4lang subgraphs

While some of these newly introduced mechanisms are still rudimentary, improving the general mechanisms of building task-independent semantic representations is a central goal of our work—we present our error analysis in Section 5. The pipeline for building 4lang definition graphs from Wiktionary is currently implemented for three languages: English, German, and Italian. Extending it to additional languages requires the existence of an accurate UD parser and a machine-readable monolingual dictionary of sufficient coverage. Once the UD parses of definitions are available, the remainder of the pipeline is language-independent, although for some languages it might be necessary to extend the dep_to_4lang mapping to include reference to morphological features, as done in Recski, Borbély, and Bolevácz (Reference Recski, Borbély and Bolevácz2016). We apply this pipeline to dictionary definitions extracted from data dumps of Wiktionary, a large crowd-sourced dictionary containing more than 100,000 entries for 40+ languages (and more than 10,000 entries for about twice as many). Section 3.2 will describe our method for detecting entailment between pairs of words or predicates using their corresponding 4lang graphs. Entailment relations extracted using this method may be of lower quality than those encoded by manually built databases such as WordNet, but cover larger vocabularies and thus improve performance even for languages with large WordNets (see Section 4 for details). While in our current experiments we chose to build pipelines for three relatively well-resourced languages (English, German, Italian), both a large Wiktionary and an UD parser model are available for many more.
3.2 Modeling lexical entailment
A Wiktionary page for a given word form typically contains several definitions corresponding to multiple word senses and/or parts-of-speech, but, given the crowd-sourced nature of the dataset, without adhering to any particular lexicographic principles. After identifying individual entries on each Wiktionary page using simple language-specific templates, our approach is to pick the first definition of each word unless it is explicitly marked by editors as obsolete, archaic, historical, or rare. Based on manual analysis of a small sample, we estimate that for over 98% of words in the Semeval dataset this method chooses the sense that is apparently intended in the dataset. For example, for the word pair letter–mail in the Semeval dataset, we assume that the intended sense is that defined as a written or printed communication and not a symbol in an alphabet.
The entailment candidates in the SherLliC dataset pose a greater challenge. Predicates are implicitly disambiguated by their type signatures, yet we do not attempt to select some subset of the available definitions based on this information, instead we establish entailment between a pair of predicates iff there is any pair of definitions for which the conditions of entailment, to be defined in this section, are fulfilled. In Section 4, we shall see that this does not lead to a drastic decrease of precision as it would on the Semeval dataset, likely because of the relatively higher bar of matching an argument-predicate structure as opposed to a single word. Meanwhile this enables detecting entailment based on any listed definition of predicates; for example, we correctly detect that the premise “A is releasing update for B’’ entails the hypothesis “A is releasing version of B’’ based on the third Wiktionary definition of update: “A modification of something to a more recent, up-to-date version; (in software) a minor upgrade”. We shall discuss the issue of polysemy in more detail in Section 5.
Our core method for modeling entailment is based on the intuition that all semantic relationships marked by 0-edges in 4lang graphs constitute entailment, that is dog entails not only mammal but also four-legged and bark, and that this relation is transitive, that is if dog entails bark and bark entails sound then dog must also entail sound. In other words, we equate entailment with inheritance and consequently with accessibility via a directed path of 0-edges in a 4lang concept graph. Here, we shall not discuss whether the relationship between for example the concepts dog and bark are an example of entailment, causation, correlation, or something else; this comprehensive definition is rooted in our view that modeling lexical entailment should be an enabler of the modeling of natural language inference (NLI). We note that this view on entailment may be incompatible with task formulations involving statements about specific events or scenes, such as the SNLI dataset that is largely based on image captions, since in such descriptions A dog is there should not entail A dog is barking. It can be argued, however, that it is precisely the omission of such type-theoretic details that gives the 4lang system its flexibility. Where there is a dog, there can be a bark(ing). Kornai (Reference Kornai2010) further argues that the episodic readings that have occupied Montague Grammarians ever since the inception of MG are practically nonexistent in natural language.
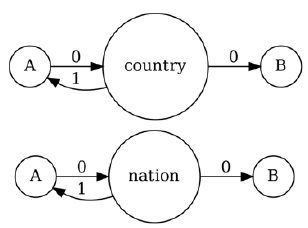
Figure 8. 4lang representations of A is nation in B and A is country in B.
Implementing the above definition as a function over pairs of semantic graphs involves the recursive expansion of the premise graph based on the definitions of its defining words. This, after only a small number of iterations, leads to the proliferation of errors and ambiguities, caused primarily by imperfections of the dep_to_4lang mapping and the inherent ambiguity of definitions (see Section 5 for more details). We found it practical in our experiments to limit the depth of expansion to 2 (although in certain cases 3 would lead to a higher F-score, see Section 4 for details). On the Semeval dataset of word pairs, we then establish entailment iff the hypothesis word is present in the expanded premise graph. The depth of recursive expansion is the major tunable parameter of our method, set to 2 for both tasks based on early experimental results, but recall can be increased considerably by allowing our system to establish entailment without full coverage, requiring only some percentage of edges in the hypothesis graph to be covered by the premise graph. Optimal values for this threshold were obtained by optimizing on the development portion of the dataset. For the high-precision configurations, we set the threshold to 0.8 while for the highest F-score required a value of 0.2. Such tweaking admittedly weakens full explainability, since one has to justify a partial overlap of premise and hypothesis graphs. Still, the interpretability of our representation remains, enabling deep error analysis (see Section 5) and further development of our semantic parsing methods.
On the SherLlic task, we use 4lang graphs built from the example sentences associated with each predicate in the dataset. For example, the pair of premise and hypothesis predicates “A is nation in B” and “A is country in B” will be represented by the graphs in Figure 8. We define entailment to hold iff all edges of the hypothesis graph are found in the expanded premise graph, which requires us to refine the expansion process to also allows nodes to inherit relations along paths of 0-edges. After a graph has been extended with the definition graphs of its nodes, we allow relations to be inherited along directed paths of 0-edges using the algorithm in Figure 9 and exemplified in Figure 10, representing the modus ponens reasoning that if A is a nation in B and nation is a type of country, then A is a country in B.

Figure 9. Appending zero edges to premise.

Figure 10. Expanded 4lang representations of A is nation in B.
Let us now consider the premise “A is center of B” and the hypothesis “A is heart of B”. The concept heart is not accessible from the premise, but one of its definitions is The centre. In this case, we can detect entailment via the reduction mechanism, which substitutes a concept with its definition graph (while still allowing relations to be inherited by defining concepts, as in the case of expansion). In other words, reduction is equivalent to expansion followed by removal of the original concept, as shown in Figure 11. This mechanism represents the intuition that if all defining properties of some concept can be inferred then the concept itself is also entailed.

Figure 11. 4lang definition graphs of expanding and reducing A is heart of B.
On the simpler word-level task, we increase our overall performance by incorporating additional lexical resources: we extract for all premise words lists of synonyms from their Wiktionary pages as well as a list of synonyms and all their hypernyms from WordNet (Miller Reference Miller1995). We use such additional resources in two ways. First, we can choose to establish entailment if the hypothesis word is present in the set of hypernyms for any WordNet synset containing the premise word. Second, we may use synonyms of the premise word from both WordNet synsets and Wiktionary to extend the 4lang definition graph of the premise with additional concepts before performing expansion. In Section 4, we shall quantify the contribution of these additions. On the SherLlic dataset, we decided not to use these extensions as they appeared to introduce too much noise.
Our method for detecting entailment described in this section produces decisions that are directly explainable due to the presence of at least one path of 0-edges leading from the premise word to the hypothesis word, and these paths can be further explained by the dictionary definitions on which they were based. For example, the decision in the above example that “A is center of B” entails “A is heart of B” could be explained by citing the original Wiktionary definition heart: 12. (figuratively) The centre, essence, or core. Although we have not observed it during our manual error analysis (see Section 5), it is possible for our method to make a correct decision based on edges that were introduced in error, which would ultimately result in an incorrect explanation.
Our approach treats lexical entailment detection as a binary classification task and in this work we shall not attempt to give an account of entailment as a graded phenomenon, even though the Semeval dataset (see Section 2.1) provides evaluation data also for graded lexical entailment. While this dataset is validated by high agreement among annotators answering the question To what degree is X a type of Y and represents common intuitions such as that chess is a sport to a lesser degree than basketball (Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017), we consider such distinctions more an issue of prototypicality than of implicature as such. Basketball may be uniformly viewed as more of a sport than chess, but the implications we want to employ, for example that it is a contest, a fight between participants with a winner and a loser, and that the winner is proven stronger by this outcome in the sport at hand, are the same, and they operate in a 0-1, rather than a gradient, fashion.
4. Evaluation
In this section, we present the results of experiments on both the Semeval and SherLlic datasets. On the Semeval dataset, we compare our system to the previous state-of-the-art and some strong baselines, while on the SherLlic task we use for comparison both the set of baselines published by Schmitt and Schütze (Reference Schmitt and Schütze2019) and a recent SOTA NLI system. We also evaluate the effect of some of the processing steps discussed in Section 3 by comparing various configurations of our method on both benchmarks.
For the word-level entailment task, we evaluate on the English, German, and Italian portions of the Semeval 2020 dataset. We used the development portion of each dataset for experimentation and for determining the optimal value of the single tunable parameter of our system, the depth of recursion when expanding 4lang graphs. We set this value to 2 in all configurations and on both datasets. It was also based on these experiments that we made the determination to limit expansion to nodes connected to each word by 0-paths, as opposed to expanding all nodes in the definition graphs, as we have done for the SherLlic task.
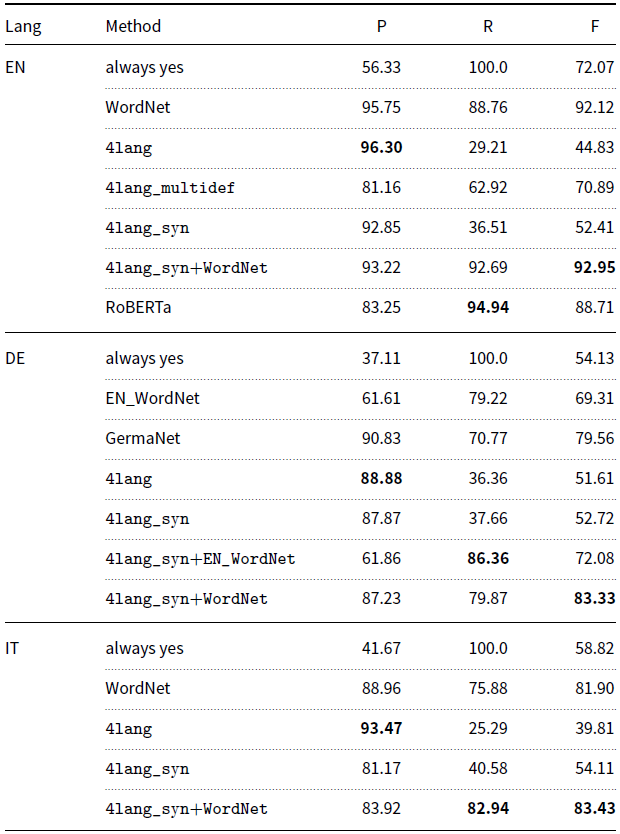
Performance of various configurations on the Semeval development data is presented in Table 5. Our core method, using expanded 4lang definition graphs built from Wiktionary definitions, achieves high precision on all three languages and recall values in the 0.25–0.35 range. Extending our definition graphs with additional synonyms from WordNet and Wiktionary improves recall at the cost of some precision, on all languages. On the German data, we also compare the contribution of the translation-based method EN_WordNet that uses English Wordnet to the high-quality German WordNet release GermaNet (Hamp and Feldweg Reference Hamp and Feldweg1997; Henrich and Hinrichs Reference Henrich and Hinrichs2010). Since WordNet graphs explicitly encode the hypernymy–hyponymy relationship between synsets, they can be evaluated as standalone baselines and achieve strong precision and recall scores on all languages. Our method, however, can be used to improve their recall further, thus the top-performing system for all three languages is that which labels word pairs as entailment if either our system or the WordNet baseline labeled it as such. On the English dataset, we also illustrate the negative effect of including all Wiktionary definitions. On the SherLlic task the effect is reversed, using multiple definitions increases performance (4lang_multidef). In Table 6, we list some examples of entailment pairs that have been detected by our method but not by WordNet, along with their Wiktionary definition of the premise that was used for building 4lang representations.
Table 5. Performance on the Semeval development set. 4lang and 4lang_syn is our method without and with additional synonym nodes from WordNet and Wiktionary. WordNet is the baseline using WordNet hypernyms, 4lang_syn+WordNet is the union of 4lang+syn and WordNet
Bold values represents best scores.
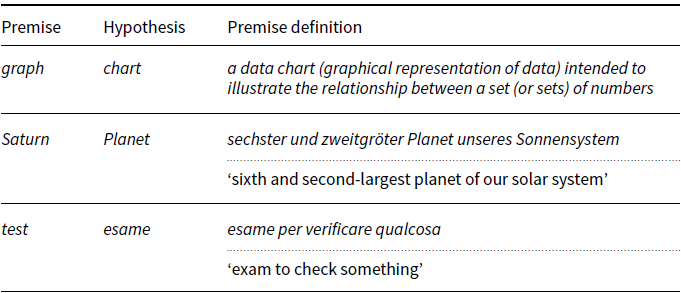
Table 6. Examples of entailment pairs not in WordNet but detected by our system
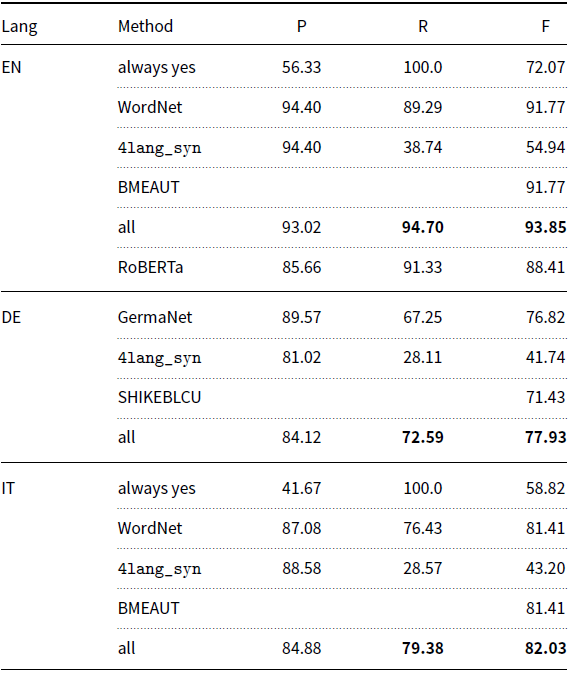
We also evaluate our system on the Semeval test set, figures are presented in Table 7. We compare our current configuration with the top-scoring system from the 2020 Semeval competition (Glavaš et al. Reference Glavaš, Vulić, Korhonen and Ponzetto2020). On English and Italian, the previous top system is our own BMEAUT submission (Kovács et al. Reference Kovács, Gémes, Kornai and Recski2020) and on German it is the SHIKEBLCU (Wang et al. Reference Wang, Fan, Luo and Yu2020) system, which specializes distributional word vectors for lexical relations. The results on the test dataset shows that after improving 4lang with additional methods and synonyms we achieve state-of-the-art results in all three languages. For German, the greatest improvement is clearly brought about by the new, high-quality German WordNet release GermaNet. Finally, we also evaluate a state-of-the-art neural NLI system on the Semeval datasets. RoBERTa (Zhuang et al. Reference Zhuang, Wayne, Ya and Jun2021) was trained on a dataset with three labels: entailment, neutral, and contradiction. We interpret its predictions by merging the latter two labels into a single label “not entailment”. In absence of sufficient training data, we tuned the model to the dataset by setting the threshold of the output weights for optimal performance on the development set. The resulting model was evaluated on both the development and test portions of the dataset.
Table 7. Performance on the Semeval test set. 4lang and 4lang_syn is our method without and with additional synonym nodes from WordNet and Wiktionary. WordNet is the baseline using WordNet hypernyms, all is the union of 4lang+syn and WordNet. Previous top-scoring systems on each task are BMEAUT (Kovács et al. Reference Kovács, Gémes, Kornai and Recski2020) and SHIKEBLCU (Wang et al. Reference Wang, Fan, Luo and Yu2020)
Bold values represents best scores.
Next we performed evaluation on the SherLlic dataset, comparing several configurations of our method to both the RoBERTa system and a wide variety of baselines published alongside the dataset (Schmitt and Schütze Reference Schmitt and Schütze2019). Figures are presented in Table 8. We experimented with two configurations of our current system, tuned to high F-score and to high precision respectively. The trivial “always yes” baseline yields
 $F=49.9$
on this dataset, and tellingly, the best earlier rule-based systems, Berant II (Berant Reference Berant2012) and PPDB (Pavlick et al. Reference Pavlick, Rastogi, Ganitkevitch, Van Durme and Callison-Burch2015), achieved only
$F=49.9$
on this dataset, and tellingly, the best earlier rule-based systems, Berant II (Berant Reference Berant2012) and PPDB (Pavlick et al. Reference Pavlick, Rastogi, Ganitkevitch, Van Durme and Callison-Burch2015), achieved only
 $F=30.0$
and
$F=30.0$
and
 $F=34.7$
. In the high F-score configuration (using the method described in Section 3.2 complete with all postprocessing steps (expansion, reduction) and using all Wiktionary definitions), 4lang, though clearly better than the earlier systems and WordNet, is still below the trivial baseline. The high-precision configuration, obtained by blocking the inheritence of relations in the premise graph after expansion and also the reduction of the hypothesis graphs, is worse than the earlier rule-based systems, but proves its usefulness in the hybrid configuration with RoBERTa, where it improves not just over the high-F variant but also over RoBERTa used alone, which defined the state-of-the-art before this work.
$F=34.7$
. In the high F-score configuration (using the method described in Section 3.2 complete with all postprocessing steps (expansion, reduction) and using all Wiktionary definitions), 4lang, though clearly better than the earlier systems and WordNet, is still below the trivial baseline. The high-precision configuration, obtained by blocking the inheritence of relations in the premise graph after expansion and also the reduction of the hypothesis graphs, is worse than the earlier rule-based systems, but proves its usefulness in the hybrid configuration with RoBERTa, where it improves not just over the high-F variant but also over RoBERTa used alone, which defined the state-of-the-art before this work.
Table 8. Performance on the SherLlic test set. WordNet is the baseline using WordNet hypernyms, ESIM (Chen et al. Reference Chen, Zhu, Ling, Wei, Jiang and Inkpen2017) is the strongest system evaluated that wasn’t tuned on SherLlic’s held-out portion and w2v+tsg_rel_emb is the overall strongest system of Schmitt and Schütze (Reference Schmitt and Schütze2019). 4lang_high_prec and 4lang_high_fscore are the configurations of our system tuned for high precision and high F-score, respectively
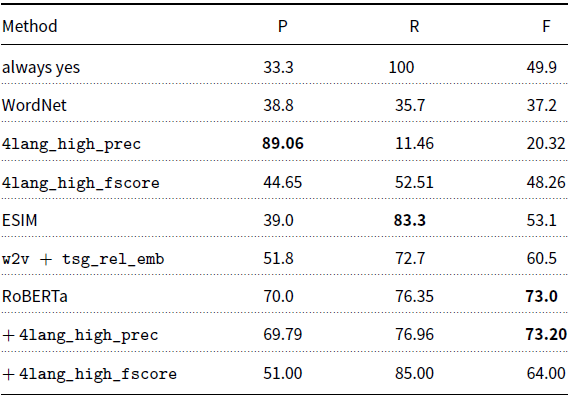
Bold values represents best scores.
5. Error analysis
The graph-based method presented in previous sections is an example of eXplainable AI (XAI). Decisions taken by any variant of our algorithm can be represented as paths of concepts between premise and hypothesis in a concept graph, or lack thereof, making qualitative error analysis straightforward. Our method is high-precision by design, and on the simpler word-level task its false positives are limited to a small number of unique accidents, such as Wiktionary defining video as television. Therefore, in this section, we focus on tracing the reasons behind false negatives, a task that simply cannot be performed outside the XAI context.
We begin with the simpler, word-level task, where our standalone method achieves considerably lower recall and F-score than what is already possible by including another lexical resource with an explicit model of hypernymy. We manually inspected 60 positive entailment pairs in the English Semeval dev dataset that were missed by our core method, that is the system without additional synonyms.
By far the most common, and in our opinion, the most interesting, source of false negatives is when the expanded premise graph correctly contains most or even all of the semantic content of the hypothesis word, yet there is no direct match, the hypothesis word cannot be accessed. An example is the word pair lettuce
 $\rightarrow$
food. Lettuce is defined in Wiktionary as “an edible plant, Lactuca sativa and its close relatives, having a head of green and/or purple leaves”, edible means “can be eaten without harm” and finally eat is simply defined as “to ingest”. Since this is as far as our iterative expansion goes, we are missing the word food altogether.
$\rightarrow$
food. Lettuce is defined in Wiktionary as “an edible plant, Lactuca sativa and its close relatives, having a head of green and/or purple leaves”, edible means “can be eaten without harm” and finally eat is simply defined as “to ingest”. Since this is as far as our iterative expansion goes, we are missing the word food altogether.
The main issue here is that the default object of eating is food, a fact well represented in the definition of eat in dictionaries such as LDOCE (Bullon Reference Bullon2003) “to put food in your mouth and chew and swallow it”; Webster’s New World (Guralnik 1958) “to chew and swallow (food)”; The Concise Oxford (McIntosh Reference McIntosh1951) “masticate and swallow (solid food)”; Webster’s 3rd (Gove Reference Gove1961) “to take in through the mouth as food”. The connection with the object is so strong that it is also regularly present in the definition of edible: “fit to eat, food” (Collins); “suitable by nature for use as food” (Webster’s 3rd); etc. Even ingest, a word that can be appropriately used for drinks, poison, etc. that are clearly not fit to be eaten, will generally include the default: “to take food or other substances into your body” (LDOCE); “to take (food) to the stomach” (Concise Oxford); “consume food or drink” (FrameNet) etc.
Since the association between eating and food is direct, we simply need to enhance the definition base further. A more interesting case is presented by mussel and seafood, where we do not believe that any reasonable lexical resource can help. This is because dictionaries are not at all good sources for plants, animals, minerals, and common encyclopedic knowledge about them: basically every dictionary we consulted defines mussel as a kind of mollusc (often using the technical term “bivalvate”), but gives up on defining mollusc by shunting the reader to the encyclopedia “animal belonging to Mollusca, a subkingdom of soft-bodied and usually hard-shelled animals”. As we learn for example from the Concise Oxford, this subkingdom includes limpets, snails, cuttlefish, etc, and most of these (with the exception of oysters) are actually not considered as seafood. All of this points to the conclusion that for these cases a different, encyclopedic knowledge source should be consulted and here Wikipedia works well: the article en.wikipedia.org/wiki/Mussel actually has a heading As food.
A further error class comprises words for which the first definition in Wiktionary does not correspond to the sense intended in the entailment pair, most often because it is in fact not the most common sense of the word. An example is submarine, whose first sense in Wiktionary is defined as “underwater”. Quite often, there is no clear “main sense” of the word and it is only the entailment candidate that allows us to disambiguate between multiple senses. Examples are letter
 $\rightarrow$
mail which is labeled as entailment but simply is not if we choose the definition “symbol in an alphabet”, or mole
$\rightarrow$
mail which is labeled as entailment but simply is not if we choose the definition “symbol in an alphabet”, or mole
 $\rightarrow$
animal, which fails for the sense “pigmented skin” the same way. When constructing the Hyperlex dataset (Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017), which later became the basis of the Semeval dataset used in this paper, annotators were instructed that “two words stand in a type-of relation if any of their senses stand in a type-of relation.”(Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017, p. 797). This might suggest that we consider the union of all definitions of a word for our method, but our early experiments showed that (because of the crowd-sourced nature of Wiktionary entries) such an approach would very often lead to the proliferation of erroneous representations built from low-quality and/or unwarranted definitions. Alternative solutions might include disambiguating among definitions based on context and/or building meaning representations from groups of definitions that describe multiple uses of the same abstract word sense. For a discussion of the difficulties of such approaches, the reader is referred to Section 4.4.3 of Recski (Reference Recski2018).
$\rightarrow$
animal, which fails for the sense “pigmented skin” the same way. When constructing the Hyperlex dataset (Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017), which later became the basis of the Semeval dataset used in this paper, annotators were instructed that “two words stand in a type-of relation if any of their senses stand in a type-of relation.”(Vulić et al. Reference Vulić, Gerz, Kiela, Hill and Korhonen2017, p. 797). This might suggest that we consider the union of all definitions of a word for our method, but our early experiments showed that (because of the crowd-sourced nature of Wiktionary entries) such an approach would very often lead to the proliferation of erroneous representations built from low-quality and/or unwarranted definitions. Alternative solutions might include disambiguating among definitions based on context and/or building meaning representations from groups of definitions that describe multiple uses of the same abstract word sense. For a discussion of the difficulties of such approaches, the reader is referred to Section 4.4.3 of Recski (Reference Recski2018).
In Table 9, we highlight some cases where the predictions of 4lang and RoBERTa differ. In the first case, 4lang misses the meaning “support, protect” for the verb back (also seen in the multi-word expression have the back of), but we simply do not know why RoBERTa is getting this right, and have no performance guarantees that further training or other improvements to F will preserve this particular instance. The second example is more subtle: ambassadors always represent their country but presidents do this much more rarely. Under a strict logical reading the implication fails, but as a practical matter, we should accept it, since representing their country is a typical activity of their presidents. While 4lang has the means of expressing typicality (defaults), and some dictionaries such as Guralnik (1958) make reference to “formal head”, it is again the more encyclopedic sources that must be consulted to find formal or ceremonial from which eventually represent(ative) can be inferred.
Table 9. Comparing our system to RoBERTa. Examples from Schmitt and Schütze (Reference Schmitt and Schütze2019)

That such inference is fraught with difficulties is clear from the third and fourth examples, where RoBERTa has false positives, we think precisely because dictator often appears in text sufficiently close to president, and war-winning to declaring war. While in principle this hypothesis could be tested by retraining RoBERTa on its original training set minus these sentences, and rerunning the experiment with the RoBERTa’ so obtained, devising a less CPU-intense experiment seems warranted.
False positives of our system are considerably easier to track: for example, we lack a rule for handling modally subordinated predicates. Therefore, we conclude invade from planning to invade and worse yet, win from failing to win. Short and too generic definitions in Wiktionary are another main source of our false positives: we conclude A is selling to B from A is leaving to B because sell and leave both contain act in their definition.
In some cases, valuable information is lost when we prune the contents of prepositional phrases from our premise graph (to avoid false positive entailments such as nose
 $\rightarrow$
face, as discussed in Section 3.2). For example, our system does not detect the entailment husband
$\rightarrow$
face, as discussed in Section 3.2). For example, our system does not detect the entailment husband
 $\rightarrow$
spouse because Wiktionary defines husband as “a man in a marriage or marital relationship, especially in relation to his spouse”. In dictionaries that are built on stronger lexicographic principles, this is avoided by reliance on a strict defining vocabulary, a limited set of concepts capable of defining all other concepts. For example in LDOCE, spouse is defined as “a husband or wife’’ which avoids any complication. Following Webster’s 3rd, modern lexicographic practice avoids defining the simple by the more complex, and the idea of defining eat by means of “masticate” or “ingest’’ is seen as useless, as the language learner who does not know eat is quite unlikely to know these other verbs. Wiktionary, however, has not fully incorporated modern lexicographic principles.
$\rightarrow$
spouse because Wiktionary defines husband as “a man in a marriage or marital relationship, especially in relation to his spouse”. In dictionaries that are built on stronger lexicographic principles, this is avoided by reliance on a strict defining vocabulary, a limited set of concepts capable of defining all other concepts. For example in LDOCE, spouse is defined as “a husband or wife’’ which avoids any complication. Following Webster’s 3rd, modern lexicographic practice avoids defining the simple by the more complex, and the idea of defining eat by means of “masticate” or “ingest’’ is seen as useless, as the language learner who does not know eat is quite unlikely to know these other verbs. Wiktionary, however, has not fully incorporated modern lexicographic principles.
Replacing Wiktionary with modern explanatory dictionaries would make it possible to extract higher quality representations, but only at the cost of broad applicability to the ever-increasing set of languages that already have significant Wiktionaries. That said, high-quality data sources can significantly reduce the inherent difficulty of polysemous words. For example, English does not mark causativization on the verb, so that run can express both “go fast” and “make go fast”. If we consider the 50+ senses that Wiktionary provides for the verb run, there is little chance of finding the one appropriate for the type signature (PERSON, COMPANY), which is meaning 22 “to control or manage, be in charge of’’ or the one appropriate for (COMPUTER, SOFTWARE) (meaning 26) “to execute or carry out a plan, procedure or program’’. Yet this level of disambiguation, between plain and causative forms, seems quite feasible, especially using dynamic embeddings earlier in the analysis process.
6. Conclusion
The value of a well-constructed dataset is that it leads to interesting problems. In this regard, SherLIiC is truly valuable, as it inspires us to think more deeply about synonymy, polysemy, disambiguation, definitional economy, prepositional linkers, modal subordination, causativization, and a host of other questions that are traditionally considered central to natural language semantics.
We are fortunate to have WordNet, with its extensive hypernym links, tailor-made for entailment detection. Yet as we have seen, even WordNet can be profitably combined with other resources, dictionaries in particular. But for other relationals, such as causation, possession, mereological implications, spatiotemporal reasoning, etc, we would need similar datasets that highlight these very real problems. Since WordNet is less helpful there, we could expect considerably worse results, but it is unclear how progress could be made on grand semantic challenges in the absence of such new datasets.
In this article, we presented an explainable, multilingual method for detecting lexical entailment using a pipeline for the automatic construction of semantic graphs from dictionary definitions and a simple rule-based method for detecting entailment between pairs of such graphs. Our method presents a strong, high-precision baseline on the simpler task of detecting hypernymy and lets us improve over the performance of a manually created resource like WordNet. On the more complex task presented by the SherLlic dataset, our method outperforms all known rule-based baselines and is outperformed only by systems that have been adapted to the dataset. We also presented a baseline using a pretrained version of RoBERTa trained on MultiNLI, achieving even better results then the previously published distributional baselines, but combining it with our rule-based method further increases its performance eventually achieving state-of-the-art performance.
In future work, we hope to address several of the issues exemplified in our error analysis. One particularly promising avenue is to invoke a more explicit disambiguation process before, or in parallel to, the modeling of lexical entailment.
Acknowledgements
We are grateful to the three anonymous reviewers for their thoughtful comments, for questions leading to additional discussion in the manuscript, and for excellent references. Work partly supported by BRISE-Vienna (UIA04-081), a European Union Urban Innovative Actions project. Kovacs and Kornai were partially supported by MILAB, the Hungarian Artificial Intelligence National Laboratory. Competing interests: The authors declare none. The authors acknowledge TU Wien Bibliothek for financial support through its Open Access Funding Program.





















 Open access
Open access