


“…. it’s like trying to build the ship whilst sailing it”
Prof Jonathan Van Tam (Deputy Chief Medical Officer for England)
1. Introduction
The world has changed. Since the beginning of 2020 and well into 2021, nearly all countries have been in the grip of a worldwide pandemic that no living person has ever experienced. To date (at the time of writing), at least 4 million people all over the world have died due to the pandemic and many more might still die before it is over. Many different academic communities have focussed their minds on modelling all aspects of the fall-out from this pandemic. The initial priorities were obviously to attempt to predict what the scale and spread of the epidemic in each country and help prioritise the resources of the health systems. Epidemiological models have been extensively used to prescriptively model the short-run effects of the virus, advise policy-makers regarding lockdowns and other non-pharmaceutical interventions (NPIs). But other statisticians, econometricians and scholars could have had a complementary role in modelling the pandemic in the longer run and framing the policies to combat it, and best prepare us for future such episodes.
One important feature of the modelling of this pandemic is that, unlike modelling elsewhere in, for example, macro-economics, the emphasis is on the urgent need for prediction and advice in the immediate short run to plan the allocation of resources in each nation’s health service and provide direction on advisable restrictions on our daily lives whilst the emergency is in progress. Literally, we have been in the business of ‘building the ship whilst sailing it’. But now it is time to take stock of how the pandemic was modelled and whether we can do better in the future.
This review will neither focus on the modelling of hospital numbers, the demand for beds or intensive care unit (ICU) requirements, nor on behavioural issues or the controversy regarding the so-called ‘Health–Wealth’ trade-off be discussed as these subjects are treated in separate papers in this issue. Also, the aim is not to review all the literature on modelling Covid or assess the timing and quality of government decisions on the handling of COVIDFootnote 1. Rather, it is the intention that we explain the main data modelling problems and the conceptual differences between some of the main methods being used. We also seek to compare the strengths and limitations of these different tools.
The theme of this NIER issue is to explore the interface between economics and epidemiology. It is apparent that some epidemiologists (e.g. Gog, Reference Gog2020 Footnote 2; Murray, Reference Murray2020 Footnote 3) suggest that economists (and other subject specialists) are ill-equipped to examine the data relating to Covid and have attempted to model this pandemic without understanding what the subject of epidemiology has produced over the last 100 years. To a certain degree, they are right of course. But, notwithstanding, it may also be possible that other well-known statistical methods may provide an alternative perspective on certain aspects of modelling this pandemic and that this should be subject to some scrutiny. Avery et al. (Reference Avery, Bossert, Clark, Ellison and Ellison2020) described the susceptible, infected and recovered (SIR) model to economists, at an earlier stage of the pandemic, but it is now timely to appraise some of the plethora of contributions which have been made since this paper was published. After all, we have an abundance of data available to us now (see e.g. Stock, Reference Stock2020, and Harford, Reference Harford2020). The aim of this review is to take a fresh look at the underlying statistical modelling issues and put into a comparative context which other tools may offer a complementary adjunct to extant epidemiological methods.
This review of the modelling approaches will begin by answering the question of why we need to model this worldwide pandemic and its separate epidemics in each country. We will ask basic questions about the nature of the data we have, how it is measured and why this throws up additional modelling challenges. A basic taxonomy on the structure of the different models which have been used in conjunction with these data will be suggested. The economist’s distinctive focus on the thorny problem of the endogeneity of the impact of NPIs will be discussed. The simple taxonomy of different modelling approaches and their characteristics permit a review their relative strengths and limitations. The possible policy implications of different modelling strategies for data collection and impact evaluation are contextualised.
2. Describing the essential trends and patterns
Figure 1a,b has become familiar in the media. But economists and epidemiologists scrutinise it with some trepidation in view of the modelling task. The examination of figure 1 graphing deaths in different countries would immediately suggest that the course of this pandemic has been very heterogenous in different countries. Countries such as the United States and the United Kingdom have experienced three or four different peaks to the process, whereas countries like India have only experienced two peaks. The scale of the absolute numbers of deaths has been particularly large in the United States and India, but much lower in many other countries, for example, the United Kingdom. Of concern is not only the scale of this pandemic, but also how unequal the impact has been in different countries. The second feature the econometrician would notice would be that clearly the trend on this series is not stationary and has been subject to exogenous and endogenous shocks. A central part of this concern would be the separating out the endogenous interaction between the adoption of NPI’s and the extent to which the population, or certain sectors of it, has adopted a behavioural adjustment in their social distancing decisions (see e.g. Makris, Reference Makris2021; Toxvaerd, Reference Toxvaerd2020). A third issue which would confront any analysis would be whether this raw series of confirmed cases needs to be normalised by the size of the population in different countries. If we do this, then the patterns in figure 1b for the same countries can be graphed. When we do this, we can see that the heterogeneity of the pattern in different countries is remarkably different to the series observed in figure 1a. Specifically, the United Kingdom and the United States now have large spikes in their series at different times, whereas India’s latest wave due to the ‘Delta variant’ is now much less dramatic. This poses many difficult questions about exactly what series should be modelled.

Figure 1. (Colour online) Daily new confirmed COVID-19 cases and cases per millions for Brazil, India, United Kingdom and United States
A more detailed scrutiny of the official daily pattern of cases and deaths in figure 2a,b in the United Kingdom reveals other basic facts which need to be taken on board in any consideration of the modelling challenges. These modelling problems are also applicable to nearly all countries, but the United Kingdom serves as a good exemplar which illustrates most of the issues we would wish to address.

Figure 2. (Colour online) Daily new cases and new deaths in the United Kingdom

Figure 3. (Colour online) Alternative dependent variable for the United Kingdom
A first question of importance is why the epidemic in the United Kingdom had four ‘waves’ in the confirmed cases data? The first wave from March 2020 to June 2020, the second wave beginning in October 2020. This appeared to be beginning to fall by December 2020, only to take off again in late December 2020 and into January 2021. At the time of writing, we are in the middle of a fourth wave due to the Delta variant from India. Most theories of epidemics do not easily model such ‘waves’. Indeed, most epidemiological models do not easily accommodate second or third waves and are relatively silent on why, for the same virus, this pattern may be so heterogenous across different countries. Clearly, much of the answer lies in the lockdown which began in March 2020, the premature easing of the restrictions in late November 2020 and the large-scale roll-out of the vaccination programme from early in 2021. This means that much of the pattern we see in the data is due to the endogenous NPI and vaccination responses of the government.
A second clear puzzle is why the numbers of cases in the ‘first wave’ were so low relative to the numbers of deaths. In contrast, the case numbers in the ‘second (and subsequent) waves’ were very high, relative to the deaths. Indeed, the daily death numbers were quite comparable to two (three) waves. The clear answer to this puzzle is that the amount of testing that was going on over the period from March to June 2020 was much lower than over the period October 2020 to March 2021. In addition, many advances in the treatment, both pharmacological (e.g. Dexamethasone and Remdesivir) and non-pharmacological, such as the use of ICU and ventilators, were made during the first wave, which we later used to good effect in the second waves to minimise deaths.
A third clear feature of the data from the United Kingdom (and other countries) is that there is a marked weekly pattern to the oscillations in cases and deaths. This is revealed by superimposing a 3-day moving overage on the series. This is not surprising, and it is often reported in the media that deaths at the weekend are lower than on weekdays. This is clearly an artifact of the way in which the data are collected, recorded and reported. It is less commonly known that deaths and cases in the United Kingdom are higher on Mondays. Again, this is a direct consequence of the administrative structure which collates the data. This pattern is not the same in all countries which will have different methods for collecting and reporting the data.
3. The rationale and requirements for modelling
To contextualise what follows, we need to understand why modelling of the pandemic (and its epidemic course in each country) is important as this will set the scope for data requirements and their limitations.
3.1. Forecasting
A foremost consideration is the calculation of the numbers of cases and deaths and forecasting them. Literally, seeing into the short-run future, to combat the crisis. Put crudely, we need to know who gets Covid, who dies and who has long-term health conditions. Forecasting these numbers is necessary to understand the practical needs of each health service, at each location, within a country. For example, how many people, at any point of time, will need to be hospitalised and, of these, how many of them will be in ICU wards or need ventilators. These practical considerations demand that we can predict the numbers of people who will be affected and exactly where these cases and deaths will occur. It is also imperative that we can predict and forecast these trends into, at least the short-run future, to potentially avoid each country’s health service from being overrun. To predict the number of cases, hospitalisations, and deaths it is necessary to facilitate the planning of medical resources to meet emergency and longer-term requirements. This has been the essential goal of the epidemiological modelling effort from the very beginning (see Ferguson et al., Reference Ferguson, Walker and Whittaker2020). The collection of spatial incidence data at the local level will facilitate the planning of regional hospital resources. But the goal of short-run forecasting has also been the goal of the time series econometrics teams working at Oxford (see Doornik et al., Reference Doornik, Castle and Hendry2020),Footnote 4 Cambridge and NIESR (see Harvey (Reference Harvey2020), Harvey et al., Reference Harvey, Kattuman and Thamotheram2021) and elsewhere across the globe.
3.2. Monitoring the epidemic’s course
It is also important to ascertain who in the population are most at risk of contracting the virus and who are most at risk of serious health consequences, so that preventative measures can be most effectively targeted. This is most effectively done with micro-individual level data at the patient level with administrative data (see OpenSAFELY, 2020). Time series and epidemiological modelling are also crucial to predict the likely longer-run course of the epidemic in terms of: how quickly it will spread; when it will stop spreading so fast – that is when it will start to wane; how long will it last – when will it be over; when exactly will turning point in the pandemic’s progress occur and whether there will be a second, third (or subsequent) wave of the epidemic.
Underlying all these concerns is the choice of the appropriate theoretical mathematical model to understand the pandemic process and its dynamic properties to better prepare for future mutations of the virus, potential waves of the epidemic, or indeed, the next pandemic.
3.3. Understanding the effect of NPIs
An essential goal of government in fighting Covid is to introduce NPIs in a timely and effective manner to combat the spread of the virus and minimise its consequences on the population at risk. It is then incumbent on modellers to ascertain which NPIs have been effective and to predict the most effective measures to counter the epidemic and ascertain the relative effectiveness of different policies (see e.g. Han et al., Reference Han, Tan and Turk2020; Qiu et al., Reference Qiu, Chen and Shi2020; Acemoglu et al., Reference Acemoglu, Chernozhukov, Werning and Whinston2020; Vokó and Pitter, Reference Vokó and Pitter2020; Lai et al., Reference Lai, Ruktanonchai and Zhou2020; Li et al., Reference Li, Xiang and He2020; Meunier, Reference Meunier2020). But understanding exactly what effect these different policies have and over what time horizon remains problematic. This was, and remains, a very difficult task. To analyse the data to demonstrate that specific NPI policies have a direct causal effect on the case numbers or mortality rates is a question which can only be tackled with statistical modelling. To appreciate exactly how long it takes for any policy to work on cases or deaths which are themselves dynamically up to 6–21 days apart is difficult, as is the understanding of exactly which policies are effective, and to what degree. Governments cannot conduct experiments in real time when human lives are at stake. But at the same time, throwing a plethora of policies, (closing schools and shops, social distancing, banning public gatherings and sporting events, etc.) all at the same time, means that it is very hard to disentangle what exactly works and how effective each policy might be.
3.4. Prioritising resources
At each stage in the epidemic, it is important to be able to plan what resources need to be deployed and where to, not only combat the short-run medical needs of those at risk of death, but also to marshal resources for those individuals who have been furloughed or lost their jobs and families who have lost their means of support. Knowing when and how to: stop live sports, live cinema and theatre attendance, close schools, shops, colleges and prevent social gatherings and enforce social distancing are all important and require a clear insight and up to date information about how the epidemic is progressing. Further, longer-run planning is needed to combat inequality, poverty and destitution for those most affected and awareness of the needs and problems of those with long-run symptoms and incapacities due to ‘long Covid’.
3.5. Vaccination priorities
Detailed statistical modelling is also necessary to determine which groups of people have the highest priority for vaccination, how effective it is and how this vaccination programme is to be rolled out. As the vaccination is given to more and more people than the number of cases and deaths should fall. This then prompts the question of what NPI measures still need to be enforced and how we might disentangle the effects of the vaccine from the effects of the NLPIs. Further complications arise if the vaccine was designed to be administered in two doses 4 weeks apart. But the authorities have an incentive to delay the second dose as it means that more people can obtain the first dose and so a basic level of immunity can be given to many more people, which may have a much bigger effect on the control of the epidemic. The trade-off is that those waiting for a second dose slowly become less immune and more likely to catch the virus. Effective data collection and modelling should mitigate these concerns.
Recent concerns relating to the AstraZeneca vaccination and blood clot risk also suggest that it may be prudent to limit its use for those aged under 30. Such concerns require vigilance and remodelling as new data become available.
3.6. Mutation and strain prediction with multiple waves
It is important for the health authorities to understand what new strains of the virus are coming out and the general pattern of mutation of the virus and how this may change the rate of infection and feed through into the numbers of cases and deaths. Ultimately, as the virus mutates, there will be many different variants of the virus abroad and may have different strains in different countries. For example, we have already seen the effects of the B.1.1.7 strain in the United Kingdom, the B.1.4.2.9 variant in the United States, the B.1.3.5.1 and P1 variants in Brazil and the ‘Delta’ variant in India, and their knok-on effects on other countries. There is some evidence that these new mutant variants of the virus have reaped a toll in the United Kingdom, the United States and Brazil, respectively with evidence that they are now responsible for the spread of (what is widely being called) the ‘second and third wave’ in Europe. Modelling these trends within each country and the spread between countries and predicting how they may affect each country is paramount to continued control of the pandemic in the future.
3.7. Behavioural responses
Many of the NPIs imposed by governments over the last year have themselves had unintended as well as intended consequences. Locking down shops, pubs and restaurants, and banning public gatherings has had clear knock-on effects on people’s behaviour. Observing social distancing rules and curtailing travel and meeting-up has affected the way we conduct our lives. Not surprisingly, people have found ways of circumventing these rules and changed their behaviour because of these law changes. It is also possible that making the ‘Reproduction Number’,
 $ {\mathcal{R}}_t, $
a part of daily briefings to the nation, has itself induced changes in people’s behaviour. Ideally, these behavioural changes could be predicted from the appropriately configured statistical or theoretical models. Such modelling may help us to minimise the harmful consequences (or enhance the beneficial side-effects) of these behavioural reactions.
$ {\mathcal{R}}_t, $
a part of daily briefings to the nation, has itself induced changes in people’s behaviour. Ideally, these behavioural changes could be predicted from the appropriately configured statistical or theoretical models. Such modelling may help us to minimise the harmful consequences (or enhance the beneficial side-effects) of these behavioural reactions.
It is clear that all the above requirements of a modelling strategy require elements of: statistical theory, mathematical biology, epidemiology, time series and panel econometrics, as well as forecasting. By marrying the insights and advances in all of these disciplines, the most rigorous predictions can be made as to the likely spread of the pandemic and its consequences.
4. Statistical data and measurement error
There is a remarkable amount of data relating to aspect of Covid across the countries of the world, much of them are available on a daily basis.Footnote 5 An extraordinary amount of effort has gone into its collection and collation. Data on deaths and cases on a daily basis can be obtained from the Our World in Data (OWID) COVID-19 dataset. The OWID dataset is a comprehensive dataset that contains data on cases, deaths and tests, as well as a OxCGRT stringency index variable (Hale et al., Reference Hale, Angrist and Goldszmidt2020) and 14 time-invariant variables for 212 countries. The data for these variables can be obtained from various sources and the full list of original sources is available from their website. Several other organisations report COVID-19 deaths and cases. The European Centre for Disease Prevention and Control (2020) reports daily worldwide situation updates, but these data are based on the OWID. The John Hopkins University (2020) dataset has the advantage that it also includes information on cases and deaths for smaller geographical areas in some countries, although it does not include data on tests or any time-invariant variables.
In common with other high frequency data issues, we need to be concerned about how they are collected, what is missing, which variables are imperfectly measured and what biases this might induce, what are the time lags in the dynamic relationships under scrutiny and if the units of observation are related. But it is appropriate to start with exactly what it is we wish to model.
4.1. What is the dependent variable we should be modelling?
One of the most fundamental problems in any modelling exercise is – what is the key dependent variable which one wants to model. It could be one (or more) of many candidates:
-
1. Number of new cases or infections per day.
-
2. Number of new hospitalisations per day, or the total number of those still in hospital
-
3. Number of deaths per day, or another measure of fatalities.
-
4. Number of deaths per day per 100,000 (or per million) of the population.
-
5. Number of deaths per day moderated by the number of cases or hospitalisations.
-
6. Moving average (over 3 or 7 days) of deaths per day
-
7. The reproduction number,
 $ {\mathcal{R}}_t $
.
$ {\mathcal{R}}_t $
. -
8. Infections per 100,000 of population, or another measure of the infection rate.
-
9. The number of excess deaths over what might normally be expected based on what happened in the same months in previous years.
-
10. The capacity utilisation rate in our hospitals.

Even this is not an exhaustive list, as we may consider the rate of change or cumulative versions of these variables, but most of these have their proponents in the Covid literature. The reality is that we are, of course, interested in all of these series to a greater or lesser degree, depending on our perspective. In addition, our fundamental issue is that they are all inter-related. Some are more prone to measurement error that others. Eyeballing the figures 1a–2b shows us that there is a major problem with any of these variables. Namely, that they will be non-stationary and trended but with huge heterogeneity between (or within) countries and therefore any regression with other non-stationary variables could lead us to estimate spurious relationships with estimates of coefficients which could be biased. Many have chosen the alternative of modelling the log of the daily numbers as the dependent variable. To see the problem, compare figures 2a,b and 3, Panels A and B relating to the
 $ {\mathcal{R}}_t $
number and the fatality rate (as a percentage of cases) for the United Kingdom. Clearly, a simple visual inspection shows that they are radically different in shape and may require quite different modelling.
$ {\mathcal{R}}_t $
number and the fatality rate (as a percentage of cases) for the United Kingdom. Clearly, a simple visual inspection shows that they are radically different in shape and may require quite different modelling.
4.2. Measurement error in official deaths and cases
Measurement error on any of the series we wish to quantify, and track can be an issue for many reasons. Let us first consider the series on deaths. Obviously, deaths that are recorded as being due to COVID-19 may be incorrectly recorded. If a death is counted as a COVID-19 death because the individual tested positive, this can lead to an over-reporting of deaths. In fact, it may be that the patient was about to die of another primary cause and then contracted Covid in their final days. Hence, there may not be a clear link between the infection and the death. (Williams et al., Reference Williams, Crookes, Glass and Glass2020) An individual may have died with COVID-19 and not of COVID-19. However, this argument can used to suggest that there could alternatively result in an underreporting of deaths (Aron and Muellbauer, Reference Aron and Muellbauer2020). If deaths are only classified as COVID-19 if the individual also tested positive, deaths will be missed from the count for all those who died of COVID-19 but were not tested (Leon et al., Reference Leon, Shkolnikov, Smeeth, Magnus, Pechholdová and Jarvis2020).
There are also problems with the measurement and definition of cases. Spencer et al. (Reference Spencer, Jefferson, Brassey and Heneghan2020) collate definitions for a COVID-19 case from different sources to highlight the lack of an international standard. In most countries, a probable case is based on clinical symptoms and a confirmed case is based on a positive laboratory result. Once a single positive test result is reached, clinical symptoms are discarded. Spencer et al. (Reference Spencer, Jefferson, Brassey and Heneghan2020) argue that a positive result should be a combination of clinical symptoms and a test result. In addition, the polymerase chain reaction test requires a standardised threshold level of detection. Furthermore, the level of testing has been very different between countries, with some countries employing rigorous testing regimes and others less so. In combination with missing data and imperfect accuracy of tests, partial identification methods show that reported cases may be estimated to be lower than actual cases (Manski and Molinari, Reference Manski and Molinari2020). The lack of testing in some countries will also impact on the number of deaths that are reported, if a death classification is reliant on a positive test result.
This leads to another issue regarding the definition and recording of a COVID-19 death. As the pandemic has evolved, some countries have changed the way that deaths are reported. For example, the United Kingdom initially defined and reported a COVID-19 death only if the death occurred in a hospital and the individual tested positive for COVID-19. (NHS England, 2020) From the 28 April 2020, deaths that were documented as COVID-19 on the death certificate, but the individual had not been tested, were also included in the reported figures. On the 12 August 2020, the death definition was changed to only include deaths that happened within 28 days of a positive test (Hughes, Reference Hughes2020). The effect of these differences in definition has been tracked by the Financial Times in figure 4. The classification of a COVID-19 death has not only changed within countries, but there is also great variation in the methods of recording deaths between countries. This is problematic in an analysis of deaths between countries if they are not measured the same way (Leon et al., Reference Leon, Shkolnikov, Smeeth, Magnus, Pechholdová and Jarvis2020).

Figure 4. (Colour online) Different FT definitions of deaths Source: Financial Times.
To compound these problems there may be endogeneity of reporting. For example, in March 2020, it was being suggested, based on evidence from drones counting coffins, that there was reason to believe that Iran was under-reporting the actual number of deaths per day. It has also been widely suggested that the numbers of cases and deaths in India, because of the Delta variant, have been widely under-reported. Clearly, governments may have an incentive to minimise the reporting of deaths in order to suppress panic on the streets. These practical problems may be further compounded by the fact that official data collection agencies coordinated by government departments may have an incentive to hide or manipulate the data for political and media purposes. As a result, it is difficult (see Gibbons et al., Reference Gibbons, Mangen and Plass2014) to always have complete faith in the numbers reported in different countries. Closer to home, it is clear that the politicisation of the data collection, release and dissemination was also taking place in the United Kingdom (see House of Commons, 2021).
4.3. Excess deaths
One possible solution to measurement error in COVID-19 deaths is to use data on excess deaths. Excess deaths are defined as the difference between the number of total deaths observed in a month compared to the expected number of deaths based on historic averages for the same month in previous years. Excess deaths may be a better measure for three reasons (Krelle et al., Reference Krelle, Barclay and Tallack2020). Firstly, the excess deaths measure captures indirect effects caused by COVID-19. Individuals who may have not died from COVID-19 directly but died from an alternative cause, for example, due to lack of access to healthcare (Griffin, Reference Griffin2020). Secondly, excess deaths are independent of changes to the COVID-19 mortality definition. This means changes in the way the government defines a death does not change the excess deaths figure. Thirdly, if excess deaths are definitionally robust, it is a measure that can, more easily, be compared across countries.
Figure 5 tracks the position in the United Kingdom and makes clear the large mortality spike in April 2020 compared to historical seasonal averages. Figure 6 shows that the United Kingdom was not alone in experiencing the worst of the pandemic during this period. The United States, Italy, France and Spain were also going through the worst of the pandemic at this time. In contrast, the figure shows that Brazil is only now going through its worst spell.

Figure 5. (Colour online) The measurement of excess deaths Source: @ColinAngus.

Figure 6. (Colour online) Excess deaths across selected countries
4.4. Epidemic starting date heterogeneity
Most panel studies of the pandemic assume that the epidemic started on the same date in each country or region within a country. This is not correct as it took 15 months to travel around the world. To get an idea of the heterogeneity of these start dates consider that China had 5.373 cases per million on 30 January 2020. If we use this as a benchmark, we can examine the dates when other countries reached five cases per million. This is graphed in figure 7. The United Kingdom reached this benchmark by 8 March and the United States by 13 March. Figure 7 shows this heterogeneity in the start date distribution for most countries. The majority of start dates are between 1st March and the end of April 2020. In the middle of this, WHO declared Covid a pandemic. But notice that some countries did not start their own epidemic until the beginning of 2021 and a few (Vanuatu, Bhutan and Cambodia) only in April 2021!! This highlights the importance of modelling a different start date for each country rather than taking the same date, as is assumed in much of the literature.

Figure 7. (Colour online) The distribution of epidemic start dates across countries
4.5. Problems with lags
One difficult issue is the nature of the dynamic relationship between our key times series of interest. An enduring problem in modelling the link between cases and deaths is what the appropriate lag to use is. The media consensus seems to be that deaths will follow cases with around a 10-day lag. To choose a lag for new cases in a more rigorous way one can simply examine the regression coefficients for all possible lags. If we perform such an analysis by regressing new deaths on all lags for new cases, up to a 22-day lag, controlling for country and day of the week fixed effects using data over the whole period (from 12 March 2020 to 24 June 2021 for 175 countries) we find the size of the coefficients varies markedly. Figure 8 plots them. We can see that the highest coefficients on the lags are at 21, 6, 7, 20 and 14 days in that order.

Figure 8. (Colour online) Partial correlation coefficients of different lagged cases on deaths
This pattern suggests that there may well be a 1-, 2- or 3-week lag between cases and deaths – but this is likely to be related to hospital, clinical or administrative reporting cycles rather than the natural rhythm of the virus. Despite controlling and day of the week effects, the optimal cases lag varies hugely from one country to another. This means that potentially one might ideally want to have different lag lengths for different countries in the panel data, but this is not possible. One is then left with the only pragmatic alternative of using the data from all countries and imposing the average lag structure across the whole dataset. But it should be recognised that this could introduce some bias, notwithstanding the country fixed effects controls.
4.6. The modelling of Covid is a complex spatial modelling exercise
It is self-evident that a single infected person on a flight from China in January 2020 was potentially enough to start a world-wide pandemic. Therefore, in statistical modelling, we cannot treat all countries ‘as if’ they were autonomous units of observation which are cross sectionally independent. At the beginning of the pandemic, it was clear that the countries where the epidemic took off most quickly after China were the ones most immediately connected via international air travel. See figure 9 (see Chinazzi et al., Reference Chinazzi, Davis and Ajelli2020; Inga et al., Reference Inga, Jiarui Liu and Schwieg2020; Li et al., Reference Li, Xiang and He2020; Wells et al., Reference Wells, Sah and Moghadas2020) which shows the direct flights available from China in January 2020. Likewise, it is also clear that the boundaries of all countries are porous with transmission across international boundaries taking place all the time. In this sense, irrespective of what geographical unit we use in our data, it is clear that the data are not cross sectionally independent. Since this means that the units of observation are related so we cannot assume a zero-covariance structure in any panel regression type model.

Figure 9. (Colour online) International flights from China in January 2020
A further problem which presents itself with data collected at spatially different locations arises when we aggregate that data. If we were to consider the pattern of cases or deaths in the 50 different U.S. states, we would see that they are all very distinct. When we aggregate these data to get the trends for the whole of the United States, the series looks very different again. This leaves us with the issue of what is the right level of geography to use for the analysis and raises the question of what biases may be induced by using spatially aggregated data.
Various articles have tackled this modelling issue. For example, Hortacşu et al. (2020) model the arrival of travellers to the United States from known epicentre to estimate the fraction of unreported cases. The method also allows for estimates for the infection fatality rate using data on reported COVID-19 fatalities.
5. Exponential trends, log modelling and understanding turning points
A commonly used way of presenting pandemic time series data is to employ a linear vertical scale to trace out the trend in new cases each day over time (as in figure 2a). An alternative way to plot time series data – especially when that series rises dramatically and exhibits an exponential trend – is to use a logarithmic scale on the vertical axis – this is a common practice in epidemiology due to the explosive increases in numbers involved. On a log scale, the variable increases multiplicatively as it rises. In the Panel B of figure 10, we see that the visual distance between 100 and 10 k is the same as that between 10 k and 1 m, that is, a 10-fold increase. These figures should be compared to the number of new cases every day in figure 2. The slope of a log-scaled graph measures the relative change in the variable of interest. This makes it a powerful tool to assess growth rates, which are particularly meaningful when the epidemic is an exponential process. The log-scale is appropriate for a visual representation – especially when the epidemic is in a first wave. On a log-scale, this exponential increase appears as a straight line, which only bends when the growth rate changes. These properties explain why this visualisation strategy is so popular in epidemiology.

Figure 10. (Colour online) Total COVID-19 cases in the United Kingdom from Feb 2020 to March 2021
Another useful graphic capability is to plot the log of falling cases on a time axis. The slope of this line then gives the percentage rate of change and deviations from the line exhibit less (below) or more (above) than linear decline. Many statisticians (including Oliver Johnson at Bristol and Colin Angus at Sheffield) have been posting these meaningful graphs on Twitter throughout the epidemic in the United Kingdom. For example, consider figure 11 from Colin AngusFootnote 6 posted in January 2020 when the vaccination programme had recently got underway for those older ages. Here, we clearly see that cases of those aged above 60 are declining linearly, whereas cases amongst the three groups between 15 and 64 not yet vaccinated are still increasing. One important point about these plots is how we choose to ‘fit’ the line through the points. What is being done in this figure is to project the line of best fit from first six dates forward to see how the daily data departs from this line, some 2 months later. But should we take the first 6 days data or the first 14 days data, and should we compare this with a line fitted to the last 6 or 14 days data. This is a substantive point as it will convey quite a different visual impression. There is no ‘right’ answer here, but we need to be aware of the impact of these distinctions on the visual impression it creates.

Figure 11. (Colour online) Log plots of declining case numbers by age in the United Kingdom from January to February 2021 Source: Colin Angus.
A question of importance though is whether the use of logarithmic scales confuses the general public or policy-makers and politicians.Footnote 7 This is especially true when the epidemic has gone through more than one wave as we saw from figure 10, where it is not so obvious which method is clearer in revealing the pattern of the epidemic. In this figure, we plot the total cases for the United Kingdom over the same time frame as in figure 2b using a linear scale on the left in Panel A and a log scale in Panel B. In Panel A, the nonlinear kinks in the trend are the separate waves of the epidemic. In the log version of Panel B, the waves are not evident. Rather, one’s eye is caught by the first wave peaking in April 2020. As a result, one does not notice the second wave which took place between September 2020 and peaked by the end of January 2021. Nor is it easy to distinguish when the epidemic is slowing down in February 2021 on the log graph. Whereas the lower slowdown in the linear graph from February 2021 is quite clear. The lesson of these observations is that for a single wave of epidemic, a log scale series is appropriate but that for a multi-wave epidemic caution is necessary.
When will the epidemic peak? When will it no longer being accelerating and getting worse? At any given point in time, will it accelerate or diminish? These are crucial questions as it is important to locate the turning points in any process. To see this, consider what the world did not know on the 23 January 2020. Looking at the graph of cases in Hubei, China in figure 12, we did not know whether we were on the cusp of a world pandemic or not! The turning point problem has been analysed in Li and Linton (Reference Li and Linton2020) and Chudik et al. (Reference Chudik, Persaran and Rebucci2020). Li and Linton (Reference Li and Linton2020) who analyse of the daily data on the number of new cases and the number of new deaths in 191 countries using ECDC data up to June 2020. Their benchmark model is a quadratic time trend model estimating the log of new cases for each country separately. They use their model to predict when the peak of the epidemic will rise in terms of new cases or new deaths in each country and the peak level. They also predict how long the number of new daily cases in each country will fall by an order of magnitude and forecast the total number of cases and deaths for each country. Unfortunately, this work was all done prior to the results of widespread second (and subsequent) waves in most countries. They find that the course of the epidemic in each country is very heterogenous. This would point to the logical problem of estimating the model and applying it to data as the epidemic is in process in each country. Essentially the basic problem is that nonlinear processes normally require second-order differential equations to model turning points (and points of inflexion) and basically, SIR type models are only a system of first order differential equations.

Figure 12. (Colour online) Cases in Hubei, China from January to February 2020
One useful visual clue which may be adopted is a ‘phase portrait’ is a dynamic pairwise bivariate plot of the levels of two variables which are changing daily. In figure 13, for example, the path traced out by the pattern of daily admissions and the number of hospital beds that are full, produces a clear insight into what is going on. The pattern of the Wave 1 (from September 2020 to January 2021) dots, is dramatically different from the much more severe, Wave 2 dots relating to the period from March to April 2021.

Figure 13. (Colour online) Phase portrait of admissions and beds in the United Kingdom during Waves 1 and 2 Source: Oliver Johnson (@BrisOliver).
6. Endogeneity and behavioural responses
From the beginning of the COVID-19 pandemic, governments have been making decisions on what policies to implement and how stringent these should be partially based on the data series they observe on cases and deaths (and potentially other estimated epidemiological model parameters like the
 $ {\mathcal{R}}_t $
number). The implementation of policies and government responses has varied greatly. The responses from the countries that implemented policies can be grouped into three main strategies. The first, initially adopted by most Western countries, focuses on mitigating the spread of the virus (Qiu et al., Reference Qiu, Chen and Shi2020). For example, on 12 March 2020, the UK government announced that the country would switch from a strategy of attempting to contain the virus to one based on delaying its transmission, that is ‘flattening the curve’. This involved attempting to delay the peak of the outbreak to limit the strain that the pandemic would place the NHS system. The second strategy, adopted by countries such as South Korea, China and later on by some Western countries, seeks to suppress and prevent the spread of COVID-19 cases and, by extension, reduce the number of deaths (Qiu et al., Reference Qiu, Chen and Shi2020). For example, by the start of March 2020, South Korea had developed a rigorous testing regime to track and trace and isolate cases to prevent the spread of the virus. Finally, some countries such as Sweden adopted a relaxed approach by imposing very few restrictions on movement, with the possible aim of achieving herd immunity. These countries were heavily criticised. This means that there is an endogeneity of policy choices as each government is at least partially deciding which policy to be invoked determined by the death figures and case numbers it is experiencing on a daily basis. At the same time the course of the spread of the pandemic will also be at least partially determined by the strength of the lockdown policies being employed. This poses inherent endogeneity modelling difficulties. Not least, there will be an element of reverse causality – we would hope that the NPIs invoked will reduce the epidemic and lower cases and deaths, but, at the same time, mounting cases and deaths will induce the government to invoke more restrictive policies. The other cause of endogeneity relates to measurement error in the explanatory variables. For example, if cases included as an explanatory variable in modelling deaths, then there will be a problem if the recording of cases exhibits any of the measurement errors discussed above. In the event this may result in the estimated coefficients being biased and inconsistent.
$ {\mathcal{R}}_t $
number). The implementation of policies and government responses has varied greatly. The responses from the countries that implemented policies can be grouped into three main strategies. The first, initially adopted by most Western countries, focuses on mitigating the spread of the virus (Qiu et al., Reference Qiu, Chen and Shi2020). For example, on 12 March 2020, the UK government announced that the country would switch from a strategy of attempting to contain the virus to one based on delaying its transmission, that is ‘flattening the curve’. This involved attempting to delay the peak of the outbreak to limit the strain that the pandemic would place the NHS system. The second strategy, adopted by countries such as South Korea, China and later on by some Western countries, seeks to suppress and prevent the spread of COVID-19 cases and, by extension, reduce the number of deaths (Qiu et al., Reference Qiu, Chen and Shi2020). For example, by the start of March 2020, South Korea had developed a rigorous testing regime to track and trace and isolate cases to prevent the spread of the virus. Finally, some countries such as Sweden adopted a relaxed approach by imposing very few restrictions on movement, with the possible aim of achieving herd immunity. These countries were heavily criticised. This means that there is an endogeneity of policy choices as each government is at least partially deciding which policy to be invoked determined by the death figures and case numbers it is experiencing on a daily basis. At the same time the course of the spread of the pandemic will also be at least partially determined by the strength of the lockdown policies being employed. This poses inherent endogeneity modelling difficulties. Not least, there will be an element of reverse causality – we would hope that the NPIs invoked will reduce the epidemic and lower cases and deaths, but, at the same time, mounting cases and deaths will induce the government to invoke more restrictive policies. The other cause of endogeneity relates to measurement error in the explanatory variables. For example, if cases included as an explanatory variable in modelling deaths, then there will be a problem if the recording of cases exhibits any of the measurement errors discussed above. In the event this may result in the estimated coefficients being biased and inconsistent.
One solution to endogeneity is the use of instrumental variables (IV). The chosen IV needs to be highly correlated with the endogenous variable but uncorrelated with the error term to produce consistent results. One example in this literature is the use of weather variables to instrument for the government response indicator (Qiu et al., Reference Qiu, Chen and Shi2020). However, this variable is unlikely to be a valid IV due to the effect of weather conditions may have on the spread of the virus cases or the unobserved heterogeneity of this effect.
A related problem to that of endogeneity of the NPI variable is the possibility that there is a related behavioural response by the public to measures like the
 $ {\mathcal{R}}_t $
which is widely reported in the media on an almost daily basis. If the public change their behaviour as a result of the reported
$ {\mathcal{R}}_t $
which is widely reported in the media on an almost daily basis. If the public change their behaviour as a result of the reported
 $ {\mathcal{R}}_t $
that they see on their television, then this adds a further source of possible endogeneity.
$ {\mathcal{R}}_t $
that they see on their television, then this adds a further source of possible endogeneity.
Notwithstanding the possible endogeneity of an NPI summary measure it is worth describing the available data for understanding the policy response to Covid. The most prominent source of data on the use of NPIs is from the Oxford COVID-19 Government Response Tracker, OxCGRT (Hale et al., Reference Hale, Angrist and Goldszmidt2020). The dataset contains data on 17 different sub-indicators regarding different government responses for 185 countries under three different categories: containment and closure policies, economic policies and health system policies. Various combinations of these sub-indicators make up the four indices. These are an economic support index, a containment and health index, a stringency index, and an overall government response index – here graphed as OxCGRT Stringency Index. Overall, 173 countries are included in the Oxford data, but the data are an unbalanced panel. These data have been used by many papers most commonly aggregated into a Stringency Index which is graphed in figure 14 below for six countries during the ‘first wave’. We can see quite clearly that many countries adopt more stringent policies as the deaths rise, for example Italy, Iran, the United Kingdom and even Sweden. But some countries do not seem to adopt this strategy, such as Brazil and the United States.

Figure 14. (Colour online) New (smoothed) daily deaths and the Stringency Index by selected countries
The data on the Stringency Index for eight countries is graphed in figure 15 over the course of the pandemic. The series shows that the index has a value which has between 40 and 80 percentage point difference between the most locked-down and the least locked-down country at different points in time. The country which is most locked-down changes frequently over the course of the last 16 months. One possible solution to the endogeneity of the NPI is to use a synthetic control strategy which examines the difference between the ‘treated’ country with the maximal OxCGRT Stringency Index employed and the ‘control country’ which employs the minimum possible Stringency Index of NPI measures. The synthetic control method in this case would typically use a weighted average of other countries to compare with the ‘treated’ country. A limited use of the synthetic control method to model Covid has been explored by Harvey and Kattuman (2020a). But to exploit the idea of using a different individual synthetic control for different time periods would involve an extension to its conventional use.

Figure 15. (Colour online) Stringency Index for selected countries
7. Simple taxonomy of different models
There are now thousands of academic papers which model the course of the COVID-19 pandemic.Footnote 8 A simplistic taxonomy is explored in this discussion. This is inevitably a gross simplification of the plethora of models which can be devised. We characterise them in their basic variants following a select few papers published in high profile journals to present their main features and strengths, so that we may compare them.
7.1. The SEIR and SEIDR Model
The majority of the modelling which has been done on the pandemic over the last 18 months has used variants of the deterministic, compartmental SIR model.Footnote 9 This is part of the epidemiologist’s toolkit and it has dominated the modelling advice given to governments and technical committees like SAGE in the United Kingdom. The so-called SIR model has been used as the basic building block of epidemiological modelling (see Kermack and McKendrick, Reference Kermack and McKendrick1927; Ferguson et al., Reference Ferguson, Walker and Whittaker2020; Kucharski et al., Reference Kucharski, Russell and Diamond2020 for its application to the United Kingdom and IHME, and Kucharski et al., Reference Kucharski, Russell and Diamond2020 for its use on separate U.S. states). This model has been extended to include a fourth category of person, those Exposed, to create the SEIR which is the workhorse model which has been repeatedly extended. Each extension to the model adds further complexity to the differential equations which model the dynamics of system. Arguably, the most important extensions of most concern to the modelling of the COVID pandemic are to add the number of fatalities, the Dead, D, and the number of those Vaccinated, V. In the first instance, we follow the model notation of Carcione et al. (Reference Carcione, Santos, Claudio Bagaini and Ba2020) to set out the model with Deaths, that is the SEIDR model (see Keeling and Rohani, Reference Keeling and Rohani2008).
The total (initial) population, P, is categorised in four groups, namely, the susceptible,
 $ S(t) $
, the exposed,
$ S(t) $
, the exposed,
 $ \dot{E(t)} $
, the infected,
$ \dot{E(t)} $
, the infected,
 $ \dot{I(t)} $
and the recovered,
$ \dot{I(t)} $
and the recovered,
 $ \dot{R(t)} $
, where t is the time variable. The governing differential equations of the SEIR model are:
$ \dot{R(t)} $
, where t is the time variable. The governing differential equations of the SEIR model are:
 $$ \dot{S}=\Lambda -\mu S-\beta S\frac{I}{P} $$
$$ \dot{S}=\Lambda -\mu S-\beta S\frac{I}{P} $$
 $$ \dot{E}=\beta S\frac{I}{P}-\left(\mu +\epsilon \right)E $$
$$ \dot{E}=\beta S\frac{I}{P}-\left(\mu +\epsilon \right)E $$
 $$ \dot{I}=\epsilon E-\left(\gamma +\mu +\alpha \right)I $$
$$ \dot{I}=\epsilon E-\left(\gamma +\mu +\alpha \right)I $$
 $$ \dot{R}=\gamma I-\mu R, $$
$$ \dot{R}=\gamma I-\mu R, $$
where P = S + E + I + R in this case, and a dot above a variable denotes time differentiation. These equations are subject to the initial conditions S(0), E(0), I(0) and R(0). The parameters of the model are defined as:
 $ \Lambda $
: Per-capita birth rate.
$ \Lambda $
: Per-capita birth rate.
 $ \mu $
: Per-capita natural death rate.
$ \mu $
: Per-capita natural death rate.
 $ \alpha $
: Virus induced average fatality rate.
$ \alpha $
: Virus induced average fatality rate.
 $ \beta $
: Probability of disease transmission per contact (dimensionless) times the number of contacts per unit time.
$ \beta $
: Probability of disease transmission per contact (dimensionless) times the number of contacts per unit time.
 $ \epsilon $
: Rate of progression from exposed to infected (the reciprocal is the incubation period).
$ \epsilon $
: Rate of progression from exposed to infected (the reciprocal is the incubation period).
 $ \gamma $
: Recovery rate of infected individuals (the reciprocal is the infection period).
$ \gamma $
: Recovery rate of infected individuals (the reciprocal is the infection period).
The SEIDR model is a simple supplement to the above system by adding the assumption that a specific fraction of the infected die:
 $$ \dot{D}=\alpha I. $$
$$ \dot{D}=\alpha I. $$
However, such an extension, may not be straightforward. For example, Korolev (Reference Korolev2020) shows how the identification and estimation of an SEIDR epidemic model for COVID-19 can be problematic and indicates how various parameters which we might want to estimate cannot be identified.
The basic initial reproduction ratio,
 $ {\mathcal{R}}_0 $
, is the classical epidemiological measure associated with the reproductive power of the disease.Footnote
10 For the SEIR model (see Diekmann et al., 2000), it is
$ {\mathcal{R}}_0 $
, is the classical epidemiological measure associated with the reproductive power of the disease.Footnote
10 For the SEIR model (see Diekmann et al., 2000), it is
 $$ {\mathcal{R}}_0=\frac{\beta \epsilon}{\left(\epsilon +\mu \right)\left(\gamma +\alpha +\mu \right)}. $$
$$ {\mathcal{R}}_0=\frac{\beta \epsilon}{\left(\epsilon +\mu \right)\left(\gamma +\alpha +\mu \right)}. $$
This ratio gives the average number of new cases of infection generated by an infectious individual. The real life effective (instantaneous) reproduction number, in practice, at any subsequent time period t,
 $ {\mathcal{R}}_t $
, is time varying, and will depend on the fraction of the population which have become immune or been vaccinated. Therefore, when it is used to estimate the growth of the virus outbreak.
$ {\mathcal{R}}_t $
, is time varying, and will depend on the fraction of the population which have become immune or been vaccinated. Therefore, when it is used to estimate the growth of the virus outbreak.
 $ {\mathcal{R}}_t $
provides a threshold for the stability of the disease-free equilibrium point. When
$ {\mathcal{R}}_t $
provides a threshold for the stability of the disease-free equilibrium point. When
 $ {\mathcal{R}}_t $
< 1, the disease dies out; when
$ {\mathcal{R}}_t $
< 1, the disease dies out; when
 $ {\mathcal{R}}_t $
> 1, an epidemic accelerates.
$ {\mathcal{R}}_t $
> 1, an epidemic accelerates.
The system of differential equations can be solved by using forward Euler finite-differences discretising the time variable to daily or weekly data to obtain estimates of the key parameters which can be used to simulate the future levels of S, E, I, R and D by observing the base levels of each number in the population and then estimating the parametersFootnote
11:
 $ \Lambda $
,
$ \Lambda $
,
 $ \mu $
,
$ \mu $
,
 $ \alpha $
,
$ \alpha $
,
 $ \beta $
,
$ \beta $
,
 $ \epsilon $
and
$ \epsilon $
and
 $ \gamma $
then simulating the future levels of S, E, I, R and D in the population in future time periods. Not surprisingly, at the early stages on the epidemic these numbers can vary wildly and be somewhat erratic. So, the starting point in this analysis is the fixed assumptions of the form in the set of differential equations. In contrast to conventional econometric models, this is not an ex poste model and does not use the full nature of the data over all time periods to model the dynamic course of the epidemic – since the model is usually being used as the epidemic is progressing. Rather it is assumed that the future course of the epidemic unfolds according to the prescribed dynamic relations with parameters determined by earlier real data or assumed changes in the parameters. This deterministic model is not conducive to inference on the possible distribution of the future outcome predictions or the modelling of measurement error in the data. The model can of course be extended to a stochastic one at the cost of complexity. The model is most often used to model single countries (or other specific geographies) under the assumption that there is no connection between countries. Although there are papers which explicitly consider the spatial modelling issues of the spread of COVID-19 between countries (see for example Hortacşu et al., 2020), there is limited scope for using panel data in this model. This is a disadvantage as one would expect that the patterns of the diffusion of the epidemic into each country have underlying features in common and may help us to understand the pandemic spread and repeated waves across the world.
$ \gamma $
then simulating the future levels of S, E, I, R and D in the population in future time periods. Not surprisingly, at the early stages on the epidemic these numbers can vary wildly and be somewhat erratic. So, the starting point in this analysis is the fixed assumptions of the form in the set of differential equations. In contrast to conventional econometric models, this is not an ex poste model and does not use the full nature of the data over all time periods to model the dynamic course of the epidemic – since the model is usually being used as the epidemic is progressing. Rather it is assumed that the future course of the epidemic unfolds according to the prescribed dynamic relations with parameters determined by earlier real data or assumed changes in the parameters. This deterministic model is not conducive to inference on the possible distribution of the future outcome predictions or the modelling of measurement error in the data. The model can of course be extended to a stochastic one at the cost of complexity. The model is most often used to model single countries (or other specific geographies) under the assumption that there is no connection between countries. Although there are papers which explicitly consider the spatial modelling issues of the spread of COVID-19 between countries (see for example Hortacşu et al., 2020), there is limited scope for using panel data in this model. This is a disadvantage as one would expect that the patterns of the diffusion of the epidemic into each country have underlying features in common and may help us to understand the pandemic spread and repeated waves across the world.
One considerable advantage of SEIR framework is that the structural model can be theoretically augmented to address behavioural issues of direct interest to economists. For example, Chernozhukov et al. (Reference Chernozhukov, Kasaharab and Schrimp2020), examine a dynamic structural model of Covid cases with the aim of making causal predictions and evaluation. They examine the impact of face masks, stay at home orders and school closures among other mandated policies. Other prominent papers have also considered other aspects of the behavioural role of social distancing in the context of an SIR model (see Makris, Reference Makris2021; Toxvaerd, Reference Toxvaerd2020).
Hence, the SEIR model is not commonly used to model repeated waves of the epidemic, although there are recent theoretical advances of the model which seek to examine the conditions under which a stochastic version of the model can generate repeated waves (Cacciapaglia et al., Reference Cacciapaglia, Corentin Cot and Sannino2020; Faranda and Alberti, Reference Faranda and Alberti2020). So far, these models are not suitable for comprehensive use with cross country data.
The deterministic version of the SEIR model produces point estimates of predictions which does not provide confidence intervals around these predictions. The Ferguson et al. (Reference Ferguson, Walker and Whittaker2020) model at an early stage predicted for the United Kingdom that there would be 510,000 deaths without lockdown and 20,000 deaths with lockdown – but these predictions were based on different parameter assumptions in the basic equations and not borne of the stochastic nature of the model. Another potential limitation of the most SEIR models is that it does not routinely incorporate conditioning regressors. Specifically, the SEIR model does not allow day of the week effects, observed country – based heterogeneity or the adoption of NPI policies or the roll out of the vaccines.
7.2. Bayesian dynamic and hybrid models
There is a rich tradition of using Bayesian models in epidemiology. There are now many papers which use these methods to model Covid, for example Anderson et al. (Reference Anderson, Edwards and Yerlanov2020) and Wibbens et al. (Reference Wibbens, Wu-Yi Koo and McGahan2020). They typically adapt the deterministic SIR type framework to a stochastic Bayesian framework. Here, assumptions on the form of prior distribution of model parameters are made which determine the updating of the model in the light of real time data to formulate posteriors which are used in a dynamic setting to predict outcomes for key variables of interest. Typically, these models need to make assumptions about the priors of the parameters of interest (e.g. the reproduction rate in the case of Anderson et al., Reference Anderson, Edwards and Yerlanov2020, or the growth rate of infections in the case of Wibbens et al., Reference Wibbens, Wu-Yi Koo and McGahan2020) which have attractive properties when combined with tractable conjugate likelihood distributions to derive the posterior of interest. An important component of such compartmental models is typically the exploitation of real time series data, assumptions regarding population dynamics and modelling of the transition probabilities between states. The model is usually then simulated repeatedly, often using Markov Chain Monte Carlo or Variance Inference methods and can be used to forecast the course of the epidemic.
There are also many papers on Bayesian dynamic models which augment the structure of SEIR type models. (e.g. Bertozzia et al., Reference Bertozzia, Franco, Mohler, Martin, Short and Sledge2020) Some of these may be termed ‘hybrid models’ as they use elements of both the SEIR epidemiological models and dynamic Bayesian models. One prominent example recently in the media is the technically complex model of Friston et al. (Reference Friston, Parr and Zeidman2020). The model is one which augments a SEIR model with other compartmental population dynamics using conditional dependencies to model a richer set of interactions, such as social distancing. They model responses of neural ensembles to perturbations using model inversion and comparison procedures. Specifically, the team have been predicting the scale of a possible third wave the United Kingdom ‘bounce back’ now the second lockdown is over.
7.3. Time series and error correction models
One of the leading epidemiology texts, Keeling and Rohani, Reference Keeling and Rohani2008 suggest that time series analysis ‘can be used to examine longitudinal data and to extract meaningful patterns such as periodic oscillations or density dependence’, (p14). This suggests a recognition that the long run, maybe in an ex-poste explanation of the course of the pandemic or its variation across different countries, can be achieved by the use of time series models. Over the last year there have been scores of papers published using a whole array of time series estimation techniques to model the course of different epidemics in many different countries (see Finkenstadt et al., Reference Finkenstadt, Bryan and Grenfell2000). However, for the most part, time series analysis has not been much used by epidemiologists to study Covid-19. We turn to a simple explanation of why this might be.
A straightforward visual inspection of the time series data on deaths or cases (like in figure 2,b) for any country tells us that the data to be modelled is highly nonlinear, trended and/or non-stationary. This means that any estimated relationship between, for example, cases and deaths may be subject to the potential problem of spurious regressions which may bias the estimated coefficients and distort any conclusions. A conventional approach to this problem in applied time series econometrics is to exploit possible cointegrated relationships between the variables of interest which means that we can use a vector autoregression model (VECM). There are some case studies (Bhangu et al., Reference Bhangu, Sandhu and Sapra2021; Imai et al., Reference Imai, Armstrong, Chalabi, Mangtani and Hashizume2015; Inga et al., Reference Inga, Jiarui Liu and Schwieg2020; Vokó and Pitter, Reference Vokó and Pitter2020) relating to epidemic research which use these methods. We follow the notation of one example, Turk et al. (Reference Turk, Thao, Rose and McWilliams2021), which uses this technique to study the relationship between hospitalisation and community behaviour and activity as measured by Google Trends.
Specifically, let
 $ {\boldsymbol{y}}_t $
be an n × 1 vector of variables which are either difference-stationary or trend-stationary. This vector is cointegrated if there exists an n × 1 (cointegrating) vector
$ {\boldsymbol{y}}_t $
be an n × 1 vector of variables which are either difference-stationary or trend-stationary. This vector is cointegrated if there exists an n × 1 (cointegrating) vector
 $ {\boldsymbol{\beta}}_{\boldsymbol{i}}\left(\ne 0\right) $
such that
$ {\boldsymbol{\beta}}_{\boldsymbol{i}}\left(\ne 0\right) $
such that
 $ \boldsymbol{\beta}^{\prime }{\boldsymbol{y}}_t $
is trend stationary. It is possible that there are r linearly independent vectors
$ \boldsymbol{\beta}^{\prime }{\boldsymbol{y}}_t $
is trend stationary. It is possible that there are r linearly independent vectors
 $ {\boldsymbol{\beta}}_{\boldsymbol{i}} $
(i = 1, …, r). A vector autoregression model of order K (VAR(K)) can be written as:
$ {\boldsymbol{\beta}}_{\boldsymbol{i}} $
(i = 1, …, r). A vector autoregression model of order K (VAR(K)) can be written as:
 $$ {\boldsymbol{y}}_t=\sum_{\boldsymbol{i}=\mathbf{1}}^{\boldsymbol{K}}{\boldsymbol{\Pi}}_i\ {\boldsymbol{y}}_{t-i}+\boldsymbol{\mu} +\boldsymbol{\Phi} {\boldsymbol{d}}_t+{\boldsymbol{\varepsilon}}_t, $$
$$ {\boldsymbol{y}}_t=\sum_{\boldsymbol{i}=\mathbf{1}}^{\boldsymbol{K}}{\boldsymbol{\Pi}}_i\ {\boldsymbol{y}}_{t-i}+\boldsymbol{\mu} +\boldsymbol{\Phi} {\boldsymbol{d}}_t+{\boldsymbol{\varepsilon}}_t, $$
where t = 1,…,T. Here,
 $ {\boldsymbol{y}}_t $
is an n × 1 vector of time series at time t,
$ {\boldsymbol{y}}_t $
is an n × 1 vector of time series at time t,
 $ {\boldsymbol{\Pi}}_i $
(i = 1,…,K) is an n × n matrix of coefficients for the lagged time series,
$ {\boldsymbol{\Pi}}_i $
(i = 1,…,K) is an n × n matrix of coefficients for the lagged time series,
 $ \boldsymbol{\mu} $
is an n × 1 vector of constants,
d
t is an p × 1 vector of deterministic variables (e.g. day of the week dummies, time, etc.), and
$ \boldsymbol{\mu} $
is an n × 1 vector of constants,
d
t is an p × 1 vector of deterministic variables (e.g. day of the week dummies, time, etc.), and
 $ \boldsymbol{\Phi} $
is a corresponding n x p matrix of coefficients. We assume the
$ \boldsymbol{\Phi} $
is a corresponding n x p matrix of coefficients. We assume the
 $ {\boldsymbol{\varepsilon}}_t $
are independent n × 1 multivariate white noise. To determine a value for K in practice, one can sequentially fit a VAR model, for K = 1, …, 20, to determine the appropriate lag length (e.g. between cases and deaths), and compare Akaike’s Information Criterion (AIC) values.
$ {\boldsymbol{\varepsilon}}_t $
are independent n × 1 multivariate white noise. To determine a value for K in practice, one can sequentially fit a VAR model, for K = 1, …, 20, to determine the appropriate lag length (e.g. between cases and deaths), and compare Akaike’s Information Criterion (AIC) values.
The VAR model can be rewritten is as a vector error correction model (VECM):
 $$ \Delta {\boldsymbol{y}}_t=\sum_{\boldsymbol{i}=\mathbf{1}}^{\boldsymbol{K}}{\boldsymbol{\Gamma}}_i\Delta {\boldsymbol{y}}_{t-i+1}+\boldsymbol{\Pi} {\boldsymbol{y}}_{t-1}+\boldsymbol{\mu} +\boldsymbol{\Phi} {\boldsymbol{d}}_{\boldsymbol{t}}+{\boldsymbol{\varepsilon}}_t, $$
$$ \Delta {\boldsymbol{y}}_t=\sum_{\boldsymbol{i}=\mathbf{1}}^{\boldsymbol{K}}{\boldsymbol{\Gamma}}_i\Delta {\boldsymbol{y}}_{t-i+1}+\boldsymbol{\Pi} {\boldsymbol{y}}_{t-1}+\boldsymbol{\mu} +\boldsymbol{\Phi} {\boldsymbol{d}}_{\boldsymbol{t}}+{\boldsymbol{\varepsilon}}_t, $$
where
 $ \Delta {\boldsymbol{y}}_t $
is a first difference
,
$ \Delta {\boldsymbol{y}}_t $
is a first difference
,
 $ {\boldsymbol{\Gamma}}_i $
= −(
$ {\boldsymbol{\Gamma}}_i $
= −(
 $ {\boldsymbol{\Pi}}_{i+1} $
+ · +
$ {\boldsymbol{\Pi}}_{i+1} $
+ · +
 $ {\boldsymbol{\Pi}}_K $
), for i = 1, …, K − 1 and K ≥ 2, and
$ {\boldsymbol{\Pi}}_K $
), for i = 1, …, K − 1 and K ≥ 2, and
 $ \boldsymbol{\Pi} =-\left(\mathbf{I}-{\boldsymbol{\Pi}}_i-\dots \kern1.25em -{\boldsymbol{\Pi}}_K\right) $
for an identifying matrix
$ \boldsymbol{\Pi} =-\left(\mathbf{I}-{\boldsymbol{\Pi}}_i-\dots \kern1.25em -{\boldsymbol{\Pi}}_K\right) $
for an identifying matrix
 $ \mathbf{I} $
of order n. Hence, a VECM is a VAR model (in the differences of the data) allowing for co-integration (in the levels of the data). The matrix
$ \mathbf{I} $
of order n. Hence, a VECM is a VAR model (in the differences of the data) allowing for co-integration (in the levels of the data). The matrix
 $ \boldsymbol{\Pi} $
measures the long-run relationships among the elements of
$ \boldsymbol{\Pi} $
measures the long-run relationships among the elements of
 $ {\boldsymbol{y}}_t $
, while the
$ {\boldsymbol{y}}_t $
, while the
 $ {\boldsymbol{\Gamma}}_i $
measure short-run effects.
$ {\boldsymbol{\Gamma}}_i $
measure short-run effects.
 $ {\boldsymbol{y}}_{t-i} $
is the ‘error correction term’ and it is assumed this term is (trend-)stationary.Footnote
12 The separation of long-run and short-run elements of epidemic data may prove to be insightful.
$ {\boldsymbol{y}}_{t-i} $
is the ‘error correction term’ and it is assumed this term is (trend-)stationary.Footnote
12 The separation of long-run and short-run elements of epidemic data may prove to be insightful.
Fitting a VECM involves determining the number (r) of co-integrating relationships in the data. It can be shown that the rank of the matrix
 $ {\boldsymbol{\Pi}}_K $
is equal to r. When r ∈ (0, n), we can use a rank factorisation to write,
$ {\boldsymbol{\Pi}}_K $
is equal to r. When r ∈ (0, n), we can use a rank factorisation to write,
 $ \boldsymbol{\Pi} =\boldsymbol{\alpha} \boldsymbol{\beta}^{\prime }, $
where both
$ \boldsymbol{\Pi} =\boldsymbol{\alpha} \boldsymbol{\beta}^{\prime }, $
where both
 $ \boldsymbol{\alpha} $
and
$ \boldsymbol{\alpha} $
and
 $ \boldsymbol{\beta} $
are of size n × r. Therefore,
$ \boldsymbol{\beta} $
are of size n × r. Therefore,
 $ \boldsymbol{\Pi} {\boldsymbol{y}}_{t-1}=\boldsymbol{\alpha} \boldsymbol{\beta}^{\prime }{\boldsymbol{y}}_{t-i} $
is stationary since
$ \boldsymbol{\Pi} {\boldsymbol{y}}_{t-1}=\boldsymbol{\alpha} \boldsymbol{\beta}^{\prime }{\boldsymbol{y}}_{t-i} $
is stationary since
 $ \boldsymbol{\alpha} $
is a scale transformation and,
$ \boldsymbol{\alpha} $
is a scale transformation and,
 $ \boldsymbol{\beta}^{\prime }{\boldsymbol{y}}_{t-i} $
is (trend-) stationary where
$ \boldsymbol{\beta}^{\prime }{\boldsymbol{y}}_{t-i} $
is (trend-) stationary where
 $ \boldsymbol{\beta} $
are the set of cointegrating vectors, which specifies a ‘long-run relationship’ among the individual time series. Elements in the vector
$ \boldsymbol{\beta} $
are the set of cointegrating vectors, which specifies a ‘long-run relationship’ among the individual time series. Elements in the vector
 $ \boldsymbol{\alpha} $
are often interpreted as ‘speed of adjustment coefficients’ (or short-run model) that modify the co-integrating relationships. The number of co-integrating relationships can be formally determined using Johansen’s procedure. Following Hamilton (Reference Hamilton1994) and Johansen and Juselius (Reference Johansen and Juselius1990), it is possible to specify the deterministic terms in the VECM using AIC and a likelihood ratio test on linear trend.
$ \boldsymbol{\alpha} $
are often interpreted as ‘speed of adjustment coefficients’ (or short-run model) that modify the co-integrating relationships. The number of co-integrating relationships can be formally determined using Johansen’s procedure. Following Hamilton (Reference Hamilton1994) and Johansen and Juselius (Reference Johansen and Juselius1990), it is possible to specify the deterministic terms in the VECM using AIC and a likelihood ratio test on linear trend.
The challenges of this procedure are: to find the co-integrating vectors, determine the appropriate dynamic lag lengths, and account for the inherent nonlinearities of the epidemic process. The difficulties of these tasks are compounded by the relationships in question being time varying, which may mean that the potential co-integrating relationship breaks down. In addition, the possibility of including (endogenous) controlling regressors like an indicator for the stringency of NPIs is potentially problematic. Although this model is suited to making forecasts and estimating impulse functions it is not immediately possible to estimate specific parameters like the
 $ {\mathcal{R}}_t $
rate. A further challenge is to use this model with panel data from many countries in the same estimation framework (Pesaran and Smith, Reference Pesaran and Smith1995). Ultimately, this type of model is best employed after the pandemic is over, when all the data is in, and we can then determine out which NPIs are effective, and which are not. In the light of these difficulties with the VECM it is likely that its application to modelling Covid is limited to quite special circumstances.
$ {\mathcal{R}}_t $
rate. A further challenge is to use this model with panel data from many countries in the same estimation framework (Pesaran and Smith, Reference Pesaran and Smith1995). Ultimately, this type of model is best employed after the pandemic is over, when all the data is in, and we can then determine out which NPIs are effective, and which are not. In the light of these difficulties with the VECM it is likely that its application to modelling Covid is limited to quite special circumstances.
7.4. Forecasting models
There are many ways of estimating short-run forecasting models which may be applicable to the prediction of the COVID-19 pandemic (e.g. Liu et al., Reference Liu, Hyungsik and Schorfheide2020, and Gecili et al., Reference Gecili, Assem Ziady and Szczesniak2021). An innovative example is that of Doornik et al. (Reference Doornik, Castle and Hendry2020). Using
 $ {y}_t $
to denote the dependent variable that needs to be decomposed in an unobserved trend term
$ {y}_t $
to denote the dependent variable that needs to be decomposed in an unobserved trend term
 $ {\hat{\mu}}_t $
, and residual or irregular
$ {\hat{\mu}}_t $
, and residual or irregular
 $ {\hat{\varepsilon}}_t $
. For the logarithmic model, we have:
$ {\hat{\varepsilon}}_t $
. For the logarithmic model, we have:
 $$ \log {y}_t={\hat{\mu}}_t+{\hat{\varepsilon}}_t. $$
$$ \log {y}_t={\hat{\mu}}_t+{\hat{\varepsilon}}_t. $$
The idea of this model is to split the data up into several discrete overlapping and moving windows, fitting short-run time trends using a method the authors devising called local averaged time trend estimation (LATTE). Let
 $ {x}_t=\log {y}_t $
denote the dependent variable. Then, a typical window w runs from observation
$ {x}_t=\log {y}_t $
denote the dependent variable. Then, a typical window w runs from observation
 $ {i}_w $
to
$ {i}_w $
to
 $ {j}_w $
and provides estimates for
$ {j}_w $
and provides estimates for
 $ {\hat{\ x}}_{w,t} $
,
$ {\hat{\ x}}_{w,t} $
,
 $ t={i}_w,\dots, {j}_w $
. After selection of the window, the final model is:
$ t={i}_w,\dots, {j}_w $
. After selection of the window, the final model is:
 $$ {\hat{x}}_{w,t}={\hat{\alpha}}_w^F+{\hat{\beta}}_w^Ft+\sum_{S\in {\mathrm{T}}_w}{\hat{\theta}}_{w,s}\left(t-s-1\right)I\left\{t\le s\right\},\kern5em t={i}_w,\dots, {j}_w. $$
$$ {\hat{x}}_{w,t}={\hat{\alpha}}_w^F+{\hat{\beta}}_w^Ft+\sum_{S\in {\mathrm{T}}_w}{\hat{\theta}}_{w,s}\left(t-s-1\right)I\left\{t\le s\right\},\kern5em t={i}_w,\dots, {j}_w. $$
For each window,
 $ {\hat{\alpha}}_w^F $
,
$ {\hat{\alpha}}_w^F $
,
 $ {\hat{\beta}}_w^F $
and
$ {\hat{\beta}}_w^F $
and
 $ {\hat{\theta}}_{w,s} $
are estimated by ordinary least squares. The superscript F indicates that terms are always in the model, so selection is conducted only over the broken trend terms. The variants of how to estimate this model are detailed in Doornik et al. (Reference Doornik, Castle and Hendry2020) and can involve the prescriptive use of machine learning methods to determine the most appropriate specifications.
$ {\hat{\theta}}_{w,s} $
are estimated by ordinary least squares. The superscript F indicates that terms are always in the model, so selection is conducted only over the broken trend terms. The variants of how to estimate this model are detailed in Doornik et al. (Reference Doornik, Castle and Hendry2020) and can involve the prescriptive use of machine learning methods to determine the most appropriate specifications.
Doornik et al. (Reference Doornik, Castle and Hendry2020) use their short-term forecasting model to compare predictions from it with those from the SIR model. Figure 16 above shows how their own model tracks the actual UK data over the short run with greater accuracy as each segment of their average forecast line (in black) tracks the grey ![]() line of the actual trend much better than the green (x) line of longer-run predictions of the SIR model. We see that the SIR predictions are very sensitive to perturbations in the
line of the actual trend much better than the green (x) line of longer-run predictions of the SIR model. We see that the SIR predictions are very sensitive to perturbations in the
 $ {\mathcal{R}}_t $
number and can quickly deviate from the actual path. Doornik et al. (Reference Doornik, Castle and Hendry2020) justifiably suggest that their forecasting model ‘can outperform several epidemiological models in the early stages, thereby providing an alternative complementary approach to forecasting’.Footnote
13 At the same time the authors are the first to acknowledge that their model does not estimate structural parameters which describe the whole of the pandemic process or have validity for policy prescription or behavioural adaption of the population.
$ {\mathcal{R}}_t $
number and can quickly deviate from the actual path. Doornik et al. (Reference Doornik, Castle and Hendry2020) justifiably suggest that their forecasting model ‘can outperform several epidemiological models in the early stages, thereby providing an alternative complementary approach to forecasting’.Footnote
13 At the same time the authors are the first to acknowledge that their model does not estimate structural parameters which describe the whole of the pandemic process or have validity for policy prescription or behavioural adaption of the population.

Figure 16. (Colour online) Forecasts of confirmed cases from Doornik et al. (Reference Doornik, Castle and Hendry2020)
There are, of course, many other forecasting techniques being suggested. For example, Lee et al. (Reference Lee, Liao, Seo and Shin2020) develop a new trend filtering method that is a variant of the Hodrick–Prescott filter, constrained by the number of possible kinks and apply it to data from five countries. Their models also fit the data well and they propose using the model to monitor outbreaks of COVID-19. Being more specific, the short-run forecasting model is most vulnerable to periods when the series being modelled is at a crucial turning point, as by definition, what is being fitted is short-run linear piecewise segments to short time intervals and this may not easily capture the nonlinearities inherent in exponential models when they ‘take off’ or accelerate quickly, in their sigmoid shape periods.
7.5. Growth curve models
Growth curve models have been known to statisticians for some time. They involve modelling the log of daily new deaths (or cases). Such a model has convenient properties. Most importantly, that it can routinely be used with series which rise (even exponentially) and then fall away, however large the exponential growth of the epidemic. Such a series can, in principle, be fitted (like modelling a cumulative distribution function) using any sigmoid function, but the most commonly used are the Logistic or Gompertz. Such a function rises at an increasing rate then slows and reaches a turning point, after which it rises at a slower rate before reaching a maximum and then falling away, so, just like a single wave epidemic. Recently, economists have been using them to forecast the Covid epidemic. Li and Linton (Reference Li and Linton2020) use the model to forecast the peak of infections in the Covid pandemic in various countries. This also leads to being able to forecast of the number of cases and deaths in any country. Harvey and Kattuman (Reference Harvey and Kattuman2020) use a model for a special case of a Gompertz growth curve. Following their notation:
where
 $ {Y}_t $
= cumulative cases or deaths up to time t, then the change in cases at t is:
$ {Y}_t $
= cumulative cases or deaths up to time t, then the change in cases at t is:
 $$ {y}_t=\Delta {Y}_t={Y}_t-{Y}_{t-1}. $$
$$ {y}_t=\Delta {Y}_t={Y}_t-{Y}_{t-1}. $$
Growth rate of cases is:
 $$ {g}_t=\frac{y_t}{Y_{t-1}}=\mathit{\ln}\Delta {Y}_t. $$
$$ {g}_t=\frac{y_t}{Y_{t-1}}=\mathit{\ln}\Delta {Y}_t. $$
Then
 $$ \mathit{\ln}{y}_t=\mathit{\ln}{Y}_t+\delta -\gamma t+{\epsilon}_t $$
$$ \mathit{\ln}{y}_t=\mathit{\ln}{Y}_t+\delta -\gamma t+{\epsilon}_t $$
 $$ \mathit{\ln}{g}_t=\delta -\gamma t+{\epsilon}_t, $$
$$ \mathit{\ln}{g}_t=\delta -\gamma t+{\epsilon}_t, $$
where,
 $ \delta $
and
$ \delta $
and
 $ \gamma $
are estimable parameters.
$ \gamma $
are estimable parameters.
Harvey and Kattuman (Reference Harvey and Kattuman2020) show that within this model the trend is an Integrated Random Walk. This model also allows us to neatly sidestep the problem of non-stationarity in the underlying data.
The model can used to predict the
 $ {\mathcal{R}}_t $
number. Figure 17 is from the NIESR Covid Tracker website and is based on an application of this model to the UK data during the so called ‘second wave’. It shows a comparison of the model with the SAGE estimates of the
$ {\mathcal{R}}_t $
number. Figure 17 is from the NIESR Covid Tracker website and is based on an application of this model to the UK data during the so called ‘second wave’. It shows a comparison of the model with the SAGE estimates of the
 $ {\mathcal{R}}_t $
number from their SEIR model. It seems quite possible that the NEISR prediction is potentially more accurate for this period in February.
$ {\mathcal{R}}_t $
number from their SEIR model. It seems quite possible that the NEISR prediction is potentially more accurate for this period in February.

Figure 17. (Colour online) NIESR growth curve
 $ {\mathcal{R}}_t $
estimates compared to SAGE estimates
$ {\mathcal{R}}_t $
estimates compared to SAGE estimates
One further note of caution in the use of the growth curve approach is in order. This is that the sigmoid function approach may not be appropriate for modelling multi-wave epidemics. To see this, consider the position in the United Kingdom up to the beginning of May 2020 in the left-hand panel of figure 18. During this time period, the time series shows a conventional unimodal epidemic and clearly the growth curve is a good approximation. In sharp contrast, the right-hand panel of figure 18 shows what happens to the growth curve over the multi-wave period up to the middle of April 2021. Clearly, the growth model is much less appropriate for the whole time series.

Figure 18. (Colour online) Comparing UK log daily cases. (a) 19 February to 3 May 2020. (b) 19 February 2020 to 21 June 2021
7.6. Dynamic panel NPI regression models
The most general form of a panel data regression framework might be to explain the daily variation (t) in deaths
 $ {d}_{it}, $
in each country (or other location), i. Important explanatory variables would include some function of the number of cases
$ {d}_{it}, $
in each country (or other location), i. Important explanatory variables would include some function of the number of cases
 $ {c}_{it} $
with an appropriate dynamic lag.
$ {c}_{it} $
with an appropriate dynamic lag.
 $$ {d}_{it}=f\left(\tau, {\tau}^2,{\tau}^3,\dots .\right)+g\left({c}_{it},{c}_{it-?}\right)+h\left({d}_{1,}\dots {d}_6\right)+k\left({X}_{it}\right)+l\left({P}_{imt}\right)+I+{\epsilon}_{it}, $$
$$ {d}_{it}=f\left(\tau, {\tau}^2,{\tau}^3,\dots .\right)+g\left({c}_{it},{c}_{it-?}\right)+h\left({d}_{1,}\dots {d}_6\right)+k\left({X}_{it}\right)+l\left({P}_{imt}\right)+I+{\epsilon}_{it}, $$
where:
-
•
$ f\left(\tau, {\tau}^2,{\tau}^3,\dots .\right) $
is polynomial in elapsed country specific epidemic time duration,
$ \tau $
. -
•
$ h\left({d}_{1,}\dots {d}_6\right) $
day of week dummies -
•
$ g\left({c}_{it},{c}_{it-?}\right) $
– lagged cases -
•
$ k\left({X}_{it}\right) $
– country characteristics -
•
$ l\left({P}_{imt}\right) $
– m NPI policy instruments -
•
$ I $
– country fixed effects







The use of
 $ \tau $
and functions of
$ \tau $
and functions of
 $ \tau $
is included to control for the underlying nonlinear nature of the pandemic – rising, then falling and maybe over several waves. However, the pattern and shape of the pandemic varies greatly between countries. This means, modelling time using
$ \tau $
is included to control for the underlying nonlinear nature of the pandemic – rising, then falling and maybe over several waves. However, the pattern and shape of the pandemic varies greatly between countries. This means, modelling time using
 $ \tau $
and functions of
$ \tau $
and functions of
 $ \tau $
may ideally need to be specific to each country. In using panel data, we presently know how to include country fixed effects to allow for country specific effects (or even country specific linear trends). However, including country specific nonlinear trends is not presently feasible. By default, if we constrain the model with the same nonlinear function of time and apply it to each country this will be a misspecification. One only needs to look at how different the pattern of the epidemic is in each country to appreciate this problem.
$ \tau $
may ideally need to be specific to each country. In using panel data, we presently know how to include country fixed effects to allow for country specific effects (or even country specific linear trends). However, including country specific nonlinear trends is not presently feasible. By default, if we constrain the model with the same nonlinear function of time and apply it to each country this will be a misspecification. One only needs to look at how different the pattern of the epidemic is in each country to appreciate this problem.
Versions of this general panel model have been estimated by many authors using data from sometimes many countries. A small sample of the available papers is briefly summarised in table 1. This general framework also has crucial estimation problems, some of which are addressed by the literature. But other problems are more difficult to treat. Typically, all the key variables will likely be non-stationary which immediately brings us back to using a panel version of VECM model outlined above. Carrero et al. (Reference Carraro, Ferrone and Squarcina2020), Derigiades et al. (Reference Dergiades, Milas, Mossiaslos and Panagiotidis2020), Hadjidemetriou et al. (2021), Jinjarak et al. (Reference Jinjarak, Ahmed, Nair-Desai, Xin and Aizenman2020), and Voko and Pitter (Reference Vokó and Pitter2020) attempt to address these problems by various difference or growth transformations. The second crucial problem is the endogeneity of the use of NPIs as explained earlier, as the government response index is inherently endogenous. Some authors (Bodenstein et al., Reference Bodenstein, Corsetti and Guerrieri2021; Qiu et al., Reference Qiu, Chen and Shi2020) have used various IV strategies in an attempt to circumvent this endogeneity problem. Considerable attention has been devoted to these estimation technicalities to try to retrieve estimates of the effects of the crucially important NPIs. Most of the studies listed in table 1 find real effects of the various NPIs although there does not seem to be a consensus of the relative importance of the different lockdown measures or their behavioural responses.
Table 1. Selected literature summary of panel models of NPIs

One advantage of the dynamic panel structure is that it does afford us the flexibility to estimation a spatial model to control for cross section dependence due to the integrated network of countries and the resulting speed with which the virus is passed more readily between more highly interconnected geographies. Dynamic panel models can also be extended for other purposes. In another example, Liu et al. (Reference Liu, Hyungsik and Schorfheide2020) estimate a model that is able to generate density forecasts for daily active COVID-19 infections by exploiting a flexible Bayesian specification which provides 1-week horizon forecasts that are updated from week to week and are used for a group of countries.
8. Criteria for comparing models
There are many criteria one may wish to use in comparing and evaluating different statistical models of epidemics and their usefulness. The most important characteristics of any statistical model used to explain the epidemic and its course are numerous. They can be usefully subdivided into those which are technical properties of the statistical model and those which are useful for predictive or practical policy reasons.
8.1. Technical Properties
-
1. Accurate short-run prediction. Reliable short-run prediction is one of the main purposes of modelling. This is necessary to understand what the short-run future of the virus is and what effect, if any, the NPIs are having on the course of the epidemic. Also, it must be stressed that this modelling effort will, at the beginning, need to be based on relatively little data about the virus or how the epidemic is progressing.
-
2. Conditioning regressors. In modelling, we will ideally be able to include many conditioning regressors as we wish to be able to assess the extent to which different characteristics of the population (e.g. age, gender and ethnicity) are most at risk are important in terms of its escalation and duration. This will help to control for different geographies in the data and permit comparison between them. We do not observe all the controls for the country level analysis that we would like. Specifically, for example, in the determination of the number of cases we would like to know reliably how many tests were conducted. In the determination of deaths, we would like to know how well the hospitals were configured. A desirable property of the model would be that it permitted the conditioning of regressors.Footnote 14
-
3. Panel data capability. A good model would enable us to use panel data across countries (or other geographies) over time to understand the generic nature of the pandemic and its properties. Many models have mainly been run on single countries. It is desirable that we have more general models which permit us to use data from many countries (or within country geographies) at the same time, as we would wish to make the most of the heterogenous experiences of different countries.
-
4. Flexible dynamic structure. SEIR and related models are explicit about the nature of the dynamic structure of an epidemic. Since the delayed effect of: infection on cases; tests on cases; cases on deaths, and cases on recovery may all be heterogenous and difficult to determine then a desirable modelling characteristic would be flexibility with respect to lagged dependent (and lagged exogenous) variables.
-
5. Non-stationarity. Dealing effectively with high frequency time domain data is the province of time series econometrics. Much effort has been devoted to the development of models which avoid the non-stationarity problems and circumvent the possibility of spurious regression. These lessons could and should be deployed effectively (or in combination with other models) in the estimation of epidemic time series data models if we wish to predict the course of the epidemic in each country in a flexible way.
-
6. Cross section dependence. It is desirable that the model can handle spatial locational considerations and cross section dependence, possibly by directly modelling the nature of the network like nature of the degree of interconnectedness between different countries.
-
7. Endogeneity. Models which explicitly facilitated the modelling of the endogeneity of policy interventions by the government would be desirable. Clearly, as described in Section 6, most governments are more likely to invoke more restrictive NPIs when cases and deaths are highest or look to be rising most quickly. The aspiration of dealing with endogeneity is a demanding requirement in the context of regression-based models where the simple inclusion of stringency measures, as if, they were valid exogenous regressors is problematic.
-
8. Parametric restrictions. We would also want the model used to not be over reliant on restrictive parametric or distributional assumptions. Ideally, we would not want to have to invoke specific assumptions to derive an estimable model. An example would be the use of a specific functional form, like the Gompertz, to derive a Growth model – this is a necessary but undesirable restriction which may be partly overcome in the dynamic Gompertz model where the deterministic trend is replaced by a stochastic trend (see Harvey et al., Reference Harvey, Kattuman and Thamotheram2021).
8.2. Predictive and policy practical characteristics
-
9. Policy parameters. A desirable feature of a model is the possible retrieval of parameters which have clear policy importance like the case fatality ratio (CFR) or the reproduction number,
$ {\mathcal{R}}_t $
. These assume a special significance, if they have become part of the vocabulary of people trying to understand the epidemic and what is happening. We would also want the model used to not be subject to restrictive parametric or distributional assumptions -
10. Facilitate imparting the policy message. One important dimension of comparison is the extent to which the messages of: what stage the epidemic is at, what non-technical politicians and policy makers can readily understand and communicate, what directives the authorities need to get across to the public in terms of the best interests of dampening the worst effects of the spread of the virus and maintaining public safety and order. At the same time, politicians are naturally concerned with other issues which might mitigate against lockdown measures which are too restrictive. Hence, all concerned need preferably single numbers they can understand. Cases (or case rates per 100,000 of the population), deaths, hospitalisations, number of patients on ventilators, and vaccinations administered are all readily understood in a comparative sense. It also now seems that the
$ {\mathcal{R}}_t $
number is also understood by the majority. This is quite a subtle concept which now seems to have become part of common parlance. It has the nice feature of being scaled relative to 1 and so easily calibrated. This is convenient as it has an important role to play in the SEIR type models. Hence, if possible, it would be a useful characteristic of any alternative model – that it allowed us to also retrieve an estimate of this parameter directly from the use of the model with data. -
11. Graphical and visual representation: A related desirable property would be that the model used had easily understandable graphical depictions. By this, I mean that we wish to have appropriate ways of plotting how the course of the epidemic is advancing. Whether it is accelerating and at what rate; is it waning; have we reached a turning point and are we at the height of the epidemic yet; how much longer might it go on; when might it end, and what is the likelihood of a second or third wave. Many statistical models are not easily represented with graphical answers or provide visual responses to many of these questions. This leaves in the position of being able to judge the answers from basic plots like figure 2a,b. One exception is the ‘Portrait Phase’ diagrams promoted by Prof Johnson.Footnote 15 These may provide visually appealing answers to some of these questions.
-
12. NPI impact estimation. We would also wish to be able to evaluate the direct impact of parameters relating to NPIs, which measures are effective and to what degree, and how long it takes for their effects to be seen in terms of cases and deaths, for example. Establishing the nature of the lag between the invoking of the NPIs and their effect is problematic.
-
13. Multiple waves. An important characteristic of the time trend of the epidemics which have evolved in different countries is that some countries have had one wave, but many more have had two, three or more waves. A desirable feature of a model would be that it could cope with flexibly modelling this highly nonlinear from of the trends. This is a difficult task as coping with country specific nonlinear trends in a panel dataset is not something which we routinely handle. Footnote 16
-
14. Virus mutation. A related desirable characteristic of a model would be the capacity to handle the extension of the model to the appearance of new variants of the virus. Adaptability of the model to be able to track mutant variants and their consequences are now especially relevant is it is clear that there are new strains of the virus developing in many different countries which are behind the second, third and subsequent waves of the virus.
-
15. Behavioural modelling. A desirable feature of a model would be the capacity to explicitly recognise the behavioural response induced in the population at risk by the advance of the virus and the NPIs introduced by government to counteract it. For example, how do people react to a policy of enforced social distancing and how might that reflect on the changing course of the epidemic (see Makris, Reference Makris2021; Toxvaerd, Reference Toxvaerd2020).

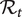
Clearly it is not possible that any single model would have all the desirable properties outlined above. Some statistical models are better designed to have one feature rather than another. No ranking on the relative importance of these properties is implied by the order that they have been described in. But such a list is worth keeping in mind if we wish to appraise the usefulness of one method rather than another and what their relative comparative advantage is.
Since the dominant default method of statistical analysis of the epidemic in the United Kingdom and many other countries has been the SEIR model and its variants it is perhaps appropriate to posit how this genus of models is characterised by these desirable properties. Table 2 is the author’s personal subjective summary of the features or possible limitations of the various models which have been discussed. Glancing across the rows and down the columns we can see that where one model may have a limitation there are alternative models which could be employed to good effect. This suggests that there is a convenient complementarity of the available statistical and graphical methods we can use. These should all potentially be exploited to best effect.
Table 2. (Colour online) Modelling traffic lights

What might the prescriptive conclusion of this comparison be? Firstly, it has be acknowledged that the prodigious development of the SEIR variants in response to the pandemic has been staggering. We have now learnt so much about how this model may be extended to take account of the situation as it changed over the course of 2020 and into 2021. A recent paper by Moore et al. (Reference Moore, Hill, Tildesley, Dyson and Keeling2021) solves a system of 16 differential equations which simultaneously take account of deaths, hospitalisations, vaccination rates and is segmented by age group to make predictions about a post lockdown ‘bounce back’ infection rates.
The conclusion is that as a pandemic develops there is no substitute for the SEIR modelling to adapt to changing circumstances and provide prescriptions and guidance for policy-makers. The essential feature of this model is that it allows you to at least attempt to steer the boat whilst building and repairing it. However, it should be recognised that its sensitivity to assumptions relating to key parameters and its reliance of rapidly moving data are a weakness which can provide erratic predictions. Many of these key parameters could and should be the subject of separate statistical modelling in their own right (as in the IMHE, 2021 model). A second augmentation is to consider the short-run forecasting methods being used to good effect by the applied econometricians and others to provide the most accurate forecasts of the number of infections. A third contribution would be cross-validate the methods used for the prediction of
 $ {\mathcal{R}}_t $
numbers by the use of growth curve models especially within a given wave of the epidemic (notwithstanding the caveats from Section 5). One could regard these second and third remarks as being akin to keeping an open mind about the necessary running repairs on the boat’s hull as you go along when it is letting in water, or ways in which the boat’s helm may be a little less erratic and blow you off course.
$ {\mathcal{R}}_t $
numbers by the use of growth curve models especially within a given wave of the epidemic (notwithstanding the caveats from Section 5). One could regard these second and third remarks as being akin to keeping an open mind about the necessary running repairs on the boat’s hull as you go along when it is letting in water, or ways in which the boat’s helm may be a little less erratic and blow you off course.
A final area for supplementary analysis is to consider the use of detailed econometric models on all the data, over all countries and other geographies, over all time periods and waves of the epidemic, to model the precise effect of different NPIs as variously applied in different contexts. In this setting rigorous methods may be used to counteract non-stationarity problems by the use of the latest VECM models, and endogeneity problems by the use of synthetic controls. This would be akin to a post voyage overhaul in the dry dock to understand not only how we built the ship wrong as we went along, but how our running repairs improved things or made matters worse.
9. Conclusion
In this paper, we have reviewed the problems involved in modelling the Covid pandemic across the world and how this has influenced the modelling of the epidemic in specific countries. The enduring issue is how we can reconcile and compare the recent use of the epidemiological models with some modelling alternatives which have been advocated from other subjects. All these models face the same challenges: measurement error, endogeneity, stationarity, non-linearities with multiple waves, cross section dependence with networks or spatial aggregation, and the implementation of NPIs when we do not know and cannot test their effectiveness and many of them may have their own behavioral responses.
Notwithstanding the considerable advances that have been made in the last 18 months to understand this pandemic we should acknowledge that the process of contagion is one which we do not really understand very well. Unless we have data on the movements of all individuals and their interactions – like they do in China and Korea – then any understanding of how this virus transmits itself from one person to another is unknown. Why it is that one person may contract COVID by simply being in the same room as an infected person for a very limited time and yet another who is living with and sharing a house with an infected person does not contract the virus? In turn, conditional on being infected, why does one person die quite quickly, and another suffers only mild symptoms or remains asymptomatic? These questions remain largely unanswered. This must be a fundamental limitation to all the models we have discussed. Although this may explain, at least partially, the dominance of the epidemiological model as it comes closest to positing how the epidemic actually works as a biological process. Forecasting models, even at their best, have limited scope for revealing the mechanism of transmission and escalation.
We do not know how to link the basic SEIR framework with the time series econometrics necessary to model the pandemic. Clearly the epidemiological model, under certain conditions, is a satisfactory way of approximating the dynamics of how the pandemic works. Its strongest suit is as an early warning of how big a problem a specific epidemic might be, how many fatalities may occur and how long it might last. The model’s aim is to estimate parameters to predict the short-run course of the epidemic. At the beginning of any epidemic, we need to know what the scale of the problem might be and how quickly it might escalate in order to marshal hospital and medical facilities. The epidemiological model allows us to do this. It is less well suited to modelling the effectiveness of different NPIs, or the likelihood of a second or subsequent wave. Arguably it is also less well suited to detailed forecasting, in the middle of the epidemic, over the next few days or 2 weeks. This is a crucial issue as, on any given day early in the epidemic, we need to know where we are on the curve. Are we facing an increasing exponential growth or are we through the worst and about to slow down?
Fundamentally the modelling of Covid involves complex non-linear heterogeneity. Definitionally, data with turning points, and points of inflexion need second order and possibly higher order terms. In summary, Kalman filters may be a useful common framework for such a process if we wish to model a ‘state equation’ which captures where we are now, and an ‘adaptation equation’ which governs how we can predict the next step of the process. In general terms, we suggest that econometric and other statistical models and graphical methods may have a complementary role to play to SEIR models. Specifically, in terms of communicating the main messages of when an epidemic is accelerating, when it is diminishing, and what the key turning points are. In these circumstances simple logarithmic plots and ‘portrait phase’ diagrams have a lot to commend them. It is possible that the general public and policy makers are much more likely to understand these simple graphs – when they cannot understand the complex mathematics behind the epidemiological models. Although there is a caution on the routine use of these logarithmic scales graphs when we are trying to understand multiple waves of an epidemic. Likewise, growth curve and other forecasting models can be used to predict more accurately the short-run future of cases and deaths and the course of the
 $ {\mathcal{R}}_t $
number. It is also the case that panel data estimation methods may make a real contribution to understanding how the pandemic spread, why it is so heterogenous across countries, and which NPIs are globally the most effective in combatting the growth of the pandemic and getting it under control.
$ {\mathcal{R}}_t $
number. It is also the case that panel data estimation methods may make a real contribution to understanding how the pandemic spread, why it is so heterogenous across countries, and which NPIs are globally the most effective in combatting the growth of the pandemic and getting it under control.
Cross section individual level patient data with regression (or logistic regression) may also be used to better understand which patients are most likely to contract the virus and, given those who contract Covid, who is most likely to survive. In turn such estimation techniques can also be used to work out who responds best to the vaccines and what the likely effectiveness of the vaccine is and over what time horizon.
An important implication of the logic in this discussion is that there should be cross validation studies employing all different models on the same data, at the same stage of the epidemic. Most specifically, to conduct an evaluation of different models on a level playing field, one must not just compare the model predictions from where we stand now. Rather we need to require the econometric model to be run to predict the course of the epidemic with the data available, circa March or April 2020, as the epidemiological models were compelled to do. Such an exercise would be a valid test of the alternative econometric and statistical models in comparison with the SIR/SEIR models which were used to guide policy at this earlier stage in the epidemic. Could these alternative policies have told us anything? Either way, even when the COVID-19 pandemic is over, we will still need to put in place a rigorous way of comparing the models with the same data. For the future we need to know which of our modelling tools, applied when, will give us the best chance of fighting any pandemic.
A further possible implication of our discussion is that the composition and scope of SAGE would be improved if it had a complementary input from other statisticians, health professionals and applied econometricians and economists. The decision making on the policies adopted and the timing of these decisions may well have been better if there had been a contribution from other modelers from a wider set of subject disciplines.
Acknowledgements
I wish to acknowledge the detailed comments on an earlier version of this paper from: Andrew Tremayne, Andrew Harvey, Colin Angus, Oliver Johnson, Tony Lancaster, Chris Giles, Jorgen Doornik and Arno Hantzsche.
























 Open access
Open access