



No CrossRef data available.
Published online by Cambridge University Press: 14 March 2023
Alternating direction method of multipliers (ADMM) receives much attention in the field of optimization and computer science, etc. The generalized ADMM (G-ADMM) proposed by Eckstein and Bertsekas incorporates an acceleration factor and is more efficient than the original ADMM. However, G-ADMM is not applicable in some models where the objective function value (or its gradient) is computationally costly or even impossible to compute. In this paper, we consider the two-block separable convex optimization problem with linear constraints, where only noisy estimations of the gradient of the objective function are accessible. Under this setting, we propose a stochastic linearized generalized ADMM (called SLG-ADMM) where two subproblems are approximated by some linearization strategies. And in theory, we analyze the expected convergence rates and large deviation properties of SLG-ADMM. In particular, we show that the worst-case expected convergence rates of SLG-ADMM are 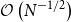 $\mathcal{O}\left( {{N}^{-1/2}}\right)$ and
$\mathcal{O}\left( {{N}^{-1/2}}\right)$ and 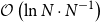 $\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has
$\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has 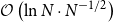 $\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and
$\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and 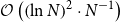 $\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
$\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
 $O(1/n)$
convergence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis 50 (2) 700–709.CrossRefGoogle Scholar
$O(1/n)$
convergence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis 50 (2) 700–709.CrossRefGoogle Scholar