



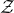
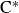
1. Introduction
Inductive limit constructions lie at the very heart of operator algebras. Beginning with Murray and von Neumann’s analysis of hyperfinite factors [
Reference Murray and von Neumann43
], continuing with Glimm’s description of their
 $\mathrm{C}^*$
-analogues, the uniformly hyperfinite (UHF) algebras [
Reference Glimm23
], and later with Elliott’s pioneering work on approximately finite-dimensional (AF) algebras [
Reference Elliott15
], and beyond, not only have inductive limits of type
$\mathrm{C}^*$
-analogues, the uniformly hyperfinite (UHF) algebras [
Reference Glimm23
], and later with Elliott’s pioneering work on approximately finite-dimensional (AF) algebras [
Reference Elliott15
], and beyond, not only have inductive limits of type
 $\rm I$
algebras featured consistently and prominently in the natural
$\rm I$
algebras featured consistently and prominently in the natural
 $\mathrm{C}^*$
-world, but their classification has been a perennial pursuit of
$\mathrm{C}^*$
-world, but their classification has been a perennial pursuit of
 $\mathrm{C}^*$
-taxonomists.
$\mathrm{C}^*$
-taxonomists.
In fact (see [
Reference Gong, Lin and Niu24
, Theorem 13·50]), every (unital) simple, separable
 $\mathrm{C}^*$
-algebra that has finite decomposition rank and satisfies the UCT (that is, every stably finite classifiable
$\mathrm{C}^*$
-algebra that has finite decomposition rank and satisfies the UCT (that is, every stably finite classifiable
 $\mathrm{C}^*$
-algebra) is isomorphic to an ASH algebra, that is, to an inductive limit of subhomogeneous
$\mathrm{C}^*$
-algebra) is isomorphic to an ASH algebra, that is, to an inductive limit of subhomogeneous
 $\mathrm{C}^*$
-algebras. Even on the other branch of the classifiable tree, purely infinite
$\mathrm{C}^*$
-algebras. Even on the other branch of the classifiable tree, purely infinite
 $\mathrm{C}^*$
-algebras can be built from limits of circle algebras by taking crossed products by trace-scaling endomorphisms (see [
Reference Rørdam and Størmer51
, Proposition 4·3·3]). The known examples [
Reference Rørdam49
,
Reference Toms55
,
Reference Toms56
,
Reference Villadsen59
] of amenable
$\mathrm{C}^*$
-algebras can be built from limits of circle algebras by taking crossed products by trace-scaling endomorphisms (see [
Reference Rørdam and Størmer51
, Proposition 4·3·3]). The known examples [
Reference Rørdam49
,
Reference Toms55
,
Reference Toms56
,
Reference Villadsen59
] of amenable
 $\mathrm{C}^*$
-algebras exhibiting Elliott invariants with more exotic behaviour also arise from inductive limits.
$\mathrm{C}^*$
-algebras exhibiting Elliott invariants with more exotic behaviour also arise from inductive limits.
In this paper, we address the question: what can be said about the distributions of the random
 $\mathrm{C}^*$
-algebras obtained by viewing these constructions as probabilistic rather than deterministic? To make sense of this, and to answer the questions posed in the abstract, we outline specific procedures for probabilistic model building and examine the distributions of suitable invariants. In particular, we will:
$\mathrm{C}^*$
-algebras obtained by viewing these constructions as probabilistic rather than deterministic? To make sense of this, and to answer the questions posed in the abstract, we outline specific procedures for probabilistic model building and examine the distributions of suitable invariants. In particular, we will:
-
(i) as a warmup example, use random walks on the prime numbers to build UHF algebras of random type (see Section 3);
-
(ii) similarly build simple inductive limits of prime dimension drop algebras with random tracial state spaces, guided by random walks on the natural numbers (see Section 4);
-
(iii) use random walks on binary trees to evolve Villadsen algebras whose radii of comparison are random variables with tractable distributions (see Section 5);
-
(iv) investigate the distribution of the K-theory of graph
 $\mathrm{C}^*$
-algebras associated to random regular multigraphs (see Section 6).
$\mathrm{C}^*$
-algebras associated to random regular multigraphs (see Section 6).

There are two sources of context for this line of investigation. First, our use of classifying invariants to develop various classes of
 $\mathrm{C}^*$
-algebras into probability spaces is telegraphed by the Borel parameterisations established in [
Reference Farah, Toms and Törnquist18
,
Reference Farah, Toms and Törnquist19
]. Second, in work that builds on the Erdös–Rényi construction of the random graph [
Reference Erdös and Rényi17
], it is shown in [
Reference Droste and Kuske11
] how to probabilistically construct (
$\mathrm{C}^*$
-algebras into probability spaces is telegraphed by the Borel parameterisations established in [
Reference Farah, Toms and Törnquist18
,
Reference Farah, Toms and Törnquist19
]. Second, in work that builds on the Erdös–Rényi construction of the random graph [
Reference Erdös and Rényi17
], it is shown in [
Reference Droste and Kuske11
] how to probabilistically construct (
 $\omega$
-categorical) universal homogeneous relational structures (briefly, one decides by coin toss whether or not a given tuple of generators satisfies a relation). What unites the universal UHF algebra
$\omega$
-categorical) universal homogeneous relational structures (briefly, one decides by coin toss whether or not a given tuple of generators satisfies a relation). What unites the universal UHF algebra
 $\mathcal{Q}$
, the Jiang–Su algebra
$\mathcal{Q}$
, the Jiang–Su algebra
 $\mathcal{Z}$
and the stably projectionless algebra
$\mathcal{Z}$
and the stably projectionless algebra
 $\mathcal{W}$
, apart from (strong) self-absorption, is that they are the Fraïssé limits of suitable categories of tracial
$\mathcal{W}$
, apart from (strong) self-absorption, is that they are the Fraïssé limits of suitable categories of tracial
 $\mathrm{C}^*$
-algebras (see [
Reference Eagle, Farah, Hart, Kadets, Kalashnyk and Lupini13
,
Reference Jacelon and Vignati27
,
Reference Masumoto41
]). In other words, they are the generic objects that can be built as limits from their associated Fraïssé classes. While for the most part we have found it more natural to work with the inductive limit structure inherent to
$\mathrm{C}^*$
-algebras (see [
Reference Eagle, Farah, Hart, Kadets, Kalashnyk and Lupini13
,
Reference Jacelon and Vignati27
,
Reference Masumoto41
]). In other words, they are the generic objects that can be built as limits from their associated Fraïssé classes. While for the most part we have found it more natural to work with the inductive limit structure inherent to
 $\mathcal{Q}$
,
$\mathcal{Q}$
,
 $\mathcal{Z}$
,
$\mathcal{Z}$
,
 $\mathcal{W}$
and other
$\mathcal{W}$
and other
 $\mathrm{C}^*$
-algebras of interest, and consequently to appeal to the theory of Markov chains Section 2, the model employed in Section 6 may be thought of as closer in spirit to the relational approach.
$\mathrm{C}^*$
-algebras of interest, and consequently to appeal to the theory of Markov chains Section 2, the model employed in Section 6 may be thought of as closer in spirit to the relational approach.
Computations of specific probabilities
 $\mathbb{P}$
and expectations
$\mathbb{P}$
and expectations
 $\mathbb{E}$
are included alongside our random constructions, but the reader should not attach much significance to, say, the assertion that the probability that a random simple inductive limit of prime dimension drop algebras has at most k extremal traces is
$\mathbb{E}$
are included alongside our random constructions, but the reader should not attach much significance to, say, the assertion that the probability that a random simple inductive limit of prime dimension drop algebras has at most k extremal traces is
 $\sum\limits_{i=0}^k ({k-i})/\left({(k+1)2^{i+1}}\right)$
(see Remark 4·2). Rather, the point being illustrated is that, with the right framework, such calculations are indeed possible. Our suggestion is that, whether via random walks or the creation of random pairings, (multi)graphs provide a natural and manageable way of probabilistically generating large classes of interesting
$\sum\limits_{i=0}^k ({k-i})/\left({(k+1)2^{i+1}}\right)$
(see Remark 4·2). Rather, the point being illustrated is that, with the right framework, such calculations are indeed possible. Our suggestion is that, whether via random walks or the creation of random pairings, (multi)graphs provide a natural and manageable way of probabilistically generating large classes of interesting
 $\mathrm{C}^*$
-algebras. And the take-home message should be that graph properties like recurrence or transience of random walks translate to almost-sure predictions about the structure of the associated random
$\mathrm{C}^*$
-algebras. And the take-home message should be that graph properties like recurrence or transience of random walks translate to almost-sure predictions about the structure of the associated random
 $\mathrm{C}^*$
-algebras (for example, a simple symmetric walk on the natural numbers almost surely generates the universal UHF algebra).
$\mathrm{C}^*$
-algebras (for example, a simple symmetric walk on the natural numbers almost surely generates the universal UHF algebra).
2. Markov chains
The random constructions in Sections 3 and 4 are based on the following continuous-time Markov chain (specifically, a birth-and-death process). For an introduction to Markov chains, see [ Reference Norris45 ].
2·1. The model
The random variable
 $X_0$
is specified by a probability distribution
$X_0$
is specified by a probability distribution
 $\pi$
on
$\pi$
on
 $\mathbb{N}=\{0,1,2,\dots\}$
. At time
$\mathbb{N}=\{0,1,2,\dots\}$
. At time
 $t\ge0$
, the value of
$t\ge0$
, the value of
 $X_t$
is governed by the rate matrix
$X_t$
is governed by the rate matrix
 \begin{equation} Q = \begin{pmatrix} -(\lambda_0+\mu_0) & \quad \lambda_0 & \quad & \quad & \quad \\[3pt] \mu_1 & \quad -(\lambda_1+\mu_1) & \quad \lambda_1 & \quad & \quad & \quad \\[3pt] & \quad \mu_2 & \quad -(\lambda_2+\mu_2) & \quad \lambda_2 & \quad & \quad \\[3pt] & \quad & \quad \ddots & \quad \ddots & \quad \ddots \end{pmatrix},\end{equation}
\begin{equation} Q = \begin{pmatrix} -(\lambda_0+\mu_0) & \quad \lambda_0 & \quad & \quad & \quad \\[3pt] \mu_1 & \quad -(\lambda_1+\mu_1) & \quad \lambda_1 & \quad & \quad & \quad \\[3pt] & \quad \mu_2 & \quad -(\lambda_2+\mu_2) & \quad \lambda_2 & \quad & \quad \\[3pt] & \quad & \quad \ddots & \quad \ddots & \quad \ddots \end{pmatrix},\end{equation}
where
 $\mu_i >0$
for
$\mu_i >0$
for
 $i\ge1$
and
$i\ge1$
and
 $\lambda_i >0$
for
$\lambda_i >0$
for
 $i\ge0$
. It was shown in [
Reference Karlin and McGregor33
, Theorems 14,15] (see also the introduction of [
Reference Karlin and McGregor31
]) that, if the sequences
$i\ge0$
. It was shown in [
Reference Karlin and McGregor33
, Theorems 14,15] (see also the introduction of [
Reference Karlin and McGregor31
]) that, if the sequences
 \begin{align*}\alpha_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{\lambda_{i-1}}{\mu_i},\quad \beta_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{\mu_i}{\lambda_i},\quad n\ge1\end{align*}
\begin{align*}\alpha_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{\lambda_{i-1}}{\mu_i},\quad \beta_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{\mu_i}{\lambda_i},\quad n\ge1\end{align*}
are such that
 $\sum\limits_{n=1}^{\infty}(\alpha_n+\beta_n)=\infty$
, then there exists a unique matrix P(t) associated to Q that satisfies
$\sum\limits_{n=1}^{\infty}(\alpha_n+\beta_n)=\infty$
, then there exists a unique matrix P(t) associated to Q that satisfies
 $P^{\prime}(t)=QP(t)=P(t)Q$
,
$P^{\prime}(t)=QP(t)=P(t)Q$
,
 $P(0)=I$
,
$P(0)=I$
,
 $P(s+t)=P(s)P(t)$
,
$P(s+t)=P(s)P(t)$
,
 $P_{ij}(t)\ge0$
and
$P_{ij}(t)\ge0$
and
 $\sum_{j}P_{ij}(t)\le1$
(for all s, t, i, j as appropriate), and that consequently determines the transition probabilities:
$\sum_{j}P_{ij}(t)\le1$
(for all s, t, i, j as appropriate), and that consequently determines the transition probabilities:
 \begin{align*}\mathbb{P}\left(X_{s+t}=j \mid X_{s}=i\right) = P_{ij}(t).\end{align*}
\begin{align*}\mathbb{P}\left(X_{s+t}=j \mid X_{s}=i\right) = P_{ij}(t).\end{align*}
While the continuous process provides important context, what we actually pay attention to is its jump chain, that is, the discrete Markov chain
 $(Y_n)_{n\in\mathbb{N}}$
on
$(Y_n)_{n\in\mathbb{N}}$
on
 $\mathbb{N}$
whose initial distribution is
$\mathbb{N}$
whose initial distribution is
 $\pi$
and whose transition matrix
$\pi$
and whose transition matrix
 $\Pi$
has entries
$\Pi$
has entries
 \begin{equation} \Pi_{ij} = \begin{cases} p_i\,:\!=\,\frac{\lambda_i}{\lambda_i+\mu_i} & \text{ if }\: j=i+1\\[4pt] q_i\,:\!=\,\frac{\mu_i}{\lambda_i+\mu_i} & \text{ if }\: j=i-1\\[4pt] 0 & \text{ if }\: |i-j|>1. \end{cases}\end{equation}
\begin{equation} \Pi_{ij} = \begin{cases} p_i\,:\!=\,\frac{\lambda_i}{\lambda_i+\mu_i} & \text{ if }\: j=i+1\\[4pt] q_i\,:\!=\,\frac{\mu_i}{\lambda_i+\mu_i} & \text{ if }\: j=i-1\\[4pt] 0 & \text{ if }\: |i-j|>1. \end{cases}\end{equation}
The jump chain is represented by the diagram

There are two possibilities for what happens at
 $i=0$
:
$i=0$
:
-
(I) 0 is a reflecting barrier (that is,
$q_0=\mu_0=0$
); -
(II)
$-1$
is an absorbing state (that is, with probability
$q_0= {\mu_0}/({\lambda_0+\mu_0})>0$
,
$Y_n$
moves from 0 to
$-1$
and stays there).





We will use the process
 $(Y_n)_{n\in\mathbb{N}}$
to construct a random UHF algebra in Section 3 and a random simple inductive limit of prime dimension drop algebras in Section 4. If we want a nonzero probability of ending up with a nontrivial finite structure (a finite matrix algebra or finite-dimensional tracial simplex), then we go with option (II).
$(Y_n)_{n\in\mathbb{N}}$
to construct a random UHF algebra in Section 3 and a random simple inductive limit of prime dimension drop algebras in Section 4. If we want a nonzero probability of ending up with a nontrivial finite structure (a finite matrix algebra or finite-dimensional tracial simplex), then we go with option (II).
2·2. Absorption, recurrence and transience
The behaviour of the Markov chain
 $(Y_n)_{n\in\mathbb{N}}$
is determined by the growth of the sequences
$(Y_n)_{n\in\mathbb{N}}$
is determined by the growth of the sequences
 \begin{equation} a_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{p_{i-1}}{q_i} ,\quad b_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{q_i}{p_i} ,\quad n\ge1.\end{equation}
\begin{equation} a_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{p_{i-1}}{q_i} ,\quad b_n\,:\!=\,\prod\limits_{i=1}^{n}\frac{q_i}{p_i} ,\quad n\ge1.\end{equation}
Recall that every state is of one of three types:
-
(a) positive recurrent (or ergodic) if with probability 1 it is visited infinitely often, the mean return time between visits being finite;
-
(b) null recurrent if with probability 1 it is visited infinitely often, but with infinite mean return time between visits;
-
(c) transient if with probability 1 it is visited only finitely many times.
In Case (I), the chain is irreducible (that is, there is a nonzero probability of transitioning between any two given states), so all states are of the same type.
The following results are by now well known. See [ Reference Karlin and McGregor32 , Section 2] for a discussion of how they can be deduced from the analysis of the continuous birth-and-death process carried out in [ Reference Karlin and McGregor31 ].
Theorem 2·1.
In Case (I), the chain
 $(Y_n)_{n\in\mathbb{N}}$
is:
$(Y_n)_{n\in\mathbb{N}}$
is:
-
(a) positive recurrent if and only if
$\sum\limits_{n=1}^\infty b_n = \infty$
and
$\sum\limits_{n=1}^\infty a_n < \infty$
; -
(b) null recurrent if and only if
$\sum\limits_{n=1}^\infty b_n = \infty$
and
$\sum\limits_{n=1}^\infty a_n = \infty$
; -
(c) transient if and only if
$\sum\limits_{n=1}^\infty b_n < \infty$
.





Proposition 2·2.
In Case (II), if the initial state is i, then the probability of eventual absorption at zero (that is, of reaching the state
 $-1$
) is
$-1$
) is
 \begin{align*}\left(\sum\limits_{n=i}^\infty c_n\right)\bigg/\left(1+\sum\limits_{n=0}^\infty c_n\right),\end{align*}
\begin{align*}\left(\sum\limits_{n=i}^\infty c_n\right)\bigg/\left(1+\sum\limits_{n=0}^\infty c_n\right),\end{align*}
where
 $c_n\,:\!=\,\prod\limits_{j=0}^{n}{q_j}/{p_j}$
. Absorption is transient (that is, occurs with probability
$c_n\,:\!=\,\prod\limits_{j=0}^{n}{q_j}/{p_j}$
. Absorption is transient (that is, occurs with probability
 $<1$
) if
$<1$
) if
 $\sum c_n$
converges, is almost sure (that is, occurs with probability 1) if
$\sum c_n$
converges, is almost sure (that is, occurs with probability 1) if
 $\sum c_n$
diverges, and is ergodic (that is, almost sure with finite expected time) if in addition
$\sum c_n$
diverges, and is ergodic (that is, almost sure with finite expected time) if in addition
 $\sum a_n$
converges.
$\sum a_n$
converges.
Notice that, by shifting the problem one unit to the right, Proposition 2·2 implies that in Case (I), the probability of never reaching 0 from the initial state i is
 \begin{align*}\left(\sum\limits_{n=0}^{i-1} b_n\right)\bigg/\left(\sum\limits_{n=0}^\infty b_n\right),\end{align*}
\begin{align*}\left(\sum\limits_{n=0}^{i-1} b_n\right)\bigg/\left(\sum\limits_{n=0}^\infty b_n\right),\end{align*}
(where
 $b_0\,:\!=\,1$
). The computation of this probability appears at least as far back as [
Reference Harris26
, Theorem 2a].
$b_0\,:\!=\,1$
). The computation of this probability appears at least as far back as [
Reference Harris26
, Theorem 2a].
We might also be interested in the largest value attained before absorption. As a reminder of the flavour of some of the arguments involved, we will provide the easy proof of the following (which is really the same as [ Reference Harris26 , Theorem 2b]).
Proposition 2·3.
In Case (II), the probability
 $h_{k,i}$
that, starting at
$h_{k,i}$
that, starting at
 $i\in I = \mathbb{N}$
, the maximum attained value is at most
$i\in I = \mathbb{N}$
, the maximum attained value is at most
 $k\ge1$
is
$k\ge1$
is
 \begin{align*}h_{k,i} = \begin{cases} 0 & \text{ if }\: i\ge k+1\\[4pt] \left(\sum\limits_{n=i}^{k}c_n\right)\bigg/\left(1+\sum\limits_{n=0}^{k}c_n\right) & \text{ if }\: 0\le i\le k, \end{cases}\end{align*}
\begin{align*}h_{k,i} = \begin{cases} 0 & \text{ if }\: i\ge k+1\\[4pt] \left(\sum\limits_{n=i}^{k}c_n\right)\bigg/\left(1+\sum\limits_{n=0}^{k}c_n\right) & \text{ if }\: 0\le i\le k, \end{cases}\end{align*}
where
 $c_n\,:\!=\,\prod\limits_{j=0}^{n}{q_j}/{p_j}$
.
$c_n\,:\!=\,\prod\limits_{j=0}^{n}{q_j}/{p_j}$
.
Proof. The event in question is the complement of the event that, starting at i, the chain ever hits the set
 $A=\{k+1,k+2,\dots\}$
. Let us write
$A=\{k+1,k+2,\dots\}$
. Let us write
 $h^{\prime}_{k,i}$
for the probability of this latter event
$h^{\prime}_{k,i}$
for the probability of this latter event
 $\big($
that is,
$\big($
that is,
 $h^{\prime}_{k,i}=1-h_{k,i}\big)$
. By an application of the Markov property (see [
Reference Norris45
, Theorem 1·3·2]),
$h^{\prime}_{k,i}=1-h_{k,i}\big)$
. By an application of the Markov property (see [
Reference Norris45
, Theorem 1·3·2]),
 $\left(h^{\prime}_{k,i}\right)_{i\in I}$
is the minimal non-negative solution to
$\left(h^{\prime}_{k,i}\right)_{i\in I}$
is the minimal non-negative solution to
 \begin{equation} h^{\prime}_{k,i} = \begin{cases} 1 & \text{ if }\: i\in A\\[4pt] \sum\limits_{j\in I}\Pi_{ij}h^{\prime}_{k,j} & \text{ if }\: i\notin A. \end{cases}\end{equation}
\begin{equation} h^{\prime}_{k,i} = \begin{cases} 1 & \text{ if }\: i\in A\\[4pt] \sum\limits_{j\in I}\Pi_{ij}h^{\prime}_{k,j} & \text{ if }\: i\notin A. \end{cases}\end{equation}
Since
 $-1$
is an absorbing state, we also know that
$-1$
is an absorbing state, we also know that
 $h^{\prime}_{k,-1}=0$
. So far, we know that
$h^{\prime}_{k,-1}=0$
. So far, we know that
 $h_{k,-1}=1$
and
$h_{k,-1}=1$
and
 $h_{k,i}=0$
for
$h_{k,i}=0$
for
 $i\ge k+1$
. For
$i\ge k+1$
. For
 $0\le i\le k$
, we have from (2·4) that
$0\le i\le k$
, we have from (2·4) that
 \begin{align*}h^{\prime}_{k,i} = p_ih^{\prime}_{k,i+1}+q_ih^{\prime}_{k,i-1}.\end{align*}
\begin{align*}h^{\prime}_{k,i} = p_ih^{\prime}_{k,i+1}+q_ih^{\prime}_{k,i-1}.\end{align*}
Writing
 $u_{i}=h^{\prime}_{k,i}-h^{\prime}_{k,i-1}$
for
$u_{i}=h^{\prime}_{k,i}-h^{\prime}_{k,i-1}$
for
 $0\le i\le k+1$
, this gives
$0\le i\le k+1$
, this gives
 \begin{align*}u_{i}=\frac{q_{i-1}}{p_{i-1}}u_{i-1}=\frac{q_{i-1}q_{i-2}}{p_{i-1}p_{i-2}}u_{i-2}=\dots=c_{i-1}u_0\end{align*}
\begin{align*}u_{i}=\frac{q_{i-1}}{p_{i-1}}u_{i-1}=\frac{q_{i-1}q_{i-2}}{p_{i-1}p_{i-2}}u_{i-2}=\dots=c_{i-1}u_0\end{align*}
(with
 $c_{-1}\,:\!=\,1$
), which implies that
$c_{-1}\,:\!=\,1$
), which implies that
 \begin{align*}h^{\prime}_{k,i}=(u_0+\dots+u_i)+h^{\prime}_{k,-1}=u_0\left(1+\sum\limits_{n=0}^{i-1}c_n\right).\end{align*}
\begin{align*}h^{\prime}_{k,i}=(u_0+\dots+u_i)+h^{\prime}_{k,-1}=u_0\left(1+\sum\limits_{n=0}^{i-1}c_n\right).\end{align*}
Since
 $h^{\prime}_{k,k+1}=1$
, it follows that
$h^{\prime}_{k,k+1}=1$
, it follows that
 $u_0=\left(1+\sum\limits_{n=0}^{k}c_n\right)^{-1}$
. Finally, this gives
$u_0=\left(1+\sum\limits_{n=0}^{k}c_n\right)^{-1}$
. Finally, this gives
 \begin{align*}h_{k,i}=1-h^{\prime}_{k,i}=\left(\sum\limits_{n=i}^{k}c_n\right)\bigg/\left(1+\sum\limits_{n=0}^{k}c_n\right)\end{align*}
\begin{align*}h_{k,i}=1-h^{\prime}_{k,i}=\left(\sum\limits_{n=i}^{k}c_n\right)\bigg/\left(1+\sum\limits_{n=0}^{k}c_n\right)\end{align*}
for
 $0\le i\le k$
.
$0\le i\le k$
.
Example 2·4. A case of particular interest is that of constant transition probabilities (that is, for all
 $i\ge1$
,
$i\ge1$
,
 $p_i=p=1-q=1-q_i$
). We can interpret this as a one-dimensional drunkard’s walk: a drunkard stumbles along a semi-infinite street of constant slope, walking one block to the right with probability p and one block to the left with probability q (with
$p_i=p=1-q=1-q_i$
). We can interpret this as a one-dimensional drunkard’s walk: a drunkard stumbles along a semi-infinite street of constant slope, walking one block to the right with probability p and one block to the left with probability q (with
 $p<q$
,
$p<q$
,
 $p=q$
or
$p=q$
or
 $p>q$
depending on the sign of the slope). His home is at the origin and the bar is at position
$p>q$
depending on the sign of the slope). His home is at the origin and the bar is at position
 $k+1\in\{1,2,\dots\}\cup\{\infty\}$
. In Case (I), even if he makes it home, he refuses to stay there. By Theorem 2·1, with probability 1, these visits home occur:
$k+1\in\{1,2,\dots\}\cup\{\infty\}$
. In Case (I), even if he makes it home, he refuses to stay there. By Theorem 2·1, with probability 1, these visits home occur:
-
(a) infinitely often with finite mean return time if
$p<q$
; -
(b) infinitely often with infinite mean return time if
$p=q$
; -
(c) at most finitely often if
$p>q$
$\Big($
in which case, the probability that he starts at i and never reaches home is
$1-\left(\frac{q}{p}\right)^i\Big)$
.





In Case (II), if he makes it to his front door (at 0) he can be persuaded, with probability
 $q_0>0$
(which for simplicity we assume is equal to q), to go inside to bed (at
$q_0>0$
(which for simplicity we assume is equal to q), to go inside to bed (at
 $-1$
). On the other hand, if he makes it to the bar then he will never leave. By Proposition 2·2 and Proposition 2·3, the event that, starting at i, he eventually goes to bed:
$-1$
). On the other hand, if he makes it to the bar then he will never leave. By Proposition 2·2 and Proposition 2·3, the event that, starting at i, he eventually goes to bed:
-
(a) (if the bar is at
$\infty$
) is almost sure if
$p\le q$
(with finite expected time if
$p<q$
and infinite expected time if
$p=q$
), and has probability if
\begin{align*}\left(\frac{q_0}{p_0}\left(\frac{q}{p}\right)^i\right)\bigg/\left(1-\frac{q}{p}+\frac{q_0}{p_0}\right) = \left(\frac{q}{p}\right)^{i+1}\end{align*}
$p>q$
;
-
(b) (if the bar is at
$k+1\in\{i+1,i+2,\dots\}\subseteq\mathbb{N}$
) has probability if
\begin{align*}\frac{k+1-i}{k+2}\end{align*}
$p=q=q_0$
(and is given by a less appealing expression if
$p\ne q$
).










3. UHF algebras
3·1. The construction
Let
 $m_{-1}=m_0=1$
and let
$m_{-1}=m_0=1$
and let
 $(m_n)_{n=1}^\infty$
be an enumeration of the primes. Recall that
$(m_n)_{n=1}^\infty$
be an enumeration of the primes. Recall that
 $\Pi=(\Pi_{ij})_{i,j\in\mathbb{N}\cup\{-1\}}$
is the transition matrix of the Markov chain
$\Pi=(\Pi_{ij})_{i,j\in\mathbb{N}\cup\{-1\}}$
is the transition matrix of the Markov chain
 $(Y_n)_{n\in\mathbb{N}}$
described in Section 2·1 (that is,
$(Y_n)_{n\in\mathbb{N}}$
described in Section 2·1 (that is,
 $\Pi_{ij}=\mathbb{P}(Y_{n+1}=j \mid Y_n=i$
)) and
$\Pi_{ij}=\mathbb{P}(Y_{n+1}=j \mid Y_n=i$
)) and
 $\pi=(\pi_i)_{i\in\mathbb{N}}$
is its initial distribution (that is,
$\pi=(\pi_i)_{i\in\mathbb{N}}$
is its initial distribution (that is,
 $\pi_i=\mathbb{P}(Y_0=i)$
). In this section, we construct a UHF algebra
$\pi_i=\mathbb{P}(Y_0=i)$
). In this section, we construct a UHF algebra
 \begin{align*}M(\Pi,\pi) = M_{m_{Y_0}} \otimes M_{m_{Y_1}} \otimes M_{m_{Y_2}} \otimes \dots.\end{align*}
\begin{align*}M(\Pi,\pi) = M_{m_{Y_0}} \otimes M_{m_{Y_1}} \otimes M_{m_{Y_2}} \otimes \dots.\end{align*}
In Case (I) we always obtain an infinite-dimensional
 $\mathrm{C}^*$
-algebra, while in Case (II) it is possible to end up with a finite matrix algebra.
$\mathrm{C}^*$
-algebra, while in Case (II) it is possible to end up with a finite matrix algebra.
3·2. Probabilities
The following is immediate from Theorem 2·1, Proposition 2·2, Proposition 2·3 and Example 2·4.
Theorem 3·1.
-
(i) If
$q_0=0$
, then with probability 1:-
(a)
$M(\Pi,\pi)$
is isomorphic to the universal UHF algebra
$\mathcal{Q}$
if
$\sum\limits_{n=1}^\infty\prod\limits_{i=1}^{n}{q_i}/{p_i}=\infty$
, in particular if
$p_i=p\le q=q_i$
for all
$i\ge 1$
; -
(b)
$M(\Pi,\pi)$
is of ‘finite type’, that is, every prime factor of the supernatural number associated to
$M(\Pi,\pi)$
has finite multiplicity, if
$\sum\limits_{n=1}^\infty\prod\limits_{i=1}^{n}{q_i}/{p_i}<\infty$
, in particular if
$p_i=p > q=q_i$
for all
$i\ge 1$
.
-
-
(ii) If
$q_0>0$
, then the probability that:-
(a)
$M(\Pi,\pi)$
is finite dimensional is 1 if
$\sum\limits_{n=0}^\infty \prod\limits_{j=0}^{n}{q_j}/{p_j}=\infty$
, in particular if
$p_i=p\le q=q_i$
for all
$i\ge 1$
, and otherwise is which simplifies to
\begin{align*}\left(\sum\limits_{i=0}^\infty\pi_i\sum\limits_{n=i}^\infty \prod\limits_{j=0}^{n}\frac{q_j}{p_j}\right)\bigg/\left(1+\sum\limits_{n=0}^\infty \prod\limits_{j=0}^{n}\frac{q_j}{p_j}\right),\end{align*}
if
\begin{align*}\sum\limits_{i=0}^\infty\pi_i\left(\frac{q}{p}\right)^{i+1}\end{align*}
$p_i=p> q=q_i$
for all
$i\ge 0$
;
-
(b)
$M(\Pi,\pi)$
is isomorphic to
$M_N$
, with the highest prime factor of N at most
$m_k$
, is which simplifies to
\begin{align*}\left(\sum\limits_{i=0}^k\pi_i\sum\limits_{n=i}^{k}\prod\limits_{j=0}^{n}\frac{q_j}{p_j}\right)\bigg/\left(1+\sum\limits_{n=0}^{k}\prod\limits_{j=0}^{n}\frac{q_j}{p_j}\right),\end{align*}
if
\begin{align*}\sum\limits_{i=0}^k\pi_i\frac{k+1-i}{k+2}\end{align*}
$p_i=p = q=q_i$
for all
$i\ge 0$
.
-



























3·3. Variations
The particular random walk we have chosen as our model is of course just one of many possibilities. We might instead for example list the primes as the elements of the grid
 $\mathbb{Z}^d$
for
$\mathbb{Z}^d$
for
 $d\ge1$
. It is a classical theorem of Pólya [
Reference Pólya46
] (see also [
Reference Feller20
, Chapter XIV·7] or [
Reference Norris45
, Section 1·6]) that a simple symmetric walk on this grid (that is, one in which it is only possible to move from a given point to one of the 2d neighbouring points, each with equal probability), is recurrent for
$d\ge1$
. It is a classical theorem of Pólya [
Reference Pólya46
] (see also [
Reference Feller20
, Chapter XIV·7] or [
Reference Norris45
, Section 1·6]) that a simple symmetric walk on this grid (that is, one in which it is only possible to move from a given point to one of the 2d neighbouring points, each with equal probability), is recurrent for
 $d=1$
and
$d=1$
and
 $d=2$
, but transient for
$d=2$
, but transient for
 $d\ge3$
.
$d\ge3$
.
In particular, if our random UHF algebra is constructed according to a drunken walk through an infinite flat city, we still obtain the universal UHF algebra
 $\mathcal{Q}$
. For this reason, one might (and the author personally does) think of
$\mathcal{Q}$
. For this reason, one might (and the author personally does) think of
 $\mathcal{Q}$
as the drunkard’s UHF algebra. On the other hand, to paraphrase Kakutani [
Reference Durrett12
, Section 3·2], a drunk bird (who flies around
$\mathcal{Q}$
as the drunkard’s UHF algebra. On the other hand, to paraphrase Kakutani [
Reference Durrett12
, Section 3·2], a drunk bird (who flies around
 $\mathbb{Z}^3$
) will almost surely produce a UHF algebra of finite type.
$\mathbb{Z}^3$
) will almost surely produce a UHF algebra of finite type.
4. Simple limits of point-line algebras
4·1. Background
The Lazar–Lindenstrauss simplex theorem [
Reference Lazar and Lindenstrauss37
, Theorem 5·2 and its Corollary] says that every infinite-dimensional metrisable Choquet simplex
 $\Delta$
is affinely homeomorphic to a projective limit
$\Delta$
is affinely homeomorphic to a projective limit
 \begin{equation} \Delta \cong \varprojlim(\Delta_n,\psi_n),\end{equation}
\begin{equation} \Delta \cong \varprojlim(\Delta_n,\psi_n),\end{equation}
where for each
 $n\in\mathbb{N}$
,
$n\in\mathbb{N}$
,
 $\Delta_n$
is an n-dimensional simplex and
$\Delta_n$
is an n-dimensional simplex and
 $\psi_n\colon\Delta_{n}\to\Delta_{n-1}$
is affine and surjective. Equivalently, the space
$\psi_n\colon\Delta_{n}\to\Delta_{n-1}$
is affine and surjective. Equivalently, the space
 $\mathrm{Aff}(\Delta)$
of continuous affine maps
$\mathrm{Aff}(\Delta)$
of continuous affine maps
 $\Delta\to\mathbb{R}$
is isomorphic to the limit
$\Delta\to\mathbb{R}$
is isomorphic to the limit
 \begin{equation} \mathrm{Aff}(\Delta) \cong \varinjlim\left(\mathrm{Aff}(\Delta_{n-1}),\psi_n^*\right) \cong \varinjlim\left(\mathbb{R}^{n},\psi_n^*\right)\end{equation}
\begin{equation} \mathrm{Aff}(\Delta) \cong \varinjlim\left(\mathrm{Aff}(\Delta_{n-1}),\psi_n^*\right) \cong \varinjlim\left(\mathbb{R}^{n},\psi_n^*\right)\end{equation}
in the category of complete order unit spaces (in which the morphisms are positive unital linear maps). Here, we identify
 $\mathrm{Aff}(\Delta_{n-1})$
with
$\mathrm{Aff}(\Delta_{n-1})$
with
 $\mathbb{R}^n$
via the basis
$\mathbb{R}^n$
via the basis
 $(f_{j,n})_{0\le j\le n-1}$
that is defined on the vertices
$(f_{j,n})_{0\le j\le n-1}$
that is defined on the vertices
 $e_{0,n-1},e_{1,n-1},\dots,e_{n-1,n-1}$
of
$e_{0,n-1},e_{1,n-1},\dots,e_{n-1,n-1}$
of
 $\Delta_{n-1}$
by
$\Delta_{n-1}$
by
 \begin{equation} f_{j,n}(e_{i,n})=\delta_{ij}.\end{equation}
\begin{equation} f_{j,n}(e_{i,n})=\delta_{ij}.\end{equation}
We will refer to these equivalent statements of the theorem as, respectively, the geometric version and the algebraic one.
Both versions have proved useful in the construction of simple inductive limit
 $\mathrm{C}^*$
-algebras
$\mathrm{C}^*$
-algebras
 $A=\varinjlim A_n$
with prescribed tracial state space T(A). We would in particular like to highlight the approximately homogeneous (AH) cases
$A=\varinjlim A_n$
with prescribed tracial state space T(A). We would in particular like to highlight the approximately homogeneous (AH) cases
 $A_n=p_nC\left(X_n,M_{m_n}\right)p_n$
, where:
$A_n=p_nC\left(X_n,M_{m_n}\right)p_n$
, where:
-
[ Reference Blackadar4 , Reference Goodearl25 ]
$X_n=\{1,\dots,l_n\}$
(so that A is an approximately finite-dimensional (AF) algebra); -
[ Reference Thomsen53 ]
$X_n=[0,1]$
(so that A is an approximately interval (AI) algebra).


The AF construction uses the geometric version (4·1) of Lazar–Lindenstrauss. The AI construction uses the algebraic one (4·2), together with an intertwining [ Reference Thomsen53 , Lemma 3·8]

,
(where
 $C_\mathbb{R}([0,1])$
is identified with
$C_\mathbb{R}([0,1])$
is identified with
 $\mathrm{Aff}\left(T\left(C\left([0,1],M_{m_n}\right)\right)\right)$
via the embedding of C([0,1]) into the centre of
$\mathrm{Aff}\left(T\left(C\left([0,1],M_{m_n}\right)\right)\right)$
via the embedding of C([0,1]) into the centre of
 $C([0,1],M_{m_n}))$
and a suitable Krein–Milman theorem [
Reference Thomsen53
, Theorem 2·1] to approximate each positive unital linear map
$C([0,1],M_{m_n}))$
and a suitable Krein–Milman theorem [
Reference Thomsen53
, Theorem 2·1] to approximate each positive unital linear map
 $\varphi_n$
by an average of maps induced by
$\varphi_n$
by an average of maps induced by
 $^*$
-homomorphisms.
$^*$
-homomorphisms.
Simple AI algebras are particularly noteworthy for demonstrating the necessity for a classifying invariant for simple amenable
 $\mathrm{C}^*$
-algebras to include not just traces and ordered K-theory but also the pairing between the two (see [
Reference Rørdam and Størmer51
, p. 29]). For us though, the key point is that the construction of these AH algebras is via an algorithm whose
$\mathrm{C}^*$
-algebras to include not just traces and ordered K-theory but also the pairing between the two (see [
Reference Rørdam and Størmer51
, p. 29]). For us though, the key point is that the construction of these AH algebras is via an algorithm whose
Input is a sequence of affine surjections
 $\psi_n\colon\Delta_n\to\Delta_{n-1}$
$\psi_n\colon\Delta_n\to\Delta_{n-1}$
 $\big($
or positive unital linear maps
$\big($
or positive unital linear maps
 $\psi_n^*\colon\mathbb{R}^n\to\mathbb{R}^{n+1}\big)$
, and whose
$\psi_n^*\colon\mathbb{R}^n\to\mathbb{R}^{n+1}\big)$
, and whose
Output is a simple
 $\mathrm{C}^*$
-algebra whose tracial simplex is specified by (4·1) or (4·2).
$\mathrm{C}^*$
-algebra whose tracial simplex is specified by (4·1) or (4·2).
In Section 4·2, we will use ‘representing matrices’ to turn the space of sequences (4·1) into a measure space in which we can compute probabilities. First though, for the sake of noise reduction we switch our attention from homogeneous to subhomogeneous building blocks.
The introduction of boundary conditions at the endpoints of the interval (obtaining what are variously referred to as point-line algebras, Elliott–Thomsen building blocks or one-dimensional noncommutative CW complexes) provides access to a wider range for the K-theory of the limit algebra. (To exhaust the full range, in particular to account for torsion in
 $K_0$
, one must allow for slightly higher dimensional base spaces; see [
Reference Elliott16
].) That said, our interest in this section is altogether to rid ourselves of this turbulent K-theory, and focus on a class for which the only thing that matters is traces, namely,
$K_0$
, one must allow for slightly higher dimensional base spaces; see [
Reference Elliott16
].) That said, our interest in this section is altogether to rid ourselves of this turbulent K-theory, and focus on a class for which the only thing that matters is traces, namely,
 $\mathrm{C}^*$
-algebras built from prime dimension drop algebras
$\mathrm{C}^*$
-algebras built from prime dimension drop algebras
 \begin{align*}Z_{x,y} = \{f\in C([0,1],M_x\otimes M_y) \mid f(0)\in M_x\otimes 1_y,\: f(1)\in 1_x\otimes M_y\}, \quad (x,y)=1.\end{align*}
\begin{align*}Z_{x,y} = \{f\in C([0,1],M_x\otimes M_y) \mid f(0)\in M_x\otimes 1_y,\: f(1)\in 1_x\otimes M_y\}, \quad (x,y)=1.\end{align*}
By [ Reference Jiang and Su30 , Theorems 4·5 and 6·2], simple inductive limits of these building blocks are completely classified by the tracial simplex. The ‘existence’ part of the classification is still based on Thomsen’s algorithm, with a suitably refined Krein–Milman theorem [ Reference Li38 , Theorem 2·1].
4·2. Representing matrices
By reordering the set
 $(e_{i,n})_{0\le i\le n}$
of vertices of
$(e_{i,n})_{0\le i\le n}$
of vertices of
 $\Delta_n$
if necessary, we can visualise (4·1) as follows:
$\Delta_n$
if necessary, we can visualise (4·1) as follows:
 $\Delta_{n}$
sits atop its base
$\Delta_{n}$
sits atop its base
 $\Delta_{n-1}$
, and
$\Delta_{n-1}$
, and
 $\psi_n$
is the collapsing map that fixes the base and sends
$\psi_n$
is the collapsing map that fixes the base and sends
 $e_{n,n}$
to
$e_{n,n}$
to
 $\sum\limits_{i=1}^{n}a_{i,n}e_{i-1,n-1}\in\Delta_{n-1}$
. Dually,
$\sum\limits_{i=1}^{n}a_{i,n}e_{i-1,n-1}\in\Delta_{n-1}$
. Dually,
 $\psi_n^*\colon\mathbb{R}^{n}\cong\mathrm{Aff}(\Delta_{n-1})\to\mathrm{Aff}(\Delta_n)\cong\mathbb{R}^{n+1}$
has matrix
$\psi_n^*\colon\mathbb{R}^{n}\cong\mathrm{Aff}(\Delta_{n-1})\to\mathrm{Aff}(\Delta_n)\cong\mathbb{R}^{n+1}$
has matrix
 \begin{equation} \begin{pmatrix}1 & \quad & \quad & \quad \\[3pt] & \quad 1 & \quad & \quad \\[3pt] & \quad & \quad \ddots & \quad \\[3pt] & \quad & \quad & \quad 1\\[3pt] a_{1,n} & \quad a_{2,n} & \quad \dots & \quad a_{n,n}\end{pmatrix}.\end{equation}
\begin{equation} \begin{pmatrix}1 & \quad & \quad & \quad \\[3pt] & \quad 1 & \quad & \quad \\[3pt] & \quad & \quad \ddots & \quad \\[3pt] & \quad & \quad & \quad 1\\[3pt] a_{1,n} & \quad a_{2,n} & \quad \dots & \quad a_{n,n}\end{pmatrix}.\end{equation}
The triangular matrix
 $(a_{i,n})_{1\le i\le n,\,n\ge1}$
is called a representing matrix for the simplex
$(a_{i,n})_{1\le i\le n,\,n\ge1}$
is called a representing matrix for the simplex
 $\Delta$
. Assigning to a representing matrix A the simplex
$\Delta$
. Assigning to a representing matrix A the simplex
 $\Delta_A$
defined by (4·4) is a well-defined function, but is
$\Delta_A$
defined by (4·4) is a well-defined function, but is
 $\infty$
-to-1: for a start, [
Reference Lindenstrauss, Olsen and Sternfeld39
, Theorem 4·7] says that a sufficient condition for matrices A and B to represent the same simplex is that they have the same asymptotic behaviour, that is, satisfy
$\infty$
-to-1: for a start, [
Reference Lindenstrauss, Olsen and Sternfeld39
, Theorem 4·7] says that a sufficient condition for matrices A and B to represent the same simplex is that they have the same asymptotic behaviour, that is, satisfy
 $\sum\limits_{n=1}^\infty\sum\limits_{i=1}^n |a_{i,n}-b_{i,n}|<\infty$
. The full story is more complicated, because this condition is certainly not necessary. For example, it can be shown (see [
Reference Sternfeld52
, p. 317 and Theorem 4·3]) that the representing matrices for which:
$\sum\limits_{n=1}^\infty\sum\limits_{i=1}^n |a_{i,n}-b_{i,n}|<\infty$
. The full story is more complicated, because this condition is certainly not necessary. For example, it can be shown (see [
Reference Sternfeld52
, p. 317 and Theorem 4·3]) that the representing matrices for which:
 \begin{equation} (a)\quad a_{n,n}=1 \quad (b)\quad a_{1,n}=1 \quad (c)\quad a_{i,n}=\frac{1}{n} \quad\text{ for } n\ge1 \text{ and } 1\le i\le n,\end{equation}
\begin{equation} (a)\quad a_{n,n}=1 \quad (b)\quad a_{1,n}=1 \quad (c)\quad a_{i,n}=\frac{1}{n} \quad\text{ for } n\ge1 \text{ and } 1\le i\le n,\end{equation}
all give rise to the Bauer simplex K whose extreme boundary is homeomorphic to
 $\{{1}/{n}\}_{n=1}^\infty\cup\{0\}$
.
$\{{1}/{n}\}_{n=1}^\infty\cup\{0\}$
.
In the random constructions to follow, we use
 \begin{equation}(a_{i,j})_{i,j\ge1}\, \mbox{$\mapsto$} \left(\sum\limits_{i=1}^na_{in}e_{i-1,n-1}\right)_{n\ge1}\end{equation}
\begin{equation}(a_{i,j})_{i,j\ge1}\, \mbox{$\mapsto$} \left(\sum\limits_{i=1}^na_{in}e_{i-1,n-1}\right)_{n\ge1}\end{equation}
to identify the set R of representing matrices with
 $\prod\limits_{n\in\mathbb{N}}\Delta_n$
. Probabilities in the set
$\prod\limits_{n\in\mathbb{N}}\Delta_n$
. Probabilities in the set
 $\Delta(R)$
of all metrisable Choquet simplexes (which, as in [
Reference Edwards, Kalenda and Spurný14
], can be viewed as a subset of the unit sphere of
$\Delta(R)$
of all metrisable Choquet simplexes (which, as in [
Reference Edwards, Kalenda and Spurný14
], can be viewed as a subset of the unit sphere of
 $\ell_1$
with its
$\ell_1$
with its
 $w^*$
-topology) are computed by pushing forward a choice of product measure
$w^*$
-topology) are computed by pushing forward a choice of product measure
 $\gamma=\otimes_{n\in\mathbb{N}}\gamma_n$
on R. We will consider three possibilities for
$\gamma=\otimes_{n\in\mathbb{N}}\gamma_n$
on R. We will consider three possibilities for
 $\gamma$
:
$\gamma$
:
-
(K)
$\gamma_n$
the point mass at
$\sum_{i=0}^{n}\frac{1}{n}e_{i,n}$
; -
(C)
$\gamma_n$
the uniform measure on the
$n+1$
vertices of
$\Delta_n$
; -
(P)
$\gamma_{s_n+i}$
normalised Lebesgue measure on
$\mathrm{conv}\left\{e_{0,n},\dots,e_{n-i+1,n}\right\}\subseteq\Delta_n\subseteq\Delta_{s_{n}+i}$
for
$1\le i\le n+1$
, where
$s_n=0+1+\dots+n=({n(n+1)})/{2}$
.









4·3. The constructions
We use the Markov chain
 $(Y_n)_{n\in\mathbb{N}}$
of Section 2·1, a choice of probability measure
$(Y_n)_{n\in\mathbb{N}}$
of Section 2·1, a choice of probability measure
 $\gamma$
of the form (K), (C) or (P) as described in Section 4·2, and Thomsen’s algorithm (Section 4·1), to build a simple inductive limit
$\gamma$
of the form (K), (C) or (P) as described in Section 4·2, and Thomsen’s algorithm (Section 4·1), to build a simple inductive limit
 \begin{align*}Z(\Pi,\pi,\gamma) = \varinjlim\left(Z_{x_n,y_n},\varphi_n\right)\end{align*}
\begin{align*}Z(\Pi,\pi,\gamma) = \varinjlim\left(Z_{x_n,y_n},\varphi_n\right)\end{align*}
whose tracial state space is affinely homeomorphic to
 $\varprojlim\left(\Delta_{Y_n},\psi_{n}\right)$
. Here,
$\varprojlim\left(\Delta_{Y_n},\psi_{n}\right)$
. Here,
 $\Delta_{-1}\,:\!=\,\Delta_0$
and the connecting map
$\Delta_{-1}\,:\!=\,\Delta_0$
and the connecting map
 $\psi_{n}\colon\Delta_{Y_n}\to\Delta_{Y_{n-1}}$
is either:
$\psi_{n}\colon\Delta_{Y_n}\to\Delta_{Y_{n-1}}$
is either:
-
(i) the standard inclusion
$\big($
that is, assigns the vertices of
$\Delta_{Y_n}$
to the first
$Y_n+1$
vertices of
$\Delta_{Y_{n-1}}\big)$
if
$Y_{n}=Y_{n-1}-1$
; or -
(ii) chosen randomly according to the probability measure
$\gamma$
if
$Y_{n}=Y_{n-1}+1$
.







4·4. Probabilities
Theorem 4·1. (i) If
 $q_0=0$
, then with probability 1,
$q_0=0$
, then with probability 1,
 $Z(\Pi,\pi,\gamma)$
:
$Z(\Pi,\pi,\gamma)$
:
-
(a) is monotracial (hence, is isomorphic to the Jiang–Su algebra
$\mathcal{Z}$
) if
$\sum\limits_{n=1}^\infty\prod\limits_{i=1}^{n}{q_i}/{p_i}=\infty$
, in particular if
$p_i=p\le q=q_i$
for all
$i\ge 1$
; -
(b) has infinite-dimensional tracial state space if
$\sum\limits_{n=1}^\infty\prod\limits_{i=1}^{n}{q_i}/{p_i}<\infty$
, in particular if
$p_i=p > q=q_i$
for all
$i\ge 1$
; moreover, in this case
$T(Z(\Pi,\pi,\gamma))$
is with probability 1 affinely homeomorphic to either








-
K the Bauer simplex whose extremal boundary is
$\left\{\frac{1}{n}\right\}_{n=1}^\infty\cup\{0\}$
or
-
C the Bauer simplex whose extremal boundary is the Cantor set or
-
P the Poulsen simplex.

-
(ii) If
$q_0>0$
, then the probability that
$Z(\Pi,\pi,\gamma)$
is isomorphic to
$\mathcal{Z}$
is 1 if
$\sum\limits_{n=0}^\infty \prod\limits_{j=0}^{n} {q_j}/{p_j}=\infty$
, in particular if
$p_i=p\le q=q_i$
for all
$i\ge 1$
, and otherwise is which simplifies to
\begin{align*}\left(\sum\limits_{i=0}^\infty\pi_i\sum\limits_{n=i}^\infty \prod\limits_{j=0}^{n}\frac{q_j}{p_j}\right)\bigg/\left(1+\sum\limits_{n=0}^\infty \prod\limits_{j=0}^{n}\frac{q_j}{p_j}\right),\end{align*}
if
\begin{align*}\sum\limits_{i=0}^\infty\pi_i\left(\frac{q}{p}\right)^{i+1}\end{align*}
$p_i=p> q=q_i$
for all
$i\ge 0$
.










Proof. (i) First, since an inverse limit is isomorphic to the limit over any cofinal subset of the index set,
 $Z(\Pi,\pi,\gamma)$
is monotracial precisely when the walk
$Z(\Pi,\pi,\gamma)$
is monotracial precisely when the walk
 $(Y_n)$
visits the states
$(Y_n)$
visits the states
 $\{0,-1\}$
infinitely often. This demonstrates (i)(
a
) and the first assertion of (i)(
b
).
$\{0,-1\}$
infinitely often. This demonstrates (i)(
a
) and the first assertion of (i)(
b
).
Case K is not just almost sure, but is the uniquely determined possibility (see (4·5)).
Case C follows from Brouwer’s Theorem [
Reference Brouwer7
, Theorem 3], which characterises the Cantor set up to homeomorphism as the unique nonempty totally disconnected compact metrisable space without isolated points. By [
Reference Lazar and Lindenstrauss37
, Theorem 5·1],
 $T(Z(\Pi,\pi,\gamma))$
is a Bauer simplex with totally disconnected extremal boundary. Essentially, the dual bases
$T(Z(\Pi,\pi,\gamma))$
is a Bauer simplex with totally disconnected extremal boundary. Essentially, the dual bases
 $(f_{j,n})_{0\le j\le n-1}$
of (4·3) correspond to partitions of unity over a decreasing sequence of clopen covers of the boundary, with the representing matrix describing the way that successive partitions sit inside each other (at each stage, the subsequent partition is obtained from the current one by splitting one element into two pieces). We might picture the random process as a population tree, where at each level, one member of the population is chosen at random to reproduce. In this language, the probability that
$(f_{j,n})_{0\le j\le n-1}$
of (4·3) correspond to partitions of unity over a decreasing sequence of clopen covers of the boundary, with the representing matrix describing the way that successive partitions sit inside each other (at each stage, the subsequent partition is obtained from the current one by splitting one element into two pieces). We might picture the random process as a population tree, where at each level, one member of the population is chosen at random to reproduce. In this language, the probability that
 $\partial_eT(Z(\Pi,\pi,\gamma))$
has an isolated point (or equivalently, is not homeomorphic to the Cantor set) is the probability that some branch of the tree eventually becomes an evolutionary dead end, which is at most
$\partial_eT(Z(\Pi,\pi,\gamma))$
has an isolated point (or equivalently, is not homeomorphic to the Cantor set) is the probability that some branch of the tree eventually becomes an evolutionary dead end, which is at most
 \begin{align*}\sum_{n=2}^\infty\left( n\cdot\prod_{i=n}^{\infty}\frac{i-1}{i} \right) = \sum_{n=2}^\infty n\cdot\lim_{m\to\infty} \frac{n-1}{m} = 0.\end{align*}
\begin{align*}\sum_{n=2}^\infty\left( n\cdot\prod_{i=n}^{\infty}\frac{i-1}{i} \right) = \sum_{n=2}^\infty n\cdot\lim_{m\to\infty} \frac{n-1}{m} = 0.\end{align*}
Case P similarly follows from (the remark after) [
Reference Lazar and Lindenstrauss37
, Theorem 5·6]. A representing matrix yields the Poulsen simplex if the vectors
 $(a_{1n},\dots,a_{nn},0,\dots)$
are dense in the positive face of the unit sphere of
$(a_{1n},\dots,a_{nn},0,\dots)$
are dense in the positive face of the unit sphere of
 $\ell_1$
. This fails to happen only if there exist
$\ell_1$
. This fails to happen only if there exist
 $\varepsilon>0$
,
$\varepsilon>0$
,
 $n\ge 1$
and some barycentric coordinates
$n\ge 1$
and some barycentric coordinates
 $(x_0,\dots,x_n)$
such that each choice of random point in
$(x_0,\dots,x_n)$
such that each choice of random point in
 $\mathrm{conv}\{e_{0,m},\dots,e_{n,m}\}$
,
$\mathrm{conv}\{e_{0,m},\dots,e_{n,m}\}$
,
 $m\ge n$
, misses the
$m\ge n$
, misses the
 $\ell_1$
-ball B centred at
$\ell_1$
-ball B centred at
 $\sum\limits_{i=0}^nx_ie_{i,m}$
with
$\sum\limits_{i=0}^nx_ie_{i,m}$
with
 $\gamma(B)=\varepsilon$
. The probability of this is at most
$\gamma(B)=\varepsilon$
. The probability of this is at most
 $\prod_{m\ge n}(1-\varepsilon)$
, which is 0.
$\prod_{m\ge n}(1-\varepsilon)$
, which is 0.
Finally, (ii) follows from Example 2·4.
Remark 4·2.
-
(i) To allow for the possibility of a nontrivial finite-dimensional trace space, we might in the case
$q_0>0$
take the dimension of the randomly constructed simplex to be
$\sup\{Y(n) \mid n\in\mathbb{N}\}$
. As in Example 2·4, supposing that
$p_i=p=q_i$
for all i, the probability that
$Z(\Pi,\pi,\gamma)$
has at most
$k\ge1$
extremal traces is then
\begin{align*}\sum\limits_{i=0}^k\pi_i\frac{k-i}{k+1}.\end{align*}
-
(ii) We could equally well have opted for the stably projectionless versions of dimension drop algebras, so-called ‘Razak blocks’, simple inductive limits of which (assuming ‘continuous scale’) are completely classified by the tracial state space [ Reference Razak48 , Reference Tsang58 ]. In this case, the almost-sure monotracial limit obtained in Theorem 4·1 would be the
$\mathrm{C}^*$
-algebra
$\mathcal{W}$
instead of
$\mathcal{Z}$
.









5. Villadsen algebras of the first type
By once again making a random choice at each step of an inductive limit, we this time build an approximately homogeneous (AH) algebra, the radius of comparison of which is a random variable whose distribution is the subject of this section.
5·1. Background
The radius of comparison is a numerical invariant of the Cuntz semigroup that was used in [
Reference Toms55
] to distinguish
 $\mathrm{C}^*$
-algebras with the same Elliott invariant. In [
Reference Toms54
, Theorem 5·1], it is shown how to construct simple, unital AH algebras with arbitrary ‘dimension-rank ratio’ c. Moreover, as pointed out in [
Reference Asadi and Asadi–Vasfi2
, Corollary 5·2], an algebra constructed in this way has radius of comparison
$\mathrm{C}^*$
-algebras with the same Elliott invariant. In [
Reference Toms54
, Theorem 5·1], it is shown how to construct simple, unital AH algebras with arbitrary ‘dimension-rank ratio’ c. Moreover, as pointed out in [
Reference Asadi and Asadi–Vasfi2
, Corollary 5·2], an algebra constructed in this way has radius of comparison
 $r={c}/{2}$
.
$r={c}/{2}$
.
These algebras of Toms are, in the language of [
Reference Toms and Winter57
], Villadsen algebras of the first type. That is, they are inductive limits
 $A_X=\varinjlim\left(M_{m_i}\otimes C\left(X^{\times n_i}\right), \varphi_i\right)$
, with a fixed compact Hausdorff X (the ‘seed space’) and each connecting map
$A_X=\varinjlim\left(M_{m_i}\otimes C\left(X^{\times n_i}\right), \varphi_i\right)$
, with a fixed compact Hausdorff X (the ‘seed space’) and each connecting map
 $\varphi_i$
of the form
$\varphi_i$
of the form
 $\varphi_i(f)=\mathrm{diag}\left(f\circ\xi_{i,1},\dots,f\circ\xi_{i,m_{i+1}/m_i}\right)$
, where each
$\varphi_i(f)=\mathrm{diag}\left(f\circ\xi_{i,1},\dots,f\circ\xi_{i,m_{i+1}/m_i}\right)$
, where each
 $\xi_{i,j}\colon X^{\times n_{i+1}} \to X^{\times n_i}$
is either constant or a coordinate projection. Following [
Reference Toms54
], we will take X to be the sphere
$\xi_{i,j}\colon X^{\times n_{i+1}} \to X^{\times n_i}$
is either constant or a coordinate projection. Following [
Reference Toms54
], we will take X to be the sphere
 $S^2$
, but as in [
Reference Toms and Winter57
, Section 8], any finite (but nonzero) dimensional CW complex would do.
$S^2$
, but as in [
Reference Toms and Winter57
, Section 8], any finite (but nonzero) dimensional CW complex would do.
5·2. The construction
This time, we take a random walk not on the natural numbers but on an infinite complete binary tree (or rather, on the countable disjoint union of copies of this tree). The initial position
 $W_0$
of the walk is specified by a probability distribution
$W_0$
of the walk is specified by a probability distribution
 $\pi$
on
$\pi$
on
 $I=\{0\}\cup\left\{2^k\mid k\in\mathbb{Z}\right\}$
. Once the starting point is decided, the walk constructs a random binary number, that is, determines the value of a random variable
$I=\{0\}\cup\left\{2^k\mid k\in\mathbb{Z}\right\}$
. Once the starting point is decided, the walk constructs a random binary number, that is, determines the value of a random variable
 \begin{equation} W = 0.W_1W_2 \dots = \sum_{i=1}^\infty \frac{W_i}{2^i},\end{equation}
\begin{equation} W = 0.W_1W_2 \dots = \sum_{i=1}^\infty \frac{W_i}{2^i},\end{equation}
where
 $\{W_i\}_{i\in\mathbb{N}}$
are independent, as follows. After i steps, our position is on the ith level of the tree. We descend to the level below by taking either the left branch (with probability
$\{W_i\}_{i\in\mathbb{N}}$
are independent, as follows. After i steps, our position is on the ith level of the tree. We descend to the level below by taking either the left branch (with probability
 $p_{i+1}$
), in which case
$p_{i+1}$
), in which case
 $W_{i+1}=0$
, or the right branch (with probability
$W_{i+1}=0$
, or the right branch (with probability
 $q_{i+1}=1-p_{i+1}$
), in which case
$q_{i+1}=1-p_{i+1}$
), in which case
 $W_{i+1}=1$
. Just as in (2·2), the transition probabilities can be encoded by a matrix
$W_{i+1}=1$
. Just as in (2·2), the transition probabilities can be encoded by a matrix
 $\Pi$
.
$\Pi$
.
By following the procedure outlined in the proof of [
Reference Toms54
, Theorem 5·1], we use the random variables
 $\{W_i\}_{i\in\mathbb{N}}$
to construct a Villadsen algebra of the first type
$\{W_i\}_{i\in\mathbb{N}}$
to construct a Villadsen algebra of the first type
 \begin{align*}B(\Pi,\pi) = \varinjlim(B_i,\varphi_i).\end{align*}
\begin{align*}B(\Pi,\pi) = \varinjlim(B_i,\varphi_i).\end{align*}
Here,
 $B_i=M_{n_i}(C(T_i))$
, where
$B_i=M_{n_i}(C(T_i))$
, where
 $T_i=\left(S^2\right)^{m_0m_1\dots m_i}$
, and the connecting map
$T_i=\left(S^2\right)^{m_0m_1\dots m_i}$
, and the connecting map
 $\varphi_i\colon B_i\to B_{i+1}$
is of the form
$\varphi_i\colon B_i\to B_{i+1}$
is of the form
 \begin{align*}\varphi_i(f)(t) = \mathrm{diag}\left(f\circ\pi_i^1(t),\dots,f\circ\pi_i^{m_{i+1}}(t),f\Big(t_i^1\Big),\dots,f\Big(t_i^{s_{i+1}}\Big)\right),\end{align*}
\begin{align*}\varphi_i(f)(t) = \mathrm{diag}\left(f\circ\pi_i^1(t),\dots,f\circ\pi_i^{m_{i+1}}(t),f\Big(t_i^1\Big),\dots,f\Big(t_i^{s_{i+1}}\Big)\right),\end{align*}
where
 $\pi_i^j\colon T_{i+1}=T_i^{m_{i+1}}\to T_i$
,
$\pi_i^j\colon T_{i+1}=T_i^{m_{i+1}}\to T_i$
,
 $1\le j\le m_{i+1}$
, are the coordinate projections, and the points
$1\le j\le m_{i+1}$
, are the coordinate projections, and the points
 $t_i^j$
are chosen to make the limit simple (as in [
Reference Villadsen59
]). There is some flexibility in the choice of the natural numbers
$t_i^j$
are chosen to make the limit simple (as in [
Reference Villadsen59
]). There is some flexibility in the choice of the natural numbers
 $m_i$
and
$m_i$
and
 $s_i$
(which determine
$s_i$
(which determine
 $n_i=(m_i+s_i)n_{i-1}$
). The ratios
$n_i=(m_i+s_i)n_{i-1}$
). The ratios
 ${m_i}/({m_i+s_i})$
are what govern the radius of comparison R of
${m_i}/({m_i+s_i})$
are what govern the radius of comparison R of
 $B(\Pi,\pi)$
, and these ratios are dictated by the random walk. We set
$B(\Pi,\pi)$
, and these ratios are dictated by the random walk. We set
 ${m_0}/{n_0}=W_0$
, and
${m_0}/{n_0}=W_0$
, and
 ${m_i}/({m_i+s_i})=2^{{-W_i/2^i}}$
for
${m_i}/({m_i+s_i})=2^{{-W_i/2^i}}$
for
 $i\ge1$
. In other words, we relate
$i\ge1$
. In other words, we relate
 \begin{align*}R = \lim_{i\to\infty}\frac{\dim T_{i}}{2n_{i}} = \lim_{i\to\infty}\frac{m_0m_1\dots m_{i}}{n_{i}} = \lim_{i\to\infty}\frac{m_0m_1\dots m_{i-1}}{n_{i-1}} \frac{m_{i}}{m_{i}+s_{i}} = \prod_{i\in\mathbb{N}}\frac{m_i}{m_i+s_i}\end{align*}
\begin{align*}R = \lim_{i\to\infty}\frac{\dim T_{i}}{2n_{i}} = \lim_{i\to\infty}\frac{m_0m_1\dots m_{i}}{n_{i}} = \lim_{i\to\infty}\frac{m_0m_1\dots m_{i-1}}{n_{i-1}} \frac{m_{i}}{m_{i}+s_{i}} = \prod_{i\in\mathbb{N}}\frac{m_i}{m_i+s_i}\end{align*}
to
 $\{W_i\}_{i\in\mathbb{N}}$
by
$\{W_i\}_{i\in\mathbb{N}}$
by
 \begin{equation} R = W_0\cdot2^{-W}.\end{equation}
\begin{equation} R = W_0\cdot2^{-W}.\end{equation}
By the Jessen–Wintner law of pure types (see [ Reference Jessen and Wintner29 , Theorem 35], or [ Reference Breiman6 , Theorem 3·26] for an elementary treatment), the distribution of W is either:
-
(a) discrete (that is, there is a countable set J such that
$\mathbb{P}(W\in J) =1$
); or -
(b) singular (that is,
$\mathbb{P}(W=w)=0$
for every
$w\in\mathbb{R}$
, but there is a Borel set B of Lebesgue measure zero such that
$\mathbb{P}(W\in B) =1$
); or -
(c) absolutely continuous with respect to Lebesgue (so has a density f).




(Distributions can in general be of mixed type, but this is not the case for a convergent series of discrete random variables.)
For the sake of computing the expected value of R, we will assume that we are in case (c). By the results of [
Reference Marsaglia40
] (see also [
Reference Chatterji8
]), this occurs precisely when there is
 $\beta\in\mathbb{R}$
such that, for every
$\beta\in\mathbb{R}$
such that, for every
 $n\ge1$
,
$n\ge1$
,
 \begin{align*}p_n = \frac{1}{1+e^{\beta/2^n}} \quad\text{and}\quad q_n = \frac{e^{\beta/2^n}}{1+e^{\beta/2^n}}.\end{align*}
\begin{align*}p_n = \frac{1}{1+e^{\beta/2^n}} \quad\text{and}\quad q_n = \frac{e^{\beta/2^n}}{1+e^{\beta/2^n}}.\end{align*}
Then, the probability density function of W is
 \begin{equation} f_\beta(x) = \frac{\beta e^{\beta x}}{e^\beta-1} ,\quad 0\le x\le 1\end{equation}
\begin{equation} f_\beta(x) = \frac{\beta e^{\beta x}}{e^\beta-1} ,\quad 0\le x\le 1\end{equation}
if
 $\beta\ne0$
, or
$\beta\ne0$
, or
 $f_0=1$
, that is, representing the uniform distribution, if
$f_0=1$
, that is, representing the uniform distribution, if
 $\beta=0$
.
$\beta=0$
.
5·3. Probabilities
Within the framework of Section 5·2, we can compute the expected value of the radius of comparison of the random
 $\mathrm{C}^*$
-algebra
$\mathrm{C}^*$
-algebra
 $B(\Pi,\pi)$
.
$B(\Pi,\pi)$
.
Theorem 5·1. (i) With probability
 $\pi_0$
,
$\pi_0$
,
 $B(\Pi,\pi)$
is
$B(\Pi,\pi)$
is
 $\mathcal{Z}$
-stable (in fact, a UHF algebra).
$\mathcal{Z}$
-stable (in fact, a UHF algebra).
-
(ii) For every
$r>0$
, where
\begin{align*}\mathbb{P}(R\ge r) = \sum_{k\in \mathbb{Z}}\pi_{2^k}G_\beta\left(\frac{r}{2^k}\right),\end{align*}
if
\begin{align*}G_\beta(x) = \begin{cases} 1 & \:\text{ if }\: x\le\frac{1}{2}\\[4pt] \frac{x^{-\beta/\ln2}-1}{e^\beta-1} & \:\text{ if }\: \frac{1}{2}<x<1\\[4pt] 0 & \:\text{ if }\: x\ge1 \end{cases}\end{align*}
$\beta\ne0$
, and
\begin{align*}G_0(x) = \begin{cases} 1 & \:\text{ if }\: x\le\frac{1}{2}\\[4pt] -\frac{\ln x}{\ln2} & \:\text{ if }\: \frac{1}{2}<x<1\\[4pt] 0 & \:\text{ if }\: x\ge1. \end{cases}\end{align*}
-
(iii) The expected value of R satisfies
if
\begin{align*}\frac{\mathbb{E}(R)}{\sum\limits_{k\in \mathbb{Z}}2^k\pi_{2^k}} = \begin{cases} \frac{1}{\ln4} & \:\text{ if }\: \beta=0\\[4pt] \ln2 & \:\text{ if }\: \beta=\ln2\\[4pt] \frac{\beta\left(e^\beta-2\right)}{2\left(e^\beta-1\right)(\beta-\ln2)} & \:\text{ if }\: \beta\notin\{0,\ln2\} \end{cases}\end{align*}
$\sum\limits_{k\in \mathbb{N}}2^k\pi_{2^k}$
is finite. Otherwise,
$\mathbb{E}(R)=\infty$
.








Proof. (i) follows from the fact that
 $\mathcal{Z}$
-stability implies strict comparison of positive elements [
Reference Rørdam50
, Corollary 4·6], or in other words radius of comparison
$\mathcal{Z}$
-stability implies strict comparison of positive elements [
Reference Rørdam50
, Corollary 4·6], or in other words radius of comparison
 $R=0$
. With the present construction, this is only possible with initial value
$R=0$
. With the present construction, this is only possible with initial value
 $W_0=0$
, in which case each
$W_0=0$
, in which case each
 $X_i$
is a point, so
$X_i$
is a point, so
 $B(\Pi,\pi)$
is a UHF algebra (which is
$B(\Pi,\pi)$
is a UHF algebra (which is
 $\mathcal{Z}$
-stable).
$\mathcal{Z}$
-stable).
(ii) can be deduced using the probability density function
 $f_\beta$
of (5·3) and independence of
$f_\beta$
of (5·3) and independence of
 $W_0$
and W. From (5·3), we compute the (complementary) cumulative distribution function of
$W_0$
and W. From (5·3), we compute the (complementary) cumulative distribution function of
 $2^{-W}$
: for
$2^{-W}$
: for
 $\beta\ne0$
and
$\beta\ne0$
and
 ${1}/{2}\le x\le 1$
we have
${1}/{2}\le x\le 1$
we have
 \begin{align*}\mathbb{P}\left(2^{-W} \ge x\right) = \mathbb{P}\left(W\le\log_2\frac{1}{x}\right)= \int_0^{\log_2\frac{1}{x}} \frac{\beta e^{\beta t}}{e^\beta-1}dt= \frac{x^{-\beta/\ln2}-1}{e^\beta-1}= G_\beta(x).\end{align*}
\begin{align*}\mathbb{P}\left(2^{-W} \ge x\right) = \mathbb{P}\left(W\le\log_2\frac{1}{x}\right)= \int_0^{\log_2\frac{1}{x}} \frac{\beta e^{\beta t}}{e^\beta-1}dt= \frac{x^{-\beta/\ln2}-1}{e^\beta-1}= G_\beta(x).\end{align*}
If
 $\beta=0$
, this probability is
$\beta=0$
, this probability is
 \begin{align*}\mathbb{P}\left(2^{-W} \ge x\right) = \int_0^{\log_2\frac{1}{x}} 1\:dt= \log_2\frac{1}{x}= -\frac{\ln x}{\ln2}= G_0(x).\end{align*}
\begin{align*}\mathbb{P}\left(2^{-W} \ge x\right) = \int_0^{\log_2\frac{1}{x}} 1\:dt= \log_2\frac{1}{x}= -\frac{\ln x}{\ln2}= G_0(x).\end{align*}
Then, for
 $r>0$
we have
$r>0$
we have
 \begin{align*}\mathbb{P}(R\ge r) &= \mathbb{P}\left(W_0\cdot 2^{-W} \ge r\right)\\&= \sum_{k\in\mathbb{Z}}\mathbb{P}\left(W_0=2^k, W_0\cdot 2^{-W} \ge r\right)\\&= \sum_{k\in\mathbb{Z}}\pi_{2^k} \mathbb{P}\left(2^{-W} \ge \frac{r}{2^k}\right)\\&= \sum_{k\in \mathbb{Z}}\pi_{2^k}G_\beta\left(\frac{r}{2^k}\right).\end{align*}
\begin{align*}\mathbb{P}(R\ge r) &= \mathbb{P}\left(W_0\cdot 2^{-W} \ge r\right)\\&= \sum_{k\in\mathbb{Z}}\mathbb{P}\left(W_0=2^k, W_0\cdot 2^{-W} \ge r\right)\\&= \sum_{k\in\mathbb{Z}}\pi_{2^k} \mathbb{P}\left(2^{-W} \ge \frac{r}{2^k}\right)\\&= \sum_{k\in \mathbb{Z}}\pi_{2^k}G_\beta\left(\frac{r}{2^k}\right).\end{align*}
(iii) now follows from (ii), thanks to the well-known formula
 \begin{align*}\mathbb{E}(R) = \int_0^\infty \mathbb{P}(R\ge r) dr\end{align*}
\begin{align*}\mathbb{E}(R) = \int_0^\infty \mathbb{P}(R\ge r) dr\end{align*}
(see for example [ Reference Feller21 , V·6, Lemma 1]). Using (ii) and the monotone convergence theorem, we can compute this as
 \begin{align*}\mathbb{E}(R) = \sum_{k\in \mathbb{Z}}\pi_{2^k}\int_0^\infty G_\beta\left(\frac{r}{2^k}\right) dr.\end{align*}
\begin{align*}\mathbb{E}(R) = \sum_{k\in \mathbb{Z}}\pi_{2^k}\int_0^\infty G_\beta\left(\frac{r}{2^k}\right) dr.\end{align*}
If
 $\beta=0$
, this is
$\beta=0$
, this is
 \begin{align*}\mathbb{E}(R) &= \sum_{k\in \mathbb{Z}}\pi_{2^k}\left(2^{k-1}+\int_{2^{k-1}}^{2^k} -\frac{\ln r/2^k}{\ln2} dr\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\left(\frac{1}{2}+\int_{\frac{1}{2}}^{1} -\frac{\ln t}{\ln2} dt\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\frac{1}{\ln4}.\end{align*}
\begin{align*}\mathbb{E}(R) &= \sum_{k\in \mathbb{Z}}\pi_{2^k}\left(2^{k-1}+\int_{2^{k-1}}^{2^k} -\frac{\ln r/2^k}{\ln2} dr\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\left(\frac{1}{2}+\int_{\frac{1}{2}}^{1} -\frac{\ln t}{\ln2} dt\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\frac{1}{\ln4}.\end{align*}
If
 $\beta=\ln2$
, we have
$\beta=\ln2$
, we have
 \begin{align*}\mathbb{E}(R) &= \sum_{k\in \mathbb{Z}}\pi_{2^k}\left(2^{k-1}+\int_{2^{k-1}}^{2^k}\left(\frac{2^k}{r}-1\right)dr\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\left(\frac{1}{2}+\int_{\frac{1}{2}}^{1}\left(\frac{1}{t}-1\right)dt\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\ln2.\end{align*}
\begin{align*}\mathbb{E}(R) &= \sum_{k\in \mathbb{Z}}\pi_{2^k}\left(2^{k-1}+\int_{2^{k-1}}^{2^k}\left(\frac{2^k}{r}-1\right)dr\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\left(\frac{1}{2}+\int_{\frac{1}{2}}^{1}\left(\frac{1}{t}-1\right)dt\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\ln2.\end{align*}
Finally, if
 $\beta\notin\{0,\ln2\}$
, we have
$\beta\notin\{0,\ln2\}$
, we have
 \begin{align*}\mathbb{E}(R) &= \sum_{k\in \mathbb{Z}}\pi_{2^k}\left(2^{k-1}+\int_{2^{k-1}}^{2^k}\left(\frac{\left(r/2^k\right)^{-\beta/\ln2}-1}{e^\beta-1}\right)dr\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\left(\frac{1}{2}+\int_{\frac{1}{2}}^{1}\left(\frac{t^{-\beta/\ln2}-1}{e^\beta-1}\right)dt\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\frac{\beta\left(e^\beta-2\right)}{2\left(e^\beta-1\right)(\beta-\ln2)}.\end{align*}
\begin{align*}\mathbb{E}(R) &= \sum_{k\in \mathbb{Z}}\pi_{2^k}\left(2^{k-1}+\int_{2^{k-1}}^{2^k}\left(\frac{\left(r/2^k\right)^{-\beta/\ln2}-1}{e^\beta-1}\right)dr\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\left(\frac{1}{2}+\int_{\frac{1}{2}}^{1}\left(\frac{t^{-\beta/\ln2}-1}{e^\beta-1}\right)dt\right)\\&= \sum_{k\in \mathbb{Z}}2^k\pi_{2^k}\frac{\beta\left(e^\beta-2\right)}{2\left(e^\beta-1\right)(\beta-\ln2)}.\end{align*}
5·4. Variations
In an alternative scenario, we proceed as follows. The initial value
 ${m_0}/{n_0}$
is once again specified by a probability distribution
${m_0}/{n_0}$
is once again specified by a probability distribution
 $\pi$
, let us say on the nonzero natural numbers (although this is immaterial for the ensuing discussion). The construction is essentially the same as in Section 5·2. The connecting maps
$\pi$
, let us say on the nonzero natural numbers (although this is immaterial for the ensuing discussion). The construction is essentially the same as in Section 5·2. The connecting maps
 $\varphi_i\colon B_i\to B_{i+1}$
are of the form
$\varphi_i\colon B_i\to B_{i+1}$
are of the form
 \begin{align*}\varphi_i(f)(t) = \mathrm{diag}\left(f\circ\pi_i^1(t),\dots,f\circ\pi_i^{m_{i+1}}(t),f\left(t_i^1\right),\dots,f\left(t_i^{i+1}\right)\right),\end{align*}
\begin{align*}\varphi_i(f)(t) = \mathrm{diag}\left(f\circ\pi_i^1(t),\dots,f\circ\pi_i^{m_{i+1}}(t),f\left(t_i^1\right),\dots,f\left(t_i^{i+1}\right)\right),\end{align*}
the point evaluations chosen to ensure simplicity of the limit. But this time, there are two possibilities:
-
(a) with probability
$p_i$
, we make a tame choice, that is, we set
$m_{i}=1$
, so that
${m_{i}}/({m_{i}+i}) = {1}/({i+1})$
; or -
(b) with probability
$q_i=1-p_i$
, we make a more exotic choice, that is, we set
$m_{i}=i(2^i-1)$
, so that
${m_{i}}/({m_{i}+i}) = 1-{1}/{2^i}$
.






The random inductive limit constructed this way is
 $\mathcal{Z}$
-stable if and only if we make the tame choice infinitely often, which occurs with probability
$\mathcal{Z}$
-stable if and only if we make the tame choice infinitely often, which occurs with probability
 \begin{align*}1-\sum_{j=0}^\infty p_{j}\prod_{i\ge j+1} q_i\end{align*}
\begin{align*}1-\sum_{j=0}^\infty p_{j}\prod_{i\ge j+1} q_i\end{align*}
(where
 $p_0=1$
). This means that, if for example
$p_0=1$
). This means that, if for example
 $q_i={1}/{2}$
for every i, then we almost surely construct a
$q_i={1}/{2}$
for every i, then we almost surely construct a
 $\mathcal{Z}$
-stable
$\mathcal{Z}$
-stable
 $\mathrm{C}^*$
-algebra.
$\mathrm{C}^*$
-algebra.
Suppose on the other hand that, while
 $q_1={1}/{2}$
, subsequently
$q_1={1}/{2}$
, subsequently
 $q_i=1-{1}/{i^2}$
for
$q_i=1-{1}/{i^2}$
for
 $i\ge2$
(say). Then, using the fact that
$i\ge2$
(say). Then, using the fact that
 \begin{align*}\prod_{i\ge m} \left(1-\frac{1}{i^2}\right) = \lim_{k\to\infty}\prod_{i=m}^k\frac{i-1}{i}\cdot\frac{i+1}{i} = \lim_{k\to\infty}\frac{m-1}{m}\cdot\frac{k+1}{k} = \frac{m-1}{m},\end{align*}
\begin{align*}\prod_{i\ge m} \left(1-\frac{1}{i^2}\right) = \lim_{k\to\infty}\prod_{i=m}^k\frac{i-1}{i}\cdot\frac{i+1}{i} = \lim_{k\to\infty}\frac{m-1}{m}\cdot\frac{k+1}{k} = \frac{m-1}{m},\end{align*}
the probability of a
 $\mathcal{Z}$
-stable limit is
$\mathcal{Z}$
-stable limit is
 \begin{align*}1-\left(\frac{2-1}{2} + \sum_{j=2}^\infty\frac{1}{j^2}\cdot\frac{j}{j+1}\right) = 1-\left(\frac{1}{2}+\frac{1}{2}\right) = 0,\end{align*}
\begin{align*}1-\left(\frac{2-1}{2} + \sum_{j=2}^\infty\frac{1}{j^2}\cdot\frac{j}{j+1}\right) = 1-\left(\frac{1}{2}+\frac{1}{2}\right) = 0,\end{align*}
so our random
 $\mathrm{C}^*$
-algebra is almost surely not
$\mathrm{C}^*$
-algebra is almost surely not
 $\mathcal{Z}$
-stable.
$\mathcal{Z}$
-stable.
6. Graph
$\mathrm{C}^*$
-algebras

By repeatedly creating random pairings, we construct a random r-regular multigraph
 $\hat{\mathbb{G}}_{n,r}$
on n labelled vertices, then generate the associated graph
$\hat{\mathbb{G}}_{n,r}$
on n labelled vertices, then generate the associated graph
 $\mathrm{C}^*$
-algebra
$\mathrm{C}^*$
-algebra
 $\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
. In this section, we investigate the asymptotic distribution of the
$\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
. In this section, we investigate the asymptotic distribution of the
 $K_0$
-group of this algebra.
$K_0$
-group of this algebra.
6·1. Background
A (countable) directed graph E consists of a vertex set
 $E^0$
, an edge set
$E^0$
, an edge set
 $E^1$
, and range and source maps
$E^1$
, and range and source maps
 $r,s\colon E^1\to E^0$
. A path in E is a (possibly finite) sequence of edges
$r,s\colon E^1\to E^0$
. A path in E is a (possibly finite) sequence of edges
 $(\alpha_i)_{i\ge1}$
such that
$(\alpha_i)_{i\ge1}$
such that
 $r(\alpha_i)=s(\alpha_{i+1})$
for every i, and a loop is a finite path whose initial and final vertices coincide. A loop
$r(\alpha_i)=s(\alpha_{i+1})$
for every i, and a loop is a finite path whose initial and final vertices coincide. A loop
 $\alpha=(\alpha_1,\dots,\alpha_n)$
has an exit if there exist
$\alpha=(\alpha_1,\dots,\alpha_n)$
has an exit if there exist
 $e\in E^1$
and
$e\in E^1$
and
 $i\in\{1,\dots,n\}$
such that
$i\in\{1,\dots,n\}$
such that
 $s(e)=s(\alpha_i)$
but
$s(e)=s(\alpha_i)$
but
 $e \ne \alpha_i$
. A vertex
$e \ne \alpha_i$
. A vertex
 $v\in E^0$
is called:
$v\in E^0$
is called:
-
(a) a source if
$r^{-1}(v)=\emptyset$
; -
(b) a sink if
$s^{-1}(v)=\emptyset$
; -
(c) an infinite emitter if
$|s^{-1}(v)|=\infty$
; -
(d) cofinal if it can be connected to some point in any given infinite path in E.



A Cuntz–Krieger E-family associated to a finite directed graph
 $E=(E^0,E^1,s,r)$
is a set
$E=(E^0,E^1,s,r)$
is a set
 \begin{equation} \left\{p_v \mid v\in E^0\right\} \cup \left\{s_e \mid e\in E^1\right\},\end{equation}
\begin{equation} \left\{p_v \mid v\in E^0\right\} \cup \left\{s_e \mid e\in E^1\right\},\end{equation}
where the
 $p_v$
are mutually orthogonal projections and the
$p_v$
are mutually orthogonal projections and the
 $s_e$
are partial isometries satisfying:
$s_e$
are partial isometries satisfying:
 \begin{align} s_e^*s_f &= 0 &&\forall\: e,f\in E^1 \text{ with } e\ne f \nonumber\\s_e^*s_e &= p_{r(e)} &&\forall\: e\in E^1 \nonumber\\s_es_e^* &\le p_{s(e)} &&\forall\: e\in E^1 \nonumber\\p_v &= \sum\limits_{e\in s^{-1}(v)} s_es_e^* &&\forall\: v\in E^0 \:\text{that is not a sink}.\end{align}
\begin{align} s_e^*s_f &= 0 &&\forall\: e,f\in E^1 \text{ with } e\ne f \nonumber\\s_e^*s_e &= p_{r(e)} &&\forall\: e\in E^1 \nonumber\\s_es_e^* &\le p_{s(e)} &&\forall\: e\in E^1 \nonumber\\p_v &= \sum\limits_{e\in s^{-1}(v)} s_es_e^* &&\forall\: v\in E^0 \:\text{that is not a sink}.\end{align}
(For countably infinite graphs, which we do not consider here, the last equation should hold for vertices v that are neither sinks nor infinite emitters.)
The graph algebra
 $\mathrm{C}^*(E)$
is the universal
$\mathrm{C}^*(E)$
is the universal
 $\mathrm{C}^*$
-algebra with generators (6·1) satisfying the relations (6·2). A Cuntz–Krieger algebra may be defined as the graph
$\mathrm{C}^*$
-algebra with generators (6·1) satisfying the relations (6·2). A Cuntz–Krieger algebra may be defined as the graph
 $\mathrm{C}^*$
-algebra of a finite graph without sinks or sources. By [
Reference Kumjian, Pask, Raeburn and Renault35
, Section 4], this is equivalent to the original definition [
Reference Cuntz and Krieger9
]. In fact (see [
Reference Arklint and Ruiz1
, Theorem 3·12]), a graph algebra
$\mathrm{C}^*$
-algebra of a finite graph without sinks or sources. By [
Reference Kumjian, Pask, Raeburn and Renault35
, Section 4], this is equivalent to the original definition [
Reference Cuntz and Krieger9
]. In fact (see [
Reference Arklint and Ruiz1
, Theorem 3·12]), a graph algebra
 $\mathrm{C}^*(E)$
is isomorphic to a Cuntz–Krieger algebra if and only if E is a finite graph with no sinks, or equivalently if
$\mathrm{C}^*(E)$
is isomorphic to a Cuntz–Krieger algebra if and only if E is a finite graph with no sinks, or equivalently if
 $\mathrm{C}^*(E)$
is unital and
$\mathrm{C}^*(E)$
is unital and
 \begin{align*}\mathrm{rank} (K_0(\mathrm{C}^*(E))) = \mathrm{rank} (K_1(\mathrm{C}^*(E))).\end{align*}
\begin{align*}\mathrm{rank} (K_0(\mathrm{C}^*(E))) = \mathrm{rank} (K_1(\mathrm{C}^*(E))).\end{align*}
In general, if E is a finite graph with no sinks, and
 $A_E$
is its adjacency matrix
$A_E$
is its adjacency matrix
 \begin{align*}A_E(i,j) = \left|\left\{e\in E^1 \mid s(e)=i, r(e)=j\right\}\right|,\end{align*}
\begin{align*}A_E(i,j) = \left|\left\{e\in E^1 \mid s(e)=i, r(e)=j\right\}\right|,\end{align*}
then
 $K_*(\mathrm{C}^*(E))$
is given by
$K_*(\mathrm{C}^*(E))$
is given by
 \begin{equation} K_0\left(\mathrm{C}^*(E)\right) \cong \mathrm{coker}\left(A_E^t-I\right) \quad\text{and}\quad K_1\left(\mathrm{C}^*(E)\right) \cong \ker\left(A_E^t-I\right).\end{equation}
\begin{equation} K_0\left(\mathrm{C}^*(E)\right) \cong \mathrm{coker}\left(A_E^t-I\right) \quad\text{and}\quad K_1\left(\mathrm{C}^*(E)\right) \cong \ker\left(A_E^t-I\right).\end{equation}
(See [ 47 , Theorem 3·2], where this is proved for row-finite graphs possibly with sinks, and also [ Reference Drinen and Tomforde10 , Theorem 3·1], which considers arbitrary graphs.)
Finally, we recall conditions on E that correspond to
 $\mathrm{C}^*(E)$
being a Kirchberg algebra (see [
Reference Bates, Pask, Raeburn and Szymański3
, Propositions 5·1 and 5·3] and [
Reference Kumjian, Pask and Raeburn34
, Corollary 3·10]).
$\mathrm{C}^*(E)$
being a Kirchberg algebra (see [
Reference Bates, Pask, Raeburn and Szymański3
, Propositions 5·1 and 5·3] and [
Reference Kumjian, Pask and Raeburn34
, Corollary 3·10]).
Proposition 6·1. Let E be a finite directed graph.
-
(i) If every vertex connects to a loop and every loop has an exit, then
$\mathrm{C}^*(E)$
is purely infinite.
-
(ii) If E has no sinks, then
$\mathrm{C}^*(E)$
is simple if and only if every loop in E has an exit and every vertex in E is cofinal. In this case,
$\mathrm{C}^*(E)$
is an AF algebra if E has no loops, and otherwise is purely infinite.



6·2. The construction
For a given natural number r, a multigraph E is said to be r-regular if every vertex has degree r. There are several probability distributions that can be used to construct a random r-regular (undirected, multi-) graph on
 $n\in2\mathbb{N}$
labelled vertices. We will use the perfect matchings model
$n\in2\mathbb{N}$
labelled vertices. We will use the perfect matchings model
 \begin{align*}\hat{\mathbb{G}}_{n,r}=\underbrace{\mathbb{G}_{n,1}+\dots+\mathbb{G}_{n,1}}_r,\end{align*}
\begin{align*}\hat{\mathbb{G}}_{n,r}=\underbrace{\mathbb{G}_{n,1}+\dots+\mathbb{G}_{n,1}}_r,\end{align*}
that is, the union of r independent, uniformly random perfect matchings. One might also consider the uniform model
 $\mathbb{G}^{\prime}_{n,r}$
, that is, a random element of the set of r-regular multigraphs with the uniform distribution, conditioned on there being no loops. By [
Reference Janson28
, Theorem 11], these two models are contiguous, which means that a sequence of events that occurs asymptotically almost surely (that is, with probability approaching 1 as
$\mathbb{G}^{\prime}_{n,r}$
, that is, a random element of the set of r-regular multigraphs with the uniform distribution, conditioned on there being no loops. By [
Reference Janson28
, Theorem 11], these two models are contiguous, which means that a sequence of events that occurs asymptotically almost surely (that is, with probability approaching 1 as
 $n\to\infty$
) according to one distribution, occurs asymptotically almost surely according to the other.
$n\to\infty$
) according to one distribution, occurs asymptotically almost surely according to the other.
We convert the undirected graph
 $\hat{\mathbb{G}}_{n,r}$
into a directed one by replacing each edge (between given vertices i, j) by two (one from i to j and one from j to i).
$\hat{\mathbb{G}}_{n,r}$
into a directed one by replacing each edge (between given vertices i, j) by two (one from i to j and one from j to i).
Remark 6·2. One can expect strong connectivity in random regular graphs. Conditioning
 $\mathbb{G}^{\prime}_{n,r}$
on there being no multiple edges, one obtains (up to contiguity) the random r-regular graph
$\mathbb{G}^{\prime}_{n,r}$
on there being no multiple edges, one obtains (up to contiguity) the random r-regular graph
 $\mathbb{G}_{n,r}$
. By work of Bollobás [
Reference Bollobás5
] (see [
22
, Theorem 11·9]),
$\mathbb{G}_{n,r}$
. By work of Bollobás [
Reference Bollobás5
] (see [
22
, Theorem 11·9]),
 $\mathbb{G}_{n,r}$
is asymptotically almost surely (a.a.s.) r-connected. For our purposes, it will be enough for us to know that
$\mathbb{G}_{n,r}$
is asymptotically almost surely (a.a.s.) r-connected. For our purposes, it will be enough for us to know that
 $\hat{\mathbb{G}}_{n,r}$
is a.a.s. (1-) connected, which is not difficult to show (see [
Reference Lavrov36
]).
$\hat{\mathbb{G}}_{n,r}$
is a.a.s. (1-) connected, which is not difficult to show (see [
Reference Lavrov36
]).
6·3. Probabilities
Theorem 6·3.
For every even integer n and every integer
 $r\ge3$
,
$r\ge3$
,
 $\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
is isomorphic to a Cuntz–Krieger algebra that is purely infinite and is asymptotically almost surely simple. Moreover, for any finite set P of odd primes not dividing
$\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
is isomorphic to a Cuntz–Krieger algebra that is purely infinite and is asymptotically almost surely simple. Moreover, for any finite set P of odd primes not dividing
 $r-1$
, and any finite abelian group V such that
$r-1$
, and any finite abelian group V such that
 $|V|$
is in the multiplicative semigroup generated by
$|V|$
is in the multiplicative semigroup generated by
 $P\subseteq\mathbb{N}$
,
$P\subseteq\mathbb{N}$
,
 \begin{equation} \lim_{n\in2\mathbb{N}}\mathbb{P}\left(K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes\prod_{p\in P}\mathbb{Z}_p\cong V\right) = N(V)\prod_{p\in P}\prod_{k\ge0}\left(1-p^{-2k-1}\right),\end{equation}
\begin{equation} \lim_{n\in2\mathbb{N}}\mathbb{P}\left(K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes\prod_{p\in P}\mathbb{Z}_p\cong V\right) = N(V)\prod_{p\in P}\prod_{k\ge0}\left(1-p^{-2k-1}\right),\end{equation}
where
 $\mathbb{Z}_p$
denotes the p-adic integers, and
$\mathbb{Z}_p$
denotes the p-adic integers, and
 \begin{align*}N(V) = \frac{|\{\text{symmetric, bilinear, perfect } \varphi\colon V\times V\to\mathbb{C}^*\}|}{|V|\cdot|\mathrm{Aut}(V)|}.\end{align*}
\begin{align*}N(V) = \frac{|\{\text{symmetric, bilinear, perfect } \varphi\colon V\times V\to\mathbb{C}^*\}|}{|V|\cdot|\mathrm{Aut}(V)|}.\end{align*}
Here, a symmetric,
 $\mathbb{Z}$
-bilinear map
$\mathbb{Z}$
-bilinear map
 $\varphi\colon V\times V\to\mathbb{C}^*$
is perfect if the only
$\varphi\colon V\times V\to\mathbb{C}^*$
is perfect if the only
 $v\in V$
with
$v\in V$
with
 $\varphi(v,V)=1$
or
$\varphi(v,V)=1$
or
 $\varphi(V,v)=1$
is
$\varphi(V,v)=1$
is
 $v=0$
. For a discussion of the significance of the normalising factor
$v=0$
. For a discussion of the significance of the normalising factor
 $|V|\cdot|\mathrm{Aut}(V)|$
, see [
Reference Wood60
, Section 1], where it is also noted that, if V is a finite abelian p-group
$|V|\cdot|\mathrm{Aut}(V)|$
, see [
Reference Wood60
, Section 1], where it is also noted that, if V is a finite abelian p-group
 \begin{align*}V=\bigoplus_{i=1}^M \mathbb{Z}/p^{\lambda_i}\mathbb{Z}\end{align*}
\begin{align*}V=\bigoplus_{i=1}^M \mathbb{Z}/p^{\lambda_i}\mathbb{Z}\end{align*}
with
 $\lambda_1\ge\lambda_2\ge\dots\ge\lambda_M$
, then
$\lambda_1\ge\lambda_2\ge\dots\ge\lambda_M$
, then
 \begin{align*}N(V) = p^{-\sum_i\frac{\mu_i(\mu_i+1)}{2}}\prod_{i=1}^{\lambda_1}\prod_{j=1}^{\big\lfloor\frac{\mu_i-\mu_{i+1}}{2}\big\rfloor}\left(1-p^{-2j}\right)^{-1},\end{align*}
\begin{align*}N(V) = p^{-\sum_i\frac{\mu_i(\mu_i+1)}{2}}\prod_{i=1}^{\lambda_1}\prod_{j=1}^{\big\lfloor\frac{\mu_i-\mu_{i+1}}{2}\big\rfloor}\left(1-p^{-2j}\right)^{-1},\end{align*}
where
 $\mu_i=|\{j\mid \lambda_j\ge i\}|$
. Consequently, for large p,
$\mu_i=|\{j\mid \lambda_j\ge i\}|$
. Consequently, for large p,
 \begin{align*}\lim_{n\in2\mathbb{N}}\mathbb{P}\left(K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes \mathbb{Z}_p\cong \mathbb{Z}/p^N\mathbb{Z}\right) \approx p^{-N},\end{align*}
\begin{align*}\lim_{n\in2\mathbb{N}}\mathbb{P}\left(K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes \mathbb{Z}_p\cong \mathbb{Z}/p^N\mathbb{Z}\right) \approx p^{-N},\end{align*}
while
 \begin{align*}\lim_{n\in2\mathbb{N}}\mathbb{P}\left(K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes \mathbb{Z}_p\cong (\mathbb{Z}/p\mathbb{Z})^N\right) \approx p^{-\frac{N(N+1)}{2}}.\end{align*}
\begin{align*}\lim_{n\in2\mathbb{N}}\mathbb{P}\left(K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes \mathbb{Z}_p\cong (\mathbb{Z}/p\mathbb{Z})^N\right) \approx p^{-\frac{N(N+1)}{2}}.\end{align*}
As for the left-hand side of (6·4) when
 $P=\{p\}$
, note that
$P=\{p\}$
, note that
 $K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes\mathbb{Z}_p\cong V$
precisely when
$K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)\otimes\mathbb{Z}_p\cong V$
precisely when
 $K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)$
is a finite abelian group whose p-Sylow subgroup is isomorphic to V. This means that, compared to its counterpart
$K_0\left(\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)\right)$
is a finite abelian group whose p-Sylow subgroup is isomorphic to V. This means that, compared to its counterpart
 $(\mathbb{Z}/p\mathbb{Z})^N$
, the cyclic group
$(\mathbb{Z}/p\mathbb{Z})^N$
, the cyclic group
 $\mathbb{Z}/p^N\mathbb{Z}$
is much more likely to appear in the
$\mathbb{Z}/p^N\mathbb{Z}$
is much more likely to appear in the
 $K_0$
-group of a random graph algebra
$K_0$
-group of a random graph algebra
 $\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
.
$\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
.
Proof of Theorem 6·3. By construction,
 $\hat{\mathbb{G}}_{n,r}$
has neither sinks nor sources, and every vertex is the starting point of at least
$\hat{\mathbb{G}}_{n,r}$
has neither sinks nor sources, and every vertex is the starting point of at least
 $r\ge3$
loops, so by Proposition 6·1(i),
$r\ge3$
loops, so by Proposition 6·1(i),
 $\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
is isomorphic to a purely infinite Cuntz-Krieger algebra. Since
$\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
is isomorphic to a purely infinite Cuntz-Krieger algebra. Since
 $\hat{\mathbb{G}}_{n,r}$
is a.a.s. connected (see [
Reference Lavrov36
]), it follows from Proposition 6·1(ii) that
$\hat{\mathbb{G}}_{n,r}$
is a.a.s. connected (see [
Reference Lavrov36
]), it follows from Proposition 6·1(ii) that
 $\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
is a.a.s. simple.
$\mathrm{C}^*\left(\hat{\mathbb{G}}_{n,r}\right)$
is a.a.s. simple.
The second statement is proved in exactly the same way as [
Reference Nguyen and Wood44
, Theorem 1·5], but with the (symmetric) adjacency matrix
 $C_n$
replaced by
$C_n$
replaced by
 $C_n-I$
. The key point is that, by Wood’s incredibly powerful limiting distribution/moment machinery [
Reference Wood60
, Theorem 6·1, Theorem 8·3 and Corollary 9·2], it suffices to show that the expected number of surjections from
$C_n-I$
. The key point is that, by Wood’s incredibly powerful limiting distribution/moment machinery [
Reference Wood60
, Theorem 6·1, Theorem 8·3 and Corollary 9·2], it suffices to show that the expected number of surjections from
 $\mathrm{coker}(C_n-I)$
to V tends to the size
$\mathrm{coker}(C_n-I)$
to V tends to the size
 $|\wedge^2V|$
of the exterior power of V as
$|\wedge^2V|$
of the exterior power of V as
 $n\in2\mathbb{N}$
tends to
$n\in2\mathbb{N}$
tends to
 $\infty$
. Here is a brief summary of the argument.
$\infty$
. Here is a brief summary of the argument.
Write
 $I(V) = \mathrm{span}_\mathbb{Z}\{v\otimes v \mid v\in V\}$
, so that
$I(V) = \mathrm{span}_\mathbb{Z}\{v\otimes v \mid v\in V\}$
, so that
 $\wedge^2V = (V\otimes V)/I(V)$
. For
$\wedge^2V = (V\otimes V)/I(V)$
. For
 $q=(q_1,\dots,q_n)\in V^n=\mathrm{Hom}(\mathbb{Z}^n,V)$
, let
$q=(q_1,\dots,q_n)\in V^n=\mathrm{Hom}(\mathbb{Z}^n,V)$
, let
 $\mathrm{MinCos}_q$
be the minimal coset of V containing
$\mathrm{MinCos}_q$
be the minimal coset of V containing
 $\{q_1,\dots,q_n\}$
, that is,
$\{q_1,\dots,q_n\}$
, that is,
 \begin{align*}\mathrm{MinCos}_q = q_n+\mathrm{span}_\mathbb{Z}\{q_i-q_n \mid 1\le i\le n-1\}.\end{align*}
\begin{align*}\mathrm{MinCos}_q = q_n+\mathrm{span}_\mathbb{Z}\{q_i-q_n \mid 1\le i\le n-1\}.\end{align*}
For
 $k\in\mathbb{N}$
, define
$k\in\mathbb{N}$
, define
 \begin{align*}R^S(q,k) = \left\{s\in(k\cdot\mathrm{MinCos}_q)^n \mid \sum_{i=1}^n q_i\otimes s_i\in I(V) \text{ and } \sum_{i=1}^n s_i = k\sum_{i=1}^n q_i \right\}.\end{align*}
\begin{align*}R^S(q,k) = \left\{s\in(k\cdot\mathrm{MinCos}_q)^n \mid \sum_{i=1}^n q_i\otimes s_i\in I(V) \text{ and } \sum_{i=1}^n s_i = k\sum_{i=1}^n q_i \right\}.\end{align*}
For every
 $q\in V^n$
, we have
$q\in V^n$
, we have
 \begin{align*}q \in R^S(q,r) \iff 0 \in R^S(q,r-1)\end{align*}
\begin{align*}q \in R^S(q,r) \iff 0 \in R^S(q,r-1)\end{align*}
and, since
 $C_n$
is obtained from r perfect matchings on
$C_n$
is obtained from r perfect matchings on
 $\{1,\dots,n\}$
, it is not hard to see that
$\{1,\dots,n\}$
, it is not hard to see that
 $(C_n-I)q\in R^S(q,r-1)$
. By [
Reference Mészáros42
, Theorem 1·6] and the computations that appear in the proof of [
Reference Nguyen and Wood44
, Theorem 1·5],
$(C_n-I)q\in R^S(q,r-1)$
. By [
Reference Mészáros42
, Theorem 1·6] and the computations that appear in the proof of [
Reference Nguyen and Wood44
, Theorem 1·5],
 \begin{align*}\lim_{n\in2\mathbb{N}}\mathbb{E}(|\mathrm{Sur}(\mathrm{coker}(C_n-I),V)|) &= \lim_{n\in2\mathbb{N}}\sum_{\substack{q\in\mathrm{Sur}(\mathbb{Z}^n,V)\\q\in R^S(q,r)}} \mathbb{P}(C_nq=q)\\&= \lim_{n\in2\mathbb{N}}\sum_{\substack{q\in\mathrm{Sur}(\mathbb{Z}^n,V)\\q\in R^S(q,r)}} |R^S(q,r)|^{-1}\end{align*}
\begin{align*}\lim_{n\in2\mathbb{N}}\mathbb{E}(|\mathrm{Sur}(\mathrm{coker}(C_n-I),V)|) &= \lim_{n\in2\mathbb{N}}\sum_{\substack{q\in\mathrm{Sur}(\mathbb{Z}^n,V)\\q\in R^S(q,r)}} \mathbb{P}(C_nq=q)\\&= \lim_{n\in2\mathbb{N}}\sum_{\substack{q\in\mathrm{Sur}(\mathbb{Z}^n,V)\\q\in R^S(q,r)}} |R^S(q,r)|^{-1}\end{align*}
 \begin{align*}&= \lim_{n\in2\mathbb{N}}\sum_{\substack{q\in\mathrm{Sur}(\mathbb{Z}^n,V)\\0\in R^S(q,r-1)}} \frac{|\wedge^2V|}{|V|^{n-1}}\\&= \lim_{n\in2\mathbb{N}}(|V|^{n-1} + o(|V|^n))\frac{|\wedge^2V|}{|V|^{n-1}}\\&= |\wedge^2V|.\end{align*}
\begin{align*}&= \lim_{n\in2\mathbb{N}}\sum_{\substack{q\in\mathrm{Sur}(\mathbb{Z}^n,V)\\0\in R^S(q,r-1)}} \frac{|\wedge^2V|}{|V|^{n-1}}\\&= \lim_{n\in2\mathbb{N}}(|V|^{n-1} + o(|V|^n))\frac{|\wedge^2V|}{|V|^{n-1}}\\&= |\wedge^2V|.\end{align*}
Acknowledgements
This research was supported by the GAČR project 22-07833K and RVO: 67985840. It germinated in conversations with Ali Asadi–Vasfi, Tristan Bice, Karen Strung and other members of the Prague NCG&T group. I am grateful for the kind hospitality of my colleagues Dr. Dane Mejias in Seattle and Dr. Holly Morgan in Halifax during a visit to North America in the summer of 2022, when much of this paper was completed.


























 Open access
Open access