



1. Introduction
When we look at the natural niche in which language occurs, that is, in face-to-face interactions, it is evident that not only are arbitrary and categorical properties (Hockett, Reference Hockett1960, Reference Hockett1978) used to express meaning, but also meanings communicated with depictions through iconic representations constitute an integral part of how speakers and signers actually use language. In fact, the distinction between the descriptive and depictive properties of language has been made for at least the last 15 years (Clark & Gerrig, Reference Clark and Gerrig1990; Cormier, Smith, & Sevcikova-Sehyr Reference Cormier, Smith and Sevcikova-Sehyr2015a; Ferrara & Hodge, Reference Ferrara and Hodge2018; Holt, Reference Holt2000; Liddell Reference Liddell2003, among others). The definition of depiction, and its contrast with description, is well captured by Clark (Reference Clark2016):
To describe something is to tell others about its properties—to represent it categorically. […] To depict something, however, is to show others what it looks or sounds or feels like. (2016, p.342).
In recent years there has been an ever-growing interest with regard to depiction as an integral part of linguistic structure in both signed and spoken languages (e.g., Clark, Reference Clark2016, Reference Clark and Hagoort2019; Dingemanse, Reference Dingemanse2018; Dingemanse, Blasi, Lupyan, Christiansen, & Monaghan, Reference Dingemanse, Blasi, Lupyan, Christiansen and Monaghan2015; Dudis, Reference Dudis2004, Reference Dudis and Roy2011; Ferrara & Halvorsen, Reference Ferrara and Halvorsen2017; Johnston, Reference Johnston2013; Kendon, Reference Kendon2014; Müller, Reference Müller2018). In the present study, we focus on so-called ‘depiction’ and show that in sign languages it can also actually be used for descriptive or referential purposes, and in particular to attain communicative efficiency. Communicative efficiency can be described as a fundamental property that shapes the structure of languages “to facilitate easy, rapid, and robust communication” (Gibson et al., Reference Gibson, Futrell, Piantadosi, Dautriche, Mahowald, Bergen and Levy2019, p. 389).
In a previous study, Slonimska, Özyürek, and Capirci (Reference Slonimska, Özyürek and Capirci2020) investigated whether signers use simultaneity, a property afforded by use of multiple articulators and iconicity, for achieving communicative efficiency. Namely, authors assessed whether signers increased their use of simultaneous structures to encode information as a function of an increase in the amount of information that needed to be communicated. In this study, the amount of information signers needed to encode was experimentally manipulated, in a non-narrative context, and as the amount of information that needed to be communicated by the signers increased, so did the use of simultaneous constructions. The present study uses the same data and experimental manipulation of communicative efficiency as in Slonimska et al. (Reference Slonimska, Özyürek and Capirci2020) and further investigates whether greater need for communicative efficiency also results in greater use of depiction, something that has not been investigated in the previous or any other study.
In sign languages, depiction plays a prominent role, given the rich iconic potential of the visual modality in which these languages are realized. Depictions in sign languages can be grouped into two types: depictions from an observer perspective and depictions from a character perspective (see Kurz, Mullaney, & Occhino, Reference Kurz, Mullaney and Occhino2019, for a different terminology). Manual depictions from the observer perspective are called ‘depicting constructions’ (also called ‘classifier constructions’, ‘classifier predicates’, ‘polycomponential verbs’, and ‘polymorphemic verbs’; see Schembri, Reference Schembri and Emmorey2003). These constructions depict events in the signing space in front of the signer on a miniature scale. Non-manual depictions known as ‘mouth gestures’ or ‘mouth actions’ (Boyes-Braem & Sutton-Spence, Reference Boyes-Braem and Sutton-Spence2001) can be used to provide adjectival or adverbial information in respect to the manual depicting constructions (Crasborn, Van Der Kooij, Waters, Woll, & Mesch, Reference Crasborn, Van Der Kooij, Waters, Woll and Mesch2008; Fontana, Reference Fontana2008). Depictions from the character perspective, in contrast, put the signer’s body at the center of the production as the signer projects the referent directly onto their body and depicts the actions performed by the referent with corresponding body parts in life-sized scale (Cormier et al., Reference Cormier, Smith and Sevcikova-Sehyr2015a; Kurz et al., Reference Kurz, Mullaney and Occhino2019; Perniss, Reference Perniss2007). Such a depicting strategy is called a ‘constructed action’ (Metzger, Reference Metzger1995; Tannen, Reference Tannen1989), and it is the focus of the present study.
Recent studies have argued that constructed action (CA) is used for referential purposes, including encoding the core meaning elements, i.e., argument and predicate (Cormier, Smith, & Zwets, Reference Cormier, Smith and Sevcikova2013; Pizzuto, Rossini, Sallandre, & Wilkinson, Reference Pizzuto, Rossini, Sallandre and Wilkinson2006; Ferrara & Johnston, 2014; Hodge & Ferrara, Reference Hodge and Ferrara2014; Hodge & Johnson, Reference Hodge and Johnston2014; Jantunen, Reference Jantunen2017). However, most research on CA is embedded in a narrative context. Such a context might pose a problem in assessing the whole spectrum of the referential capacity of CA considering that a crucial factor in narration is the evaluative function (or ‘emotive function’, in the terms of Jakobson, Reference Jakobson and Sebeok1960), which is used to ‘enhance’ referential information (Labov & Waletzky, Reference Labov and Waletzky1967). Accordingly, when looking at encodings of narratives it becomes practically impossible to tease apart whether CA is used because of its contribution to the evaluative function (i.e., making narration more vivid and entertaining through depiction) or for referential purposes (i.e., to encode the core meaning elements of the event), or a mix of the two. For example, research has shown that in narratives, the same content can be signed with or without CA, indicating that its use is not obligatory but rather can be a matter of “idiosyncratic preferences, storytelling experience, and sociolinguistic effects such as age and education” (Hodge & Ferrara, Reference Hodge and Ferrara2014, p. 388). Accordingly, in order to truly comprehend CA’s referential capacity, it also has to be studied in contexts in which the necessity for referential function is unquestionable, as in contexts where information has to be communicated efficiently.
Slonimska et al. (Reference Slonimska, Özyürek and Capirci2020) hypothesized that when signers are faced with increasing information encoding demands they might achieve communicative efficiency in a comparable way as spoken languages do, i.e., by reducing dependency distances. Dependency distance minimization refers to a tendency of language users (studied only in spoken languages so far) to cluster semantically and syntactically related words closer together (Temperley & Gildea, Reference Temperley and Gildea2018). This strategy has been argued to lead to faster access to syntactic and semantic representation in production and comprehension (Hawkins, Reference Hawkins2004), and thus to increase communicative efficiency (Gibson et al., Reference Gibson, Futrell, Piantadosi, Dautriche, Mahowald, Bergen and Levy2019). Slonimska et al. (Reference Slonimska, Özyürek and Capirci2020) were interested in exploring whether sign language users exploited multiple articulators and iconicity for encoding multiple information simultaneously, considering that dependency distances could be reduced to the minimum in this way. Thus, they assessed whether signers increase the use of simultaneous constructions with the increase of the information that is required to be communicated. They found that this was indeed the case. For example, signers could encode information about the agent, patient, and their actions (e.g., a stimulus representing a cartoon image of a woman holding a boy and the boy pinching the cheek of the woman) in a single simultaneous construction as opposed to encoding each piece of information in a one-by-one fashion. Not only did the signers increase the encoding of information in a simultaneous as opposed to a strictly linear manner, but they also increased the density of the simultaneously encoded information. Density of simultaneity was quantified as the number of semantic information units forming a single event (stimuli representing a cartoon image of, e.g., a cat holding a bear, a dog holding a bird, and the bird pecking the cheek of the dog). While the aforementioned study provides evidence that signers use more simultaneous constructions when faced with increasing information demands, the linguistic strategies used and the role of depictions in achieving communicative efficiency still remain to be explored.
The aim of the present study is twofold. First, we aim to extend the assessment of the referential function of CA to a controlled experimental context through a study designed to elicit strictly referential information, thereby reducing to a minimum the need for the evaluative function. Second, we aim to assess whether CA is used to achieve efficient communication by way of an experimental design (used in Slonimska et al., Reference Slonimska, Özyürek and Capirci2020) in which signers are required to encode messages with increasing information density (i.e., the number of semantic information units that need to be encoded). In such a setting a signer is expected to communicate in a way that encodes the message efficiently in terms of minimizing their own effort as well as making the message informative enough for the addressee (Gibson et al., Reference Gibson, Futrell, Piantadosi, Dautriche, Mahowald, Bergen and Levy2019; Grice, Reference Grice, Cole and Morgan1975). As the information demands increase, the task of accommodating both of these aspects becomes harder. As a result, we expect that when signers are faced with increasing information encoding demands they will be likely to employ linguistic strategies which lead to efficient communication. Thus, if CA use increases as the amount of information to be communicated also increases, it would serve as a strong indicator that this strategy is used with referential purpose in order to achieve communicative efficiency.
1.1. constructed action and types of iconicity
Constructed action (Metzger Reference Metzger1995), also known as ‘role shift’ (Padden Reference Padden1986; Quer, Reference Quer2011), ‘transfer of person’ (Cuxac, Reference Cuxac1999, Reference Cuxac2000; Cuxac & Sallandre, Reference Cuxac and Sallandre2007; Volterra, Roccaforte, Di Renzo, & Fontana, Reference Volterra, Roccaforte, Di Renzo and Fontana2019), and ‘enactment’ (Ferrara & Johnston, Reference Ferrara and Johnston2014; Hodge & Johnston, Reference Hodge and Johnston2014), is a depicting strategy attested in a plethora of sign languages (see Kurz et al., Reference Kurz, Mullaney and Occhino2019) and is when the signer uses one or more bodily articulators, including hands, torso, head, eye-gaze, and facial expressions, to directly map the referent to the signer’s corresponding body part. Accordingly, the event depicted is represented as if it were from the perspective of the character involved in the event. Thus, the actions performed or feelings expressed by the referent are encoded by the signer depicting the actions and/or feelings with their own upper body. Such depiction might sound quite familiar to non-signers considering that speakers also make use of a vast array of depictions, including ‘demonstrations’ and character viewpoint gestures reminiscent of CA (Clark & Gerrig, Reference Clark and Gerrig1990; Clark, Reference Clark2016). Possibly for this reason, CA has been mostly regarded as exploiting only ‘imagistic iconicity’, i.e., resemblance between the form of the sign and its meaning (Cuxac, Reference Cuxac1999; Perniss, Reference Perniss2007; Taub, Reference Taub2001), and thus as representing the referent and all its properties imagistically (e.g., Hodge & Ferrara, Reference Hodge and Ferrara2014; Ferrara & Johnston, Reference Ferrara and Johnston2014; Jantunen, Reference Jantunen2017). While some research does identify sub-elements out of which CA is actually constructed, it appears to be treated mainly as a degree of how intensely the referent depicted by CA is marked (Cormier et al., Reference Cormier, Smith and Sevcikova-Sehyr2015a). For example, Cormier et al. propose that CA can vary in how intensely it marks a depicted character based on how many articulators are used in the construction. That is, different articulators can be used to varying degrees and thus CA can be considered as being overt, reduced, or subtle. Under this view, the signer chooses how strongly to mark the imagistic resemblance between the referent and the depiction. Cormier et al. also mention the possibility of using a type of mixed CA (although it was not attested in their data), in which two or more characters can be encoded simultaneously. However, they also note that “the situations when [mixed CA] may be expected to occur are not well understood” (Reference Cormier, Smith and Sevcikova-Sehyr2015a, p. 192).
In the present study we argue that the use of a varying number of articulators during CA can not only be considered a stronger or weaker character marker but also a tool to encode different information by means of different articulators, and thus can be used for informative rather than intensifying purposes. For example, a signer who tilts their head upwards while depicting a person shaking hands does not only intensify the depiction of the character but also provides information in its own right, i.e., that the character is shorter than the person he or she is shaking hands with. Furthermore, this example also illustrates that both the articulators and their relation to each other provide information that is necessary for the decoding. In other words, we argue that CA possesses not only imagistic iconicity but also ‘diagrammatic iconicity’, i.e., the relation between the components of the sign or the construction representing the relation between the components of meaning (see Perniss, Reference Perniss2007, for an overview of views on imagistic versus diagrammatic iconicity). If such a view is adopted, then the use of specific body articulators in CA does not necessarily function as a stronger marker of CA but instead serves to integrate multiple pieces of information about the event into a single representation more efficiently.
Given that the signer’s body is central for CA, the articulators can be interpreted in a diagrammatic fashion – the information encoded by the hands and their relation to each other as well as the hands in relation to the information encoded by the body (Meir, Padden, Aronoff, & Sandler, Reference Meir, Padden, Aronoff and Sandler2007). For example, a signer can establish different diagrammatic relations by using diverse articulators: the signer can integrate information about space/direction with hand and torso movement (a woman pinching a child to her right with her right hand), and also add deictic information with the eye-gaze direction and a referent’s emotional state with a facial expression (a woman pinching a child while lovingly gazing at the child; Figure 1a). All those little details alter the interpretation of the depiction not only in an imagistic but also a diagrammatic fashion, since such alterations inevitably establish new relations between sub-components of the construction.

Fig. 1. Diagrammatic properties of CA when encoding relations between two referents and their interaction.
Furthermore, CA allows for the encoding of not only the same referent and its actions but also for the encoding of multiple referents and their relation to each other by depicting one referent and/or its actions with some articulators while encoding the other referent and/or its actions with other articulators (e.g., a child being pinched on the left cheek by a person taller than the child (a woman) on the left; Figure 1b). The strategy of splitting the body in order to encode different referents is known as ‘body partitioning’ (Dudis, Reference Dudis2004), or ‘mixed CA type’, in the terms of Cormier et al. (Reference Cormier, Smith and Sevcikova-Sehyr2015a). Such constructions involve not only imagistic properties but also diagrammatic schematization of the event, which arguably makes CA an efficient strategy for encoding complex events involving multiple information elements (e.g., agent, patient, and action). Accordingly, CA can be viewed as not simply a more or less intense imagistic depiction of the referent but as a diagrammatic depiction in which multiple articulators are employed and the specific information they convey are interrelated and increase the informativeness of the message.
Because signed languages use multiple articulators, different linguistic strategies (i.e., lexical signs, depicting constructions, CA) are not mutually exclusive and can be combined during encoding (Ferrara & Hodge, Reference Ferrara and Hodge2018; Perniss, Reference Perniss2007). Note that subtle and reduced CA types, in Cormier et al.’s (Reference Cormier, Smith and Sevcikova-Sehyr2015a) terms, include the use of other linguistic strategies together with CA. For example, a signer can use CA to encode a referent with bodily articulators (e.g., eye-gaze, facial expression, torso) and articulate a lexical sign on one or both hands to encode an action. Such combinations may be particularly useful for encoding transitive actions in relation to their patients, e.g., kissing the cheek of the child, considering that some lexical signs (so-called ‘directional verbs’ or ‘indicating verbs’) can also make use of the body to establish a diagrammatic relation with components of CA (Cormier, Fenlon, & Schembri, Reference Cormier, Fenlon and Schembri2015). Thus, even in instances where different linguistic strategies are used for different articulators, the addressee has no problem decoding them because each piece of semantic information that is encoded by a specific articulator is decoded in relation to all the other articulators employed. Or in other words, each articulator is embedded in a larger representation which constitutes a sum of meanings accessible through the articulators used and their relation to each other. The fact that multiple articulators can be linked together to simultaneously encode multiple semantic information units in a single construction provides a clear opportunity for efficiency considering that related meanings can be encoded together to form a larger representation. Indeed, Slonimska et al. (Reference Slonimska, Özyürek and Capirci2020) showed that signers exploit simultaneity with the increasing information demands. It is therefore highly probable that the properties of CA described above, including the possibility of the combination of CA with other strategies, are used for achieving efficient communication in sign languages.
1.2. constructed action and informativeness
Until now, previous research has overwhelmingly concentrated on CA use in narratives (Cormier et al., Reference Cormier, Smith and Sevcikova-Sehyr2015a; Hodge, Ferrara, & Anible, Reference Hodge, Ferrara and Anible2019; Hodge & Johnston, Reference Hodge and Johnston2014; Jantunen, Reference Jantunen2017; Pizzuto et al., Reference Pizzuto, Rossini, Sallandre and Wilkinson2006, among others). The only two studies comparing CA use in narratives and other communicative contexts seem to indicate that in narratives CA occurs considerably more frequently. Sallandre, Balvet, Besnard, and Garcia (Reference Sallandre, Balvet, Besnard and Garcia2019) reported that the use of CA (called ‘transfer of person’ or ‘double transfer’ in their study) in LSF (French Sign Language) in narratives amounted to approximately 50% of all strategies used, while in a dialogue corpus it was only 7%, in an argumentative corpus it was 15%, and in recipe descriptions it was 27%. In line with the findings on the dialogue data, Ferrara (Reference Ferrara2012) found that in an Auslan (Australian Sign Language) conversation corpus CA was used six times less in comparison to narrative data, which led her to conclude that CA “should not be considered necessary, but that it is exploited in narrative contexts” (2012, p. 212). However, Quinto-Pozos (Reference Quinto-Pozos2007a, Reference Quinto-Pozos2007b) found that in a movie clip description task signers of ASL were likely to use CA and could not come up with other possibilities for encoding specific meaning when presented with stimuli of the animate entities involved in an action. Moreover, perceivers rated CA use as being clearer and more appropriate. Quinto-Pozos (Reference Quinto-Pozos2007a, Reference Quinto-Pozos2007b) argued that when encoding information about animate entities, CA “provides, in a simultaneous fashion, information that cannot be provided efficiently or robustly by using only signs or polycomponential signs” (2007b, p. 464) and that the prevalent iconicity and the possibility of one-to-one mapping between the body of the signer and the referent might prove to be a defining factor in the obligatory nature of CA in specific instances. To summarize, it appears that the need to use CA may vary depending on different contexts, and on the requirements that come with them, as well as on the type of the stimuli.
While narratives appear to be the most obvious context for eliciting CA, the fact that it has also been found outside narrative contexts, and that it even appears to be preferred over other linguistic strategies in some instances, might indicate that it is used to communicate information efficiently in its own right. Indeed, the referential value of CA has been acknowledged with regard to visibly depicting referents, indexing referents in space, and discourse cohesion (Cormier, Fenlon, & Schembri, Reference Cormier, Fenlon and Schembri2015; Cormier, Smith, & Sevcikova-Sehyr, Reference Cormier, Smith and Sevcikova-Sehyr2015a; Liddell, Reference Liddell2003; Winston, Reference Winston1991). For example, some research has shown that, while lexical signs are used to introduce referents in a story, CA is used more than lexical signs to maintain and/or reintroduce the referents (Cormier, Smith, & Zwets, Reference Cormier, Smith and Sevcikova2013; Frederiksen & Mayberry, Reference Frederiksen and Mayberry2016; Hodge et al., Reference Hodge, Ferrara and Anible2019; Özyürek & Perniss, Reference Ozyurek, Perniss, Bohnemeyer and Pederson2011; Perniss & Özyürek, Reference Perniss and Özyürek2015; Pizzuto et al., Reference Pizzuto, Rossini, Sallandre and Wilkinson2006). Recently, research on narrative data has shown that CA can function as the ‘sole conveyer’ of information, i.e., encoding the core argument and predicate elements in a clause (Ferrara & Hodge; Reference Ferrara and Hodge2018; Ferrara & Johnston, Reference Ferrara and Johnston2014; Hodge & Johnston, Reference Hodge and Johnston2014; Jantunen, Reference Jantunen2017), leading some authors to suggest that “CA can function similarly to linguistic signs as a […] predicate and arguments” (Ferrara & Johnston, Reference Ferrara and Johnston2014, p. 204).
While Quinto-Pozos’s (Reference Quinto-Pozos2007a, Reference Quinto-Pozos2007b) research indicates that the referential properties of CA can also be taken advantage of for efficient communication outside narrative contexts, the design of that study did not allow this assumption to be assessed. In the same vein, while studies based on narrative corpora indicate that CA may indeed function as the carrier of the core information and not solely as an evaluative device, the narrative context might prove to be problematic for such an inquiry and conclusions. In the next section, we argue why the assessment of CA should go beyond narrative context in order to truly understand the referential capacity of this depicting strategy.
1.3. what narratives can and cannot tell us about the function of ca
Narratives require mastery of two functions: referential and evaluative (Labov & Waletzky, Reference Labov and Waletzky1967). The referential function serves to make sense of the story and can be considered “a straightforward report of what occurred” (Cortazzi, Reference Cortazzi2014, p. 44). The evaluative function, on the other hand, serves to “[establish] some point of personal involvement” (2014, p. 44), which in turn implies the intensification of the factual information in the story with additional linguistic and paralinguistic strategies. For example, a signer might add a depiction to emphasize how a dog actually runs by using an excited facial expression with their tongue out, representing the emotional state of the dog during the action. Thus, the referential and evaluative functions are so intertwined in narratives that it becomes impossible to distinguish which linguistic strategy is used for which purpose. Curiously, some research has suggested that CA is used for evaluative function, i.e., to add color to the content, to make it more entertaining or vivid, and to capture the attention of the addressee (e.g., Roy, Reference Roy and Lucas1989; Winston, Reference Winston and Plant-Moeller1992; Poulin & Miller, Reference Poulin, Miller, Emmorey and Reilly1995; Wilson, Reference Wilson and Lucas1996; Mather & Winston, Reference Mather, Winston and Lucas1998; Dudis, Reference Dudis and Lucas2002). Although there are some recent studies that argue for the referential function of CA in narratives, they do not show whether it is used primarily for informative rather than evaluative function.
Note also that ‘addressee’ or ‘recipient design’ (i.e., adjusting the message by taking into account the needs of the addressee; Campisi & Özyürek, Reference Campisi and Özyürek2013; Clark, Reference Clark1996) is radically different in narratives compared to purely informative tasks. In narratives, the goal is to tell a story and to be captivating and interesting while delivering information. Thus, the evaluative function is used deliberately. In cases where the goal of communication is efficient information transmission, the referential function is mainly required. Efficient communication can be interpreted according to Grice’s (Reference Grice, Cole and Morgan1975) cooperative principle, where interlocutors have to be as informative as possible but also as concise as possible in transmitting information. As the amount of information that needs to be communicated increases, communicators are faced with the ever-growing challenge of accommodating the communicative needs of the addressee as well as their own. As a result, they are likely to adopt the most efficient strategy for doing so. Hypothetically, if the use of CA could be observed in such a setting, that is, when the information to be encoded increases in an experimentally controlled manner and communicators need to be efficient, it would be a strong indicator that it is not only used for referential purpose but also for achieving efficient information communication.
2. The present study
In the present study we undertake to explore whether CA is used in a referential function in order to achieve efficient communication. We used a design (the same as in Slonimska et al., Reference Slonimska, Özyürek and Capirci2020) which reduces the confound of the evaluative function by presenting participants with a purely informative task of increasing demand with regard to the amount of information that has to be transmitted. In such a task, the only requirement is to communicate the event’s referential information. If we observe that signers increase their use of CA as a function of the increasing informative load, we would have a strong argument for the referential use of CA. We hypothesize that signers will not opt to exclusively use lexical signs but instead will also use CA alone or in combination with other strategies in an informative task. Furthermore, we hypothesize that, as the amount of information that has to be encoded increases, so does the use of CA.
2.1. method
We used the video data collected by Slonimska et al. (Reference Slonimska, Özyürek and Capirci2020). Here we report the design of the Slonimska et al. study in a shortened form and elaborate on the data coding scheme developed for the present study. The study was approved by the Ethics Council of the Institute of Cognitive Sciences and Technologies, CNR, Rome (protocol n. 0003821).
2.1.1. Participants
Data was collected from 23 deaf adult participants (12 females, M-age = 30.5, range 18–57, all native or near-native signers of LIS). All participants were daily users of LIS and reported it as their primary language for communication.
2.1.2. Material and design
The elicitation material for the experiment consisted of 30 unique images that represented an event involving two animate referents (there were six different character pairs with 5 Information Density Levels; see character pair Bunny-Cat in Figure 2). All stimuli represented animate referents in order to give signers the opportunity to opt for CA as an encoding strategy, considering that CA enables signers to give referents agency (Hodge et al., Reference Hodge, Ferrara and Anible2019). The images were divided across five levels (the images for Levels 1–2 were in JPG format and the images for Levels 3–5 were in GIF format), with each consecutive level representing an increase in the information density of the event. There were a minimum of two and maximum of five information units that needed to be encoded. Note that the number of information units in Level 4 is the same as in Level 3, but in Level 4 both referents are simultaneously agent and patient, as opposed to the single agent and patient in Level 3. Accordingly, Level 4 increased in terms of perceptual complexity relative to Level 3, but not in terms of information density. In all images both referents were represented as looking at each other, but because this information was not manipulated and remained constant across all levels, it was not considered in the encoding. Our aim was to use non-linguistic stimuli to elicit linguistic encoding in order to approximate as closely as possible situations in everyday life, in which people use language to describe events happening in the world. The format of the drawings (i.e., JPG or GIF) was chosen in order to sufficiently control the detail of each stimulus and assure that all stimuli were homogeneous.

Fig. 2. Stimuli of the images representing the event of various semantic information density levels. Levels 1–2 are in JPG format, and Levels 3–5 are in GIF format where only dynamic action is animated.
2.1.3. Procedure
The participant was informed that they were about to play a director–matcher game in which they would play the role of the director and another player, (a deaf confederate, native signer of LIS) who was seated facing the participant (see detailed set-up in Slonimska et al., Reference Slonimska, Özyürek and Capirci2020, p. 7), was assigned the role of the matcher. The participant’s task was to look at the images appearing on a screen one by one and in a semi-randomized order, and describe these images to the matcher, who would choose the correct image on a laptop. Before the experimental stimuli were presented, images with each referent were presented separately, one by one. The participant was invited to identify and describe these referents to the matcher. Once all the referents had been identified, the experimenter proceeded with the presentation of the experimental stimuli. The confederate always replied with positive feedback (e.g., signs for OK; yes; got it) after the images were described. Considering that participants were in a goal-oriented setting, they were expected to adopt a communicative strategy that was as efficient as possible when faced with increasing information demands in order to ensure that communication had been successful and their descriptions understood. After all the images had been described, the experimenter debriefed the participant about the experiment and answered the questions, if any were raised.
2.1.4. Coding
The video-recorded data was coded in the multimodal data annotation software ELAN, developed by Max Planck Institute for Psycholinguistics (Wittenburg, Brugman, Russel, Klassmann, & Sloetjes, Reference Wittenburg, Brugman, Russel, Klassmann and Sloetjes2006). The duration of the videos was 7.23 min on average (SD = 1.39).
To determine the sequential organization of the production, we used the segmentation criteria set out in Slonimska et al. (Reference Slonimska, Özyürek and Capirci2020, pp. 7–8: “Data segmentation was based on when a new movement of the signer’s hand(s) started and ended, i.e., a stroke that could also be preceded by preparation, following Kendon (Reference Kendon2004).” The start of a new segment was delimited by the start of the new movement of the other hand (i.e., preparation or stroke), and the new movement segment (MS) could also include the holding of the previous movement (see Figure 3, MS 3–5). Coders annotated the presence of non-manual movements (change in torso position, head position, facial expression, eye-gaze direction) in each movement segment. Therefore, a movement segment is determined by a change in at least one hand movement. Furthermore, if two hands were used to produce independent signs at the same time (e.g., CA with the left hand and pointing to self as the referent with the right hand; see Figure 3, MS 2), that was coded as a single movement segment.

Fig. 3. Example of the segmentation of a single stimulus with 5 MS and coding of linguistic strategy used in each MS.
All movement segments that were clear disfluencies or mistakes that signers corrected themselves were excluded from the analyses. Moreover, given that our focus was on how signers encoded the five information units that we manipulated in the different levels, we excluded additional movement segments that added extra information that was not the focus of our study (e.g., the size or shape of the referents, or movement segments encoding only the eye-gaze direction of the referents). We then proceeded to assess how each movement segment was constructed with regard to the linguistic strategy used.
Each movement segment was coded with regard to the linguistic strategy or strategies it contained. First, we coded the ‘general linguistic strategy’ of each movement segment: ‘lexical unit’, ‘constructed action’, ‘depicting construction’, ‘pointing’, and ‘combined’. Next, it was noted which strategies were used in combination.
-
• Lexical Unit (LU) – a conventionalized sign with a fixed meaning, roughly comparable to words in spoken language;
-
• Constructed action (CA) – a depicting strategy where the signer adopts a character’s perspective of the event and maps a referent and its actions onto his own body;
-
• Depicting Construction (DC) – a depicting strategy where the signer adopts an observer’s perspective of the event, which is depicted in miniature scale in the signing space in front of the signer;
-
• Pointing – use of index finger or palm for deixis;
-
• Combined:
Lexical unit+Constructed action (LU + CA)
Lexical unit+Depicting Construction (LU + DC)
Lexical Unit+Pointing (LU + Point)
Pointing+Constructed action (Point + CA)
Pointing+Depicting construction (Point + DC)
Constructed action+Depicting construction (CA + DC)
Considering that it is often impossible to distinguish the handling and enactment of lexical signs (e.g., to pet; to hold) from CA (Cormier et al., Reference Cormier, Smith and Zwets2013a, Reference Cormier, Fenlon and Schembri2015; Ferrara & Halvorsen, Reference Ferrara and Halvorsen2017), we followed Cormier et al. (Reference Cormier, Smith and Sevcikova-Sehyr2015a) and coded the signs as ‘lexical units’ if they were produced in an exclusively citational form as demonstrated on the Spread the sign webpage (www.spreadthesign.com), and/or they were available in the LIS–Italian dictionary by Radutzky (Reference Radutzky1992), and/or we were instructed by deaf informants.
We coded an MS as a CA if a referent and/or its actions were enacted. If two referents or the actions of different referents were enacted through CA, the linguistic strategy for encoding was also noted as CA. In order to determine whether non-manual articulators were used to encode the referents via CA, we followed the criteria for detecting CA in Cormier et al. (Reference Cormier, Smith and Sevcikova-Sehyr2015a). We coded for eye-gaze if it was used for the purposes of enactment. If eye-gaze to pointing or depicting signs was present during CA we did not code it as marker of CA and instead considered it referential eye-gaze. With regard to the ‘combined’ strategy, we noted combinations of linguistic strategies in each movement segment. For example, if CA was used simultaneously with a lexical sign, it was coded as CA + LU. If CA was used with pointing it was coded as CA + Pointing.
2.1.5. Reliability
All data was initially coded by the first author of the study. All coded data was double-checked by a deaf researcher, a native signer of LIS. Another native signer of LIS coded 20% of the data. Reliability for linguistic strategy coded for each movement segment was very strong as revealed by Cohen’s κ = 0.90.
2.1.6 Analyses
We analyzed the data in R using the lme4 package (Bates, Maechler, Ben Bolker & Walker, Reference Bates, Maechler, Bolker, Walker, Christensen, Singmann and Grothendieck2012). We used the method of generalized mixed effect models (family=binomial) to test the effect of the ‘density level’ on the ‘linguistic strategy’ chosen for the encoding. The following random effects were considered for the baseline model: random intercept for stimuli sample (‘trial’), random intercept for ‘participant’, random intercept for ‘character pair’, and random slope for ‘density level by participant’. The following fixed effects were considered: ‘gender’, ‘age’, ‘age of LIS acquisition’, and ‘handedness’. The final baseline model was determined based on the best fit as revealed by ANOVA tests, or alternatively on the maximal random effects structure that converged in the model, following Barr et al. (Reference Barr2013). The best fit baseline model for each analysis is reported in the respective paragraph. Hierarchical contrasts between the levels were attained by re-levelling the primary model.
2.2. results
We tested whether participants varied the proportion of specific linguistic strategies as a function of the increasing amount of information to be communicated. We hypothesized that participants would increase their use of CA and combine CA with other linguistic strategies (lexical units, depicting constructions, pointing) as the amount of information that had to be encoded increased. Given the type of the events represented in the stimuli (i.e., animate referents interacting with each other), we did not expect frequent use of depicting constructions.
Figure 4 presents the results with regard to the linguistic strategies participants used to encode stimuli for each density level. Pointing and depicting constructions were scarcely used, and therefore in the analyses we concentrate on the three dominant strategies: lexical units, CA, and the combined strategy (simultaneous use of different strategies).

Fig. 4. Raw proportions of linguistic strategies used to encode a stimulus in each density level.
2.2.1. Lexical units
In the present analysis, we assessed how the use of lexical units was distributed across the density levels. The baseline model consisted of the random effects of ‘participant’ and ‘stimulus’. The outcome variable was the proportion of lexical units used: movement segments encoded via lexical units versus total number of coded movement segments per stimulus. Density level was compared to the baseline model and revealed a significant main effect (χ2(4) = 70.27, p < .001). The primary model was releveled in order to attain hierarchical contrasts between the levels. Pairwise comparisons revealed that there was a significant gradual decrease in use of lexical units.
The strategy of using lexical units was used significantly more (β = –0.82, SE = 0.13, CI[–1.07; –0.57], z = –6.37, p < .001; see Table1) in Level 1 (M = 0.66, SD = 0.19) than in Level 2 (M = 0.43, SD = 0.16). In Level 2 it was used significantly more (β = –0.38, SE = 0.12, CI[–0.61; –0.15], z = –3.22, p = .001) than in Level 3 (M = 0.34, SD = 0.12), while in Level 3 it was comparable (β = –0.13, SE = 0.11, CI[–0.58; 0.10], z = –1.12, p = .262) with Level 4 (M = 0.31, SD = 0.10), and Level 4 was comparable (β = –0.18, SE = 0.11, CI[–0.393; 0.032], z = –1.67, p = .096) with Level 5 (M = 0.27, SD = 0.11).
Table 1. Best fit model in a logit scale (model fit by maximum likelihood, Laplace Approximation) regarding the proportion of lexical units used for encoding. Contrasts reflect pairwise comparisons between Level 1 and all other levels.

2.2.2. Constructed action
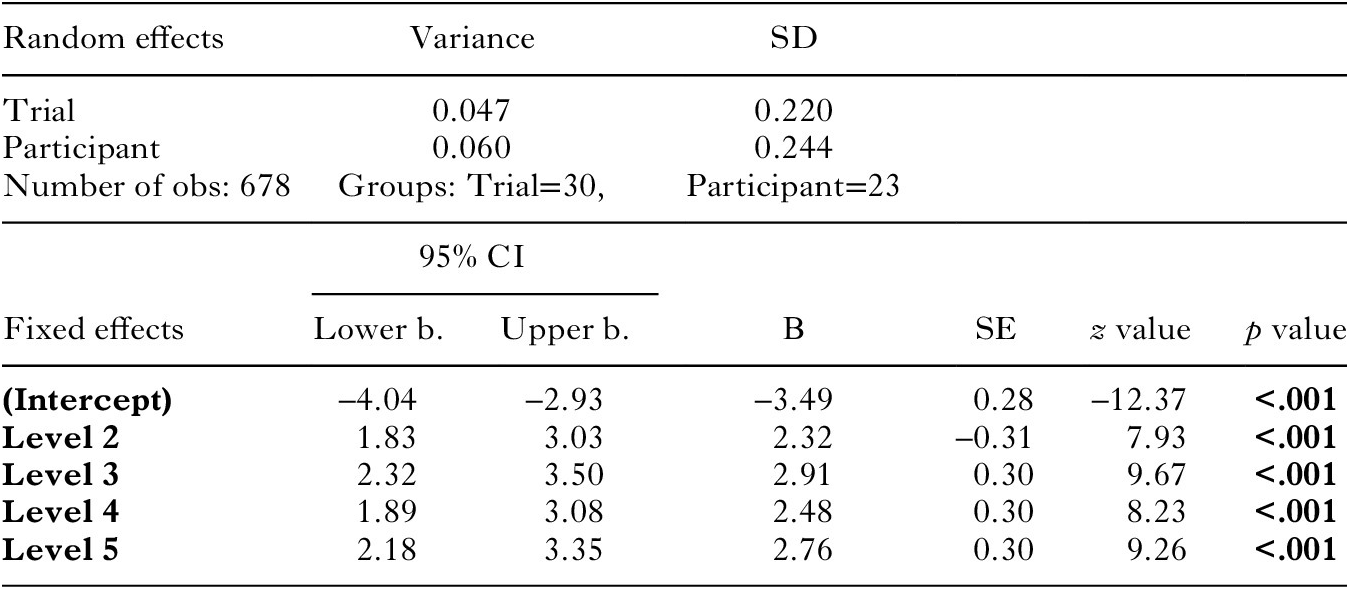
Next, we explored the effect of density level on the use of CA (i.e., proportion of movement segments encoded via CA versus total number of coded movement segments per stimulus). We compared the fixed effect of density level to the baseline model, which consisted of random effects of ‘participant’ and ‘stimulus’ (see Table 2). There was a significant effect of ‘density level’ (χ2(4) = 68.68, p < .001). CA was used significantly more (β = 7.93, SE = –0.31, CI[1.83; 3.03], z = 2.32, p < .001) in Level 2 (M = 0.26, SD = 0.7) than in Level 1 (M = 0.02, SD = 0.05.), and significantly more (β = 0.48, SE = 0.18, CI[0.14; 0.82], z = 2.73, p < .006) in Level 3 (M = 0.37, SD = 0.08) than in Level 2. However, in Level 3 CA was used significantly more (β = –0.43, SE = –0.17, CI[–0.43; –0.75], z = –2.53, p < .011) than in Level 4 (M = 0.28, SD = 0.08). Levels 4 and 5 (M = 0.34, SD = 0.07) were comparable (β = 0.28, SE = –0.16, CI[–0.04; 0.60], z = 1.71, p < .087).
Table 2. Best fit model in a logit scale (model fit by maximum likelihood, Laplace Approximation) regarding the proportion of CA used for encoding. Contrasts reflect pairwise comparisons between Level 1 and all other levels.
The results confirmed our hypotheses that signers are likely to increase use of CA as the amount of information that has to be encoded increases. For example, in Level 2 signers could encode both Referent 1 and its static action by means of CA (Figure 5), and in Level 3 they could encode Referent 1, its static action, and add a dynamic action in a single CA (Figure 6).

Fig. 5. A signer depicting Referent 1 – woman (encoded through head direction, facial expression, and eye-gaze) and the static action (the signer's right hand) via CA (Level 2).

Fig. 6. A signer depicting Referent 1 – bear (encoded through torso, head, eye-gaze, and facial expression of the signer), his static action (the signer's right hand), and dynamic action 1 – caressing (the signer's left hand) via CA (Level).
In Levels 4 and 5 they could encode Referent 2 and its dynamic action 2 (Figure 7) or, alternatively, Referent 1, its static action, and Referent 2’s dynamic action via CA (Figure 8). Encoding both referents and all three actions was not attested in our data.

Fig. 7. A signer depicting Referent 2 – bunny (encoded through torso, head, eye-gaze, and facial expression of the signer) and dynamic action 2 – tapping (the signer’s right hand) via CA (Level 4).

Fig. 8. A signer depicting Referent 1 – bird (encoded through torso, head, facial expression) and its static action (the signer’s left hand) and Active action of Referent 2 (the signer’s right hand) via CA (Level 4).
We note that we found a discrepancy with regard to Level 3, where CA was used significantly more than in Level 4, contrary to what was expected. In Level 3, all the information about Referent 1, the agent of the actions, can be given in a single CA in which the signer’s entire body represents Referent 1 and its actions can be easily mapped through CA onto the signer’s body parts (Figure 6). In Level 4, Referent 1 is the patient of the action produced by Referent 2 (Figure 7). Inspection of the data showed that the action performed by Referent 2 could be encoded not only by means of CA but also by LU or a depicting construction. We explore the ‘combined’ strategy in the next section.
2.2.3. Combined strategies
We assessed how combinations of different linguistic strategies (i.e., proportion of movement segments encoded via a combination of multiple linguistic strategies versus total number of coded movement segments per stimulus) were distributed across the density levels. We compared the fixed effect of density level to the baseline model, which consisted of a random effect of ‘participant’ and ‘stimulus’ (see Table 3). There was a significant effect of density level (χ2(4) = 44.041, p < .001). Combined strategies were used significantly more (β = 1.64, SE = 0.29, CI[1.073; 2.22], z = 5.64, p < .001) in Level 2 (M = 0.23, SD = 0.19) than in Level 1 (M = 0.06, SD = 0.09). Level 2 and Level 3 (M = 0.22, SD = 0.15) were comparable (β = –0.03, SE = 0.24, CI[0.51;0.44], z = –0.14, p = .89). Combined strategies were used significantly more (β = 0.58, SE = 0.24, CI[0.12; 1.04], z = –0.25, p < .01) in Level 4 (M = 0.35, SD = 0.12) than in Level 3, though use in Level 4 (β = 0.03, SE = 0.23, CI[–0.42; 0.48], z = 0.13, p = .09) was comparable to Level 5 (M = 0.34, SD = 0.13).
Table 3. Best fit model in a logit scale (model fit by maximum likelihood, Laplace Approximation) regarding the proportion of combined strategies used for encoding. Contrasts reflect pairwise comparisons between Level 1 and all other levels.

When we explored the use of each type of combination, we found that CA was combined with another strategy (LU, Point, DC) almost exclusively (96%) except in Level 1, where CA + another strategy constituted 65% (Figure 9) of combined strategies. In Level 2 and Level 4 only CA + another strategy was used, while in Level 3 and Level 5 only one instance of a combination that did not contain CA occurred. Accordingly, the ‘combined’ strategy was mostly used to combine CA with another linguistic strategy for encoding; in the majority of cases, CA was combined with lexical signs, followed by combination with pointing in Levels beyond 1.

Fig. 9. Raw proportions of the linguistic strategy combinations used for encoding a stimulus in each level.
As mentioned above, CA as a single strategy was used significantly more in Level 3 (Referent 1, Referent 2, Static act, Dynamic act 1) than Level 4 (Referent 1, Referent 2, Static act, Dynamic act 2). However, we also found that there is a significant increase in the combined strategy between Levels 3 and 4. In other words, in Level 4 signers used more CA in combination with another linguistic strategy. Data examination revealed that, regardless of the fact that signers could use full CA in cases where action was produced by the mouth and head articulators (as in licking, kissing, pecking) by mapping the articulators of the referent onto the signer’s articulators, they nevertheless chose to encode it through the hand by means of lexical sign or a depicting construction. Such combined strategies consisted of encoding Referent 2 via CA and its action via another strategy, e.g., a depicting construction (Figure 10). Alternatively, it could be used to encode the actions of both referents: while CA was used to encode Referent 1 and the holding action, one of the hands was partitioned off in order to encode the action of the Referent 2 via a lexical sign (Figure 11). Interestingly, some signers would accompany the action sign encoded by the hand with non-manual articulators as well, but they never used non-manual articulators only. For example, when encoding a bird mapped on the body through a torso shift and the pecking action with a depicting construction, a signer would also map the beak of the bird by pursing her lips and moving her head back and forth to reproduce the pecking action (Figure 10). Some signers, however, did not do this, indicating that redundancy in action encoding is to some extent a feature of a signer’s individual style.

Fig. 10. A signer encoding Referent 2 –bird (encoded through the torso, head, eye-gaze, and facial expression of the signer) and dynamic action 2 –pecking (the signer’s right hand) with depicting construction (Level 4).

Fig. 11. A signer encoding Referent 1 – dog (encoded through the torso, head, and eye-gaze of the signer) and holding action (the signer’s left hand) via CA and dynamic action 2 – pecking (the signer’s right hand) with a depicting construction (Level 4).
3. Discussion
In the present study we hypothesized that if CA in sign languages can serve a primarily referential function, we would see an increase in their use when the main goal of the task was efficient information transmission. Assessing CA in a controlled experimental setting allowed us to reduce the need for signers to use the evaluative function and instead focus primarily on referential function. Furthermore, the design of the study allowed us to assess not only whether CA was used for referential purposes, but whether its properties of implementing diagrammatic iconicity to encode multiple event elements simultaneously was also used to achieve communicative efficiency when faced with increasing information demands. Our results revealed that CA (also in combination with other strategies) was the prevalent strategy used in all levels except in Level 1. We also found that, as the amount of information that needed to be encoded increased, CA (alone and in combination with other strategies) either increased or was comparable to the preceding level (e.g., Levels 4 and 5). An exception to this finding was more use of CA alone in Level 3 than in Level 4. Yet the use of CA combined with other strategies was found more in Level 4 than in Level 3. We address these findings below.
3.1. CA as a referential device
In our data, we found an overwhelming amount of CA use, both as an independent strategy and in combination with another linguistic strategy, such as lexical signs, pointing, and depicting constructions. Thus, the present findings corroborate previous research arguing that CA is an integral part of sign languages and that it can be used for referential purposes. The general tendency to increase the use of CA (apart from Levels 4 and 5) as well as the use of CA in combination with another strategy indicates that this strategy and its use in combination with other strategies can be employed to achieve communicative efficiency. Note that the design of the study was based on the increase of one information unit in each consecutive level (except Levels 3 and 4, which differed in perceptual complexity and not informative density), which might have been too small of a difference to detect the significant effect between all levels we compared. In addition, it is also possible that different information units (e.g., different types of action in our study) have their own constraints on whether CA can or cannot be used for referential purposes. Indeed, exactly this factor appears to explain the unexpected finding of CA alone being used less in Level 4 compared to Level 3. We address this finding later on in this ‘Discussion’.
Given that even languages that have another primary communication channel (i.e., voice) resort to iconic gestures in some instances to communicate efficiently (e.g., Holler & Wilkin, Reference Holler and Wilkin2011; Campisi & Ozyurek, Reference Campisi and Özyürek2013), it appears only logical to assume that, in languages that employ a visual channel exclusively, depiction would also play a crucial role in information transmission – a view that has been rapidly gaining prominence in sign language research (Cormier et al., Reference Cormier, Smith and Sevcikova-Sehyr2015a; Ferrara & Hodge; Reference Ferrara and Hodge2018; Hodge & Johnston, Reference Hodge and Johnston2014; Jantunen, Reference Jantunen2017; Puupponen, Reference Puupponen2019). Indeed, the act of combining depictive properties with more discrete conventionalized properties for linguistic purposes appears to be a rather sophisticated task as exemplified by research demonstrating that the use of CA together with other strategies is particularly hard for children to acquire (BSL: Cormier, Smith, & Sevckova, Reference Cormier, Smith and Sevcikova2013; LIS: Slonimska, Di Renzo, & Capirci, Reference Slonimska, Di Renzo and Capirci2018). Assessment of how CA is used in combination with other strategies in various contexts can thus further our understanding of the interplay between the linguistic strategies that signers have at their disposal. An undertaking for future research would be to implement the same task design presented in this study to assess how increasing information demands influences the use of CA (alone and in combination) in children.
It is important to highlight that the consecutive and simultaneous interplay between highly conventionalized (i.e., lexical) and gradient iconic signs (i.e., CA) allows great flexibility in encoding. Specifically, the lexical signs for referents frame the use of CA so that it can be interpreted unambiguously (BSL: Cormier, Smith, & Zwets, Reference Cormier, Smith and Sevcikova2013; Auslan: Hodge & Ferrara, Reference Hodge and Ferrara2014). Accordingly, once the referents are introduced via lexical signs, the signer can take advantage of the depictive properties of the language in order to encode the event more efficiently than would be possible if strictly consecutive encoding of one sign–one meaning were used.
The advantage of encoding multiple information units in a single construction has been shown in our recent study that used the same video data (Slonimska et al., Reference Slonimska, Özyürek and Capirci2020). Results revealed that, as the amount of information that had to be encoded increased, signers increased the simultaneous encoding of multiple units of information. These findings indicated that signers take advantage of the affordances of sign language to exploit its referential capacity to the fullest. The present study contributes to the findings by Slonimska et al. by illuminating linguistic strategies used to achieve communicative efficiency, something that has not been investigated so far. In our data, we found that a majority of the combined strategies included CA. This indicates that signers can use CA flexibly with different linguistic strategies to encode multiple information units in a construction. Considering that the body of the signer serves as a central coordinate point, each element can be interpreted in relation to each of the others (i.e., diagrammatic iconicity), forming a single but also complex representation in which each sub-element is depicted simultaneously (Slonimska et al., Reference Slonimska, Özyürek and Capirci2020). For example, in order to encode both referents, signers could use body partitioning (Dudis, Reference Dudis2004) instead of encoding information about each referent separately. Note that we observed that actions of the Referent 2 that were not performed with the hand but that could be encoded via CA by the use of head or mouth articulators were nevertheless encoded with the signer’s hand and thus via another strategy (either LU or DC). Exactly this observation could explain why CA alone was used less in Level 4 compared to Level 3. Namely, in Level 4 a subset of the actions by Referent 2 were not encoded by CA only but by CA in combination with another strategy, thus diminishing the overall proportion of CA as a sole strategy used in Level 4 (see Section 2.2.3). There might be some very practical reasons for signers using their hands to encode actions. If an action is encoded by the signer’s hand it can then be added to the diagram in a meaningful way. That is, it can establish the relation between the action, its agent, and its patient. For example, to encode that Referent 2 is pecking Referent 1 on the cheek, the signer can use a manual sign for pecking by simply directing it to the body part where the action occurs (i.e., the cheek of Referent 1). In contrast, the signer cannot encode Referent 1 by mapping it onto their own body (i.e., torso and head) and at the same time encode Referent 2’s pecking action by using their mouth to establish the relation between Referent 1 and Referent 2. In other words, a signer directing their mouth to their own cheek is simply impossible from an articulatory viewpoint (i.e., modal affordances; Puupponen, Reference Puupponen2019). The problem is solved, however, if the action performed by the mouth is encoded by the hand, which can then be easily directed to any part of the patient’s body. In such an instance, body partitioning comes in handy for encoding information precisely and at the same time efficiently by explicitly keeping the patient of the action present (Dudis, Reference Dudis2004). Thus, in order to communicate efficiently, signers do not stick to description by means of lexical signs only but can additionally take advantage of the rich resources of depictive properties which are in the repertoire of their language.
3.2. The quest of iconicity towards language: the lexical/discrete vs. gestural/gradient dichotomy
Although research has gone a long way in acknowledging the crucial role of iconicity for sign language organization, production, and processing (Vigliocco et al., Reference Vigliocco, Vinson, Woolfe, Dye and Woll2005; Perniss, Thompson, & Vigliocco, Reference Perniss, Thompson and Vigliocco2010), the leading view has nevertheless stressed the necessity of distinguishing between linguistic and gestural features (Duncan, Reference Duncan2005; Quinto-Pozos & Mehta, Reference Quinto-Pozos and Mehta2010; Goldin-Meadow & Brentari, Reference Goldin-Meadow and Brentari2017) or alternatively between discrete + conventional and gradient + unconventional features in sign languages (Cormier et al., Reference Cormier, Quinto-Pozos, Sevcikova and Schembri2012; Johnston & Schembri, Reference Johnston and Schembri1999; Liddell, Reference Liddell2003). It is only relatively recently that researchers have started arguing for revisiting the juxtaposition of ‘arbitrary/categorical = lexical’ versus ‘iconic/gradient = gestural/non-lexical’ properties as a decisive factor of linguistic status (Clark, Reference Clark2016; Dotter, Reference Dotter2018; Kendon, Reference Kendon2014; Müller, Reference Müller2018). Furthermore, our findings suggest that the sharp distinction between depicting and describing functions of language should possibly be reconsidered (Clark & Gerrig, Reference Clark and Gerrig1990; Clark, Reference Clark2016).
The fact that the signers in the present study preferred using CA over lexical signs in an informative task indicates that some concepts that are rooted in human experience, like actions that are performed on a daily basis, e.g., holding different objects, do not require a lexicalization process in order to be included in the linguistic structure of the populations that rely heavily on such constructions, like signers. Indeed, Fuks (Reference Fuks2014, p. 152) notes: “Arbitrariness in the visualgestural modality, by contrast, is a constraint resulting from the entity’s features. That is, it is used in signed languages only in those cases when iconicity cannot be used […].” Hockett (Reference Hockett1978), in comparing spoken and signed languages, notes that, while in spoken languages the majority of iconicity has to be squeezed out due to its linear organization (when speech only is considered), sign languages have the chance to maintain iconicity to far greater extent. As a consequence, languages in both modalities adapt to work with what they have. In this respect, iconicity can be taken full advantage of not only for the imagistic iconicity of lexical signs that resemble their referents but also for both imagistic and diagrammatic iconicity when it comes to communicating about what a body looks like, what kind of actions it makes, and where it stands in relation to the world and phenomena around it. And given that bodily actions are entrenched in human experience, they do not pose a decoding problem, all the more so when embedded in context.
When coding the data, we were faced with ever-growing doubts about the correctness and feasibility of distinguishing between lexical signs and CA. Specifically, determining the cut-off point between lexical and gestural signs was sometimes quite problematic. For example, an action like caressing turned out to be particularly difficult to classify, given that the handshape is similar to the actual action of caressing (see Figure 6). Using citational forms as a benchmark is not an optimal solution, given that the citational forms of verbs found in dictionaries serve more as an umbrella term for a concept (e.g., ‘take’) that, when used in context, is most often encoded via a specific verb specifying the referent, e.g., take a book, take a pen (Tomasuolo, Bonsignori, Rinaldi, & Volterra, Reference Tomasuolo, Bonsignori, Rinaldi and Volterra2020). The fact that categorizing signs is difficult even in an experimental setting with a highly controlled design goes against the view of bounded lexicality in sign languages and instead supports the concept of gradience. Accordingly, language should be viewed as a set of complex structures that speakers and signers can bring into play as appropriate and tweak, squeeze, and stretch according to need in order to transmit their desired meaning as truthfully as possible. In that respect, the possibility of gradience is precisely what allows language to be as rich as it is. Rather than dividing the world into two based on linguistic vs. gestural or discrete vs. gradient dichotomies, it would perhaps be wiser to consider it as a continuum with signs having the possibility of being used on a spectrum between the two categories, which are equally linguistic on both ends and in between (Ferrara & Halvorsen, Reference Ferrara and Halvorsen2017; Jantunen, Reference Jantunen2017; Johnston & Ferrara, Reference Ferrara2012; Occhino & Wilcox, Reference Occhino and Wilcox2017).
4. Conclusion
In the present study we found that CA was frequently used in an informative task, extending findings on the referential function of CA in a primarily informative and non-narrative context. Furthermore, we found that signers tended to use more CA and more often combined CA with other linguistic strategies as the amount of information that had to be encoded increased, that is to be communicatively efficient. Thus, we showed that depictions like CA can be used with referential function, which is usually considered to be achieved with descriptions. We argue that signers use CA for descriptive purposes, due to the efficiency afforded by imagistic and diagrammatic iconicity, which allows for the meaningful combination of multiple information units into a single representation. Language does not consist merely of words or signs that people organize in strictly linear structures, but rather it consists of fascinatingly rich depictive strategies that can combine different levels of linguistic representation to transmit meaning.















 Open access
Open access