



1. Introduction
When speakers are engaged in everyday conversation, they constantly negotiate and coordinate their stances to establish mutual understanding of what the conversation is about, and they do so in a turn-taking fashion (Brennan & Clark, Reference Brennan and Clark1996; Clark, Reference Clark1996; Du Bois & Giora, Reference Du Bois and Giora2014; Fusaroli & Tylén, Reference Fusaroli and Tylén2012; Linell, Reference Linell2009; Põldvere & Paradis, Reference Põldvere and Paradis2019, Reference Põldvere and Paradis2020). Based on conversational data from the London–Lund Corpus 2 (LLC–2) of spoken British English (Põldvere et al., Reference Põldvere, Frid, Johansson and Paradis2021, in press), this study focuses on a compelling type of coordination, namely dialogic resonance in stance alignment in speaker turns. Following Du Bois (Reference Du Bois and Englebretson2007, Reference Du Bois2014), we define dialogic resonance as the reproduction of constructions across speaker turns. Stance alignment in this study ranges from agreement to disagreement. For instance, consider the utterances in bold in (1), where speaker A resonates with B’s prior contribution at the level of both forms and meanings (e.g., the stance adverb particularly, the negated constructions, the metonymical reformulation of interested in religious things into up at seven AM). In contrast, if A’s response had been a simple no, the utterances would not have included any resonating items.

The stance alignment between the turns taken by A and B in (1) is one of disagreement in that there is a certain clash between the stances that the two speakers take vis-à-vis the person talked about. Also, A’s response is given very quickly after B’s prior turn (the square brackets indicate an overlap), which is intriguing because such a turn-taking pattern has previously been considered to be more common in agreement than disagreement (Pomerantz, Reference Pomerantz, Atkinson and Heritage1984).
Resonance in dialogue has been dealt with in both linguistics and psychology, with slightly different yet overlapping foci and terminologies. For instance, Du Bois (Reference Du Bois2014) argues that resonance is an intersubjectively motivated phenomenon that occurs because speakers want to engage with the words of their interlocutors for various communicative reasons (see Clark, Reference Clark1996, for similar views). Garrod and Pickering (Reference Garrod and Pickering2004), on the other hand, regard the phenomenon as an automatic cognitive process whereby the preceding expression primes the reuse of the same linguistic representations by the next speaker. Both lines of research, however, argue that resonance has a facilitating effect due to the cognitive activation in the mind of the second speaker by the prior speaker’s turn, a phenomenon that may also have the effect of speeding up turn transitions. It is precisely at this juncture that our study contributes new knowledge with an approach that straddles the gap between communicative and cognitive aspects of resonance production.
Using data consisting of stance-taking sequences in everyday face-to-face conversation in LLC–2, we examine why and when speakers resonate with each other’s contributions. The aim is to further our understanding of the intersubjective motivations and cognitive facilitation of dialogic resonance in stance-taking turns, where cognitive facilitation is operationalized as the time it takes for speakers to respond to the interlocutor’s prior stance. Two questions are at the core of this study.
-
1. Is resonance more likely than non-resonance to appear in disagreement than in agreement? If so, why may this be the case?
-
2. Does resonance lead to faster turn transitions than non-resonance and, if so, why may this be the case? Are there differences in this respect between agreement and disagreement?
The background sections provide more information about dialogic resonance (Section 2) and the timing of turns in conversation (Section 3).
2. Dialogic resonance
Dialogic resonance emerges “when speakers selectively reproduce aspects of prior utterances, and when recipients recognize the resulting parallelisms and draw inferences from them” (Du Bois, Reference Du Bois2014, p. 359), thus using it as a way of establishing common ground and interpersonal engagement between interlocutors (see also, e.g., Brône & Zima, Reference Brône and Zima2014; Dori-Hacohen, Reference Dori-Hacohen2017; Du Bois, Reference Du Bois and Englebretson2007; Du Bois et al., Reference Du Bois, Hobson and Hobson2014; Maschler & Nir, Reference Maschler and Nir2014; Nir, Reference Nir2017; Nir et al., Reference Nir, Dori-Hacohen and Maschler2014; Nir & Zima, Reference Nir and Zima2017; Zima et al., Reference Zima, Brône, Feyaerts and Sambre2009). A particularly compelling environment for resonance is stance-taking. In the present study, stance is understood as an umbrella term for a range of linguistic expressions that convey (i) speakers’ opinions, viewpoints, and attitudes towards objects, states, and events (e.g., happy, unsafe, effective), (ii) assessments of certainty, reliability, and limitations of what is conveyed (e.g., I think, obviously, must), and (iii) comments on the discourse itself (e.g., honestly, with all due respect, finally; Chafe & Nichols, Reference Chafe and Nichols1986; Fuoli, Reference Fuoli2017; Hunston & Thompson, Reference Hunston and Thompson2000; Marín-Arrese, Reference Marín-Arrese2015; Martin & White, Reference Martin and White2005; Palmer, Reference Palmer2001; Põldvere et al., Reference Põldvere, Fuoli and Paradis2016; Simaki et al., Reference Simaki, Skeppstedt, Paradis, Kerren and Sahlgren2017). While there is great variability in our data regarding the functions that these expressions perform, they all contribute to the three key components of stance-taking as proposed by Du Bois (Reference Du Bois and Englebretson2007): evaluation, positioning, and alignment. These three components have three different consequences for the stance-taking act. Figure 1 visualizes a stance-taking act between two subjects, where the subjects (i) evaluate an object, (ii) position themselves, and (iii) align with each other. Du Bois defines alignment as “the act of calibrating the relationship between two stances, and by implication between two stancetakers” (Reference Du Bois and Englebretson2007, p. 144). The intersubjective alignment between the stances may range from agreement to disagreement, and it may be made more noticeable by formal and semantic mappings from one speaker to the next through dialogic resonance.
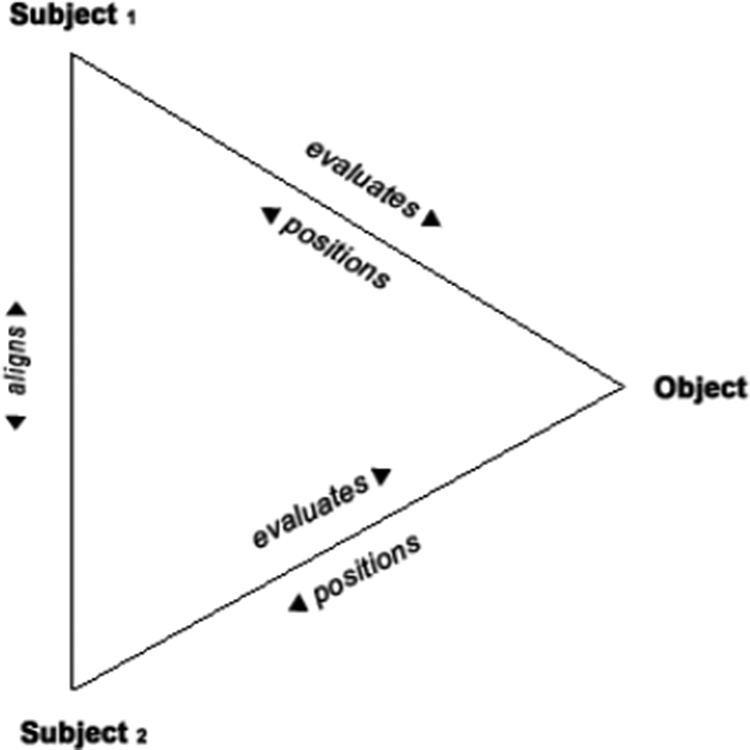
Fig. 1: The stance triangle represents the stance-taking act (Du Bois, Reference Du Bois and Englebretson2007, p. 163).
Consider (2) as a concrete example of the stance triangle and resonance.Footnote 1 It involves two speakers, Alice and Mary, who evaluate the same stance object (a third person and her intentions to carry out an action). Alice produces a so-called stance lead in which she expresses uncertainty about the stance object (I don’t know if she’d do it). The stance lead is followed by a stance follow in which Mary expresses agreement with Alice, while at the same time formally resonating with her (I don’t know if she would either). Formal resonance emerges when elements from the prior turn are reused through repetition and minor changes (see Dori-Hacohen, Reference Dori-Hacohen2017; Du Bois, Reference Du Bois and Englebretson2007, Reference Du Bois2010).Footnote 2 The resonance in (2) is further highlighted through either, which is tagged on to mark agreement. In cases of disagreement expressed through formal resonance, markers of opposition such as negation (e.g., not, never, hardly) or conventionalized antonyms (e.g., good–bad, hot–cold, slow–fast) may be used by speakers.

Within resonance research, much of the work so far has focused on dialogic exchanges where the speakers express some kind of stance differential (e.g., Brône & Zima, Reference Brône and Zima2014; Dori-Hacohen, Reference Dori-Hacohen2017; Zima et al., Reference Zima, Brône, Feyaerts and Sambre2009), thus suggesting that resonance is a fruitful way to express disagreement in dialogue. Consider (3), where two speakers, Joanne and Lenore, are talking about a mutual acquaintance who is a recovering alcoholic. The parallelism in this example is between the utterances yet he’s still healthy and he’s still walking around.

On the one hand, the utterances in (3) are framed by the phrase he’s still (formal resonance), which identifies the stance object to be evaluated. On the other hand, the prosodically focal element, the adjective healthy, in Joanne’s utterance resonates with the verb phrase walking around in Lenore’s utterance. Out of context, these expressions have very little in common, but the dialogic juxtaposition of healthy and walking around invites the inference that, in this particular context, the phrases are understood as related to each other through opposition. They are meanings at opposite poles of health (healthy ≠ walking around), but since they are not conventionalized antonyms, they require contextual boosting to be understood as opposites of the same meaning dimension (Paradis & Willners, Reference Paradis and Willners2011; van de Weijer et al., Reference van de Weijer, Paradis, Willners and Lindgren2014). We refer to this type of resonance as semantic resonance in that it involves resonating semantic structures, i.e., opposites or near-synonyms depending on whether the speakers express disagreement or agreement, respectively.Footnote 3 In the case of agreement, it is again the focal elements that are near-synonyms (e.g., confusing and wobbly in it’s a little bit confusing →t is all a bit wobbly; see Section 5).
Resonance, and particularly semantic resonance, is an effective way to express disagreement in a range of discourse contexts. Brône and Zima (Reference Brône and Zima2014) and Zima et al. (Reference Zima, Brône, Feyaerts and Sambre2009), for instance, show that semantic resonance is commonly used in parliamentary debates to strike one’s political opponents with a skillful play on the meaning potential of constructions. As for everyday conversation, which typically is much less adversarial, a different pattern seems to emerge. Based on a comprehensive analysis of a conversation in Hebrew carried out during a car ride, Dori-Hacohen (Reference Dori-Hacohen2017) shows that semantic resonance is an effective way to reject requests for driving directions and to enhance distance between the interlocutors. However, the focus of the study is on a very specific type of action (i.e., requests for driving directions) and a single conversation, which makes us hesitant to interpret the results as transferrable to everyday conversation in general.
The view of resonance adopted by Du Bois is in line with the general view of language by Clark (Reference Clark1996), namely as intentional joint action undertaken by speakers with specific goals in mind. According to Clark, speakers are oriented towards a common goal, and they actively monitor and infer each other’s intentions and assumptions to achieve this goal. However, Du Bois (Reference Du Bois2014) also acknowledges the facilitating role of the cognitive process of priming in resonance. According to Du Bois, lexical and structural priming, in particular, create cognitive conditions that trigger the reuse of linguistic forms and structures, but the nature of the role of cognitive facilitation in resonance production has not been backed up by empirical evidence. In contrast, priming is central in interactive alignment theory in cognitive psychology (e.g., Garrod & Pickering, Reference Garrod and Pickering2004; Pickering & Garrod, Reference Pickering and Garrod2004), but note that, in their theory, the term ‘alignment’ refers to the reuse of prior linguistic material (i.e., what we refer to as resonance), not to an intersubjective relation between two stances as understood in this study (see also Rasenberg et al., Reference Rasenberg, Özyürek and Dingemanse2020, for a review of other related theories). According to Garrod and Pickering (Reference Garrod and Pickering2004), interlocutors come to understand a conversation in the same way due to an automatic process whereby the reuse of prior material at lower levels of linguistic representation, ranging from words and syntax to semantic and pragmatic relations, leads to mutual understanding at the critical level of the situation model. Moreover, the primed linguistic representations become available to interlocutors with reduced cognitive effort. While Pickering and Garrod (Reference Pickering, Garrod and Cutler2005) contend that “the pressures of actual conversation … mean that in practice interlocutors perform very little ‘other modelling’” (2005, p. 87), they do not deny the role of intentional processes. Since Garrod and Pickering’s seminal publication from Reference Garrod and Pickering2004, interactive alignment has come to be used in many disciplines as a cover term for repetition, and this more recent literature has not necessarily been committed to the original automatic view or it has not taken a clear stand in the intentional vs. automatic debate (e.g., Allen et al., Reference Allen, Haywood, Rajendran and Branigan2011; Dideriksen et al., Reference Dideriksen, Fusaroli, Tylén, Dingemanse, Christiansen, Goel, Seifert and Freksa2019; Fusaroli et al., Reference Fusaroli, Bahrami, Olsen, Roepstorff, Rees, Frith and Tylén2012). In this study, we have decided to adhere to the original version of interactive alignment as proposed by Garrod and Pickering in our theoretical discussion.
3. Timing of turns
Spoken interaction is characterized by rapid transitions of speaker turns that, according to the influential model by Sacks et al. (Reference Sacks, Schegloff and Jefferson1974), overwhelmingly occur with no gaps and no overlaps. This means that speakers avoid starting their turns too early (perceived overlaps) or too late (perceived gaps). While the study by Sacks et al. was largely based on qualitative observations of spoken interaction, more recent corpus studies on a range of the world’s languages have confirmed that the majority of turn transitions in conversation take place within the time course of around 200 to 300 ms (e.g., Heldner & Edlund, Reference Heldner and Edlund2010; Levinson & Torreira, Reference Levinson and Torreira2015; Roberts et al., Reference Roberts, Torreira and Levinson2015; Stivers et al., Reference Stivers, Enfield, Brown, Englert, Hayashi, Heinemann, Hoymann, Rossano, de Ruiter, Yoon and Levinson2009). This is interesting in the light of the fact that psycholinguistic research has shown that it takes around 600 ms to produce a single word (e.g., Levelt et al., Reference Levelt, Roelofs and Meyer1999), which is an indication that speakers project the end of the incoming turn to then launch their own turn immediately (Sacks et al., Reference Sacks, Schegloff and Jefferson1974). Experimental studies have shown that speakers start planning their turns as soon as they have gathered enough information about the incoming turn; the earlier this is made possible, the faster the upcoming turn (e.g., Barthel et al., Reference Barthel, Sauppe, Levinson and Meyer2016).
The timing of turns in conversation depends on many different communicative and cognitive factors. Much of the work on this topic so far has focused on question–response sequences. For example, Meyer et al. (Reference Meyer, Alday, Decuyper and Knudsen2018) found strong effects of response length and response polarity on the timing of responses to polar questions. They found that the response latencies were shorter for one-word responses (yes and no) and longer in responses where yes and no were further qualified in the second part of the utterance. This indicates that the participants did not plan the long responses in a truly incremental fashion but instead “carried out at least some of the planning for the second part of the utterance before responding” (2018, p. 9), especially since they rarely paused between the first and the second part of the response. Furthermore, regardless of length, negative responses to polar questions were given more slowly than positive responses, a result that suggests some reluctance on the part of the participants to provide a negative response (see also Stivers et al., Reference Stivers, Enfield, Brown, Englert, Hayashi, Heinemann, Hoymann, Rossano, de Ruiter, Yoon and Levinson2009).
This result is in line with the notion of preference organization in conversation analytic and interactional linguistic research (e.g., Atkinson & Heritage, Reference Atkinson, Heritage, Atkinson and Heritage1984; Pomerantz, Reference Pomerantz, Atkinson and Heritage1984; Schegloff, Reference Schegloff1988), which reports that there is a tendency for preferred responses (e.g., agreement) to occur relatively early and often in overlap with the prior turn, and for dispreferred responses (e.g., disagreement) to occur after a delay. However, when Kendrick and Torreira (Reference Kendrick and Torreira2015) set out to quantitatively verify these claims based on a sample of acceptances and rejections in corpora of telephone calls, they instead found that the timing of turns was not so much a function of the action performed in the turn (acceptance or rejection) as it was of the way the turn had been designed. With the exception of long gaps of 700 to 800 ms after which the responses were almost exclusively rejections, both positive and negative response tokens (yes and no) occurred significantly earlier than qualified acceptances (e.g., yes, but …) and rejections (e.g., no, I don’t think so). Roberts et al. (Reference Roberts, Torreira and Levinson2015) found a similarly weak effect of preference organization in their analysis of a range of utterance types in telephone calls from the Switchboard corpus (see also Robinson, Reference Robinson2020, for issues with the two-way distinction between preferred and dispreferred responses).
To the best of our knowledge, no corpus or experimental studies have investigated the effect of dialogic resonance on the timing of turns in conversation. A mention in passing is made in Meyer et al. (Reference Meyer, Alday, Decuyper and Knudsen2018), who acknowledge that long utterances may be initiated faster if they are activated in the preceding context (see also Garrod & Pickering, Reference Garrod and Pickering2015, for similar observations), but no empirical evidence is provided to support this claim. This is in spite of the fact that resonance seems essential in conversational turn-taking due to the very tight time constraints under which conversation operates, and the facilitating effect that resonance may have on turn uptake (cf. Du Bois et al., Reference Du Bois, Hobson and Hobson2014; Garrod & Pickering, Reference Garrod and Pickering2004). Concepts that have already been mentioned in the prior discourse are more accessible and therefore produced earlier in order to minimize cognitive demands on the next speaker (Ariel, Reference Ariel1988; Tachihara & Goldberg, Reference Tachihara and Goldberg2020). The shorter time it takes for speakers to resonate with each other may also shed light on the role of cognitive facilitation in resonance production. However, as Nir and Zima (Reference Nir and Zima2017) put it, this does not mean that resonance should be reduced to lower cognitive effort but that intentional processes are also at play: “when resonance is created between utterances, speakers (or writers) not only make use of the linguistic resources that are already available but they create new meaning by re-contextualizing these resources” (2017, p. 7). This is particularly true of semantic resonance, which can be expected to be more cognitively demanding for the next speaker than formal resonance due to differences in mapping relations.
4. The present study
While previous research has acknowledged a reciprocal relationship between intersubjective motivations and cognitive facilitation in dialogic resonance, they have not expanded on, or empirically tested, how communicative and cognitive aspects relate to each other in resonance production. Based on data of stance-taking sequences in everyday face-to-face conversation, this corpus-based study takes an interest in both aspects in order to bridge the gap between interactional linguistic and cognitive approaches to resonance.
Based on the literature, we make two predictions. Prediction 1 relates to the intersubjective motivations of resonance, explored through the type of alignment in the stance-taking sequence. The prediction is that resonance is more likely to be used by speakers in disagreement, while non-resonance is the preferred option in agreement. Support for Prediction 1 comes from previous work on resonance in contesting situations (Brône & Zima, Reference Brône and Zima2014; Dori-Hacohen, Reference Dori-Hacohen2017; Zima et al., Reference Zima, Brône, Feyaerts and Sambre2009).
Prediction 2 relates to the role of cognitive facilitation in resonance, which we operationalize by measuring the time it takes for speakers to respond to the interlocutor’s prior stance. The prediction is that, due to the facilitating effect of reusing prior linguistic material, transitions between speaker turns are faster in resonating sequences than when the turns are constructed from scratch. We expect the effect to be observable both for formal and semantic resonance, but to a lesser extent for semantic resonance, which relies on meaning mappings only. This said, the short latencies observed for response tokens such as yes and no (Kendrick & Torreira, Reference Kendrick and Torreira2015; Meyer et al., Reference Meyer, Alday, Decuyper and Knudsen2018) suggest that formal resonance does not trump the ease of production of these short and highly frequent linguistic expressions. Therefore, response tokens are set in contrast to another type of non-resonating sequences, namely elaborated responses, which are longer and may or may not contain a response token (e.g., you need to moderate the length → yeah that was a long essay; see Section 5). They correspond roughly to long responses in Meyer et al. (Reference Meyer, Alday, Decuyper and Knudsen2018) and qualified acceptances and rejections in Kendrick and Torreira (Reference Kendrick and Torreira2015). The specific prediction we make is that response tokens are produced the fastest, followed by formal and semantic resonance, and, finally, by elaborated responses of non-resonance. Due to conflicting evidence in the literature regarding preference organization and the timing of turns in conversation, the effect of intersubjective alignment on the duration of turn transitions in this study is presented as an exploratory question rather than a prediction.
5. Methods
5.1. the sample
The data are from a new corpus of spoken British English, the London–Lund Corpus 2 (LLC–2), recorded between 2014 and 2019. LLC–2 contains approximately 500,000 words stored in 100 texts of 5,000 words each, and corresponding audio files. The sample drawn for this study comes from face-to-face conversation, the most important conversational setting in LLC–2. In order to control for the number of speakers, only dyadic conversations were included. The sample contains 20 texts of 5,000 words each, totaling some 100,000 words. While 12 of the texts correspond to one single conversation, eight texts contain two different conversations of 2,500 words each. This means that the final sample contains 28 different conversations among 48 unique speakers (age range 18–71; M = 36). Among the 28 conversations, 11 are mixed between male and female, 14 are all female and three are all male.
5.2. extracting the stance-taking sequences
The basic unit of analysis in this study is the stance-taking sequence, which comprises two utterances: the stance lead (the first utterance produced by the first speaker) and the stance follow (the second utterance produced by the second speaker; Du Bois, Reference Du Bois and Englebretson2007). A stance-taking sequence may perform a range of functions in discourse (e.g., affect, epistemic modality, evidentiality), but it must make reference to the evaluation, positioning, and alignment of the stance-taking act (see Section 2 above). Example (4) illustrates a stance-taking sequence consisting of the stance lead that was a bit odd and the stance follow yeah I found it quite strange, in which speaker B expresses agreement with the evaluation of A, and where both speakers simultaneously position themselves as the stance-takers. Note that all examples in this section are from LLC–2.
Intersubjective alignment may also be expressed by response tokens only, in particular response tokens that signal (dis)agreement and engagement with the stance lead (e.g., yeah, no, brilliant; see O’Keeffe & Adolphs, Reference O’Keeffe, Adolphs, Schneider and Barron2008). We excluded response tokens that are primarily used for discourse organizational purposes (e.g., mhm, uh huh, right) because they do not express (dis)agreement. Since some response tokens such as yeah are ambiguous between the two readings, prosodic prominence was considered a criterion of agreement (cf. Müller, Reference Müller, Couper-Kuhlen and Selting1996). This was determined auditorily or, if necessary, instrumentally in Praat (Boersma, Reference Boersma2001). We also excluded response tokens that position the stance-taker as not knowing (I don’t know).
In order to obtain accurate measurements of the durations of turn transitions, we decided to limit the analysis to certain contexts only. It was important to make sure that any difference in the timing of the stance-taking sequences was due to the factors tested in this study (resonance and alignment) and not to some confounding factors. Thus, the stance-taking sequences included in the study had to meet a number of criteria that, in previous research, have been found to either speed up or slow down turn transitions. Table 1 lists all the criteria (column 1). Columns 2 and 3 provide examples of the different kinds of stance-taking sequences (in italics) that were included and excluded, respectively. Horizontally, the table is divided into two parts. The first part lists the criteria that were expected to speed up turn transitions, and the second part lists the criteria that were expected to slow down the turn transitions. For example, the first criterion in Table 1 states that the stance lead had to be a statement or an exclamation, which means that it could not fall under any of the question types identified in Stivers and Enfield (Reference Stivers and Enfield2010). The reason for this is that questions anticipate a response and may elicit earlier responses from the interlocutor than utterance types where the interlocutor’s response is often not necessary, such as stance-taking sequences (see Holler & Kendrick, Reference Holler and Kendrick2015, on early gaze shifts in questions). An exception was made for tag questions that were uttered in overlap with the stance follow, because in those cases the second speaker did not react to the tag question but to what came before. The example in the second column meets this criterion and was included in the analysis, while the yes–no question in the third column was excluded.
Table 1. Criteria for the inclusion of stance-taking sequences in the analysis based on previous research on factors that are expected to either speed up or slow down turn transitions (the first and the second part of the table, respectively). The criteria are accompanied by examples from LLC–2 where the stance-taking sequences are given in italics and the square brackets indicate overlaps.
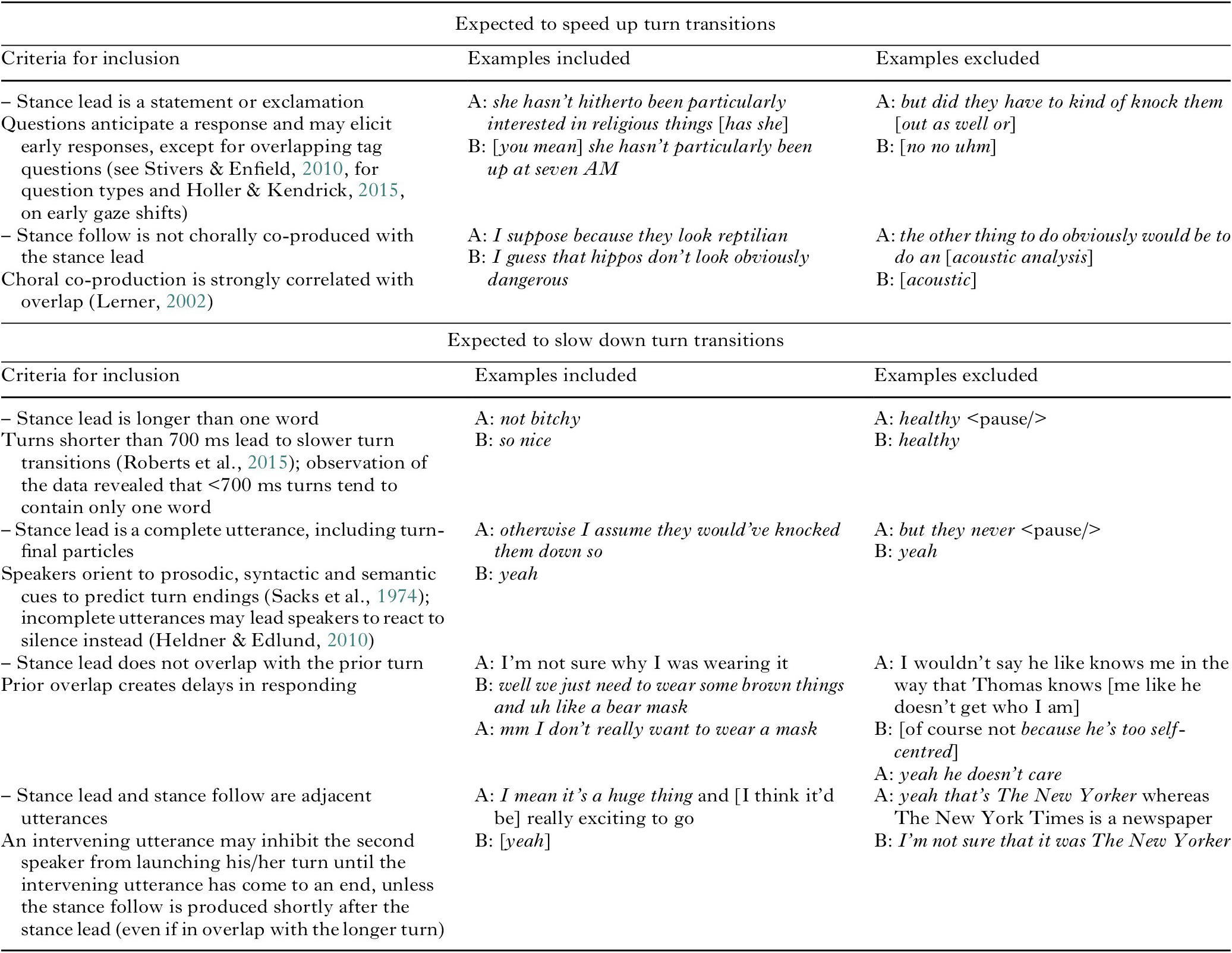
As can be seen in Table 1, none of the criteria make reference to non-verbal turn-yielding cues such as gaze, hand gestures, and facial expressions (e.g., Holler et al., Reference Holler, Kendrick and Levinson2017; Stivers et al., Reference Stivers, Enfield, Brown, Englert, Hayashi, Heinemann, Hoymann, Rossano, de Ruiter, Yoon and Levinson2009). This is because there is no video-recording in LLC–2. However, the focus of this study on verbal communication, and the rigorous manual treatment of a large number of verbal cues as demonstrated in Table 1, to some extent compensates for the lack of video material. Also, we acknowledge the possible influence of other communicative and cognitive factors on the timing of turns in conversation (see, e.g., Roberts et al., Reference Roberts, Torreira and Levinson2015), but the use of corpus methods in this study limited the number of confounding factors for which we could control. Thus, the criteria in Table 1 provide the constraints for what kinds of sequences to include in this study.
The stance-taking sequences were extracted from the sample in the following way. First, the 28 conversations were read in full in order to identify stance-taking sequences that also included resonance (see below). We found 263 such sequences. We then extracted five-minute excerpts from the 28 conversations, and from those excerpts non-resonating stance-taking sequences were retrieved; all in all, we found 319 non-resonating sequences. Non-resonance is much more common and therefore there was no need to scrutinize whole texts to obtain such sequences. S ection 5.3 describes how the sequences were classified.
5.3. the classification of dialogic resonance and intersubjective alignment
The classification of the stance-taking sequences was carried out in ELAN 5.4, which is a multimodal annotation tool that allows for a multi-layered description of digital research data (Wittenburg et al., Reference Wittenburg, Brugman, Russel, Klassmann, Sloetjes, Calzolari, Choukri, Gangemi, Maegaard, Mariani, Odijk and Tapias2006). ELAN was chosen because of the multimodal nature of the study, involving both the classification of the stance-taking sequences and measurements of the turn transitions. A detailed and context-specific annotation manual was devised for this purpose.Footnote 4 This sub-section provides a brief overview of the first part of the analysis and how the stance-taking sequences were classified in terms of (i) dialogic resonance and (ii) intersubjective alignment.
5.3.1. The classification of dialogic resonance
Two different schemes were devised for classifying the stance-taking sequences: a broad classification and a fine-grained classification. The broad classification corresponds to Prediction 1 about the intersubjective motivations of dialogic resonance, where a distinction was made between resonance and non-resonance (see Section 4 above). The key method for distinguishing between resonating and non-resonating stance-taking sequences was to try to place them in a diagraph, defined as “a higher-order, supra-sentential syntactic structure that emerges from the structural coupling of two or more utterances (or utterance portions), through the mapping of a structured array of resonance relations between them” (Du Bois, Reference Du Bois2014, p. 376). The diagraph helped us visualize and detect mappings across the utterances that would otherwise go unnoticed. In order to qualify as an instance of resonance, the utterances in the stance-taking sequence had to map onto each other in the diagraph. In case the utterances resisted being placed in a diagraph, the sequence was considered non-resonating instead. For example, the stance-taking sequence in (5) meets this criterion, while the sequence in (6) does not.
Next, the fine-grained classification corresponds to Prediction 2 about the cognitive facilitation of dialogic resonance, where further distinctions of (non)-resonance were made. As for resonance, we made a distinction between formal and semantic resonance (see Section 2 above and the annotation manual for details). Example (5), for instance, is a case of semantic resonance, because confusing and wobbly may not be immediately obvious candidates for near-synonymy out of context. They require contextual boosting to be understood as such. We also made a distinction between two types of non-resonance: elaborated responses and response tokens. Stance-taking sequences of the former kind cannot be placed in a diagraph because of major structural differences between the utterances, as shown in (6), while in the case of response tokens (e.g., if B’s response had been a simple yeah), resonance is by definition impossible.
5.3.2. The classification of intersubjective alignment
The stance-taking sequences were then classified in terms of the type of intersubjective alignment. For this, a distinction was made between agreement and disagreement (see the annotation manual). Although we agree with Du Bois (Reference Du Bois and Englebretson2007) that intersubjective alignment is not a strict binary choice between the two types of alignment, the distinction was necessary in order to obtain better control over the data.
To assess the reliability of the analysis above, a series of inter-rater reliability tests were carried out based on our annotation and the annotation of ~10% of the stance-taking sequences by a research assistant with no prior experience in dialogic resonance. Comparisons of the annotation of resonance revealed 94.83% agreement for the broad classification, yielding a Cohen’s chance-corrected kappa coefficient of .891 (‘almost perfect agreement’ according to the scale of Landis & Koch, Reference Landis and Koch1977), and 89.66% agreement for the fine-grained classification (k = .824; ‘almost perfect agreement’). Disagreements between the annotators were discussed and resolved together. Intersubjective alignment yielded 100% agreement.
5.4. measuring the turn transitions
This sub-section concerns the second part of the analysis in which durations of transitions from the stance lead to the stance follow were measured in ELAN. The measurements were made from the last acoustic signal of the stance lead to the first acoustic signal of the stance follow, excluding vocal noises such as out-breaths, in-breaths, and clicks (see Kendrick & Torreira, Reference Kendrick and Torreira2015). The transition was either a gap or an overlap and was given either a positive or a negative value, respectively. Very long gaps (longer than 2800 ms) and very long overlaps (longer than –2800 ms; e.g., –3000 ms) were discarded from the analysis (~1% of the data; cf. Roberts et al., Reference Roberts, Torreira and Levinson2015), leaving us with 260 resonating stance-taking sequences and 316 non-resonating sequences.
To assess the reliability of our measurements, a research assistant measured the turn transitions of ~10% of the stance-taking sequences in ELAN following the annotation manual. A comparison between the research assistant’s and our measurements yielded a high degree of intraclass correlation (ICC(1) = .96).
5.5. statistical analysis
The statistical analysis of the data was conducted in RStudio (version 1.0.136; R Core Team, 2014). The plots were generated using the ggplot2 package, and we fitted the mixed-effects regression models to our data using the glmer (logistic) and lmer (linear) functions of the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015). Models of different complexity were created and the model with the best predictive accuracy, i.e., with the lowest AIC value, was chosen. The model comparisons were made using the AICcmodavg package. The best model for the logistic regression analysis had intersubjective alignment as the dependent variable and dialogic resonance as the fixed effect, with by-speaker (the second speaker) random slopes and by-conversation random intercepts. In the best model for the linear regression analysis, duration was the dependent variable, and resonance and alignment the fixed effects, with by-speaker (the second speaker) and by-conversation random intercepts. Additionally, in the case of the second model, we used the multcomp package (Hothorn et al., Reference Hothorn, Bretz and Westfall2008) to carry out six pairwise comparisons between levels of the fixed effects.Footnote 5
6. Results
This section reports the results of the descriptive and inferential statistical analyses of the 260 resonating stance-taking sequences and 316 non-resonating sequences.
6.1. the association between dialogic resonance and intersubjective alignment
To test Prediction 1, we based the analysis on the broad classification of (non)-resonance as described in Section 5 above. Specifically, we studied the distribution of the two types of intersubjective alignment – agreement and disagreement – across the broad categories of resonance and non-resonance. The results show that, while 35% (n = 92) of the resonating stance-taking sequences appear in disagreement, only 11% (n = 35) of the non-resonating sequences do. The mixed-effects model confirmed a significant association between resonance and disagreement (ß = 1.8139, SE = 0.5057, z = 3.587, p < .001), thus providing full support for the prediction that resonance is more likely than non-resonance to appear in disagreement than agreement.
6.2. the effects of dialogic resonance and intersubjective alignment on the duration of turn transitions
Next, we tested Prediction 2 about the effects of dialogic resonance and intersubjective alignment on the duration of turn transitions. The analysis was based on the fine-grained classification of (non)-resonance, which included distinctions between the two types of resonance, formal and semantic, and response tokens and elaborated responses of non-resonance. Intersubjective alignment remained the same, i.e., agreement and disagreement. All combinations of the fixed effects had an observed frequency of at least 10.
Figure 2 shows density plots of the durations of turn transitions for (non)-resonance and intersubjective alignment. The top panels represent the distributions (in ms) of formal and semantic resonance and the bottom panels the distributions of response tokens and elaborated responses of non-resonance. The vertical dotted lines are the mean durations. According to the observed values of central tendency, the fastest turn transitions were attested for response tokens (M = –56.71, Mdn = 40.00, SD = 638.33) and the slowest for elaborated responses (M = 605.21, Mdn = 526.50, SD = 554.39). Of the two types of resonance, formal resonance was produced faster (M = 114.13, Mdn = 67.00, SD = 605.25) than semantic resonance (M = 253.75, Mdn = 211.00, SD = 789.28). The jittered rugs below each panel demonstrate how the density plots were created based on the individual data points. Each panel in Figure 2 also shows a comparison of agreement (dark gray) and disagreement (light gray). In all cases, there are noticeable differences in the distribution of the two types of intersubjective alignment with a concentration of disagreement to the right, thus suggesting slower turn transitions.

Fig. 2: The distribution of the durations of turn transitions (in ms) for formal and semantic resonance (top panels), and response tokens and elaborated responses of non-resonance (bottom panels). The vertical dotted lines represent the mean durations. The dark gray distributions in each panel correspond to agreement and the light gray distributions to disagreement. The jittered rugs below each panel display the individual data points.
The results of the mixed-effects model provide partial support for Prediction 2. The prediction was that resonance, and particularly formal resonance, is produced faster than elaborated responses of non-resonance but slower than response tokens. The results also provide a positive answer to the open question of whether or not there are differences in timing between agreement and disagreement. Specifically, the model revealed a significant main effect of intersubjective alignment showing that disagreement was produced later than agreement on all four levels of (non)-resonance (ß = 304.52, SE = 72.19, t = 4.218, p < .001). As for (non)-resonance itself, the following results were observed. Significantly slower turn transitions were found for elaborated responses compared to formal resonance (ß = 404.22, SE = 117.25, z = 3.448, p = .003) but not compared to semantic resonance (ß = 245.62, SE = 122.27, z = 2.009, p = .176), which was produced slower than formal resonance. The difference between formal and semantic resonance was not significant (ß = 158.61, SE = 79.47, z = 1.996, p = .181). Moreover, response tokens were not produced significantly slower than formal resonance (ß = 55.35, SE = 65.76, z = 0.842, p = .828) or significantly faster than semantic resonance (ß = –103.25, SE = 75.97, z = –1.359, p = .513). It should be noted that there was also a significant difference between the two types of non-resonance, response tokens and elaborated responses (ß = 348.87, SE = 118.39, z = 2.947, p = .016), which suggests an effect of response length, but this result is not particularly relevant for this study. Table 2 summarizes the durations of turn transitions for the four types of (non)-resonance and the two types of intersubjective alignment in the regression model.
Table 2. Predicted mean durations of turn transitions (in ms) for the four types of (non)-resonance (formal, semantic, response tokens, and elaborated responses) and the two types of intersubjective alignment (agreement and disagreement) in the regression model (standard errors are in parentheses).

As can be seen in the table, agreements are consistently produced earlier than disagreements (e.g., for formal resonance –109.31 ms and 195.21 ms, respectively). In all cases, formal resonance is produced fastest, and elaborated responses of non-resonance slowest, with semantic resonance and response tokens of non-resonance in between. However, despite being expressed later than agreement, the apparent ease with which the speakers expressed disagreement through resonance is striking when compared with findings from previous research (see Section 7.2).
7. Discussion
This study examined the dialogic occurrence of resonance in stance-taking turns in everyday face-to-face conversation. In order to gain a better understanding of the phenomenon, we approached it both from an intersubjective and a cognitive perspective. The following sub-sections discuss the results previously presented in the light of the study’s predictions.
7.1. the role of dialogic resonance in disagreement
Prediction 1 targeted the intersubjective motivations of resonance. It stated that resonance is more likely to appear in disagreement than non-resonance, which is more likely to be the case in agreement. The study provides full support for this prediction. While this study is not the first one to point this out (e.g., Dori-Hacohen, Reference Dori-Hacohen2017; Du Bois, Reference Du Bois2014; Zima et al., Reference Zima, Brône, Feyaerts and Sambre2009), there have been no previous attempts at strict operationalization and statistical confirmation of the close relationship between resonance and disagreement. The result raises the question of why resonance is more common in disagreement. It seems reasonable to assume that, like other dispreferred responses, disagreement is a face-threatening act that may change the preferred joint project initiated by the first speaker, i.e., to seek some sort of agreement, which means that the second speaker must do extra work to plan and formulate an appropriate response (Clark, Reference Clark1996; see also Sacks, Reference Sacks, Button and Lee1987, for the ‘preference for agreement’ principle). This is particularly important in everyday conversation where speakers typically are inclined to be cooperative and promote solidarity and affiliation among themselves. Therefore, our interpretation of the corpus data is that resonance helps speakers achieve the goal of countering the negative social consequences associated with dispreferred responses. Consider examples (7) and (8), taken from conversations among close family members in LLC–2, where the stance-taking sequences are in bold.


In both (7) and (8), the speakers have different views on the topics being discussed, but the disagreement is achieved by different means. While speaker B’s stance follow in (7) is only minimally coherent with A’s stance lead (the only content word that links them is hill), the stance-taking sequence in (8) displays structural parallelisms along multiple levels of linguistic representation (e.g., the stance adverb particularly, the negated and predicative constructions, but also co-reference (she) and, as revealed in the original audio file, rise–fall intonation). In other words, speaker A in (8) seems to construe her response in a way that foregrounds what is shared by the interlocutors rather than where they differ, which is the case in (7). Based on this, we propose that the reason why resonance is often used in disagreement in our data of impromptu speech is because the reuse of prior linguistic material at the lower levels of lexical items, syntactic structure, semantics, and intonation reinforces the perception of interpersonal solidarity at the higher level of social relations. Resonance may thereby have the effect of mitigating the force of the disagreement and narrowing the conceptual gap between the interlocutors through such linguistic parallels. By hearing their own words and ideas back, speakers may feel reassured about the interlocutor’s engagement with their beliefs and attitudes, and therefore they are not so easily offended even though these beliefs and attitudes are actually being contested. This is in line with Nir (Reference Nir2017), who argues that resonance evokes a sense of affinity and coherence, while non-resonance creates “a distancing effect” (2017, p. 117), both at the lower level of linguistic material and at the higher level of social rapport (cf. Dori-Hacohen, Reference Dori-Hacohen2017).
An alternative interpretation of the occurrence of resonance in disagreement can be found in Heritage and Raymond’s (Reference Heritage and Raymond2005) framework of epistemic authority. According to them, speakers are sensitive to who has primary epistemic rights to claims, and one way in which second speakers make claims to those rights is by repeating what the first speaker said (see also Stivers, Reference Stivers2005). Research on such epistemic independence from the second speaker has almost exclusively focused on agreements, and it has been taken for granted that the results will generalize to disagreements too. However, we are hesitant to interpret our results in the light of this generalization because of the fact that there are fundamental functional and social differences between agreement and disagreement. Vatanen (Reference Vatanen2018), for instance, notes that “in disagreements, the question is more about how things should be thought of in the first place rather than about whose (similar) knowledge is primary” (2018, p. 113). In (8) above, the question is not about epistemic independence but rather about setting the record straight on a debatable issue (a third person’s reason for not knowing a radio programme). Moreover, disagreements by default convey epistemic independence from the interlocutor’s claims because the claims are not the same, or similar, to start with. Finally, this alternative interpretation would not explain the difference in the occurrence of resonance in disagreement compared to agreement in this study. This said, future research should aim to confirm the interpretation of the mitigating function of resonance under more strict experimental conditions in order to be able to validate the arguments that we made based on frequency in LLC–2.
7.2. the role of cognitive facilitation in resonance production
Prediction 2 targeted the role of cognitive facilitation in resonance, which we tested based on strictly controlled measurements of durations of turn transitions in the conversations. We made a distinction between two types of resonance (formal and semantic) and two types of non-resonance (response tokens and elaborated responses), and predicted that turn transitions are fastest for response tokens, followed by formal and semantic resonance, and elaborated responses, in that order. Thus, with the exception of response tokens, which are short and highly frequent, we expected resonance to be produced faster than non-resonance due to the facilitating effect of reusing prior linguistic material. In the statistical model presented in Section 6 above, we tested this prediction together with the open question of whether or not there are differences in timing between agreement and disagreement. The results provided a positive answer to this question, showing that disagreement was expressed later than agreement (cf. Meyer et al., Reference Meyer, Alday, Decuyper and Knudsen2018; Roberts et al., Reference Roberts, Torreira and Levinson2015; Stivers et al., Reference Stivers, Enfield, Brown, Englert, Hayashi, Heinemann, Hoymann, Rossano, de Ruiter, Yoon and Levinson2009), and that this effect was independent of whether they included resonance or not. However, there were differences in the amount of time that the speakers took to express those views. Specifically, we found significantly faster turn transitions for formal resonance compared to elaborated responses of non-resonance. The non-significant association between elaborated responses and the other type of resonance – semantic – may have been because of the greater variation of form in semantic resonance, which reduces the degree to which speakers can access and quickly reproduce prior linguistic material.
However, when compared with findings from previous research, the predicted mean durations in this study are small for both types of resonance and for both types of intersubjective alignment (cf. Table 2 above). We would especially like to draw the reader’s attention to the apparent ease with which the speakers expressed disagreement through resonance, based on the observation made in Section 7.1 above that resonance is common in disagreement situations. Specifically, it took the speakers less than 200 ms (M = 195.21 ms) to disagree with each other via formal resonance (e.g., it was boring → it wasn’t that boring) and 353.84 ms to do so through semantic resonance. This is very fast considering that it took them on average 250.56 ms to produce a single response token such as no, and that the nearly 600 ms (M = 599.43 ms) recorded for elaborated responses comes close to the temporal threshold of 700–800 ms after which a dispreferred response is imminent (Kendrick & Torreira, Reference Kendrick and Torreira2015). Moreover, only elaborated responses come close to the mean latencies observed in Meyer et al. (Reference Meyer, Alday, Decuyper and Knudsen2018), where long negative responses to polar questions were given as late as c. 700 ms (depending on the experimental condition). Examples (7) and (8) above illustrate the difference between the timing of elaborated responses of non-resonance and semantic resonance, respectively. While the stance follow in (7) is produced after a noticeable gap of 431 ms, the stance follow in (8) occurs in slight overlap with the prior turn.Footnote 6
Based on the assumed relationship between faster turn transitions on the one hand and greater cognitive accessibility of previously mentioned words and structures on the other hand (cf. Ariel, Reference Ariel1988; Tachihara & Goldberg, Reference Tachihara and Goldberg2020; see Prediction 2), the fast turn transitions observed for resonance in both agreement and disagreement situations provide empirical evidence in support of the view that cognitive facilitation plays an important role in resonance production. Specifically, it gives the speakers the necessary means to counter the temporal challenges of impromptu speech. Similarly, Du Bois et al. (Reference Du Bois, Hobson and Hobson2014) view cognitive facilitation and syntactic and lexical priming as a distinct phase in the larger resonance cycle that creates conditions for the uptake of certain linguistic constructions. This is, however, not where the resonance cycle ends. We know that speakers do not simply blurt out words without any consideration for the interpersonal effects that their words may have. Dispreferred responses given too early are especially risky because they defy social expectations (see, e.g., Bögels et al., Reference Bögels, Kendrick and Levinson2015, on the processing cost of no after a short gap compared to a long gap). To mitigate these risks, speakers make use of various qualification devices such as turn-initial in-breaths, particles, and hedges, which delay the onset of the base dispreferred response (Kendrick & Torreira, Reference Kendrick and Torreira2015). In fact, almost half of all the elaborated responses in our data are qualified in such a way, while only 11% of the resonating stance-taking sequences are. Yet, the latter are still produced at a noticeably greater speed than the former.
The conclusion we draw based on the results above is that intersubjective motivations and cognitive facilitation provide different, yet complementary, affordances for the occurrence of resonance in dialogue. The fast turn transitions observed for disagreement, in particular, seem to indicate that, while cognitive facilitation gives speakers the means to provide a swift response, it is the mitigating function of resonance that allows them to respond swiftly in disagreement situations. In this way, resonance performs a similar function to, say, turn-initial hedges, allowing the speakers to avoid a long gap. The absence of resonance (or turn-initial hedges) creates further distance between the interlocutors, reflected in their resistance to provide a swift response. Therefore, the combined data suggest that cognitive facilitation goes hand in hand with the strategic and appropriate formulation of one’s personal beliefs and attitudes, and the achievement of interpersonal engagement between the interlocutors. We agree with Du Bois et al. (Reference Du Bois, Hobson and Hobson2014) that the activation of linguistic material in the prior discourse constitutes only one phase of the larger resonance cycle, and that it is the subsequent uptake and selective reproduction of the material that completes the cycle and gives life to dialogic resonance with all its ancillary social consequences. Based on this, it is possible to say that dialogic resonance in particular and linguistic coordination in general do not lie in the privileged role of any one process, either communicative or cognitive, but in the close interplay between intersubjective motivations and cognitive facilitation. As stated in Section 7.1 above, there is a need to confirm the mitigating function of resonance in a laboratory setting. The same is true of the role of cognitive facilitation. The present study examined properties that were expected to correlate with cognitive facilitation such as the timing of turns in conversation (see also Roberts et al., Reference Roberts, Torreira and Levinson2015), but future research should aim to extract more direct online measures of cognitive facilitation and priming in order to uncover the exact nature of interactive priming (Garrod & Pickering, Reference Garrod and Pickering2004) in Du Bois’ resonance cycle.
8. Conclusion
Natural conversation is highly coordinated and draws simultaneously on the social goals that speakers have in dialogue and the cognitive aspects that underpin it. This study demonstrates this empirically by focusing on a compelling type of coordination, namely resonance in stance-taking turns in everyday face-to-face conversation in LLC–2. The corpus analysis was carried out in two parts. At the core of the first part of the analysis were the intersubjective motivations of resonance and the question of whether resonance is more likely than non-resonance to appear in disagreement than agreement, and, if so, why this may be the case. The results provided a positive answer to this question. Arguably, this is due to the cooperative nature of everyday conversation and the important role that resonance plays in mitigating the force of the ensuing disagreement through parallels along multiple levels of linguistic representation. In the second part of the analysis, we investigated the role of cognitive facilitation in resonance production. The results showed that utterances that included formal resonance were produced faster than utterances constructed from scratch. We interpret this as an indication that formal resonance has a facilitating effect on turn uptake, prompted by the activation of the same linguistic representations in the mind of the second speaker by the prior speaker’s turn. We also found that disagreement was expressed later than agreement; however, the resonating sequences expressing disagreement were still produced strikingly fast. Taken together, then, the results point to the close and reciprocal relationship between communicative and cognitive aspects of resonance whereby the face-saving intersubjective motivation of resonance combines with its facilitating cognitive effect to promote appeasing communication.





 Open access
Open access