



1. Introduction
Every day, we perform different actions: We cook, we ride a bike, we make ourselves up, we use tools, or practice sports. Many of these actions are learned from others, by imitation (Heyes, Reference Heyes2001; Shipton & Nielsen, Reference Shipton and Nielsen2015) or by others teaching us (Gärdenfors & Högberg, Reference Gärdenfors and Högberg2017). When teaching bodily actions, we typically use demonstration, which is an act whereby the instructor attempts to teach an action by actually performing it in front of the learner (Gärdenfors, Reference Gärdenfors2017). Another ubiquitous method of teaching is pantomime: Here, the instructor attempts to teach an action by executing movements that are characteristic of this action but without actually performing it, for example by pretending to hammer in a nail without using a hammer and a nail (Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Gärdenfors, Reference Gärdenfors2017). Pantomime has also another function: It can be performed with the intention of making the recipient think about an object or an event, which is often absent from the immediate surroundings (cf. displacement, Section 2.3),for example a pantomime of hammering can be used to communicate to the recipient ‘find a hammer and bring it to me’ (Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Gärdenfors, Reference Gärdenfors2021). Accordingly, there are two types of pantomime: for teaching and for communication (alternatively, pantomime for showing and for telling; Gärdenfors, Reference Gärdenfors, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024).
There has recently been an upsurge in research on demonstration and pantomime (e.g. Arbib, Reference Arbib2012; Gärdenfors, Reference Gärdenfors2017, Reference Gärdenfors2021; Osiurak et al., Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023; Tomasello, Reference Tomasello2008; Trujillo et al., Reference Trujillo, Simanova, Bekkering and Ozyurek2018; Zlatev et al., Reference Zlatev, Wacewicz, Zywiczynski and van de Weijer2017; Żywiczyński et al., Reference Żywiczyński, Wacewicz and Sibierska2018), with claims that demonstrators and pantomimers slow down and exaggerate represented actions in order to help the intended receiver perceive their important features (Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Gärdenfors, Reference Gärdenfors2021; Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020). In this article, we present the results of a motion capture study that tests whether demonstration and pantomime are indeed slower and exaggerated relative to the performance of an action, that is ‘praxis’.
2. Theoretical background
Our hypotheses (Section 3.1) as well as our definitions of demonstration and pantomime are directly derived from language-evolution research. Before presenting it in more detail in Section 2.3, we briefly summarize the other two lines of investigation that have been important in the study of kinematic characteristics of demonstration and pantomime: Motionese (Section 2.1) and neuropsychology (Section 2.2).
2.1. Motionese
Child development studies have revealed that parents’ actions directed toward children differ from their adult-directed actions. This phenomenon is called Motionese (in parallel with Motherese – the form of language directed to children; Snow, Reference Snow1972). Adults use Motionese to assist children in processing and interpreting complex actions, which are key to the development of social referencing by establishing and controlling joint attention with infants (Gergely et al., Reference Gergely, Egyed and Király2007). In a comparative analysis of video recordings of adult–children and adult–adult interactions, Brand et al. (Reference Brand, Baldwin and Ashburn2002) showed that Motionese is characterized by such kinematic properties as simplification of movement and its larger span. Rohlfing and colleagues (Fritsch et al., Reference Fritsch, Hofemann and Rohlfing2005; Nagai & Rohlfing, Reference Nagai and Rohlfing2009; Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006) conducted experiments which showed that adults tend to make more pauses between actions, partition a rounded movement into several linear segments and decrease movement velocity when demonstrating an action to a child, but not to an adult.
There is also a line of research that investigates kinematic properties of child-directed signing (for a short review, see Pizer et al., Reference Pizer, Meier, Points, Channon and van der Hulst2011). Masataka’s (Reference Masataka1992, Reference Masataka1996) research indicates that signs directed by deaf parents to their deaf children have a larger span, are slower and more repetitive than adult-directed signs. Similar results were obtained by Holzrichter and Meier (Reference Holzrichter, Meier, Chamberlain, Morford and Mayberry2000), who also found that compared to adult-directed signing, signs produced by deaf parents for their deaf infants were slower, more repetitive (i.e. had more cyclicity) and had larger span, particularly when there was no eye contact between the parent and the child. On the side of comprehension, there is evidence that both deaf and hearing infants are attentionally and affectively more responsive to child-directed than adult-directed signing (Masataka, Reference Masataka1998; cf. Holzrichter & Meier, Reference Holzrichter, Meier, Chamberlain, Morford and Mayberry2000).
Taken together, these results suggest that Motionese, including child-directed signing (Pizer et al., Reference Pizer, Meier, Points, Channon and van der Hulst2011), helps children structure movements that are relevant for practical tasks, and as a result facilitates the process of learning these tasks. In this regard, the movement parameters associated with Motionese, such as decreased velocity, increased duration, partitioning and larger span (see Hypotheses 1, 2, 4 and 5 in Section 3.1), can inform us about the kinematics of teaching by demonstration.
2.2. Neuropsychology
Research on pantomime has a long tradition in clinical neuropsychology, where pantomime has been the gold standard to diagnose limb apraxia (De Renzi et al., Reference De Renzi, Faglioni and Sorgato1982; De Renzi & Faglioni, Reference De Renzi, Faglioni, Denes and Pizzamiglio1999; Heilman et al., Reference Heilman, Rothi and Valenstein1982). Pantomime in this line of research is defined as ‘pretending to use a tool as if it was held in hand’ by the execution of the relevant motor sequence (Osiurak et al., Reference Osiurak, Reynaud, Baumard, Rossetti, Bartolo and Lesourd2021, cf. Hughlings Jackson, Reference Hughlings Jackson and Taylor1893). More generally, this research emphasizes that, despite being closely related to real tool use, pantomime also requires higher-order cognitive processes (Osiurak et al., Reference Osiurak, Reynaud, Baumard, Rossetti, Bartolo and Lesourd2021), in particular the theory of mind, which allows the instructor-pantomimer to assess the state of knowledge of the intended student. In this regard, neuropsychological studies on pantomime can shed light on how it is used for teaching (see ‘pantomime for teaching’ in Section 2.3).
A key point of interest in neuropsychological research is how pantomime is related to semantic knowledge (Osiurak et al., Reference Osiurak, Reynaud, Baumard, Rossetti, Bartolo and Lesourd2021). To successfully complete a pantomimic task, the subject must understand the socially expected manner of using a tool, regardless of any idiosyncratic ways of using this tool (e.g. reading a newspaper vs. using a newspaper to start fire, Osiurak et al., Reference Osiurak, Reynaud, Baumard, Rossetti, Bartolo and Lesourd2021). This problem relates to several important points for diagnostic practice. First, in studies that aim to limit the interference from semantic knowledge, the participants should be shown a demonstration of target tool use before they perform pantomimes (Clark et al., Reference Clark, Merians, Kothari, Poizner, Macauley, Rothi and Heilman1994; cf. imitation modality, Osiurak et al., Reference Osiurak, Reynaud, Baumard, Rossetti, Bartolo and Lesourd2021). Second, it should be decided whether to precede a task by a practice session (Lesourd et al., Reference Lesourd, Baumard, Jarry, Etcharry-Bouyx, Belliard, Moreaud, Croisile, Chauvire, Granjon, Le Gall and Osiurak2016) with or without a tool, and whether to ask the participants to pantomime familiar or novel tool use (Heilman et al., Reference Heilman, Maher, Greenwald and Rothis1997). Arguably, an optimal way to reduce the interference from participants’ semantic knowledge is to ask them to pantomime the use of a novel tool and to precede this task by a demonstration and a practice session (Osiurak et al., Reference Osiurak, Reynaud, Baumard, Rossetti, Bartolo and Lesourd2021, see Section 3.2.2 for the design of our study).
2.3. Evolution of communication
In recent debates on the evolutionary origins of language, the ability to pantomime has come into focus as an intermediary step on the road to fully fledged language (Abramova, Reference Abramova2018; Arbib, Reference Arbib2012, 2018; Brown et al., Reference Brown, Mittermaier, Kher and Arnold2019; Gärdenfors, Reference Gärdenfors2017, Reference Gärdenfors, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Żywiczyński et al., Reference Żywiczyński, Wacewicz and Sibierska2018). In this line of research, pantomime has been used in a range of meanings that do not always distinguish it from related notions, in particular gesture (as is the case in neuroscience; see Section 2.2). For this reason, Żywiczyński and colleagues used mimesis theory (Donald, Reference Donald1991) to propose a definition intended specifically for language origins: ‘pantomime [is] a non-verbal, mimetic and non-conventionalized means of communication, which is executed […] by coordinated movements of the whole body’ (Żywiczyński et al., Reference Żywiczyński, Wacewicz and Sibierska2018, p. 315).
This definition has two critical points: robust iconicity and whole-bodiness. Robust iconicity (or: primary iconicity, see Sonesson, Reference Sonesson, Zimke, Zlatev and Frank2007) is necessary for pantomimes to be easily understood when the interlocutors cannot use conventional, agreed-upon signs, because none have yet emerged. This implies that – at least until conventional gestures become available – a large share of basic actions involved in activities such as hunting, combat or athletic performance must be conveyed in a maximally transparent way, that is through whole-body enactment (sensu Müller, Reference Müller and Müller2013) rather than purely manual gestures (see esp. Mineiro et al., Reference Mineiro, Carmo, Caroça, Moita, Carvalho, Paço and Zaky2017, Reference Mineiro, Baez-Montero, Moita, Galhano-Rodrigues and Castro-Caldas2021; Placiński et al., Reference Placiński, Żywiczyński, Matzinger, Sibierska, Boruta-Żywiczyńska, Szala and Wacewicz2023; Żywiczyński et al., Reference Żywiczyński, Wacewicz and Lister2021, for examples from a nascent sign language). Hence, though individual pantomimes may primarily rely on manual-only or facial-only movements, whole-bodiness is a systemic property of pantomime (see Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Żywiczyński et al., Reference Żywiczyński, Wacewicz and Lister2021, for a detailed discussion). For instance, a pantomime of kicking a football thematizes the action of the legs but does so by mapping the whole body of the football player onto the whole body of the pantomimer (Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020).
The origins of language and teaching are often traced back to the same evolutionary trajectory which incorporates both pantomime and demonstration (e.g. Arbib, Reference Arbib2012; Fitch, Reference Fitch2010). This idea lies at the heart of mimetic theory (Arbib, Reference Arbib2012; Donald, Reference Donald1991, Reference Donald, Hurford, Studdert-Kennedy and Knight1998, Reference Donald, Tallerman and Gibson2012, Reference Donald, Hatfield and Pittman2013; Gärdenfors, Reference Gärdenfors2017; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020), whose proponents argue that a major breakthrough in the hominin evolution was the emergence of mimesis: the ability for voluntary and systematic rehearsal and imitation of body movements (Donald, Reference Donald1991). A key argument here is that the acquisition of the Oldowan knapping technique, which appeared at least 2.5 million years ago, required active pedagogy (Donald, Reference Donald1991; Gärdenfors, Reference Gärdenfors2017; Heyes, Reference Heyes2023). As indicated by experimental studies in cognitive archaeology, it is likely that the principal form of such pedagogy was demonstration, which in kinematic terms would involve slowing down the striking action (see Hypothesis 1 in Section 3.1), pointing to appropriate targets, demonstrating core rotation, and manually shaping the pupil’s grasp (Morgan et al., Reference Morgan, Uomini, Rendell, Chouinard-Thuly, Street, Lewis, Cross, Evans, Kearney, de la Torre, Whiten and Laland2015).
Gärdenfors (Reference Gärdenfors2022) builds on this research and proposes a mimetic definition of demonstration:
-
(D1) The demonstrator actually performs the actions involved in the task.
-
(D2) The demonstrator makes sure that the learner attends to the series of actions.
-
(D3) The demonstrator’s intention is that the learner can perceive the right actions in the correct sequence.
-
(D4) The demonstrator slows down and exaggerates some parts of the actions (see Research questions in Section 3.1) in order to facilitate for the learner to perceive their important features (Gärdenfors, Reference Gärdenfors2017)
From an evolutionary point of view, an important quality of demonstration is that it is both a praxic action, that is its movements lead to a practical goal (e.g. the nail being hammered in), but it is also a representation of a praxic action. For both the teacher and the learner, demonstrative movements do not only have a praxic orientation but also stand for an action (Gärdenfors, Reference Gärdenfors2022).
Hence, in many mimetic scenarios of language evolution (Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Donald, Reference Donald1991; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020), paradigmatically that of Gärdenfors (Reference Gärdenfors1995, Reference Gärdenfors2017), demonstration is a stepping stone in the emergence of communication and a direct predecessor of pantomime – the form of communication similar to demonstration but more detached from the praxic context (Gärdenfors, Reference Gärdenfors1995, Reference Gärdenfors2017; cf. Arbib, Reference Arbib2012). The key difference between demonstration and pantomime posited by Gärdenfors is in the first criterion of his definition (D1, see above), which makes the latter a form of pretense: While the demonstrator actually performs the action that is being taught, the pantomimer ‘acts as if’ performing the action (Gärdenfors, Reference Gärdenfors2017; Leslie, Reference Leslie1987; Piaget, Reference Piaget1962). For this reason, unlike demonstration, pantomime can be executed without the objects that are involved in the action; for example, the pantomimer can show how to execute a tennis backhand without using a ball and a racquet. Another difference with respect to demonstration is that pantomime is displaced in the sense of Hockett (Reference Hockett1977) [1960], that is, it can refer to entities not present in the immediate environment (Żywiczyński et al., Reference Żywiczyński, Wacewicz and Sibierska2018).
Functionally and semiotically, there are two basic forms of pantomime: for teaching and for communication (Gärdenfors, Reference Gärdenfors2021). The function of pantomime for teaching is that of instruction: ‘You need to copy these movements when you do the real thing!’. Pantomime for communication has the function of informing, as Arbib puts it: ‘pantomime is performed with the intention of getting the observer to think of a specific action or event’ (Arbib, Reference Arbib2012, pp. 217–218). In other words, pantomime for teaching is a form of dyadic mimesis in that it involves the teacher and the learner; pantomime for communication is triadic: It involves the communicator, the recipient and the intended meaning (i.e. an action or an event that a pantomime serves to represent; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020).
To reiterate, according to mimetic scenarios of language origins (esp. Donald, Reference Donald1991; Gärdenfors, Reference Gärdenfors, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024), there are three principal forms of representational action: demonstration, pantomime for teaching and pantomime for communication. Within this theoretical context, there is a general prediction regarding their kinematics: Demonstration and the two types of pantomime are slower and more exaggerated than praxis (Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Gärdenfors, Reference Gärdenfors2017).
Gärdenfors (Reference Gärdenfors2017, Reference Gärdenfors2021, Reference Gärdenfors2022); but see also Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020) hypothesizes that the origin of pantomime was within teaching contexts and, consequently, posits the following evolutionary sequence in the development of human communication: demonstration – pantomime for teaching – pantomime for communication. His argument, supported by developmental research (DeLoache, Reference DeLoache2004; Leslie, Reference Leslie1987; Nielsen, Reference Nielsen2012; Pleyer, Reference Pleyer2020; Tomasello et al., Reference Tomasello, Striano and Rochat1999), is based on the principle of cognitive parsimony, according to which cognitive capacities associated with later stages are built on the capacities associated with earlier stages (cf. the idea of mimesis hierarchy, Zlatev see Section 3.2.2; cf. Donald, Reference Donald1991; Stern, Reference Stern1998; Zlatev & Andrén, Reference Zlatev, Andrén and Zlatev2009).
2.4. The objective of the study
In this study, we address the problem of demonstration and pantomime from the perspective of mimetic hypotheses on language origins, most importantly Gärdenfors’s evolutionary scenario (Section 2.3). Our objective is to find out if this scenario is feasible with regard to one of its most important claims – kinematic differences between praxis, on the one hand, and demonstration, pantomime for teaching and pantomime for communication, on the other; that is, whether the latter are slower and more exaggerated than the former (see Section 3.2.2 for the information about experimental conditions). Below, we review empirical research on demonstration and pantomime with a view to operationalizing movement speed and exaggeration, the measures of which are fully explained in Section 3.4. This allows us to formulate hypotheses about the kinematic differences between praxis, demonstration, pantomime for teaching and pantomime for communication, and then to study them by means of motion capture technology.
2.5. Kinematic characteristics of demonstration and pantomime relative to praxis
Demonstrative and pantomimic movements are often assumed to be slower and exaggerated relative to praxic movements (esp. Arbib, Reference Arbib2012; Donald, Reference Donald1991; Morgan et al., Reference Morgan, Uomini, Rendell, Chouinard-Thuly, Street, Lewis, Cross, Evans, Kearney, de la Torre, Whiten and Laland2015; Sterelny, Reference Sterelny2014). This assumption has some empirical backing coming from observational studies on Motionese (see Section 2.1), observational and experimental studies on pantomime in limb apraxia (see Section 2.2) as well as studies on the kinematics of bodily movements that are intended as communicative (Trujillo et al., Reference Trujillo, Simanova, Bekkering and Ozyurek2018; Section 2.6).
Exaggeration is usually understood as increased span between body parts at the peak of a movement when measured in space (Namboodiripad et al., Reference Namboodiripad, Lenzen, Lepic and Verhoef2016; cf. movement amplitude in Osiurak et al., Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023) or increased volume taken by body parts during movement when measured in three-dimensional space (Placiński et al., Reference Placiński, Żywiczyński, Matzinger, Sibierska, Boruta-Żywiczyńska, Szala and Wacewicz2023). This point is underlined by works on Motionese (e.g. Brand et al., Reference Brand, Baldwin and Ashburn2002) and the literature on the evolution of communication (e.g. Arbib, Reference Arbib2012; Gärdenfors, Reference Gärdenfors2017, Reference Gärdenfors2022; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020; Żywiczyński et al., Reference Żywiczyński, Wacewicz and Lister2021). Exaggeration is also considered in terms of kinematic emphasis put on select elements of a demonstrated or pantomimed action (Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024; Gärdenfors, Reference Gärdenfors2017; Gergely et al., Reference Gergely, Egyed and Király2007).
To account for this kinematic characteristic, Gärdenfors appeals to research on categorizing actions by force patterns (Runeson, Reference Runeson and Jansson1994), whereby we are able to understand a particular type of action (e.g. walking) by extracting the kinematic patterns distinctive for this action from the overall perception of movements (Gärdenfors, Reference Gärdenfors2007; Gärdenfors & Warglien, Reference Gärdenfors and Warglien2012; see also Gharaee et al., Reference Gharaee, Gärdenfors and Johnsonn2017). These distinctive elements are produced faster than the rest of the movements, making them stand out in the perception of the whole action (Section 2.1; Arbib, Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024). Another strategy to put kinematic emphasis on key elements of an action is to partition it into segments delimited by peaks of acceleration: The greater the number of peaks of acceleration, the stronger the perception of segmentation. For example, a rounded, smooth motion trajectory can be changed into a trajectory that consists of simpler, straight movements (cf. submovements in Trujillo et al., Reference Trujillo, Simanova, Bekkering and Ozyurek2018), as is the case in child–adult interactions compared to adult–adult interactions (Section 2.1).
The features related to kinematic emphasis should be distinguished from the speed of the action. Hence, the claim about reduced speed of demonstration and pantomime relative to praxis (Arbib, Reference Arbib2012; Gärdenfors, Reference Gärdenfors2017; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020; Żywiczyński et al., Reference Żywiczyński, Wacewicz and Sibierska2018) needs to be understood in terms of overall velocity and not speed patterns within the action. For example, partitioning an action into a series of motion segments may well result in a decrease in the overall velocity of an action, but this does not have to happen if these segments are performed quicker than an unsegmented action (contra Osiurak et al., Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023; Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006; Trujillo et al., Reference Trujillo, Simanova, Bekkering and Ozyurek2018; see Section 5.3). In the study reported below, we also used time as a complementary measure of overall velocity: Since movements in demonstrations and pantomimes are hypothesized to be overall slower than in praxic actions, their completion should take longer.
In the teaching context, reduced speed and exaggeration, including partitioning, are assumed to help the recipient learn how to perform an action. This function is encapsulated by Gärdenfors’s fourth definitional criterion of demonstration and pantomime when it is used for teaching (see D4 in 2.3; Gärdenfors, Reference Gärdenfors2017). He argues that demonstrators slow down and exaggerate movements to help learners perceive important features of demonstrated actions; to further facilitate the learning process, they also use pauses to accentuate the key elements of demonstrated and pantomimed actions (see also Gärdenfors). A similar point is made by Arbib (Reference Arbib, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024), who argues that demonstrating an action involves (1) slowing down movements to make their trajectory more obvious and (2) placing gaps to emphasize breakpoints between movements, which makes it easier for the learner to break a performance into components even when these components are themselves still unfamiliar.
In the case of pantomime for communication, reduced speed and exaggeration, including partitioning, serve to identify a referent that the producer intends her pantomime to communicate (see Section 2.3; cf. Żywiczyński et al., Reference Żywiczyński, Wacewicz and Sibierska2018; Zlatev et al., Reference Zlatev, Żywiczyński and Wacewicz2020). In the neuropsychological context, Osiurak et al. (Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023, p. 2) offer an almost identical explanation for the role of exaggeration in pantomimes produced by apraxic individuals: ‘[they] tend to exaggerate the amplitude of their pantomime compared to the real tool use action […], as if there was an implicit attempt to facilitate the recognition of the action by the observers’.
2.6. Motion capture studies
In recent years, many studies on bodily visual communication have been conducted with the use of motion capture technology, which allows us to collect data on kinematic parameters, such as positions of body parts, direction of their movements, as well as movement acceleration and velocity. Motion capture has been successfully used not only for studying Motionese (as mentioned above, in Section 2.1; see also e.g. van Schaik et al., Reference van Schaik, Meyer, van Ham and Hunnius2020), but also co-speech gestures (e.g. Jégo et al., Reference Jégo, Meyrueis and Boutet2019), silent gestures (i.e. hand movements used by participants when made to communicate without speech, e.g. Namboodiripad et al., Reference Namboodiripad, Lenzen, Lepic and Verhoef2016), or sign languages (e.g. Flaherty et al., Reference Flaherty, Sato and Kirby2023; Stamp et al., Reference Stamp, Dachkovsky, Hel-Or, Cohn, Raz and Sandler2018a,Reference Stamp, Hel-Or, Cohn, Raz and Sandlerb, Reference Stamp, Cohn, Hel-Or and Sandler2024).
From motion capture studies we know that silent gestures tend to change their characteristics over time in a repeated interaction. Namboodiripad et al. (Reference Namboodiripad, Lenzen, Lepic and Verhoef2016) conducted an experimental-semiotic study and observed that in successive rounds of interaction there was: a decrease (1) in the articulatory space (i.e. the total three-dimensional span of gestures) as well as (2) in the distance travelled by the hands. Building up on this experiment, Placiński et al. (Reference Placiński, Żywiczyński, Matzinger, Sibierska, Boruta-Żywiczyńska, Szala and Wacewicz2023) showed that when participants perform whole-body pantomimes, the bounding box of their movement volume and path traversed by articulators decreases over successive rounds of interaction, but also that their movements become increasingly brachiomanual, that is gradually transform from whole-body pantomimes into manual gestures. Pouw et al. (Reference Pouw, Dingemanse, Motamedi and Özyürek2021) conducted a motion capture analysis in an iterated learning experiment. The study showed that gestures become simpler over generations within transmission chains; apart from occupying smaller space, gestures had a reduced number of submovements and became more rhythmic.
Osiurak et al. (Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023) investigated the interface between social cognition and exaggeration in gestural representations of tool use (see Section 2.2). Operationalizing exaggeration as movement amplitude (three-dimensional span of the radial styloid), they did not find difference between the non-social condition when a gesture is performed for oneself (e.g. for the sake of rehearsal) and the social condition when a gesture is performed for somebody else (e.g. for the sake of identifying a particular tool). However, they observed that gestures had a significantly higher amplitude than corresponding actual tool use actions.
Most interestingly from our perspective, Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) looked into basic kinematic characteristics of communicative intention in bodily movement (see also Trujillo et al., Reference Trujillo, Simanova, Ozyurek and Bekkering2019, Reference Trujillo, Simanova, Bekkering and Ozyurek2020 for follow-up studies on the perception of communicative intent from movement profiles). The participants in that study demonstrated manual instrumental actions to a confederate observer in two conditions, ‘more communicative’ and ‘less communicative’. Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) found that in the ‘more communicative’ condition, the kinematic parameters of movements were exaggerated: they were characterized by a larger path distance, larger maximum amplitude, larger hold time, and more submovements. Further, the participants in Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) performed actions in two modalities: instrumental actions with objects (‘action modality’), and gestural representations of such actions without objects (‘gesture modality’).
There are correspondences between the design of Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) and our own study reported below: Both include actions performed with and without objects, as well as with communicative and without communicative context (for design, see Section 3.2.2). However, the study by Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) was interested in the effects of communicative intention on movement characteristics, and as such did not include an actual communicative condition as understood in semiotic experiments (Delliponti et al., Reference Delliponti, Raia, Sanguedolce, Gutowski, Pleyer, Sibierska, Placiński, Żywiczyński and Wacewicz2023). Trujillo’s et al.’s distinction between the ‘less communicative’ and the ‘more communicative’ conditions in the action modality loosely corresponds to the conditions of praxis and demonstration in our study (see Sections 3.2.2 and 5.2.3 for a detailed discussion). Next, their distinction between the ‘more communicative’ conditions in the action and gesture modalities approximates demonstration vs pantomime for teaching in our design; importantly, however, this distinction was not a target of comparison in Trujillo et al. (see Section 3.2.2). Finally, like other silent gestures studies (Fay et al., Reference Fay, Arbib and Garrod2013; Motamedi et al., Reference Motamedi, Schouwstra, Smith, Culbertson and Kirby2019; Namboodiripad et al., Reference Namboodiripad, Lenzen, Lepic and Verhoef2016; Nölle et al., Reference Nölle, Staib, Fusaroli and Tylén2018; Schouwstra & de Swart, Reference Schouwstra and de Swart2014, contra Placiński et al., Reference Placiński, Żywiczyński, Matzinger, Sibierska, Boruta-Żywiczyńska, Szala and Wacewicz2023), but unlike our experiment, Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) considered only data from the upper body (see Section 2.3 for the importance of whole-bodiness in language origins).
3. The experimental study
3.1. Research questions and hypotheses
Following the proposals presented in the previous sections, we investigated whether movements are (1) slowed down and (2) exaggerated in demonstration, pantomime for teaching and pantomime for communication in comparison with praxis. Importantly, our research questions do not address the problem of how demonstration and the two types of pantomime differ between themselves.Footnote 1 This is because no extant literature, including Gärdenfors’s works, jointly addresses the problem of kinematic differences between demonstration, pantomime for teaching and pantomime for communication. However, since we would like to open an in-depth discussion about the kinematics of demonstration and pantomime, we decided to conduct pairwise comparisons between all of our experimental conditions (see Section 3.2.2) to get some preliminary understanding of the relations between them. We stress, however, the exploratory nature of these analyses, which serve to provide a starting point for further research.Footnote 2
We addressed the first research question (slowing down) in terms of two main hypotheses:
Hypothesis 1: The overall velocity of movements in demonstration, pantomime for teaching and pantomime for communication is lower than that in praxic action movements.
Hypothesis 2: The overall duration of demonstration, pantomime for teaching and pantomime for communication is longer than that of praxic action.
The second research question (exaggeration) was addressed by three hypotheses:
Hypothesis 3. The absolute acceleration (i.e., acceleration as well as deceleration) of movements in demonstration, pantomime for teaching and pantomime for communication is higher than that of praxic action movements.
This operationalization is derived from research on categorizing actions by force patterns (see Section 2.5). Since the body mass is constant, measuring bodily force can be operationalized via movement acceleration. Spikes in acceleration and resulting decelerations contribute to the saliency of selected components of actions.
Hypothesis 4. The number of peaks of acceleration of movements in demonstration, pantomime for teaching and pantomime for communication is higher than in praxic action movements.
Here, peaks of acceleration of movements operationalize the partitioning of actions into segments. Both Hypotheses 2 and 3 investigate if movements are exaggerated through increasing the saliency of some of their parts. Whereas Hypothesis 3 relates to saliency being accomplished by performing select fragments of movements with greater force, Hypothesis 4 posits that movements are partitioned into distinct kinematic segments.
Hypothesis 5. The bounding box of movement volume in demonstration, pantomime for teaching and pantomime for communication is larger than that in praxic action.
Here, the bounding box of movement volume operationalizes the spatial dimension of movement exaggeration (i.e., captures the difference in size between standard and exaggerated movements).
3.2. Experimental method
In the experiment, we elicited non-verbal performances from participants in order to investigate quantitative changes in movement velocity, duration, acceleration, partitioning and bounding box of movement volume for praxic actions, demonstrations, pantomimes for teaching and pantomimes for communication.
3.2.1. Participants
Forty-six participants were enrolled via a recruitment system at the IMSErt Centre of Excellence, Nicolaus Copernicus University. The participants (female = 28, mean age = 22, all students at NCU Toruń) received a PLN 50 (~ EUR 11) shopping voucher. Data from one female participant were discarded due to tracking issues during the experiment, yielding data from a total of 45 participants.
3.2.2. Design and procedure
The participants were asked to perform actions from four different sports disciplines: football (trivela kick), footbag (sidekick), kendo (kesa giri, a lateral cut with a bokken, a Japanese training sword) and baseball (simple pitch). We chose these actions for three reasons. Firstly, they were assumed to be simple enough so that every participant could perform them following a brief rehearsal and training session (see below), but also uncommon enough so that the participants had little to no experience in the actual correct performance of these actions (cf. Section 2.2 for the problem of semantic interference in performing familiar vs. novel actions). In relation to the last point, we expected that novel actions would make the experimental procedure more ecologically valid. Notably, teaching, either by demonstration or pantomime, requires that the teacher assumes lack of knowledge on the part of the student (see Section 2.3). We concluded that our selection of actions better corresponds to the demands of actual teaching than everyday actions, already well-known to the participants (contra Osiurak et al., Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023).Footnote 3 Secondly, in line with the research on Motionese (Section 2.1), we chose actions that have some degree of complexity so as to enable the participants to use the structure of an action when demonstrating or pantomiming it for the intended receiver (i.e., by putting kinematic emphasis on its key elements; cf. Hypotheses 3 and 4). Lastly, these actions foregrounded both the upper (lateral cut and baseball pitch) and lower (sidekick and trivela kick) parts of the body; this was intended to capture the whole-bodied nature of pantomime, as it is defined in language origins (see Section 2.3 for the importance of whole-bodiness in language origins).
An experimental session consisted of four rounds, corresponding to the four actions. Before each round, the participants underwent training, during which they watched an instructional video (displayed in Full HD resolution on a 22″ screen) of an expert performing and explaining the relevant action in Polish (see Figure 1; the whole videos can be accessed via https://osf.io/s2bh8/). During that period, the participants could rehearse the action, using a prop supplied by the experimenter (football, footbag, bokken and baseball). Following the instruction, the participants were asked to perform the action in four conditions:
-
1. Praxic action (Condition 1): the participant was instructed to perform the action as if they were actually carrying it out in a real-life scenario;
-
2. Demonstration (Condition 2): the participant was instructed to perform the action with a prop, in such a way that their video recording could be used to teach others how to perform this action;
-
3. Pantomime for teaching (Condition 3): the same as in Condition 2, but without a prop.

Figure 1. Stills from an instructional video.
Having performed the action in these three conditions, the participant watched another video that contained an action similar to the one they had just performed:
-
• for the trivela kick, the football toe kick;
-
• for the inside kick, the footbag toe kick;
-
• for the kesa giri, the shomen giri (straight downward cut);
-
• for the baseball pitch, the cricket pitch;
and was instructed to perform the action in the last condition:
-
4. pantomime for communication (Condition 4): the participant was instructed to pantomime the action they had practised at the beginning of the round in such a way that it could be easily distinguished from the related action they had just seen.
The participant was informed that their pantomime was going to be used in a new study, in which participants would see the videos of two related actions (e.g. the videos of the baseball pitch and the cricket pitch) and then the video of the participant’s pantomime, and asked to decide which of the two actions was represented by the pantomime (see Supplementary Appendix for the English translation of the instructions and for a detailed motivation for this design decision).
The order of the rounds for each participant was randomized (i.e. trivela kick, sidekick, kesa giri, baseball pitch). However, the order of conditions within rounds was fixed: 1 – praxic action, 2 – demonstration, 3 – pantomime for teaching, 4 – pantomime for communication. This was done for two partly related reasons: the principle of cognitive parsimony (see Section 2.3) and the problem of interference from semantic knowledge (Section 2.2). See Supplementary Appendix for a detailed explanation of our decision to adopt a fixed order of conditions.
3.2.3. Apparatus and data collection
All of the participants’ trials were recorded with a Panasonic HC-V700 camera mounted on a tripod. To ensure whole body tracking, we used the Rokoko SmartSuit Pro I motion capture system (www.rokoko.com/products/smartsuit-pro). Rokoko SmartSuit is a wearable motion capture device that uses 19 inertial measurement units (IMUs), that is sensors composed of a three-axis accelerometer, a three-axis gyroscope and a three-axis magnetometer (Bin et al., Reference Bin, Sun, Liu and Liu2018), embedded within the suit. These sensors allow for capturing 3D acceleration, orientation (with an accuracy of ±1 degree) and angular velocity at a stable sampling rate of 100 Hz of the movement of the whole body (the pelvis, legs – upper and lower parts as well as the knees – feet and ankles, scapulae, hips, arms, shoulders, hands, elbows, wrists, chest, thorax, neck and head). The participants’ movements were captured and recorded separately for each trial via Rokoko’s proprietary SmartStudio (www.rokoko.com/studio). Irrelevant portions of the videos (e.g. handing out props to the participants) were trimmed manually.
3.3. Data analysis
Motion capture data, exported from Rokoko Studio, contained information about the position and acceleration of each joint in three dimensions (separately for x, y and z axes) at a given timestamp. Rokoko Studio estimates a joint’s position as a deviation (measured in meters) of the sensor from the point of origin of the coordinate system. The origin of the coordinate system, that is position (0, 0, 0), is located at the hub position (above the hips) of the SmartSuit Pro I.
Rokoko uses the absolute world coordinate system, with the x-, y- and z-axes representing leftward-rightward, upward-downward and forward-backward movement, respectively. Rightward, upward, and forward movements are represented by positive values, whereas movements in the opposite direction by negative ones. See Section 3.4 for operationalizations and Data availability statement for more information about source data.
All statistical analyses were performed using the R programming language (R Core Team, 2016) and several of its packages.Footnote 4 Five separate linear mixed-effects models were fitted to the data.
3.4. Operationalizations
We obtained velocity of an articulator in an axis by dividing the distance traversed by that articulator by the duration of the movement. Three-dimensional velocity of that articulator was computed on the basis of the equation below:
 $$ v=\sqrt{v_x^2+{v}_y^2+{v}_z^2,} $$
$$ v=\sqrt{v_x^2+{v}_y^2+{v}_z^2,} $$
where v is the overall velocity of an articulator and vx, vy and vz velocity on the x, y and z axes, respectively. Overall velocity of the whole body was obtained through summing up three dimensional velocities from all articulators.
To obtain the overall space that the participant traversed in a trial, we computed the bounding box of movement volume (BBMV) based on the equation below. Similar to velocity, we first obtained a unidimensional span (difference between the most extreme points) for each joint in each axis, and then computed the BBMV of that joint:
 $$ V={s}_x\times {s}_y\times {s}_z, $$
$$ V={s}_x\times {s}_y\times {s}_z, $$
where V is the BBMV of an articulator, and sx, sy and sz is the span of a joint’s movement on the x, y and z axes, respectively. These values were summed up in order to obtain the whole-body BBMV.
We extracted acceleration directly from Rokoko Studio. In this way, we obtained absolute acceleration values for all joints, and subsequently computed the square root of the sum of squares for each articulator (similar to velocity). All values were summed up to obtain the overall acceleration of the whole body. We also obtained trial duration directly from Studio.
Finally, we operationalized movement partitions as the number of these parts in the performance of an action where the participant’s movement was executed with greatest acceleration. First, we obtained the total acceleration of an articulator in three dimensions. These values were subsequently summed up for each frame of the recording, which gave us total bodily acceleration in that frame. We smoothed the signal with the Savitzky–Golay filter (Savitzky & Golay, Reference Savitzky and Golay1964) and automatically identified peaks within the smoothed signal: A movement component was deemed a peak provided that its acceleration was above a threshold (which was the mean acceleration) and that no other peak was identified in the component’s direct adjacency. Finally, the number of peaks per trial was counted.
4. Results
For each outcome variable, we built a series of mixed-effects linear regression models with increasing degree of complexity in order to select the maximal model, and compared them with a null model to choose the best-fit statistical model. Praxic action was always the intercept of the model, against which all other conditions were compared (see Footnote 1). The model, apart from the fixed effect (the condition), also included the activity and participant as random intercepts. All outcome variables were z-scored. The procedure we used to build the models and their comparisons with null models is explained in Tables A–E in the Supplementary Appendix. Here, we report only significant main effects. Regression tables are given in Tables 1–5 in the Supplementary Appendix.
The results of our analyses are displayed in Figures 2–6. Demonstration with an object had significantly: lower velocity (β = −0.46, p < 0.001), longer duration (β = 0.72, p < 0.001), more acceleration (β = 0.65, p < 0.001) and more peaks (β = 1.42, p < 0.001) than praxic action. Pantomime for teaching had significantly: lower velocity (β = −0.25, p < 0.001), longer duration (β = 0.36, p < 0.001), more acceleration (β = 0.32, p < 0.001), more peaks (β = 0.89, p < 0.001) and larger BBMV (β = 0.27, p < 0.001) than praxic action. Pantomime for communication had a significantly larger BBMV (β = 0.26, p < 0.001) than praxic action.

Figure 2. The influence of condition on the velocity of movement. The abbreviated names, Demo., PfT and PfC, stand for demonstration, pantomime for teaching and pantomime for communication, respectively.
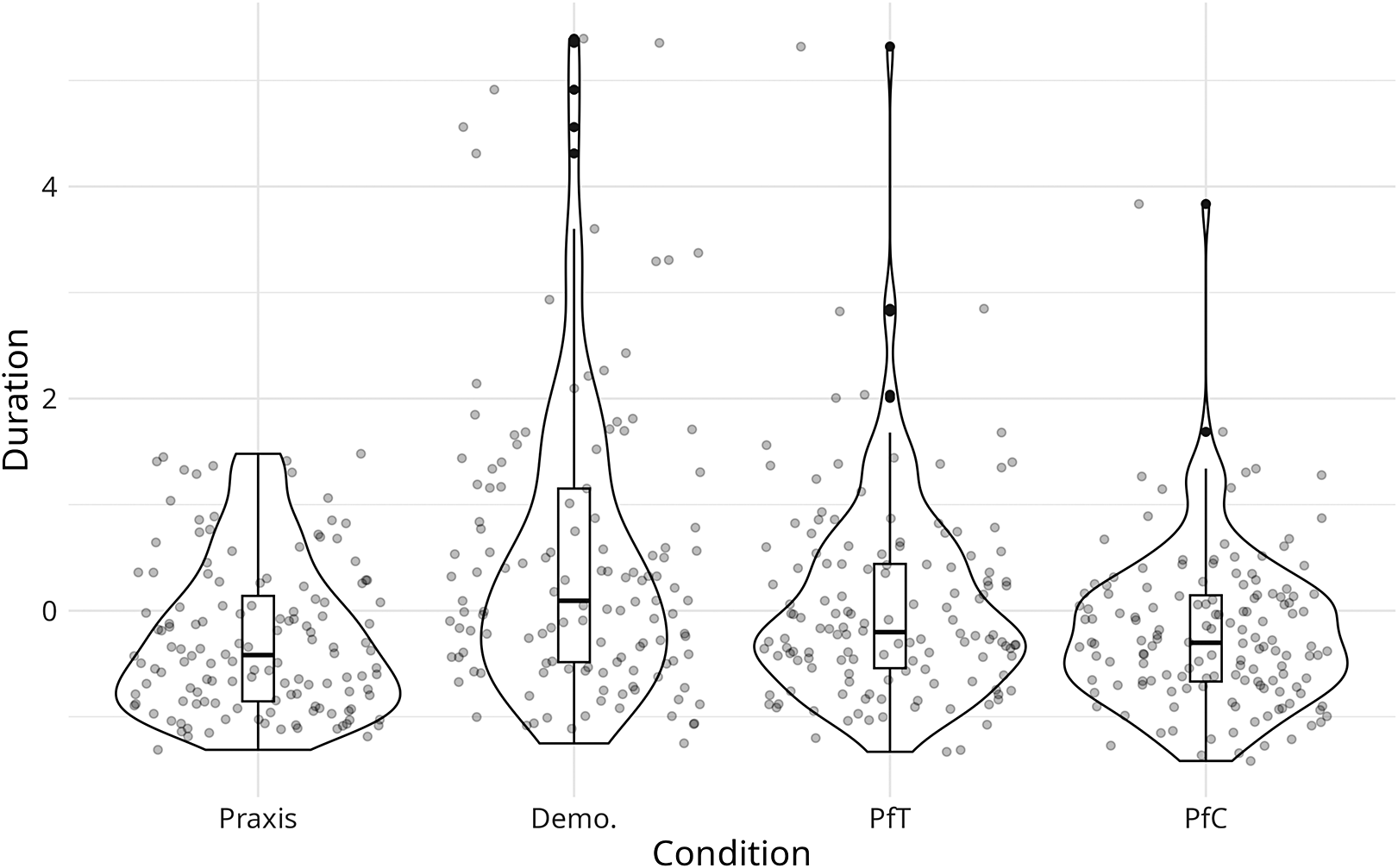
Figure 3. The influence of condition on the duration of movement.

Figure 4. The influence of condition on the acceleration of movement.

Figure 5. The influence of condition on the bounding box of movement volume.

Figure 6. The influence of condition on the number of peaks.
5. Discussion of results and post hoc analysis
5.1. Slowing down
We expected that demonstrations, pantomimes for teaching and pantomimes for communication would have lower velocity (Hypothesis 1) and longer duration (Hypothesis 2) than praxic actions. Both hypotheses were confirmed for demonstrations and pantomimes for teaching, and neither of them for pantomimes for communication. Looking at this pattern of results, it may be argued that the instructor calibrates the speed of her movements to the needs of the intended receiver, so as to make it easier for the student to follow the movements and learn how to imitate them correctly (see Section 2.5). In praxic action and pantomime for communication, there is no such pressure. In the former case, the participants’ goal was to perform the action in the way they would carry it out in real life, for example to produce a baseball pitch that is maximally difficult for the (imagined) batter to hit. When communicating, they had to produce such a pattern of movements that would make it easy for the (imagined) receiver to distinguish the pantomimed action (e.g. a baseball pitch) from another similar action (e.g. a cricket pitch). In neither of the above conditions, a decrease in movement velocity would further the participants’ goals: to achieve a sports objective of praxic actions or to facilitate a correct interpretation of pantomimes.
Such an interpretation is supported by a post hoc pairwise comparison between demonstration and pantomime for teaching against pantomime for communication.Footnote 5 The results indicate that compared to pantomime for communication: Demonstration has lower velocity and longer duration than pantomime for communication (velocity: β = −0.42, p < 0.001; duration: β = 0.68, p < 0.001), and similarly pantomime for teaching has lower velocity than pantomime for communication (velocity: β = −0.21, p < 0.001; duration: β = 0.30, p < 0.001). It should however be noted that the pairwise comparison also indicates a significant difference between the two pedagogical conditions, that is demonstration and pantomime for teaching, where the former has lower velocity and longer duration than the latter (velocity: β = −0.2162, p = 0.0007; duration: β = 0.3698, p < .0001). We briefly address this problem in Section 6.
Our kinematic analyses of representational actions are primarily interested in exaggeration (see below), but there are also studies that take into account velocity and whose results seem to confirm our findings. Importantly, these studies focus on demonstration and on what we define as pantomime for teaching (for definitions, see Section 2.3). One of them is Rohlfing and colleagues’ work (Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006), where 3D posture tracking was used to study interactions between parents and preverbal children versus interactions between adults. They found that parents who were showing children how to perform novel actions (e.g. putting one cylinder into one another) produced slower movements than when they were demonstrating these actions to adults. Since the pedagogical function of demonstration is much more pronounced in children-directed interactions than adult-directed interactions (cf. Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006 for the importance of learning in child-directed interactions), we can speculate that decreased velocity is a general characteristic of demonstration.
Regarding pantomime for teaching (cf. Hermsdörfer et al., Reference Hermsdörfer, Li, Randerath, Roby-Brami and Goldenberg2013 for the concept of ‘tool use demonstration’), Clark et al.’s (Reference Clark, Merians, Kothari, Poizner, Macauley, Rothi and Heilman1994) and Poizner et al.’s (Reference Poizner, Clark, Merians, Macauley, Rothi and Heilman1995) neuropsychological studies of apraxic patients found decreased velocity (particularly tangential wrist velocity) in pantomimic tasks compared to real tool use (sawing and slicing bread). A similar result was obtained by Hermsdörfer et al. (Reference Hermsdörfer, Hentze and Goldenberg2006) and Laimgruber et al. (Reference Laimgruber, Goldenberg and Hermsdörfer2005), whose motion-capture analyses of praxis and pantomime in left-brain damaged patients with and without apraxia showed reduced velocity during pantomimic tasks in both groups. However, it should be stressed that the significance of these studies for a general understanding of pantomime (in this case, pantomime for teaching) is limited. First, the sample sizes, as is expected in studies on neuropathology, are small (ranging from 3 to 7 subjects in the studies mentioned above). More importantly, since individuals with apraxia are prone to make more errors in pantomime than praxis (see Section 2.2), it is difficult to determine the extent to which these findings are generalizable to a healthy population.
Going back to our results, we should also acknowledge that decreased overall velocity (and increased duration) in demonstration and pantomime for teaching may result from slower execution of movements but (also) from other kinematic parameters, such as partitioning an action into kinematic segments (cf. Hypothesis 4). We return to this problem in Section 5.3.
5.2. Exaggeration
5.2.1. Acceleration
We first operationalized exaggeration in terms of the acceleration of the articulators (i.e. body parts; Hypothesis 3) and expected that movements in demonstrations and in pantomimes for teaching and communication would involve more acceleration than in praxic actions. When formulating this hypothesis, we argued that demonstrations and the two types of pantomimes require kinematic emphasis, which is accomplished by accelerating the most distinct elements of the demonstrated or pantomimed action. Such a kinematic profile would serve to facilitate the understanding of the action, that is, in the teaching context, it would facilitate the understanding how to perform this action, and in the communicative context, it would facilitate the identification of the action (Gärdenfors, Reference Gärdenfors2007; Runeson, Reference Runeson and Jansson1994; see Section 2.5). Our hypothesis was confirmed for demonstration and pantomime for teaching, but not for pantomime for communication.
Again, it can be argued that the pedagogical context promotes the exaggeration of relevant movement patterns to aid the student in mastering the details of the action that is being taught (see Section 2.5). The communicative context does not seem to put a pressure on pantomimers to kinematically emphasize such details of the action. Again, to further support this interpretation, we performed post hoc comparisons between demonstration and pantomime for teaching against pantomime for communication. The results indicate that compared to pantomime for communication both demonstration and pantomime for teaching have higher acceleration (demonstration vs. pantomime for communication: β = 0.62, p < 0.001; pantomime for teaching vs. pantomime for communication: β = 0.30, p < 0.05). This said, as in the case of velocity and duration, we also saw a significant difference between demonstration and pantomime for teaching, with demonstration having greater acceleration (β = 0.317, p < 0.05). We address this problem in Section 6.
In the analysis of acceleration, we used a novel measure derived from the literature on the role of force patterns in categorizing actions (see Section 2.5). To our knowledge, the only study that pays attention to the role of speed in representational actions is the motion capture study by Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018), who looked at peak velocity of the dominant hand to determine how people modulate movement to signal communicative intent. If we allow that at some level of granularity the two measures are comparable, then the findings of both studies seem to support each other. Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) observed:
-
• a near significant increase in peak velocity in their ‘more communicative’ condition in the action modality, which roughly corresponds to our demonstration condition, relative to the corresponding ‘less communicative’ condition;
-
• a significant increase in peak velocity in their ‘more communicative’ condition in the gesture modality, which is roughly equivalent to our pantomime for teaching condition, relative to the corresponding ‘less communicative’ condition (see Sections 2.6 and 5.2.3 for the comparability of the conditions in the two studies).
Taken together, these results indicate that the kinematic feature of acceleration is important for signaling communicative intent, particularly in the teaching context.
5.2.2. Partitioning
Next, we investigated if partitioning actions into kinematic segments distinguishes demonstrations and the two types of pantomime from praxis. We operationalized partitioning as the number of peaks of acceleration during an action and expected that demonstration and the two types of pantomime would have more acceleration peaks than praxis (Hypothesis 4; for a similar measure of partitioning, see Hermsdörfer et al., Reference Hermsdörfer, Li, Randerath, Roby-Brami and Goldenberg2013).
In line with the literature on the evolution of language (Section 2.3), we assumed that partitioning actions into segments:
-
• in the teaching context (demonstration and pantomime for teaching), serves to help the student break an unfamiliar action into a sequence of components that are easier to remember and imitate;
-
• in the communicative context (pantomime for communication), serves to help the receiver identify these elements of an action that distinguish it from other actions.
This hypothesis was again confirmed for demonstration and pantomime for teaching, but not for pantomime for communication. Once again, we argue that the pedagogical context requires kinematic emphasis, here accomplished by partitioning an action (see Section 2.5), while the communicative context does not put such a pressure on pantomimers.
A post hoc pairwise comparison seems to support our explanation of the results along pedagogical lines. It showed that the two pedagogical conditions, demonstration and pantomime for teaching, significantly differ from pantomime for communication in having more peaks of acceleration (demonstration vs. pantomime for communication: β = 1.24, p < 0.05; pantomime for teaching has vs. pantomime for communication: β = 0.71, p < 0.05). However, similar to the results of the pairwise comparisons discussed above, we recorded a significant difference between demonstration and pantomime for teaching, where the former was more partitioned than the latter (β = 0.52, p < 0.05). We briefly address this problem in Section 6.
In the case of demonstration, our findings are supported by works on Motionese (Section 2.1). Brand et al. (Reference Brand, Baldwin and Ashburn2002) used a manual coding system to investigate how mothers explain action properties of objects to infants. They found that compared to adult–adult interactions, mothers punctuated their movement into distinct kinematic segments. A similar result was obtained by Rohlfing et al. (Reference Rohlfing, Fritsch, Wrede and Jungmann2006), who by means of 3D posture tracking studied the parameter of roundness in adult–child and adult–adult interactions. Roundness, which was intended to capture the degree of motion smoothness and precision, was measured by dividing the motion path by the distance between motion on- and offset (Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006, p. 1190). They observed that actions performed toward children were less round, that is had more pauses between single movements, which were shorter and straighter (Rohlfing et al., Reference Rohlfing, Fritsch, Wrede and Jungmann2006, p. 1190). Trujillo et al.’s study (Trujillo et al., Reference Trujillo, Simanova, Bekkering and Ozyurek2018) offers insight into the process of partitioning in both demonstration and pantomime for teaching (see Section 2.6). Their operationalization was based on the idea of submovements, that is individual ballistic movements performed by the hand during an action. The analysis showed that their ‘more communicative’ condition in the action modality (cf. our notion of demonstration) and the gesture modality (cf. our notion of pantomime for teaching) had more submovements than the corresponding ‘less communicative’ conditions.
5.2.3. Bounding box of movement volume
Our final operationalization of exaggeration was BBMV, that is the total space taken up by the articulators during a condition. We expected an increase in BBMV in demonstrations and pantomimes compared to praxic actions (Hypothesis 5). Our hypothesis was confirmed for the two types of pantomime, but not for demonstration. A plausible interpretation of this result may rest on the presence versus absence of an object, which we highlighted as the factor distinguishing praxic action and demonstration from pantomime for teaching and for communication. Since, unlike praxic action and demonstration, both types of pantomime are a form of pretense (see Section 2.3), it stands to reason that they require kinematic emphasis in the form of increased movement volume to make up for absent objects – in contrast to the corresponding praxic actions and demonstrations, which are cued by physically present objects and have to meet the ‘mechanical demands’ of handling them (Hermsdörfer et al., Reference Hermsdörfer, Hentze and Goldenberg2006). This interpretation is supported by the results of a pairwise comparison, which showed that BBMV is significantly larger in pantomime for teaching and pantomime for communication than in demonstration (demonstration vs. pantomime for teaching: β = −0.24, p < 0.05; demonstration vs. pantomime for communication: β = −0.22, p < 0.05), while there is no significant difference between the two types of pantomime.
The explanation of our results given above is in line with the findings obtained by Osiurak et al. (Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023). They found that the amplitude of movements in pretend tool use is bigger than that of actual tool use. Further, they did not find any significant differences in movement amplitude between various conditions of pretend tool use: free condition (when pretend tool use does not serve any function), social condition (when pretend tool is intended for another person) and non-social condition (when it is intended for oneself, e.g. as action rehearsal).
Our result and its interpretation are only partly in line with the results obtained by Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018). On the one hand, their results are compatible with our finding about the increase in volume in pantomime: in the ‘more communicative’ condition in the gesture modality, which approximates our ‘pantomime-for-teaching’ condition, they observed an increase in the total distance travelled by both hands compared to the ‘less communicative’ condition in the gesture modality (which, as already discussed, is not directly comparable to any of our experimental conditions – see Section 2.6). Importantly, they also found an increase in distance in the ‘more communicative’ condition in the action modality with respect to the ‘less communicative’ condition in this modality, roughly corresponding to our ‘demonstration’ and ‘praxis’ conditions. This finding stands in contrast to our study, as we did not find any significant difference between praxis and demonstration. One line of explanation for the difference between our results and those of Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) relates to the difference between familiar versus novel actions (see Sections 2.2 and 3.2.2). In contrast to their design, which included familiar everyday actions (squeezing a lemon, slicing bread, stirring tea, etc.), we asked our participants to perform actions they were not familiar with. It may have been this novelty element that increased the mechanical demands of using the target objects, which made demonstrations more similar to the corresponding praxic actions than the pretense, pantomimic conditions, where the objects were not present (see Section 5.5).
In this section, we indicated evidence from other studies that corroborates our findings; however, the significance of this corroboratory evidence should not be overemphasized. First, as already explained, the experimental conditions and experimental manipulation in our work are not directly equivalent to the other studies mentioned in this section. Another key difference is that we looked at whole-body expression instead of manual-only action (see esp. Section 2.3), and it is possible that whole-bodiness at least partly operates under different kinematic pressures than manual-only action (cf. Placiński et al., Reference Placiński, Żywiczyński, Matzinger, Sibierska, Boruta-Żywiczyńska, Szala and Wacewicz2023).
5.3. Relation between velocity, partitioning and bounding box of movement volume
Finally, we would like to return to the problem of overall velocity (Hypothesis 1), which in our study served to operationalize the speed of the bodily articulator during an action. This operationalization directly relates to the assumptions about demonstration and pantomime in the literature on the evolution of teaching and language (Section 2.3), but is also occasionally employed in studies on Motionese and on pretend tool use (Sections 2.1 and 2.2). In Section 5.1, we noted that overall velocity may result not only from the speed of movements but also from other factors, such as partitioning and bounding box of movement volume. Indeed, some authors suggest that the latter is the case. Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018) argue that if an action takes more visual space and involves more submovements, it takes longer to produce (as we explain, overall duration of an action is directly related to overall velocity). A similar explanation is offered by Osiurak et al. (Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023), who conclude that increased volume translates into decreased velocity.
To investigate the dependence of overall velocity on partitioning and BBMV, we performed a post hoc analysis and built a model with overall velocity as the outcome variable, the number of peaks of acceleration of movements and BBMV as the fixed effects, and the activity, participants and condition as random intercepts. The outcome and predictor variables were z-scored. The regression Table is provided in the Supplementary Appendix.
If, as predicted by the authors mentioned above, overall velocity depends on the amount of partitioning and BBMV, we should see a decrease in overall velocity when the number of acceleration peaks and BBMV increase. The result that we obtained does not confirm this hypothesis in a straightforward manner. While an increase in the value of BBMV results in a significant increase in velocity of movement (β = 0.49, p < 0.05), an increase in the value of partitioning predicts lower overall velocity (β = −0.12, p < 0.05). Finally, the interaction between the predictors results in decreased velocity (β = −0.04, p < 0.05). In other words, velocity is greater when volume is bigger, velocity is lower when the number of partitions is higher; however, when we take in consideration both BBMV and the number of partitions, the effect of BBMV for velocity is cancelled for high numbers of partitions. We stress the post hoc nature of our analysis, but, in our view, it suggests that overall velocity is not reducible to the parameters of partitioning and volume and, hence, it deserves to be taken a separate measure in studies such as ours. More generally, relationships between velocity and other kinematic parameters should be researched in studies specifically designed to address this problem.
5.4. Limitations of the study
The most serious challenge to the interpretation of our results is the fixed order of presenting the experimental conditions to the participants (see Section 3.2.2 and Supplementary Appendix). On examining the results, we would like to argue that it is difficult to explain their pattern as resultant from order effects. First, we found that in the conditions of demonstration and pantomime for teaching velocity, acceleration and the number of acceleration peaks increase with respect to praxis, but the values for all these parameters fall to the level of praxis in the last condition. In our view, this trend suggests that the impact of learning effect, if present, was not substantial enough to skew the results. Then, BBMV increases in the last two conditions – the two types of pantomime – but does not for the preceding condition of demonstration, which could suggest that there was no strong effect of fatigue. To eliminate the problem of fixed ordering of conditions, a between-participants design could be used with participants allocated to three groups: The first group would be asked to perform praxic actions and demonstrations; the second one, praxic actions and pantomimes for teaching; the last one, praxic actions and pantomimes for communication. However, given the nature of motion capture data, in particular very large individual differences between participants, the application of such a design would be extremely challenging in terms of logistics (Meina et al., Reference Meina, Janusz, Rykaczewski, Ślęzak, Celmer and Krasuski2015).
Another question worth addressing is the distinct profile of the pantomime-for-communication condition compared to the other conditions. As explained in Section 3.2.2 and Supplementary Appendix, the specific manner of presenting the communicative condition is designed to capture the nature of this condition. In future research, a semantic space comprised of well-known actions could be used, as is commonly done in neuropsychological studies on pretend tool use (Section 2.2, see also Trujillo et al., Reference Trujillo, Simanova, Bekkering and Ozyurek2018). This would make it possible to present this condition in a much simpler way (e.g. ask participants to pantomime chiseling in a way that is distinct from the action of hammering). Such a procedure would, however, decrease the ecological validity of teaching, which implies that the demonstrator thinks the action taught is unfamiliar to the recipient (see Sections 2.2 and 2.3).
5.5. Future directions
Our study opens several interesting directions for future research. We could, for instance, study the size and crowdedness of a semantic space. In accordance with the literature on experimental semiotics (particularly Nölle et al., Reference Nölle, Staib, Fusaroli and Tylén2018; Wilson et al., Reference Wilson, Ellison and Fay2014), we should expect that a more crowded semantic space will result in more pronounced kinematic differences between pantomime for communication compared to praxis. Another interesting line is to investigate a potential impact of repairs on our experimental conditions: for example the confederate is unable to perform an action that she has been taught and asks the participant to repeat it. Should we adopt a more interactive design similar to the one used by Trujillo et al. (Reference Trujillo, Simanova, Bekkering and Ozyurek2018), we could see how repairs affect the kinematics of demonstration and pantomime. Most importantly, further research should, on the one hand, focus on movement properties that characterize teaching and explain their pedagogical significance; on the other hand, it should explore the kinematics of activities based on pretense: pantomime, but also others, such as autocuing and pretend play (Gärdenfors, Reference Gärdenfors2017; Leslie, Reference Leslie1987; Lillard, Reference Lillard2017; Pleyer, Reference Pleyer2020; Weisberg, Reference Weisberg2015). Finally, we would like to emphasize the selection of actions that participants are to perform during an experiment. As pointed out in Section 5.2.3, the choice of novel versus familiar actions may potentially have a non-trivial influence on the results, especially in terms of exaggeration (see Sections 2.2 and 3.2.2 for the motivation of using novel actions in this study). Unfamiliar actions may lead to greater exaggeration of performances. Hence, future studies could address the problem by comparing kinematic parameters between praxis, demonstration and pantomime in two conditions: with familiar and unfamiliar actions.
6. General discussion
Measuring motion parameters gives only a limited picture of movement-based behaviors, let alone directly informs us about their evolutionary origins. Naturally, this limitation also applies to our project focused on corroborating Gärdenfors’s hypothesis about the evolutionary emergence of demonstration and pantomime, and specifically its pivotal claim that these behaviors are kinematically distinct from praxis. What we can do is try to meaningfully map our results onto the successive evolutionary stages posited in Gärdenfors’s scenario and indicate kinematic characteristics that they share. In this way, our study is not only relevant to research on the evolution of teaching and language, but is also informative about the representational activities of demonstration and pantomime in their own right (Sections 2.5 and 5.5).
One of our most important findings is that there is a clear line separating praxis from the pedagogical activities of demonstration and pantomime for teaching (cf. Gärdenfors & Högberg, Reference Gärdenfors and Högberg2017). In both conditions, our participants significantly slowed down their movements, arguably to better control the attention of the intended learner (Gärdenfors, Reference Gärdenfors2017, Reference Gärdenfors2021; see also criterion D4 in Section 2.3). Demonstration and pantomime for teaching are also alike in terms of acceleration and partitioning, which we used as a measure of perceptual saliency. Accordingly, we argued that saliency, whereby key elements of demonstrated and pantomimed actions become kinematically foregrounded, serves to help the learner understand the technical details of these actions (Section 2.3).
Having said that, the pairwise comparisons reported in Sections 5.1 and 5.2 also indicated significant differences in velocity, duration, acceleration and partitioning between demonstration and pantomime for teaching. These results may point to a systematic difference in how teaching is performed by these two types of activity, which deserves further exploration.
Finally, we found that movements in pantomime for teaching and pantomime for communication are more exaggerated, in the sense that they have larger BBMV than praxis. This in turn may be related to the key characteristic of pantomime, that is pretense (Section 2.3). We suggest that pantomimers produce larger movements as a form of kinematic emphasis to make up for the absence of objects relative to praxic actions and demonstrations (cf. Osiurak et al., Reference Osiurak, Delporte, Revol, Melgar, Robert de Beauchamp, Quesque and Rossetti2023). Hence, increase in BBMV could be seen as indicative of the breaking point between non-pretense and pretense actions.
If we relate these findings to mimetic hypotheses on language origins and specifically Gärdenfors’s evolutionary scenario, we can speculate about two transition points in the development of representational activities based on body movements: one that differentiates praxis from pedagogical activities (slowing down and saliency), and the other that differentiates demonstration and pantomime (increased BBMV). The element that joins these two types of activities is pantomime for teaching, which is similar to demonstration in terms of velocity, movement partitioning and acceleration, and to pantomime for communication in terms of BBMV. This interpretation gives some support for Gärdenfors’s thesis that communication, and specifically pantomime for communication, emerged from the teaching context, and specifically from pantomime for teaching (Gärdenfors, Reference Gärdenfors2017, Reference Gärdenfors2021, Reference Gärdenfors2022; see also Wacewicz & Żywiczyński, Reference Wacewicz, Żywiczyński, Żywiczyński, Wacewicz, Boruta-Żywiczyńska and Blomberg2024, for a complementary account).
7. Conclusion
Our study attempted to corroborate a clearly delineated prediction – derived from the literature on the origins of teaching and language – about differences between praxis versus demonstration, pantomime for teaching and pantomime for communication: demonstrators and pantomimers slow down and exaggerate represented actions. Motion capture technology, which we used to study the participants’ movements, allowed us to uncover a more complex pattern of differences between these behaviors than suggested by the original prediction. We discovered that demonstration and the two types of pantomime differ in terms of low-level motion characteristics from praxis, but each type of bodily performance in its unique way. Pantomime for teaching stands out as distinct from praxis along all the dimensions that we investigated here: velocity (and duration), acceleration, partitioning and bounding box of movement volume (BBMV). Demonstration is similar to pantomime for teaching, and hence dissimilar from praxis, in the first three parameters, whereas pantomime for communication, in the last one. Since our work is the first to jointly address the problem of the kinematic nature of demonstration and the two types of pantomime, it has an important exploratory aspect regarding the similarities and differences between these representational actions.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/langcog.2024.8.
Data availability statement
The instructional videos, motion capture and Rokoko files, the code used to obtain the response variables (Python files) are available online and the R file containing the final version of the analysis and data visualization are available under this link https://osf.io/s2bh8/.
Funding statement
This research was supported by the Polish National Science Centre (NCN) under grant agreement UMO-2017/27/B/HS2/00642.









 Open access
Open access