


1. Introduction
A learner’s goal is to understand intended messages given the particular forms that are witnessed for the sake of comprehension, and to choose particular forms, given the intended information she wishes to convey for the sake of production. Therefore it is clear that speakers must learn the ways in which forms and functions are paired in the languages they speak. These learned pairings of form and function are referred to here as constructions . Constructions are understood to vary in their degree of complexity and abstraction, and to form an inter-related dynamic network of linguistic knowledge. A few English constructions are provided in Table 1, along with exemplars of each, attested in the Corpus of Contemporary American English (COCA: Davies, Reference Davies2008a). Footnote 1
table 1. Four English constructions (learned pairings of form and function) and exemplars of each from COCA

The ability to cluster – dynamically categorize – witnessed exemplars into distributions of types is clearly ubiquitous in humans and throughout the animal kingdom. For example, the next door we encounter may differ from previous doors in being larger or smaller, wooden or windowed, and may require pushing, pulling, or sliding to open. And yet we have no trouble recognizing a new door as a door; nor, fortunately, do we normally have trouble distinguishing doors from windows. We categorize linguistic elements as well (e.g., Kuhl, Reference Kuhl2000; Lakoff, Reference Lakoff1987; Langacker, Reference Langacker1987; Taylor, Reference Taylor2003). As discussed below, each construction forms a category, and this allows us to apply our linguistic knowledge to new situations and experiences. That is, constructions are productive to varying degrees. A few examples of productive uses of familiar constructions (again labeled on the right) are provided in Table 2.
table 2. Novel linguistic exemplars that demonstrate the productivity of various constructions
At the same time, the same constructions exemplified in Tables 1 and 2 resist being used productively with certain other words, even when the intended meaning is perfectly clear and the examples do not violate system-wide semantic, syntactic, or phonological generalizations. Examples that illustrate the lack of full productivity are provided in Table 3, along with related acceptable examples in parentheses.
table 3. Novel formulations that are judged odd by native speakers

Thus, constructions are typically partially productive in that they can be extended for use with some words (Table 2), but they are not necessarily completely productive, even when no general semantic, phonological, or syntactic constraints are violated (Table 3). The present paper investigates the long-standing paradox that this partial productivity presents: How do learners know when and how far a given construction’s productivity extends?
A good deal of work has demonstrated that the solution is non-trivial. Learners do not reliably receive overt corrections for ill-formed utterances, because people are much more interested in the content of a speaker’s contribution than its form (Baker, Reference Baker1979; Bowerman, Reference Bowerman and Hawkins1988, Reference Bowerman, Johnson, Juge and Moxley1996; Braine, Reference Braine and Reed1971; Brown & Hanlon, Reference Brown, Hanlon and Hayes1970; Marcus, Reference Marcus1993; Pinker, Reference Pinker1989). That the words used ‘fit’ the constraints on the construction is required, as explained in Section 2 (see also Ambridge, Pine, Rowland, Jones, & Clark, Reference Ambridge, Pine, Rowland, Jones and Clark2009; Coppock, Reference Coppock2008; Goldberg, Reference Goldberg1995; Gropen, Pinker, Hollander, & Goldberg, Reference Gropen, Pinker, Hollander and Goldberg1991; Gropen, Pinker, Hollander, Goldberg, & Wilson, Reference Gropen, Pinker, Hollander, Goldberg and Wilson1989; Pinker, Reference Pinker1989), but it is not sufficient to insure acceptability, as illustrated in the examples in Table 3. Positing underlying or invisible features does not address the learning issue, since doing so would beg the question of how it is that learners know to assign the relevant diacritics to some lexical items and not others (Ambridge, Pine, & Lieven, Reference Ambridge, Pine and Lieven2015; Goldberg, Reference Goldberg2011b; Pinker, Reference Pinker1989, section 5.2).
It is tempting to believe that speakers only use familiar words in the ways in which they have been witnessed, i.e., that speakers are wholly conservative (Baker, Reference Baker1979; Braine & Brooks, Reference Braine, Brooks, Tomasello and Merriman1995). In line with this idea, it has been predicted that the more often a word is witnessed in one construction, the more difficult it is to extend it for use in a different construction (Ambridge et al., Reference Ambridge, Pine, Rowland, Jones and Clark2009; Stefanowitsch, Reference Stefanowitsch2008). In fact, children are relatively more willing to overgeneralize infrequent verbs (e.g., to use vanish transitively) than to overgeneralize frequent verbs (e.g., to use disappear transitively) (Ambridge, Pine, & Rowland, Reference Ambridge, Pine and Rowland2012; Theakston, Reference Theakston2004). The suggestion has been that this is due to the fact that disappear has been heard in the simple intransitive construction much more often than vanish, and that it is more difficult to creatively causativize because it is more entrenched intransitively. We revisit this finding in Section 3.
This proposal, which is referred to here as conservativism via entrenchment, faces a problem, because if learners only use predicates in ways in which they have already been witnessed, and if predicates more strongly resist novel uses for higher-frequency verbs, then the following attested examples ought to be quite ill-formed:
-
(13) [she] prayed her way through the incomprehension of her atheist friends
-
(14) The python coughed her back out (<www.rabbit.org/journal/3-7/snake-bite.html>)
-
(15) Aladar [a dinosaur] swam his friends to the mainland. (Disney, Aladar)
-
(16) He’s right here at my feet, snoring his head off.
Each of the verbs in (13)–(16) (pray, cough, swim, snore) is very frequent (‘entrenched’) in the intransitive construction, and only exceedingly rarely, if ever, witnessed in the various transitive constructions in (13)–(16). Footnote 2 And yet, although Robenalt and Goldberg (Reference Robenalt and Goldberg2015) find that such novel sentences are in fact judged to be less acceptable than sentences in which the same verbs are used intransitively, they are not as ill-formed as the types of novel examples in Table 3. Moreover, speakers readily extend verbs in new ways that have not been witnessed when the intended message is conveyed better by a different construction (Perek & Goldberg, Reference Perek and Goldberg2015). Thus, the solution to the issue of partial productivity is not merely a matter of learners being conservative via entrenchment.
In the following sections, it is argued the solution follows from the fact that attested exemplars cluster together to form constructional categories, and that constructions can compete with one another in particular contexts. A concrete example may be helpful. If we learn that many varieties of leafy green vegetables are called lettuce, we are likely to label a new, only subtly different, leafy green vegetable as lettuce as well. That is, if we know that a category is attested by a variety of exemplars, and a new exemplar is sufficiently similar to attested instances, we are very likely to assign it to the same category. At the same time, if we hear a different label, say kale, consistently assigned to a new type of leafy green vegetable in contexts in which we might have expected to hear lettuce, then we will learn that kale is not lettuce (see also Bowerman & Choi, Reference Bowerman and Choi2003).
Briefly, the analogy to syntactic productivity outlined in more detail below is as follows. A potential productive use of an existing construction (a new coinage) is acceptable to the extent that the extended category that includes previously attested examples and the potential coinage is well attested (i.e., is dense or well-covered). The idea that speakers generalize over attested exemplars suggests that semantic, pragmatic, and phonological constraints emerge, as exemplars that share the same surface form are categorized. For example, exemplars of the English double-object formal pattern construction will almost all share an implication of transfer from one entity to another, and they will almost always involve a more topical recipient argument and a more focal theme argument. As these exemplars are categorized as instances of the same construction, the well-known semantic and information structure constraints of the double-object construction will emerge.
At the same time, as we saw in Table 3, there are certain formulations that are avoided by native speakers even though they seem to fit within these types of emergent constraints. It is proposed that a new coinage will be inhibited to the extent that there already exists a readily available alternative formulation that serves the requisite function; in this case, the alternative will statistically preempt the coinage. To return to our lettuce example, the category of lettuce is well attested by a variety of exemplars, all of which are leafy green vegetables. But, since a particular type of leafy green is consistently labeled kale in contexts where one might have expected to hear lettuce, people learn that that type of leafy green is kale and not lettuce. In Sections 2 and 3, these two aspects of the proposal, coverage – which encourages productivity while capturing emergent semantic and phonological generalizations – and statistical preemption – which constrains productivity and accounts for the learning of seemingly arbitrary exceptions – are discussed in turn.
2. The range of generalization is determined by coverage
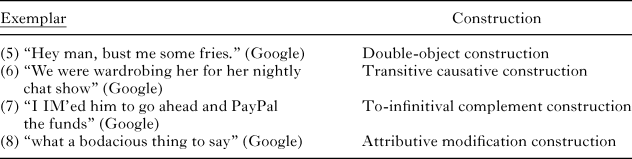
Work by Suttle and Goldberg (Reference Suttle and Goldberg2011) and Perek (Reference Perek2016) has argued that the critical factor in determining when a construction is productive is coverage, an idea borrowed from the non-linguistic categorization literature (Goldberg, Reference Goldberg2006, p. 98; Osherson, Smith, Wilkie, Lopez, & Shafir, Reference Osherson, Smith, Wilkie, Lopez and Shafir1990). Coverage relates type frequency, variability, and similarity of the coinage to attested tokens: all factors that have been independently found to be relevant. The idea is depicted in Figure 1. A new coinage is acceptable to the extent that the semantic (pragmatic, and/or phonological) space is well covered by the smallest convex category that encompasses both the coinage and attested instances that share the same formal pattern: the category is represented by the larger oval. Exemplars with shared form are represented in a high degree similarity space, projected here onto two dimensions for expository purposes. The degree of coverage corresponds to the degree to which the attested instances fill or ‘cover’ the entire category.
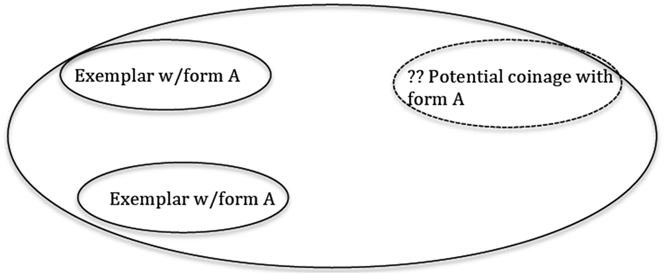
Fig. 1. The smallest convex category in similarity space that includes both attested examples and a potential coinage. The extent to which the instances cover the category correlates with how acceptable the coinage is judged to be.
In a series of experiments performed using Amazon’s Mechanical Turk, Suttle and Goldberg (Reference Suttle and Goldberg2011) found that type frequency, variability of attested instances, and similarity of a target utterance to attested instances interact in ways that are predicted by the notion of coverage. The design of the experiment was as follows. We provided one to six attested utterances of a fictitious language, Zargotian, and then asked participants to judge how likely it was that a final utterance would also be acceptable in Zargotian. As example stimulus trial is given below:
-
(17) Assume you can say these sentences.
Scrape-nu the vip the hap.
Load-nu the yib the vork.
Flip-nu the loof the rolm.
How likely is it, on a scale of 1–100, that you can also say:
Rumple-nu the pheb the jirm.
We systematically varied (i) whether participants were given one, three, or six distinct attested exemplars (type frequency), (ii) the diversity of verb classes the exemplars were chosen from (variability), and (iii) the degree of similarity between the target utterance and its closest attested neighbor, as determined by Latent Semantic Analysis (Landauer, Reference Landauer2006). Ten verb classes were varied across participants and items and included verbs of breaking, loading, bending, cooking, cutting, acquiring, throwing, hitting, holding, and cognition.
The findings confirmed that when coverage is relatively high, a coinage is judged to be more acceptable. For example, in the situation depicted in Figure 2, in which three attested examples come from different verb classes and the potential coinage comes from yet a different class, participants judged the potential coinage to be less acceptable than if type frequency was increased and all else was held constant (as depicted in Figure 3).

Fig. 2. Sample stimuli involving relatively low coverage from Suttle and Goldberg (2011, experiment 1), represented pictorially.
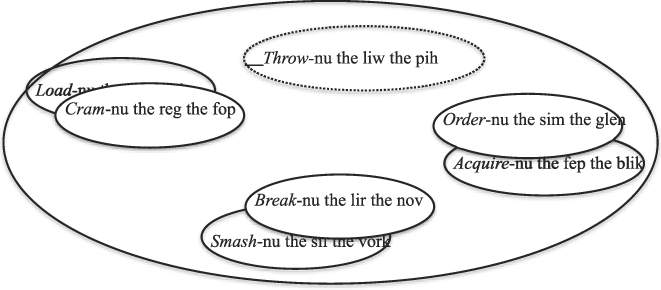
Fig. 3. Sample stimuli involving higher coverage than that depicted in Figure 2 due to higher type frequency, from Suttle and Goldberg (2011, experiment 2) represented pictorially.
If a new coinage is sufficiently semantically dissimilar so that coverage is again low, the coinage is judged less acceptable, even if the type frequency and variability of attested instances is relatively high (Suttle & Goldberg, Reference Suttle and Goldberg2011, experiment 3). This situation is depicted in Figure 4 (see also Barðdal, Reference Barðdal2008; Bybee & Eddington, Reference Bybee and Eddington2006; Croft & Cruse, Reference Croft and Cruse2004; Kalyan, Reference Kalyan2012; Langacker, Reference Langacker1987; Wonnacott, Boyd, Thompson, & Goldberg, Reference Wonnacott, Boyd, Thompson and Goldberg2012; Zeschel & Bildhauer, Reference Zeschel and Bildhauer2009).
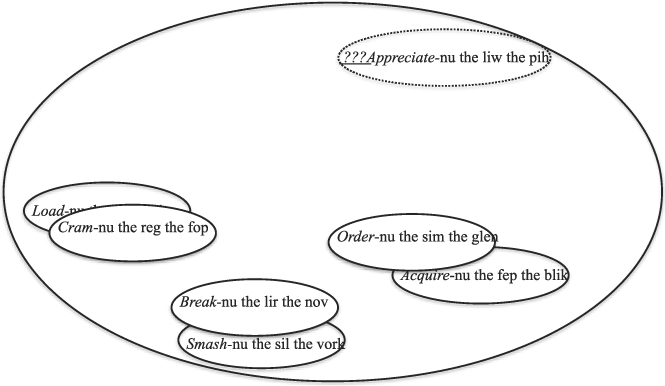
Fig. 4. Type frequency and variability is the same as is represented in Figure 3, and yet coverage is reduced because the potential coinage is less similar to the attested types.
The role of type frequency interacts with semantic similarity in the following way. If the potential coinage is semantically similar to a cluster of examples with high type frequency and high semantic similarity, then the coinage is likely to be judged quite acceptable. However, acceptability decreases as the semantic similarity of the potential coinage to the cluster decreases. Thus, a lack of semantic variability of attested tokens inhibits generalization if the potential coinage is not part of the same cluster of related tokens, as depicted in Figure 5. This type of relationship between type frequency and variability has also been reported previously (Barðdal, Reference Barðdal2008; Bowerman & Choi, Reference Bowerman, Choi, Bowerman and Levinson2001; Bybee, Reference Bybee1985, Reference Bybee1995; Clausner & Croft, Reference Clausner and Croft1997; Goldberg, Reference Goldberg1995; Janda, Reference Janda1990; Tomasello, Reference Tomasello2003; Xu & Tenenbaum, Reference Xu and Tenenbaum2007).
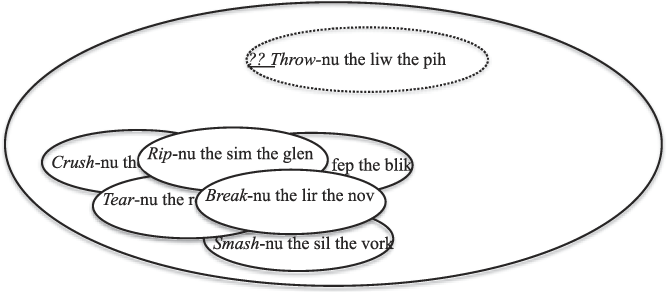
Fig. 5. High type frequency does not increase coverage if the potential coinage falls outside the similarity space defined by attested tokens.
Thus the notion of coverage is a way of combining the well-supported and independently recognized factors of type frequency, variability, and similarity of a potential coinage to attested exemplars. Support for the notion of coverage comes from Perek (Reference Perek2016), who investigates the nature of productivity over time by examining the ‘V the hell out of NP’ construction exemplified in (18).
-
(18) Santas that would scare the hell out of Jesus. (Google)
He examines the semantic distribution of verbs used in the construction in each of four 20-year time periods between 1930 and 2009, using distributional semantics and multidimensional scaling on the attested verbs found in COHA (Davies, Reference Davies2008b). Perek’s results demonstrate that the degree of density of a semantic cluster during one period strongly correlates with how many new verbs are added to the cluster in the following two decade time period. That is, clusters with higher density tend to attract near neighbors to their cluster, just as the notion of coverage predicts. Footnote 3
Categorization, as captured by the notion of coverage, thus allows for the fact that language is often productive within a circumscribed semantic, pragmatic, and phonological space. That is, coverage captures the idea that new uses of verbs must fit, or be able to accommodate, the semantic, pragmatic, and phonological constraints of the constructions they appear in (Ambridge et al., Reference Ambridge, Pine, Rowland, Jones and Clark2009; Coppock, Reference Coppock2008; Goldberg, Reference Goldberg1995; Gropen et al., Reference Gropen, Pinker, Hollander, Goldberg and Wilson1989; Gropen, et al., Reference Gropen, Pinker, Hollander and Goldberg1991; Pinker, Reference Pinker1989). Since speakers implicitly categorize instances of each construction, and thereby form generalizations about semantic, pragmatic, and phonological constraints, new expressions are judged to be well-formed to the extent that they satisfy the general constraints of the constructions involved.
At the same time, coverage is not sufficient in itself to account for the actual distribution of acceptable and non-acceptable exemplars. Recalling the examples in Table 3, it is clear that certain exemplars are ill-formed, even though they satisfy the general constraints on the constructions in question. That is, attested instances of the constructions involved appear to cover the similarity space that should include the examples in Table 3, and yet these examples nonetheless sound odd to native speakers.
3. Statistical preemption: competition-dependent learning
How is it that children learn to avoid the unacceptable examples in Table 3? This question has bedeviled researchers for decades (Ambridge, Pine, & Rowland, Reference Ambridge, Pine and Rowland2012; Ambridge, Pine, Rowland, & Young, Reference Ambridge, Pine, Rowland and Young2008; Ambridge et al., Reference Ambridge, Pine, Rowland, Jones and Clark2009; Baker, Reference Baker1979; Braine, Reference Braine and Reed1971; Bowerman, Reference Bowerman and Hawkins1988; Goldberg, Reference Goldberg1995, Reference Goldberg2006, Reference Goldberg2011a; Pinker, Reference Pinker1989). In this section, it is argued that a process of statistical preemption plays a key role (Clark, Reference Clark and MacWhinney1987; Foraker, Regier, Khetarpal, Perfors, & Tenenbaum, Reference Foraker, Regier, Khetarpal, Perfors, Tenenbaum, McNamara and Trafton2007; Goldberg Reference Goldberg1993, Reference Goldberg1995, Reference Goldberg2006, Reference Goldberg2011a; Marcotte, Reference Marcotte2005). Statistical preemption is a particular type of indirect negative evidence that results from repeatedly hearing a formulation, B, in a context where one might have expected to hear a semantically and pragmatically related alternative formulation, A. Given this type of input, speakers recognize that B is the appropriate formulation in such a context, and implicitly learn that A is not appropriate.
Morphological preemption (or ‘blocking’) has long been familiar from morphology: went preempts goed, and feet preempts foots (Aronoff, Reference Aronoff1976; Kiparsky, Reference Kiparsky, Hargus and Kaisse1993; Rainer, Reference Rainer, Hüllen and Schulze1988). That is, children learn to produce feet instead of foots because they systematically hear feet every time the ‘plural of foot’ is expressed. At the same time, in the case of phrasal constructions, the role of statistical preemption requires discussion, since, unlike feet and the potential foots, distinct phrasal constructions are virtually never semantically and pragmatically identical (Bolinger, Reference Bolinger1977; Clark, Reference Clark and MacWhinney1987; Goldberg, Reference Goldberg1995). Since two constructions that are semantically related often happily co-occur with the same verb, some have argued that statistical preemption cannot be effective (Bowerman, Reference Bowerman, Johnson, Juge and Moxley1996; Pinker, Reference Pinker1989). Certainly, knowledge that the to-dative paraphrase is licensed for explain should not immediately preempt the use of the double-object construction, since a large number of verbs freely appear in both constructions (e.g., tell).
But the fact that each construction has a distinct function can actually work in favor of statistical preemption. Consider the to-dative and double-object constructions. They have overlapping, but distinct, semantic and information structure properties in that many corpus and production studies have demonstrated that the double-object construction is preferred over the to-dative if the recipient argument is pronominal and the transferred entity is a lexical noun phrase (Arnold, Eisenband, Brown-Schmidt, & Trueswell, Reference Arnold, Eisenband, Brown-Schmidt and Trueswell2000; Bresnan, Cueni, Nikitina, & Baayen, Reference Bresnan, Cueni, Nikitina, Baayen, Bouma, Kraemer and Zwarts2007; Collins, Reference Collins1995; Dryer, Reference Dryer1986; Erteschik-Shir, Reference Erteschik-Shir, Laberge and Sankoff1979; Givón, Reference Givón1979, Reference Givón1984; Goldberg, Reference Goldberg1995, Reference Goldberg2006; Green, Reference Green1974; Oehrle, Reference Oehrle1975; Thompson, Reference Thompson, Edmondson, Feagin and Mühlhäusler1990, Reference Thompson and Landsberg1995; Wasow, Reference Wasow2002). For instance, examples like (19) are vastly more common than those like (20).
-
(19) She gave me the ball.
-
(20) She gave the ball to me.
The difference between the double-object and to-dative constructions is subject to some dialect differences and gradability, yet it is possible to predict with high probability which construction will be preferred in a given context, for a given dialect (Bresnan & Ford, Reference Bresnan and Ford2010; Bresnan & Hay, Reference Bresnan and Hay2008). Therefore learners will witness situations in which the double-object construction is expected for a given verb, because the relevant information structure suits the double-object construction at least as well as the to-dative. If, in these situations, the to-dative is systematically witnessed instead, the learner can infer that the double-object construction is not after all appropriate (Goldberg, Reference Goldberg1995, Reference Goldberg2006, Reference Goldberg2011a). As Goldberg (Reference Goldberg2006) emphasizes, the process is necessarily statistical, because a single use of the to-dative could be due to an unrecognized factor that actually encourages the to-dative, or even to an error by the speaker. But if the to-dative is consistently heard in such contexts, statistical preemption will lead to an avoidance of the double-object construction in favor of the to-dative. More generally, because of the difference in function between two constructions, A and B, there will exist contexts in which A is at least as appropriate as B for a particular verb. If B is consistently witnessed instead, people can learn that A is not possible for that verb.
Statistical preemption of phrasal forms has been investigated experimentally in only a few studies. Brooks and colleagues have found that novel intransitive verbs that have been witnessed in the preemptive periphrastic causative construction are much less likely to be used in the simple transitive than those that have not (Brooks & Tomasello, Reference Brooks and Tomasello1999; Brooks, & Zizak Reference Brooks and Zizak2002). For example, if a child hears both The cow is chamming and Ernie’s making the cow cham, they are less likely to respond to “What did Elmo do to the cow?” with Ernie chammed the cow (the causative), than they are if only the intransitive construction had been witnessed (Brooks & Tomasello, Reference Brooks and Tomasello1999). It seems that hearing the novel verb used in the periphrastic causative construction provides a readily available alternative to the causative construction, statistically preempting the use of the latter (cf. also Tomasello, Reference Tomasello2003).
Another case of an unpredictable restriction involves certain adjectives such as afraid which resist prenominal attributive position (21a), despite the fact that near synonyms and phonologically analogous adjectives readily appear in this position (21b):
-
(21)
-
a. ??the afraid boy
-
b. the scared/aloof boy
-
These a-adjectives begin with an unstressed schwa and can be morphologically segmented into a- plus a semantically related stem (e.g., a-live, a-sleep). The distribution is motivated by the fact that the majority of a-adjectives historically were prepositional phrases and, as prepositional phrases, they could not be expected to appear prenominally. Like typical adjectives, a-adjectives are inseparable phonological units, modify nouns, can be conjoined with uncontroversial adjectives (22) and can appear after the verb seem (23):
-
(22) The man was quiet and afraid.
-
(23) The man seemed afraid/asleep.
Thus, since speakers are generally unaware of the historical facts, the question arises as to how the restriction can be learned.
Boyd and Goldberg (Reference Boyd and Goldberg2011) examined adult naturalistic productions of such adjectives in three experiments, all of which required participants to describe scenes in which one of two animals with different adjective labels moved to a star. The experiments all included four classes of adjectives: real a-adjectives; nearly synonymous real non-a-adjectives; nonsense a-adjectives; and nonsense non-a-adjectives. The task resulted in either a relative clause or prenominal (attributive) use of the target adjective (e.g., (24) or (25)).
-
(24) Prenominal:
The sleepy/??asleep/?adax fox.
(judgments based on data from Experiment 1 of Boyd & Goldberg, Reference Boyd and Goldberg2011)
-
(25) Relative clause:
The fox that’s sleepy/asleep/adax.
The first experiment established that real a-adjectives (e.g., asleep) strongly disprefer prenominal use, relative to non-a adjectives (e.g., sleepy). In addition, novel a-adjectives (e.g., adax) disprefer prenominal use relative to non-a adjectives (e.g., chammy) to a significant extent as well. This indicates that participants tentatively assimilate never-before-seen a-adjectives to the category of familiar a-adjectives. The real a-adjectives were much less likely to occur prenominally than the novel a-adjectives were, but it suggests that speakers can tentatively generalize a restriction to unwitnessed but similar exemplars.
A second experiment investigated the role of statistical preemption. It was found that in fact witnessing two of the four novel a-adjectives used in a preemptive relative clause context just three times each dramatically decreased prenominal uses so that all four novel a-adjectives behaved indistinguishably from familiar a-adjectives in avoiding prenominal uses. Non-a-adjectives were unaffected. This result is striking because it not only demonstrates the effectiveness of preemption, but it also demonstrates that speakers are able to generalize evidence gleaned from statistical preemption to other members of the same category.
A final experiment showed that learners rationally disregard pseudo-preemptive input. Speakers did not display an increased avoidance of prenominal uses when exposed to pseudo-preemptive contexts like (26), presumably because they rationally attributed adax’s appearance in the relative clause to the complex adjective (cf. (27)), rather than to adax.
-
(26) The hamster, adax and proud of itself, moved to the star.
-
(27) *The proud of itself hamster moved to the star.
Productions in the last experiment patterned like those in the first experiment where no preemptive context was provided. Fillers were used to obscure the goal of the experiment and to guard against the effects being a simple result of structural priming. Debriefing confirmed that speakers were unaware of the manipulations (see Goldberg & Boyd, Reference Goldberg and Boyd2015, Yang, Reference Yang2015, for further discussion).
Collectively, these experiments go some way toward establishing how speakers are able to learn arbitrary distributional restrictions in their language – i.e., how they learn what not to say. Learners categorize their input, tentatively generalizing restrictions to new members of a perceived category. Familiar formulations statistically preempt other formulations when the former are repeatedly witnessed instead of a hypothesized formulation. Providing evidence that speakers categorize restrictions, the second experiment demonstrated that speakers extended the information gained from preemptive contexts to other instances of the same category. At the same time, speakers use statistical preemption wisely: they are impressively adept at ignoring alternative formulations when those formulations can be attributed to some irrelevant factor.
The preemptive process, unlike the notion of conservatism via entrenchment, predicts that expressions like (13)–(16) would not be preempted by the overwhelmingly more frequent uses of pray, cough, swim, and snore intransitively because the expressions in (13)–(16) are not in competition with the intransitive uses. For example, the meanings of causing a change of state (28) and an involuntary intransitive action (29) would not be used in the same contexts:
-
(28) And he sneezed the house in! (Joseph Robinette, The trial of the big bad wolf)
-
(29) She sneezed.
The intriguing finding that high-frequency intransitive verbs (e.g., disappear NP) are less acceptable when used causatively than low-frequency intransitive verbs (e.g., vanish NP) is consistent with the idea that it is preemption that prevents overgeneralization, rather than the frequency of the verb per se. Note that the periphrastic causative of high-frequency verbs is more frequent than that of low-frequency verbs. In fact, a corpus search of the Corpus of Contemporary American English confirms that (30) is more frequent than (31), by a factor of ten.
-
(30) [NP] made [NP] disappear.
(statistically preempts [NP disappeared NP])
-
(31) [NP] made [NP] vanish.
(statistically preempts [NP vanished NP])
Robenalt and Goldberg (Reference Robenalt and Goldberg2015) revisit the finding that lower-frequency verbs are more acceptable in novel constructions, relative to their baseline acceptability in familiar types of sentences. If it is preemptive expressions that lead to the novel uses of the verbs being judged unacceptable, rather than baseline expressions, we should not find the same frequency effect for those novel expressions that do not have a readily available alternative. To see whether this prediction held, pairs of novel sentences were created, each involving both low- and high-frequency near-synonyms, with novelty confirmed using the COCA corpus (Davies, Reference Davies2008a). In a separate norming study, the sentence pairs were classified into two groups according to whether there exists a readily available paraphrase. Specifically, if more than half of a group of naive participants suggested the same paraphrase for a given sentence, the sentence was considered to have a competing alternative; if instead no single paraphrase was agreed upon by the majority of participants, the sentence was considered not to have a readily available competing alternative. For example, in response to (32), the majority of respondents suggested the same alternative: Natalie smacked the mosquito with a newspaper. On the other hand, in the case of (33), people instead proposed a wide variety of paraphrases, e.g., The magician was so fascinating the toddlers went into a trance; The magician entertained the toddlers and they became fascinated, etc.
-
(32) Natalie smacked a newspaper onto the mosquito.
-
(33) The magician fascinated the toddlers into a trance.
Thus (32) has a readily available competing alternative and (33) does not.
Findings replicated the stronger dispreference for a novel use with a high-frequency verb relative to its lower-frequency counterpart, but only for those sentences with a competing alternative phrasing. That is, while smack is judged worse than swatted in the caused motion construction (Natalie smacked/swatted a newspaper onto the mosquito), frequency had no effect on novel sentences that had no readily available alternative, such as (33) or (13)–(16). For example, despite the fact that fascinate is more frequent than enthrall, the sentence The magician fascinated the toddlers into a trance was not judged to be less acceptable than The magician enthralled the toddlers into a trance. Thus, when there is no consensus about a preferred way to phrase a sentence, verb frequency is not a predictive factor in a sentence’s ratings. This result implies that speakers are not simply conservative overall – they are willing to extend familiar words in new ways, but they are conservative when a readily available alternative formulation already exists. When it does, the readily available formulation is preferred – and the strength of the preference varies with the frequency of the competing alternative. Thus witnessing exemplars of one construction and not exemplars of a competing construction can lead learners to judge the non-occurring form to be unacceptable. This is represented schematically in Figure 6.
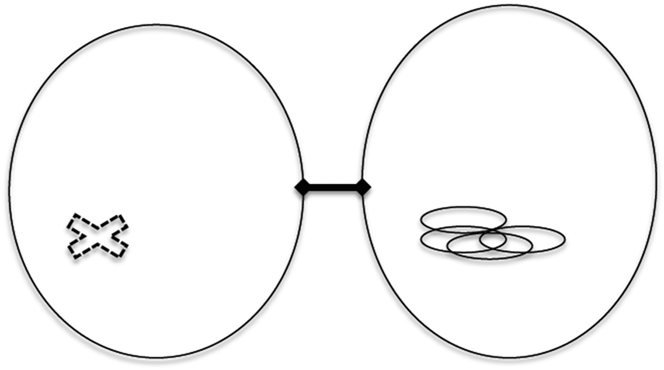
Fig. 6. Two competing constructions (competition indicated by the solid bar linking them). Attested instances on the right serve to statistically preempt the productive use on the left (indicated by the cross).
If a novel formulation is not in competition with a familiar formulation, additional evidence of the familiar formulation does not weigh against the use of the novel formulation (Figure 7).
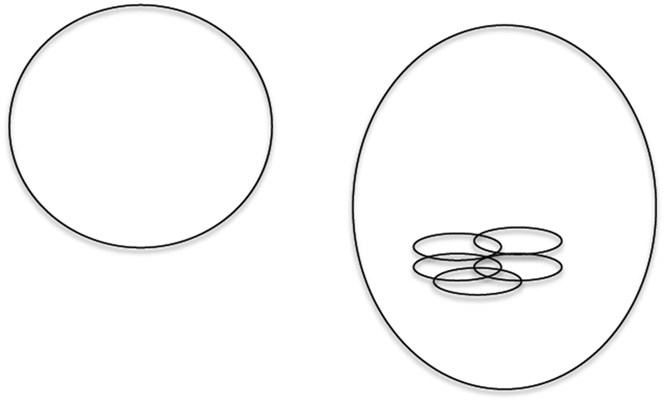
Fig. 7. If there is no competition between two constructions, witnessing instances of one has no bearing on whether a novel instance of the other is judged acceptable.
This is not to say that the degree of familiarity is irrelevant. Robenalt and Goldberg (Reference Robenalt and Goldberg2015) found that, overall, sentences in which verbs were used in their familiar argument structure pattern were strongly preferred over novel formulations, whether there existed a readily available alternative to the novel sentences or not (see also work by Ambridge and colleagues, e.g., Ambridge et al. Reference Ambridge, Pine and Rowland2012). Footnote 4 We can thus summarize the results as follows. Speakers prefer to use the types of exemplars they have witnessed in the input, but they are willing to extend constructions productively unless there exists a readily available alternative way of expressing the intended meaning.
3.1. mechanism: competition-driven learning
There is a great deal of evidence that we often predict what others will say as they speak (e.g., Johnson, Turk-Browne, & Goldberg, Reference Johnson, Turk-Browne and Goldberg2013; Kutas & Hillyard, Reference Kutas and Hillyard1984; McRae, Spivey-Knowlton, & Tanenhaus, Reference McRae, Spivey-Knowlton and Tanenhaus1998; Pickering and Garrod, Reference Pickering and Garrod2007, Reference Pickering and Garrod2013; Stephens, Silbert, & Hasson, Reference Stephens, Silbert and Hasson2010; Tanenhaus, Spivey-Knowlton, Eberhard, & Sedivy, Reference Tanenhaus, Spivey-Knowlton, Eberhard and Sedivy1995). When speakers anticipate a particular construction, we can assume that the construction is partially activated. Intriguingly, it turns out that if one representation is partially activated, but a competing form is accessed instead, the partially activated form is subsequently harder to retrieve. This is true at the level of individual neurons: strong excitatory input leads to long-term synaptic strengthening, but moderate excitatory input leads to long-term synaptic weakening (Artola, Brocher, & Singer, Reference Artola, Brocher and Singer1990).
Behaviorally, too, partial activation of a competing form leads to learned dissociation (Anderson, Green, & McCulloch Reference Anderson, Green and McCulloch2000; Anderson & Spellman, Reference Anderson and Spellman1995; Kim, Lewis-Peacock, Norman, & Turk-Browne, Reference Kim, Lewis-Peacock, Norman and Turk-Browne2014; Newman & Norman, Reference Newman and Norman2010; Norman, Newman, & Detre, Reference Norman, Newman and Detre2007; Storm & Levy, Reference Storm and Levy2012). The effect, often referred to as retrieval induced forgetting , has been demonstrated, for example, in the following type of paradigm. Anderson and Spellman (Reference Anderson and Spellman1995) had a group of subjects learn paired associations, e.g., Fruit–Apple, Fruit–Pear, Fruit–Kiwi, Furniture–Table, Sport–tennis, Furniture–Chair, and so on. Participants were then provided incomplete cues in order to retrieve a subset of these pairs. For instances, one incomplete cue had the form:
-
(34) Fruit-Pe___.
Note that since ‘Pear’ is only partially cued in (34), subjects can be expected to partially activate other prototypical associates of Fruit, e.g., Apple. Retrieval-induced forgetting predicts that the partial activation and subsequent suppression of Fruit–Apple in favor of Fruit–Pear will lead to worse memory for Fruit–Apple. In fact, Anderson and Spellman found that subjects’ memory for Fruit–Apple was weakened when compared with witnessed pairs that had not been partially activated, such as Sport–Tennis. The suppression only held for pairs such as Fruit–Apple that involved prototypical exemplars of the superordinate category (here, Fruit), because non-prototypical exemplars are less strongly associated with the category. As expected, then, memory for Fruit–Kiwi was not weakened.
Retrieval-induced forgetting predicts that a construction that is in competition will be weakened whenever another form ‘wins’ (is used). For example, if, whenever a double-object pattern with explain, as in (35), is expected, (36) is repeatedly and consistently witnessed instead, (35) will become harder to retrieve. In this way, (36) will come to preempt (35).
-
(35) ??She explained him something.
-
(36) She explained something to him.
3.2. predictions as conditional probabilities
As explained in Goldberg (Reference Goldberg2011a), the probability of a construction CxB statistically preempting CxA for a particular verb, verb i, is:
-
(37) P(CxB | context suitable for CxA, and verb i.)
For example, if we assume that explain does not readily occur in the double-object construction because it is statistically preempted by the to-dative construction, we predict the probability in (38) to be high:
-
(38) P(dative | context suitable for the double-object construction and explain)
In order to operationalize how to count ‘contexts that are at least as suitable for the double-object construction’, we can use the total number of double-object and to-dative uses in a given corpus, when the semantics and information structure of the double-object construction are satisfied. That is,
-
(39) P(dative | context suitable for double-object construction and verb i. ) ≈
P(dative | verb i. and (dativewith relevant restrictions or double-object construction))
In fact, this probability has been estimated to be quite high (.99) on the basis of a corpus analysis (Goldberg, Reference Goldberg2011a).
Also relevant is the frequency with which the preempting situation is witnessed. That is, suppose that the first time a learner hears explain, she expects to hear it used in the double-object construction, but instead hears it used in the to-dative. At that moment, the probability of witnessing explain in a preemptive context is 1, but only a single case has been witnessed. Clearly, the learner should not infer from a single exposure that the double-object construction is preempted for explain. On the other hand, if a learner hears explain used datively 100 times, without ever hearing it used in the double-object construction, the probability hasn’t changed – it is still 1 – but the confidence of preemption should be increased. In fact, it has been demonstrated experimentally that essentially a gap is more likely to be considered to be non-accidental when the overall token frequency is increased (Reeder, Newport, & Aslin, Reference Reeder, Newport and Aslin2013; Xu & Tenenbaum, Reference Xu and Tenenbaum2007). We can observe further that it is not likely that confidence increases linearly with frequency, so we appeal to the logarithmic function. Thus we can separate the two factors that determine the strength of preemption as follows: Probability (40), and Confidence (41):
-
(40) Probability of CxB statistically preempting CxA for verbi:
P(CxB| contexts in which CxA would be suitable)
-
(41) Confidence of statistical preemption for verbi, where F=frequency:
ln F(CxB when CxA would be suitable)
4. Conclusion
Constructions are typically partially but not fully productive. The present paper sketches the two complementary factors: dynamic categorization and statistical preemption. Much more work is needed to provide a fully comprehensive and explicit account (see Goldberg & Ambridge, forthcoming), but it is clear that, as learners record statistics of their language, they dynamically categorize their input on the basis of form and function. Productivity is to a large extent determined by coverage, which is a general principle of induction: essentially, a potential new coinage is judged acceptable to the extent that the formal linguistic category it would join is well attested by similar exemplars. This idea captures the fact that each construction has a restricted range of distribution, typically dependent on various semantic, pragmatic, and phonological properties of the exemplars that are witnessed.
Recognizing that categories do not exist in isolation from one another, it is also important to recognize a process of statistical preemption whereby learners learn to avoid using one construction, even when the construction’s constraints would seem to be satisfied, if an alternative formulation has been systematically witnessed instead. The mechanism required for statistical preemption is competition-driven learning, which is a domain-general process. When two competitors are activated, but one systematically wins, the loser becomes less accessible over time. In this way, with a recognition of both general properties of categorization and the role of competition among categories, we can begin to explain ourselves the paradox of partial productivity.










