



1 Introduction
Although some Bantu languages have lost tone (most notably Swahili), the vast majority of Bantu languages are two-tone languages with a surface high (H) and low (L) level tone. Tone in Bantu languages has a lexical and a grammatical function (see Kisseberth & Odden Reference Kisseberth, David, Derek and Gerard2003, Downing Reference Downing, Marc, Ewen, Elizabeth and Keren2011, Marlo & Odden Reference Marlo, David, Mark, Koen, Derek and Gerard2019 for overviews). Phonologically, in many Bantu languages only lexical high tones are assumed to be underlyingly represented, and low tones are inserted late in the derivation as default tones (Hyman Reference Hyman and Shigeki2001; Yip Reference Yip2002; Marlo & Odden Reference Marlo, David, Mark, Koen, Derek and Gerard2019: 151–153). High tones can be observed to be the active tones, taking part in tone shift, spread, deletion, and/or fusion. Some examples will be provided below. Bantu languages are particularly known for their tonal mobility (see Yip Reference Yip2002: 66) and tone sandhi. Tone sandhi, i.e. tonal changes due to neighbouring tones, can be observed at the word and phrase level. The focus of the article is on the phonetic lowering of a lexical high tone due to the presence of a preceding high tone. This process is commonly referred to as downstep. Two adjacent high tones constitute a typical environment which violates the Obligatory Contour Principle (OCP; Leben Reference Leben1973) prohibiting identical adjacent elements. Although they violate the OCP they constitute the context for downstep. This study addresses the conditions for downstep in Tswana analysing it as a phrasal phenomenon.
Our study has the aim of presenting an empirical study for establishing the structural conditions for downstep in (a variety of) Tswana, taking both number of adjacent high tones and syntactic structure into consideration as suggested in previous literature. Next to a qualitative analysis based on auditory impression, the current study also provides a quantitative acoustic analysis of the data of twelve speakers. Although a number of studies exist on OCP violations in Bantu languages (see references below), there are only a few acoustic studies available on downstep (see GjersØe Reference GjersØe2015 and contributions in Downing & Rialland Reference Downing and Rialland2017; Liberman et al. Reference Liberman and Schultz1993 is an experimental study on downstep in Igbo, a Kwa language of West Africa).
The article is structured as follows: Section 2 introduces the OCP in Bantu languages and discusses two existing approaches concerning the structural conditions for downstep in the languages of the Sotho-Tswana family. Section 3 presents the elicited-production study that was carried out in order to test which structural condition causes downstep in Tswana. It includes a qualitative analysis of auditory downstep transcription and a quantitative analysis of an acoustic measure of downstep. Section 4 addresses the theoretical account of the data and explores further predictions. Section 5 concludes.
2 The Obligatory Contour Principle
2.1 The OCP in Bantu languages
The Obligatory Contour Principle (OCP; Leben Reference Leben1973) expresses the dispreference of identical adjacent elements. It was originally proposed for the representation of tones in an autosegmental framework in which tones are organized on separate tiers. For instance, sequences of high-toned syllables must be represented phonologically as in (1a), where a single high tone is multiply associated with a number of adjacent syllables, and not as in (1b), where identical elements, i.e. high tones in case of (1), are adjacent.

The OCP was initially formulated as a morpheme-structure constraint which rules out sequences of identical tones in underlying representations like in (1b). The argument for a preference of a representation like in (1a) comes from Meeussen’s rule, which targets a dissimilation process that changes one of two adjacent high tones to low (Odden Reference Odden1980). In case of (1b), Meeussen’s rule predicts a realization of an HLH tone sequence. If, however, a sequence of three high tones is realized, a representation as in (1a) is more likely: If the sequence is associated with only one high tone, Meeussen’s rule does not apply as no further (second) high tone is present. The existence of Meeussen’s rule in other contexts thus provides a good argument to assume a representation as in (1a). The OCP has since been extended in a variety of ways to also refer to phonological derivations, e.g. by blocking the application of a phonological rule (McCarthy Reference McCarthy1986) if the outcome results in adjacency of identical elements or by triggering a phonological rule in order to avoid a surface OCP violation (Yip Reference Yip1988). The OCP has also been extended from a constraint on morpheme structure to a constraint applying to higher prosodic constituents.
In Bantu tone languages, OCP violations are avoided in a variety of ways, e.g. through deletion of tones, tone movement, blocking of tone spreading, and fusion of two tones into one (see Myers Reference Myers1997 for an overview). For instance, in the Bantu language Shona, several of these mechanisms are used to avoid OCP violations or ‘repair’ them (data from Myers Reference Myers1997).
In some Bantu languages, violations of the OCP lead to downstep, e.g. in Kishambaa, a Bantu language spoken in Tanzania (Odden Reference Odden1982, Reference Odden1986). Kishambaa shows a surface contrast between two adjacent high-toned syllables and a sequence of a high tone and a downstepped high tone. The first case has been analysed as the realization of a single high tone associated with two TBUs (along the representation in (1a)) and the second case as a sequence of two lexical high tones. In the latter case, a downstep occurs between the two lexical high tones, i.e. that the pitch level of the second high tone is lower than that of the first (Odden Reference Odden1982, Reference Odden1986).
This contrast is illustrated in (2a) and (2b). Underlining refers to a lexical high tone. Downstep is indicated by the superscript exclamation mark.Footnote 1
(2)Downstep in Kishambaa (Odden Reference Odden1986: 363; Myers Reference Myers1997: 883 citing Odden Reference Odden1982)
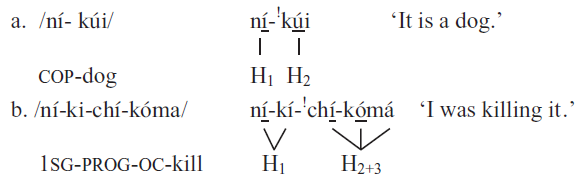
Downstep occurs between two adjacent high tones associated with different morphemes, as in (2a) (although it can also occur in the same morpheme; Odden Reference Odden1982: 187, 189). The data in (2b) show that no downstep occurs between the surface high tones that are multiply linked to the same underlying tone. Multiple linking in (2b) arises from two tonal processes: First, High Tone Spread from the subject prefix nÍ - onto the following aspect marker -ki-; second, high tone fusion of the high tone of the object marker -chÍ - and that of the verb stem -kóma. Note that the OCP does not act as a rule blocker for High Tone Spread or tone fusion in this context to avoid the adjacency of H1 and H2. High Tone Spread of H1 takes place although another high-toned syllable follows, namely H2 on the object prefix -chÍ -. Kishambaa is thus an example of a language that violates the OCP by tolerating adjacent high tones in the surface representation, but resolves their potential non-distinctness by downstepping the second high tone.
To sum up, it is well-documented that the OCP is an important constraint on tonal representations. Many languages obey the OCP at the level of the word or its subconstituents, which leads to tone deletion, blocking of tone spread, and/or fusion. However, in other languages, violations of the OCP lead to a downstepped phonetic implementation.
2.2 The OCP in Sotho-Tswana
Since the current study explores OCP violations across word boundaries in Tswana, the following section provides relevant background to Tswana and a review of OCP effects in the language family Tswana belongs to. Tswana belongs to the Sotho-Tswana group of Southern Bantu languages (S30 in Guthrie’s (Reference Guthrie1967–1971) classification), together with Southern Sotho (Sesotho), Northern Sotho (Sepedi) and Lozi (Silozi). There are several descriptions available in the linguistic literature on aspects of the tonal system of these languages (see Ziervogel, Lombard & Mokgokong Reference Ziervogel, Lombard and Mokgokong1969, Lombard Reference Lombard1976, Monareng Reference Monareng1992 for Northern Sotho; Khoali Reference Khoali1991 for Southern Sotho; Mmusi Reference Mmusi1992, Chebanne, Creissels & Nkhwa Reference Chebanne, Denis and Nkhwa1997, Creissels Reference Creissels, Blanchon and Denis1999, Reference Creissels, Ekkehard and Orin2000 for Tswana). Tone has a lexical and a grammatical function in Tswana. Like Shona and Kishambaa and most other Bantu languages, Tswana contrasts two level tones, high (H) and low (L) on the surface. As in many other Bantu languages, only high tones are present underlyingly (see Mmusi Reference Mmusi1992: 39; Hyman & Monaka Reference Hyman, Monaka, Sónia, Gorka and Pilar2011 for varieties of Tswana).
Previous research on Tswana has claimed that this language has an active OCP restriction according to which sequences of singly-linked adjacent high tones are allowed but sequences of multiply-linked adjacent high tones are not allowed (Mmusi Reference Mmusi1992). Mmusi (Reference Mmusi1992) cites examples from the domain of the root and word that illustrate the various processes that apply in order to avoid OCP violations. In (3a), the singly-linked lexical high tone of the subject prefix and that of the verb root are both realized.
(3)OCP in Tswana (Mmusi Reference Mmusi1992: 70, 112)
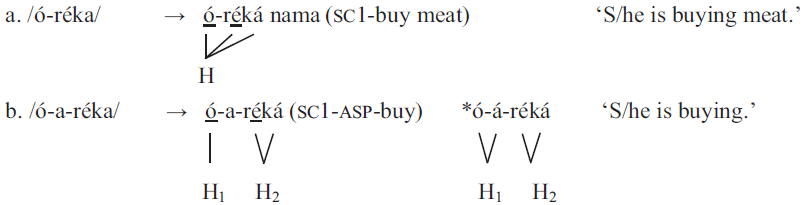
Mmusi (Reference Mmusi1992) suggests an analysis according to which these separate lexical high tones are fused into one, which is shown in (3a). In (3a), also the rule of High Tone Spread applies. High Tone Spread takes place from a lexical high-toned syllable to an adjacent toneless syllable if this syllable is not phrase-final and if this does not result in adjacent multiply-linked high tones. Example (3b) shows that the OCP acts as a rule blocker for High Tone Spread if it were to create a sequence of multiply-linked high tones.
For the closely related language Southern Sotho, Khoali (Reference Khoali1991) also describes tonal processes that counteract violations of the OCP, among them fusion (4a) which merges adjacent lexical high tones within the verb into a multiply-linked high tone (co-occurring with High Tone Spread of the lexical high-toned syllable to the adjacent syllable in (4a)).
(4)OCP in Southern Sotho varieties (Khoali Reference Khoali1991: 296)
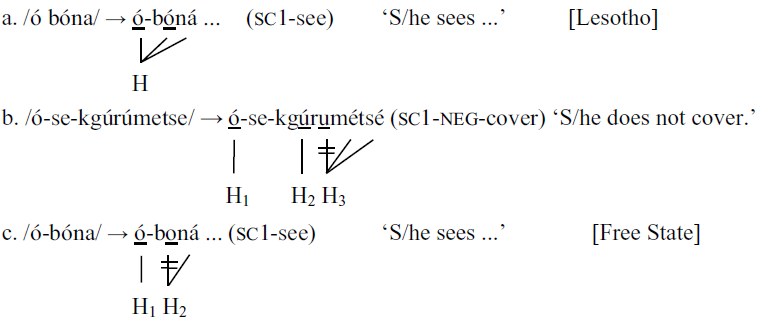
High Tone Spread and then left-branch delinking occurs with a grammatical high tone (H3) co-occurring with the negated verb form in the verb stem, as in (4b). Khoali (Reference Khoali1991) also investigates dialectal variation and observes that some dialects apply left-branch delinking in the verb, as in Southern Sotho spoken in the Free State, (4c), compared to fusion in Southern Sotho spoken in Lesotho, (4a).
2.3 Downstep in Sotho-Tswana
For OCP violations above the word level, downstep has been reported as one resolution strategy, i.e. the phonetically lowered realization of the second in a sequence of two adjacent high tones. There exist two distinct accounts in the literature on the Sotho-Tswana languages which differ in the structural conditions that trigger downstep. They will be introduced in this section.
2.3.1 The tonotactic approach
The ‘tonotactic approach’ (Creissels Reference Creissels, Larry and Charles1998; term suggested to us by a reviewer) postulates an exclusively tonally determined context for the occurrence of downstep in Tswana. More precisely, a downstep occurs across word boundaries when a word-final high tone is followed by at least two successive high-toned syllables. ‘This downstep occurs irrespective of the precise syntactic nature of the boundary between the two words and of their morphological structure’ (Creissels Reference Creissels, Larry and Charles1998: 146). Examples are provided in (5) below, where, according to Creissels (Reference Creissels, Larry and Charles1998: 145), downstep between the subject and the verb takes place in (5a) and is blocked in the same syntactic environment in (5b) because the tonotactic condition of three adjacent high tones, of which two follow the word boundary, is not met. The final high tone of the first word can be either lexical, or derived by High Tone Spread; Creissels gives examples from the latter (as in (5a, b)).
(5)Tswana (Creissels Reference Creissels, Larry and Charles1998: 145)

2.3.2 The phrasal approach
In contrast, Khoali (Reference Khoali1991) postulates a ‘phrasal approach’ (our term) to downstep in Southern Sotho (see also Kunene Reference Kunene1972 for a descriptive pilot study on downstep in Southern Sotho). Within the framework of Prosodic Domains (Nespor & Vogel Reference Nespor and Irene1986), Khoali (Reference Khoali1991) states that in a sequence of two adjacent high tones across word boundaries, a word-initial high tone is downstepped if both words occur within the same phonological phrase. Khoali (Reference Khoali1991) adopts the indirect reference approach (e.g. Nespor & Vogel Reference Nespor and Irene1986; Selkirk Reference Selkirk1986, Reference Selkirk, John, Jason and Alan2011; Truckenbrodt Reference Truckenbrodt1995) which proposes that phonology is not directly conditioned by syntactic information. Rather, the interface is mediated by phrasal prosodic constituents, like phonological phrase (abbreviated as φ), which are defined with reference to syntactic constituents but need not match them. Khoali (Reference Khoali1991) provides a phrasing algorithm that derives the phonological phrasing from the syntax.Footnote 2
According to Khoali’s phrasing algorithm, the subject and a following verb constitute one phonological phrase in Southern Sotho. An example from Southern Sotho with the phrase structure made explicit is shown in (6).
(6)Southern Sotho (Khoali Reference Khoali1991: 65, 76)

Khoali’s (Reference Khoali1991) approach predicts downstep on the high tone of the subject concord in (6a) and also in (6b).
Khoali adduces language-internal and external evidence for the phrasing in (6): Nouns with an underlying lexical high tone on the stem-initial syllable (pó- in (6a) and (6b)) are realized with an HL-pattern (as opposed to an HH-pattern) when they occur final in a phonological phrase. Thus, the High Tone Spread to the final syllable of the subject in (6) marks it as not phrase-final (Khoali Reference Khoali1991: 70).
In (7), the noun and following possessive concord are separated by a phonological phrase boundary according to Khoali (Reference Khoali1991).
(7)Absence of downstep in Southern Sotho (Khoali Reference Khoali1991: 114, 117)

Again, such a phrasing is supported by language-internal evidence. In non-phrase-final position, High Tone Spread to the word-final syllable would have taken place. As shown in (7), the final syllables of the head nouns are low toned, which Khoali interprets as an indication of their phrase-final status.
Interestingly, both approaches predict downstep for the data in (6), yet for different reasons. While for Khoali (Reference Khoali1991) the prosodic structure of two words within the same phonological phrase is decisive for downstep, for Creissels (Reference Creissels, Larry and Charles1998) it is the phonological condition of three adjacent high tones. Thus, we have two competing accounts of downstep for the Sotho-Tswana languages by Creissels (Reference Creissels, Larry and Charles1998) and Khoali (Reference Khoali1991), and the present study investigates experimentally which of the two accounts holds for the variety of Tswana under investigation. The data of the previous studies are based on elicitation (Creissels Reference Creissels, Larry and Charles1998) and introspection (Khoali Reference Khoali1991), and they come from different, though closely related languages. It is not clear whether the reported differences are linked to the languages investigated or if they form part of dialectal variation. After all, there is evidence that Tswana shares the phrasing of subject and verb (as in (6) above) and noun and possessive (as in (7a) above) with Southern Sotho, as will be shown and discussed in Section 4.1. Furthermore, both Creissels and Khoali explicitly state that they expect dialectal variation across the different varieties of Sotho-Tswana, including the tone system. The data in Creissels (Reference Creissels, Larry and Charles1998) come from a single speaker who is a native of the town Kanye and identifies herself as a speaker of the Sengwaketse dialect. In Cole’s (Reference Cole1955: xvi) classification, Sengwaketse belongs to the Central division of the Setswana cluster of dialects. Khoali’s work investigates the variety of Southern Sotho spoken in Qacha’s Nek in Lesotho and the Maluti area of South Africa.
The current study tests both approaches empirically with speakers of Tswana spoken around Vryburg in the North-West province in South Africa. Vryburg is reported to host dialects of the Southern division of Tswana (Cole Reference Cole1955: xvi). Geographically the three varieties of Sotho-Tswana discussed in this article are thus distributed across an extended area in Southern Africa. By running a production study obtaining acoustic data from several speakers, the current study thus presents the first instrumental approach to the occurrence of downstep in Tswana (as spoken in Vryburg).
2.4 Predictions and hypotheses
In order to test whether the ‘tonotactic’ or the ‘phrasal’ approach accounts for downstep patterns in Tswana, we constructed experimental stimuli that systematically take the predictions of the tonotactic and phrasal approaches into account. In particular, two syntactic structures which differ in phonological phrasing, namely subject–verb sequences and noun–possessive sequences are tested with two different tonal contexts. We follow a 2 × 2 design with tonal context (tone) and syntactic structure/phonological phrasing (phrasing) as the two factors, resulting in four contexts as shown in (8) below. As a structural prerequisite, the tonotactic approach requires three adjacent high tones on the surface that are divided such that a word boundary occurs between the first and the second high tone. The phrasal approach, on the other hand, requires at least two adjacent high tones and a word boundary between them. Crucially, for downstep to occur, the two words must belong to the same phonological phrase.
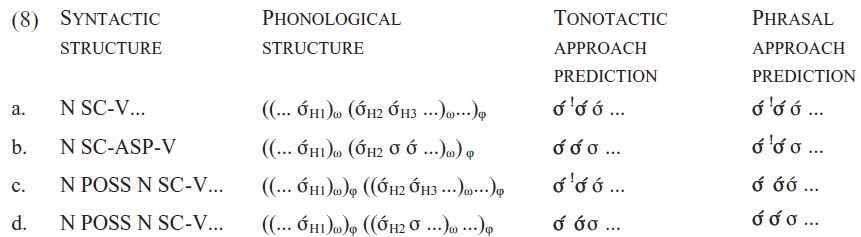
The two approaches converge in their predictions for contexts (8a) and (8d). In (8a), a subject noun (N) with a final high tone (H1) is followed by a lexically high-toned subject concord (SC) (H2) which itself is followed by a lexically high-toned verb (V) (H3), as in (5a) above. Both approaches predict downstep to occur before the subject concord, though for different reasons. In (8d), a head noun (N) with a final high tone (H1) is followed by a high-toned possessive concord marker (POSS) (H2) which itself is followed by a low-toned noun (N). Both approaches predict downstep not to occur before the possessive concord, again for different reasons.
The two approaches make different predictions for contexts (8b) and (8c) since these differ in their structural conditions, i.e. in tonal structure and phonological phrasing. In (8b), a subject noun (N) with a final high tone (H1) is followed by a lexical high-toned subject concord (SC) (H2) which itself is followed by a low-toned aspect marker (asp). In (8c), three adjacent high tones occur across a word boundary in a possessive construction with a phonological phrase break between the noun and its possessor.
The tonotactic approach (Creissels Reference Creissels, Larry and Charles1998) predicts downstep to occur in (8c) since three adjacent high tones occur across a word boundary but not in (8b) and (8d) since only two high tones are adjacent across a word boundary. It thus predicts contexts (8a) and (8c) to pattern together (downstep) vis-à-vis contexts (8b) and (8d) (no downstep).
The phrasal approach (Khoali Reference Khoali1991) predicts downstep in contexts (8a) and (8b) due to their parallel phrasal structure. Contexts (8c) and (8d), in contrast, show an intervening phrase boundary induced to the left of a nominal modifier (POSS N) that blocks the application of downstep. It thus predicts contexts (8a) and (8b) to pattern together (downstep) vis-à-vis contexts (8c) and (8d) (no downstep).
3. Production study
3.1 Method
3.1.1 Target sentences
In order to test the predictions outlined in (8), the production experiment followed a 2 × 2 design, such that two surface tonal conditions appeared in two boundary conditions. The tonal conditions had two adjacent high tones across word boundaries and differed in the third tone, either (i) H)ω ω(HH, or (ii) H)ω ω(HL. The boundary conditions at the ω-boundary distinguished between the absence and presence of a φ-phrase boundary: H)ω, and H)ω)φ, respectively.
For each of the contexts A, B, C, and D (corresponding to (8a–d), four different sentences were constructed. Examples are given in (9). A full list can be found in the appendix.Footnote 3 The total set of test sentences comprised three repetitions of those 16 sentences.
(9)Illustration of contexts A, B, C, D

Although considerable care was taken in the construction of the stimuli, a number of asymmetries emerged at the locus of interest (final syllable of the noun (H1) and first syllable of the following word (H2)). These are listed here: (i) The stimuli vary in the number of syllables that precede the locus of interest in contexts A, B and C between one and three. (ii) In contexts A and B, a voiced obstruent intervenes in the locus of interest, whereas it is a voiceless obstruent in contexts C and D. (iii) There are lexical high tones and derived high tones in the locus of interest (on the verb in context A, on the noun in context B). Remember that this should not make a difference; see example (6) above, for instance, for a case of a derived high tone that causes downstep. (iv) The number of low-toned syllables following H2 in context D varies between one and two, and shows even a syllabic nasal in one case. (v) In contexts B, C and D, there are obstruents before H1, whereas it is sonorants in context A. Despite these asymmetries, we believe that none of them affect the presence or absence of downstep. Some of these factors may affect the acoustic analysis of downstep since microprosodic influences due to different types of segments show up in f0. However, this was taken care of by applying different types of f0 analyses (see Section 3.3.1 below).
3.1.2 Recording procedure and participants
The 48 sentences (4 contexts × 4 sentences × 3 repetitions) were presented in pseudo-randomized order using presentation software, interspersed with a small number of fillers showing a similar syntactic structure. Stimuli were presented in Tswana only, using Tswana orthography which does not mark tone. Care was taken that the same contexts did not occur twice after each other. Participants were given the possibility to read through the sentences first to familiarize themselves with the sentences. They were then asked to read out the sentences from the screen one-by-one. There was a short break after one third of the full set of stimuli.
Recordings were done in people’s homes in Vryburg and Huhudi, North-West Province, South Africa. An M-audio microtrack II recording device was used (sampling rate 44.1 kHz) together with a head-mounted microphone. Care was taken to minimize background noise. Data were transferred to a computer hard drive for further analysis.
Twelve speakers (five male and seven female, aged between 15 years and about 50 years) took part in the study. Speakers whose speech was considered representative for the area by the local pastor were invited by him to take part in the research voluntarily. According to Cole (Reference Cole1955: xvi), the variety of Tswana spoken in this region belongs to the Southern division of Tswana. In total, 576 sentences were recorded (4 contexts × 4 sentences × 3 repetitions × 12 speakers).
3.2 Qualitative analysis
Of the data collected, 530 sentences were annotated based on auditory impression (46 sentences had to be discarded due to disfluencies or mispronunciations). The question asked during annotation was if from the two high-toned syllables under consideration, the second syllable is perceived as downstepped. Both authors of the study listened to the sound files of all speakers in all conditions and transcribed each token according to this question. The transcription was first done independently of each other and was based solely on auditory impression. Information on actual fundamental frequency (f0), e.g. by means of a pitch track, was not taken into consideration. Both authors are phonetically-trained and have experience with African tone languages.
Each target sentence thus received two judgments concerning the occurrence of downstep, one from each labeller. The inter-annotator reliability, i.e. the agreement between the two judgments across the whole data set, was calculated after this initial round of annotation using Cohen’s kappa (weights: unweighted). The resulting κ = 0.683 (z = 16.1, p = 0) shows substantial agreement (see Landis & Koch Reference Landis and Koch1977 for the interpretation of kappa). The total agreement was 84.3%.
There were 82 cases of disagreement in the first round of annotation (i.e. 15.7%). As we had a closer look into their distribution, we will briefly comment on them here. Table 1 shows the disagreements per speakers.
Table 1 Count of number of disagreements per speaker.

The number of disagreements also differed across the different contexts (A = 30, B = 25, C = 11, D = 16). Presumably, segmental characteristics might have contributed to the disagreement. In 36 cases, disagreement occurred when the vowels of the two high tones in question differed in vowel quality. In this case, the vowel of H1 was always a front high or mid vowel (/i/ or /e/) and the vowel of H2 was the low, back vowel /a/, as in the sentences A4, B3, B4, C1, and D4 (see Appendix). Vowel-intrinsic pitch is lower in low vowels (e.g. Whalen & Levitt Reference Whalen and Levitt1995). In 14 cases, the vowel in H2 was preceded by the affricate /ts/ which was realized as an ejective, leading to clearly perceivable coarticulated laryngealization on the vowel. We will not pursue this further though, given that speaker-specific and segmental influences on tone perception lie outside the scope of the present paper and agreement could be reached in nearly all cases after discussion.
Table 2 lists the reported occurrence of downstep, no downstep, and unresolved disagreements between the two annotators in the different contexts per speaker.
Table 2 Auditory impression per speaker and context, giving the number of downstep/no downstep/unresolved disagreement.

There is a clear pattern that emerges across all speakers, namely that downstep occurs in context B but not in context C or context D. In context A, we find speaker-specific variation since a clear pattern of downstep is not perceived in all speakers. Speakers 04, 05, 06, 07, and 09 are not perceived to consistently produce downstep. We take up the speaker-specific variation in Section 3.3.2 below. The quantitative analysis will be discussed in the next section.
3.3 Quantitative analysis
3.3.1 Data analysis
The main acoustic correlate of tone is fundamental frequency (f0) (see Myers Reference Myers1998), which can only be realized on voiced segments. In order to guarantee comparability across all stimulus items, the vowels of the high-toned syllables were delineated and analysed for their f0, following segmentation criteria in Turk, Nakai & Sugahara (Reference Turk, Nakai and Sugahara2006), except for double vowels which we divided by half of their total duration. For every sentence, the vowels carrying the noun-final high tone and the following word-initial high tone were the target vowels used for analysis.
Studies on the acoustic realization of a single high tone in the closely related Bantu language Northern Sotho have shown that fundamental frequency starts rising on the tone-bearing syllable but the f0 peak is only reached later (Zerbian & Barnard Reference Zerbian and Etienne2009). Its exact location varies according to a number of factors: It is reached earlier in syllables containing a voiceless onset than in syllables with a sonorant onset, it occurs earlier in utterance-initial onsetless syllables, and its exact location is speaker-dependent. Frequently, however, the f0 peak is only found between two or three syllables away, counting from the tone-bearing syllable. This behaviour has been described as High Tone Spread in the literature, and occurs when no low tone target follows the high-toned syllable.
Peak spread into the adjacent syllable as in High Tone Spread is not expected to occur in the present data as the second syllable is associated with a lexical high tone and has thus its own tonal target. We thus expect the tonal target to be realized locally.
It remains an open question where to measure the acoustic correlate of the tone of a syllable in such a case. In the following we motivate our choice. Myers (Reference Myers1998, Reference Myers1999) used local f0 maxima in his study on the alignment and scaling of high tones in Chichewa. Zerbian & Barnard (Reference Zerbian and Etienne2009, Reference Ziervogel, Lombard and Mokgokong2010) displayed time-normalized pitch contours across relevant syllables in their study on Northern Sotho and used the average f0 of a vowel for the statistical analysis. For the exposition of our acoustic results, we compared the three measures in (10), based on the respective vowels’ f0 average.
(10)Measures for comparing the tone of the final vowel of the noun (H1) to the initial vowel of the following word (H2)
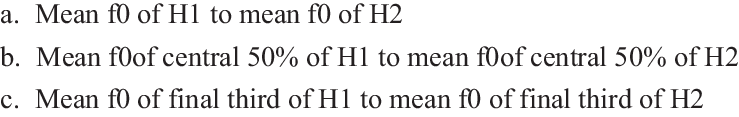
Both the local f0 maximum (Myers Reference Myers1998) and the mean f0 over a vowel (measure (10a), Zerbian & Barnard Reference Zerbian and Etienne2009, Reference Zerbian and Etienne2010) are susceptible to microprosodic disturbances induced by segments and/or tones (Lehiste & Peterson Reference Lehiste and Peterson1961, Hombert, Ohala & Ewan Reference Hombert, Ohala and Ewan1979). While the latter is controlled for in the study and at least kept constant within contexts, the former could not be fully controlled due to restrictions posed by the language itself. For instance, there are few subject concords in Tswana which start with a sonorant. It was therefore unavoidable that we use subject concords starting with a voiced plosive which is known to lower the f0 slightly (Hombert et al. Reference Hombert, Ohala and Ewan1979). Similarly, in the possessive construction some concords start with voiceless plosives which raise the f0 slightly (Lehiste & Peterson Reference Lehiste and Peterson1961).
In measure (10b), the microprosodic influences by preceding and/or following segments and tones are cut off by using the mean f0 of only the central 50% of the vowel. However, it is known since Myers’ (Reference Myers1999) study that the pitch peak of a high-toned syllable in Bantu can be reached late in the syllable or even only in the following syllable. Zerbian & Barnard (Reference Zerbian and Etienne2009) showed that this holds if the syllable carrying the high tone has a sonorant onset. Thus, using only the central 50% for analysis might leave out the actual pitch target from analysis. This would speak in favour of measure (10c), which considers the f0 only in the last third of the vowel, thereby cutting off microprosodic influences of a preceding segment but retaining a possible pitch target towards the end of the syllable. However, the segment boundary and thus duration of the vowels in context B (bÁ-a- …) could not be determined reliably. Additionally, the long vowel was often accompanied with creaky voice (and hence undefined f0 values) halfway through the vowel. These facts would not affect measure (10b), which looks at the mean f0 of the central 50% around the mid of the vowel.
For the quantitative analysis items were excluded which contained hesitations, mispronunciations, or pauses affecting the syllables under consideration (n = 59), and/or a considerable amount of creaky voice (n = 13) which does not allow f0 measures. Hence, the quantitative analysis was based on 517 cases. A comparison of the means and standard deviations of the three measures in (10) shows that the differences between the measures are not substantial (see Table 3).
Table 3 Comparison of three phonetic measures for phonological tone in Hz.

Given that the differences between the measures are not substantial, the mean of the mid-50% of the tone-bearing vowel is used as acoustic reference because it cuts off microprosodic influences. The further analysis will be based on this measure.
As a reviewer suggested, an alternative method of measuring f0 contours is to fit them to polynomial curves based on f0 values at landmarks in the contour, such as onset of rise, peak, plateau, or offset of fall (e.g. Andruski & Castello Reference Andruski and Costello2004). Given that Tswana is a tone language with only two level tones and little tonal density, the mentioned landmarks are not necessarily local or salient. Figures 1 and 3 below illustrate the problem of defining suitable landmarks for tones in the current study. Whereas f0 maximum seems an appropriate landmark of the tonal target for H1 in context A, in context C, the f0 maximum of H1 clearly shows undesirable but unavoidable microprosodic influences of the affricate. We thus decided against such a modelling approach also because the main focus of the current study is the occurrence of phonological downstep, not the detailed phonetic modelling of the contour. Moreover, our acoustic measures are to be seen in conjunction with the auditory transcription reported in the previous section.
The presence or absence of downstep is established through a comparison between the f0 of H1 and H2 (see Snider Reference Snider1998, Reference Snider2007 for downstep in Bimoba and Chumburung, and Dolphyne Reference Dolphyne1994, Genzel & Kügler Reference Genzel and Frank2011 for downstep in Akan). Downstep occurs when H2 is systematically lower than H1.
3.3.2 Inter-speaker variability
In context A, both the tonotactic and the phrasal approach predict downstep between the final high tone of the first word (H1) and the first high tone of the second word (H2). We thus expected to find the comparison between H1 and H2 to be significantly different across all speakers, which means that downstep is realized. Surprisingly, we found considerable inter-speaker variability in this context (only), which we report on in this section. A series of paired samples t-tests were run examining for each speaker whether H1 and H2 were significantly downstepped in context A. Seven out of 12 speakers realized a significantly downstepped H2 (see Table 4). One speaker (speaker 06) very closely approached the significance level of p < .05. The results from auditory impression mirror the statistical results: There is an equal number of perceived downsteps and non-downsteps in context A, furthermore there was a high number of disagreements in this context. For two speakers (speakers 04 and 09) the difference between H1 and H2 in context A is not significant, which we conclude to be an indication that downstep was not realized. This is confirmed by the auditory impression as these speakers realize more contours that were perceived as non-downstepped than as downstepped. Two other speakers (speakers 05 and 07) show a significant effect, though in the other direction (indicated by negative t-values). Again, this result is mirrored in the results from auditory impression because these two speakers are not perceived as realizing downstep at all.
Table 4 Estimation of downstep realization between H1 and H2 for each speaker in context A.

Significance levels: *.05, **.01, ***.001
The speakers who did not produce downstep in context A pattern with the other speakers in contexts B, C, and D though as will be evident later. There is no comparable inter-speaker variation in contexts B, C, and D. This means that the speakers do produce downstep in context B consistently, as well as they did produce no downstep in contexts C and D. The reason for the high inter-speaker variability in context A remains unclear, neither age nor gender seems to be decisive.
3.3.3 Results
This section presents the results of the analysis of the mean f0 in the central 50% of the high-toned vowels H1 and H2. It starts out with representative illustrations, followed by descriptive statistics before it turns to testing the hypotheses inferentially. Figures 1–4 exemplify the realization of each context. In each figure, the oscillogram, the spectrogram, the pitch track, orthographic words and target vowels are shown.

Figure 1 Context A, sentence 2 from speaker 01 (‘The children fear the White people’).

Figure 2 Context B, sentence 2 from speaker 01 (‘The children are calling’).

Figure 3 Context C, sentence 3 from speaker 01 (‘Your dog has eaten my food’).

Figure 4 Context D, sentence 1 from speaker 01 (‘The ears of the cow are large’).
The pitch track in Figure 1 shows that the lexical high tone H1 is realized at a higher pitch (mean of mid-50%: 235 Hz) than the lexical high tone H2 (179 Hz).
The example in Figure 2 represents context B. Similar to Figure 1, the lexical high tone H1 is realized at a higher pitch (mean of mid-50%: 227 Hz) than the lexical high tone H2 (183 Hz), which in turn is realized higher than the following low-toned a.
The example in Figure 3 represents context C. We see in the pitch track that both lexical high tones H1 (mean of mid-50%: 189 Hz) and H2 (194 Hz) are realized at roughly equal pitch heights.
The example in Figure 4 represents context D. Tone H2 (mean of mid-50%: 215 Hz) is clearly realized with a higher pitch than H1 (193 Hz) at a high level.
Turning to descriptive statistics, Figure 5 shows the mean values of H1 and H2 in the mid-50% of the vowels respectively in the four contexts, averaged across all twelve speakers (comprising male and female). The black circles give the average mean f0, the blue lines the 95% confidence interval.

Figure 5 Averaged f0 means measured in the central 50% of the vowels on H1 and H2 across all speakers split by contexts.
Figure 5 shows that, on average, there is a considerable drop in f0 from H1 to H2 in context A and B whereas f0 stays level or rises slightly in context C and D. The exact numerical values for the means together with the standard deviations are given in Table 3 above, rightmost two columns.Footnote 4 Figure 5 suggests that downstep takes place in contexts A and B but not in C and D.
Table 5 Report of the linear mixed-effects model specified in the text with the f0 difference between H1 and H2 in Hz as dependent variable.


Figure 6 Interaction plot of fixed factors phrasing and tones, illustrating the mean f0 difference between H1 and H2 in Hz as an indicator of downstep as dependent variable. The negative amount of downstep in the two-phrases condition illustrates no downstep with a slight increase of f0 between the two high tones.
For the statistical analysis, we fit a multilevel model (Bates et al. Reference Bates, Mächler, Bolker and Walker2015) using crossed random factors speaker and item applying random intercepts and slopes for speaker. phrasing (with two levels ‘one phrase’/‘two phrases’) and tones (with two levels ‘two high tones’/‘three high tones’) were used as fixed factors. The analysis relied on the difference in f0 between H1 and H2 in Hz as a dependent variable. Contrast-coding was applied with level ‘one phrase’ as baseline of the factor phrasing, and level ‘three high tones’ as baseline of the factor tones. Model comparisons for the random effect structure was applied. Backward modelling (Barr et al. Reference Barr, Roger, Christoph and Tily2013) of random slopes for speaker was applied, and likelihood ratio tests were run to evaluate the models. The basis for removing factors was set at a p-value of the likelihood ratio test of p < .05 and lower AIC values. However, the maximal model turned out to be the best fit model. This model assumes that differences exist for each speaker’s individual realization of the items.
As shown in Table 5, we find a significant effect for the factors phrasing and tones as well as a significant interaction. From the interaction plot in Figure 6 it becomes clear that the factor phrasing is significant because both contexts A and B differ from contexts C and D in that they show a difference in f0 between H1 and H2 that amounts to 18 Hz on average indicating that the two high tones are downstepped. The mean f0 difference between H1 and H2 in Hz, i.e. downstep, in context A is smaller than in context B due to two facts: First, the following tone differs, which is H in context A and L in context B. Second, in context A only eight of the twelve speakers realized a difference in f0 between H1 and H2. Four speakers realize no difference of f0 between the two vowels which results in an overall lower mean difference. Contexts C and D show an average f0 difference between H1 and H2 of −1.8 to −3.8 Hz indicating that the two adjacent high tones are not downstepped. The fact that the factor tones becomes significant is presumably due to the large difference between contexts A and B. Relevant for interpretation is the significant interaction (see Figure 6), which clearly shows that downstep is realized in contexts A and B, and not in contexts C and D.
4 Discussion
The study presented is one of the few that addresses OCP violations above the word level, and furthermore to our knowledge the first study to provide acoustic data on downstep in a Bantu language. The acoustic data confirm the results reached at by auditory impression. In addition to the categorical difference, they reveal a systematic difference in the magnitude of downstep depending on tonal context. We interpret downstep thus as a repair strategy to OCP violations above the word level in Tswana, similar to Kishambaa, a Bantu language spoken in Tanzania (Odden Reference Odden1982, Reference Odden1986), and the Zambian Bantu language Namwanga (Bickmore Reference Bickmore2000: 302).
Our qualitative and quantitative analyses thus confirm for a Southern division variety of Tswana what has been claimed for closely related Southern Sotho previously, namely that in the realization of two adjacent high tones across word boundaries the occurrence of downstep depends on the syntactic structure, and in turn on the prosodic structure. More precisely, downstep takes place between adjacent high tones belonging to a subject and a verb, which are mapped into one phonological phrase, but not between high tones belonging to a noun and a following modifier, which are mapped into two distinct phonological phrases. Our data thus provide empirical evidence that from the two competing approaches to downstep in the Sotho-Tswana languages which we presented in Section 2.3 the phrasal approach makes the correct predictions for the variety of Tswana under investigation.
This section first discusses the phrase-based analysis put forward by Khoali (Reference Khoali1991) for downstep in Southern Sotho before it discusses predictions for an additional syntactic context.
4.1 Phrase-based analysis for downstep
The four contexts investigated in the current study differ in their syntactic structure, and hence in the phonological constituency derived from it (Nespor & Vogel Reference Nespor and Irene1986): Following Khoali (Reference Khoali1991), in this language, subject and verb form one phonological phrase whereas head noun and modifier form two separate phonological phrases (for the concrete phrasing algorithm see footnote 2). Downstep can then be reformulated as a phonological rule which takes place if the relevant tonal context is met within a phonological phrase (e.g. between subject and verb) but crucially not across phonological phrase boundaries (e.g. nominal head and modifier).
The phrasing put forward here in which the subject constitutes one phonological phrase with the verb is not the default pattern cross-linguistically and thus needs further motivation. It finds its parallels in other Bantu languages (e.g. Kanerva Reference Kanerva1990 for Chichewa; Jokweni Reference Jokweni1995 for Xhosa; Cheng & Downing Reference Cheng and Downing2007, Reference Cheng, Downing, Geertje and Helen2009 for Zulu; Zerbian Reference Zerbian2007 for Northern Sotho). The phrasing is supported by a tonal rule in Tswana parallel to the one exemplified for Southern Sotho in (7): The last syllable of a phonological phrase is exempt as a target for High Tone Spread in Tswana. The examples in (11) from Tswana show that this is the case in a noun monna ‘man’ followed by a modifier, (11b), but not if this noun is a subject followed by a verb, (11a).
(11)Tswana (Cole & Mokaila Reference Cole and Mokaila1962: 7, 83)

The postulated intervening phrase boundary between a noun and its modifier is also not the most common pattern but also finds parallels in other languages, e.g. in the Bantu language Bàsàá (A43, spoken in Cameroon; Hamlaoui, GjersØe & Makasso Reference Hamlaoui, GjersØe, Makasso, Gussenhoven, Chen and Dediu2014). It is furthermore supported by tonal evidence in Tswana, see (11b).
This generalization concerning the occurrence of downstep in Tswana makes the correct predictions for the phonetic realization of adjacent high tones in verb–object sequences as will be shown in the following section.
4.2 Predictions for other syntactic structures
Verb–object sequences constitute a syntactic configuration in which both constituents are phrased together in a phonological phrase in many Bantu languages (e.g. Kanerva Reference Kanerva1990 for Chichewa, Jokweni Reference Jokweni1995 for Xhosa, Zerbian Reference Zerbian2007 for Northern Sotho). The prediction is that, given two adjacent high tones across word boundaries, downstep will occur on the initial syllable of the object because no phrase boundaries intervene. The example in (12) illustrates this prediction.
(12) Downstep between verb and object in Tswana

Four target sentences with adjacent high tones between verb and object, as in (12), were recorded from the same speakers (again in three repetitions) in order to empirically test the prediction concerning the occurrence of downstep. A representative pitch track is given in Figure 7. The example in Figure 7 clearly shows that H2 (mean of mid-50%: 197 Hz) is downstepped in relation to H1 (228 Hz), as predicted by the phrase-based approach.

Figure 7 Context of a verb–object sequence, sentence 1 from speaker 01 (‘I call the goat in the evening’).
A qualitative analysis of this type of sentences (following the procedure detailed in Section 3.2) revealed the following results: Of the overall 144 recorded sentences (12 speakers × 4 target sentences × 3 repetitions), six had to be excluded due to hesitations. For the remaining 138 sentences, both annotators agreed on the occurrence of downstep in 129 cases. In two cases, both annotators perceived no downstep, and in seven cases there was disagreement in the first round of annotations.
The predictions made by the phrase-based approach concerning the occurrence of downstep in verb–object sequences are thus borne out in the perceptual analysis, and we expect downstep to occur in other syntactic structures too that meet the respective phonological, i.e. tonal and phrasal, requirements.
5 Conclusion
The article started with the discussion of the Obligatory Contour Principle (OCP; Leben Reference Leben1973), a cross-linguistically relevant principle that prohibits adjacent identical elements. For Sotho-Tswana there is consensus among Khoali (Reference Khoali1991) and Mmusi (Reference Mmusi1992) that these languages obey the OCP at the word level. The current study has provided the first instrumental data that show how OCP violations are resolved at the phrase-level: Across words within a phonological phrase, OCP violations are resolved by downstep in the Tswana variety investigated in this study, whereas across words and across phonological phrases, two adjacent high tones are realized without downstep.
Acknowledgements
The study has been presented at various conferences. We thank the audiences for helpful comments. We want to express our thanks to the various (anonymous) reviewers of previous versions of the manuscript who provided helpful comments, as well as Jonathan Barnes, Andrew Simpson and Oliver Niebuhr for very constructive feedback. We are grateful to the late Moruti Mascher, Vryburg, for establishing the contact to the speakers, to all speakers for their participation, to Eric Tabbert, Svenja Schuermann, and Elisabeth Pieplow-Stagg for assistance in data analysis and to Sabrina Gerth for discussing statistical issues. This work was funded by the DFG, grant to the Collaborative Research Centre 632 Information Structure at Potsdam University (projects B9 and D5), and further supported by DFG grants to the first (ZE 940/3-1) and second author (KU 2323/4-1).
Appendix. Overview of target sentences
Context A (see example (8a) in the text)
















 Open access
Open access