



1. Introduction
The examples in (1) illustrate what Huddleston & Pullum (Reference Huddleston and Pullum2002; CGEL) call the English Preposing in PP construction (PiPP):

On the CGEL analysis (in chapter 7, ‘Prepositions and prepositional phrases’, by Geoffrey K. Pullum and Rodney Huddleston), PiPPs are PPs headed by the preposition though or as, and the preposed predicational phrase enters into a long-distance dependency relationship with a gap inside a complement clause. The following is CGEL’s core constituency analysis (p. 633):
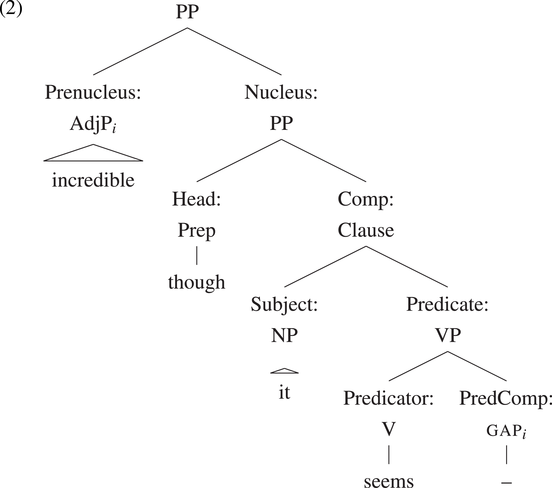
This structure uses the CGEL convention of giving functional labels first, followed by category labels, separated by a colon. The long-distance dependency is indicated by the subscript i on the category labels for the Prenucleus and the PredComp.
The CGEL description of PiPPs focuses on three central characteristics of the construction: (1) it is limited to though and as, with as optionally taking on a concessive sense only in PiPPs; (2) it can target a wide range of phrases; and (3) it is a long-distance dependency construction (Ross Reference Ross1967:§6.1.2.5), as seen in (3).

In my first year in graduate school, Geoff Pullum taught a mathematical linguistics course (Spring 2000 quarter) that drew on his ongoing work with Rodney Huddleston on CGEL. At one of the meetings, Geoff challenged the class to find attested cases of PiPP constructions spanning finite-clause boundaries, and he offered a $1 reward for each example presented to him by the next meeting.
At the time, the best I could muster was (4). These are single-clause PiPPs, but Geoff awarded $0.05 in cash in recognition of my habit of collecting interesting examples.

I kept an eye out for long-distance PiPPs, but this mostly turned up infinitival cases like (5).

It was not until 2002 that I found (6a). My triumphant message to Geoff is given in Appendix A. This was sadly too late to help with CGEL, and Geoff awarded no cash prize. However, I am proud to report that the example is cited in Pullum Reference Pullum, Konopka and und Wöllstein2017. It appears alongside (6b), which was found by Mark Davies in 2009. Mark apparently heard about Geoff’s quixotic PiPP hunt and tracked down at least one case in Corpus of Contemporary American English (CoCA) (Davies Reference Davies2008).Footnote 1 In 2011, Geoff finally found his own case, (6c), which is noteworthy for being from unscripted speech.

I believe Geoff’s motivations for issuing the PiPP challenge were twofold. First, PiPPs embody a central insight: linguistic phenomena can be both incredibly rare and sharply defined. Second, he was hoping we might nonetheless turn up attested examples to inform the characterization of PiPPs that he and Rodney were developing for CGEL. My sense is that, happy though Geoff is to make use of invented examples, he feels that a claim isn’t secure until it is supported by independently attested cases.Footnote 2 This aligns with how he reported (6c) to me: ‘At last, confirmation of the unboundedness from speech!’ (Geoff’s email message is reproduced in full in Appendix B.)
Ever since that turn-of-the-millennium seminar, PiPPs have occupied a special place in my thinking about language and cognition. Because of Geoff’s challenge, PiPPs are, for me, the quintessential example of a linguistic phenomenon that is both incredibly rare and sharply defined. With the present paper, I offer a deep dive on the construction using a mix of linguistic intuitions, large-scale corpus resources, large language models, and model-theoretic syntax. My goal is to more fully understand what PiPPs are like and what they can teach us. My investigation centers around corpus resources that are larger than the largest Web indices were in 1999–2000 (Section 2).Footnote 3 These corpora provide a wealth of informative examples that support and enrich the CGEL description of PiPPs (Section 3). They also allow me to estimate the frequency of PiPPs (Section 4). The overall finding here is that PiPPs are indeed incredibly rare: I estimate that under 0.03% of sentences in literary text contain the construction (and rates are even lower for general Web text). By comparison, about 12% of sentences include a restrictive relative clause. Nonetheless, and reassuringly, this corpus work does turn up naturalistic PiPP examples in which the long-distance dependency crosses a finite-clause boundary; were Geoff’s offer still open, I would stand to earn $58 (see Appendix E).
The vanishingly low frequency of PiPPs raises the question of how people manage to acquire and use the construction so systematically. It’s very hard to imagine that these are skills honed entirely via repeated uses or encounters with the construction itself. In this context, it is common for linguists to posit innate learning mechanisms – this would be the start of what Pullum & Scholz (Reference Pullum and Scholz2002) call a stimulus poverty argument (Chomsky Reference Chomsky1980), based in this case on the notion that the evidence underdetermines the final state in ways that can only be explained by innate mechanisms. Such mechanisms may well be at work here, but we should ask whether this is truly the only viable account.
To probe this question, I explore whether present-day large language models (LLMs) have learned anything about PiPPs. Building on methods developed by Wilcox et al. (Reference Wilcox, Futrell and Levy2023), I present evidence that the fully open-source Pythia series of models (Biderman et al. Reference Biderman, Schoelkopf, Anthony, Bradley, O’Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika and van der Wal2023) have an excellent command of the core properties of PiPPs identified in CGEL and summarized in Section 3. These models are exposed to massive amounts of text as part of training, but they are in essentially the same predicament as humans are when it comes to direct evidence about PiPPs: PiPPs are exceedingly rare in their training data. Importantly, these models employ only very general purpose learning mechanisms, so their success indicates that specialized innate learning mechanisms are not strictly necessary for becoming proficient with PiPPs (for discussion, see Dupoux Reference Dupoux2018, Wilcox et al. Reference Wilcox, Futrell and Levy2023, Warstadt & Bowman Reference Warstadt and Bowman2022, Piantadosi Reference Piantadosi2023, Frank Reference Frank2023a, Reference Frankb).
As an alternative account, I argue that, for LLMs and for humans, PiPPs arise from more basic and robustly supported facts about English. To begin to account for this capacity, I develop a model-theoretic syntax (MTS; Rogers Reference Rogers1997, Reference Rogers1998, Pullum & Scholz Reference Pullum, Scholz, de Groote, Morrill and Retoré2001, Pullum Reference Pullum, Rogers and Kepser2007a, Reference Pullum2020) account, in which PiPPs follow from a mix of mostly general patterns and a few very specific patterns (Section 6). My central claim is that this MTS account is a plausible basis for explaining how PiPPs might arise in a stable way, even though they are so rare.
2. Corpus Resources
The qualitative and quantitative results in this paper are based primarily in examples from two very large corpus resources: BookCorpusOpen and C4.
2.1. BookCorpusOpen
This is a collection of books mostly or entirely by amateur writers. The original BookCorpus was created and released by Zhu et al. (Reference Zhu, Kiros, Zemel, Salakhutdinov, Urtasun, Torralba and Fidler2015), and it formed part of the training data for a number of prominent LLMs, including BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), RoBERTa (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019), and GPT (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018).Footnote 4
Bandy & Vincent (Reference Bandy and Vincent2021) offer a deep investigation of BookCorpus in the form of an extensive datasheet (Gebru et al. Reference Gebru, Morgenstern, Vecchione, Vaughan, Wallach, Daumeé and Crawford2018) with commentary. This provides important insights into the limitations of the resource. For instance, though BookCorpus contains 11,038 book files, Bandy & Vincent find that it contains only 7,185 unique books. In addition, they emphasize that the corpus is heavily skewed toward science fiction and what everyone in this literature refers to euphemistically as ‘Romance’. Zhu et al. (Reference Zhu, Kiros, Zemel, Salakhutdinov, Urtasun, Torralba and Fidler2015) stopped distributing BookCorpus some time in late 2018, but a version of it was created and released by Shawn Presser as BookCorpusOpen.Footnote 5 BookCorpusOpen addresses the issue of repeated books in the original corpus but seems to have a similar distribution across genres. This is the corpus of literary texts that I use in this paper. It consists of 17,688 books. The Natural Language Toolkit (NLTK) TreebankWordTokenizer yields 1,343,965,395 words, and the NLTK Punkt sentence tokenizer (Kiss & Strunk Reference Kiss and Strunk2006) yields 90,739,117 sentences.
2.2. C4
C4 is the Colossal Clean Crawled Corpus developed by Raffel et al. (Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020). Those authors did not release the raw data, but rather scripts that could be used to recreate the resource from a snapshot of the Common Crawl.Footnote 6 Dodge et al. (Reference Dodge, Sap, Marasović, Agnew, Ilharco, Groeneveld and Gardner2021) subsequently created and released a version of the corpus as C4, and explored its contents in detail. Overall, they find that C4 is dominated by mostly recent texts from patent documents, major news sources, government documents, and blogs, along with a very long tail of other sources.
Dodge et al.’s (Reference Dodge, Sap, Marasović, Agnew, Ilharco, Groeneveld and Gardner2021) discussion led me to use the en portion of their C4 release. This is the largest subset focused on English. The steps that were taken to create the en.clean and en.NoBlocklist subsets seemed to me to create a risk of losing relevant examples, whereas my interest is in seeing as much variation as possible. The en subset of C4 contains 365M documents (156B tokens). I tokenized the data into sentences using the NLTK Punkt sentence tokenizer, which yields 7,546,154,665 sentences.
3. English Preposing in PP Constructions
This section reviews the core characterization of PiPPs developed in CGEL (see also Ross Reference Ross1967, Culicover Reference Culicover1980). Examples from C4 are marked C, and those from OpenBooks with B. To find these examples, I relied on ad hoc regular expressions and the annotation work reported in Section 4. At a certain point, I realized I had annotated enough data to train a classifier model. This model is extremely successful (nearly perfect precision and recall on held-out examples) and so it turned out to be a powerful investigative tool. This model is described in Appendix D. I used it in conjunction with regular expressions (regexs) to find specific example types.
3.1. Prepositional-head restrictions
Perhaps the most distinctive feature of PiPPs is that they are limited to the prepositional heads though and as:

As observed in CGEL, even semantically very similar words do not participate in the construction:
Another peculiarity of PiPPs is that as can take on a concessive reading that it otherwise lacks. For example, (9a) invites an additive reading of as that is comparable to (9b).
By contrast, the concessive context of (10) means that, whereas the PiPP is fine, the non-PiPP variant seems pragmatically contradictory because the concessive reading of as is unavailable.
It seems unlikely that we will be able to derive the prepositional-head restrictions from deeper syntactic or semantic properties. First, PiPPs don’t generalize to other semantically similar concessive markers like although and while. Second, the primary distributional difference between though and these other candidate heads is that though has a wider set of parenthetical uses (They said, though/*although, that it was fine). However, the PiPP use is not a parenthetical one. Third, even if invoking the parenthetical uses of though seemed useful somehow, it would likely predict that as does not participate in the construction, since as lacks the relevant parenthetical uses. Fourth, PiPPs license an otherwise unattested concessive reading of as. However, fifth, PiPPs are not invariably concessive, as we see from the additive readings of as-headed cases. These facts seem to indicate that the prepositional-head restrictions are idiomatic and highly construction-specific.
3.2. Gap licensing
While the prepositional-head restrictions in PiPPs are likely construction-specific, many properties of PiPPs do seem to follow from general principles. For example, I would venture that any Predicator that takes a PredComp in the sense of (2) can host the gap in a PiPP. Here is the relevant configuration from (2):

Here are some examples that help to convey the diversity of PiPP Predicators (which are in bold):

Other predicational constructions seem clearly to license PiPPs as well. Some invented examples:
Thus, I venture that any local tree structure with Predicator and PredComp children (as in (11)) is a potential target for a PiPP gap.
PiPP gaps can also be VP positions:

The try as/though X might locution is extremely common by the standards of PiPPs. There are at least 870 of them in BookCorpusOpen, 861 of which are as-headed. Examples like (14c) are less common but still relatively easy to find.
These non-predicational PiPP gaps can be assimilated to the others if we assume that the fronted constituent is abstractly a property-denoting expression and so has the feature PredComp. Constituents with other semantic types are clearly disallowed:

CGEL briefly discusses adverbial and degree modifier PiPP gaps as well (p. 635). Here are two such cases:

These cases seem not to satisfy the generalization that the preposed element is property denoting. It is also hard to determine what is licensing the gaps; (16b) could involve a head–complement relationship between look and hard, but there seems not to be such a relationship for much in (16a).
3.3. A diverse range of preposable predicates
PiPPs also permit a wide range of predicational phrases to occupy the preposed position (the Prenucleus in (2)). Here is a selection of examples:

I would hypothesize that any phrase that can be a predicate is in principle possible as the preposed element in a PiPP. However, there are two important caveats to this, to which I now turn.
3.3.1. Adverbial as modification
CGEL notes that ‘With concessive as some speakers have a preposed predicative adjective modified by the adverb as’ (p. 634). This version of the construction is very common in the datasets I am using:

In addition, the following may be a case in which the as… as version of the construction has an additive rather than a concessive sense:
Here, the author seems to use the PiPP to offer rationale; a concessive reading would arise naturally if the continuation said she was unaware of the gesture.
In these cases, there is a mismatch between the preposed constituent and what could appear in the gap site, since this kind of as modification is not permitted in situ; examples like (20a) and (20b) work only on a reading meaning ‘equally fast’, which is quite distinct from the PiPP (20c).

These PiPP variants superficially resemble equative comparative constructions of the form X is as ADJ as Y, and they are united semantically in being restricted to gradable predicates. However, the meanings of the two seem clearly to be different (CGEL, p. 634). In particular, whereas (20c) seems to assert that they were fast (probably in order to concede this point), examples like Kim is as fast as Sandy is do not entail speediness for Kim or Sandy, but rather only compare two degrees (Kennedy Reference Kennedy2007). Thus, it seems that the as… as form is another construction-specific fact about PiPPs, though the adverbial as seems to have a familiar degree-modifying sense.
3.3.2. Missing determiners
When the preposed predicate is a nominal, it typically has no determiner (CGEL, p. 634):

In all these cases, the non-preposed version requires an indefinite determiner:
Conversely, retaining the determiner in the PiPP seems to be marked. However, Brett Reynolds found the following attested case in CoCA (personal communication, August 24, 2023):
The option to drop the determiner in the preposed phrase seems like another construction-specific aspect of PiPPs.
3.4. Modifier stranding
In PiPPs, the entire complement to the Predicator can generally be preposed. However, it is common for parts of the phrase to be left behind, even when they are complements to the head of the PredComp phrase (CGEL, p. 634):

In these situations, the fronted element must include the head of the predicative phrase; parts of the embedded modifier cannot be the sole target:

The generalization seems to be that the preposed element needs to be a phrasal head of the PredComp. For example, in (27), both the PredComp:AdjP and Head:AdjP nodes are potential targets, but the AdjComp:AdjP is not (nor is the non-phrasal Head:Adj):

On this approach, the ungrammatical cases in (26) are explained: their gap sites do not match (27). Where there is such a match, the examples are actually fine (assuming independent constraints on long-distance dependencies are satisfied). For example, (28) contains four local trees in which a Predicator and PredComp are siblings, and in turn, there are four ways to form the PiPP:Footnote 7

3.5. Long-distance dependencies
It is common for PiPPs to span infinitival clause boundaries, as in (5) and (29).

As discussed in Section 1, the initial impetus for this project was the question of whether we could find naturalistic examples of PiPPs spanning finite-clause boundaries. Intuitively, these examples seem natural, but they are incredibly rare in actual data. However, they can be found. Here are two such cases:

Appendix E contains all of the examples of this form that I have found. All are from written text. Geoff’s example, (6c), is a spoken example.
It is natural to ask whether PiPPs are sensitive to syntactic islands (Ross Reference Ross1967:§6.1.2.5). This immediately raises broader questions of island sensitivity in general (Postal Reference Postal1998, Hofmeister & Sag Reference Hofmeister and Sag2010). I leave detailed analysis of this question for another occasion. Suffice it to say that I would expect PiPPs to be island-sensitive to roughly the same extent as any other long-distance dependency construction.
3.6. Discussion
The following seeks to summarize the characterization of PiPPs that emerges from the above CGEL-based discussion:
-
1. PiPP heads are limited to though and as, and PiPPs are the only environment in which as can take on a concessive reading.
-
2. Any complement X to a Predicator, or one of X’s phrasal heads can, in principle, be a PiPP gap.
-
3. The Preposed element can be any property-denoting expression (and even an adverbial in some cases), and PiPPs show two idiosyncrasies here: gradable preposed elements can be modified by an initial adverbial as, and the expected determiner on preposed nominals is (at least usually) missing.
-
4. PiPPs are long-distance dependency constructions.
What sort of evidence do people (and machines) get about this constellation of properties? The next section seeks to address this question with a frequency analysis of PiPPs.
4. Corpus Analyses
The goal of this section is to estimate the frequency of PiPPs in usage data.
4.1. Materials
I rely on the corpora described in Section 2, which entails a restriction to written language. In addition, while C4 is a very general Web corpus, BookCorpusOpen is a collection of literary works. Intuitively, PiPPs are literary constructions, and so using BookCorpusOpen will likely overstate the rate of PiPPs in general texts, and we can expect that rates of PiPPs are even lower in spoken language. Overall, though, even though I have chosen resources that are biased in favor of PiPPs, the central finding is that they are vanishingly rare even in these datasets.
4.2. Methods
PiPPs are infrequent enough in random texts that even large random samples from corpora often turn up zero cases, and thus using random sampling is noisy and time-consuming. To get around this, I employ the following procedure for each of our two corpora
 $ C $
, both of which are parsed at the sentence level:
$ C $
, both of which are parsed at the sentence level:
-
1. Extract a subset of sentences
 $ M $
from
$ C $
using a very permissive regular expression. We assume that
$ M $
contains every PiPP in all of
$ C $
. The regex I use for this is given in Appendix C.
$ M $
from
$ C $
using a very permissive regular expression. We assume that
$ M $
contains every PiPP in all of
$ C $
. The regex I use for this is given in Appendix C. -
2. Sample a set of
$ S $
sentences from
$ M $
, and annotate them by hand. -
3. To estimate the overall frequency of sentences containing PiPPs and get a 95% confidence interval, use bootstrapped estimates based on
$ S $
:-
(a) Sample 100 examples
$ B $
from
$ S $
with replacement, and use these samples to get a count estimate
$ \tilde{c}=\left(p/100\right)\cdot \mid M\mid $
, where
$ p $
is the number of PiPP-containing cases in B. -
(b) Repeat this experiment 10,000 times, and use the resulting
$ \tilde{c} $
values to calculate a mean
$ \hat{c} $
and 95% confidence interval.
-
-
4. By assumption 1,
$ \hat{c} $
is the same as the estimated number of cases in the entire corpus C. Thus, we can estimate the percentage of sentences containing a PiPP as
$ \hat{c}/\mid C\mid $
.















4.3. Frequency estimates
4.3.1. BookCorpusOpen
For BookCorpusOpen, we begin with 90,739,117 sentences. The regex in Appendix C matches 5,814,960 of these sentences. I annotated 1,000 of these cases, which yielded five annotated examples. This gives us an estimate of
 $ \left(5/\mathrm{1,000}\right)\cdot \mathrm{5,814,960}=\mathrm{29,075} $
examples in all of BookCorpusOpen. The bootstrapping procedure in step 3 above yields an estimated count of
$ \left(5/\mathrm{1,000}\right)\cdot \mathrm{5,814,960}=\mathrm{29,075} $
examples in all of BookCorpusOpen. The bootstrapping procedure in step 3 above yields an estimated count of
 $ \mathrm{29,249}\pm 761 $
, which, in turn, means that roughly 0.0322% of sentences in BookCorpusOpen contain a PiPP.
$ \mathrm{29,249}\pm 761 $
, which, in turn, means that roughly 0.0322% of sentences in BookCorpusOpen contain a PiPP.
4.3.2. C4
For C4, we begin with 7,546,154,665 sentences. The permissive regex matches 540,516,902 of them. I again annotated 1,000 sentences, which identified four positive cases. This gives us an estimate of
 $ \left(4/\mathrm{1,000}\right)\cdot \mathrm{540,516,902}=\mathrm{2,162,068} $
, which is very close to the bootstrapped estimate of
$ \left(4/\mathrm{1,000}\right)\cdot \mathrm{540,516,902}=\mathrm{2,162,068} $
, which is very close to the bootstrapped estimate of
 $ \mathrm{2,108,556}\pm \mathrm{63,370} $
, which says that roughly 0.0279% of sentences in C4 contain a PiPP. This is lower than the BooksCorpusOpen estimate, which is consistent with the intuition that PiPPs are a highly literary construction (C4 consists predominantly of prose from non-literary genres; Section 2.2).
$ \mathrm{2,108,556}\pm \mathrm{63,370} $
, which says that roughly 0.0279% of sentences in C4 contain a PiPP. This is lower than the BooksCorpusOpen estimate, which is consistent with the intuition that PiPPs are a highly literary construction (C4 consists predominantly of prose from non-literary genres; Section 2.2).
4.4. Discussion
The frequency estimates help to confirm that PiPPs are extremely rare constructions, present in only around 0.03% of sentences.
To contextualize this finding, I annotated 100 randomly selected cases from C4 for whether or not they contained restrictive relative clauses. I found that 12/100 cases (12%) contained at least one such relative clause. This leads to an estimate of 905,538,559 C4 sentences containing restrictive relative clauses, compared with 2,215,038 for PiPPs. These are very different situations when it comes to inferring the properties of these constructions.
How do these numbers compare with human experiences? It is difficult to say because estimates concerning the quantity and nature of the words people experience vary greatly. Gilkerson et al. (Reference Gilkerson, Richards, Warren, Montgomery, Greenwood, Oller, John and Paul2017) estimate that children hear roughly 12,300 adult words per day, or roughly 4.5M words per year. Other estimates are higher. Drawing on analyses by Hart & Risley (Reference Hart and Risley1995), Wilcox et al. (Reference Wilcox, Futrell and Levy2023:§6.2) estimate that ‘a typical child in a native English environment’ hears roughly 11M words per year. Frank (Reference Frank2023a) offers a higher upper bound for people who read a lot of books: perhaps as many as 20M words per year.
At the time Geoff issued his PiPP challenge, I was 23 years old, and I was excellent at identifying and using PiPPs, if I do say so myself. The above suggests that I had experienced 100M–460M words by then. Assuming 12 words per sentence on average, and using our rough estimate of 0.03% as the percentage of PiPP-containing sentences, this means that I had heard between 2,500 and 11,500 PiPPs in my lifetime, compared with 1M–4.6M sentences containing restrictive clauses. Is 2.5K–11.5K encounters sufficient for such impressive proficiency? I am not sure, but it seems useful to break this down into a few distinct subquestions.
In Section 3, I reviewed the CGEL account of PiPPs. Some of the properties reviewed there seem highly construction-specific: the prepositional-head restrictions (Section 3.1), the quirky adverbial as appearances (Section 3.3.1), and the missing determiners (Section 3.3.2). For these properties, 2.5K–11.5K may be sufficient for learning. However, it seems conceptually like this holds only if we introduce an inductive bias: the learning agent should infer that the attested cases exhaust the range of possibilities in the relevant dimensions, so that, for example, the absence of although-headed PiPPs in the agent’s experience leads the agent to conclude that such forms are impossible.
We need to be careful in positing this inductive bias, though. Consider the generalization that any predicate is preposable (Section 3.3). This seems intuitively true: I presented attested PiPPs with a wide range of preposed phrases. However, the attested cases cannot possibly cover what is possible; even 11.5K examples is tiny compared to the number of licit two-word adverb–adjective combinations in English, and of course, preposed phrases can be longer than two words. Thus, the learning agent seemingly needs to venture that the set of attested cases is not exhaustive. Here, experience needs to invite a generalization that all property-denoting phrases work.
The same seems true of the long-distance nature of the construction (Section 3.5). Despite working very, very hard to track down such cases, I have found only 58 PiPPs spanning finite-clause boundaries in my corpus resources (Appendix E). This seems insufficient to support the conclusion that PiPPs can span such boundaries. And none of these cases spans three finite-clause boundaries. Yet we all recognize such examples as grammatical.
This seems genuinely puzzling. Language learners have no direct experience indicating that PiPPs can span multiple finite-clause boundaries, and yet they infer that such constructions are grammatical. On the other hand, learners have no direct experience with PiPPs involving although as the prepositional head, and they infer that such constructions are ungrammatical. What accounts for these very different inferences? It is, of course, tempting to invoke very specific inductive biases of human learners, biases that cannot be learned from experience but rather are in some sense innate. This is a reasonable explanation for the above description. Before adopting it, though, we should consider whether agents that demonstrably do not have such inductive biases are able to learn to handle PiPPs. I turn to this question next.
5. Large Language Models
Over the last 5 years, LLMs have become central to nearly all research in AI. This trend began in earnest with the ELMo model (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), which showed how large-scale training on unstructured text could lead to very rich contextualized representations of words and sentences (important precursors to ELMo include Dai & Le Reference Dai, Le, Cortes, Lawrence, Lee, Sugiyama and Garnett2015 and McCann et al. Reference McCann, Bradbury, Xiong, Socher, Guyon, Luxburg, Bengio, Wallach, Fergus, Vishwanathan and Garnett2017). The arrival of the Transformer architecture is the second major milestone (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin, Guyon, Luxburg, Bengio, Wallach, Fergus, Vishwanathan and Garnett2017). The Transformer is the architecture behind the GPT family of models (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018, Reference Radford, Wu, Child, Luan, Amodei and Sutskever2019, Brown et al. Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krüger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020), the BERT model (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), and many others. These models not only reshaped Artificial Intelligence (AI) and Natural Language Processing (NLP) research, but they are also having an enormous impact on society.
The Transformer architecture marks the culmination of a long journey in NLP toward models that are low-bias, in the sense that they presuppose very little about how to process and represent data. In addition, when the Transformer is trained as a pure language model, it is given no supervision beyond raw strings. Rather, the model is self-supervised: it learns to assign a high probability to attested inputs through an iterative process of making predictions at the token level, comparing those predictions to attested inputs, and updating its parameters so that it comes closer to predicting the attested strings. This can be seen as a triumph of the distributional hypotheses of Firth (Reference Firth1935), Harris (Reference Harris1954), and others: LLMs are given only information about cooccurrence, and from these patterns, they are expected to learn substantive things about language.
One of the marvels of modern NLP is how much models can, in fact, learn about language when trained in this mode on massive quantities of text. The best present-day LLMs clearly have substantial competence in highly specific and rare constructions (Socolof et al. Reference Socolof, Cheung, Wagner and O’Donnell2022, Mahowald Reference Mahowald2023, Misra & Mahowald Reference Misra and Mahowald2024), novel word formation (Pinter et al. Reference Pinter, Jacobs and Eisenstein2020, Malkin et al. Reference Malkin, Lanka, Goel, Rao and Jojic2021, Yu et al. Reference Yu, Zang and Wan2020, Li et al. Reference Li, Carlson and Potts2022), morphological agreement (Marvin & Linzen Reference Marvin and Linzen2018), constituency (Futrell et al. Reference Futrell, Wilcox, Morita, Qian, Ballesteros and Levy2019, Prasad et al. Reference Prasad, van Schijndel and Linzen2019, Hu et al. Reference Hu, Gauthier, Qian, Wilcox and Levy2020), long-distance dependencies (Wilcox et al. Reference Wilcox, Levy, Morita and Futrell2018, Reference Wilcox, Futrell and Levy2023), negation (She et al. Reference She, Potts, Bowman and Geiger2023), coreference and anaphora (Marvin & Linzen Reference Marvin and Linzen2018, Li et al. Reference Li, Nye and Andreas2021), and many other phenomena (Warstadt et al. Reference Warstadt, Singh and Bowman2019, Reference Warstadt, Parrish, Liu, Mohananey, Peng, Wang and Bowman2020, Tenney et al. Reference Tenney, Das and Pavlick2019, Rogers et al. Reference Rogers, Kovaleva and Rumshisky2020). The evidence for this is, at this point, absolutely compelling in my view: LLMs induce the causal structure of language from purely distributional training. They do not use language perfectly (no agents do), but they have certainly mastered many aspects of linguistic form.
In the following experiments, I ask what LLMs have learned about PiPPs, focusing on long-distance dependencies (as reviewed in Section 3.5) and prepositional-head restrictions (Section 3.1).
5.1. Experiment 1: Long-distance dependencies
The first question I address for LLMs is whether they process PiPPs as long-distance dependency constructions.
5.1.1. Models
I report on experiments using the Pythia family of models released by Biderman et al. (Reference Biderman, Schoelkopf, Anthony, Bradley, O’Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika and van der Wal2023), which are based in the GPT architecture. The initial set of Pythia models range in size from 70M parameters (very small by current standards) to 12B (quite large, though substantially smaller than OpenAI’s GPT-3 series).Footnote 8 The Pythia models were all trained on The Pile (Gao et al. Reference Gao, Biderman, Black, Golding, Hoppe, Foster, Phang, He, Thite, Nabeshima, Presser and Leahy2020), a dataset containing roughly 211M documents (Biderman et al. Reference Biderman, Bicheno and Gao2022). The results of Section 4 lead me to infer that the rate of PiPPs is around 0.03% of sentences at best in The Pile. At 21 sentences per document (my estimate for C4), this means The Pile contains roughly 4.4B sentences and thus around 1.3M PiPPs – a large absolute number, but tiny relative to other phenomena and infinitesimal alongside the number of possible PiPPs.Footnote 9
Figure 1 is a schematic diagram of the GPT architecture. Inputs are represented as sequences of one-hot vectors used to look up k-dimensional vector representations in a dense embedding space for the vocabulary V.Footnote 10 The resulting sequence of token-level vectors (the labeled gray rectangles) is the input to a series of Transformer layers. These layers are depicted as green boxes. Each green box represents a deep, complex neural network with parameters shared throughout each layer.

Figure 1 Schematic GPT architecture diagram. This toy model has three layers and a vocab size V of 8. Pythia 12B has 36 layers, a vocabulary size of around 50K items, and k (the dimensionality of almost all the model’s representations) is 5,120.
Attention connections are given as gray arrows. These connect the different columns of representations, and they can be seen as sophisticated ways of learning to model the distributional similarities between the different columns. GPT is an autoregressive architecture, meaning that it is trained to predict text left-to-right. Thus, the attention connections go backward but not forward – future tokens have not been generated and so attending to them is impossible. The original Transformer paper (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin, Guyon, Luxburg, Bengio, Wallach, Fergus, Vishwanathan and Garnett2017) is called ‘Attention is all you need’ to convey the hypothesis that these very free-form attention mechanisms suffice to allow the model to learn sophisticated things about sequential data.
In the final layer of the model, the output Transformer representations are combined with the initial embedding layer to create a vector of scores over the entire vocabulary. These scores are usually given as log probabilities. In training, the output scores are compared with the one-hot encodings for the actual sequence of inputs, and the divergence between these two sequences of vectors serves as the learning signal used to update all the model parameters via backpropagation. For our experiments, the output scores are the basis for the surprisal values that serve as our primary tool for probing models for structure. In Figure 1, the model’s highest score corresponds to the actual token everywhere except where the actual token is with, in the final position. Here, the model assigns a low score to with, which would correspond to a high surprisal for this as the actual token. In some sense, with is unexpected for the model at this point (additional training on examples like this might change that).
The Transformer depicted in Figure 1 has three layers. The Pythia model used for the main experiments in this paper (Pythia 12B) has 36 layers. The value of k sets the dimensionality of essentially all of the representations in the Transformer. Pythia 12B has k = 5,120. In my diagram, the size of the vocabulary V is 8 (as seen in the dimensionality of the one-hot and score vectors). The size of the vocabulary for the Pythia models is 50,277 items. This is tiny compared with the actual size of the lexicon of a language like English, because many tokens are subword tokens capturing fragments of words.Footnote 11 The entire model has roughly 12B parameters, most of them inside the Transformer blocks.
The Pythia models are trained with pure self-supervision. In contrast, many present-day models are additionally instruct fine-tuned, meaning that they are trained on human-created input–output pairs designed to imbue the model with specific capabilities (Ouyang et al. Reference Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike and Lowe2022). This process could include direct or indirect supervision about PiPPs. For this reason, I do not use instruct fine-tuned models for the core experiments in this paper.
5.1.2. Methods
To assess whether an LLM has learned to represent PiPPs, I employ the behavioral methods of Wilcox et al. (Reference Wilcox, Futrell and Levy2023): the model is prompted with examples as strings, and we compare its surprisals (i.e., negative log probabilities) at the gap site (see also Wilcox et al. Reference Wilcox, Levy, Morita and Futrell2018, Futrell et al. Reference Futrell, Wilcox, Morita, Qian, Ballesteros and Levy2019, Hu et al. Reference Hu, Gauthier, Qian, Wilcox and Levy2020). To obtain surprisals and other values, I rely on the minicons library (Misra Reference Misra2022).
In a bit more detail: as discussed above, autoregressive LLMs process input sequences token-by-token. At each position, they generate a sequence of scores (log probabilities) over the entire vocabulary. For instance, suppose the model processes the sequence
 $ \left\langle s\right\rangle $
happy though we were with, as in Figure 1. Here,
$ \left\langle s\right\rangle $
happy though we were with, as in Figure 1. Here,
 $ \left\langle s\right\rangle $
is a special start token that has probability 1. The output after processing
$ \left\langle s\right\rangle $
is a special start token that has probability 1. The output after processing
 $ \left\langle s\right\rangle $
will be a distribution over the vocabulary, and we can then look up what probability it assigns to the next token, happy. Similarly, when we get all the way to were, we can see what probability the model assigns to the token with as the next token. The surprisal is the negative of the log of this probability value. Lower surprisal indicates that the token with is more expected by the model. In Figure 1, with has low log probability, that is, high surprisal.
$ \left\langle s\right\rangle $
will be a distribution over the vocabulary, and we can then look up what probability it assigns to the next token, happy. Similarly, when we get all the way to were, we can see what probability the model assigns to the token with as the next token. The surprisal is the negative of the log of this probability value. Lower surprisal indicates that the token with is more expected by the model. In Figure 1, with has low log probability, that is, high surprisal.
Wilcox et al. (Reference Wilcox, Futrell and Levy2023) use surprisals to help determine whether models know about filler–gap dependencies, using sets of items like the following:Footnote 12

The examples in (31) contain gaps. For these, Wilcox et al. (Reference Wilcox, Futrell and Levy2023) define the wh-effect as the difference in surprisal for the post-gap word yesterday between the long-distance dependency case (31a) and the minimal variant without that dependency (31b):
 $$ {\displaystyle \begin{array}{l}-{\log}_2P(\mathtt{yesterday}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \ \mathtt{what}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})-\\ {}\hskip1em -{\log}_2P(\mathtt{yesterday}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \ \mathtt{that}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})\end{array}} $$
$$ {\displaystyle \begin{array}{l}-{\log}_2P(\mathtt{yesterday}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \ \mathtt{what}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})-\\ {}\hskip1em -{\log}_2P(\mathtt{yesterday}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \ \mathtt{that}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})\end{array}} $$
In the context of an autoregressive neural language model, the predicted scores provide these conditional probabilities. We expect these to be large negative values, since the left term will have low surprisal and the right term will be very surprising indeed. Following Wilcox et al. (Reference Wilcox, Futrell and Levy2023), I refer to this as the +gap effect. We can perform a similar comparison between the cases without gaps in (32):
 $$ {\displaystyle \begin{array}{l}-{\log}_2P(\mathtt{the}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \mathtt{what}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})-\\ {}\hskip3em -{\log}_2P(\mathtt{the}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \ \mathtt{that}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})\end{array}} $$
$$ {\displaystyle \begin{array}{l}-{\log}_2P(\mathtt{the}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \mathtt{what}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})-\\ {}\hskip3em -{\log}_2P(\mathtt{the}\hskip0.35em |\hskip0.35em \mathtt{I}\hskip0.24em \mathtt{know}\ \ \mathtt{that}\ \ \mathtt{the}\ \ \mathtt{lion}\ \ \mathtt{devoured})\end{array}} $$
For these comparisons, we expect positive values: the is a high surprisal element in the left-hand context and low surprisal in the right-hand context. This is the –gap effect. An important caveat here is that the gap in the filler–gap dependency could be later in the string (as in I know what the lion devoured the gazelle with), and so the positive values here are expected to be modestly sized.
5.1.3. Materials
Wilcox et al. (Reference Wilcox, Futrell and Levy2023) show that both wh-effects in (33) and (34) are robustly attested for GPT-3 as well as a range of smaller models. Their methodology is easily adapted to other long-distance dependency constructions, and so we can ask whether similar effects are seen for PiPPs. To address this question, I created a dataset of 33 basic examples covering a range of different predicators, preposed phrases, and surrounding syntactic contexts. Each of these sentences can be transformed into four items, reflecting the four conditions we need in order to assess wh-effects. These materials are included in the code repository for this paper.
An example of this paradigm is given in Table 1. Each item can be automatically transformed into ones with different prepositional heads, and we can add embedding layers by inserting strings like they said that directly after the PiPP head preposition. I consider three head-types in this paper: as, though, and as… as. The final variant is not, strictly speaking, a variant in terms of the prepositional head, but it is the most common type in my corpus studies, and so it seems useful to single it out for study rather than collapsing it with the less frequent plain as variants.
Table 1 Sample experimental item. To obtain variants with Preposition as or although, we change though and capitalize as appropriate. To create embedding variants, we insert the fixed string they said that we knew that right after the PiPP prepositional head. The target word is in bold. This is the word whose surprisal we primarily measure.

Before proceeding, I should mention that there are some relevant contrasts between PiPPs and the long-distance dependencies studied by Wilcox et al. (Reference Wilcox, Futrell and Levy2023).Footnote 13 Perhaps the most salient of these concerns the Filler/No Gap condition. For Wilcox et al., these are cases like *I know what the lion devoured the gazelle, whereas the PiPP versions are cases like *Happy though we were happy. First, the PiPP involves repetition of a content word, whereas the embedded wh-construction does not. LLMs may have learned a global dispreference for such repetition, which could artificially increase surprisals and thus overstate the extent of the effect that we can attribute to PiPPs in particular. Second, as noted above, it is easy to ‘save’ the wh-construction (I know what the lion devoured the gazelle with), whereas I believe the PiPP can only be saved with unusual continuations (e.g., the multi-clause Happy though we were happy to say we were).
The above factors could lead us to overstate the –gap effects, since they could inflate surprisals for the Filler/No Gap condition. However, my focus is on +gap comparisons. For these, it is worth noting that No Filler/Gap cases like Though we were with can be continued with him in principle, the group at the time, and many other sequences. This could lower their surprisal and weaken the true +gap effect for PiPPs. Thus, the +gap effects we estimate below may be conservative in nature.
5.1.4. Results
Figure 2 summarizes the results for the Pythia 12B model. Each pair of panels shows a different prepositional head. The single-clause items are on the left and multi-clause items are on the right. The multi-clause variants are created using the fixed string they said that we knew that, which results in PiPPs that span two finite-clause boundaries.
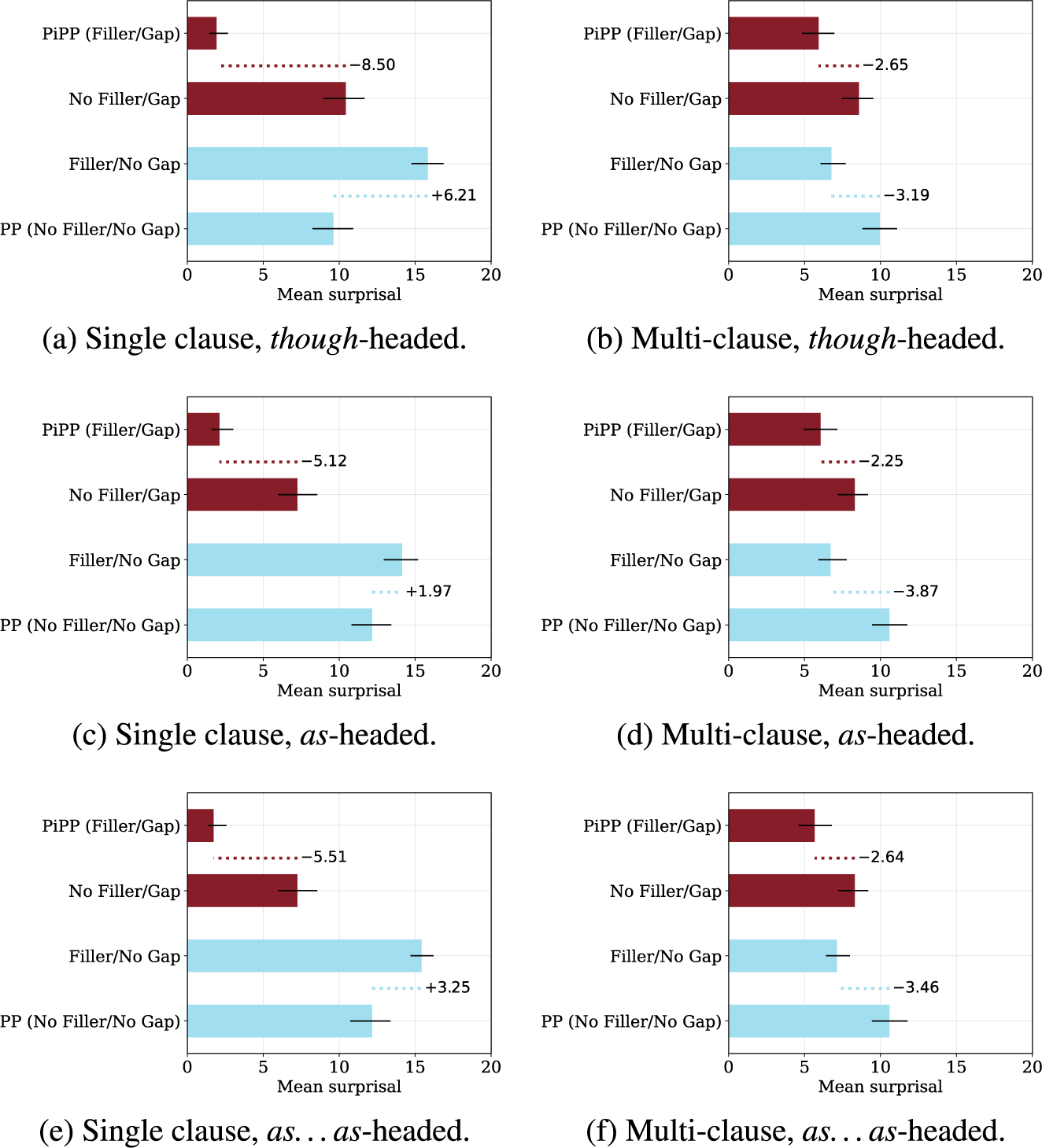
Figure 2 Testing wh-effects for Pythia 12B. The model shows +gap effects in all conditions (red bars). The –gap effects (blue bars) are clear for the single-clause cases, but they are not in the expected direction for the multi-clauses cases.
The dotted lines indicate the two wh-effects. As noted above, we expect the wh-effect for the +gap cases (red bars) to be large and negative, and the wh-effects for the –gap cases (blue bars) to be positive and modest in size.
Across all preposition types and the embedded and unembedded conditions, we see very robust effects for the +gap condition. For the –gap condition, the results also go in the expected direction for the single-clauses cases, but they do not go in the expected direction for the multi-clause ones. It is difficult to isolate exactly why this is. We expected the –gap contrasts to be weaker given the nature of the construction, and this could be exacerbated by left-to-right processing ambiguities that arise in multi-clause contexts. On the other hand, it may also be the case that these models are simply struggling to completely track the long-distance dependency. Importantly, though, the gap in the true PiPP construction (top bars) is very low surprisal across all conditions.
The (presumably ungrammatical) No Filler/Gap cases are consistently lower surprisal than the (grammatical) No Filler/No Gap cases. These two are not compared in the wh-effects methodology, but the difference is still noteworthy. I suspect this traces to the observation, noted in Section 5.1.3 above, that the No Filler/Gap cases are not unambiguously ungrammatical at the point where we take the surprisal measurement.
Appendix F reports results for Pythia models at 70M and 410M. 70M is the smallest Pythia model in the original release; it shows small +gap effects but does not show the expected –gap effects. The 410M model is the smallest one to show the same qualitative pattern as the one in Figure 2. Overall, this pattern grows stronger as model size increases. The full set of results is available in the code repository associated with this paper. I note that each Pythia model is also released with a series of checkpoints from the training process; future work might explore how a model’s capacity to handle PiPPs evolves during training.
5.2. Experiment 2: Prepositional heads
We would also like to probe models for the prepositional-head restrictions discussed in Section 3.1. However, we can’t simply apply the wh-effects methodology to these phenomena, for two reasons.Footnote 14 First, we need to compare different lexical items, whereas the above hypotheses assess the same item conditional on different contexts. Second, the autoregressive nature of the GPT architecture is limiting when it comes to studying aspects of well-formedness that might depend on the surrounding context in both directions. For PiPPs, the prepositional head occurs too early in the construction to ensure that the PiPP parse is even a dominant one for a model (or any agent processing the input in a temporal order). What we would like is to study strings like Happy X we were with the idea, to see what expectations the model has for X. Luckily, masked language models support exactly this kind of investigation.
5.2.1. Model
To investigate prepositional-head effects with masked language models, I use BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). BERT is also based in the Transformer, but it is trained with a masked language modeling objective in which the model learns to fill in missing items based on the surrounding context. The structure of BERT is schematically just like Figure 1, except the attention connections go in both directions. I use the bert-large-cased variant, which has 24 layers, dimensionality k = 1,024, a vocabulary of roughly 30K items, and about 340M parameters in total.
5.2.2. Methods
Because BERT uses bidirectional context, we can ask it for the score of a word that we have masked out in the entire string. Thus, I propose to compare the PiPP construction with its minimal grammatical variant, the regular PP construction, as in the following example:
These pairs of examples have the same lexical content, differing only in word order. At these [MASK] sites, BERT predicts a distribution of scores over the entire vocabulary, just as autoregressive models do. Here, though, the scores are influenced by the entire surrounding context. For a given preposition P, we compare the surprisal for P in the PiPP with the surprisal in the PP.Footnote 15 The difference is the prepositional-head effect for PiPPs.
5.2.3. Materials
The materials for this experiment are the same as those used in Experiment 1 (Section 5.1.3).
5.2.4. Results
Figure 3 summarizes the findings for the prepositional-head effect, for single clause and multi-clauses cases. It seems clear that BERT finds although extremely surprising in PiPPs. Strikingly, on average, although is the lowest surprisal of the prepositions tested in the regular PP cases like (35b). The PiPP context reverses this preference. In contrast, though and as are low surprisal in PiPP contexts as compared to the PP context.
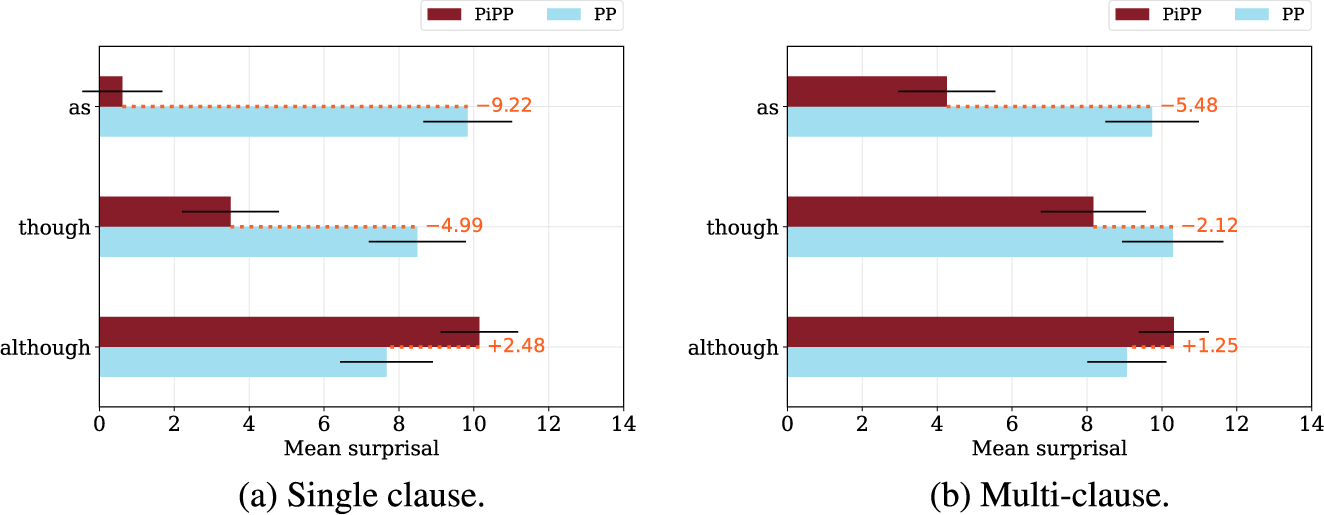
Figure 3 Prepositional-head comparisons using BERT.
We can probe deeper here. The prepositional-head constraints lead us to expect that though and as will be the top-ranked choices for PiPPs. Figure 4 assesses this by keeping track of which words are top-scoring in each of the 33 items, for the [MASK] position corresponding to the prepositional head. For the single-clause cases (Figure 4a), as is the top prediction for 30 of the 33 items, and though is the second-place prediction for 25 of the 33 items. This looks like an almost categorial preference for these items. Interestingly, when we insert a single finite-clause boundary (Figure 4b), these preferences are less clear, though as and though remain dominant. For the double embedding (Figure 4c), the preference for as and though has mostly disappeared. This is interesting when set alongside the clear gap-sensitivity for these multi-clause embeddings in Figure 2 (though those results are for Pythia 12B and these are for BERT, so direct comparisons are speculative).

Figure 4 Ranking of PiPP prepositional heads for BERT, at different levels of embedding.
5.3. Discussion
Pythia 12B seems to have learned to latently represent PiPPs at least insofar as it has an expectation that (1) a PiPP gap will appear only if there is an earlier PiPP filler configuration, and (2) the prepositional head will be as or though. These expectations hold not only in the single-clauses case but also in the sort of multi-clause context that we know to be vanishingly rare, even in massive corpora like those used to train the models (Figure 2).
Where does this capacity to recognize PiPPs come from? In thinking about humans, it was reasonable to imagine that PiPP-specific inductive biases might be at work in allowing the relevant abstract concepts to be learned. For LLMs, this is not an option: the learning mechanisms are very general and completely known to us, and thus any such inductive biases must not be necessary. This does not rule out that the human solution is very different, but it shows that the argument for innate learning mechanisms will need to be made in a different way. There evidently is enough information in the input strings for the learning task at hand.
The above experiments are just the start of what could be done to fully characterize what LLMs have learned about PiPPs. We could also consider probing the internal representations of LLMs to assess whether they are encoding more abstract PiPP features. For example, we might ask whether a preposed phrase followed by a PiPP preposition triggers the model to begin tracking that it is in a long-distance dependency state. Ravfogel et al. (Reference Ravfogel, Prasad, Linzen and Goldberg2021) begin to develop such methods for relative clause structures. More recent intervention-based methods for model explainability seem ideally suited to these tasks (Geiger et al. Reference Geiger, Lu, Icard and Potts2021, Reference Geiger, Wu, Lu, Rozner, Kreiss, Icard, Goodman, Potts, Chaudhuri, Jegelka, Le Song, Niu and Sabato2022, Reference Geiger, Potts and Icard2023a, Reference Geiger, Wu, Potts, Icard and Goodmanb, Wu et al. Reference Wu, Geiger, Icard, Potts, Goodman, Oh, Naumann, Globerson, Saenko, Hardt and Levine2023). We could process minimal pairs like those used in our experiments, swap parts of their internal Transformer representations, and see whether this has a predictable effect on their expectations with regard to gaps. This would allow us to identify where these features are stored in the network. For experiments along these lines for other English constructions, see Arora et al. Reference Arora, Jurafsky and Potts2024.
One final note: one might wonder whether LLMs can perform the intuitive transformation that relates PPs to PiPPs, as in Though we were happy
 $ \Rightarrow $
Happy though we were. I should emphasize that I absolutely do not think this ability is a prerequisite for being proficient with PiPPs. Many regular human users of PiPPs would be unable to perform this transformation in the general case. Still, the question of whether LLMs can do it is irresistible. I take up the question in Appendix H. The quick summary: LLMs are good at this transformation.
$ \Rightarrow $
Happy though we were. I should emphasize that I absolutely do not think this ability is a prerequisite for being proficient with PiPPs. Many regular human users of PiPPs would be unable to perform this transformation in the general case. Still, the question of whether LLMs can do it is irresistible. I take up the question in Appendix H. The quick summary: LLMs are good at this transformation.
6. Model-Theoretic Syntax Characterization of PiPPs
It seems that both people and LLMs are able to become proficient with PiPPs despite very little experience with them. Moreover, this proficiency entails a few different kinds of inference from data: for some properties (prepositional heads, dropping the determiner in preposed nominals), the learner needs to infer that the attested cases exhaust the possibilities. For other properties (which phrases can be preposed, where gaps can occur), the inferences need to generalize beyond what exposure would seem to support. In addition, the LLM evidence suggests that a simple, uniform learning mechanism suffices to achieve this. What sort of theoretical account can serve as a basis for explaining these observations?
In this section, I argue that MTS is an excellent tool for this job. In MTS, grammars take the form of collections of constraints on forms. More precisely, we cast these constraints as necessary (but perhaps not sufficient) conditions for well-formedness by saying that a form is licensed only if it satisfies all the constraints. Rogers (Reference Rogers1997, Reference Rogers1998) showed how to define prominent generative approaches to syntax in MTS terms, and began to identify the consequences of this new perspective. Pullum & Scholz (Reference Pullum, Scholz, de Groote, Morrill and Retoré2001) trace the history of the ideas and offer a visionary statement of how MTS can be used both to offer precise grammatical descriptions and to address some of the foundational challenges facing generative syntactic approaches in general. Pullum (Reference Pullum, Rogers and Kepser2007a, Reference Pullum2020) refines and expands this vision.
In offering an MTS description of PiPPs, I hope to further elucidate the nature of the construction. However, I seek in addition to connect the MTS formalism with the very simple learning mechanisms employed by LLMs. In essence, this reduces to the scores that LLMs assign to the vocabulary at each position. In training, these scores are continually refined to be closer to the vectors for the training sequences. In this way, frequent patterns achieve higher scores, and infrequent patterns get low scores. What counts as a ‘pattern’ in this context? That is a difficult question. We know from the results I summarized at the start of Section 5, and from our lived experiences with the models themselves, that they are able to identify extremely abstract patterns that allow them to recognize novel sequences and produce novel grammatical sequences.
My MTS description will be somewhat informal to avoid notational overload. The constraints themselves all seem to be of a familiar form, and it is hard to imagine a reader coming away from reading Rogers (Reference Rogers1998) or Pullum & Scholz (Reference Pullum, Scholz, de Groote, Morrill and Retoré2001) with concerns that MTS grammars cannot be made formally precise, so I think an informal approach suffices given my current goals.
6.1. Gap licensing
Let’s begin with the most substantive and interesting constraint on PiPPs: the gap licensing environment. The following states the proposed constraint:
Here, XP is a variable over phrasal syntactic categories. The notation /XP i is a slash category feature (Gazdar et al. Reference Gazdar, Klein, Pullum and Sag1985), tracking a long-distance dependency via a series of local dependencies. I assume that the feature PredComp is itself licensed on a node only if that node is the complement of a Predicator node or part of a head path that ends in such a complement node.
Constraint (36) centers on the gap site, enforcing requirements for the surrounding context. The goal is to license gaps in the following sort of configurations:

As I noted briefly in connection with (2), CGEL node labels include functional information (before the colon) and category information (after the colon). On the left, we have the simple case where the relevant PredComp is the direct complement of a Predicator. On the right, we have a head path of two nodes. This opens the door to the sort of modifier stranding we saw in Section 3.4.
The above constraint does not cover PiPPs in which the preposed phrase is an adverbial or degree modifier, as in (16). For (16b), there is a case to be made that the adverb is a complement of the predicate, but this seems less plausible for (16a). I leave these cases as a challenge for future work.
The complex feature XP/XP i begins to track the filler–gap dependency. In (37), I have shown how this would be inherited through the chain of nodes that constitute the head path for the PredComp and up to the Predicate node. The full MTS grammar should include constraints that manage the series of local dependencies that make up these long-distance dependencies constructions. Such an MTS theory is given in full for both GPSG and GB in Rogers Reference Rogers1998.
Arguably the most important feature of constraint (36) is that it does not have any PiPP-specific aspects to it. Any predicational environment of the relevant sort is expected to license gaps in this way, all else being equal. This seems broadly correct, as PiPPs are just one of a number of constructions that seem to involve this same local structure:

If learners are able to infer from examples like these that they contain gaps and those gaps are licensed by predicators – that is, if they infer the latent structure depicted in (37) – then they have learned a substantial amount about PiPPs even if they never encounter an actual PiPP.
6.2. Prenucleus constraints
Constraint (36) licenses a long-distance dependency gap element, and we assume that this dependency is passed up through a series of local feature relationships. The following constraint requires that this dependency be discharged at the top of the PiPP construction:

This describes trees like (40), in which the slash dependency of the right child matches the feature XP i on the left child, leading to a parent node with no slash dependency.

The rule entails that the PiPP long-distance dependency is discharged here.
We could supplement constraint (39) with additional constraints on the Prenucleus phrase, for example, to make determiners optional (Section 3.3.2) and to allow adverbial as (Section 3.3.1).
Importantly, nothing about the above set of constraints requires that the Prenucleus element would be grammatical if placed in the gap site. There is no ‘movement’ in any formal sense. The constraints center around the dependency, which tracks only an index and a syntactic category type. Similar mismatches between filler and gap are discussed by Bresnan (Reference Bresnan2001), Potts (Reference Potts2002), and Arnold & Borsley (Reference Arnold and Borsley2010).
This constraint is very close to being PiPP-specific; the local tree it describes in (40) is certainly indicative of a PiPP. It may be fruitful to generalize it to cover the way slash dependencies are discharged in the constructions represented in (38) and perhaps others.
6.3. Prepositional-head constraints
The final constraint I consider is the prepositional-head constraint. It is highly specific to PiPPs:

For LLMs, this is reflected in the fact that they will assign very low scores to other prepositions in this environment. People may do something similar and intuitively feel that those low scores mean the structures are ungrammatical.
A fuller account would refer to the semantics of the prepositional head, in particular, to specify that if as has a concessive reading, then it is in the above environment.
Why is constraint (41) so much more specific than the others we have given so far? There may not be a deep answer to this question. After all, it is easy to imagine a version of English in which PiPP licensing is broader. On the other hand, many constructions are tightly associated with specific prepositions, so LLMs (and people) may form a statistical expectation that encounters with prepositions should not be generalized to other forms in that class.
6.4. Discussion
I offered three core constraints: one highly PiPP-specific one relating to prepositional heads (41), one that mixes PiPP-specific things with general logic relating to discharging long-distance dependencies (39), and one that is general to gap licensing (36). Taken together, these capture the core syntactic features of PiPPs.
It seems natural to infer from this description that PiPPs are, in some sense, epiphenomenal – the consequence of more basic constraints in the grammar. From this perspective, we might not be able to clearly and confidently say exactly which constructions do or don’t count as PiPPs. For example, the adverbial cases in (16) might be in a gray area in terms of PiPP status. But ‘PiPP’ is a post hoc label without any particular theoretical status, and so lack of clarity about its precise meaning doesn’t mean that the theory is unclear. This seems aligned with the diverse theoretical perspectives of Goldberg (Reference Goldberg1995), Culicover (Reference Culicover1999), Culicover & Jackendoff (Reference Culicover and Jackendoff1999), and Sag et al. (Reference Sag, Chaves, Abeillé, Estigarribia, Flickinger, Kay, Michaelis, Müller, Pullum, van Eynde and Wasow2020), and the core idea is expressed beautifully for long-distance dependencies by Sag (Reference Sag2010:531) :Footnote 16
The filler–gap clauses exhibit both commonalities and idiosyncrasies. The observed commonalities are explained in terms of common supertypes whose instances are subject to high-level constraints, while constructional idiosyncrasy is accommodated via constraints that apply to specific subtypes of these types. A well-formed filler–gap construct must thus satisfy many levels of constraint simultaneously.
I am confident that the constraints I proposed can be learned purely from data by sophisticated LLMs. For the prepositional-head constraint, this seems like a straightforward consequence of LLM scoring. For the other constraints, we need to posit that LLMs induce latent variables for more abstract features relating to syntactic categories, constituents, and slash categories. The precise way this happens remains somewhat mysterious, but I cited extensive experimental evidence that it does arise even in LLMs trained only with self-supervision on unstructured text (Section 5).Footnote 17 The final state that LLMs are in after all this will also not reify PiPPs as a specific construction. Rather, PiPPs will arise when the model’s inputs and internal representations are in a particular kind of state, and this will be reflected in how they score both well-formed PiPPs and ill-formed ones, as we saw in Section 5.
7. Conclusion
The origins of this paper stretch back to a challenge Geoff Pullum issued in the year 2000: find some naturally occurring PiPPs spanning finite-clause boundaries. With the current paper, I feel I have risen to the challenge: conducting numerous highly motivated searches in corpora totaling over 7.6B sentences, I managed to find 58 cases (see Section 3.5 and Appendix E).
This paper was partly an excuse to find and present these examples to Geoff. However, I hope to have accomplished more than that. The massive corpora we have today allowed me to further support the CGEL description of PiPPs, and perhaps modestly refine that description as well (Section 3). We can also begin to quantify the intuition that PiPPs are very rare in usage data. Section 4 estimates that around 0.03% of sentences contain them, compared to 12% for restrictive relative clauses (a common long-distance dependency construction).
The low frequency of PiPPs raises the question of how people become proficient with them. It is tempting to posit innate learning mechanisms that give people a head start. Such mechanisms may be at work, but data sparsity alone will not carry this argument: I showed in Section 5 that present-day LLMs are also excellent PiPP recognizers. Their training data also seem to underdetermine the full nature of PiPPs, and yet LLMs learn them. This suggests an alternative explanation on which very abstract information is shared across different contexts, so that PiPPs emerge from more basic elements rather than being acquired from scratch. I offered an MTS account that I think could serve as a formal basis for such a theory of PiPPs and how they are acquired.
Geoff’s research guided me at every step of this journey: the initial PiPP challenge, the CGEL description, the role of corpus evidence, the nature of stimulus poverty arguments, and the value of MTS as a tool for formal descriptions that can serve a variety of empirical and analytical goals. What is next? Well, Geoff already implicitly issued a follow-up challenge when commenting on Mark Davies’ (6b) :
That is enough to settle my question about whether the construction can have an unbounded dependency, provided we assume – a big but familiar syntactician’s assumption – that if the gap can be embedded in one finite subordinate clause it can be further embedded without limit. (Pullum Reference Pullum, Konopka and und Wöllstein2017:290).
A clear, careful generalization from data, and a clear statement of the risk that the generalization entails. To reduce the risk, we need at least one naturally occurring PiPP case spanning at least two finite-clause boundaries. On the account I developed here, such an example would provide no new information to linguists or to language users, but it still felt important to me to find some. With the help of a powerful NLP model (Appendix D) and some intricate regexs, I searched through the roughly 7.6B sentences in C4 and BookCorpusOpen, and I eventually found three double finite-clause cases:

Acknowledgements
My thanks to the anonymous reviewers for this paper for their extremely valuable ideas and suggestions. Thanks also to Peter Culicover, Richard Futrell, Julie Kallini, Kanishka Misra, Kyle Mahowald, Isabel Papadimitriou, Brett Reynolds, and participants at the tribute event for Geoff Pullum at the University of Edinburgh on August 31, 2023. And a special thanks to Geoff for all his guidance and support over the years. Geoff’s research reflects the best aspects of linguistics, and of scientific inquiry in general: it is open-minded, rigorous, empirically rich, methodologically diverse, and carefully and elegantly reported. In all my research and writing, Geoff is an imagined audience for me, and this has helped push me (and, indirectly, my own students) to try to live up to the incredibly high standard he has set. The code and data for this paper are available at https://github.com/cgpotts/pipps.
Supplementary Materials
To view supplementary material for this article, please visit http://doi.org/10.1017/S0022226724000227.








 Open access
Open access