


1. Introduction
One of the contributing factors to the emergence of linguistic geography was the interest in finding connections between the spatial distribution of linguistic characteristics and other external facts of a geographic nature that could contribute to explaining language history and development. For many decades, linguists and researchers from other disciplines involved in these studies have been looking for similarities and links between the spatial variation shown by linguistic varieties and elements of a geographic, social, ethnic, cultural, and biological nature. Initial geolinguistic research focused on discovering the correlations between the spatial distribution of linguistic traits and the historical frontiers of communities, since it was assumed that the linguistic boundaries established by isogloss tracing were the consequence of old barriers between religious or tribal demarcations (Schrambke, Reference Schrambke, Auer and Schmidt2010). Later, interest was concentrated in finding connections between geolinguistic variation and geographic, ethnic, anthropological, and archaeological events that were also traceable in space and history. Both in the earlier research, and in the later research carried out in the last century, geolinguistic information was compared with historical data collected basically from textual documentation and different types of field surveys. The advances in genetic sciences that have taken place since the middle of the last century have led to the studies of population genetics starting to be used to explore the relationships between linguistic diversity and genetic diversity. As Dediu (Reference Dediu, Enfield, Kockelman and Sidnell2014) comments, the relationship between human and linguistic biology, already pointed out by Charles Darwin, is evident when we bear in mind the simple fact that different human groups speak different linguistic varieties.
Although modern humans are, genetically, a very homogeneous species, there are differences that allow for an identification of population genetic structure and, as a result, research the parallels between the diversification of genes and linguistic varieties. Cavalli-Sforza and colleagues started from the study of these differences to propose that the relationships between linguistic and genetic diversity are a reflection of a demographic process that affects the two elements in the same sense. This process can be verified in the comparison between genes geography and the geography of the great linguistic families (Sokal, Reference Sokal1988; Cavalli-Sforza, Menozzi & Piazza, Reference Cavalli-Sforza, Menozzi and Piazza1994; Cavalli-Sforza, Reference Cavalli-Sforza1996). The parallelism between genetics and linguistics has been used, for example, to explain the origins and dissemination of the linguistic Indo-European and Austronesian families, even from opposite explanatory proposals (Dediu, Reference Dediu, Enfield, Kockelman and Sidnell2014:691-692), and also to the correlation between areas of genetic changes and linguistic boundaries in Europe (Barbujani & Sokal, Reference Barbujani and Sokal1990).
In the last two decades, there have been several studies that have confronted the results of the analysis of geolinguistic diversity and the genetic structuring of populations in linguistic domains and smaller territorial spaces than those discussed in the pioneering works of Cavalli-Sforza, Sokal and followers. The conclusions reached by these studies, especially those carried out as regards European territories, are contributing to the development of a more complete and based image of the structuring and evolution of linguistic diversity and the relationships between space and human population (Goebl, Reference Goebl1996; Rodríguez-Díaz, Blanco-Villegas & Manni, Reference Rodríguez-Díaz, Blanco Villegas and Manni2017; Bycroft et al., Reference Bycroft, Fernández-Rozadilla, Ruiz-Ponte, Quintela-García, Carracedo, Donnelly and Myers2019).Footnote 1
Most of these investigations are interdisciplinary and combine the analysis of genetic information with linguistic and historical data. Linguistic information is mainly based on linguistic typology research and linguistic geography projects. In turn, the structure of the populations is identified by the study of the genetic distance between human groups that occupy a specific space. The most reliable and direct way of knowing the genetic distance between populations is the genes analysis, although this method has so far been very expensive and has only offered a partial image of the population as a whole, given that the unrepresentative number of samples. For decades now, telephone directories, electoral censuses, population censuses and other onomastic lists of the populations under study have been used as a less reliable but more widespread source of genetic analysis complementary data. This second kind of data has been used by researchers since the end of the 19th century and allows a reliable establishment of the population isonymy structure, especially in societies with hereditary personal nomination systems and few variations in the demographic composition in the past, as is the case of the majority of the populations of Europe (Viereck, Reference Viereck2009; Kennett, Reference Kennett2012; Cheshire, Reference Cheshire2014; Sousa, Reference Sousa2017). The first studies on the regional distribution of surnames carried out in the 19th century had already realized that many surnames, especially the least commonplace, have regional distribution patterns (Guppy, Reference Guppy1890).
The aim of the present study is to examine linguistic and onomastic information of Asturias, a small size community in north-west Spain, to probe the existence of correlations in the spatial distribution of these two types of data. This paper is organized as follows. Firstly, the characteristics of the geolinguistic and onomastic data analyzed and the method used to identify the surnames regions are presented. The method used in this work follows preceding models in order to select a significant set of surnames, from the historical and demographic point of view. Secondly, the results obtained in the comparative analysis of the information are discussed and the correlations detected from cartographic displays are highlighted. Finally, it concludes with the overall findings of the study and situates these findings in relation with previous studies on the origins of geolinguistic diversity in the Asturian territory.
2. Data and method
The data analyzed in this study correlates to the onomastic and linguistic information of Asturias (officially Principado de Asturias), autonomous community of Spain located in the northwest of the Iberian Peninsula (Map 1). This administrative territory is the product of the provincial distribution of Spain held in 1833 (Burgueño, Reference Burgueño1996), and since then it has not undergone many modifications in its limits or its internal administrative organization. Asturias is bordered on the west by Galicia, on the east by Cantabria, on the north by the Cantabrian Sea and on the south by the province of León (Community of Castilla y León). The community has an extension of 10,604 km2 and a population of 1,034,960 people (INE, 2017), concentrated mainly in the cities of Gijón and Oviedo. The region has a hilly and mountainous inland with a scattered population since ancient times. This region was one of the last areas of the peninsula to be Romanized and, like the rest of the northern end of the peninsula, was not conquered permanently during the Umayyad conquest of Hispania (Collins, Reference Collins1989). In the 8th century the territory gave rise to the first Christian kingdom of the Iberian Peninsula, the birthplace of the Reconquista ‘Reconquest’, a name traditionally applied to the military campaigns chiefly conducted between the 11th and 13th century to liberate Iberian territories from Muslim Moors.
Map 1. Asturias in Spain.
At present Asturias is an autonomous community divided administratively in 78 municipalities. The languages used by the population are Asturian, Galician-Asturian, and Spanish, the official language. Asturian is the native language of a significant part of the population; it has been protected by law since 1998 and promoted by the autonomous government in the educational, cultural, and administrative fields. According to 2017 data, 90% of Asturias’s inhabitants are considered potential speakers of Asturian and 40% show their agreement to claim the total official status of this language (Llera, Reference Llera Ramo2017).
The data on the linguistic variation of Asturian and on the divisions of the territory in dialectal areas are extracted from works of linguistic and geolinguistic variation of Asturian and Leonese. The onomastic information analyzed is taken from the official population register of 2012. Using these data, the map of regions of surnames was created following a method used in prior studies.
2.1. Linguistic data: isoglosses and Asturian varieties
The territory included in the community of Asturias is part of the northern Iberian Peninsula occupied by the constituent Romance varieties, that is, historical Latin dialects that originate in this area and which, as a result of the Christian repopulations linked to the Reconquista, spread southward giving rise to consecutive dialects (Gimeno-Menéndez, Reference Gimeno-Menéndez1990; Penny, Reference Penny1991; Gargallo, Reference Gargallo1995, Reference Gargallo, Sousa, Romero and Álvarez2014). When analyzed from an integrative perspective, these northern varieties constitute a dialectal continuum with internal differences, but without abrupt and well-defined dialectal borders (Penny, Reference Penny and Fernández Catón2004). The differences that occur between the Romance varieties spoken from the Atlantic coast of Galicia to the Mediterranean coast of Catalonia are gradual, smooth, and marked by independent isoglosses that predominantly have a north to south orientation.Footnote 2 Asturias is in an area where these isoglosses, essentially those corresponding to phonetic variables, are concentrated without overlapping.
The historical varieties spoken in the northern area between the Galician and Portuguese domains, and Spanish are traditionally identified with the cover labels of Leonese and Astur-Leonese (Andreose & Renzi, Reference Andreose, Renzi, Maiden, Smith and Ledgeway2013). The Spanish philologist, Ramón Menéndez Pidal, was the one to discover, for Romance linguistics, the singularity of this peninsular variety spoken in the territory occupied by the former Leonese kingdom (Andrés, Reference Andrés and Rodríguez2007). In his 1906 work, El dialecto leonés, he analyses a series of linguistic features that serve to characterize and identify a Romance variety used in areas of the provinces of Asturias, León, Zamora, Salamanca, in adjacent areas of Cantabria and Extemadura, and in the Portuguese municipality of Miranda do Douro (Menéndez Pidal, Reference Menéndez Pidal1906). The study is part of the observation of the rural varieties spoken in this area in his time—beginning of the 20th century—of the research into previous medieval texts and of the consideration of the historical limits of the ancient kingdom of León. Although some authors of the 19th century had already drawn attention to the similarities between Asturian and the languages used in different areas of the kingdom of León, it was Menéndez Pidal who established the leonés label to identify this Romance linguistic variety (Gómez, Reference Gómez Turiel2012). It is possible that, for the author, the denomination was basically justified for historical reasons, since the popular names for the varieties spoken in this area were very diverse and were determined by the local or regional nature of the language (Morala, Reference Morala Rodríguez and Rodríguez2007; Fernández-Ordóñez, Reference Fernández-Ordóñez and Juan Carlos2010).
The work of Menéndez Pidal on Leonese served as a stimulus for subsequent research that allowed us to know the linguistic characteristics of the domain in greater depth, to specify the choice of a less limited name (Astur-Leonese) and distinguish between Asturian, Leonese, and Mirandese (Cano, Reference Cano González, Holtus, Metzeltin and Schmitt1992; Ferreira, Reference Ferreira1995; Borrego, Reference Borrego Nieto and Alvar1996; Martínez, Reference Martínez Álvarez and Alvar1996; García Arias, Reference García Arias1997; Andrés, Reference Andrés and Rodríguez2007). The Asturian varieties—collectively known as Bable, Asturian or Asturian language—stand out in the Leonese domain because of their greater vitality and because they are popularly identified and denominated in a unitary way (Morala, Reference Morala Rodríguez and Rodríguez2007:99; see also Navarro, Reference Navarro Tomás1962, map 4 for the popular denominations of these varieties). Despite linguistically belonging to the Astur-Leonese domain, Asturian is distinguished from Leonese and Mirandese by “peculiar sociolinguistic attributes: great volume of speakers, high linguistic preservation, intense literary activity, urban presence” (Andrés, Reference Andrés and Rodríguez2007:245).Footnote 3 In addition, it is necessary to indicate that since 1981 there is a standard model for the Asturian written language used in education and written publications.
Although an Asturian linguistic atlas is not, as yet, available, there is a massive set of publications that allow us to know the dialectal variation of the Asturian rural languages in detail. Since the pioneering studies of Menéndez Pidal, four linguistic areas, one belonging to the Galician linguistic domain and three other properly Asturian ones, and therefore of the Astur-Leonese domain, have been distinguished within the administrative territory of Asturias. Studies carried out after Menéndez Pidal’s publications which use traditional dialectology methods confirm this division, especially in the most conservative rural language. Following the proposals of Cano (Reference Cano González, Holtus, Metzeltin and Schmitt1992) and García Arias (Reference García-Arias2003), the four identifiable linguistic areas within the territory of Asturias are: Galician-Asturian area; western Asturian area; central Asturian area; and eastern Asturian area (Map 2).
Map 2. Dialectal areas in Asturias.
The boundaries between these varieties are established based on the layout of three isoglosses that run from north to south and that correspond to phonetic variables related to modern results of vowel and consonantal units of vulgar Latin: vocalic diphthongization (terra ‘soil’, porta ‘door’ vs. tierra, puerta); decreasing diphthongs (queisu ‘cheese’, cousa ‘thing’ vs. quesu, cosa); aspiration of f-, [f]echa ‘date’ vs. [h]echa (Map 2). Starting from these phonetic features, and following the model proposed by García Arias (Reference García-Arias2003: 43), it is possible to suggest a dialectal classification of Asturias in four areas (Table 1).Footnote 4
Table 1. Classification of language varieties in Asturias

In previous studies similar in objectives and methods to ours, the dialectal data used to establish correlations with the geographical distribution of surnames are taken from linguistic atlas and are analyzed by quantitative methods (Goebl, Reference Goebl1996; Manni, Heeringa & Nerbonne, Reference Manni, Heeringa and Nerbonne2006; Rodríguez-Díaz, Manni & Blanco-Villegas, Reference Rodríguez-Díaz, Manni and Blanco-Villegas2015). The linguistic information used in these analyses enables more refined and solid comparisons. As for the linguistic domain analyzed in this work, up to now there is no available geolinguistic data source that allows such detailed analyses, as discussed above. However, we consider that the classification of the varieties spoken in Asturias, based on the analysis of the most conservative rural varieties and established from phonetic features, which we take as reference, is endorsed by the Romance tradition of dialectal studies.Footnote 5
2.2. Surname data
The basic origin of Asturian surnames, like the rest of the names of Spain and Portugal, is the naming system that became widespread in Europe from the 13th century onwards. The Spanish Civil Code of 1870 made it official for citizens to maintain a uniform surname. Thus, the custom of transmission of surnames was formalized, a custom which, with few variations, traditionally had been used since medieval times (Kremer, Reference Kremer2004). Official surnames in Spain consist of two parts: the father’s family name and the mother’s family name, in this order.
Basic etymological categories of surnames of the Iberian Peninsula are patronymics, habitational names, and lexically derived names (Kremer, Reference Kremer and Hanks2003). The Asturian territory is part of the north of the peninsula, an area that some students point out as the birthplace of most of the surnames extended in Spain during and after the Reconquista (Mir, Reference Mir de la Cruz1981). Proof of this statement is the fact that the most common surnames in all of Spain are also those that show the highest frequencies in the northern regions (García, Fernández, González, Rodríguez, López, etc.). As northern Atlantic Spain, the Asturian population is also characteristic in the abundance of surnames that originate in place names (Faure, Ribes & García, Reference Faure, Ribes and García2001) and in a high frequency of isonymy, a measure of surname similarity inside a group (Rodríguez-Larralde et al., Reference Rodríguez-Larralde, Martin, Scapoli and Barrai2003; Scapoli et al., Reference Scapoli, Mamolini, Carrieri, Rodriguez-Larralde and Barrai2006).
The list of Asturian surnames was formed mainly in the middle ages and the comparative studies with the current surname corpus show that, essentially, the repertoire of more common forms has hardly changed (Viejo, Reference Viejo Fernández1997). The surnames of patronymic origin (the greater part ending in -ez) still are the most frequent ones in the population. Furthermore, they are the same, with little variation, as those that are found in the 15th century, at the end of the 19th (Viejo, Reference Viejo Fernández1997), and in the first decades of the 21st century. Table 2 shows the 50 most common surnames in the population analyzed and the number of councils in which each one was registered, the percentage of occurrences and the percentage of municipalities in which it appears. It may be verified that most of these surnames belong to the class of patronymics and that are common in all or in most of the Asturian councils. Maps 3 and 4 show the onomastic diversity of the Asturian councils on maps. Map 3 presents the distribution of onomastic diversity based on the total data; in Map 4 the data for each municipality has been weighted based on the number of inhabitants of the municipality, which corrects the effect produced by the most populated municipalities. In both maps, the counties with darker colors are those with a greater number of different surnames. The map on the left allows you to appreciate the greater onomastic diversity of the eastern and western extremes of the territory.
Table 2. The 50 most frequent names in Asturias (INE, 2012)
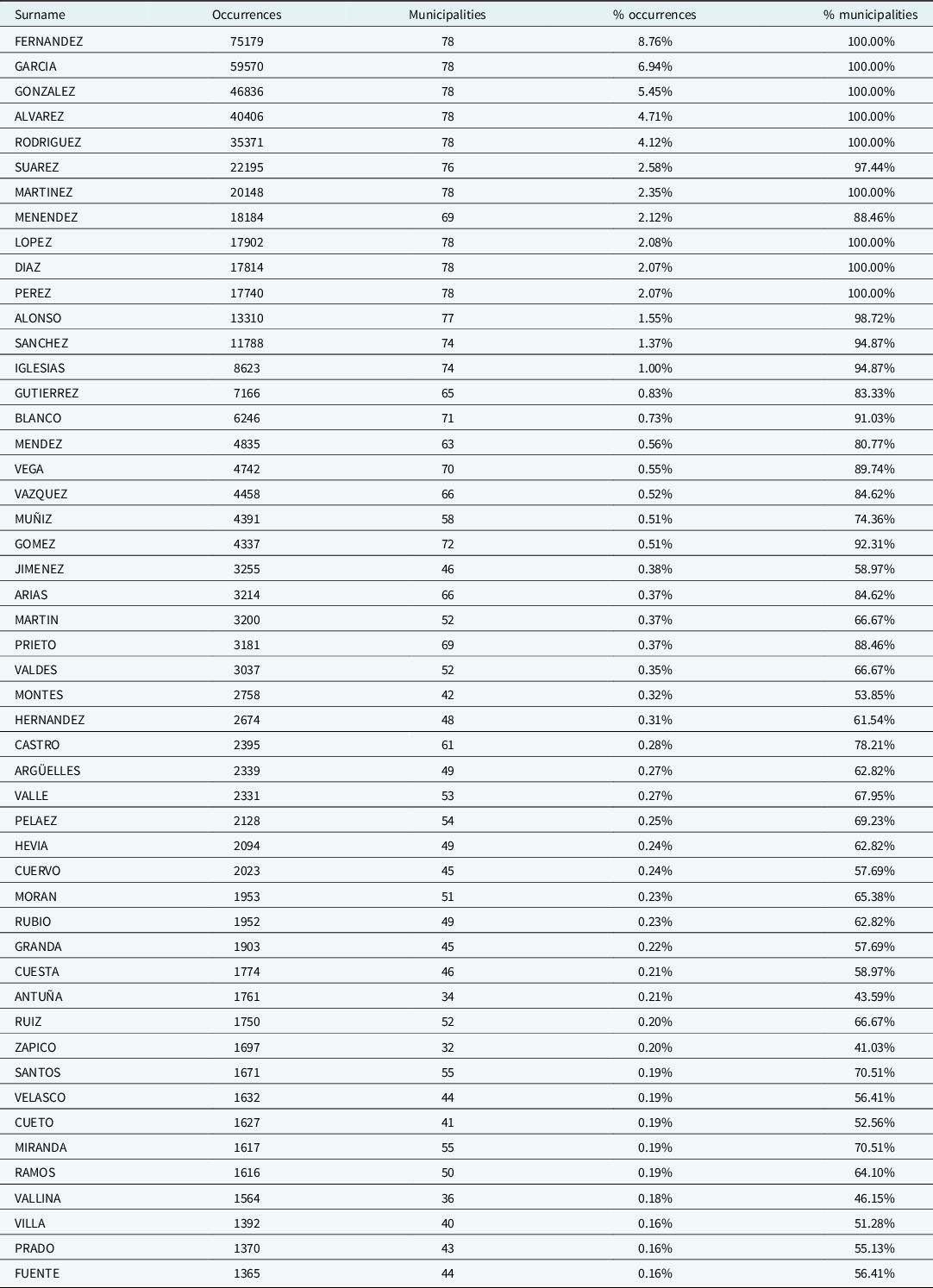
Map 3. Surname diversity in Asturias (total data).
Map 4. Surname diversity in Asturias (weighted data).
The onomastic information used in our research is more complete and detailed than most of the research of the same type carried out on the whole or specific areas of the Iberian Peninsula (Scapoli et al., Reference Scapoli, Mamolini, Carrieri, Rodriguez-Larralde and Barrai2006; Rodríguez Díaz & Blanco Villegas, Reference Rodríguez-Díaz and Blanco Villegas2010; Rodríguez-Díaz, Blanco-Villegas & Manni Reference Rodríguez-Díaz, Blanco Villegas and Manni2017).Footnote 6 Onomastic data were taken from the 2012 registry of inhabitants of Asturias, provided by the Sociedad Asturiana de Estudios Económicos e Industriales (SADEI). This database contains onomastic information of 1,077,360 people with reference to each of the 78 municipalities of Asturias. The total number of different surnames contained in the database is 18,418.Footnote 7 As a geographical area of reference, most of the studies on surname distribution carried out on Spain or on Spanish communities use the province, an administrative entity that is much larger than the municipality.Footnote 8 The use of the municipalities,Footnote 9 the fine scale and discrete unit, allows us to have more in-depth knowledge of the geographical distribution of surnames, especially when dealing with geographical areas of reduced extension, such as Asturias.
2.3. Method
The basic procedure to identify the onomastic structure of a population and to discover the regions of surnames is the use of isonymy measures. Surnames, as a cultural element, are transmitted from generation to generation according to precise rules similar to those governing the transmission of Y chromosomes, especially in those cultures in which surnames pass from parents to children. In general, the identity of surnames involves the existence of family ties; as a consequence, the measures of isonymy serve to account for the inbreeding levels of a population. In 1875, George H. Darwin (Reference Darwin1875) proposed using surnames to determine the proportion of marriages between cousins; in the early 20th century, surnames were also used to analyze consanguinity in marriages in the United States (Arner, Reference Arner1908). From the 1960s onwards, the analysis of isonymy was extended as a procedure for the study of population structure (Shaw, Reference Shaw1960). In recent years, the filtering methods of the data analyzed have been refined (Cheshire, Reference Cheshire2014), although the most commonly used procedures are essentially the same (Lasker, Nei, isonymy between groups, etc.).
In the last decade, there have been many published studies that combine the methods of isonymy determination and cartographic results visualization in order to offer detailed analysis of the spatial distribution of surnames. Cheshire, Longley & Singleton (Reference Cheshire, Longley and Singleton2010) show a strong relationship between district surname and geographic locations in Great Britain, constructing clusters from surrounding districts based on Lasker distances. In Italy, some scholars (Boattini et al. 2010; Reference Boattini, Lisa, Fiorani, Zei, Pettener and Manni2012) analyzed the geographic location of different Italian surnames using neural networks, which allow for distinguishing monophyletic and polyphyletic surnames. Novotný & Cheshire (Reference Novotný and Cheshire2012) have studied the surname space of the Czech Republic, finding clear parallelism between their network representation and ethno-cultural boundaries in the country. Recently, Mikerezi et al. (Reference Mikerezi, Xhina, Scapoli, Barbujani, Mamolini, Sandri, Carrieri, Rodriguez-Larralde and Barrai2013) describe the isonymic structure of Albania. Using a different perspective, Cheshire & Longley (Reference Cheshire and Longley2012) turn to kernel density estimation in order to produce heat maps that detect those areas in Great Britain in which certain surnames are more concentrated.
In order to obtain the regions of the surnames of the Asturian population, we analyzed surnames from the 2012 census across the 78 councils. For the result to provide a better account of population structure, the number of surnames analyzed has been shortened, following procedures used in other works (Cheshire, Reference Cheshire2014, for instances). As in previous studies, only the data referring to the first surname of each person were considered. In the first place, those names that appear in one municipality and those that are below the 5% quartile, that is to say, names that because of their low diffusion do not show an interesting spatial distribution, have been eliminated from the base; some examples are Abellas, Lemiña, Terroba, and a large number of surnames of foreign origin (Abbassi, Chapman, Kadlec, Mailhe, Saffar, Woodrow, Zielinski, etc.). In addition, also removed from the base were surnames above the 95% quartile, which are the most repeated surnames in the population, present in most Asturian councils and most of them of a polyphyletic origin. Exclusion of polyphyletic surnames is quite common in the studies of surname regionalization as they are so widespread. Moreover, due to their diffuse origin, they make it difficult to identify the patterns of regional organization of local surnames. Among the removed surnames are those with at least one representative in each council (Álvarez, Díaz, Fernández, García, González, López, Martínez, Pérez, and Rodríguez). Once these reductions have been made, the final number of different surnames analyzed is 6,502.
2.4. Isonymy measures
Surname (dis)similarity among regions can be quantified by different measures. Consider index
 $i=1\comma \ldots \comma n$
for denoting a certain geographical region (for two regions,
$i=1\comma \ldots \comma n$
for denoting a certain geographical region (for two regions,
 $\left( {i\comma j} \right)$
). Each region has an associated collection
$\left( {i\comma j} \right)$
). Each region has an associated collection
 ${S_i}$
of surnames, and for a pair of regions, the collection of all the surnames in them is denoted by
${S_i}$
of surnames, and for a pair of regions, the collection of all the surnames in them is denoted by
 ${S_{ij}}$
(
${S_{ij}}$
(
 ${S_{ij}} = {S_i} \cup {S_j}$
). The total number of surnames in a certain region is denoted by
${S_{ij}} = {S_i} \cup {S_j}$
). The total number of surnames in a certain region is denoted by
 ${n_i}$
.
${n_i}$
.
Isonymy refers to the possession of the same surname, a premise in genetics being that individuals with the same surname are more likely to share the same family lineage, so isonymy indicates biological relation. With the notation introduced above, isonymy (as an internal measure, within a region
 $i$
) is defined as
$i$
) is defined as
 ${I_i} = \mathop \sum \nolimits_{k \in {S_i}} p_{ki}^2$
where
${I_i} = \mathop \sum \nolimits_{k \in {S_i}} p_{ki}^2$
where
 ${p_{ki}}$
denotes the relative frequency of surname
${p_{ki}}$
denotes the relative frequency of surname
 $k$
in region
$k$
in region
 $i$
. High values of isonymy are possible in a population where there are few surnames, and low values of isonymy are obtained when the number of surnames is large. Using an analogy with genetics, as with alleles, surname drift is proportional to time, therefore, small isonymy values suggest recent immigration or settlement.
$i$
. High values of isonymy are possible in a population where there are few surnames, and low values of isonymy are obtained when the number of surnames is large. Using an analogy with genetics, as with alleles, surname drift is proportional to time, therefore, small isonymy values suggest recent immigration or settlement.
Isonymy can be extended as a measure of population similarities between groups. Under the assumption of a common origin, isonymy between two regions
 $i$
and
$i$
and
 $j$
is defined as
$j$
is defined as
 ${I_{ij}} = \mathop \sum \nolimits_{k \in {S_{ij}}} {p_{{k_i}}}{p_{{k_j}}}$
(1). Other different measures of the isonymic distance between a pair of locations can be derived from (1). For instance, the Lasker distance is given by
${I_{ij}} = \mathop \sum \nolimits_{k \in {S_{ij}}} {p_{{k_i}}}{p_{{k_j}}}$
(1). Other different measures of the isonymic distance between a pair of locations can be derived from (1). For instance, the Lasker distance is given by
 $L = - \log ({I_{ij}})$
.
$L = - \log ({I_{ij}})$
.
Lasker distances can be interpreted as a measure of similarity or difference between two areas, where large distances show less similarity in surname composition. Nevertheless, Lasker distance is not the only choice to quantify surname similarity. Other common coefficients are the Euclidean distance, introduced by Cavalli-Sforza & Edwards (Reference Cavalli-Sforza and Edwards1967) and Nei’s distance (Nei, Reference Nei1973), both given by:
 $$E = \sqrt {1 - \mathop \sum \limits_{k \in {S_{ij}}} \sqrt {{p_{ki}}{p_{kj}}} } \quad {\rm{and}}\quad N = - \log\left( {{{{I_{ij}}} \over {\sqrt {{I_i}{I_j}} }}} \right)\comma\ {\rm{respectively}}.$$
$$E = \sqrt {1 - \mathop \sum \limits_{k \in {S_{ij}}} \sqrt {{p_{ki}}{p_{kj}}} } \quad {\rm{and}}\quad N = - \log\left( {{{{I_{ij}}} \over {\sqrt {{I_i}{I_j}} }}} \right)\comma\ {\rm{respectively}}.$$
Euclidean and Nei’s distances have been developed for purely genetic data, but they can be applied to the frequencies of surnames, as those carried out by Mikerezi et al. (Reference Mikerezi, Xhina, Scapoli, Barbujani, Mamolini, Sandri, Carrieri, Rodriguez-Larralde and Barrai2013). In addition, to detect isolation by distance between locations
 $i$
and
$i$
and
 $j$
, the linear correlation of surname distances (Lasker’s, Euclidean and Nei’s) with their geographic distances can be computed.
$j$
, the linear correlation of surname distances (Lasker’s, Euclidean and Nei’s) with their geographic distances can be computed.
Once the measures are obtained, the final output is a graphical representation of the different surname regions obtained by Multivariate Analysis. This is usually done by representing the clusters given by dendrograms constructed from the matrices of Lasker’s distances (see Cheshire et al., Reference Cheshire, Longley and Singleton2010), so the basic information of splitting or merging clusters is the similarity or isonymic distance between areas. The basic information for splitting or merging clusters is the similarity or distance between the clusters, and this distance can be obtained by different methods, such as complete linkage or Ward’s procedure. Ward’s method is a hierarchical agglomerative clustering procedure successfully used in linguistic variation analysis (Nerbonne & Heeringa, Reference Nerbonne and Heeringa1997; Goebl, Reference Goebl2006; Szmrecsanyi, Reference Szmrecsanyi2012; Strauss & von Maltitz, Reference Strauss and von Maltitz2017).
3. Results and discussion
3.1. Surname regions and linguistic divisions
The analysis of the geographical distribution of surnames enables the study of the spatial and temporal human population structure. The spatial information obtainable from surnames, combined with their ubiquity, makes them a rich resource for regionalization studies. Despite showing distinctive geographical patterning, surnames have remained an underutilized source of information about population origins, migration, and identity. Indeed, individuals who share location specific surnames are also likely to share a number of linguistic, genetic, historical, and social characteristics as well as common ancestry. The significance of surnames is important in a historically rural area like Asturias, since in Europe, and especially in rural areas and during pre-industrial times, marital migrations involved displacements of very few kilometres (Lasker, Reference Lasker1980; Manni et al., Reference Manni, Heeringa, Toupance and Nerbonne2008; Zúñiga, Pueyo & Calvo, Reference Zúñiga, Pueyo and Calvo2012; Rodríguez-Díaz et al., Reference Rodríguez-Díaz, Manni, Colino-Rabanal, Peris, Lizana and Blanco Villegas2017; Bycroft et al., Reference Bycroft, Fernández-Rozadilla, Ruiz-Ponte, Quintela-García, Carracedo, Donnelly and Myers2019).
Figure 1. Dendrogram obtained from Ward’s clustering of the Lasker distances calculated at Municipality level. The Figure shows two main aggregations associated with two linguistic areas: Galician and Asturian.

Figure 1. Dendrogram obtained from Ward’s clustering of the Lasker distances calculated at Municipality level. The Figure shows two main aggregations associated with two linguistic areas: Galician and Asturian.
The results of the analysis of the isonymy of the considered data and the resulting municipality clusters are represented in the dendrogram of Figure 1. In this graph, two main clusters can be identified: the smaller cluster includes the councils located in the west of the territory (A), and the greater cluster is made up of the remaining Asturian councils (B). In the map corresponding to the dendrogram it can be verified that cluster A is contiguous to the Galician territory and occupies a surface somewhat superior to a third of Asturias (Map 5). This cluster is also very compact, since the three successive divisions that are seen in the dendrogram happen in cluster B (B1, B2, and B3). In the visualization of the clusters on the map of municipalities of Asturias, it is also observed that the boundaries between them follow the north-south direction (Map 5). The groupings of municipalities located below the fourth partition show a much lower degree of similarity and they have a disaggregated distribution around the Asturias territory.
Map 5. Regions of surnames in Asturias.
The comparison between the map of surname regions and the map of the dialectal divisions of Asturias allows the identification of interesting correlations (Map 6):
-
a. The first division in two regions of surnames shows a general correspondence with the division of Asturias into two linguistic domains: that corresponding to the languages in the Galician domain (A) and that belonging to the Asturian-Leon domain (B). In the dendrogram it can be observed that the successive divisions (B1, B2, and B3) take place in the center-east cluster, which accounts for a greater distance between cluster A and the remains of the clusters that are scattered in B.
-
b. The borders between the four main regions of surnames and the isoglosses with which the boundaries are marked between the linguistic varieties follow the same direction from north to south and run almost parallel. In addition, these separation limits of the two types of data are distributed in the territory creating similar divisions in their distribution, especially those that segment the linguistic space within the Asturian dominion.
-
c. The similarity between the distributions of the two types of data allows us to recognize a relation between the onomastic isoglosses of the regions of surnames and the phonetic isoglosses which separate the dialectal varieties. This connection becomes very interesting, since some authors consider phonetic isoglosses as reliable evidence of ancient linguistic groups. Viejo (Reference Viejo Fernández2003:239), when studying the dialectal borders of Asturian, indicates that the limits of phonetic phenomena that follow a north-south path identify old changes which had already begun in the passing from Latin to the first Asturian romance.
Map 6. Linguistic isoglosses and regions of surnames in Asturias.
In a much more general way, some of the aspects detected in this comparison have already been pointed out in some previous works carried out in the field of population genetics studies. In Rodríguez-Díaz et al (Reference Rodríguez-Díaz, Manni and Blanco-Villegas2015), a study carried out on the provincial division and with a smaller number of onomastic data, the authors already indicate the linguistic proximities between Galicia and the provinces of Asturias and León.Footnote 10 The authors comment that the groups recognized through the study of surnames of the Spanish population show obvious correlations with the medieval linguistic and political borders. The most recent research by Bycroft et al. (Reference Bycroft, Fernández-Rozadilla, Ruiz-Ponte, Quintela-García, Carracedo, Donnelly and Myers2019) proposes similar conclusions from the analysis of genetic data of the Iberian population.
Although our work focused on a small community of the northwestern Iberian Peninsula, the correlation detected between the boundaries of the Leonese and Galician language domains and the first two cognitive clusters is in line with the results of these two previous investigations and allows further fine-tuning of the similarities detected between the two types of data.
3.2. Surnames, dialects, and history
The population structure demonstrates surnames regionalization in the Asturian space, identifying areas in which the inhabitants of this area were related and associated in community. Surnames serve as footprints in reconstructing part of the history of the populations and communities that inhabited this space; the regions of surnames identify the areas in which the interrelations (social, economic, cultural, etc.) among the inhabitants were more close-knit. The hereditary nature of surnames and the fact that matrimonial migrations in European rural communities have been limited to a few kilometers for centuries make family names mirrors of historical phenomena (Manni et al., Reference Manni, Heeringa, Toupance and Nerbonne2008). As Cavalli-Sforza (Reference Cavalli-Sforza1991) points out, the strong correlation detected between genetic and linguistic data is not explained by genetic determinism but by history. At moments of a remote past, there have been territorial segmentations that conditioned the linguistic and biological fragmentation which today may be observed in the distribution of linguistic features and surnames.
Historic factors are considered determinant by several authors to explain the linguistic division within the Asturian-Leon domain. Menéndez Pidal (Reference Menéndez Pidal1906), when dealing with the extension of Asturian rule, links his history to the evolution of Latin spoken in the Conventum Asturum, a legal demarcation of the Roman occupation era, and with the subsequent development between the 8th and 13th centuries of the medieval kingdoms of Asturias and of León. It should be taken into account that Menéndez Pidal assumed the existence of a very close relationship between extralinguistic historical factors and the dimension of the dialectal boundaries, not only for Asturian rule, but also in general for constitutional peninsular Romance languages (Fernández-Ordóñez Reference Fernández-Ordóñez and Juan Carlos2010). The relationship between historical facts and linguistic facts is also found in the authors who investigate the history of Asturian territory. In his study of proto-historic Asturias, González (Reference González y Fernández Valles and Ojeda1978) emphasizes the territorial coincidence between the ancient pre-Roman tribes and the dialectal configuration of modern Asturian. This scholar affirms that linguistic fragmentation in the interior of Asturias can be explained by tribal configurations prior to the Roman period. The distribution of Galician peoples (albioni, egovarri) and Asturian people (paesici, luggoni, cantabri) coincides, according to the author, with the division of the varieties recognized by dialectal studies. Other later works point out that this old tripartite tribal configuration may be the basis of later territorial distributions of different kinds (administrative, conventual, ecclesiastical, political, etc.; Santos, Reference Santos Yanguas1992).
However, firmer proof would be necessary to confirm the link between modern dialect divisions and the territorial distribution of ancient peoples and languages. In a more recent study on the historical formation of Asturian, Viejo (Reference Viejo Fernández2003) considers it necessary to review the ideas established in traditional linguistic studies as to the weight of the ancient demarcations for the explanation of modern isogloss distribution. This author proposes referring not only to historical elements to explain the differences between varieties, but also in a special way to those elements that determine the particular articulation of the territory: economic activities, types of population, communication channels, population nucleus, etc. He highlights, for example, the remarkable coincidence between the most representative isoglosses in the Asturian domain, the great communication routes, and the banks of the Navia, Nalón, and Sella rivers (Viejo Reference Viejo Fernández2003:16).
4. Concluding remarks
The main aim of this study was to explore new methods that help to deepen the knowledge of the relationships between the demographic and social structure of the populations and the spatial organization of linguistic diversity. The research object was onomastic and geolinguistic data from Asturias, an autonomous community in north-west Spain, which is part of the linguistic domain historical called Asturian-Leonese. The methods applied in the analysis of the distribution of the surnames of Asturias, in part similar to those used for years to study the structure of the populations in other spaces, have helped us to discover the existence of four onomastic regions of configuration similar to dialectal areas traditionally recognized in the Asturian domain.
The study of the relationship between the territorial distribution of surnames and dialects has given different results in the studies of European countries and communities. As regards France (Scapoli et al., Reference Scapoli, Mamolini, Carrieri, Rodriguez-Larralde and Barrai2006), Italy (Goebl, Reference Goebl1996), and Belgium (Barrai et al., Reference Barrai, Rodríguez-Larralde, Manni, Ruggiero, Tartari and Scapoli2004) the dialectal transitions generally agree with the boundaries between the regions of surnames. In the Netherlands (Manni et al., Reference Manni, Heeringa, Toupance and Nerbonne2008), the studies carried out so far acknowledge that there seems to be no relevant similarities between regional varieties and surnames, but probably between surnames and religion areas. In the case of Spain, the studies carried out so far identify a certain similarity, although it would be necessary to review the analyses using more solvent and robust data, both on the onomastic and linguistic levels (Rodríguez-Díaz, Blanco-Villegas & Manni Reference Rodríguez-Díaz, Blanco Villegas and Manni2017).
The study of isonymy and the identification of the surname regions of Asturias have brought to light some features relevant to the analysis of the geolinguistic variation of Asturian Romance and the organization of the population of this territory.
Firstly, the main surname clusters are organized in areas separated by boundaries that follow a vertical line from north to south. These limits show evident similarities with the phonetic isoglosses that have been used to delimit the main varieties of Asturian. The territory division into four clusters of surnames also makes it obvious that there are many coincidences with the four recognized linguistic varieties of Asturian and with the distribution of tribal groups of antiquity identified in previous studies.
Secondly, the cluster analysis of onomastic data also makes it possible to identify two groups that reflect certain general similarities with the partition in linguistic domains of the territory of Asturias (A and B in Figure 1 and Map 6). Although of a greater extension, the western cluster (A in Map 6) occupies an area similar to the area that dialectal studies place, due to their linguistic characteristics, within the Galician linguistic domain. In turn, the center-eastern cluster (B in Map 6), which is larger than the first one, coincides with its extension with the territory of Asturias included in the Leonese language domain.
In addition, we can add that the results obtained in this comparative analysis confirm the usefulness of onomastic data in research into the origins and historical causes of linguistic variety spatial distribution. This type of research, which has so far been focused on the analysis of extensive linguistic domains, should also be applied to the study of minor linguistic areas. Geolinguistic and dialectal studies will be enriched by the interdisciplinary contributions of linguistics and other disciplines. All of them will contribute to broaden our knowledge about societies and the way they relate to languages and space. The names themselves are revealed as an important source of information to study languages, both now and in the past.
Proper names prove to be an important source of information to study languages, both now and in the past. The phonetic, morphological, and lexical characteristics of place names and proper names have long been used to trace the history and evolution of linguistic variables. In this sense, dialectology uses onomastic information as evidence of the distribution in the past of linguistic traits (Scott, Reference Scott and Hough2016). With this paper we aim to contribute to prove the value of the onomastics data as evidence of the structure of the modern and ancient populations, and, therefore, as a complement to better understand the way in which linguistic diversity is organized in space.Footnote 11 This study is a sample of the interesting results that can be drawn from this field of interdisciplinary research.
Acknowledgements
We would like to thank the Sociedad Asturiana de Estudios Económicos e Industriales (SADEI) for giving access to the 2012 Asturias census.
Funding
This work was supported by the Spanish Ministerio de Economía y Competitividad [FFI2015-65208-P and MTM2016-76969-P], European Regional Development Fund (multiannual financial framework 2014-2020]) and the Xunta de Galicia (TecAnDali research network, ED341D R2016/011).










 Open access
Open access