




1. Introduction
Gravity currents are fluid flows driven across a horizontal or shallowly sloped boundary by a density difference with the surrounding fluid. These include industrial accidents such as the spreading of toxic gas (Rottman, Simpson & Hunt Reference Rottman, Simpson and Hunt1985), the failure of carbon dioxide pipelines (Liu et al. Reference Liu, Godbole, Lu, Michal and Linton2019) and oil spills (Hoult Reference Hoult1972), along with environmental flows such as cold fronts, katabatic winds, salinity currents (Simpson Reference Simpson1982, Reference Simpson1997) and currents within frozen lakes (Jansen et al. Reference Jansen2021). In submarine environments, suspended particle loads cause an excess of density over the surrounding ambient water, generating a gravity current. These particle-driven turbidity currents play a dominant role in oceanic transport processes, distributing particulates, nutrients and pollutants from the continental margin to the deep ocean, preserving a record of palaeo-environments, and posing a hazard to submarine infrastructure such as cables and pipes (Hsu et al. Reference Hsu, Kuo, Lo, Tsai, Doo, Ku and Sibuet2008; Carter et al. Reference Carter, Gavey, Talling and Liu2015). The run-out of these currents is impressive, some currents traversing thousands of kilometres (Lewis Reference Lewis1994; Savoye et al. Reference Savoye, Babonneau, Dennielou and Bez2009), and the cumulative deposits can be enormous, up to
 $10^7 \, \mathrm {km}^3$
(Curray, Emmel & Moore Reference Curray, Emmel and Moore2002). Consequently, the dynamics of these currents is of practical interest (Reece, Dorrell & Straub Reference Reece, Dorrell and Straub2024).
$10^7 \, \mathrm {km}^3$
(Curray, Emmel & Moore Reference Curray, Emmel and Moore2002). Consequently, the dynamics of these currents is of practical interest (Reece, Dorrell & Straub Reference Reece, Dorrell and Straub2024).
1.1. Background
To maintain their excess density, turbidity currents must suspend their particle load (Wells & Dorrell Reference Wells and Dorrell2021). Early investigation into the energetics of particle suspension was performed by Knapp (Reference Knapp1938) and Bagnold (Reference Bagnold1962). They investigated the auto-suspension for steady currents on sloped beds, where an arbitrarily large amount of particles of a particular size can be transported by a current. These authors observed that, for flow downhill, the driving force of the current was enhanced by having an additional particle in suspension due to the mass of the particle. When the energy required to lift a particle against settling was below the energy provided by the increased driving force then having the particle in suspension was a net gain to the current’s energy, and auto-suspension was possible. However, this analysis gives no thought to the means by which the work done by the downslope force turns into work uplifting particles, which will involve energy losses so that the Knapp–Bagnold condition is necessary but not sufficient. As discussed by Bagnold (Reference Bagnold1966), the uplift of particles is turbulent in nature. Consequently, it is understood that the downslope force maintains the speed of the current against Reynolds stresses, the energy lost to Reynolds stresses transferred to entrained fluid and the turbulent kinetic energy (TKE), and this turbulence uplifts the particles as a buoyancy flux. In turbidity currents, the bulk energetics of this process has been captured in the model of Parker, Fukushima & Pantin (Reference Parker, Fukushima and Pantin1986) by depth averaging the governing equations. The model captures the self-acceleration that can happen when the work by downslope gravity exceeds the energy required to suspend particles, resulting in an igniting current that progressively increases in both volume and sediment mass.
After four decades the model presented by Parker et al. (Reference Parker, Fukushima and Pantin1986), and similar depth-average shallow-water models (Bonnecaze, Huppert & Lister Reference Bonnecaze, Huppert and Lister1993), remain a foundation for the theoretical understanding of turbidity currents (Wells & Dorrell Reference Wells and Dorrell2021; Wahab et al. Reference Wahab, Hoyal, Shringarpure and Straub2022; Talling et al. Reference Talling2023). The depth-average model itself captures the body of the current, which is well approximated as hydrostatic; the non-hydrostatic front of the current must be captured separately as a boundary condition (Benjamin Reference Benjamin1968; Ungarish & Hogg Reference Ungarish and Hogg2018). Depth-average models in general are used across the breadth of gravity current research (Stoker Reference Stoker1957; Ellison & Turner Reference Ellison and Turner1959; Huppert Reference Huppert2006; Meiburg, Radhakrishnan & Nasr-Azadani Reference Meiburg, Radhakrishnan and Nasr-Azadani2015; Ungarish Reference Ungarish2020). These models are mathematically simple, and can therefore be used to analyse idealised gravity current dynamics such as collision with obstacles (Skevington & Hogg Reference Skevington and Hogg2020, Reference Skevington and Hogg2023, Reference Skevington and Hogg2024; Hogg & Skevington Reference Hogg and Skevington2021) or flow over an edge (Momen et al. Reference Momen, Aheng, Bou-Zeid and Stone2017; Ungarish, Zhu & Stone Reference Ungarish, Zhu and Stone2019; Skevington, Hogg & Ungarish Reference Skevington, Hogg and Ungarish2021). In addition to the conceptual insights they provide, there is a substantial reduction in complexity from a three-dimensional model which would be simulated directly, or through a large-eddy or Reynolds-averaged approach, to a depth-average model. This simplicity results in a substantial increase in the spatial and temporal scales which can be simulated. For example, Wahab et al. (Reference Wahab, Hoyal, Shringarpure and Straub2022) were able to simulate the morphodynamic evolution of the submarine fans generated by turbidity currents over geophysical scales. Similarly, vast numbers of large-scale events must be simulated for the hazard forecasting and risk management of other classes of gravity currents, such as hazardous gas spills, avalanches and pyroclastic density currents. Thus, it is important to continue the development of the depth-average modelling framework to ensure accurate prediction.
For accurate prediction of particle-driven currents, depth-average models must accurately capture the energetics. The energy expended to hold the particles in suspension consumes the TKE of the current. It is entirely possible for the sinks of TKE from uplift and viscous dissipation to exceed production, at which point the turbulent energy begins to decrease. In equilibrium simulations, it has been shown that there is a sharp threshold, with the magnitude and distribution of TKE varying weakly with settling velocity until a total collapse of the turbulence at a critical value (Cantero, Shringarpure & Balachandar Reference Cantero, Shringarpure and Balachandar2012; Shringarpure, Cantero & Balachandar Reference Shringarpure, Cantero and Balachandar2012) which has been confirmed empirically (Eggenhuisen, Cartigny & de Leeuw Reference Eggenhuisen, Cartigny and de Leeuw2017). Out of equilibrium, being overloaded with particles does not necessarily result in a collapse of turbulence, instead causing deposition to a reduced sediment load (Dorrell, Hogg & Pritchard Reference Dorrell, Hogg and Pritchard2013). There is evidence that after transition onto a shallow slope the self-acceleration feedback sometimes runs in reverse, a reduction in driving force causing less turbulence causing particle deposition causing less driving force, resulting in a sudden deposition of the full transported load (Talling et al. Reference Talling2007).
1.2. Motivation
We ask the question: Are the energetics predicted by Parker et al. (Reference Parker, Fukushima and Pantin1986) reliable? There is a substantial simplification in the derivation of the model to a top-hat profile, wherein the velocity, concentration and TKE are uniform up to some depth, above which they discontinuously vanish. A more general approach incorporates the key effects of the profiles through shape factors. Top-hat models are not realistic, Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) show that the shape factors change by
 $38\,\%$
in real experimental flows, increasing to
$38\,\%$
in real experimental flows, increasing to
 $45\,\%$
in the work of Islam & Imran (Reference Islam and Imran2010). Moreover, it was shown in Dorrell et al. (Reference Dorrell, Darby, Peakall, Sumner, Parsons and Wynn2014) that including the shape in a depth-average model results in considerably different predictions. While the simplification to top-hat models is not always present (e.g. Sher & Woods Reference Sher and Woods2015; Negretti, Flòr & Hopfinger Reference Negretti, Flòr and Hopfinger2017), the models being used to predict the bulk energetics of gravity currents do not account for realistic profiles of velocity and density, and the considerable differences caused by shape factors indicates that the energetics are not reliably captured. For the discussion going forward, it will be important that the derivation of Parker et al. (Reference Parker, Fukushima and Pantin1986) eliminates any explicit inclusion of turbulence beyond a quantification of the TKE. They show that, under the top-hat assumption, there is a consistency relationship between the turbulent production (which passes energy from the mean-flow kinetic energy to the TKE) and other properties of the flow (basal drag and entrainment of ambient). A similar consistency relationship exists for the buoyancy flux (energy from TKE to gravitational potential energy (GPE)). Thus, it is not possible to specify either of these effects, and instead they are implied by the model. In Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) the assumption of a top-hat flow structure is relaxed, but no equivalent consistency relationships for the turbulence are provided. This makes it appear as though no such relationships exist and the turbulence requires some additional closure. However, this cannot be the case: there is nothing special about the top-hat model except for its analytical simplicity. The consistency relationships do exist, they are just complicated and unstated. To upgrade the modelling framework to one which includes the vertical profiles, a new model is required similar to Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) but which eliminates the turbulent production and uplift like in Parker et al. (Reference Parker, Fukushima and Pantin1986). We also require explicit expressions for the consistency relationships, to ensure model closures such as vertical profiles and entrainment produce the correct energetics.
$45\,\%$
in the work of Islam & Imran (Reference Islam and Imran2010). Moreover, it was shown in Dorrell et al. (Reference Dorrell, Darby, Peakall, Sumner, Parsons and Wynn2014) that including the shape in a depth-average model results in considerably different predictions. While the simplification to top-hat models is not always present (e.g. Sher & Woods Reference Sher and Woods2015; Negretti, Flòr & Hopfinger Reference Negretti, Flòr and Hopfinger2017), the models being used to predict the bulk energetics of gravity currents do not account for realistic profiles of velocity and density, and the considerable differences caused by shape factors indicates that the energetics are not reliably captured. For the discussion going forward, it will be important that the derivation of Parker et al. (Reference Parker, Fukushima and Pantin1986) eliminates any explicit inclusion of turbulence beyond a quantification of the TKE. They show that, under the top-hat assumption, there is a consistency relationship between the turbulent production (which passes energy from the mean-flow kinetic energy to the TKE) and other properties of the flow (basal drag and entrainment of ambient). A similar consistency relationship exists for the buoyancy flux (energy from TKE to gravitational potential energy (GPE)). Thus, it is not possible to specify either of these effects, and instead they are implied by the model. In Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) the assumption of a top-hat flow structure is relaxed, but no equivalent consistency relationships for the turbulence are provided. This makes it appear as though no such relationships exist and the turbulence requires some additional closure. However, this cannot be the case: there is nothing special about the top-hat model except for its analytical simplicity. The consistency relationships do exist, they are just complicated and unstated. To upgrade the modelling framework to one which includes the vertical profiles, a new model is required similar to Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) but which eliminates the turbulent production and uplift like in Parker et al. (Reference Parker, Fukushima and Pantin1986). We also require explicit expressions for the consistency relationships, to ensure model closures such as vertical profiles and entrainment produce the correct energetics.
Work by Toniolo et al. (Reference Toniolo, Parker, Voller and Beaubouef2006) highlighted another connected deficiency in the standard formulation: how entrainment is modelled. The particle settling velocity should reduce the extent to which fluid is entrained, and in the non-turbulent case fluid should be detrained (Toniolo et al. Reference Toniolo, Parker, Voller and Beaubouef2006; Dorrell & Hogg Reference Dorrell and Hogg2010). This deficiency arises because we are parametrising the effect of the turbulent energetics in mixing the fluid, and not the turbulent energetics themselves: previous authors have stressed that the physical origin of entrainment is the turbulent buoyancy flux (Strang & Fernando Reference Strang and Fernando2001; Odier, Chen & Ecke Reference Odier, Chen and Ecke2014). Arneborg et al. (Reference Arneborg, Fiekas, Umlauf and Burchard2007) and Wells, Cenedese & Caulfield (Reference Wells, Cenedese and Caulfield2010) have formulated a top-hat model of compositional currents where the buoyancy flux replaces entrainment. Would an interpretation of entrainment in terms of buoyancy flux give rise to the particulate effects discussed by Toniolo et al. (Reference Toniolo, Parker, Voller and Beaubouef2006), Bolla Pittaluga, Frascati & Falivene (Reference Bolla Pittaluga, Frascati and Falivene2018) and Ma et al. (Reference Ma, Parker, Cartigny, Viparelli, Balachander, Fu and Luchi2024)?
The present paper answers the questions above. First, we build a new model which allows for the specification of vertical structure, but otherwise requires an identical set of closures to Parker et al. (Reference Parker, Fukushima and Pantin1986), and we present the consistency relationships for the implied turbulent processes. Thus, this model is a direct generalisation. By representing entrainment in the same way, this first model inherits the same problems when it comes to closing entrainment, and questions arise around the effect of particle settling. We present an alternative model where we shift from requiring a closure for entrainment to a closure for buoyancy flux, which is enabled by our consistency relationships. This alternative model naturally includes the type of particulate effects demonstrated by Toniolo et al. (Reference Toniolo, Parker, Voller and Beaubouef2006).
Exploration of the energetics is further motivated by the results of Fukuda et al. (Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) who demonstrated that the top-hat model (Parker et al. Reference Parker, Fukushima and Pantin1986) has a missing source of energy, and postulated that these arise from the flow profiles. Here, we show that this is in part true, the profiles of velocity and density give rise to a large number of additional terms which cannot be neglected at leading order. However, a pseudo-equilibrium balance can be established wherein the effects of profiles, while important, do not resolve the energetic imbalance. Instead, this is resolved by two changes: the change in how entrainment is incorporated into the model, and the inclusion of the viscous dissipation of mean-flow energy.
1.3. Structure
This paper is structured as follows. We first derive the depth-average model in § 2, starting from a three-dimensional system of equations (§ 2.1), averaging over depth (§ 2.2) and discussing how to interpret the equations as a predictive model (§ 2.3). We then derive the rates of transfer between the different energies in the current (§ 3.1), which are the consistency relationships for model closures (§ 3.2). The full model is compared with simulations, showing the importance of flow shape (§ 4.1) and mean-flow dissipation (§ 4.2). We then discuss the difficulties of defining the depth and entrainment in gravity currents (§ 5.1), an alternative approach in terms of buoyancy flux (§ 5.2) and how this give rise to alternative model which incorporates particulate effects (§ 5.3). Particle auto-suspension in turbidity currents is discussed in § 6. We highlight future research directions in § 7 and conclude in § 8. Appendices are provided discussing the dimensional scales within gravity currents (Appendix A), comparing with the variables used by Ellison & Turner (Reference Ellison and Turner1959) (Appendix B), the depth average (Appendix C) and the depth-rescaling symmetry group (§ D). The supplementary material includes details of the ensemble averaging in § 2.1 and algebraic manipulations in § 3.1.
2. The generalised depth-average model
Here, we carefully derive the generalised depth-averaged model for a gravity current, as depicted in figure 1. The model is constructed following similar arguments to Parker et al. (Reference Parker, Fukushima and Pantin1986). The derivation is presented to enable us to detail the reduced set of assumptions about the shape of the velocity, density and turbulence profiles. We begin in § 2.1 with the three-dimensional system of equations (2.1), which have been simplified by the scaling analysis in § A. Then, in § 2.2, we average the simplified three-dimensional system over the depth using the results in Appendix C to obtain the generalised system (2.16)–(2.22), which is interpreted in § 2.3.
The system of equations is derived for a particle-driven turbidity current. However, the essential feature that we rely upon is that the excess density of the current is linearly dependent on some scalar,
 $\phi$
, which is advected by the current up to some velocity offset. A thermal or salinity current could be captured by the model by taking
$\phi$
, which is advected by the current up to some velocity offset. A thermal or salinity current could be captured by the model by taking
 $\phi$
to be the temperature or salinity anomaly and neglecting settling and erosion.
$\phi$
to be the temperature or salinity anomaly and neglecting settling and erosion.

Figure 1. The configuration of the turbidity current, with the bed in grey, ambient in blue and current in brown fading toward blue in the less concentrated upper regions. (a) A two-dimensional slice oriented with the vertical direction up for the case when
 $x$
is the downslope direction. (b) A three-dimensional view oriented with respect to the coordinate system.
$x$
is the downslope direction. (b) A three-dimensional view oriented with respect to the coordinate system.
2.1. The three dimensional system
We define a coordinate system
 $(\boldsymbol {x},t)=(x,y,z,t)$
, where
$(\boldsymbol {x},t)=(x,y,z,t)$
, where
 $t$
is time. The
$t$
is time. The
 $z$
direction is approximately bed normal with
$z$
direction is approximately bed normal with
 $b(x,y)$
the bed elevation (slowly varying) and the current exists in the region
$b(x,y)$
the bed elevation (slowly varying) and the current exists in the region
 $z\gt b$
. The coordinate system is not necessarily so that
$z\gt b$
. The coordinate system is not necessarily so that
 $z$
is vertical, so that the first two components of gravity
$z$
is vertical, so that the first two components of gravity
 $\boldsymbol {g}$
need not be zero. We denote the angle of
$\boldsymbol {g}$
need not be zero. We denote the angle of
 $z$
to the vertical by
$z$
to the vertical by
 $\theta$
so that
$\theta$
so that
 $g_3 = - g \cos \theta$
. In later sections (§§ 4 and 6) we restrict ourselves to a two-dimensional bottom current where
$g_3 = - g \cos \theta$
. In later sections (§§ 4 and 6) we restrict ourselves to a two-dimensional bottom current where
 $0\lt \theta \lt \pi /2$
,
$0\lt \theta \lt \pi /2$
,
 $g_1 = g \sin \theta$
and
$g_1 = g \sin \theta$
and
 $g_2 = 0$
, as depicted in figure 1; we do not make these assumptions in the derivation. Velocity is denoted by
$g_2 = 0$
, as depicted in figure 1; we do not make these assumptions in the derivation. Velocity is denoted by
 $\boldsymbol {u} = (u,v,w)$
and volumetric concentration of particles by
$\boldsymbol {u} = (u,v,w)$
and volumetric concentration of particles by
 $\phi$
.
$\phi$
.
Our goal is to represent each property of the flow field as a depth-averaged quantity multiplied by a relatively steady shape function (i.e. slowly varying in
 $x,y,t$
). Due to the turbulent nature of the flow each variable, say
$x,y,t$
). Due to the turbulent nature of the flow each variable, say
 $f$
, has high wavenumber and high frequency fluctuations. For this reason we introduce Reynolds averaging, specifically ensemble averaging, with the average of a function
$f$
, has high wavenumber and high frequency fluctuations. For this reason we introduce Reynolds averaging, specifically ensemble averaging, with the average of a function
 $f$
denoted
$f$
denoted
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }f}\:\!}$
and fluctuation
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }f}\:\!}$
and fluctuation
 $ \vphantom {\phi }f^{\prime} = f - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }f}\:\!}$
(e.g. Drew & Passman Reference Drew and Passman1999; Pope Reference Pope2000). The averaged variables,
$ \vphantom {\phi }f^{\prime} = f - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }f}\:\!}$
(e.g. Drew & Passman Reference Drew and Passman1999; Pope Reference Pope2000). The averaged variables,
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }f}\:\!}$
, are sufficiently smooth to have their profiles represented by a slowly varying shape.
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }f}\:\!}$
, are sufficiently smooth to have their profiles represented by a slowly varying shape.
The (constant) density of water is
 $\rho _f$
and the density of the particles is
$\rho _f$
and the density of the particles is
 $\rho _s$
(
$\rho _s$
(
 $\rho _s\gt \rho _f$
for bottom currents); it is assumed that the only density variations come from the concentration so that the current density is
$\rho _s\gt \rho _f$
for bottom currents); it is assumed that the only density variations come from the concentration so that the current density is
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }\:\!} = \rho _f + {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} (\rho _s-\rho _f)$
. It is assumed that the particles are non-cohesive, dilute (
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }\:\!} = \rho _f + {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} (\rho _s-\rho _f)$
. It is assumed that the particles are non-cohesive, dilute (
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \ll 1$
) and Boussinesq (
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \ll 1$
) and Boussinesq (
 $R {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \ll 1$
where
$R {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \ll 1$
where
 $R = (\rho _s-\rho _f)/\rho _f$
) so that the bed elevation can be treated as constant in time and there are no high-concentration effects on the flow such as hindered settling or concentration dependent rheology.
$R = (\rho _s-\rho _f)/\rho _f$
) so that the bed elevation can be treated as constant in time and there are no high-concentration effects on the flow such as hindered settling or concentration dependent rheology.
To ensure that the the model only includes leading-order effects we introduce dimensional scales. We employ a time scale
 $\mathscr {T}$
, and length scales
$\mathscr {T}$
, and length scales
 $\mathscr {L}_i$
corresponding to the length (
$\mathscr {L}_i$
corresponding to the length (
 $i=1$
), width (
$i=1$
), width (
 $i=2$
) and depth (
$i=2$
) and depth (
 $i=3$
) of the current. The current is assumed to be shallow, that is
$i=3$
) of the current. The current is assumed to be shallow, that is
 $\mathscr {L}_\alpha \gg \mathscr {L}_3$
for
$\mathscr {L}_\alpha \gg \mathscr {L}_3$
for
 $\alpha \in \{1,2\}$
. (Throughout, the subscripts
$\alpha \in \{1,2\}$
. (Throughout, the subscripts
 $\alpha,\beta,\gamma$
will be used for indices limited to
$\alpha,\beta,\gamma$
will be used for indices limited to
 $1,2$
.) This also aligns the coordinate system:
$1,2$
.) This also aligns the coordinate system:
 $ {\partial b}/{\partial x_\alpha }$
scales as
$ {\partial b}/{\partial x_\alpha }$
scales as
 $\mathscr {L}_3/\mathscr {L}_\alpha \ll 1$
, the bed elevation is slowly varying. Considering the rotation of the coordinate system
$\mathscr {L}_3/\mathscr {L}_\alpha \ll 1$
, the bed elevation is slowly varying. Considering the rotation of the coordinate system
 $\theta$
, the bed can be quite steep provided that
$\theta$
, the bed can be quite steep provided that
 $\mathscr {L}_\alpha /\mathscr {L}_3 \gg \lvert \tan \theta \rvert$
in the downslope direction. We assume the averaged velocities
$\mathscr {L}_\alpha /\mathscr {L}_3 \gg \lvert \tan \theta \rvert$
in the downslope direction. We assume the averaged velocities
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!}$
scale as
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!}$
scale as
 $\mathscr {U}_i = \mathscr {L}_i/\mathscr {T}$
, this can be viewed as a definition of the time scale. The scales of the turbulent transport terms are approximated by an eddy viscosity model. The details of the scaling analysis are given in Appendix A. Eliminating the small terms we deduce that at leading order
$\mathscr {U}_i = \mathscr {L}_i/\mathscr {T}$
, this can be viewed as a definition of the time scale. The scales of the turbulent transport terms are approximated by an eddy viscosity model. The details of the scaling analysis are given in Appendix A. Eliminating the small terms we deduce that at leading order
 \begin{align} \frac {\partial \:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }u_j}\:\!}{\partial x_j} &= 0, \end{align}
\begin{align} \frac {\partial \:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }u_j}\:\!}{\partial x_j} &= 0, \end{align}
 \begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}}{\partial t} + \frac {\partial }{\partial x_j} \left ({\overline{\vphantom{{{\phi }}}u_j}}\, {\overline{\phi }}\right) + \frac {\partial }{\partial z} \left ({\tilde {w} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + J_3}\right) &= 0, \end{align}
\begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}}{\partial t} + \frac {\partial }{\partial x_j} \left ({\overline{\vphantom{{{\phi }}}u_j}}\, {\overline{\phi }}\right) + \frac {\partial }{\partial z} \left ({\tilde {w} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + J_3}\right) &= 0, \end{align}
 \begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!}}{\partial t} \!+\! \frac {\partial }{\partial x_{j}}\left ({{\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }\right) \!-\! \frac {\partial }{\partial z} \left ( {\! \tau _{3\alpha }^R + \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!}}{\partial z}}\right) \!+\! \frac {\partial p^T}{\partial x_\alpha } &= R g_\alpha {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \quad \text { for } \alpha \in \lbrace {1,2} \rbrace, \end{align}
\begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!}}{\partial t} \!+\! \frac {\partial }{\partial x_{j}}\left ({{\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }\right) \!-\! \frac {\partial }{\partial z} \left ( {\! \tau _{3\alpha }^R + \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!}}{\partial z}}\right) \!+\! \frac {\partial p^T}{\partial x_\alpha } &= R g_\alpha {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \quad \text { for } \alpha \in \lbrace {1,2} \rbrace, \end{align}
 \begin{align} \frac {\partial p^T}{\partial z} &= R g_3 {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}, \end{align}
\begin{align} \frac {\partial p^T}{\partial z} &= R g_3 {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}, \end{align}
 \begin{align} \frac {\partial k}{\partial t} + \frac {\partial }{\partial x_j}\left ({{\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} k}\right) + \frac {\partial T_3}{\partial z} &= \tilde {\mathcal {P}} - \tilde {\epsilon }_K + R g_3 J_3, \end{align}
\begin{align} \frac {\partial k}{\partial t} + \frac {\partial }{\partial x_j}\left ({{\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} k}\right) + \frac {\partial T_3}{\partial z} &= \tilde {\mathcal {P}} - \tilde {\epsilon }_K + R g_3 J_3, \end{align}
which represent conservation of volume, particles,
 $x$
and
$x$
and
 $y$
momentum,
$y$
momentum,
 $z$
momentum and TKE, respectively. For three-dimensional variables (as used here) we use the convention that repeated indices should be summed over
$z$
momentum and TKE, respectively. For three-dimensional variables (as used here) we use the convention that repeated indices should be summed over
 $\{1,2,3\}$
. We denote the constant settling velocity of the particles by
$\{1,2,3\}$
. We denote the constant settling velocity of the particles by
 $\tilde {\boldsymbol {u}}$
(
$\tilde {\boldsymbol {u}}$
(
 $\tilde {w}\lt 0$
for dense particles in a bottom current), the transport of particles by
$\tilde {w}\lt 0$
for dense particles in a bottom current), the transport of particles by
 $\boldsymbol {J}$
, the Reynolds stress by
$\boldsymbol {J}$
, the Reynolds stress by
 $\boldsymbol {\tau }^R$
, the viscosity by
$\boldsymbol {\tau }^R$
, the viscosity by
 $\nu$
, the combined effect of pressure and TKE relative to the hydrostatic ambient by
$\nu$
, the combined effect of pressure and TKE relative to the hydrostatic ambient by
 $p^T$
and the TKE by
$p^T$
and the TKE by
 $k$
which is transported by
$k$
which is transported by
 $\boldsymbol {T}$
, produced by
$\boldsymbol {T}$
, produced by
 $\tilde {\mathcal {P}}$
and the dissipated by
$\tilde {\mathcal {P}}$
and the dissipated by
 $\tilde {\epsilon }_K$
. The hydrostatic approximation is common across the gravity current literature (e.g. Ellison & Turner Reference Ellison and Turner1959; Parker et al. Reference Parker, Fukushima and Pantin1986; Bonnecaze et al. Reference Bonnecaze, Huppert and Lister1993; Ungarish Reference Ungarish2020).
$\tilde {\epsilon }_K$
. The hydrostatic approximation is common across the gravity current literature (e.g. Ellison & Turner Reference Ellison and Turner1959; Parker et al. Reference Parker, Fukushima and Pantin1986; Bonnecaze et al. Reference Bonnecaze, Huppert and Lister1993; Ungarish Reference Ungarish2020).
The form of the system (2.1) is generic, and can be derived by averaging a variety of models of dilute Boussinesq particle-laden flow. Following Parker et al. (Reference Parker, Fukushima and Pantin1986), a simple approach is applicable to situations where the particles are smaller than the Kolmogorov length scale. From the perspective of the turbulent micro-scales the particles act as a concentration field
 $\phi$
, similar to a concentration of salinity but moving at a speed
$\phi$
, similar to a concentration of salinity but moving at a speed
 $\boldsymbol {u} + \tilde {\boldsymbol {u}}$
, where by diluteness the velocity of the mixture is the same as the velocity of the fluid, and
$\boldsymbol {u} + \tilde {\boldsymbol {u}}$
, where by diluteness the velocity of the mixture is the same as the velocity of the fluid, and
 $k = ({1}/{2}) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}} \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_i^{\prime}}\:\!}$
. Averaging we obtain (2.1) (strictly the unsimplified system (A1)) with
$k = ({1}/{2}) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}} \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_i^{\prime}}\:\!}$
. Averaging we obtain (2.1) (strictly the unsimplified system (A1)) with
 \begin{align} \tau _{ij}^R &= - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} } \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_j^{\prime} }\:\!}, & T_j &= {\textstyle \frac {1}{\rho }} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} } \vphantom {\phi }u_j^{\prime} \vphantom {\phi }p^{\prime} }\:\!} + {\textstyle \frac {1}{2}} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} } \vphantom {\phi }u_j^{\prime} \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_i^{\prime} }\:\!} - \nu \frac {\partial k}{\partial x_j}, & \tilde {\mathcal {P}} &= \tau _{ji}^R \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j}, \end{align}
\begin{align} \tau _{ij}^R &= - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} } \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_j^{\prime} }\:\!}, & T_j &= {\textstyle \frac {1}{\rho }} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} } \vphantom {\phi }u_j^{\prime} \vphantom {\phi }p^{\prime} }\:\!} + {\textstyle \frac {1}{2}} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} } \vphantom {\phi }u_j^{\prime} \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_i^{\prime} }\:\!} - \nu \frac {\partial k}{\partial x_j}, & \tilde {\mathcal {P}} &= \tau _{ji}^R \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j}, \end{align}
 \begin{align} J_j &= {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\vphantom {\phi }u^{\prime}_j \vphantom {\phi }\phi ^{\prime}}\:\!}, & \tilde {\epsilon }_K &= \nu {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}}\:\!}. \end{align}
\begin{align} J_j &= {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\vphantom {\phi }u^{\prime}_j \vphantom {\phi }\phi ^{\prime}}\:\!}, & \tilde {\epsilon }_K &= \nu {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}}\:\!}. \end{align}
The particles are moved by the coherent fluctuations of the concentration and velocity, and energy in these velocity fluctuations dissipated by viscosity.
For larger particles, we must use a more rigorous phase-averaging approach. We use the results in Drew & Passman (Reference Drew and Passman1999), and the details are provided in the supplementary material. We will state the non-dilute version of the definitions of variables and later impose the dilute assumption. The velocity field of the mixture is the weighted average of the velocity of the fluid and solid phases
 \begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} &= \frac {1}{ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }\:\!} } \left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \rho _f {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} _f + (1- {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}) \rho _s {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} _s }\right). \end{align}
\begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} &= \frac {1}{ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }\:\!} } \left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \rho _f {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} _f + (1- {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}) \rho _s {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} _s }\right). \end{align}
In this formalism, the concentration is only defined during the ensemble average so that
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} =\phi$
. The particles move relative to the the mixture for two reasons, settling
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} =\phi$
. The particles move relative to the the mixture for two reasons, settling
 $\tilde {\boldsymbol {u}}$
and turbulent effects
$\tilde {\boldsymbol {u}}$
and turbulent effects
 $\Delta {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!}$
, so that
$\Delta {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!}$
, so that
 \begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} _s &= {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} + \tilde {\boldsymbol {u}} + \Delta {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!}. \end{align}
\begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} _s &= {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!} + \tilde {\boldsymbol {u}} + \Delta {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\boldsymbol {u}}\:\!}. \end{align}
The TKE is defined as
 \begin{align} k = \frac { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho u_j u_j}\:\!} - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} }{2 {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }\:\!} }. \end{align}
\begin{align} k = \frac { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho u_j u_j}\:\!} - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} }{2 {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\rho }\:\!} }. \end{align}
In the dilute limit,
 $ {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\boldsymbol {u}}\:\!}$
tends to
$ {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\boldsymbol {u}}\:\!}$
tends to
 $ {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\boldsymbol {u}}\:\!}_f$
,
$ {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\boldsymbol {u}}\:\!}_f$
,
 $k$
tends to
$k$
tends to
 $({1}/{2}){\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}} \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_i^{\prime}}\:\!}$
and the expressions in (2.2) apply. However, the transport of particles and the viscous dissipation appear different
$({1}/{2}){\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}} \vphantom {\phi }u_i^{\prime} \vphantom {\phi }u_i^{\prime}}\:\!}$
and the expressions in (2.2) apply. However, the transport of particles and the viscous dissipation appear different
 \begin{align} J_j & : = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \Delta {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} _j, & \tilde {\epsilon }_K & : = \nu {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}}\:\!} - R {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!} g_i \tilde {u}_i. \end{align}
\begin{align} J_j & : = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \Delta {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} _j, & \tilde {\epsilon }_K & : = \nu {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}\frac {\partial \vphantom {\phi }u_i^{\prime}}{\partial x_j}}\:\!} - R {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!} g_i \tilde {u}_i. \end{align}
The particles are transported by relative motion of the particle phase to the mixture, this relative motion a consequence of turbulence. The settling velocity is, by definition, that velocity at which the work done by gravity due to the settling motion is precisely balanced by the viscous dissipation in the fluid, and we take
 $\tilde {\epsilon }_K$
to represent all other viscous dissipation of TKE.
$\tilde {\epsilon }_K$
to represent all other viscous dissipation of TKE.
The boundary conditions for (2.1) (strictly the unsimplified system (A1)) are as follows. At the bed we impose no slip, i.e.
 \begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}u_j}\:\!} = \vphantom {\phi }u^{\prime} = \vphantom {\phi }v^{\prime} &= 0 &&\text {for}& z &= b(x,y). \end{align}
\begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}u_j}\:\!} = \vphantom {\phi }u^{\prime} = \vphantom {\phi }v^{\prime} &= 0 &&\text {for}& z &= b(x,y). \end{align}
Over a rigid bed we additionally have
 $w^{\prime}=J_3=0$
, and the treatment of the viscous boundary layer at the bed requires care (important in the analysis of §§ 4 and 6); for this reason, we include the full wall boundary layer in the model. For flows over an erosional bed we allow
$w^{\prime}=J_3=0$
, and the treatment of the viscous boundary layer at the bed requires care (important in the analysis of §§ 4 and 6); for this reason, we include the full wall boundary layer in the model. For flows over an erosional bed we allow
 $w^{\prime} \neq 0$
,
$w^{\prime} \neq 0$
,
 $J_3 \neq 0$
, so that the erosion is captured by
$J_3 \neq 0$
, so that the erosion is captured by
 $J_3$
. In the far field we require
$J_3$
. In the far field we require
 \begin{align} \vphantom {\phi }u_j^{\prime} = J_j = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} = p^T = \vphantom {\phi }p^{\prime} &= 0 &&\text {for}& z &=H(x,y,t). \end{align}
\begin{align} \vphantom {\phi }u_j^{\prime} = J_j = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} = p^T = \vphantom {\phi }p^{\prime} &= 0 &&\text {for}& z &=H(x,y,t). \end{align}
In Parker et al. (Reference Parker, Fukushima and Pantin1986, Reference Parker, Garcia, Fukushima and Yu1987),
 $z=H$
is taken to be
$z=H$
is taken to be
 $z \to \infty$
, and it is also assumed that
$z \to \infty$
, and it is also assumed that
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}u}\:\!} = {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }v}\:\!} = 0$
in the far field, so that all entrainment comes from the
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}u}\:\!} = {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }v}\:\!} = 0$
in the far field, so that all entrainment comes from the
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}w}\:\!}$
at
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}w}\:\!}$
at
 $z \to \infty$
. A similar approximation is used for jets, mixing layers, wakes and boundary layers (e.g. Pope Reference Pope2000). The entrainment velocity is then defined, for a top-hat model, as
$z \to \infty$
. A similar approximation is used for jets, mixing layers, wakes and boundary layers (e.g. Pope Reference Pope2000). The entrainment velocity is then defined, for a top-hat model, as
 \begin{align} w_e = \frac {\partial h}{\partial t} - \overline {w}\,\Bigg |_{z \to \infty }. \end{align}
\begin{align} w_e = \frac {\partial h}{\partial t} - \overline {w}\,\Bigg |_{z \to \infty }. \end{align}
The function
 $h(x,y,t)$
is termed the depth of the current: for a top-hat model this is the location of the interface between the current and ambient. In gravity currents, the approximation
$h(x,y,t)$
is termed the depth of the current: for a top-hat model this is the location of the interface between the current and ambient. In gravity currents, the approximation
 $z\to \infty$
works well under a deep quiescent ambient fluid which is our primary focus, but interpretation becomes problematic with a weakly counterflowing ambient. We use a more careful formulation with
$z\to \infty$
works well under a deep quiescent ambient fluid which is our primary focus, but interpretation becomes problematic with a weakly counterflowing ambient. We use a more careful formulation with
 $z=H$
some interface beyond the strong influence of the gravity current, but still with
$z=H$
some interface beyond the strong influence of the gravity current, but still with
 $H-b \sim \mathscr {L}_3$
. This change does not alter the depth-average model but aids interpretation. The equivalent condition in our formulation is
$H-b \sim \mathscr {L}_3$
. This change does not alter the depth-average model but aids interpretation. The equivalent condition in our formulation is
 \begin{align} w_e = \frac {\partial }{\partial t} ({\varsigma _h h}) + {\left ({ \sum _{\alpha =1}^2 {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}} u_\alpha }\:\!} \frac {\partial H}{\partial x_\alpha } - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}w}\:\!} }\right)}\Bigg |_{z=H}. \end{align}
\begin{align} w_e = \frac {\partial }{\partial t} ({\varsigma _h h}) + {\left ({ \sum _{\alpha =1}^2 {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}} u_\alpha }\:\!} \frac {\partial H}{\partial x_\alpha } - {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}w}\:\!} }\right)}\Bigg |_{z=H}. \end{align}
We require that, at the elevation
 $z=H$
,
$z=H$
,
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!}$
(
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!}$
(
 $\alpha \in \{1,2\}$
) are small compared with their values within the current so that minimal momentum is transferred between the ambient and the current,
$\alpha \in \{1,2\}$
) are small compared with their values within the current so that minimal momentum is transferred between the ambient and the current,
 ${ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }_H \ll \mathscr {U}_\alpha$
. In turbulent flow
${ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }_H \ll \mathscr {U}_\alpha$
. In turbulent flow
 $w_e\gt 0$
, the flow entrains ambient fluid. The depth function
$w_e\gt 0$
, the flow entrains ambient fluid. The depth function
 $h$
, the inclusion of the factor
$h$
, the inclusion of the factor
 $\varsigma _h$
, and other consequences of this definition are explored in § 5. For now we simply note that typically
$\varsigma _h$
, and other consequences of this definition are explored in § 5. For now we simply note that typically
 $\varsigma _h \approx 1$
.
$\varsigma _h \approx 1$
.
We close this subsection by performing some manipulations of the system (2.1). Firstly, the mean-flow kinetic energy (MKE) equation is obtained by multiplying (2.1c
) by
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_{\alpha }}\:\!}$
and summing over
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_{\alpha }}\:\!}$
and summing over
 $\alpha \in \{1,2\}$
and adding (2.1d
) times
$\alpha \in \{1,2\}$
and adding (2.1d
) times
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!}$
, giving
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!}$
, giving
 \begin{equation} \frac {\partial e}{\partial t} + \frac {\partial }{\partial x_j}\left ({\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} e + {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }u_j}\:\! p^T}\right) - \frac {\partial }{\partial z} \sum _{\alpha =1}^2\left ({\tau _{3\alpha }^R + \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z}}\right) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} = - \tilde {\mathcal {P}} -\tilde {\epsilon }_M + R g_j {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}, \end{equation}
\begin{equation} \frac {\partial e}{\partial t} + \frac {\partial }{\partial x_j}\left ({\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} e + {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }u_j}\:\! p^T}\right) - \frac {\partial }{\partial z} \sum _{\alpha =1}^2\left ({\tau _{3\alpha }^R + \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z}}\right) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} = - \tilde {\mathcal {P}} -\tilde {\epsilon }_M + R g_j {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}, \end{equation}
where
 \begin{align} e & : = \frac {1}{2} \sum _{\alpha =1}^2 {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} ^2, & \tilde {\epsilon }_M & : = \sum _{\alpha =1}^2 \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z}\frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z}. \end{align}
\begin{align} e & : = \frac {1}{2} \sum _{\alpha =1}^2 {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} ^2, & \tilde {\epsilon }_M & : = \sum _{\alpha =1}^2 \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z}\frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z}. \end{align}
Technically,
 $e$
is only the portion of the full kinetic energy resulting from the
$e$
is only the portion of the full kinetic energy resulting from the
 $x,y$
components of the mean flow; this expression arises naturally under the shallow assumption
$x,y$
components of the mean flow; this expression arises naturally under the shallow assumption
 $\mathscr {L}_1, \mathscr {L}_2 \gg \mathscr {L}_3$
and turns out to be the useful quantity in this context. Secondly, the GPE that would be released if the excess mass of the current
$\mathscr {L}_1, \mathscr {L}_2 \gg \mathscr {L}_3$
and turns out to be the useful quantity in this context. Secondly, the GPE that would be released if the excess mass of the current
 $R {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}$
was moved from elevation
$R {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}$
was moved from elevation
 $z$
to
$z$
to
 $b$
is
$b$
is
 $R g (z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \cos \theta$
. The evolution equation for
$R g (z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \cos \theta$
. The evolution equation for
 $(z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}$
is, by (2.1b
),
$(z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}$
is, by (2.1b
),
 \begin{align} \frac {\partial }{\partial t} (z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} & + \frac {\partial }{\partial x_j} (z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + \frac {\partial }{\partial z} (z-b) \left (\tilde {w} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!+ J_3}\right)\nonumber \\[-3pt] &\quad = \lbrack { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!} + \tilde {w}}\rbrack {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + J_3 - \sum _{\alpha =1}^2 \frac {\partial b}{\partial x_\alpha } {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}u_\alpha }}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}. \end{align}
\begin{align} \frac {\partial }{\partial t} (z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} & + \frac {\partial }{\partial x_j} (z-b) {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + \frac {\partial }{\partial z} (z-b) \left (\tilde {w} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!+ J_3}\right)\nonumber \\[-3pt] &\quad = \lbrack { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!} + \tilde {w}}\rbrack {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + J_3 - \sum _{\alpha =1}^2 \frac {\partial b}{\partial x_\alpha } {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}u_\alpha }}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}. \end{align}
Again, technically this is not the full GPE, which is
 $R g_i x_i {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\phi }\:\!}$
, but the portion of the GPE that turns out to be the useful quantity for shallow flows.
$R g_i x_i {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\phi }\:\!}$
, but the portion of the GPE that turns out to be the useful quantity for shallow flows.
2.2. Averaging over the depth
The equations in § 2.1 are integrated over the depth
 $b \leq z \leq H$
. The resulting system of equations is written in terms of the depth-averaged variables
$b \leq z \leq H$
. The resulting system of equations is written in terms of the depth-averaged variables
 \begin{align} \Phi = \frac {1}{h} \int _b^{H} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\phi }\:\!} \mathrm {d}{z}, \qquad U_1 \frac {1}{h} \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}u_1}\:\!} \mathrm {d}{z}, \qquad U_2 = \frac {1}{h} \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}u_2}\:\!} \mathrm {d}{z}, \qquad K = \frac {1}{h} \int _b^{H} k \mathrm {d}{z}. \end{align}
\begin{align} \Phi = \frac {1}{h} \int _b^{H} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\phi }\:\!} \mathrm {d}{z}, \qquad U_1 \frac {1}{h} \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}u_1}\:\!} \mathrm {d}{z}, \qquad U_2 = \frac {1}{h} \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}u_2}\:\!} \mathrm {d}{z}, \qquad K = \frac {1}{h} \int _b^{H} k \mathrm {d}{z}. \end{align}
Recall that, in general,
 $h \neq H-b$
, and that under a deep quiescent ambient we may take
$h \neq H-b$
, and that under a deep quiescent ambient we may take
 $H \to \infty$
to simplify. For the concentration field
$H \to \infty$
to simplify. For the concentration field
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!}$
(as an example) at a single point in
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!}$
(as an example) at a single point in
 $(x,y,t)$
, the depth average
$(x,y,t)$
, the depth average
 $\Phi$
has eliminated all information about the variation of concentration with
$\Phi$
has eliminated all information about the variation of concentration with
 $z$
. We carry this information forwards using a shape function
$z$
. We carry this information forwards using a shape function
 $\xi _\phi = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!} /\Phi$
which describes the variation of concentration relative to the depth average. It is informative to write the shape function not as a function of
$\xi _\phi = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!} /\Phi$
which describes the variation of concentration relative to the depth average. It is informative to write the shape function not as a function of
 $z$
but of
$z$
but of
 $\zeta : = (z-b)/h$
. For some gravity currents, a careful choice of
$\zeta : = (z-b)/h$
. For some gravity currents, a careful choice of
 $h$
will enable the shape functions to be invariant with respect to
$h$
will enable the shape functions to be invariant with respect to
 $(x,y,t)$
, all profiles of
$(x,y,t)$
, all profiles of
 $ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!}$
being the same up to a rescaling in magnitude,
$ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime}}\phi }\:\!}$
being the same up to a rescaling in magnitude,
 $\Phi$
, and a vertical stretch,
$\Phi$
, and a vertical stretch,
 $h$
; self-similarity. Generalising to all variables the decomposition takes the form
$h$
; self-similarity. Generalising to all variables the decomposition takes the form
 \begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\phi }\:\!}(x,y,z,t) &= \xi _\phi (x,y,\zeta,t) \cdot \Phi (x,y,t), \end{align}
\begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime}}\phi }\:\!}(x,y,z,t) &= \xi _\phi (x,y,\zeta,t) \cdot \Phi (x,y,t), \end{align}
 \begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }u_1}\:\!} (x,y,z,t) &= \xi _1(x,y,\zeta,t) \cdot U_1(x,y,t), \end{align}
\begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }u_1}\:\!} (x,y,z,t) &= \xi _1(x,y,\zeta,t) \cdot U_1(x,y,t), \end{align}
 \begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_2}\:\!} (x,y,z,t) &= \xi _2(x,y,\zeta,t) \cdot U_2(x,y,t), \end{align}
\begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_2}\:\!} (x,y,z,t) &= \xi _2(x,y,\zeta,t) \cdot U_2(x,y,t), \end{align}
 \begin{align} k(x,y,z,t) &= \xi _k(x,y,\zeta,t) \cdot K(x,y,t), \end{align}
\begin{align} k(x,y,z,t) &= \xi _k(x,y,\zeta,t) \cdot K(x,y,t), \end{align}
where
 $\xi _\phi$
,
$\xi _\phi$
,
 $\xi _1$
,
$\xi _1$
,
 $\xi _2$
and
$\xi _2$
and
 $\xi _k$
are shape functions satisfying
$\xi _k$
are shape functions satisfying
 \begin{align} \int _0^{\zeta _H} \xi _{\scriptstyle \bullet }(x,y,\zeta,t) \mathrm {d}{\zeta } &= 1, & \zeta _H & : = \frac {H-b}{h}. \end{align}
\begin{align} \int _0^{\zeta _H} \xi _{\scriptstyle \bullet }(x,y,\zeta,t) \mathrm {d}{\zeta } &= 1, & \zeta _H & : = \frac {H-b}{h}. \end{align}
Consequently,
 $\Phi$
,
$\Phi$
,
 $U_1$
,
$U_1$
,
 $U_2$
and
$U_2$
and
 $K$
are the depth-average values of density, velocity and TKE, while
$K$
are the depth-average values of density, velocity and TKE, while
 $\xi _\phi$
,
$\xi _\phi$
,
 $\xi _1$
,
$\xi _1$
,
 $\xi _2$
and
$\xi _2$
and
 $\xi _k$
capture the shape of the current. In particular, the expressions defined in table 1 are the features of the shape that influence the averaged properties of the current. The majority of the shape factors are of the form
$\xi _k$
capture the shape of the current. In particular, the expressions defined in table 1 are the features of the shape that influence the averaged properties of the current. The majority of the shape factors are of the form
 \begin{align} \sigma _{AB} &= \int _0^{\zeta _H} \xi _A \xi _B \mathrm {d}{\zeta }, &&\text {or}& \sigma _{ABC} &= \int _0^{\zeta _H} \xi _A \xi _B \xi _C \mathrm {d}{\zeta }, \end{align}
\begin{align} \sigma _{AB} &= \int _0^{\zeta _H} \xi _A \xi _B \mathrm {d}{\zeta }, &&\text {or}& \sigma _{ABC} &= \int _0^{\zeta _H} \xi _A \xi _B \xi _C \mathrm {d}{\zeta }, \end{align}
where we use
 $\xi _z = 2 \zeta$
. The exceptions are indicated by the
$\xi _z = 2 \zeta$
. The exceptions are indicated by the
 $\tilde {\sigma }_{\scriptstyle \bullet }$
or
$\tilde {\sigma }_{\scriptstyle \bullet }$
or
 $\varsigma _{\scriptstyle \bullet }$
notation. Note that our choice of normalisation (2.13e
) and shape factors (table 1 and figure 2) are different to those used by some authors, see Appendix B.
$\varsigma _{\scriptstyle \bullet }$
notation. Note that our choice of normalisation (2.13e
) and shape factors (table 1 and figure 2) are different to those used by some authors, see Appendix B.
Table 1. Definitions and properties of the shape factors. In the definitions we use the subscripts
 $\alpha,\beta,\gamma$
to indicate numerical values of
$\alpha,\beta,\gamma$
to indicate numerical values of
 $1$
or
$1$
or
 $2$
. We state the equations in this section where the shape factor appears, or else the first equation where it appears. The values for top-hat flow are calculated using (2.15).
$2$
. We state the equations in this section where the shape factor appears, or else the first equation where it appears. The values for top-hat flow are calculated using (2.15).


Figure 2. Violin plots of the distribution of values that each shape factor can take, computed from the dataset compiled by Fukuda et al. (Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) (Simmons et al. (Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020) are field data, all others are experimental). For each shape factor (marked to the left) we plot the probability density for the distribution (computed using a kernel method) as a black line. In the computation, the data are weighted to account for the large number of samples from some sources. The data points for each shape factor are plotted at the horizontal location of their value, and given a random vertical displacement within the kernel. Here,
 $h$
is calculated by setting
$h$
is calculated by setting
 $\sigma _{11}=1$
, and
$\sigma _{11}=1$
, and
 $\varsigma _h$
by (5.1) with
$\varsigma _h$
by (5.1) with
 $\delta =10^{-2}$
.
$\delta =10^{-2}$
.
There are two special cases of flows we will consider, along with the general case. Firstly, when the shape of the current is in self-similar form, the shape functions do not depend on
 $x$
,
$x$
,
 $y$
or
$y$
or
 $t$
, meaning the shape factors in table 1 are constants. Secondly, for top-hat flow, the shape functions take the form
$t$
, meaning the shape factors in table 1 are constants. Secondly, for top-hat flow, the shape functions take the form
 \begin{align} \xi _{\phi } &= \begin{cases} 0, & 1 \lt \zeta, \\ 1, & 0 \lt \zeta \lt 1, \\ \varsigma _\phi & \zeta = 0, \end{cases} & \xi _1 = \xi _2 = \xi _k &= \begin{cases} 0, & 1 \lt \zeta, \\ 1, & 0 \lt \zeta \lt 1, \end{cases} \end{align}
\begin{align} \xi _{\phi } &= \begin{cases} 0, & 1 \lt \zeta, \\ 1, & 0 \lt \zeta \lt 1, \\ \varsigma _\phi & \zeta = 0, \end{cases} & \xi _1 = \xi _2 = \xi _k &= \begin{cases} 0, & 1 \lt \zeta, \\ 1, & 0 \lt \zeta \lt 1, \end{cases} \end{align}
which yields the special values in table 1.
We next integrate the equations in § 2.1 over the depth
 $b \leq z \leq H$
using the results in Appendix C and applying the boundary conditions (2.8) (Ellison & Turner Reference Ellison and Turner1959; Parker et al. Reference Parker, Fukushima and Pantin1986). The indices
$b \leq z \leq H$
using the results in Appendix C and applying the boundary conditions (2.8) (Ellison & Turner Reference Ellison and Turner1959; Parker et al. Reference Parker, Fukushima and Pantin1986). The indices
 $\alpha,\beta,\gamma$
take a value of
$\alpha,\beta,\gamma$
take a value of
 $1$
or
$1$
or
 $2$
and sums range over these values. Conservation of fluid volume is, by (2.1a
),
$2$
and sums range over these values. Conservation of fluid volume is, by (2.1a
),
 \begin{gather} \frac {\partial }{\partial t} (\varsigma _h h) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big (\underbrace { h U_\beta }_{{\text {volume flux}}} \Big) = S_h = \underbrace { w_e \vphantom {\big)}}_{{\qquad \text {entrainment velocity}}}. \end{gather}
\begin{gather} \frac {\partial }{\partial t} (\varsigma _h h) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big (\underbrace { h U_\beta }_{{\text {volume flux}}} \Big) = S_h = \underbrace { w_e \vphantom {\big)}}_{{\qquad \text {entrainment velocity}}}. \end{gather}
Conservation of particle volume is, by (2.1b ),
 \begin{gather} \frac {\partial }{\partial t}\left ({h \Phi }\right) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace { \sigma _{\beta \phi } h U_\beta \Phi \vphantom {\big)}}_{{\text {particle flux}}} \Big) = S_{\Phi } = - \underbrace { \varsigma _{\phi } w_s \Phi \cos \theta \vphantom {\big)} }_{{\text {deposition}}} + \underbrace { E_s. \vphantom {\big)} }_{{\text {erosion}}} \end{gather}
\begin{gather} \frac {\partial }{\partial t}\left ({h \Phi }\right) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace { \sigma _{\beta \phi } h U_\beta \Phi \vphantom {\big)}}_{{\text {particle flux}}} \Big) = S_{\Phi } = - \underbrace { \varsigma _{\phi } w_s \Phi \cos \theta \vphantom {\big)} }_{{\text {deposition}}} + \underbrace { E_s. \vphantom {\big)} }_{{\text {erosion}}} \end{gather}
Conservation of momentum is, by (2.1c ), using (2.1d ) to calculate the hydrostatic pressure,
 \begin{gather} \frac {\partial }{\partial t} \left ({h U_\alpha }\right) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big (\underbrace { \sigma _{\beta \alpha } h U_\beta U_\alpha \vphantom {\big)}}_{{\text {momentum flux}}} \Big) + \frac {\partial }{\partial x_\alpha } \Big (\underbrace { {\frac {1}{2}} \sigma _{z\phi } R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\text {pressure}}} \Big) = S_{\alpha }, \end{gather}
\begin{gather} \frac {\partial }{\partial t} \left ({h U_\alpha }\right) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big (\underbrace { \sigma _{\beta \alpha } h U_\beta U_\alpha \vphantom {\big)}}_{{\text {momentum flux}}} \Big) + \frac {\partial }{\partial x_\alpha } \Big (\underbrace { {\frac {1}{2}} \sigma _{z\phi } R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\text {pressure}}} \Big) = S_{\alpha }, \end{gather}
 \begin{gather} S_{\alpha } = - \underbrace { R g h \Phi \cos \theta \frac {\partial b}{\partial x_\alpha } \vphantom {\bigg)} }_{{\text {pressure on bed slope}}} \qquad - \underbrace { u_{\alpha \ast }^2 \vphantom {\bigg)} }_{{\text {basal drag}}} \qquad + \underbrace { R g_\alpha h \Phi. \vphantom {\bigg)} }_{{\text {downslope gravity}}} \end{gather}
\begin{gather} S_{\alpha } = - \underbrace { R g h \Phi \cos \theta \frac {\partial b}{\partial x_\alpha } \vphantom {\bigg)} }_{{\text {pressure on bed slope}}} \qquad - \underbrace { u_{\alpha \ast }^2 \vphantom {\bigg)} }_{{\text {basal drag}}} \qquad + \underbrace { R g_\alpha h \Phi. \vphantom {\bigg)} }_{{\text {downslope gravity}}} \end{gather}
Conservation of MKE is, by (2.9),
 \begin{align} &\sum _\beta \frac {\partial }{\partial t} \left ({ {\textstyle \frac {1}{2}} \sigma _{\beta \beta } h U_\beta ^2 }\right) + \sum _{\beta \gamma } \frac {\partial }{\partial x_\beta } \Big ( \underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta \gamma \gamma } h U_\beta U_\gamma ^2 \vphantom {\big)}}_{{\text {MKE flux}}}\Big)\nonumber \\ &\qquad \qquad + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace {{\textstyle \frac {1}{2}} \tilde {\sigma }_{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\text {pressure work}}} \Big) = S_M = \tilde {S}_M - \underbrace {h \mathcal {P} - h \mathcal {B}_M \vphantom {\big)}}_{{\text {energy transfer}}}, \end{align}
\begin{align} &\sum _\beta \frac {\partial }{\partial t} \left ({ {\textstyle \frac {1}{2}} \sigma _{\beta \beta } h U_\beta ^2 }\right) + \sum _{\beta \gamma } \frac {\partial }{\partial x_\beta } \Big ( \underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta \gamma \gamma } h U_\beta U_\gamma ^2 \vphantom {\big)}}_{{\text {MKE flux}}}\Big)\nonumber \\ &\qquad \qquad + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace {{\textstyle \frac {1}{2}} \tilde {\sigma }_{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\text {pressure work}}} \Big) = S_M = \tilde {S}_M - \underbrace {h \mathcal {P} - h \mathcal {B}_M \vphantom {\big)}}_{{\text {energy transfer}}}, \end{align}
 \begin{align} &\tilde {S}_M = \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g_\beta h \Phi \vphantom {\Big)}}_{{\text {work by downslope gravity}}} \qquad \qquad - \underbrace {h \epsilon _M \vphantom {\Big)}}_{{\text {MKE dissipation}}}.\end{align}
\begin{align} &\tilde {S}_M = \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g_\beta h \Phi \vphantom {\Big)}}_{{\text {work by downslope gravity}}} \qquad \qquad - \underbrace {h \epsilon _M \vphantom {\Big)}}_{{\text {MKE dissipation}}}.\end{align}
Conservation of GPE is, by the product of (2.11) and
 $R g \cos \theta$
,
$R g \cos \theta$
,
 \begin{align} \frac {\partial }{\partial t}\!\left ({ {\textstyle \frac {1}{2}} \sigma _{z\phi } R g h^2 \Phi \cos \theta }\right) & + \sum _\beta \frac {\partial }{\partial x_\beta } \Big (\! \underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\text {GPE flux}}}\! \Big) = S_G = \tilde {S}_G + \underbrace {h \mathcal {B}_M + h \mathcal {B}_K \vphantom {\big)}}_{{\text {energy transfer}}},\nonumber\\[4pt] \end{align}
\begin{align} \frac {\partial }{\partial t}\!\left ({ {\textstyle \frac {1}{2}} \sigma _{z\phi } R g h^2 \Phi \cos \theta }\right) & + \sum _\beta \frac {\partial }{\partial x_\beta } \Big (\! \underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\text {GPE flux}}}\! \Big) = S_G = \tilde {S}_G + \underbrace {h \mathcal {B}_M + h \mathcal {B}_K \vphantom {\big)}}_{{\text {energy transfer}}},\nonumber\\[4pt] \end{align}
 \begin{align} \tilde {S}_G = - \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g h \Phi \cos \theta \frac {\partial b}{\partial x_\beta }}_{{\text {variation in datum}}} - \underbrace { w_s R g h \Phi (\cos \theta)^2}_{{\text {energy loss to settling}}}. \end{align}
\begin{align} \tilde {S}_G = - \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g h \Phi \cos \theta \frac {\partial b}{\partial x_\beta }}_{{\text {variation in datum}}} - \underbrace { w_s R g h \Phi (\cos \theta)^2}_{{\text {energy loss to settling}}}. \end{align}
(The variation in datum arises because we measure GPE relative to the local bed elevation in (2.11)). Conservation of TKE is, by (2.1e ),
 \begin{gather} \frac {\partial }{\partial t} ({ h K }) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace {\sigma _{\beta k} h U_\beta K \vphantom {\big)}}_{{\text {TKE flux}}} \Big) = S_K = \tilde {S}_K + \underbrace {h \mathcal {P} - h \mathcal {B}_K \vphantom {\big)}}_{{\text {energy transfer}}}, \end{gather}
\begin{gather} \frac {\partial }{\partial t} ({ h K }) + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace {\sigma _{\beta k} h U_\beta K \vphantom {\big)}}_{{\text {TKE flux}}} \Big) = S_K = \tilde {S}_K + \underbrace {h \mathcal {P} - h \mathcal {B}_K \vphantom {\big)}}_{{\text {energy transfer}}}, \end{gather}
 \begin{gather} \tilde {S}_K = - \underbrace {h \epsilon _K \vphantom {\big)}}_{{\text {TKE dissipation}}}. \end{gather}
\begin{gather} \tilde {S}_K = - \underbrace {h \epsilon _K \vphantom {\big)}}_{{\text {TKE dissipation}}}. \end{gather}
Summing (2.19)–(2.21) yields the equation for conservation of total energy,
 $E$
,
$E$
,
 \begin{align} &\frac {\partial }{\partial t} ({h E}) + \sum _{\beta \gamma } \frac {\partial }{\partial x_\beta } \Big (\underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta \gamma \gamma } h U_\beta U_\gamma ^2 \vphantom {\big)}}_{{\text {MKE flux}}} \Big)\nonumber \\ &\qquad \qquad + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace {\sigma _{\beta k} h U_\beta K \vphantom {\big)}}_{{\text {TKE flux}}} + \underbrace {\varsigma _{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\qquad \text {GPE flux and pressure work}}} \Big) = S_E, \end{align}
\begin{align} &\frac {\partial }{\partial t} ({h E}) + \sum _{\beta \gamma } \frac {\partial }{\partial x_\beta } \Big (\underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta \gamma \gamma } h U_\beta U_\gamma ^2 \vphantom {\big)}}_{{\text {MKE flux}}} \Big)\nonumber \\ &\qquad \qquad + \sum _\beta \frac {\partial }{\partial x_\beta } \Big ( \underbrace {\sigma _{\beta k} h U_\beta K \vphantom {\big)}}_{{\text {TKE flux}}} + \underbrace {\varsigma _{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta \vphantom {\big)}}_{{\qquad \text {GPE flux and pressure work}}} \Big) = S_E, \end{align}
 \begin{align} S_E &= - \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g h \Phi \cos \theta \frac {\partial b}{\partial x_\beta } \vphantom {\bigg)} }_{{\text {variation in GPE datum}}} + \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g_\beta h \Phi \vphantom {\bigg)} }_{{\text {work by downslope gravity}}} \qquad \qquad \nonumber \\ &\quad - \underbrace { h \epsilon _T \vphantom {\big)} }_{{\text {total dissipation}}} \qquad - \underbrace { w_s R g h \Phi (\cos \theta)^2, \vphantom {\big)} }_{{\text {GPE loss to settling}}} \end{align}
\begin{align} S_E &= - \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g h \Phi \cos \theta \frac {\partial b}{\partial x_\beta } \vphantom {\bigg)} }_{{\text {variation in GPE datum}}} + \sum _\beta \underbrace { \sigma _{\beta \phi } U_\beta R g_\beta h \Phi \vphantom {\bigg)} }_{{\text {work by downslope gravity}}} \qquad \qquad \nonumber \\ &\quad - \underbrace { h \epsilon _T \vphantom {\big)} }_{{\text {total dissipation}}} \qquad - \underbrace { w_s R g h \Phi (\cos \theta)^2, \vphantom {\big)} }_{{\text {GPE loss to settling}}} \end{align}
where the total energy (per unit mass) is defined as
 \begin{equation} E = \sum _\beta \underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta \beta } U_\beta ^2 \vphantom {\big)}}_{{\text {MKE}}} + \underbrace {K \vphantom {\big)}}_{{\text {TKE}}} + \underbrace {{\textstyle \frac {1}{2}} \sigma _{z\phi } R g h \Phi \cos \theta \vphantom {\big)}}_{{\text {GPE}}}. \end{equation}
\begin{equation} E = \sum _\beta \underbrace {{\textstyle \frac {1}{2}} \sigma _{\beta \beta } U_\beta ^2 \vphantom {\big)}}_{{\text {MKE}}} + \underbrace {K \vphantom {\big)}}_{{\text {TKE}}} + \underbrace {{\textstyle \frac {1}{2}} \sigma _{z\phi } R g h \Phi \cos \theta \vphantom {\big)}}_{{\text {GPE}}}. \end{equation}
While we will call
 $E$
the total energy going forward, it is technically only the portion of the total energy that is useful for describing shallow flows; see the discussion below (2.10) and (2.11). Throughout our stating of the depth-averaged system, we have used the definitions of settling velocity, erosion, basal shear velocity and depth-average total, mean flow and turbulent dissipation as
$E$
the total energy going forward, it is technically only the portion of the total energy that is useful for describing shallow flows; see the discussion below (2.10) and (2.11). Throughout our stating of the depth-averaged system, we have used the definitions of settling velocity, erosion, basal shear velocity and depth-average total, mean flow and turbulent dissipation as
 \begin{equation} \begin{gathered} \begin{aligned} w_s \cos \theta &= - \tilde {w}, & E_s &= { J_3 }\Bigg |_b, & u_{\alpha \ast }^2 &= { \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z} }\Bigg |_b, \end{aligned} \\ \begin{aligned} \epsilon _T &= \epsilon _M + \epsilon _K, & h \epsilon _M &= \int _b^{H} \tilde {\epsilon }_M \mathrm {d}{z}, & h \epsilon _K &= \int _b^{H} \tilde {\epsilon }_K \mathrm {d}{z} - {T_3}\Big |_b. \end{aligned} \end{gathered} \end{equation}
\begin{equation} \begin{gathered} \begin{aligned} w_s \cos \theta &= - \tilde {w}, & E_s &= { J_3 }\Bigg |_b, & u_{\alpha \ast }^2 &= { \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} }{\partial z} }\Bigg |_b, \end{aligned} \\ \begin{aligned} \epsilon _T &= \epsilon _M + \epsilon _K, & h \epsilon _M &= \int _b^{H} \tilde {\epsilon }_M \mathrm {d}{z}, & h \epsilon _K &= \int _b^{H} \tilde {\epsilon }_K \mathrm {d}{z} - {T_3}\Big |_b. \end{aligned} \end{gathered} \end{equation}
The terms marked as ‘energy transfer’ are the depth-averaged TKE production, turbulent buoyancy flux and mean-flow buoyancy flux, defined as
 \begin{align} \mathcal {P} & : = \frac {1}{h} \int _b^{H} \tilde {\mathcal {P}} \mathrm {d}{z}, \end{align}
\begin{align} \mathcal {P} & : = \frac {1}{h} \int _b^{H} \tilde {\mathcal {P}} \mathrm {d}{z}, \end{align}
 \begin{align} \mathcal {B}_K & : = \frac {R g \cos \theta }{h} \int _b^{H} J_3 \mathrm {d}{z}. \end{align}
\begin{align} \mathcal {B}_K & : = \frac {R g \cos \theta }{h} \int _b^{H} J_3 \mathrm {d}{z}. \end{align}
 \begin{align} \mathcal {B}_M & : = \frac {R g \cos \theta }{h} \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \mathrm {d}{z}, \end{align}
\begin{align} \mathcal {B}_M & : = \frac {R g \cos \theta }{h} \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \mathrm {d}{z}, \end{align}
respectively. We understand
 $\mathcal {P}$
as the rate of conversion of MKE to TKE,
$\mathcal {P}$
as the rate of conversion of MKE to TKE,
 $\mathcal {B}_K$
as the rate of conversion of TKE to GPE and
$\mathcal {B}_K$
as the rate of conversion of TKE to GPE and
 $\mathcal {B}_M$
as the rate of conversion of MKE to GPE.
$\mathcal {B}_M$
as the rate of conversion of MKE to GPE.
We briefly note that in figure 2 and other figures going forward, the data considered are for unidirectional currents (
 $U_2=\partial /\partial y=0$
) and the depth is defined following Ellison & Turner (Reference Ellison and Turner1959) and Parker et al. (Reference Parker, Fukushima and Pantin1986) by setting
$U_2=\partial /\partial y=0$
) and the depth is defined following Ellison & Turner (Reference Ellison and Turner1959) and Parker et al. (Reference Parker, Fukushima and Pantin1986) by setting
 $\sigma _{11} = 1$
; that is take
$\sigma _{11} = 1$
; that is take
 \begin{equation} h = \left ({ \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} \mathrm {d}{z} } \right)^2 \Bigg / { \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} ^2 \mathrm {d}{z} }. \end{equation}
\begin{equation} h = \left ({ \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} \mathrm {d}{z} } \right)^2 \Bigg / { \int _b^{H} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} ^2 \mathrm {d}{z} }. \end{equation}
In our analysis
 $h$
is arbitrary, and will be discussed thoroughly in § 5.
$h$
is arbitrary, and will be discussed thoroughly in § 5.
2.3. Interpretation as a classical volumetric model
As discussed in the introduction, the purpose of this derivation is to produce a system of equations for the same unknown functions as Parker et al. (Reference Parker, Fukushima and Pantin1986), but allowing for the imposition of shape functions selected by the modeller to improve accuracy. We have also incorporated arbitrary slowly varying topography
 $b$
, again this can be specified by the modeller, along with generalising to three-dimensional flows (that is, we include variation in
$b$
, again this can be specified by the modeller, along with generalising to three-dimensional flows (that is, we include variation in
 $y$
). The equations governing volume (2.16), particles (2.17) and momentum (2.18) are precisely these generalisations, and the case
$y$
). The equations governing volume (2.16), particles (2.17) and momentum (2.18) are precisely these generalisations, and the case
 $\varsigma _h=1$
has been used previously (Dorrell et al. Reference Dorrell, Darby, Peakall, Sumner, Parsons and Wynn2014; Sher & Woods Reference Sher and Woods2015; Negretti et al. Reference Negretti, Flòr and Hopfinger2017). For the energetics, we have derived a set of three equations for the separate contributions from MKE (2.19), GPE (2.20) and TKE (2.21), along with their sum, which describes the evolution of the total energy (2.22). Parker et al. (Reference Parker, Fukushima and Pantin1986) present their model with an equation for the evolution of TKE, and so we may naively think that (2.21) is the appropriate equation. However, the key consideration is not the component of energy modelled, but the closures required to complete the model. As was found by Parker et al. (Reference Parker, Fukushima and Pantin1986) in their top-hat model, the energy transfer terms are intimately related to other model closures, and we must therefore eliminate them from the model. That is not to say these terms are not important (Odier et al. Reference Odier, Chen and Ecke2014), but rather that they cannot be specified independently. The only equation which does not include energy transfer terms is the equation for total energy (2.22). This forms the model: the functions
$\varsigma _h=1$
has been used previously (Dorrell et al. Reference Dorrell, Darby, Peakall, Sumner, Parsons and Wynn2014; Sher & Woods Reference Sher and Woods2015; Negretti et al. Reference Negretti, Flòr and Hopfinger2017). For the energetics, we have derived a set of three equations for the separate contributions from MKE (2.19), GPE (2.20) and TKE (2.21), along with their sum, which describes the evolution of the total energy (2.22). Parker et al. (Reference Parker, Fukushima and Pantin1986) present their model with an equation for the evolution of TKE, and so we may naively think that (2.21) is the appropriate equation. However, the key consideration is not the component of energy modelled, but the closures required to complete the model. As was found by Parker et al. (Reference Parker, Fukushima and Pantin1986) in their top-hat model, the energy transfer terms are intimately related to other model closures, and we must therefore eliminate them from the model. That is not to say these terms are not important (Odier et al. Reference Odier, Chen and Ecke2014), but rather that they cannot be specified independently. The only equation which does not include energy transfer terms is the equation for total energy (2.22). This forms the model: the functions
 $h$
,
$h$
,
 $\Phi$
,
$\Phi$
,
 $U_\alpha$
,
$U_\alpha$
,
 $K$
are solved for using the system of equations (2.16)–(2.18) and (2.22). To close the system the modeller must specify the topography,
$K$
are solved for using the system of equations (2.16)–(2.18) and (2.22). To close the system the modeller must specify the topography,
 $b$
, and shape of the concentration, velocity and turbulence fields through the shape functions in (2.13) which give rise to the shape factors in the model through the expressions in table 1. Additionally, the modeller must specify the parameters and closures present in the model from Parker et al. (Reference Parker, Fukushima and Pantin1986), including entrainment of ambient fluid at speed
$b$
, and shape of the concentration, velocity and turbulence fields through the shape functions in (2.13) which give rise to the shape factors in the model through the expressions in table 1. Additionally, the modeller must specify the parameters and closures present in the model from Parker et al. (Reference Parker, Fukushima and Pantin1986), including entrainment of ambient fluid at speed
 $w_e$
, erosion of the bed at rate
$w_e$
, erosion of the bed at rate
 $E_s$
, drag from the bed with shear velocity
$E_s$
, drag from the bed with shear velocity
 $u_{\alpha \ast }$
and viscous dissipation of energy at rate
$u_{\alpha \ast }$
and viscous dissipation of energy at rate
 $\epsilon _T$
.
$\epsilon _T$
.
3. Consistency requirements for energy transfer
The system of governing equations (2.16)–(2.18) and (2.22) lacks explicit inclusion of the energy transfer terms defined in (2.25), and yet it forms a closed system of equations for the unknown functions
 $h$
,
$h$
,
 $\Phi$
,
$\Phi$
,
 $U_\alpha$
and
$U_\alpha$
and
 $K$
. Consequently, we can eliminate the time evolution in the additional energetic equations (2.19)–(2.21) to obtain expressions for
$K$
. Consequently, we can eliminate the time evolution in the additional energetic equations (2.19)–(2.21) to obtain expressions for
 $\mathcal {P}$
,
$\mathcal {P}$
,
 $\mathcal {B}_M$
and
$\mathcal {B}_M$
and
 $\mathcal {B}_K$
in terms of the source terms and the spatial gradients of the unknown functions. This allows us to explore the bulk energetics of gravity currents. The expressions obtained are, unfortunately, rather complicated, but they give the full implications of the equations in § 2.2. We endeavour to give some interpretation of the expressions here, and give simplified expressions in § 4. Verification of these manipulations using the computer algebra software Maple is provided as supplemental information. We begin with a derivation of the energy transfer terms in § 3.1, and discuss their use for the development of energetically consistent model closures in § 3.2.
$\mathcal {B}_K$
in terms of the source terms and the spatial gradients of the unknown functions. This allows us to explore the bulk energetics of gravity currents. The expressions obtained are, unfortunately, rather complicated, but they give the full implications of the equations in § 2.2. We endeavour to give some interpretation of the expressions here, and give simplified expressions in § 4. Verification of these manipulations using the computer algebra software Maple is provided as supplemental information. We begin with a derivation of the energy transfer terms in § 3.1, and discuss their use for the development of energetically consistent model closures in § 3.2.
3.1. Derivation of energetic consistency requirements
We begin by rearranging the equations for MKE (2.19a ) and GPE (2.20a ) so that the time derivatives can be easily substituted from the governing equations for volume, particles and momentum (2.16)–(2.18)
 \begin{align} S_M = - \left (\!{\sum _\beta \frac {1}{2} \sigma _{\beta \beta } U_\beta ^2}\right) \frac {\partial h}{\partial t} & + \sum _\beta \sigma _{\beta \beta } U_\beta \frac {\partial }{\partial t}(h U_\beta) + \sum _\beta \frac {1}{2} h U_\beta ^2 \frac {\partial \sigma _{\beta \beta }}{\partial t}\nonumber \\ & + \sum _\beta \frac {\partial }{\partial x_\beta } \left (\!{ \sum _\gamma \frac {1}{2} \sigma _{\beta \gamma \gamma } h U_\beta U_\gamma ^2 + \frac {1}{2} \tilde {\sigma }_{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta }\right)\!, \end{align}
\begin{align} S_M = - \left (\!{\sum _\beta \frac {1}{2} \sigma _{\beta \beta } U_\beta ^2}\right) \frac {\partial h}{\partial t} & + \sum _\beta \sigma _{\beta \beta } U_\beta \frac {\partial }{\partial t}(h U_\beta) + \sum _\beta \frac {1}{2} h U_\beta ^2 \frac {\partial \sigma _{\beta \beta }}{\partial t}\nonumber \\ & + \sum _\beta \frac {\partial }{\partial x_\beta } \left (\!{ \sum _\gamma \frac {1}{2} \sigma _{\beta \gamma \gamma } h U_\beta U_\gamma ^2 + \frac {1}{2} \tilde {\sigma }_{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta }\right)\!, \end{align}
 \begin{align} S_G = \frac {1}{2} \sigma _{z\phi } R g h \Phi \cos \theta \frac {\partial h}{\partial t} & + \frac {1}{2} \sigma _{z\phi } R g h \cos \theta \frac {\partial }{\partial t} \left ({h\Phi }\right) + \frac {1}{2} R g h^2 \Phi \cos \theta \frac {\partial \sigma _{z\phi }}{\partial t}\qquad\qquad\nonumber \\ & \qquad\qquad\qquad\quad\qquad + \sum _\beta \frac {\partial }{\partial x_\beta } \left ({ \frac {1}{2} \sigma _{\beta z \phi } U_\beta R g h^2 \Phi \cos \theta }\right). \end{align}
\begin{align} S_G = \frac {1}{2} \sigma _{z\phi } R g h \Phi \cos \theta \frac {\partial h}{\partial t} & + \frac {1}{2} \sigma _{z\phi } R g h \cos \theta \frac {\partial }{\partial t} \left ({h\Phi }\right) + \frac {1}{2} R g h^2 \Phi \cos \theta \frac {\partial \sigma _{z\phi }}{\partial t}\qquad\qquad\nonumber \\ & \qquad\qquad\qquad\quad\qquad + \sum _\beta \frac {\partial }{\partial x_\beta } \left ({ \frac {1}{2} \sigma _{\beta z \phi } U_\beta R g h^2 \Phi \cos \theta }\right). \end{align}
Due to the structure of the source terms
 $S_M$
,
$S_M$
,
 $S_G$
and
$S_G$
and
 $S_K$
, it is not possible to rearrange them into expressions for
$S_K$
, it is not possible to rearrange them into expressions for
 $\mathcal {P}$
,
$\mathcal {P}$
,
 $\mathcal {B}_K$
and
$\mathcal {B}_K$
and
 $\mathcal {B}_M$
. Instead, two of these can be expressed in terms of the remaining one. We choose to express
$\mathcal {B}_M$
. Instead, two of these can be expressed in terms of the remaining one. We choose to express
 $\mathcal {P}$
and
$\mathcal {P}$
and
 $\mathcal {B}_K$
in terms of
$\mathcal {B}_K$
in terms of
 $\mathcal {B}_M$
, which yields
$\mathcal {B}_M$
, which yields
 \begin{align} h \mathcal {P} &= - h \mathcal {B}_M - \left ({ S_M - \tilde {S}_M }\right),& h \mathcal {B}_K = - h \mathcal {B}_M + \left ({ S_G - \tilde {S}_G }\right), \end{align}
\begin{align} h \mathcal {P} &= - h \mathcal {B}_M - \left ({ S_M - \tilde {S}_M }\right),& h \mathcal {B}_K = - h \mathcal {B}_M + \left ({ S_G - \tilde {S}_G }\right), \end{align}
with the second equality in the TKE equation (2.21a
) then stating simply
 $S_{E} + S_K + S_G = \tilde {S}_{E} + \tilde {S}_K + \tilde {S}_G$
. The reason for this choice is that
$S_{E} + S_K + S_G = \tilde {S}_{E} + \tilde {S}_K + \tilde {S}_G$
. The reason for this choice is that
 $\mathcal {B}_M$
is a property of the mean flow, and can therefore be deduced from the equations describing the mean flow, whereas the others are properties of the turbulence requiring closure. A consequence of this choice is that
$\mathcal {B}_M$
is a property of the mean flow, and can therefore be deduced from the equations describing the mean flow, whereas the others are properties of the turbulence requiring closure. A consequence of this choice is that
 $h \mathcal {P}$
will be derived as the implied loss of MKE, while
$h \mathcal {P}$
will be derived as the implied loss of MKE, while
 $h \mathcal {B}_K$
is derived as the implied gain of GPE, and this will be seen in the expressions to follow. To deduce
$h \mathcal {B}_K$
is derived as the implied gain of GPE, and this will be seen in the expressions to follow. To deduce
 $\mathcal {B}_M$
, we employ the continuity equation
$\mathcal {B}_M$
, we employ the continuity equation
 \begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial x} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} }{\partial y} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!} }{\partial z} &= 0, &&\text {thus}& {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!} &= - \int _b^{z} { \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial x} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} }{\partial y} }\Big |_{z^{\prime}} \mathrm {d}{z^{\prime}}. \end{align}
\begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial x} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} }{\partial y} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!} }{\partial z} &= 0, &&\text {thus}& {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }w}\:\!} &= - \int _b^{z} { \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial x} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} }{\partial y} }\Big |_{z^{\prime}} \mathrm {d}{z^{\prime}}. \end{align}
Substituting into the definition of
 $\mathcal {B}_M$
(2.25c
) and decomposing into shape functions (2.13) to rewrite in terms of shape factors, we obtain the expression for
$\mathcal {B}_M$
(2.25c
) and decomposing into shape functions (2.13) to rewrite in terms of shape factors, we obtain the expression for
 $h \mathcal {B}_M$
given below. To obtain expressions for the other turbulent energy transfers, we begin with the expressions in (3.2), into which we substitute our expression for
$h \mathcal {B}_M$
given below. To obtain expressions for the other turbulent energy transfers, we begin with the expressions in (3.2), into which we substitute our expression for
 $h \mathcal {B}_M$
, the rearranged energy equations (3.1) and eliminate time derivatives using the governing equations (2.16)–(2.18). These manipulations are algebraically challenging, and verification of the results using the computer algebra package Maple are provided as supplemental information. Firstly, the depth-integrated rate of conversion of MKE to TKE is
$h \mathcal {B}_M$
, the rearranged energy equations (3.1) and eliminate time derivatives using the governing equations (2.16)–(2.18). These manipulations are algebraically challenging, and verification of the results using the computer algebra package Maple are provided as supplemental information. Firstly, the depth-integrated rate of conversion of MKE to TKE is
 \begin{align} h \mathcal {P} = & \frac {1}{2} \left ({\sum _\beta \frac {\sigma _{\beta \beta }}{\varsigma _h} U_\beta ^2}\right) w_e + \sum _\beta \sigma _{\beta \beta } U_\beta u_{\beta \ast }^2 - h \epsilon _M\nonumber \\ & + \sum _\beta (\sigma _{\beta \phi }-\sigma _{\beta \beta }) U_\beta R h \Phi \left ({ g_\beta - g \cos \theta \frac {\partial b}{\partial x_\beta } }\right)\nonumber \\ & + \frac {1}{2} \sum _{\beta \gamma } \left ({ - \frac {\sigma _{\gamma \gamma }}{\varsigma _h} + 2 \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) U_\gamma ^2 U_\beta \frac {\partial h}{\partial x_\beta }\nonumber \\ & + \frac {1}{2} \sum _{\beta } \left ({ - \frac {\sigma _{\beta \beta }}{\varsigma _h} + 4\sigma _{\beta \beta }^2 - 3\sigma _{\beta \beta \beta } }\right) h U_\beta ^2 \frac {\partial U_\beta }{\partial x_\beta }\nonumber \\ & + \frac {1}{2} \sum _{\beta \neq \gamma } \Bigg\lgroup \left ({ - \frac {\sigma _{\gamma \gamma }}{\varsigma _h} + 2 \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) h U_\gamma ^2 \frac {\partial U_\beta }{\partial x_\beta }\nonumber\\ & \qquad\qquad\ \ + 2 \left ({ \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) h U_\beta U_\gamma \frac {\partial U_\gamma }{\partial x_\beta } \Bigg\rgroup \nonumber \\[3pt] & + \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \varsigma _{\beta z\phi } }\right) U_\beta R g h \Phi \cos \theta \frac {\partial h}{\partial x_\beta }\nonumber \\[3pt] & + \frac {1}{2} \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \tilde {\sigma }_{\beta z\phi } }\right) U_\beta R g h^2 \cos \theta \frac {\partial \Phi }{\partial x_\beta }\nonumber \\[3pt] & + \frac {1}{2} \sum _\beta \Bigg\lgroup { - \frac {1}{\varsigma _h} \frac {\partial }{\partial t} \left ({\varsigma _h \sigma _{\beta \beta }}\right) + \sum _\gamma \left ({ 2 \sigma _{\beta \beta } \frac {\partial \sigma _{\beta \gamma }}{\partial x_\gamma } - \frac {\partial \sigma _{\beta \beta \gamma }}{\partial x_\gamma } }\right) U_\gamma }\Bigg\rgroup h U_\beta ^2\nonumber \\[3pt] & + \frac {1}{2} \sum _\beta \left ({\sigma _{\beta \beta } \frac {\partial \sigma _{z\phi }}{\partial x_\beta } - \frac {\partial \tilde {\sigma }_{\beta z \phi }}{\partial x_\beta } + \tilde {\sigma }_{D\beta z \phi }}\right) U_\beta R g h^2 \Phi \cos \theta. \end{align}
\begin{align} h \mathcal {P} = & \frac {1}{2} \left ({\sum _\beta \frac {\sigma _{\beta \beta }}{\varsigma _h} U_\beta ^2}\right) w_e + \sum _\beta \sigma _{\beta \beta } U_\beta u_{\beta \ast }^2 - h \epsilon _M\nonumber \\ & + \sum _\beta (\sigma _{\beta \phi }-\sigma _{\beta \beta }) U_\beta R h \Phi \left ({ g_\beta - g \cos \theta \frac {\partial b}{\partial x_\beta } }\right)\nonumber \\ & + \frac {1}{2} \sum _{\beta \gamma } \left ({ - \frac {\sigma _{\gamma \gamma }}{\varsigma _h} + 2 \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) U_\gamma ^2 U_\beta \frac {\partial h}{\partial x_\beta }\nonumber \\ & + \frac {1}{2} \sum _{\beta } \left ({ - \frac {\sigma _{\beta \beta }}{\varsigma _h} + 4\sigma _{\beta \beta }^2 - 3\sigma _{\beta \beta \beta } }\right) h U_\beta ^2 \frac {\partial U_\beta }{\partial x_\beta }\nonumber \\ & + \frac {1}{2} \sum _{\beta \neq \gamma } \Bigg\lgroup \left ({ - \frac {\sigma _{\gamma \gamma }}{\varsigma _h} + 2 \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) h U_\gamma ^2 \frac {\partial U_\beta }{\partial x_\beta }\nonumber\\ & \qquad\qquad\ \ + 2 \left ({ \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) h U_\beta U_\gamma \frac {\partial U_\gamma }{\partial x_\beta } \Bigg\rgroup \nonumber \\[3pt] & + \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \varsigma _{\beta z\phi } }\right) U_\beta R g h \Phi \cos \theta \frac {\partial h}{\partial x_\beta }\nonumber \\[3pt] & + \frac {1}{2} \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \tilde {\sigma }_{\beta z\phi } }\right) U_\beta R g h^2 \cos \theta \frac {\partial \Phi }{\partial x_\beta }\nonumber \\[3pt] & + \frac {1}{2} \sum _\beta \Bigg\lgroup { - \frac {1}{\varsigma _h} \frac {\partial }{\partial t} \left ({\varsigma _h \sigma _{\beta \beta }}\right) + \sum _\gamma \left ({ 2 \sigma _{\beta \beta } \frac {\partial \sigma _{\beta \gamma }}{\partial x_\gamma } - \frac {\partial \sigma _{\beta \beta \gamma }}{\partial x_\gamma } }\right) U_\gamma }\Bigg\rgroup h U_\beta ^2\nonumber \\[3pt] & + \frac {1}{2} \sum _\beta \left ({\sigma _{\beta \beta } \frac {\partial \sigma _{z\phi }}{\partial x_\beta } - \frac {\partial \tilde {\sigma }_{\beta z \phi }}{\partial x_\beta } + \tilde {\sigma }_{D\beta z \phi }}\right) U_\beta R g h^2 \Phi \cos \theta. \end{align}
The terms in the first line are the energy required to accelerate entrained fluid, the work done by drag and the MKE lost to viscous effects. The second line results from an imbalance between work done by downslope gravity on the mean velocity and that from velocity/density profiles, along with the imbalance of the implied work by varying GPE datum and the vertical transport of material. The third line is the result of imbalances in the energy changes associated with varying depth from a changing volume of fluid, work done by depth-average momentum and the depth-resolved transport of MKE; the fourth, fifth, and sixth lines similarly with the effect of varying velocity. The seventh and eighth lines result from an imbalance of work done by the depth-average pressure/GPE and depth-resolved transport of these quantities. The ninth line includes the effective variation in MKE from the shape functions varying temporally and spatially, and similarly the variation in MKE flux. The tenth line includes the imbalance between depth-average and depth-resolved pressure work from varying shape functions, along with the vertical transport generated by varying
 $\xi _\beta$
. Next, the depth-integrated rate of conversion of TKE to GPE is
$\xi _\beta$
. Next, the depth-integrated rate of conversion of TKE to GPE is
 \begin{align} h \mathcal {B}_K = & \frac {1}{2} R g h \cos \theta \Bigg \lgroup \frac {\sigma _{z\phi }}{\varsigma _h} \Phi w_e + \lbrack { 2 - \sigma _{z\phi } \varsigma _\phi }\rbrack w_s \Phi \cos \theta + \sigma _{z\phi } E_s\nonumber \\ & + \sum _\beta\! \left (\!{ - \frac {\sigma _{z\phi }}{\varsigma _h} - \sigma _{\beta \phi }\sigma _{z\phi } + 2\varsigma _{\beta z \phi } }\right)\! \Phi \frac {\partial}{\partial x_\beta} {(h U_\beta)} + \sum _\beta \left ({ - \sigma _{\beta \phi }\sigma _{z\phi } + \sigma _{\beta z \phi } }\right) U_\beta h \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ & + \Bigg\lbrack {\varsigma _h \frac {\partial }{\partial t} \left ({ \frac {\sigma _{z\phi }}{\varsigma _h}}\right) + \sum _{\beta } \left ({ - \sigma _{z\phi } \frac {\partial \sigma _{\beta \phi }}{\partial x_\beta } + \frac {\partial \sigma _{\beta z \phi }}{\partial x_\beta } + \tilde {\sigma }_{D\beta z \phi } }\right) U_\beta }\Bigg\rbrack h \Phi \Bigg \rgroup. \end{align}
\begin{align} h \mathcal {B}_K = & \frac {1}{2} R g h \cos \theta \Bigg \lgroup \frac {\sigma _{z\phi }}{\varsigma _h} \Phi w_e + \lbrack { 2 - \sigma _{z\phi } \varsigma _\phi }\rbrack w_s \Phi \cos \theta + \sigma _{z\phi } E_s\nonumber \\ & + \sum _\beta\! \left (\!{ - \frac {\sigma _{z\phi }}{\varsigma _h} - \sigma _{\beta \phi }\sigma _{z\phi } + 2\varsigma _{\beta z \phi } }\right)\! \Phi \frac {\partial}{\partial x_\beta} {(h U_\beta)} + \sum _\beta \left ({ - \sigma _{\beta \phi }\sigma _{z\phi } + \sigma _{\beta z \phi } }\right) U_\beta h \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ & + \Bigg\lbrack {\varsigma _h \frac {\partial }{\partial t} \left ({ \frac {\sigma _{z\phi }}{\varsigma _h}}\right) + \sum _{\beta } \left ({ - \sigma _{z\phi } \frac {\partial \sigma _{\beta \phi }}{\partial x_\beta } + \frac {\partial \sigma _{\beta z \phi }}{\partial x_\beta } + \tilde {\sigma }_{D\beta z \phi } }\right) U_\beta }\Bigg\rbrack h \Phi \Bigg \rgroup. \end{align}
The terms in the first line are the GPE generated by entrainment, the energy expended holding particles in suspension less the amount deposited, and the energy required to erode. The first term in the second line is the imbalance in GPE from varying volume flux as a consequence of changing depth, depth-average transport of GPE and depth-resolved transport of both GPE and pressure; the second term similar with varying concentration. The third line includes the effect of varying shape factors, including the direct change of GPE, the imbalance between depth-average and depth-resolved GPE flux, along with the vertical transport generated by varying
 $\xi _\beta$
. Finally, the depth-average rate of conversion of MKE to GPE is
$\xi _\beta$
. Finally, the depth-average rate of conversion of MKE to GPE is
 \begin{align} h \mathcal {B}_M = & \frac {1}{2} R g h \Phi \cos \theta \sum _\beta \Bigg ( 2 \sigma _{\beta \phi } U_\beta \frac {\partial b}{\partial x_\beta } - \tilde {\sigma }_{\beta z\phi } h \frac {\partial U_\beta }{\partial x_\beta }\qquad\quad\qquad\nonumber\\ & \qquad\qquad\qquad\qquad\qquad\qquad\quad + \left ({\sigma _{\beta z\phi }-\tilde {\sigma }_{\beta z\phi }}\right) U_\beta \frac {\partial h}{\partial x_\beta } - \tilde {\sigma }_{D\beta z\phi } h U \Bigg), \end{align}
\begin{align} h \mathcal {B}_M = & \frac {1}{2} R g h \Phi \cos \theta \sum _\beta \Bigg ( 2 \sigma _{\beta \phi } U_\beta \frac {\partial b}{\partial x_\beta } - \tilde {\sigma }_{\beta z\phi } h \frac {\partial U_\beta }{\partial x_\beta }\qquad\quad\qquad\nonumber\\ & \qquad\qquad\qquad\qquad\qquad\qquad\quad + \left ({\sigma _{\beta z\phi }-\tilde {\sigma }_{\beta z\phi }}\right) U_\beta \frac {\partial h}{\partial x_\beta } - \tilde {\sigma }_{D\beta z\phi } h U \Bigg), \end{align}
where the terms are the increase in GPE from flow generated by varying bed elevation, the work done by pressure due to velocity gradients, the imbalance in the change of GPE and work done by pressure due to changing depth and the vertical transport generated by varying
 $\xi _\beta$
.
$\xi _\beta$
.

Figure 3. The difference between the coefficients of the energy transfer terms and the top-hat approximation to these terms (3.7), plotted using the same format as figure 2. Note that the majority of coefficients vanish in a top-hat model, in which case the coefficients are plotted without modification. There are sections dedicated to:
 $h\mathcal {P}$
(3.4);
$h\mathcal {P}$
(3.4);
 $h \mathcal {B}_K$
(3.5);
$h \mathcal {B}_K$
(3.5);
 $h \mathcal {B}_M$
(3.6); the pseudo-equilibrium simplification (4.4); and the volume-free production (5.14), as indicated to the right.
$h \mathcal {B}_M$
(3.6); the pseudo-equilibrium simplification (4.4); and the volume-free production (5.14), as indicated to the right.
Using the values of the shape factors in table 1, top-hat flows simplify to
 \begin{align} h \mathcal {P} &= U_1 u_{1\ast }^2 + U_2 u_{2\ast }^2 + {\textstyle \frac {1}{2}} (U_1^2 + U_2^2) w_e - h \epsilon _M, \end{align}
\begin{align} h \mathcal {P} &= U_1 u_{1\ast }^2 + U_2 u_{2\ast }^2 + {\textstyle \frac {1}{2}} (U_1^2 + U_2^2) w_e - h \epsilon _M, \end{align}
 \begin{align} h \mathcal {B}_K &= {\textstyle \frac {1}{2}} R g h \cos \theta \left ({ \Phi w_e + \lbrack { 2 - \varsigma _\phi }\rbrack w_s \Phi \cos \theta + E_s }\right), \end{align}
\begin{align} h \mathcal {B}_K &= {\textstyle \frac {1}{2}} R g h \cos \theta \left ({ \Phi w_e + \lbrack { 2 - \varsigma _\phi }\rbrack w_s \Phi \cos \theta + E_s }\right), \end{align}
 \begin{align} h \mathcal {B}_M &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ 2 U \frac {\partial b}{\partial x} + 2 V \frac {\partial b}{\partial y} - h \frac {\partial U}{\partial x} - h \frac {\partial V}{\partial y} }\right). \end{align}
\begin{align} h \mathcal {B}_M &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ 2 U \frac {\partial b}{\partial x} + 2 V \frac {\partial b}{\partial y} - h \frac {\partial U}{\partial x} - h \frac {\partial V}{\partial y} }\right). \end{align}
For two-dimensional flow (
 $U_2={\partial b}/{\partial y}=0$
) with negligible mean-flow dissipation in the boundary layer (
$U_2={\partial b}/{\partial y}=0$
) with negligible mean-flow dissipation in the boundary layer (
 $\epsilon _M=0$
), the first two expressions match those from Parker et al. (Reference Parker, Fukushima and Pantin1986), and the third is consistent though never explicitly stated.
$\epsilon _M=0$
), the first two expressions match those from Parker et al. (Reference Parker, Fukushima and Pantin1986), and the third is consistent though never explicitly stated.
However, using the values from figure 2 we find that the additional terms from a complete analysis (3.4)–(3.6) are not negligible. The difference between the coefficients and the top-hat approximation is plotted in figure 3. This can be understood as representing each of
 $h \mathcal {P}$
,
$h \mathcal {P}$
,
 $h \mathcal {B}_K$
and
$h \mathcal {B}_K$
and
 $h \mathcal {B}_M$
as the sum of the top-hat model and a correction based on the shape of the current, and a coefficient of
$h \mathcal {B}_M$
as the sum of the top-hat model and a correction based on the shape of the current, and a coefficient of
 $\pm 1$
means the correction from including shape factors is as large as the contribution from the top-hat model. Of course, we are only comparing the size of the coefficients, and the size of the term also depends on what this coefficient multiplies, but this analysis gives an indication of which terms are important. The region where the terms are of magnitude less than
$\pm 1$
means the correction from including shape factors is as large as the contribution from the top-hat model. Of course, we are only comparing the size of the coefficients, and the size of the term also depends on what this coefficient multiplies, but this analysis gives an indication of which terms are important. The region where the terms are of magnitude less than
 $10\,\%$
of the top-hat terms is indicated by a grey band, and while a few of the coefficients do lie in this region where they can (arguably) be neglected, many of them lie substantially outside of this region. Thus, we cannot neglect the effect of shape on the energetics.
$10\,\%$
of the top-hat terms is indicated by a grey band, and while a few of the coefficients do lie in this region where they can (arguably) be neglected, many of them lie substantially outside of this region. Thus, we cannot neglect the effect of shape on the energetics.
3.2. Using energetic consistency requirements
The governing equations we have derived includes balances for volume (2.16), particles (2.17), momentum (2.18) and total energy (2.22). This system is similar to that proposed by Parker et al. (Reference Parker, Fukushima and Pantin1986), but crucially allows for the specification of flow shape in a model that captures energetics. Shape factors are known to have a substantial influence on prediction in models which do not capture energetics (Dorrell et al. Reference Dorrell, Darby, Peakall, Sumner, Parsons and Wynn2014). This modelling framework has the potential to be much more accurate because it allows for the inclusion of additional physics. However, these additional physics appear in the model as closures specified by the modeller, and there is a possibility that the selected closures are unsuitable in a subtle way. Suppose that we take a selection of developed closures for shape functions (Islam & Imran Reference Islam and Imran2010; Abad et al. Reference Abad, Sequeiros, Spinewine, Pirmez, Garcia and Parker2011), entrainment (Ellison & Turner Reference Ellison and Turner1959; Parker et al. Reference Parker, Fukushima and Pantin1986; Cenedese & Adduce Reference Cenedese and Adduce2010) and erosion (Parker et al. Reference Parker, Fukushima and Pantin1986; Dorrell et al. Reference Dorrell, Amy, Peakall and McCaffrey2018; Guo Reference Guo2020), in addition to making some reasonable choice of drag coefficient, and constructing some expression for the total dissipation (while method for this construction is presented in Parker et al. (Reference Parker, Fukushima and Pantin1986), it would be better to have an empirically verified closure). Then we can simulate a current using the governing equations, and post-process the results to obtain the energy transfer that implicitly occurred using (3.4)–(3.6). It is extremely unlikely that independently developed closures will somehow yield the energy transfer seen in real currents.
Consequently, the purpose of (3.4)–(3.6) is as consistency requirements to be used during the development of closures. When a set of closures for the governing equations have been developed using data from experiment or simulation, a final verification can be performed by using the developed closures to predict the energy transfer, which can be compared with the measured energy transfer. This final verification, if successful, demonstrates that the set of closures are energetically consistent and will produce the correct evolution of TKE. While the TKE may not always be the subject of interest, having a model which is tightly constrained to real physics gives confidence in the model in general.
For these consistency requirements to be useful in closure development, two things are required. Firstly, the balances must be verified. Provided we are dealing with a shallow Boussinesq gravity current under a deep unstratified ambient, this is principally verification that there have been no algebraic mistakes in the derivation. Secondly, some simplification of the consistency requirements must be made in order to make them usable for model development. The supplied Maple script can be used to apply simplifications to specific circumstances. The next section provides an example of simplifying the system to a specific simulation configuration, and verifying the accuracy of both the full and simplified form of the energetic transfer expressions.
4. Comparison of model with high resolution simulations
4.1. Two-dimensional pseudo-equilibrium flow
In this subsection we consider two-dimensional steady flow down a smooth slope (
 ${\partial }/{\partial t} = {\partial }/{\partial y} = U_2 = b = 0$
,
${\partial }/{\partial t} = {\partial }/{\partial y} = U_2 = b = 0$
,
 $\theta \neq 0$
, use notation
$\theta \neq 0$
, use notation
 $U \equiv U_1$
). Under such conditions we may expect the fluid to reach a pseudo-equilibrium configuration after flowing a sufficient distance, where the shape enters self-similar form (shape factors constant) and the following dimensionless parameters become independent of
$U \equiv U_1$
). Under such conditions we may expect the fluid to reach a pseudo-equilibrium configuration after flowing a sufficient distance, where the shape enters self-similar form (shape factors constant) and the following dimensionless parameters become independent of
 $x$
:
$x$
:
 \begin{align} \frac {U}{\sqrt {R g h \cos \theta }}, && \frac {w_s\cos \theta }{\sqrt {K}}, && \frac {U^2}{2 K}. \end{align}
\begin{align} \frac {U}{\sqrt {R g h \cos \theta }}, && \frac {w_s\cos \theta }{\sqrt {K}}, && \frac {U^2}{2 K}. \end{align}
Up to constant coefficients, these are the Froude number (ratio of flow speed to velocity scale), the Rouse number (ratio of particle settling to upwards turbulent diffusion) and the ratio of MKE to TKE, respectively. These conditions imply
 \begin{align} \frac {\partial }{\partial x} \left ({h \Phi }\right) = \frac {\partial U}{\partial x} = \frac {\partial K}{\partial x} = 0,\end{align}
\begin{align} \frac {\partial }{\partial x} \left ({h \Phi }\right) = \frac {\partial U}{\partial x} = \frac {\partial K}{\partial x} = 0,\end{align}
as used by Parker et al. (Reference Parker, Fukushima and Pantin1986). Simplifying the governing system (2.16)–(2.18) and (2.22) using the pseudo-equilibrium conditions (4.2)
 \begin{gather} \frac {\partial h}{\partial x} = \frac {w_e}{U}, \end{gather}
\begin{gather} \frac {\partial h}{\partial x} = \frac {w_e}{U}, \end{gather}
 \begin{gather} 0 = \varsigma _{\phi } w_s \Phi \cos \theta - E_s, \end{gather}
\begin{gather} 0 = \varsigma _{\phi } w_s \Phi \cos \theta - E_s, \end{gather}
 \begin{gather} \left ({ \sigma _{11} U^2 + {\textstyle \frac {1}{2}} \sigma _{z\phi } R g h \Phi \cos \theta }\right) \frac {w_e}{U} = R g h \Phi \sin \theta - u_{1\ast }^2, \end{gather}
\begin{gather} \left ({ \sigma _{11} U^2 + {\textstyle \frac {1}{2}} \sigma _{z\phi } R g h \Phi \cos \theta }\right) \frac {w_e}{U} = R g h \Phi \sin \theta - u_{1\ast }^2, \end{gather}
 \begin{align} & \left ({ {\textstyle \frac {1}{2}} \sigma _{111} U^2 + \sigma _{1k} K + \varsigma _{1z\phi } R g h \Phi \cos \theta }\right) w_e\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \nonumber \\& \qquad\qquad\qquad\qquad\qquad\qquad = \sigma _{1\phi } U R g h \Phi \sin \theta - h \epsilon _T - w_s R g h \Phi (\cos \theta)^2. \end{align}
\begin{align} & \left ({ {\textstyle \frac {1}{2}} \sigma _{111} U^2 + \sigma _{1k} K + \varsigma _{1z\phi } R g h \Phi \cos \theta }\right) w_e\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \nonumber \\& \qquad\qquad\qquad\qquad\qquad\qquad = \sigma _{1\phi } U R g h \Phi \sin \theta - h \epsilon _T - w_s R g h \Phi (\cos \theta)^2. \end{align}


To obtain consistency requirements for the energetics in pseudo-equilibrium we substitute (4.2) and (4.3) into the full expressions for
 $h \mathcal {P}$
,
$h \mathcal {P}$
,
 $h \mathcal {B}_K$
and
$h \mathcal {B}_K$
and
 $h \mathcal {B}_M$
(3.4)–(3.6) to obtain
$h \mathcal {B}_M$
(3.4)–(3.6) to obtain
 \begin{align} h \mathcal {P} &= \sigma _{1\phi } U u_{1\ast }^2 + \left ({ 2 \sigma _{11} \sigma _{1\phi } - \sigma _{111} }\right) {\textstyle \frac {1}{2}} U^2 w_e \notag \\ & \quad + \left ({ \sigma _{z\phi } \sigma _{1\phi } - \sigma _{1z\phi } }\right) {\textstyle \frac {1}{2}} R g h \Phi \cos \theta w_e - h \epsilon _M, \end{align}
\begin{align} h \mathcal {P} &= \sigma _{1\phi } U u_{1\ast }^2 + \left ({ 2 \sigma _{11} \sigma _{1\phi } - \sigma _{111} }\right) {\textstyle \frac {1}{2}} U^2 w_e \notag \\ & \quad + \left ({ \sigma _{z\phi } \sigma _{1\phi } - \sigma _{1z\phi } }\right) {\textstyle \frac {1}{2}} R g h \Phi \cos \theta w_e - h \epsilon _M, \end{align}
 \begin{align} h \mathcal {B}_K &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ( { \tilde {\sigma }_{1z\phi } w_e + 2 w_s \cos \theta }\right), \end{align}
\begin{align} h \mathcal {B}_K &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ( { \tilde {\sigma }_{1z\phi } w_e + 2 w_s \cos \theta }\right), \end{align}
 \begin{align} h \mathcal {B}_M &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ \sigma _{1z\phi } - \tilde {\sigma }_{1z\phi } }\right) w_e. \end{align}
\begin{align} h \mathcal {B}_M &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ \sigma _{1z\phi } - \tilde {\sigma }_{1z\phi } }\right) w_e. \end{align}
This simplification puts
 $h \mathcal {P}$
and
$h \mathcal {P}$
and
 $h \mathcal {B}_K$
in a format where they are easily compared with top-hat expressions in (3.7), revealing an alteration in the magnitude of the terms and the introduction of some additional terms, see figure 3. Compared with (3.7) the turbulent production
$h \mathcal {B}_K$
in a format where they are easily compared with top-hat expressions in (3.7), revealing an alteration in the magnitude of the terms and the introduction of some additional terms, see figure 3. Compared with (3.7) the turbulent production
 $h \mathcal {P}$
typically has a smaller contribution from the energy needed to accelerate entrained fluid up to speed, but a new contribution from the energy required to uplift the mass, while the turbulent production induced by entrainment is reduced, and similarly the production by the mean flow
$h \mathcal {P}$
typically has a smaller contribution from the energy needed to accelerate entrained fluid up to speed, but a new contribution from the energy required to uplift the mass, while the turbulent production induced by entrainment is reduced, and similarly the production by the mean flow
 $h \mathcal {B}_M$
has a negative contribution from the energy consumed by the entrainment uplift. The magnitude of the pseudo-equilibrium transfer in real currents is plotted in figure 4, showing that
$h \mathcal {B}_M$
has a negative contribution from the energy consumed by the entrainment uplift. The magnitude of the pseudo-equilibrium transfer in real currents is plotted in figure 4, showing that
 $h \mathcal {B}_M$
is small for this regime (but the non-equilibrium terms may be large). It is difficult to compare the sizes of
$h \mathcal {B}_M$
is small for this regime (but the non-equilibrium terms may be large). It is difficult to compare the sizes of
 $h \mathcal {B}_K$
and
$h \mathcal {B}_K$
and
 $h \mathcal {P}$
without knowing the mean-flow dissipation
$h \mathcal {P}$
without knowing the mean-flow dissipation
 $h \epsilon _M$
. Note that the currents used to plot figure 4 are not necessarily in pseudo-equilibrium balance, see § 6.
$h \epsilon _M$
. Note that the currents used to plot figure 4 are not necessarily in pseudo-equilibrium balance, see § 6.

Figure 5. Plots computed from the DNS data of Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024). (a-c) The time-averaged fields of concentration, velocity and TKE, the depths
 $h$
(2.26) and
$h$
(2.26) and
 $\tilde {h}$
(5.1) shown in dashed and dash-dot white respectively. (d) The spatial variation of the depth-average quantities. (e) The spatial variation of the shape factors. (f) The residual in the full depth-averaged equations (2.16)–(2.18) and (2.22) or the pseudo-equilibrium equations (4.3), computed from the simulation data using (4.5). In the legend the equation is indicated using the corresponding conserved quantity. (g) The residual in the energy equations (2.22) and (4.3d
) split over contributions from MKE, GPE and TKE in (2.19)–(2.21), dividing by full energy flux rather than the flux for the specific equation.
$\tilde {h}$
(5.1) shown in dashed and dash-dot white respectively. (d) The spatial variation of the depth-average quantities. (e) The spatial variation of the shape factors. (f) The residual in the full depth-averaged equations (2.16)–(2.18) and (2.22) or the pseudo-equilibrium equations (4.3), computed from the simulation data using (4.5). In the legend the equation is indicated using the corresponding conserved quantity. (g) The residual in the energy equations (2.22) and (4.3d
) split over contributions from MKE, GPE and TKE in (2.19)–(2.21), dividing by full energy flux rather than the flux for the specific equation.
To investigate the pseudo-equilibrium dynamics we employ data from a Direct Numerical Simulation (DNS) originally published in Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024). (For similar simulations see Salinas et al. Reference Salinas, Cantero, Shringarpure and Balachandar2019a
,Reference Salinas, Cantero, Shringarpure and Balachandar
b
, Reference Salinas, Zúñiga, Cantero, Shringarpure, Fedele, Hoyal and Balachandar2020, Reference Salinas, Balachandar, Shringarpure, Fedele, Hoyal and Cantero2021, Reference Salinas, Balachandar and Cantero2022, Reference Salinas, Balachandar, Zúñiga, Shringarpure, Fedele and Cantero2023, and for an experimental configuration see Odier et al. Reference Odier, Chen and Ecke2014.) Here, a conservative (
 $w_s=E_s=0$
) gravity current flowed down a slope of
$w_s=E_s=0$
) gravity current flowed down a slope of
 $\theta = 3^{\circ }$
over
$\theta = 3^{\circ }$
over
 $0\lt x\lt 730$
(
$0\lt x\lt 730$
(
 $b=0$
), having been fed into the domain at
$b=0$
), having been fed into the domain at
 $Re = 5650$
at
$Re = 5650$
at
 $x=0$
,
$x=0$
,
 $0\lt z\lt 2$
, the units of their simulation such that
$0\lt z\lt 2$
, the units of their simulation such that
 $Rg = 1/\sin \theta$
. The flow was simulated until it became statistically steady in time, and then time-averaged statistics were computed. The resulting flow is shown in figures 5(a)–5(c). We compute the depth-averaged variables and shape factors directly through integration over
$Rg = 1/\sin \theta$
. The flow was simulated until it became statistically steady in time, and then time-averaged statistics were computed. The resulting flow is shown in figures 5(a)–5(c). We compute the depth-averaged variables and shape factors directly through integration over
 $0 = b \leq z \leq H = 60$
, the full height of the simulation domain, see figure 5(d,e). On
$0 = b \leq z \leq H = 60$
, the full height of the simulation domain, see figure 5(d,e). On
 $x\gt 300$
the depth averages satisfy well the pseudo-equilibrium conditions (4.2),
$x\gt 300$
the depth averages satisfy well the pseudo-equilibrium conditions (4.2),
 $K$
being the last to become steady. However, the concentration shape
$K$
being the last to become steady. However, the concentration shape
 $\xi _\phi$
continues to slowly evolve over the entire length of the simulation as can be seen through the shape factors
$\xi _\phi$
continues to slowly evolve over the entire length of the simulation as can be seen through the shape factors
 $\sigma _{z\phi }$
,
$\sigma _{z\phi }$
,
 $\sigma _{1z\phi }$
and
$\sigma _{1z\phi }$
and
 $\tilde {\sigma }_{1z\phi }$
.
$\tilde {\sigma }_{1z\phi }$
.
Before going any further, we validate the depth-average model (2.16)–(2.18) and (2.22). In steady state each equation is of the form
 ${\mathcal {F}}/{x} = \mathcal {S}$
for some flux
${\mathcal {F}}/{x} = \mathcal {S}$
for some flux
 $\mathcal {F}$
and source
$\mathcal {F}$
and source
 $\mathcal {S}$
, and we calculate the residual in each as
$\mathcal {S}$
, and we calculate the residual in each as
 \begin{align} \mathcal {R} = \frac {1}{\mathcal {F}} \left \lvert { \frac {\partial \mathcal {F}}{\partial x} - \mathcal {S} } \right \rvert,\end{align}
\begin{align} \mathcal {R} = \frac {1}{\mathcal {F}} \left \lvert { \frac {\partial \mathcal {F}}{\partial x} - \mathcal {S} } \right \rvert,\end{align}
were the flux and source are computed directly from the simulation data. Consequently,
 $\mathcal {R}^{-1}$
is the distance over which cumulative error would produce an
$\mathcal {R}^{-1}$
is the distance over which cumulative error would produce an
 $\mathcal {O}{(1)}$
change to the flux if we were to integrate (4.5) with the given source. (In fact, since the residuals alternate sign, the change to the flux may be seen as a random walk and thus residuals accumulate over a distance of
$\mathcal {O}{(1)}$
change to the flux if we were to integrate (4.5) with the given source. (In fact, since the residuals alternate sign, the change to the flux may be seen as a random walk and thus residuals accumulate over a distance of
 $\mathcal {R}^{-2}$
.) By figure 5( f), once the current has established (
$\mathcal {R}^{-2}$
.) By figure 5( f), once the current has established (
 $x\gt 100$
) the length scale of residual accumulation is around
$x\gt 100$
) the length scale of residual accumulation is around
 $10^5$
, vastly longer than the simulation domain. Splitting the residual in the energy equation over its components (figure 5
g) we see a similarly good agreement. The larger residual on
$10^5$
, vastly longer than the simulation domain. Splitting the residual in the energy equation over its components (figure 5
g) we see a similarly good agreement. The larger residual on
 $x\lt 100$
is a consequence of the assumption that horizontal scales are much larger than vertical by which we omitted terms in (2.1). We also plot the residual in the pseudo-equilibrium balance, ensuring the computed residual is simply the direct simplification of (4.5) employing the assumptions. Once the flow has reached the balance (
$x\lt 100$
is a consequence of the assumption that horizontal scales are much larger than vertical by which we omitted terms in (2.1). We also plot the residual in the pseudo-equilibrium balance, ensuring the computed residual is simply the direct simplification of (4.5) employing the assumptions. Once the flow has reached the balance (
 $x\gt 300$
) the residual in the system (figure 5
f) is no larger than for the full equation, showing that this is an accurate simplification, however, the residual in the split energy equations (figure 5
g) is slightly larger with an accumulation length scale of
$x\gt 300$
) the residual in the system (figure 5
f) is no larger than for the full equation, showing that this is an accurate simplification, however, the residual in the split energy equations (figure 5
g) is slightly larger with an accumulation length scale of
 $10^4$
, which we will find is a consequence of the varying shape factors.
$10^4$
, which we will find is a consequence of the varying shape factors.

Figure 6. Further plots computed from the DNS data of Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024). (a) The properties of turbulence, entrainment and drag computed directly from DNS data. (b–d) Comparing the values of
 $h\mathcal {P}$
,
$h\mathcal {P}$
,
 $h\mathcal {B}_K$
and
$h\mathcal {B}_K$
and
 $h\mathcal {B}_M$
direct from simulation to the expressions in the full model (3.4)–(3.6), along with the simplifications of self-similar flow ((3.4)–(3.6) neglecting derivatives of shape factors), the pseudo-equilibrium balance (4.4) and top-hat flow (3.7). (e) The coefficients of the additional terms in (4.4) with respect to top-hat flow. ( f) The dimensionless mean-flow dissipation (red) and the approximation using Reichardt (Reference Reichardt1951) (black dashed).
$h\mathcal {B}_M$
direct from simulation to the expressions in the full model (3.4)–(3.6), along with the simplifications of self-similar flow ((3.4)–(3.6) neglecting derivatives of shape factors), the pseudo-equilibrium balance (4.4) and top-hat flow (3.7). (e) The coefficients of the additional terms in (4.4) with respect to top-hat flow. ( f) The dimensionless mean-flow dissipation (red) and the approximation using Reichardt (Reference Reichardt1951) (black dashed).
The properties of the turbulence and other source terms used in the residual analysis are computed directly from the simulation data using (2.8d
), (2.24) and (2.25), and are plotted in figure 6(a). Crucially, we find that the viscous dissipation of the mean flow
 $h \epsilon _M$
is almost equal to the turbulent production
$h \epsilon _M$
is almost equal to the turbulent production
 $h \mathcal {P}$
. Whether
$h \mathcal {P}$
. Whether
 $h \mathcal {P} \simeq h \epsilon _M$
in general is discussed later.
$h \mathcal {P} \simeq h \epsilon _M$
in general is discussed later.
The values of
 $h\mathcal {P}$
,
$h\mathcal {P}$
,
 $h\mathcal {B}_K$
and
$h\mathcal {B}_K$
and
 $h\mathcal {B}_M$
are plotted in figures 6(b)–6(d). We see that the values of the full model expressions from (3.4) to (3.6) agree very well with the exact values from the simulations across all
$h\mathcal {B}_M$
are plotted in figures 6(b)–6(d). We see that the values of the full model expressions from (3.4) to (3.6) agree very well with the exact values from the simulations across all
 $x$
(including small
$x$
(including small
 $x$
where the curves go out of the figure, the small amount of noise at large
$x$
where the curves go out of the figure, the small amount of noise at large
 $x$
arises from the
$x$
arises from the
 $x$
derivatives). Reducing to self-similar form by neglecting the
$x$
derivatives). Reducing to self-similar form by neglecting the
 $x$
derivatives of shape functions in the consistency requirements (3.4)–(3.6) introduces a large error in the proximal region
$x$
derivatives of shape functions in the consistency requirements (3.4)–(3.6) introduces a large error in the proximal region
 $x\lt 300$
(see figure 6
b–d), but in the distal region
$x\lt 300$
(see figure 6
b–d), but in the distal region
 $x\gt 300$
where the flow is equilibrated the error is small and provides a reasonable approximation. Simplifying further to the pseudo-equilibrium expressions (4.4) does not increase the error in the distal regions, the assumptions on the depth-averaged variables (4.2) being satisfied to a much greater degree of accuracy than the assumption that shape functions are independent of
$x\gt 300$
where the flow is equilibrated the error is small and provides a reasonable approximation. Simplifying further to the pseudo-equilibrium expressions (4.4) does not increase the error in the distal regions, the assumptions on the depth-averaged variables (4.2) being satisfied to a much greater degree of accuracy than the assumption that shape functions are independent of
 $x$
. The top-hat approximation increases the error more substantially. Plotting the coefficients of the difference of the top-hat approximation and the pseudo-equilibrium approximation in figure 6(e) (the same coefficients as in figure 3) we find that they are moderately large, which is the cause of the error.
$x$
. The top-hat approximation increases the error more substantially. Plotting the coefficients of the difference of the top-hat approximation and the pseudo-equilibrium approximation in figure 6(e) (the same coefficients as in figure 3) we find that they are moderately large, which is the cause of the error.
4.2. Mean-flow dissipation
Given the comparison in figures 6(b)–6(d), the greatest error in approximating the turbulent processes arises from neglecting the mean-flow dissipation
 $h \epsilon _M$
because
$h \epsilon _M$
because
 $h \mathcal {P} \simeq h \epsilon _M$
. We ask, is this an unusual property of this flow or something we should expect to see in general? The mean-flow dissipation is a property of near bed flow. Working in dimensionless wall variables
$h \mathcal {P} \simeq h \epsilon _M$
. We ask, is this an unusual property of this flow or something we should expect to see in general? The mean-flow dissipation is a property of near bed flow. Working in dimensionless wall variables
 $u^+ = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} /u_{1\ast }$
and
$u^+ = {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} /u_{1\ast }$
and
 $z^+ = z u_{1\ast }/\nu$
we see that
$z^+ = z u_{1\ast }/\nu$
we see that
 \begin{align} h \epsilon _M = \int _0^{H} \nu \left ({\frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial z}}\right)^2 \mathrm {d}{z} = u_{1\ast }^3 \int _0^{H u_{1\ast }/\nu } \left ({\frac {\partial u^+}{\partial z^+}}\right)^2 \mathrm {d}{z^+}. \end{align}
\begin{align} h \epsilon _M = \int _0^{H} \nu \left ({\frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial z}}\right)^2 \mathrm {d}{z} = u_{1\ast }^3 \int _0^{H u_{1\ast }/\nu } \left ({\frac {\partial u^+}{\partial z^+}}\right)^2 \mathrm {d}{z^+}. \end{align}
While internal shear layers also technically contribute to this dissipation, these produce a change in velocity of order
 $U$
and thus to have a leading-order contribution the the mean-flow dissipation they must have a thickness of order
$U$
and thus to have a leading-order contribution the the mean-flow dissipation they must have a thickness of order
 $\nu U^2/u_{1\ast }^3$
so that the Reynolds number of the shear layer is of order
$\nu U^2/u_{1\ast }^3$
so that the Reynolds number of the shear layer is of order
 $U^3/u_{1\ast }^3$
. In environmental currents the Reynolds number of shear layers is much larger, even in the presence of jet sharpening (Dorrell et al. Reference Dorrell, Peakall, Darby, Parsons, Johnson, Sumner, Wynn, Özsoy and Tezcan2019), and so the contribution to the mean-flow dissipation is only from the viscous sub-layer between the bed and the logarithmic layer. This motivates a definition of the dimensionless mean-flow dissipation as
$U^3/u_{1\ast }^3$
. In environmental currents the Reynolds number of shear layers is much larger, even in the presence of jet sharpening (Dorrell et al. Reference Dorrell, Peakall, Darby, Parsons, Johnson, Sumner, Wynn, Özsoy and Tezcan2019), and so the contribution to the mean-flow dissipation is only from the viscous sub-layer between the bed and the logarithmic layer. This motivates a definition of the dimensionless mean-flow dissipation as
 \begin{align} \epsilon _M^+ : = \int _0^{H u_{1\ast }/\nu } \left ({\frac {\partial u^+}{\partial z^+}}\right)^2 \mathrm {d}{z^+} = \frac {h \epsilon _M}{u_{1\ast }^3}. \end{align}
\begin{align} \epsilon _M^+ : = \int _0^{H u_{1\ast }/\nu } \left ({\frac {\partial u^+}{\partial z^+}}\right)^2 \mathrm {d}{z^+} = \frac {h \epsilon _M}{u_{1\ast }^3}. \end{align}
As a rough estimate, we may expect that there is a viscous sub-layer with
 $u^+ = z^+$
over
$u^+ = z^+$
over
 $0\lt z^+\lt 10$
, and a turbulent log layer where
$0\lt z^+\lt 10$
, and a turbulent log layer where
 $u^+ = \kappa ^{-1} \ln z^+ + \text {const}$
on
$u^+ = \kappa ^{-1} \ln z^+ + \text {const}$
on
 $z^+\gt 10$
, where
$z^+\gt 10$
, where
 $\kappa = 0.41$
is the von Kármán constant, resulting in the approximation
$\kappa = 0.41$
is the von Kármán constant, resulting in the approximation
 $\epsilon _M^+ \approx 10 + {1}/{10 \kappa ^2} = 10.6$
showing that even the log layer does not contribute significantly to the value. The estimate can be improved using the matched asymptotic of Reichardt (Reference Reichardt1951) (see Kadivar, Tormey & McGranaghan Reference Kadivar, Tormey and McGranaghan2021) which yields a value of
$\epsilon _M^+ \approx 10 + {1}/{10 \kappa ^2} = 10.6$
showing that even the log layer does not contribute significantly to the value. The estimate can be improved using the matched asymptotic of Reichardt (Reference Reichardt1951) (see Kadivar, Tormey & McGranaghan Reference Kadivar, Tormey and McGranaghan2021) which yields a value of
 $\epsilon _M^+ = 9.15$
. We plot
$\epsilon _M^+ = 9.15$
. We plot
 $\epsilon _M^+$
in figure 6( f) and find that it lies very close to this estimate, but there is some slow downstream evolution which is similar in kind to the evolution of the shape factors in figure 5(e).
$\epsilon _M^+$
in figure 6( f) and find that it lies very close to this estimate, but there is some slow downstream evolution which is similar in kind to the evolution of the shape factors in figure 5(e).

Figure 7. Extrapolation of the dissipation to high Reynolds numbers, using three datasets of channel flow simulations:
 $+$
from Lee & Moser (Reference Lee and Moser2015),
$+$
from Lee & Moser (Reference Lee and Moser2015),
 $\times$
from Kaneda & Yamamoto (Reference Kaneda and Yamamoto2021) and
$\times$
from Kaneda & Yamamoto (Reference Kaneda and Yamamoto2021) and
 $\circ$
from Orlandi (Reference Orlandi2019). Here,
$\circ$
from Orlandi (Reference Orlandi2019). Here,
 $\epsilon _M^+$
is red and
$\epsilon _M^+$
is red and
 $\epsilon _K^+$
is blue. (a) The channel flow data and the gravity current data from Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024) (solid). (b) Curves of best fit for the channel flow dissipation. Plotted faintly are samples from a probability distribution over curves, showing the uncertainty of the best-fit curve. (c) Extrapolation of the dissipation best fit, and ratio of the extrapolations (purple). We also show a power-law extrapolation of the best-fit ratio through the final data point. Two abscissae are given for (c) showing
$\epsilon _K^+$
is blue. (a) The channel flow data and the gravity current data from Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024) (solid). (b) Curves of best fit for the channel flow dissipation. Plotted faintly are samples from a probability distribution over curves, showing the uncertainty of the best-fit curve. (c) Extrapolation of the dissipation best fit, and ratio of the extrapolations (purple). We also show a power-law extrapolation of the best-fit ratio through the final data point. Two abscissae are given for (c) showing
 $Re_\tau$
and
$Re_\tau$
and
 $Re$
. (d) The Reynolds number for particulate gravity currents, plotted using the same format as figure 2.
$Re$
. (d) The Reynolds number for particulate gravity currents, plotted using the same format as figure 2.
While it is true that
 $\epsilon _M^+$
is finite at high Reynolds numbers, the dimensionless turbulent dissipation,
$\epsilon _M^+$
is finite at high Reynolds numbers, the dimensionless turbulent dissipation,
 $\epsilon _K^+ : = h \epsilon _K / u_{\ast 1}^3$
, grows at high Reynolds number, so that
$\epsilon _K^+ : = h \epsilon _K / u_{\ast 1}^3$
, grows at high Reynolds number, so that
 $\epsilon _M^+/\epsilon _K^+ \to 0$
as
$\epsilon _M^+/\epsilon _K^+ \to 0$
as
 $Re \to \infty$
. But how large does
$Re \to \infty$
. But how large does
 $Re$
need to be for
$Re$
need to be for
 $\epsilon _K^+$
to dominate? To answer, we use data from channel flow between two boundaries (sometimes called plane Poiseuille flow) from Lee & Moser (Reference Lee and Moser2015) and Kaneda & Yamamoto (Reference Kaneda and Yamamoto2021). For this analysis we will employ a Reynolds number
$\epsilon _K^+$
to dominate? To answer, we use data from channel flow between two boundaries (sometimes called plane Poiseuille flow) from Lee & Moser (Reference Lee and Moser2015) and Kaneda & Yamamoto (Reference Kaneda and Yamamoto2021). For this analysis we will employ a Reynolds number
 $Re_\tau$
where the length scale is the half-height of the channel and the velocity scale is
$Re_\tau$
where the length scale is the half-height of the channel and the velocity scale is
 $u_{\ast 1}$
. Figure 7(a) shows that, sufficiently far downstream of the release, the gravity current of Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024) has the same dissipations as channel flow (length scale in
$u_{\ast 1}$
. Figure 7(a) shows that, sufficiently far downstream of the release, the gravity current of Zúñiga et al. (Reference Zúñiga, Balachandar, Yang, Zhang, Smith, Loppi, Cantero and Kerkemeier2024) has the same dissipations as channel flow (length scale in
 $Re_\tau$
is flow depth (2.26)). From the data, the dissipations have curves of best fit given by
$Re_\tau$
is flow depth (2.26)). From the data, the dissipations have curves of best fit given by
 \begin{align} \epsilon _M^+ &= 9.17 \cdot (\ln Re_\tau - 5.01)^{-0.0148}, & \epsilon _K^+ &= 3.62 \cdot (\ln Re_\tau - 3.28)^{0.856}, \end{align}
\begin{align} \epsilon _M^+ &= 9.17 \cdot (\ln Re_\tau - 5.01)^{-0.0148}, & \epsilon _K^+ &= 3.62 \cdot (\ln Re_\tau - 3.28)^{0.856}, \end{align}
with coefficients of determination (
 $R^2$
) of
$R^2$
) of
 $0.8867$
and
$0.8867$
and
 $0.9997$
, respectively (figure 7
b). To account for the uncertainty in parameters we use a Bayesian approach. The uncertainty of the data is estimated as the root-mean-square difference between the points and the respective best-fit line. We use a uniform (improper) prior for the parameters, so the Bayesian approach is equivalent to a likelihood approach. Sample curves from the resulting posterior distribution are plotted faintly in figure 7(b,c) showing almost no scatter. Extrapolations of these curves, and their ratio, are plotted in figure 7(c), which has axes for both
$0.9997$
, respectively (figure 7
b). To account for the uncertainty in parameters we use a Bayesian approach. The uncertainty of the data is estimated as the root-mean-square difference between the points and the respective best-fit line. We use a uniform (improper) prior for the parameters, so the Bayesian approach is equivalent to a likelihood approach. Sample curves from the resulting posterior distribution are plotted faintly in figure 7(b,c) showing almost no scatter. Extrapolations of these curves, and their ratio, are plotted in figure 7(c), which has axes for both
 $Re_\tau$
and
$Re_\tau$
and
 $Re$
. The latter is calculated with the channel-average velocity as the velocity scale (equivalent to depth-average velocity for gravity currents), the two Reynolds numbers related by
$Re$
. The latter is calculated with the channel-average velocity as the velocity scale (equivalent to depth-average velocity for gravity currents), the two Reynolds numbers related by
 $Re_\tau \simeq 0.09 Re^{0.88}$
(Pope Reference Pope2000). To account for error in the functional form in the extrapolation we also show a power-law (straight line in log scale) extrapolation of the best fit curve from the final data-point (dashed). We say that the mean-flow dissipation is small when it is below
$Re_\tau \simeq 0.09 Re^{0.88}$
(Pope Reference Pope2000). To account for error in the functional form in the extrapolation we also show a power-law (straight line in log scale) extrapolation of the best fit curve from the final data-point (dashed). We say that the mean-flow dissipation is small when it is below
 $10\,\%$
of the turbulent dissipation, and negligible when below
$10\,\%$
of the turbulent dissipation, and negligible when below
 $1\,\%$
. The small threshold is reached somewhere in the interval
$1\,\%$
. The small threshold is reached somewhere in the interval
 $10^{18} \lesssim Re_\tau \lesssim 10^{21}$
(
$10^{18} \lesssim Re_\tau \lesssim 10^{21}$
(
 $10^9$
for power-law extrapolation). The threshold is substantially above the largest values ever measured in gravity currents,
$10^9$
for power-law extrapolation). The threshold is substantially above the largest values ever measured in gravity currents,
 $Re_\tau \lesssim 10^7$
(figure 7
d, green points from Simmons et al. Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020). Thus, mean-flow dissipation is relevant at the Reynolds numbers of all geophysical currents.
$Re_\tau \lesssim 10^7$
(figure 7
d, green points from Simmons et al. Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020). Thus, mean-flow dissipation is relevant at the Reynolds numbers of all geophysical currents.

Figure 8. (a) Extrapolation of the dissipation to high roughness,
 $\circ$
are data from Orlandi (Reference Orlandi2019). Here,
$\circ$
are data from Orlandi (Reference Orlandi2019). Here,
 $\epsilon _M^+$
is red,
$\epsilon _M^+$
is red,
 $\epsilon _K^+$
is blue and their ratio is purple, with
$\epsilon _K^+$
is blue and their ratio is purple, with
 $Re_\tau$
given above. Curves of best fit are shown, and plotted faintly are samples from a probability distribution over curves, showing the uncertainty of the best-fit curves. (b) The mean particle diameter for particulate gravity currents, plotted using the same format as figure 2.
$Re_\tau$
given above. Curves of best fit are shown, and plotted faintly are samples from a probability distribution over curves, showing the uncertainty of the best-fit curves. (b) The mean particle diameter for particulate gravity currents, plotted using the same format as figure 2.
The data from channel flow considered so far are all from smooth channels, and particulate gravity currents always flow over a rough bed, the roughness appearing at the particle scale and (for environmental currents) at the sales of benthic fauna and bedforms (Olu et al. Reference Olu, Decker, Pastor, Caprais, Khripounoff, Morineaux, Baziz, Menot and Rabouille2017; Sen et al. Reference Sen, Dennielou, Tourolle, Arnaubec, Rabouille and Olu2017; Azpiroz-Zabala et al. Reference Azpiroz-Zabala2024). A large body of research exists into flow over rough beds, see the recent review of Kadivar et al. (Reference Kadivar, Tormey and McGranaghan2021). There are a great many parameters which can be used to characterise the bed roughness as documented by Thakkar, Busseb & Sandhama (Reference Thakkar, Busseb and Sandhama2017). For research on how roughness effects the log-law region see Shringarpure et al. (Reference Shringarpure, Cantero and Balachandar2012)and Bilgin & Cantwell (Reference Bilgin and Cantwell2023), and for the additional layers of the flow which are present in flow over roughness see Nikora et al. (Reference Nikora, Koll, McEwan, McLean and Dittrich2004), Mazzuoli & Uhlmann (Reference Mazzuoli and Uhlmann2017)and Forooghi et al. (Reference Forooghi, Stroh, Schlatter and Frohnapfel2018). We use data from Orlandi (Reference Orlandi2019), representing the roughness using the equivalent sand roughness
 $k_s^+$
which is calculated from the log layer by fitting
$k_s^+$
which is calculated from the log layer by fitting
 $u^+ = (1/\kappa) \log (y^+/k_s^+) + 8$
(e.g. Schlichting & Gersten Reference Schlichting and Gersten2016). The best fit curves in figure 8(a) are
$u^+ = (1/\kappa) \log (y^+/k_s^+) + 8$
(e.g. Schlichting & Gersten Reference Schlichting and Gersten2016). The best fit curves in figure 8(a) are
 \begin{align} \epsilon _M^+ &= 38.9 \cdot (k_s^+ + 5.62)^{-0.719}, & \epsilon _K^+ &= 15.5 \cdot (k_s^+ + 70.3)^{-0.201}, \end{align}
\begin{align} \epsilon _M^+ &= 38.9 \cdot (k_s^+ + 5.62)^{-0.719}, & \epsilon _K^+ &= 15.5 \cdot (k_s^+ + 70.3)^{-0.201}, \end{align}
with coefficients of determination
 $0.9978$
and
$0.9978$
and
 $0.7126$
. For the mean-flow dissipation to be small we require
$0.7126$
. For the mean-flow dissipation to be small we require
 $k_s^+ \gtrsim 500$
and to be negligible
$k_s^+ \gtrsim 500$
and to be negligible
 $k_s^+ \gtrsim 10^4$
. We expect these thresholds to be only weakly dependent on
$k_s^+ \gtrsim 10^4$
. We expect these thresholds to be only weakly dependent on
 $Re_\tau$
, because
$Re_\tau$
, because
 $\epsilon _K^+$
is largely independent of
$\epsilon _K^+$
is largely independent of
 $k_s^+$
and only varying by a factor of
$k_s^+$
and only varying by a factor of
 $\sim 10$
over the
$\sim 10$
over the
 $Re_\tau$
of gravity currents, while
$Re_\tau$
of gravity currents, while
 $\epsilon _M^+$
is independent of
$\epsilon _M^+$
is independent of
 $Re_\tau$
. To reach
$Re_\tau$
. To reach
 $k_s^+ \gtrsim 10^4$
requires bedforms
$k_s^+ \gtrsim 10^4$
requires bedforms
 $\gtrsim 10^4 d_{50}^+$
high (figure 8
b), green points from Simmons et al. Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020), which may occur in natural settings but not in experiments. Mean-flow dissipation is therefore important for experimental flows and moderately sized turbidity currents, but not for large currents over bedforms.
$\gtrsim 10^4 d_{50}^+$
high (figure 8
b), green points from Simmons et al. Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020), which may occur in natural settings but not in experiments. Mean-flow dissipation is therefore important for experimental flows and moderately sized turbidity currents, but not for large currents over bedforms.
4.3. Summary of comparison with simulations
There are two distinct alterations to the energetics of Parker et al. (Reference Parker, Fukushima and Pantin1986) that have been discussed in this section: flow shape and mean-flow dissipation. Regarding flow shape, there is a clear hierarchy of approaches shown in figure 6: the top-hat model is the least accurate, then the approaches which include flow shape but not its variation, and most accurate is the model which includes the variations of flow shape. When fully including flow shape and providing closures from the simulation, the model approaches the accuracy of the full simulation, showing that the energetics can, in principle, be accurately captured by a depth-average model. This accuracy improvement is relevant for predictive models (§ 2.3) because the flow shape is incorporated into the models. Conversely, the mean-flow dissipation is only relevant for assessing the consistency requirements (§ 3), which are important for model development and interpretation. It is not included in the predictive model outside of the total dissipation, which can be approximated separately. Nonetheless, it can make a leading-order contribution to the implied energetics which is important for the use of consistency requirements in closure development (§ 3.2), and the understanding of particle suspension (§ 6).
5. Depth, entrainment and detrainment
5.1. Gravity current depth
To this point we have not discussed the depth
 $h(x,y,t)$
; the model presented is independent of the definition. A wide variety of measures of depth can be used (e.g. Salinas et al. Reference Salinas, Balachandar, Zúñiga, Shringarpure, Fedele and Cantero2023), and the symmetry group in Appendix D can be used to transform between different measures. For two-dimensional flow (
$h(x,y,t)$
; the model presented is independent of the definition. A wide variety of measures of depth can be used (e.g. Salinas et al. Reference Salinas, Balachandar, Zúñiga, Shringarpure, Fedele and Cantero2023), and the symmetry group in Appendix D can be used to transform between different measures. For two-dimensional flow (
 $U_2= {\partial }/{\partial y}=0$
) Ellison & Turner (Reference Ellison and Turner1959) measure the depth by enforcing
$U_2= {\partial }/{\partial y}=0$
) Ellison & Turner (Reference Ellison and Turner1959) measure the depth by enforcing
 $\sigma _{11} = 1$
, equivalent to (2.26). To be consistent with previous work we have used (2.26) in all figures, and state explicitly whenever it is used with most expressions being for general depth. The advantage of (2.26) is that it enables self-similar flow to be captured whenever it occurs, if instead depth is taken to be some arbitrary function then even if the flow profiles are self-similar the shape functions in (2.13) will still depend on
$\sigma _{11} = 1$
, equivalent to (2.26). To be consistent with previous work we have used (2.26) in all figures, and state explicitly whenever it is used with most expressions being for general depth. The advantage of (2.26) is that it enables self-similar flow to be captured whenever it occurs, if instead depth is taken to be some arbitrary function then even if the flow profiles are self-similar the shape functions in (2.13) will still depend on
 $(x,y,t)$
. As a general point, whatever definition of depth is used in a depth-averaged model, it must enable self-similar flow to be captured.
$(x,y,t)$
. As a general point, whatever definition of depth is used in a depth-averaged model, it must enable self-similar flow to be captured.
There is another measure of depth in the system:
 $\tilde {h} : = \varsigma _h h$
appears in the definition of entrainment (2.8d
) which gives rise to the volume equation (2.16). By (2.8a
) the entrainment across
$\tilde {h} : = \varsigma _h h$
appears in the definition of entrainment (2.8d
) which gives rise to the volume equation (2.16). By (2.8a
) the entrainment across
 $z=b+\tilde {h}$
should be the same as across
$z=b+\tilde {h}$
should be the same as across
 $z=H$
, so
$z=H$
, so
 $b+\tilde {h}$
can be taken to be any elevation above the region in which the velocity field is influenced by the presence of the current. However, the surface
$b+\tilde {h}$
can be taken to be any elevation above the region in which the velocity field is influenced by the presence of the current. However, the surface
 $z=b+\tilde {h}$
moves with the velocity field, and we wish for the shape factor
$z=b+\tilde {h}$
moves with the velocity field, and we wish for the shape factor
 $\varsigma _h=\tilde {h}/h$
to be a constant for self-similar flow. This means that it must be on the edge of where the velocity field is influenced by the current, that is
$\varsigma _h=\tilde {h}/h$
to be a constant for self-similar flow. This means that it must be on the edge of where the velocity field is influenced by the current, that is
 \begin{align} \int _{b}^{b+\tilde {h}} \sqrt { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} ^2+ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} ^2} \mathrm {d}{z} &= (1-\delta) \int _b^{H} \sqrt { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} ^2+ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} ^2} \mathrm {d}{z} &&\text {for}& 0 \lt \delta &\ll 1. \end{align}
\begin{align} \int _{b}^{b+\tilde {h}} \sqrt { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} ^2+ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} ^2} \mathrm {d}{z} &= (1-\delta) \int _b^{H} \sqrt { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} ^2+ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} ^2} \mathrm {d}{z} &&\text {for}& 0 \lt \delta &\ll 1. \end{align}
Our definition of
 $\tilde {h}$
is comparable to that used in some experimental investigations of entrainment, in that it seeks a level at which the bed-parallel velocity has become small (Odier et al. Reference Odier, Chen and Ecke2014; Maggi et al. Reference Maggi, Negretti, Hopfinger and Adduce2023). In these, the entrainment rate is defined for steady flow in terms of the velocity of fluid flow across this surface,
$\tilde {h}$
is comparable to that used in some experimental investigations of entrainment, in that it seeks a level at which the bed-parallel velocity has become small (Odier et al. Reference Odier, Chen and Ecke2014; Maggi et al. Reference Maggi, Negretti, Hopfinger and Adduce2023). In these, the entrainment rate is defined for steady flow in terms of the velocity of fluid flow across this surface,
 $w_e = - w(z=\tilde {h})$
. However, in a depth-average model, the conditions which arise most naturally are
$w_e = - w(z=\tilde {h})$
. However, in a depth-average model, the conditions which arise most naturally are
 \begin{equation} \begin{aligned} w_e &= \frac {\partial }{\partial x} (Uh) &&&& \text {for spatially evolving steady flow, and} \\ w_e &= \frac {\partial \tilde {h}}{\partial t} &&&&\text {for temporally evolving uniform flow.} \end{aligned} \end{equation}
\begin{equation} \begin{aligned} w_e &= \frac {\partial }{\partial x} (Uh) &&&& \text {for spatially evolving steady flow, and} \\ w_e &= \frac {\partial \tilde {h}}{\partial t} &&&&\text {for temporally evolving uniform flow.} \end{aligned} \end{equation}
The condition for steady flow is well known (Ellison & Turner Reference Ellison and Turner1959; Negretti et al. Reference Negretti, Flòr and Hopfinger2017; Martin, Negretti & Hopfinger Reference Martin, Negretti and Hopfinger2019; Maggi et al. Reference Maggi, Negretti, Hopfinger and Adduce2023), the uniform case less so. The definition of
 $\tilde {h}$
is important because it controls the time evolution of depth through conservation of volume (2.16): steady currents should have the same entrainment rate as uniform currents when they have the same flow properties. Further investigation is required to establish whether (5.1) gives the same entrainment in these two scenarios. Throughout, we use (5.1) with
$\tilde {h}$
is important because it controls the time evolution of depth through conservation of volume (2.16): steady currents should have the same entrainment rate as uniform currents when they have the same flow properties. Further investigation is required to establish whether (5.1) gives the same entrainment in these two scenarios. Throughout, we use (5.1) with
 $\delta = 0.01$
.
$\delta = 0.01$
.
5.2. Relating entrainment to turbulence
The discussion above reveals the ad hoc nature of the volume equation (2.16). The interface
 $z = \tilde {h}$
is not a physical property, but rather is constructed through heuristic arguments, with different researchers coming up with different constructions. The entrainment rate
$z = \tilde {h}$
is not a physical property, but rather is constructed through heuristic arguments, with different researchers coming up with different constructions. The entrainment rate
 $w_e$
then measures the flow rate across our constructed interface. This formulation is a historical artefact: the original depth-averaged model was presented by Saint-Venant (Reference Saint-Venant1871) for open-channel flow, and in that context there is a clear interface between air and water determining
$w_e$
then measures the flow rate across our constructed interface. This formulation is a historical artefact: the original depth-averaged model was presented by Saint-Venant (Reference Saint-Venant1871) for open-channel flow, and in that context there is a clear interface between air and water determining
 $z = \tilde {h}$
. The source term is no longer entrainment, but could be interpreted as heavy rain inflating the volume of the river or canal. There is no such clarity for gravity currents: sometimes the upper interface is moderately sharp, but often it is highly diffuse and the attempt to represent it as a mathematical surface is artificial.
$z = \tilde {h}$
. The source term is no longer entrainment, but could be interpreted as heavy rain inflating the volume of the river or canal. There is no such clarity for gravity currents: sometimes the upper interface is moderately sharp, but often it is highly diffuse and the attempt to represent it as a mathematical surface is artificial.
Likewise, the physical interpretation of entrainment
 $w_e$
is not clear: it is some measure of the progressive mixing and dilution of the current, but one dependent on the imposed interface. The physical origin of entrainment is known to be turbulence, in particular it is the buoyancy flux which leads to the fluid becoming more dilute and disperse (Strang & Fernando Reference Strang and Fernando2001; Arneborg et al. Reference Arneborg, Fiekas, Umlauf and Burchard2007; Wells et al. Reference Wells, Cenedese and Caulfield2010; Odier et al. Reference Odier, Chen and Ecke2014). There is a natural velocity which arises from these turbulent fluctuations, which we will term the turbulent buoyancy velocity,
$w_e$
is not clear: it is some measure of the progressive mixing and dilution of the current, but one dependent on the imposed interface. The physical origin of entrainment is known to be turbulence, in particular it is the buoyancy flux which leads to the fluid becoming more dilute and disperse (Strang & Fernando Reference Strang and Fernando2001; Arneborg et al. Reference Arneborg, Fiekas, Umlauf and Burchard2007; Wells et al. Reference Wells, Cenedese and Caulfield2010; Odier et al. Reference Odier, Chen and Ecke2014). There is a natural velocity which arises from these turbulent fluctuations, which we will term the turbulent buoyancy velocity,
 \begin{equation} w_{\mathcal {B}} : = {2 \int _b^H J_3 \mathrm {d}{z}}\Bigg / {\int _b^H {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \mathrm {d}{z}} = \frac {2 \mathcal {B}_K}{R g \Phi \cos \theta }.\end{equation}
\begin{equation} w_{\mathcal {B}} : = {2 \int _b^H J_3 \mathrm {d}{z}}\Bigg / {\int _b^H {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \mathrm {d}{z}} = \frac {2 \mathcal {B}_K}{R g \Phi \cos \theta }.\end{equation}
For a top-hat model (table 1) of a compositional current (
 $w_s=E_s=0$
) the consistency requirement for
$w_s=E_s=0$
) the consistency requirement for
 $\mathcal {B}_K$
(3.7b
) gives
$\mathcal {B}_K$
(3.7b
) gives
 $w_e = w_{\mathcal {B}}$
, consistent with Wells et al. (Reference Wells, Cenedese and Caulfield2010). For a particle-driven current, (3.7b
) becomes
$w_e = w_{\mathcal {B}}$
, consistent with Wells et al. (Reference Wells, Cenedese and Caulfield2010). For a particle-driven current, (3.7b
) becomes
 \begin{equation} w_{\mathcal {B}} = w_e + \lbrack { 2 - \varsigma _\phi }\rbrack w_s \cos \theta + \frac {E_s}{\Phi }. \end{equation}
\begin{equation} w_{\mathcal {B}} = w_e + \lbrack { 2 - \varsigma _\phi }\rbrack w_s \cos \theta + \frac {E_s}{\Phi }. \end{equation}
This can be used to eliminate
 $w_e$
from the governing equations, after which the top-hat volume equation becomes
$w_e$
from the governing equations, after which the top-hat volume equation becomes
 \begin{gather} \frac {\partial h}{\partial t} + \sum _\beta \frac {\partial }{\partial x_\beta } (h U_\beta) = w_e = w_{\mathcal {B}} - \lbrack { 2 - \varsigma _\phi }\rbrack w_s \cos \theta - \frac {E_s}{\Phi }.\end{gather}
\begin{gather} \frac {\partial h}{\partial t} + \sum _\beta \frac {\partial }{\partial x_\beta } (h U_\beta) = w_e = w_{\mathcal {B}} - \lbrack { 2 - \varsigma _\phi }\rbrack w_s \cos \theta - \frac {E_s}{\Phi }.\end{gather}
Different approaches have been taken to close the entrainment in model of particle-driven currents. Suppose that
 $\hat {w}_e$
is a closure of entrainment in compositional currents. Historical models either neglect entrainment outright (Bonnecaze et al. Reference Bonnecaze, Huppert and Lister1993), or assume that closures can be transferred directly from compositional to particle-driven currents as
$\hat {w}_e$
is a closure of entrainment in compositional currents. Historical models either neglect entrainment outright (Bonnecaze et al. Reference Bonnecaze, Huppert and Lister1993), or assume that closures can be transferred directly from compositional to particle-driven currents as
 $w_e = \hat {w}_e$
(Parker et al. Reference Parker, Fukushima and Pantin1986). However, there is a range of physical processes in particle-driven currents that are not present in compositional currents, and so it is not obvious that the aggregate effect of these processes (entrainment) is transferred so easily. Instead, it is reasonable to suppose that the effects of turbulence are most similar, the large-scale vortices performing the mixing will view the particles as a concentration field. Thus
$w_e = \hat {w}_e$
(Parker et al. Reference Parker, Fukushima and Pantin1986). However, there is a range of physical processes in particle-driven currents that are not present in compositional currents, and so it is not obvious that the aggregate effect of these processes (entrainment) is transferred so easily. Instead, it is reasonable to suppose that the effects of turbulence are most similar, the large-scale vortices performing the mixing will view the particles as a concentration field. Thus
 $w_{\mathcal {B}}$
can be approximated as the same in the two classes of current. That is, if
$w_{\mathcal {B}}$
can be approximated as the same in the two classes of current. That is, if
 $\hat {w}_{\mathcal {B}}$
is a closure for buoyancy velocity in compositional currents (top-hat gives
$\hat {w}_{\mathcal {B}}$
is a closure for buoyancy velocity in compositional currents (top-hat gives
 $\hat {w}_{\mathcal {B}} = \hat {w}_e$
) then
$\hat {w}_{\mathcal {B}} = \hat {w}_e$
) then
 $w_{\mathcal {B}} \simeq \hat {w}_{\mathcal {B}}$
. Thus
$w_{\mathcal {B}} \simeq \hat {w}_{\mathcal {B}}$
. Thus
 \begin{equation} w_e \simeq \hat {w}_e - \lbrack { 2 - \varsigma _\phi }\rbrack w_s \cos \theta - \frac {E_s}{\Phi }, \end{equation}
\begin{equation} w_e \simeq \hat {w}_e - \lbrack { 2 - \varsigma _\phi }\rbrack w_s \cos \theta - \frac {E_s}{\Phi }, \end{equation}
we expect particle-driven currents to be modified relative to compositional currents by some detrainment, driven by settling and a reduction of available energy due to erosion. In the limit of no turbulence and a horizontal bed (
 $w_{\mathcal {B}} = E_s = \theta = 0$
) with vertical continuity near the bed (
$w_{\mathcal {B}} = E_s = \theta = 0$
) with vertical continuity near the bed (
 $\varsigma _\phi =1$
) this becomes the standard expression for dilute laminar detrainment
$\varsigma _\phi =1$
) this becomes the standard expression for dilute laminar detrainment
 $w_e \simeq - w_s$
(in this case
$w_e \simeq - w_s$
(in this case
 $w_e = - w_s$
at early times, the approximation is exact despite the top-hat criterion not always being satisfied as time advances, Dorrell & Hogg Reference Dorrell and Hogg2010). For bypass flows where erosion balances deposition (
$w_e = - w_s$
at early times, the approximation is exact despite the top-hat criterion not always being satisfied as time advances, Dorrell & Hogg Reference Dorrell and Hogg2010). For bypass flows where erosion balances deposition (
 $E_s = \varsigma _\phi \Phi w_s \cos \theta$
) we find that
$E_s = \varsigma _\phi \Phi w_s \cos \theta$
) we find that
 $w_e \simeq \hat {w}_e - 2 w_s \cos \theta$
.
$w_e \simeq \hat {w}_e - 2 w_s \cos \theta$
.
The approach (5.6) is comparable to the approach of Toniolo et al. (Reference Toniolo, Parker, Voller and Beaubouef2006) who linearly interpolated between the dynamics of compositional currents and laminar deposition to model their experiments. Bolla Pittaluga et al. (Reference Bolla Pittaluga, Frascati and Falivene2018) effectively use
 $w_e=\hat {w}_e - w_s \cos \theta$
, which is subsequently adopted by Ma et al. (Reference Ma, Parker, Cartigny, Viparelli, Balachander, Fu and Luchi2024). The energetic interpretation of detrainment presented here gives a clear guide of how it is best implemented.
$w_e=\hat {w}_e - w_s \cos \theta$
, which is subsequently adopted by Ma et al. (Reference Ma, Parker, Cartigny, Viparelli, Balachander, Fu and Luchi2024). The energetic interpretation of detrainment presented here gives a clear guide of how it is best implemented.
To understand the impact of detrainment on the turbulence, we first reconstruct the TKE equation from Parker et al. (Reference Parker, Fukushima and Pantin1986) by substituting the top-hat consistency requirements from (4.4) into our TKE equation (2.21), yielding
 \begin{align} \frac {\partial }{\partial t} ({ h K }) + \sum _\beta \frac {\partial }{\partial x_\beta }(h U_\beta K) & = \sum _\alpha \left ({ U_\alpha u_{\alpha \ast }^2 + {\textstyle \frac {1}{2}} U_\alpha ^2 w_e }\right)\nonumber \\ & \quad - {\textstyle \frac {1}{2}} R g h \cos \theta \left ({ \Phi w_e + \underbrace {\lbrack { 2 - \varsigma _\phi }\rbrack w_s \Phi \cos \theta } + E_s }\right) - h \epsilon _T. \end{align}
\begin{align} \frac {\partial }{\partial t} ({ h K }) + \sum _\beta \frac {\partial }{\partial x_\beta }(h U_\beta K) & = \sum _\alpha \left ({ U_\alpha u_{\alpha \ast }^2 + {\textstyle \frac {1}{2}} U_\alpha ^2 w_e }\right)\nonumber \\ & \quad - {\textstyle \frac {1}{2}} R g h \cos \theta \left ({ \Phi w_e + \underbrace {\lbrack { 2 - \varsigma _\phi }\rbrack w_s \Phi \cos \theta } + E_s }\right) - h \epsilon _T. \end{align}
The term with an underbrace has a rather strange interpretation. If
 $\varsigma _\phi \lt 2$
it is reasonable; the TKE is expended holding particles against gravity. However, for
$\varsigma _\phi \lt 2$
it is reasonable; the TKE is expended holding particles against gravity. However, for
 $\varsigma _\phi =2$
particle suspension costs no energy, and for
$\varsigma _\phi =2$
particle suspension costs no energy, and for
 $\varsigma _\phi \gt 2$
TKE is generated by particle settling (
$\varsigma _\phi \gt 2$
TKE is generated by particle settling (
 $1 \lesssim \varsigma _\phi \lesssim 5$
by figure 2). This term has long been recognised by Parker as greatly troubling (private correspondence). Rewriting using
$1 \lesssim \varsigma _\phi \lesssim 5$
by figure 2). This term has long been recognised by Parker as greatly troubling (private correspondence). Rewriting using
 $w_{\mathcal {B}}$
we arrive at
$w_{\mathcal {B}}$
we arrive at
 \begin{align} \frac {\partial }{\partial t} \left ({ h K }\right) + \sum _\beta \frac {\partial }{\partial x_\beta }(h U_\beta K) & = \sum _\alpha \left ({ U_\alpha u_{\alpha \ast }^2 + \overbrace {{\textstyle \frac {1}{2}} U_\alpha ^2 w_e }}\right)\nonumber \\ &\quad - {\textstyle \frac {1}{2}} R g h \Phi \cos \theta w_{\mathcal {B}} - h \epsilon _T, \end{align}
\begin{align} \frac {\partial }{\partial t} \left ({ h K }\right) + \sum _\beta \frac {\partial }{\partial x_\beta }(h U_\beta K) & = \sum _\alpha \left ({ U_\alpha u_{\alpha \ast }^2 + \overbrace {{\textstyle \frac {1}{2}} U_\alpha ^2 w_e }}\right)\nonumber \\ &\quad - {\textstyle \frac {1}{2}} R g h \Phi \cos \theta w_{\mathcal {B}} - h \epsilon _T, \end{align}
with
 $w_e$
computed using (5.4). This reformulation, and reinterpretation as
$w_e$
computed using (5.4). This reformulation, and reinterpretation as
 $w_{\mathcal {B}}$
being the specified closure and not
$w_{\mathcal {B}}$
being the specified closure and not
 $w_e$
, removes the troubling term. Energy is now simply expended generating buoyancy velocity according to some closure for
$w_e$
, removes the troubling term. Energy is now simply expended generating buoyancy velocity according to some closure for
 $w_{\mathcal {B}}$
, as would be the case in a compositional current. The expression with the overbrace is the MKE converted to TKE during the process of accelerating entrained fluid. Provided that the entire term is positive (i.e. the net entrainment is positive,
$w_{\mathcal {B}}$
, as would be the case in a compositional current. The expression with the overbrace is the MKE converted to TKE during the process of accelerating entrained fluid. Provided that the entire term is positive (i.e. the net entrainment is positive,
 $w_e\gt 0$
) there is no problem with interpretation. However, in a situation where the particle dynamics does not just reduce the entrainment (
$w_e\gt 0$
) there is no problem with interpretation. However, in a situation where the particle dynamics does not just reduce the entrainment (
 $w_e \lt w_{\mathcal {B}}$
) but actually creates detrainment (
$w_e \lt w_{\mathcal {B}}$
) but actually creates detrainment (
 $w_e \lt 0$
) there is a loss of TKE in the model. This is because the top-hat model does not account for the momentum loss to the ambient fluid in this case. This can be resolved by adding another source term to the momentum equation (2.18) which is
$w_e \lt 0$
) there is a loss of TKE in the model. This is because the top-hat model does not account for the momentum loss to the ambient fluid in this case. This can be resolved by adding another source term to the momentum equation (2.18) which is
 $0$
for
$0$
for
 $w_e \geq 0$
and
$w_e \geq 0$
and
 $w_e U_\alpha$
when
$w_e U_\alpha$
when
 $w_e\lt 0$
, and similarly a term to the MKE and total energy equations (2.19) and (2.22) which is
$w_e\lt 0$
, and similarly a term to the MKE and total energy equations (2.19) and (2.22) which is
 $w_e (U_1^2+U_2^2)/2$
when
$w_e (U_1^2+U_2^2)/2$
when
 $w_e\lt 0$
. Tracking through the influence of these extra terms, the overbraced term in (5.8) is zero when
$w_e\lt 0$
. Tracking through the influence of these extra terms, the overbraced term in (5.8) is zero when
 $w_e\lt 0$
.
$w_e\lt 0$
.
This remedy for
 $w_e\lt 0$
in the TKE equation is specific to the case of the top-hat model, and is not required in the model with shape functions. Instead, the detrainment of fluid adjusts the velocity shape function to be raised relative to the concentration profile, capturing the real physics at play. The principal goal of this manuscript is to include flow shape in the modelling framework, which is important to the flow generally and not just for detrainment. The pseudo-equilibrium case in § 4 is quite straightforward, the consistency requirement (4.4b
) yields
$w_e\lt 0$
in the TKE equation is specific to the case of the top-hat model, and is not required in the model with shape functions. Instead, the detrainment of fluid adjusts the velocity shape function to be raised relative to the concentration profile, capturing the real physics at play. The principal goal of this manuscript is to include flow shape in the modelling framework, which is important to the flow generally and not just for detrainment. The pseudo-equilibrium case in § 4 is quite straightforward, the consistency requirement (4.4b
) yields
 \begin{equation} w_e = \frac {w_{\mathcal {B}} - 2 w_s \cos \theta }{\tilde {\sigma }_{1z\phi }}. \end{equation}
\begin{equation} w_e = \frac {w_{\mathcal {B}} - 2 w_s \cos \theta }{\tilde {\sigma }_{1z\phi }}. \end{equation}
Note that, typically,
 $\tilde {\sigma }_{1z\phi }\lt 1$
(figure 2) and thus for compositional currents
$\tilde {\sigma }_{1z\phi }\lt 1$
(figure 2) and thus for compositional currents
 $w_e\gt w_{\mathcal {B}}$
. The expression for
$w_e\gt w_{\mathcal {B}}$
. The expression for
 $w_e$
can be substituted into the pseudo-equilibrium governing equations (4.3) to obtain the balances written in terms of the buoyancy velocity
$w_e$
can be substituted into the pseudo-equilibrium governing equations (4.3) to obtain the balances written in terms of the buoyancy velocity
 $w_{\mathcal {B}}$
. Perhaps more importantly, we can obtain the consistency requirements for turbulent production and mean-flow buoyancy flux by substitution into (4.4a
) and (4.4c
), which are
$w_{\mathcal {B}}$
. Perhaps more importantly, we can obtain the consistency requirements for turbulent production and mean-flow buoyancy flux by substitution into (4.4a
) and (4.4c
), which are
 \begin{align} h \mathcal {P} &= \sigma _{1\phi } U u_{1\ast }^2 + \frac { 2 \sigma _{11} \sigma _{1\phi } - \sigma _{111} }{\tilde {\sigma }_{1z\phi }} {\textstyle \frac {1}{2}} U^2 \left ({ w_{\mathcal {B}} - 2 w_s \cos \theta }\right) \notag \\ & \hspace {2cm} + \frac { \sigma _{z\phi } \sigma _{1\phi } - \sigma _{1z\phi } }{\tilde {\sigma }_{1z\phi }} {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ w_{\mathcal {B}} - 2 w_s \cos \theta }\right) - h \epsilon _M, \end{align}
\begin{align} h \mathcal {P} &= \sigma _{1\phi } U u_{1\ast }^2 + \frac { 2 \sigma _{11} \sigma _{1\phi } - \sigma _{111} }{\tilde {\sigma }_{1z\phi }} {\textstyle \frac {1}{2}} U^2 \left ({ w_{\mathcal {B}} - 2 w_s \cos \theta }\right) \notag \\ & \hspace {2cm} + \frac { \sigma _{z\phi } \sigma _{1\phi } - \sigma _{1z\phi } }{\tilde {\sigma }_{1z\phi }} {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ w_{\mathcal {B}} - 2 w_s \cos \theta }\right) - h \epsilon _M, \end{align}
 \begin{align} h \mathcal {B}_M &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ \frac {\sigma _{1z\phi }}{\tilde {\sigma }_{1z\phi }} - 1 }\right) \left ({ w_{\mathcal {B}} - 2 w_s \cos \theta }\right). \end{align}
\begin{align} h \mathcal {B}_M &= {\textstyle \frac {1}{2}} R g h \Phi \cos \theta \left ({ \frac {\sigma _{1z\phi }}{\tilde {\sigma }_{1z\phi }} - 1 }\right) \left ({ w_{\mathcal {B}} - 2 w_s \cos \theta }\right). \end{align}
We can also use (5.9) to get an approximation for entrainment in pseudo-equilibrium particulate currents
 \begin{align} \tilde {\sigma }_{1z\phi } w_e + 2 w_s \cos \theta = w_{\mathcal {B}} &\simeq \hat {w}_{\mathcal {B}} = \tilde {\sigma }_{1z\phi } \hat {w}_e, &&\text {thus}& w_e &\simeq \hat {w}_e - \frac {2 w_s \cos \theta }{\tilde {\sigma }_{1z\phi }}. \end{align}
\begin{align} \tilde {\sigma }_{1z\phi } w_e + 2 w_s \cos \theta = w_{\mathcal {B}} &\simeq \hat {w}_{\mathcal {B}} = \tilde {\sigma }_{1z\phi } \hat {w}_e, &&\text {thus}& w_e &\simeq \hat {w}_e - \frac {2 w_s \cos \theta }{\tilde {\sigma }_{1z\phi }}. \end{align}
5.3. A volume-free energetic model of gravity currents
The approach used up to now is to rearrange a consistency requirement for buoyancy flux
 $h \mathcal {B}_K$
to express entrainment
$h \mathcal {B}_K$
to express entrainment
 $w_e$
in terms of the buoyancy velocity
$w_e$
in terms of the buoyancy velocity
 $w_{\mathcal {B}}$
, which we expect to have the same closures in particle-driven and compositional currents. We then substitute for
$w_{\mathcal {B}}$
, which we expect to have the same closures in particle-driven and compositional currents. We then substitute for
 $w_e$
wherever we see it. To apply this to the general case we would need to rearrange (3.5) and substitute the result into the volume equation (2.16). This is algebraically complex; here we present an equivalent but simpler approach (the equivalence is shown in the supplemental Maple document). The consistency requirement (3.5) is derived from the GPE equation (2.20) (see (3.2)), as
$w_e$
wherever we see it. To apply this to the general case we would need to rearrange (3.5) and substitute the result into the volume equation (2.16). This is algebraically complex; here we present an equivalent but simpler approach (the equivalence is shown in the supplemental Maple document). The consistency requirement (3.5) is derived from the GPE equation (2.20) (see (3.2)), as
 \begin{align} \frac {\partial }{\partial t}\left ({ {\textstyle \frac {1}{2}} \sigma _{z\phi } R g h^2 \Phi \cos \theta }\right) & + \sum _\beta \frac {\partial }{\partial x_\beta } \left ({ {\textstyle \frac {1}{2}} \sigma _{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta }\right)\qquad\qquad\qquad\qquad\qquad \nonumber \\ & \qquad\qquad\qquad\qquad = \tilde {S}_G + \frac {1}{2} R g h \Phi \cos \theta w_{\mathcal {B}} + h \mathcal {B}_M. \end{align}
\begin{align} \frac {\partial }{\partial t}\left ({ {\textstyle \frac {1}{2}} \sigma _{z\phi } R g h^2 \Phi \cos \theta }\right) & + \sum _\beta \frac {\partial }{\partial x_\beta } \left ({ {\textstyle \frac {1}{2}} \sigma _{\beta z\phi } U_\beta R g h^2 \Phi \cos \theta }\right)\qquad\qquad\qquad\qquad\qquad \nonumber \\ & \qquad\qquad\qquad\qquad = \tilde {S}_G + \frac {1}{2} R g h \Phi \cos \theta w_{\mathcal {B}} + h \mathcal {B}_M. \end{align}
Here,
 $\tilde {S}_G$
is defined in (2.20b
) and contains the effects of bed variation and particle settling;
$\tilde {S}_G$
is defined in (2.20b
) and contains the effects of bed variation and particle settling;
 $h \mathcal {B}_M$
can be found in (3.6) derived as the uplift of concentration by the mean flow, and is a consequence of the incompressibility condition (2.1a
).
$h \mathcal {B}_M$
can be found in (3.6) derived as the uplift of concentration by the mean flow, and is a consequence of the incompressibility condition (2.1a
).
We can now offer an alternative to the classical volumetric framework for modelling gravity currents, which was outlined in § 2.3. The governing equations are those for particles (2.17), momentum (2.18), GPE (5.12) and total energy (2.22). This model is closed by imposition of shape functions along with buoyancy velocity
 $w_{\mathcal {B}}$
; erosion
$w_{\mathcal {B}}$
; erosion
 $E_s$
; drag
$E_s$
; drag
 $u_{\alpha \ast }$
; and dissipation
$u_{\alpha \ast }$
; and dissipation
 $\epsilon _T$
. Consistency requirements for this system of equations can be derived using the volume equation (2.16) to obtain an expression for entrainment
$\epsilon _T$
. Consistency requirements for this system of equations can be derived using the volume equation (2.16) to obtain an expression for entrainment
 $w_e$
, and either the MKE equation (2.19) or the TKE equation (2.21) to obtain a closure for turbulent production
$w_e$
, and either the MKE equation (2.19) or the TKE equation (2.21) to obtain a closure for turbulent production
 $h \mathcal {P}$
. This is equivalent to rearranging the expressions in § 3, see there for interpretation of terms. Substituting the definition of
$h \mathcal {P}$
. This is equivalent to rearranging the expressions in § 3, see there for interpretation of terms. Substituting the definition of
 $w_{\mathcal {B}}$
from (5.3) into the consistency requirement for
$w_{\mathcal {B}}$
from (5.3) into the consistency requirement for
 $h \mathcal {B}_K$
(3.5) and rearranging for
$h \mathcal {B}_K$
(3.5) and rearranging for
 $w_e$
we obtain
$w_e$
we obtain
 \begin{align} w_e = & \frac {\varsigma _h}{\sigma _{z\phi }} \Bigg \lgroup w_{\mathcal {B}} - \lbrack { 2 - \sigma _{z\phi } \varsigma _\phi }\rbrack w_s \cos \theta - \sigma _{z\phi } \frac {E_s}{\Phi }\nonumber \\ & + \sum _\beta \left ({ \frac {\sigma _{z\phi }}{\varsigma _h} + \sigma _{\beta \phi }\sigma _{z\phi } - 2\varsigma _{\beta z \phi } }\right) \frac {\partial }{\partial x_\beta } (h U_\beta) + \sum _\beta \left ({ \sigma _{\beta \phi }\sigma _{z\phi } - \sigma _{\beta z \phi } }\right) \frac {U_\beta h}{\Phi } \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ & + \Bigg\lbrack { - \varsigma _h \frac {\partial }{\partial t} \left ({ \frac {\sigma _{z\phi }}{\varsigma _h}}\right) + \sum _{\beta } \left ({ \sigma _{z\phi } \frac {\partial \sigma _{\beta \phi }}{\partial x_\beta } - \frac {\partial \sigma _{\beta z \phi }}{\partial x_\beta } - \tilde {\sigma }_{D\beta z \phi } }\right) U_\beta }\Bigg\rbrack h \Bigg \rgroup. \end{align}
\begin{align} w_e = & \frac {\varsigma _h}{\sigma _{z\phi }} \Bigg \lgroup w_{\mathcal {B}} - \lbrack { 2 - \sigma _{z\phi } \varsigma _\phi }\rbrack w_s \cos \theta - \sigma _{z\phi } \frac {E_s}{\Phi }\nonumber \\ & + \sum _\beta \left ({ \frac {\sigma _{z\phi }}{\varsigma _h} + \sigma _{\beta \phi }\sigma _{z\phi } - 2\varsigma _{\beta z \phi } }\right) \frac {\partial }{\partial x_\beta } (h U_\beta) + \sum _\beta \left ({ \sigma _{\beta \phi }\sigma _{z\phi } - \sigma _{\beta z \phi } }\right) \frac {U_\beta h}{\Phi } \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ & + \Bigg\lbrack { - \varsigma _h \frac {\partial }{\partial t} \left ({ \frac {\sigma _{z\phi }}{\varsigma _h}}\right) + \sum _{\beta } \left ({ \sigma _{z\phi } \frac {\partial \sigma _{\beta \phi }}{\partial x_\beta } - \frac {\partial \sigma _{\beta z \phi }}{\partial x_\beta } - \tilde {\sigma }_{D\beta z \phi } }\right) U_\beta }\Bigg\rbrack h \Bigg \rgroup. \end{align}
The two formulations of entrainment,
 $w_e$
from velocity of ambient fluid fluid into the current and
$w_e$
from velocity of ambient fluid fluid into the current and
 $w_{\mathcal {B}}$
from the turbulent mixing, are thus related as is expected but has not previously been shown. (Note that the appropriate way to approximate a current by a top-hat model when using a closure for buoyancy velocity is to define depth by
$w_{\mathcal {B}}$
from the turbulent mixing, are thus related as is expected but has not previously been shown. (Note that the appropriate way to approximate a current by a top-hat model when using a closure for buoyancy velocity is to define depth by
 $\sigma _{z\phi }=1$
, so
$\sigma _{z\phi }=1$
, so
 $h$
is twice the elevation of the centre of excess mass, Arneborg et al. Reference Arneborg, Fiekas, Umlauf and Burchard2007; Anjum, Mcelwaine & Caulfield Reference Anjum, Mcelwaine and Caulfield2013.) The expression for
$h$
is twice the elevation of the centre of excess mass, Arneborg et al. Reference Arneborg, Fiekas, Umlauf and Burchard2007; Anjum, Mcelwaine & Caulfield Reference Anjum, Mcelwaine and Caulfield2013.) The expression for
 $w_e$
, (5.13), can be substituted into the consistency requirement for
$w_e$
, (5.13), can be substituted into the consistency requirement for
 $h \mathcal {P}$
(3.4) yielding
$h \mathcal {P}$
(3.4) yielding
 \begin{align} h \mathcal {P} &= \frac {1}{2} \left({\sum _\beta \frac {\sigma _{\beta \beta }}{\sigma _{z\phi }}U_\beta ^2}\right) \left ({ w_{\mathcal {B}} - \lbrack { 2 - \sigma_{z\phi } \varsigma _\phi }\rbrack w_s \cos \theta - \sigma _{z\phi }\frac {E_s}{\Phi } }\right) + \sum _\beta \sigma _{\beta \beta }U_\beta u_{\beta \ast }^2 - h \epsilon _M\nonumber \\ &\qquad + \sum_\beta (\sigma _{\beta \phi }-\sigma _{\beta \beta }) U_\beta R h\Phi \left ( { g_\beta - g \cos \theta \frac {\partial b}{x_\beta } }\right)\nonumber \\ &\qquad + \frac {1}{2} \sum _{\beta\gamma } \left ({ \sigma _{\gamma \gamma } \left\lbrack { 2 \sigma _{\beta\gamma } + \sigma _{\beta \phi } - 2 \frac {\varsigma _{\beta z \phi}}{\sigma _{z\phi }} }\right\rbrack - \sigma _{\beta \gamma \gamma }}\right) U_\gamma ^2 U_\beta \frac {\partial h}{\partial x_\beta}\nonumber \\ & \qquad + \frac {1}{2} \sum _{\beta } \left ({ \sigma_{\beta \beta } \left\lbrack { 4\sigma _{\beta \beta } + \sigma _{\beta\phi } - 2 \frac {\varsigma _{\beta z \phi }}{\sigma _{z\phi }}}\right\rbrack - 3\sigma _{\beta \beta \beta } }\right) h U_\beta ^2 \frac{\partial U_\beta }{\partial x_\beta }\nonumber \\ &\qquad + \frac{1}{2} \sum _{\beta \neq \gamma } \Bigg\lgroup \left ({ \sigma_{\gamma \gamma } \left\lbrack { 2\sigma _{\beta \gamma } + \sigma _{\beta\phi } - 2 \frac {\varsigma _{\beta z \phi }}{\sigma _{z\phi }}}\right\rbrack - \sigma _{\beta \gamma \gamma } }\right) h U_\gamma ^2\frac {\partial U_\beta }{\partial x_\beta } \nonumber\\ &\qquad\quad\qquad\qquad + 2 \left ({ \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) h U_\beta U_\gamma \frac {\partial U_\gamma }{\partial x_\beta } \Bigg\rgroup \nonumber \\ &\qquad + \frac {1}{2} \sum _{\beta \gamma } \sigma _{\gamma \gamma } \left ({ \sigma _{\beta \phi } - \frac {\sigma _{\beta z\phi }}{\sigma _{z\phi }} }\right) \frac {h U_\gamma ^2 U_\beta }{\Phi } \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ & \qquad + \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \varsigma _{\beta z\phi } }\right) U_\beta R g h \Phi \cos \theta \frac {\partial h}{\partial x_\beta }\nonumber \\ &\qquad + \frac {1}{2} \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \tilde {\sigma }_{\beta z\phi } }\right) U_\beta R g h^2 \cos \theta \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ &\qquad + \frac {1}{2} \sum _\beta \Bigg\lgroup - \frac {1}{\sigma _{z\phi }} \frac {\partial }{\partial t} \left ({ \sigma _{z\phi } \sigma _{\beta \beta } }\right) \nonumber\\ & \qquad+ \sum _\gamma \left ({ \sigma _{\beta \beta } \frac {\partial }{\partial x_\gamma } \lbrack { 2\sigma _{\beta \gamma } + \sigma _{\gamma \phi } }\rbrack - \frac {\partial \sigma _{\beta \beta \gamma }}{\partial x_\gamma } - \frac {\sigma _{\beta \beta }}{{\sigma _{z\phi }}} \left\lbrack { \frac {\partial \sigma _{\gamma z \phi }}{\partial x_\gamma } + \tilde {\sigma }_{D\gamma z \phi } }\right\rbrack }\right) U_\gamma \Bigg\rgroup h U_\beta ^2\nonumber \\ &\qquad\qquad\quad\qquad + \frac {1}{2} \sum _\beta \left ({ \sigma _{\beta \beta } \frac {\partial \sigma _{z\phi }}{\partial x_\beta } - \frac {\partial \tilde {\sigma }_{\beta z \phi }}{\partial x_\beta } + \tilde {\sigma }_{D\beta z \phi } }\right) U_\beta R g h^2 \Phi \cos \theta. \end{align}
\begin{align} h \mathcal {P} &= \frac {1}{2} \left({\sum _\beta \frac {\sigma _{\beta \beta }}{\sigma _{z\phi }}U_\beta ^2}\right) \left ({ w_{\mathcal {B}} - \lbrack { 2 - \sigma_{z\phi } \varsigma _\phi }\rbrack w_s \cos \theta - \sigma _{z\phi }\frac {E_s}{\Phi } }\right) + \sum _\beta \sigma _{\beta \beta }U_\beta u_{\beta \ast }^2 - h \epsilon _M\nonumber \\ &\qquad + \sum_\beta (\sigma _{\beta \phi }-\sigma _{\beta \beta }) U_\beta R h\Phi \left ( { g_\beta - g \cos \theta \frac {\partial b}{x_\beta } }\right)\nonumber \\ &\qquad + \frac {1}{2} \sum _{\beta\gamma } \left ({ \sigma _{\gamma \gamma } \left\lbrack { 2 \sigma _{\beta\gamma } + \sigma _{\beta \phi } - 2 \frac {\varsigma _{\beta z \phi}}{\sigma _{z\phi }} }\right\rbrack - \sigma _{\beta \gamma \gamma }}\right) U_\gamma ^2 U_\beta \frac {\partial h}{\partial x_\beta}\nonumber \\ & \qquad + \frac {1}{2} \sum _{\beta } \left ({ \sigma_{\beta \beta } \left\lbrack { 4\sigma _{\beta \beta } + \sigma _{\beta\phi } - 2 \frac {\varsigma _{\beta z \phi }}{\sigma _{z\phi }}}\right\rbrack - 3\sigma _{\beta \beta \beta } }\right) h U_\beta ^2 \frac{\partial U_\beta }{\partial x_\beta }\nonumber \\ &\qquad + \frac{1}{2} \sum _{\beta \neq \gamma } \Bigg\lgroup \left ({ \sigma_{\gamma \gamma } \left\lbrack { 2\sigma _{\beta \gamma } + \sigma _{\beta\phi } - 2 \frac {\varsigma _{\beta z \phi }}{\sigma _{z\phi }}}\right\rbrack - \sigma _{\beta \gamma \gamma } }\right) h U_\gamma ^2\frac {\partial U_\beta }{\partial x_\beta } \nonumber\\ &\qquad\quad\qquad\qquad + 2 \left ({ \sigma _{\gamma \gamma } \sigma _{\beta \gamma } - \sigma _{\beta \gamma \gamma } }\right) h U_\beta U_\gamma \frac {\partial U_\gamma }{\partial x_\beta } \Bigg\rgroup \nonumber \\ &\qquad + \frac {1}{2} \sum _{\beta \gamma } \sigma _{\gamma \gamma } \left ({ \sigma _{\beta \phi } - \frac {\sigma _{\beta z\phi }}{\sigma _{z\phi }} }\right) \frac {h U_\gamma ^2 U_\beta }{\Phi } \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ & \qquad + \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \varsigma _{\beta z\phi } }\right) U_\beta R g h \Phi \cos \theta \frac {\partial h}{\partial x_\beta }\nonumber \\ &\qquad + \frac {1}{2} \sum _{\beta } \left ({ \sigma _{\beta \beta } \sigma _{z\phi } - \tilde {\sigma }_{\beta z\phi } }\right) U_\beta R g h^2 \cos \theta \frac {\partial \Phi }{\partial x_\beta }\nonumber \\ &\qquad + \frac {1}{2} \sum _\beta \Bigg\lgroup - \frac {1}{\sigma _{z\phi }} \frac {\partial }{\partial t} \left ({ \sigma _{z\phi } \sigma _{\beta \beta } }\right) \nonumber\\ & \qquad+ \sum _\gamma \left ({ \sigma _{\beta \beta } \frac {\partial }{\partial x_\gamma } \lbrack { 2\sigma _{\beta \gamma } + \sigma _{\gamma \phi } }\rbrack - \frac {\partial \sigma _{\beta \beta \gamma }}{\partial x_\gamma } - \frac {\sigma _{\beta \beta }}{{\sigma _{z\phi }}} \left\lbrack { \frac {\partial \sigma _{\gamma z \phi }}{\partial x_\gamma } + \tilde {\sigma }_{D\gamma z \phi } }\right\rbrack }\right) U_\gamma \Bigg\rgroup h U_\beta ^2\nonumber \\ &\qquad\qquad\quad\qquad + \frac {1}{2} \sum _\beta \left ({ \sigma _{\beta \beta } \frac {\partial \sigma _{z\phi }}{\partial x_\beta } - \frac {\partial \tilde {\sigma }_{\beta z \phi }}{\partial x_\beta } + \tilde {\sigma }_{D\beta z \phi } }\right) U_\beta R g h^2 \Phi \cos \theta. \end{align}
The consistency requirement for mean-flow uplift of particles (3.6) is not affected, and is used to close (5.12). The accuracy of these expressions is verified in figure 9 in the same way as the consistency expressions for the classical volumetric model were verified in figure 6, § 4. The coefficients in (5.13) and (5.14) calculated for real currents are included in figure 3.

This new formulation does not contain an equation for volume, and eliminates the need for an arbitrary imposition of a interfacial surface. This model is closed directly by a measure of the turbulence, the buoyancy velocity (5.3). The only time when the interfacial surface
 $z=\tilde {h}$
needs to be specified is when using the consistency relationship for entrainment (5.13), which depends on
$z=\tilde {h}$
needs to be specified is when using the consistency relationship for entrainment (5.13), which depends on
 $\varsigma _h = \tilde {h}/h$
. This model is volume free in that it does not explicitly include a volume equation, and instead the evolution is governed by the energetics. The way that incompressibility (2.1a
) enters the formulation is through the derivation of mean-flow uplift of concentration (3.3), and in deducing the implied entrainment rate (5.13).
$\varsigma _h = \tilde {h}/h$
. This model is volume free in that it does not explicitly include a volume equation, and instead the evolution is governed by the energetics. The way that incompressibility (2.1a
) enters the formulation is through the derivation of mean-flow uplift of concentration (3.3), and in deducing the implied entrainment rate (5.13).
A key observation is that, even for compositional currents, the entrainment
 $w_e$
is no longer equal to, or even proportional to, the buoyancy velocity
$w_e$
is no longer equal to, or even proportional to, the buoyancy velocity
 $w_{\mathcal {B}}$
(5.13). Consequently, in the general case, we require new closures for
$w_{\mathcal {B}}$
(5.13). Consequently, in the general case, we require new closures for
 $w_{\mathcal {B}}$
. Early results on this have been documented by Wells et al. (Reference Wells, Cenedese and Caulfield2010), but further work is required to parametrise the stirring and mixing of the density field. See Caulfield (Reference Caulfield2021) for a review of this research area.
$w_{\mathcal {B}}$
. Early results on this have been documented by Wells et al. (Reference Wells, Cenedese and Caulfield2010), but further work is required to parametrise the stirring and mixing of the density field. See Caulfield (Reference Caulfield2021) for a review of this research area.
6. Novel implications for particle auto-suspension
Here, we investigate how the energetics of a gravity current influence the particle load it carries. We begin our discussion by illustrating how the Knapp–Bagnold criterion (Knapp Reference Knapp1938; Bagnold Reference Bagnold1962) can be derived from our system of equations. This criterion identifies when the increased downslope gravitational work provided by suspended particles provides the requisite energy to keep the particles suspended, a condition referred to as auto-suspension. From the TKE equation (2.21), to not deplete the supply of turbulent energy we require the turbulent production exceeds the buoyancy flux. Using the pseudo-equilibrium balance, which was shown in § 4 to give a good description of a slowly evolving current on a flat bed, the TKE equation (2.21) simplifies to
 \begin{align} h \mathcal {P} = h \mathcal {B}_K + h \epsilon _K + \sigma _{1k} K w_e. \end{align}
\begin{align} h \mathcal {P} = h \mathcal {B}_K + h \epsilon _K + \sigma _{1k} K w_e. \end{align}
This implies the Knapp–Bagnold energetic principle
 \begin{equation} h \mathcal {P} \gt h \mathcal {B}_K. \end{equation}
\begin{equation} h \mathcal {P} \gt h \mathcal {B}_K. \end{equation}
Consequently, neglecting entrainment and mean-flow dissipation,
 \begin{align} \sigma _{1\phi } U u_{1\ast }^2 \gt w_s R g h \Phi (\cos \theta)^2.\end{align}
\begin{align} \sigma _{1\phi } U u_{1\ast }^2 \gt w_s R g h \Phi (\cos \theta)^2.\end{align}
Approximating
 $\sigma _{1\phi } \approx 1$
and
$\sigma _{1\phi } \approx 1$
and
 $(\cos \theta)^2 \approx 1$
, and using (4.3c
) to rewrite drag in terms of bed slope, we arrive at
$(\cos \theta)^2 \approx 1$
, and using (4.3c
) to rewrite drag in terms of bed slope, we arrive at
 \begin{align} U \sin \theta \gt w_s, \end{align}
\begin{align} U \sin \theta \gt w_s, \end{align}
the standard representation of the Knapp–Bagnold criterion. This can either be interpreted as the maximum particle size that can be transported by a given current (upper bound on
 $w_s$
), or the minimum speed of the gravity current to be sustainable over long distances (lower bound on
$w_s$
), or the minimum speed of the gravity current to be sustainable over long distances (lower bound on
 $U$
). For gravity currents, this simple analysis ignores a lot of effects, and we expand on it using the understanding of gravity current energetics developed.
$U$
). For gravity currents, this simple analysis ignores a lot of effects, and we expand on it using the understanding of gravity current energetics developed.
For dilute mono- and poly-disperse fluvial systems, it has been observed that (Garcia Reference Garcia2008; van Maren et al. Reference van Maren, Winterwerp, Wang and Pu2009; Dorrell et al. Reference Dorrell, Amy, Peakall and McCaffrey2018; Fukuda et al. Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023)
 \begin{align} h \mathcal {B}_K = \mathcal {E}_{\Phi } \cdot h \mathcal {P}, \end{align}
\begin{align} h \mathcal {B}_K = \mathcal {E}_{\Phi } \cdot h \mathcal {P}, \end{align}
where
 $\mathcal {E}_{\Phi }$
, related to the flux Richardson number, represents the efficiency of suspending sediment, and typically satisfies
$\mathcal {E}_{\Phi }$
, related to the flux Richardson number, represents the efficiency of suspending sediment, and typically satisfies
 $0 \lt \mathcal {E}_{\Phi } \lt 1$
. For gravity currents (Fukuda et al. Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) we treat (6.5) as the definition of the efficiency and explore when its value may be predictable. From the quasi-equilibrium balance (6.1), the final term can be neglected because TKE,
$0 \lt \mathcal {E}_{\Phi } \lt 1$
. For gravity currents (Fukuda et al. Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) we treat (6.5) as the definition of the efficiency and explore when its value may be predictable. From the quasi-equilibrium balance (6.1), the final term can be neglected because TKE,
 $K$
, is small compared with the MKE,
$K$
, is small compared with the MKE,
 $\propto {\textstyle {1}/{2}} U^2$
, see (4.4a
). Substituting in (6.5) we obtain
$\propto {\textstyle {1}/{2}} U^2$
, see (4.4a
). Substituting in (6.5) we obtain
 \begin{align} \frac {h \mathcal {B}_K}{h \epsilon _K} = \frac {\mathcal {E}_{\Phi }}{1 - \mathcal {E}_{\Phi }} = \Gamma, \end{align}
\begin{align} \frac {h \mathcal {B}_K}{h \epsilon _K} = \frac {\mathcal {E}_{\Phi }}{1 - \mathcal {E}_{\Phi }} = \Gamma, \end{align}
where
 $\Gamma$
is a mixing coefficient. The analysis of Osborn (Reference Osborn1980) gives
$\Gamma$
is a mixing coefficient. The analysis of Osborn (Reference Osborn1980) gives
 $\Gamma \lt 1/5$
so that
$\Gamma \lt 1/5$
so that
 $\mathcal {E}_{\Phi }\lt 1/6$
. More recently larger values of
$\mathcal {E}_{\Phi }\lt 1/6$
. More recently larger values of
 $\Gamma$
have been reported (Maffioli, Brethouwer & Lindborg Reference Maffioli, Brethouwer and Lindborg2016; Mashayek, Caulfield & Alford Reference Mashayek, Caulfield and Alford2021), we take
$\Gamma$
have been reported (Maffioli, Brethouwer & Lindborg Reference Maffioli, Brethouwer and Lindborg2016; Mashayek, Caulfield & Alford Reference Mashayek, Caulfield and Alford2021), we take
 $\mathcal {E}_{\Phi }=1/6$
as a reasonable estimate.
$\mathcal {E}_{\Phi }=1/6$
as a reasonable estimate.

Figure 10. Energetics of particle suspension in a classical volumetric model using the entrainment models of Ellison & Turner (Reference Ellison and Turner1959) (a,c,e) and Cenedese & Adduce (Reference Cenedese and Adduce2010) (b,d,f), for symbols see legend in figure 2. (a,b) Turbulent production (neglecting mean-flow dissipation) against buoyancy flux, rearranged in (c,d) to show the concentration. In both (b,c) lines of constant efficiency are shown in black (
 $\mathcal {E}_\Phi =1$
), grey (
$\mathcal {E}_\Phi =1$
), grey (
 $\mathcal {E}_\Phi = 1/6$
) and dashed black (
$\mathcal {E}_\Phi = 1/6$
) and dashed black (
 $\mathcal {E}_\Phi \in \lbrace {10^{-1},10^{-2},10^{-3}}\rbrace$
), and a best fit line is shown in purple. (e,f) The dimensionless mean-flow dissipation against the concentration, the region outside of the bounds (6.9) shaded grey.
$\mathcal {E}_\Phi \in \lbrace {10^{-1},10^{-2},10^{-3}}\rbrace$
), and a best fit line is shown in purple. (e,f) The dimensionless mean-flow dissipation against the concentration, the region outside of the bounds (6.9) shaded grey.
To be able to examine the suspension efficiency of the dataset used in figure 2 we require values of
 $h \mathcal {P}$
and
$h \mathcal {P}$
and
 $h \mathcal {B}_K$
. Ideally, we would use direct measurements, which we do not have for most of the data, or we would use the full expressions (3.4)–(3.6) but these require derivatives of the depth-averaged quantities and shape factors. Instead, we use the pseudo-equilibrium expressions (4.4) which were shown to provide a good level of accuracy provided the current is slowly evolving (figure 6). We make the weak requirement that the flow has a non-zero erosion rate (
$h \mathcal {B}_K$
. Ideally, we would use direct measurements, which we do not have for most of the data, or we would use the full expressions (3.4)–(3.6) but these require derivatives of the depth-averaged quantities and shape factors. Instead, we use the pseudo-equilibrium expressions (4.4) which were shown to provide a good level of accuracy provided the current is slowly evolving (figure 6). We make the weak requirement that the flow has a non-zero erosion rate (
 $E_s\gt 0$
) by the condition of Guo (Reference Guo2020) (see Fukuda et al. Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) and is dilute,
$E_s\gt 0$
) by the condition of Guo (Reference Guo2020) (see Fukuda et al. Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) and is dilute,
 $\Phi \leq 10^{-2}$
. We also require that the residual (4.5) in the pseudo-equilibrium momentum balance (4.3c
) is such that error accumulates over a distance of more than
$\Phi \leq 10^{-2}$
. We also require that the residual (4.5) in the pseudo-equilibrium momentum balance (4.3c
) is such that error accumulates over a distance of more than
 $10^{3/2} h$
, that is
$10^{3/2} h$
, that is
 $h \mathcal {R} \lt 10^{-3/2}$
, where we use the entrainment closure from Cenedese & Adduce (Reference Cenedese and Adduce2010). We include only experimental data, the field measurements reported by Simmons et al. (Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020) are for flow in a sinuous channel and levee overspill and are not in pseudo-equilibrium.
$h \mathcal {R} \lt 10^{-3/2}$
, where we use the entrainment closure from Cenedese & Adduce (Reference Cenedese and Adduce2010). We include only experimental data, the field measurements reported by Simmons et al. (Reference Simmons, Azpiroz-Zabala, Cartigny, Clare, Cooper, Parsons, Pope, Sumner and Talling2020) are for flow in a sinuous channel and levee overspill and are not in pseudo-equilibrium.
For the moment we neglect the mean-flow dissipation (we will discuss this later), and examine the balance (6.5) in figure 10(a,b). We use the entrainment relationships from Ellison & Turner (Reference Ellison and Turner1959) and Cenedese & Adduce (Reference Cenedese and Adduce2010) to show how little different empirical closures effect the results, and in figure 10 a classical volumetric model is assumed (§ 2.3) where entrainment models from compositional currents are used directly (§ 5.2). We observe an approximately linear trend (figure 10
a,b), indicating that (6.5) is perhaps a reasonable approximation, although there is over an order of magnitude of variation in the efficiency
 $\mathcal {E}_\Phi$
. It is possible to rewrite (6.5) to give a prediction of the sediment concentration
$\mathcal {E}_\Phi$
. It is possible to rewrite (6.5) to give a prediction of the sediment concentration
 \begin{align} \Phi = \mathcal {E}_{\Phi } \cdot \frac {h \mathcal {P}}{h \mathcal {N}_K}. \end{align}
\begin{align} \Phi = \mathcal {E}_{\Phi } \cdot \frac {h \mathcal {P}}{h \mathcal {N}_K}. \end{align}
Here,
 $\mathcal {N}_K$
is the normalised buoyancy flux, that is the buoyancy flux per unit sediment concentration. In pseudo-equilibrium this is, by (4.4b
),
$\mathcal {N}_K$
is the normalised buoyancy flux, that is the buoyancy flux per unit sediment concentration. In pseudo-equilibrium this is, by (4.4b
),
 \begin{equation} h \mathcal {N}_K : = \frac {h \mathcal {B}_K}{\Phi } = {\textstyle \frac {1}{2}} R g h \cos \theta \left ({ \tilde {\sigma }_{uz\phi } w_e + 2 w_s \cos \theta }\right). \end{equation}
\begin{equation} h \mathcal {N}_K : = \frac {h \mathcal {B}_K}{\Phi } = {\textstyle \frac {1}{2}} R g h \cos \theta \left ({ \tilde {\sigma }_{uz\phi } w_e + 2 w_s \cos \theta }\right). \end{equation}
Plotting the balance (6.7) in figure 10(c,d) we observe that the scatter collapses around a nonlinear trend (these plots are very similar to figure 3c in Fukuda et al. Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023). This implies that some process correlated with the particle concentration is controlling the mixing efficiency. This should not be the case, and indicates a problem with the analysis.
So far we have neglected
 $h \epsilon _M$
, the mean-flow dissipation, which was shown in § 4.2 to be of leading order for the experimental flows in the dataset, with bounds
$h \epsilon _M$
, the mean-flow dissipation, which was shown in § 4.2 to be of leading order for the experimental flows in the dataset, with bounds
 \begin{align} 0 \lt \epsilon _M^+ \lessapprox 9.15. \end{align}
\begin{align} 0 \lt \epsilon _M^+ \lessapprox 9.15. \end{align}
Narrowing down this value further requires both detailed information about the structure of the bed roughness and how this relates to dissipation. Consequently, we engage in a plausibility analysis: Could the results be explained by mean-flow dissipation in the permissible range?
The effect of increasing
 $h \epsilon _M$
moves points in figure 10(c,d) to the left, and we observe what happens when we move all the points to a line of equal efficiency and back calculate the dissipation. Moving all the points to the line
$h \epsilon _M$
moves points in figure 10(c,d) to the left, and we observe what happens when we move all the points to a line of equal efficiency and back calculate the dissipation. Moving all the points to the line
 $\mathcal {E}_\Phi = 1/6$
results in figure 10(e,f). Many of the points require
$\mathcal {E}_\Phi = 1/6$
results in figure 10(e,f). Many of the points require
 $\epsilon _M^+\lt 0$
, which we interpret as the real current either having more production or less buoyancy flux than captured by the model.
$\epsilon _M^+\lt 0$
, which we interpret as the real current either having more production or less buoyancy flux than captured by the model.

Figure 11. The same as figure 10 but for a volume-free energetic model.
To this point we have been considering a classical volumetric model (§ 2.3), where a closure for entrainment developed for compositional currents,
 $\hat {w}_e$
, may be directly used for a particle-driven current,
$\hat {w}_e$
, may be directly used for a particle-driven current,
 $w_e \simeq \hat {w}_e$
. In the volume-free energetic model (§ 5.3), it is the turbulent buoyancy velocity (5.3) for which a closure for a compositional current,
$w_e \simeq \hat {w}_e$
. In the volume-free energetic model (§ 5.3), it is the turbulent buoyancy velocity (5.3) for which a closure for a compositional current,
 $\hat {w}_{\mathcal {B}}$
, may be used in a particle-driven current,
$\hat {w}_{\mathcal {B}}$
, may be used in a particle-driven current,
 $w_{\mathcal {B}} \simeq \hat {w}_{\mathcal {B}}$
. We do not have such a closure, but have shown how to construct something equivalent from entrainment models in (5.11). We repeat the analysis of energetics in particle suspension, see figure 11. Now, there is a difference between the closures of Ellison & Turner (Reference Ellison and Turner1959) and Cenedese & Adduce (Reference Cenedese and Adduce2010), which arises because
$w_{\mathcal {B}} \simeq \hat {w}_{\mathcal {B}}$
. We do not have such a closure, but have shown how to construct something equivalent from entrainment models in (5.11). We repeat the analysis of energetics in particle suspension, see figure 11. Now, there is a difference between the closures of Ellison & Turner (Reference Ellison and Turner1959) and Cenedese & Adduce (Reference Cenedese and Adduce2010), which arises because
 $h \mathcal {B}_K$
is determined solely by the entrainment closure and is not dependent on the settling velocity. For both closures, there is a broad range of efficiencies when mean-flow dissipation is neglected. Exploring what values
$h \mathcal {B}_K$
is determined solely by the entrainment closure and is not dependent on the settling velocity. For both closures, there is a broad range of efficiencies when mean-flow dissipation is neglected. Exploring what values
 $\epsilon _M^+$
could take (figure 11
e–f) there is reasonably narrow range of values for satisfying the bounds (6.9), except for three points in figure 11( f) (perhaps these flows are rapidly depositing sediment, or the entrainment model is in error).
$\epsilon _M^+$
could take (figure 11
e–f) there is reasonably narrow range of values for satisfying the bounds (6.9), except for three points in figure 11( f) (perhaps these flows are rapidly depositing sediment, or the entrainment model is in error).
Our plausibility analysis is thus a success, the departure from constant efficiency (6.7) observed by Fukuda et al. (Reference Fukuda, de Vet, Skevington, Bastianon, Fernández, Wu, McCaffrey, Naruse, Parsons and Dorrell2023) and reproduced in figure 10(c) can be corrected using two effects: mean-flow dissipation, and the settling velocity reducing the entrainment rate. Compared with Parker et al. (Reference Parker, Fukushima and Pantin1986), both of these effects reduce the implied rate of turbulent production by (4.4a ). The reduced entrainment rate, by design, exactly cancels the settling term in (4.4b ), meaning that the implied buoyancy flux is no longer given an artificial boost to account for the need to suspend particles. The reduction in both of these turbulent terms allows, in principle, for the suspension efficiency (6.5) to be independent of particle concentration as expected.
7. Future work
We here overview additional work required to realise the potential of this new modelling framework. To enable the model to be used predictively, accurate closures are required for the shape, entrainment, erosion, drag and dissipation. A large experimental dataset exists for the shape of the velocity and concentration profiles, but comparatively little data exist for TKE (figure 2). The shape depends on the Froude number (Abad et al. Reference Abad, Sequeiros, Spinewine, Pirmez, Garcia and Parker2011) along with a wider set of dimensionless parameters (4.1), and establishing this dependence is key to understanding the evolution of currents. The total dissipation also needs to be properly quantified, Parker et al. (Reference Parker, Fukushima and Pantin1986) provide an approximate form based on heuristic arguments but an empirically verified closure would be preferable. Closures for the other parameters exist, but have been developed separately; ideally, the full set of closures should be developed in accordance with the consistency relationships (§ 3) which would ensure that the energetics predicted by the model are accurate. At laboratory scale or over smooth beds, the use of the consistency requirement for turbulent production requires an understanding of the mean-flow dissipation and how this relates to roughness (§ 4.2). Regarding entrainment, it is worth further exploring whether an energetic approach would be more accurate than the prevailing volumetric approach (§ 5). The transfer of closures from compositional to particulate currents needs to be verified against high-resolution velocity and concentration fields across different settling velocities. The model and closures capture the body of the current, and require boundary conditions for the front to be developed, similar those by Benjamin (Reference Benjamin1968) and Ungarish & Hogg (Reference Ungarish and Hogg2018) but with the profiles in the current specifiable. The goal is to develop a set of closures sufficiently accurate to capture the extremely long run-out of real-world currents (Azpiroz-Zabala et al. Reference Azpiroz-Zabala, Cartigny, Talling, Parsons, Sumner, Clare, Simmons, Cooper and Pope2017) and the development of sedimentary deposits over geological time scales (Wahab et al. Reference Wahab, Hoyal, Shringarpure and Straub2022).
8. Summary and conclusion
In this work we have constructed a novel depth-averaged modelling framework that for the first time accurately captures the bulk dynamics of a gravity current, allowing for arbitrarily shaped profiles of concentration, velocity and TKE to be implemented (§ 2). Prior to this work, profiles of velocity and concentration have been used in depth-average models of gravity current that do not attempt to capture energetics, and separately research has been conducted on the turbulence and mixing processes. Our work connects these two research efforts, enabling models which accurately capture energetics in a depth-average framework (§ 4). These energetic balances inform the dynamics of particle suspension, and by providing a robust mathematical framework within which to understand the energetics we enable a new and deeper understanding of particulate gravity currents (§ 6).
With the modelling framework we propose two classes of predictive model for the flow depth, concentration, velocity and TKE, which require different closures. Both require specification of the shape of the velocity, concentration and TKE profiles, along with expressions for the erosion of particles, basal drag and viscous dissipation of energy. The first class of model, which we term a classical volumetric model (§ 2.3), requires specification of some interface over which entrainment occurs along with the entrainment rate (§ 5.1). The resulting model consists of equations for volume, concentration, momentum and total energy. Models which make use of volume are by far the most common class of model in the gravity current community, and go back to Ellison & Turner (Reference Ellison and Turner1959) and Parker et al. (Reference Parker, Fukushima and Pantin1986). Our model is a direct generalisation of the classical model derived by Parker et al. (Reference Parker, Fukushima and Pantin1986), and differs from it only by the possibility to specify arbitrary profiles through shape factors. The top-hat version of our model where all shape factors are unity precisely recovers the model of Parker et al. (Reference Parker, Fukushima and Pantin1986). In the optimal case where the shape factors are taken directly from DNS simulation, the model is able to reproduce the results of DNS with almost no error and is substantially more accurate than the top-hat version (§ 4). This gives confidence that, with high-quality closures, the new model can produce accurate predictions of the flow evolution including the energetics.
This approach has some shortcomings in its capturing of entrainment. The construction of an interface over which there is entrainment of ambient fluid is artificial, the upper region of a gravity current is highly diffuse and there is no surface separating the current from the ambient (§ 5.2). Moreover, it is commonplace to using an entrainment closure from compositional currents in a particulate current, which results in the implied uplift of particles by turbulence (the turbulent buoyancy flux) being an increasing function of particle settling velocity (§ 3.1). The buoyancy flux should only be dependent on the distribution of particles and the strength of the turbulence, and artificially inflating it to provide additional support for the particles is not only erroneous but also confuses attempts to understand particle suspension (§ 6). Instead, the available work of the buoyancy flux is split between upholding the particles against settling and entraining ambient fluid.
For these reasons, we propose a second class of model wherein it is the buoyancy flux which is closed for directly, not the entrainment, which removes the need for an interface over which the entrainment occurs. Careful consideration shows that the appropriate formulation of the model is as equations for concentration, momentum, GPE and total energy, and we term this class volume-free energetic models (§ 5.3). This class corresponds much more closely to a physical understanding of gravity currents, which do have budgets of excess mass, momentum and energy, but typically not a clear region to define a volume. Models which require a closure of the buoyancy flux directly are far less common, but do exist (Arneborg et al. Reference Arneborg, Fiekas, Umlauf and Burchard2007; Wells et al. Reference Wells, Cenedese and Caulfield2010). It is likely that the processes which generate buoyancy flux in compositional currents are the same as those in particulate currents, which would allow for the same closures to be used for both. This assumption was used to help understand the dynamics of particle suspension in § 6.
Both classes of predictive model have some effects which are directly closed for, and others which are implied by the model as indirect predictions. For these indirect predictions to be accurate, model closures must be validated to ensure they give the correct indirect predictions through what we have termed consistency requirements (§ 3.2). In both classes the turbulent production, which transfers energy from the mean flow to the turbulence, is implied from the loss of mean-flow energy (§§ 3.1 and 5.3). There is also loss of mean-flow energy directly to viscosity in the boundary layer by the bed, and we show that this makes a leading-order contribution at Reynolds numbers up to and beyond geophysical scales (§ 4.2). For the case of bed roughness, which is present for almost all particulate currents and many compositional currents, structures that are very large (
 $\sim 10^4$
wall units) are required before the mean-flow dissipation is negligible. However, an understanding of mean-flow dissipation is lacking in the literature at large, which makes using the consistency requirements challenging. Large-scale particulate currents over bedforms, along with gravity currents propagating along a strong density interface rather than a solid boundary (a type of intrusion), will not have such a strong mean-flow dissipation and so the consistency requirement may be more easily employed. What is much more straightforward is in the use of the consistency requirement for buoyancy flux in classical volumetric models (§ 3.1), which becomes a consistency requirement for entrainment in volume-free energetic models (§ 5.3). For particulate currents, the implied entrainment incorporates the particle detainment by settling, which has been discussed by several authors without theoretical justification (Toniolo et al. Reference Toniolo, Parker, Voller and Beaubouef2006; Bolla Pittaluga et al. Reference Bolla Pittaluga, Frascati and Falivene2018; Ma et al. Reference Ma, Parker, Cartigny, Viparelli, Balachander, Fu and Luchi2024); here, we provide that justification. These consistency requirements not only provide insight into entrainment, but in future can be used to constrain closures to produce energetically consistent models in the developed depth-average framework. This would enable the energetics to be captured in system-scale models, giving accurate prediction of hazardous environmental flows at geophysical scales.
$\sim 10^4$
wall units) are required before the mean-flow dissipation is negligible. However, an understanding of mean-flow dissipation is lacking in the literature at large, which makes using the consistency requirements challenging. Large-scale particulate currents over bedforms, along with gravity currents propagating along a strong density interface rather than a solid boundary (a type of intrusion), will not have such a strong mean-flow dissipation and so the consistency requirement may be more easily employed. What is much more straightforward is in the use of the consistency requirement for buoyancy flux in classical volumetric models (§ 3.1), which becomes a consistency requirement for entrainment in volume-free energetic models (§ 5.3). For particulate currents, the implied entrainment incorporates the particle detainment by settling, which has been discussed by several authors without theoretical justification (Toniolo et al. Reference Toniolo, Parker, Voller and Beaubouef2006; Bolla Pittaluga et al. Reference Bolla Pittaluga, Frascati and Falivene2018; Ma et al. Reference Ma, Parker, Cartigny, Viparelli, Balachander, Fu and Luchi2024); here, we provide that justification. These consistency requirements not only provide insight into entrainment, but in future can be used to constrain closures to produce energetically consistent models in the developed depth-average framework. This would enable the energetics to be captured in system-scale models, giving accurate prediction of hazardous environmental flows at geophysical scales.
Supplementary materials.
Supplementary materials are available at https://doi.org/10.1017/jfm.2025.285.
Acknowledgements.
We thank S. Fukuda, for providing the compiled experimental data used to produce Figure 2 and subsequent figures with the same data. We also thank S. Zúñiga and S. Balachandar for providing the simulation data used in Figures 5, 6 and 9, and likewise P. Orlandi for the data used in Figure 8. We thank G. Parker for frank discussions on the successes and shortcomings of his 4-equation model on which this work is based. Finally, we thank C. Lloyd and S. Sarwar for informative discussions of bed roughness.
Funding.
E.W.G.S. was supported by the Turbidites Research Group, University of Leeds (funded by AkerBP, CNOOC, ConocoPhillips, Harbour Energy, Murphy Oil, OMV, Oxy and PetroChina) and by UKRI as a National Fellow in Fluid Dynamics (grant number EP/X028577/1); R.M.D. was supported by the UK Natural Environment Research Council (grant number NE/S014535/1).
Declaration of interests.
The authors report no conflict of interest.
Appendix A. The scales of the flow within the current
The full system of Boussinesq Reynolds averaged Navier-Stokes equations is
 \begin{align} \frac{\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}}{\partial x_j} &= 0, \end{align}
\begin{align} \frac{\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}}{\partial x_j} &= 0, \end{align}
 \begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} }{\partial t} + \frac {\partial }{\partial x_j} \left ({\lbrack { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} + \tilde {u}_j}\rbrack {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + J_j }\right) &= 0, \end{align}
\begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} }{\partial t} + \frac {\partial }{\partial x_j} \left ({\lbrack { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} + \tilde {u}_j}\rbrack {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} + J_j }\right) &= 0, \end{align}
 \begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial t} + \frac {\partial }{\partial x_j} \left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} - \tau _{ji}^R - \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j}}\right) + \frac {1}{\rho _f} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }p}\:\!} }{\partial x_i} &= R g_i {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}, \end{align}
\begin{align} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial t} + \frac {\partial }{\partial x_j} \left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} - \tau _{ji}^R - \nu \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j}}\right) + \frac {1}{\rho _f} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }p}\:\!} }{\partial x_i} &= R g_i {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}, \end{align}
 \begin{align} \frac {\partial k}{\partial t} + \frac {\partial }{\partial x_j}\left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} k + T_j}\right) &= P - \tilde {\epsilon }_K + R g_j J_j. \end{align}
\begin{align} \frac {\partial k}{\partial t} + \frac {\partial }{\partial x_j}\left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} k + T_j}\right) &= P - \tilde {\epsilon }_K + R g_j J_j. \end{align}
Here, we document the scale analysis used to simplify (A1) to (2.1). Throughout this section we will make claims of processes that occur in the flow, and use these to balance terms. We do not claim that these processes are always occurring, but simply that they are processes we wish to capture, and they set the largest scale the terms can take anywhere in the current given a particular slope.
As stated in the main text, we employ a time scale
 $\mathscr {T}$
, and length scales
$\mathscr {T}$
, and length scales
 $\mathscr {L}_i$
(
$\mathscr {L}_i$
(
 $\lbrace { \mathscr {L}_1,\mathscr {L}_2 }\rbrace \gg \mathscr {L}_3$
), and assume the Reynolds-averaged velocities scale as
$\lbrace { \mathscr {L}_1,\mathscr {L}_2 }\rbrace \gg \mathscr {L}_3$
), and assume the Reynolds-averaged velocities scale as
 $\mathscr {U}_i = \mathscr {L}_i/\mathscr {T}$
. We denote the scale of the Reynolds-averaged pressure by
$\mathscr {U}_i = \mathscr {L}_i/\mathscr {T}$
. We denote the scale of the Reynolds-averaged pressure by
 $\mathscr {P}$
, the TKE scale by
$\mathscr {P}$
, the TKE scale by
 $\mathscr {K}$
, the TKE dissipation scale by
$\mathscr {K}$
, the TKE dissipation scale by
 $\mathscr {E}$
and the scale of the Reynolds-averaged concentration as
$\mathscr {E}$
and the scale of the Reynolds-averaged concentration as
 $\varphi$
. Without loss of generality we assume that the
$\varphi$
. Without loss of generality we assume that the
 $x,y$
plane is orientated so that
$x,y$
plane is orientated so that
 $y$
is horizontal and
$y$
is horizontal and
 $g_2=0$
. We define the gravitational scales to be
$g_2=0$
. We define the gravitational scales to be
 $\mathscr {G}_i = \lvert R g_i \varphi \rvert$
so that
$\mathscr {G}_i = \lvert R g_i \varphi \rvert$
so that
 $\mathscr {G}_1 = \mathscr {G}_3 \lvert \tan \theta \rvert$
. All scales should be understood as the scale of the depth average (Appendix C) of the given quantity. Note that it is possible to perform the depth average first and then the analysis of scales, which is preferable from the perspective of formal justification. However, this approach increases the complexity of the analysis substantially, which is why the order of presentation here has been chosen.
$\mathscr {G}_1 = \mathscr {G}_3 \lvert \tan \theta \rvert$
. All scales should be understood as the scale of the depth average (Appendix C) of the given quantity. Note that it is possible to perform the depth average first and then the analysis of scales, which is preferable from the perspective of formal justification. However, this approach increases the complexity of the analysis substantially, which is why the order of presentation here has been chosen.
We first consider the momentum equation (A1c). To examine the scales of the system we require scales for the components of the Reynolds stress. For the purpose of constructing scales only we employ the eddy viscosity approximation, that is
 \begin{align} \tau _{ij}^R &= - {\textstyle \frac {2}{3}} k \delta _{ij} + \tau _{ij}^D, &\text {where}&& \tau _{ij}^D &= \nu _t \left ({ \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} }{\partial x_i}}\right),\end{align}
\begin{align} \tau _{ij}^R &= - {\textstyle \frac {2}{3}} k \delta _{ij} + \tau _{ij}^D, &\text {where}&& \tau _{ij}^D &= \nu _t \left ({ \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j} + \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} }{\partial x_i}}\right),\end{align}
is the deviatoric Reynolds stress, and the eddy viscosity
 $\nu _t(\boldsymbol {x},t)$
has scale
$\nu _t(\boldsymbol {x},t)$
has scale
 $\mathscr {N}$
. We also employ the scales
$\mathscr {N}$
. We also employ the scales
 \begin{align} \lVert \tilde {\boldsymbol {u}} \rVert &\lesssim \frac {\mathscr {L}_3}{\mathscr {T}}, & J_i &\sim \frac { \mathscr {N} \varphi }{ \mathscr {L}_i }, &&\text {and}& T_i &\sim \frac { \mathscr {N} \mathscr {K} }{ \mathscr {L}_i }. \end{align}
\begin{align} \lVert \tilde {\boldsymbol {u}} \rVert &\lesssim \frac {\mathscr {L}_3}{\mathscr {T}}, & J_i &\sim \frac { \mathscr {N} \varphi }{ \mathscr {L}_i }, &&\text {and}& T_i &\sim \frac { \mathscr {N} \mathscr {K} }{ \mathscr {L}_i }. \end{align}
Now (A1c ) becomes (outside of the viscous boundary layer so we can neglect viscosity)
 \begin{align} \underbrace { \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial t} + \frac {\partial }{\partial x_j}\left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }\right) \vphantom {\Bigg)}}_{\textstyle \mathscr {L}_i/\mathscr {T}^2} &= - \underbrace { \frac {1}{\rho _f} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }p}\:\!} }{\partial x_i} \vphantom {\Bigg)}}_{\textstyle \mathscr {P}/\rho _f\mathscr {L}_i} - \underbrace { \frac {2}{3} \frac {\partial k}{\partial x_i} \vphantom {\Bigg)}}_{\textstyle \mathscr {K}/\mathscr {L}_i} + \underbrace { \frac {\partial }{\partial x_j} \left ({ \nu _t \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j} }\right) \vphantom {\Bigg)}}_{\textstyle \mathscr {N}\mathscr {L}_i/\mathscr {L}_j^2\mathscr {T}} + \underbrace { \frac {\partial \nu _t}{\partial x_j} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} }{\partial x_i} \vphantom {\Bigg)}}_{\textstyle \mathscr {N}/\mathscr {L}_i\mathscr {T}} + \underbrace { R g_i {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}\vphantom {\Bigg)}}_{\textstyle \mathscr {G}_i}, \end{align}
\begin{align} \underbrace { \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial t} + \frac {\partial }{\partial x_j}\left ({ {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}}\, {\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }\right) \vphantom {\Bigg)}}_{\textstyle \mathscr {L}_i/\mathscr {T}^2} &= - \underbrace { \frac {1}{\rho _f} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }p}\:\!} }{\partial x_i} \vphantom {\Bigg)}}_{\textstyle \mathscr {P}/\rho _f\mathscr {L}_i} - \underbrace { \frac {2}{3} \frac {\partial k}{\partial x_i} \vphantom {\Bigg)}}_{\textstyle \mathscr {K}/\mathscr {L}_i} + \underbrace { \frac {\partial }{\partial x_j} \left ({ \nu _t \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_i}\:\!} }{\partial x_j} }\right) \vphantom {\Bigg)}}_{\textstyle \mathscr {N}\mathscr {L}_i/\mathscr {L}_j^2\mathscr {T}} + \underbrace { \frac {\partial \nu _t}{\partial x_j} \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_j}\:\!} }{\partial x_i} \vphantom {\Bigg)}}_{\textstyle \mathscr {N}/\mathscr {L}_i\mathscr {T}} + \underbrace { R g_i {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!}\vphantom {\Bigg)}}_{\textstyle \mathscr {G}_i}, \end{align}
where the scales of the flow within the current are given beneath the brace under each term. In the downslope direction (
 $i=1$
) the driving force, scale
$i=1$
) the driving force, scale
 $\mathscr {D}$
, is provided by the larger of the pressure + TKE gradient and the longitudinal component of gravity, i.e.
$\mathscr {D}$
, is provided by the larger of the pressure + TKE gradient and the longitudinal component of gravity, i.e.
 \begin{align} \mathscr {D} = \max \left ({ \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1}, \mathscr {G}_1 }\right). \end{align}
\begin{align} \mathscr {D} = \max \left ({ \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1}, \mathscr {G}_1 }\right). \end{align}
The driving force accelerates the flow until the turbulent viscous effects are sufficiently strong, causing all three effects to appear at leading order
 \begin{align} \frac {\mathscr {L}_1}{\mathscr {T}^2} &= \mathscr {D} = \frac {\mathscr {N}\mathscr {L}_1}{\mathscr {L}_3^2\mathscr {T}}, &\text {thus}&& \mathscr {D} &= \frac {\mathscr {L}_1}{\mathscr {T}^2}, & \mathscr {N} &= \frac {\mathscr {L}_3^2}{\mathscr {T}}. \end{align}
\begin{align} \frac {\mathscr {L}_1}{\mathscr {T}^2} &= \mathscr {D} = \frac {\mathscr {N}\mathscr {L}_1}{\mathscr {L}_3^2\mathscr {T}}, &\text {thus}&& \mathscr {D} &= \frac {\mathscr {L}_1}{\mathscr {T}^2}, & \mathscr {N} &= \frac {\mathscr {L}_3^2}{\mathscr {T}}. \end{align}
In the bed-normal (
 $i=3$
) direction, the pressure+TKE gradient is generated by the effects of gravity
$i=3$
) direction, the pressure+TKE gradient is generated by the effects of gravity
 \begin{align} \frac {{\textstyle \frac {1}{\rho _f}}\mathscr {P} + \mathscr {K}}{\mathscr {L}_3} &= \mathscr {G}_3 \gg \frac {\mathscr {L}_3}{\mathscr {T}^2}. \end{align}
\begin{align} \frac {{\textstyle \frac {1}{\rho _f}}\mathscr {P} + \mathscr {K}}{\mathscr {L}_3} &= \mathscr {G}_3 \gg \frac {\mathscr {L}_3}{\mathscr {T}^2}. \end{align}
How this balance interacts with the downslope balance depends on the slope angle. On a very shallow slope
 \begin{equation} \begin{gathered} \begin{aligned} \lvert \tan \theta \rvert &\leq \frac {\mathscr {L}_3}{\mathscr {L}_1} &\text {we have}&& \mathscr {G}_1 &\leq \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1}, &\text {thus}&& \mathscr {D} &= \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1} \end{aligned} \\ \begin{aligned} &\text {so that}& \mathscr {G}_3 \mathscr {L}_3 &= {\textstyle \frac {1}{\rho _f}}\mathscr {P} + \mathscr {K} = \mathscr {D} \mathscr {L}_1 = \frac {\mathscr {L}_1^2}{\mathscr {T}^2}, \end{aligned} \\ \begin{aligned} &\text {and}& \mathscr {G}_3 &\gg \frac {\mathscr {L}_3}{\mathscr {T}^2} &\text {implies}&& \mathscr {L}_1 &\gg \mathscr {L}_3; \end{aligned} \end{gathered} \end{equation}
\begin{equation} \begin{gathered} \begin{aligned} \lvert \tan \theta \rvert &\leq \frac {\mathscr {L}_3}{\mathscr {L}_1} &\text {we have}&& \mathscr {G}_1 &\leq \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1}, &\text {thus}&& \mathscr {D} &= \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1} \end{aligned} \\ \begin{aligned} &\text {so that}& \mathscr {G}_3 \mathscr {L}_3 &= {\textstyle \frac {1}{\rho _f}}\mathscr {P} + \mathscr {K} = \mathscr {D} \mathscr {L}_1 = \frac {\mathscr {L}_1^2}{\mathscr {T}^2}, \end{aligned} \\ \begin{aligned} &\text {and}& \mathscr {G}_3 &\gg \frac {\mathscr {L}_3}{\mathscr {T}^2} &\text {implies}&& \mathscr {L}_1 &\gg \mathscr {L}_3; \end{aligned} \end{gathered} \end{equation}
the current is driven by longitudinal pressure gradients. On a moderate to steep slope
 \begin{equation} \begin{gathered} \begin{aligned} \lvert \tan \theta \rvert &\geq \frac {\mathscr {L}_3}{\mathscr {L}_1} &\text {we have}&& \mathscr {G}_1 &\geq \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1}, &\text {thus}&& \mathscr {D} &= \mathscr {G}_1 \end{aligned} \\ \begin{aligned} &\text {so that}& {\textstyle \frac {1}{\rho _f}}\mathscr {P} + \mathscr {K} &= \mathscr {G}_3 \mathscr {L}_3 = \frac {\mathscr {G}_1 \mathscr {L}_3}{\lvert \tan \theta \rvert } = \frac {\mathscr {D} \mathscr {L}_3}{\lvert \tan \theta \rvert } = \frac {\mathscr {L}_1 \mathscr {L}_3}{\mathscr {T}^2 \lvert \tan \theta \rvert }, \end{aligned} \\ \begin{aligned} &\text {and}& \mathscr {G}_3 &\gg \frac {\mathscr {L}_3}{\mathscr {T}^2} &\text {implies}&& \mathscr {L}_1 &\gg \mathscr {L}_3 \lvert \tan \theta \rvert ; \end{aligned} \end{gathered} \end{equation}
\begin{equation} \begin{gathered} \begin{aligned} \lvert \tan \theta \rvert &\geq \frac {\mathscr {L}_3}{\mathscr {L}_1} &\text {we have}&& \mathscr {G}_1 &\geq \frac {{\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K}}{\mathscr {L}_1}, &\text {thus}&& \mathscr {D} &= \mathscr {G}_1 \end{aligned} \\ \begin{aligned} &\text {so that}& {\textstyle \frac {1}{\rho _f}}\mathscr {P} + \mathscr {K} &= \mathscr {G}_3 \mathscr {L}_3 = \frac {\mathscr {G}_1 \mathscr {L}_3}{\lvert \tan \theta \rvert } = \frac {\mathscr {D} \mathscr {L}_3}{\lvert \tan \theta \rvert } = \frac {\mathscr {L}_1 \mathscr {L}_3}{\mathscr {T}^2 \lvert \tan \theta \rvert }, \end{aligned} \\ \begin{aligned} &\text {and}& \mathscr {G}_3 &\gg \frac {\mathscr {L}_3}{\mathscr {T}^2} &\text {implies}&& \mathscr {L}_1 &\gg \mathscr {L}_3 \lvert \tan \theta \rvert ; \end{aligned} \end{gathered} \end{equation}
the current is driven directly by the longitudinal component of gravity. Combining the two cases, the scales have bounds
 \begin{align} \mathscr {G}_1 &\leq \frac {\mathscr {L}_1}{\mathscr {T}^2}, & \mathscr {G}_3 &\leq \frac {\mathscr {L}_1^2}{\mathscr {T}^2 \mathscr {L}_3}, & {\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K} &\leq \frac {\mathscr {L}_1^2}{\mathscr {T}^2}, \end{align}
\begin{align} \mathscr {G}_1 &\leq \frac {\mathscr {L}_1}{\mathscr {T}^2}, & \mathscr {G}_3 &\leq \frac {\mathscr {L}_1^2}{\mathscr {T}^2 \mathscr {L}_3}, & {\textstyle \frac {1}{\rho _f}} \mathscr {P} + \mathscr {K} &\leq \frac {\mathscr {L}_1^2}{\mathscr {T}^2}, \end{align}
where the first is equality on moderate to steep slopes, and the latter two are equality on shallow slopes. Analysing the turbulent production, the dominant contribution is
 \begin{gather} P \simeq \nu _t \left ({ \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial z} }\right)^2 + \nu _t \left ({ \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} }{\partial z} }\right)^2 \sim \mathscr {N} \frac {\mathscr {U}_1^2 + \mathscr {U}_2^2}{\mathscr {L}_3^2} = \frac {\mathscr {L}_1^2 + \mathscr {L}_2^2}{\mathscr {T}^3}, \end{gather}
\begin{gather} P \simeq \nu _t \left ({ \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} }{\partial z} }\right)^2 + \nu _t \left ({ \frac {\partial {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} }{\partial z} }\right)^2 \sim \mathscr {N} \frac {\mathscr {U}_1^2 + \mathscr {U}_2^2}{\mathscr {L}_3^2} = \frac {\mathscr {L}_1^2 + \mathscr {L}_2^2}{\mathscr {T}^3}, \end{gather}
thus by (A1d )
 \begin{gather} \mathscr {K} = \frac {\mathscr {L}_1^2 + \mathscr {L}_2^2}{\mathscr {T}^2}, \qquad \mathscr {E} = \frac {\mathscr {L}_1^2 + \mathscr {L}_2^2}{\mathscr {T}^3}. \end{gather}
\begin{gather} \mathscr {K} = \frac {\mathscr {L}_1^2 + \mathscr {L}_2^2}{\mathscr {T}^2}, \qquad \mathscr {E} = \frac {\mathscr {L}_1^2 + \mathscr {L}_2^2}{\mathscr {T}^3}. \end{gather}
Using the developed scales, simplifications can be made to the system of equations (A1) by neglecting terms order
 $\mathscr {L}_3/\mathscr {L}_1$
or
$\mathscr {L}_3/\mathscr {L}_1$
or
 $\mathscr {L}_2/\mathscr {L}_1$
smaller than the largest, yielding (2.1). This analysis preserves terms which are large in the wall boundary layer which is dominated by
$\mathscr {L}_2/\mathscr {L}_1$
smaller than the largest, yielding (2.1). This analysis preserves terms which are large in the wall boundary layer which is dominated by
 $z$
derivatives, up to the fact that we need to re-include the viscous stress.
$z$
derivatives, up to the fact that we need to re-include the viscous stress.
Appendix B. Comparison with Ellison–Turner variables and shape factors
The choice of shape factors used in the main text differs from the choice made by Ellison & Turner (Reference Ellison and Turner1959), and developed by Parker et al. (Reference Parker, Fukushima and Pantin1986, Reference Parker, Garcia, Fukushima and Yu1987). There, the fluxes were simplified by defining
 \begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} (x,y,z,t) &= {\xi _u}_{\text {ET}} (x,y,\zeta,t) \cdot {U}_{\text {ET}} (x,t), \end{align}
\begin{align} {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u}\:\!} (x,y,z,t) &= {\xi _u}_{\text {ET}} (x,y,\zeta,t) \cdot {U}_{\text {ET}} (x,t), \end{align}
 \begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }\phi }\:\!} (x,y,z,t) &= {\xi _\phi }_{\text {ET}} (x,y,\zeta,t) \cdot \Phi _{\text {ET}} (x,t), \end{align}
\begin{align} {\:\!\overline {\vphantom {\vphantom {\phi }\phi ^{\prime} }\phi }\:\!} (x,y,z,t) &= {\xi _\phi }_{\text {ET}} (x,y,\zeta,t) \cdot \Phi _{\text {ET}} (x,t), \end{align}
 \begin{align} k(x,y,z,t) &= {\xi _k}_{\text {ET}} (x,y,\zeta,t) \cdot K_{\text {ET}} (x,t), \end{align}
\begin{align} k(x,y,z,t) &= {\xi _k}_{\text {ET}} (x,y,\zeta,t) \cdot K_{\text {ET}} (x,t), \end{align}
where the quantities
 ${\xi _u}_{\text {ET}}$
,
${\xi _u}_{\text {ET}}$
,
 ${\xi _\phi }_{\text {ET}}$
,
${\xi _\phi }_{\text {ET}}$
,
 ${\xi _k}_{\text {ET}}$
satisfy
${\xi _k}_{\text {ET}}$
satisfy
 \begin{align} \int _0^{\zeta _H} {\xi _u}_{\text {ET}} \mathrm {d}{\zeta } &= 1, & \int _0^{\zeta _H} {\xi _u^2}_{\text {ET}} \mathrm {d}{\zeta } &= 1, \end{align}
\begin{align} \int _0^{\zeta _H} {\xi _u}_{\text {ET}} \mathrm {d}{\zeta } &= 1, & \int _0^{\zeta _H} {\xi _u^2}_{\text {ET}} \mathrm {d}{\zeta } &= 1, \end{align}
 \begin{align} \int _0^{\zeta _H} {\xi _u}_{\text {ET}} {\xi _\phi }_{\text {ET}} \mathrm {d}{\zeta } &= 1, & \int _0^{\zeta _H} {\xi _u}_{\text {ET}} {\xi _k}_{\text {ET}} \mathrm {d}{\zeta } &= 1. \end{align}
\begin{align} \int _0^{\zeta _H} {\xi _u}_{\text {ET}} {\xi _\phi }_{\text {ET}} \mathrm {d}{\zeta } &= 1, & \int _0^{\zeta _H} {\xi _u}_{\text {ET}} {\xi _k}_{\text {ET}} \mathrm {d}{\zeta } &= 1. \end{align}
Above, we have identified variables specific to the Ellison–Turner scaling by an ET subscript. The definitions have been modified to be compatible with our lack of self-similar assumption so that the variables
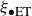 ${\xi _{\scriptstyle \bullet }}_{\text {ET}}$
depend on
${\xi _{\scriptstyle \bullet }}_{\text {ET}}$
depend on
 $x$
,
$x$
,
 $y$
and
$y$
and
 $t$
as well as
$t$
as well as
 $\zeta$
, and our finite range of integration in the vertical direction.
$\zeta$
, and our finite range of integration in the vertical direction.
These shape functions may be used to compute shape factors, and those measured by Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) and Islam & Imran (Reference Islam and Imran2010) are defined in table 2. In this table, several of the shape factors have simplified expressions listed, and in each case this has been achieved by switching the order of integration of
 $\zeta _1$
and
$\zeta _1$
and
 $\zeta _2$
. For
$\zeta _2$
. For
 $a_5$
, we subsequently integrate the product
$a_5$
, we subsequently integrate the product
 $\zeta \mathrm {d}{\xi _u}_{\text {ET}}/\zeta$
by parts. The simplifications for
$\zeta \mathrm {d}{\xi _u}_{\text {ET}}/\zeta$
by parts. The simplifications for
 $a_2$
,
$a_2$
,
 $a_4$
,
$a_4$
,
 $a_5$
and
$a_5$
and
 $a_6$
do not rely on the finite extent of the integrals and we may take the limit
$a_6$
do not rely on the finite extent of the integrals and we may take the limit
 $\zeta _H \to \infty$
; nor on the shape functions satisfying (B2). Thus, these equalities are satisfied by any shape function, including those measured in experiment. What is concerning, is that some experimental results do not satisfy the equalities proved above. In the measurements of Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) we have
$\zeta _H \to \infty$
; nor on the shape functions satisfying (B2). Thus, these equalities are satisfied by any shape function, including those measured in experiment. What is concerning, is that some experimental results do not satisfy the equalities proved above. In the measurements of Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987) we have
 \begin{align} \frac {a_4}{a_7} = 1.00, \qquad \frac {a_5}{{\textstyle \frac {1}{2}} (a_8-a_7)} = 0.86, \qquad \frac {a_6}{a_8} = 1.16, \end{align}
\begin{align} \frac {a_4}{a_7} = 1.00, \qquad \frac {a_5}{{\textstyle \frac {1}{2}} (a_8-a_7)} = 0.86, \qquad \frac {a_6}{a_8} = 1.16, \end{align}
while in those of Islam & Imran (Reference Islam and Imran2010)
 \begin{align} \frac {a_4}{a_7} = 0.87, \qquad \frac {a_5}{{\textstyle \frac {1}{2}} (a_8-a_7)} = 1.08, \qquad \frac {a_6}{a_8} = 0.71. \end{align}
\begin{align} \frac {a_4}{a_7} = 0.87, \qquad \frac {a_5}{{\textstyle \frac {1}{2}} (a_8-a_7)} = 1.08, \qquad \frac {a_6}{a_8} = 0.71. \end{align}
If the integrals were evaluated exactly then all the ratios would be
 $1$
. We expect that the discrepancy comes from under-resolved numerical integration, though differences of up to
$1$
. We expect that the discrepancy comes from under-resolved numerical integration, though differences of up to
 $30\,\%$
do suggest significant problems.
$30\,\%$
do suggest significant problems.
Table 2. The shape factors used by Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987), with
 $a_0$
being additional here. The first column is the symbols used for the shape factors. The second is their definition (modified here to account for possible lateral variation). The third is simplified expressions for the shape factors. In the fourth we express these shape factors in terms of the ones defined in table 1.
$a_0$
being additional here. The first column is the symbols used for the shape factors. The second is their definition (modified here to account for possible lateral variation). The third is simplified expressions for the shape factors. In the fourth we express these shape factors in terms of the ones defined in table 1.

To close this section, we demonstrate how to convert between the Ellison–Turner variables (table 2) and those used here (table 1). Observe that
 \begin{align} U_{\text {ET}}^2 = U_1^2, \qquad U_{\text {ET}} \Phi _{\text {ET}} = \sigma _{1\phi } U_1 \Phi, \qquad U_{\text {ET}} K_{\text {ET}} = \sigma _{1k} U_1 K. \end{align}
\begin{align} U_{\text {ET}}^2 = U_1^2, \qquad U_{\text {ET}} \Phi _{\text {ET}} = \sigma _{1\phi } U_1 \Phi, \qquad U_{\text {ET}} K_{\text {ET}} = \sigma _{1k} U_1 K. \end{align}
Consequently
 \begin{equation} \begin{aligned} U_{\text {ET}} & = U, \qquad \Phi _{\text {ET}} = \sigma _{1\phi } \Phi, \ \ \qquad K_{\text {ET}} = \sigma _{1k} K,\\ {\xi _u}_{\text {ET}} & = \xi _1, \!\qquad {\xi _\phi }_{\text {ET}} = \frac {1}{\sigma _{1\phi }} \xi _\phi, \qquad {\xi _k}_{\text {ET}} = \frac {1}{\sigma _{1k}} \xi _k. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} U_{\text {ET}} & = U, \qquad \Phi _{\text {ET}} = \sigma _{1\phi } \Phi, \ \ \qquad K_{\text {ET}} = \sigma _{1k} K,\\ {\xi _u}_{\text {ET}} & = \xi _1, \!\qquad {\xi _\phi }_{\text {ET}} = \frac {1}{\sigma _{1\phi }} \xi _\phi, \qquad {\xi _k}_{\text {ET}} = \frac {1}{\sigma _{1k}} \xi _k. \end{aligned} \end{equation}
Substitution of (B6) into the definitions in table 2 yields the equivalent expressions listed, which can be inverted to obtain
 \begin{equation} \begin{aligned} \sigma _{z\phi } &= \frac {a_2}{a_1}, & \sigma _{11} &= 1, & \sigma _{111} &= a_3, & \sigma _{1\phi } &= \frac {1}{a_1}, \\ \sigma _{1k} &= \frac {1}{a_9}, & \sigma _{1z\phi } &= \frac {a_8}{a_1}, & \tilde {\sigma }_{1z\phi } &= \frac {a_7}{a_1}, & \varsigma _\phi &= \frac {r_0}{a_1}. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \sigma _{z\phi } &= \frac {a_2}{a_1}, & \sigma _{11} &= 1, & \sigma _{111} &= a_3, & \sigma _{1\phi } &= \frac {1}{a_1}, \\ \sigma _{1k} &= \frac {1}{a_9}, & \sigma _{1z\phi } &= \frac {a_8}{a_1}, & \tilde {\sigma }_{1z\phi } &= \frac {a_7}{a_1}, & \varsigma _\phi &= \frac {r_0}{a_1}. \end{aligned} \end{equation}
These can in turn be substituted into (2.16)–(2.18) and (2.21) and taking the steady state over a flat bed with constant
 $a_i$
obtain the system from Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987).
$a_i$
obtain the system from Parker et al. (Reference Parker, Garcia, Fukushima and Yu1987).
Appendix C. The depth-average operator
To average the system of equations (2.1) over the depth we introduce the depth-averaging operator,
 $\left \langle \scriptstyle \bullet \right \rangle$
, defined as
$\left \langle \scriptstyle \bullet \right \rangle$
, defined as
 \begin{equation} \left \langle f \right \rangle (x,y,t) : = \frac {1}{h(x,y,t)} \int _{b(x,y)}^{H(x,y,t)} f(x,y,z,t) \mathrm {d}{z}. \end{equation}
\begin{equation} \left \langle f \right \rangle (x,y,t) : = \frac {1}{h(x,y,t)} \int _{b(x,y)}^{H(x,y,t)} f(x,y,z,t) \mathrm {d}{z}. \end{equation}
Using the Leibniz rule, the depth average of derivatives transforms as
 \begin{align} & h \left \langle \frac {\partial f_t}{\partial t} + \frac {\partial f_x}{\partial x} + \frac {\partial f_y}{\partial y} + \frac {\partial f_z}{\partial z} \right \rangle \nonumber \\ &\qquad = \frac {\partial }{\partial t} \left(h \langle f_t \rangle \right) + \frac {\partial }{\partial x} \left ({h} \langle f_x \rangle \right) + {f_x}\Big |_{b} \frac {\partial b}{\partial x} + {f_y}\Big |_{b} \frac {\partial b}{\partial y} - {f_z}\Big |_{b}\nonumber \\ &\qquad \qquad -{f_t}\Big |_{H} \frac {\partial H}{\partial t} - {f_x}\Big |_{H} \frac {\partial H}{\partial x} - {f_y}\Big |_{H} \frac {\partial H}{\partial y} + {f_z}\Big |_{H}. \end{align}
\begin{align} & h \left \langle \frac {\partial f_t}{\partial t} + \frac {\partial f_x}{\partial x} + \frac {\partial f_y}{\partial y} + \frac {\partial f_z}{\partial z} \right \rangle \nonumber \\ &\qquad = \frac {\partial }{\partial t} \left(h \langle f_t \rangle \right) + \frac {\partial }{\partial x} \left ({h} \langle f_x \rangle \right) + {f_x}\Big |_{b} \frac {\partial b}{\partial x} + {f_y}\Big |_{b} \frac {\partial b}{\partial y} - {f_z}\Big |_{b}\nonumber \\ &\qquad \qquad -{f_t}\Big |_{H} \frac {\partial H}{\partial t} - {f_x}\Big |_{H} \frac {\partial H}{\partial x} - {f_y}\Big |_{H} \frac {\partial H}{\partial y} + {f_z}\Big |_{H}. \end{align}
To depth integrate an equation we apply the operator
 $h \left \langle \scriptstyle \bullet \right \rangle$
using (C2) to the system (2.1) and apply the boundary conditions (2.8). We substitute for the depth-average variables as
$h \left \langle \scriptstyle \bullet \right \rangle$
using (C2) to the system (2.1) and apply the boundary conditions (2.8). We substitute for the depth-average variables as
 \begin{align} \Phi = \left \langle {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \right \rangle, \qquad U_\alpha = \left \langle {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} \right \rangle \qquad K &= \left \langle k \vphantom { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} } \right \rangle. \end{align}
\begin{align} \Phi = \left \langle {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }\phi }\:\!} \right \rangle, \qquad U_\alpha = \left \langle {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }u_\alpha }\:\!} \right \rangle \qquad K &= \left \langle k \vphantom { {\:\!\overline {\vphantom { \vphantom {\phi }\phi ^{\prime} }v}\:\!} } \right \rangle. \end{align}
Appendix D. Depth-rescaling symmetry group
For any
 $c(x,y,t)\gt 0$
, equations (2.16)–(2.22) are invariant under
$c(x,y,t)\gt 0$
, equations (2.16)–(2.22) are invariant under
 \begin{align} h &\mapsto c h, & \Phi &\mapsto \frac {1}{c} \Phi, & U_\alpha &\mapsto \frac {1}{c} U_\alpha, & K &\mapsto \frac {1}{c} K, \end{align}
\begin{align} h &\mapsto c h, & \Phi &\mapsto \frac {1}{c} \Phi, & U_\alpha &\mapsto \frac {1}{c} U_\alpha, & K &\mapsto \frac {1}{c} K, \end{align}
 \begin{align} \zeta &\mapsto \frac {1}{c} \zeta, & \xi _\phi &\mapsto c \xi _\phi, & \xi _\alpha &\mapsto c \xi _\alpha, & \xi _k &\mapsto c \xi _k, \end{align}
\begin{align} \zeta &\mapsto \frac {1}{c} \zeta, & \xi _\phi &\mapsto c \xi _\phi, & \xi _\alpha &\mapsto c \xi _\alpha, & \xi _k &\mapsto c \xi _k, \end{align}
with
 $b$
and
$b$
and
 $H$
unchanging, which results in the changes to the shape factors
$H$
unchanging, which results in the changes to the shape factors
 \begin{gather} \begin{aligned} \varsigma _h & \mapsto c^{-1} \varsigma _h, & \sigma _{z\phi } & \mapsto c^{-1} \sigma _{z\phi }, & \sigma _{\alpha \beta } & \mapsto c \sigma _{\alpha \beta }, \end{aligned} \end{gather}
\begin{gather} \begin{aligned} \varsigma _h & \mapsto c^{-1} \varsigma _h, & \sigma _{z\phi } & \mapsto c^{-1} \sigma _{z\phi }, & \sigma _{\alpha \beta } & \mapsto c \sigma _{\alpha \beta }, \end{aligned} \end{gather}
 \begin{gather} \begin{aligned} \sigma _{\alpha \beta \gamma } & \mapsto c^2 \sigma _{\alpha \beta \gamma }, & \sigma _{\alpha \phi } & \mapsto c \sigma _{\alpha \phi }, & \sigma _{\alpha k} & \mapsto c \sigma _{\alpha k}, \end{aligned} \end{gather}
\begin{gather} \begin{aligned} \sigma _{\alpha \beta \gamma } & \mapsto c^2 \sigma _{\alpha \beta \gamma }, & \sigma _{\alpha \phi } & \mapsto c \sigma _{\alpha \phi }, & \sigma _{\alpha k} & \mapsto c \sigma _{\alpha k}, \end{aligned} \end{gather}
 \begin{gather} \begin{aligned} \sigma _{\alpha z\phi } & \mapsto \sigma _{\alpha z\phi }, & \tilde {\sigma }_{\alpha z\phi } & \mapsto \tilde {\sigma }_{\alpha z\phi }, & \varsigma _{\alpha z\phi } & \mapsto \varsigma _{\alpha z\phi }, & \tilde {\sigma }_{D\alpha z\phi } & \mapsto \tilde {\sigma }_{D\alpha z\phi }, \end{aligned} \end{gather}
\begin{gather} \begin{aligned} \sigma _{\alpha z\phi } & \mapsto \sigma _{\alpha z\phi }, & \tilde {\sigma }_{\alpha z\phi } & \mapsto \tilde {\sigma }_{\alpha z\phi }, & \varsigma _{\alpha z\phi } & \mapsto \varsigma _{\alpha z\phi }, & \tilde {\sigma }_{D\alpha z\phi } & \mapsto \tilde {\sigma }_{D\alpha z\phi }, \end{aligned} \end{gather}
 \begin{gather} \varsigma _{\phi } \mapsto c \varsigma _\phi. \end{gather}
\begin{gather} \varsigma _{\phi } \mapsto c \varsigma _\phi. \end{gather}
This symmetry can be used to transform between different measures of depth.

















































 Open access
Open access