
















1. Introduction
There is firm evidence (Joseph, Renardy & Renardy Reference Joseph, Renardy and Renardy1984; Hu, Lundgren & Joseph Reference Hu, Lundgren and Joseph1990; Joseph et al. Reference Joseph, Bai, Chen and Renardy1997; Kim & Choi Reference Kim and Choi2018; Roccon, Zonta & Soldati Reference Roccon, Zonta and Soldati2019) that the injection of a small amount of a low viscosity fluid into a pipeline used to transport a high viscosity fluid produces drag reduction (DR). The key physical principle at the heart of the observed DR mechanism is the natural tendency for the low viscosity fluid to migrate to the pipe wall and to lubricate the flow (Joseph et al. Reference Joseph, Bai, Chen and Renardy1997). Known since the beginning of the last century (Isaac & Speed Reference Isaac and Speed1904; Looman Reference Looman1916; Clark & Shapiro Reference Clark and Shapiro1949), this DR mechanism has received a lot of attention, precisely because of its potential applicability to the strategically and industrially relevant case of water-lubricated oil pipelines (Russel & Charles Reference Russel and Charles1959; Charles, Govier & Hodgson Reference Charles, Govier and Hodgson1961; Hasson, Mann & Nir Reference Hasson, Mann and Nir1970).
Literature in the field is vast (see Joseph et al. (Reference Joseph, Bai, Chen and Renardy1997), Ghosh, Mandal & Das (Reference Ghosh, Mandal and Das2009) for reviews on the topic), but it is essentially limited to theoretical studies focused on the stability and persistency of the proposed flow configuration (Yih Reference Yih1967; Hickox Reference Hickox1971; Hooper & Boyd Reference Hooper and Boyd1983; Joseph et al. Reference Joseph, Renardy and Renardy1984), or to experimental studies measuring the overall performance and effectiveness of the targeted DR strategy (Oliemans et al. Reference Oliemans, Ooms, Wu and Duijvestijn1987; Bai, Chen & Joseph Reference Bai, Chen and Joseph1992; Arney et al. Reference Arney, Bai, Guevara, Joseph and Liu1993; Bannwart Reference Bannwart2001). Detailed experimental measurements of the flow field near the walls and near the liquid/liquid interface remain extremely challenging, in particular when optical techniques cannot easily be applied, as for example when opaque fluids (i.e. oils) are employed (Reinecke et al. Reference Reinecke, Petritsch, Schmitz and Mewes1998; Lindken, Gui & Merzkirch Reference Lindken, Gui and Merzkirch1999; Heindel Reference Heindel2011). In this context, accurate simulations can be considered as a valuable alternative tool that, giving access to the entire velocity/stress field and to the corresponding liquid/liquid interface deformation, can be used – by dissecting the relevant flow phenomena occurring in the near-wall region and in the proximity of the interface – to fully characterize the underlying physics of the DR mechanisms. Not surprisingly, direct numerical simulations (DNS) of lubricated channels/pipelines have been performed more frequently in recent years (Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib; Kim & Choi Reference Kim and Choi2018; Roccon et al. Reference Roccon, Zonta and Soldati2019), and have demonstrated the importance of both viscosity and surface tension on selectively modulating turbulence so as to give the observed DR. Reportedly, in these numerical studies, the flow is forced to move inside the channel/pipeline either by imposing a constant pressure gradient (CPG), or by imposing a constant flow rate (CFR). With the CPG approach, the mean pressure gradient that drives the flow is constant – and it is usually set via the shear Reynold number,  $Re_{\tau }$ – while the volume flow rate can exhibit fluctuations that ultimately depend on the turbulent nature of the flow. In contrast, with the CFR approach, the flow rate is constant – usually set via the bulk Reynolds number,
$Re_{\tau }$ – while the volume flow rate can exhibit fluctuations that ultimately depend on the turbulent nature of the flow. In contrast, with the CFR approach, the flow rate is constant – usually set via the bulk Reynolds number,  $Re_b$ – while the mean pressure gradient that pushes the flow is adapted at each time step so as to give the prescribed value of the volume flow rate. The effectiveness of the CPG or CFR approach in evaluating the DR performance is, however, questionable (Hasegawa, Quadrio & Frohnapfel Reference Hasegawa, Quadrio and Frohnapfel2014), and precisely because, by keeping the pressure gradient constant and increasing the total flow rate (respectively by keeping the flow rate constant and decreasing the pressure drop), the power injected into the flow – proportional to the product between the pressure gradient and the flow rate – increases (respectively decreases).
$Re_b$ – while the mean pressure gradient that pushes the flow is adapted at each time step so as to give the prescribed value of the volume flow rate. The effectiveness of the CPG or CFR approach in evaluating the DR performance is, however, questionable (Hasegawa, Quadrio & Frohnapfel Reference Hasegawa, Quadrio and Frohnapfel2014), and precisely because, by keeping the pressure gradient constant and increasing the total flow rate (respectively by keeping the flow rate constant and decreasing the pressure drop), the power injected into the flow – proportional to the product between the pressure gradient and the flow rate – increases (respectively decreases).
Motivated by this idea, we decided to reconsider the DR problem in lubricated channels by running a completely new set of finely resolved DNS using the so-called constant power input (CPI) approach (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014; Gatti et al. Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018). Within the CPI approach, the pressure gradient used to drive the flow is dynamically adjusted depending on the measured instantaneous flow rate so as to keep constant the overall power injected into the system. Thanks to this feature, the CPI approach paves the way for a more meaningful comparison among the different DR techniques, since the obtained results are no longer biased by the different powers injected into the system (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014).
In this work we focus on a simplified, yet practically relevant, configuration in which a thick layer of a primary fluid (also referred to as the primary layer hereinafter, and characterized by density  $\rho _2$, viscosity
$\rho _2$, viscosity  $\eta _2$, thickness
$\eta _2$, thickness  $h_2$) and a thin layer of a lubricating fluid (also referred to as lubricating layer hereinafter, and characterized by density
$h_2$) and a thin layer of a lubricating fluid (also referred to as lubricating layer hereinafter, and characterized by density  $\rho _1$, viscosity
$\rho _1$, viscosity  $\eta _1$, thickness
$\eta _1$, thickness  $h_1$) are forced to flow inside a channel lying one on top of the other, in a way such that the lubricating layer wets the top wall of the channel only. The primary and the lubricating fluids, which are immiscible, are characterized by the same density (
$h_1$) are forced to flow inside a channel lying one on top of the other, in a way such that the lubricating layer wets the top wall of the channel only. The primary and the lubricating fluids, which are immiscible, are characterized by the same density ( $\rho _1=\rho _2=\rho$) but different viscosity, so that a viscosity ratio
$\rho _1=\rho _2=\rho$) but different viscosity, so that a viscosity ratio  $\lambda =\eta _1/\eta _2$ can be introduced. To cover a meaningful range of all possible situations, we consider five different values of
$\lambda =\eta _1/\eta _2$ can be introduced. To cover a meaningful range of all possible situations, we consider five different values of  $\lambda$ in the range
$\lambda$ in the range  $0.25 \le \lambda \le 4$, indicating that the lubricating fluid can be either less or more viscous than the primary fluid. We unambiguously show that a significant DR can be achieved. In particular, the observed DR is a non-monotonic function of
$0.25 \le \lambda \le 4$, indicating that the lubricating fluid can be either less or more viscous than the primary fluid. We unambiguously show that a significant DR can be achieved. In particular, the observed DR is a non-monotonic function of  $\lambda$, and appears to be maximized for
$\lambda$, and appears to be maximized for  $\lambda = 1.00$. However, and counter to intuition, we demonstrate that DR occurs not only for
$\lambda = 1.00$. However, and counter to intuition, we demonstrate that DR occurs not only for  $\lambda \le 1.00$ – i.e. when the viscosity of the lubricating layer is smaller than that of the primary layer – but also for
$\lambda \le 1.00$ – i.e. when the viscosity of the lubricating layer is smaller than that of the primary layer – but also for  $\lambda = 2.00$ – i.e. when the viscosity of the lubricating layer is twice that of the primary layer. The situation changes on further increasing
$\lambda = 2.00$ – i.e. when the viscosity of the lubricating layer is twice that of the primary layer. The situation changes on further increasing  $\lambda$, and for
$\lambda$, and for  $\lambda =4.00$ we report a slight drag enhancement. These observations seem to suggest the presence of different turbulence modulation mechanisms, which we try to characterize by looking at the mean and turbulent kinetic energy budget, and at the corresponding energy fluxes. To do this, and precisely to evaluate the different energy fluxes – injected, transferred and dissipated by the system – we adopt the energy-box representation (introduced by Ricco et al. (Reference Ricco, Ottonelli, Hasegawa and Quadrio2012), Gatti et al. (Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018) for single-phase flows), and we purposely extend it to the case of a liquid–liquid multiphase flow.
$\lambda =4.00$ we report a slight drag enhancement. These observations seem to suggest the presence of different turbulence modulation mechanisms, which we try to characterize by looking at the mean and turbulent kinetic energy budget, and at the corresponding energy fluxes. To do this, and precisely to evaluate the different energy fluxes – injected, transferred and dissipated by the system – we adopt the energy-box representation (introduced by Ricco et al. (Reference Ricco, Ottonelli, Hasegawa and Quadrio2012), Gatti et al. (Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018) for single-phase flows), and we purposely extend it to the case of a liquid–liquid multiphase flow.
The paper is organized as follows: in § 2 we present the governing equations, the numerical method and the CPI approach; the main results of the simulations are shown in § 3: first, we compute and discuss the main global parameters of the flow, including the overall pressure gradient and the flow rates of the two fluid layers, as well as the corresponding flow structures; then, we study the mean and turbulent kinetic energy budget and we graphically explain the obtained results employing the modified energy-box representation. Finally, conclusions are outlined in § 4.
2. Methodology
We consider the case of two immiscible fluid layers flowing one on top of the other inside a rectangular flat channel. The channel has dimensions  $L_x \times L_y \times L_z = 4 \pi h \times 2 \pi h \times 2h$ along the streamwise (
$L_x \times L_y \times L_z = 4 \pi h \times 2 \pi h \times 2h$ along the streamwise ( $x$), spanwise (
$x$), spanwise ( $y$) and wall-normal (
$y$) and wall-normal ( $z$) directions. The bottom part of the channel is occupied by the primary fluid layer, having thickness
$z$) directions. The bottom part of the channel is occupied by the primary fluid layer, having thickness  $h_2$, density
$h_2$, density  $\rho _2$ and viscosity
$\rho _2$ and viscosity  $\eta _2$, while the top part of the channel is occupied by the thin lubricating layer, having thickness,
$\eta _2$, while the top part of the channel is occupied by the thin lubricating layer, having thickness,  $h_1$, density
$h_1$, density  $\rho _1$ and viscosity
$\rho _1$ and viscosity  $\eta _1$. The two layers have the same density (
$\eta _1$. The two layers have the same density ( $\rho _1=\rho _2=\rho$) but different viscosity, so that a viscosity ratio
$\rho _1=\rho _2=\rho$) but different viscosity, so that a viscosity ratio  $\lambda =\eta _1/\eta _2$ can be defined. The interface separating the two phases is characterized by a constant and uniform value of the surface tension,
$\lambda =\eta _1/\eta _2$ can be defined. The interface separating the two phases is characterized by a constant and uniform value of the surface tension,  $\sigma$. To capture the dynamics of the system, we couple direct numerical simulation (DNS) of the Navier–Stokes equations, used to describe the flow field, with a phase-field method (PFM), used to describe the interfacial motion (Jacqmin Reference Jacqmin1999; Badalassi, Ceniceros & Banerjee Reference Badalassi, Ceniceros and Banerjee2003; Roccon et al. Reference Roccon, De Paoli, Zonta and Soldati2017; Soligo, Roccon & Soldati Reference Soligo, Roccon and Soldati2019b).
$\sigma$. To capture the dynamics of the system, we couple direct numerical simulation (DNS) of the Navier–Stokes equations, used to describe the flow field, with a phase-field method (PFM), used to describe the interfacial motion (Jacqmin Reference Jacqmin1999; Badalassi, Ceniceros & Banerjee Reference Badalassi, Ceniceros and Banerjee2003; Roccon et al. Reference Roccon, De Paoli, Zonta and Soldati2017; Soligo, Roccon & Soldati Reference Soligo, Roccon and Soldati2019b).
2.1. Phase-field method
In the framework of the PFM, the sharp interface between the two fluids is replaced by a thin transition layer where the interfacial forces are applied. The basic idea of the PFM is to introduce an order parameter, the phase field  $\phi$, that is uniform in the bulk of the two phases (
$\phi$, that is uniform in the bulk of the two phases ( $\phi =1$ in the lubricating layer and
$\phi =1$ in the lubricating layer and  $\phi =-1$ in the primary layer) and that changes rapidly, yet smoothly, across the thin interfacial layer that separates the two phases. The transport of the phase field
$\phi =-1$ in the primary layer) and that changes rapidly, yet smoothly, across the thin interfacial layer that separates the two phases. The transport of the phase field  $\phi$ is described by a Cahn–Hilliard equation, which in dimensionless form reads as
$\phi$ is described by a Cahn–Hilliard equation, which in dimensionless form reads as
 \begin{equation} \frac{\partial\phi}{\partial t} + u_i \frac{\partial \phi}{\partial x_i} = \frac{1}{Pe_\varPi} \frac{\partial^2 \mu}{\partial x_i^2}, \end{equation}
\begin{equation} \frac{\partial\phi}{\partial t} + u_i \frac{\partial \phi}{\partial x_i} = \frac{1}{Pe_\varPi} \frac{\partial^2 \mu}{\partial x_i^2}, \end{equation}
where  $u_i$ is the
$u_i$ is the  $i$th component of the velocity vector,
$i$th component of the velocity vector,  $Pe_\varPi$ is the Péclet number and
$Pe_\varPi$ is the Péclet number and  $\mu$ is the chemical potential. The Péclet number is defined as follows:
$\mu$ is the chemical potential. The Péclet number is defined as follows:
 \begin{equation} Pe_\varPi=\frac{u_\varPi h}{\mathcal{M} \beta} , \end{equation}
\begin{equation} Pe_\varPi=\frac{u_\varPi h}{\mathcal{M} \beta} , \end{equation}
where  $u_\varPi$ is the characteristic velocity (that will be properly introduced and discussed later, see (2.11) for details),
$u_\varPi$ is the characteristic velocity (that will be properly introduced and discussed later, see (2.11) for details),  $h$ is the channel half-height,
$h$ is the channel half-height,  $\mathcal {M}$ is the mobility and
$\mathcal {M}$ is the mobility and  $\beta$ is a positive constant introduced to make the chemical potential dimensionless. The Péclet number identifies the ratio between the diffusive time scale,
$\beta$ is a positive constant introduced to make the chemical potential dimensionless. The Péclet number identifies the ratio between the diffusive time scale,  $h^2/\mathcal {M} \beta$, and the convective time scale,
$h^2/\mathcal {M} \beta$, and the convective time scale,  $h/u_\varPi$ of the interface.
$h/u_\varPi$ of the interface.
The chemical potential  $\mu$ is defined as the functional derivative of a Ginzburg–Landau free-energy functional, the expression of which is chosen to represent an immiscible binary mixture of isothermal fluids (Soligo, Roccon & Soldati Reference Soligo, Roccon and Soldati2019a, Reference Soligo, Roccon and Soldati2020a,Reference Soligo, Roccon and Soldatib; Soligo et al. Reference Soligo, Roccon and Soldati2019b). The functional is composed by the sum of two different contributions: the first contribution,
$\mu$ is defined as the functional derivative of a Ginzburg–Landau free-energy functional, the expression of which is chosen to represent an immiscible binary mixture of isothermal fluids (Soligo, Roccon & Soldati Reference Soligo, Roccon and Soldati2019a, Reference Soligo, Roccon and Soldati2020a,Reference Soligo, Roccon and Soldatib; Soligo et al. Reference Soligo, Roccon and Soldati2019b). The functional is composed by the sum of two different contributions: the first contribution,  $f_0$, accounts for the tendency of the system to separate into the two pure stable phases, while the second contribution,
$f_0$, accounts for the tendency of the system to separate into the two pure stable phases, while the second contribution,  $f_{mix}$ (mixing energy), is a non-local term accounting for the energy stored at the interface. The mathematical expression of the functional is
$f_{mix}$ (mixing energy), is a non-local term accounting for the energy stored at the interface. The mathematical expression of the functional is
 \begin{equation} \mathcal{F}[\phi, \partial \phi /\partial x_i]=\int_{\varOmega} \left( \underbrace{\frac{(\phi^2-1)^2}{4}}_{\,f_0}+\underbrace{\frac{Ch^2}{2} \left| \frac{\partial \phi}{\partial x_i} \right|^2}_{\,f_{mix}} \right)\, \textrm{d} \varOmega ,\end{equation}
\begin{equation} \mathcal{F}[\phi, \partial \phi /\partial x_i]=\int_{\varOmega} \left( \underbrace{\frac{(\phi^2-1)^2}{4}}_{\,f_0}+\underbrace{\frac{Ch^2}{2} \left| \frac{\partial \phi}{\partial x_i} \right|^2}_{\,f_{mix}} \right)\, \textrm{d} \varOmega ,\end{equation}
where  $\varOmega$ is the domain considered and
$\varOmega$ is the domain considered and  $Ch$ is the Cahn number, which represents the dimensionless thickness of the interface between the two fluids and is defined as
$Ch$ is the Cahn number, which represents the dimensionless thickness of the interface between the two fluids and is defined as
 \begin{equation} Ch=\frac{\xi}{h} , \end{equation}
\begin{equation} Ch=\frac{\xi}{h} , \end{equation}
where  $\xi$ is the physical thickness of the interface. From (2.3), we can obtain the expression of the chemical potential as
$\xi$ is the physical thickness of the interface. From (2.3), we can obtain the expression of the chemical potential as
 \begin{equation} \mu=\frac{\delta \mathcal{F}[\phi, \partial \phi /\partial x_i]}{\delta \phi}=\phi^3 - \phi - Ch^2 \frac{\partial^2 \phi}{\partial x_i^2} . \end{equation}
\begin{equation} \mu=\frac{\delta \mathcal{F}[\phi, \partial \phi /\partial x_i]}{\delta \phi}=\phi^3 - \phi - Ch^2 \frac{\partial^2 \phi}{\partial x_i^2} . \end{equation}Note that, upon substitution of this expression into (2.1), a fourth-order equation for the phase field variable is obtained.
2.2. Hydrodynamics
To describe the hydrodynamics of the multiphase system, the Cahn–Hilliard equation is coupled with the Navier–Stokes equations. The presence of an interface (and of the corresponding surface tension forces) is accounted for by introducing an interfacial term in the Navier–Stokes equations. Recalling that in the present study we consider two fluids with the same density ( $\rho =\rho _1=\rho _2$) but different viscosity (
$\rho =\rho _1=\rho _2$) but different viscosity ( $\eta _1 \neq \eta _2$), continuity and Navier–Stokes equations become
$\eta _1 \neq \eta _2$), continuity and Navier–Stokes equations become
 \begin{gather} \frac{\partial u_i}{\partial x_i}=0, \end{gather}
\begin{gather} \frac{\partial u_i}{\partial x_i}=0, \end{gather} \begin{gather}\frac{\partial u_i}{\partial t} + u_j\frac{\partial u_i}{\partial x_j} = - p_x \delta_{xi} -\frac{\partial p}{\partial x_i} + \frac{1}{Re_\varPi} \frac{\partial }{\partial x_j} \left[{\eta} (\phi)\left(\frac{\partial u_i}{\partial x_j}+\frac{\partial u_j}{\partial x_i}\right)\right] + \frac{3Ch}{\sqrt{8}We_\varPi} \frac{\partial \tau^c_{ij}}{\partial x_j} , \end{gather}
\begin{gather}\frac{\partial u_i}{\partial t} + u_j\frac{\partial u_i}{\partial x_j} = - p_x \delta_{xi} -\frac{\partial p}{\partial x_i} + \frac{1}{Re_\varPi} \frac{\partial }{\partial x_j} \left[{\eta} (\phi)\left(\frac{\partial u_i}{\partial x_j}+\frac{\partial u_j}{\partial x_i}\right)\right] + \frac{3Ch}{\sqrt{8}We_\varPi} \frac{\partial \tau^c_{ij}}{\partial x_j} , \end{gather}
where  $u_i$ is the
$u_i$ is the  $i$th component of the velocity vector,
$i$th component of the velocity vector,  $p$ is the pressure field,
$p$ is the pressure field,  $p_x$ is the mean pressure gradient driving the flow,
$p_x$ is the mean pressure gradient driving the flow,  $\delta _{ij}$ the Kronecker delta,
$\delta _{ij}$ the Kronecker delta,  ${\eta }(\phi )$ is the viscosity map accounting for the viscosity contrast between the two phases and defined as (Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib)
${\eta }(\phi )$ is the viscosity map accounting for the viscosity contrast between the two phases and defined as (Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib)
 \begin{equation} \eta(\phi)=1 + \frac{(1+\phi)}{2}(1 - \lambda). \end{equation}
\begin{equation} \eta(\phi)=1 + \frac{(1+\phi)}{2}(1 - \lambda). \end{equation} Finally,  $\tau ^c_{ij}$ is the Korteweg tensor (Korteweg Reference Korteweg1901), which is used to account for the surface tension forces, and is defined as follows:
$\tau ^c_{ij}$ is the Korteweg tensor (Korteweg Reference Korteweg1901), which is used to account for the surface tension forces, and is defined as follows:
 \begin{equation} \tau^c_{ij}=\left|\frac{\partial \phi}{\partial x_i} \right|^2 \delta_{ij} - \frac{\partial \phi}{\partial x_i} \frac{\partial \phi}{\partial x_j}.\end{equation}
\begin{equation} \tau^c_{ij}=\left|\frac{\partial \phi}{\partial x_i} \right|^2 \delta_{ij} - \frac{\partial \phi}{\partial x_i} \frac{\partial \phi}{\partial x_j}.\end{equation}
The dimensionless groups appearing in the Navier–Stokes equations are the power Reynolds number,  $Re_\varPi$, and the Weber number,
$Re_\varPi$, and the Weber number,  $We_\varPi$, which are defined as
$We_\varPi$, which are defined as
 \begin{equation} Re_{\varPi}=\frac{\rho u_{\varPi} h}{\eta_2}, \quad We_\varPi=\frac{\rho u_{\varPi}^2 h}{\sigma}.\end{equation}
\begin{equation} Re_{\varPi}=\frac{\rho u_{\varPi} h}{\eta_2}, \quad We_\varPi=\frac{\rho u_{\varPi}^2 h}{\sigma}.\end{equation} The Reynolds number represents the ratio between inertial and viscous forces and is defined based on the viscosity of the primary layer  $\eta _2$, while the Weber number is the ratio between inertial and surface tension forces.
$\eta _2$, while the Weber number is the ratio between inertial and surface tension forces.
In contrast with our previous works (Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib; Roccon et al. Reference Roccon, Zonta and Soldati2019), in which we applied a constant mean pressure gradient to drive the flow through the channel (Lyons, Hanratty & McLaughlin Reference Lyons, Hanratty and McLaughlin1991; Soldati & Banerjee Reference Soldati and Banerjee1998), in the present work we employ a CPI approach Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014; Gatti et al. Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018 based on driving the flow by an imposed constant pumping power,  $P_p$. Naturally, to keep the pumping power constant over time, the mean pressure gradient is dynamically adjusted according with the overall flow rate,
$P_p$. Naturally, to keep the pumping power constant over time, the mean pressure gradient is dynamically adjusted according with the overall flow rate,  $Q_t$ (see appendices A and B for details).
$Q_t$ (see appendices A and B for details).
Within the CPI approach, instead of using the commonly adopted friction velocity  $u_\tau$ (or the bulk velocity
$u_\tau$ (or the bulk velocity  $u_b$), the following velocity is introduced as reference:
$u_b$), the following velocity is introduced as reference:
 \begin{equation} u_\varPi=\sqrt{\frac{B^2}{D} \frac{P_p h}{3 \eta_2}},\end{equation}
\begin{equation} u_\varPi=\sqrt{\frac{B^2}{D} \frac{P_p h}{3 \eta_2}},\end{equation}
where, as stated above,  $\eta _2$ is the viscosity of the primary layer, while
$\eta _2$ is the viscosity of the primary layer, while  $B$ and
$B$ and  $D$ are two coefficients used to account for the presence of a thin lubricating layer with different viscosity in the upper part of the channel (see details in appendix A). From a physical point of view, the characteristic velocity
$D$ are two coefficients used to account for the presence of a thin lubricating layer with different viscosity in the upper part of the channel (see details in appendix A). From a physical point of view, the characteristic velocity  $u_\varPi$ represents the bulk velocity (average velocity across the channel section) of the actual two-phase flow configuration (i.e. two immiscible fluid layers having different viscosity and flowing inside a channel under the action of a pumping power
$u_\varPi$ represents the bulk velocity (average velocity across the channel section) of the actual two-phase flow configuration (i.e. two immiscible fluid layers having different viscosity and flowing inside a channel under the action of a pumping power  $P_p$), but in laminar conditions. When the viscosity of the two layers is the same (single-phase case and
$P_p$), but in laminar conditions. When the viscosity of the two layers is the same (single-phase case and  $\lambda =1.00$ case), the coefficients
$\lambda =1.00$ case), the coefficients  $B$ and
$B$ and  $D$ are unitary and the characteristic velocity reduces to
$D$ are unitary and the characteristic velocity reduces to
 \begin{equation} u_\varPi=u_\varPi^{sp}=\sqrt{\frac{P_p h}{3 \eta_2}}, \end{equation}
\begin{equation} u_\varPi=u_\varPi^{sp}=\sqrt{\frac{P_p h}{3 \eta_2}}, \end{equation}clearly matching the standard definition of the reference velocity under CPI conditions (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014).
2.3. Numerical method
The governing equations (2.1)–(2.6) and (2.7) are solved using a pseudo-spectral method based on transforming the field variables into wavenumber space via a combination of Fourier series (along the periodic streamwise and spanwise directions) and Chebyshev polynomials (along the inhomogeneous wall-normal direction). In particular, (2.7) is rewritten as a fourth-order equation for the wall-normal component of the velocity  $u_z$ and a second-order equation for the wall-normal component of the vorticity
$u_z$ and a second-order equation for the wall-normal component of the vorticity  $\omega _z$ (Kim, Moin & Moser Reference Kim, Moin and Moser1987; Speziale Reference Speziale1987) while (2.1) is split into two second-order equations (Badalassi et al. Reference Badalassi, Ceniceros and Banerjee2003).
$\omega _z$ (Kim, Moin & Moser Reference Kim, Moin and Moser1987; Speziale Reference Speziale1987) while (2.1) is split into two second-order equations (Badalassi et al. Reference Badalassi, Ceniceros and Banerjee2003).
The governing equations are advanced in time using a mixed implicit–explicit scheme. For the Navier–Stokes equations, the nonlinear diffusive term is first rewritten as the sum of a linear and a nonlinear contribution (Zonta, Marchioli & Soldati Reference Zonta, Marchioli and Soldati2012a; Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib). The linear part is then integrated using a Crank–Nicolson scheme (second-order accurate) while the nonlinear part, together with the nonlinear convective terms, is integrated using an Adams–Bashforth scheme (second-order accurate). Similarly, for the Cahn–Hilliard equation, the linear term is integrated using an implicit Euler scheme (first-order accurate), while the nonlinear term is integrated in time using an Adams–Bashforth scheme (second-order accurate). The adoption of the implicit Euler scheme helps damping unphysical high-frequency oscillations that could arise from the steep gradients of  $\phi$. Note that the applied mean pressure gradient is also updated at each time step, so as to keep constant the power injected into the system (see appendix B). Further details on the code implementation, parallelization and validation can be found in Soligo et al. (Reference Soligo, Roccon and Soldati2019b, Reference Soligo, Roccon and Soldati2020a).
$\phi$. Note that the applied mean pressure gradient is also updated at each time step, so as to keep constant the power injected into the system (see appendix B). Further details on the code implementation, parallelization and validation can be found in Soligo et al. (Reference Soligo, Roccon and Soldati2019b, Reference Soligo, Roccon and Soldati2020a).
2.4. Boundary conditions
The resulting set of governing equations is complemented by suitable boundary conditions. For the Navier–Stokes equations, no-slip boundary conditions are enforced at the top and bottom walls ( $z/h=\pm 1$)
$z/h=\pm 1$)
 \begin{equation} u_i(z/h=\pm 1)=0. \end{equation}
\begin{equation} u_i(z/h=\pm 1)=0. \end{equation}For the Cahn–Hilliard equation, no-flux boundary conditions are applied at the two walls, and finally give
 \begin{equation} \frac{\partial \phi}{\partial z}(z/h=\pm 1)=0 , \quad \frac{\partial^3 \phi}{\partial z^3}(z/h=\pm 1)=0 . \end{equation}
\begin{equation} \frac{\partial \phi}{\partial z}(z/h=\pm 1)=0 , \quad \frac{\partial^3 \phi}{\partial z^3}(z/h=\pm 1)=0 . \end{equation}
Along the streamwise and spanwise directions ( $x$ and
$x$ and  $y$), periodic boundary conditions are imposed for all variables (Fourier discretization). The adoption of these boundary conditions leads to the conservation of the phase field over time
$y$), periodic boundary conditions are imposed for all variables (Fourier discretization). The adoption of these boundary conditions leads to the conservation of the phase field over time
 \begin{equation} \frac{\partial}{\partial t} \int_{\varOmega} \phi \,\textrm{d} \varOmega = 0. \end{equation}
\begin{equation} \frac{\partial}{\partial t} \int_{\varOmega} \phi \,\textrm{d} \varOmega = 0. \end{equation}
This gives the mass conservation of the entire system but does not guarantee the mass conservation of each of the two phases  $\phi =+1$ and
$\phi =+1$ and  $\phi =-1$ (Yue, Zhou & Feng Reference Yue, Zhou and Feng2007; Soligo, Roccon & Soldati Reference Soligo, Roccon and Soldati2019c) and some small leakages between the phases may occur. In the present case, mass leakage is always below 1 %.
$\phi =-1$ (Yue, Zhou & Feng Reference Yue, Zhou and Feng2007; Soligo, Roccon & Soldati Reference Soligo, Roccon and Soldati2019c) and some small leakages between the phases may occur. In the present case, mass leakage is always below 1 %.
2.5. Simulations set-up
We run six different simulations: a single-phase reference simulation and five simulations of lubricated channels, each characterized by a different value of the viscosity ratio  $\lambda$. We consider both the case of
$\lambda$. We consider both the case of  $\lambda <1$, i.e. the lubricating fluid is less viscous than the primary fluid, and of
$\lambda <1$, i.e. the lubricating fluid is less viscous than the primary fluid, and of  $\lambda >1$, i.e. the lubricating fluid is more viscous than the primary fluid. In particular, we set:
$\lambda >1$, i.e. the lubricating fluid is more viscous than the primary fluid. In particular, we set:  $\lambda =0.25$,
$\lambda =0.25$,  $\lambda =0.50$,
$\lambda =0.50$,  $\lambda =1.00$,
$\lambda =1.00$,  $\lambda =2.00$ and
$\lambda =2.00$ and  $\lambda =4.00$. All simulations are performed injecting into the system the same physical power
$\lambda =4.00$. All simulations are performed injecting into the system the same physical power  $P_p$ (CPI approach). For the single-phase case and
$P_p$ (CPI approach). For the single-phase case and  $\lambda =1.00$ (uniform viscosity), this leads to a power Reynolds number equal to
$\lambda =1.00$ (uniform viscosity), this leads to a power Reynolds number equal to  $Re_\varPi =12220$ (approximately corresponding to a shear Reynolds number
$Re_\varPi =12220$ (approximately corresponding to a shear Reynolds number  $Re_\tau \simeq 300$). However, when the viscosity is not uniform (
$Re_\tau \simeq 300$). However, when the viscosity is not uniform ( $\lambda \ne 1$), the characteristic velocity
$\lambda \ne 1$), the characteristic velocity  $u_\varPi$ changes, leading to slightly different power Reynolds numbers: from
$u_\varPi$ changes, leading to slightly different power Reynolds numbers: from  $Re_\varPi =14830$ (
$Re_\varPi =14830$ ( $\lambda =0.25$) down to
$\lambda =0.25$) down to  $Re_\varPi =11240$ (
$Re_\varPi =11240$ ( $\lambda =4.00$).
$\lambda =4.00$).
The surface tension value of the liquid–liquid interface is constant for all cases and is set via the Weber number so as to be representative of an oil/water interface (Than et al. Reference Than, Preziosi, Joseph and Arney1988). The resulting Weber number is  $We_\varPi =830$ for
$We_\varPi =830$ for  $\lambda =1.00$, while it changes – because of the different characteristic velocity – for the other cases.
$\lambda =1.00$, while it changes – because of the different characteristic velocity – for the other cases.
The grid resolution is chosen to fulfil requirements imposed by DNS and at the same time to guarantee a proper resolution of the thin interface between the two fluid layers. For the single-phase reference case, we use  $N_x \times N_y \times N_z = 512 \times 256 \times 257$ grid points, while for the lubricated channel cases we use
$N_x \times N_y \times N_z = 512 \times 256 \times 257$ grid points, while for the lubricated channel cases we use  $N_x \times N_y \times N_z = 1024 \times 512 \times 513$. The Cahn number is set to
$N_x \times N_y \times N_z = 1024 \times 512 \times 513$. The Cahn number is set to  $Ch = 0.01$ to allow for the accurate description of the steep gradients present at the interface (Soligo et al. Reference Soligo, Roccon and Soldati2019b). The Péclet number (or more specifically the mobility) is chosen following previous investigations (see for example Yue, Zhou & Feng Reference Yue, Zhou and Feng2010), which prescribe an optimal value
$Ch = 0.01$ to allow for the accurate description of the steep gradients present at the interface (Soligo et al. Reference Soligo, Roccon and Soldati2019b). The Péclet number (or more specifically the mobility) is chosen following previous investigations (see for example Yue, Zhou & Feng Reference Yue, Zhou and Feng2010), which prescribe an optimal value  $Pe=3/Ch$ to obtain an asymptotic convergence to the sharp-interface limit. The resulting Péclet number is
$Pe=3/Ch$ to obtain an asymptotic convergence to the sharp-interface limit. The resulting Péclet number is  $Pe_\varPi =12\ 220$ for
$Pe_\varPi =12\ 220$ for  $\lambda =1.00$ and changes slightly for the other cases (different characteristic velocity). Please refer to table 1 for an overview of the simulation parameters.
$\lambda =1.00$ and changes slightly for the other cases (different characteristic velocity). Please refer to table 1 for an overview of the simulation parameters.
Table 1. Overview of the main parameters employed to run the different simulations: viscosity ratio  $\lambda$, power Reynolds number
$\lambda$, power Reynolds number  $Re_\varPi$, Weber number
$Re_\varPi$, Weber number  $We_\varPi$, Cahn number
$We_\varPi$, Cahn number  $Ch$ and Péclet number
$Ch$ and Péclet number  $Pe_\varPi$. The number of grid points used to discretize the domain along the streamwise (
$Pe_\varPi$. The number of grid points used to discretize the domain along the streamwise ( $N_x$), spanwise (
$N_x$), spanwise ( $N_y$) and wall-normal (
$N_y$) and wall-normal ( $N_z$) directions is explicitly indicated. The corresponding parameters for the single-phase simulations are also included for comparison. Note that all simulations are performed driving the flow with the same the pumping power
$N_z$) directions is explicitly indicated. The corresponding parameters for the single-phase simulations are also included for comparison. Note that all simulations are performed driving the flow with the same the pumping power  $P_p$ in physical units (CPI approach).
$P_p$ in physical units (CPI approach).

For all simulations, the initial condition is taken from a preliminary DNS of a single-phase fully developed turbulent channel flow at  $Re_\tau = 300$ (performed using a CPG approach), and complemented by a proper definition of the initial distribution of the phase field
$Re_\tau = 300$ (performed using a CPG approach), and complemented by a proper definition of the initial distribution of the phase field  $\phi$, so that the liquid–liquid interface is at the beginning flat and located at distance
$\phi$, so that the liquid–liquid interface is at the beginning flat and located at distance  $h_1=0.15h$ from the top wall. Specifically, the initial condition used for the phase field is
$h_1=0.15h$ from the top wall. Specifically, the initial condition used for the phase field is
 \begin{equation} \phi(x,y,z)=\tanh \left( \frac{z-(1-h_1)}{\sqrt{2}Ch} \right). \end{equation}
\begin{equation} \phi(x,y,z)=\tanh \left( \frac{z-(1-h_1)}{\sqrt{2}Ch} \right). \end{equation}2.6. CPI scaling and flow field decomposition
In the following, results are presented using the CPI scaling system, which employs  $u_\varPi$ as reference velocity,
$u_\varPi$ as reference velocity,  $h$ as reference length and
$h$ as reference length and  $h/u_\varPi$ as reference time. Unless otherwise mentioned, and for the sake of comparison, all results are normalized by the single-phase reference velocity,
$h/u_\varPi$ as reference time. Unless otherwise mentioned, and for the sake of comparison, all results are normalized by the single-phase reference velocity,  $u_\varPi ^{sp}$.
$u_\varPi ^{sp}$.
Angular brackets,  $\langle \cdot \rangle$, indicate average in space along the two homogeneous directions (
$\langle \cdot \rangle$, indicate average in space along the two homogeneous directions ( $x$ and
$x$ and  $y$), while square brackets,
$y$), while square brackets,  $[ \cdot ]$, indicate average in space (along
$[ \cdot ]$, indicate average in space (along  $x$ and
$x$ and  $y$) and in time. The flow field, pressure field and Korteweg tensor are decomposed into a mean and a fluctuating component using a standard Reynolds decomposition (Reynolds Reference Reynolds1895): the mean component is a function of the wall-normal coordinate (
$y$) and in time. The flow field, pressure field and Korteweg tensor are decomposed into a mean and a fluctuating component using a standard Reynolds decomposition (Reynolds Reference Reynolds1895): the mean component is a function of the wall-normal coordinate ( $z$) and time (
$z$) and time ( $t$), while the fluctuating component depends on all the three spatial coordinates (
$t$), while the fluctuating component depends on all the three spatial coordinates ( $x,y,z$) and time (
$x,y,z$) and time ( $t$). Therefore, a generic field,
$t$). Therefore, a generic field,  $a(x,y,z,t)$, is decomposed as follows:
$a(x,y,z,t)$, is decomposed as follows:
 \begin{equation} a(x,y,z,t)=\underbrace{\langle a (z,t) \rangle}_{{Mean}}+ \underbrace{ a'(x,y,z,t)}_{{Fluctuating}}. \end{equation}
\begin{equation} a(x,y,z,t)=\underbrace{\langle a (z,t) \rangle}_{{Mean}}+ \underbrace{ a'(x,y,z,t)}_{{Fluctuating}}. \end{equation}Note that the mean pressure gradient, used to drive the flow, has been already separated from the pressure field (see (2.7)).
3. Results
First, results will be discussed on a qualitative basis, by looking at instantaneous flow visualizations. Then, suitable flow statistics such as the flow rate of the two liquid layers, the mean pressure gradient and the corresponding mean velocity, will be used to quantify more closely the overall turbulence modulation in the lubricated channel. To detail the different mechanisms that contribute more significantly to the observed flow behaviour, we will focus on the mean and turbulent kinetic energy budget, which we will also describe with the help of the so-called energy-box representation (Ricco et al. Reference Ricco, Ottonelli, Hasegawa and Quadrio2012). The energy-box representation will be presented and applied to the entire domain first (ensemble average), and to each phase separately later (phase average) – so as to characterize the energy fluxes exchanged between the two phases (Dodd & Ferrante Reference Dodd and Ferrante2016; Rosti et al. Reference Rosti, Ge, Jain, Dodd and Brandt2019).
3.1. Qualitative behaviour of the multiphase flow
We start our discussion by looking at the qualitative structure of the flow in the statistically steady state that develops when the initial transient – required to absorb the initial conditions – is finished. Figure 1 shows a map of the TKE,  $\text {TKE}= u'_i u'_i/2$, on a cross-section of the channel (
$\text {TKE}= u'_i u'_i/2$, on a cross-section of the channel ( $y$–
$y$– $z$) located at
$z$) located at  $x=L_x/2$. Each panel refers to a different case: single phase (a),
$x=L_x/2$. Each panel refers to a different case: single phase (a),  $\lambda =0.25$ (b),
$\lambda =0.25$ (b),  $\lambda =0.50$ (c),
$\lambda =0.50$ (c),  $\lambda =1.00$ (d),
$\lambda =1.00$ (d),  $\lambda =2.00$ (e) and
$\lambda =2.00$ (e) and  $\lambda =4.00$ (f). The position of the interface (iso-level
$\lambda =4.00$ (f). The position of the interface (iso-level  $\phi =0$) is indicated by a white line.
$\phi =0$) is indicated by a white line.

Figure 1. Contour plot of turbulent kinetic energy (TKE) on a cross-section of the channel ( $y$–
$y$– $z$) located at
$z$) located at  $x=L_x/2$. Each panel refers to a different case: (a), single phase; (b),
$x=L_x/2$. Each panel refers to a different case: (a), single phase; (b),  $\lambda =0.25$; (c),
$\lambda =0.25$; (c),  $\lambda =0.50$; (d),
$\lambda =0.50$; (d),  $\lambda =1.00$; (e),
$\lambda =1.00$; (e),  $\lambda =2.00$, (f),
$\lambda =2.00$, (f),  $\lambda =4.00$. The position of the interface is explicitly rendered via the thin white line. The different flow behaviour inside the thin lubricating layer, ranging from sustained turbulence (
$\lambda =4.00$. The position of the interface is explicitly rendered via the thin white line. The different flow behaviour inside the thin lubricating layer, ranging from sustained turbulence ( $\lambda <1$) to completely suppressed turbulence (
$\lambda <1$) to completely suppressed turbulence ( $\lambda >1$), can be appreciated.
$\lambda >1$), can be appreciated.
The qualitative results presented here confirm and extend our previous observations (Roccon et al. Reference Roccon, Zonta and Soldati2019). To discuss the flow modifications induced by the thin lubricating layer on the overall flow behaviour, we conveniently keep the single-phase case (figure 1a), for which classical near-wall turbulence structures are observed near the top and bottom boundaries, as reference. We immediately observe that, for all the viscosity stratified cases, the symmetry about the channel centre is broken, and the top and bottom boundaries behave differently based on the specific value of  $\lambda$. We will focus on the bottom wall first, on the top wall later.
$\lambda$. We will focus on the bottom wall first, on the top wall later.
At the bottom wall ( $z/h=-1$) the turbulence structure for all viscosity stratified cases (figure 1b–f) is similar to that of the single-phase case (figure 1a). The thin lubricating layer is too far to influence the near-wall turbulence regeneration cycle at the bottom wall (Lam & Banerjee Reference Lam and Banerjee1992; Jiménez Reference Jiménez2013). Nevertheless, a slight enhancement of the turbulence activity is observed for
$z/h=-1$) the turbulence structure for all viscosity stratified cases (figure 1b–f) is similar to that of the single-phase case (figure 1a). The thin lubricating layer is too far to influence the near-wall turbulence regeneration cycle at the bottom wall (Lam & Banerjee Reference Lam and Banerjee1992; Jiménez Reference Jiménez2013). Nevertheless, a slight enhancement of the turbulence activity is observed for  $\lambda =0.25$,
$\lambda =0.25$,  $\lambda =0.50$ and
$\lambda =0.50$ and  $\lambda =1.00$. We anticipate here, but it will become clear later by looking at the fluid statistics, that this increase can be traced back to the larger gradients of the mean velocity profile and to the associated enhancement of the TKE production (Mansour, Kim & Moin Reference Mansour, Kim and Moin1988; Zonta et al. Reference Zonta, Marchioli and Soldati2012a).
$\lambda =1.00$. We anticipate here, but it will become clear later by looking at the fluid statistics, that this increase can be traced back to the larger gradients of the mean velocity profile and to the associated enhancement of the TKE production (Mansour, Kim & Moin Reference Mansour, Kim and Moin1988; Zonta et al. Reference Zonta, Marchioli and Soldati2012a).
At the top wall the situation is completely different and depends on the specific value of  $\lambda$. For ease of discussion, we focus first on
$\lambda$. For ease of discussion, we focus first on  $\lambda =1.00$. Results for this case, which are given in figure 1(d), clearly show that turbulence is almost completely suppressed in the lubricating layer. This result, which confirms the observations made in our previous work (Roccon et al. Reference Roccon, Zonta and Soldati2019), can be directly attributed – as will be shown below – to the lubricating layer being too thin (or, alternatively to the local Reynolds number being too small) to sustain the near-wall turbulence cycle (Jiménez & Moin Reference Jiménez and Moin1991; Jiménez & Pinelli Reference Jiménez and Pinelli1999; Jiménez Reference Jiménez2013; Roccon et al. Reference Roccon, Zonta and Soldati2019). From a physical viewpoint, turbulence suppression is in this case due to the presence of the liquid–liquid interface – an elasticity element with the corresponding surface tension – that limits the wall-normal vertical transport of momentum and decouples the dynamics of the primary layer from that of the lubricating layers, which is then too thin to sustain turbulence itself. Mild velocity fluctuations might appear occasionally, and are induced by the motion of the liquid–liquid interface. The turbulence suppression process observed in the lubricating layer for
$\lambda =1.00$. Results for this case, which are given in figure 1(d), clearly show that turbulence is almost completely suppressed in the lubricating layer. This result, which confirms the observations made in our previous work (Roccon et al. Reference Roccon, Zonta and Soldati2019), can be directly attributed – as will be shown below – to the lubricating layer being too thin (or, alternatively to the local Reynolds number being too small) to sustain the near-wall turbulence cycle (Jiménez & Moin Reference Jiménez and Moin1991; Jiménez & Pinelli Reference Jiménez and Pinelli1999; Jiménez Reference Jiménez2013; Roccon et al. Reference Roccon, Zonta and Soldati2019). From a physical viewpoint, turbulence suppression is in this case due to the presence of the liquid–liquid interface – an elasticity element with the corresponding surface tension – that limits the wall-normal vertical transport of momentum and decouples the dynamics of the primary layer from that of the lubricating layers, which is then too thin to sustain turbulence itself. Mild velocity fluctuations might appear occasionally, and are induced by the motion of the liquid–liquid interface. The turbulence suppression process observed in the lubricating layer for  $\lambda = 1.00$ appears magnified for
$\lambda = 1.00$ appears magnified for  $\lambda \ge 1$ (figure 1e,f), since the effect of the larger viscosity of the lubricating layer sums up with the action of the surface tension forces (Roccon et al. Reference Roccon, De Paoli, Zonta and Soldati2017). By contrast, for
$\lambda \ge 1$ (figure 1e,f), since the effect of the larger viscosity of the lubricating layer sums up with the action of the surface tension forces (Roccon et al. Reference Roccon, De Paoli, Zonta and Soldati2017). By contrast, for  $\lambda =0.25$ and
$\lambda =0.25$ and  $\lambda =0.50$ (figure 1b,c), the viscosity in the lubricating layer is small enough – and the corresponding local Reynolds number large enough (Pecnik & Patel Reference Pecnik and Patel2017) – to sustain turbulence in the lubricating layer.
$\lambda =0.50$ (figure 1b,c), the viscosity in the lubricating layer is small enough – and the corresponding local Reynolds number large enough (Pecnik & Patel Reference Pecnik and Patel2017) – to sustain turbulence in the lubricating layer.
To appreciate better the different flow structures in the lubricating layer, we turn now our attention to the distribution of TKE on a  $x-y$ horizontal plane located in the proximity of the top wall, at distance
$x-y$ horizontal plane located in the proximity of the top wall, at distance  $d/h=0.03$. Results are shown in figure 2 and each panel refers to a different case: single phase (a),
$d/h=0.03$. Results are shown in figure 2 and each panel refers to a different case: single phase (a),  $\lambda =0.25$ (b),
$\lambda =0.25$ (b),  $\lambda =0.50$ (c) and
$\lambda =0.50$ (c) and  $\lambda =1.00$ (d). Note that results for
$\lambda =1.00$ (d). Note that results for  $\lambda =2.00$ and
$\lambda =2.00$ and  $\lambda =4.00$ are not shown since velocity fluctuations are largely suppressed and are therefore not visible. For the single-phase case (figure 2a), we recover the classical near-wall turbulence structure in which elongated high and low speed streaks appear side by side and line up along the streamwise direction (Lam & Banerjee Reference Lam and Banerjee1992; Schoppa & Hussain Reference Schoppa and Hussain2002; Chernyshenko & Baig Reference Chernyshenko and Baig2005). The picture changes quite significantly for the lubricated channel. In particular, for
$\lambda =4.00$ are not shown since velocity fluctuations are largely suppressed and are therefore not visible. For the single-phase case (figure 2a), we recover the classical near-wall turbulence structure in which elongated high and low speed streaks appear side by side and line up along the streamwise direction (Lam & Banerjee Reference Lam and Banerjee1992; Schoppa & Hussain Reference Schoppa and Hussain2002; Chernyshenko & Baig Reference Chernyshenko and Baig2005). The picture changes quite significantly for the lubricated channel. In particular, for  $\lambda =1.00$ (figure 2d), we see no evidence of turbulence activity, as turbulence is almost completely suppressed by the presence of the interface (Verschoof et al. Reference Verschoof, van der Veen, Sun and Lohse2016; Roccon et al. Reference Roccon, Zonta and Soldati2019). For
$\lambda =1.00$ (figure 2d), we see no evidence of turbulence activity, as turbulence is almost completely suppressed by the presence of the interface (Verschoof et al. Reference Verschoof, van der Veen, Sun and Lohse2016; Roccon et al. Reference Roccon, Zonta and Soldati2019). For  $\lambda =0.25$ and
$\lambda =0.25$ and  $\lambda =0.50$ (figure 2b,c) turbulence appears reactivated in the lubricating layer. Yet, compared to the single-phase case, turbulence is less homogeneous, with the presence of banded structures of turbulent–laminar patches closely recalling those observed in other important flow instances (for example in thermally stratified turbulence, see García-Villalba & Del Álamo Reference García-Villalba and Del Álamo2011; Zonta, Onorato & Soldati Reference Zonta, Onorato and Soldati2012b; Zonta & Soldati Reference Zonta and Soldati2018). The coexistence of turbulent and laminar patches seems to be due to the deformation of the underneath interface separating the primary and the lubricating layer: crests and troughs (see appendix C for details) that naturally develop at the interface sometimes make the lubricating layer thin enough to locally suppress the turbulence activity. As a side observation – but we will not further comment on it – we report the change of size of turbulence structures at the wall, which appear smaller for smaller viscosity (i.e. larger local Reynolds number).
$\lambda =0.50$ (figure 2b,c) turbulence appears reactivated in the lubricating layer. Yet, compared to the single-phase case, turbulence is less homogeneous, with the presence of banded structures of turbulent–laminar patches closely recalling those observed in other important flow instances (for example in thermally stratified turbulence, see García-Villalba & Del Álamo Reference García-Villalba and Del Álamo2011; Zonta, Onorato & Soldati Reference Zonta, Onorato and Soldati2012b; Zonta & Soldati Reference Zonta and Soldati2018). The coexistence of turbulent and laminar patches seems to be due to the deformation of the underneath interface separating the primary and the lubricating layer: crests and troughs (see appendix C for details) that naturally develop at the interface sometimes make the lubricating layer thin enough to locally suppress the turbulence activity. As a side observation – but we will not further comment on it – we report the change of size of turbulence structures at the wall, which appear smaller for smaller viscosity (i.e. larger local Reynolds number).

Figure 2. Contour plot of TKE on a  $x-y$ plane located at
$x-y$ plane located at  $z/h=0.97$ (i.e. taken inside the lubricating layer, at a distance
$z/h=0.97$ (i.e. taken inside the lubricating layer, at a distance  $d/h=0.03$ from the top wall). (a) Refers to the single-phase case, (b) to the case
$d/h=0.03$ from the top wall). (a) Refers to the single-phase case, (b) to the case  $\lambda =0.25$, (c) to
$\lambda =0.25$, (c) to  $\lambda =0.50$ and (d) to
$\lambda =0.50$ and (d) to  $\lambda =1.00$.
$\lambda =1.00$.
From a quantitative viewpoint, the presence of two distinct flow regimes (laminar/turbulent) in the lubricating layer can be justified using a semi-local scaling (Pecnik & Patel Reference Pecnik and Patel2017; Roccon et al. Reference Roccon, Zonta and Soldati2019) and computing the thickness of the lubricating layer in wall units (w.u.)
 \begin{equation} h_1^+=h_1 \frac{Re_\tau}{\lambda} \sqrt{\frac{2 |\tau_{w,1}|}{|\tau_{w,1}| + |\tau_{w,2}|}}, \end{equation}
\begin{equation} h_1^+=h_1 \frac{Re_\tau}{\lambda} \sqrt{\frac{2 |\tau_{w,1}|}{|\tau_{w,1}| + |\tau_{w,2}|}}, \end{equation}
where  $h_1$ is the lubricating layer thickness in outer units,
$h_1$ is the lubricating layer thickness in outer units,  $Re_\tau$ is the equivalent shear Reynolds number (approximately
$Re_\tau$ is the equivalent shear Reynolds number (approximately  $300$ here) and
$300$ here) and  $\tau _{w,1}$ and
$\tau _{w,1}$ and  $\tau _{w,2}$ are the wall-shear stresses at the top and bottom wall, respectively. In the present case,
$\tau _{w,2}$ are the wall-shear stresses at the top and bottom wall, respectively. In the present case,  $h_1^+\simeq 30$ w.u. for
$h_1^+\simeq 30$ w.u. for  $\lambda =1.00$, while it increases up to
$\lambda =1.00$, while it increases up to  $h_1^+= 138$ w.u. for
$h_1^+= 138$ w.u. for  $\lambda =0.25$. These results suggest that the lubricating layer is too small to sustain turbulence for
$\lambda =0.25$. These results suggest that the lubricating layer is too small to sustain turbulence for  $\lambda =1.00$, whereas it becomes large enough to sustain turbulence for
$\lambda =1.00$, whereas it becomes large enough to sustain turbulence for  $\lambda <1$. Note that Jiménez & Pinelli (Reference Jiménez and Pinelli1999) established that the minimum dimensionless channel height to maintain a self-sustained near-wall turbulence cycle is
$\lambda <1$. Note that Jiménez & Pinelli (Reference Jiménez and Pinelli1999) established that the minimum dimensionless channel height to maintain a self-sustained near-wall turbulence cycle is  $h^+\simeq 60$ w.u.
$h^+\simeq 60$ w.u.
3.2. Flow rates and pressure gradient
The qualitative flow changes observed above naturally reflect into corresponding changes of the macroscopic flow parameters. Here, we focus on the time-averaged flow rate through the entire cross-section,  $[Q_t]$, on the time-averaged flow rate of the primary layer,
$[Q_t]$, on the time-averaged flow rate of the primary layer,  $[Q_2]$, and on the time-averaged mean pressure gradient,
$[Q_2]$, and on the time-averaged mean pressure gradient,  $[p_x]$. These results, which are represented in figure 3, are normalized by the corresponding values for the single-phase case,
$[p_x]$. These results, which are represented in figure 3, are normalized by the corresponding values for the single-phase case,  $[Q_{sp}]$ and
$[Q_{sp}]$ and  $[p_{x}^{sp}]$, respectively. The region coloured in light grey in the diagram refers to flow configurations for which the viscosity of the lubricating layer is smaller than that of the primary layer (i.e.
$[p_{x}^{sp}]$, respectively. The region coloured in light grey in the diagram refers to flow configurations for which the viscosity of the lubricating layer is smaller than that of the primary layer (i.e.  $\lambda <1$), while the region coloured in dark grey refers to flow configurations for which the viscosity of the lubricating layer is larger than that of the primary layer (i.e.
$\lambda <1$), while the region coloured in dark grey refers to flow configurations for which the viscosity of the lubricating layer is larger than that of the primary layer (i.e.  $\lambda > 1$).
$\lambda > 1$).

Figure 3. Volume flow rate through the entire channel  $[Q_t]$ (filled circles), volume flow rate of the primary layer
$[Q_t]$ (filled circles), volume flow rate of the primary layer  $[Q_2]$ (empty circles), and mean pressure gradient
$[Q_2]$ (empty circles), and mean pressure gradient  $[p_x]$ (filled squares) as a function of the viscosity ratio
$[p_x]$ (filled squares) as a function of the viscosity ratio 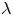 $\lambda$. All results are normalized by the corresponding single-phase value. Note the non-monotonic behaviour of the different quantities which, for the cases here tested, reach an optimum (maximum flow rates and minimum pressure gradient, i.e. maximum DR) for
$\lambda$. All results are normalized by the corresponding single-phase value. Note the non-monotonic behaviour of the different quantities which, for the cases here tested, reach an optimum (maximum flow rates and minimum pressure gradient, i.e. maximum DR) for  $\lambda =1.00$. For
$\lambda =1.00$. For  $\lambda =4.00$, we report a marginal drag increase.
$\lambda =4.00$, we report a marginal drag increase.
We immediately observe that, for  $\lambda \leq 2.00$,
$\lambda \leq 2.00$,  $[Q_2]/[Q_{sp}]>1$ (empty circles) and
$[Q_2]/[Q_{sp}]>1$ (empty circles) and  $[Q_t]/[Q_{sp}]>1$ (filled circles). In other words, by keeping the applied power constant, the transferred flow rate is increased. This is a clear indication of DR, which is maximum for
$[Q_t]/[Q_{sp}]>1$ (filled circles). In other words, by keeping the applied power constant, the transferred flow rate is increased. This is a clear indication of DR, which is maximum for  $\lambda =1.00$ (
$\lambda =1.00$ ( ${\simeq }13\,\%$ of flow-rate increase), and is only slightly reduced for
${\simeq }13\,\%$ of flow-rate increase), and is only slightly reduced for  $\lambda = 0.50$ and
$\lambda = 0.50$ and  $\lambda = 0.25$ (
$\lambda = 0.25$ ( ${\simeq }11\,\%$ of flow-rate increase). The reduction appears more intense for
${\simeq }11\,\%$ of flow-rate increase). The reduction appears more intense for  $\lambda = 2.00$ (
$\lambda = 2.00$ ( ${\simeq }5\,\%$ of flow-rate increase). When the viscosity of the lubricating layer is increased beyond
${\simeq }5\,\%$ of flow-rate increase). When the viscosity of the lubricating layer is increased beyond  $\lambda > 2$, we observe a drop of the flow rate that, giving
$\lambda > 2$, we observe a drop of the flow rate that, giving  $[Q_2]/[Q_{sp}]< 1$ for
$[Q_2]/[Q_{sp}]< 1$ for  $\lambda = 4.00$ (
$\lambda = 4.00$ ( ${\simeq }5\,\%$ of flow-rate decrease), marks the occurrence of a drag increase.
${\simeq }5\,\%$ of flow-rate decrease), marks the occurrence of a drag increase.
Consistently with the previous observations, for  $\lambda \leq 2.00$ the normalized pressure gradient is
$\lambda \leq 2.00$ the normalized pressure gradient is  $[p_{x}]/[p_{x}^{sp}]<1$, so as to balance the increased flow rate and to keep the total power – product between the flow rate and the applied pressure gradient, in physical units – constant. The pressure gradient, which attains a minimum for
$[p_{x}]/[p_{x}^{sp}]<1$, so as to balance the increased flow rate and to keep the total power – product between the flow rate and the applied pressure gradient, in physical units – constant. The pressure gradient, which attains a minimum for  $\lambda = 1.00$ (
$\lambda = 1.00$ ( $[p_{x}]/[p_{x}^{sp}]\simeq 0.86$), increases only slightly for
$[p_{x}]/[p_{x}^{sp}]\simeq 0.86$), increases only slightly for  $\lambda <1$ (
$\lambda <1$ (  $[p_{x}]/[p_{x}^{sp}]\simeq 0.9$ for
$[p_{x}]/[p_{x}^{sp}]\simeq 0.9$ for  $\lambda = 0.5$ and
$\lambda = 0.5$ and  $\lambda = 0.25$); on the other hand, it increases more vigorously for
$\lambda = 0.25$); on the other hand, it increases more vigorously for  $\lambda >1$, up to the point at which, for
$\lambda >1$, up to the point at which, for  $\lambda = 4.00$, it becomes slightly larger than unity.
$\lambda = 4.00$, it becomes slightly larger than unity.
Note that, since simulations are performed at slightly different power Reynolds numbers (see table 1), the product between the total flow rate and the mean pressure gradient, which is by construction constant in physical units, is slightly different when considered in dimensionless units.
3.3. Mean velocity profiles
Linked to the previous analysis on the flow-rate and pressure gradient modulations in the lubricated channel, we focus now on the behaviour of the mean streamwise velocity profile,  $[ u_x ]$, as a function of the wall-normal coordinate. Results are shown in figure 4 according to the following colour code: red is used for
$[ u_x ]$, as a function of the wall-normal coordinate. Results are shown in figure 4 according to the following colour code: red is used for  $\lambda =0.25$, yellow for
$\lambda =0.25$, yellow for  $\lambda =0.50$, green for
$\lambda =0.50$, green for  $\lambda =1.00$, light blue for
$\lambda =1.00$, light blue for  $\lambda =2.00$ and dark blue
$\lambda =2.00$ and dark blue  $\lambda =4.00$. The single-phase case is represented by the thin black line, while the reference position of the interface (
$\lambda =4.00$. The single-phase case is represented by the thin black line, while the reference position of the interface ( $z/h=0.85$) is identified by the vertical dashed black line. As expected, the shape of the mean velocity profile appears skewed by the presence of the liquid–liquid interface.
$z/h=0.85$) is identified by the vertical dashed black line. As expected, the shape of the mean velocity profile appears skewed by the presence of the liquid–liquid interface.

Figure 4. Wall-normal behaviour of the mean streamwise velocity,  $[ u_x ]$. The different cases of lubricated channel considered in the present study are reported using different colours:
$[ u_x ]$. The different cases of lubricated channel considered in the present study are reported using different colours:  $\lambda =0.25$ (red),
$\lambda =0.25$ (red),  $\lambda =0.50$ (yellow),
$\lambda =0.50$ (yellow),  $\lambda =1.00$ (green),
$\lambda =1.00$ (green),  $\lambda =2.00$ (blue) and
$\lambda =2.00$ (blue) and  $\lambda =4.00$ (dark blue). The single-phase case (thin black line) is also shown for reference. The nominal position of the interface (
$\lambda =4.00$ (dark blue). The single-phase case (thin black line) is also shown for reference. The nominal position of the interface ( $z/h=0.85$) is given by a dashed vertical black line.
$z/h=0.85$) is given by a dashed vertical black line.
In the primary layer, and consistently with the previous analysis on the overall flow rate, the behaviour of  $[ u_x ]$ is non-monotonic and is maximized for
$[ u_x ]$ is non-monotonic and is maximized for  $\lambda =1.00$. A reduction of the viscosity ratio from
$\lambda =1.00$. A reduction of the viscosity ratio from  $\lambda =1.00$ to
$\lambda =1.00$ to  $\lambda =0.50$ and
$\lambda =0.50$ and  $\lambda =0.25$ – which almost overlap – induces only a small decrease of
$\lambda =0.25$ – which almost overlap – induces only a small decrease of  $[ u_x ]$. On the other hand, an increase of
$[ u_x ]$. On the other hand, an increase of  $\lambda$ beyond unity,
$\lambda$ beyond unity,  $\lambda > 1.00$, produces stronger modification. For
$\lambda > 1.00$, produces stronger modification. For  $\lambda = 2.00$, the mean velocity profile appears largely reduced – although in any case well above the single-phase limit – compared to
$\lambda = 2.00$, the mean velocity profile appears largely reduced – although in any case well above the single-phase limit – compared to  $\lambda =1.00$. Moving to
$\lambda =1.00$. Moving to  $\lambda = 4.00$, we reach a condition at which the velocity profile is very close to that of the single-phase case in a large proportion of the primary layer, but suddenly drops in the proximity of the interface.
$\lambda = 4.00$, we reach a condition at which the velocity profile is very close to that of the single-phase case in a large proportion of the primary layer, but suddenly drops in the proximity of the interface.
In the lubricating layer,  $0.85 < z/h < 1.00$, the trend of the mean velocity turns out to be monotonic with the viscosity ratio
$0.85 < z/h < 1.00$, the trend of the mean velocity turns out to be monotonic with the viscosity ratio  $\lambda$:
$\lambda$:  $[u_x]$ increases consistently with decreasing
$[u_x]$ increases consistently with decreasing  $\lambda$. A similar behaviour characterizes the mean velocity gradient that, being minimum for
$\lambda$. A similar behaviour characterizes the mean velocity gradient that, being minimum for  $\lambda =4.00$ and maximum for
$\lambda =4.00$ and maximum for  $\lambda =0.25$, reflects the different flow structure in the lubricating layer – with turbulence progressively suppressed for increasing
$\lambda =0.25$, reflects the different flow structure in the lubricating layer – with turbulence progressively suppressed for increasing  $\lambda$ (see also figures 1 and 2). To have a classical view of the velocity profiles, they must be rescaled with the local friction velocity (i.e. evaluated at the corresponding wall). This comparison is offered in appendix D.
$\lambda$ (see also figures 1 and 2). To have a classical view of the velocity profiles, they must be rescaled with the local friction velocity (i.e. evaluated at the corresponding wall). This comparison is offered in appendix D.
3.4. Energy box: preliminary concepts
To provide a sound characterization of the energy fluxes in the lubricated channel, we decide to use the so-called energy-box technique (Ricco et al. Reference Ricco, Ottonelli, Hasegawa and Quadrio2012; Gatti et al. Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018). This technique, starting from the mean and TKE balance equations, provides a thorough and meaningful representation of the energy fluxes in the system. Note that, and precisely because of the adoption of a CPI approach, all simulations are performed driving the system with the same physical power input  $P_p$. Therefore, a direct comparison between the different cases is possible (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014).
$P_p$. Therefore, a direct comparison between the different cases is possible (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014).
To compute the energy budget, the total kinetic energy of the flow is decomposed into mean kinetic energy (MKE),  $\text {MKE}=\frac {1}{2}\langle u_i \rangle \langle u_i \rangle$, and TKE,
$\text {MKE}=\frac {1}{2}\langle u_i \rangle \langle u_i \rangle$, and TKE,  $\text {TKE} =\frac {1}{2}u'_i u'_i$. In the following, and building on top of the MKE and TKE definitions, we will present and discuss the energy-box technique for single and multiphase flows.
$\text {TKE} =\frac {1}{2}u'_i u'_i$. In the following, and building on top of the MKE and TKE definitions, we will present and discuss the energy-box technique for single and multiphase flows.
3.5. Energy box for a single-phase flow
The starting points of the energy-box technique are the MKE and TKE transport equations, obtained multiplying the Navier–Stokes equations by the mean velocity field – MKE balance equation – and by the fluctuating velocity field – TKE balance equation (Mansour et al. Reference Mansour, Kim and Moin1988; Kasagi, Tomita & Kuroda Reference Kasagi, Tomita and Kuroda1992; Iwamoto, Suzuki & Kasagi Reference Iwamoto, Suzuki and Kasagi2002). For the reference single-phase case, the ensemble average balance equation for the MKE becomes
 \begin{align} \frac{\textrm{D} [ \text{MKE} ]}{\textrm{D} t}&= \underbrace{ - [ \langle u_i \rangle \langle p_x \rangle ]}_{\varPi_m} +\underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} -\underbrace{ \left[ \frac{\partial (\langle u'_i u'_j \rangle \langle u_i \rangle) }{\partial x_j} \right]}_{T_m} \nonumber\\ &\quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial^2 \langle u_i \rangle^2 }{\partial x_j^2} \right]}_{D_m} \underbrace{ - \left[ \frac{1}{Re_{\varPi}} \frac{\partial \langle u_i \rangle}{\partial x_j}\frac{\partial \langle u_i \rangle}{\partial x_j} \right]}_{\epsilon_m}, \end{align}
\begin{align} \frac{\textrm{D} [ \text{MKE} ]}{\textrm{D} t}&= \underbrace{ - [ \langle u_i \rangle \langle p_x \rangle ]}_{\varPi_m} +\underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} -\underbrace{ \left[ \frac{\partial (\langle u'_i u'_j \rangle \langle u_i \rangle) }{\partial x_j} \right]}_{T_m} \nonumber\\ &\quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial^2 \langle u_i \rangle^2 }{\partial x_j^2} \right]}_{D_m} \underbrace{ - \left[ \frac{1}{Re_{\varPi}} \frac{\partial \langle u_i \rangle}{\partial x_j}\frac{\partial \langle u_i \rangle}{\partial x_j} \right]}_{\epsilon_m}, \end{align}
where  $\langle u'_i u'_j \rangle$ are the Reynolds stresses. While the left-hand side represents the material rate of change of MKE, the different terms on the right-hand side represent the power injected in the system via the mean pressure gradient,
$\langle u'_i u'_j \rangle$ are the Reynolds stresses. While the left-hand side represents the material rate of change of MKE, the different terms on the right-hand side represent the power injected in the system via the mean pressure gradient,  $\varPi _m$, the production of TKE,
$\varPi _m$, the production of TKE,  $P_k$, the work done by the Reynolds stresses,
$P_k$, the work done by the Reynolds stresses,  $T_m$, the viscous diffusion of MKE,
$T_m$, the viscous diffusion of MKE,  $D_m$, and the mean flow viscous dissipation,
$D_m$, and the mean flow viscous dissipation,  $\epsilon _m$.
$\epsilon _m$.
The ensemble-averaged balance equation for the TKE reads as
 \begin{align} \frac{\textrm{D} [ \text{TKE} ]}{\textrm{D} t}&= \underbrace{- \left[ \frac{ \partial \langle p'u'_i \rangle}{\partial x_i} \right]}_{\varPi_k} -\underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} \underbrace{- \left[ \frac{1}{2}\frac{\partial \langle u'_i u'_i u'_j \rangle }{\partial x_j} \right]}_{T_k} \nonumber\\ &\quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial^2 \langle u'_i u'_i \rangle}{\partial x_j^2} \right]}_{D_k} \underbrace{- \left[ \frac{1}{Re_{\varPi}} \frac{\partial u'_i }{\partial x_j}\frac{\partial u'_i }{\partial x_j} \right]}_{\epsilon_k}. \end{align}
\begin{align} \frac{\textrm{D} [ \text{TKE} ]}{\textrm{D} t}&= \underbrace{- \left[ \frac{ \partial \langle p'u'_i \rangle}{\partial x_i} \right]}_{\varPi_k} -\underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} \underbrace{- \left[ \frac{1}{2}\frac{\partial \langle u'_i u'_i u'_j \rangle }{\partial x_j} \right]}_{T_k} \nonumber\\ &\quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial^2 \langle u'_i u'_i \rangle}{\partial x_j^2} \right]}_{D_k} \underbrace{- \left[ \frac{1}{Re_{\varPi}} \frac{\partial u'_i }{\partial x_j}\frac{\partial u'_i }{\partial x_j} \right]}_{\epsilon_k}. \end{align}
The left-hand side represents the material rate of change of TKE. The terms on the right-hand side represent the pressure diffusion,  $\varPi _k$, the production of TKE,
$\varPi _k$, the production of TKE,  $P_k$, the turbulent diffusion,
$P_k$, the turbulent diffusion,  $T_k$, the viscous diffusion of TKE,
$T_k$, the viscous diffusion of TKE,  $D_k$, and the turbulent viscous dissipation,
$D_k$, and the turbulent viscous dissipation,  $\epsilon _k$.
$\epsilon _k$.
We can now proceed to discuss the different terms of each equation from a physical point of view. For (3.2) – MKE balance – the left-hand side is zero, since the flow is statistically steady. On the right-hand side, the power input,  $\varPi _m$, is a source term and represents the power injected in the system via the mean pressure gradient. This power is then partially dissipated by the mean flow viscous dissipation,
$\varPi _m$, is a source term and represents the power injected in the system via the mean pressure gradient. This power is then partially dissipated by the mean flow viscous dissipation,  $\epsilon _m$, and partially used to generate turbulent fluctuations via the production term,
$\epsilon _m$, and partially used to generate turbulent fluctuations via the production term,  $P_k$. Therefore,
$P_k$. Therefore,  $\epsilon _m$ and
$\epsilon _m$ and  $P_k$ represent a sink of energy in the MKE balance equation. The two remaining terms, the energy transport by the Reynolds stress,
$P_k$ represent a sink of energy in the MKE balance equation. The two remaining terms, the energy transport by the Reynolds stress,  $T_m$, and the viscous diffusion,
$T_m$, and the viscous diffusion,  $D_m$, redistribute the energy across the channel and thus act only as internal transport mechanisms that do not bear a net contribution. In other words, they are neither sinks nor sources.
$D_m$, redistribute the energy across the channel and thus act only as internal transport mechanisms that do not bear a net contribution. In other words, they are neither sinks nor sources.
Considering (3.3) – TKE balance – the left-hand side is also zero, always in light of the statistically steady condition. On the right-hand side, the TKE production term,  $P_k$, accounts for the generation of velocity fluctuations via mean shear. This term, which was a sink in the MKE equation, represents a source in the TKE equation. The power injected via
$P_k$, accounts for the generation of velocity fluctuations via mean shear. This term, which was a sink in the MKE equation, represents a source in the TKE equation. The power injected via  $P_k$ is entirely dissipated by the turbulent dissipation,
$P_k$ is entirely dissipated by the turbulent dissipation,  $\epsilon _k$, which is the only sink term in (3.3). The pressure diffusion,
$\epsilon _k$, which is the only sink term in (3.3). The pressure diffusion,  $\varPi _k$, the turbulent diffusion,
$\varPi _k$, the turbulent diffusion,  $T_k$, and the viscous diffusion,
$T_k$, and the viscous diffusion,  $D_k$, are redistribution terms with no net contribution.
$D_k$, are redistribution terms with no net contribution.
To evaluate the overall importance of the different terms, we compute the integral of the two balance equations along the wall-normal direction. With reference to a generic term  $A_{m/k}$, and using an overbar to indicate the integral over the wall-normal direction
$A_{m/k}$, and using an overbar to indicate the integral over the wall-normal direction  $z$, we obtain
$z$, we obtain
 \begin{equation} \overline{A_{m/k}}=\int^{z/h=+1}_{z/h=-1} [A_{m/k} ]\, \textrm{d} z .\end{equation}
\begin{equation} \overline{A_{m/k}}=\int^{z/h=+1}_{z/h=-1} [A_{m/k} ]\, \textrm{d} z .\end{equation}Clearly, this integral is zero for the internal transport (redistribution) terms, while it is positive (respectively negative) for the source (respectively sink) terms. Therefore, the integral counterparts of the MKE and TKE balance equations, (3.2) and (3.3), read as
 \begin{gather} \overline{{P}_k} + \overline{\varPi_m}+ \overline{\epsilon_m} =0 , \end{gather}
\begin{gather} \overline{{P}_k} + \overline{\varPi_m}+ \overline{\epsilon_m} =0 , \end{gather} \begin{gather}- \overline{{P}_k}+ \overline{\epsilon_k}=0 , \end{gather}
\begin{gather}- \overline{{P}_k}+ \overline{\epsilon_k}=0 , \end{gather}respectively. Combining (3.5) and (3.6), we obtain a balance equation for the total kinetic energy
 \begin{equation} \overline{\varPi_m}+\overline{\epsilon_m} + \overline{\epsilon_k}=0 ,\end{equation}
\begin{equation} \overline{\varPi_m}+\overline{\epsilon_m} + \overline{\epsilon_k}=0 ,\end{equation}
which states that the entire power injected into the system,  $\overline {\varPi _m}$, is ultimately dissipated by viscosity, both via the viscous dissipation term of the mean field,
$\overline {\varPi _m}$, is ultimately dissipated by viscosity, both via the viscous dissipation term of the mean field,  $\overline {\epsilon _m}$, and via the viscous dissipation term of the fluctuating field,
$\overline {\epsilon _m}$, and via the viscous dissipation term of the fluctuating field,  $\overline {\epsilon _k}$. We can now visualize the energy fluxes in the present configuration using the energy-box representation, as shown in figure 5.
$\overline {\epsilon _k}$. We can now visualize the energy fluxes in the present configuration using the energy-box representation, as shown in figure 5.

Figure 5. Energy-box representation for the single-phase reference case. The left box represents the MKE of the flow, while the right box identifies the TKE of the flow. Each arrow refers to a different energy flux, whose magnitude is normalized by the value of the injected power,  $\overline {\varPi _m}$, represented by a green arrow. The mean flow viscous dissipation,
$\overline {\varPi _m}$, represented by a green arrow. The mean flow viscous dissipation,  $\overline {\epsilon _m}$, and the turbulent dissipation,
$\overline {\epsilon _m}$, and the turbulent dissipation,  $\overline {\epsilon _k}$, are represented by a red arrow – leaving the left and right box, respectively – while the TKE production,
$\overline {\epsilon _k}$, are represented by a red arrow – leaving the left and right box, respectively – while the TKE production,  $\overline {P_k}$, is represented by a blue arrow.
$\overline {P_k}$, is represented by a blue arrow.
The two adjacent boxes represent the MKE (left) and TKE (right) content of the flow, respectively. Arrows are used to represent energy source (green), energy exchange (blue) and energy sink (red). The magnitude of each contribution, normalized by the power input, is given near the corresponding arrow. By looking at the left box, it is apparent that the applied power,  $\overline {\varPi _m}$, which is injected into the mean flow (MKE), is in part (
$\overline {\varPi _m}$, which is injected into the mean flow (MKE), is in part ( ${\simeq }54\,\%$) dissipated by the mean flow itself,
${\simeq }54\,\%$) dissipated by the mean flow itself,  $\overline {\epsilon _m}$, and in part (
$\overline {\epsilon _m}$, and in part ( ${\simeq }46\,\%$) transferred to TKE,
${\simeq }46\,\%$) transferred to TKE,  $\overline {P_k}$. The power transferred to TKE is then dissipated by turbulent dissipation,
$\overline {P_k}$. The power transferred to TKE is then dissipated by turbulent dissipation,  $\overline {\epsilon _k}$. When lumped together, the MKE and TKE boxes represent the energy balance of the total kinetic energy, (3.7).
$\overline {\epsilon _k}$. When lumped together, the MKE and TKE boxes represent the energy balance of the total kinetic energy, (3.7).
3.6. Energy box for the lubricated channel
We now extend the energy-box representation to the case of a lubricated channel. As done before, to derive the modified energy balance equations, we multiply the Navier–Stokes equations by the mean and fluctuating velocity field and we average the resulting equations in space and time. For the MKE, we get
 \begin{align} \frac{\textrm{D} [ \text{MKE} ]}{\textrm{D} t}&= \underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} \underbrace{ - [ \langle u_i \rangle \langle p_x \rangle ]}_{\varPi_m} -\underbrace{ \left[ \frac{\partial (\langle u'_i u'_j \rangle \langle u_i \rangle) }{\partial x_j} \right]}_{T_m} \nonumber\\ & \quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \langle \eta (\phi) \rangle \frac{\partial \langle u_i \rangle^2}{\partial x_j} \right) \right]}_{D_m} \underbrace{ - \left[ \frac{\langle \eta (\phi) \rangle}{Re_{\varPi}} \frac{\partial \langle u_i \rangle}{\partial x_j}\frac{\partial \langle u_i \rangle}{\partial x_j} \right]}_{\epsilon_m} \nonumber\\ & \quad +\underbrace{\left[ \langle u_i \rangle \frac{3 Ch}{\sqrt{8} We_\varPi} \frac{\partial \langle \tau^c_{ij} \rangle }{\partial x_j} \right]}_{\psi_m} , \end{align}
\begin{align} \frac{\textrm{D} [ \text{MKE} ]}{\textrm{D} t}&= \underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} \underbrace{ - [ \langle u_i \rangle \langle p_x \rangle ]}_{\varPi_m} -\underbrace{ \left[ \frac{\partial (\langle u'_i u'_j \rangle \langle u_i \rangle) }{\partial x_j} \right]}_{T_m} \nonumber\\ & \quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \langle \eta (\phi) \rangle \frac{\partial \langle u_i \rangle^2}{\partial x_j} \right) \right]}_{D_m} \underbrace{ - \left[ \frac{\langle \eta (\phi) \rangle}{Re_{\varPi}} \frac{\partial \langle u_i \rangle}{\partial x_j}\frac{\partial \langle u_i \rangle}{\partial x_j} \right]}_{\epsilon_m} \nonumber\\ & \quad +\underbrace{\left[ \langle u_i \rangle \frac{3 Ch}{\sqrt{8} We_\varPi} \frac{\partial \langle \tau^c_{ij} \rangle }{\partial x_j} \right]}_{\psi_m} , \end{align}
where we can observe the appearance of an additional term,  $\psi _m$, which represents the work of the surface tension forces on the mean flow.
$\psi _m$, which represents the work of the surface tension forces on the mean flow.
For the TKE, we get
 \begin{align} \frac{\textrm{D} [ \text{TKE} ]}{\textrm{D} t}&= -\underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} \underbrace{- \left[ \frac{ \partial \langle p'u'_i \rangle}{\partial x_i} \right]}_{\varPi_k} \underbrace{- \left[ \frac{1}{2}\frac{\partial \langle u'_i u'_i u'_j \rangle }{\partial x_j} \right]}_{T_k} \nonumber\\ &\quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \eta (\phi) \frac{\partial \langle u'_i u'_i \rangle}{\partial x_j} \right) \right]}_{D_k} \underbrace{- \left[ \frac{\eta(\phi)}{Re_{\varPi}} \frac{\partial u'_i }{\partial x_j}\frac{\partial u'_i }{\partial x_j} \right]}_{\epsilon_k} +\underbrace{\left[ u'_i \frac{3 Ch}{\sqrt{8} We_\varPi} \frac{\partial \tau'^{c}_{ij}}{\partial x_j} \right]}_{\psi_k} . \end{align}
\begin{align} \frac{\textrm{D} [ \text{TKE} ]}{\textrm{D} t}&= -\underbrace{ \left[ \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_k} \underbrace{- \left[ \frac{ \partial \langle p'u'_i \rangle}{\partial x_i} \right]}_{\varPi_k} \underbrace{- \left[ \frac{1}{2}\frac{\partial \langle u'_i u'_i u'_j \rangle }{\partial x_j} \right]}_{T_k} \nonumber\\ &\quad +\underbrace{\left[ \frac{1}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \eta (\phi) \frac{\partial \langle u'_i u'_i \rangle}{\partial x_j} \right) \right]}_{D_k} \underbrace{- \left[ \frac{\eta(\phi)}{Re_{\varPi}} \frac{\partial u'_i }{\partial x_j}\frac{\partial u'_i }{\partial x_j} \right]}_{\epsilon_k} +\underbrace{\left[ u'_i \frac{3 Ch}{\sqrt{8} We_\varPi} \frac{\partial \tau'^{c}_{ij}}{\partial x_j} \right]}_{\psi_k} . \end{align}
Even in this case, there is an additional term,  $\psi _k$, which represents the work exchanged, via the surface tension forces, between the interface and the fluctuating field (Li & Jaberi Reference Li and Jaberi2009).
$\psi _k$, which represents the work exchanged, via the surface tension forces, between the interface and the fluctuating field (Li & Jaberi Reference Li and Jaberi2009).
To derive the macroscopic balance equations for the lubricate channel and hence to set the corresponding energy-box representation, we integrate over the wall-normal direction the obtained MKE/TKE balance equations. For the MKE, we have
 \begin{equation} \overline{{P}_k} + \overline{\varPi_m}+ \overline{\epsilon_m} + \overline{\psi_m} =0 ,\end{equation}
\begin{equation} \overline{{P}_k} + \overline{\varPi_m}+ \overline{\epsilon_m} + \overline{\psi_m} =0 ,\end{equation}while for the TKE, we have
 \begin{equation} - \overline{{P}_k}+ \overline{\epsilon_k} + \overline{\psi_k}=0 .\end{equation}
\begin{equation} - \overline{{P}_k}+ \overline{\epsilon_k} + \overline{\psi_k}=0 .\end{equation}At this point, it is worth further elaborating on the energetics associated with the presence of an interface – an elasticity element – inside the flow. Following Joseph (Reference Joseph1976, p. 242), and under the assumption of constant and uniform surface tension, we can obtain an energy balance equation for the liquid–liquid interface (see appendix E for details)
 \begin{equation} -\frac{1}{L_x L_y} \frac{1}{We_{\varPi}} \left[ \frac{\textrm{d} A}{\textrm{d} t } \right]=\overline{\psi_m} + \overline{\psi_k} =0, \end{equation}
\begin{equation} -\frac{1}{L_x L_y} \frac{1}{We_{\varPi}} \left[ \frac{\textrm{d} A}{\textrm{d} t } \right]=\overline{\psi_m} + \overline{\psi_k} =0, \end{equation}which states that an increase of the interfacial area (i.e. an increase of the interfacial energy) must correspond to a negative work of the surface tension forces (i.e. velocity and surface tension forces act in opposite directions). In statistically steady state conditions, the average value of the interfacial area remains constant and thus
 \begin{equation} \overline{\psi_m} + \overline{\psi_k} =0,\end{equation}
\begin{equation} \overline{\psi_m} + \overline{\psi_k} =0,\end{equation}indicating that the total power – sum of mean and fluctuating contributions – absorbed/released by the surface tension forces is null (Joseph Reference Joseph1976; Aris Reference Aris1989; Dodd & Ferrante Reference Dodd and Ferrante2016). Equation (3.13) highlights the pure elastic behaviour of the interface and thus the absence of net energy dissipation associated with its deformation. Combining (3.13) with (3.10) and (3.11), we get the balance equation for the total kinetic energy
 \begin{equation} \overline{\varPi_m}+\overline{\epsilon_m} + \overline{\epsilon_k}=0 .\end{equation}
\begin{equation} \overline{\varPi_m}+\overline{\epsilon_m} + \overline{\epsilon_k}=0 .\end{equation}
Therefore, very much like the TKE production term, surface tension forces act as a transfer of energy between MKE and TKE. We anticipate here that the surface tension contribution is a sink term in the MKE equation, and a source term in the TKE equation. However, it must be also mentioned that as customary when a one-fluid approach is employed to analyse a multiphase system (Prosperetti & Tryggvason Reference Prosperetti and Tryggvason2009; Popinet Reference Popinet2018), and precisely because the surface tension forces are smeared out on a thin interfacial layer, the two interfacial contributions do not exactly match and  $|\overline {\psi _{m}}| \geq |\overline {\psi _{k}}|$. Nevertheless, for the cases presented here, this difference is always smaller (in the worst condition) than
$|\overline {\psi _{m}}| \geq |\overline {\psi _{k}}|$. Nevertheless, for the cases presented here, this difference is always smaller (in the worst condition) than  $0.4\,\%$ of the total power injected in the system. For ease of notation, in the energy-box representation reported below, the surface tension contribution is conventionally identified by the value of
$0.4\,\%$ of the total power injected in the system. For ease of notation, in the energy-box representation reported below, the surface tension contribution is conventionally identified by the value of  $\overline {\psi _{m}}$. A mechanistic view of the role of the surface tension forces on the energy transfer between the main and the lubricating layer is given in appendix F.
$\overline {\psi _{m}}$. A mechanistic view of the role of the surface tension forces on the energy transfer between the main and the lubricating layer is given in appendix F.
The energy-box representation for the lubricated channel is shown in figure 6. Each panel refers to a different viscosity ratio:  $\lambda =0.25$ (a),
$\lambda =0.25$ (a),  $\lambda =1.00$ (b) and
$\lambda =1.00$ (b) and  $\lambda =4.00$ (c). The results for
$\lambda =4.00$ (c). The results for  $\lambda =0.50$ and
$\lambda =0.50$ and  $\lambda =2.00$ are not shown since they represent only intermediate cases that do not add to the discussion. As set above, source terms are represented by green arrows, transport terms by blue arrows and sink terms by red arrows. The additional contribution of the interfacial terms is rendered by a yellow arrow connecting the MKE box to the TKE box via an additional box that represents the interface and its dynamics – an elastic component absorbing and releasing energy.
$\lambda =2.00$ are not shown since they represent only intermediate cases that do not add to the discussion. As set above, source terms are represented by green arrows, transport terms by blue arrows and sink terms by red arrows. The additional contribution of the interfacial terms is rendered by a yellow arrow connecting the MKE box to the TKE box via an additional box that represents the interface and its dynamics – an elastic component absorbing and releasing energy.

Figure 6. Ensemble-averaged energy box for the different cases of the lubricated channel:  $\lambda =0.25$ (a),
$\lambda =0.25$ (a),  $\lambda =1.00$ (b) and
$\lambda =1.00$ (b) and  $\lambda =4.00$ (c). Note that
$\lambda =4.00$ (c). Note that  $\lambda =0.50$ and
$\lambda =0.50$ and  $\lambda =2.00$ are not shown since they do not add to the present discussion. The left box refers to the MKE of the flow while the right box refers to the TKE of the flow. The power injected into the system,
$\lambda =2.00$ are not shown since they do not add to the present discussion. The left box refers to the MKE of the flow while the right box refers to the TKE of the flow. The power injected into the system,  $\overline {\varPi _m}$, is represented by a green arrow. The mean flow viscous dissipation,
$\overline {\varPi _m}$, is represented by a green arrow. The mean flow viscous dissipation,  $\overline {\epsilon _m}$, is represented by a red arrow (left box); the TKE production,
$\overline {\epsilon _m}$, is represented by a red arrow (left box); the TKE production,  $\overline {P_k}$, and the surface tension contribution,
$\overline {P_k}$, and the surface tension contribution,  $\overline {\psi _{m}}$, are represented by a blue and a yellow arrow, respectively. Finally, the turbulent dissipation,
$\overline {\psi _{m}}$, are represented by a blue and a yellow arrow, respectively. Finally, the turbulent dissipation,  $\overline {\epsilon _k}$, is represented by a red arrow (right box).
$\overline {\epsilon _k}$, is represented by a red arrow (right box).
We will discuss the case  $\lambda =1.00$ (figure 6b) first, the case
$\lambda =1.00$ (figure 6b) first, the case  $\lambda =0.25$ (figure 6a) and
$\lambda =0.25$ (figure 6a) and  $\lambda =4.00$ (figure 6c) later. This strategy helps explicating the impact of surface tension and viscosity ratio on the energy fluxes in a more systematic way, focusing on the contribution of each single property one independently to each other. For
$\lambda =4.00$ (figure 6c) later. This strategy helps explicating the impact of surface tension and viscosity ratio on the energy fluxes in a more systematic way, focusing on the contribution of each single property one independently to each other. For  $\lambda =1.00$, and compared to the single-phase case, we observe an increase of the mean flow viscous dissipation,
$\lambda =1.00$, and compared to the single-phase case, we observe an increase of the mean flow viscous dissipation,  $\overline {\epsilon _m}$, from 54 % up to 58 %. This result indicates that the reduced velocity gradients in the lubricating layer, which are due to the documented turbulence suppression therein (see § 3.1), are completely compensated by the increased velocity gradients at the bottom wall.
$\overline {\epsilon _m}$, from 54 % up to 58 %. This result indicates that the reduced velocity gradients in the lubricating layer, which are due to the documented turbulence suppression therein (see § 3.1), are completely compensated by the increased velocity gradients at the bottom wall.
In addition, and precisely because of the observed turbulence suppression in the lubricating layer, we notice a significant decrease of TKE production,  $\overline {P_k}$, which goes from 46 % (single phase) down to 39 % (
$\overline {P_k}$, which goes from 46 % (single phase) down to 39 % ( $\lambda =1.00$). The contribution of the surface tension forces,
$\lambda =1.00$). The contribution of the surface tension forces,  $\overline {\psi _{m}}$, is in this case rather small (
$\overline {\psi _{m}}$, is in this case rather small ( ${\simeq }2\,\%$). The sum of the TKE production and of the interfacial contribution gives the amount of power used to generate TKE, which is ultimately dissipated via turbulent dissipation,
${\simeq }2\,\%$). The sum of the TKE production and of the interfacial contribution gives the amount of power used to generate TKE, which is ultimately dissipated via turbulent dissipation,  $\overline {\epsilon _k}$. Examined under this perspective, the DR turns out to be induced by the surface tension forces that, blocking the wall-normal transfer of momentum, promote the laminarization of the lubricating layer (which is characterized by a small thickness, hence a small local Reynolds number) and induce a sharp decrease of the overall turbulence production. As a consequence, the power injected in the system is more efficiently used to drive the motion of the two liquid layers.
$\overline {\epsilon _k}$. Examined under this perspective, the DR turns out to be induced by the surface tension forces that, blocking the wall-normal transfer of momentum, promote the laminarization of the lubricating layer (which is characterized by a small thickness, hence a small local Reynolds number) and induce a sharp decrease of the overall turbulence production. As a consequence, the power injected in the system is more efficiently used to drive the motion of the two liquid layers.
Moving to  $\lambda =0.25$ (figure 6a), we now observe remarkable differences. The mean flow viscous dissipation,
$\lambda =0.25$ (figure 6a), we now observe remarkable differences. The mean flow viscous dissipation,  $\overline {\epsilon _m}$, reduces to 48 %, while the TKE production increases up to 49 %. Accordingly, and considering that the contribution of the interfacial term,
$\overline {\epsilon _m}$, reduces to 48 %, while the TKE production increases up to 49 %. Accordingly, and considering that the contribution of the interfacial term,  $\overline {\psi _{m}}$, remains rather small (
$\overline {\psi _{m}}$, remains rather small ( ${\simeq }3\,\%$), we notice a corresponding increase of the turbulent dissipation up to 51 %. Present results, reporting a decrease of
${\simeq }3\,\%$), we notice a corresponding increase of the turbulent dissipation up to 51 %. Present results, reporting a decrease of  $\overline {\epsilon _m}$ and an increase of
$\overline {\epsilon _m}$ and an increase of  $\overline {\epsilon _k}$, seem to be in contrast to the observed DR. Note indeed that, in the framework of the CPI approach and using passive DR techniques, DR is usually associated with an increase of
$\overline {\epsilon _k}$, seem to be in contrast to the observed DR. Note indeed that, in the framework of the CPI approach and using passive DR techniques, DR is usually associated with an increase of  $\overline {\epsilon _m}$ and a decrease of
$\overline {\epsilon _m}$ and a decrease of  $\overline {\epsilon _k}$ (although, strictly speaking, this latter conclusion is based on the specific procedure used in Gatti et al. (Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018) to model the wall-normal behaviour of the wall-shear stress). To reconcile present results with previous predictions, an extended version of the energy-box technique –as will be discussed in § 3.8 – must be introduced.
$\overline {\epsilon _k}$ (although, strictly speaking, this latter conclusion is based on the specific procedure used in Gatti et al. (Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018) to model the wall-normal behaviour of the wall-shear stress). To reconcile present results with previous predictions, an extended version of the energy-box technique –as will be discussed in § 3.8 – must be introduced.
For  $\lambda =4.00$ (figure 6c), the energy box is similar to that observed for
$\lambda =4.00$ (figure 6c), the energy box is similar to that observed for  $\lambda =1.00$ (figure 6a), with an increase of the mean flow dissipation up to 57 %, and a decrease of the TKE production down to 38 % – again due to the turbulence suppression in the lubricating layer. Interestingly, we also report a slight increase of the contribution of the interfacial term,
$\lambda =1.00$ (figure 6a), with an increase of the mean flow dissipation up to 57 %, and a decrease of the TKE production down to 38 % – again due to the turbulence suppression in the lubricating layer. Interestingly, we also report a slight increase of the contribution of the interfacial term,  $\overline {\psi _{m}}$, which becomes
$\overline {\psi _{m}}$, which becomes  ${\simeq }5\,\%$. This latter observation seems to be related to the dynamics of interfacial waves: when the viscosity of the lubricating layer is increased, the larger shear rate induces a larger deformation of the interface and this leads to a larger
${\simeq }5\,\%$. This latter observation seems to be related to the dynamics of interfacial waves: when the viscosity of the lubricating layer is increased, the larger shear rate induces a larger deformation of the interface and this leads to a larger  $\overline {\psi _{m}}$ (see also appendix F). The increase of
$\overline {\psi _{m}}$ (see also appendix F). The increase of  $\overline {\psi _{m}}$ (in magnitude) is also reflected by the release of TKE near the interface: increasing the viscosity of the lubricating layer, the liquid–liquid interface becomes less and less compliant and behaves almost like a solid wavy interface that promotes the generation of velocity fluctuations (Breugem, Boersma & Uittenbogaard Reference Breugem, Boersma and Uittenbogaard2006; Rosti & Brandt Reference Rosti and Brandt2017) (see also the higher TKE levels close to the interface – on the primary layer side – shown in figure 1f). Overall, for
$\overline {\psi _{m}}$ (in magnitude) is also reflected by the release of TKE near the interface: increasing the viscosity of the lubricating layer, the liquid–liquid interface becomes less and less compliant and behaves almost like a solid wavy interface that promotes the generation of velocity fluctuations (Breugem, Boersma & Uittenbogaard Reference Breugem, Boersma and Uittenbogaard2006; Rosti & Brandt Reference Rosti and Brandt2017) (see also the higher TKE levels close to the interface – on the primary layer side – shown in figure 1f). Overall, for  $\lambda =4.00$, the analysis of the energy budgets seems to indicate DR (increasing
$\lambda =4.00$, the analysis of the energy budgets seems to indicate DR (increasing  $\overline {\epsilon _m}$ and decreasing
$\overline {\epsilon _m}$ and decreasing  $\overline {\epsilon _k}$), which it is in fact not observed in practice (see § 3.2).
$\overline {\epsilon _k}$), which it is in fact not observed in practice (see § 3.2).
Altogether, these results for  $\lambda \ne 1$ show that the original energy-box technique, when applied straightforwardly to a multiphase flow, leads to conclusions which seem to be in contrast with previous findings (Gatti et al. Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018). To overcome these limitations, the energy-box technique must be extended – and a phase discrimination procedure must be included – to account for the multiphase nature of the system. This is the objective of the next sections.
$\lambda \ne 1$ show that the original energy-box technique, when applied straightforwardly to a multiphase flow, leads to conclusions which seem to be in contrast with previous findings (Gatti et al. Reference Gatti, Cimarelli, Hasegawa, Frohnapfel and Quadrio2018). To overcome these limitations, the energy-box technique must be extended – and a phase discrimination procedure must be included – to account for the multiphase nature of the system. This is the objective of the next sections.
3.7. Virtually lubricated channel
Before proceeding with the derivation of the phase-averaged approach applied to the lubricated channel, and precisely to evaluate a representative reference case against which current results can be conveniently compared, we introduce the concept of a virtually lubricated channel. A virtually lubricated channel is a single-phase flow that is a posteriori split – using a virtual interface located at a distance  $0.15h$ far from the top wall. This virtual interface has no surface tension and therefore does not have any effects on the velocity field, since the flow is obtained by the solution of the Navier–Stokes equations in a single-phase system with uniform density and viscosity. The energy-box representation for the virtually lubricated channel is given in figure 7. Since the different terms refer now to a specific subregion of the domain (lubricating or primary layer), an additional subscript is used to distinguish between the virtual lubricating layer – subscript 1 – and the virtual primary layer – subscript 2 – contributions. Note also the presence of dark blue arrows, which identify the energy fluxes (transport/redistribution terms, referred to as
$0.15h$ far from the top wall. This virtual interface has no surface tension and therefore does not have any effects on the velocity field, since the flow is obtained by the solution of the Navier–Stokes equations in a single-phase system with uniform density and viscosity. The energy-box representation for the virtually lubricated channel is given in figure 7. Since the different terms refer now to a specific subregion of the domain (lubricating or primary layer), an additional subscript is used to distinguish between the virtual lubricating layer – subscript 1 – and the virtual primary layer – subscript 2 – contributions. Note also the presence of dark blue arrows, which identify the energy fluxes (transport/redistribution terms, referred to as  $\overline {F_m}$ and
$\overline {F_m}$ and  $\overline {F_k}$) exchanged between the two virtual fluid layers – redistribution terms are indeed null only when integrated over the entire volume.
$\overline {F_k}$) exchanged between the two virtual fluid layers – redistribution terms are indeed null only when integrated over the entire volume.

Figure 7. Energy box for the virtually lubricated channel, namely a single-phase case virtually separated into a lubricating and a primary layer. The virtual separation is located at the nominal position of the interface (distance  $0.15~\textrm {h}$ from top wall). The left dashed box represents the MKE of the flow while the right box represents the TKE of the flow. Inside each dashed box, the top and bottom rectangles identify the (virtual) lubricating and primary layers, respectively. Each arrow refers to a different energy flux, whose magnitude is reported (near the arrow) normalized by the power input value. Compared to the previous energy boxes (ensemble averaged), an additional subscript is used to distinguish between the lubricating and primary layer contributions. The power injected in the system,
$0.15~\textrm {h}$ from top wall). The left dashed box represents the MKE of the flow while the right box represents the TKE of the flow. Inside each dashed box, the top and bottom rectangles identify the (virtual) lubricating and primary layers, respectively. Each arrow refers to a different energy flux, whose magnitude is reported (near the arrow) normalized by the power input value. Compared to the previous energy boxes (ensemble averaged), an additional subscript is used to distinguish between the lubricating and primary layer contributions. The power injected in the system,  $\overline {\varPi _m}$, is represented by a green arrow; the mean flow viscous dissipations,
$\overline {\varPi _m}$, is represented by a green arrow; the mean flow viscous dissipations,  $\overline {\epsilon _{m,1}}$ and
$\overline {\epsilon _{m,1}}$ and  $\overline {\epsilon _{m,2}}$, by red arrows (left), and the TKE production terms,
$\overline {\epsilon _{m,2}}$, by red arrows (left), and the TKE production terms,  $\overline {P_{k,1}}$ and
$\overline {P_{k,1}}$ and  $\overline {P_{k,2}}$, by blue arrows. Finally, the turbulent dissipations,
$\overline {P_{k,2}}$, by blue arrows. Finally, the turbulent dissipations,  $\overline {\epsilon _{k,1}}$ and
$\overline {\epsilon _{k,1}}$ and  $\overline {\epsilon _{k,2}}$, are represented with red arrows (right). Note the appearance of dark blue arrows, identifying energy fluxes exchanged between the primary and the lubricating layer,
$\overline {\epsilon _{k,2}}$, are represented with red arrows (right). Note the appearance of dark blue arrows, identifying energy fluxes exchanged between the primary and the lubricating layer,  $\overline {F_m}$ and
$\overline {F_m}$ and  $\overline {F_k}$.
$\overline {F_k}$.
By looking at figure 7 we notice that the viscous dissipation of MKE has a similar value in both layers,  $\overline {\epsilon _{m,1}}\simeq \overline {\epsilon _{m,2}}$, while there is a sharp difference in the viscous dissipation of TKE,
$\overline {\epsilon _{m,1}}\simeq \overline {\epsilon _{m,2}}$, while there is a sharp difference in the viscous dissipation of TKE,  $\overline {\epsilon _{k,1}} \ne \overline {\epsilon _{k,2}}$. This representation gives a clearcut idea of the energy that is transferred and dissipated in the region virtually corresponding to the primary layer of the channel, and favours the introduction of an energy transfer efficiency, which we conveniently define as
$\overline {\epsilon _{k,1}} \ne \overline {\epsilon _{k,2}}$. This representation gives a clearcut idea of the energy that is transferred and dissipated in the region virtually corresponding to the primary layer of the channel, and favours the introduction of an energy transfer efficiency, which we conveniently define as
 \begin{equation} \mathcal{H}_{sp}=\frac{\overline{\epsilon_{m,2}}}{( \overline{\epsilon_{m,2}}+ \overline{\epsilon_{k,2}})}=0.456. \end{equation}
\begin{equation} \mathcal{H}_{sp}=\frac{\overline{\epsilon_{m,2}}}{( \overline{\epsilon_{m,2}}+ \overline{\epsilon_{k,2}})}=0.456. \end{equation}This parameter represents the ratio between the mean energy dissipation in the primary layer, and the total energy dissipation, i.e. after deduction of the energy transferred to the lubricating layer, in the primary layer.
In the following, we will make specific reference to this configuration.
3.8. Phase-averaged energy box for viscosity stratified flow
Based on the above discussion (see § 3.6), it is apparent that the original energy-box technique must be properly extended to analyse the case of a lubricated channel. Because of the multiphase nature of the flow, an averaging procedure applied to the entire volume – such as the one employed above – does not provide a separation between the primary and the lubricating layer contributions and, more importantly, does not grant access to the evaluation of the energy fluxes between these two layers.
To investigate these aspects, we compute the energy budget for each layer in isolation (Dodd & Ferrante Reference Dodd and Ferrante2016; Rosti et al. Reference Rosti, Ge, Jain, Dodd and Brandt2019). The obtained results are then represented in an opportunely modified energy box. To derive the phase-averaged MKE/TKE balance equations, we use the phase-field variable  $\phi$ and we define a local concentration,
$\phi$ and we define a local concentration,  $0 \le c_l \le 1$, for each liquid layer
$0 \le c_l \le 1$, for each liquid layer
 \begin{equation} c_1=\frac{1+\phi}{2}, \quad c_2=\frac{1-\phi}{2}, \end{equation}
\begin{equation} c_1=\frac{1+\phi}{2}, \quad c_2=\frac{1-\phi}{2}, \end{equation}
where, as anticipated before, the subscript  $l=1,2$ is used to identify the lubricating and primary layer local concentrations, respectively. Multiplying MKE and TKE balance equations by the two local concentrations, and averaging in space (
$l=1,2$ is used to identify the lubricating and primary layer local concentrations, respectively. Multiplying MKE and TKE balance equations by the two local concentrations, and averaging in space ( $x,y$) and in time as explained in § 3.6, we obtain the energy balance equations for each liquid layer. In particular, the phase-averaged MKE for each layer
$x,y$) and in time as explained in § 3.6, we obtain the energy balance equations for each liquid layer. In particular, the phase-averaged MKE for each layer  $l$,
$l$,  $[\text {MKE}]_l$ – counterpart of (3.8) – becomes
$[\text {MKE}]_l$ – counterpart of (3.8) – becomes
 \begin{align} \frac{\textrm{D} [ \text{MKE} ]_l}{\textrm{D} t}&= \underbrace{ \left[ c_l \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_{k,l}} \underbrace{ - \left[ c_l \langle u_i \rangle \left\langle p_x \right\rangle \right]}_{\varPi_{m,l}} -\underbrace{ \left[ c_l \frac{\partial (\langle u'_i u'_j \rangle \langle u_i \rangle) }{\partial x_j} \right]}_{T_{m,l}} \nonumber\\ &\quad +\underbrace{\left[ \frac{c_l}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \langle \eta (\phi) \rangle \frac{\partial \langle u_i \rangle^2}{\partial x_j} \right) \right]}_{D_{m,l}} \underbrace{ - \left[ c_l \frac{\langle \eta (\phi) \rangle}{Re_{\varPi}} \frac{\partial \langle u_i \rangle}{\partial x_j}\frac{\partial \langle u_i \rangle}{\partial x_j} \right]}_{\epsilon_{m,l}} \nonumber\\ &\quad +\underbrace{\left[ c_l \langle u_i \rangle \frac{3 Ch}{\sqrt{8}We_\varPi} \frac{\partial \langle \tau^c_{ij} \rangle}{\partial x_j} \right]}_{\psi_{m,l}} . \end{align}
\begin{align} \frac{\textrm{D} [ \text{MKE} ]_l}{\textrm{D} t}&= \underbrace{ \left[ c_l \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_{k,l}} \underbrace{ - \left[ c_l \langle u_i \rangle \left\langle p_x \right\rangle \right]}_{\varPi_{m,l}} -\underbrace{ \left[ c_l \frac{\partial (\langle u'_i u'_j \rangle \langle u_i \rangle) }{\partial x_j} \right]}_{T_{m,l}} \nonumber\\ &\quad +\underbrace{\left[ \frac{c_l}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \langle \eta (\phi) \rangle \frac{\partial \langle u_i \rangle^2}{\partial x_j} \right) \right]}_{D_{m,l}} \underbrace{ - \left[ c_l \frac{\langle \eta (\phi) \rangle}{Re_{\varPi}} \frac{\partial \langle u_i \rangle}{\partial x_j}\frac{\partial \langle u_i \rangle}{\partial x_j} \right]}_{\epsilon_{m,l}} \nonumber\\ &\quad +\underbrace{\left[ c_l \langle u_i \rangle \frac{3 Ch}{\sqrt{8}We_\varPi} \frac{\partial \langle \tau^c_{ij} \rangle}{\partial x_j} \right]}_{\psi_{m,l}} . \end{align}
Similarly, the phase-averaged TKE for each liquid layer  $l$,
$l$,  $[\text {TKE}]_l$ – counterpart of (3.9) – becomes
$[\text {TKE}]_l$ – counterpart of (3.9) – becomes
 \begin{align} \frac{\textrm{D} [ \text{TKE} ]_l}{\textrm{D} t}&= -\underbrace{ \left[ c_l \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_{k,l}} \underbrace{- \left[ c_l \frac{ \partial \langle p'u'_i \rangle}{\partial x_i} \right]}_{\varPi_{k,l}} \underbrace{- \left[ \frac{c_l}{2}\frac{\partial \langle u'_i u'_i u'_j \rangle }{\partial x_j} \right]}_{T_{k,l}} \nonumber\\ &\quad +\underbrace{\left[ \frac{c_l}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \eta (\phi) \frac{\partial \langle u'_i u'_i \rangle}{\partial x_j} \right) \right]}_{D_{k,l}} \underbrace{- \left[ c_l \frac{\eta(\phi)}{Re_{\varPi}} \frac{\partial u'_i }{\partial x_j}\frac{\partial u'_i }{\partial x_j} \right]}_{\epsilon_{k,l}} +\underbrace{\left[ c_l u'_i \frac{3Ch}{\sqrt{8}We_\varPi} \frac{\partial \tau'^c_{ij}}{\partial x_j} \right]}_{\psi_{k,l}} . \end{align}
\begin{align} \frac{\textrm{D} [ \text{TKE} ]_l}{\textrm{D} t}&= -\underbrace{ \left[ c_l \langle u'_i u'_j \rangle \frac{\partial \langle u_i \rangle }{\partial x_j} \right]}_{P_{k,l}} \underbrace{- \left[ c_l \frac{ \partial \langle p'u'_i \rangle}{\partial x_i} \right]}_{\varPi_{k,l}} \underbrace{- \left[ \frac{c_l}{2}\frac{\partial \langle u'_i u'_i u'_j \rangle }{\partial x_j} \right]}_{T_{k,l}} \nonumber\\ &\quad +\underbrace{\left[ \frac{c_l}{2Re_{\varPi}} \frac{\partial }{\partial x_j} \left( \eta (\phi) \frac{\partial \langle u'_i u'_i \rangle}{\partial x_j} \right) \right]}_{D_{k,l}} \underbrace{- \left[ c_l \frac{\eta(\phi)}{Re_{\varPi}} \frac{\partial u'_i }{\partial x_j}\frac{\partial u'_i }{\partial x_j} \right]}_{\epsilon_{k,l}} +\underbrace{\left[ c_l u'_i \frac{3Ch}{\sqrt{8}We_\varPi} \frac{\partial \tau'^c_{ij}}{\partial x_j} \right]}_{\psi_{k,l}} . \end{align}
From a physical point of view, the meaning of the different MKE/TKE terms remains unchanged. However, the contributions refer now to a specific layer; for instance,  $P_{k,1}$ is the TKE production in the lubricating layer, while
$P_{k,1}$ is the TKE production in the lubricating layer, while  $P_{k,2}$ is the TKE production in the primary layer.
$P_{k,2}$ is the TKE production in the primary layer.
Upon integration of the MKE/TKE balance equations along the wall-normal direction, a set of macroscopic balance equations is obtained for each liquid layer. For the MKE, we get
 \begin{gather} \overline{P_{k,1}} + \overline{\varPi_{m,1}} + \overline{T_{m,1} } + \overline{D_{m,1}} + \overline{\epsilon_{m,1}} + \overline{\psi_{m,1}} =0, \end{gather}
\begin{gather} \overline{P_{k,1}} + \overline{\varPi_{m,1}} + \overline{T_{m,1} } + \overline{D_{m,1}} + \overline{\epsilon_{m,1}} + \overline{\psi_{m,1}} =0, \end{gather} \begin{gather}\overline{P_{k,2}} + \overline{\varPi_{m,2}} + \overline{T_{m,2}} + \overline{D_{m,2}} + \overline{\epsilon_{m,2}} +\overline{ \psi_{m,2}} =0, \end{gather}
\begin{gather}\overline{P_{k,2}} + \overline{\varPi_{m,2}} + \overline{T_{m,2}} + \overline{D_{m,2}} + \overline{\epsilon_{m,2}} +\overline{ \psi_{m,2}} =0, \end{gather}
in the lubricating and in the primary layer, respectively. We recall that, compared to (3.10), the integral of the work done by the Reynolds stress,  $\overline {T_{m,l}}$, and the integral of the viscous diffusion,
$\overline {T_{m,l}}$, and the integral of the viscous diffusion,  $\overline {D_{m,l}}$, is not anymore zero since these contributions are now evaluated only in a portion of the domain (Dodd & Ferrante Reference Dodd and Ferrante2016; Rosti et al. Reference Rosti, Ge, Jain, Dodd and Brandt2019). Combining (3.19) and (3.20), and taking into account that the contribution of the internal transport terms – which represent the energy fluxes between the two phases – cancels out, we have
$\overline {D_{m,l}}$, is not anymore zero since these contributions are now evaluated only in a portion of the domain (Dodd & Ferrante Reference Dodd and Ferrante2016; Rosti et al. Reference Rosti, Ge, Jain, Dodd and Brandt2019). Combining (3.19) and (3.20), and taking into account that the contribution of the internal transport terms – which represent the energy fluxes between the two phases – cancels out, we have
 \begin{equation} \underbrace{\overline{P_{k,1} }+ \overline{P_{k,2}}}_{\overline{P_k}} + \underbrace{\overline{\varPi_{m,1}}+ \overline{\varPi_{m,2}}}_{\overline{\varPi_m}}+ \underbrace{ \overline{\epsilon_{m,1}} + \overline{\epsilon_{m,2}}}_{\overline{\epsilon_{m}}} + \underbrace{\overline{\psi_{m,1}}+ \overline{ \psi_{m,2}}}_{\overline{\psi_m}} =0 , \end{equation}
\begin{equation} \underbrace{\overline{P_{k,1} }+ \overline{P_{k,2}}}_{\overline{P_k}} + \underbrace{\overline{\varPi_{m,1}}+ \overline{\varPi_{m,2}}}_{\overline{\varPi_m}}+ \underbrace{ \overline{\epsilon_{m,1}} + \overline{\epsilon_{m,2}}}_{\overline{\epsilon_{m}}} + \underbrace{\overline{\psi_{m,1}}+ \overline{ \psi_{m,2}}}_{\overline{\psi_m}} =0 , \end{equation}
from which, employing mass conservation  $c_1+c_2=1$, we recover the total MKE balance, (3.8).
$c_1+c_2=1$, we recover the total MKE balance, (3.8).
In a similar fashion, for the TKE, we get
 \begin{gather} -\overline{P_{k,1}} + \overline{\varPi_{k,1}} + \overline{T_{k,1} } + \overline{D_{k,1}} + \overline{\epsilon_{k,1}} + \overline{\psi_{k,1}} =0, \end{gather}
\begin{gather} -\overline{P_{k,1}} + \overline{\varPi_{k,1}} + \overline{T_{k,1} } + \overline{D_{k,1}} + \overline{\epsilon_{k,1}} + \overline{\psi_{k,1}} =0, \end{gather} \begin{gather}-\overline{P_{k,2}} + \overline{\varPi_{k,2}} + \overline{T_{k,2}} + \overline{D_{k,2}} + \overline{\epsilon_{k,2}} +\overline{ \psi_{k,2}} =0, \end{gather}
\begin{gather}-\overline{P_{k,2}} + \overline{\varPi_{k,2}} + \overline{T_{k,2}} + \overline{D_{k,2}} + \overline{\epsilon_{k,2}} +\overline{ \psi_{k,2}} =0, \end{gather}
in the lubricating and in the primary layer, respectively. Even in this case, the integral of the pressure diffusion,  $\overline {\varPi _{k,l}}$, turbulent diffusion,
$\overline {\varPi _{k,l}}$, turbulent diffusion,  $\overline {T_{k,l}}$, and viscous diffusion,
$\overline {T_{k,l}}$, and viscous diffusion,  $\overline {D_{m,l}}$, is not anymore zero since it is evaluated only in a portion of the domain. Naturally, combining (3.22) and (3.23), these contributions cancel out and we have
$\overline {D_{m,l}}$, is not anymore zero since it is evaluated only in a portion of the domain. Naturally, combining (3.22) and (3.23), these contributions cancel out and we have
 \begin{equation} \underbrace{-\overline{P_{k,1} }- \overline{P_{k,2}}}_{- \overline{P_k}} + \underbrace{ \overline{\epsilon_{k,1}} + \overline{\epsilon_{k,2}}}_{\overline{\epsilon_{k}}} + \underbrace{\overline{\psi_{k,1}}+ \overline{ \psi_{k,2}}}_{\overline{\psi_k}} =0 , \end{equation}
\begin{equation} \underbrace{-\overline{P_{k,1} }- \overline{P_{k,2}}}_{- \overline{P_k}} + \underbrace{ \overline{\epsilon_{k,1}} + \overline{\epsilon_{k,2}}}_{\overline{\epsilon_{k}}} + \underbrace{\overline{\psi_{k,1}}+ \overline{ \psi_{k,2}}}_{\overline{\psi_k}} =0 , \end{equation}which represents the phase-averaged counterpart of the global TKE balance, (3.9).
The resulting energy-box representation is given in figure 8. Each panel refers to a different case:  $\lambda =0.25$ (a),
$\lambda =0.25$ (a),  $\lambda =1.00$ (b) and
$\lambda =1.00$ (b) and  $\lambda =4.00$ (c). As done for figure 6, the cases
$\lambda =4.00$ (c). As done for figure 6, the cases  $\lambda = 0.50$ and
$\lambda = 0.50$ and  $\lambda = 2.00$ are not shown since they are intermediate configurations that do not add to the discussion. For completeness, we briefly recall the convention used in this representation. The left dashed rectangle refers to the MKE flow content, while the right dashed rectangle refers to the TKE flow content. The surface tension contribution is represented by a yellow arrow connecting the MKE box to the TKE box via an additional box (interface). The power input, which is in part injected into the primary layer, and in part injected into the lubricating layer, is represented by green arrows. The mean flow and turbulent dissipations of each layer are represented by red arrows, while the TKE production terms are represented by blue arrows. Vertical arrows, coloured in dark blue, connect the lubricating and primary layer boxes and identify the mean and TKE fluxes between the two phases (Dodd & Ferrante Reference Dodd and Ferrante2016; Rosti et al. Reference Rosti, Ge, Jain, Dodd and Brandt2019). Specifically, for the MKE box (left), these arrows account for the work done by the Reynolds stress and the MKE viscous diffusion – lumped together into the quantity
$\lambda = 2.00$ are not shown since they are intermediate configurations that do not add to the discussion. For completeness, we briefly recall the convention used in this representation. The left dashed rectangle refers to the MKE flow content, while the right dashed rectangle refers to the TKE flow content. The surface tension contribution is represented by a yellow arrow connecting the MKE box to the TKE box via an additional box (interface). The power input, which is in part injected into the primary layer, and in part injected into the lubricating layer, is represented by green arrows. The mean flow and turbulent dissipations of each layer are represented by red arrows, while the TKE production terms are represented by blue arrows. Vertical arrows, coloured in dark blue, connect the lubricating and primary layer boxes and identify the mean and TKE fluxes between the two phases (Dodd & Ferrante Reference Dodd and Ferrante2016; Rosti et al. Reference Rosti, Ge, Jain, Dodd and Brandt2019). Specifically, for the MKE box (left), these arrows account for the work done by the Reynolds stress and the MKE viscous diffusion – lumped together into the quantity  $\overline {F_m}$ – while, for the TKE box (right), they account for the energy fluxes due to pressure, viscous and turbulent diffusion – lumped together into the quantity
$\overline {F_m}$ – while, for the TKE box (right), they account for the energy fluxes due to pressure, viscous and turbulent diffusion – lumped together into the quantity  $\overline {F_k}$.
$\overline {F_k}$.

Figure 8. Phase-averaged energy boxes for the different cases of lubricated channel:  $\lambda =0.25$ (a),
$\lambda =0.25$ (a),  $\lambda =1.00$ (b) and
$\lambda =1.00$ (b) and  $\lambda =4.00$ (c). The left dashed box represents the MKE of the flow while the right one represents the TKE of the flow. Inside each dashed box, the top and bottom rectangles identify the lubricating and the primary layer, respectively. The power injected in the system,
$\lambda =4.00$ (c). The left dashed box represents the MKE of the flow while the right one represents the TKE of the flow. Inside each dashed box, the top and bottom rectangles identify the lubricating and the primary layer, respectively. The power injected in the system,  $\overline {\varPi _m}$, is represented by a green arrow. The mean flow viscous dissipations,
$\overline {\varPi _m}$, is represented by a green arrow. The mean flow viscous dissipations,  $\overline {\epsilon _{m,1}}$ and
$\overline {\epsilon _{m,1}}$ and  $\overline {\epsilon _{m,2}}$, and turbulent dissipations,
$\overline {\epsilon _{m,2}}$, and turbulent dissipations,  $\overline {\epsilon _{k,1}}$ and
$\overline {\epsilon _{k,1}}$ and  $\overline {\epsilon _{k,2}}$, are represented by red arrows, and the TKE production terms,
$\overline {\epsilon _{k,2}}$, are represented by red arrows, and the TKE production terms,  $\overline {P_{k,2}}$ and
$\overline {P_{k,2}}$ and  $\overline {P_{k,1}}$, by blue arrows. Finally, surface tension contribution,
$\overline {P_{k,1}}$, by blue arrows. Finally, surface tension contribution,  $\overline {\psi _{m}}$, is represented by a yellow arrow. The dark blue arrows linking the lubricating and the primary layer boxes (inside each dashed box) represent the energy fluxes of MKE and TKE exchanged between the two layers,
$\overline {\psi _{m}}$, is represented by a yellow arrow. The dark blue arrows linking the lubricating and the primary layer boxes (inside each dashed box) represent the energy fluxes of MKE and TKE exchanged between the two layers,  $\overline {F_m}$ and
$\overline {F_m}$ and  $\overline {F_k}$, respectively.
$\overline {F_k}$, respectively.
As was explicitly discussed at the end of § 3.6, the value of the energy fluxes in the primary and in the lubricating layer cannot be directly compared with that observed in the canonical single-phase flow, since the latter is characterized by a different volume. Yet, they can be conveniently compared to those of the virtually lubricated channel, the conceptual framework in which the virtual (primary and lubricating) layers are characterized by the same nominal volume as the actual layers in the lubricated channel.
We consider first the case  $\lambda =1.00$ (figure 8b). Not surprisingly, most of the injected energy goes into the primary layer (
$\lambda =1.00$ (figure 8b). Not surprisingly, most of the injected energy goes into the primary layer ( ${\simeq }96\,\%$) while only a small amount of it goes into the lubricating layer (
${\simeq }96\,\%$) while only a small amount of it goes into the lubricating layer ( ${\simeq }4\,\%$). Focusing on the primary layer, we observe that a larger proportion of the injected power is dissipated by the mean flow (
${\simeq }4\,\%$). Focusing on the primary layer, we observe that a larger proportion of the injected power is dissipated by the mean flow ( ${\simeq }41\,\%$). As expected in case of sustained turbulence, production of TKE is also large (
${\simeq }41\,\%$). As expected in case of sustained turbulence, production of TKE is also large ( ${\simeq }38\,\%$) and is entirely dissipated by viscous dissipation (
${\simeq }38\,\%$) and is entirely dissipated by viscous dissipation ( ${\simeq }39\,\%$). In the lubricating layer the situation changes completely. While the mean flow dissipation remains very important (
${\simeq }39\,\%$). In the lubricating layer the situation changes completely. While the mean flow dissipation remains very important ( ${\simeq }17\,\%$), the production of TKE drops down drastically (
${\simeq }17\,\%$), the production of TKE drops down drastically ( ${\simeq }1\,\%$), as does TKE viscous dissipation (
${\simeq }1\,\%$), as does TKE viscous dissipation ( ${\simeq }2\,\%$). These results are consistent with the turbulence suppression mechanism observed in the lubricating layer (see also figures 1d and 2d). The contribution of the interfacial terms is rather small (
${\simeq }2\,\%$). These results are consistent with the turbulence suppression mechanism observed in the lubricating layer (see also figures 1d and 2d). The contribution of the interfacial terms is rather small ( ${\simeq }2\,\%$), whereas the contribution of the energy redistribution terms (dark blue arrows), in particular for the MKE, is not negligible (
${\simeq }2\,\%$), whereas the contribution of the energy redistribution terms (dark blue arrows), in particular for the MKE, is not negligible ( ${\simeq }8\,\%$). These observations confirm our previous intuition that, for
${\simeq }8\,\%$). These observations confirm our previous intuition that, for  $\lambda =1.00$ and thanks to the action of the surface tension forces, the lubricating layer becomes laminar and reduces the irreversible energy dissipation. As a consequence, a larger amount of energy is available for the transportation of the primary layer (surface tension-driven DR).
$\lambda =1.00$ and thanks to the action of the surface tension forces, the lubricating layer becomes laminar and reduces the irreversible energy dissipation. As a consequence, a larger amount of energy is available for the transportation of the primary layer (surface tension-driven DR).
For the case  $\lambda =0.25$ (figure 8a), and compared to the case
$\lambda =0.25$ (figure 8a), and compared to the case  $\lambda =1.00$, in the primary layer we do not observe significant differences in the energy transfer rates, which appear only slightly reduced. What does change significantly is the energy transfer in the lubricating layer, which is characterized by slightly smaller mean flow dissipation (
$\lambda =1.00$, in the primary layer we do not observe significant differences in the energy transfer rates, which appear only slightly reduced. What does change significantly is the energy transfer in the lubricating layer, which is characterized by slightly smaller mean flow dissipation ( ${\simeq }13\,\%$) but a definitely larger TKE production (
${\simeq }13\,\%$) but a definitely larger TKE production ( ${\simeq }14\,\%$), and TKE viscous dissipation (
${\simeq }14\,\%$), and TKE viscous dissipation ( ${\simeq }14\,\%$). This clearly indicates a sustained turbulence activity in the lubricating layer. As for the case
${\simeq }14\,\%$). This clearly indicates a sustained turbulence activity in the lubricating layer. As for the case  $\lambda =1.00$, the interfacial term is rather small (
$\lambda =1.00$, the interfacial term is rather small ( ${\simeq }3\,\%$), whereas the energy redistribution – in particular for the MKE – becomes progressively significant (
${\simeq }3\,\%$), whereas the energy redistribution – in particular for the MKE – becomes progressively significant ( ${\simeq }15\,\%$). This latter observation, which is particularly important, suggests that a considerable fraction of the total energy is removed from the primary layer, and spent into the lubricating layer. In this case, DR decreases compared to
${\simeq }15\,\%$). This latter observation, which is particularly important, suggests that a considerable fraction of the total energy is removed from the primary layer, and spent into the lubricating layer. In this case, DR decreases compared to  $\lambda =1.00$.
$\lambda =1.00$.
We turn now to the case  $\lambda =4.00$ (figure 8c). While in the primary layer the dynamics does not change much, and the amount of mean flow dissipation, TKE production and TKE dissipation are only slightly different compared to
$\lambda =4.00$ (figure 8c). While in the primary layer the dynamics does not change much, and the amount of mean flow dissipation, TKE production and TKE dissipation are only slightly different compared to  $\lambda =0.25$, in the lubricating layer the situation changes drastically, becoming somehow similar to that observed for
$\lambda =0.25$, in the lubricating layer the situation changes drastically, becoming somehow similar to that observed for  $\lambda =1.00$. Indeed, and consistently with a situation in which turbulence is almost entirely suppressed, in the lubricating layer the mean flow dissipation is very large (
$\lambda =1.00$. Indeed, and consistently with a situation in which turbulence is almost entirely suppressed, in the lubricating layer the mean flow dissipation is very large ( ${\simeq }25\,\%$) while the TKE production and dissipation are very small (
${\simeq }25\,\%$) while the TKE production and dissipation are very small ( ${\simeq }1\,\%$) and (
${\simeq }1\,\%$) and ( ${\simeq }4\,\%$), respectively. The interfacial terms are only slightly larger (
${\simeq }4\,\%$), respectively. The interfacial terms are only slightly larger ( ${\simeq }5\,\%$), whereas the energy redistribution – in particular for the MKE – becomes important (
${\simeq }5\,\%$), whereas the energy redistribution – in particular for the MKE – becomes important ( ${\simeq }16\,\%$). Despite the fact that the distribution of energy fluxes for
${\simeq }16\,\%$). Despite the fact that the distribution of energy fluxes for  $\lambda =4.00$ is seemingly close to that for
$\lambda =4.00$ is seemingly close to that for  $\lambda =1.00$, the final outcome of these two cases is completely different, with the case
$\lambda =1.00$, the final outcome of these two cases is completely different, with the case  $\lambda =4.00$ being characterized by drag increase rather than DR.
$\lambda =4.00$ being characterized by drag increase rather than DR.
A physically sound interpretation of these results can only be given upon comparison with the virtually lubricated channel (see figure 7 and corresponding discussion). Recalling the transfer efficiency parameter defined before,  $\mathcal {H}=\epsilon _{m,2}/( \epsilon _{m,2}+ \epsilon _{k,2})$, and applying it for
$\mathcal {H}=\epsilon _{m,2}/( \epsilon _{m,2}+ \epsilon _{k,2})$, and applying it for  $\lambda =1.00$,
$\lambda =1.00$,  $\lambda =0.25$ and
$\lambda =0.25$ and  $\lambda =4.00$, we obtain:
$\lambda =4.00$, we obtain:  $\mathcal {H}_{\lambda =1.00}/ \mathcal {H}_{sp}=1.11$,
$\mathcal {H}_{\lambda =1.00}/ \mathcal {H}_{sp}=1.11$,  $\mathcal {H}_{\lambda =0.25}/ \mathcal {H}_{sp}=1.06$ and
$\mathcal {H}_{\lambda =0.25}/ \mathcal {H}_{sp}=1.06$ and  $\mathcal {H}_{\lambda =4.00}/ \mathcal {H}_{sp}=0.99$. Written in these terms, previous results can be interpreted as follows. For
$\mathcal {H}_{\lambda =4.00}/ \mathcal {H}_{sp}=0.99$. Written in these terms, previous results can be interpreted as follows. For  $\lambda =1.00$, and precisely because of the combined effect of the turbulence suppression in the lubricating layer, and of the small energy fraction transferred from the primary to the lubricating layer, the amount of energy that remains available in the primary layer is larger compared to the virtually lubricated channel. DR is therefore observed. For
$\lambda =1.00$, and precisely because of the combined effect of the turbulence suppression in the lubricating layer, and of the small energy fraction transferred from the primary to the lubricating layer, the amount of energy that remains available in the primary layer is larger compared to the virtually lubricated channel. DR is therefore observed. For  $\lambda =0.25$, the lubricating layer becomes turbulent, and the associated TKE production and dissipation increase. However, the viscosity of the lubricating layer is smaller, and the corresponding energy transfer from the primary to the lubricating layer remains small enough so that DR can still be observed. For
$\lambda =0.25$, the lubricating layer becomes turbulent, and the associated TKE production and dissipation increase. However, the viscosity of the lubricating layer is smaller, and the corresponding energy transfer from the primary to the lubricating layer remains small enough so that DR can still be observed. For  $\lambda =4.00$, turbulence is suppressed in the lubricating layer, with corresponding increase of the mean dissipation and decrease of TKE production and dissipation. However, in this case, the energy extracted from the primary layer to help driving the motion of the more viscous lubricating layer becomes important to such an extent that a slight drag increase is observed, and the overall energy loss is marginally larger than that observed for the single-phase case.
$\lambda =4.00$, turbulence is suppressed in the lubricating layer, with corresponding increase of the mean dissipation and decrease of TKE production and dissipation. However, in this case, the energy extracted from the primary layer to help driving the motion of the more viscous lubricating layer becomes important to such an extent that a slight drag increase is observed, and the overall energy loss is marginally larger than that observed for the single-phase case.
3.9. Theoretical prediction of the DR performance
Before moving to the conclusions, we would like to present a simplified theoretical approach that can be used to predict the effects of the control parameters – lubricating layer thickness, Reynolds number and viscosity ratio – on the DR performance. To this aim, we can consider a simplified version of (3.1), which gives an estimate of the lubricating layer thickness in wall units
 \begin{equation} h_1^+=h_1 \frac{Re_\tau}{\lambda},\end{equation}
\begin{equation} h_1^+=h_1 \frac{Re_\tau}{\lambda},\end{equation}
where  $h_1$ is the lubricating layer thickness in outer units,
$h_1$ is the lubricating layer thickness in outer units,  $Re_\tau$ the equivalent shear Reynolds number and
$Re_\tau$ the equivalent shear Reynolds number and  $\lambda$ the viscosity ratio. Comparing the value obtained from (3.25) with the minimum value require to generate a self-sustained near-wall turbulence cycle (
$\lambda$ the viscosity ratio. Comparing the value obtained from (3.25) with the minimum value require to generate a self-sustained near-wall turbulence cycle ( $h_1^+ \simeq 60~w.u.$, Jiménez & Moin Reference Jiménez and Moin1991; Jiménez & Pinelli Reference Jiménez and Pinelli1999), we can predict the flow regime in the lubricating layer and thus the DR performance.
$h_1^+ \simeq 60~w.u.$, Jiménez & Moin Reference Jiménez and Moin1991; Jiménez & Pinelli Reference Jiménez and Pinelli1999), we can predict the flow regime in the lubricating layer and thus the DR performance.
For  $\lambda <1$ (viscosity-driven DR), increasing
$\lambda <1$ (viscosity-driven DR), increasing  $h_1$ or the Reynolds number (or both), the lubricating layer remains large enough (
$h_1$ or the Reynolds number (or both), the lubricating layer remains large enough ( $h_1^+ > 60~w.u.$) to sustain turbulence. As a result, the main driving mechanism for the DR is the viscosity difference between the two fluids, and large modifications of the DR are not expected. It must be also noted that the larger inertial forces that characterize the flow at larger Reynolds numbers can lead to the breakage of the thin lubricating layer and to a consequent loss of the DR performance. By contrast, decreasing
$h_1^+ > 60~w.u.$) to sustain turbulence. As a result, the main driving mechanism for the DR is the viscosity difference between the two fluids, and large modifications of the DR are not expected. It must be also noted that the larger inertial forces that characterize the flow at larger Reynolds numbers can lead to the breakage of the thin lubricating layer and to a consequent loss of the DR performance. By contrast, decreasing  $h_1$ or the Reynolds number (Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib), we expect a partial laminarization of the lubricating layer and thus an increase of the lubricating layer velocity. This can potentially lead to a further improvement of the DR performance.
$h_1$ or the Reynolds number (Ahmadi et al. Reference Ahmadi, Roccon, Zonta and Soldati2018a,Reference Ahmadi, Roccon, Zonta and Soldatib), we expect a partial laminarization of the lubricating layer and thus an increase of the lubricating layer velocity. This can potentially lead to a further improvement of the DR performance.
For  $\lambda \ge 1$ (surface tension-driven DR), increasing
$\lambda \ge 1$ (surface tension-driven DR), increasing  $h_1$ or the Reynolds number (or both), the lubricating layer could at some point become turbulent. The transition to turbulence – or the presence of turbulence patches – will be more pronounced for
$h_1$ or the Reynolds number (or both), the lubricating layer could at some point become turbulent. The transition to turbulence – or the presence of turbulence patches – will be more pronounced for  $\lambda =1.00$ and less pronounced for the larger viscosity ratios. Overall, this can lead to a weakening of the surface tension-driven DR mechanism and thus to a reduction of the DR performance. Decreasing
$\lambda =1.00$ and less pronounced for the larger viscosity ratios. Overall, this can lead to a weakening of the surface tension-driven DR mechanism and thus to a reduction of the DR performance. Decreasing  $h_1$ or the Reynolds number, we do not expect large modifications of the DR performance since the flow in the lubricating layer will remain laminar.
$h_1$ or the Reynolds number, we do not expect large modifications of the DR performance since the flow in the lubricating layer will remain laminar.
Finally, note that decreasing the thickness of the lubricating layer – which is in principle a good strategy to improve the DR performances – might have some drawbacks, since the waves generated at the liquid/liquid interface could reach the top wall, thereby destroying the lubricating layer configuration and the possibility of having DR.
4. Conclusions
In this work, we have used DNS to analyse the problem of DR in a lubricated channel, a flow configuration in which a thin layer of a lubricating fluid is injected in the near-wall region of a plane channel so as to favour the transportation of a primary fluid.
To examine a wide range of possible situations, we have considered not only the case of a lubricating layer that is less viscous than the primary fluid ( $\lambda <1$), but also the case of a more viscous lubricating layer (
$\lambda <1$), but also the case of a more viscous lubricating layer ( $\lambda >1$). In particular, we have tested five different viscosity ratios, from
$\lambda >1$). In particular, we have tested five different viscosity ratios, from  $\lambda =0.25$ up to
$\lambda =0.25$ up to  $\lambda =4.00$. A PFM has been used to describe the dynamics of the interface, which is characterized by a uniform value of the surface tension. An important aspect of the present study is the use of the CPI approach to perform the simulations. This implies that the channel flow rate is modified depending on the actual value of the pressure gradient, in a way that the total power injected into the flow is kept constant. The CPI approach offers a well-defined theoretical framework for the analysis of the different DR techniques since the obtained results are not anymore influenced by the amount of power injected into the flow. Originally developed for single-phase flows, the CPI approach has been extended here for the first time to the case of multiphase flows.
$\lambda =4.00$. A PFM has been used to describe the dynamics of the interface, which is characterized by a uniform value of the surface tension. An important aspect of the present study is the use of the CPI approach to perform the simulations. This implies that the channel flow rate is modified depending on the actual value of the pressure gradient, in a way that the total power injected into the flow is kept constant. The CPI approach offers a well-defined theoretical framework for the analysis of the different DR techniques since the obtained results are not anymore influenced by the amount of power injected into the flow. Originally developed for single-phase flows, the CPI approach has been extended here for the first time to the case of multiphase flows.
Our results have clearly shown that a significant DR can be obtained in a lubricated channel flow. The observed DR is a non-monotonic function of  $\lambda$, and reaches a maximum for
$\lambda$, and reaches a maximum for  $\lambda =1$ – a case for which a flow-rate increase of
$\lambda =1$ – a case for which a flow-rate increase of  ${\simeq }13\,\%$ is observed. This result directly points to the crucial role played by the surface tension in the DR process. The surface tension – an elasticity element that hinders the exchange of momentum between the primary and the lubricating layer – decouples the wall-normal momentum transfer mechanisms between the primary and the lubricating layer, suppresses turbulence in the lubricating layer (laminarization process) and naturally reduces the overall drag (surface-tension-driven DR). It is well known in the literature that the introduction of an elasticity factor inside a flow – for example, polymers or wall elasticity – can induce DR (White & Mungal Reference White and Mungal2008). However, and differently from previous investigations, in the present work, the elasticity is concentrated in a deformable surface inside the channel. When the viscosity of the lubricating layer is reduced (
${\simeq }13\,\%$ is observed. This result directly points to the crucial role played by the surface tension in the DR process. The surface tension – an elasticity element that hinders the exchange of momentum between the primary and the lubricating layer – decouples the wall-normal momentum transfer mechanisms between the primary and the lubricating layer, suppresses turbulence in the lubricating layer (laminarization process) and naturally reduces the overall drag (surface-tension-driven DR). It is well known in the literature that the introduction of an elasticity factor inside a flow – for example, polymers or wall elasticity – can induce DR (White & Mungal Reference White and Mungal2008). However, and differently from previous investigations, in the present work, the elasticity is concentrated in a deformable surface inside the channel. When the viscosity of the lubricating layer is reduced ( $\lambda \le 1.00$), turbulence is sustained in the lubricating layer, because of the increased local Reynolds number. In this case, DR is attributed to the smaller viscosity of the lubricating layer that directly decreases the corresponding wall friction (viscosity-driven DR). Interestingly, we have shown that DR can be obtained also for
$\lambda \le 1.00$), turbulence is sustained in the lubricating layer, because of the increased local Reynolds number. In this case, DR is attributed to the smaller viscosity of the lubricating layer that directly decreases the corresponding wall friction (viscosity-driven DR). Interestingly, we have shown that DR can be obtained also for  $\lambda = 2.00$ – i.e. when the viscosity of the lubricating fluid is twice the size of that of the primary fluid. In this case, DR is the outcome of the combined surface tension/large viscosity effect, which, reducing the vertical momentum and leading to a full relaminarization of the lubricating layer, completely balances the enhanced friction induced by the larger viscosity. We have also demonstrated that an upper limit for
$\lambda = 2.00$ – i.e. when the viscosity of the lubricating fluid is twice the size of that of the primary fluid. In this case, DR is the outcome of the combined surface tension/large viscosity effect, which, reducing the vertical momentum and leading to a full relaminarization of the lubricating layer, completely balances the enhanced friction induced by the larger viscosity. We have also demonstrated that an upper limit for  $\lambda$ exists and, for
$\lambda$ exists and, for  $\lambda =4.00$ we report a slight drag enhancement.
$\lambda =4.00$ we report a slight drag enhancement.
A clearcut explanation of all present results have been offered by looking at the mean and TKE budgets, which has been graphically rendered with the help of the energy-box representation. The energy-box representation has been presented and applied to the single-phase case first, and extended to the multiphase case later (phase-average technique). Thanks to this approach, we have been able to characterize the energy fluxes exchanged between the two phases, and to explain from a quantitative viewpoint the observed DR. In particular, introducing the energy transfer efficiency parameter,  $\mathcal {H}$ – which quantifies the ratio between the mean and the total energy dissipation in the primary layer – we have been able to show that DR is observed when
$\mathcal {H}$ – which quantifies the ratio between the mean and the total energy dissipation in the primary layer – we have been able to show that DR is observed when  $\mathcal {H}$/
$\mathcal {H}$/ $\mathcal {H}_{sp} > 1$ (with
$\mathcal {H}_{sp} > 1$ (with  $\mathcal {H}_{sp}$ the energy transfer efficiency for the single phase flow), whereas drag enhancement is expected when
$\mathcal {H}_{sp}$ the energy transfer efficiency for the single phase flow), whereas drag enhancement is expected when  $\mathcal {H}$/
$\mathcal {H}$/ $\mathcal {H}_{sp} < 1$.
$\mathcal {H}_{sp} < 1$.
Funding
Vienna Scientific Cluster (Vienna, Austria) and CINECA supercomputing center (Bologna, Italy) are gratefully acknowledged for generous allowance of computer resources under grants 71026, HP10BCFP82 and HP10BAX0FY.
The authors acknowledge the TU Wien University Library for financial support through its Open Access Funding Program.
Declaration of interest
The authors report no conflict of interest.
Appendix A. Extension of the CPI approach to viscosity stratified multiphase flows
We present here the extension of the CPI approach to viscosity stratified flows. We start by briefly recapping its derivation for a single-phase flow. In particular, we consider the flow inside a plane channel bounded by two walls located at  $z=\pm h$, figure 9(a). The fluid is characterized by uniform viscosity
$z=\pm h$, figure 9(a). The fluid is characterized by uniform viscosity  $\eta$. A constant pumping power per unit area,
$\eta$. A constant pumping power per unit area,  $P_p$, is used to drive the flow along the streamwise direction. Assuming the flow laminar, the following velocity profile is obtained:
$P_p$, is used to drive the flow along the streamwise direction. Assuming the flow laminar, the following velocity profile is obtained:
 \begin{equation} u_x(z)=\frac{1}{2 \eta} ( p_x) (z^2 - h^2) , \end{equation}
\begin{equation} u_x(z)=\frac{1}{2 \eta} ( p_x) (z^2 - h^2) , \end{equation}
where  $( p_x)$ is the pressure gradient along the streamwise direction. The bulk velocity (i.e. the average velocity across the channel section) can be computed integrating the velocity profile along the wall-normal direction
$( p_x)$ is the pressure gradient along the streamwise direction. The bulk velocity (i.e. the average velocity across the channel section) can be computed integrating the velocity profile along the wall-normal direction
 \begin{equation} u_b=\frac{1}{2h} \int^{z=h}_{z=-h} u_x \textrm{d} z = \frac{1}{3 \eta} ( -p_x ) h^2 .\end{equation}
\begin{equation} u_b=\frac{1}{2h} \int^{z=h}_{z=-h} u_x \textrm{d} z = \frac{1}{3 \eta} ( -p_x ) h^2 .\end{equation}The power dissipated by the viscous forces can be computed as
 \begin{equation} \epsilon=\frac{1}{2} \int^{z=h}_{z=-h} \eta \left( \frac{\textrm{d} u_x}{\textrm{d} z} \right)^2 \textrm{d} z= \frac{1}{\eta} ( p_x)^2 \frac{h^3}{3} = \frac{3 \eta}{h} \underbrace{( p_x)^2 \frac{h^4}{9 \eta^2}}_{u_b^2}= \frac{3 \eta u_b^2 }{h} , \end{equation}
\begin{equation} \epsilon=\frac{1}{2} \int^{z=h}_{z=-h} \eta \left( \frac{\textrm{d} u_x}{\textrm{d} z} \right)^2 \textrm{d} z= \frac{1}{\eta} ( p_x)^2 \frac{h^3}{3} = \frac{3 \eta}{h} \underbrace{( p_x)^2 \frac{h^4}{9 \eta^2}}_{u_b^2}= \frac{3 \eta u_b^2 }{h} , \end{equation}
where the expression of the bulk velocity has been highlighted. At equilibrium (i.e. fully developed flow), the power dissipated by the viscous forces is equal to the power injected in the system. Matching the expression of  $P_p$ with (A3), we can identify a velocity scale,
$P_p$ with (A3), we can identify a velocity scale,  $u_\varPi$, for the problem
$u_\varPi$, for the problem
 \begin{equation} u_b=u_\varPi=u_\varPi^{sp}=\sqrt{\frac{P_p h}{3\eta}} .\end{equation}
\begin{equation} u_b=u_\varPi=u_\varPi^{sp}=\sqrt{\frac{P_p h}{3\eta}} .\end{equation}
Figure 9. Sketch of the channel configurations used to derive the laminar flow solution: single phase (a) and viscosity stratified (b). For the single phase, the viscosity,  $\eta$, is uniform and thus a symmetric velocity profile,
$\eta$, is uniform and thus a symmetric velocity profile,  $u_x$, is obtained. For the viscosity stratified case, the thin lubricating layer (
$u_x$, is obtained. For the viscosity stratified case, the thin lubricating layer ( $mh<z<h$) has viscosity
$mh<z<h$) has viscosity  $\eta _1$ while the primary layer (
$\eta _1$ while the primary layer ( $-h<z<mh$) has viscosity
$-h<z<mh$) has viscosity  $\eta _2$ and an asymmetric velocity profile (
$\eta _2$ and an asymmetric velocity profile ( $u_{x,1}$ in the lubricating layer and
$u_{x,1}$ in the lubricating layer and  $u_{x,2}$ in the primary layer) is obtained. For both panels, the maximum velocity,
$u_{x,2}$ in the primary layer) is obtained. For both panels, the maximum velocity,  $u_m$, and the bulk velocity,
$u_m$, and the bulk velocity,  $u_b$, have been highlighted.
$u_b$, have been highlighted.
To extend the CPI approach to viscosity stratified flows, we can proceed in a similar way. We consider now a fully developed channel flow in which two liquid layers flow one on top of the other, as sketched in figure 9(b). The top layer is characterized by viscosity  $\eta _1$ while the bottom (primary) layer is characterized by viscosity
$\eta _1$ while the bottom (primary) layer is characterized by viscosity  $\eta _2$. The flow is laminar and the interface between the two layers is located at
$\eta _2$. The flow is laminar and the interface between the two layers is located at  $z=mh$ (note that
$z=mh$ (note that  $m=0.85$ in the present work). No-slip boundary conditions are applied at the two walls, while continuity of velocity and stress is enforced at the interface (Leal Reference Leal1992, p. 198). The resulting velocity profile is
$m=0.85$ in the present work). No-slip boundary conditions are applied at the two walls, while continuity of velocity and stress is enforced at the interface (Leal Reference Leal1992, p. 198). The resulting velocity profile is
 \begin{equation} u_x(z) = \begin{cases} u_{x,1}(z) & \text{for } mh < z < h \\ u_{x,2}(z) & \text{for } -h < z < mh, \end{cases} \end{equation}
\begin{equation} u_x(z) = \begin{cases} u_{x,1}(z) & \text{for } mh < z < h \\ u_{x,2}(z) & \text{for } -h < z < mh, \end{cases} \end{equation}
where  $u_{x,1}$ is the velocity in the thin lubricating layer and
$u_{x,1}$ is the velocity in the thin lubricating layer and  $u_{x,2}$ is the velocity in the primary layer. These two velocities are defined as follows:
$u_{x,2}$ is the velocity in the primary layer. These two velocities are defined as follows:
 \begin{gather} u_{x,1}(z)=\frac{1}{2 \eta_1} ( p_x) ( z^2 +Ahz -h^2 - Ah^2), \end{gather}
\begin{gather} u_{x,1}(z)=\frac{1}{2 \eta_1} ( p_x) ( z^2 +Ahz -h^2 - Ah^2), \end{gather} \begin{gather}u_{x,2}(z)=\frac{1}{2 \eta_2} ( p_x) ( z^2 +Ahz -h^2 + Ah^2) , \end{gather}
\begin{gather}u_{x,2}(z)=\frac{1}{2 \eta_2} ( p_x) ( z^2 +Ahz -h^2 + Ah^2) , \end{gather}
where the coefficient  $A$, which depends on the thickness of the lubricating layer (i.e. on the parameter
$A$, which depends on the thickness of the lubricating layer (i.e. on the parameter  $m$) and on the viscosity ratio
$m$) and on the viscosity ratio  $\lambda =\eta _1/\eta _2$, is defined as
$\lambda =\eta _1/\eta _2$, is defined as
 \begin{equation} A(\lambda,m)=\frac{(m^2-1)(1-\lambda)}{(1-m + \lambda m + \lambda)} . \end{equation}
\begin{equation} A(\lambda,m)=\frac{(m^2-1)(1-\lambda)}{(1-m + \lambda m + \lambda)} . \end{equation}The bulk velocity can be computed integrating the velocity profile along the wall-normal direction (i.e. the two velocity profiles over the corresponding thickness)
 \begin{equation} u_b=\frac{1}{2h}\left[ \int^{z=h}_{z=mh} u_{x,1} \textrm{d} z + \int^{z=mh}_{z=-h} u_{x,2} \textrm{d} z \right] = \frac{1}{4 \eta_1} ( -p_x ) A_1 h^2 + \frac{1}{4 \eta_2} ( -p_x ) A_2 h^2 , \end{equation}
\begin{equation} u_b=\frac{1}{2h}\left[ \int^{z=h}_{z=mh} u_{x,1} \textrm{d} z + \int^{z=mh}_{z=-h} u_{x,2} \textrm{d} z \right] = \frac{1}{4 \eta_1} ( -p_x ) A_1 h^2 + \frac{1}{4 \eta_2} ( -p_x ) A_2 h^2 , \end{equation}
where the coefficients  $A_1$ and
$A_1$ and  $A_2$ are
$A_2$ are
 \begin{gather} A_1(A,m)= -m(A+1) + \frac{A(1+ m^2)}{2} + \frac{(m^3+2)}{3} , \end{gather}
\begin{gather} A_1(A,m)= -m(A+1) + \frac{A(1+ m^2)}{2} + \frac{(m^3+2)}{3} , \end{gather} \begin{gather}A_2(A,m)= m(A-1) - \frac{A(1+ m^2)}{2} - \frac{(m^3-2)}{3}. \end{gather}
\begin{gather}A_2(A,m)= m(A-1) - \frac{A(1+ m^2)}{2} - \frac{(m^3-2)}{3}. \end{gather}Employing the definition of viscosity ratio, (A9) can be written as
 \begin{equation} u_b=\frac{1}{3 \eta_2} ( -p_x ) h^2 \underbrace{ \left[ \frac{3 A_1}{4 \lambda} + \frac{3 A_2}{4} \right] }_{B} , \end{equation}
\begin{equation} u_b=\frac{1}{3 \eta_2} ( -p_x ) h^2 \underbrace{ \left[ \frac{3 A_1}{4 \lambda} + \frac{3 A_2}{4} \right] }_{B} , \end{equation}
where the coefficient  $B$ has been introduced to highlight the main difference with the expression of the bulk velocity for a single-phase flow (equation A2). From a physical point of view, the ratio
$B$ has been introduced to highlight the main difference with the expression of the bulk velocity for a single-phase flow (equation A2). From a physical point of view, the ratio  $\eta _2/B$ can be interpreted as the equivalent viscosity of the system. The power dissipated by the viscous forces can be computed from the expression of the velocity profiles
$\eta _2/B$ can be interpreted as the equivalent viscosity of the system. The power dissipated by the viscous forces can be computed from the expression of the velocity profiles
 \begin{equation} \epsilon=\frac{1}{2} \left[ \int^{z=h}_{z=mh} \eta_1 \left( \frac{\textrm{d} u_{x,1}}{\textrm{d} z} \right)^2 \textrm{d} z + \int^{z=mh}_{z=-h} \eta_2 \left( \frac{\textrm{d} u_{x,2}}{\textrm{d} z} \right)^2 \textrm{d} z \right]. \end{equation}
\begin{equation} \epsilon=\frac{1}{2} \left[ \int^{z=h}_{z=mh} \eta_1 \left( \frac{\textrm{d} u_{x,1}}{\textrm{d} z} \right)^2 \textrm{d} z + \int^{z=mh}_{z=-h} \eta_2 \left( \frac{\textrm{d} u_{x,2}}{\textrm{d} z} \right)^2 \textrm{d} z \right]. \end{equation}After some algebra, we obtain
 \begin{equation} \epsilon=\frac{1}{\eta_1} ( p_x)^2 h^3 C_1 + \frac{1}{\eta_2} ( p_x)^2 h^3 C_2, \end{equation}
\begin{equation} \epsilon=\frac{1}{\eta_1} ( p_x)^2 h^3 C_1 + \frac{1}{\eta_2} ( p_x)^2 h^3 C_2, \end{equation}
where the coefficients  $C_1$ and
$C_1$ and  $C_2$ are defined as follows:
$C_2$ are defined as follows:
 \begin{gather} C_1=\frac{A(1-m^2)}{2} +\frac{1-m^3}{3} - \frac{A^2(m-1)}{4} , \end{gather}
\begin{gather} C_1=\frac{A(1-m^2)}{2} +\frac{1-m^3}{3} - \frac{A^2(m-1)}{4} , \end{gather} \begin{gather}C_2=\frac{A(m^2-1)}{2} + \frac{1+m^3}{3} + \frac{A^2(m+1)}{4} . \end{gather}
\begin{gather}C_2=\frac{A(m^2-1)}{2} + \frac{1+m^3}{3} + \frac{A^2(m+1)}{4} . \end{gather}
With the definition of  $\lambda$, we finally have
$\lambda$, we finally have
 \begin{equation} \epsilon=\frac{1}{3 \eta_2} ( p_x)^2 h^3 \underbrace{ \left[ \frac{3 C_1}{2 \lambda} + \frac{3 C_2}{2} \right] }_{D} . \end{equation}
\begin{equation} \epsilon=\frac{1}{3 \eta_2} ( p_x)^2 h^3 \underbrace{ \left[ \frac{3 C_1}{2 \lambda} + \frac{3 C_2}{2} \right] }_{D} . \end{equation}As previously done for the single-phase flow case, we can highlight the expression of the bulk velocity
 \begin{equation} \epsilon=\frac{3 \eta_2}{h} \frac{D}{B^2} \underbrace{ ( -p_x )^2 \frac{h^4}{ 9 \eta_2^2} B^2 }_{u_b^2} . \end{equation}
\begin{equation} \epsilon=\frac{3 \eta_2}{h} \frac{D}{B^2} \underbrace{ ( -p_x )^2 \frac{h^4}{ 9 \eta_2^2} B^2 }_{u_b^2} . \end{equation}Consistently with the previous derivation, the bulk velocity is used as reference velocity scale and its expression can be obtained by matching the expression of the viscous dissipation (equation A18) with that of the pumping power. This gives
 \begin{equation} u_\varPi=u_b=\sqrt{\frac{B^2}{D}\frac{P_p h}{3\eta_2}}=\sqrt{\frac{B^2}{D}} \underbrace{\sqrt{\frac{P_p h}{3\eta_2}}}_{u_\varPi^{sp}}. \end{equation}
\begin{equation} u_\varPi=u_b=\sqrt{\frac{B^2}{D}\frac{P_p h}{3\eta_2}}=\sqrt{\frac{B^2}{D}} \underbrace{\sqrt{\frac{P_p h}{3\eta_2}}}_{u_\varPi^{sp}}. \end{equation}
Under CPI conditions, the coefficient  $\sqrt {B^2/D}$ is used to account for the presence of a lubricating layer of different viscosity near the top wall (equation A4).
$\sqrt {B^2/D}$ is used to account for the presence of a lubricating layer of different viscosity near the top wall (equation A4).
Appendix B. Details of the implementation of the CPI approach
The characteristic feature of the CPI approach is that the mean pressure gradient,  $p_x$, used to drive the flow along the streamwise direction is updated every time step so as to keep constant the power injected in the system (proportional to the product between the mean pressure gradient and the overall channel flow rate). The mean pressure gradient at the new time step
$p_x$, used to drive the flow along the streamwise direction is updated every time step so as to keep constant the power injected in the system (proportional to the product between the mean pressure gradient and the overall channel flow rate). The mean pressure gradient at the new time step  $n+1$ is obtained using a first-order accurate scheme (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014)
$n+1$ is obtained using a first-order accurate scheme (Hasegawa et al. Reference Hasegawa, Quadrio and Frohnapfel2014)
 \begin{equation} -{ p_x }^{n+1}=\frac{3}{B Re_\varPi {u_b^n}} ,\end{equation}
\begin{equation} -{ p_x }^{n+1}=\frac{3}{B Re_\varPi {u_b^n}} ,\end{equation}
where  $u_b^n$ is the bulk velocity at the old time step
$u_b^n$ is the bulk velocity at the old time step  $n$ and
$n$ and  $B$ is the coefficient defined in (A12). The coefficient
$B$ is the coefficient defined in (A12). The coefficient  $B$ has been introduced to rescale the power Reynolds number on the equivalent system viscosity
$B$ has been introduced to rescale the power Reynolds number on the equivalent system viscosity  $\eta _2/B$. Indeed, the power Reynolds number is computed using the viscosity of the primary layer
$\eta _2/B$. Indeed, the power Reynolds number is computed using the viscosity of the primary layer  $\eta _2$ as a reference, (2.10a,b).
$\eta _2$ as a reference, (2.10a,b).
Appendix C. Interface elevation
To characterize the wave properties, we compute the probability density function (PDF) of the interface elevation,  $\zeta /h$, i.e. the difference between the local interface position and the nominal interface position (
$\zeta /h$, i.e. the difference between the local interface position and the nominal interface position ( $z/h=0.85$). The results are shown in figure 10: positive values of
$z/h=0.85$). The results are shown in figure 10: positive values of  $\zeta /h$ indicate an interface crest, whereas negative values of
$\zeta /h$ indicate an interface crest, whereas negative values of  $\zeta /h$ indicate an interface trough. The hatched box identifies the location of the top wall (
$\zeta /h$ indicate an interface trough. The hatched box identifies the location of the top wall ( $\zeta /h=0.15$). For all the PDFs, the most probable values of the interface location range between
$\zeta /h=0.15$). For all the PDFs, the most probable values of the interface location range between  $\zeta /h=-0.05$ and
$\zeta /h=-0.05$ and  $\zeta /h=0.05$. We immediately notice that the shape of the PDFs strongly depends on the viscosity ratio (and thus on the flow regime observed in the lubricating layer). For
$\zeta /h=0.05$. We immediately notice that the shape of the PDFs strongly depends on the viscosity ratio (and thus on the flow regime observed in the lubricating layer). For  $\lambda < 1$, the PDFs are negatively skewed: large negative fluctuations are more likely to occur than larger positive fluctuations. This effect can be ascribed to the wall confinement, which limits the amplitude of the positive fluctuations but not of the negative fluctuations. For
$\lambda < 1$, the PDFs are negatively skewed: large negative fluctuations are more likely to occur than larger positive fluctuations. This effect can be ascribed to the wall confinement, which limits the amplitude of the positive fluctuations but not of the negative fluctuations. For  $\lambda \ge 1$, the PDFs are almost symmetric and the effects of the wall confinement are weaker. In these cases, the interfaces are smaller compared to the cases
$\lambda \ge 1$, the PDFs are almost symmetric and the effects of the wall confinement are weaker. In these cases, the interfaces are smaller compared to the cases  $\lambda <1$, and large negative fluctuations (
$\lambda <1$, and large negative fluctuations ( $\zeta /h < 0.2$) are very unlikely to occur. It is interesting to observe that, going from
$\zeta /h < 0.2$) are very unlikely to occur. It is interesting to observe that, going from  $\lambda =1$ to
$\lambda =1$ to  $\lambda =4$, the PDF widens. This trend seems to be due to the larger shear rate observed for
$\lambda =4$, the PDF widens. This trend seems to be due to the larger shear rate observed for  $\lambda \ge 2.00$, which acts to deform more the interface. Indeed, for
$\lambda \ge 2.00$, which acts to deform more the interface. Indeed, for  $\lambda \ge 2.00$, the interfacial contribution in the energy box (
$\lambda \ge 2.00$, the interfacial contribution in the energy box ( $\overline {\psi _m}$), whose magnitude depends on the combined effect of the interface shape and mean velocity profile, is larger.
$\overline {\psi _m}$), whose magnitude depends on the combined effect of the interface shape and mean velocity profile, is larger.

Figure 10. PDF of interface elevation  $\zeta /h$. Positive values of the interface elevation identify an interface crest while negative values identify interface trough. The hatched box indicates the top wall boundary, i.e.
$\zeta /h$. Positive values of the interface elevation identify an interface crest while negative values identify interface trough. The hatched box indicates the top wall boundary, i.e.  $\zeta /h=0.15$.
$\zeta /h=0.15$.
Appendix D. Rescaling of the mean velocity profiles in wall units
The mean velocity profiles reported in figure 4 using the CPI scaling system, can be also represented in wall units using a semi-local scaling (Pecnik & Patel Reference Pecnik and Patel2017; Roccon et al. Reference Roccon, Zonta and Soldati2019) that relies on the local value of the wall-shear stress and viscosity (local friction velocity). The resulting friction velocity is then used to rescale the different mean velocity profiles, see figure 11. Panel (a) refers to the bottom wall (primary layer) while panel (b) refers to the top wall (lubricating layer). The classical law of the wall,  $u^+ = z^+$ and
$u^+ = z^+$ and  $u^+ = (1/k) \log (z^+) + 5$, with
$u^+ = (1/k) \log (z^+) + 5$, with  $k = 0.41$ the von Kármán constant (Von Kármán Reference Von Kármán1931), is also shown by a thin black line for comparison purposes.
$k = 0.41$ the von Kármán constant (Von Kármán Reference Von Kármán1931), is also shown by a thin black line for comparison purposes.

Figure 11. Mean velocity profiles at the bottom wall (a) and at the top wall (b) rescaled in wall units using the local friction scale at the corresponding wall. The classical law of the wall:  $u^+ = z^+$ and
$u^+ = z^+$ and  $u^+ = (1/k )\log (z^+) + 5$ (where
$u^+ = (1/k )\log (z^+) + 5$ (where  $k = 0.41$ is the von Kármán constant) is also reported as a reference. At the bottom wall, all profiles collapse on the classical law of the wall while at the top wall, for
$k = 0.41$ is the von Kármán constant) is also reported as a reference. At the bottom wall, all profiles collapse on the classical law of the wall while at the top wall, for  $\lambda > 1$, the velocity profiles depart significantly from the law of the wall and gradually approach the laminar behavior.
$\lambda > 1$, the velocity profiles depart significantly from the law of the wall and gradually approach the laminar behavior.
At the bottom wall (figure 11a), all the velocity profiles (for both the single-phase and the multiphase case) collapse on the classical law of the wall. This indicates that the presence of the interface induces only negligible effects on the near-wall turbulence cycle in the lower part of the channel.
At the top wall (figure 11b), the mean velocity profiles are remarkably different. For  $\lambda < 1.00$, the velocity profiles match the laminar behaviour
$\lambda < 1.00$, the velocity profiles match the laminar behaviour  $u^+=z^+$ only very close the wall, but they seem to approach soon a logarithmic behaviour (although with a different steepness). For
$u^+=z^+$ only very close the wall, but they seem to approach soon a logarithmic behaviour (although with a different steepness). For  $\lambda \ge 1.00$, the velocity profiles depart significantly from the law of the wall and gradually collapse onto the laminar behaviour
$\lambda \ge 1.00$, the velocity profiles depart significantly from the law of the wall and gradually collapse onto the laminar behaviour  $u^+ = z^+$. Please note that, due to the rescaling (which is based on the local friction scale), the nominal interface position – which also corresponds to the lubricating layer thickness expressed in wall units
$u^+ = z^+$. Please note that, due to the rescaling (which is based on the local friction scale), the nominal interface position – which also corresponds to the lubricating layer thickness expressed in wall units  $h_1^+$ – is different among the various cases. In particular, the nominal interface position for the different cases is:
$h_1^+$ – is different among the various cases. In particular, the nominal interface position for the different cases is:  $z^+ \simeq 138~w.u.$
$z^+ \simeq 138~w.u.$  $(\lambda =0.25$),
$(\lambda =0.25$),  $z^+ \simeq 70~w.u.$ (
$z^+ \simeq 70~w.u.$ ( $\lambda =0.50$),
$\lambda =0.50$),  $z^+ \simeq 30~w.u.$ (
$z^+ \simeq 30~w.u.$ ( $\lambda =1.00$),
$\lambda =1.00$),  $z^+ \simeq 19~w.u.$ (
$z^+ \simeq 19~w.u.$ ( $\lambda =2.00$) and
$\lambda =2.00$) and  $z^+ \simeq 12~w.u.$ (
$z^+ \simeq 12~w.u.$ ( $\lambda =4.00$).
$\lambda =4.00$).
Appendix E. Energy balance equation for surface tension
To derive the energy balance equation for the surface tension, we follow Joseph (Reference Joseph1976, p. 242). Under the assumption of constant and uniform surface tension – namely,  $\textrm {d} \sigma / \textrm {d} t= 0$ and
$\textrm {d} \sigma / \textrm {d} t= 0$ and  $\nabla _s \sigma =\textbf {0}$, with
$\nabla _s \sigma =\textbf {0}$, with  $\nabla _s$ the surface gradient operator (see Slattery, Sagis & Oh Reference Slattery, Sagis and Oh2007, p. 624) – the balance equation at the liquid–liquid interface can be written as
$\nabla _s$ the surface gradient operator (see Slattery, Sagis & Oh Reference Slattery, Sagis and Oh2007, p. 624) – the balance equation at the liquid–liquid interface can be written as
 \begin{equation} \frac{1}{We_{\varPi}} \frac{\textrm{d} A}{\textrm{d} t}=- \int_A u_i \,f_i^\sigma \textrm{d} A , \end{equation}
\begin{equation} \frac{1}{We_{\varPi}} \frac{\textrm{d} A}{\textrm{d} t}=- \int_A u_i \,f_i^\sigma \textrm{d} A , \end{equation}
where  $A$ is the interfacial area,
$A$ is the interfacial area,  $u_i$ is the
$u_i$ is the  $i$th component of the velocity vector and
$i$th component of the velocity vector and  $f_i^\sigma$ is the
$f_i^\sigma$ is the  $i$th component of the surface tension forces. Since the interface has a finite, yet very small, thickness, the right-hand side of (E1) can be rewritten as a volume integral
$i$th component of the surface tension forces. Since the interface has a finite, yet very small, thickness, the right-hand side of (E1) can be rewritten as a volume integral
 \begin{equation} \frac{1}{We_{\varPi}}\frac{\textrm{d} A}{\textrm{d} t}=- \int_A u_i \,f_i^\sigma \textrm{d} A = -\int_V u_i \underbrace{\frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j}}_{{Interfacial\ forces}} \textrm{d} V . \end{equation}
\begin{equation} \frac{1}{We_{\varPi}}\frac{\textrm{d} A}{\textrm{d} t}=- \int_A u_i \,f_i^\sigma \textrm{d} A = -\int_V u_i \underbrace{\frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j}}_{{Interfacial\ forces}} \textrm{d} V . \end{equation}Recalling the mean value theorem for integrals, the right-hand side of (E2) can be rewritten as
 \begin{equation} - \int_V u_i \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j} \textrm{d} V = - L_x L_y \int^{z/h=+1}_{z/h=-1}\left\langle u_i \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_i} \right\rangle \textrm{d} z , \end{equation}
\begin{equation} - \int_V u_i \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j} \textrm{d} V = - L_x L_y \int^{z/h=+1}_{z/h=-1}\left\langle u_i \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_i} \right\rangle \textrm{d} z , \end{equation}which, after averaging in time, becomes
 \begin{equation} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right]= \int^{z/h=+1}_{z/h=-1}\left[ u_i \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_i} \right] \textrm{d} z. \end{equation}
\begin{equation} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right]= \int^{z/h=+1}_{z/h=-1}\left[ u_i \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_i} \right] \textrm{d} z. \end{equation}Decomposing the velocity field into a mean and a fluctuating component, we have
 \begin{align} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right] &= \int^{z/h=+1}_{z/h=-1} \left[ \langle u_i \rangle \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j}\right] \textrm{d} z \nonumber\\ &\quad+\int^{z/h=+1}_{z/h=-1} \left[ u_i' \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j} \right] \textrm{d} z. \end{align}
\begin{align} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right] &= \int^{z/h=+1}_{z/h=-1} \left[ \langle u_i \rangle \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j}\right] \textrm{d} z \nonumber\\ &\quad+\int^{z/h=+1}_{z/h=-1} \left[ u_i' \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau^c_{ij}}{\partial x_j} \right] \textrm{d} z. \end{align}This expression can be further simplified decomposing also the Korteweg tensor into a mean and a fluctuating component
 \begin{align} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right] &= \int^{z/h=+1}_{z/h=-1} \underbrace{\left[ \langle u_i \rangle \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \langle \tau^c_{ij} \rangle}{\partial x_j}\right]}_{\psi_m} \textrm{d} z \nonumber\\ &\quad +\int^{z/h=+1}_{z/h=-1} \underbrace{ \left[ u_i' \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau'^c_{ij}}{\partial x_j} \right]}_{\psi_k} \textrm{d} z, \end{align}
\begin{align} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right] &= \int^{z/h=+1}_{z/h=-1} \underbrace{\left[ \langle u_i \rangle \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \langle \tau^c_{ij} \rangle}{\partial x_j}\right]}_{\psi_m} \textrm{d} z \nonumber\\ &\quad +\int^{z/h=+1}_{z/h=-1} \underbrace{ \left[ u_i' \frac{3Ch}{\sqrt{8}We_{\varPi}} \frac{\partial \tau'^c_{ij}}{\partial x_j} \right]}_{\psi_k} \textrm{d} z, \end{align}where, thanks to the properties of the average operator, the cross-terms vanish. Using the definition introduced in (3.4), we obtain
 \begin{equation} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right] = \overline{\psi_m} + \overline{\psi_k}. \end{equation}
\begin{equation} -\frac{1}{ L_x L_y} \frac{1}{We_{\varPi}}\left[ \frac{\textrm{d} A}{\textrm{d} t} \right] = \overline{\psi_m} + \overline{\psi_k}. \end{equation}Appendix F. Physical interpretation of the interfacial contribution
To obtain a physical interpretation of the interfacial contribution,  $\overline {\psi _m}$, we can consider the wall-normal behaviour of the mean velocity profile and of the mean component of the surface tension forces. Indeed, once integrated along the wall-normal direction, the product between these two quantities represents the interfacial contribution in the MKE balance equation. In figure 12, we report the qualitative behaviour of the mean velocity profile (left side), the mean component of the surface tension forces (centre) and a sketch of the interfacial waves (right side) and of the corresponding surface tension forces (red arrows). In addition, the nominal interface position (
$\overline {\psi _m}$, we can consider the wall-normal behaviour of the mean velocity profile and of the mean component of the surface tension forces. Indeed, once integrated along the wall-normal direction, the product between these two quantities represents the interfacial contribution in the MKE balance equation. In figure 12, we report the qualitative behaviour of the mean velocity profile (left side), the mean component of the surface tension forces (centre) and a sketch of the interfacial waves (right side) and of the corresponding surface tension forces (red arrows). In addition, the nominal interface position ( $z/h=0.85$) is reported with a dashed horizontal line. As can be appreciated from the sketch, the waves are not symmetric (with respect to the nominal interface position axis) and the resulting contribution of the surface tension forces (i.e. the mean component of the surface tension forces) is positive above the nominal interface position and negative below it. These two contributions (positive and negative), which have the same magnitude, are then multiplied by the mean velocity and integrated along the wall-normal direction to compute the interfacial contribution
$z/h=0.85$) is reported with a dashed horizontal line. As can be appreciated from the sketch, the waves are not symmetric (with respect to the nominal interface position axis) and the resulting contribution of the surface tension forces (i.e. the mean component of the surface tension forces) is positive above the nominal interface position and negative below it. These two contributions (positive and negative), which have the same magnitude, are then multiplied by the mean velocity and integrated along the wall-normal direction to compute the interfacial contribution  $\overline {\psi _m}$. Since the velocity is larger below the nominal interface position than above it, the negative part dominates and we obtain
$\overline {\psi _m}$. Since the velocity is larger below the nominal interface position than above it, the negative part dominates and we obtain  $\overline {\psi _m} <0$. From an energetic point of view, a negative value for the interfacial term identifies a situation in which surface tension forces absorb power from the mean flow. A corresponding amount of power is necessarily released in the flow in the form of turbulence fluctuations (TKE) by the term
$\overline {\psi _m} <0$. From an energetic point of view, a negative value for the interfacial term identifies a situation in which surface tension forces absorb power from the mean flow. A corresponding amount of power is necessarily released in the flow in the form of turbulence fluctuations (TKE) by the term  $\overline {\psi _k}$ so that the overall power absorbed/released by the interface is zero (Joseph Reference Joseph1976; Aris Reference Aris1989; Dodd & Ferrante Reference Dodd and Ferrante2016). Although the present discussion is only qualitative, the very same conclusions can be obtained using a more quantitative approach.
$\overline {\psi _k}$ so that the overall power absorbed/released by the interface is zero (Joseph Reference Joseph1976; Aris Reference Aris1989; Dodd & Ferrante Reference Dodd and Ferrante2016). Although the present discussion is only qualitative, the very same conclusions can be obtained using a more quantitative approach.

Figure 12. Lateral view of the upper part of the channel. The sketch shows the wall-normal behaviour (qualitative) of the mean velocity profile (left), the mean component of the surface tension forces (centre) and the interfacial waves (right) together with the corresponding surface tension forces (red arrows near the interface). The nominal interface position ( $z/h=0.85$) is represented with a dashed horizontal line.
$z/h=0.85$) is represented with a dashed horizontal line.










































































































 Open access
Open access