


Introduction
Word learning is a core part of early development, but requires multiple, interactive and related cognitive processes to be successful. To learn just a single new word a child must engage in fast in-the-moment mapping and encoding of a word and its referent, strengthen those initial word-referent associations such that they can be retained over time, and be able to generalize this information to new examples in future moments. Each process builds on each other and has cascading effects on the others – successful mapping lays a foundation for more robust retention, and robust retention strengthens the network that supports generalization (Kucker, McMurray & Samuelson, Reference Kucker, McMurray and Samuelson2015; McMurray, Horst & Samuelson, Reference McMurray, Horst and Samuelson2012). Thus, in order to successfully build their vocabulary, a child needs to integrate each of these processes relatively well. Success across each process (mapping, retention, and generalization) predicts future lexical growth. Conversely, failure at one or more points can lead to delays in development, most notably recognized as being a late talker.
Late-talking (LT) children are those who represent the lowest end of a normative vocabulary distribution, scoring lower in expressive vocabulary for their age (MacRoy-Higgins, Shafer, Fahey & Kaden, Reference MacRoy-Higgins, Shafer, Fahey and Kaden2016). For the purposes of this study we used a slightly more liberal 25th percentile as the cut-off to capture heterogeneity within the group (see also Jones, Reference Jones2003). Late-talking is not attributed to cognitive or developmental disorders, genetic abnormalities, neuromuscular disabilities, or hearing disorders (Rescorla, Reference Rescorla2011). By definition, LT children exhibit slower expressive language growth and have smaller normative vocabularies than their peers with normal language (NL). However, less is known about why LT children may struggle to gain a robust vocabulary and what impact their small vocabularies have across the timescales of word learning.
Timescales of word learning
Initial in-the-moment processes of word learning
Communication starts with real-time, in-the-moment processing. In order for a child to comply when her father says, “go get your cup,” the child must, in the span of mere seconds, parse cup from the rest of the speech stream, interpret it as referring to the plastic blue hollow container on the counter, and ignore the silver metal spoon next to it, and the white liquid in the milk carton in the fridge. This in-the-moment behavior draws on a child’s lexicon, requiring recollection of prior knowledge and, critically, an application of such knowledge in real time. By around one year of age, children can do this, correctly attending to a known target when presented with its auditory label (Oviatt, Reference Oviatt1980; Woodward, Markman & Fitzsimmons, Reference Woodward, Markman and Fitzsimmons1994); a process which becomes efficient between 17- and 24-months (Fernald, Pinto, Swingley, Weinbergy & McRoberts, Reference Fernald, Pinto, Swingley, Weinbergy and McRoberts1998) and is seen both in the home and lab (Garrison, Baudet, Breitfeld, Aberman & Bergelson, Reference Garrison, Baudet, Breitfeld, Aberman and Bergelson2020).
A similar in-the-moment process supports communication and learning about unknown, novel words as well, such as when her father says, “let’s play with your new slinky.” Children as young as 16-months-old can reliably map novel words (slinky) to their unknown referents (silver metal coil) by either looking or reaching toward the target (Mervis & Bertrand, Reference Mervis and Bertrand1994). This behavior is thought to be driven by multiple word learning constraints which operate in the span of seconds as the child disambiguates a target from the foil items. For instance, Mutual Exclusivity (Markman & Wachtel, 1988) proposes that children avoid a second label for an already known item, instead attributing any novel words to novel items (the Novel-Name Nameless-Category principle; Mervis & Bertrand, Reference Mervis and Bertrand1994). Children can also use the principle of contrast (Clark, Reference Clark1990), disjunctive syllogism (Halberda, 2003), or even social pragmatic cues such as joint attention (Tomasello & Akhtar, Reference Tomasello and Akhtar1995) to, upon hearing a word, select the correct referent from an array and avoid foils.
Decades of work have demonstrated that this initial, in-the-moment behavior is driven by both lexical and perceptual biases, suggesting that children with poorer lexical or perceptual processing skills may struggle with this phase of word learning. In fact, younger children (e.g., 18-month-olds) and those with lower vocabularies for their age have poorer disambiguation skills, selecting a novel or known target from an array at or near chance levels (Bion, Borovsky & Fernald, Reference Bion, Borovsky and Fernald2013; see also Kucker, McMurray & Samuelson, Reference Kucker, McMurray and Samuelson2018). Similar patterns are seen with LT children. Work measuring visual attention during novel word mapping (MacRoy-Higgin & Montemenaro, 2015) and millisecond level eye-tracking during referent selection (Ellis, Borovsky, Elman & Evans, Reference Ellis, Borovsky, Elman and Evans2015) reveals real-time processing differences for LT vs. NL children. However, the process of (quickly) identifying and selecting the referent (traditionally referred to as “fast-mapping”) is not equivalent to learning and does not mean a word has integrated robustly into the lexicon (Horst & Samuelson, Reference Horst and Samuelson2008). This initial in-the-moment period is followed by a slower process of strengthening word-referent links such that the information can be recalled at a later time (known as “slow mapping”, or here referred to as “Retention”; see Carey, Reference Carey2010; Horst & Samuelson, Reference Horst and Samuelson2008; Kucker et al., Reference Kucker, McMurray and Samuelson2015; Swingley, Reference Swingley2010). Though fast and slow mapping were at the forefront of research on NL children for decades, less work has explored the processes in LT children. In fact, the majority of “fast-mapping” work with LT children does not directly test children’s accuracy at known word selection, nor explicitly measure mapping, mutual exclusivity, disambiguation, or encoding abilities for novel words. Instead, canonical “fast-mapping” work in LT children has examined retention or recollection of a new word-referent pair after an extensive (albeit “fast”) training of the name via ostensive naming or repeated exposures (e.g., Ellis Weismer, Venker, Evans & Moyle, Reference Ellis Weismer, Venker, Evans and Moyle2013).
This distinction in prior work is important because mapping and retention are related but distinct processes (Kucker et al., Reference Kucker, McMurray and Samuelson2015): being good at mapping does not guarantee success at retention (Horst & Samuelson, Reference Horst and Samuelson2008). For example, 18-month-old children typically are very good at selecting a novel target when asked, but also demonstrate a robust novelty bias when asked to select a known item, choosing a novel foil item instead. Despite good novel referent selection, these children largely fail to select known referents when there is a novel distractor and fail to retain novel word-referent pairs after a short break. However, there is also evidence that in-the-moment mapping ability may impact retention. For instance, some 18-month-old children who, for an unknown reason, lack a novelty bias (selecting the known referents correctly in-the-moment) subsequently show above-chance retention (Kucker et al., Reference Kucker, McMurray and Samuelson2018). Similarly, Bion et al. (Reference Bion, Borovsky and Fernald2013) found a positive correlation between referent selection accuracy and retention in a looking-based task. There might then be possible downstream effects of mapping behaviors on later retention. Moreover, other work suggests LT children are also subject to the same cascading effects. For instance, real-time processes like attention are correlated with later retention in LT children (MacRoy-Higgins & Montemarano, 2015; see also Tenenbaum et al., 2014). However, we also know that the impact of LT children’s in-the-moment behaviors may be unique from that of their NL peers – LT children who are more efficient at known word recognition at 18-months (look to a target faster) are more likely to catch-up to their NL peers a year later (Fernald & Marchman, Reference Fernald and Marchman2012). That is, early in-the-moment behavior and mapping of words and referents are distinct from slower learning and retention processes, but have cascading effects on later vocabulary growth. This in-the-moment behavior and mapping of words and referents will hence be referred to as in-the-moment mapping.
Slower associative processes of retention in word learning
In addition to in-the-moment mapping, a child must also retain the new word-referent pair. Retention can be boosted with a richer initial encoding/mapping context that includes repetition or additional cues. With multiple exposures to the word-referent pair, children as young as 16-months retain (Mervis & Bertrand, Reference Mervis and Bertrand1994). Likewise, 24-month-old children retain when given additional familiarization time with the target items (Kucker & Samuelson, Reference Kucker and Samuelson2012). By 30-months, normal language children demonstrate retention with as little as one prior exposure to the word-referent pair (Bion et al., Reference Bion, Borovsky and Fernald2013). This suggests that over development, the lexicon strengthens such that it can support both old and new words well. Children’s ability to retain newly learned words, especially as they near 24-30-months, then gives insight into their potential for further growth.
However, not all children demonstrate the same ability to retain word-referent pairs. Ellis Weismer et al. (Reference Ellis Weismer, Venker, Evans and Moyle2013) found that known word comprehension (i.e., in-the-moment selection of a known target) did not differentiate LT and NL children, but performance on novel word retention was significantly lower for LT children. Similarly, after an extended training session, LT two-year-olds retain fewer new words than their NL peers (MacRoy-Higgins & Montemarano, 2015; MacRoy-Higgins et al., 2013). On the other hand, Ellis et al. (Reference Ellis, Borovsky, Elman and Evans2015) found that in-the-moment looking and fixation behaviors of 18-month-old children more reliably differentiated LT from NL children than their subsequent retention/learning accuracy. That is, LT children may not be behind their peers on all aspects of word learning, but which processes are impacted is less clear. Taken together, this again demonstrates the importance of analyzing the process of word learning across timescales, especially in late talking children.
Generalization and the refinement of learning
Critically, learning a word does not end with retention. Children must also learn that most words do not map to just a single referent in the world, but instead represent a category of items. As a child is exposed to each new example of a referent, not only is their lexical network becoming refined and chances of retention increasing, but they are also building statistics about what a referent can be and which properties are relevant for generalizing the word to other exemplars. In the case of nouns, these relevant properties are often aspects of the item’s physical shape – e.g., the majority of cups have a similar round, hollow shape and most things called “ball” are spherical but can vary on color or material. As a child’s vocabulary (and the proportion of nouns in particular) increases, so does attention to shape (Samuelson & Smith, Reference Samuelson and Smith1999). As such, by the time children have 150-250 words in their productive vocabulary (roughly 20-months-old), they have experienced enough regularities in language to reliably generalize labels to other novel items with similar shape, an ability called the shape bias (Landau, Smith & Jones, Reference Landau, Smith and Jones1988). This bias helps children learn how to learn, such that the next encounter with a word is more efficient. In this way, the shape bias is a critical mechanism for predicting future vocabulary growth (Perry, Samuelson, Malloy & Schiffer, Reference Perry, Samuelson, Malloy and Schiffer2010; Smith, Jones, Landau, Gershkoff-Stowe & Samuelson, Reference Samuelson2002).
Some children, however, do not acquire a shape-based vocabulary and do not show a robust shape bias. A handful of studies have found that LT children lag behind their peers in both the structure of nouns in their vocabulary (Colunga & Sims, Reference Colunga and Sims2017) and novel word extensions/generalizations (Jones, Reference Jones2003). When given a novel word for a novel item and asked to find similar items that match in a single feature (e.g., same shape but different color and material, or same material but different color and shape), NL children choose the shape-match, but as a group, LT children were less likely to do so (Jones, Reference Jones2003; Perry & Kucker, Reference Perry and Kucker2019). Furthermore, LT children have difficulty recognizing shape caricatures of known items (Jones & Smith, Reference Jones and Smith2005), suggesting weaker knowledge for overall shape features. These same deficits in generalization likely persist as children develop – older preschool children diagnosed with Specific Language Impairment also fail to demonstrate a shape bias on the standard novel noun generalization (NNG) task (Collisson, Grela, Spaulding, Rueckl & Magnuson, Reference Collisson, Grela, Spaulding, Rueckl and Magnuson2015). Overall, the ability to generalize is a critical skill for advancing one’s vocabulary and deficits in this area may help explain why some children fail to demonstrate significant growth over time.
Current Study
While each process of word learning is intimately related to the next, being good at one process does not necessarily mean success at the others. However, most prior studies examine only one process in isolation and few have combined various measures of both known and novel word processing in the same children. Furthermore, recent work with children with autism spectrum disorder suggests that a holistic approach examining multiple timescales and processes can lend itself to a more thorough picture of language delay (Hartley, Bird & Monaghan, Reference Hartley, Bird and Monaghan2019, Reference Hartley, Bird and Monaghan2020). The first goal of the current study is to do so. First, in-the-moment known word comprehension was examined in two different referent selection contexts. Then, in-the-moment novel word-referent mapping was tested via a referent selection task. Extended learning processes were then examined – novel word retention from two tasks were measured and children’s ability to generalize novel words via a Novel Noun Generalization (NNG) task was assessed.
Importantly, tasks were administered through a within-subject design across a wide age range of children who fell along the entire normal bell curve for productive vocabulary. That is, both children who would traditionally be classified as “late talkers” (LT) as well as those defined as having “normal language” (NL) participated. The second goal of the current study is to examine this vast heterogeneity in children’s language abilities. To do so, all children were first analyzed as a large group with age and vocabulary percentile as predictors. A second analysis looked at the younger subset of children (those under 30-months) more in-depth and included vocabulary size and vocabulary structure as a predictor for performance on each task. A secondary analysis using traditional dichotomous groups (LT vs. NL) as the independent variable replicated most findings and allows for comparison to prior work. The results also highlight the variability of vocabulary within LT children, reinforcing the utility of using continuous measures (e.g., vocabulary) to classify children with potential delays.
Methods
Participants
A total of 114 children (61 female) between 17- and 40-months (M = 26;30, SD = 6;23) from an urban metropolitan area participated. See Table 1 for demographic information. All children were reported to be monolingual English speakers with no major developmental delays (e.g., no autism, William’s syndrome, Down’s syndrome). However, in order to ensure a wide distribution of language abilities, children were allowed to participate if parents had concerns about their child’s language or if the child was enrolled in a birth-to-three program provided they had no diagnosed developmental disorders. A vocabulary percentile was calculated for each child by comparing each child’s total productive vocabulary size to the national norms (Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis & Stiles, Reference Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis and Stiles1994). This number was used to identify LT children (those <25th percentile). The 25th percentile was used to have a broad sample of children at the lower end of the range, similar to other recent studies (Colunga & Sims, Reference Colunga and Sims2017; Perry & Kucker, Reference Perry and Kucker2019) emphasizing the heterogeneity of children’s language skills. An additional 45 children were dropped for not completing all four tasks (n = 20), exposure of more than 50% of another language (n = 21), or parents not completing the vocabulary form (n = 4). The demographic and vocabulary distribution of dropped participants did not differ significantly from those kept.
Table 1. Demographic information for children in the full sample and NL/LT sub-groups

Note: Means shown with standard deviation in parentheses and range in brackets. *N for the overall MCDI-WS sample was 86, MCDI-III was 28. N for the Age-matched MCDI-WS in NL and LT were respectively 22 and 21, MCDI-III was 4 and 5. N for the Vocab-matched MCDI-WS and MCDI-III was 10 and 5 for both groups. Education was rank ordered with 1 as less than 7th grade and 8 as Doctoral degree; a score of 6 indicated a 4-year college degree. Income was also rank ordered with a 1 as “less than $10,000” and 9 as “more than $100,000”.
In order to draw comparisons to prior work using specific groups of LT vs. NL, multiple subsets were created from the full sample. First, an LT group that fell below the 25th percentile for productive vocabulary and a NL group above the 25th percentile were selected and matched on gender and age within 2 weeks. This Age-Matched subset of 52 children (26 NL) were equal on parent education and income. A separate Vocabulary-Matched subset of 30 children (15 LT) were matched on vocabulary (within 12 words on the MCDI-WS and 5 words on the MCDI-III), see Table 1.
Stimuli
Each task consisted of a selection of known and/or novel objects. Known items (Figure 1a) were selected from a pool of items commonly known by the majority of 17-month-old children (Fenson et al., Reference Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis and Stiles1994). Novel items were unknown objects that children under 40-months-old are not likely familiar with (see Figures 1b and 1c). Novel Noun Generalization items (Figure 1d) consisted of four sets of novel items; each set consisted of one exemplar object, two items that matched the exemplar in shape (but differed in color and material), and two material-matching items (differing on shape and color). Parents confirmed their child knew the names of the known objects and was unfamiliar with all novel items. Items were replaced as necessary. Novel words were simple words that were phonologically legal in English and had no known referents.

Figure 1. Stimuli. Known items used in known word comprehension and referent selection (a), novel items in Referent Selection (b), novel items used in Direct Naming (c), and Novel Noun Generalization items (d).
Procedure
The child was seated across a table from the experimenter in a booster seat next to their parents or on their parents’ lap. Parents completed an age-appropriate version of the MacArthur-Bates Communicative Development Inventory (MCDI) during the session (MCDI: Words and Sentences [MCDI-WS] for those 30-months and under, and MCDI-III for those over 30-months; Dale & Fenson, Reference Dale and Fenson1996; Fenson et al., Reference Fenson, Dale, Reznick, Bates, Thal, Pethick, Tomasello, Mervis and Stiles1994) and were instructed to avoid interacting with their child, offering minimal encouragement only if needed. Each child completed a series of four separate tasks (Figure 2), taking breaks as needed between tasks. Each of the tasks paralleled the procedures used in prior work and tap into different timescales of word learning. In order to ensure that even the youngest, lowest vocabulary children could complete the tasks, receptive accuracy was the main dependent variable of interest in each task.

Figure 2. Schematic of the procedure. During training periods, items were held up by the experimenter one at a time. During the remainder of the trials, items were presented as real 3D items in a row on a white tray
Known Word Comprehension. Known word comprehension was designed to test children’s in-the-moment mapping of known words by testing children’s ability to recognize prototypical items by name in the lab context. These trials also serve a secondary purpose of familiarizing children with the testing procedures. The task mimicked that used in prior comprehension tests (e.g., looking-while-listening) but used real items and a live experimenter for both logistic reasons and to capture a more ecologically valid learning experience that parallels with that used in the referent selection tasks below.
This phase began with the experimenter arranging three name-known items equidistant apart in a horizontal row on a white tray out of sight of the child. Then, while maintaining eye contact with the child, the experimenter placed the tray within sight, but out of reach. After three seconds, the experimenter prompted the child to retrieve one item by name (e.g., “Can you get the shoe?”) and pushed the tray forward. The child was re-prompted up to three times if necessary and then praised and/or corrected as needed. Children’s initial answer (prior to any praise or correction) as well as their final responses (after praise/correction) were noted. Each object was the target only once. Target location and trial order were randomized.
Referent Selection and Retention. Referent selection and retention consisted of two phases tapping into the in-the-moment selection of known and novel referents (mapping), as well as retention of novel word-referent links after a five-minute break. This is similar to prior referent selection (fast-mapping) paradigms (Horst & Samuelson, Reference Horst and Samuelson2008). Importantly, these trials tap children’s ability to use their prior knowledge (or lack of) in-the-moment to disambiguate a familiar from a novel word and item. Retention trials followed to test if the new words were encoded robustly enough to be recalled from memory.
Initial referent selection consisted of eight to sixteen trialsFootnote 1 , each consisting of two randomly selected known items from the prior Known Comprehension task and a single randomly selected novel item from the pool. On half the trials, children were asked to select a known item by name in the same manner as the Known Comprehension trials (“Can you get the shoe?”); these are referred to as the Known RS trials and represent another approach to testing children’s in-the-moment known word comprehension. On the alternating trials, children were asked to select a novel item by name (“Can you get the cheem?”); these Novel RS trials tap children’s in-the-moment novel word mapping. Across trials, novel items were present only once and object locations and trial order were randomized. Children were re-prompted up to three times if needed, but without correction or praise.
A five-minute coloring break immediately followed the referent selection trials and preceded retention. A single warm-up trial (mimicking Known Comprehension) followed the break to re-engage children; four to eight retention trials immediately followed. These retention trials critically tested children’s memory for newly mapped words. On each retention trial, children were presented with three novel items – two of which had previously been targets on Novel RS trials (and thus, presumably had a novel label), and one of which was a novel foil item on Known RS trials. Targets and item locations were randomized and did not repeat across trials; however, the novel targets from the first half of the retention trials served as foils on the second half of the retention trials. There was no difference on performance between the first half and second half of the trials, however, so all trials were analyzed together.
Direct Naming and Retention. Direct Naming parallels classic novel word learning paradigms in which a child is ostensively taught the name for a new item, then immediately tested on their recollection of its label (e.g., Ellis Weismer et al., Reference Ellis Weismer, Venker, Evans and Moyle2013). While the direct, ostensive naming/training period includes mapping of words to objects, unlike referent selection, the training here presented items in isolation, without competitors or foils, and with repetition to make mapping easy. Thus, the critical test of children’s retention of these newly learned words is (mostly) independent of their disambiguation abilities.
This task began with a training period in which children were presented with one novel item at a time (see Figure 1c) and taught its label. Items were held up by the experimenter and named once, then given to the child for the child to explore, during which it was named three more times. After roughly 10 seconds, the experimenter retrieved the item, named it once more while holding it up, and then removed it from sight. The process was repeated for each of the four stimuli in a random order. After all four items were trained, children were immediately tested on their retention for the novel labelsFootnote 2 . Items were presented in pairs on a white tray equidistant apart. While maintaining eye contact with the child, the tray was placed on the table out of reach of the child. Children were then asked to retrieve an item by name (“Can you get the neem?”) and the tray was pushed within reach of the child. Children were re-prompted up to three times if needed, but no correction or praise were given. Order of trials were counterbalanced.
Novel Noun Generalization (NNG). The final task tapped generalization skills and used the canonical Novel Noun Generalization procedure by Smith and colleagues (Landau et al., Reference Landau, Smith and Jones1988; Smith et al., Reference Smith, Jones, Landau, Gershkoff-Stowe and Samuelson2002). A key aspect of this task is children’s ability to generalize a novel label to other members of the same category. Importantly, exemplars were present for reference at all times, so children’s ability to respond required less emphasis on mapping or retention abilities. The key question is if children demonstrate a shape bias, applying a new word to other items with similar shapes.
The NNG task began with two warm-up trials, followed by the test trials. On each warm-up trial, the experimenter placed the target item (e.g., a fabric flower) and the foil item (e.g., wood block) on a white tray equidistant apart and out of reach of the child. The experimenter then held up an item identical to the target (e.g., flower), naming it three times in a neutral syntax (e.g., “This is my flower”). The child was then asked “Can you get your flower?” and the tray was pushed forward for the child to make a selection. As above, children were re-prompted up to three times if needed and corrected and/or praised for their selections during warm-up. Sixteen test trials with novel items immediately followed warm-up and were nearly identical, but without correction or praise. On each trial, three items were present – a novel exemplar, a novel item matching the exemplar in shape, and a novel item matching the exemplar in material (see Figure 1d). The experimenter placed the shape-matching test item and the material-matching test item on a white tray equidistant apart, out of reach of the child. The experimenter then named the exemplar item with a novel name three times in a syntactically neutral context (e.g., “This is my zup”). Children were then asked “Can you get your zup?” and the tray was pushed forward. Children were re-prompted up to three times if needed but no praise was given. There were four test trials for each stimuli set with each test item appearing twice, but paired with a different competitor and in a different location on each trial. Order of sets and trials were randomized.
Coding
Coders blind to the hypotheses and talker status indicated children’s final selections offline via video recordings. Data from 50 random subjects (44%) were re-coded for reliability purposes. Inter-coder agreement was 97.3%. Discrepancies were settled via independent judgments by a third blind coder.
Analysis
While the sample of participants included both children who met the criteria for LT and children with NL, the vocabulary abilities of the participants represented the entire range of the normative continuum. We aimed to capture that variability in the analysis by first using a continuous measure of vocabulary percentile as the primary predictor. This dimensional approach avoids the assumptions of an arbitrary cut-off for a delay and has the potential to better capture individual variability (see JLSHR special issue on statistical approaches to language, 2019; Perry & Kucker, Reference Perry and Kucker2019). In order to compare to prior work, a second set of traditional group-level analyses comparing LT and NL children were also conducted.
First, binomial linear mixed models were used to examine the effect of a child’s vocabulary abilities and age on performance in each task. Each task was analyzed separately with a linear mixed model of children’s trial by trial performance (correct or not). Vocabulary percentile (centered) and age (in days, centered) were included as fixed effects and the maximum random effect structure justifiable was used (Barr, Levy, Scheepers & Tily, Reference Barr, Levy, Scheepers and Tily2013). In order to examine how vocabulary size (not just normative percentile) directly impacts performance, a total vocabulary score was calculated for all children who completed the longer, more detailed MCDI-WS (n=86). A shape residual score was also calculated for these children in order to obtain a measure of vocabulary structure. This shape residual score represents the proportion of the child’s vocabulary dedicated to shape-based words, without being skewed by their overall vocabulary size (Perry, Axelsson & Horst, Reference Perry, Axelsson and Horst2016; Perry & Samuelson, Reference Perry and Samuelson2011; Slone & Sandhofer, Reference Slone and Sandhofer2017). Shape vocabulary is known to be critical for generalization performance (Samuelson, Reference Samuelson2002) and prior work suggests it may differ between LT and NL children (Colunga & Sims, Reference Colunga and Sims2017; Perry & Kucker, Reference Perry and Kucker2019). Additional mixed model regression analyses were then run on this MCDI sub-set with fixed effects of vocabulary size and shape residual score and the maximal justified random effects structure. Vocabulary percentile and age were not included in these additional models because both are highly collinear with vocabulary size.
Second, in order to draw comparisons to prior work, we also used between groups t-tests to compare LT vs. NL performance on each of the tasks. These subsets of LT and NL children were matched on age and gender, selected from the larger sample.
Finally, an important part of language development is understanding how the different processes of learning impact each other. Thus, a final analysis compared across tasks to examine if performance in one task predicted a child’s performance in a different task. Overall correlations between the tasks were run and then separate generalized linear mixed models examined trial-by-trial performance on each task as predicted by average ability on the other tasks. Each model included vocabulary percentile and performance on each other task as fixed effects, a co-variate of age, and the maximal justified random effect structure. Data files and R scripts for all analyses are available via The Open Science Framework (OSF) https://osf.io/qf73r/?view_only=bbcbdb54c9cc4f6e806322a4e2183ff8.
Results
In-the-moment mapping
Known Word Comprehension
The known word comprehension task served two purposes – to test children’s ability to use known words in-the-moment and familiarize the child with the testing procedure. Thus, children were ultimately corrected and/or praised on these trials, and responses were coded for both their initial response (prior to any praise or correction) and their final response (after praise and/or correction). Initial responses represent a child’s ability to use their lexical knowledge in-the-moment; final responses represent a child’s ability to ultimately learn the procedure and respond accurately after feedback. Thus, initial responses are the primary variable of interest here, but both initial and final are analyzed.
The best fitting model for initial responses included only a random intercept for subject. There were significant positive correlations of both age, β = 1.01, z = 5.70, p <.0001, and vocabulary percentile, β = .51, z = 3.16, p = .002 (see Figure 3, red circles, top panels). In order to further explore the impact of specific vocabulary size and structure on performance, children who completed the MCDI-WS were entered into a second model that included a fixed factor of total vocabulary size and shape residual score. The best fitting model included a random effect of subject. This vocabulary model revealed a significant effect of vocabulary size, β = .92, z = 5.24, p <.0001, but not specific shape vocabulary (shape residual), β = -.02, z = -.01, p = .99 (Figure 3, red circles, bottom panels). Notably, the age-matched categorical analysis also revealed a significant difference between LT and NL children, t(50) = 2.31, p = .025 (see Figure 7, after NNG results), with NL children (M accuracy = .80, SD = .20) out-performing LT (M accuracy .62, SD = .36). The vocabulary-matched comparison did not reveal a significant difference between groups (NL: M = .70, SD = .26; LT: M = .79, SD = .26), t(28) = -.77, p = .45.
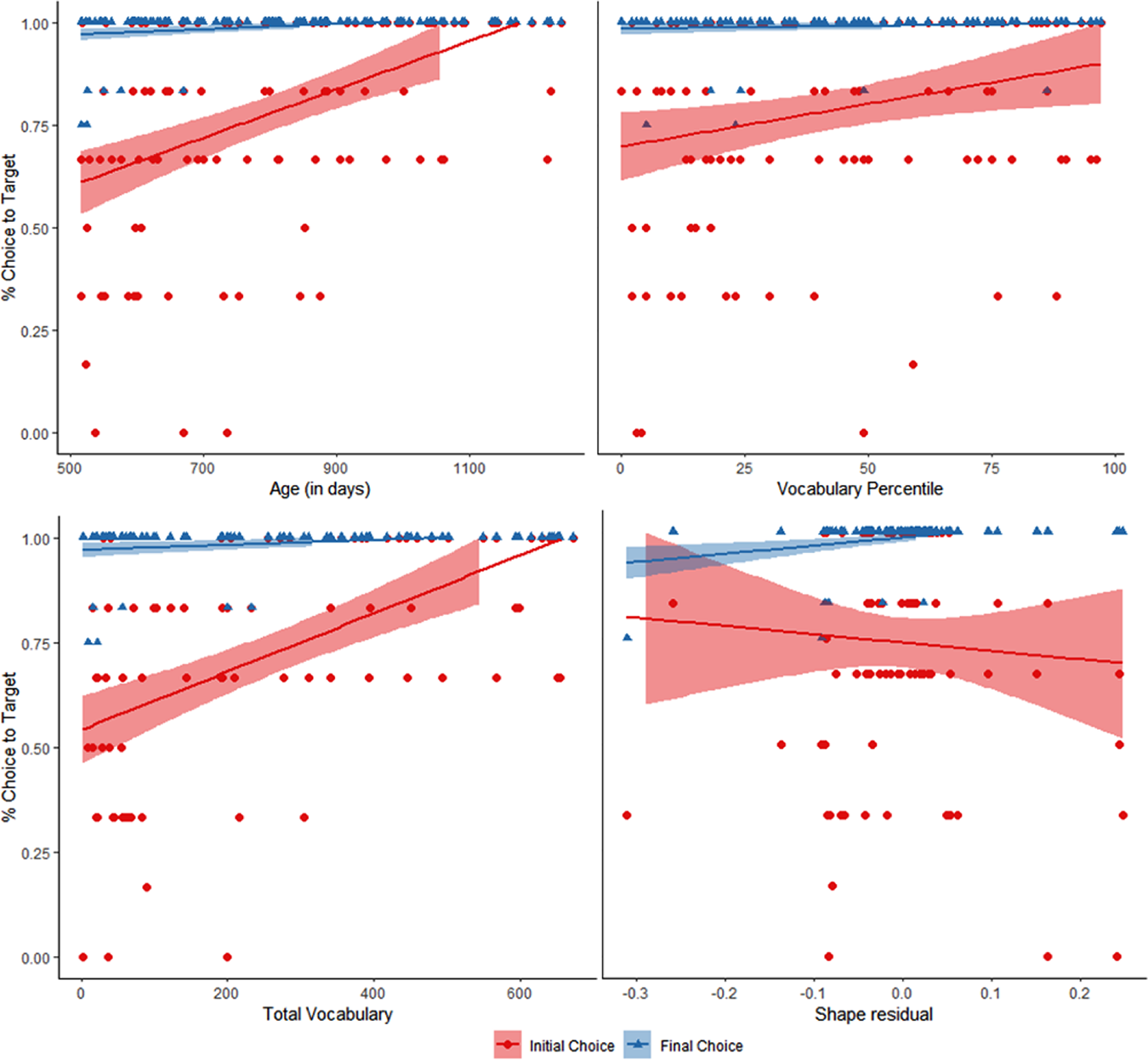
Figure 3. Performance on Known Comprehension trials. All children’s performance included in the top two panels; children with the MCDI-WS included in the bottom panels. Note: lines represent linear regressions for visualization purposes only.
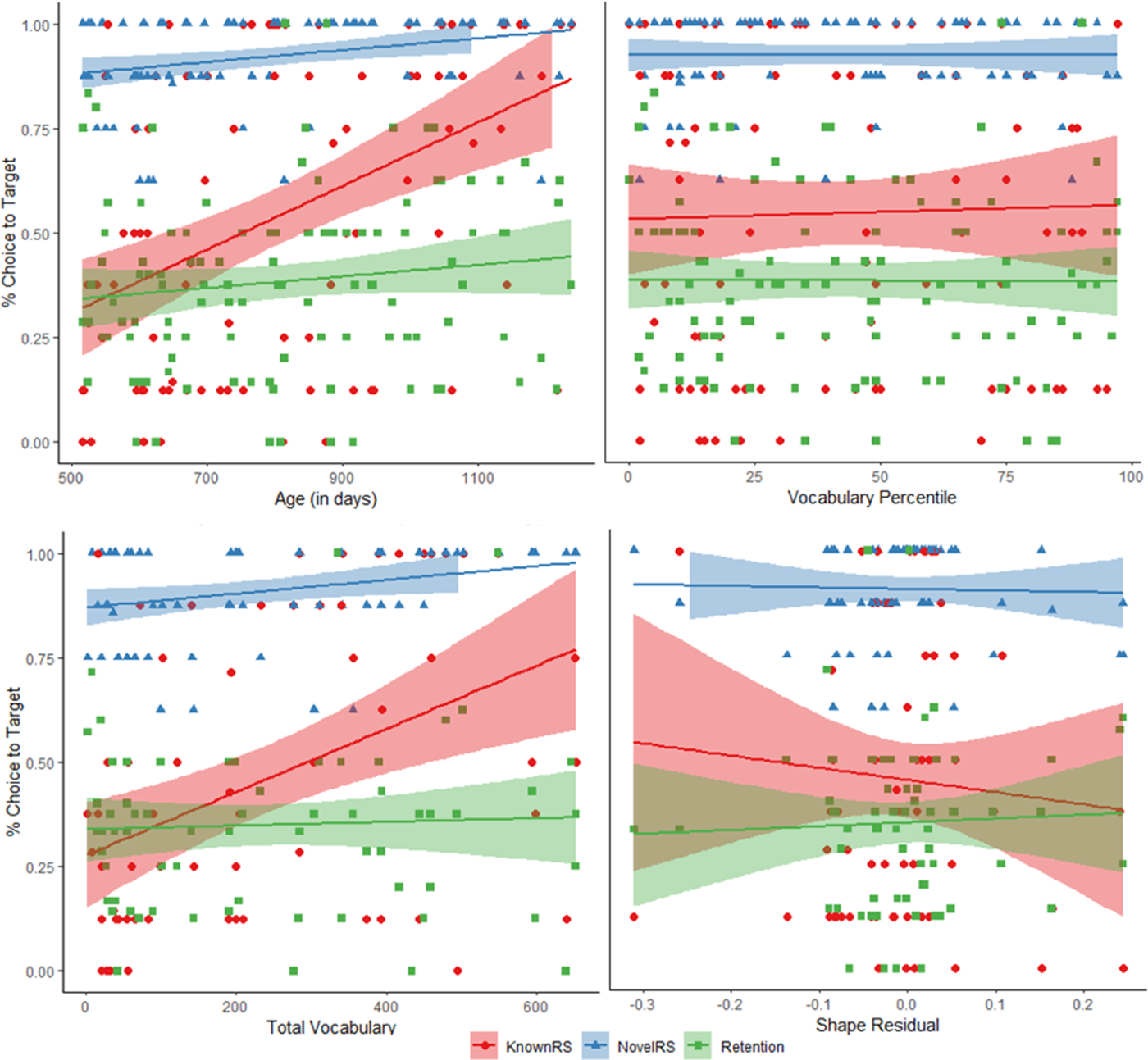
Figure 4. Performance on Referent Selection and Retention. All children’s performance included in the top two panels; children with the MCDI-WS included in the bottom panels. Note: lines represent linear regressions for visualization purposes only.
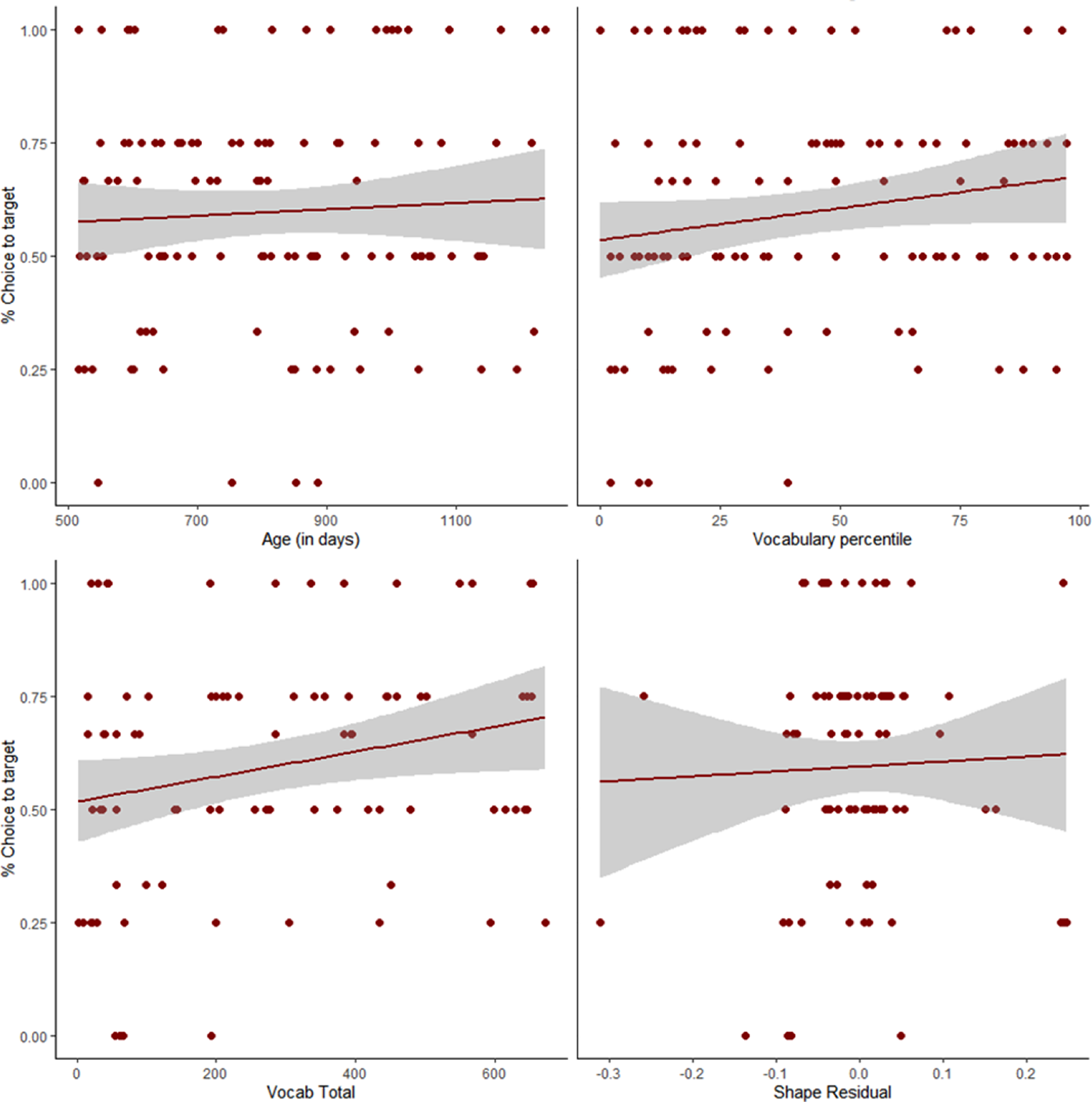
Figure 5. Performance on Direct Naming and Retention. All children’s performance included in the top two panels; children with the MCDI-WS included in the bottom panels. Note: lines represent linear regressions for visualization purposes only.
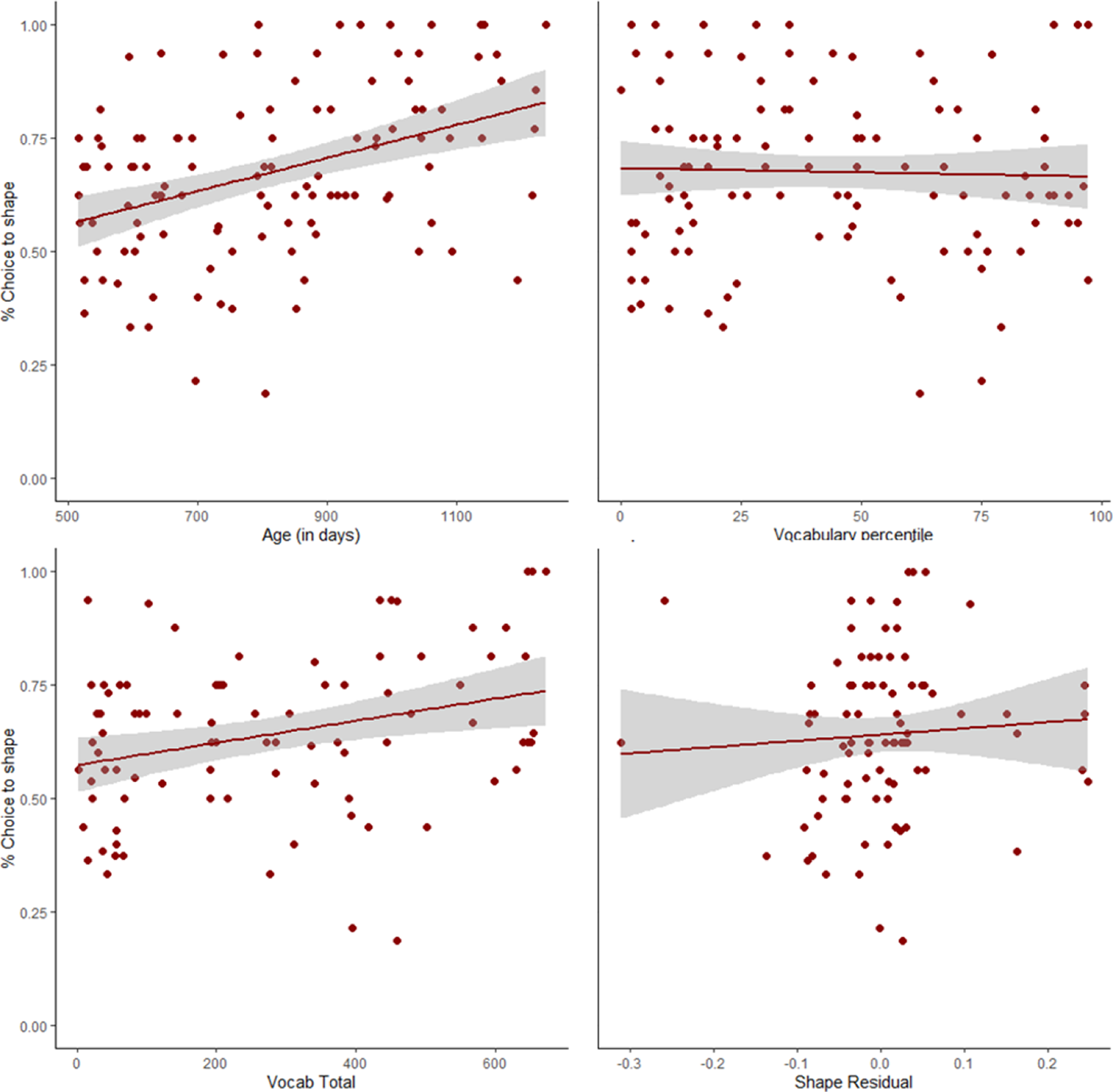
Figure 6. Performance on Novel Noun Generalization. All children’s performance included in the top two panels; children with the MCDI-WS included in the bottom panels. Note: lines represent linear regressions for visualization purposes only.

Figure 7. Performance on each task for age-matched NL children vs. LT children. Dashed line represents chance. Asterisk within bars represent difference from chance; above bars represent difference between NL and LT groups on that task. ***p<.001 **p<.01, *p<.05, mp<.10
After children were corrected and praised, their final selections were analyzed (Figure 3, blue triangles); the best fitting model included only a random effect of subject. Final selections were significantly predicted by a child’s age, β = 3.70, z = 2.18, p = .03, but not vocabulary percentile, β = .26, z = .58, p = .56. The second model with total vocabulary size and shape residual scores included a random effect of subject and revealed no effect of vocabulary size, β = 1.29, z = 1.51, p =.13 and a marginal effect of shape residual, β = 6.94, z = 1.95, p = .05. Neither the analysis with age-matched groups, t(43.56) = .28, p =.78 (NL: M = .99, SD = .02; LT: M = .99, SD = .02), nor the vocabulary-matched groups, t(14) = -1.00, p = .33 (NL: M = .99, SD = .03; LT: M = 1.00, SD = 0), show an effect of talker status. However, nearly all children were at ceiling on the final choices here with low variability, thus the lack of group differences is not surprising.
Performance on Known Comprehension offers two conclusions. First, as seen in initial performance, both vocabulary and age matter for in-the-moment known word processing. Though nearly all children were well above chance overall, there were clear differences in the robustness of this ability dependent on vocabulary and age. On the surface, even LT children can operate in-the-moment to respond accurately to a known label as demonstrated by their above-chance performance. However, a child’s ability to do so seamlessly appears to be influenced by their specific vocabulary size and age – LT children (and those with lower vocabularies or who were younger in general) performed much more poorly than their NL peers (and those with higher vocabularies or whom were older). A second conclusion is that the near-ceiling performance on children’s final choices demonstrates that children understood the procedures, giving faith that any poor performance in the subsequent tasks is unlikely to be due to confusion over basic methods used.
Referent Selection
Known Referent Selection. Known Referent Selection (Known RS) presents children with the same familiar, name-known items presented in the Known Comprehension phase, but now in the context of a novel foil distractor item. Thus, Known RS represents a critical test of the robustness of a child’s word knowledge against their novelty biases (see Kucker et al., Reference Kucker, McMurray and Samuelson2018). Again, multiple linear mixed models were run. The best fitting model included random intercepts for both subject and item. Vocabulary percentile marginally predicted a child’s Known RS performance, β = .36, z = 1.69, p = .09, while age significantly predicted performance, β = 1.32, z = 5.67, p <.0001 (Figure 4, red circles, top panels). A second vocabulary model included a random effect of subject and item and revealed a significant effect of vocabulary size, β = 1.29, z = 5.27, p <.0001, but no effect of shape residual, β = -3.86, z = -1.41, p = .16 (Figure 4, red circles, bottom panels). Furthermore, age-matched groups, t(50) = 1.85, p = .07, but not vocabulary-matched groups, t(28) = -1.23, p = .23, showed marginally significant differences between LT and NL. Within the age-matched groups, the LT children selected the known target at levels no different than chance (.33) (M = .39, SD = .30), t(25) = .77, p = .45, whereas the NL children selected the known target above chance (M = .57, SD = .32), t(25) = 3.48, p = .002 (Figure 7).
Overall, there was a substantial drop in performance from the just-prior Known Comprehension trials for both LT and NL children, with LT children now at chance. Unlike the Known Comprehension trials, however, here novel foil items were present, which requires the child to ignore novel distractors while mapping the known word and referent. Known RS is thus an arguably more difficult test of children’s in-the-moment use of their lexicon and provides a measure of a child’s novelty bias – how often do they select the novel foil item instead of the familiar target? To test this, additional models were run to examine the correlation between choices to the novel item with vocabulary and age. The mixed model of children’s novel choices included only a random intercept of subject and revealed no effect of vocabulary β = -.30, z = -1.53, p = .13, but a significant effect of age, β = -1.11, z = -5.39, p <.0001. A second vocabulary regression included a random effect of subject and found a significant main effect of vocabulary size, β = -1.08, z = -5.07, p <.001, but not shape residual, β = 2.09, z = .91, p = .36. The age-matched groups also show a marginal effect of talker status, t(50) = -1.66, p = .104 (NL: M = .40, SD = .33; LT: M = .55, SD = .35), but the vocabulary-matched groups do not, t(28) = 1.29, p = .21. In fact, in the age-matched group, the LT children were selecting the novel foil distractor the majority of the time, significantly above chance (33%), t(25)=3.25, p=.003, whereas the NL group was at chance for selecting the novel distractor, t(25)=.99, p=.33. That is, LT children’s chance performance on Known RS appears due to an overriding bias toward novelty, similar to that seen in 18-month-old word learners (Kucker et al., Reference Kucker, McMurray and Samuelson2018).
Novel Referent Selection. The Novel RS trials are set up identically to Known RS with two known items and a single novel item, but here, children are asked to select the novel item by name. This provides a measure of initial novel word mapping or disambiguation ability. The best fitting model included a random effect of subject and found a significant effect of age, β = .48, z = 2.79, p = .005, but no effect of vocabulary percentile, β = .05, z = .30, p = .76 (Figure 4, blue triangles, top panels). The vocabulary model included only a random effect of subject and found a significant effect of vocabulary size, β = .40, z = 2.13, p = .03, but not shape residual, β = .18, z = .11, p = .91 (Figure 4, blue triangles, bottom panels). Neither the age-matched, t(50) = .58, p = .56, nor the vocabulary-matched, t(28) = -.38, p = .71, groups found significant differences between LT and NL. Overall, all children were well above chance, near ceiling (age group NL: M = .92, SD = .16; LT: M = .90, SD = .21, see Figure 7). Given the novelty biases seen on the Known RS trials, selection of the novel item when it is the target, even by the LT children, is not terribly surprising. However, the overall high performance combined with the relatively poor performance on Known RS (especially for LT children) should lend caution to interpreting a child’s ability to learn new words on these Novel RS trials given their indiscriminate ability to always select the unknown item regardless of what label is given. Testing learning is the goal of the Retention trials.
Retention
Referent Selection Retention (RS Retention)
After a short break, children were tested on their retention for the words exposed during the RS trials. A linear mixed model for RS retention was run with fixed effects of vocabulary percentile and age. The best fitting model included both subject and item as random effects. There was a marginally significant effect of age on performance, β = .16, z = 1.81, p = .07, but no effect of vocabulary, β = .01, z = .08, p = .94 (Figure 4, green squares, top panels). The vocabulary model included both subject and item as random effects and showed no effect of vocabulary, β = .13, z = 1.17, p = .24, nor shape residual, β = .64, z = .50, p = .62 (Figure 4, green squares, bottom panels). The categorical analysis revealed no significant differences between LT and NL for either age-matched, t(50) = .87, p = .39 or vocabulary-matched, t(28) = .24, p = .81 groups.Footnote 3 However, NL children in the age-matched groups selected the target 41% of the time, significantly above chance (33%), t(25) = 2.14, p = .04, whereas the LT children did not, selecting it only 36% of the time, t(25) = .78, p = .44 (Figure 7, in next section). This is consistent with prior work that, for most children under three years old, retention is difficult (Horst & Samuelson, Reference Horst and Samuelson2008), but as children get older, their ability to recall new word-referent pairs increases (see also Bion et al., Reference Bion, Borovsky and Fernald2013). Notably, however, prior work with LT children has found mixed results for retention in this group and LT children here (matched to NL on age) were not above chance, suggesting a possible area of weakness.
Direct Naming Retention
For the Direct Naming task, children’s ability to retain the novel word-referent pairs after a repetitive, ostensive, naming period was tested. While also a test of retention like RS Retention, this task eliminates the competition during learning and minimizes the in-the-moment processing that is required. Thus, it is arguably a more direct test of retention because it is less dependent on disambiguation abilities. It also parallels some of the more traditional “fast-mapping” tasks in which children are ostensively taught a label and immediately tested on that knowledge. The best fitting model included both subject and item and revealed a marginal main effect of vocabulary percentile, β = .20, z = 1.89, p = .06, but not age, β = .11, z = 1.06, p = .29 (Figure 5, top panels). The vocabulary model included only a random effect of subject and found a significant effect of vocabulary size, β = .24, z = 2.10, p = .04, but not shape vocabulary, β = -.25, z = -.19, p = .85 (Figure 5, bottom panels). The categorical analysis was not significant for the age-matched, t(50) = 1.60, p = .11, or vocabulary-matched, t(28) = .35, p = .73, groups. However, as with RS Retention, the age-matched NL group retained the newly taught words above chance (50%), whereas the LT group did not – NL: (M=.62, SD = .40), t(25)=2.37, p = .026; LT: (M=.50, SD = .41), t(25)=0.0, p = 1.0, Figure 7 (end of NNG section). Though there were not group-level differences or consistent vocabulary effects across both retention tasks (neither RS or here), the chance performance of the LT children suggests that overall lexical knowledge may impact retention abilities in subtle ways, but further work may be needed to tease this apart.
Generalization
Novel Noun Generalization
Once a child makes an association between a novel word and its referent, another critical step is the ability to generalize those novel labels to other exemplars of the same category – for solid nouns, this is demonstrated via a shape bias (Smith et al., Reference Smith, Jones, Landau, Gershkoff-Stowe and Samuelson2002). The linear mixed model used predicted children’s selection of the shape-matching item and included random effects of both subject and item. The model revealed a main effect of age, β = .40, z = 4.61, p <.001, but not vocabulary percentile, β = .02, z = .23, p = .82 (Figure 6, top panels). The vocabulary model included a random effect of both subject and item, revealing a significant effect of vocabulary size, β = .25, z = 2.91, p = .003, but no effect of shape vocabulary, β = .54, z = .54, p = .59 (Figure 6, bottom panels). Similar to prior work (Colunga & Sims, Reference Colunga and Sims2017), there were no differences in the age-matched NL and LT groups, t(50) = .93, p = .36, nor in the vocabulary-matched groups, t(28) = .97, p = .34. However, the majority of children were above chance (50%), showing a shape bias in both the age-matched NL group (M = .68, SD = .45), t(25)=5.40, p<.001, and the LT group (M = .63, SD = .45), t(25)= 3.60, p=.001 (see Figure 7). However, like prior work by Perry and Kucker (Reference Perry and Kucker2019), a child’s status as a late talker may not tell the entire story – for children under 30-months, the size of their vocabulary is predictive of performance, not their category label as LT. And, we know from prior work that the structure of one’s vocabulary is key for showing a shape bias. In fact, evidence suggests that LT children’s noun structure is unique and that uniqueness matters for generalization (Beckage, Smith & Hills, Reference Beckage, Smith and Hills2011; Colunga & Sims, Reference Colunga and Sims2017; Perry & Kucker, Reference Perry and Kucker2019). Though shape residual was not significant in the full model, exploratory analysis showed an interaction of the LT group and shape residual such that LT children with fewer shape-based nouns in their vocabulary than what is expected are less likely to show a shape bias, much like prior work.
Across tasks
Word learning is not a quick, instant process. Instead, it unfolds over multiple, inter-related timescales. How those phases are related is critical. Thus, two final sets of analyses compared performance across each of the tasks. First, bivariate correlations between performance on each task were run. These correlations give an overview of relationships between processes, but are limited to the group-level data. Thus, a second analysis incorporating within-subject repeated measures was conducted. Here, a generalized mixed model predicting an individual’s performance on a given task from their average performance on each of the other tasks were run. To examine if language delay predicts different patterns of relationships, binomial mixed models were run for each task and talker group (LT vs. NL) individually. These models included the maximal random effects structure justified.
Correlations between average performance in each task are presented in Table 2. Much like the by-task analyses, a child’s age significantly correlates with their performance in nearly every task, except those tapping retention (RS Retention and Direct Naming Retention). Vocabulary percentile is also significantly positively associated with Initial Known Comprehension and marginally with Direct Naming Retention. Importantly, there are also strong correlations between tasks, and across phases (in-the-moment mapping, retention, and generalization). All tasks tapping in-the-moment known selection are related – Initial Known Comprehension correlated with Final Known Comprehension and Known RS. However, the retention tasks do not correlate, suggesting as we hypothesized, that they either tap into slightly different elements of retention or that the differences in prior mapping (learning/selection) exposures indeed have different cascading effects. There are also relationships across timescales – Initial Known Comprehension positively correlated with NNG, Known RS correlated with Direct Naming Retention as well as with NNG, Novel RS is associated with Direct Naming, and Direct Naming and NNG are positively correlated.Footnote 4
Table 2. Correlations between vocabulary percentile, age, and task performance

*** p<.001
** p<.01
* p<.05
m p<.1
To further probe these correlations, repeated measures regressions were run. As before, in each of these models, children’s trial-by-trial performance on a given task was the outcome variable. Fixed effects included average performance (centered) on each of the other tasks as well as covariates of vocabulary percentile (centered) and age (in days, centered). Final Known Comprehension was not included as a predictor due to the ceiling effect seen by most children and its less central goal of orienting children to the task procedure. The best fitting models all included random intercepts of subject and/or item. See Table 3 for the full data table of each model. There was some evidence of a relationship between the tasks tapping in-the-moment mapping; Known RS significantly predicted Initial and Final Known Comprehension performance, and Initial Known Comprehension performance predicted Known RS ability. Novel RS and Direct Naming also predicted each other. Overall, however, few other predictors or models revealed significant effects, suggesting that while overall performance across tasks are correlated in the bivariate correlations, the variability makes relationships within a specific child harder to detect.
Table 3. Predicting performance on each task.
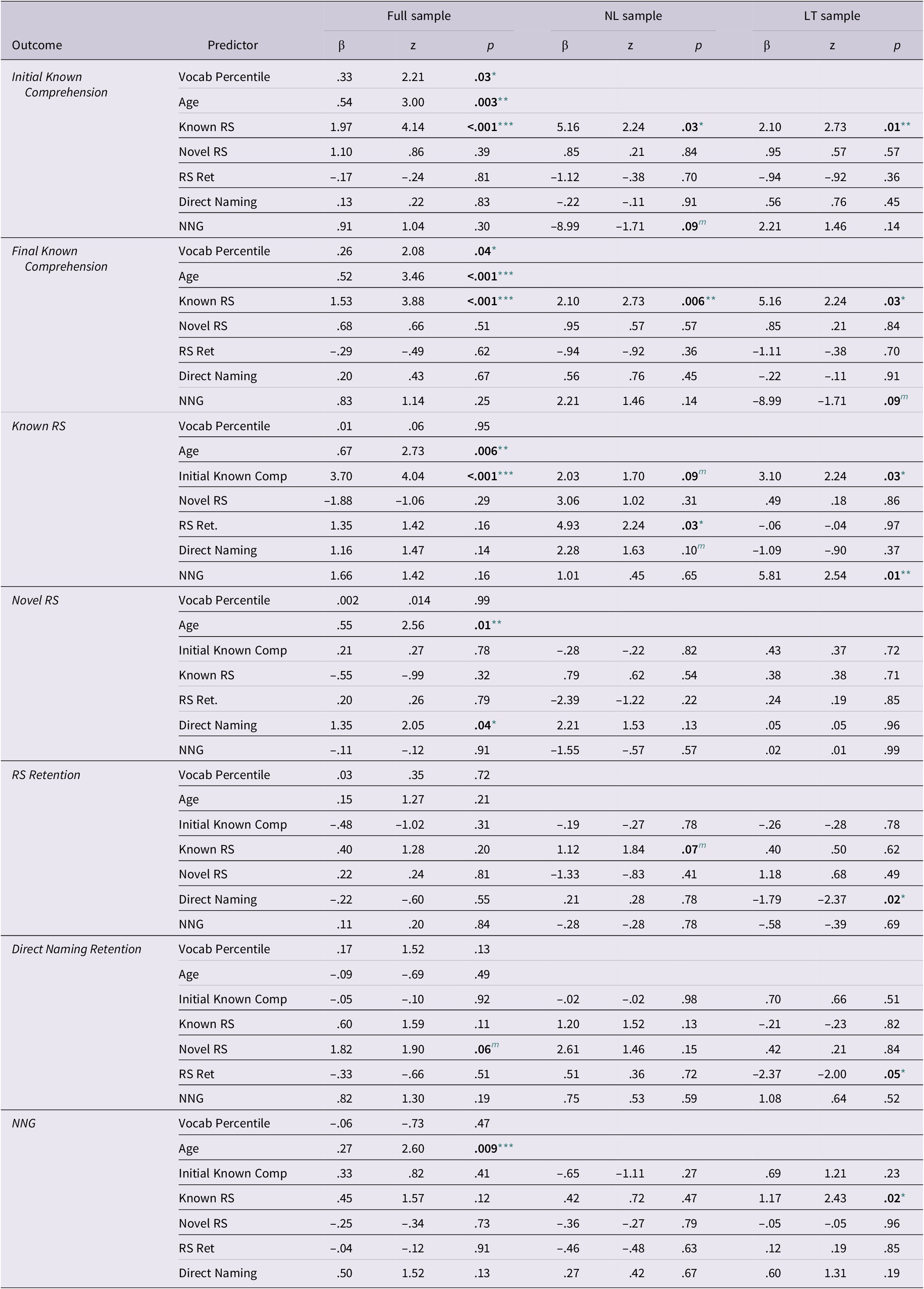
*** p<.001
** p<.01
* p<.05
m p<.1
A critical final question is if this pattern of relationships across tasks/processes is different for NL vs. LT children. Thus, a final set of follow-up models for the age-matched NL and LT groups were run (see Table 3, right columns). As with the full sample, predictions between tasks was largely non-significant. However, there were a few notable differences between NL and LT patterns. For instance, NNG predicts Initial Known Comprehension performance for NL, but only predicts Final Known Comprehension in the LT sample. This reinforces that robust known vocabulary (as tested via Initial Known Comprehension performance) may support a shape bias and potentially on-track vocabulary growth. Likewise, Known RS performance is predicted by Initial Known Comprehension ability for both groups – suggesting that both tap the ability to use known words in-the-moment. However, other predictors of Known RS diverge across the groups – RS Retention predicts Known RS in the NL group, whereas NNG predicts Known RS in the LT group. In the LT group, there is some evidence that the two tasks tapping retention correlate – RS Retention and Direct Naming predict each other in the LT group, but not the NL group. Given the large amount of null results, the evidence here is merely preliminary, but suggests LT and NL children may differ in the types of processes that support word learning and cascades for future learning.
Discussion
The current study aimed to systematically measure the multi-faceted nature of word learning across timescales (in-the-moment mapping, retention, and generalization) in a wide range of children, including those with language delays. There were two key conclusions. First, the results reinforce that across multiple timescales both age and vocabulary abilities contribute to children’s word learning. Second, children with smaller vocabularies, including LT children, demonstrate the biggest deficits in tasks that tap in-the-moment processing of known words, with some evidence for additional cascading deficits in retention. Taken together, the results suggest that approaches to studying word learning that cross multiple timescales may offer a holistic view for capturing word learning potential in both NL and LT children.
The importance of age and vocabulary across timescales
Replicating prior work (Bion et al., Reference Bion, Borovsky and Fernald2013; Samuelson, Schutte & Horst, Reference Samuelson, Schutte and Horst2009), child’s age was a significant predictor of their language ability. What is expanded upon here is that age positively predicted across multiple different timescales/processes of the word learning process – significantly influenced known word identification (in Initial Known Comprehension, Final Known Comprehension, and Known RS), novel word selection and disambiguation (in Novel RS), some elements of novel word retention (in the RS Retention task), and generalization (in NNG). Moreover, while the children here represent a wide age range from as young as 17-months to as old as 40-months, there are still large changes in abilities even across a few months within that span. Age thus continues to be a critical variable to consider when comparing children’s word learning abilities at any point in the word learning process.
A second consistent finding is that timescales of word learning are all influenced in some way by vocabulary, normative percentile rank, as well as specific vocabulary size and structure. Children with lower vocabulary sizes, those lower on normative vocabulary, and those classified as LT children perform poorer on in-the-moment known word comprehension tasks (Initial Known Comprehension, Known RS) and some elements of retention (Direct Naming). Total vocabulary size (but not percentile rank or LT status) predicts in-the-moment Novel RS, and generalization (NNG). This emphasizes the critical role that the vocabulary knowledge a child brings to the task plays in their ability to use that knowledge and acquire new words. Importantly, it suggests that deficits in word learning seen in LT children with smaller vocabularies may stem from their weak lexical foundation, which prevents them from acting in-the-moment as accurately as their NL peers. Though, in part, unsurprisingly, this lays a foundation for future work more closely tracking cascading effects across processes.
Finally, the results lend initial support that word learning processes were likely related – overall performance on some tasks correlate with performance in another – namely, some in-the-moment processes (Initial Known Comprehension, Known RS) correlate with some retention processes (Direct Naming) and generalization (NNG). The within-child analyses comparing performance for an individual child to their performance in other tasks were largely non-significant, however. Though prior work has demonstrated relationships between in-the-moment mapping accuracy and retention in the same child (Bion et al., Reference Bion, Borovsky and Fernald2013; Kucker et al., Reference Kucker, McMurray and Samuelson2018), the lack of relationship here may be due to the high variability even within children and limited number of trials in each task – e.g., to minimize the chance of fatigue, Direct Naming included only four new words/test trials. Nonetheless, when correlations were separately examined for LT vs. NL children, there was some indication that different relationships may exist for each group. The LT group’s in-the-moment known word selection (Known RS) was predicted by their generalization ability (and vice versa), whereas NL children’s Known RS was correlated with both RS Retention and NNG. The fact that Known RS and NNG are related in both LT and NL groups reinforces that the strength of current vocabulary (demonstrated by the ability to use that vocabulary in-the-moment) supports stronger lexical foundations, which supports generalization (see also Samuelson, Reference Samuelson2002). The current results also found that LT children’s RS Retention was predicted by Direct Naming and vice versa, which was not the case for NL children. This tentatively suggests that LT children may be using similar processes for both retention tasks, whereas for NL children, their retention is more likely supported by cascading effects of strong in-the-moment processes (given that RS Retention was predicted by Known RS in NL children). Taken together, these findings demonstrate that discrepancies in word learning abilities across children may lie in poor in-the-moment known word processing, and because any individual word does not exist in isolation (it is part of a larger lexical network), this can cascade to influence retention and generalization and, thus, possibly vocabulary growth more broadly.
Implications for LT children
The results suggest that as a group “late talkers” (and those with smaller vocabularies in general) may struggle most prominently with tasks that tap their (limited) vocabulary, as demonstrated by their significantly lower performance on Initial Known Comprehension and Known RS. On the surface, this is unsurprising because we know that, though a caregiver may report that a child says a word, it does not necessarily mean that the child has robust knowledge of that word. That fact is underscored here – caregivers reported that all children knew the known items used, but children still varied quite remarkably in their ability to bring such knowledge to bear in the lab setting. In fact, recent laboratory tests recognize this variability, showing that while, overall, children do recognize “known” items in the lab, there is a bias for specific familiar exemplars (Garrison et al., Reference Garrison, Baudet, Breitfeld, Aberman and Bergelson2020), suggesting that representation of known items may still be weak in some ways. What the current work adds is that overall vocabulary size predicts the use of any individual word in a given moment. The smaller the vocabulary, the weaker the lexical network and, thus, the harder it is for children to use their vocabulary even for well-known words. This is particularly true for LT children here and consistent with prior work with LT children (Ellis et al., Reference Ellis, Borovsky, Elman and Evans2015) and younger children with smaller vocabularies (Kucker et al., Reference Kucker, McMurray and Samuelson2018). This also means that LT children may not be able to use the same mechanisms for learning new words as their NL peers. Because many of the known word learning constraints require a focus on vocabulary (e.g., mutual exclusivity, contrast), a lack of robust knowledge can impair use of these mechanisms. In fact, LT children here showed a robust novelty bias on Known RS trials, suggesting that novelty (not vocabulary) may be driving their in-the-moment behavior and selections, even on the Novel RS trials. Nevertheless, teasing the role of weak lexical knowledge apart from novelty remains an open question (see Mather, Reference Mather2013).
In NL children, good in-the-moment processing tends to correlate with better retention, both in looking-based measures (Bion et al., Reference Bion, Borovsky and Fernald2013) and real item reaching measures (Kucker et al., Reference Kucker, McMurray and Samuelson2018). However, this does not seem to be the case for the LT children here. While there are generally strong correlations across tasks at the group level, LT children showed stronger correlations between the in-the-moment tasks (Initial Known Comprehension and Known RS) and between the retention tasks (RS Retention and Direct Naming Retention) than they did across timescales. NL children’s retention (in RS Retention at least) was predicted by their RS performance, however. This is consistent with prior work showing differences in known word processing between LT and NL children, but not overall retention (Ellis et al., Reference Ellis, Borovsky, Elman and Evans2015). Work with children with autism spectrum disorder also found delays in in-the-moment processing, but less so with retention and generalization (Hartley et al., Reference Hartley, Bird and Monaghan2019, Reference Hartley, Bird and Monaghan2020). Nonetheless, the processes have reciprocal effects – a smaller vocabulary may be a result of that child’s inability to retain and integrate words into their lexicon in the first place.
The final task here tested children’s generalization abilities. Overall, children showed a stronger shape bias as they got older, and there were no large differences between NL and LT children. This contrasts with prior work (Jones, Reference Jones2003; Perry & Kucker, Reference Perry and Kucker2019) which found deficits in generalization for LT children. However, the children here spanned a wider age range than that in prior work and the majority of children were already demonstrating a shape bias. As discussed previously, the structure of one’s vocabulary has increasingly been found to be a key predictor for generalization, especially in LT children (Beckage et al., Reference Beckage, Smith and Hills2011; Colunga & Sims, Reference Colunga and Sims2017; Perry & Kucker, Reference Perry and Kucker2019). Indeed, exploratory analyses found an interaction of shape vocabulary and the LT group on NNG performance here, replicating prior work (Perry & Kucker, Reference Perry and Kucker2019). Further exploration of vocabulary structure and deeper analysis of heterogeneity within the vocabulary abilities of LT children will be critical for future work.
Future steps and conclusions
The current study takes a first step toward examining variability in word learning across multiple timescales. It offers both a foundation highlighting the complex nature of word learning as well as incentive for future work further examining these processes. For one, LT children in the current sample were identified based on caregiver report of productive vocabulary size, yet the tasks used here were comprehension based and did not require children to verbalize their response. As such, the current methods serve as a validity test that reported deficits in production extend to at least some observable comprehension deficits. Comprehension, however, does also require slightly different processes – robust semantic representations of the referents are required, for instance, but only weak phonological representations are needed as the labels are provided for the child. Thus, differences between comprehension and production ought to be further examined, especially as they relate to potential phonological delays in LT children.
While the current study offers only a first step to assessing cascading effects, it does suggest that a lack of an ability to use current vocabulary in-the-moment may have cascading effects on other word learning processes. Critically, this means that targeting (and improving) in-the-moment processing of LT children may be fundamental for improving their language trajectories, and potentially have implications for interventions and the assessment of children with other language delays (e.g., Developmental Language Disorder). Long-term growth and longitudinal analyses are needed to fully quantify these effects, however.
Taking a more dynamic, pathways-based approach, in which different timescales as well as different individual abilities are included, is critical for a holistic picture of word learning. The results here suggest that fast and slow processes cannot be fully separated – performance on one task correlates with performance on others – but that the mechanisms driving behavior and therefore learning may shift as children grow their vocabularies. Such variability calls for more multi-dimensional approaches that vary the weight of in-the-moment context-dependent processing vs. memory processes vs. generalization abilities. To fully understand both normative development and also the nature of delays in LT children, multiple underlying word learning processes ought to be measured and considered.
Acknowledgments
Funding was provided by a Callier Center postdoctoral fellowship at the University of Texas Dallas to the first author. The authors would like to thank the former members of the Oshkosh Development Lab at the University of Wisconsin Oshkosh and the current members of the Language, Learning, and Development Lab at Oklahoma State for help with coding.











 Open access
Open access