Introduction
While all typically developing children acquire native proficiency in their language, there are individual differences in the pace and trajectory of early language development. One important factor in explaining the variance in early language acquisition is the quantity and quality of the linguistic input children receive (e.g., Hart & Risley, Reference Hart and Risley1995; Hoff, Reference Hoff2003; Huttenlocher, Haight, Bryk, Seltzer, & Lyons, Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991). Young children are exposed to a special register of speech with unique characteristics often called child-directed speech (CDS). Infants attend more to CDS compared to adult-to-adult speech (Cooper & Aslin, Reference Cooper and Aslin1990; Pegg, Werker, & McLeod, Reference Pegg, Werker and McLeod1992), and it has various properties that facilitate language learning (see Golinkoff, Can, Soderstrom, & Hirsh-Pasek, Reference Golinkoff, Can, Soderstrom and Hirsh-Pasek2015; Soderstrom, Reference Soderstrom2007, for reviews). Children who hear more child-directed speech start talking earlier, have larger expressive vocabularies, and are earlier to acquire more complex syntactic structures (Hart & Risley, Reference Hart and Risley1995; Huttenlocher, Waterfall, Vasilyeva, Vevea, & Hedges, Reference Huttenlocher, Waterfall, Vasilyeva, Vevea and Hedges2010). They also learn new words faster than children who hear less child-directed speech (Huttenlocher et al., Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991), and are more efficient in processing familiar words in real time (Weisleder & Fernald, Reference Weisleder and Fernald2013).
The effect of input variation on language development is also found at the group level. One of the key findings in the language acquisition literature is that socioeconomic status (SES) impacts the input children receive: high-SES children generally receive more input and higher-quality input than lower-SES children, a pattern that has cascading effects on language development (Fernald, Marchman, & Weisleder, Reference Fernald, Marchman and Weisleder2013; Hart and Risley, Reference Hart and Risley1995; Hoff, Reference Hoff2006; Hoff, Laursen, & Tardif, Reference Hoff, Laursen, Tardif and Bornstein2002). In their seminal work, Hart and Risley (Reference Hart and Risley1995) found that higher-SES caregivers tend to speak more to their children: over the course of one week higher-SES children heard almost four times as many words as lower-SES children, a gap that remained constant over their first three years. SES also impacts the quality of speech to children. Higher-SES children are exposed to greater lexical diversity, more syntactic complexity, and a larger proportion of conversation-eliciting questions (Hart & Risley, Reference Hart and Risley1995; Hoff, Reference Hoff2006; Hoff-Ginsberg, Reference Hoff-Ginsberg1991; Huttenlocher et al., Reference Huttenlocher, Waterfall, Vasilyeva, Vevea and Hedges2010; Rowe, Reference Rowe2012; see Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016b, for a recent review).
Importantly, these quantitative and qualitative differences are predictive of various language learning outcomes, leading to SES differences that emerge early on and persist across development. Hart and Risley (Reference Hart and Risley1995) found that, by the age of three, higher-SES children spoke twice as many words as the lower-SES children. Further work has shown that the productive vocabularies of high-SES children grow faster during their second year than those of mid-SES children (Hoff, Reference Hoff2003). Disparities in vocabulary size and online language processing between infants from higher- and lower-SES families are already evident at 18 months of age, resulting in a 6-month gap in processing speed between the two groups by the age of 24 months (Fernald et al., Reference Fernald, Marchman and Weisleder2013). There are additional output differences between high- and low-SES children in grammatical development, syntactic complexity, and communication skills (Hoff, Reference Hoff2006). Similarly, variation within SES is predictive of language abilities: low-SES children who heard more child-directed speech processed new words better and had larger expressive vocabularies compared to other low-SES children who heard fewer words (Weisleder & Fernald, Reference Weisleder and Fernald2013). Taken together, these findings suggest a strong link between SES, the kind of input children hear, and their language learning trajectory.
What characteristics of children's input are influenced by SES? The vast literature on CDS documents an effect of SES on several core properties of child-directed speech. We distinguish between three different characteristics: (1) the amount of speech, e.g., the number of words or utterances; (2) how rich the input is, reflected in the variety of words or constructions; and (3) how information is structured, reflected in how words and sentences are organized. Much of the work on SES-related differences has focused on the first two properties. Here, we ask how SES impacts the way information is structured in CDS. We know that SES impacts the amount of speech children hear (Fernald et al., Reference Fernald, Marchman and Weisleder2013; Hart & Risley, Reference Hart and Risley1995; Hoff, Reference Hoff2006; Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002), and the diversity of lexical items and syntactic constructions (Huttenlocher et al., Reference Huttenlocher, Waterfall, Vasilyeva, Vevea and Hedges2010; Rowe, Leech, & Cabrera, Reference Rowe, Leech and Cabrera2016). However, child-directed speech is also characterized by certain ways of organizing words and sentences. Compared to adult-directed speech, child-directed speech is highly repetitive, containing frequently recurring phrases (e.g., Where are you ___ ; Cameron-Faulkner, Lieven, & Tomasello, Reference Cameron-Faulkner, Lieven and Tomasello2003). This repetition can facilitate learning: the frequency of maternal self-repetitions and expansions is positively correlated with language growth, specifically verb phrase development (Fernald & Hurtado, Reference Fernald and Hurtado2006; Hoff-Ginsberg, Reference Hoff-Ginsberg1986; Küntay & Slobin, Reference Küntay, Slobin, Slobin, Gerhardt, Kyratzis and Guo1996; Lew-Williams, Pelucchi, & Saffran, Reference Lew-Williams, Pelucchi and Saffran2011; Newport, Gleitman, & Gleitman, Reference Newport, Gleitman, Gleitman, Snow and Ferguson1977; Waterfall, Reference Waterfall2006). CDS also includes additional repetitions of a specific sort: caregivers tend to use successive utterances with partial self-repetitions often called variation sets (Küntay & Slobin, Reference Küntay, Slobin, Slobin, Gerhardt, Kyratzis and Guo1996; Waterfall, Reference Waterfall2006). The following sequence (taken from the Howe corpus; Howe, Reference Howe1981), is an example of a variation set, in which a mother addresses her two-year-old child:
– Yes yes, he's got toes.
– Four toes.
– Have you got toes, Richard?
– Where are your toes?
– Show me your toes.
– Come and show me your toes.
– Where are your toes?
Variation sets were shown to be frequent in CDS (Küntay & Slobin, Reference Küntay, Slobin, Slobin, Gerhardt, Kyratzis and Guo1996; Onnis, Waterfall, & Edelman, Reference Onnis, Waterfall and Edelman2008). Brodsky, Waterfall, and Edelman (Reference Brodsky, Waterfall and Edelman2007) showed that this characteristic cannot be the result of the bigram or trigram statistics of the corpus, thus concluding that variation sets are a unique feature of CDS. Variation sets are both frequent in CDS and related to better learning outcomes in both naturalistic and experimental settings. In a longitudinal corpus study, Waterfall (Reference Waterfall2006) found that nouns, verbs, and multiword constituents that appeared inside variation sets were produced earlier by children compared to ones that did not appear inside variation sets. In addition, she found that the proportion of variation sets moderately decreased during the second year of life (between ages 1;2 and 2;6), suggesting their usefulness for early language learning (Waterfall, Reference Waterfall2006). In an artificial language learning study, Onnis et al. (Reference Onnis, Waterfall and Edelman2008) showed that adults who were exposed to variation sets (20% of their input) showed better word segmentation compared to a different group who received the same utterances without variation sets. In an experiment conducted on two-year-olds, children were better at learning new words when they were repeated across adjacent sentences rather than repeated throughout the input (Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016a).
However, despite the facilitative role of variation sets for learning, and the growing evidence that SES impacts the language children are exposed to, no study to date has examined the use of variation sets in lower-SES groups, or compared their use between different high- and low-SES caregivers. In the current study, we compare the use of variation sets in child-directed speech of high- and low-SES mothers in two languages (Hebrew and English). In doing so, we aim to connect two distinct but related findings: those documenting the use of variation sets in child-directed speech and those illustrating the effect of SES on the properties of child-directed speech. If SES impacts the quality of children's input, as has been found for other linguistic measures, then we should see reduced use of variation sets in lower-SES input. Such a finding would show that the input children from different SES groups are exposed to differs not only in its quantity and richness but also in the way it is organized. An additional goal is to examine the use of variation sets in another language: the findings to date have been obtained from Turkish, English, and Swedish (Küntay & Slobin, Reference Küntay, Slobin, Slobin, Gerhardt, Kyratzis and Guo1996; Onnis et al., Reference Onnis, Waterfall and Edelman2008; Waterfall, Reference Waterfall2006; Wirén, Nilsson Björkenstam, Grigonytė, & Cortes, Reference Wirén, Nilsson Björkenstam, Grigonytė and Cortes2016), though the samples for the non-English languages were very small. Looking at Hebrew will allow us to expand these findings to another language, using a larger number of children.
Method
Defining variation sets
The first studies on variation sets identified them manually as clusters of utterances that have the same communicative intent (Küntay & Slobin, Reference Küntay, Slobin, Slobin, Gerhardt, Kyratzis and Guo1996), or that refer to the same extra-linguistic event (Waterfall, Reference Waterfall2006), and differ in at least one lexical item or in the order of the lexical items. This manual method draws on both linguistic and extra-linguistic cues, but it is highly labor intensive and cannot be used for large corpora. Brodsky et al. (Reference Brodsky, Waterfall and Edelman2007) were the first to automatically extract variation sets from a corpus. They defined variation sets as two consecutive utterances that share at least one word, excluding a list of high-frequency words. Following Brodsky et al., we automatically extracted variation sets along the same criteria (see full code at <https://osf.io/3bcp5/>). However, while Brodsky et al., excluded from consideration a very limited set of high-frequency closed-class words, we used a stricter criterion. Following Waterfall (Reference Waterfall2006), who allowed only open-class words to anchor a variation set, our list of excluded words included fillers, pronouns, prepositions, auxiliaries, wh-questions, proper names, and a set of function words (see the full table of excluded words in the ‘Appendix’). The motivation for using this stricter criterion was to exclude high-frequency words that tend to repeat regardless of context (such as auxiliaries or articles). Variation sets are matched over word-forms. The algorithm finds or expands a variation set by comparing two successive sentences at a time, meaning that a repeated word can change throughout the variation set, as long as there is a continuity of successive partial repetition (e.g., –Oh, there's your hand. –Is that hand a horse? –I think I can see a horse. –Hello horse). In addition, identical utterances were not defined as variation sets: a pair of utterances had to differ in either at least one word or in the ordering of the words in the sentence in order to qualify as a variation set (for example: wow, a tiny dog! and A tiny dog, wow! would be defined as a variation set even though they have the same lexical items since they differ in word order). Previous studies differed in whether they allowed intervening utterances between the repeated elements in each variation set: while Waterfall (Reference Waterfall2006) and Wirén et al. (Reference Wirén, Nilsson Björkenstam, Grigonytė and Cortes2016) allowed intervening utterances, Brodsky et al. (Reference Brodsky, Waterfall and Edelman2007) did not. We follow Brodsky et al., in not allowing intervening utterances to prevent the length of the intervening utterances from impacting the proportion of words and utterances in variation sets in ways that are not theoretically motivated. Note that the mean length of utterance (MLU) is inherently related to the extraction of variation sets in the sense that longer sentences are more likely to have overlapping words with an adjacent sentence. This is not due to the specific algorithm used in this study, but results from the definition of variation sets as partial repetitions across consecutive utterances.
Finally, in order to validate our automated procedure, we had a subset of the transcripts (two from each language, 8% of the data) hand coded for variation sets by a research assistant. The RA was asked to manually identify variation sets along the same criteria used by the algorithm. The overlap between the variation sets found by the algorithm and identified by the human coder was striking: 99% of the variation sets identified by the research assistant were also extracted by the algorithm (159/160), indicating that the automated measure does as well as a human coder.
The corpora used
In order to check the influence of SES on the use of variation sets, we compared the proportion of variation sets in the speech of higher- and lower-SES parents. It is important to note that it is exceptionally difficult to find corpora that allow for a good comparison between high- and low-SES populations since very few corpora include lower-SES families. We eventually found two sets of corpora, in two languages (Hebrew and English; see Table 1). For English, we used the Howe Corpus (Howe, Reference Howe1981). This corpus contains transcripts of 16 children, half middle-class and half working-class, who were recorded twice (once at age 1;6 to 1;8, and five months later at ages 1;11 to 2;1). SES was defined by Howe according to the father's occupation: in the low-SES sample the fathers had skilled or semi-skilled manual occupations, while in the high-SES sample they had professional or managerial occupations. Each mother and child were recorded for 40 minutes of free play with toys in their homes. One of recordings was only 16 minutes long (in the original corpora) and was excluded from the analysis. This left us with a total of 35,921 words of CDS from both sessions. The second corpus was in Hebrew and contained 18 filmed interactions of parents and their 18-month-old infants filmed in the lab. These were courtesy of Ariel Knafo's Developmental Social Psychology Lab (Abramson, Mankuta, Yagel, Gagne, & Knafo-Noam, Reference Abramson, Mankuta, Yagel, Gagne and Knafo-Noam2014). Each film contained ten minutes of free interaction between parent and child with no experimenter present in the room. These interactions were transcribed by the first author as part of a different project, not looking at variation sets. SES here was defined by a combination of maternal education and income: families were defined as high-SES when maternal education was over 12 years (mean 17.8 years) and the income level was 4 or 5 (on a scale of 1–5). Families were defined as mid- to low-SES when maternal education was 12 years or under (mean 12 years) and the income level was 3 or less. This corpus contained 10,319 words of CDS. For each corpus, we calculated various measures that are known to be affected by SES: number of words spoken to child (averaged over children), lexical diversity (type/token ratio), and MLU (see Table 1).
Table 1. Summary of Corpus Properties for Both SES Groups in the Two Languages

The measure
We wanted to compare the proportion of variation sets between high- and low-SES caregivers. Following previous literature (Brodsky et al., Reference Brodsky, Waterfall and Edelman2007; Waterfall, Reference Waterfall2006), our dependent variables were the proportion of words (PW) and the proportion of utterances (PU) spoken to the child that appeared inside variation sets. This enabled us to control for the total number of words and utterances, such that differences in the frequency of variation sets could not be explained away simply by differences in the amount of CDS (which is known to differ with SES; Hart & Risley, Reference Hart and Risley1995; Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016b).
Results
English
We used a linear mixed-effect model to test our main prediction about the effect of SES on PW and PU (using the lme4 package; Bates, Maechler, Bolker, & Walker, Reference Bates, Mächler, Bolker and Walker2015). We used the maximum random effect structure justified by the data that converged (Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013), and assessed significance using model comparisons. The model included fixed effects for SES, time of recording (first vs. second), and gender of child (male vs. female), and random intercepts for subjects (see Tables 2 and 3 for the full models). In line with our predictions, we found an SES-effect for PW and a marginal effect for PU, such that both were higher in the higher SES group [PW: 34% vs. 27% (β = 0.03, SE = 0.01, T = 2.16, model comparisons, χ 2(df = 1) = 4.13, p = .04); PU: 27.6% vs. 22% (β = 0.02, SE = 0.01, T = 1.98, model comparisons, χ 2(df = 1) = 3.53, p = .06)]. In addition, PU was found to be higher in the second recording, with more use of variation sets with older children (β = 0.02, SE = 0.008, T = 2.2, model comparisons, χ 2(df = 1) = 4.56, p = .03). This finding was not expected, since these age bins are very close to each other (a difference of 5 months) and belong to the same age bin in other studies (Wirén et al., Reference Wirén, Nilsson Björkenstam, Grigonytė and Cortes2016), or to ages in which no change in the use of variation sets was found (Waterfall, Reference Waterfall2006). Since this effect was found for only one of our measures, we do not think any clear conclusions can be drawn from it. There was no interaction between SES and time of recording (β = –0.0007, SE = 0.008, T = –0.09), showing that SES affected the rate of variation sets in both sessions. Figures 1 and 2 show the individual patterns of PW and PU for the different children. As can be seen, there is a low-SES child who received high scores, and a high-SES child who received low scores. These findings are not surprising since SES differences are group-level differences and, as such, do not necessarily apply to each individual in the group. Furthermore, such findings are expected under the assumption that SES is a proxy for different parameters that influence the input (Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002). This point will be further elaborated in the ‘Discussion’ section.
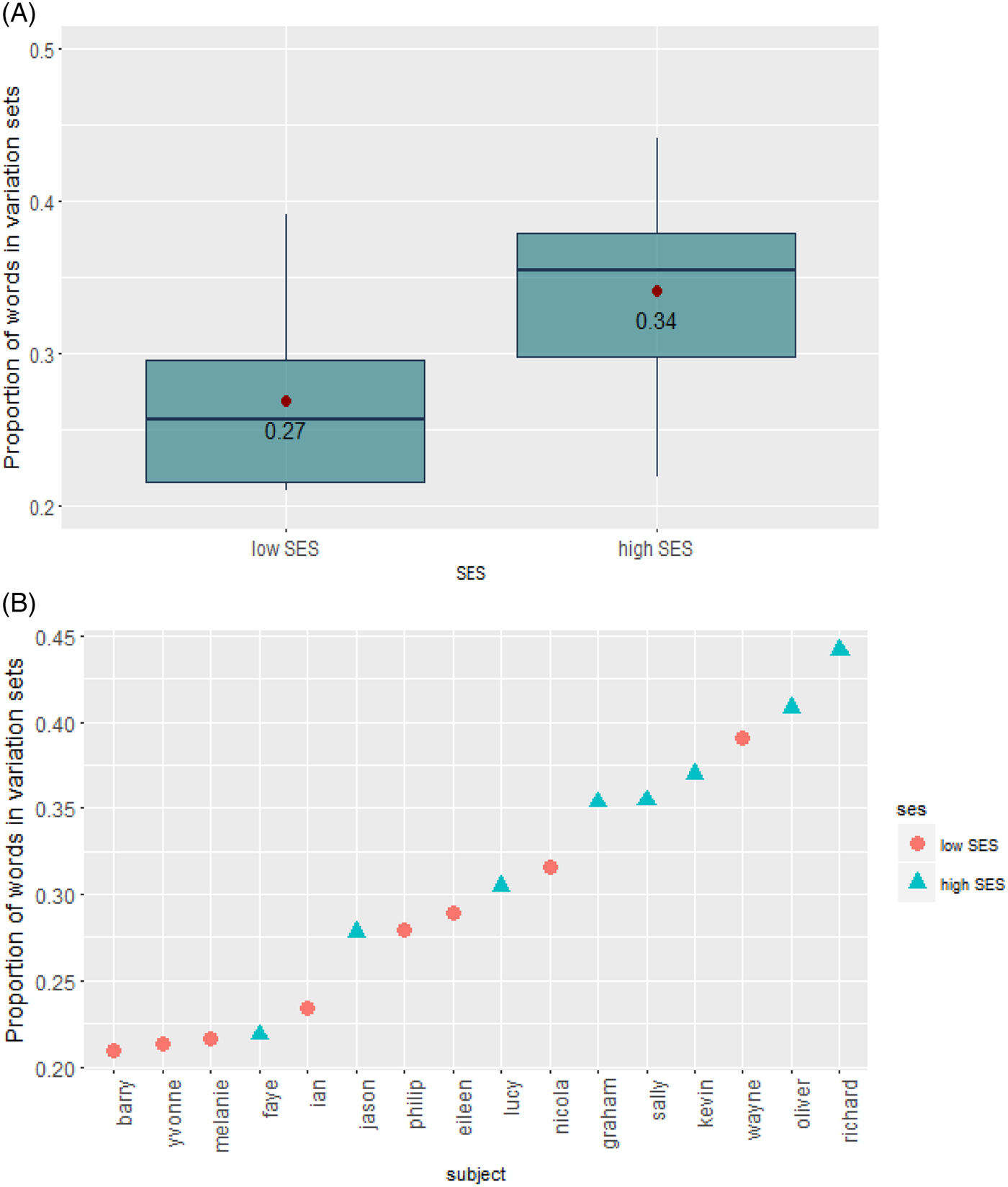
Figure 1. Proportion of words that appear in variation sets in low- and high-SES CDS in English corpora: (A) group level differences; (B) individual differences.
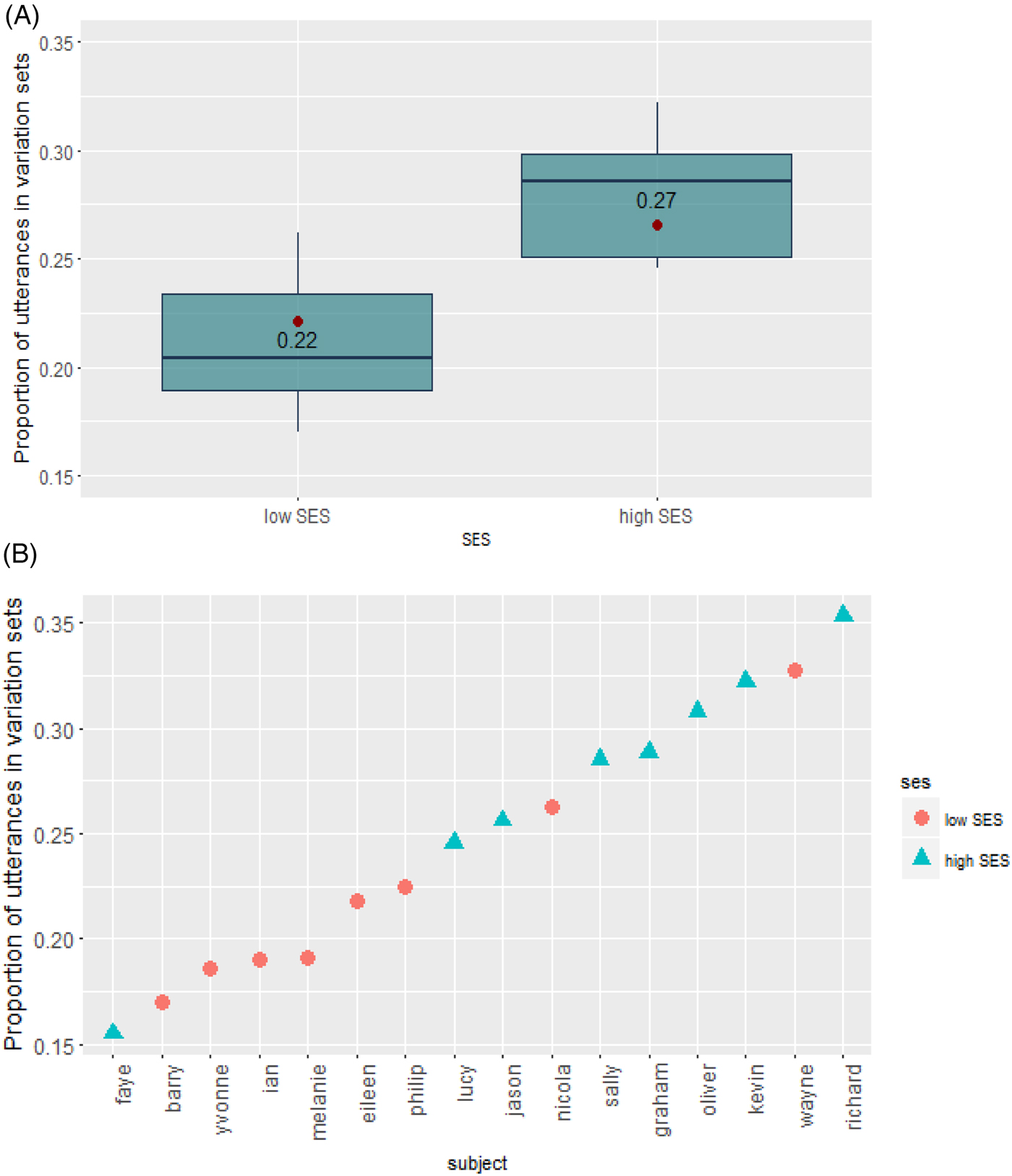
Figure 2. Proportion of utterances that appear in variation sets in low- and high-SES CDS in English corpora: (A) group level differences; (B) individual differences.
Table 2. Mixed-Effect Regression Model of PW for the English Corpora (Significant Variables in Bold)

Table 3. Mixed-Effect Regression Model of PU for the English Corpora (Significant Variables in Bold)

We ran another series of mixed-effect models to examine the effect of SES on other aspects of the input: MLU, lexical diversity, and number of words. Interestingly, we did not find the classical quantitative difference in number of words between the two groups: high-SES mothers did not talk more with their children compared to lower-SES mothers (β = 96.65, SE = 129.6, T = 0.74, model comparisons, χ 2(df = 1) = 0.55, p = .46). There was also no difference in lexical diversity between the two groups (β = 0.002, SE = 0.014, T = 0.19, model comparisons, χ 2(df = 1) = 0.04, p = .85). However, replicating previous findings (e.g., Hoff, Reference Hoff2003), we did find that MLU was higher in the higher-SES group (β = 0.21, SE = 0.1, T = 2.12, model comparisons, χ 2(df = 1) = 3.98, p = .046). These results are compatible with other SES studies in which the differences found were not in the sheer amount of speech but rather in more qualitative characteristics of the input (e.g., McGillion, Pine, Herbert, & Matthews, Reference McGillion, Pine, Herbert and Matthews2017). While the two SES groups do differ in MLU (as we report in Table 1), the difference is in less than one word (3.62 vs., 4.08), meaning that it would have a very weak effect on the number of variation sets detected. There was no correlation between MLU and the two variation sets measures, indicating that the difference in MLU is not driving the effect (first recording: PW and MLU: r = 0.27, p = .33; PU and MLU: r = 0.32, p = .23. second recording: PW and MLU: r = 0.44, p = .08; PU and MLU: r = 0.42, p = .1).
To further explore the difference in the number of variation sets we conducted two additional analyses. First, we checked whether SES impacts the number of anchor words in variation sets to see if parents create variation sets around the same words, or whether the anchoring words are varied. To asses this, we calculated for each child the type/token ratio of the words that are repeated inside variation sets, with higher scores (closer to 1) indicating greater lexical diversity of anchoring words. We found that both groups used a similar, and high, number of different words as anchors in their variation sets (0.75 vs. 0.78, β = 0.02, SE = 0.02, T = 0.8). Second, because we identified variation sets based on repetition of open-class elements, we wanted to make sure that their proportion did not differ between the two SES groups (such a difference could have led to detection of more variation sets in one group). We used the morphological tagging in the English corpora to calculate the average proportion of open-class words spoken to children in both SES groups (using the childes-db package; Sanchez, Meylan, Braginsky, MacDonald, Yurovsky, & Frank, Reference Sanchez, Meylan, Braginsky, MacDonald, Yurovsky and Frank2018). We found no difference between the two groups [44.8% vs. 45.3%, t(df = 12.19) = –0.3, p = .76], suggesting that the difference in the amount of variation sets could not be explained by lower-SES caregivers using fewer open-class words.
Hebrew
A simple linear regression was calculated to predict PW and PU based on SES and gender (we had only one recorded interaction per child–parent dyad in this dataset, so could not use mixed-effects model in this study). Here, too, we found that both measures were higher in the higher-SES group compared to in the mid- to low-SES group [PW: 40% vs. 32% (β = 0.08, SE = 0.03, p = .04); PU: 32% vs. 25% (β = 0.07, SE = 0.03, p = .047)]. Figures 3 and 4 show the individual patterns of PW and PU. One child from the high-SES group received very high scores (PW: 62%, PU: 55%). However, excluding this child from the analysis did not change the effect: the average PW changed to 37% and the average PU changed to 29% but the effect of SES was still significant (PW: β = 0.05, SE = 0.025, p = .05; PU: β = 0.04, SE = 0.02, p = .03). We also checked for classical measures of SES differences. As with the results from the English corpora, there was no difference in the number of words spoken to children between the two groups (β = 48.7, SE = 89.7, p = .6) or in their lexical diversity (β = 0.01, SE = 0.02, p = .46). We found a marginally significant difference of MLU (β = 0.4, SE = 0.22, p = .095). However, as in the English sample, the MLU difference here is less than one word (3.04 vs. 3.45), and there is no correlation between MLU and the two variation sets measures (PW and MLU: r = 0.25, p = .3; PU and MLU: r = 0.42, p = .08). This indicates that here too the difference in MLU is not driving the effect. While the proportion of PU and PW are slightly higher in the Hebrew corpus compared to the English one, this difference is most likely due to recording differences. Whereas the English recordings were collected at home for 40 minutes, the Hebrew ones were collected in the lab for 10 minutes. It is therefore hard to tell if the numerical difference is related to language or to the context of recording. Importantly, the corpora that were compared within each language had the same recording setting, precisely in order to control for other possible differences.

Figure 3. Proportion of words that appear in variation sets in mid- to low- and high-SES CDS in Hebrew corpora: (A) group level differences; (B) individual differences.

Figure 4. Proportion of utterances that appear in variation sets in mid- to low- and high-SES CDS in Hebrew corpora: (A) group level differences; (B) individual differences.
Finally, as in the English sample, we checked whether the number of anchor words differs between the two SES groups. Here too we found that both groups used a similar number of different anchor words in their variation sets (0.79 vs. 0.8, β = –0.009, SE = 0.03, T = –0.27), suggesting again that the difference is in the quantity of variation sets, not in kind. Examples of variation sets from both languages are given in Table 4.
Table 4. Examples for Variation Sets from the Two Corpora Sets (Repeated Words Are Underlined)

Discussion
The present study set out to examine the effect of SES on a structural feature of child-directed speech: the use of variation sets. While variation sets have been shown to impact language learning outcomes (Onnis et al., Reference Onnis, Waterfall and Edelman2008; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016a; Waterfall, Reference Waterfall2006), very little work has examined their use by low-SES parents. Given the growing evidence that SES impacts many aspects of child-directed speech, we expected to find that the use of variation sets will be reduced in lower-SES input. Indeed, we found that high-SES children are exposed to more variation sets, with more of the words and utterances they hear appearing in clusters of successive self-repetitions. The effect of SES on the use of variation sets was found for two ages and in two typologically different languages. These findings show that SES impacts the structure of the information given in the input, as has been shown for other characteristics of CDS (Hart & Risley, Reference Hart and Risley1995; Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002). Our findings mirror the pattern found by Waterfall (Reference Waterfall2006), who used manual identification of variation sets in a longitudinal corpus. Based on the analysis of eight children (four in each group), Waterfall found that mothers with advanced degrees produced more variation sets than mothers with high-school diplomas when talking with 18-month-old infants. Our results replicate this finding for a larger number of participants, at another age, and for another language, and strengthen the validity of using automatic extraction of variation sets instead of manual extraction. Importantly, while there was a difference in the proportion of variation sets, we found no difference in the diversity of the repeated words between the two groups, suggesting that the variation sets were similarly varied. Together, the findings highlight the prevalence of variation sets in child-directed speech and the impact of SES on their use.
Interestingly, we did not find SES effects on the total number of words children heard. This finding differs from what is often reported (Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016b). This may be driven by the type of interaction recorded in our corpora. In both languages the transcripts are of relatively short interactions in experimental settings. That is, whether the recordings took place in the lab (Hebrew) or at home (English), parents were very much aware they were being recorded, which may have impacted the amount of speech they produced. Importantly, while the number of words did not differ, the use of variation sets did, suggesting that the organization of the input may vary even when the amount of speech and the richness of the language used do not. This highlights the need to direct more attention to different kinds of properties of CDS, especially since the amount of speech has been found to be less predictive of language learning than other, more qualitative measures of the input (Hirsh-Pasek et al., Reference Hirsh-Pasek, Adamson, Bakeman, Owen, Golinkoff, Pace, Yust and Suma2015; Pan, Rowe, Singer, & Snow, Reference Pan, Rowe, Singer and Snow2005). The current study does not demonstrate a link between the reduced use of variation sets and language learning outcomes. Future work will examine whether these differences independently predict later linguistic outcomes. Relying on findings on the beneficial nature of variation sets (Onnis et al., Reference Onnis, Waterfall and Edelman2008; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016a; Waterfall, Reference Waterfall2006), differences in the proportion of variation sets in the input children receive should result in differences in their output.
While our findings illustrate an effect of SES on the use of variation sets, it is still largely unclear what exactly underlies SES differences in linguistic measures. SES is often considered a proxy for a cluster of factors that influence the type of input children receive from their parents (Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002). Different mediating factors, such as stress, time, and availability, and culturally transmitted knowledge and practices, have been proposed to be the crucial parameters that SES stands for (for a review see Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016b). Since variation sets are clusters of local repetitions that typically illustrate a shared communicative goal, it could be that their reduced use stems from differences in communicative engagement or differences in object-labeling practices (Hoff et al., Reference Hoff, Laursen, Tardif and Bornstein2002). This suggestion is compatible with previous findings according to which high-SES mothers produce more topic-continuing replies to their children compared to lower-SES mothers (Hoff, Reference Hoff2003). Related to this, SES may impact not only the quantity but also the type of variation sets used. Variation sets can serve different communicative functions (Küntay & Slobin, Reference Küntay and Slobin2002). In the current paper, we collapsed over the different types. However, in other work, we ask if SES impacts the kinds of variation sets used with children. We classified variation sets extracted from an English corpus into three communicative functions (as defined by Küntay & Slobin) and showed that their distribution is impacted by SES (Tal & Arnon, Reference Tal, Arnon, Bertolini and Kaplan2018). While SES did not impact the amount of behavior-directing variation sets (e.g., – Come on, make a wall. – Make a wall. – A big long wall), high-SES parents used more information-providing variation sets compared to low-SES parents (e.g., – That's a watering can. – Teeny-weeny watering can). It is precisely this type of variation set that may have a stronger link to language learning: further work is needed to see if this type is more strongly correlated with language outcomes. More generally, the findings highlight the impact of SES on the way information is organized in child-directed speech.
The current research on variation sets leaves several questions unanswered. The first is why variation sets are beneficial for learning in the first place. Several explanations have been proposed over the years. Brodsky et al. (Reference Brodsky, Waterfall and Edelman2007) suggest that variation sets are optimally informative because they provide a balance between overlap and change (as opposed to sentence pairs that are completely different or entirely identical). This finding is in line with the claim that intermediate rates of information (not too simple and not too complex) are ideal for capturing humans’ attention (Kidd, Piantadosi, & Aslin, Reference Kidd, Piantadosi and Aslin2012). An additional explanation suggests that variation sets are beneficial because they aid young learners in forming stable memories (Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016a; Vlach & Johnson, Reference Vlach and Johnson2013). Given the relatively limited short-term memory capacity of young children (e.g., Ross-Sheehy & Newman, Reference Ross-Sheehy and Newman2015) and time pressures of language use in general (Christiansen & Chater, Reference Christiansen and Chater2016), adjacent repetitions are preferable over non-adjacent ones. A third explanation is attention-based: repeated elements might become more salient and thus more learnable by the virtue of their adjacency (Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016a). In accordance with these suggestions, findings from the statistical learning literature show learning advantages for relying on local relations compared to global ones (Onnis, Edelman, & Waterfall, Reference Onnis, Edelmann and Waterfall2011). The second, and related, question has to do with the function of variation sets in CDS. Are variation sets used to introduce new words (as in Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016a)? Or do they facilitate interaction more generally? A recent study provides some initial support for the latter explanation: parents of toddlers with Autistic Spectrum Disorders (ASD) – who are generally less talkative – use more variation sets when they talk to their children compared to parents of typically developing toddlers (Onnis, Edelman, Esposito, & Venuti, unpublished observations). In addition, the current study is limited in that it is based on two sets of corpora that contain short, and somewhat unnatural, interactions (one is lab-based and the second is set in the home but with an experimenter present). These analyses need to be extended to larger corpora and more naturalistic settings. To conclude, the findings of this study highlight the need to examine the effect of SES on how information is structured in child-directed speech. More broadly, it calls for bridging between two related literatures, as the literature of CDS provides many insights regarding what qualifies as high-quality linguistic input (Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016b). Thus, further integration of the CDS and the SES literature is promising in helping us to better understand individual and socially driven differences in early language acquisition.
Acknowledgements
We wish to thank Zohar Aizenbud for her help with coding. The research was funded by the Israeli Science Foundation grant number 584/16 awarded to the second author, and by Starting Grant 240994 from the European Research Council (to Ariel Knafo).
Appendix