



No CrossRef data available.
Article contents
Tree trace reconstruction using subtraces
Published online by Cambridge University Press: 15 December 2022
Abstract
Tree trace reconstruction aims to learn the binary node labels of a tree, given independent samples of the tree passed through an appropriately defined deletion channel. In recent work, Davies, Rácz, and Rashtchian [10] used combinatorial methods to show that
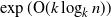 $\exp({\mathrm{O}} (k \log_{k} n))$
samples suffice to reconstruct a complete k-ary tree with n nodes with high probability. We provide an alternative proof of this result, which allows us to generalize it to a broader class of tree topologies and deletion models. In our proofs we introduce the notion of a subtrace, which enables us to connect with and generalize recent mean-based complex analytic algorithms for string trace reconstruction.
$\exp({\mathrm{O}} (k \log_{k} n))$
samples suffice to reconstruct a complete k-ary tree with n nodes with high probability. We provide an alternative proof of this result, which allows us to generalize it to a broader class of tree topologies and deletion models. In our proofs we introduce the notion of a subtrace, which enables us to connect with and generalize recent mean-based complex analytic algorithms for string trace reconstruction.
MSC classification
Primary:
60C05: Combinatorial probability
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2022. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Ban, F., Chen, X., Freilich, A., Servedio, R. A. and Sinha, S. (2019). Beyond trace reconstruction: population recovery from the deletion channel. In 60th IEEE Annual Symposium on Foundations of Computer Science (FOCS), pp. 745–768.CrossRefGoogle Scholar
Ban, F., Chen, X., Servedio, R. A. and Sinha, S. (2019). Efficient average-case population recovery in the presence of insertions and deletions. In Approximation, Randomization, and Combinatorial Optimization: Algorithms and Techniques (APPROX/RANDOM) (LIPIcs 145), pp. 44:1–44:18. Schloss Dagstuhl–Leibniz-Zentrum für Informatik.Google Scholar
Batu, T., Kannan, S., Khanna, S. and McGregor, A. (2004). Reconstructing strings from random traces. In Proceedings of the 15th Annual ACM–SIAM Symposium on Discrete Algorithms (SODA), pp. 910–918.Google Scholar
Bhardwaj, V., Pevzner, P. A., Rashtchian, C. and Safonova, Y. (2021). Trace reconstruction problems in computational biology. IEEE Trans. Inf. Theory 67, 3295–3314.CrossRefGoogle ScholarPubMed
Brakensiek, J., Li, R., and Spang, B. (2020). Coded trace reconstruction in a constant number of traces. In Proceedings of the IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS), pp. 482–493.CrossRefGoogle Scholar
Chase, Z. (2020). New upper bounds for trace reconstruction. Available at arXiv:2009.03296.Google Scholar
Chase, Z. (2021). New lower bounds for trace reconstruction. Ann. Inst. H. Poincaré Prob. Statist., to appear.CrossRefGoogle Scholar
Chen, X., De, A., Lee, C. H., Servedio, R. A. and Sinha, S. (2021). Polynomial-time trace reconstruction in the smoothed complexity model. In Proceedings of the 32nd Annual ACM–SIAM Symposium on Discrete Algorithms (SODA), pp. 54–73.CrossRefGoogle Scholar
Cheraghchi, M., Gabrys, R., Milenkovic, O. and Ribeiro, J. (2020). Coded trace reconstruction. IEEE Trans. Inf. Theory 66, 6084–6103.CrossRefGoogle Scholar
Davies, S., Rácz, M. Z. and Rashtchian, C. (2021). Reconstructing trees from traces. Ann. Appl. Prob., to appear.CrossRefGoogle Scholar
Davies, S., Racz, M. Z., Rashtchian, C. and Schiffer, B G. (2020). Approximate trace reconstruction. Available at arXiv:2012.06713.Google Scholar
De, A., O’Donnell, R. and Servedio, R. A. (2017). Optimal mean-based algorithms for trace reconstruction. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC), pp. 1047–1056.CrossRefGoogle Scholar
De, A., O’Donnell, R. and Servedio, R. A. (2019). Optimal mean-based algorithms for trace reconstruction. Ann. Appl. Prob. 29, 851–874.CrossRefGoogle Scholar
Grigorescu, E., Sudan, M. and Zhu, M. (2020). Limitations of mean-based algorithms for trace reconstruction at small distance. Available at arXiv:2011.13737.Google Scholar
Hartung, L., Holden, N. and Peres, Y. (2018). Trace reconstruction with varying deletion probabilities. In Proceedings of the 15th Workshop on Analytic Algorithmics and Combinatorics (ANALCO), pp. 54–61.CrossRefGoogle Scholar
Holden, N. and Lyons, R. (2020). Lower bounds for trace reconstruction. Ann. Appl. Prob. 30, 503–525.CrossRefGoogle Scholar
Holden, N., Pemantle, R., Peres, Y. and Zhai, A. (2020). Subpolynomial trace reconstruction for random strings and arbitrary deletion probability. Math. Statist. Learning 2, 275–309.CrossRefGoogle Scholar
Holenstein, T., Mitzenmacher, M., Panigrahy, R. and Wieder, U. (2008). Trace reconstruction with constant deletion probability and related results. In Proceedings of the 19th ACM–SIAM Symposium on Discrete Algorithms (SODA), pp. 389–398.Google Scholar
Krishnamurthy, A., Mazumdar, A., McGregor, A. and Pal, S. (2019). Trace reconstruction: generalized and parameterized. In 27th Annual European Symposium on Algorithms (ESA 2019), pp. 68:1–68:25.Google Scholar
Levenshtein, V. I. (2001). Efficient reconstruction of sequences. IEEE Trans. Inf. Theory 47, 2–22.CrossRefGoogle Scholar
Maranzatto, T. J. (2020). Tree trace reconstruction: some results. Thesis, New College of Florida, Sarasota, FL.Google Scholar
Narayanan, S. (2021). Population recovery from the deletion channel: nearly matching trace reconstruction bounds. In Proceedings of the ACM–SIAM Symposium on Discrete Algorithms (SODA).
CrossRefGoogle Scholar
Narayanan, S. and Renk, M. (2021). Circular trace reconstruction. In Proceedings of the 12th Innovations in Theoretical Computer Science Conference (ITCS) (LIPIcs 185), pp. 18:1–18:18. Schloss Dagstuhl–Leibniz-Zentrum für Informatik.Google Scholar
Nazarov, F. and Peres, Y. (2017). Trace reconstruction with
 $\exp(O(n^{1/3}))$
samples. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC), pp. 1042–1046.CrossRefGoogle Scholar
$\exp(O(n^{1/3}))$
samples. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC), pp. 1042–1046.CrossRefGoogle Scholar
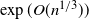 $\exp(O(n^{1/3}))$
samples. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC), pp. 1042–1046.CrossRefGoogle Scholar
$\exp(O(n^{1/3}))$
samples. In Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC), pp. 1042–1046.CrossRefGoogle Scholar