



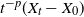
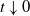
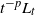
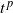
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Gradinaru, Mihai
and
Luirard, Emeline
2024.
Kinetic time-inhomogeneous Lévy-driven model
.
Latin American Journal of Probability and Mathematical Statistics,
Vol. 21,
Issue. 1,
p.
815.